
Do básico ao intermediário: Filas, Listas e Árvores (IV)

Introdução
No artigo anterior Do básico ao intermediário: Filas, Listas e Árvores (III), foi demonstrada toda a parte básica e essencial sobre o que seria de fato uma Lista encadeada. Vimos que com uma simples mudança no código, poderíamos ter a capacidade de construir uma lista duplamente encadeada ou uma lista singularmente encadeada. Coisa que muitos consideram ser algo difícil e muito complicado de ser feito. No entanto, o que foi visto no artigo anterior, não demonstra totalmente o que podemos fazer dentro do que seria uma lista encadeada. E porque ela em muitos casos é a melhor escolha, quando precisamos implementar algum tipo de sistema, cujo objetivo seria o de analisar uma imensa quantidade de dados.
Lembrando que estes dados, originalmente seriam colocados dentro de arrays. Porém usar arrays, pode tornar todo o nosso código, bastante dispendioso no que diz respeito a performance durante a execução do mesmo. Tentando resolver justamente esta questão acadêmicos e pesquisadores de ciência de dados, desenvolveram este mecanismo que está sendo explicado nestes artigos. Lembrando que aqui, estou tentando deixar as coisas o mais simples e didáticas quanto é possível de ser feito.
Muito bem, o mecanismo até agora apresentado, apenas nos permite incluir e excluir valores que se encontram presentes nas bordas da lista encadeada. Porém, e não é nada raro, muitas vezes precisamos adicionar e remover valores, em algum ponto fora das bordas da lista encadeada. E é justamente este mecanismo, que falta ser explicado. Já que ele ainda não foi implementado. Então, vamos ao nosso ritual. Que é o de remover qualquer tipo de distração, ou coisa que possa lhe tirar o foco do que será visto no artigo. E vamos começar a implementar a última parte a fim de tornar a lista encadeada totalmente funcional. E como de costume vamos a um novo tópico para começar o nosso passeio, pelo divertido mundo da programação.
Filas, listas e árvores (IV)
No artigo anterior, terminamos com o seguinte código que pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. 25. (*loc).info = arg; 26. (*loc).prev = NULL; 27. switch(pos) 28. { 29. case SEEK_SET: 30. (*loc).start = start; 31. (*start).prev = loc; 32. start = loc; 33. break; 34. case SEEK_END: 35. if (prev != NULL) (*prev).start = loc; 36. (*loc).prev = prev; 37. prev = loc; 38. start = (start == NULL ? loc : start); 39. break; 40. } 41. } 42. //+----------------+ 43. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 44. { 45. stList <T> *loc = NULL; 46. 47. if ((prev == NULL) || (start == NULL)) 48. return false; 49. 50. switch (pos) 51. { 52. case SEEK_SET: 53. loc = start; 54. start = (*loc).start; 55. break; 56. case SEEK_END: 57. loc = prev; 58. prev = (*loc).prev; 59. break; 60. } 61. arg = (*loc).info; 62. 63. delete loc; 64. 65. return true; 66. } 67. //+----------------+ 68. void Debug(void) 69. { 70. Print("===== DEBUG ====="); 71. for (stList <T> *loc = prev; loc != NULL; loc = (*loc).prev) 72. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]",(*loc).start, loc, (*loc).prev, (*loc).info); 73. Print("================="); 74. } 75. //+----------------+ 76. }; 77. //+------------------------------------------------------------------+ 78. void OnStart(void) 79. { 80. stList <char> list; 81. 82. list.Store(10); 83. list.Store(84); 84. list.Store(-6); 85. list.Store(47, SEEK_SET); 86. 87. list.Debug(); 88. 89. for (char info; list.Restore(info, SEEK_SET);) 90. Print(info); 91. }; 92. //+------------------------------------------------------------------+
Código 01
Este código, nos permite tanto criar o que seria uma lista com o objetivo de se comportar como uma pilha. Quanto também uma lista que consegue trabalhar com algo parecido com FIFO, ou seja, primeiro a entrar, primeiro a sair. Tudo isto de maneira muito simples e fácil de ser feito. Para maiores detalhes, veja o artigo anterior. No entanto, apesar de termos esta capacidade, o que já torna este código 01, algo bastante útil para diversos problemas. Ele não contém o mecanismo para incluir ou excluir elementos dentro de uma lista. Desde que estes elementos não estejam nas bordas da lista. Ou para deixar mais claro. Este código 01, somente nos permite remover ou adicionar o que seria o primeiro, ou o último elemento presente na lista. NUNCA um elemento intermediário.
Apesar disto, no artigo anterior, deixei um desafio para você tentar resolver. Isto para que você, meu caro leitor, pudesse perceber o quanto você conseguiu entender o que foi explicado e demonstrado durante o artigo. Se você conseguiu cumprir o desafio, devo lhe dar os meus parabéns. Já que apesar de eu ter dado algumas dicas de como vencer o desafio. O mesmo não é tão fácil para quem está começando a aprender programação. Já que é necessário, pensar em como resolver certos detalhes no próprio código que deverá ser implementado.
De qualquer forma, tendo ou não conseguido resolver a questão proposta no artigo anterior. Vamos aqui ver a minha proposta de solução. Lembrando que o objetivo aqui é a didática. Então mãos à obra.
Para começar vamos rever o resultado da execução deste código 01. Este é mostrado logo abaixo.
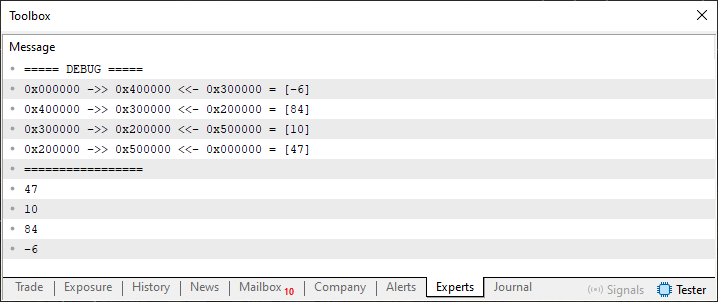
Imagem 01
A ideia aqui, seria primeiro remover um destes valores. No caso o valor 84 ou o valor 10. Isto sem de fato mexer muito no código 01, e sem precisar copiar a lista vista nesta imagem 01, para outro local da memória. E a maneira mais simples de se fazer isto é modificando os valores prev e start, da própria lista. Isto a fim de que o elemento desejado seja removido. Ok, a ideia básica é este. Mas como fazer isto? Bem, se você observar na própria imagem 01, irá notar que na parte onde estamos debugando a lista. Nos é mostrado como os endereços estão se relacionando. Então suponhamos que desejamos eliminar o elemento cujo valor é 84.
Se você observar na imagem 01, irá notar que o endereço onde este elemento se encontra é o 0x300000, note a coluna do meio. E que o endereço antecessor é 0x200000 e o posterior é 0x400000. Muito bem, com base nestas informações, podemos bolar uma forma de eliminar o elemento cujo valor é 84. Então para fazer isto, precisamos que o elemento antecessor, que no caso é o 10, aponte para o elemento posterior, que no caso é o -6. Ao mesmo tempo em que precisamos que o elemento cujo valor é -6, venha a apontar para o elemento cujo valor é 10. Ao fazermos isto, o elemento cujo valor é 84 poderá ser removido da lista, sem nenhum problema.
Acredito que agora você tenha começado a entender o que precisamos fazer. Assim, para que você entenda como isto será feito na prática, vamos ver o código que remove justamente este elemento 84. Este pode ser visto logo abaixo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. //+----------------+ 012. public: 013. //+----------------+ 014. stList(void) 015. :prev(NULL), 016. start(NULL) 017. {} 018. //+----------------+ 019. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 020. { 021. stList <T> *loc; 022. 023. loc = new stList <T>; 024. 025. (*loc).info = arg; 026. (*loc).prev = NULL; 027. switch(pos) 028. { 029. case SEEK_SET: 030. (*loc).start = start; 031. (*start).prev = loc; 032. start = loc; 033. break; 034. case SEEK_END: 035. if (prev != NULL) (*prev).start = loc; 036. (*loc).prev = prev; 037. prev = loc; 038. start = (start == NULL ? loc : start); 039. break; 040. } 041. } 042. //+----------------+ 043. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 044. { 045. stList <T> *loc = NULL; 046. 047. if ((prev == NULL) || (start == NULL)) 048. return false; 049. 050. switch (pos) 051. { 052. case SEEK_SET: 053. loc = start; 054. start = (*loc).start; 055. break; 056. case SEEK_END: 057. loc = prev; 058. prev = (*loc).prev; 059. break; 060. } 061. arg = (*loc).info; 062. 063. delete loc; 064. 065. return true; 066. } 067. //+----------------+ 068. bool Exclude(const T arg) 069. { 070. stList <T> *loc = start, 071. *ptr = NULL; 072. 073. for (; loc != NULL; ptr = loc, loc = (*loc).start) 074. if ((*loc).info == arg) break; 075. 076. if (loc == NULL) return false; 077. 078. (*ptr).start = (*loc).start; 079. (*loc).start.prev = ptr; 080. 081. delete loc; 082. 083. return true; 084. } 085. //+----------------+ 086. void Debug(void) 087. { 088. Print("===== DEBUG ====="); 089. for (stList <T> *loc = prev; loc != NULL; loc = (*loc).prev) 090. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]",(*loc).start, loc, (*loc).prev, (*loc).info); 091. Print("================="); 092. } 093. //+----------------+ 094. }; 095. //+------------------------------------------------------------------+ 096. void OnStart(void) 097. { 098. stList <char> list; 099. 100. list.Store(10); 101. list.Store(84); 102. list.Store(-6); 103. list.Store(47, SEEK_SET); 104. 105. list.Debug(); 106. list.Exclude(84); 107. list.Debug(); 108. 109. for (char info; list.Restore(info, SEEK_SET);) 110. Print(info); 111. }; 112. //+------------------------------------------------------------------+
Código 02
Agora preste atenção meu caro leitor. Este código 02, implementa justamente o que foi explicado a pouco. Ou seja, quando a linha 106 é executada, iremos chamar uma função cujo objetivo é justamente remover o elemento cujo valor é igual a 84. Antes de entrarmos nos detalhes de como esta função presente na linha 68 funciona. Vamos ver o resultado da execução do código 02. Este pode ser visto logo abaixo.
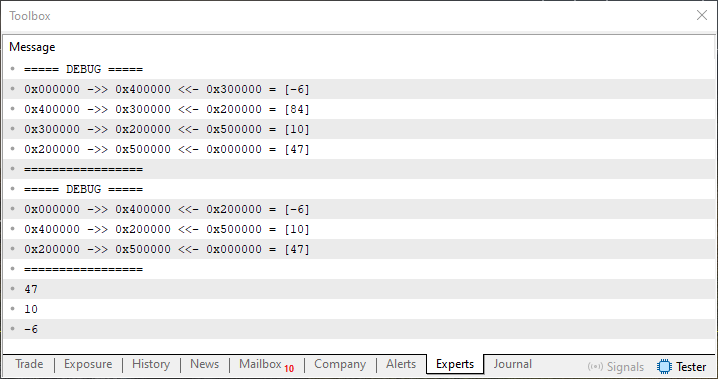
Imagem 02
Esta imagem 02, deixa bastante claro o que está sendo feito. Se você observar os valores que foram impressos devido a linha 105 irá notar que quando a linha 107 é executada. Os valores de endereço dos elementos -6 e 10 foram modificados. Isto de forma que o valor do elemento 84 simplesmente deixasse de fazer parte da lista. Mas espere um pouco. Para onde foi o elemento cujo valor era de 84? Bem, meu caro leitor, este elemento foi destruído. E para entender isto, vamos agora entender o código que faz justamente este trabalho.
Para que as coisas fiquem o mais simples quanto for possível ser feito, e para que você não confunda lista encadeada com outra coisa. Vamos inicialmente trabalhar no âmbito de valores dos elementos. Então a função da linha 68 irá receber o valor do elemento que queremos eliminar da lista encadeada. Como não sabemos onde este elemento se encontra na lista, já que ele pode estar em qualquer lugar. Iniciamos nas linhas 70 e 71 algumas variáveis auxiliares. Pois bem, agora começa o trabalho de procurar o elemento dentro da lista. Isto é feito pelo laço da linha 73. Quando o elemento for encontrado, a linha 74 irá finalizar o laço.
Mas também pode acontecer do elemento não ser encontrado. Neste caso o laço também irá terminar quando nenhum novo elemento existir na lista. Por conta disto, precisamos da linha 76, a fim de verificar se o fim da lista foi encontrado, ou se encontramos o elemento a ser eliminado. Caso tenhamos encontrado o elemento a ser eliminado da lista, iremos executar as próximas linhas. Caso contrário a função de eliminação termina.
Ok, agora vem a parte que muita gente fica confusa. Como o nosso elemento tem um antecessor e um precessor. Precisamos fazer com que o antecessor se ligue diretamente com o precessor. Somente assim poderemos eliminar o elemento encontrado. E para que esta ligação seja feita, precisamos das linhas 78 e 79. Uma vez que esta ligação tenha ocorrido, o elemento pode ser eliminado. Isto acontece na linha 81. No final a lista encadeada continua funcionando perfeitamente, como se nada tivesse mudado nela.
Esta foi a parte fácil. Procure entender muito bem esta parte que foi explicada até aqui. Pois agora vem a parte que faz muita gente desejar, que as pessoas que criaram ou implementam, o conceito de lista encadeada, sejam enviadas para uma temporada no inferno. Tamanha a confusão que muita gente faz, em cima do que será visto de agora em diante.
Para começar, o fato de informarmos qual o valor que deverá ser removido de uma lista encadeada, não é algo realmente muito prático. Mesmo que em alguns momentos, possamos vir a utilizar as coisas desta forma, ela na prática não se aplica muito. O que realmente, muitos programadores fazem é implementar a coisa toda de uma outra maneira.
No artigo anterior, mostrei que uma lista encadeada, poderia ser pensada como sendo um array. Sendo dada uma explicação do por que delas terem surgido. Como uma lista encadeada pode ser pensada como sendo um array, nada mais prático do que dizer o index do valor que queremos remover. Pense na seguinte situação: Você pode estar lidando com um conjunto qualquer de valores, mas apesar de você não saber qual o valor que deverá ser removido, muito provavelmente você sabe onde ele está. Então isto de informa o index do valor, não seria algo muito mais prático? De fato, seria, meu caro leitor. No entanto, existe um pequeno problema. E este pode ser visto nos próprios códigos mostrados até aqui.
E para explicar, vamos pegar o código 02. Observe o seguinte: Na linha 100, começamos a nossa lista, isto com o valor 10, logo depois incluímos o valor 84, seguido do valor -6. No entanto o valor 47 e colocado antes do elemento de valor 10. Poderíamos ter diversos outros valores sendo incluídos em qualquer ponto da lista. Como será feito depois. Mas vamos nos manter nestes valores e neste problema por hora. A pergunta é: Em que posição se encontra o valor 84? Se você prestar atenção irá ver que ele se encontra no index dois. Lembrando que a contagem se inicia em zero. No entanto, se você olhar o código, sem entender o que está sendo feito, irá imaginar que o valor 84 se encontra no index um. Isto por que ele é adicionado depois do elemento de valor 10. O que de fato estaria correto, se não fosse a linha 103, onde adicionamos o elemento de valor 47, ANTES do elemento de valor 10. E é justamente este tipo de coisa que gera uma baita de uma confusão na cabeça de muitos iniciantes.
Existe uma segunda questão, que no entanto é menos complexa e confusa. Isto porque, dependendo da forma como você irá varrer a lista encadeada, pode ser que você venha a eliminar o elemento errado. Isto devido ao fato de estar varrendo a lista de trás para frente. Por conta disto, é necessária uma boa dose de cuidado ao definir o que será o primeiro elemento e o que será o último elemento. Este tipo de coisa, pode suar com bobagem, mas se você por ventura, vir a criar uma lista encadeada circular, este tipo de situação pode fazer com que as coisas fiquem mesmo muito confusas. Apesar de listas encadeadas não serem muito comuns devido justamente a esta confusão gerada, para se saber qual seria o primeiro elemento. Pode ser que você precise criar uma. E se isto ocorrer, tome cuidado, durante a implementação do código.
Ok, então já sabemos e conhecemos alguns dos perigos que temos de lidar. E também, já sabemos como visualizar a lista encadeada, de forma a termos uma noção de como ela se parece com um array. Sendo assim, podemos partir para a parte divertida. Que é justamente o de implementar o código que irá trabalhar com index no lugar de trabalhar com valores. O código que faz isto, pode ser visto logo abaixo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. bool RemoveNode(stList <T> *arg) 014. { 015. delete arg; 016. counter--; 017. 018. return true; 019. } 020. //+----------------+ 021. public: 022. //+----------------+ 023. stList(void) 024. :prev(NULL), 025. start(NULL), 026. counter(0) 027. {} 028. //+----------------+ 029. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END, const uint index = 0) 030. { 031. stList <T> *loc; 032. 033. loc = new stList <T>; 034. 035. (*loc).info = arg; 036. (*loc).prev = NULL; 037. switch(pos) 038. { 039. case SEEK_SET: 040. (*loc).start = start; 041. (*start).prev = loc; 042. start = loc; 043. break; 044. case SEEK_CUR: 045. break; 046. case SEEK_END: 047. if (prev != NULL) (*prev).start = loc; 048. (*loc).prev = prev; 049. prev = loc; 050. start = (start == NULL ? loc : start); 051. break; 052. } 053. counter++; 054. } 055. //+----------------+ 056. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 057. { 058. stList <T> *loc = NULL; 059. 060. if ((prev == NULL) || (start == NULL)) 061. return false; 062. 063. switch (pos) 064. { 065. case SEEK_SET: 066. loc = start; 067. start = (*loc).start; 068. if (start != NULL) 069. (*start).prev = NULL; 070. break; 071. case SEEK_END: 072. loc = prev; 073. prev = (*loc).prev; 074. if (prev != NULL) 075. (*prev).start = NULL; 076. break; 077. } 078. arg = (*loc).info; 079. 080. return RemoveNode(loc); 081. } 082. //+----------------+ 083. bool Exclude(const uint index) 084. { 085. T arg; 086. ENUM_FILE_POSITION pos = (index == 0 ? SEEK_SET : (index >= counter ? SEEK_END : SEEK_CUR)); 087. 088. if (pos == SEEK_CUR) 089. { 090. stList <T> *loc = start, 091. *ptr = NULL; 092. 093. for (uint c = 0; (loc != NULL) && (c < index); ptr = loc, loc = (*loc).start, c++); 094. if (loc == NULL) return false; 095. 096. (*ptr).start = (*loc).start; 097. (*loc).start.prev = ptr; 098. 099. return RemoveNode(loc); 100. } 101. 102. return Restore(arg, pos); 103. } 104. //+----------------+ 105. void Debug(void) 106. { 107. Print("===== DEBUG ====="); 108. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 109. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 110. Print("================="); 111. } 112. //+----------------+ 113. }; 114. //+------------------------------------------------------------------+ 115. void OnStart(void) 116. { 117. stList <char> list; 118. 119. list.Store(10); 120. list.Store(84); 121. list.Store(-6); 122. list.Store(47, SEEK_SET); 123. 124. list.Debug(); 125. 126. list.Exclude(2); 127. 128. list.Debug(); 129. 130. for (char info; list.Restore(info, SEEK_SET);) 131. Print(info); 132. }; 133. //+------------------------------------------------------------------+
Código 03
Cara, você só pode estar de sacanagem. Que código mais maluco é este? Bem, talvez eu tenha apelado um pouco, apresentando o código desta maneira. ( RISOS ). Mas este código, não é assim tão maluco. Para ser sincero, ele é até mesmo muito simples de ser entendido. Apesar de não ser o mais bonito. Mas vamos entender o que se passa aqui. Primeiramente, adicionei na linha onze uma nova variável. Esta tem como objetivo, nos dizer o número de elementos presentes dentro da lista. Algo parecido com o que seria usar a função ArraySize a fim de saber quantos elementos existem atualmente em um array dinâmico.
Como este número de elementos pode variar conforme adicionamos ou removemos elementos. As linhas 16 e 53, corrigem isto para nós. Observe que na linha 44 deste código 03, já estou deixando reservado uma nova opção, que será implementada em breve. Mas vamos focar na parte responsável por excluir os elementos. Note que agora a função Exclude, presente na linha 83, recebe um valor que irá apontar para qual elemento deveremos remover da lista. Isto se baseando em que posição o elemento se encontra na lista.
Agora preste atenção, meu caro leitor, pois esta parte é bem interessante. Devido ao fato de que a leitura de elementos presentes na lista, ser uma atividade destrutiva. Ou seja, quando lemos a lista, seja em qualquer ordem, iremos remover aquele elemento da lista. Podemos usar isto ao nosso favor. Isto por que, quando o índice passado for igual a zero, podemos usar a própria função Restore, vista na linha 56, para remover o elemento inicial da lista. A mesma coisa acontece, se estamos removendo o último elemento na lista. Para tornar isto possível, usamos a linha 86. Cujo objetivo é justamente este de nos informa, se o elemento a ser removido é o primeiro, o último ou algum outro dentro destes limites.
Caso o elemento a ser removido, se encontra em uma posição dentro da lista, o teste da linha 88 irá ser positivo. No dando assim a possibilidade de efetuar algo parecido com o que foi feito no código 02. No entanto, diferente do que foi feito no código 02, aqui no código 03, o teste que fazemos para encontrar qual elemento será removido é outro. No caso basta olhar o laço da linha 93 e o comparar como o que foi feito no código 02. Você nota que aqui estamos usando um contador para encontrar o elemento a ser removido. Isto porque não sabemos exatamente onde ele está. Apenas sabemos qual o índice a ser usado. O restante do código é basicamente igual ao que foi feito no código 02.
Com isto, quando a linha 126 for executada, iremos forçar com que este código 03, venha a produzir o mesmo resultado visto na execução do código 02. Ou seja, a imagem 02. Este código 03 é de fato muito interessante, mas podemos fazer algo um pouco diferente. Então antes de mostrar como será o código de inclusão de elementos na lista, vamos fazer uma brincadeira neste código 03. Esta pode ser vista logo abaixo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. bool RemoveNode(stList <T> *arg) 014. { 015. delete arg; 016. counter--; 017. 018. return true; 019. } 020. //+----------------+ 021. public: 022. //+----------------+ 023. stList(void) 024. :prev(NULL), 025. start(NULL), 026. counter(0) 027. {} 028. //+----------------+ 029. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END, const uint index = 0) 030. { 031. stList <T> *loc; 032. 033. loc = new stList <T>; 034. 035. (*loc).info = arg; 036. (*loc).prev = NULL; 037. switch(pos) 038. { 039. case SEEK_SET: 040. (*loc).start = start; 041. (*start).prev = loc; 042. start = loc; 043. break; 044. case SEEK_CUR: 045. break; 046. case SEEK_END: 047. if (prev != NULL) (*prev).start = loc; 048. (*loc).prev = prev; 049. prev = loc; 050. start = (start == NULL ? loc : start); 051. break; 052. } 053. counter++; 054. } 055. //+----------------+ 056. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 057. { 058. stList <T> *loc = NULL; 059. 060. if ((prev == NULL) || (start == NULL)) 061. return false; 062. 063. switch (pos) 064. { 065. case SEEK_SET: 066. loc = start; 067. start = (*loc).start; 068. if (start != NULL) 069. (*start).prev = NULL; 070. break; 071. case SEEK_END: 072. loc = prev; 073. prev = (*loc).prev; 074. if (prev != NULL) 075. (*prev).start = NULL; 076. break; 077. } 078. arg = (*loc).info; 079. 080. return RemoveNode(loc); 081. } 082. //+----------------+ 083. bool Exclude(const int arg) 084. { 085. T tmp; 086. uint index = MathAbs(arg); 087. ENUM_FILE_POSITION pos = (index == 0 ? SEEK_SET : (index >= counter ? SEEK_END : SEEK_CUR)); 088. 089. if (pos == SEEK_CUR) 090. { 091. stList <T> *loc = (arg < 0 ? prev : start), 092. *ptr = NULL; 093. 094. for (uint c = 0; (loc != NULL) && (c < index); ptr = loc, loc = (arg < 0 ? (*loc).prev : (*loc).start), c++); 095. if (loc == NULL) return false; 096. 097. if (arg < 0) 098. { 099. (*ptr).prev = (*loc).prev; 100. (*loc).prev.start = ptr; 101. }else{ 102. (*ptr).start = (*loc).start; 103. (*loc).start.prev = ptr; 104. } 105. 106. return RemoveNode(loc); 107. } 108. 109. return Restore(tmp, pos); 110. } 111. //+----------------+ 112. void Debug(void) 113. { 114. Print("===== DEBUG ====="); 115. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 116. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 117. Print("================="); 118. } 119. //+----------------+ 120. }; 121. //+------------------------------------------------------------------+ 122. void OnStart(void) 123. { 124. stList <char> list; 125. 126. list.Store(10); 127. list.Store(84); 128. list.Store(-6); 129. list.Store(47, SEEK_SET); 130. 131. list.Debug(); 132. 133. list.Exclude(-2); 134. 135. list.Debug(); 136. 137. for (char info; list.Restore(info, SEEK_SET);) 138. Print(info); 139. }; 140. //+------------------------------------------------------------------+
Código 04
A brincadeira aqui, foi mudar o tipo de argumento que pode ser recebido pela função Exclude. Observe que diferente do que estava ocorrendo no código 03, aqui no código 04, podemos tanto passar valores positivos quanto valores negativos para a função Exclude. Mas o que isto significa na prática? Bem, meu caro leitor, isto significa que podemos tanto remover elementos partindo do início da lista, como também podemos remover elementos partindo do final da lista. Cara, você não pega leve mesmo. Eu mal consigo começar a entender o código, e já vem você tornar as coisas ainda mais confusas. Você não se cansa disto não? Nem um pouco meu caro leitor. Acho muito divertido isto que podemos e estamos fazendo. E quanto mais a coisa parece ficar confusa, mais eu me divirto criando o código.
Mas apesar desta aparente confusão que está sendo criada. Você facilmente entende o que irá acontecer. Note que tudo que foi preciso fazer de mudança no código 04, foi ajustar como o laço de procura irá trabalhar. Assim como um pequeno ajuste, que também precisou ser feito, devido ao fato de que podemos tanto estar olhando a lista do início, quanto também do final.
Mas como controlamos isto? Esta é a parte simples meu caro leitor. Se o valor do argumento da função Exclude for positivo, iremos trabalhar da mesma forma que foi visto no código 03. No entanto, caso o valor seja negativo, as coisas irão ser vista de uma outra maneira. Para começar, precisamos tornar o valor sempre positivo. Isto para evitar problemas. Assim, temos a linha 86, para termos o valor correto, independentemente de ele ser positivo ou negativo. No entanto, caso o laço da linha 94 venha a ser executado, iremos mudar o direcionamento da varredura. Ou seja, se o valor for negativo, iremos sempre apontar para o elemento antecessor. Caso seja positivo iremos apontar para o elemento sucessor. De qualquer forma, algum elemento irá ser apontado aqui. Mas agora vem a parte onde precisamos reajustar as coisas de maneira adequada.
Como podemos estar lendo a lista de trás para frente. Os ponteiros podem estar investidos. Por conta disto, na linha 97, checamos se estamos indo em uma direção ou em outra. Caso estejamos lendo a lista ao contrário, ou seja, do fim para o início, precisamos usar as linhas 99 e 100 para corrigir adequadamente os ponteiros. No final o resultado será sempre correto. Desde que você tome os devidos cuidados.
Para demonstrar isto, veja que na linha 133 estamos repassando um valor negativo para a função Exclude. Assim sendo, o elemento de índice dois, partindo do final da lista, irá ser removido. Se você entendeu tudo que está sendo feito desde o início, sabe que este elemento tem como valor 10. Assim, ao executarmos este código 04, o resultado é o que pode ser visto na imagem logo abaixo.
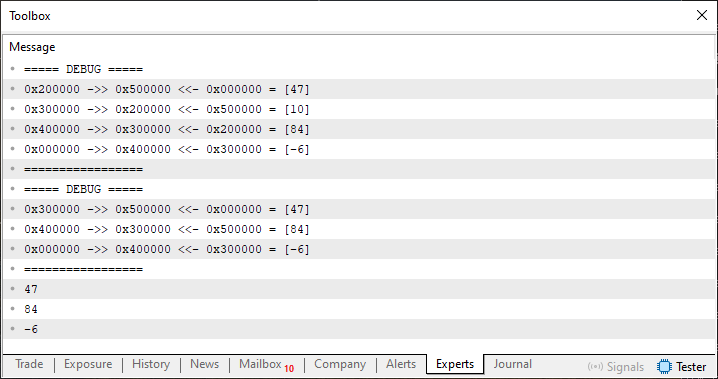
Imagem 03
Muito bem, chega de ficar fazendo graça. Chegou a hora de implementar a parte responsável por incluir valores em posições arbitrárias dentro da lista. Algo parecido com o que acabamos de fazer usando uma metodologia de exclusão. Mas como você pode estar imaginando, não vamos fazer as coisas de qualquer forma, iremos brincar com o código, conforme ele for sendo construído. Assim acredito que você irá entender melhor como as coisas funcionam. E por que são implementadas daquela maneira.
Ok, então vamos focar no código 04, na parte responsável por armazenar os valores na lista. Se você observar o comando switch da linha 37 irá notar que para adicionar um novo elemento, seja no final ou início da lista, executamos alguns passos. E estes passos tem como objetivo, justamente configurar o que seria o endereço de memória do elemento anterior e posterior ao novo elemento que estamos adicionando. É muito importante que você consiga notar isto sendo feito. Tanto que a diferença entre colocar o novo elemento no início ou final da fila, é justamente o ponteiro que irá receber o novo elemento. Mas como assim? Bem, meu caro leitor, se você olhar para o case da linha 39, saberá que estamos adicionando um novo elemento no início da fila. E o motivo é justamente a linha 42.
Já se você olhar o case da linha 46, saberá que estamos adicionando o elemento no final da fila. Sendo a linha 49 a responsável por isto. Mas agora vem uma questão. Quando formos indicar um índice, as coisas irão mudar de figura. Já que neste caso, passaremos a informar onde o elemento será incluído. Mas é neste ponto em que as coisas precisam ser pensadas com calma. E o motivo de certa forma está ligado justamente a questão vista na própria exclusão de elementos da lista.
Para não complicar as coisas logo de cara, vamos fazer o seguinte: Vamos adicionar um novo elemento, baseando a posição partindo do início da lista. Assim sendo, o que precisamos fazer é visto no código logo abaixo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. bool RemoveNode(stList <T> *arg) 014. { 015. delete arg; 016. counter--; 017. 018. return true; 019. } 020. //+----------------+ 021. public: 022. //+----------------+ 023. stList(void) 024. :prev(NULL), 025. start(NULL), 026. counter(0) 027. {} 028. //+----------------+ 029. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END, const uint index = 0) 030. { 031. stList <T> *loc; 032. 033. loc = new stList <T>; 034. 035. (*loc).info = arg; 036. (*loc).prev = NULL; 037. switch(pos) 038. { 039. case SEEK_SET: 040. (*loc).start = start; 041. (*start).prev = loc; 042. start = loc; 043. break; 044. case SEEK_CUR: 045. { 046. stList <T> *ptr1 = start, 047. *ptr2 = NULL; 048. 049. for (uint c = 0; (ptr1 != NULL) && (c < index); ptr2 = ptr1, ptr1 = (*ptr1).start, c++); 050. 051. (*loc).start = (ptr2 != NULL ? (*ptr2).start : ptr1); 052. (*loc).prev = (ptr1 != NULL ? (*ptr1).prev : ptr2); 053. if (ptr2 != NULL) (*ptr2).start = loc; else start = loc; 054. if (ptr1 != NULL) (*ptr1).prev = loc; else prev = loc; 055. } 056. break; 057. case SEEK_END: 058. if (prev != NULL) (*prev).start = loc; 059. (*loc).prev = prev; 060. prev = loc; 061. start = (start == NULL ? loc : start); 062. break; 063. } 064. counter++; 065. } 066. //+----------------+ 067. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 068. { 069. stList <T> *loc = NULL; 070. 071. if ((prev == NULL) || (start == NULL)) 072. return false; 073. 074. switch (pos) 075. { 076. case SEEK_SET: 077. loc = start; 078. start = (*loc).start; 079. if (start != NULL) 080. (*start).prev = NULL; 081. break; 082. case SEEK_END: 083. loc = prev; 084. prev = (*loc).prev; 085. if (prev != NULL) 086. (*prev).start = NULL; 087. break; 088. } 089. arg = (*loc).info; 090. 091. return RemoveNode(loc); 092. } 093. //+----------------+ 094. bool Exclude(const uint index) 095. { 096. T tmp; 097. ENUM_FILE_POSITION pos = (index == 0 ? SEEK_SET : (index >= counter ? SEEK_END : SEEK_CUR)); 098. 099. if (pos == SEEK_CUR) 100. { 101. stList <T> *loc = start, 102. *ptr = NULL; 103. 104. for (uint c = 0; (loc != NULL) && (c < index); ptr = loc, loc = (*loc).start, c++); 105. if (loc == NULL) return false; 106. 107. (*ptr).start = (*loc).start; 108. (*loc).start.prev = ptr; 109. 110. return RemoveNode(loc); 111. } 112. 113. return Restore(tmp, pos); 114. } 115. //+----------------+ 116. void Debug(void) 117. { 118. Print("===== DEBUG ====="); 119. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 120. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 121. Print("================="); 122. } 123. //+----------------+ 124. }; 125. //+------------------------------------------------------------------+ 126. void OnStart(void) 127. { 128. stList <char> list; 129. 130. list.Store(10); 131. list.Store(84); 132. list.Store(-6); 133. list.Store(47, SEEK_SET); 134. 135. list.Debug(); 136. 137. list.Store(35, SEEK_CUR, 2); 138. 139. list.Debug(); 140. 141. for (char info; list.Restore(info, SEEK_SET);) 142. Print(info); 143. }; 144. //+------------------------------------------------------------------+
Código 05
Antes de explicar como este código 05 funciona, que tal ver o resultado da execução do mesmo? Isto pode ser observado vendo a imagem logo abaixo.
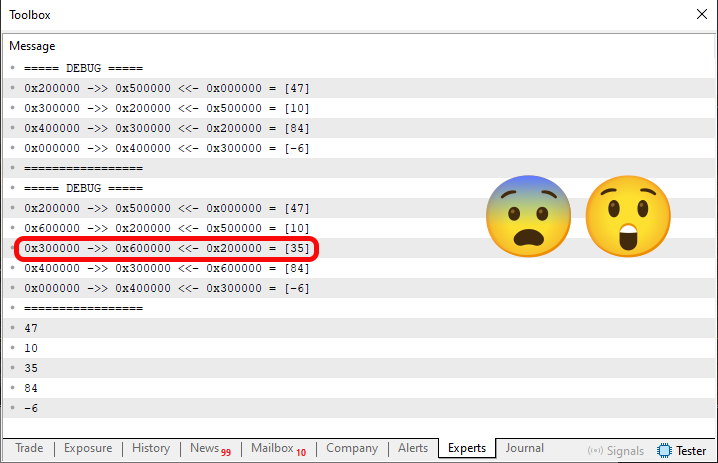
Imagem 04
Ok, nesta imagem 04 estou destacando o resultado de adicionarmos algum valor em uma dada posição na lista. E ao observar o código 05, você pode estar pensando: Cara, mas como você fez isto? Bem, como o objetivo aqui é ser didático, modifiquei o código 04, para algo mais simples. E isto pode ser visto no código 05, na parte referente a exclusão de valores. No entanto, neste código 05, o que nos interessa de fato é a inclusão de valores. Por conta disto, quero que você meu caro e estimado leitor, procure fazer um paralelo entre o código de exclusão que pode ser visto na linha 94, com o código e inclusão que é visto entre as linhas 44 e 56.
Novamente o objetivo aqui é ser o mais didático possível. Assim sendo, se você comparar o código de exclusão com o código de inclusão irá notar que boa parte do código se parece. Porém, e é aqui onde muitos acabam ficando perdidos no código. O código de inclusão, precisa de três ponteiros, diferente do código de exclusão que necessita de apenas dois ponteiros. E por que desta diferença? O motivo é simples.
Quando estamos incluindo algum valor dentro da lista, NÃO MOVEMOS NENHUM VALOR, como seria feito caso estivéssemos trabalhando com arrays. No caso de uma lista encadeada, tudo que precisamos fazer é ajustar os ponteiros para que eles indiquem o antecessor ou sucessor de um elemento dentro da lista. Devido a isto, o código que realmente inclui um novo elemento na lista é composto pelas linhas 53 e a linha 54. Ou seja, usamos dois comandos if para ajustar adequadamente a lista. Porém para que a lista se mantenha intacta, no que diz respeito a sua estrutura. Usamos as linhas 51 e 52 para fazer com que o atual elemento a ser inserido na lista, aponte para os elementos já existentes na lista.
Agora preste atenção. Estas linhas que acabei de mencionar, são capazes de fazer com que a lista duplamente encadeada seja criada, sem a necessidade do código presente nos case SEEK_SET e SEEK_END. Ou seja, este código dentro do case SEEK_CUR, é capaz tanto de adicionar elementos no começo, final e também em alguma posição arbitrária dentro da lista. Bastando que pera isto informemos qual o índice a ser utilizado.
Hum. Deixe-me ver se entendi. Você está me dizendo que este código 05 pode ser modificado, de maneira que possamos ter menos coisas presentes nele. E ainda assim ele irá funcionar. Nos dando o mesmo resultado que é mostrado na imagem 04. É isto? Sim, meu caro leitor. Este código 05, foi criado desta maneira para que você pudesse entender como as coisas podem ser implementadas. No entanto, este mesmo código 05, pode ser modificado a ponto de produzir o que é visto logo abaixo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. bool RemoveNode(stList <T> *arg) 014. { 015. delete arg; 016. counter--; 017. 018. return true; 019. } 020. //+----------------+ 021. public: 022. //+----------------+ 023. stList(void) 024. :prev(NULL), 025. start(NULL), 026. counter(0) 027. {} 028. //+----------------+ 029. void Store(T arg, const uint index = 0xFFFFFFFF) 030. { 031. stList <T> *loc, 032. *ptr1 = start, 033. *ptr2 = NULL; 034. 035. for (uint c = 0; (ptr1 != NULL) && (c < index); ptr2 = ptr1, ptr1 = (*ptr1).start, c++); 036. 037. loc = new stList <T>; 038. (*loc).info = arg; 039. (*loc).start = (ptr2 != NULL ? (*ptr2).start : ptr1); 040. (*loc).prev = (ptr1 != NULL ? (*ptr1).prev : ptr2); 041. if (ptr2 != NULL) (*ptr2).start = loc; else start = loc; 042. if (ptr1 != NULL) (*ptr1).prev = loc; else prev = loc; 043. 044. counter++; 045. } 046. //+----------------+ 047. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 048. { 049. stList <T> *loc = NULL; 050. 051. if ((prev == NULL) || (start == NULL)) 052. return false; 053. 054. switch (pos) 055. { 056. case SEEK_SET: 057. loc = start; 058. start = (*loc).start; 059. if (start != NULL) 060. (*start).prev = NULL; 061. break; 062. case SEEK_END: 063. loc = prev; 064. prev = (*loc).prev; 065. if (prev != NULL) 066. (*prev).start = NULL; 067. break; 068. } 069. arg = (*loc).info; 070. 071. return RemoveNode(loc); 072. } 073. //+----------------+ 074. bool Exclude(const uint index) 075. { 076. T tmp; 077. ENUM_FILE_POSITION pos = (index == 0 ? SEEK_SET : (index >= counter ? SEEK_END : SEEK_CUR)); 078. 079. if (pos == SEEK_CUR) 080. { 081. stList <T> *loc = start, 082. *ptr = NULL; 083. 084. for (uint c = 0; (loc != NULL) && (c < index); ptr = loc, loc = (*loc).start, c++); 085. if (loc == NULL) return false; 086. 087. (*ptr).start = (*loc).start; 088. (*loc).start.prev = ptr; 089. 090. return RemoveNode(loc); 091. } 092. 093. return Restore(tmp, pos); 094. } 095. //+----------------+ 096. void Debug(void) 097. { 098. Print("===== DEBUG ====="); 099. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 100. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 101. Print("================="); 102. } 103. //+----------------+ 104. }; 105. //+------------------------------------------------------------------+ 106. void OnStart(void) 107. { 108. stList <char> list; 109. 110. list.Store(10); 111. list.Store(84); 112. list.Store(-6); 113. list.Store(47, 0); 114. 115. list.Debug(); 116. 117. list.Store(35, 2); 118. 119. list.Debug(); 120. 121. for (char info; list.Restore(info, SEEK_SET);) 122. Print(info); 123. }; 124. //+------------------------------------------------------------------+
Código 06
Agora preste muita, mas muita atenção ao que irei explicar. Caso contrário você irá perder o fio da meada. E não irá entender o que será feito depois. Se você observar o procedimento da linha 29 deste código 06, irá notar que ele foi modificado, mas de maneira muito suave. Isto por que, agora este procedimento irá apenas receber o elemento que será armazenado assim com um índice. Porém, para manter o código 06 funcionando da mesma forma como é visto no código 05. Isto se tratando do que se encontra dentro do procedimento OnStart. O índice padrão do procedimento Store é o limite superior da lista. Ou seja, se nenhum valor for informado como sendo o índice de posição do elemento, SEMPRE iremos colocar o novo elemento no topo, ou final como queira, da lista.
É muito importante que você entenda isto meu caro leitor. Caso contrário você poderá ficar tentando fazer as coisas de uma forma, sendo que elas estarão sendo executadas de uma outra maneira. Para tornar isto um tanto mais claro, compare o procedimento OnStart deste código 06 com o mesmo procedimento visto no código 05. Note que são muito parecidos.
Agora para terminar, vamos fazer um pequeno ajuste neste mesmo código 06. Isto para que possamos ler qualquer posição dentro da lista. Lembrando que ao fazermos esta leitura, estaremos destruindo o valor da lista. Mas como aqui o objetivo é a didática, não vejo problema em fazer isto. Sendo assim, uma vez que a mudança seja efetivada temos o que pode ser visto no código logo na sequência.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> class stList 005. { 006. private: 007. //+----------------+ 008. T info; 009. stList <T> *prev, 010. *start; 011. uint counter; 012. //+----------------+ 013. public: 014. //+----------------+ 015. stList(void) 016. :prev(NULL), 017. start(NULL), 018. counter(0) 019. {} 020. //+----------------+ 021. void Store(T arg, const uint index = 0xFFFFFFFF) 022. { 023. stList <T> *loc, 024. *ptr1 = start, 025. *ptr2 = NULL; 026. 027. for (uint c = 0; (ptr1 != NULL) && (c < index); ptr2 = ptr1, ptr1 = (*ptr1).start, c++); 028. 029. loc = new stList <T>; 030. (*loc).info = arg; 031. (*loc).start = (ptr2 != NULL ? (*ptr2).start : ptr1); 032. (*loc).prev = (ptr1 != NULL ? (*ptr1).prev : ptr2); 033. if (ptr2 != NULL) (*ptr2).start = loc; else start = loc; 034. if (ptr1 != NULL) (*ptr1).prev = loc; else prev = loc; 035. 036. counter++; 037. } 038. //+----------------+ 039. bool Restore(T &arg, const uint index = 0xFFFFFFFF) 040. { 041. if ((prev == NULL) || (start == NULL)) 042. return false; 043. 044. stList <T> *loc = (index < counter ? start : prev), 045. *ptr = NULL; 046. 047. for (uint c = 0; (loc != NULL) && (c < index) && (index < counter); ptr = loc, loc = (*loc).start, c++); 048. if (loc == NULL) return false; 049. 050. if (index == 0) 051. { 052. start = (*loc).start; 053. if (start != NULL) (*start).prev = NULL; 054. } else if (index >= (counter - 1)) 055. { 056. prev = (*loc).prev; 057. if (prev != NULL) (*prev).start = NULL; 058. } 059. else 060. { 061. (*ptr).start = (*loc).start; 062. (*loc).start.prev = ptr; 063. } 064. arg = (*loc).info; 065. delete loc; 066. counter--; 067. 068. return true; 069. } 070. //+----------------+ 071. bool Exclude(const uint index) 072. { 073. T tmp; 074. 075. return Restore(tmp, index); 076. } 077. //+----------------+ 078. void Debug(void) 079. { 080. Print("===== DEBUG ====="); 081. for (stList <T> *loc = start; loc != NULL; loc = (*loc).start) 082. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]", (*loc).start, loc, (*loc).prev, (*loc).info); 083. Print("================="); 084. } 085. //+----------------+ 086. }; 087. //+------------------------------------------------------------------+ 088. void OnStart(void) 089. { 090. stList <char> list; 091. 092. list.Store(10); 093. list.Store(84); 094. list.Store(-6); 095. list.Store(47, 0); 096. 097. list.Debug(); 098. 099. list.Exclude(3); 100. list.Store(35, 2); 101. 102. list.Debug(); 103. 104. for (char info; list.Restore(info, 0);) 105. Print(info); 106. }; 107. //+------------------------------------------------------------------+
Código 07
Este código 07 é quase um código final daquilo que seria de fato uma implementação de uma lista duplamente encadeada. Mas o que nos interessa de fato, é o tipo de resultado que ele é capaz de gerar. Então quando executado ele irá nos fornecer o resultado visto logo abaixo.
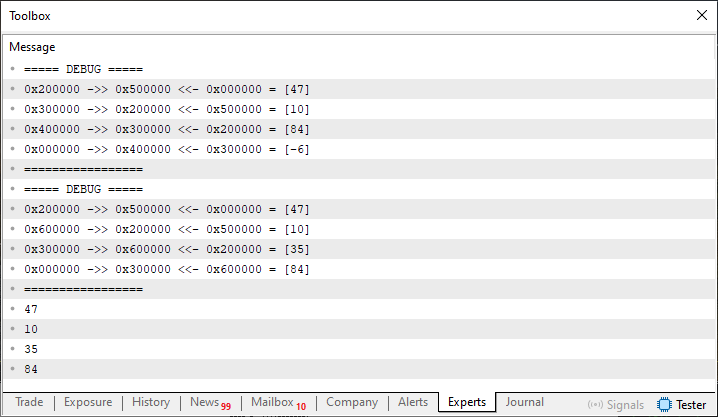
Imagem 05
Observe que este código 07 é muito mais simples do que os demais vistos até este momento. Porém, ele é mais simples se você entendeu os passos até chegar nele. Se ele fosse apresentado logo de cara, como sendo o primeiro e único código. Com toda a certeza você teria muita dificuldade em entender como este código funciona. Mas acredito que não preciso dar mais explicações a este respeito. Tendo em vista que as mudanças feitas, foram sendo feitas aos poucos.
Considerações finais
Neste artigo vimos como seria possível implementar uma lista encadeada perfeitamente funcional. Claro que ficou faltando um ponto para ser explicado. Que é justamente o fato de que toda leitura que estaremos fazendo, promove a remoção do elemento da lista. Existe meios de se evitar isto. Porém, como ainda não foi explicado como trabalhar realmente trabalhar com classes. Não irei me aprofundar nesta questão neste momento. Ficando assim isto para ser feito em outra oportunidade futura. Assim sendo no próximo artigo iremos ver o que resulta a evolução de uma lista encadeada. E o resultado desta evolução fará surgir um novo tipo de estrutura de dados.
| MQ5 | Descrição |
|---|---|
| Code 01 | Lista simples |
| Code 02 | Lista simples |
| Code 03 | Lista simples |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Utilizando o modelo de Machine Learning CatBoost como Filtro para Estratégias de Seguimento de Tendência
Utilizando o modelo de Machine Learning CatBoost como Filtro para Estratégias de Seguimento de Tendência
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso