
Operações de arquivo agrupadas

Introdução
Não é problema ler ou escrever um arquivo. Até mesmo se você usar o WinaPI para isso, como descrito no artigo Operações de arquivo via WinAPI. Mas o que deveríamos fazer se não sabemos exatamente o nome do arquivo, somente sua localização em uma certa pasta e sua extensão? Claro, podemos inserir o nome necessário manualmente, como um parâmetro, mas o que faríamos se houvesse dez ou mais arquivos? Precisamos de um método de processamento agrupado de arquivos do mesmo tipo em uma certa pasta. Essa tarefa pode ser resolvida de forma eficiente usando funções FindFirstFile(), FindNextFile() and FindClose() incluídas no kernel32.dll.
Função FindFirstFile()
A descrição da função é dada no msdn em: http://msdn.microsoft.com/en-us/library/aa364418(VS.85).aspx.
HANDLE WINAPI FindFirstFile( __in LPCTSTR lpFileName, __out LPWIN32_FIND_DATA lpFindFileData );
Segue dessa descrição que a função retorna o descritor do arquivo encontrado e cumpre com as exigências de busca. A condição de busca é especificada na variável lpFileName que contém o caminho para buscar pelo arquivo e um possível nome do arquivo. Essa função é conveniente, uma vez que pode especificar a busca por máscara, por exemplo, encontrar um arquivo por máscara "C:\folder\*.txt". A função irá retornar o primeiro arquivo encontrado na pasta de "C:\folder e tendo a extensão de txt.
O resultado retornado da função é do tipo "int" no MQL4. Para passar o parâmetro de entrada, podemos usar o tipo 'string'. Agora temos que escolher sobre o que passar para essa função como o segundo parâmetro e como processar aquele parâmetro depois. Essa função será importada aproximadamente dessa forma:
#import "kernel32.dll" int FindFirstFileA(string path, .some second parameter); #import
Aqui podemos ver a já conhecida biblioteca de kernel32.dll. Entretanto, o nome da função é especificado como FindFirstFileA(), não como FindFirstFile(). Isso vem do fato que muitas funções nessa biblioteca tem duas versões: para trabalhar com string em Unicode, a letra "W" (FindFirstFileW) é adicionada ao nome, e para trabalhar com ANSI, a letra 'A' (FindFirstFileA) é adicionada.
Agora temos que escolher o segundo parâmetro da função que é descrito como:
lpFindFileData [out] - Um apontador na estrutura WIN32_FIND_DATA que recebe informação sobre um arquivo encontrado ou diretório.
Significa que é o apontador de uma certa estrutura de WIN32_FIND_DATA. Nesse caso, a estrutura é uma certa área no PC RAM. O apontador para essa área (endereço) é passado para a função. Podemos alocar a memória no MQL4 usando um arranjo de dados. O apontador é especificado com o caractere '&'. Temos somente que saber o tamanho da memória necessária em bytes para passar o apontador para ela. Abaixo está a descrição da estrutura.
typedef struct _WIN32_FIND_DATA {
DWORD dwFileAttributes;
FILETIME ftCreationTime;
FILETIME ftLastAccessTime;
FILETIME ftLastWriteTime;
DWORD nFileSizeHigh;
DWORD nFileSizeLow;
DWORD dwReserved0;
DWORD dwReserved1;
TCHAR cFileName[MAX_PATH];
TCHAR cAlternateFileName[14];
} WIN32_FIND_DATA,
No MQL4, não há nenhum tipo de DWORD, TCHAR ou FILETIME. Sabe-se que DWORD ocupa 4 bytes, como int no MQL4, TCHAR tem uma representação interna de um byte. Para calcular o tamanho total da estrutura WIN32_FIND_DATA em bytes, temos somente que escolher qual FILETIME é.
typedef struct _FILETIME {
DWORD dwLowDateTime;
DWORD dwHighDateTime;
} FILETIME
FILETIME acaba contendo dois DWORDS, o que significa que DWORD faz 88 bytes. Vamos tabular tudo isso:
| Tipo | Tamanho em bytes |
|---|---|
| DWORD | 4 |
| TCHAR | 1 |
| FILETIME | 8 |
Agora podemos calcular o tamanho da estrutura WIN32_FIND_DATA e visualizar o que e onde pode ser encontrado nela.
| Tipo |
Tamanho em bytes | Nota |
|---|---|---|
| dwFileAttributes | 4 | Atributos de arquivo |
| ftCreationTime | 8 | Tempo de criação do arquivo/pasta |
| ftLastAccessTime | 8 | Último tempo acessado |
| ftLastWriteTime | 8 | Último tempo de escrita |
| nFileSizeHigh | 4 | Tamanho máximo em bytes |
| nFileSizeLow | 4 | Tamanho mínimo em bytes |
| dwReserved0 | 4 | Geralmente não é definido e não é usado |
| dwReserved1 | 4 | É reservado para o futuro |
| cFileName[MAX_PATH] | 260 (MAX_PATH = 260) | Nome do arquivo |
| cAlternateFileName[14] | 14 | Nome alternativo no formato 8,3 |
Então o tamanho total da estrutura é: 4 + 8 + 8 + 8 + 4 + 4 + 4 +4 + 260 +14 = 318 bytes.

Como você pode ver a partir da figura abaixo, o nome do arquivo começa com o 45º byte, o byte anterior 44º contendo várias informações auxiliares. É necessário passar para a função FindFirstFile() algumas estruturas no tamanho do MQL4 como 318 bytes, como segundo parâmetro. Seria mais conveniente usar um arranjo do tipo 'int' que teria um tamanho não menor do que o exigido. Divida 318 por 4 (uma vez que a representação interna do tipo 'int' é 4 bytes), obtenha 79,5, arredonde para o inteiro maior mais próximo e veja que precisamos de um arranjo de 80 elementos.
A importação da função por si só parecerá com a seguinte:
#import "kernel32.dll" int FindFirstFileA(string path, int & answer[]); #import
Aqui estamos usando a versão da função com a letra 'A' no final do nome, FindFirstFileA(), para codificação ANSI. O arranjo 'resposta' é passado por um link e serve para ser preenchido com a estrutura de WIN32_FIND_DATA. Uma solicitação exemplar:
int win32_DATA[80]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA);
Funções FindNextFileA() e FindClose()
A função FindNextFileA() recebe, no primeiro parâmetro, o 'handle' do arquivo obtido preliminarmente pela função FindFirstFileA() ou por outra, a solicitação prévia da função FindNextFileA(). O segundo parâmetro é o mesmo. A função FindClose() apenas fecha a busca. É por isso que a aparência total dos dados de importação de funções será assim:
#import "kernel32.dll" int FindFirstFileA(string path, int & answer[]); bool FindNextFileA(int handle, int & answer[]); bool FindClose(int handle); #import
Agora acabamos de aprender como extrair o nome de um arquivo escrito para um arranjo 'answer[]'.
Obtendo o nome do arquivo
O nome do arquivo está contido pelo arranjo que começa do 45º e vai até o 304º byte. O tipo 'int' contém 4 bytes, então cada elemento de arranjo contém 4 caracteres, se presumirmos que o arranjo seja preenchido por caracteres. Então, para se referir ao primeiro caractere no nome do arquivo, deveríamos pular 44/4 = 11 elementos do arranjo 'answer[]'. O nome do arquivo está dentro da cadeia de elementos de arranjo 65 (260/4=65), começando do 'answer[11]' (o índice começando de zero) e terminando com 'answer[76]'.
Assim, obtemos do arranjo 'answer[]' o nome de arquivo nos blocos por 4 caracteres em cada. O número 'int' representa uma sequência de 32 bits que, por sua vez, representa 4 blocos de 8 bits em cada.
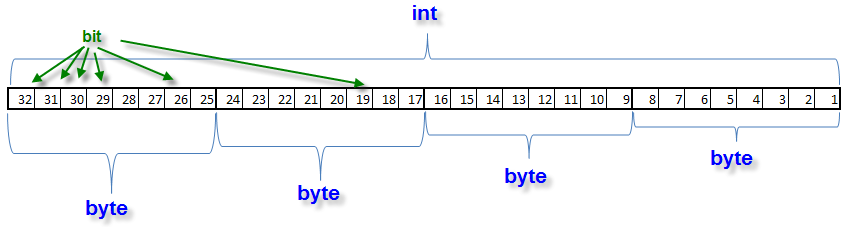
O byte mais novo está à direita e o mais velho à esquerda. Os bits são numerados em ordem ascendente, ou seja, bits de 1 a 8 fazem o byte mais novo. Podemos extrair os bytes necessários usando operações bit a bit. Para obter o valor do byte mais novo, devemos preencher todos os bits com valores zero, do 9º até o 32º. Isso é realizado usando operação lógica AND.
int a = 234565; int b = a & 0x000000FF;
Aqui 0x000000FF é o bit-32 inteiro que tem zero valores de todos os lugares, começando do 9º, enquanto os lugares do 1 até o 8 são iguais a um. Assim, o número obtido b irá conter somente um (o mais novo) byte de número a. Iremos retornar o byte obtido (o código de caractere) em um string de um caractere usando a função CharToStr().
Ok, obtivemos o primeiro caractere. Como devemos obter o próximo? Muito fácil: Fazemos um desvio do bit 8 bit a bit para a direita e o segundo bit substitui o mais novo. Então, aplicaremos a já conhecida operação de lógica AND.
int a = 234565; int b = (a >>8) & 0x000000FF;
Como você pode adivinhar, o terceiro byte será obtido pelo desvio de 16 bits, enquanto o mais velho será obtido pelo desvio de 24 bits. Assim, podemos extrair 4 caracteres de um elemento do arranjo de tipo 'int'. Abaixo mostramos como os 4 primeiros caracteres no nome do arquivo são obtidos do arranjo 'answer[]':
string text=""; int pos = 11; int curr = answer[pos]; { text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } Print("text = ", text);
Vamos criar uma função separada que retorna um string de texto do arranjo passado nomeado 'buffer'.
//+------------------------------------------------------------------+ //| read text from buffer | //+------------------------------------------------------------------+ string bufferToString(int buffer[]) { string text=""; int pos = 10; for (int i=0; i<64; i++) { pos++; int curr = buffer[pos]; text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } return (text); }
Assim, o problema de obter o nome do arquivo a partir da estrutura é resolvido.
Obtendo a lista de todos os Expert Advisors com seus códigos fonte
Um simples script demonstra as características das funções acima:
//+------------------------------------------------------------------+ //| CheckFindFile.mq4 | //| Copyright © 2008, MetaQuotes Software Corp. | //| https://www.metaquotes.net/ | //+------------------------------------------------------------------+ #property copyright "Copyright © 2008, MetaQuotes Software Corp." #property link "https://www.metaquotes.net/" #property show_inputs #import "kernel32.dll" int FindFirstFileA(string path, int& answer[]); bool FindNextFileA(int handle, int& answer[]); bool FindClose(int handle); #import //+------------------------------------------------------------------+ //| script program start function | //+------------------------------------------------------------------+ int start() { //---- int win32_DATA[79]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA); Print(bufferToString(win32_DATA)); ArrayInitialize(win32_DATA,0); while (FindNextFileA(handle,win32_DATA)) { Print(bufferToString(win32_DATA)); ArrayInitialize(win32_DATA,0); } if (handle>0) FindClose(handle); //---- return(0); } //+------------------------------------------------------------------+ //| read text from buffer | //+------------------------------------------------------------------+ string bufferToString(int buffer[]) { string text=""; int pos = 10; for (int i=0; i<64; i++) { pos++; int curr = buffer[pos]; text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } return (text); } //+------------------------------------------------------------------+
Aqui, depois das solicitações das funções FindFirstFileA() and FindNextFileA(), o arranjo de win32_DATA (estrutura WIN32_FIND_DATA) é modificado para um status "vazio", a saber, todos os elementos do arranjo são preenchidos com zeros:
>ArrayInitialize(win32_DATA,0);
Se não fizermos isso, pode acontecer de "fragmentos" do nome de arquivo da solicitação anterior penetrarem no processo e chegaremos a algo sem sentido.
Realização do exemplo: Criando backups de códigos fonte
Um simples exemplo que demonstra características práticas do que foi dito acima é a criação de backups de códigos fonte em um diretório especial. Para isso, deveríamos combinar as funções consideradas nesse presente artigo com aquelas no artigo Operações de arquivo via WinAPI. Iremos, então, obter o script simples backup.mq4 dado abaixo. Você pode ver o código completo no arquivo em anexo. Aqui está apenas a função de início () que usa todas as funções descritas em ambos os artigos:
//+------------------------------------------------------------------+ //| script program start function | //+------------------------------------------------------------------+ int start() { //---- string expert[1000]; // must be enough string EAname=""; // EA name int EAcounter = 0; // EAs counter int win32_DATA[80]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA); EAname = bufferToString(win32_DATA); expert[0] = EAname; ArrayInitialize(win32_DATA,0); int i=1; while (FindNextFileA(handle,win32_DATA)) { EAname = bufferToString(win32_DATA); expert[i] = EAname; ArrayInitialize(win32_DATA,0); i++; if (i>=1000) ArrayResize(expert,2000); // now it will surely be enough } ArrayResize(expert, i); int size = i; if (handle>0) FindClose(handle); for (i = 0 ; i < size; i++) { Print(i,": ",expert[i]); string backupPathName = backup_folder + "experts\\" + expert[i]; string originalName = TerminalPath() + "\\experts\\" + expert[i]; string buffer=ReadFile(originalName); WriteFile(backupPathName,buffer); } if (size > 0 ) Print("There are ",size," files were copied to folder "+backup_folder+"experts\\"); //---- return(0); } //+------------------------------------------------------------------+
Conclusão
Foi mostrado como realizar operações com um grupo de arquivos do mesmo tipo. Você pode ler e processar arquivos usando as funções acima e praticar sua própria lógica. Você pode fazer backups oportunos usando um Expert Advisor ou sincronizar dois conjuntos de arquivos em pastas diferentes, importar cotações de algumas bases de dados e assim por diante. É recomendado controlar o uso de DLLs e não habilitar a conexão de bibliotecas para arquivos de terceiros tendo a extensão de ex4. Você deve ter certeza que o programa que está abrindo não irá danificar os dados no seu PC.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/1543
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.

 Passo a passo do HTML usando MQL4
Passo a passo do HTML usando MQL4
 Expert Advisors baseado em sistemas de trading populares e alquimia da otimização de robô de trading (Parte II)
Expert Advisors baseado em sistemas de trading populares e alquimia da otimização de robô de trading (Parte II)
 Como escrever ZigZags rápidos que não são redesenhados
Como escrever ZigZags rápidos que não são redesenhados
 Operações de arquivo via WinAPI
Operações de arquivo via WinAPI
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso