
Análise das principais características da série temporal

Introdução
A análise de processos representados por uma série de preços é uma tarefa desafiadora que geralmente requer tempo e esforços significativos. Isso é devido a peculiaridades das sequências em estudo bem como o fato de que, apesar de um grande número de publicações diversas, às vezes, é difícil encontrar uma solução de programação adequada para determinado problema.
Mesmo se um script ou indicador adequado tenha sido encontrado, isso não significa que o seu código-fonte não precisaria ser ajustado à tarefa em análise.
Além disso, mesmo para a solução de problemas simples, esses programas podem requerer o uso de parâmetros de entrada, ponto que é bem conhecido pelos desenvolvedores, mas não é sempre totalmente claro para um usuário.
Essas dificuldades certamente não podem se tornar um obstáculo insuperável após uma pesquisa aprofundada, mas quando alguém quiser testar uma hipótese ou simplesmente satisfazer sua curiosidade, tal curiosidade irá mais frequentemente permanecer insatisfeita. Por essa razão, tive a ideia de criar uma ferramenta de programação universal que permita a análise preliminar facilitada das principais características e parâmetros de uma sequência de entrada.
A instalação desta ferramenta deve ser totalmente simples, sem necessidade de quaisquer parâmetros de entrada, para que seu uso seja simplificado ao máximo. Ao mesmo tempo, os parâmetros e características estimados devem refletir claramente e adequadamente a natureza da sequência em consideração.
Uma estimativa preliminar de características poderá ajudar a determinar os caminhos para estudo mais aprofundado ou ajudar a rejeitar qualquer hipótese determinada durante uma etapa inicial e evitar a perda de tempo com estudos adicionais.
É notório que as características de um software universal são frequentemente consideradas piores quando comparadas às de um software personalizado. Este é um preço regular que se paga pela universalidade, a qual é quase sempre alcançada por meio de um sistema completo de negociações. Este artigo, entretanto, representa um esforço para criar uma ferramenta universal que permite facilitar ao máximo a análise preliminar das características das sequências.
Instalação e capacidade
O arquivo TSAnalysis.zip, que pode ser encontrado ao final deste artigo, inclui o diretório \TSAnalysis que contém todos os arquivos requeridos para o trabalho. Após a extração, o diretório com todo o seu conteúdo (sem renomeá-lo) deve ser copiado dentro do diretório \MQL5\Scripts. O diretório \TSAnalysis que foi copiado contém um script de teste TSAexample.mq5 que pode ser executado após a compilação.
Este script deverá preparar os dados e chamar o navegador padrão para exibí-los utilizando a classe TSAnalysis. Devemos destacar que, para a operação normal da classe TSAnalysis, o uso de DLLs externos deverá estar habilitado no terminal. Para desinstalar, simplesmente delete o diretório \TSAnalysis.
O código-fonte completo utilizado para a análise de sequências é representado pela classe TSAnalysis e pode ser encontrado apenas no arquivo TSAnalysis.mqh.
Quando se utiliza esta classe para uma sequência de entrada, ela realiza o cálculo e pode exibir as seguintes informações:
- Número de elementos na sequência;
- Valores máximo e mínimo da sequência (máx, mín);
- Mediana;
- Média;
- Variação;
- Desvio padrão;
- Variação não tendenciosa;
- Desvio padrão não tendencioso;
- Assimetria;
- Curtose;
- Excesso de curtose;
- Teste de Jarque-Bera;
- Valor-p do teste de Jarque-Bera;
- Teste de Jarque-Bera ajustado;
- Valores-p do teste de Jarque-Bera ajustado;
- Limites para valores não pertencentes à sequência analisada (valores atípicos);
- Dados do histograma;
- Dados do gráfico de probabilidade normal;
- Dados do correlograma;
- Bandas de confiança de 95% para a função de autocorrelação;
- Dados do gráfico de espectro calculado através da função de autocorrelação;
- Dados do gráfico da função de autocorrelação parcial;
- Dados do gráfico de estimativa de espectro calculado com o uso do método de entropia máxima.
Para exibir visualmente os resultados obtidos na classe TSAnalysis em análise, utiliza-se um método de exibição virtual encarregado de um método predeterminado de exibição de informações.
Assim, ao redefinir este método nos descendentes da classe TSAnalysis, é possível organizar a saída de resultados de qualquer maneira possível, não apenas através do uso de um arquivo HTML como na classe base em que, mediante a geração de um arquivo de dados para exibição de gráficos, um navegador de internet é chamado.
Antes de passarmos à revisão da classe TSAnalysis, ilustraremos o resultado do seu uso através do teste de uma sequência de dados. A figura abaixo demonstra o resultado de operação do script TSAexample.mq5.

Figura 1. Resultado de operação do script TSAexample.mq5
Após nos familiarizarmos brevemente com a capacidade da classe, passaremos agora a uma consideração mais detalhada sobre a classe em si.
Classe TSAnalysis
A classe TSAnalysis (vide TSAnalysis.mqh) inclui apenas um método Calc disponível (público), que está encarregado de todos os cálculos necessários após os quais o método de exibição virtual é chamado. Posteriormente, o método de exibição será brevemente analisado. Agora, realizaremos um esclarecimento passo a passo sobre o principal aspecto dos cálculos realizados.
Durante a utilização da classe TSAnalysis, algumas restrições são impostas à sequência de entrada que se está estudando.
Primeiramente, a sequência deve conter no mínimo oito elementos. Esta restrição provavelmente não é tão rígida, visto que dificilmente será necessário estudar sequências tão curtas para propósitos práticos.
Além da restrição de comprimento mínimo de sequência, o valor de variação da sequência de entrada deve ser diferente de próximo de zero. Este requisito se deve ao fato de que o valor de variação é utilizado em cálculos posteriores e não pode ser inferior a um determinado valor para a obtenção de um resultado estável.
As sequências com um valor de variação muito baixo não são muito comuns, de forma que esta restrição provavelmente não será também uma grande desvantagem. Onde a sequência for muito curta e houver um valor de variação próximo de zero, os cálculos serão interrompidos e uma mensagem de erro relevante aparecerá no registro.
Há ainda outra restrição implícita em relação ao comprimento máximo permitido de sequência de entrada. Esta restrição não é explicitamente definida e depende do desempenho de um computador em uso e de sua capacidade de memória, sendo determinado de forma puramente subjetiva pelo tempo requerido para a execução do script e pela velocidade de inscrição de resultados em um navegador de internet. Presume-se que o processamento de sequências que consistem em 2-3 mil elementos não deve causar grandes dificuldades.
O cálculo de parâmetros estatísticos da sequência será baseado no fragmento do código-fonte do método Calc (vide TSAnalysis.mqh) abaixo.
A descrição do algoritmo utilizado pode ser encontrada no link "Algoritmos para o cálculo de variação".
. . . Mean=0; sum2=0; sum3=0; sum4=0; for(i=0;i<NumTS;i++) { n=i+1; delta=TS[i]-Mean; a=delta/n; Mean+=a; // Mean (average) sum4+=a*(a*a*delta*i*(n*(n-3.0)+3.0)+6.0*a*sum2-4.0*sum3); // sum of fourth degree b=TS[i]-Mean; sum3+=a*(b*delta*(n-2.0)-3.0*sum2); // sum of third degree sum2+=delta*b; // sum of second degree } . . .
Como resultado da execução desse fragmento, os seguintes valores são calculados:
![]()
em que n = NumTS é o número de elementos da sequência.
Utilizando os valores obtidos, calculamos os seguintes parâmetros:
Variação e desvio padrão:
![]()
Variação não tendenciosa e desvio padrão:
![]()
Assimetria:
![]()
Curtose. A curtose mínima é 1 e a curtose da sequência distribuída normalmente será 3.
![]()
Excesso de curtose:
![]()
Nesse caso, a curtose mínima é -2 e a curtose da sequência distribuída normalmente será 0.
Convencionalmente, ao se realizar o primeiro teste de grau de adequação preliminar em uma sequência, utiliza-se a estatística Jarque-Bera, a qual é facilmente calculada com o uso dos valores de assimetria e curtose conhecidos. A significância estatística (valor-p) para a estatística Jarque-Bera, mediante o aumento do comprimento da sequência, tende assintoticamente ao inverso da função de distribuição chi-quadrado com dois graus de liberdade.
Assim,
![]()
onde a sequência é curta, o valor-p obtido dessa maneira provavelmente terá um erro considerável. Entretanto, esta opção de cálculo é usada com muita frequência. É difícil explicar a razão disto - talvez seja devido às fórmulas simples e claras utilizadas ou pode ser devido ao fato de que a estatística Jarque-Bera em si não representa um teste ideal de grau de adequação e, assim, não há sentido em obter cálculos mais precisos.
Em nosso caso, a estatística Jarque-Bera e o valor-p relevante são calculados no método Calc (TSAnalysis.mqh) de acordo com as fórmulas acima.
Além disso, um teste de Jarque-Bera adicional é calculado:
![]()
em que
![]()
A versão ajustada do teste de Jarque-Bera para sequências curtas reduz o erro do valor-p calculado da forma especificada, mas não o elimina totalmente.
O resultado final da análise deve incluir um gráfico da sequência de entrada exibindo a linha correspondente à média e as linhas que definem os limites fora dos quais os valores podem ser considerados inválidos e não pertencentes à sequência analisada (valores atípicos).
Neste caso, esses limites são calculados da seguinte forma:
![]()
![]()
Esta fórmula é fornecida no livro "Estatística para negociadores", de S. V. Bulashev, com referência ao livro de P. V. Novitsky e I.A. Zograf, "Estimativa de erro em resultados de medição". Após determinar os limites, nenhum processamento da sequência de entrada é pretendido; pretende-se exibir os limites somente a título de informação.
Além do gráfico de sequência de entrada, um histograma que reflete a estimativa empírica da distribuição da sequência de entrada deve ser exibido. O número de intervalos do histograma é definido da seguinte forma (S. V. Bulashev, "Estatística para negociadores"):
![]()
O resultado é arrendondado para baixo até chegar ao valor ímpar inteiro mais próximo. Caso o valor obtido seja inferior a cinco, utiliza-se o valor 5.
O número de elementos nos arrays de dados para os eixos X e Y do histograma corresponde ao número de intervalos obtidos mais dois, visto que uma coluna de valor zero é adicionada à esquerda e à direita do histograma.
Um fragmento do código (vide TSAnalysis.mqh) que prepara os dados para construção de um histograma é definido abaixo:
. . . n=(int)MathRound((Kurt+1.5)*MathPow(NumTS,0.4)/6.0); if((n&0x01)==0)n--; if(n<5)n=5; // Number of bins ArrayResize(XHist,n); ArrayResize(YHist,n); ArrayInitialize(YHist,0.0); a=MathAbs(TSort[0]-Mean); b=MathAbs(TSort[NumTS-1]-Mean); if(a<b)a=b; v=Mean-a; delta=2.0*a/n; for(i=0;i<n;i++)XHist[i]=(v+(i+0.5)*delta-Mean)/StDev; // Histogram. X-axis for(i=0;i<NumTS;i++) { k=(int)((TS[i]-v)/delta); if(k>(n-1))k=n-1; YHist[k]++; } for(i=0;i<n;i++)YHist[i]=YHist[i]/NumTS/delta*StDev; // Histogram. Y-axis . . .
No código acima:
- NumTS é o número de elementos da sequência;
- XHist[] e YHist[] são arrays contendo os valores dos eixos X e Y, respectivamente;
- TSort[] é o array que contém uma sequência de entrada classificada.
Utilizando este método de cálculo, os valores do eixo X serão expressos em unidades de desvio padrão e os valores do eixo Y corresponderão à densidade de probabilidade.
Para o propósito de construir um gráfico com o eixo de distribuição normal, a sequência de entrada classificada em ordem crescente é usada como os valores do eixo Y. Os números dos valores dos eixos Y e X devem ser iguais. Para calcular os valores do eixo X, primeiramente é preciso encontrar os valores medianos como na lei de distribuição uniforme:
![]()
![]()
![]()
Eles também são usados para calcular os valores do eixo X através da função de distribuição normal inversa (vide o método ndtri).
Para criar um gráfico de função de autocorrelação (ACF), um gráfico de função de autocorrelação parcial (PACF) e calcular a estimativa de espectro utilizando o método de entropia máxima, devemos encontrar os valores da função de autocorrelação da sequência de entrada.
Definiremos o número de valores que devem ser exibidos nos gráficos ACF e PACF da seguinte forma:
![]()
![]()
![]()
O número de valores determinados da forma especificada será suficiente para a exibição da função de autocorrelação no gráfico, mas para posterior cálculo da estimativa de espectro é recomendável ter um maior número de valores de ACF calculados, o que em nosso caso será igual à ordem do modelo auto-regressivo empregado.
A ordem do modelo IP será definida pelor valor NLags obtido:
![]()
![]()
É muito difícil formalizar o processo de determinação da ordem ótima do modelo para a estimativa de espectro. Um modelo de baixa ordem trará resultados extremamente suaves enquanto que um modelo de alta ordem provavelmente levará a uma estimativa de espectro instável com ampla variação de valores.
Além disso, a ordem do modelo também é afetada pela natureza da sequência de entrada. Assim, a ordem IP determinada com a utilização da fórmula acima em alguns casos será muito alta e em outros, muito baixa. Infelizmente, não foi encontrada uma abordagem eficaz para determinação da ordem de modelo requerida.
Assim, para a sequência de entrada, deve-se determinar que os números dos valores de ACF sejam iguais à ordem do modelo IP que é usado para a estimativa de espectro da sequência.
. . . ArrayResize(cor,IP); a=0; for(i=0;i<NumTS;i++)a+=TSCenter[i]*TSCenter[i]; for(i=1;i<=IP;i++) { c=0; for(k=i;k<NumTS;k++)c+=TSCenter[k]*TSCenter[k-i]; cor[i-1]=c/a; // Autocorrelation } . . .
Este fragmento do código-fonte (vide TSAnalysis.mqh) ilustra o processo de cálculo da função de autocorrelação (ACF). O resultado do cálculo é posicionado no array cor[]. Como pode ser visto, um coeficiente de autocorrelação igual a zero é calculado primeiro, seguido pelo cálculo e normalização dos coeficientes restantes do circuito. Durante esta normalização, o coeficiente zero sempre será igual a um, de forma que não há necessidade de salvá-lo no array cor[].
Este array contém o número de coeficientes iguais ao IP, iniciando do primeiro. Ao calcular o ACF, utiliza-se o array TSCenter[]; ele contém a sequência de entrada dos elementos de todos os quais o valor médio foi subtraído.
Para reduzir o tempo requerido para o cálculo do ACF, é possível utilizar os métodos empregando algoritmos de transformação rápida, tal como o FFT. Mas, neste caso, o tempo requerido para o cálculo do ACF é razoável, então não há necessidade de complicar o código de programação.
Um gráfico de ACF (correlograma) pode ser facilmente construído com o uso dos valores de coeficiente de correlação obtidos. Para ser capaz de exibir as bandas de confiança de 95% neste gráfico, os seus valores devem ser calculados com o uso das fórmulas abaixo.
Para as bandas utilizadas para testar aleatoriedade:
![]()
Para as bandas utilizadas para determinar a ordem do modelo ARIMA:
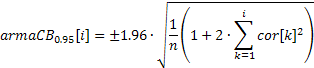
O valor da banda de confiança será constante no primeiro caso e aumentará com o aumento do coeficiente de autocorrelação no segundo caso.
Uma resposta de frequência muito suavizada da sequência de entrada refletindo somente a tendência geral da distribuição de frequência pode, às vezes, ser interessante. Por exemplo, aumentos consideráveis no limite de baixa ou alta frequência, predominância de frequências de nível intermediário, etc.
É recomendável exibir essa resposta de frequência em escala linear para enfatizar fortemente os limites de frequência dominantes. Esta resposta amplitude-frequência (AFR) pode ser desenhada com base nos coeficientes de autocorrelação obtidos anteriormente. Para cálculo da AFR, usaremos o número de coeficientes igual ao número exibido no gráfico de ACF.
Considerando que esse número não é grande, as estimativas de espectro obtidas como resultado devem ser bem suaves.
A resposta de frequência da sequência, neste caso, pode ser expressa por meio de coeficientes de autocorrelação como segue:
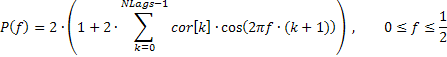
Um fragmento do código (vide TSAnalysis.mqh) que é usado para calcular a AFR com base na fórmula fornecida é definido abaixo.
. . . n=320; // Number of X-points ArrayResize(Spect,n); v=M_PI/n; for(i=0;i<n;i++) { a=i*v; b=0; for(k=0;k<NLags;k++)b+=((double)NLags-k)/(NLags+1.0)*ACF[k]*MathCos(a*(k+1)); Spect[i]=2.0*(1+2*b); // Spectrum Y-axis } . . .
Deve-se ressaltar que os valores de coeficiente de correlação do código acima são, para maior atenuamento, multiplicados pela função de intervalo triangular.
Para uma análise de espectro mais detalhada, o método de entropia máxima foi selecionado como outro acordo. A seleção de um método de estimativa de espectro universal é muito difícil. As desvantagens associadas aos métodos não-paramétricos clássicos de análise de espectro são bem conhecidas.
Os métodos de periodograma e correlograma podem servir como exemplos desse métodos que são facilmente implementados com o uso de algoritmos de transformada rápida de Fourier. Porém, apesar da alta estabilidade dos resultados, esses métodos requerem sequências de entrada muito longas para a obtenção do poder de resolução adequado. Em contraste, métodos paramétricos de estimativa de espectro (métodos auto-regressivos, por exemplo) podem assegurar uma resolução muito maior para sequências curtas.
Infelizmente, ao usá-los, é preciso levar em consideração não apenas as peculiaridades de uma determinada implementação desses métodos, mas também a natureza da sequência de entrada. Ao mesmo tempo, é muito difícil determinar a ordem ótima do modelo AR, cujo aumento leva a um aumento de poder de resolução, mas com resultados dispersos obtidos. Se modelos de ordem muito alta são utilizados, esses métodos começam a apresentar resultados instáveis.
Características comparativas de diferentes algoritmos de estimativa de espectro podem ser encontradas no livro de S. L. Marple, "Análise de espectro digital com aplicações". Como já mencionado, o método de entropia máxima foi selecionado para este caso. O método provavelmente resulta no menor poder de resolução quando comparado a outros métodos auto-regressivos, mas foi selecionado com vistas à obtenção de estimativas de espectro mais estáveis.
Vamos observar a ordem dos cálculos da estimativa de espectro auto-regressiva. Já discorremos acerca da escolha da ordem de modelo, de forma que presumiremos que a ordem de modelo já foi selecionada como sendo igual ao IP e que os coeficientes de autocorrelação de IP cor[] já tenham sido calculados.
Para obtenção dos coeficientes auto-regressivos com o uso dos coeficientes de autocorrelação conhecidos, o algoritmo de Levinson-Durbin é utilizado implementado como método Recursividade de Levinson.
//----------------------------------------------------------------------------------- // Calculate the Levinson-Durbin recursion for the autocorrelation sequence R[] // and return the autoregression coefficients A[] and partial autocorrelation // coefficients K[] //----------------------------------------------------------------------------------- void TSAnalysis::LevinsonRecursion(const double &R[],double &A[],double &K[]) { int p,i,m; double km,Em,Am1[],err; p=ArraySize(R); ArrayResize(Am1,p); ArrayInitialize(Am1,0); ArrayInitialize(A,0); ArrayInitialize(K,0); km=0; Em=1; for(m=0;m<p;m++) { err=0; for(i=0;i<m;i++)err+=Am1[i]*R[m-i-1]; km=(R[m]-err)/Em; K[m]=km; A[m]=km; for(i=0;i<m;i++)A[i]=(Am1[i]-km*Am1[m-i-1]); Em=(1-km*km)*Em; ArrayCopy(Am1,A); } return; }
O método possui três parâmetros de entrada. Todos os três parâmetros são referências a arrays. Ao chamar este método, os coeficientes de autocorrelação de entrada devem ser colocados no primeiro array R[]. Durante os cálculos, estes valores permanecem inalterados.
Os coeficientes de autocorrelação obtidos serão colocados no array A[]. Além disso, o array K[] conterá valores de função de autocorrelação parcial iguais aos coeficientes de reflexão do modelo auto-regressivo, tomados com o sinal oposto. A ordem do modelo não é passada como um parâmetro de entrada; presume-se que ela seja igual ao número de elementos do array de entrada R[].
Os tamanhos de array de saída, portanto, não podem ser inferiores ao tamanho de array de entrada; o preenchimento deste requisito não é verificado dentro da função. Ao completar os cálculos, o coeficiente auto-regressivo zero e o coeficiente zero da função de autocorrelação parcial não são salvos nos arrays A[] e K[].
Presume-se que eles são sempre iguais a um. Assim, os arrays de saída conterão, assim, a sequência de entrada, coeficientes com índices de 1 a IP (não deve ser confundido com índices de array que iniciam com 0).
Os valores da função de autocorrelação parcial obtidos são posteriormente, usados apenas para exibição em um gráfico respectivo, e os coeficientes auto-regressivos servem como base para o cálculo da estimativa de resposta de frequência, que é definida pela seguinte fórmula:
![]()
A resposta de frequência é calculada para 4096 valores de frequência normalizada ao longo do período de 0 a 0,5. O cálculo direto dos valores da AFR utilizando a fórmula acima leva muito tempo, o qual pode ser substancialmente reduzido com o uso de algoritmos de transformada rápida de Fourier para o cálculo da soma de exponenciais complexas.
Para esse propósito, o método Calc utiliza a transformada rápida de Hartley (FHT) em vez da transformada rápida de Fourier.
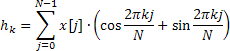
A transformada de Hartley não envolve operações complexas e tanto a sequência de entrada como de saída são válidas. A transformada inversa de Hartley é calculada com o uso da mesma fórmula, mas requer um fator 1/N adicional.
Em uma sequência de entrada válida, há uma conexão simples entre os coeficientes dessa transformada e os coeficientes da transformada de Fourier.
![]()
Informações sobre os algoritmos de transformada rápida de Hartley podem ser encontradas em "biblioteca de algoritmo FXT" e "Transformadas discretas de Fourier e de Hartley".
Nesta implementação, a função transformada rápida de Hartley é representada pelo método fht.
//----------------------------------------------------------------------------------- // Radix-2 decimation in frequency (DIF) fast Hartley transform (FHT). // Length is N = 2 ** ldn //----------------------------------------------------------------------------------- void TSAnalysis::fht(double &f[], ulong ldn) { const ulong n = ((ulong)1<<ldn); for (ulong ldm=ldn; ldm>=1; --ldm) { const ulong m = ((ulong)1<<ldm); const ulong mh = (m>>1); const ulong m4 = (mh>>1); const double phi0 = M_PI / (double)mh; for (ulong r=0; r<n; r+=m) { for (ulong j=0; j<mh; ++j) { ulong t1 = r+j; ulong t2 = t1+mh; double u = f[t1]; double v = f[t2]; f[t1] = u + v; f[t2] = u - v; } double ph = 0.0; for (ulong j=1; j<m4; ++j) { ulong k = mh-j; ph += phi0; double s=MathSin(ph); double c=MathCos(ph); ulong t1 = r+mh+j; ulong t2 = r+mh+k; double pj = f[t1]; double pk = f[t2]; f[t1] = pj * c + pk * s; f[t2] = pj * s - pk * c; } } } if(n>2) { ulong r = 0; for (ulong i=1; i<n; i++) { ulong k = n; do {k = k>>1; r = r^k;} while ((r & k)==0); if (r>i) {double tmp = f[i]; f[i] = f[r]; f[r] = tmp;} } } }
Ao chamar este método, uma referência ao array de dados de entrada f[] e o inteiro Idn que define o comprimento da transformada, N = 2 ** Idn, são passados na entrada. O tamanho do array f[] não deve ser inferior ao comprimento N da transformada. Lembre-se de que não há verificações para isto dentro da função. Também lembre-se de que o resultado da transformada é armazenado no array em que os dados de entrada foram posicionados.
Após a transformada, os dados de entrada em si não são armazenados. No método Calc em consideração, uma transformada de comprimento N=8192 é usada para calcular 4096 valores AFR. Após o cálculo da magnitude quadrada da transformada e obtenção da reciprocidade, o resultado obtido é normalizado para o seu valor máximo e dimensionado logaritmicamente.
Além disso, não há maiores peculiaridades no método Calc; se necessário, é possível observar esta implementação em detalhes em TSAnalysis.mqh.
Todos os valores obtidos e preparados para exibição como resultado dos cálculos são armazenados em variáveis que são membro da classe TSAnalysis. Assim, eles não precisam ser passados como argumentos quando se chama o método de exibição virtual para exibir os resultados.
Visualização
Como já mencionado, o método de exibição é declarado como virtual. Assim, ao redefiní-lo, é possível implementar o método requerido para a exibição de resultados de cálculos que seja diferente do proposto. A visualização na classe TSAnalysis proposta é executada através da preparação do arquivo de dados e da chamada de um navegador de internet para exibir os dados.
Para que um navegador de internet possa exibir esses dados, o arquivo TSA.htm é usado localizado no mesmo diretório do restante dos arquivos do projeto. Este método para exibição de informações gráficas foi descrito anteriormente no artigo "Gráficos e diagramas em HTML".
A classe TSAnalysis do método de exibição é encarregada de formatar e salvar todos os resultados de cálculos que serão exibidos em uma variável do tipo cadeia de caracteres (vide TSAnalysis.mqh). Uma longa linha gerada desta forma é salva em TSDat.txt em um passo único. A criação deste arquivo e o armazenamento de dados dentro dele são feitos através da utilização das ferramentas padrão do MQL5, de forma que o arquivo é criado no diretório \MQL5\Files.
Este arquivo é então movido para o diretório deste projeto através da chamada das funções externas do sistema. Isto é seguido por uma chamada de um navegador de internet exibindo TSA.htm que utilizada dados do arquivo TSDat.txt. Porque as funções do sistema são chamadas no método de exibição, o uso de DLLs externos deverá estar habilitado no terminal para trabalhar com a classe TSAnalysis.
Exemplos
O TSAexample.mq5 incluído no arquivo TSAnalysis.zip é um exemplo do uso da classe TSAnalysis.
//----------------------------------------------------------------------------------- // TSAexample.mqh // 2011, victorg // https://www.mql5.com //----------------------------------------------------------------------------------- #property copyright "2011, victorg" #property link "https://www.mql5.com" #include "TSAnalysis.mqh" //----------------------------------------------------------------------------------- // Script program start function //----------------------------------------------------------------------------------- void OnStart() { double bd[]={47,64,23,71,38,64,55,41,59,48,71,35,57,40,58,44,80,55,37,74,51,57,50, 60,45,57,50,45,25,59,50,71,56,74,50,58,45,54,36,54,48,55,45,57,50,62,44,64,43,52, 38,59,55,41,53,49,34,35,54,45,68,38,50,60,39,59,40,57,54,23}; TSAnalysis *tsa=new TSAnalysis; tsa.Calc(bd); delete tsa; }
Com pode ser visto, a referência à classe é muito simples; se há um array preparado contendo a sequência de entrada, não será necessário muito esforço para passá-lo ao método Calc para análise. Além disso, você deve se lembrar de liberar a memória chamando deletar. O resultado da execução deste script já foi apresentado no início do artigo.
Para demonstrar a eficiência das estimativas de espectro produzidas, vamos focar em exemplos adicionais em que serão usadas sequências geradas.
Inicialmente, usaremos uma sequência que consiste em duas senoides.
int i,n; double a,x[]; n=400; ArrayResize(x,n); a=2*M_PI; for(i=0;i<n;i++)x[i]=MathSin(0.064*a*i)+MathSin(0.071*a*i);
A figura abaixo demostra a estimativa de resposta de frequência desta sequência.

Figura 2. Estimativa de espectro. Duas senoides
Embora seja possível observar as senoides com clareza, a aproximação da área de interesse do gráfico permitiu que descobríssemos que os picos estão localizados nas frequências 0,0637 e 0,0712. Em outras palavras, eles são um pouco diferentes dos valores reais. Quando a sequência consiste em uma única senoide, esta distorção na estimativa não é observada. Vamos considerar que esta ocorrência seja efeito do método de análise de espectro selecionado.
Vamos complicar a tarefa mais ainda ao adicionar um componente aleatório a nossa sequência. Para isto, um gerador de sequência pseudo-aleatório será usado representado pela classe RNDXor128 que pode ser encontrada no arquivo RNDXor128.zip ao final do artigo.
O fragmento de código abaixo foi usado para gerar um sinal de teste.
int i,n; double a,x[]; RNDXor128 *rnd=new RNDXor128; n=800; ArrayResize(x,n); a=2*M_PI; for(i=0;i<n;i++)x[i]=MathSin(0.064*a*i)+MathSin(0.071*a*i)+rnd.Rand_Norm(); delete rnd;
Neste exemplo, um sinal aleatório com distribuição e variação de unidade normais foi adicionado às duas senoides.
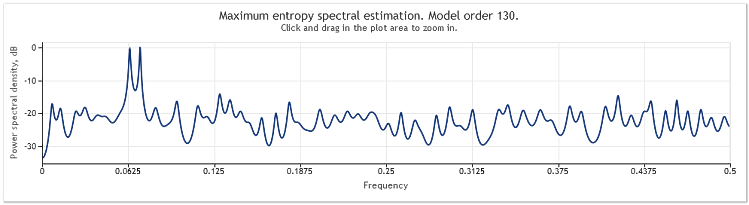
Figura 3. Estimativa de espectro. Duas senoides e um sinal aleatório
Neste caso, os componentes senoidais permanecem bem discerníveis.
Um aumento quíntuplo na amplitude do componente aleatório resulta em senoides substancialmente mascaradas.
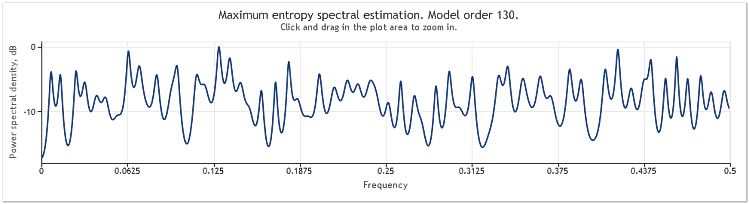
Figura 4. Estimativa de espectro. Duas senoides e um sinal aleatório com maior amplitude
Quando o comprimento da sequência aumenta de 400 para 800 elementos, as senoides tornam-se bem observáveis outra vez.
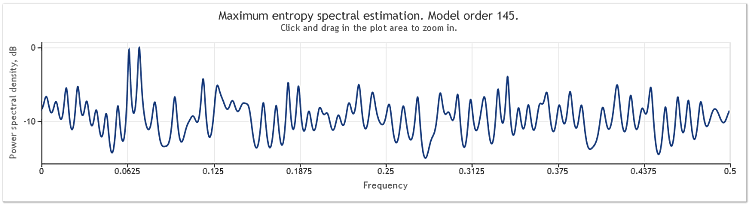
Figura 5. Duas senoides e um sinal aleatório com maior amplitude N=800
Deste modo, a ordem do modelo auto-regressivo aumentou de 130 para 145. O aumento do comprimento da sequência levou a uma maior ordem do modelo e, como resultado, o poder de resolução da estimativa de espectro aumentou - os picos do gráfico tornaram-se nitidamente mais agudos.
A estimativa de espectro para as cotações de EURUSD, D1 ao longo de dois anos (2009 e 2010) pode ser exibida da seguinte forma:
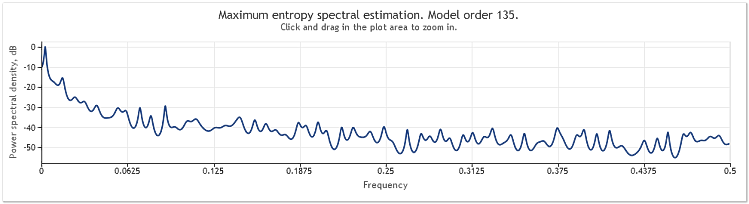
Figura 6. Cotações de EURUSD. 2009-2010. Período D1
A sequência de entrada consistiu em 519 valores e a ordem do modelo, como pode ser visto na figura, apareceu como 135.
Como pode ser observado, esta estimativa de espectro contém vários picos distintos. Mas a estimativa por si só não é suficiente para determinar se esses picos são componentes periódicos das cotações.
A ocorrência de picos em resposta de frequência pode ser causada por um componente aleatório de alto nível presente nas cotações ou pela não estacionariedade explícita da sequência em análise.
Assim, é sempre aconselhável verificar o resultado obtido utilizando os dados de outra fração da sequência ou de outro período de tempo antes de chegar a uma conclusão final sobre a presença do componente periódico. Além disso, ao estudar a recorrência cíclica, é possível tentar usar as diferenças da sequência em vez da sequência em si.
Conclusão
Porque o método de estimativa de espectro utilizado neste artigo se baseia em coeficientes de autocorrelação, a média da sequência de entrada sempre parece ter sido deletada da sequência durante a aplicação do método. Com frequência, é absolutamente necessário deletar um componente constante da sequência de entrada, mas, ao se utilizar métodos auto-regressivos, esta remoção pode, em alguns casos, ocasionar distorção da estimativa de espectro no período de baixa frequência.
Um exemplo dessas distorções é apresentado ao fim do capítulo "Sumário de resultados referentes às estimativas de espectro", no livro "Análise de espectro digital com aplicações", de S. L. Marple. Em nosso caso, o método de análise de espectro adotado não nos deixa qualquer outra opção. Desta forma, leve em consideração que a estimativa de espectro é sempre executada em relação a uma sequência de média deletada.
Referências
- Wuertz, Diethelm e Katzgraber, Helmut (2009): Precise finite-sample quantiles of the Jarque-Bera adjusted Lagrange multiplier test, Swiss Federal Institute of Technology, Zurique,2009.
- Tanweer-ul-Islam, Asad Zaman, Normality Testing - A new Direction, IIE, International Islamic University, Islamabad, Paquistão, 2008.
- Carlos M. Urzua, Portable and powerful tests for normality, Tecnologico de Monterrey, Campus Cidade do México, 2007.
- Comparison of Common Tests for Normality
- S. V. Bulashev. Estatística para negociadores. - М.: Kompania Sputnik +, 2003. - 245 pp.
- P. V. Novitsky, I. A. Zograf. Estimativa de erro em resultados de medição. Energoatomizdat, 1991.
- S. L. Marple, Jr. Análise de espectro digital com aplicações. Moscou: Mir, 1990.
- David J. Sheskin, Handbook of Parametric and Nonparametric Statistical Procedures, Chapman and Hall/CRC.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/292
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 MQL5 Wizard para leigos
MQL5 Wizard para leigos
 Teoria dos indicadores adaptativosavançados e sua implementação em MQL5
Teoria dos indicadores adaptativosavançados e sua implementação em MQL5
 Previsão de séries temporais utilizando suavização exponencial
Previsão de séries temporais utilizando suavização exponencial
 Criar critérios personalizados de otimização de Expert Advisors
Criar critérios personalizados de otimização de Expert Advisors
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
O artigo Analysing the main characteristics of time series (Analisando as principais características das séries temporais) foi publicado:
Autor: Victor
Viktor, boa tarde.
Infelizmente, não estou conseguindo obter as informações finais. As características que aparecem na forma original são exibidas: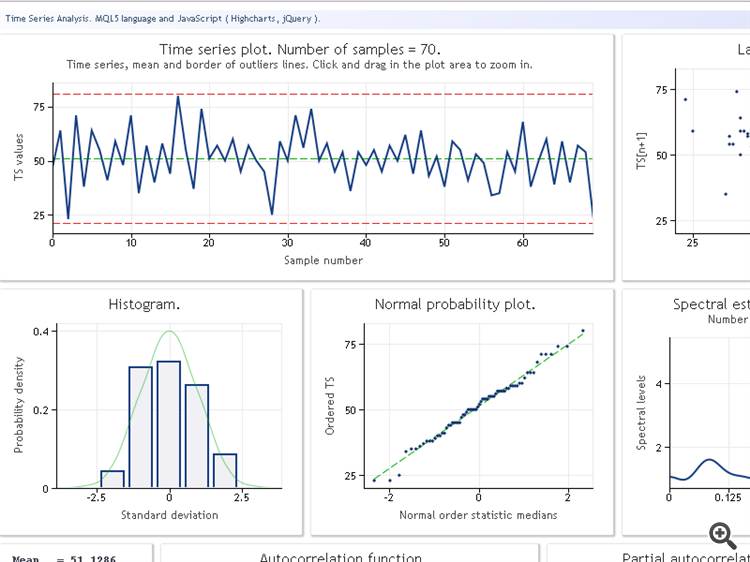
Observe o texto do script TSAexample.mq5.
Nele, a matriz bd[] é preenchida com valores da sequência investigada e, em seguida, usada como argumento ao chamar o método Calc da classe TSAnalysis.
Escreva seu próprio script (ou indicador), forme uma matriz contendo sua sequência por qualquer método disponível e passe-a como argumento para o método Calc por analogia com o exemplo dado no artigo.
Parece-me que você deve ser capaz de fazer isso.
Victor.
Por favor, o que significa o acrônimo "IP"?
Observe o texto do script TSAexample.mq5.
Nele, a matriz bd[] é preenchida com valores da sequência investigada e, em seguida, usada como argumento ao chamar o método Calc da classe TSAnalysis.
Escreva seu próprio script (ou indicador), forme uma matriz contendo sua sequência por qualquer método disponível e passe-a como argumento para o método Calc por analogia com o exemplo dado no artigo.
Parece-me que você deve ser capaz de fazer isso.
Victor.
Tudo funciona muito bem! Ferramenta muito útil! Muito obrigado!