
Rede neural na prática: Iniciando a corrente

Introdução
No artigo anterior Rede neural na prática: Uma questão de escala,foi explicado algo bastante bizarro e precisa ser muito bem compreendido. Já que aquele tipo de coisa pode acometer um sistema que está sendo treinado, inviabilizando completamente o treinamento. E o mais bizarro é que, o perceptron usando a função de mínimo quadrado, possa convergir reduzindo seu erro. O mesmo pode não acontece ao se usar o gradiente, mantendo os mesmos dados usado para treinamento.
Neste artigo atual, continuaremos a tratar daquele mesmo assunto, contudo com um foco um pouco diferente. Já que aqui, iremos analisar o que acontece quando usamos uma pequena sequência de perceptrons ligados em série. Ou de forma resumida, o que acontece quando mudamos a escala dos dados e fazemos a saída de um perceptron ser usado como entrada de um novo perceptron.
Um leve arranhão no ego
Antes de começarmos realmente a focar na parte de código, quero falar sobre algo que pode ajudar a você entender uma coisa, um tanto quanto estranha, que a princípio não faz muito sentido.
O que foi mencionado na introdução do artigo, que é que em alguns cenários um sistema perceptron conseguir convergir usando a correção de mínimo quadrado e não conseguir reduzir seu erro usando o gradiente. Pode suar um tanto quanto descontextualizada. Isto devido justamente ao fato de que todos dizem que o gradiente é melhor que a correção via mínimo quadrado.
Contudo, quem estuda e mexe com programação, sabe que às vezes algo que parece pior, pode surpreender em certas situações especificas. Um caso tipico é na ordenação de dados. Se você procurar algorítimos de ordenação irá ver que muitos mencionam o QuickSort como sendo o melhor algorítimo que existe para ordenação. E que o Bubble Sort é o pior que existe, justamente devido como a ordenação acontece. Portanto, seria obvio e admissível que sempre que uma ordenação precisasse ocorrer, o QuickSort seria a escolha mais adequada. E é aqui que a coisa começa a ficar estranha. Existem casos, que se você usar o QuickSort irá ter um desempenho pior do que se fosse utilizado o Bubble Sort. Mas como assim? Isto não faz o menor sentido. Bem, meu amigo leitor, a verdade é que nem sempre algo que é o queridinho de todos de fato é a melhor escolha.
Este tipo de coisa que vimos acontecer no artigo anterior e iremos nos aprofundar aqui, pode até trazer um certo incomodo quando você tenta olhar a coisa com menos cuidado. A escolha de qual deverá ser o mecanismo usado para corrigir o erro da rede, ou mesmo de um único perceptron, deve ser feita visando, não só a economia em termos de processamento, mas também a capacidade do próprio mecanismo permitir que o erro convirja para um patamar mais baixo. Um sistema implementado para lidar com um certo tipo de situação, pode falhar miseravelmente quando colocado para lidar com uma situação completamente diferente. Por este motivo é que ao ligarmos os perceptrons, precisamos ficar atentos ao tipo de coisa com a qual estaremos lidando. Não existindo de forma alguma um tipo de receita de bolo, na qual você deverá sempre utilizar para toda e qualquer tipo de situação.
Como estamos chegando no limite daquilo que pode ser feito, fazendo uso de um único perceptron. Talvez boa parte do que será explicado aqui, comece a ficar um tanto quanto incomodo para alguns. Isto por que, precisamos começar a pensar em topologia de rede. Onde a coisa começa a sair daquilo que seria uma simples curiosidade para algo um pouco mais sério.
Normalmente, e não está errado em se fazer isto, muitos simplesmente preferem fazer uso de algum framework para não precisar pensar em topologia de rede perceptron. Porém, fazer uso de tais ferramentas e componentes não nos ajuda a entender como as coisas de fato funcionam. Apenas simplifica as coisas, ocultando boa parte daquilo que você de fato precisaria saber antes de sair por aí dizendo que já sabe como implementar e como funciona uma rede perceptron capaz de lidar com as mais diferentes tarefas.
Imagem 01
Esta imagem mostra, as principais forma de ligação entre perceptrons, em algum tipo de configuração qualquer. Muitos de você já devem ter ouvido falar em redes contendo camadas ocultas e coisas do tipo. Mas tenho certeza, de que você não sabia que existem diferenças entre elas. E mesmo que existem redes que não tem camadas ocultas, ou pontos de entrada, ou saída de dados bem específicos, ou definidos. Já que sempre se ouve dizer que a rede tem um ponto de entrada e um ponto de saída. O grande detalhe é que você dificilmente ouve dizer que tais pontos não são sempre muito bem definidos, devido justamente a topologia a ser adotada.
Aqui nestes artigos, por estarmos focados na didática, tenho sempre usado modelos, onde temos uma entrada e uma saída bem definida. No caso da entrada, podemos ter diversas, como tem sido demonstrado. Quanto a saída, até o momento temos tido apenas a presença de uma única saída. Mas isto não significa que as coisas serão sempre assim, ou precisam ser assim. Na verdade, é mais comum uma rede ter diversas saídas, do que apenas uma. Mas para termos mais de uma saída, é bem provável que estejamos usando mais de um perceptron. Contudo, isto não é de forma alguma uma regra. Porém, não se preocupe com isto agora, em outro momento iremos ver isto com mais calma.
Muito bem, como já temos um único perceptron funcionando, e já sabemos como colocar as coisas nele para conseguir algum aprendizado, já podemos dar alguns novos passos. É bem verdade, de que ainda não expliquei, o motivo das funções de ativação. Mas isto tem motivo. As funções de ativação, só fazem sentido serem explicadas, quando começamos a trabalhar com mais de um perceptron, ou quando precisamos gerar um tipo específico de saída. Mas como não vou lidar com saídas específicas aqui, precisamos de pelo menos criar uma pequena topologia, ou arquitetura de rede, para assim conseguir entender o que significa usar uma ou outra função de ativação. O simples fato de dizer: Vou usar esta função, pois ela parece ser melhor, ou vou usar aquela outra função, pois todos dizem que ela traz bons resultados. Não passa de pura besteira. A escolha correta, depende de diversos fatores. No entanto, para entender tais fatores, antes é preciso que tenhamos uma topologia um pouco mais avançada. Não apenas usando um único perceptron. Precisamos usar mais perceptrons.
Um novo início
Muita gente, pensa que para uma rede existir, é necessário a presença de centenas, milhares ou talvez milhões de perceptrons sendo conectados de alguma maneira. Mas as coisas não são bem assim, na prática. O que realmente precisamos, é que cada perceptron individual consiga trabalhar em conjunto com outros perceptrons. Não importa se irão trabalhar de maneira síncrona ou assíncrona. Paralela ou sequencial. Isto pouco interessa. O que é preciso, na prática, é que perceptrons individuais, trabalhem como se fossem um único e poderoso perceptron. Pense nisto como se fosse o trabalho de formiguinha. Uma formiga, não consegue mover uma montanha. Mas um grande e gigantesco formigueiro, consegue mover qualquer coisa.
Desde que se dê tempo suficiente para elas fazerem o seu serviço. Individualmente, cada formiga pode mover um pequeno pedregulho. Mas quando todas se unem, a coisa realmente toma outra dimensão. Porém, se elas não estiverem organizadas, no final não conseguirão construir a montanha. Elas podem até conseguir reduzir a montanha a um monte de pedriscos. Mas não passará disto. No entanto, se cada uma conseguir dizer a outra, o trabalho que já foi executado. No final elas conseguem o objetivo. E é isto que precisamos começar a fazer de agora em diante.
Quando levamos esta ideia, mencionada acima, para ser usa no desenvolvimento de uma rede, começamos a ter uma noção de como produzir um conjunto de perceptrons, e fazer com que eles efetuem, de forma individual, algum tipo de convergência. Mas o que acontece se os ligamos? Isto é, se a saída de um perceptron, for ligada a entrada de outro. O que acontecerá de fato? Bem, é aqui onde se inicia a brincadeira e o uso de redes, na prática.
Vamos fazer o seguinte: Com base no código visto no artigo anterior. Vamos criar uma pequena corrente com dois perceptrons. Onde um terá a sua saída ligada a entrada de outro perceptron. No final, queremos que ambos perceptrons consigam aprender sobre um tema. Para deixar isto mais plausível e fácil de entender. Vamos começar vendo um código, na prática. Para início de conversa, vamos iniciar com o código que pode ser visto logo abaixo na íntegra.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. #property script_show_inputs 04. #property description "Experiencing a simple chain of neurons" 05. //+------------------------------------------------------------------+ 06. #include <Neural Network\C_Neuron.mqh> 07. //+------------------------------------------------------------------+ 08. enum eFactorization { 09. Minimum_Square, 10. Gradient_Descent, 11. }; 12. //+------------------------------------------------------------------+ 13. input eFactorization user00 = Minimum_Square; //Type of factorization 14. input double user01 = 1e-6; //Estimated error 15. input double user02 = 1e-6; //Learning Rate 16. input C_Neuron::eFnActivate user03 = C_Neuron::Identity; //Activation function 17. //+------------------------------------------------------------------+ 18. //Training expression: f(x) = (w0 * 2) 19. //+------------------------------------------------------------------+ 20. double Train[] { 21. 0, 0, 22. 1, 2, 23. 2, 4, 24. 3, 6 25. }; 26. //+------------------------------------------------------------------+ 27. #define nColumns 2 28. #define nLines Train.Size() / nColumns 29. //+------------------------------------------------------------------+ 30. void SimpleChain(void) 31. { 32. C_Neuron *neuron; 33. 34. neuron = new C_Neuron(nColumns - 1, user03, user00 == Minimum_Square); 35. 36. (*neuron).Learning(Train, 1.0, user01, user02, ULONG_MAX); 37. (*neuron).View_Variables(); 38. 39. delete neuron; 40. } 41. //+------------------------------------------------------------------+ 42. void OnStart() 43. { 44. Print("************************************"); 45. Print("A simple chain of neurons..."); 46. Print("************************************"); 47. Print("Parameters:"); 48. Print("Type of factorization: ", EnumToString(user00)); 49. Print("Estimated error: ", user01); 50. Print("Learning Rate:", user02); 51. Print("Activation function: ", EnumToString(user03)); 52. Print("************************************"); 53. 54. SimpleChain(); 55. } 56. //+------------------------------------------------------------------+
Código 01
Este é um código bem simples, e que todos que estão acompanhando estes artigos, já deve conseguir entender o que está acontecendo. Então, não vejo necessidade de comentar o funcionamento do mesmo. Contudo, e apenas como curiosidade, vamos ver o resultado que nos será apresentado.
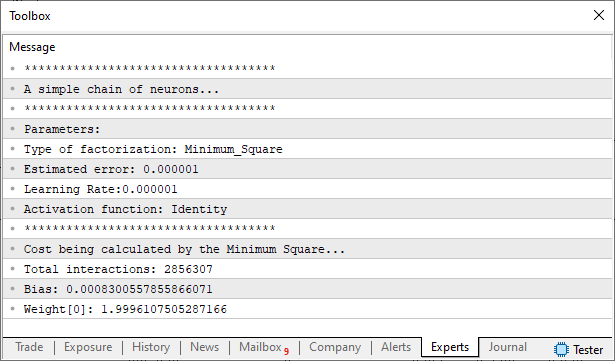
Imagem 02
Definitivamente nenhuma surpresa. Agora vamos mudar um pouco as coisas a ponto de podermos controlar a quantidade de perceptrons, que serão ligados em cadeia. Isto de modo que a saída de um seja a entrada do próximo. Bem, no final o objetivo será criar algo parecido com o que podemos ver abaixo.

Image 03
Perceba que estamos ligando apenas e tão somente dois perceptrons, o que seria o caso mais simples de todos. Mas vamos ver como isto fica em termos de código. Inicialmente modificamos o código para algo como mostrado abaixo.
18. //+------------------------------------------------------------------+ 19. void SimpleChain(const uchar nNeurons, const ulong Limit) 20. { 21. C_Neuron *neuron[]; 22. double err, tmp[], v0[nColumns - 1]; 23. 24. if (!nNeurons) 25. return; 26. 27. ArrayResize(neuron, nNeurons); 28. for (uchar c = 0; c < nNeurons; c++) 29. neuron[c] = new C_Neuron(nColumns - 1, user03, user00 == Minimum_Square); 30. 31. ArrayResize(tmp, Train.Size()); 32. for (ulong count = 0; count < Limit; count++) 33. { 34. ArrayCopy(tmp, Train); 35. for (uchar c = 0; c < nNeurons; c++) 36. { 37. if ((err = (*neuron[c]).Learning(tmp, 1.0, user01, user02, 1)) < user01) 38. break; 39. for (uchar nl = 0; nl < nLines; nl++) 40. { 41. v0[0] = tmp[nl * nColumns]; 42. tmp[nl * nColumns] = (*neuron[c]).Perceptron(v0); 43. } 44. } 45. } 46. 47. for (uchar c = 0; c < nNeurons; c++) 48. { 49. PrintFormat("====== information of neuron number #%02d ======", c); 50. (*neuron[c]).View_Variables(); 51. } 52. 53. for (uchar c = 0; c < nNeurons; c++) 54. delete neuron[c]; 55. 56. ArrayFree(tmp); 57. ArrayFree(neuron); 58. } 59. //+------------------------------------------------------------------+ 60. void OnStart() 61. { 62. Print("************************************"); 63. Print("A simple chain of neurons..."); 64. Print("************************************"); 65. Print("Parameters:"); 66. Print("Type of factorization: ", EnumToString(user00)); 67. Print("Estimated error: ", user01); 68. Print("Learning Rate:", user02); 69. Print("Activation function: ", EnumToString(user03)); 70. Print("************************************"); 71. 72. SimpleChain(1, 10); 73. } 74. //+------------------------------------------------------------------+
Fragmento 01
Obviamente isto que fizemos não irá gerar um código ideal. Já que termos informações vindas da classe C_Neuron que não nos interessa. Como pode ser visto na imagem abaixo.
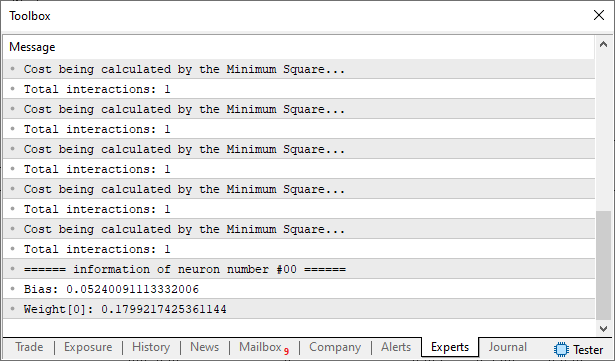
Imagem 04
Bem, podemos limpar o código, removendo estas informações. Mas, tenho uma ideia melhor, onde pretendo mostrar a você como fazer certas coisas, sem precisar ficar mudando o código a todo momento. Bastando apenas dizendo ao compilador o que ele deve ou não colocar no código final. Então preste atenção, pois agora você aprenderá algo que muitos não utilizam por não saber muito bem como funciona.
Usando diretivas de compilação
Uma das coisas que o MQL5, utiliza vindo do C/C++, e que é bem legal de ser utilizado, são as diretivas de compilação. Mas o que seria estas tais diretivas? Bem, elas servem para que você, ou melhor dizendo, para que o compilador crie um código com determinadas características. Assim sem de fato mexer no código original, você, como programador, pode dizer ao compilador, como o código deverá ser construído. E poderá criar códigos totalmente diferentes, sem se quer mexer no código original. Apenas usando diretivas de compilação correta.
Talvez a diretiva, que você, mais deve ter me visto usar até aqui, seja a #define, que gera algum tipo de definição. Seja uma macro, seja um nome para uma constante. Mas está mesma diretiva, quando empregada em conjunto com outras, torna um código C/C++, muito mais elaborado. Se bem que no MQL5, não temos todo o poder, que se encontra no C/C++, mas ainda assim, é o suficiente para conseguirmos fazer muito mais, com muito menos código sendo digitado.
O que nos vamos fazer agora, é justamente utilizar estas diretivas, para remover, ou não, certas partes do código. Este tipo de coisa, pode ser algo bastante, confuso para grande parte de vocês. Então, antes de realmente tentar fazer grandes mudanças no código, sugiro que você experimente as coisas, conforme forem sendo explicadas. Assim você conseguirá entender, como as coisas realmente ocorrem e por que as diretivas funcionam.
076. //+------------------------------------------------------------------+ 077. inline double Learning_FX(const double &train[], const double epsilon, const double LearningRate, const ulong limit) 078. { 079. double err, 080. memT, 081. err_w[]; 082. ulong count; 083. 084. #ifndef def_NO_MSG 085. Print("Cost being calculated by the Minimum Square..."); 086. #endif 087. ArrayResize(err_w, m_Infos.nInputs); 088. for (count = 0; (count < limit) && ((err = Cost_FX(train)) > epsilon); count++) 089. { 090. for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) 091. { 092. memT = m_Infos.Weight[c]; 093. m_Infos.Weight[c] += LearningRate; 094. err_w[c] = Cost_FX(train) - err; 095. m_Infos.Weight[c] = memT; 096. } 097. memT = m_Infos.Bias; 098. m_Infos.Bias += LearningRate; 099. m_Infos.Bias = memT - (Cost_FX(train) - err); 100. for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) 101. m_Infos.Weight[c] -= err_w[c]; 102. } 103. #ifndef def_NO_MSG 104. PrintFormat("Total interactions: %I64u", count); 105. #endif 106. ArrayFree(err_w); 107. 108. return err; 109. } 110. //+------------------------------------------------------------------+ . . . 131. //+------------------------------------------------------------------+ 132. inline double Learning_DX(const double &train[], const double epsilon, const double LearningRate, const ulong limit) 133. { 134. ulong count; 135. double eRet; 136. 137. #ifndef def_NO_MSG 138. Print("Cost being calculated by the Gradient..."); 139. #endif 140. for (count = 0; (count < limit) && (MathAbs(eRet = Cost_DX(train)) > epsilon); count++) 141. { 142. m_Infos.Bias -= (m_Error.bias * LearningRate); 143. for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) 144. m_Infos.Weight[c] -= (m_Error.weight[c] * LearningRate); 145. } 146. #ifndef def_NO_MSG 147. PrintFormat("Total interactions: %I64u", count); 148. #endif 149. 150. return eRet; 151. } 152. //+------------------------------------------------------------------+
Fragmento 02
O que temos aqui é algo simplesmente fantástico. Observe as linhas oitenta e quatro, cento e três, cento e trinta e sete, e a linha cento e quarenta e seis. Nelas temos a diretiva #ifndef sendo utilizada. Esta diretiva visa dizer ao compilador, que caso def_NO_MSG não seja encontrada, os trechos entre #ifndef até #endif, DEVEM SE COMPILADOS. Caso esta diretiva exista em algum ponto do código, estes mesmos trechos NÃO DEVEM fazer parte do código final.
Ok. Mas no que isto irá nos ajuda na real? Calma meu caro leitor, você já vai entender. Agora, você poderia criar a diretiva, no código do arquivo de cabeçalho da classe, ou como é mais comum por parte de programadores mais experientes, criar a diretiva no código do arquivo principal. Neste ponto é que surge o pulo do gato. Você pode adicionar a definição a qualquer momento, dependendo do momento que você a criar, o seu código terá um ou outro comportamento. Para ficar mais simples de entender, vamos ver um exemplo bem mais simples. Não precise se preocupar, no anexo, você terá estes códigos para ver e experimentar as coisas localmente, e assim entender como a coisa de fato funciona.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void Demo_Directives(const string msg) 05. { 06. #ifdef def_DEMO 07. Print("Demonstrated Directive #1: ",msg); 08. #else 09. Print("Demonstrated Directive #2: ",msg); 10. #endif 11. } 12. //+------------------------------------------------------------------+
Código 02
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define def_DEMO 05. //+------------------------------------------------------------------+ 06. #include <Tutor\Tutor.mqh> 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. Print("Experimenting with compilation guidelines"); 11. Demo_Directives("Checking..."); 12. } 13. //+------------------------------------------------------------------+
Código 03
Agora vem a parte divertida. Observe que existe na linha quatro do script, uma definição. Por conta de que ela está antes do include, o compilador entenderá que o código do include, deverá usar esta tal definição. Assim, quando o compilador for incluir o código do arquivo de cabeçalho, no executável final. Ele irá, no momento em que encontrar a linha seis, ter um status verdadeiro. Já que existe uma definição sendo feita ANTES. Assim a linha sete do arquivo de cabeçalho, é a que será de fato compilada.
Caso a definição não tenha sido feita, ou tenha sido feita, depois da diretiva #include. O compilador verá a linha seis como falsa. Porém, ele verá a linha oito como verdadeira. Com isto, o código que será compilado será o da linha nove. E isto fará com que uma mensagem totalmente diferente, apareça no terminal do MetaTrader 5. Você pode ver isto, na imagem abaixo.
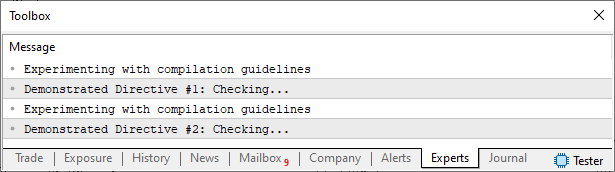
Imagem 05
Acredito que ficou simples de entender o que está ocorrendo. Caso a definição existir, tudo que estiver entre #ifdef e #endif, será usado. Se a definição não existir, qualquer coisa que estiver entre #else e #endif, será colocada para ser usado no executável. E é justamente isto que usaremos aqui, cujo objetivo é remover aquelas mensagens da classe C_Neuron. Já que se colocarmos a definição def_NO_MSG, significa que não queremos mensagens. Caso a definição não seja declarada, teremos a mensagens sendo mostradas. Por conta deste detalhe, além de outros, que em algum momento posso mostrar, é que você deve tomar o cuidado de remover definições desnecessárias entre arquivos diferentes. Caso contrário, acabará tendo dificuldades em manter seu código, conforme ele vai crescendo.
Entendido isto, podemos voltar ao nosso código principal, já modificamos o arquivo de cabeçalho, C_Neuron. Tudo que precisamos é incluir a definição, que impede as mensagens, antes que a include seja utilizada. Assim o código a ser utilizado é visto no fragmento abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. #property script_show_inputs 04. #property description "Experiencing a simple chain of neurons" 05. //+------------------------------------------------------------------+ 06. #define def_NO_MSG 07. //+------------------------------------------------------------------+ 08. #include <Neural Network\C_Neuron.mqh> 09. //+------------------------------------------------------------------+
Fragmento 03
E como mágica, agora o resultado é o que vemos logo abaixo. Com um detalhe: Se você precisar usar a classe C_Neuron, e ter as mensagens novamente. Não precisará redigitar o código, com as mensagens. Tudo que precisará fazer é não definir def_NO_MSG. Simples assim.
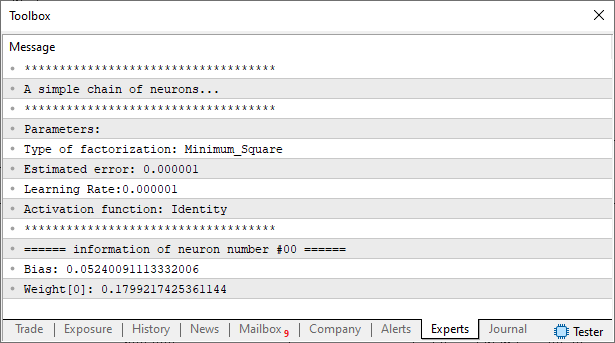
Imagem 06
Ok. Agora temos algo para brincar. Mas você deve ter notado que estou usando apenas um perceptron, e um conjunto de dez interações. Então para começar, a usar mais perceptrons, precisamos fazer algumas mudanças extras. Assim para evitar confusão, vamos iniciar um novo tópico.
Uma corrente de perceptrons
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. #property description "Experiencing a simple chain of neurons" 04. //+------------------------------------------------------------------+ 05. #define def_NO_MSG 06. #define def_ERROR_MAX 1e-3 07. //+------------------------------------------------------------------+ 08. #include <Neural Network\C_Neuron.mqh> 09. //+------------------------------------------------------------------+ 10. //Training expression: f(x) = (w0 * 2) 11. //+------------------------------------------------------------------+ 12. double Train[] { 13. 10, 20 14. }; 15. //+------------------------------------------------------------------+ 16. #define nColumns 2 17. #define nLines Train.Size() / nColumns 18. //+------------------------------------------------------------------+ 19. void SimpleChain(const uchar nNeurons, const ulong Limit) 20. { 21. C_Neuron *neuron[]; 22. double err, tmp[], in, out; 23. 24. if ((!nNeurons) || (Train.Size() > 2)) 25. return; 26. 27. ArrayResize(neuron, nNeurons); 28. for (uchar c = 0; c < nNeurons; c++) 29. neuron[c] = new C_Neuron(nColumns - 1, C_Neuron::Identity, true); 30. 31. ArrayResize(tmp, Train.Size()); 32. in = out = Train[0]; 33. for (ulong count = 0; count < Limit; count++) 34. { 35. PrintFormat("====== Interaction #%02d ======", count); 36. for (uchar c = 0; c < nNeurons; c++) 37. { 38. tmp[0] = (c > 0 ? out : in); 39. if ((err = (*neuron[c]).Learning(tmp, 1.0, def_ERROR_MAX, def_ERROR_MAX, 1)) < def_ERROR_MAX) 40. break; 41. PrintFormat("Input value in the neuron #%02d: %.8f [%.16f]", c, tmp[0], err); 42. out = (*neuron[c]).Perceptron(tmp); 43. } 44. } 45. 46. PrintFormat("Final exit: %.8f || Expected: %.8f", out, Train[1]); 47. 48. for (uchar c = 0; c < nNeurons; c++) 49. delete neuron[c]; 50. 51. ArrayFree(tmp); 52. ArrayFree(neuron); 53. } 54. //+------------------------------------------------------------------+ 55. void OnStart() 56. { 57. Print("************************************"); 58. Print("A simple chain of neurons..."); 59. Print("************************************"); 60. 61. SimpleChain(2, 1); 62. } 63. //+------------------------------------------------------------------+
Código 04
Como resultado vemos a seguinte imagem abaixo:
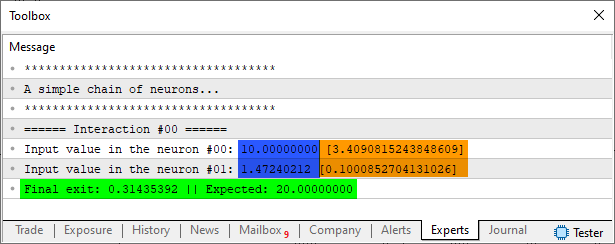
Imagem 07
O que a linha cinco faz foi explicado no tópico anterior. Já a linha seis evita que tenhamos de ficar ajustando as coisas a todo momento. Então para padronizar a explicação, você não poderá mudar as configurações até entender o que está ocorrendo. Apenas use o que está no código. Na linha doze temos nosso novo array de treinamento. Veja que o reduzi a apenas uma única linha. Agora lá na linha sessenta e um, dizemos quantos perceptrons, e quantas interações serão usadas. No caso faremos uso de dois perceptrons, onde a saída de um é ligada a entrada do outro, mas atenção, termos apenas uma única interação sendo feita. Com isto caímos na linha dezenove. Agora vem a parte que você de fato precisa entender.
Na linha vinte e sete, alocamos memória para comportar todos os perceptrons que iremos utilizar. Na linha vinte e oito, entramos em um laço que criará os perceptrons. Não importa quantos queremos criar. Todos serão criados de maneira igual, usando os mesmos valores, e estes valores são os mais básicos possível, para ficar tudo bem fácil de entender.
Já na linha trinta e um, alocamos memória para o array de treinamento. Mas por que alocar memória, se já temos o array definido? Na verdade, o array definido na linha doze, serve apenas como entrada e saída. Ele não serve para o que será feito dentro da rede, e é isto mesmo que você acabou de ler, meu caro leitor. Agora não estaremos mais lidando com um perceptron. Estaremos usando a nossa primeira rede. Agora vem a parte que pode gerar muita confusão. Na linha trinta e dois capturamos o valor de entrada. Lembre-se de que queremos apenas uma única entrada, ou seja, o sistema mais simples possível. Na linha trinta e três entramos no laço de interação. Na linha trinta e seis entramos em outro laço, e este procura, promover a FORWARD PROPAGATION, ou seja, a propagação para a frente.
Preste atenção: Na linha trinta e oito, pegamos o valor que esteja na variável out, caso não estejamos no começo da rede, e a aplicamos no array de treinamento local. Caso estejamos no começo da rede, ou seja, no primeiro perceptron, o valor usado é da variável in. Agora na linha trinta e nove executamos o treinamento do perceptron. Na linha quarenta e um imprimimos dos valores usados no treinamento. Já na linha quarenta e dois, efetivamente promovemos a propagação para a frente. Isto se o laço da linha trinta e seis vir a se repetir. Teremos a saída de um perceptron aplicada na entrada do próximo. No final temos a linha quarenta e seis imprimindo os resultados. E o resto do código é para destruir a nossa SKYNET.
Ok. Agora vem a parte complicada. Observe que estamos usando a função de mínimo quadrado. Não estamos usando nenhuma função especial na ativação. Todos os perceptrons são iguais. Mas olhe a imagem de resultado. Quero que você olhe esta imagem e me diga: estamos fazendo a retro propagação? SIM ou NÃO? Se sim, lhe pergunto: onde ela está sendo feita. Se a sua resposta for não, por que então os perceptrons estão reportando um valor de erro?
SimpleChain(2, 2);
O resultado é visto abaixo.
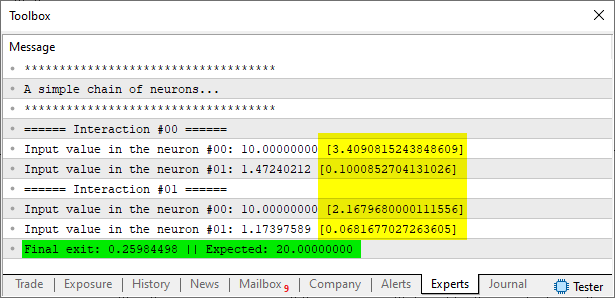
Imagem 08
Observe que o valor de erro reportado, que se encontra em amarelo, diminuiu. Significando que de fato, a retro propagação está acontecendo. Mas preste atenção ao fato do valor final acabou piorando, frente ao que havia sido obtido anteriormente. Significando que algo estranho está acontecendo. Temos a retro propagação acontecendo, mas a rede neural, não está conseguindo convergir em direção à resposta esperada. O que estamos fazendo de errado?
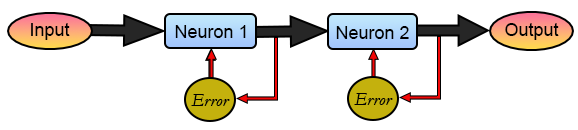
Imagem 09
Ou seja, cada um nos perceptrons está afetando o próximo. Mas a retro propagação está acontecendo apenas no âmbito das setas em vermelho, ou seja, os perceptrons estão trabalhando de maneira individualizada, não está havendo conversando entre eles. Assim o perceptron um está tentando se ajustar, mas o perceptron dois não deixa. Ao mesmo tempo, o perceptron dois tenta encontrar um caminho, mas o perceptron um o tira da direção. No final, o erro de cada perceptron individual cai. Mas o erro geral aumenta. E este é o problema que precisamos resolver.
Considerações finais
Este artigo teve como objetivo começar a demonstrar como muitas das vezes a narrativa de como redes perceptron funciona não é a mais adequada. Visto que diferente do que muitos podem imaginar, não é somente o fato de ligar a saída de um perceptron, na entrada de outro, que nos permite criar uma rede perfeitamente funcional.
Além disto, diferente do que muitos de fato pensam ou imaginam que seria a forma mais adequada de se construir uma rede perceptron, vimos que existem diferentes tipos de configuração, cada uma voltada para um dado tipo de objetivo. Contudo, a escolha do tipo certo de topologia e de como definiremos onde é a entrada e a saída da rede, muda radicalmente o tipo de processamento que se espera ser feito pela rede em si. Mas independentemente de qual topologia utilizemos, a forma de criação de um perceptron se mantém a mesma, ou pelo menos deveria se manter assim.
Muito bem, vimos que ao tentarmos ligar perceptrons em série a fim de atingir um certo resultado, o conjunto não conseguiu trabalhar bem, não conseguindo assim convergir para a solução estimada. Com isto deixo aqui uma pergunta: como você faria para implementar o perceptron a fim de poder ligar diversos deles em algum tipo de configuração, por exemplo, em série como foi feito aqui? Isto para eles trabalharem como sendo uma entidade única. Sei que pode parecer um tanto quanto complicado. Contudo, o objetivo é criar um perceptron que sem nenhuma outra modificação pudesse ser ligado em um número arbitrário, a fim de resolver algum problema, sem que percebêssemos a quantidade de perceptrons que existe entre o ponto de entrada e o ponto definido como saída.
| Arquivo MQ5 | Descrição |
|---|---|
| Scripts\Example A | Demonstração básica |
| Scripts\Tutor | Demonstração básica |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Daniel, tudo tranquilo, o ponto mais importante do artigo está bem no meio, quase de passagem:
"Não existindo de forma alguma um tipo de receita de bolo."
Essa frase resume o que a maioria nunca aceita ouvir. É muito mais confortável acreditar que existe uma arquitetura certa, um otimizador certo, um número certo de camadas — e que basta copiar e rodar.
O trabalho de entender topologia de verdade é lento, desconfortável e cheio de tentativas que não funcionam. Mas é exatamente esse desconforto que separa quem usa inteligência artificial de quem entende o que está fazendo.
Obrigado por não tomar o atalho na explicação.
Daniel, tudo tranquilo, o ponto mais importante do artigo está bem no meio, quase de passagem:
"Não existindo de forma alguma um tipo de receita de bolo."
Essa frase resume o que a maioria nunca aceita ouvir. É muito mais confortável acreditar que existe uma arquitetura certa, um otimizador certo, um número certo de camadas — e que basta copiar e rodar.
O trabalho de entender topologia de verdade é lento, desconfortável e cheio de tentativas que não funcionam. Mas é exatamente esse desconforto que separa quem usa inteligência artificial de quem entende o que está fazendo.
Obrigado por não tomar o atalho na explicação.
Agradeço as palavras. E de fato, nos artigos que ainda pretendo publicar, se não tivermos mais contratempos, pois todos estão prontos, mas... bem deixa prá lá, mostrarei que nem sempre coisa funcionará, só por que alguém disse para fazer desta ou daquela maneira.
Muitas vezes é preciso adaptar a própria topologia, rede, ou mesmo forma de treinamento, para se conseguir o resultado desejado.