
Vereinfachung von Datenbanken in MQL5 (Teil 1): Einführung in Datenbanken und SQL

Einführung
Wenn wir über MQL5 sprechen, drehen sich die meisten Gespräche um Indikatoren, Expert Advisors, Handelsstrategien und Backtests. Aber irgendwann wird jedem Händler oder Entwickler, der ernsthaft mit Automatisierung arbeitet, klar, dass die Datenpersistenz entscheidend ist. Und genau hier kommen Datenbanken ins Spiel. Sie könnten sogar denken: „Aber ich speichere meine Ergebnisse bereits in CSV- oder TXT-Dateien, warum sollte ich die Sache mit einer Datenbank verkomplizieren?“ Die Antwort liegt in der Organisation, der Leistung und der Zuverlässigkeit, die eine Datenbank bietet, insbesondere wenn es um große Informationsmengen oder komplexe Vorgänge geht.
Im Zusammenhang mit MQL5 von Datenbanken zu sprechen, mag auf den ersten Blick wie eine Übertreibung erscheinen. Schließlich ist die Sprache stark auf den Handel, Indikatoren und automatische Ausführungsroboter ausgerichtet. Wenn wir jedoch mit Strategien arbeiten, die große Datenmengen, komplexe Backtests oder detaillierte Auftragsdatensätze umfassen, erweist sich die Einfachheit von Standarddateien schnell als unzureichend. Wenn Sie wissen, wie man eine Datenbank erstellt, auf sie zugreift und sie manipuliert, wird sie zu einem Werkzeug, das Ihre Handelsabläufe verändern kann.
Ein Händler, der beginnt, Datenbanken in MQL5 zu erforschen, wird Dutzende von nativen Funktionen und eigenständigen Beispielen finden. Es reicht aus, Datensätze zu speichern und abzufragen, aber bald stellt sich die Frage: „Wie organisiert man all dies auf saubere und wiederverwendbare Weise in echten Projekten?* In dieser Artikelserie gehen wir über die Dokumentation hinaus. Wir beginnen mit den Grundfunktionen von SQLite und gehen Schritt für Schritt vor, um ein **mini-ORM in MQL5 (TickORM)** zu erstellen. Die Idee besteht darin, direkte Aufrufe in gut gestaltete Schichten umzuwandeln, die von JDBC und JPA in Java inspiriert, aber an das MetaTrader-Ökosystem angepasst sind.
In diesem Artikel zeige ich die Grundlagen von Datenbanken in MQL5 und SQL. Dies ebnet den Weg für die nachfolgenden Artikel zur Kapselung dieser Funktionen in Klassen, Schnittstellen und schließlich im ORM.
Was ist eine Datenbank und wie nützlich ist sie?
Technisch gesehen ist eine Datenbank eine organisierte Art der Strukturierung von Informationen, die es Ihnen ermöglicht, gespeicherte Daten zu speichern, abzufragen und zu bearbeiten. Sie garantiert Integrität, stellt Beziehungen zwischen verschiedenen Informationsgruppen her und ermöglicht schnelle Abläufe.
Der praktische Unterschied zwischen der Speicherung von Daten in Dateien und der Verwendung einer Datenbank liegt in der Organisation und dem einfachen Zugriff. Bei einfachen Dateien wie CSV oder TXT muss man bei jedem Lesen oder Ändern den gesamten Inhalt durchgehen, Zeichenketten manipulieren, mit Formatierungsfehlern umgehen und hoffen, dass die Datei nicht beschädigt wird. In einer Datenbank sind diese Vorgänge abstrahiert: Es ist möglich, nach bestimmten Datensätzen zu suchen, mehrere Werte auf einmal zu aktualisieren und sicherzustellen, dass vollständige Transaktionen ohne Datenverlust stattfinden.
Aber wie wird diese Organisation intern durchgeführt? Stellen Sie sich die Grundstruktur einer Datenbank wie eine Tabellenkalkulation vor, hier ein Beispiel:

- Jede Tabelle in der Datenbank entspricht einer Registerkarte in der Tabellenkalkulation, die einer bestimmten Gruppe von Informationen gewidmet ist (z. B. Handelsgeschäfte).
- In jeder Tabelle gibt es Spalten, wie in der Tabelle, die die Attribute der einzelnen Artikel darstellen (z. B. id, Symbol, Preis usw.).
- Und jede Zeile in der Tabelle entspricht einem einzelnen Datensatz, d.h. einem bestimmten Handel oder einem ausgeführten Auftrag.
Diese einfache Architektur mit Tabellen, Spalten und Zeilen ist die Grundlage für schnelle, gut strukturierte Abfragen. Es ist so, als hätten Sie unendlich viele organisierte und miteinander verbundene Tabellenkalkulationen, aber mit dem Vorteil, dass Sie Daten mit Querverweisen versehen, fortgeschrittene Filter anwenden und große Mengen an Informationen ohne Kopfschmerzen bearbeiten können.
Genau hier liegt die Motivation, unser eigenes ORM in MQL5 zu erstellen. Die Idee ist einfach: Anstatt SQL jedes Mal manuell zu schreiben, wenn wir eine Tabelle bearbeiten wollen (Datensätze erstellen, Ergebnisse abrufen, Werte aktualisieren), werden wir eine Schicht aufbauen, die Tabellen als Entitäten und Spalten als Klassenattribute behandelt. Dies wird der Kern des Projekts sein, das wir im Laufe der Serie entwickeln werden, und es wird als Grundlage für robustere und skalierbare Handelssysteme dienen. Der Name des ORM wird TickORM sein.
Kurz gesagt, Datenbanken sind die Grundlage für den Aufbau zuverlässiger und flexibler Lösungen, und unser ORM wird die Verbindung zwischen dieser Grundlage und dem Code in MQL5 sein.
Um Ihnen das Testen zu erleichtern, ist der gesamte Beispielcode am Ende beigefügt. Auf diese Weise können Sie bei Bedarf darauf verweisen, sie kopieren und anpassen, ohne die Schnipsel manuell neu zusammenstellen zu müssen.
Anmerkung: Ab hier werden einige Code-Beispiele Log-Einträge auf die Konsole bringen. Dazu verwende ich meine Logify-Bibliothek, die speziell zur Erleichterung von Tracing und Debugging in MQL5 entwickelt wurde. Wenn Sie mehr über die Funktionsweise erfahren oder die Implementierung Schritt für Schritt verfolgen möchten, habe ich eine ganze Reihe von Artikeln geschrieben, die die Entwicklung des Systems erklären.Native SQL- und MQL5-Funktionen
Die Arbeit mit Datenbanken erfordert nicht viel. Glücklicherweise bietet die Sprache eine Reihe von nativen Funktionen, mit denen Sie Daten direkt in der Sprache erstellen, darauf zugreifen und sie manipulieren können. Diese Funktionen dienen als Brücke zwischen Ihrem Code und der Datenbank.
Die Beziehung zu SQL ist direkt: Diese Funktionen dienen als Abfrageausführungsschicht. Mit anderen Worten: Sie schreiben SQL-Befehle in MQL5, und die nativen Funktionen übernehmen die Vorbereitung, Ausführung und das Lesen der Ergebnisse. Das bedeutet, dass Sie komplexe Operationen wie SELECT, INSERT, UPDATE, DELETE und sogar das Erstellen von Tabellen durchführen können, ohne auf externe Bibliotheken zurückgreifen zu müssen.
Dies ist der Ausgangspunkt, um jede Funktion und ihre Möglichkeiten zu verstehen, bevor man sich an die praktische Umsetzung macht. Um alle verfügbaren Funktionen im Detail kennenzulernen, werde ich alle verfügbaren nativen Datenbankfunktionen auflisten, da wir die Verwendung der einzelnen Funktionen behandeln werden:
- DatabaseOpen(string filename, uint flags): Öffnet oder erstellt eine Datenbank in einer angegebenen Datei
- DatabaseClose(int database): Schließt eine Datenbank
- DatabaseImport(int database,const string table,const string filename,uint flags,const string separator,ulong skip_rows,const string skip_comments): Importiert Daten aus einer Datei in eine Tabelle
- DatabaseExport(int database,const string table_or_sql,const string filename,uint flags,const string separator): Exportiert eine Tabelle oder das Ergebnis der Ausführung einer SQL-Anfrage in eine CSV-Datei
- DatabasePrint(int database,const string table_or_sql,uint flags): Zeigt eine Tabelle oder das Ergebnis der Ausführung einer SQL-Anfrage im Expertenjournal an
- DatabaseTableExists(int database,string table): Prüft, ob die Tabelle in einer Datenbank vorhanden ist
- DatabaseExecute(int database, string sql): Führt eine Anfrage an eine bestimmte Datenbank aus
- DatabasePrepare(int database, string sql): Erzeugt einen Identifikator für eine Anfrage, der dann mit DatabaseRead() ausgeführt werden kann.
- DatabaseReset(int request): Setzt eine Anfrage zurück, z.B. nach dem Aufruf von DatabasePrepare()
- DatabaseBind(int request,int index,T value): Setzt einen Parameterwert in einer Anfrage
- DatabaseRead(int request): Springt zum nächsten Eintrag als Ergebnis einer Anfrage
- DatabaseFinalize(int request): Entfernt eine in DatabasePrepare() erstellte Anfrage
- DatabaseTransactionBegin(int database): Startet die Ausführung der Transaktion
- DatabaseTransactionCommit(int database): Schließt die Ausführung der Transaktion ab
- DatabaseTransactionRollback(int database): Macht Transaktionen rückgängig
- DatabaseColumnsCount(int request): Ermittelt die Anzahl der Felder in einer Anfrage
- DatabaseColumnName(int request,int column,string& name): Ruft einen Feldnamen nach Index ab
- DatabaseColumnType(int request,int column): Ruft einen Feldtyp nach Index ab
- DatabaseColumnSize(int request,int column): Ermittelt die Größe des Feldes in Bytes
- DatabaseColumnText(int request,int column,string& value): Ruft einen Feldwert als String aus dem aktuellen Datensatz ab
- DatabaseColumnInteger(int request,int column,int& value): Ruft den Wert des Typs int aus dem aktuellen Datensatz ab
- DatabaseColumnLong(int request,int column,long& value): Ruft den Wert des Typs long aus dem aktuellen Datensatz ab
- DatabaseColumnDouble(int request,int column,double& value): Ermittelt den Wert des Typs double aus dem aktuellen Datensatz
Ausführliche Informationen zu allen verfügbaren Funktionen, Parametern und Beispielen finden Sie in der offiziellen Dokumentation von MetaQuotes unter MQL5 Database Functions.
1. Öffnen und Schließen von Datenbanken
Beginnen wir mit den Grundlagen: Öffnen Sie eine Verbindung zur Datenbank. Dies geschieht mit der Funktion DatabaseOpen, die den Namen der Datenbankdatei und optionale Flags erhält, die den Öffnungsmodus definieren, der diese möglichen Werte haben kann:
| Wert | Beschreibung |
|---|---|
| DATABASE_OPEN_READONLY | Nur lesen |
| DATABASE_OPEN_READWRITE | Offen für Lesen und Schreiben |
| DATABASE_OPEN_CREATE | Erstellen der Datei gegebenenfalls auf einem Datenträger. |
| DATABASE_OPEN_MEMORY | Erstellen einer Datenbank im RAM |
| DATABASE_OPEN_COMMON | Die Datei befindet sich in dem gemeinsamen Ordner aller Terminals |
int OnInit() { //--- Open connection int handler = DatabaseOpen("database.sqlite",DATABASE_OPEN_CREATE|DATABASE_OPEN_READWRITE); if(handler == INVALID_HANDLE) { logs.Error("Failed to open database","TickORM"); return(INIT_FAILED); } logs.Info("Open database","TickORM"); //--- Here you would perform queries, inserts or updates //--- Close connection logs.Info("Closed database","TickORM"); DatabaseClose(handler); return(INIT_SUCCEEDED); }
Im ersten Parameter geben wir den Namen der Datenbank an, in diesem Fall habe ich „database“ verwendet. Und am Ende fügen wir einfach „.sqlite“ hinzu, das ist die Dateierweiterung, weil es sich um eine Datenbank handelt, die in einer Datei gespeichert ist, aber das ist kein Problem, die Art und Weise, wie die Daten abgerufen und Abfragen gemacht werden, folgt dem SQL-Standard.
In diesem Beispiel ermöglicht DATABASE_OPEN_READWRITE das Lesen und Schreiben, während DATABASE_OPEN_CREATE garantiert, dass die Datei erstellt wird, wenn sie noch nicht existiert. Nach Abschluss der Operationen schließen Sie einfach die Verbindung mit DatabaseClose, um Ressourcen freizugeben.
Wenn Sie diesen Code ausführen, wird die Datenbank automatisch im Ordner <MQL5/Files> erstellt, den Sie im Metaeditor einsehen können:
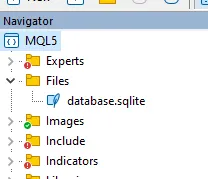
2. Erstellen einer Tabelle
Der erste Schritt nach der Verbindung mit der Datenbank besteht darin, die Struktur zu definieren, in der die Daten gespeichert werden sollen. In SQL wird dies mit dem Befehl CREATE TABLE durchgeführt. Er beschreibt den Namen der Tabelle und die Felder, die sie enthalten soll.
In MQL5 umfasst das Erstellen von Tabellen zwei Hauptfunktionen:
- DatabaseTableExists(handler, table_name): prüft, ob eine Tabelle bereits in der Datenbank existiert, gibt true oder false zurück.
- DatabaseExecute(handler, sql): Führt eine SQL-Anweisung direkt aus.
Der häufigste Ablauf ist: prüfen, ob die Tabelle existiert → wenn nicht, Tabelle erstellen. Hier ein praktisches Beispiel:
//--- Create table if(!DatabaseTableExists(handler,"trades")) { logs.Info("Creating user table...","TickORM"); if(DatabaseExecute(handler,"CREATE TABLE trades (id INTEGER PRIMARY KEY AUTOINCREMENT,symbol TEXT, price FLOAT, takeprofit FLOAT, stoploss FLOAT, volume FLOAT);")) { logs.Info("'Trades' table created","TickORM"); } else { logs.Error("Failed to create table",GetLastError(),"TickORM"); } }
In diesem Schnipsel verwenden wir CREATE TABLE trades (...), um eine Tabelle mit dem Namen trades zu erstellen, die grundlegende Informationen über ein Handelsgeschäft enthält: id (automatisch generierter eindeutiger Bezeichner), symbol, price, takeprofit, stoploss und volume.
Wenn die Tabelle bereits existiert, verhindert die Funktion DatabaseTableExists, dass der Befehl erneut ausgeführt wird. Befolgen Sie immer dieses Muster der Überprüfung auf Existenz und der Erstellung von Tabellen bei Bedarf.
Eine Darstellung des aktuellen Stadiums würde wie dieses Bild der Datenbank aussehen:
Metaeditor unterstützt die Anzeige dieser Datenbank. Doppelklicken Sie einfach auf die Datenbankdatei und der Browser wechselt automatisch die Registerkarte:
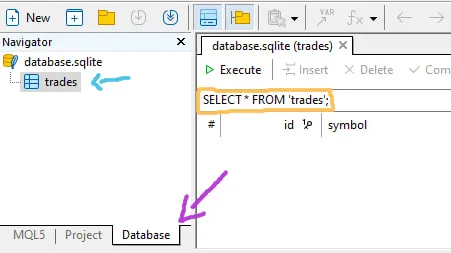
- Der blaue Pfeil zeigt die Datenbanktabellen an
- Gelb zeigt an, wo Sie den SQL-Befehl eingeben (dies kann manuell oder innerhalb des Codes geschehen, Beispiele sehen wir im nächsten Schritt)
- Lila zeigt die Browser-Registerkarte „Datenbank“ an. Wenn Sie zur Anzeige der Dateien (.mqh oder .mqh) zurückkehren möchten, wechseln Sie einfach zur Registerkarte „MQL5“.
3. Daten in die Tabelle einfügen
Folgen wir dem Ablauf und fügen wir Daten in die soeben erstellte Tabelle ein. In SQL verwenden wir den Befehl INSERT INTO, um Datensätze hinzuzufügen. Er folgt dieser Struktur:
INSERT INTO table_name (column1,column2,...) VALUES (value1,value2,...)
In den Werten übergeben wir die Daten in Rohform, wenn es sich um eine Zeichenkette handelt, schließen Sie sie einfach in einfache Anführungszeichen ein („Beispiel“). Wir verwenden dieselbe DatabaseExecute-Funktion und prüfen, ob die Ausführung erfolgreich war:
//--- Insert data ResetLastError(); if(DatabaseExecute(handler,"INSERT INTO trades (symbol,price,takeprofit,stoploss,volume) VALUES ('EURUSD',1.16110,1.15490,1.16570,0.01);")) { logs.Info("Data saved to the trades table","TickORM"); } else { logs.Error("Failed to save data to the trade table",GetLastError(),"TickORM"); }
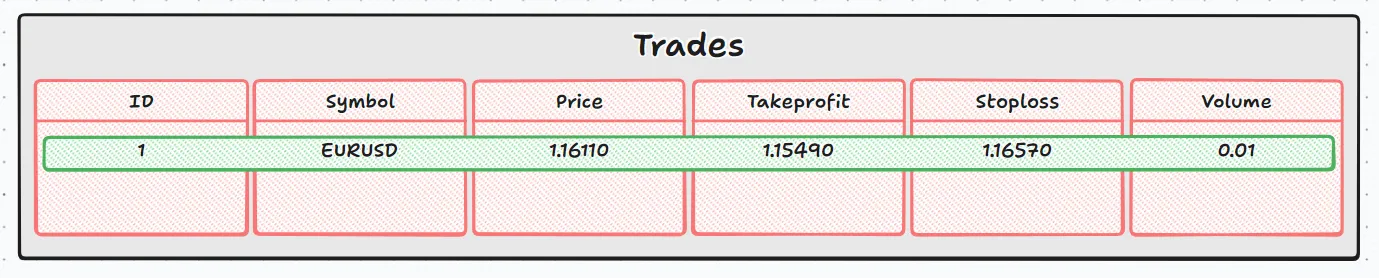
Hier fügen wir der Handelstabelle einen Datensatz hinzu, wobei jeder Spalte ein Wert zugewiesen wird:
- id: Automatisch von der Datenbank generiert
- Symbol: EURUSD'.
- price: 1.16110
- takeprofit: 1.15490
- stoploss: 1.16570
- volume: 0.01
Für die aktuelle Phase sieht das so aus:
4. Lesen von Daten aus der Tabelle
Die Speicherung der Daten in der Datenbank ist nur die halbe Miete. Das eigentliche Potenzial entsteht, wenn wir diese Daten strukturiert abfragen und extrahieren können. In MQL5 folgt dieser Prozess einem klar definierten Ablauf:
- Vorbereiten der Abfrage mit DatabasePrepare vor und übergebe den SQL-Befehl.
- Lese Zeile für Zeile mit DatabaseRead und Blättern durch die Ergebnisse.
- Schließe die Abfrage mit DatabaseFinalize ab und gib die Speicherressourcen frei.
Ein einfaches Beispiel:
//--- Data reading int request = DatabasePrepare(handler,"SELECT * FROM trades;"); //--- Number of table columns that were read int size_cols = DatabaseColumnsCount(request); //--- While data is available for reading (reading each line) while(DatabaseRead(request)) { //--- Scan across all columns of the current line of reading for(int j=0;j<size_cols;j++) { string name = ""; DatabaseColumnName(request,j,name); logs.Info(name,"TickORM"); } } //--- Reset query DatabaseFinalize(request);
Bei der Ausführung wird dies im Protokoll angezeigt:
2025.08.21 10:14:51 [INFO]: Open database 2025.08.21 10:14:51 [INFO]: id 2025.08.21 10:14:51 [INFO]: symbol 2025.08.21 10:14:51 [INFO]: price 2025.08.21 10:14:51 [INFO]: takeprofit 2025.08.21 10:14:51 [INFO]: stoploss 2025.08.21 10:14:51 [INFO]: volume 2025.08.21 10:14:51 [INFO]: Closed database
Hier holt die Abfrage SELECT * FROM trades; alle Datensätze aus der Tabelle „trades“. Jeder Aufruf von DatabaseRead(request) bewegt den Cursor zur nächsten Zeile, und die innere Schleife durchläuft alle Spalten und druckt nur die Namen.
Wenn man dies mit einem Bild vergleicht, würde es etwa so aussehen:
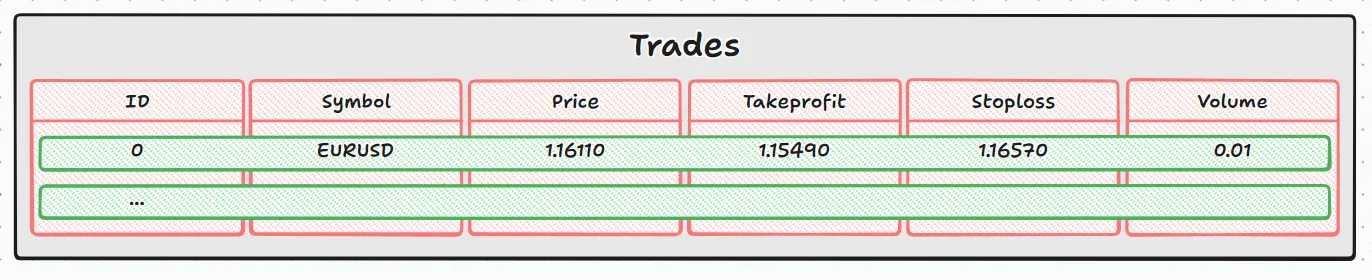
- Die äußere Schleife (while(DatabaseRead(request) )) geht Zeile für Zeile (die grünen Rechtecke).
- Die innere Schleife (for(int j=0;j<size_cols;j++) ) durchläuft Spalte für Spalte innerhalb der aktuellen Zeile (die roten Rechtecke).
Zusammen ermöglichen sie es Ihnen, durch die Datenbank Zelle für Zelle zu navigieren, so als ob Sie durch eine Tabellenkalkulation blättern würden.
Das vorherige Beispiel listet nur die Namen der Spalten auf, während nun die Werte der Spalten gelesen werden. Da wir die gespeicherten Werte benötigen, verwenden wir je nach Spaltentyp spezifische Funktionen:
- DatabaseColumnType → ermöglicht es uns, den Spaltentyp dynamisch zu ermitteln.
- DatabaseColumnText → Texte (wie Symbole oder Namen).
- DatabaseColumnDouble → Gleitkommazahlen (z. B. Preise).
- DatabaseColumnLong oder DatabaseColumnInteger → ganzzahlige Werte (z. B. IDs).
Vollständiges Beispiel:
//--- Data reading int request = DatabasePrepare(handler,"SELECT * FROM trades;"); //--- Number of table columns that were read int size_cols = DatabaseColumnsCount(request); //--- While data is available for reading (reading each line) while(DatabaseRead(request)) { //--- Scan across all columns of the current line of reading for(int j=0;j<size_cols;j++) { string name = ""; DatabaseColumnName(request,j,name); ENUM_DATABASE_FIELD_TYPE type = DatabaseColumnType(request,j); if(type == DATABASE_FIELD_TYPE_TEXT) { string data = ""; DatabaseColumnText(request,j,data); logs.Info(name + " | "+data,"TickORM"); } else if(type == DATABASE_FIELD_TYPE_FLOAT) { double data = 0; DatabaseColumnDouble(request,j,data); logs.Info(name + " | "+DoubleToString(data,5),"TickORM"); } else if(type == DATABASE_FIELD_TYPE_INTEGER) { long id = 0; DatabaseColumnLong(request,j,id); logs.Info(name + " | "+IntegerToString(id),"TickORM"); } } } //--- Reset query DatabaseFinalize(request);
Bei der Ausführung wird dies im Protokoll angezeigt:
2025.08.21 10:18:04 [INFO]: Open database 2025.08.21 10:18:04 [INFO]: id | 1 2025.08.21 10:18:04 [INFO]: symbol | EURUSD 2025.08.21 10:18:04 [INFO]: price | 1.16110 2025.08.21 10:18:04 [INFO]: takeprofit | 1.15490 2025.08.21 10:18:04 [INFO]: stoploss | 1.16570 2025.08.21 10:18:04 [INFO]: volume | 0.01000 2025.08.21 10:18:04 [INFO]: Closed database
In diesem Fall wird nicht nur durch Zeilen und Spalten geblättert, sondern auch auf den Inhalt der einzelnen Zellen zugegriffen. Um auf die Analogie des didaktischen Bildes zurückzukommen:
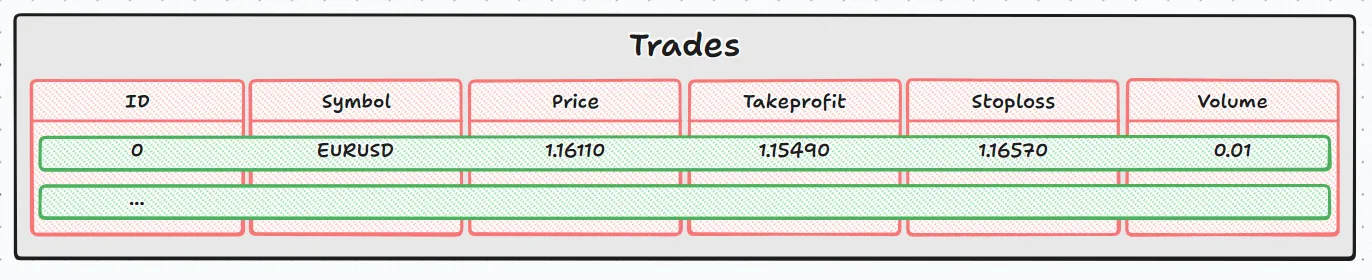
- Das graue Rechteck ist die vollständige Tabelle (Berufe).
- Jedes grüne Rechteck ist eine Zeile, die von DatabaseRead zurückgegeben wird.
- Jedes rote Rechteck ist eine Spalte, deren Wert ein Text (string), eine Dezimalzahl (double) oder eine ganze Zahl (int) sein kann.
- Bei der Verwendung von DatabaseColumnType ist es so, als ob wir fragen würden: „Welche Art von Daten befindet sich in diesem roten Rechteck?“.
- Dann erhält die entsprechende Funktion (DatabaseColumnText, DatabaseColumnDouble , DatabaseColumnLong ) den Wert.
5. Aktualisieren von Tabellendaten
Im wirklichen Leben ist es nicht ungewöhnlich, dass wir vorhandene Informationen anpassen müssen. An dieser Stelle kommt der Befehl UPDATE ins Spiel, mit dem Sie die Werte einer oder mehrerer Spalten in bestimmten Zeilen einer Tabelle ändern können.
In SQL ist die Grundstruktur des Befehls wie folgt:
UPDATE table_name SET column1=value1, column2=value2, ... WHERE condition;
In MQL5 erfolgt die Aktualisierung von Datensätzen über die Funktion DatabaseExecute, die den SQL-Befehl direkt an die Datenbank sendet. Hier ist ein Beispiel:
//--- Update data ResetLastError(); if(DatabaseExecute(handler,"UPDATE trades SET volume=0.1 WHERE id=1")) { logs.Info("Trades table data updated","TickORM"); } else { logs.Error("Failed to update trades table data",GetLastError(),"TickORM"); }
Hier haben wir einen klassischen Fall: Wir weisen die Datenbank an, den Datensatz in der Handelstabelle zu suchen, dessen ID gleich 1 ist, und, sobald sie ihn gefunden hat, den Wert der Spalte „volume“ auf 0,1 zu ändern.
Dieses Muster ist beim Handel äußerst nützlich. Stellen Sie sich vor, Sie haben einen Handel mit einem anfänglichen Volumen von 0,01 Lots gespeichert, aber nach Strategieanpassungen müssen Sie es auf 0,1 korrigieren. Mit einem einfachen UPDATE-Befehl werden die Informationen in der Datenbank zuverlässig synchronisiert, ohne dass Datensätze gelöscht und neu angelegt werden müssen.
6. Löschen von Daten aus der Tabelle
Um Daten zu löschen, verwenden wir den SQL-Befehl DELETE, der für das Löschen von Zeilen aus einer Tabelle zuständig ist. Die allgemeine Form des Befehls lautet:
DELETE FROM table_name WHERE condition;
Es folgt dem gleichen Muster, wir verwenden die Funktion DatabaseExecute, um den SQL-Befehl zu senden:
//--- Delete data ResetLastError(); if(DatabaseExecute(handler,"DELETE FROM trades WHERE id=1")) { logs.Info("Deleted trades table data","TickORM"); } else { logs.Error("Failed to delete data to the trade table",GetLastError(),"TickORM"); }
In diesem Beispiel bitten wir die Datenbank, den Datensatz aus der Handelstabelle zu entfernen, dessen Feld id gleich 1 ist. Eine einmalige, kontrollierte und sichere Löschung.
Wichtiges Detail: Wie bei UPDATE ist die Verwendung von WHERE unerlässlich, um ein versehentliches Löschen der gesamten Tabelle zu vermeiden.Mit diesem Befehl haben wir den grundlegenden Datenmanipulationszyklus abgeschlossen: Erstellen, Einfügen, Aktualisieren und Löschen. Von hier aus haben wir alle Grundlagen für den nächsten Schritt.
7. Löschen einer Tabelle
Wenn die Tabelle nicht mehr nützlich ist, können wir sie löschen.
//--- Delete table ResetLastError(); if(DatabaseExecute(handler,"DROP TABLE trades")) { logs.Info("Trades table deleted","TickORM"); } else { logs.Error("Failed to delete trades table",GetLastError(),"TickORM"); }
Es lohnt sich, dies zu betonen: DROP TABLE ist unumkehrbar. Im Gegensatz zu DELETE FROM trades, bei dem nur die Datensätze entfernt werden, die Struktur aber erhalten bleibt, werden bei DROP TABLE sowohl die Tabelle als auch die Daten gelöscht. Wenn Sie diese Anweisung ausführen, muss die Tabelle neu erstellt werden, bevor sie neue Datensätze aufnehmen kann.
8. Transaktionen und Datenintegrität
Kommen wir nun zu einem notwendigen Punkt, nämlich der Integrität der Datenbank. In jeder Anwendung, in der Daten verarbeitet werden, ist die Integrität ein kritischer Punkt. Stellen Sie sich ein Szenario vor, in dem wir mehrere Datensätze schreiben müssen. Wenn eine dieser Einfügungen fehlschlägt und die anderen bereits angewendet wurden, könnte die Datenbank in einen inkonsistenten Zustand geraten. Um dieses Problem zu vermeiden, gibt es Transaktionen.
Eine Transaktion ist ein Block von SQL-Operationen, der als atomare Einheit behandelt werden sollte:
- Entweder werden alle darin enthaltenen Anweisungen angewendet**(commit**),
- Oder es wird nichts behalten**(rollback**).
In MQL5 haben wir native Funktionen, die es uns ermöglichen, diesen Fluss zu kontrollieren:
- DatabaseTransactionBegin(handler) → Startet die Transaktion.
- DatabaseTransactionCommit(handler) → Bestätigen und Anwenden der Änderungen.
- DatabaseTransactionRollback(handler) → Alle Änderungen seit dem Start der Transaktion rückgängig machen.
Das nachstehende Beispiel zeigt, wie sie zu verwenden sind:
//--- Insert with transaction string sql="INSERT INTO trades (symbol,price,takeprofit,stoploss,volume) VALUES ('EURUSD',1.16110,1.15490,1.16570,0.01);"; DatabaseTransactionBegin(handler); logs.Info("Inserting data, preparing transaction","TickORM"); if(!DatabaseExecute(handler,sql)) { logs.Error("Transaction failed, reverting to previous state",GetLastError(),"TickORM"); DatabaseTransactionRollback(handler); } else { logs.Info("Transaction complete, changes saved","TickORM"); DatabaseTransactionCommit(handler); }
In diesem Ausschnitt:
- Wir starten die Transaktion mit DatabaseTransactionBegin .
- Wir versuchen, die Einfügung auszuführen (DatabaseExecute ).
- Wenn etwas schief geht, verwenden wir DatabaseTransactionRollback, um alles rückgängig zu machen.
- Andernfalls bestätigen wir die Änderungen mit DatabaseTransactionCommit .
Dies ist nützlich, weil es sicherstellt, dass keine unvollständigen Daten übrig bleiben. Sie können mehrere Vorgänge zusammenfassen und erst dann anwenden, wenn Sie sicher sind, dass sie alle funktioniert haben. Dies erhöht die Sicherheit: Bei unerwarteten Ausfällen (Netzwerk, Stromausfall, Ausführungsfehler) kehrt die Datenbank in ihren vorherigen Zustand zurück, ohne dass Daten gefährdet werden.
Stellen Sie sich vor, Sie erfassen zehn verschiedene Operationen an verschiedenen Tabellen. Wenn die achte fehlschlägt, würden ohne Transaktionen sieben Vorgänge aufgezeichnet und drei fehlen, ein inkonsistenter Zustand. Bei der Transaktion müssen Sie nur ein Rollback durchführen und die Datenbank ist wieder genau so, wie sie vor dem Versuch war.
9. Importieren und Exportieren von Daten
Neben den Transaktionen ist die Möglichkeit, Daten zu importieren und zu exportieren, eine weitere Ebene der Sicherheit und Praktikabilität. Auf diese Weise können regelmäßige Backups der Datenbank erstellt werden, die nicht nur Schutz vor Verlust, sondern auch Mobilität und einfache Wiederherstellung gewährleisten. Dafür gibt es die Funktionen DatabaseExport und DatabaseImport, mit denen Sie die Daten in CSV extrahieren und bei Bedarf wieder in die Datenbank zurückspielen können.
Das folgende Beispiel zeigt den Export der Handelstabelle in eine Datei namens backup_trades.csv :
//--- Export table ResetLastError(); long data = DatabaseExport(handler,"trades","backup_trades.csv",DATABASE_EXPORT_HEADER,";"); if(data > 0) { logs.Info("Backup of the 'trades' table created successfully","TickORM"); } else { logs.Error("Failed to create backup of table 'trades'",GetLastError(),"TickORM"); }
Hier sind einige wichtige Punkte:
-
Dateiname: bezieht sich auf den Ordner MQL5-Files. Das bedeutet, dass Sie Backups in Unterordnern organisieren können, wenn Sie dies wünschen.
-
CSV-Format: universell akzeptiert, kann in Excel, Google Sheets, Python, R, etc. geöffnet werden.
-
Flags: Im Beispiel haben wir DATABASE_EXPORT_HEADER verwendet, das die Spaltennamen in der ersten Zeile enthält. Das erleichtert die spätere Interpretation der Daten.
Wert Beschreibung DATABASE_EXPORT_HEADER Zeigt die Feldnamen in der ersten Zeile an DATABASE_EXPORT_INDEX Zeigt die Zeilennummern an DATABASE_EXPORT_NO_BOM Fügt kein BOM-Tag am Anfang der Datei ein (BOM wird standardmäßig eingefügt) DATABASE_EXPORT_CRLF Verwendet CRLF (standardmäßig LF) für Zeilenumbrüche DATABASE_EXPORT_APPEND Fügt Daten am Ende einer bestehenden Datei hinzu (standardmäßig wird die Datei überschrieben). Wenn die Datei nicht existiert, wird sie erstellt. DATABASE_EXPORT_QUOTED_STRINGS Zeigt Zeichenkettenwerte in doppelten Anführungszeichen an. DATABASE_EXPORT_COMMON_FOLDER Die CSV-Datei wird in dem gemeinsamen Ordner aller Terminals \Terminal\Common\File erstellt. -
Trennzeichen: Wir verwenden „;“ , aber es könnte auch „,“ , „\\t“ , usw. sein, je nach Ihren Vorlieben oder dem System, das die Datei verwenden wird.
Die Datenrückgabe gibt an, wie viele Datensätze exportiert wurden. Ist er negativ, ist ein Fehler aufgetreten, und GetLastError() sagt Ihnen, welcher.
Stellen Sie sich nun den umgekehrten Fall vor: Wiederherstellung oder Laden von Daten in die Handelstabelle:
//--- Import table ResetLastError(); long data = DatabaseImport(handler,"trades","backup_trades.csv",DATABASE_IMPORT_HEADER|DATABASE_IMPORT_APPEND,";",0,NULL); if(data > 0) { logs.Info("'trades' table imported successfully","TickORM"); } else { logs.Error("Failed to import 'trades' table",GetLastError(),"TickORM"); }
Hier sind einige wertvolle Details:
-
Kombinierte Flags: Wir verwenden DATABASE_IMPORT_HEADER (das System erkennt die erste Zeile als Kopfzeile) und DATABASE_IMPORT_APPEND (die importierten Daten werden der vorhandenen Tabelle hinzugefügt, ohne die bereits vorhandenen zu löschen).
Wert Beschreibung DATABASE_IMPORT_HEADER Die erste Zeile enthält die Namen der Tabellenfelder DATABASE_IMPORT_CRLF Zeilenumbruch ist CRLF (standardmäßig LF) DATABASE_IMPORT_APPEND Fügt Daten am Ende einer bestehenden Tabelle hinzu DATABASE_IMPORT_QUOTED_STRINGS Zeichenketten werden in doppelte Anführungszeichen gesetzt DATABASE_IMPORT_COMMON_FOLDER Die Datei befindet sich in dem gemeinsamen Ordner aller Client-Terminals \Terminal\Common\File. -
Trennzeichen: muss mit dem im Export verwendeten Trennzeichen übereinstimmen.
-
skip_rows: ermöglicht das Überspringen von Anfangszeilen (z. B. wenn Sie Kommentare oder alte Daten ignorieren wollen).
-
skip_comments: definiert Symbole, die zu überspringende Zeilen markieren. Sehr nützlich bei der Arbeit mit manuell gekennzeichneten CSV-Dateien.
Die Datenrückgabe zeigt an, wie viele Datensätze importiert wurden.
Mit DatabaseExport und DatabaseImport haben wir den grundlegenden Zyklus der Eingabe und des Verlassens von Daten in der Datenbank geschlossen. Jetzt wissen wir, wie man Tabellen erstellt, einfügt, abfragt, aktualisiert, löscht und sogar externe Kopien speichert oder Informationen bei Bedarf wiederherstellt.
Beachten Sie jedoch ein Detail: Jeder Vorgang erfordert den direkten Umgang mit SQL und spezifische Aufrufe nativer Funktionen. Bei kleinen Beispielen funktioniert das gut, aber wenn das System wächst, nimmt die Komplexität zu und damit auch das Fehlerrisiko. Genau an dieser Stelle stellt sich die nächste unvermeidliche Frage: Müssen wir wirklich alles auf unsere Fingernägel schreiben?
An dieser Stelle kommt die Idee eines ORM ins Spiel. Im nächsten Abschnitt werden wir verstehen, was es ist, warum es die Art und Weise, wie wir mit Datenbanken in MQL5 interagieren, radikal verändern kann und wie es in den Pfad passt, den wir aufbauen.
Was ist ein ORM und warum brauchen wir es?
Bisher haben wir die Verwendung von SQL direkt in MQL5 erforscht und Tabellen und Datensätze „on the fly“ manipuliert. Dieser Ansatz funktioniert, aber mit dem Wachstum des Systems wächst auch die Menge an SQL, die über den gesamten Code verstreut ist, und damit kommen Wartungsprobleme, Wiederholungen und das Risiko von Fehlern. An dieser Stelle kommt ORM (Object-Relational Mapping) ins Spiel.
Ein ORM ist eine Schicht, die die Lücke zwischen der objektorientierten Welt und der relationalen Welt der Datenbanken schließt. Anstatt SQL manuell zu schreiben, beschreiben wir unsere Entitäten als Klassen und überlassen es dem ORM, sie in SQL-Befehle zu übersetzen. Mit anderen Worten: Anstatt mit INSERT INTO trades (...) VALUES (...), erstellen wir einfach ein Trade-Objekt und rufen etwas wie repository.save(trade) auf.
Zu den wichtigsten Merkmalen eines ORM gehören:
- Automatisches Mapping: Umwandlung von Klassen und Attributen in Tabellen und Spalten.
- SQL-Abstraktion: Sie arbeiten mit Objekten und Methoden, nicht mit SQL-Strings.
- Konsistenz: Verringerung der doppelten Logik, da gemeinsame Vorgänge wie Speichern, Suchen oder Löschen zentralisiert werden.
- Portabilität: Bei einigen ORMs kann die gleiche Logik in verschiedenen Datenbanken funktionieren, ohne dass der Quellcode geändert werden muss.
In MQL5 macht diese Idee sogar noch mehr Sinn, da das Schreiben von in den Code eingebettetem SQL schnell zu einem Albtraum wird. Stellen Sie sich einen Expert Advisor mit Dutzenden von Entitäten vor (Handelsgeschäfte, Aufträge, Protokolle, Leistungsmetriken). Jedes INSERT, SELECT oder UPDATE, das über den gesamten Code verstreut ist, bedeutet mehr Fehlerpunkte, mehr Schwierigkeiten bei der Entwicklung der Logik und mehr Chancen auf Inkonsistenz.
Der „Schmerz“, den ORM behebt, ist:
- Vermeidung von doppeltem SQL in verschiedenen Teilen des EA.
- Dies erleichtert die Pflege, da sich Änderungen an der Tabellenstruktur an einer einzigen Stelle (der Entitätsklasse) niederschlagen.
- Ermöglicht es Ihnen, lesbareren und natürlicheren Code zu schreiben, indem Sie in Form von Domänenobjekten (z. B. Handel, Nutzer, Bestellung) anstelle von Tabellen und Spalten denken.
- Es eröffnet Raum für fortgeschrittene Funktionen wie automatische Tabellengenerierung, Schema-Versionskontrolle und noch einfachere Integration mit Protokollierungs- und Audit-Bibliotheken.
Kurz gesagt: Ohne ORM ist jede Operation ein SQL-Block innerhalb des Codes; mit ORM wird das SQL zu einem versteckten Detail, und Sie konzentrieren sich auf das Wesentliche, die Handelslogik.
Unser ORM-Projekt in MQL5
Nachdem wir nun die Nützlichkeit eines ORMs verstanden haben, müssen wir uns vergegenwärtigen, wie es sich in das MQL5-Ökosystem einfügt. Im Gegensatz zu traditionelleren Sprachen in der Welt der ORMs (Java, C#, Python) stehen uns hier keine robusten Frameworks zur Verfügung, sodass wir unsere eigene Lösung entwickeln müssen, die an die Einschränkungen und Besonderheiten der Sprache angepasst ist.
Der geplante Umfang dieses Projekts ist klar: Schaffung einer Schicht, die es dem Entwickler ermöglicht, mit Objekten anstelle von direktem SQL zu arbeiten, ohne jedoch die in einer Handelsumgebung erforderliche Einfachheit und Leistung zu verlieren.
Zu den geplanten Funktionalitäten gehören:
- Entitäten: Jede Tabelle in der Datenbank wird durch eine MQL5-Klasse mit Metadaten repräsentiert, die ihre Spalten beschreiben (Typ, Primärschlüssel, ob sie autoincrementierend ist, ob sie null ist, usw.). Die Handelsklasse spiegelt also direkt die Handelstabelle wider, wird aber als eigenes Objekt bearbeitet.
- Repositories: Anstatt INSERT, UPDATE oder SELECT manuell zu schreiben, wird jede Entität über ein Repository verfügen, das für Persistenz- und Wiederherstellungsoperationen zuständig ist. Zum Beispiel wird TradeRepository Methoden wie Save(trade) , FindById(id) oder Delete(trade) zentralisieren. Auf diese Weise ist der Code des EA sauber und frei von verstreutem SQL.
- Query Builder: Für Fälle, in denen komplexere Abfragen (Filter, Sortierung, Verknüpfungen) erforderlich sind, wird es einen Abfragegenerator geben. Sie ermöglicht es Ihnen, Abfragen programmatisch und sicher zu erstellen, Fehler bei der Stringverkettung zu vermeiden und den direkten Kontakt mit SQL zu reduzieren.
- Automatische Erstellung von Tabellen: Auf der Grundlage der Metadaten der Entität ist der ORM in der Lage, die entsprechende Tabelle automatisch zu erstellen, wobei er vor der Erstellung überprüft, ob sie bereits existiert. Diese Funktionalität macht manuelle SQL-Skripte zu Beginn des Projekts überflüssig und gewährleistet, dass die Datenbank mit der Entwicklung der Entitäten Schritt hält.
- Integration mit Protokollen und Audits: Jede vom ORM durchgeführte Operation (Einfügung, Aktualisierung, Löschung) kann in den Protokollen aufgezeichnet werden, wobei die bereits in MQL5 entwickelten Bibliotheken genutzt werden. Dies erleichtert die Überprüfung der Vorgänge in der Datenbank und hilft bei der Diagnose von Problemen.
- Erweiterbarkeit: Die Architektur ist so konzipiert, dass sie sich weiterentwickelt: Heute beginnen wir mit grundlegenden CRUD-Funktionen, aber es gibt nichts, was uns daran hindert, Unterstützung für Schemamigrationen, Beziehungen zwischen Entitäten (one-to-many, many-to-many) oder sogar In-Memory-Caching zur Optimierung von Abfragen hinzuzufügen.
Ziel ist es nicht, ein Hibernate-Framework in MQL5 nachzubilden, sondern eine minimalistische und effiziente Abstraktionsschicht bereitzustellen, die den tatsächlichen Bedürfnissen derjenigen entspricht, die mit algorithmischem Handel arbeiten und strukturierte Persistenz benötigen.
Schlussfolgerung und nächste Schritte
Wir sind am Ende dieses ersten Teils der Serie angelangt, und das Bild wird langsam klar: Datenbanken in MQL5 sind nicht einfach nur Dateien zum Speichern von Informationen, sondern leistungsfähige Strukturen, die es Ihnen bei richtiger Nutzung ermöglichen, Daten auf organisierte und zuverlässige Weise zu erfassen, abzufragen und zu bearbeiten. Wir haben gesehen, wie SQL in der Praxis funktioniert, von der Erstellung von Tabellen, dem Einfügen und Lesen von Datensätzen bis hin zur Manipulation von Spalten und Datentypen, unter Verwendung nativer MQL5-Funktionen wie DatabaseOpen, DatabaseExecute, DatabasePrepare und DatabaseRead.
Vor allem aber wissen wir, dass das manuelle Schreiben von SQL für jedes Projekt schnell repetitiv, fehleranfällig und schwer zu pflegen wird. Hier kommt das ORM-Konzept ins Spiel: eine Abstraktionsebene, die Tabellen in Objekte und SQL-Abfragen in einfache Methoden umwandelt, sodass Sie auf natürliche Weise mit Entitäten arbeiten können, während der Code sauber und zentralisiert bleibt.
In den nächsten Schritten der Serie werden wir mit dem Aufbau dieser Abstraktionsschicht beginnen. Unser Ziel ist es, ein minimalistisches und effizientes ORM mit Entitätsklassen, Repositories, einem Query Builder und einem automatischen Tabellenerstellungsmechanismus zu entwickeln. Auf diese Weise hängen Operationen wie das Speichern, Abrufen oder Löschen von Daten nicht mehr von SQL ab, das im Code verstreut ist, sondern von intuitiven Methoden, die direkt den Bereich des Handels widerspiegeln, den wir modellieren.
Wenn Sie diese Tools beherrschen, gewinnen Sie nicht nur an Effizienz und Sicherheit bei der Datenmanipulation, sondern schaffen auch eine solide Grundlage für die Entwicklung komplexer Handelssysteme, die fortschrittlichere Analysen, robuste Backtests und detaillierte Historien von Aufträgen und Strategien ermöglichen.
Damit ist diese erste Etappe abgeschlossen. Der nächste Teil der Serie wird praktisch sein: Wir werden mit der Definition der ersten ORM-Klassen und der Implementierung der Objektpersistenz beginnen und dabei die gesamte Theorie, die wir hier gesehen haben, mit funktionalem Code in MQL5 verbinden.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/19285
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
In diesem ersten Artikel habe ich nur die Spitze des Eisbergs gezeigt. TickORM geht viel weiter: Die Idee ist, die Art und Weise, wie Sie mit Datenbanken in MQL5 arbeiten, komplett zu ändern. Das Ziel ist es, etwas Geradliniges, Einfaches und Mächtiges zu schaffen, bei dem das Öffnen einer Datenbank, das Erstellen eines Repositorys und das Manipulieren von Entitäten so selbstverständlich ist wie das Arbeiten mit Arrays. Am Ende der Serie wird die Verwendung dem unten stehenden Beispiel ähneln, bei dem Sie Datensätze speichern, suchen, aktualisieren und löschen können, ohne eine einzige manuelle Abfrage zu schreiben. Dies ist der Weg, den ich mit TickORM beschreite.
Zu Ihrer Information: Eine ORM-Implementierung für MQL5 wird in diesem Buch vorgestellt.