
MQL5でのデータベースの簡素化(第1回):データベースとSQL入門

はじめに
MQL5に関する話題の多くは、インジケーターやエキスパートアドバイザー(EA)、取引戦略、バックテストに集中しがちです。しかし、自動化に真剣に取り組むトレーダーや開発者であれば、やがて「データの永続性」がいかに重要かに気づきます。ここで活躍するのがデータベースです。結果はすでにCSVやTXTファイルに保存しているのに、なぜわざわざデータベースを使うのかと思うかもしれません。その答えは、大量の情報や複雑な処理を扱う際に、データベースが提供する整理、性能、信頼性にあります。
MQL5の文脈では、データベースの利用は一見大げさに思えるかもしれません。結局のところ、この言語は取引や指標、自動実行ロボット向けに設計されています。しかし、大量データや複雑なバックテスト、詳細な注文履歴を扱う戦略では、単純なファイル保存だけではすぐに限界が現れます。こうした状況で、データベースの作成、アクセス、操作方法を理解することは、取引ワークフローを飛躍的に向上させる強力な手段となります。
MQL5でデータベースを学び始めるトレーダーは、ネイティブ関数や個別のサンプル例を多数目にするでしょう。これらを使ってレコードを保存し、取得することは可能ですが、次第に「これらを実プロジェクトで整理して再利用可能にするにはどうすれば良いか?」という課題が浮上します。本連載では、単なるドキュメントの紹介に留まらず、SQLiteの基本機能からスタートし、段階を追って「MQL5ミニORM (TickORM)」を構築していきます。直接関数を呼び出す代わりに、JavaのJDBCやJPAに着想を得た設計層として整理し、MetaTrader環境に最適化するのが狙いです。
本記事では、MQL5およびSQLにおけるデータベースの基礎を解説します。これにより、後続の記事でこれらの機能をクラスやインターフェースにカプセル化し、最終的にはORMに統合するための準備が整います。
データベースとは何か、そしてどのように役立つのか
技術的には、データベースとは情報を体系的に構造化し、保存したデータを格納、照会、操作できる仕組みです。データの整合性を保証し、異なる情報セット間の関係を構築し、操作を高速におこなえる利点があります。
データを単純なファイルに保存する場合とデータベースを使う場合の実務上の違いは、構造の整理とアクセスの容易さにあります。CSVやTXTなどの単純なファイルでは、読み取りや変更をおこなうたびに全内容を反復処理し、文字列を操作し、書式の不具合に対処し、ファイルが破損しないことを祈る必要があります。データベースでは、これらの操作が抽象化されており、特定のレコードを検索したり、複数の値を一度に更新したり、データ損失なしでトランザクションを実行したりできます。
では、この整理は内部でどのようにおこなわれているのでしょうか。データベースの基本構造をスプレッドシートに例えると次のようになります。

- データベース内の各テーブルは、スプレッドシートのタブに相当し、特定の情報セット(例:Trades)専用です。
- 各テーブル内には、スプレッドシートの列のように、各アイテムの属性(id、シンボル、価格など)を表す列があります。
- テーブルの各行は単一のレコード、つまり特定の取引や実行された注文に対応します。
テーブル、列、行からなるこのシンプルな構造は、迅速で整理されたクエリの基盤となります。まるで無限に整理された相互接続のスプレッドシートを持つかのようであり、データの相互参照、高度なフィルター、大量データの操作を容易におこなえる利点があります。
これが、MQL5で独自のORMを作成する動機です。アイデアはシンプルです。テーブルを操作するたびにSQLを手書きするのではなく、テーブルをエンティティ、列をクラス属性として扱う層を構築します。これが本連載全体で開発するプロジェクトの中核となり、より堅牢でスケーラブルな取引システムの基盤となります。ORMの名前はTickORMです。
要するに、データベースは信頼性が高く柔軟なソリューション構築の基盤であり、ORMはこの基盤とMQL5のコードをつなぐ橋渡しとなります。
テストを容易にするため、すべてのサンプルコードは記事の最後に添付されています。これにより、コードを手動で組み直すことなく、必要に応じて参照、コピー、適応できます。
注意:以降のコード例では、ログレコードをコンソールに表示します。これは、MQL5でのトレースやデバッグを容易にするために開発されたLogifyライブラリを使用しています。その動作や実装手順を詳しく知りたい場合は、開発過程を解説した一連の記事をご覧ください。SQLおよびMQL5ネイティブ関数
データベース操作には多くのことは必要ありません。幸いなことに、MQL5には、言語内で直接データベースを作成・アクセス・操作できる一連のネイティブ関数が用意されています。これらの関数は、コードとデータベースの橋渡しとして機能します。
SQLとの関係は直接的です。これらの関数はクエリ実行の層として働きます。つまり、MQL5内でSQLコマンドを記述すると、ネイティブ関数が結果の準備、実行、読み取りを担当します。外部ライブラリに依存せずに、SELECT、INSERT、UPDATE、DELETEなどの複雑な操作やテーブル作成も可能です。
これは、実際の実装に入る前に各関数の役割と可能性を理解するための出発点となります。以下に、利用可能なネイティブデータベース関数とその概要を示します。
- DatabaseOpen(string filename, uint flags):指定されたファイル内のデータベースを開くまたは作成する
- DatabaseClose(int database):データベースを閉じる
- DatabaseImport(int database,const string table,const string filename,uint flags,const string separator,ulong skip_rows,const string skip_comments):ファイルからテーブルにデータをインポートする
- DatabaseExport(int database,const string table_or_sql,const string filename,uint flags,const string separator):テーブルまたはSQLクエリ結果をCSVファイルにエクスポートする
- DatabasePrint(int database,const string table_or_sql,uint flags):[エキスパート]タグの操作ログにテーブルまたはSQLクエリ結果を表示する
- DatabaseTableExists(int database,string table):データベース内にテーブルが存在するか確認する
- DatabaseExecute(int database, string sql):指定したデータベースにSQLリクエストを実行する
- DatabasePrepare(int database, string sql):リクエストの識別子を作成する(DatabaseRead()で使用可能)
- DatabaseReset(int request):DatabasePrepare()呼び出し後に後のリクエストをリセットする
- DatabaseBind(int request,int index,T value):リクエスト内のパラメータ値を設定する
- DatabaseRead(int request):リクエスト結果の次のレコードに移動する
- DatabaseFinalize(int request):DatabasePrepare()で作成したリクエストを削除する
- DatabaseTransactionBegin(int database):トランザクションの実行を開始する
- DatabaseTransactionCommit(int database):トランザクションをコミットする
- DatabaseTransactionRollback(int database):トランザクションをロールバックする
- DatabaseColumnsCount(int request):リクエスト内のフィールド数を取得する
- DatabaseColumnName(int request,int column,string& name):インデックスでフィールド名を取得する
- DatabaseColumnType(int request,int column):インデックスでフィールドタイプを取得する
- DatabaseColumnSize(int request,int column):フィールドのサイズをバイト単位で取得する
- DatabaseColumnText(int request,int column,string& value):現在のレコードから文字列として値を取得する
- DatabaseColumnInteger(int request,int column,int& value):現在のレコードからint型の値を取得する
- DatabaseColumnLong(int request,int column,long& value):現在のレコードからlong型の値を取得する
- DatabaseColumnDouble(int request,int column,double& value):現在のレコードからdouble型の値を取得する
利用可能なすべての関数、パラメータ、例については、MetaQuotesが提供するMQL5データベース関数公式ドキュメントを参照してください。
1. データベースの開閉
まずは基本として、データベースへの接続を開く方法から始めます。これはDatabaseOpen関数でおこないます。この関数は、データベースファイル名と、オプションで接続モードを指定するフラグを受け取ります。フラグには次のような値があります。
| 値 | 説明 |
|---|---|
| DATABASE_OPEN_READONLY | 読み取り専用で開く |
| DATABASE_OPEN_READWRITE | 読み書き可能で開く |
| DATABASE_OPEN_CREATE | 必要に応じてディスク上にファイルを作成する |
| DATABASE_OPEN_MEMORY | RAM上にデータベースを作成する |
| DATABASE_OPEN_COMMON | ファイルはすべての端末の共通フォルダに保存する |
int OnInit() { //--- Open connection int handler = DatabaseOpen("database.sqlite",DATABASE_OPEN_CREATE|DATABASE_OPEN_READWRITE); if(handler == INVALID_HANDLE) { logs.Error("Failed to open database","TickORM"); return(INIT_FAILED); } logs.Info("Open database","TickORM"); //--- Here you would perform queries, inserts or updates //--- Close connection logs.Info("Closed database","TickORM"); DatabaseClose(handler); return(INIT_SUCCEEDED); }
最初のパラメータではデータベース名を指定します。この例では「database」を使用し、最後にファイル拡張子「.sqlite」を付けます。これはファイルとして保存されるデータベースですが、データ取得やクエリの作成方法はSQL標準に従うため問題ありません。
この例では、DATABASE_OPEN_READWRITEが読み書きを許可し、DATABASE_OPEN_CREATEがファイルが存在しない場合に自動的に作成されることを保証します。操作が完了したら、DatabaseCloseで接続を閉じ、リソースを解放します。
このコードを実行すると、<MQL5/Files>フォルダにデータベースが自動的に作成され、MetaEditorで確認できます。
2. テーブルの作成
データベースに接続した後の最初のステップは、データを保存する構造を定義することです。SQLでは、CREATE TABLEコマンドを使用して、テーブル名と含めるフィールドを指定します。
MQL5では、テーブル作成に主に以下の2つの関数を使用します。
- DatabaseTableExists(handler, table_name):データベース内にテーブルが存在するか確認し、存在すればtrue、存在しなければfalseを返す
- DatabaseExecute(handler, sql):SQL文を直接実行する
一般的な手順は、テーブルの存在を確認し、存在しなければテーブルを作成することです。実際の例は次のとおりです。
//--- Create table if(!DatabaseTableExists(handler,"trades")) { logs.Info("Creating user table...","TickORM"); if(DatabaseExecute(handler,"CREATE TABLE trades (id INTEGER PRIMARY KEY AUTOINCREMENT,symbol TEXT, price FLOAT, takeprofit FLOAT, stoploss FLOAT, volume FLOAT);")) { logs.Info("'Trades' table created","TickORM"); } else { logs.Error("Failed to create table",GetLastError(),"TickORM"); } }
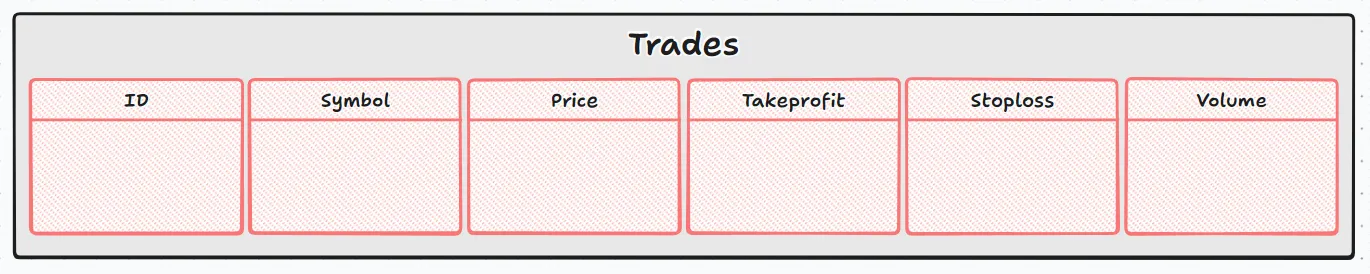
このスニペットでは、「CREATE TABLE trades (...)」を使用してtradesというテーブルを作成します。テーブルには取引に関する基本情報が含まれます。これらは、id(自動生成される一意の識別子)、symbol、price、takeprofit、stoploss、volumeです。
テーブルがすでに存在する場合、DatabaseTableExists関数がコマンドの再実行を防ぎます。テーブルを作成する際は、必ず存在確認をおこない、必要に応じて作成するというパターンに従ってください。
現在の段階でのデータベース構造は、次の図のようになります。
MetaEditorはこのデータベースの表示に対応しています。表示用テーブルファイルをダブルクリックすると、ブラウザータブが自動的に切り替わります。
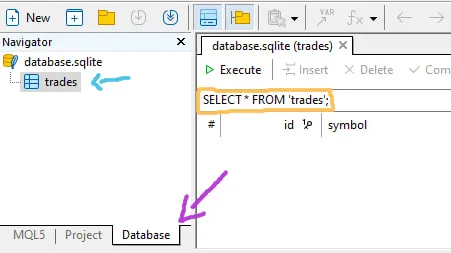
- 青矢印:データベーステーブルを示します
- 黄色:SQLコマンドを入力する場所(手動で入力することも、コード内で実行することも可能です。次の手順で例を示します)
- 紫色:[Database]ブラウザタブ。元のファイル表示(.mqhなど)に戻る場合は[MQL5]タブに切り替えてください
3. テーブルにデータを挿入する
次のステップとして、作成したテーブルにデータを挿入します。SQLでは、レコードを追加するために「INSERT INTO」コマンドを使用します。基本的な構文は次のとおりです。
INSERT INTO table_name (column1,column2,...) VALUES (value1,value2,...)
値にはデータをそのまま渡します。文字列の場合は、'example'のようにシングルクォートで囲みます。ここでもDatabaseExecute関数を使用し、実行が成功したかどうかを確認します。
//--- Insert data ResetLastError(); if(DatabaseExecute(handler,"INSERT INTO trades (symbol,price,takeprofit,stoploss,volume) VALUES ('EURUSD',1.16110,1.15490,1.16570,0.01);")) { logs.Info("Data saved to the trades table","TickORM"); } else { logs.Error("Failed to save data to the trade table",GetLastError(),"TickORM"); }
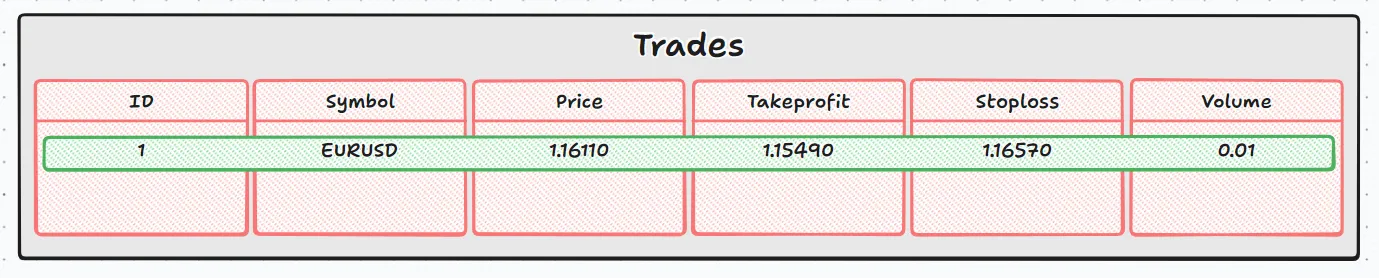
この例では、tradesテーブルに次の値を持つレコードが追加されます。
- id:銀行によって自動生成
- symbol:'EURUSD'
- price:1.16110
- takeprofit:1.15490
- stoploss:1.16570
- volume:0.01
現在の段階の状態は、次の図のようになります。
4. テーブルからデータを読み取る
データベースにデータを保存するだけでは不十分で、本当の力はそれを構造化された方法でクエリし、抽出できる点にあります。MQL5では、この処理は次の明確な流れに従います。
- DatabasePrepareでSQLクエリを準備し、SQLコマンドを渡す
- DatabaseReadで結果を1行ずつ読み進め、結果をスクロールする
- DatabaseFinalizeでクエリを終了し、メモリを解放する
基本的な例
//--- Data reading int request = DatabasePrepare(handler,"SELECT * FROM trades;"); //--- Number of table columns that were read int size_cols = DatabaseColumnsCount(request); //--- While data is available for reading (reading each line) while(DatabaseRead(request)) { //--- Scan across all columns of the current line of reading for(int j=0;j<size_cols;j++) { string name = ""; DatabaseColumnName(request,j,name); logs.Info(name,"TickORM"); } } //--- Reset query DatabaseFinalize(request);
実行すると、ログに次のように出力されます。
2025.08.21 10:14:51 [INFO]: Open database 2025.08.21 10:14:51 [INFO]: id 2025.08.21 10:14:51 [INFO]: symbol 2025.08.21 10:14:51 [INFO]: price 2025.08.21 10:14:51 [INFO]: takeprofit 2025.08.21 10:14:51 [INFO]: stoploss 2025.08.21 10:14:51 [INFO]: volume 2025.08.21 10:14:51 [INFO]: Closed database
ここで使用している「SELECT * FROM trades;」は、tradesテーブル内のすべてのレコードを取得するクエリです。DatabaseRead(request)が呼ばれるたびにカーソルが次の行へ進み、内部ループがその行のすべての列を反復処理して列名を出力します。
これを画像で比較すると次のようになります。
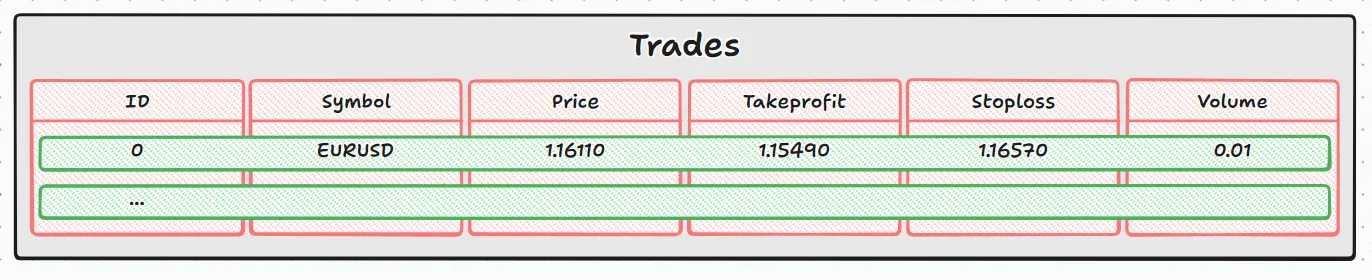
- 外側のループ(while(DatabaseRead(request) ))は行を移動します(緑の領域)
- 内側のループ(for(int j=0;j<size_cols;j++) )は列を移動します(赤の領域)
この2つのループを組み合わせることで、スプレッドシートをセルごとに巡回するように、テーブル全体を読み取ることができます。
次に進んで列の値を読み取っていきます。前の例では、列の名前だけが一覧表示されていました。今回は保存されている値が必要になるため、列の型に応じて専用の関数を使います。
- DatabaseColumnType:列のデータ型を動的に判別する
- DatabaseColumnText:テキスト(シンボルや名前など)
- DatabaseColumnDouble:浮動小数点数(価格など)
- DatabaseColumnLongまたはDatabaseColumnInteger:整数値(IDなど)
完全な例
//--- Data reading int request = DatabasePrepare(handler,"SELECT * FROM trades;"); //--- Number of table columns that were read int size_cols = DatabaseColumnsCount(request); //--- While data is available for reading (reading each line) while(DatabaseRead(request)) { //--- Scan across all columns of the current line of reading for(int j=0;j<size_cols;j++) { string name = ""; DatabaseColumnName(request,j,name); ENUM_DATABASE_FIELD_TYPE type = DatabaseColumnType(request,j); if(type == DATABASE_FIELD_TYPE_TEXT) { string data = ""; DatabaseColumnText(request,j,data); logs.Info(name + " | "+data,"TickORM"); } else if(type == DATABASE_FIELD_TYPE_FLOAT) { double data = 0; DatabaseColumnDouble(request,j,data); logs.Info(name + " | "+DoubleToString(data,5),"TickORM"); } else if(type == DATABASE_FIELD_TYPE_INTEGER) { long id = 0; DatabaseColumnLong(request,j,id); logs.Info(name + " | "+IntegerToString(id),"TickORM"); } } } //--- Reset query DatabaseFinalize(request);
実行すると、ログに次のように出力されます。
2025.08.21 10:18:04 [INFO]: Open database 2025.08.21 10:18:04 [INFO]: id | 1 2025.08.21 10:18:04 [INFO]: symbol | EURUSD 2025.08.21 10:18:04 [INFO]: price | 1.16110 2025.08.21 10:18:04 [INFO]: takeprofit | 1.15490 2025.08.21 10:18:04 [INFO]: stoploss | 1.16570 2025.08.21 10:18:04 [INFO]: volume | 0.01000 2025.08.21 10:18:04 [INFO]: Closed database
この場合は、行と列を順番に反復処理するだけでなく、各セルの中身にもアクセスしています。先ほどの表のイメージに戻ると、次のように対応します。
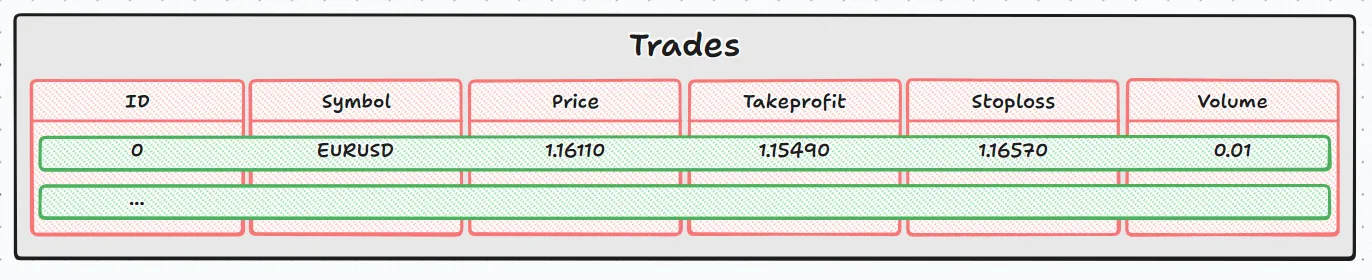
- 灰色の四角形は完全な表(trades)です。
- それぞれの緑色の四角形はDatabaseReadが返す各行です。
- それぞれの赤い四角形は列であり、値は文字列(string)、小数(double)、整数(int)のいずれかです
- DatabaseColumnTypeを使うことは、赤い四角形に入っているデータの型を尋ねることに相当します。
- その後、対応する関数(DatabaseColumnText、DatabaseColumnDouble、DatabaseColumnLong)が値を取得します。
5. テーブルデータの更新
実際の運用では、既存の情報を修正する必要が生じることは珍しくありません。そこで使用するのがUPDATEコマンドで、これはテーブル内の特定の行に対して、1つ以上の列の値を変更するためのものです。
SQLにおける基本構造は次のとおりです。
UPDATE table_name SET column1=value1, column2=value2, ... WHERE condition;
MQL5では、レコードの更新はDatabaseExecute関数を通じておこなわれます。この関数はSQLコマンドをデータベースに直接送信します。次に例を示します。
//--- Update data ResetLastError(); if(DatabaseExecute(handler,"UPDATE trades SET volume=0.1 WHERE id=1")) { logs.Info("Trades table data updated","TickORM"); } else { logs.Error("Failed to update trades table data",GetLastError(),"TickORM"); }
ここではごく典型的なケースを扱っています。tradesテーブルの中からidが1のレコードを探し、見つかったらvolume列の値を0.1に更新するよう、データベースに指示しています。
このパターンは取引の現場で非常に有用です。たとえば、最初に0.01ロットで取引を保存していたものの、戦略調整の結果0.1ロットに変更する必要が生じたとします。その場合、シンプルなUPDATEコマンドを使うだけで、レコードを削除したり再作成したりすることなく、データベース内の情報を確実に同期できます。
6. テーブルからデータを削除する
データを削除するためには、SQLのDELETEコマンドを使用します。これはテーブルから行を削除するための命令です。コマンドの一般的な形式は次のとおりです。
DELETE FROM table_name WHERE condition;
ここでも同じパターンで、DatabaseExecute関数を使ってSQLコマンドをデータベースに送信します。
//--- Delete data ResetLastError(); if(DatabaseExecute(handler,"DELETE FROM trades WHERE id=1")) { logs.Info("Deleted trades table data","TickORM"); } else { logs.Error("Failed to delete data to the trade table",GetLastError(),"TickORM"); }
この例では、idフィールドが1に等しいレコードをtradesテーブルから削除するよう、データベースに指示しています。これは一度きりの、制御された安全な削除です。
重要な注意点:UPDATEの場合と同様に、WHERE句の使用は不可欠です。これがないと、テーブル全体を誤って削除してしまう可能性があります。このコマンドによって、作成・挿入・更新・削除という基本的なデータ操作サイクルが一通り完了します。ここまでで、次のステップへ進むための基礎がすべて整いました。
7. テーブルの削除
テーブルが不要になった場合は削除できます。
//--- Delete table ResetLastError(); if(DatabaseExecute(handler,"DROP TABLE trades")) { logs.Info("Trades table deleted","TickORM"); } else { logs.Error("Failed to delete trades table",GetLastError(),"TickORM"); }
強調しておく価値がありますが、「DROP TABLE」は元に戻すことができません。レコードだけを削除してテーブル構造を保持する「DELETE FROM trades」とは異なり、「DROP TABLE」はテーブルそのものとそのデータを両方削除します。この文を実行した場合、再びレコードを追加できるようにするには、テーブルを作り直す必要があります。
8. トランザクションとデータの整合性
次に、データベースの整合性という重要なポイントに進みましょう。データを扱うどんなアプリケーションにおいても、整合性は極めて重要です。複数のレコードを書き込む必要がある状況を想像してください。そのうち1つの挿入が失敗し、他の操作がすでに反映されていた場合、データベースは不整合な状態に陥る可能性があります。この問題を防ぐために存在するのがトランザクションです。
トランザクションとは、本来ひとまとまりとして扱うべきSQL操作のブロックです。
- 内部のすべての文が適用される(コミット)
- あるいは1つも適用されない(ロールバック)
MQL5には、この処理フローを制御するためのネイティブ関数が用意されています。
- DatabaseTransactionBegin(handler):トランザクションを開始する
- DatabaseTransactionCommit(handler):変更を確認して適用する
- DatabaseTransactionRollback(handler):トランザクションの開始以降のすべての変更を元に戻す
以下の例は、それらの使用方法を示しています。
//--- Insert with transaction string sql="INSERT INTO trades (symbol,price,takeprofit,stoploss,volume) VALUES ('EURUSD',1.16110,1.15490,1.16570,0.01);"; DatabaseTransactionBegin(handler); logs.Info("Inserting data, preparing transaction","TickORM"); if(!DatabaseExecute(handler,sql)) { logs.Error("Transaction failed, reverting to previous state",GetLastError(),"TickORM"); DatabaseTransactionRollback(handler); } else { logs.Info("Transaction complete, changes saved","TickORM"); DatabaseTransactionCommit(handler); }
このスニペットでは、以下をおこないます。
- DatabaseTransactionBeginでトランザクションを開始する
- 「insert (DatabaseExecute)」の実行を試みる
- エラーが発生した場合はDatabaseTransactionRollbackによってすべてを元に戻す
- 問題がなければDatabaseTransactionCommitで変更を確定する
これは、未完了のデータが残らないようにする上で重要です。また、複数の操作を一括で管理し、すべてが正常に実行された場合にのみ適用できるようになるため、制御性が高まります。さらには、ネットワーク障害、停電、実行エラーなどの予期せぬ問題が起きても、データを破損させずに元の状態へ戻せるため、安全性も向上します。
たとえば、複数のテーブルに対して10件の操作をおこなう場合、8件目で失敗したとしましょう。トランザクションを使わなければ、7件だけが反映され残りは失われ、不整合な状態になります。しかしトランザクションを使えば、ロールバックするだけで試行前の完全な状態に戻すことができます。
9. データのインポートとエクスポート
トランザクションに加えて、セキュリティと実用性をさらに高めてくれるのが、データのインポートとエクスポート機能です。これにより、データベースの定期的なバックアップが可能となり、データ損失への備えだけでなく、可搬性や復元の容易さも確保できます。このために用意されているのがDatabaseExportとDatabaseImportという関数で、これらを使えばデータをCSV形式で抽出し、必要に応じてデータベースへ復元することができます。
以下は、tradesテーブルをbackup_trades.csvへエクスポートする例です。
//--- Export table ResetLastError(); long data = DatabaseExport(handler,"trades","backup_trades.csv",DATABASE_EXPORT_HEADER,";"); if(data > 0) { logs.Info("Backup of the 'trades' table created successfully","TickORM"); } else { logs.Error("Failed to create backup of table 'trades'",GetLastError(),"TickORM"); }
以下のような重要なポイントがあります。
-
ファイル名:MQL5\Filesフォルダを基準とします。必要であればサブフォルダに整理することも可能です。
-
CSV形式:広く利用されており、Excel、Google Sheets、Python、Rなどで開くことができます。
-
フラグ:この例ではDATABASE_EXPORT_HEADERを使用しています。これは最初の行に列名を含めるフラグで、後からデータを読む際に大いに役立ちます。
値 説明 DATABASE_EXPORT_HEADER 最初の行にフィールド名を表示する DATABASE_EXPORT_INDEX 行番号を表示する DATABASE_EXPORT_NO_BOM ファイルの先頭にBOMタグを挿入しない(デフォルトでは挿入する) DATABASE_EXPORT_CRLF 改行にCRLFを使用する(デフォルトはLF) DATABASE_EXPORT_APPEND 既存のファイルの末尾にデータを追加し(デフォルトではファイルを上書きします)、ファイルが存在しない場合は作成する DATABASE_EXPORT_QUOTED_STRINGS 文字列値を二重引用符で囲んで表示する DATABASE_EXPORT_COMMON_FOLDER CSVファイルを、全ターミナル共通フォルダ\Terminal\Common\Fileに作成します。 -
区切り文字:例では「;」を使っていますが、「,」「\t」なども利用できます。使用するツールやワークフローに応じて選択してください。
戻り値:エクスポートされたレコード数が返されます。負の値の場合、エラーが発生しており、GetLastError()で原因を確認できます。
次に、逆方向の操作、つまりtradesテーブルへデータを読み込む(復元する)例です。
//--- Import table ResetLastError(); long data = DatabaseImport(handler,"trades","backup_trades.csv",DATABASE_IMPORT_HEADER|DATABASE_IMPORT_APPEND,";",0,NULL); if(data > 0) { logs.Info("'trades' table imported successfully","TickORM"); } else { logs.Error("Failed to import 'trades' table",GetLastError(),"TickORM"); }
ここにいくつかの貴重な注意点があります。
-
結合フラグ:DATABASE_IMPORT_HEADER( 最初の行をヘッダー(列名)として認識する)とDATABASE_IMPORT_APPEND( 既存データを消さずに末尾へ追記する)の2つを使用します。
値 説明 DATABASE_IMPORT_HEADER 最初の行はテーブルのフィールド名を含みます DATABASE_IMPORT_CRLF 改行はCRLFです(デフォルトはLF) DATABASE_IMPORT_APPEND 既存のテーブルの末尾にデータを追加する DATABASE_IMPORT_QUOTED_STRINGS 文字列値を二重引用符で囲みます DATABASE_IMPORT_COMMON_FOLDER ファイルは、全クライアントターミナルの共通フォルダ\Terminal\Common\Fileにあります。 -
区切り文字:エクスポートで使用されたものと一致する必要があります。
-
skip_rows:最初の行をスキップできます(たとえば、コメントや古いデータを無視する場合)。
-
skip_comments::スキップする行をマークするシンボルを定義します。手動で注釈を付けたCSVファイルを操作するときに非常に便利です。
戻り値:インポートされたレコード数が返されます。
DatabaseExportとDatabaseImportによって、データベースへの出し入れという基本的なサイクルが構築できました。これで、テーブル作成、挿入、検索、更新、削除、そして外部へのバックアップや復元まで、一連の操作を扱えるようになりました。
しかし、1つ注意点があります。これらの処理はすべて、SQL文とネイティブ関数を直接扱う必要があります。小規模な例では問題ありませんが、システムが成長するにつれて複雑さが増し、エラーのリスクも高まります。そこで、本当にすべてを毎回手書きする必要があるのかという、避けられない疑問が生まれます。
ここで登場するのがORMという考え方です。次のセクションでは、ORMとは何か、なぜMQL5でのデータベース操作の方法を劇的に変えるのか、そしてここまで積み上げてきた流れにどのように組み込まれるのかを見ていきます。
ORMとは何で、なぜ必要なのか
これまで、MQL5でSQLを直接使用してテーブルやレコードを「オンザフライ」で操作する方法を説明してきました。このアプローチは機能しますが、システムが大きくなるにつれてコード内に散在するSQLが増え、メンテナンスの問題、重複、そしてエラーのリスクが高まります。ここでORM(オブジェクトリレーショナルマッピング)が登場します。
ORMは、オブジェクト指向の世界とデータベースのリレーショナルの世界のギャップを埋めるレイヤーです。SQLを手動で書く代わりに、エンティティをクラスとして定義し、ORMにSQLコマンドへの変換を任せます。言い換えると、「INSERT INTO trades (...) VALUES (...)」を直接扱う代わりに、Tradeオブジェクトを作成し、repository.save(trade)のように呼び出すだけで済みます。
ORMの主な機能は次のとおりです。
- 自動マッピング:クラスと属性をテーブルや列に変換します。
- SQL抽象化:SQL文字列ではなく、オブジェクトとメソッドを操作します。
- 一貫性:保存、検索、削除などの共通操作が集中管理されるため、ロジックの重複が減ります。
- 移植性:一部のORMでは、ソースコードを変更せずに異なるデータベースでも同じロジックを動作させられます。
MQL5では、コードに埋め込まれたSQLを直接記述するとすぐに管理が難しくなります。数十のエンティティ(取引、注文、ログ、パフォーマンス指標)を持つEAを想定してください。コード全体に散在するINSERT、SELECT、UPDATEは、障害の発生ポイントを増加させ、ロジックの拡張や保守を困難にし、不整合のリスクを高めます。
ORMが解決する「課題」は以下の通りです。
- EAの複数箇所に重複して存在するSQLを排除できる。
- テーブル構造の変更がエンティティクラス1箇所に反映されるため、保守が容易になる。
- テーブルや列ではなく、ドメインオブジェクト(例:Trade、User、Order)を中心にコードを記述することができるので、可読性と自然な記述性が向上する。
- 自動テーブル生成、スキーマのバージョン管理、ログや監査ライブラリとの統合など、高度な機能の導入が容易になる。
つまり、ORMを使用しない場合、各操作はコード内のSQLブロックとなりますが、ORMを利用すればSQLは内部的な詳細に隠蔽され、開発者は本来の取引ロジックに集中できます。
MQL5でのORMプロジェクト
ORMの有用性が理解できたところで、次はそれがMQL5エコシステムにどのように適用されるかを具体化する必要があります。ORMの世界で一般的な言語(Java、C#、Python)とは異なり、ここにはすぐに利用できる堅牢なフレームワークが存在しないため、言語の制約や特性に合わせて独自のソリューションを構築する必要があります。
このプロジェクトで目指す範囲は明確です。取引環境において求められるシンプルさと高いパフォーマンスを損なわず、開発者が直接SQLを扱うのではなくオブジェクトとして操作できる層を作成することです。
計画されている機能は次のとおりです。
- エンティティ:データベースの各テーブルはMQL5クラスで表現され、その列を記述するメタデータ(型、主キー、自動増分の有無、NULL許可など)を含みます。これによりTradeクラスはtradesテーブルを忠実に反映しつつ、ネイティブオブジェクトとして操作可能になります。
- リポジトリ:INSERT、UPDATE、SELECTを手動で記述する代わりに、各エンティティには永続化および復元処理を担うリポジトリが用意されます。たとえばTradeRepositoryはSave(trade)、FindById(id)、Delete(trade)といったメソッドを一元管理します。これによりEAのコードはクリーンになり、散在するSQLがなくなります。
- クエリビルダー:フィルター、ソート、結合など複雑なクエリが必要な場合にはクエリビルダーを使用します。文字列連結によるエラーを避け、安全にSQLクエリをプログラムで構築できます。
- テーブルの自動作成:ORMはエンティティのメタデータに基づき対応するテーブルを自動生成し、作成前に既存テーブルの有無を確認します。これによりプロジェクト開始時に手動でSQLスクリプトを作成する必要がなくなり、データベースをエンティティの進化に追従させられます。
- ログと監査の統合:ORMでおこなわれる操作(挿入、更新、削除)はMQL5で開発済みのライブラリを活用してログに記録可能です。これによりデータベース操作の監査が容易になり、問題の診断にも役立ちます。
- 拡張性:アーキテクチャは拡張可能に設計されます。現状は基本的なCRUDから始めますが、スキーマ移行、エンティティ間のリレーション(一対多、多対多)、あるいはクエリ最適化のためのインメモリキャッシュの追加も可能です。
目的はMQL5内でHibernate Frameworkを再現することではなく、アルゴリズム取引に従事し、構造化された永続性を必要とする開発者に向けて、最小限かつ効率的な抽象化層を提供することです。
結論と次のステップ
連載第1部が終了し、全体像が見え始めています。MQL5のデータベースは単なる情報保存用ファイルではなく、適切に活用することで体系的かつ信頼性の高い方法でデータを記録、照会、操作できる強力な構造です。DatabaseOpen、DatabaseExecute、DatabasePrepare、DatabaseReadなどのネイティブMQL5関数を用いて、テーブル作成、レコードの挿入・読み取り、列やデータ型の操作まで、SQLが実際にどのように機能するかを確認しました。
さらに重要なのは、すべてのプロジェクトでSQLを手動で記述すると、すぐに作業が重複し、エラーが発生しやすく、保守が困難になる点です。ここでORMの概念が登場します。ORMは、テーブルをオブジェクトに変換し、SQLクエリを単純なメソッドに置き換える抽象化レイヤーであり、コードをクリーンかつ集中管理された状態に保ちながら、自然な形でエンティティを操作できるようにします。
連載の次のステップでは、この抽象化層の構築を開始します。目標は、エンティティクラス、リポジトリ、クエリビルダー、自動テーブル作成メカニズムを備えた、最小限かつ効率的なORMの作成です。こうすることで、データの保存・取得・削除といった操作は、コード内に散在するSQLに依存せず、取引ドメインを直感的に反映するメソッドに依存するようになります。
これらのツールを習得することで、データ操作の効率とセキュリティが向上するだけでなく、進化する複雑な取引システムの基盤を構築でき、より高度な分析、堅牢なバックテスト、注文や戦略の詳細な履歴管理が可能になります。
これで第一段階は完了です。次回は実践的に、最初のORMクラスを定義し、オブジェクトの永続性を実装します。ここで学んだ理論をMQL5の機能コードと結び付けます。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/19285
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
この最初の記事では、氷山の一角をお見せしたに過ぎません。TickORMはさらにその上を行きます。MQL5でデータベースを扱う 方法を完全に変えることです。目標は、データベースを開き、リポジトリを作成し、エンティティを操作することが、配列を操作するのと同じくらい自然にできるような、わかりやすく、シンプルで、パワフルなものを実現することです。このシリーズが終わるころには、以下の例のように、手動でクエリを一度も書かずにレコードの保存、検索、更新、削除ができるようになるでしょう。これが私がTickORMで切り開く道です。
参考:MQL5のためのORMの実装がこの本で 紹介されています。