
Selbstoptimierende Expert Advisor in MQL5 (Teil 4): Dynamische Positionsgrößen

Elektronische und digitale Computer gibt es seit den 1950er Jahren, aber Finanzmärkte existieren schon seit Jahrhunderten. Menschliche Händler waren in der Vergangenheit ohne fortschrittliche Computerwerkzeuge erfolgreich, was eine Herausforderung für die Entwicklung moderner Handelssoftware darstellt. Sollten wir die volle Rechenleistung nutzen oder uns an erfolgreichen menschlichen Handelsprinzipien orientieren? Dieser Artikel plädiert für ein Gleichgewicht zwischen Einfachheit und moderner Technologie. Trotz der heutigen fortschrittlichen Tools haben viele Händler in komplexen dezentralen Systemen ohne leistungsstarke Software wie MQL5 API Erfolg.
Die meisten der alltäglichen Entscheidungsprozesse, die wir als Menschen nutzen, lassen sich nur schwer sinnvoll an einen Computer vermitteln. Beim Handel hört man zum Beispiel häufig die Aussage: „Ich war sehr zuversichtlich, was meine Entscheidung angeht, also habe ich die Losgröße erhöht“. Wie können wir unsere Handelsanwendungen anweisen, dasselbe zu tun und die Positionsgröße zu erhöhen, wenn sie von dem Handel „überzeugt“ sind?
Ich hoffe, es ist dem Leser sofort klar, dass man dieses Ziel nicht erreichen kann, ohne Komplexität in das System einzubringen, um zu messen, wie „sicher“ sich der Computer „fühlt“. Ein Ansatz besteht darin, probabilistische Modelle zu erstellen, um das „Vertrauen“ in ein Geschäft zu quantifizieren. In diesem Artikel werden wir ein einfaches logistisches Regressionsmodell erstellen, um das Vertrauen in unsere Handelsgeschäfte zu messen, damit unsere Anwendung unsere Positionen unabhängig skalieren kann.
Wir werden uns auf die Bollinger-Band-Strategie konzentrieren, wie sie ursprünglich von John Bollinger vorgeschlagen wurde. Wir wollen diese Strategie verfeinern und ihre Unzulänglichkeiten beseitigen, ohne den Kern der Idee zu verlieren.
Unsere Handelsanwendung wird darauf abzielen:
- Platziere ein zusätzliches Handelsgeschäft mit einer größeren Losgröße, wenn das Modell von dem Handel überzeugt ist.
- Platziere ein einzelnes Handelsgeschäft mit einer kleineren Losgröße, wenn das Modell weniger zuversichtlich ist.
Die ursprüngliche, von John Bollinger vorgeschlagene Handelsstrategie brachte in unserem Backtest 493 Handelsgeschäfte. Von allen platzierten Handelsgeschäften verzeichneten 62 % einen Gewinn. Dies ist zwar ein gesunder Anteil an erfolgreichen Handelsgeschäften, aber nicht genug, um eine profitable Handelsstrategie zu entwickeln. In unserem Backtest-Zeitraum verloren wir -813 $ und erzielten eine Sharpe Ratio von -0,33. Unsere verfeinerte Version des Algorithmus platzierte insgesamt 495 Handelsgeschäfte, von denen 63 % profitabel waren. Unser Gesamtgewinn am Ende des Backtests stieg im gleichen Zeitraum drastisch auf 2 427 $, und unsere Sharpe Ratio pendelte sich bei 0,74 ein.
Ziel dieses Artikels ist es nicht, die Leistungsfähigkeit fortschrittlicher Rechenwerkzeuge wie DNNs oder Algorithmen des Reinforcement Learning zu untergraben. Im Gegenteil, ich bin begeistert von den Möglichkeiten, die diese Technologien bieten. Es ist jedoch wichtig zu erkennen, dass Komplexität um ihrer selbst willen nicht unbedingt zu besseren Ergebnissen führt.
Ich verstehe die Herausforderungen, die sich für ein neues Mitglied einer algorithmischen Handelsgemeinschaft ergeben. Ich war auch schon so, voller Ehrgeiz, aber unsicher, wie ich anfangen soll. Es ist leicht, sich von der riesigen Anzahl von Werkzeugen, Techniken und Optionen, die Ihnen zur Verfügung stehen, überwältigt zu fühlen.
Dieser Artikel soll eine Orientierungshilfe für diejenigen sein, die noch am Anfang stehen. Indem Sie mit einfachen Aufgaben beginnen, können Sie das Selbstvertrauen aufbauen, um komplexere Probleme selbständig anzugehen und ein tieferes Verständnis für ihre Anwendung zu entwickeln. Wir haben die in diesem Artikel veröffentlichten Ergebnisse erzielt, indem wir die ursprünglichen und einfachen Handelsregeln von John Bollinger beibehalten und sie durch Komplexität ergänzt haben, um den menschlichen Entscheidungsprozess zu emulieren, anstatt Komplexität um ihrer selbst willen einzuführen.
Überblick über die Handelsstrategie

Abb. 1: Ein Bild unserer Bollinger Band Strategie in Aktion
Unsere Handelsstrategie basiert auf den von John Bollinger vorgeschlagenen Handelssignalen. Die ursprünglichen Regeln der Strategie sind erfüllt, wenn wir verkaufen, wenn die Kurse das obere Bollinger Band durchbrechen, und wir kaufen, wenn die Kurse unter das untere Band fallen.
Im Allgemeinen können wir diese Regeln auch als unsere Ausstiegsbedingungen verwenden. Das bedeutet, dass wir, sobald die Kurse über dem obersten Band liegen, alle offenen Kaufgeschäfte schließen und zusätzlich unsere Verkaufsgeschäfte eröffnen werden. Diese Regelwerke reichen aus, um ein selbstverwaltendes System zu schaffen, das selbständig weiß, wann es seine Positionen öffnen und schließen muss.
Wir werden unsere Handelsstrategie für das GBPUSD-Paar vom 1. Januar 2022 bis zum 30. Dezember 2024 auf dem Zeitrahmen M15 testen.
Erste Schritte in MQL5
Um den Ball in MQL5 ins Rollen zu bringen, definieren wir zunächst Systemkonstanten, wie das zu handelnde Paar, die zu verwendende Losgröße und andere Konstanten, die der Nutzer nicht ändern soll.
//+------------------------------------------------------------------+ //| GBPUSD BB Breakout Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define BB_SHIFT 0 // Our bollinger band should not be shifted #define SYMBOL "GBPUSD" // The intended pair for our trading system #define BB_PRICE PRICE_CLOSE // The price our bollinger band should work on #define LOT 0.1 // Our intended lot size
Von dort aus können wir die Handelsbibliothek laden.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Einige Aspekte der Handelsstrategie können vom Endnutzer gesteuert werden, wie z. B. der Zeitrahmen, den wir für die Berechnungen unserer technischen Indikatoren verwenden sollten, und der Zeitraum für den Bollinger-Band-Indikator.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Technical Indicators" input ENUM_TIMEFRAMES TF = PERIOD_M15; // Intended time frame input int BB_PERIOD = 30; // The period for our bollinger bands input double BB_SD = 2.0; // The standard deviation for our bollinger bands
Wir müssen auch globale Variablen definieren, die in unserem Programm verwendet werden.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int bb_handler; double bb_u[],bb_m[],bb_l[]; //+------------------------------------------------------------------+ //| System variables | //+------------------------------------------------------------------+ int state; double o,h,l,c,bid,ask;
Wenn unsere Handelsanwendung zum ersten Mal geladen wird, müssen wir unsere Initialisierungsfunktion aufrufen.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our system if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
Wenn unsere Anwendung nicht mehr genutzt wird, geben wir die technischen Indikatoren frei, die wir nicht mehr verwenden.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release resources we no longer need release(); }
Wenn wir aktualisierte Kursinformationen erhalten, müssen wir die neuen Kursdaten speichern und verarbeiten, um eine Handelsentscheidung zu treffen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Update our system variables update(); } //+------------------------------------------------------------------+
Diese Funktion ist für die Einrichtung unseres technischen Indikators zuständig.
//+------------------------------------------------------------------+ //| Custom functions | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Setup our technical indicators and other variables | //+------------------------------------------------------------------+ bool setup(void) { //--- Setup our system bb_handler = iBands(SYMBOL,TF,BB_PERIOD,BB_SHIFT,BB_SD,BB_PRICE); state = 0; //--- Validate our system has been setup correctly if((bb_handler != INVALID_HANDLE) && (Symbol() == SYMBOL)) return(true); //--- Something went wrong! return(false); }
Wenn wir unsere Handelsanwendung nicht mehr verwenden, geben wir den Speicher frei, der mit dem ausgewählten technischen Indikator verbunden war.
//+------------------------------------------------------------------+ //| Release the resources we no longer need | //+------------------------------------------------------------------+ void release(void) { //--- Free up system resources for our end user IndicatorRelease(bb_handler); }
Wenn wir aktualisierte Preisinformationen vom Markt erhalten, aktualisieren wir unsere globalen Variablen und prüfen dann, ob wir gültige Handels-Setups haben, wenn wir keine offenen Positionen haben.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update(void) { static datetime timestamp; datetime current_time = iTime(Symbol(),PERIOD_CURRENT,0); if(timestamp != current_time) { timestamp = current_time; //--- Update our system CopyBuffer(bb_handler,0,1,1,bb_m); CopyBuffer(bb_handler,1,1,1,bb_u); CopyBuffer(bb_handler,2,1,1,bb_l); Comment("U: ",bb_u[0],"\nM: ",bb_m[0],"\nL: ",bb_l[0]); //--- Market prices o = iOpen(SYMBOL,PERIOD_CURRENT,1); c = iClose(SYMBOL,PERIOD_CURRENT,1); h = iHigh(SYMBOL,PERIOD_CURRENT,1); l = iLow(SYMBOL,PERIOD_CURRENT,1); bid = SymbolInfoDouble(SYMBOL,SYMBOL_BID); ask = SymbolInfoDouble(SYMBOL,SYMBOL_ASK); //--- Should we reset our system state? if(PositionsTotal() == 0) { state = 0; find_setup(); } if(PositionsTotal() == 1) { manage_setup(); } } }
Unsere Regeln für das Auffinden von Handelseinträgen sind die von John Bollinger vorgeschlagenen Originalregeln.
//+------------------------------------------------------------------+ //| Find an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Check if we have breached the bollinger bands if(c > bb_u[0]) { Trade.Sell(LOT,SYMBOL,bid); state = -1; return; } if(c < bb_l[0]) { Trade.Buy(LOT,SYMBOL,ask); state = 1; } }
Wie wir bereits erwähnt haben, können die von John Bollinger bereitgestellten Regeln auch zur Erstellung von Ausstiegsregeln verwendet werden, die genau festlegen, wann eine Position zu schließen ist.
//+------------------------------------------------------------------+ //| Manage our open trades | //+------------------------------------------------------------------+ void manage_setup(void) { if(((c < bb_l[0]) && (state == -1))||((c > bb_u[0]) && (state == 1))) Trade.PositionClose(SYMBOL); } //+------------------------------------------------------------------+
Wir beginnen damit, dass wir zunächst den vorgesehenen Zeitrahmen für den M15 auswählen. Diese niedrigen Zeitrahmen eignen sich hervorragend für Scalping-Strategien wie die unsere, die darauf abzielen, die täglich auf den Finanzmärkten entstehenden Muster auszunutzen. Unser Symbol der Wahl ist das Paar GBPUSD, und wir werden unseren Test vom 1. Januar 2022 bis zum 30. Dezember 2024 durchführen.

Abb. 2: Auswahl des Zeitrahmens für unseren Rückentest
Nun werden wir die Parameter unseres Tests feinabstimmen. Wenn Sie „Zufällige Verzögerung“ wählen, sehen Sie, wie zuverlässig unser Handelssystem ist, wenn die Marktbedingungen unbeständig sind. Außerdem habe ich die Option „Jeder Tick anhand realer Ticks“ gewählt, da dies die realistischste Simulation vergangener Marktdaten darstellt. In diesem Modellierungsmodus holt unser MetaTrader 5 Terminal alle Echtzeit-Ticks ab, die der Broker an diesem Tag gesendet hat. Dieser Vorgang kann je nach Ihrer Internetgeschwindigkeit einige Zeit in Anspruch nehmen. Letztendlich ist es jedoch wahrscheinlich, dass die Ergebnisse der Wahrheit sehr nahe kommen.
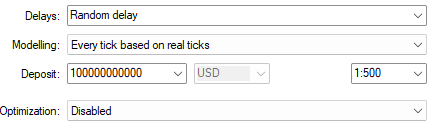
Abb. 3: Auswahl der Rückentestbedingungen für unseren Test
Zum Schluss werden wir Einstellungen definieren, die das Verhalten unserer Anwendung steuern werden. Beachten Sie, dass in unserem zweiten Test die in Abb. 4 gewählten Einstellungen durch unsere Systemvariablen konstant gehalten werden. Daher werden wir der zweiten Version unserer Anwendung keinen unfairen Vorteil gegenüber der aktuellen Version verschaffen, die wir gerade testen wollen.
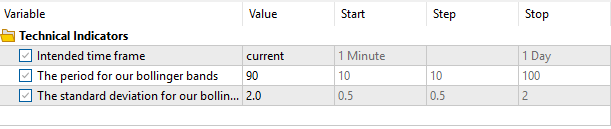
Abb. 4: Die Eingabeparameter für unseren Expert Advisor während dieses einmaligen Backtests
Die von unserem derzeitigen Algorithmus erzeugte Gewinnkurve ist von Natur aus instabil. Sie durchläuft unvorhersehbar Perioden mit schnellem Wachstum und übermäßigem Verlust. Die aktuelle Version unserer Handelsstrategie hat die meiste Zeit damit verbracht, sich von Verlusten zu erholen, anstatt Gewinne zu akkumulieren und gelegentlich Verluste zu machen. Das ist alles andere als ideal. Am Ende unseres Tests hat unser Algorithmus nur unser Kapital verloren. Es liegt auf der Hand, dass noch mehr Arbeit geleistet werden muss, bevor wir diesen Algorithmus überhaupt in Betracht ziehen können.

Abb. 5: Die Aktienkurve, die sich aus unserer aktuellen Version der ursprünglichen Handelsstrategie ergibt
Wenn wir uns die Ergebnisse unseres Backtests genauer ansehen, stellen wir fest, dass unser System einen gesunden Anteil an gewinnbringenden Handelsgeschäften hatte: 63% aller waren profitabel. Das Problem ist, dass unsere Gewinne fast halb so groß waren wie unsere Verluste. Da wir die ursprünglichen Handelsregeln nicht ändern wollen, besteht unser neues Ziel darin, das Wachstum unseres durchschnittlichen Gewinns näher an sein Maximum zu lenken und gleichzeitig sicherzustellen, dass unsere Verlustgeschäfte mit einer geringeren Rate wachsen. Dieser heikle Balanceakt wird uns die gewünschten Ergebnisse bringen.

Abb. 6: Eine detaillierte Analyse der Ergebnisse der ursprünglichen Version der Handelsstrategie
Die Verbesserung unserer ersten Ergebnisse
Wie wir sehen können, sind die ersten Ergebnisse nicht sehr ermutigend. Wir wissen jedoch, dass der menschliche Händler, der die Bollinger-Bänder erfand und diese Handelsregeln vorschlug, in jeder Hinsicht ein erfolgreicher Händler war. Wo ist also die Lücke zwischen den von John Bollinger aufgestellten Regeln und den Ergebnissen, die wir durch die algorithmische Befolgung seiner Regeln erzielt haben?

Abb. 7: Der Erfinder der Bollinger-Bänder, John Bollinger
Ein Teil des Unterschieds mag in der menschlichen Anwendung dieser Regeln liegen. Es ist wahrscheinlich, dass Bollinger im Laufe der Zeit ein Gespür dafür entwickelt hat, unter welchen Marktbedingungen seine Strategie erfolgreich ist und unter welchen Bedingungen sie zu scheitern droht. Unsere aktuelle Anwendung riskiert bei jedem Handel stets den gleichen Betrag und behandelt alle Handelsmöglichkeiten gleich. Der Mensch kann jedoch nach eigenem Ermessen mehr oder weniger riskieren, je nach seinen erlernten Erwartungen und seinem Vertrauen in die Zukunft.
Menschliche Händler gehen dann ein Risiko ein, wenn sie glauben, dass es sich am ehesten auszahlt, sie halten sich nicht starr an ein vorgegebenes Regelwerk. Wir wollen unserem Computer neben der ursprünglichen Strategie eine zusätzliche Ebene der Flexibilität geben. Die Verwirklichung dieses Ziels kann hoffentlich die Diskrepanz zwischen den von uns erwarteten und den bisher erzielten Ergebnissen erklären. Deshalb werden wir Komplexität einführen, um unsere Maschine näher an das heranzubringen, was professionelle Menschen täglich tun, anstatt nur zu versuchen, zukünftige Preisniveaus direkt vorherzusagen.
Wir können ein logistisches Regressionsmodell erstellen, um unserer Anwendung ein Gefühl von „Vertrauen“ zu geben. Die Parameter unseres Modells werden anhand historischer Marktdaten optimiert, die wir von unserem MetaTrader 5-Terminal abrufen werden. Unsere native MQL5-Implementierung bedeutet, dass unser Expert Advisor auf jedem Zeitrahmen arbeiten kann, vorausgesetzt, es gibt genügend Daten für diesen Zeitrahmen.
Ein logistisches Regressionsmodell ist möglicherweise das einfachste Modell, das wir heute erstellen können. Es gibt viele Formen von logistischen Modellen, aber die Form, die wir heute behandeln, kann nur für die Modellierung von 2 Klassen verwendet werden. Leser, die mehr als 2 Klassen klassifizieren wollen, sollten mehr Literatur über logistische Modelle lesen.
Um die gewünschten Änderungen umzusetzen und den Entscheidungsprozess unserer Anwendung näher an den menschlichen Entscheidungsprozess heranzuführen, werden wir einige wichtige Änderungen an unserer aktuellen Version des Handelssystems vornehmen:
| Vorgeschlagene Änderung | Verwendungszweck |
|---|---|
| Zusätzliche Systemkonstanten | Wir werden neue Systemkonstanten erstellen müssen, um das probabilistische Modell, das wir aufbauen wollen, und alle anderen neuen Systemteile, die wir benötigen, unterzubringen. |
| Ergänzende technische Analyse | Die gleichzeitige Anwendung von 2 Strategien kann unserem System eine höhere Rentabilität verleihen. Wir werden auch die Bestätigung durch den Stochastik-Oszillator einholen, bevor wir unsere Handelsgeschäfte eröffnen, um die Wahrscheinlichkeit profitabler Handelsgeschäfte zu erhöhen. |
| Neue Nutzereingaben | Damit unsere Nutzer die neuen Teile unseres Systems steuern können, müssen wir neue Nutzereingaben erstellen, die die neuen Funktionen steuern, die wir implementieren. |
| Modifikation von nutzerdefinierten Funktionen | Die maßgeschneiderten Funktionen, die wir bisher erstellt haben, müssen überarbeitet und erweitert werden, um alle neuen Variablen und Aufgaben, die unsere Anwendung erfüllen soll, zu berücksichtigen |
Die ersten Schritte
Um mit der Erstellung unserer überarbeiteten Version der Handelsanwendung zu beginnen, müssen wir zunächst neue Systemkonstanten erstellen, damit unsere Tests in allen vorgeschlagenen Versionen des Algorithmus konsistent bleiben.
//+------------------------------------------------------------------+ //| GBPUSD BB Breakout Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define BB_SHIFT 0 // Our bollinger band should not be shifted #define SYMBOL "GBPUSD" // The intended pair for our trading system #define BB_PRICE PRICE_CLOSE // The price our bollinger band should work on #define BB_PERIOD 90 // The period for our bollinger bands #define BB_SD 2.0 // The standard deviation for our bollinger bands #define LOT 0.1 // Our intended lot size #define TF PERIOD_M15 // Our intended time frame #define ATR_MULTIPLE 20 // ATR Multiple #define ATR_PERIOD 14 // ATR Period #define K_PERIOD 12 // Stochastic K period #define D_PERIOD 20 // Stochastic D period #define STO_SMOOTHING 12 // Stochastic smoothing #define LOGISTIC_MODEL_PARAMS 5 // Total inputs to our logistic model
Außerdem möchten wir, dass der Nutzer die Funktionalität unseres logistischen Regressionsmodells kontrolliert. Die Eingabe „fetch“ bestimmt, wie viele Daten zur Erstellung unseres Modells verwendet werden sollen. Beachten Sie, dass wir im Allgemeinen umso weniger Daten zur Verfügung haben, je größer der Zeitrahmen ist, den der Nutzer verwenden möchte. Andererseits bestimmt „look_ahead“, wie weit in die Zukunft unser Modell versuchen soll, Prognosen zu erstellen.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int fetch = 5; // How many historical bars of data should we fetch? input int look_ahead = 10; // How far ahead into the future should we forecast?
Außerdem benötigen wir neue globale Variablen in unserer Anwendung. Diese Variablen werden als Organisatoren für unsere neuen technischen Indikatoren sowie für die beweglichen Teile unseres logistischen Regressionsmodells dienen.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int bb_handler,atr_handler,stoch_handler; double bb_u[],bb_m[],bb_l[],atr[],stoch[]; double logistic_prediction; double learning_rate = 5E-3; vector open_price = vector::Zeros(fetch); vector open_price_old = vector::Zeros(fetch); vector close_price = vector::Zeros(fetch); vector close_price_old = vector::Zeros(fetch); vector high_price = vector::Zeros(fetch); vector high_price_old = vector::Zeros(fetch); vector low_price = vector::Zeros(fetch); vector low_price_old = vector::Zeros(fetch); vector target = vector::Zeros(fetch); vector coef = vector::Zeros(LOGISTIC_MODEL_PARAMS); double max_forecast = 0; double min_forecast = 0; double baseline_forecast = 0;
Die meisten anderen Teile unseres Handelssystems werden gleich bleiben, mit Ausnahme einiger Funktionen, die erweitert werden müssen, und neuer Funktionen, die wir definieren müssen. Der erste Punkt auf der Liste, der bearbeitet werden muss, ist unsere Initialisierungsfunktion. Wir müssen noch weitere Schritte durchführen, bevor wir mit dem Handel beginnen können. Wir müssen das ATR und das stochastische Modell einrichten und zusätzlich die Funktion „setup_logistic_model()“ definieren.
//+------------------------------------------------------------------+ //| Setup our technical indicators and other variables | //+------------------------------------------------------------------+ bool setup(void) { //--- Setup our system bb_handler = iBands(SYMBOL,TF,BB_PERIOD,BB_SHIFT,BB_SD,BB_PRICE); atr_handler = iATR(SYMBOL,TF,ATR_PERIOD); stoch_handler = iStochastic(SYMBOL,TF,K_PERIOD,D_PERIOD,STO_SMOOTHING,MODE_EMA,STO_LOWHIGH); state = 0; higher_state = 0; setup_logistic_model(); //--- Validate our system has been setup correctly if((bb_handler != INVALID_HANDLE) && (Symbol() == SYMBOL)) return(true); //--- Something went wrong! return(false); }
Unser logistisches Regressionsmodell geht von einer Reihe von Eingaben aus und sagt eine Wahrscheinlichkeit zwischen null und eins voraus, dass die Zielvariable zur Standardklasse gehört, wenn der aktuelle Wert von x gegeben ist. Das Modell verwendet eine Sigmoidfunktion, die in Abbildung 8 dargestellt ist, um diese Quoten zu berechnen.
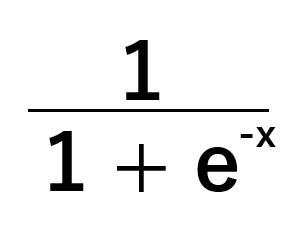
Stellen Sie sich vor, Sie möchten das folgende Problem lösen: „Wie hoch ist die Wahrscheinlichkeit, dass eine Person aufgrund ihres Gewichts und ihrer Größe männlich ist?“. In dieser Beispielfrage sei „männlich“ die Standardklasse. Wahrscheinlichkeiten über 0,5 bedeuten, dass die Person vermutlich männlich ist, und Wahrscheinlichkeiten unter 0,5 bedeuten, dass das angenommene Geschlecht weiblich ist. Dies ist die einfachste mögliche Version des logistischen Modells. Es gibt Versionen des logistischen Modells, die mehr als 2 Ziele klassifizieren können, aber wir werden sie heute nicht berücksichtigen.
Die in Abb. 8 verallgemeinerte Sigmoidfunktion wandelt jeden beliebigen Wert von x um und liefert einen Ausgangswert zwischen 0 und 1, wie in Abb. 9 unten dargestellt.
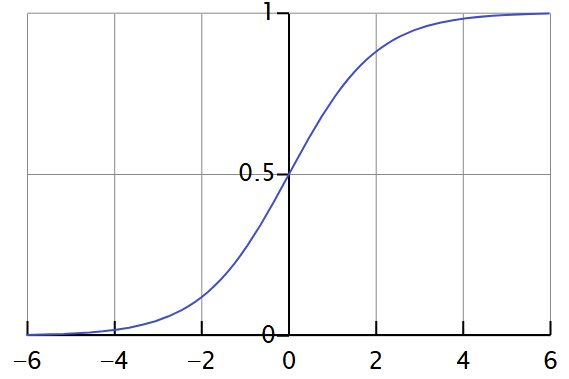
Abb. 9: Visualisierung der Transformation einer sigmoiden Funktion
Wir können unsere Sigmoidfunktion sorgfältig kalibrieren, sodass sie für alle Beobachtungen in unseren Trainingsdaten, die zur Klasse 1 gehörten, Schätzungen nahe bei 1 und für alle Werte in unseren Trainingsdaten, die zur Klasse 0 gehörten, Schätzungen nahe bei 0 erzeugt. Dieser Algorithmus wird als Maximum-Likelihood-Schätzung bezeichnet. Wir können uns diesen Ergebnissen mit einem viel einfacheren Algorithmus, dem so genannten Gradientenabstieg, nähern.
Im folgenden Code bereiten wir zunächst unsere Eingabedaten vor. Wir ermitteln die Veränderung des Eröffnungs-, Höchst-, Tiefst- und Schlusskurses, die unsere Eingaben für das Modell sein werden. Danach erfassen wir die damit verbundene zukünftige Preisänderung. Wenn das Preisniveau gesunken ist, erfassen wir dies als Klasse 0. Klasse 0 ist unsere Standardklasse. Vorhersagen, die über unserem Schwellenwert (cut-off point) liegen, bedeuten, dass unser Modell einen Rückgang des Preisniveaus in der Zukunft erwartet. Ebenso bedeuten Vorhersagen unterhalb des Schwellenwert, dass die Standardklasse nicht zutrifft, oder in unserem Fall, dass unser Modell einen Anstieg des Preisniveaus erwartet. In der Regel wird ein Schwellenwert von 0,5 bevorzugt.
Nach der Kennzeichnung unserer Daten setzen wir alle Koeffizienten unseres Modells auf 0 und machen dann die erste Vorhersage mit diesen schlechten Koeffizienten. Bei jeder Vorhersage korrigieren wir die Koeffizienten anhand der Differenz zwischen unserer Vorhersage und dem wahren Label. Dieser Vorgang wird für jeden abgefragten Balken wiederholt.
Schließlich habe ich bereits darauf hingewiesen, dass ein Schwellenwert von 0,5 klassischerweise bevorzugt wird. Die Finanzmärkte sind jedoch nicht gerade dafür bekannt, dass sie sich gut benehmen können. Der klassische Ansatz lieferte keine für uns als Händler nützlichen Wahrscheinlichkeiten, also habe ich den klassischen Algorithmus erweitert und noch weiter kalibriert.
Ich habe einen zusätzlichen Schritt eingefügt, um einen optimalen Abschneidepunkt zu berechnen, indem ich zunächst die von unserem Modell prognostizierten Höchst- und Mindestquoten aufgezeichnet habe. Anschließend haben wir den wahren Bereich der Vorhersagen unseres Modells halbiert, um unseren Grenzwert zu finden. Da der Finanzmarkt starkes Rauschen aufweisen kann, kann es für unsere Modelle eine Herausforderung sein, effektiv zu lernen, und wir müssen vielleicht kreativ werden und neue Wege zur Interpretation unserer Modelle finden. Dieser dynamische Schwellenwert wird unserem Modell helfen, seine Entscheidungen unabhängig von unserer inhärenten Voreingenommenheit zu treffen.

Abb. 10: Visualisierung der dynamischen Festlegung des Schwellenwerts
In unserem Fall werden also Wahrscheinlichkeiten oberhalb unseres dynamischen Abschneidepunkts als Standardklasse interpretiert, was bedeutet, dass unser Modell der Meinung ist, dass wir „verkaufen“ sollten. Das Gegenteil gilt für Vorhersagen, die unterhalb unseres dynamischen Schwellenwerts liegen.
//+------------------------------------------------------------------+ //| Setup our logistic regression model | //+------------------------------------------------------------------+ void setup_logistic_model(void) { open_price.CopyRates(SYMBOL,TF,COPY_RATES_OPEN,(fetch + look_ahead),fetch); open_price_old.CopyRates(SYMBOL,TF,COPY_RATES_OPEN,(fetch + (look_ahead * 2)),fetch); high_price.CopyRates(SYMBOL,TF,COPY_RATES_HIGH,(fetch + look_ahead),fetch); high_price_old.CopyRates(SYMBOL,TF,COPY_RATES_HIGH,(fetch + (look_ahead * 2)),fetch); low_price.CopyRates(SYMBOL,TF,COPY_RATES_LOW,(fetch + look_ahead),fetch); low_price_old.CopyRates(SYMBOL,TF,COPY_RATES_LOW,(fetch + (look_ahead * 2)),fetch); close_price.CopyRates(SYMBOL,TF,COPY_RATES_CLOSE,(fetch + look_ahead),fetch); close_price_old.CopyRates(SYMBOL,TF,COPY_RATES_CLOSE,(fetch + (look_ahead * 2)),fetch); open_price = open_price - open_price_old; high_price = high_price - high_price_old; low_price = low_price - low_price_old; close_price = close_price - close_price_old; CopyBuffer(atr_handler,0,0,fetch,atr); for(int i = (fetch + look_ahead); i > look_ahead; i--) { if(iClose(SYMBOL,TF,i) > iClose(SYMBOL,TF,i - look_ahead)) target[i-look_ahead-1] = 0; if(iClose(SYMBOL,TF,i) < iClose(SYMBOL,TF,i - look_ahead)) target[i-look_ahead-1] = 1; } //Fitting our coefficients coef[0] = 0; coef[1] = 0; coef[2] = 0; coef[3] = 0; coef[4] = 0; for(int i =0; i < fetch; i++) { double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_price[i]) + (coef[2] * high_price[i]) + (coef[3] * low_price[i]) + (coef[4] * close_price[i])))); coef[0] = coef[0] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * 1.0; coef[1] = coef[1] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * open_price[i]; coef[2] = coef[2] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * high_price[i]; coef[3] = coef[3] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * low_price[i]; coef[4] = coef[4] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * close_price[i]; } for(int i =0; i < fetch; i++) { double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_price[i]) + (coef[2] * high_price[i]) + (coef[3] * low_price[i]) + (coef[4] * close_price[i])))); if(i == 0) { max_forecast = prediction; min_forecast = prediction; } max_forecast = (prediction > max_forecast) ? (prediction) : max_forecast; min_forecast = (prediction < min_forecast) ? (prediction) : min_forecast; } baseline_forecast = ((max_forecast + min_forecast) / 2); Print(coef); Print("Baseline: ",baseline_forecast); }
Wenn wir nicht unseren Expert Advisor verwenden, müssen wir einige zusätzliche technische Indikatoren freigeben.
//+------------------------------------------------------------------+ //| Release the resources we no longer need | //+------------------------------------------------------------------+ void release(void) { //--- Free up system resources for our end user IndicatorRelease(bb_handler); IndicatorRelease(atr_handler); IndicatorRelease(stoch_handler); }
Unsere Bedingungen für den Aufbau von Positionen bleiben größtenteils gleich, außer wenn die Vorhersagen unseres Modells mit den von John Bollinger vorgeschlagenen Handelsregeln übereinstimmen, werden wir diese Chance doppelt nutzen und unsere Anwendung anweisen, nur unter diesen Bedingungen mehr Risiko einzugehen.
//+------------------------------------------------------------------+ //| Find an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { double open_input = iOpen(SYMBOL,TF,0) - iOpen(SYMBOL,TF,look_ahead); double close_input = iClose(SYMBOL,TF,0) - iClose(SYMBOL,TF,look_ahead); double high_input = iHigh(SYMBOL,TF,0) - iHigh(SYMBOL,TF,look_ahead); double low_input = iLow(SYMBOL,TF,0) - iLow(SYMBOL,TF,look_ahead); double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_input) + (coef[2] * high_input) + (coef[3] * low_input) + (coef[4] * close_input)))); Print("Odds: ",prediction - baseline_forecast); //--- Check if we have breached the bollinger bands if((c > bb_u[0]) && (stoch[0] < 50)) { Trade.Sell(LOT,SYMBOL,bid); state = -1; if(((prediction - baseline_forecast) > 0)) { Trade.Sell((LOT * 2),SYMBOL,bid); Trade.Sell((LOT * 2),SYMBOL,bid); state = -1; } return; } if((c < bb_l[0]) && (stoch[0] > 50)) { Trade.Buy(LOT,SYMBOL,ask); state = 1; if(((prediction - baseline_forecast) < 0)) { Trade.Buy((LOT * 2),SYMBOL,ask); Trade.Buy((LOT * 2),SYMBOL,ask); state = 1; } return; } }
Darüber hinaus wollen wir einen Stop-Loss haben, der nachgezogen werden soll, wenn unser Handel gewinnt, und der ansonsten an Ort und Stelle bleiben sollte. Dadurch wird sichergestellt, dass wir unser Risiko reduzieren, wenn wir gewinnen, was eine kluge Sache ist, die menschliche Händler die ganze Zeit tun.
//+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_setup(void) { if(((c < bb_l[0]) && (state == -1))||((c > bb_u[0]) && (state == 1))) Trade.PositionClose(SYMBOL); //--- Update the stop loss for(int i = PositionsTotal() -1; i >= 0; i--) { string symbol = PositionGetSymbol(i); if(_Symbol == symbol) { double position_size = PositionGetDouble(POSITION_VOLUME); double risk_factor = 1; if(position_size == (LOT * 2)) risk_factor = 2; double atr_stop = atr[0] * ATR_MULTIPLE * risk_factor; ulong ticket = PositionGetInteger(POSITION_TICKET); double position_price = PositionGetDouble(POSITION_PRICE_OPEN); long type = PositionGetInteger(POSITION_TYPE); double current_take_profit = PositionGetDouble(POSITION_TP); double current_stop_loss = PositionGetDouble(POSITION_SL); if(type == POSITION_TYPE_BUY) { double atr_stop_loss = (bid - (atr_stop)); double atr_take_profit = (bid + (atr_stop)); if((current_stop_loss < atr_stop_loss) || (current_stop_loss == 0)) { Trade.PositionModify(ticket,atr_stop_loss,current_take_profit); } } else+ if(type == POSITION_TYPE_SELL) { double atr_stop_loss = (ask + (atr_stop)); double atr_take_profit = (ask - (atr_stop)); if((current_stop_loss > atr_stop_loss) || (current_stop_loss == 0)) { Trade.PositionModify(ticket,atr_stop_loss,current_take_profit); } } } } } //+------------------------------------------------------------------+
Die Einstellungen, die die Dauer und den Zeitrahmen des Backtests steuern, werden beibehalten, die einzige Variable, die wir hier ändern müssen, ist der ausgewählte Experte. Wir haben die überarbeitete Version der Anwendung ausgewählt, die wir im vorangegangenen Abschnitt dieses Artikels zusammen überarbeitet haben. Achten Sie darauf, dass Sie auch Ihre Einstellungen beibehalten, während Sie die neue Version der Anwendung auswählen.
Abb. 11: Auswahl des Zeitrahmens und des Zeitraums für unseren zweiten Backtest zur Bewertung der Wirksamkeit der gewählten Einstellungen
Achten Sie wie immer darauf, dass Sie die Leverage-Einstellungen entsprechend Ihrer Vereinbarung mit Ihrem Broker wählen. Wenn Sie Ihre Leverage-Einstellungen nicht korrekt festlegen, können Sie unrealistische Erwartungen an die Rentabilität Ihrer Handelsanwendungen haben. Erschwerend kommt hinzu, dass es schwierig sein kann, die in Ihrem Backtest erzielten Ergebnisse zu reproduzieren, insbesondere wenn die Leverage-Einstellungen in Ihrem echten Konto nicht mit den Leverage-Einstellungen übereinstimmen, die Sie in Ihrem Backtest verwenden. Dies ist eine häufig übersehene Fehlerquelle bei der Durchführung von Backtests, also nehmen Sie sich Zeit.
Abb. 12: Backtests sind empfindlich gegenüber den Einstellungen, die beim Start des Backtests gewählt wurden. Seien Sie sicher, dass Sie es beim ersten Mal richtig machen
Nun werden wir festlegen, wie viele Daten unsere Handelsanwendung abrufen soll, um die Parameter unseres logistischen Regressionsmodells zu schätzen, sowie den Prognosehorizont für unser Modell. Versuchen Sie nicht, mehr Daten abzurufen, als Ihnen Ihr Makler zur Verfügung stellt. Andernfalls wird die Anwendung nicht wie vorgesehen funktionieren! Legen Sie außerdem einen Prognosehorizont fest, der mit Ihrer Risikotoleranz übereinstimmt.
Zum Beispiel können Sie Ihre Anwendung so trainieren, dass sie 2000 Schritte in der Zukunft vorausschaut. Sie müssen jedoch bedenken, dass 2000 Schritte in die Zukunft auf dem Zeitrahmen M15 etwa 20 Tagen entsprechen. Wenn Sie als Mensch nicht in der Lage sind, so weit in die Zukunft zu blicken, wenn Sie Ihre Handelsgeschäfte platzieren, dann versuchen Sie nicht, die Anwendung dazu zu zwingen, dies zu tun. Erinnern Sie sich daran, dass unser Ziel darin besteht, eine Anwendung zu entwickeln, die das nachahmt, was Sie als menschlicher Händler jeden Tag tun.

Abb. 13: Die Parameter, die das Verhalten unserer Handelsanwendung und unseres logistischen Regressionsmodells steuern
Nun sind wir beim informativsten Teil unseres Tests angelangt. Unser neues System brachte einen durchschnittlichen Gewinn von 79 Dollar. Ursprünglich erwarteten wir einen durchschnittlichen Gewinn von 45 $. Daher beträgt die Differenz zwischen unserem aktuellen erwarteten Gewinn (79 $) und unserem vorherigen erwarteten Gewinn (45 $) 34 $. Diese Differenz von 34 $ entspricht einem Zuwachs von etwa 75 % des ursprünglich erwarteten Gewinns.
Gleichzeitig beträgt unser neuer erwarteter Verlust -122 $, während unser ursprünglicher erwarteter Verlust bei -81 $ lag. Das ist ein Unterschied von 41 $ und entspricht einem Anstieg des durchschnittlichen Verlustes um etwa 50 %. Wir haben also unser Ziel erfolgreich erreicht!
Unsere neuen Einstellungen sorgen dafür, dass unsere Gewinne schneller wachsen als unsere Verluste. Dies ist auch der Grund dafür, dass wir unsere Sharpe Ratio und die erwartete Auszahlung erfolgreich korrigiert haben. Unsere ursprüngliche Version der Handelsstrategie verzeichnete einen Verlust von -791 $, während unser neues System einen Gewinn von 2.274 $ erzielte, ohne dass die Regeln des Algorithmus oder der Zeitraum des Backtests geändert wurden.
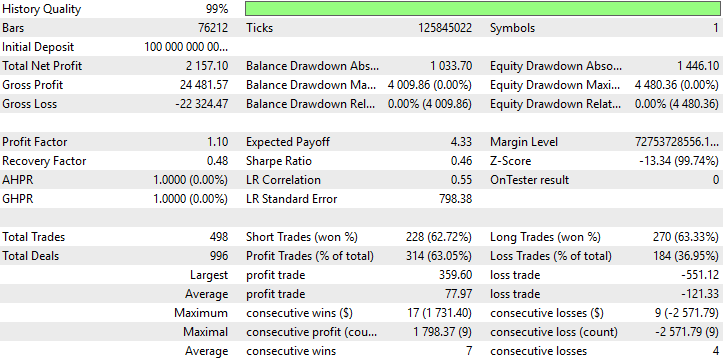
Abb. 14: Idealerweise würden wir wollen, dass unsere Verluste eine Wachstumsrate von 0 haben, aber die reale Welt ist nicht ideal
Wenn wir nun die Equity-Kurve betrachten, die unser Algorithmus erzeugt, können wir deutlich sehen, dass unser Algorithmus stabiler ist als ursprünglich. Bei allen Handelsstrategien gibt es Phasen des Rückgangs. Wir sind jedoch an der Fähigkeit der Strategie interessiert, sich von Verlusten zu erholen und ihre Gewinne zu erhalten. Eine Strategie, die zu risikoscheu ist, kann kaum Gewinne erzielen, und im Gegenteil, eine Strategie, die sehr risikofreudig ist, kann schnell alle Gewinne verlieren. Deshalb ist es uns gelungen, ein Gleichgewicht in der Mitte zu finden.
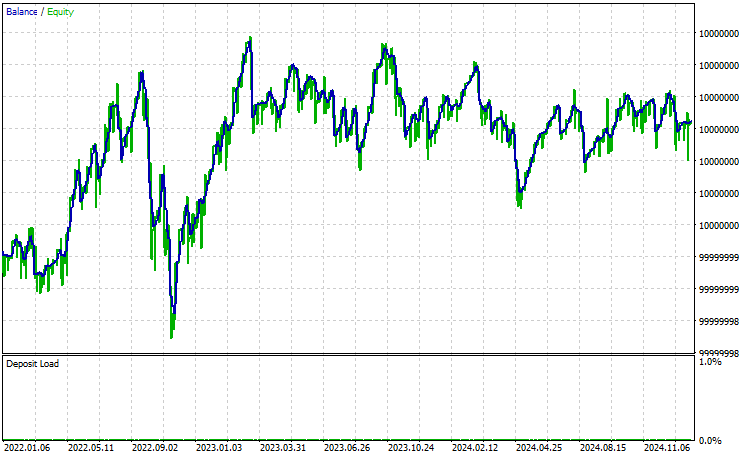
Abb. 15: Die von unserer neuen Version des Handelsalgorithmus erzeugte Aktienkurve ist wünschenswerter als unsere ursprünglichen Ergebnisse
Schlussfolgerung
Die Kontrolle des Risikos, das unsere Handelsanwendungen eingehen, ist von zentraler Bedeutung, um einen rentablen und nachhaltigen Handel zu gewährleisten. Dieser Artikel hat gezeigt, wie Sie Ihre Anwendungen so gestalten können, dass sie die Losgröße selbständig erhöhen, wenn unsere Anwendung feststellt, dass unser Handel eine hohe Gewinnchance hat. Andernfalls, wenn wir davon ausgehen, dass das Handelsgeschäft nicht zustande kommt, wird unsere Anwendung den kleinstmöglichen Betrag riskieren. Dieses dynamische Positionssizing ist für einen profitablen Handel von entscheidender Bedeutung, da es sicherstellt, dass wir das Beste aus jeder sich bietenden Gelegenheit machen und unsere Risiken verantwortungsbewusst steuern. Durch den gemeinsamen Aufbau eines probabilistischen logistischen Modells haben wir eine Möglichkeit kennengelernt, wie wir sicherstellen können, dass unsere Anwendung die optimale Positionsgröße auswählt, basierend auf dem, was sie über den jeweiligen Markt gelernt hat. | Angehängte Datei | Beschreibung |
|---|---|
| GBPUSD BB Breakout Benchmark | Dies ist die erste Version unserer Handelsanwendung, die bei unserem ersten Test nicht profitabel war. |
| GBPUSD BB Breakout Benchmark V2 | Der verfeinerte Algorithmus basiert auf denselben Handelsregeln, ist aber so konzipiert, dass er unsere Positionsgrößen auf intelligente Weise erhöht, wenn er erkennt, dass wir gute Gewinnchancen haben. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/16925
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.