
Simplifying Databases in MQL5 (Part 1): Introduction to Databases and SQL

Introduction
When we talk about MQL5, most conversations revolve around indicators, Expert Advisors, trading strategies, and backtests. But at some point, every trader or developer who seriously works with automation realizes that data persistence is crucial. And this is where databases come in. You might even think: "But I already save my results in CSV or TXT files, why complicate things with a database?" The answer lies in the organization, performance, and reliability that a database provides, especially when dealing with large volumes of information or complex operations.
In the context of MQL5, talking about databases may seem like an exaggeration at first glance. After all, the language is strongly oriented towards trading, indicators, and automated execution robots. But when we start dealing with strategies that involve large volumes of data, complex backtests, or detailed order records, the simplicity of standard files quickly proves insufficient. This is where understanding how to create, access, and manipulate a database becomes a tool capable of transforming your trading workflow.
A trader starting to explore databases in MQL5 will find dozens of native functions and standalone examples. It's enough to save and query records, but the question soon arises: *how to organize all this in a clean and reusable way in real projects?* In this series of articles, we go beyond documentation. We start with the basic functions of SQLite and progress step by step to build a **mini-ORM in MQL5 (TickORM)**. The idea is to transform direct calls into well-designed layers, inspired by Java's JDBC and JPA, but adapted to the MetaTrader ecosystem.
In this article, I demonstrate the fundamentals of databases in MQL5 and SQL. This paves the way for the subsequent articles to encapsulate these functions in classes, interfaces, and, finally, the ORM.
What is a database and how is it useful?
Technically, a database is an organized way of structuring information that allows you to store, query and manipulate saved data. It guarantees integrity, creates relationships between different sets of information and offers speed in operations.
The practical difference between saving data in files and using a database lies in its organization and ease of access. In simple files, such as CSV or TXT, each read or change requires going through all the content, manipulating strings, dealing with formatting errors and hoping the file doesn't get corrupted. In a database, these operations are abstracted: it is possible to search for specific records, update multiple values at once and ensure that complete transactions take place without data loss.
But how does this organization happen internally? Think of the basic structure of a database as a spreadsheet, here's an example:

- Each table in the database is equivalent to a tab in the spreadsheet, dedicated to a specific set of information (e.g. Trades).
- Within each table we have columns, like in the spreadsheet, which represent the attributes of each item (e.g. id, symbol, price, etc).
- And each row in the table corresponds to a single record, i.e. a specific trade or an executed order.
This simple architecture with tables, columns and rows is the basis for quick, well-structured queries. It's as if you had infinite organized and interconnected spreadsheets, but with the advantage of being able to cross-reference data, apply advanced filters and manipulate large volumes of information without a headache.
This is precisely where the motivation to create our own ORM in MQL5 comes from. The idea is simple: instead of writing SQL manually every time we want to manipulate a table (create records, fetch results, update values), we're going to build a layer that treats tables as entities and columns as class attributes. This will be the core of the project we'll be developing throughout the series, and it will serve as the foundation for more robust and scalable trading systems. The name of the ORM will be TickORM .
In short, databases are the basis for building reliable and flexible solutions, and our ORM will be the link between this basis and the code in MQL5.
To make your testing easier, all sample code is attached at the end. This way, you can reference, copy, and adapt it as needed, without having to manually reassemble the snippets.
Note: From here on, some code examples will bring log records to the console. To do this, I use my Logify library, developed precisely to facilitate tracing and debugging in MQL5. If you want to understand more about how it works or follow its implementation step by step, I've written a whole series of articles explaining its development.SQL and MQL5 Native Functions
Working with databases doesn't require much. Fortunately, the language offers a set of native functions that allow you to create, access and manipulate data directly within the language. These functions serve as a bridge between your code and the database.
The relationship with SQL is direct: these functions act as a query execution layer. In other words, you write SQL commands within MQL5, and the native functions handle the preparation, execution and reading of the results. This means that, even without relying on external libraries, you can perform complex operations such as SELECT, INSERT, UPDATE, DELETE and even create tables.
This is the starting point for understanding each function and its possibilities before diving into practical implementation. For full details of all the functions available, I'll list all the native database functions available, as we'll cover the use of each one:
- DatabaseOpen(string filename, uint flags): Opens or creates a database in a specified file
- DatabaseClose(int database): Closes a database
- DatabaseImport(int database,const string table,const string filename,uint flags,const string separator,ulong skip_rows,const string skip_comments): Imports data from a file into a table
- DatabaseExport(int database,const string table_or_sql,const string filename,uint flags,const string separator): Exports a table or the result of executing a SQL request to a CSV file
- DatabasePrint(int database,const string table_or_sql,uint flags): Displays a table or the result of executing an SQL request in the Expert journal
- DatabaseTableExists(int database,string table): Checks for the presence of the table in a database
- DatabaseExecute(int database, string sql): Executes a request to a specified database
- DatabasePrepare(int database, string sql): Creates an identifier for a request. which can then be executed using DatabaseRead()
- DatabaseReset(int request): Resets a request, such as after calling DatabasePrepare()
- DatabaseBind(int request,int index,T value): Sets a parameter value in a request
- DatabaseRead(int request): Moves to the next entry as a result of a request
- DatabaseFinalize(int request): Removes a request created in DatabasePrepare()
- DatabaseTransactionBegin(int database): Starts the execution of the transaction
- DatabaseTransactionCommit(int database): Completes the execution of the transaction
- DatabaseTransactionRollback(int database): Rolls back transactions
- DatabaseColumnsCount(int request): Gets the number of fields in a request
- DatabaseColumnName(int request,int column,string& name): Gets a field name by index
- DatabaseColumnType(int request,int column): Gets a field type by index
- DatabaseColumnSize(int request,int column): Gets the size of the field in bytes
- DatabaseColumnText(int request,int column,string& value): Gets a field value as a string from the current record
- DatabaseColumnInteger(int request,int column,int& value): Gets the value of type int from the current record
- DatabaseColumnLong(int request,int column,long& value): Gets the value of type long from the current record
- DatabaseColumnDouble(int request,int column,double& value): Gets the value of type double from the current record
For full details on all available functions, parameters and examples, MetaQuotes provides official documentation at MQL5 Database Functions.
1. Opening and closing databases
Let's start with the basics, opening a connection to the database. This is done with the DatabaseOpen function, which receives the name of the database file and optional flags that define the opening mode that can have these possible values:
| Value | Description |
|---|---|
| DATABASE_OPEN_READONLY | Read only |
| DATABASE_OPEN_READWRITE | Open for reading and writing |
| DATABASE_OPEN_CREATE | Create the file on a disk, if necessary |
| DATABASE_OPEN_MEMORY | Create a database in RAM |
| DATABASE_OPEN_COMMON | The file is in the common folder of all terminals |
int OnInit() { //--- Open connection int handler = DatabaseOpen("database.sqlite",DATABASE_OPEN_CREATE|DATABASE_OPEN_READWRITE); if(handler == INVALID_HANDLE) { logs.Error("Failed to open database","TickORM"); return(INIT_FAILED); } logs.Info("Open database","TickORM"); //--- Here you would perform queries, inserts or updates //--- Close connection logs.Info("Closed database","TickORM"); DatabaseClose(handler); return(INIT_SUCCEEDED); }
In the first parameter we define the name of the database, in this case I used "database". And at the end just add ".sqlite" which is the file extension, because this is a database that is stored in a file, but that's not a problem, the way to get the data and make queries follows the SQL standard.
In this example, DATABASE_OPEN_READWRITE allows reading and writing, while DATABASE_OPEN_CREATE guarantees that the file will be created if it doesn't already exist. After completing the operations, simply close the connection to DatabaseClose to free up resources.
When you run this code, it automatically creates the database in the <MQL5/Files> folder , which you can view in the metaeditor:
2. Creating a table
The first step after connecting to the database is to define the structure that will store the data. In SQL, this is done with the CREATE TABLE command. It describes the name of the table and the fields it should have.
In MQL5, creating tables involves two main functions:
- DatabaseTableExists(handler, table_name): checks whether a table already exists in the database, returns true or false.
- DatabaseExecute(handler, sql): directly executes an SQL statement.
The most common flow is: check if the table exists → if it doesn't, create table. Here's a practical example:
//--- Create table if(!DatabaseTableExists(handler,"trades")) { logs.Info("Creating user table...","TickORM"); if(DatabaseExecute(handler,"CREATE TABLE trades (id INTEGER PRIMARY KEY AUTOINCREMENT,symbol TEXT, price FLOAT, takeprofit FLOAT, stoploss FLOAT, volume FLOAT);")) { logs.Info("'Trades' table created","TickORM"); } else { logs.Error("Failed to create table",GetLastError(),"TickORM"); } }
In this snippet, we use CREATE TABLE trades (...) to create a table called trades, with basic information about a trade: id (automatically generated unique identifier), symbol, price, takeprofit, stoploss and volume.
If the table already exists, the DatabaseTableExists function prevents the command from being executed again. Always follow this pattern of checking for existence and creating tables on demand.
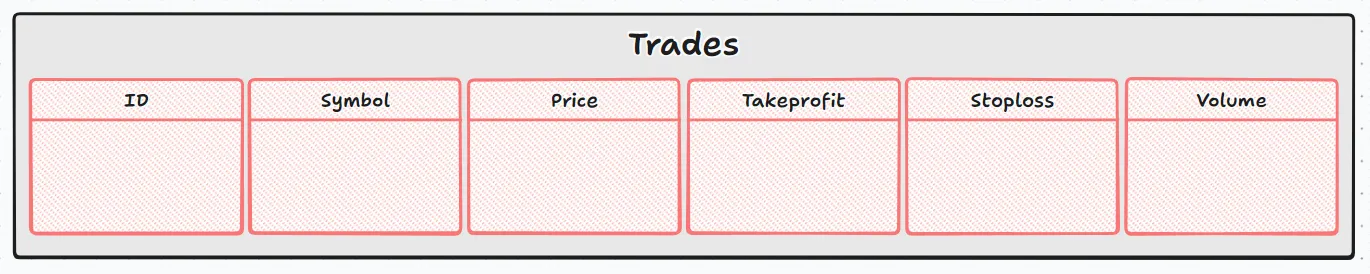
Creating a representation of the current stage would look like this image of the database:
Metaeditor has support for viewing this database, just double-click on the view tables file, it automatically changes the browser tab:
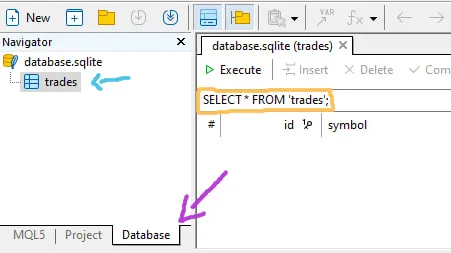
- The blue arrow indicates the database tables
- Yellow indicates where you type the SQL command (this can be done manually or within the code, we'll see examples in the next step)
- Purple shows the "Database" browser tab, if you want to go back to viewing the files (.mqh or .mqh), just go back to the "MQL5" tab.
3. Inserting data into the table
Following the flow, let's insert data into the table we've just created. In SQL, we use the INSERT INTO command to add records. It follows this structure:
INSERT INTO table_name (column1,column2,...) VALUES (value1,value2,...)
In the values we pass the data in raw form, if it's a string, just wrap it in single quotes ('example'). We use the same DatabaseExecute function and check that the execution was successful:
//--- Insert data ResetLastError(); if(DatabaseExecute(handler,"INSERT INTO trades (symbol,price,takeprofit,stoploss,volume) VALUES ('EURUSD',1.16110,1.15490,1.16570,0.01);")) { logs.Info("Data saved to the trades table","TickORM"); } else { logs.Error("Failed to save data to the trade table",GetLastError(),"TickORM"); }
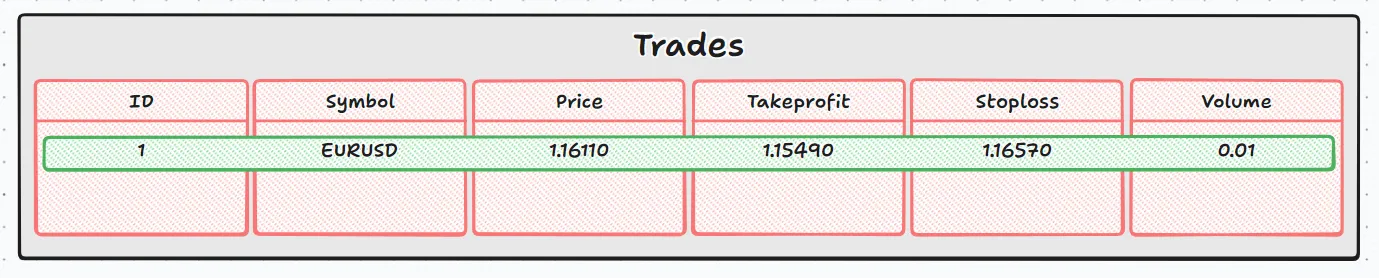
Here, we add a record to the trades table, each column is assigned a value:
- id: Generated automatically by the bank
- symbol: 'EURUSD'
- price: 1.16110
- takeprofit: 1.15490
- stoploss: 1.16570
- volume: 0.01
Representing the current stage, it looks like this:
4. Reading data from the table
Saving the data in the database is only half the job, the real potential comes when we can query and extract this data in a structured way. In MQL5, this process follows a well-defined flow:
- Prepare the query with DatabasePrepare , passing the SQL command.
- Read line by line with DatabaseRead , scrolling through the results.
- Finalize the query with DatabaseFinalize , freeing up memory resources.
A basic example:
//--- Data reading int request = DatabasePrepare(handler,"SELECT * FROM trades;"); //--- Number of table columns that were read int size_cols = DatabaseColumnsCount(request); //--- While data is available for reading (reading each line) while(DatabaseRead(request)) { //--- Scan across all columns of the current line of reading for(int j=0;j<size_cols;j++) { string name = ""; DatabaseColumnName(request,j,name); logs.Info(name,"TickORM"); } } //--- Reset query DatabaseFinalize(request);
On execution we get this in the log:
2025.08.21 10:14:51 [INFO]: Open database 2025.08.21 10:14:51 [INFO]: id 2025.08.21 10:14:51 [INFO]: symbol 2025.08.21 10:14:51 [INFO]: price 2025.08.21 10:14:51 [INFO]: takeprofit 2025.08.21 10:14:51 [INFO]: stoploss 2025.08.21 10:14:51 [INFO]: volume 2025.08.21 10:14:51 [INFO]: Closed database
Here, the query SELECT * FROM trades; fetches all records from the "trades" table. Each call to DatabaseRead(request) moves the cursor to the next row, and the inner loop goes through all the columns, printing only the names.
Comparing this to an image, it would look something like this:
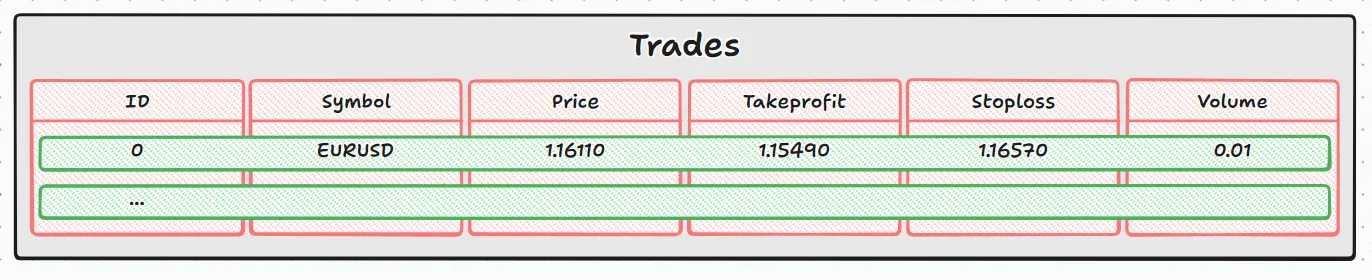
- The outer loop (while(DatabaseRead(request) )) walks row by row (the green rectangles).
- The inner loop (for(int j=0;j<size_cols;j++) ) walks column by column within the current row (the red rectangles).
Together, they allow you to navigate through the bank cell by cell, just as if you were scrolling through a spreadsheet.
Moving on and reading the values of the columns, the previous example only lists the names of the columns. We need the stored values, so we use specific functions according to the column type:
- DatabaseColumnType → allows us to dynamically discover the column type.
- DatabaseColumnText → texts (such as symbols or names).
- DatabaseColumnDouble → floating point numbers (such as prices).
- DatabaseColumnLong or DatabaseColumnInteger → integer values (such as IDs).
Complete example:
//--- Data reading int request = DatabasePrepare(handler,"SELECT * FROM trades;"); //--- Number of table columns that were read int size_cols = DatabaseColumnsCount(request); //--- While data is available for reading (reading each line) while(DatabaseRead(request)) { //--- Scan across all columns of the current line of reading for(int j=0;j<size_cols;j++) { string name = ""; DatabaseColumnName(request,j,name); ENUM_DATABASE_FIELD_TYPE type = DatabaseColumnType(request,j); if(type == DATABASE_FIELD_TYPE_TEXT) { string data = ""; DatabaseColumnText(request,j,data); logs.Info(name + " | "+data,"TickORM"); } else if(type == DATABASE_FIELD_TYPE_FLOAT) { double data = 0; DatabaseColumnDouble(request,j,data); logs.Info(name + " | "+DoubleToString(data,5),"TickORM"); } else if(type == DATABASE_FIELD_TYPE_INTEGER) { long id = 0; DatabaseColumnLong(request,j,id); logs.Info(name + " | "+IntegerToString(id),"TickORM"); } } } //--- Reset query DatabaseFinalize(request);
On execution we get this in the log:
2025.08.21 10:18:04 [INFO]: Open database 2025.08.21 10:18:04 [INFO]: id | 1 2025.08.21 10:18:04 [INFO]: symbol | EURUSD 2025.08.21 10:18:04 [INFO]: price | 1.16110 2025.08.21 10:18:04 [INFO]: takeprofit | 1.15490 2025.08.21 10:18:04 [INFO]: stoploss | 1.16570 2025.08.21 10:18:04 [INFO]: volume | 0.01000 2025.08.21 10:18:04 [INFO]: Closed database
In this case, as well as scrolling through rows and columns, we also access the contents of each cell. Returning to the analogy of the didactic image:
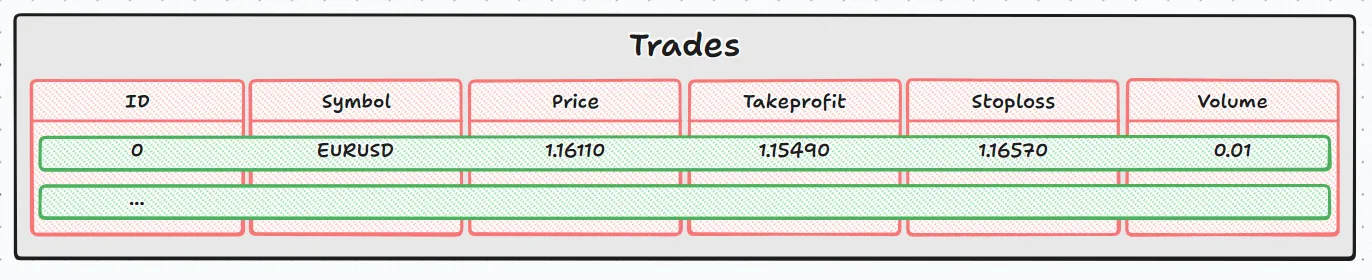
- The gray rectangle is the complete table (trades ).
- Each green rectangle is a row returned by DatabaseRead .
- Each red rectangle is a column, whose value can be text (string), decimal number (double) or integer (int).
- When using DatabaseColumnType , it's as if we were asking: "What type of data is inside this red rectangle?".
- Then the corresponding function (DatabaseColumnText , DatabaseColumnDouble , DatabaseColumnLong ) gets the value.
5. Updating table data
In real-life scenarios, it's not uncommon for us to need to adjust existing information. This is where the UPDATE command comes in, which allows you to modify the values of one or more columns in specific rows of a table.
In SQL, the basic structure of the command is:
UPDATE table_name SET column1=value1, column2=value2, ... WHERE condition;
In MQL5, updating records happens via the DatabaseExecute function, which sends the SQL command directly to the database. Here's an example:
//--- Update data ResetLastError(); if(DatabaseExecute(handler,"UPDATE trades SET volume=0.1 WHERE id=1")) { logs.Info("Trades table data updated","TickORM"); } else { logs.Error("Failed to update trades table data",GetLastError(),"TickORM"); }
Here, we have a classic case: we're telling the bank to find the record in the trades table whose id is equal to 1 and, once found, change the value of the volume column to 0.1.
This pattern is extremely useful in trading. Imagine that you have saved a trade with an initial volume of 0.01 lots, but after strategy adjustments you need to correct it to 0.1. With a simple UPDATE command, the information is reliably synchronized in the database, without having to delete and recreate records.
6. Deleting data from the table
To delete data, we use SQL's DELETE command, which is responsible for deleting rows from a table. The general form of the command is:
DELETE FROM table_name WHERE condition;
It follows the same pattern, we use the DatabaseExecute function to send the SQL command:
//--- Delete data ResetLastError(); if(DatabaseExecute(handler,"DELETE FROM trades WHERE id=1")) { logs.Info("Deleted trades table data","TickORM"); } else { logs.Error("Failed to delete data to the trade table",GetLastError(),"TickORM"); }
In this example, we ask the database to remove from the trades table the record whose id field is equal to 1. A one-off, controlled and secure deletion.
Important detail: As with UPDATE, the use of WHERE is essential to avoid accidentally deleting the entire table.With this command, we have completed the basic data manipulation cycle: create, insert, update and delete. From here we have all the basics for the next step.
7. Deleting a table
If the table is no longer useful, we can delete it.
//--- Delete table ResetLastError(); if(DatabaseExecute(handler,"DROP TABLE trades")) { logs.Info("Trades table deleted","TickORM"); } else { logs.Error("Failed to delete trades table",GetLastError(),"TickORM"); }
It's worth emphasizing: DROP TABLE is irreversible. Unlike a DELETE FROM trades, which only removes the records but keeps the structure, DROP TABLE deletes both the table and the data. If you execute this statement, the table will need to be recreated before it can receive new records.
8. Transactions and data integrity
Let's now move on to a necessary point, which is the integrity of the database. In any application that manipulates data, integrity is a critical point. Imagine a scenario in which we need to write several records, if one of these inserts fails and the others have already been applied, the database could be in an inconsistent state. Transactions exist to avoid this problem.
A transaction is a block of SQL operations that should be treated as an atomic unit:
- Either all the statements within it are applied**(commit**),
- Or none are kept**(rollback**).
In MQL5, we have native functions that allow us to control this flow:
- DatabaseTransactionBegin(handler) → Starts the transaction.
- DatabaseTransactionCommit(handler) → Confirm and apply the changes.
- DatabaseTransactionRollback(handler) → Undo all changes since the start of the transaction.
The example below shows how to use them:
//--- Insert with transaction string sql="INSERT INTO trades (symbol,price,takeprofit,stoploss,volume) VALUES ('EURUSD',1.16110,1.15490,1.16570,0.01);"; DatabaseTransactionBegin(handler); logs.Info("Inserting data, preparing transaction","TickORM"); if(!DatabaseExecute(handler,sql)) { logs.Error("Transaction failed, reverting to previous state",GetLastError(),"TickORM"); DatabaseTransactionRollback(handler); } else { logs.Info("Transaction complete, changes saved","TickORM"); DatabaseTransactionCommit(handler); }
In this snippet:
- We start the transaction with DatabaseTransactionBegin .
- We try to execute the insert (DatabaseExecute ).
- If something goes wrong, we use DatabaseTransactionRollback to undo everything.
- Otherwise, we confirm the changes with DatabaseTransactionCommit .
This is useful because it ensures that no incomplete data remains. It creates more control, you can group several operations together and only apply them when you're sure they all worked. And consequently, it increases security: in the event of unexpected failures (network, power failure, execution error), the database returns to its previous state without compromising data.
Imagine recording ten different operations on various tables. If the eighth fails, without a transaction you would have seven operations recorded and three missing, an inconsistent state. With the transaction, all you have to do is rollback and the bank returns exactly as it was before the attempt.
9. Importing and exporting data
In addition to transactions, another layer of security and practicality is the possibility of importing and exporting data. This makes it possible to create periodic backups of the database, ensuring not only protection against loss, but also mobility and ease of recovery. For this, there are the DatabaseExport and DatabaseImport functions, which allow you to extract the data in CSV and, when necessary, restore it back to the bank.
The example below shows the export of the trades table to a file called backup_trades.csv :
//--- Export table ResetLastError(); long data = DatabaseExport(handler,"trades","backup_trades.csv",DATABASE_EXPORT_HEADER,";"); if(data > 0) { logs.Info("Backup of the 'trades' table created successfully","TickORM"); } else { logs.Error("Failed to create backup of table 'trades'",GetLastError(),"TickORM"); }
Here are some important points:
-
File name: is relative to the MQL5\\Files folder. This means that you can organize backups in subfolders if you wish.
-
CSV format: universally accepted, can be opened in Excel, Google Sheets, Python, R, etc.
-
Flags: in the example we used DATABASE_EXPORT_HEADER , which includes the column names in the first line. This makes it easier when someone needs to interpret the data later.
Value Description DATABASE_EXPORT_HEADER Displays the field names in the first line DATABASE_EXPORT_INDEX Displays the row numbers DATABASE_EXPORT_NO_BOM Does not insert a BOM tag at the beginning of the file (BOM is inserted by default) DATABASE_EXPORT_CRLF Uses CRLF (by default, LF) for line breaks DATABASE_EXPORT_APPEND Adds data to the end of an existing file (by default, the file is overwritten). If the file does not exist, it will be created. DATABASE_EXPORT_QUOTED_STRINGS Displays string values in double quotes. DATABASE_EXPORT_COMMON_FOLDER The CSV file will be created in the shared folder of all terminals \Terminal\Common\File. -
Separator: we use ";" , but it could be "," , "\\t" , etc., depending on your preference or the system that will consume the file.
The data return indicates how many records were exported. If it's negative, an error has occurred and GetLastError() will tell you which one.
Now imagine the reverse case: restoring or loading data into the trades table:
//--- Import table ResetLastError(); long data = DatabaseImport(handler,"trades","backup_trades.csv",DATABASE_IMPORT_HEADER|DATABASE_IMPORT_APPEND,";",0,NULL); if(data > 0) { logs.Info("'trades' table imported successfully","TickORM"); } else { logs.Error("Failed to import 'trades' table",GetLastError(),"TickORM"); }
Here are some valuable details:
-
Combined flags: we use DATABASE_IMPORT_HEADER (the system recognizes the first row as the header) and DATABASE_IMPORT_APPEND (the imported data will be added to the existing table, without deleting what's already there).
Value Description DATABASE_IMPORT_HEADER The first line contains the names of the table fields DATABASE_IMPORT_CRLF Line break is CRLF (by default, LF) DATABASE_IMPORT_APPEND Adds data to the end of an existing table DATABASE_IMPORT_QUOTED_STRINGS String values are enclosed in double quotes DATABASE_IMPORT_COMMON_FOLDER The file is located in the common folder of all client terminals \Terminal\Common\File. -
Separator: must match the one used in the export.
-
skip_rows: allows you to skip initial lines (for example, if you want to ignore comments or old data).
-
skip_comments: defines symbols that mark lines to be skipped. Very useful when working with manually annotated CSV files.
The data return shows how many records have been imported.
With DatabaseExport and DatabaseImport , we have closed the basic cycle of entering and leaving data in the database. Now we know how to create tables, insert, query, update, delete, and even save external copies or restore information when necessary.
But note one detail: each operation requires dealing directly with SQL and specific calls to native functions. This works well in small examples, but as the system grows, complexity accumulates, and so does the risk of errors. This is exactly where the next inevitable question arises: do we really need to write everything on our fingernails?
This is where the idea of an ORM comes in. In the next section, we'll understand what it is, why it can radically change the way we interact with databases in MQL5 and how it fits into the path we're building.
What is an ORM and why do we need one?
So far, we've explored the use of SQL directly in MQL5, manipulating tables and records "on the fly". This approach works, but as the system grows, so does the amount of SQL scattered throughout the code, and with it come maintenance problems, repetition and the risk of errors. This is where ORM (Object-Relational Mapping) comes in.
An ORM is a layer that bridges the gap between the object-oriented world and the relational world of databases. Instead of writing SQL manually, we describe our entities as classes and let the ORM take care of translating them into SQL commands. In other words: instead of dealing with INSERT INTO trades (...) VALUES (...) , you simply create a Trade object and call something like repository.save(trade) .
The main features of an ORM include:
- Automatic mapping: transforms classes and attributes into tables and columns.
- SQL abstraction: you work with objects and methods, not SQL strings.
- Consistency: reduces duplication of logic, since common operations such as saving, searching or deleting are centralized.
- Portability: in some ORMs, the same logic can work in different databases without changing the source code.
In MQL5, this idea makes even more sense because writing SQL embedded in the code quickly becomes a nightmare. Imagine an Expert Advisor with dozens of entities (trades, orders, logs, performance metrics). Every INSERT , SELECT or UPDATE scattered throughout the code means more points of failure, more difficulty in evolving the logic and more chances of inconsistency.
The "pain" that ORM solves is:
- Avoids duplicate SQL in various parts of the EA.
- It makes maintenance easier, since changes to the table structure are reflected in a single place (the entity class).
- Allows you to write more readable and natural code, thinking in terms of domain objects (e.g. Trade , User , Order ) instead of tables and columns.
- It opens up space for advanced features such as automatic table generation, schema version control and even simpler integration with logging and auditing libraries.
In short: without ORM, each operation is a block of SQL within the code; with ORM, the SQL becomes a hidden detail, and you focus on what really matters, the trading logic.
Our ORM project in MQL5
Now that we understand the usefulness of an ORM, we need to visualize how it translates into the MQL5 ecosystem. Unlike more traditional languages in the world of ORMs (Java, C#, Python), here we don't have robust frameworks ready to use, which means we'll have to build our own solution, adapted to the limitations and particularities of the language.
The scope planned for this project is clear: create a layer that allows the developer to work with objects instead of direct SQL, but without losing the simplicity and performance required in a trading environment.
The planned functionalities include:
- Entities: Each table in the database will be represented by an MQL5 class, with metadata describing its columns (type, primary key, whether it is autoincrementing, whether it is null, etc.). Thus, the Trade class will directly reflect the trades table, but will be manipulated as a native object.
- Repositories: Instead of writing INSERT , UPDATE or SELECT manually, each entity will have a repository responsible for persistence and recovery operations. For example, TradeRepository will centralize methods such as Save(trade) , FindById(id) or Delete(trade) . This way, the EA's code is clean and free of scattered SQL.
- Query Builder: For cases where we need more complex queries (filters, sorting, joins), there will be a query builder. It will allow you to build queries programmatically and safely, avoiding string concatenation errors and reducing direct exposure to SQL.
- Auto-creation of tables: Based on the entity's metadata, the ORM will be able to automatically generate the corresponding table, checking that it already exists before creating it. This functionality eliminates the need for manual SQL scripts at the start of the project and ensures that the database keeps up with the evolution of the entities.
- Integration with logs and auditing: Every operation performed by the ORM (insertion, update, deletion) can be recorded in the logs, taking advantage of libraries already developed in MQL5. This makes it easier to audit what happens in the database and helps diagnose problems.
- Extensibility: The architecture will be designed to evolve: today we're starting with basic CRUD, but there's nothing to stop us from adding support for schema migrations, relationships between entities (one-to-many, many-to-many), or even in-memory caching to optimize queries.
The aim is not to recreate a Hibernate Framework within MQL5, but to provide a minimalist and efficient abstraction layer that meets the real needs of those who work with algorithmic trading and need structured persistence.
Conclusion and next steps
We've reached the end of this first part of the series, and the picture is starting to become clear: databases in MQL5 are not just files for storing information, but powerful structures that, when properly exploited, allow you to record, query and manipulate data in an organized and reliable way. We saw how SQL works in practice, from creating tables, inserting and reading records, to manipulating columns and data types, using native MQL5 functions such as DatabaseOpen, DatabaseExecute, DatabasePrepare and DatabaseRead .
More importantly, we understand that writing SQL manually on every project quickly becomes repetitive, error-prone and difficult to maintain. This is where the concept of ORM comes in: a layer of abstraction that turns tables into objects and SQL queries into simple methods, allowing you to work with entities in a natural way while keeping the code clean and centralized.
As the next steps in the series, we're going to start building this abstraction layer. Our goal will be to create a minimalist and efficient ORM, with entity classes, repositories, a query builder and an automatic table creation mechanism. This way, operations such as saving, fetching or deleting data will no longer depend on SQL scattered throughout the code, but on intuitive methods that directly reflect the domain of the trading we are modeling.
By mastering these tools, you not only gain efficiency and security in data manipulation, but also create a solid foundation for evolving complex trading systems, allowing for more advanced analysis, robust backtests and detailed histories of orders and strategies.
That brings this first stage to a close. The next part of the series will be practical: we'll start defining the initial ORM classes and implementing object persistence, connecting all the theory we've seen here with functional code in MQL5.
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
In this first article, I've only shown the tip of the iceberg. TickORM goes much further: the idea is to completely change the way you work with databases in MQL5. The goal is to achieve something straightforward, simple, and powerful, where opening a database, creating a repository, and manipulating entities is as natural as working with arrays. By the end of the series, usage will resemble the example below, where you save, search, update, and delete records without writing a single manual query. This is the path I'm paving with TickORM.
In this first article, I've only shown the tip of the iceberg. TickORM goes much further: the idea is to completely change the way you work with databases in MQL5. The goal is to achieve something straightforward, simple, and powerful, where opening a database, creating a repository, and manipulating entities is as natural as working with arrays. By the end of the series, usage will resemble the example below, where you save, search, update, and delete records without writing a single manual query. This is the path I'm paving with TickORM.
FYI: An implementation of ORM for MQL5 has been presented in the book.