
分组文件的操作

简介
读取或写入一个文件不是问题。甚至可以使用通过 WINAPI 进行文件操作一文中描述的 WinAPI 实现。。但如果我们不知道文件的确切名称,只知道文件所在的文件夹和扩展名,该怎么做呢?当然,可以手动输入必要的名称作为参数,但如果有十个或更多这种文件该怎么做呢?我们需要一种方法,对给定文件夹内相同类型的文件进行分组处理。利用 kernel32.dll 中包含的 FindFirstFile()、FindNextFile() 和 FindClose() 函数,可以有效的解决这个问题。
FindFirstFile() 函数
对函数的描述在 msdn 中给出:http://msdn.microsoft.com/en-us/library/aa364418(VS.85).aspx.
HANDLE WINAPI FindFirstFile( __in LPCTSTR lpFileName, __out LPWIN32_FIND_DATA lpFindFileData );
按照描述,函数返回找到的符合搜索要求的文件描述符。搜索条件在 lpFileName 变量中指定,包含了搜索文件的路径和文件的可能名称。该函数非常方便,我们可以用通配符指定搜索,例如,用通配符“C:\folder\*.txt”查找文件。函数将返回在“C:\folder”文件夹中找到的第一个带有 txt 扩展名的文件。
函数返回的结果在 MQL4 中是‘int’类型。要传递输入参数,可以使用‘字符串’类型。现在我们必须解决把什么传递到函数作为第二个参数以及稍后如何处理参数的问题。该函数的导入大致如下:
#import "kernel32.dll" int FindFirstFileA(string path, .some second parameter); #import
这里我们可以看到已知的 kernel32.dll 库。但是,函数的名称被指定为 FindFirstFileA() 而非 FindFirstFile()。原因在于 - 该库中的很多函数有两个版本:如果使用 Unicode 字符串,名称中会添加‘W’字母(FindFirstFileW),如果使用 ANSI,则添加‘A’字母(FindFirstFileA)。
现在我们必须解决函数第二个参数的问题,参数描述如下:
lpFindFileData [out] - 指向WIN32_FIND_DATA结构的指针,接收已找到的文件或目录的信息。
这意味着它是指向 WIN32_FIND_DATA 结构的指针。在这种情况下,结构是计算机 RAM 里的某个区域。指向该区域(地址)的指针传递到函数。我们可以使用数据数组在 MQL4 中分配内存。指针以‘&’字符指定。我们只需要知道传递指针所需的内存大小(以字节表示)。下面是对结构的描述。
typedef struct _WIN32_FIND_DATA {
DWORD dwFileAttributes;
FILETIME ftCreationTime;
FILETIME ftLastAccessTime;
FILETIME ftLastWriteTime;
DWORD nFileSizeHigh;
DWORD nFileSizeLow;
DWORD dwReserved0;
DWORD dwReserved1;
TCHAR cFileName[MAX_PATH];
TCHAR cAlternateFileName[14];
} WIN32_FIND_DATA,在 MQL4 中,没有 DWORD、TCHAR 或 FILETIME 类型。DWORD 占据 4 个字节,跟 MQL4 中的 int 类似,TCHAR 有一个字节的内部形式。要计算 WIN32_FIND_DATA 结构的总大小(字节数),我们只需要弄清 FILETIME 是什么。
typedef struct _FILETIME {
DWORD dwLowDateTime;
DWORD dwHighDateTime;
} FILETIMEFILETIME 包含两个 DWORD,意味着是 8 个字节。我们将其做成表格:
| 类型 | 字节数 |
|---|---|
| DWORD | 4 |
| TCHAR | 1 |
| FILETIME | 8 |
现在我们可以计算 WIN32_FIND_DATA 结构的大小并将其中发现的内容可视化。
| 类型 | 字节数 | 注 |
|---|---|---|
| dwFileAttributes | 4 | 文件属性 |
| ftCreationTime | 8 | 文件/文件夹创建时间 |
| ftLastAccessTime | 8 | 最后访问时间 |
| ftLastWriteTime | 8 | 最后写入时间 |
| nFileSizeHigh | 4 | 最大字节数 |
| nFileSizeLow | 4 | 最小字节数 |
| dwReserved0 | 4 | 通常不定义或不使用 |
| dwReserved1 | 4 | 为未来保留 |
| cFileName[MAX_PATH] | 260 (MAX_PATH = 260) | 文件名称 |
| cAlternateFileName[14] | 14 | 8.3 格式的替代名称 |
结构的总大小为:4 + 8 + 8 + 8 + 4 + 4 + 4 +4 + 260 +14 = 318 字节。

从上图可以看出,文件名称从第 45 个字节开始,前面的 44 个字节包含了各种辅助信息。需要将 MQL4 中一些大小为 318 字节的结构(如第二个参数)传递到 FindFirstFile() 函数。使用‘int’类型的数组最为方便,其大小不小于要求的大小。将 318 除以 4(因为‘int’类型的内部形式是 4 个字节),得到 79.5,圆整到最接近的较大整数,可见我们需要 80 个元素的数组。
现在导入函数显示如下:
#import "kernel32.dll" int FindFirstFileA(string path, int & answer[]); #import
这里我们使用了名称末尾带字母‘A’的函数版本,即 ANSI 编码的 FindFirstFileA()。‘answer’数组通过链接传递,由 WIN32_FIND_DATA 结构填充。调用示例:
int win32_DATA[80]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA);
FindNextFileA() 和 FindClose() 函数
FindNextFileA() 接收由函数 FindFirstFileA() 或另一个较早调用的函数 FindNextFileA() 初步获得文件的‘句柄’(作为第一个参数)。第二个参数相同。FindClose() 函数仅关闭搜索。这就是为什么导入函数数据的完整显示如下:
#import "kernel32.dll" int FindFirstFileA(string path, int & answer[]); bool FindNextFileA(int handle, int & answer[]); bool FindClose(int handle); #import
现在我们只要学习如何提取写入‘answer[]’数组的文件名称。
获得文件名称
文件名称包含在数组中,从第 45 个字节到第 304 个字节。‘int’类型包含 4 个字节,如果假设数组用字符填充,每个数组元素包含 4 个字节。为了引用文件名称的第一个字符,我们应该跳过‘answer[]’数组的 44/4=11 个元素。文件名称位于 65(260/4=65)个数组元素链内,始于‘answer[11]’(索引从零开始),终于‘answer[76]’。
这样,我们可以从数组‘answer[]’的位块得到文件的名称,每个位块有 4 个字符。‘int’数字代表了 32 个位序列,其中有 4 个位块,每个位块有 8 位。
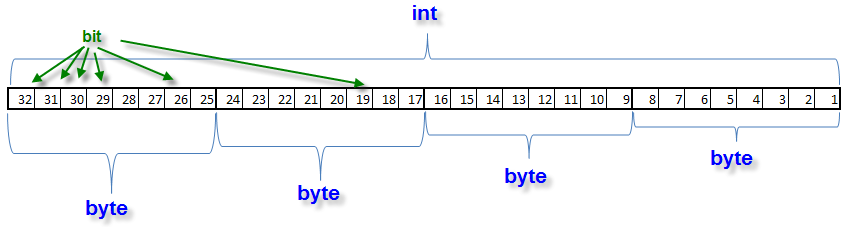
最新的字节在右侧,最旧的字节在左侧。位以升序排列,即从第 1 位到第 8 位构成最新的字节。我们可以使用逐位运算提取所需的字节。为了得到最新字节的值,我们应该将从第 9 到 32 位的所有位用零填充。使用逻辑运算 AND 来完成。
int a = 234565; int b = a & 0x000000FF;
这里的 0x000000FF 是 32 位的整数,从第 9 位开始的所有位都等于零,从第 1 到第 8 位均等于 1。因此,获得的数字b只会包含数字a。我们使用 CharToStr() 函数将获得的字节(字符代码)转换为单个字符的字符串。
好了,我们已经获得了第一个字符。如何获得第二个呢?很简单:我们向右偏移 8 个位,第二个位取代了最新的位。然后我们应用已知的逻辑运算AND 。
int a = 234565; int b = (a >>8) & 0x000000FF;
你可以猜测得到,偏移 16 位可以得到第三个字节,偏移 24 位可以得到最旧的字节。这样,我们可以从‘int'类型数组的一个元素中提取 4 个字符。下面显示了如何从‘answer[]’数组获得文件名称的前 4 个字符:
string text=""; int pos = 11; int curr = answer[pos]; { text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } Print("text = ", text);
我们来创建一个单独的函数,从命名为‘buffer’的传递的数组返回文本字符串。
//+------------------------------------------------------------------+ //| read text from buffer | //+------------------------------------------------------------------+ string bufferToString(int buffer[]) { string text=""; int pos = 10; for (int i=0; i<64; i++) { pos++; int curr = buffer[pos]; text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } return (text); }
现在,从结构获得文件名称的问题已经解决。
获得所有的 Expert Advisor 列表及其源代码
下面的简单脚本显示了以上函数的特点:
//+------------------------------------------------------------------+ //| CheckFindFile.mq4 | //| Copyright © 2008, MetaQuotes Software Corp. | //| https://www.metaquotes.net/ | //+------------------------------------------------------------------+ #property copyright "Copyright © 2008, MetaQuotes Software Corp." #property link "https://www.metaquotes.net/" #property show_inputs #import "kernel32.dll" int FindFirstFileA(string path, int& answer[]); bool FindNextFileA(int handle, int& answer[]); bool FindClose(int handle); #import //+------------------------------------------------------------------+ //| script program start function | //+------------------------------------------------------------------+ int start() { //---- int win32_DATA[79]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA); Print(bufferToString(win32_DATA)); ArrayInitialize(win32_DATA,0); while (FindNextFileA(handle,win32_DATA)) { Print(bufferToString(win32_DATA)); ArrayInitialize(win32_DATA,0); } if (handle>0) FindClose(handle); //---- return(0); } //+------------------------------------------------------------------+ //| read text from buffer | //+------------------------------------------------------------------+ string bufferToString(int buffer[]) { string text=""; int pos = 10; for (int i=0; i<64; i++) { pos++; int curr = buffer[pos]; text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } return (text); } //+------------------------------------------------------------------+
这里,在 FindFirstFileA() 和 FindNextFileA() 函数调用以后,win32_DATA 数组(WIN32_FIND_DATA 结构)变为“空”状态,即数组的所有元素填充为零:
ArrayInitialize(win32_DATA,0);
如果不这样做,可能会发生之前调用的文件名称的“片段”进入过程,从而得到一些术语天书。
实现示例:创建源代码备份
显示上述实践特点的简单示例是在特殊目录下创建源代码备份。为此,我们应综合本文讨论的函数和通过通过 WINAPI 进行文件操作一文中讨论的函数。我们将得到下面给出的简单脚本 backup.mq4。在附件中可以看到完整代码。下面只是使用了两篇文章中描述的所有函数的 start() 函数:
//+------------------------------------------------------------------+ //| script program start function | //+------------------------------------------------------------------+ int start() { //---- string expert[1000]; // must be enough string EAname=""; // EA name int EAcounter = 0; // EAs counter int win32_DATA[80]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA); EAname = bufferToString(win32_DATA); expert[0] = EAname; ArrayInitialize(win32_DATA,0); int i=1; while (FindNextFileA(handle,win32_DATA)) { EAname = bufferToString(win32_DATA); expert[i] = EAname; ArrayInitialize(win32_DATA,0); i++; if (i>=1000) ArrayResize(expert,2000); // now it will surely be enough } ArrayResize(expert, i); int size = i; if (handle>0) FindClose(handle); for (i = 0 ; i < size; i++) { Print(i,": ",expert[i]); string backupPathName = backup_folder + "experts\\" + expert[i]; string originalName = TerminalPath() + "\\experts\\" + expert[i]; string buffer=ReadFile(originalName); WriteFile(backupPathName,buffer); } if (size > 0 ) Print("There are ",size," files were copied to folder "+backup_folder+"experts\\"); //---- return(0); } //+------------------------------------------------------------------+
总结
本文展示了如何对一组相同类型的文件进行操作。你可以使用上述函数和利用自己的逻辑来读取和处理文件。可以使用 Expert Advisor 进行及时备份、在不同的文件夹内同步两组文件、从一些数据库导入报价等。建议控制 DLL 的使用,不要对具有 ex4 扩展名的第三方文件启用库连接。你必须确保启动的程序不会损坏你计算机上的数据。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/1543
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。


 使用 MQL4 的 HTML 引导
使用 MQL4 的 HTML 引导

 使用 MetaTrader 4 进行基于时间的模式分析
使用 MetaTrader 4 进行基于时间的模式分析