
Marcado de datos en el análisis de series temporales (Parte 4): Descomposición de la interpretabilidad usando el marcado de datos

Introducción
En el último artículo, hablamos del modelo NHITS, en el que probamos la previsión de los precios de cierre para una sola variable de entrada. En este artículo, analizaremos la interpretabilidad del modelo y el uso de múltiples covariables para predecir los precios de cierre. Esta vez, para la demostración, usaremos otro modelo que ofrece aún más posibilidades: NBEATS. El artículo se centrará en la interpretabilidad del modelo. También veremos para qué se introduce el tema de las covariables. Con el tiempo, deberemos aprender a utilizar distintos modelos para poner a prueba nuestras ideas siempre que lo necesitemos. Obviamente, estos dos modelos son esencialmente modelos cualitativos interpretables. Las ideas pueden ampliarse a otros modelos y probarse usando las bibliotecas comentadas en el artículo. Tenga en cuenta que esta serie de artículos está destinada exclusivamente a la tarea que nos ocupa. Deberemos evaluar sobriamente todos los riesgos antes de aplicar cualquier idea -incluidas las mencionadas en el artículo- directamente en el comercio real. La implementación de posibilidades comerciales requiere ajustes adicionales de los parámetros y técnicas de optimización suplementarias para garantizar resultados fiables y estables.
Enlaces a los tres artículos anteriores:
- Marcado de datos en el análisis de series temporales (Parte 1): Creamos un conjunto de datos con marcadores de tendencia utilizando el gráfico de un asesor
- Marcado de datos en el análisis de series temporales (Parte 2): Creando conjuntos de datos con marcadores de tendencias utilizando Python
- Marcado de datos en el análisis de series temporales (Parte 3): Ejemplo de uso del marcado de datos
Contenido:
- Introducción
- Sobre el modelo NBEATS
- Importación de bibliotecas
- Reescritura de la clase TimeSeriesDataSet
- Procesamiento de datos
- Obtención de la velocidad de aprendizaje
- Definición de la función de entrenamiento
- Entrenamiento y prueba del modelo
- Interpretación del modelo
- Conclusión
Sobre el modelo NBEATS
Este modelo ha sido ampliamente debatido y explicado en diversas revistas y sitios web. Para que usted no tenga que consultar varios sitios web y otras fuentes de información, le ofreceremos aquí una sencilla introducción a este modelo. El modelo NBEATS puede procesar secuencias de entrada y salida de cualquier longitud y no depende del desarrollo de funciones específicas ni del escalado de las entradas de series temporales. El modelo también puede usar polinomios y series de Fourier como funciones básicas para obtener configuraciones interpretables al modelizar las tendencias y realizar la descomposición estacional. Además, el modelo utiliza una topología de doble suma residual, de forma que cada bloque de construcción tiene dos ramas residuales, una para la predicción inversa y otra para la predicción directa, lo cual mejorará enormemente la capacidad de entrenamiento y la interpretabilidad del modelo. ¡Parece impresionante!Artículo original publicado aquí: https://arxiv.org/pdf/1905.10437.pdf
1. Arquitectura del modelo
2. Proceso de implementación del modelo
La serie temporal de entrada se representa como un vector de baja dimensionalidad, mientras que la segunda parte vuelve a convertir el vector en una serie temporal. Este paso también se encuentra en el AutoEncoder, donde la serie temporal se mapea con un vector de baja dimensionalidad para preservar la información básica y luego se sigue con la reconstrucción. Este proceso puede simplificarse de la siguiente forma: 
El módulo generará dos conjuntos de coeficientes de expansión: uno para predecir el futuro (forecast) y otro para predecir el pasado (backcast). Este proceso puede representarse usando la siguiente fórmula:

3.Interpretabilidad
La descomposición del modelo es interpretable. El modelo NBEATS introduce cierto conocimiento previo en cada nivel, debido al cual los niveles tienen que aprender ciertas características de las series temporales. Esto nos da una descomposición interpretable de la serie temporal. El método de aplicación consistirá en restringir los coeficientes de expansión a la forma funcional de la secuencia de salida. Por ejemplo, si deseamos que un determinado bloque de capas prediga la estacionalidad de una serie temporal, podemos utilizar la siguiente fórmula para que la capa de salida muestre exactamente los datos estacionales:


4. Covariables
En este artículo, también se nos ofrecen las covariables que ayudarán a predecir el valor objetivo. Qué covariables tenemos:- static_categoricals - lista de variables categóricas que no cambian con el tiempo.
- static_reals - lista de variables continuas que no cambian con el tiempo.
- time_varying_known_categoricals - lista de variables categóricas que cambian con el tiempo y se conocen en el futuro, por ejemplo la información sobre los festivos.
- time_varying_known_reals - lista de variables continuas que cambian con el tiempo y se conocen en el futuro, por ejemplo las fechas.
- time_varying_unknown_categoricals - lista de variables categóricas que cambian con el tiempo y son desconocidas en el futuro, por ejemplo la tendencia.
- time_varying_unknown_reals - lista de variables continuas que cambian con el tiempo y son desconocidas en el futuro, por ejemplo el crecimiento o la caída.
5. Variables externas
El modelo NBEATS permite introducir variables externas que parecen no estar relacionadas con la muestra, pero que conllevan el cambio del modelo. El equipo de investigación denominó NBEATSx a la ampliación del modelo debida a variables exógenas, pero no hablaremos de ella en este artículo.Importación de bibliotecas
Aquí no tenemos que dar explicaciones. Simplemente tomamos e importamos.
import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import numpy as np import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.metrics import MQF2DistributionLoss from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json
Reescritura de la clase TimeSeriesDataSet
Aquí tampoco hacen falta explicaciones innecesarias, ya se ha descrito todo antes. Podrá leer más sobre lo que se está haciendo y por qué en los artículos anteriores de esta serie.
class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs)
Procesamiento de datos
No repetiremos aquí la carga y el preprocesamiento de los datos: ya se han dado descripciones completas en los tres artículos anteriores, por lo que le recomiendo su lectura. En este mismo artículo, solo examinaremos los cambios relevantes por ubicación.
1. Recogida de datos
def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm
2.Procesamiento previo
A diferencia de lo que hemos hecho antes, ahora vamos a hablar de covariables. ¿Por qué las usamos? De hecho, existen otras variantes de este modelo: NBEATSx y GAGA. Si le interesan estos modelos o cualquier otro incluido en la biblioteca de previsiones pytorch que usamos, deberá comprender las covariables. Intentaremos aclararnos sin entrar en demasiados detalles.
Para los datos de divisas, utilizaremos como covariables los valores open, high y low. Por supuesto, podremos utilizar otros datos en calidad de covariables, como MACD, ADX, RSI y otros indicadores, pero recuerde que deberán estar necesariamente relacionados con nuestros datos. Como covariables de entrada no podremos añadir variables externas inapropiadas, por ejemplo, actas de reuniones de la Reserva Federal, decisiones sobre tipos de interés, datos no agrícolas, etc., porque el modelo no tiene funciones para analizar estos datos. Quizá algún día escriba un artículo sobre cómo añadir variables externas a un modelo.
Veamos ahora cómo añadir las covariables a la clase New_TmSrDt(). La clase ofrece las siguientes definiciones de variables:
- static_categoricals (List[str])
- static_reals (List[str])
- timevaryingknown_categoricals (List[str])
- timevaryingknown_reals (List[str])
- timevaryingunknown_categoricals (List[str])
- timevaryingunknown_reals (List[str])
Los valores de dichas variables se han explicado anteriormente. Pensemos ahora a qué categoría pertenecen las variables open, high y low. Estas categorías son especialmente confusas:
- timevaryingknown_categoricals
- timevaryingknown_reals
- timevaryingunknown_categoricals
- timevaryingunknown_reals
Como las variables open, high y low no son categorías en absoluto, solo quedan time_varying_known_reals y time_varying_unknown_reals para elegir. Alguien podría decir que si necesitamos predecir los valores de close, y los valores open, high y low de cada barra se pueden obtener en tiempo real, ¿por qué no se pueden añadir a time_varying_known_reals? Fijémonos bien: si predecimos el valor de una sola barra, este ya será conocido, y entonces podremos clasificarlos plenamente como time_variing_known_reals. Pero, ¿y si queremos predecir los valores de varias barras? Solo podemos averiguar los datos de la barra actual, y los valores que le siguen resultan completamente desconocidos, por lo que no son adecuados para el entorno tratado en nuestro trabajo. Resulta que deberemos añadirlos a la categoría time_varying_unknown_reals. Pero si estamos prediciendo el valor close de una sola barra, definitivamente podremos añadirlo a time_varying_known_reals, por lo que será importante considerar cuidadosamente el caso de uso específico. También existe un caso especial para time_variing_known_reals. De hecho, cada una de nuestras barras tiene un ciclo fijo, por ejemplo, M15, H1, H4, D1, etc. Gracias a ello, podremos calcular completamente el tiempo al que se refieren las barras pronosticadas. Así que bien podemos añadir el tiempo como time_variing_known_reals. No nos detendremos en ello ahora, pero si le interesa, podrá añadirlo tú mismo. Si desea utilizar covariables, podrá cambiar time_varying_unknown_reals=["close"] por time_varying_unknown_reals=["close", "high", "open", "low"]". Nuestra versión de NBEATS no es compatible con esta función.
Entonces, tendremos este código:
def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, max_prediction_length=prediction_length, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training
Obtención de la velocidad de aprendizaje
Aquí no tenemos que dar explicaciones. ya se ha descrito todo antes. Podrá leer más sobre lo que se está haciendo y por qué en los artículos anteriores de esta serie.
def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_
Nota: Existen algunas diferencias entre esta función y Nbits: la función NBeats.from_dataset() no tiene parámetros hidden_size. Y el parámetro de pérdida no puede usar el método MQF2DistributionLoss().
Definición de la función de entrenamiento
Aquí no tenemos que dar explicaciones. ya se ha descrito todo antes. Podrá leer más sobre lo que se está haciendo y por qué en los artículos anteriores de esta serie.
def train():
early_stop_callback = EarlyStopping(monitor="val_loss",
min_delta=1e-4,
patience=10,
verbose=True,
mode="min")
ck_callback=ModelCheckpoint(monitor='val_loss',
mode="min",
save_top_k=1,
filename='{epoch}-{val_loss:.2f}')
trainer = pl.Trainer(
max_epochs=ep,
accelerator="cpu",
enable_model_summary=True,
gradient_clip_val=1.0,
callbacks=[early_stop_callback,ck_callback],
limit_train_batches=30,
enable_checkpointing=True,
)
net = NBeats.from_dataset(
training,
learning_rate=lr,
log_interval=10,
log_val_interval=1,
weight_decay=1e-2,
backcast_loss_ratio=0.0,
optimizer="AdamW",
stack_types = ["trend", "seasonality"],
)
trainer.fit(
net,
train_dataloaders=t_loader,
val_dataloaders=v_loader,
# ckpt_path='best'
)
return trainer
Nota: Aquí, NBeats.from_dataset() requiere la adición de una variable de tipo de descomposición stack_types interpretada. Usaremos el valor por defecto. Además de estos dos valores por defecto, también existe una opción "genérica".
Entrenamiento y prueba del modelo
A continuación, aplicaremos la lógica de entrenamiento y predicción del modelo que se explicó en el artículo anterior. Aquí no hay cambios, así que no nos detendremos en ello.
if __name__=='__main__': ep=200 __train=False mt_data_len=200000 max_encoder_length = 2*96 max_prediction_length = 30 batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NHiTS.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NHiTS.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) plt.show()
Nota: Asegúrese de tener instalado TensorBoard antes de ejecutarlo. Esto es importante, de lo contrario se producirán errores ininteligibles.
Resultado del entrenamiento (al ejecutar el código aparecerán 10 imágenes, ofrecemos una imagen aleatoria como ejemplo):

Resultados de las pruebas:

Interpretación del modelo
Existen muchas formas de interpretar los datos, pero el modelo NBEATS es único en el sentido de que desglosa las previsiones en estacionalidad y tendencias (obviamente, dado que en este artículo se eligen estos dos factores, los resultados solo podrán desglosarse en estos dos, pero podría haber muchas otras combinaciones).
Si ha completado el entrenamiento y desea establecer una predicción, deberá añadir este tipo de código:
for idx in range(10): # plot 10 examples best_model.plot_interpretation(x, raw_predictions, idx=idx)
Si desea descomponer la previsión al ejecutar esta, podrá añadir el siguiente código:
best_model.plot_interpretation(predictions.x,predictions.output,idx=0) El resultado será el que sigue:
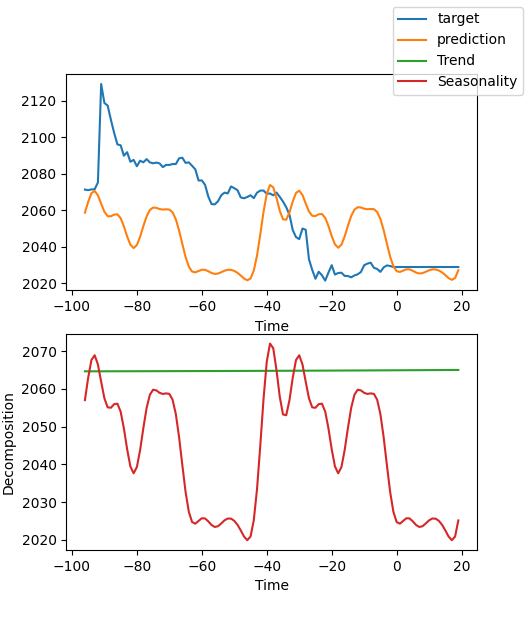
En esta figura, los resultados no son muy buenos. Pero esto es solo un ejemplo aproximado, no hemos optimizado a fondo nuestro modelo, y las métricas de los datos clave aún no están científicamente afinadas. Además, la mayoría de los parámetros del modelo solo se utilizan por defecto y no son configurables, por lo que hay mucho margen para la optimización.
Conclusión
En este artículo, hemos explicado cómo utilizar los datos marcados para predecir los precios futuros usando el modelo NBEATS. Además, el artículo presenta una función especial de descomposición de la interpretabilidad para el modelo NBEATS. Aunque los cambios en el código no son significativos, deberemos prestar atención a la discusión sobre las covariables en el texto. Si conoce bien el uso de las distintas covariables, podrá ampliar este modelo a otros escenarios de aplicación. Creo que esto ayudará a mejorar la precisión del asesor y a realizar con mayor exactitud las tareas necesarias. Naturalmente, este artículo es solo un ejemplo. Aquí solo encontrará datos aproximados, que, en su forma actual, no son adecuados para su uso en el comercio real. Hay muchos lugares en el código que necesitan una mayor optimización, ¡así que no lo utilice directamente en el comercio! El artículo también menciona variables externas. No sé si alguien está interesado en esta rama de investigación. Si consigo suficiente información, tal vez describa cómo aplicarla a esta serie de artículos en el futuro.
Con esto damos por terminado el articulo, espero que le sea de utilidad.
Aquí tenemos el código íntegro:
# Copyright 2021, MetaQuotes Ltd. # https://www.mql5.com import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json from torch.utils.data import DataLoader from torch.utils.data.sampler import Sampler,SequentialSampler class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs) def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, # min_encoder_length=max_encoder_length//2, max_prediction_length=prediction_length, # min_prediction_length=1, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.1, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_ def train(): early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=True, mode="min") ck_callback=ModelCheckpoint(monitor='val_loss', mode="min", save_top_k=1, filename='{epoch}-{val_loss:.2f}') trainer = pl.Trainer( max_epochs=ep, accelerator="cpu", enable_model_summary=True, gradient_clip_val=1.0, callbacks=[early_stop_callback,ck_callback], limit_train_batches=30, enable_checkpointing=True, ) net = NBeats.from_dataset( training, learning_rate=lr, log_interval=10, log_val_interval=1, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", stack_types=["trend", "seasonality"], ) trainer.fit( net, train_dataloaders=t_loader, val_dataloaders=v_loader, # ckpt_path='best' ) return trainer if __name__=='__main__': ep=200 __train=False mt_data_len=80000 max_encoder_length = 96 max_prediction_length = 20 # context_length = max_encoder_length # prediction_length = max_prediction_length batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() # lr=3e-3 trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NBeats.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NBeats.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) # best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) best_model.plot_interpretation(predictions.x,predictions.output,idx=0) plt.show()
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13218
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso