
Marktsimulation (Teil 23): Erste Schritte mit SQL (VI)

Einführung
Im vorherigen Artikel Marktsimulation (Teil 22): Erste Schritte mit SQL (V) haben wir uns angesehen, wie man einen Primärschlüssel mit einem Fremdschlüssel verwendet – oder genauer gesagt, wie man sie miteinander verknüpft. Falls das noch nicht ganz klar ist, empfehle ich, zuerst die vorherigen Artikel zu lesen. Diese Hintergrundinformationen sind notwendig, um vollständig zu verstehen, was wir hier unternehmen werden.
Abfrageergebnisse verstehen
Im vorherigen Artikel haben wir eine kleine Datenbank erstellt, um die Verwendung von Primärschlüsseln in Verbindung mit Fremdschlüsseln zu veranschaulichen. Wenn wir diese Konfiguration jedoch abfragen, erhalten wir wahrscheinlich ein Ergebnis, das sich deutlich von unseren Erwartungen unterscheidet. Um dies zu verdeutlichen, verwenden wir den folgenden Code, um die Datenbank abzufragen.
SELECT * FROM tb_Quotes;
Code 01
Das Ergebnis ist unten dargestellt.
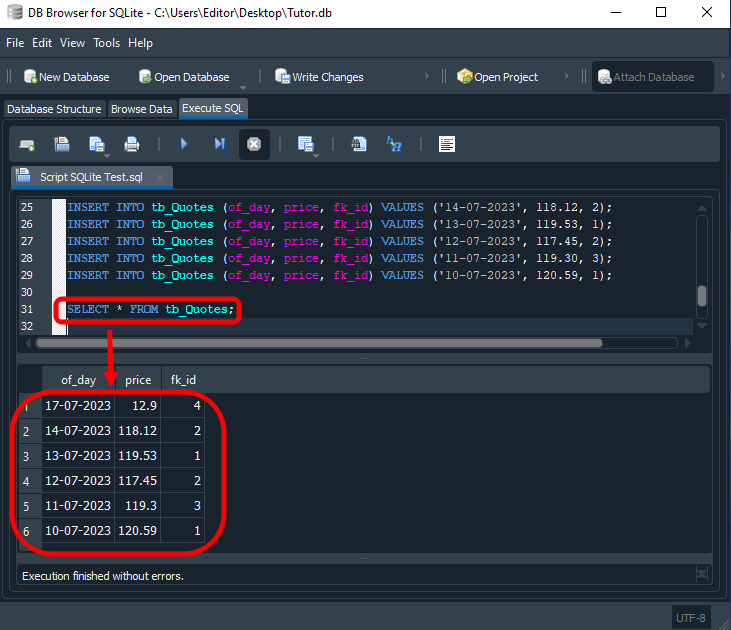
Bild 01
An dieser Stelle fragen Sie sich vielleicht: „Was habe ich falsch gemacht?“ Die Antwort lautet: nichts. Viele Menschen vermeiden die Verwendung von Fremdschlüsseln in ihren Datenbanken gerade deshalb, weil sie das Konzept hinter dieser Art von Schlüsseln nicht verstehen. Infolgedessen entstehen nicht-relationale Datenbanken, was sowohl die Wartung als auch die Struktur selbst erheblich komplizierter macht. Dies führt zudem zu einem höheren Rechenaufwand und einer höheren Arbeitslast für SQL.
Eine der größten Stärken von SQL besteht darin, dass wir damit Tabellen erstellen können, die scheinbar unabhängig voneinander sind, sie aber dennoch miteinander verknüpfen –, oder genauer gesagt: die darin gespeicherten Werte miteinander verknüpfen. Dadurch können wir eines der größten Probleme vermeiden, das vor der Einführung von SQL bestand: die Datenduplizierung. Vielleicht ist Ihnen noch nicht bewusst, wie schädlich Duplikate für eine Datenbank sind, doch sie können einen der Hauptvorteile der Verwendung von SQL beim Aufbau einer Datenbank für eine Anwendung im Grunde zunichte machen.
Visualisierung des Datenbankdiagramms
Es gibt verschiedene Tools zur Visualisierung von Datenbankdiagrammen mit unterschiedlichen Funktionen. Im DB Browser, den wir hier zur Erläuterung bestimmter Punkte verwenden, lässt sich ein solches Diagramm – zumindest zum Zeitpunkt der Erstellung dieses Artikels – nicht erstellen. Da DB Browser Open Source ist und über GitHub aktualisiert wird, ist diese Funktion möglicherweise bereits verfügbar, wenn Sie diesen Artikel lesen. Eine Alternative ist die Verwendung von DBeaver. Dieses Programm verfügt über eine kostenlose Version, die sich problemlos herunterladen und nutzen lässt. Sobald DBeaver installiert ist, führen Sie die folgenden Schritte aus, um das Diagramm anzuzeigen:
Bild 02
Dadurch wird ein neues Fenster geöffnet, wie unten dargestellt.
Bild 03
Hier müssen wir den anzuzeigenden Datenbanktyp auswählen. Denken Sie daran, dass wir SQLite verwenden. Suchen und wählen Sie es aus, wie unten gezeigt.

Bild 04
Super, jetzt erscheint das folgende Fenster.
Bild 05
Hier müssen Sie den Pfad und den Namen der zu öffnenden Datenbank eingeben, wie unten gezeigt.
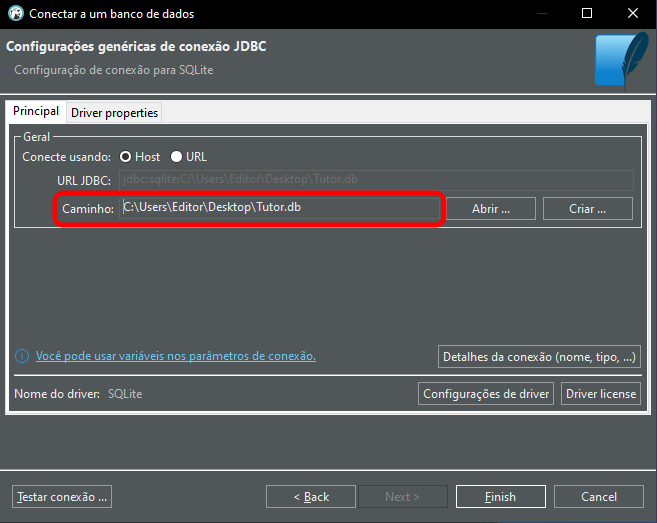
Bild 06
Klicken Sie anschließend auf „Finish“, woraufhin die letzte Ansicht erscheint.
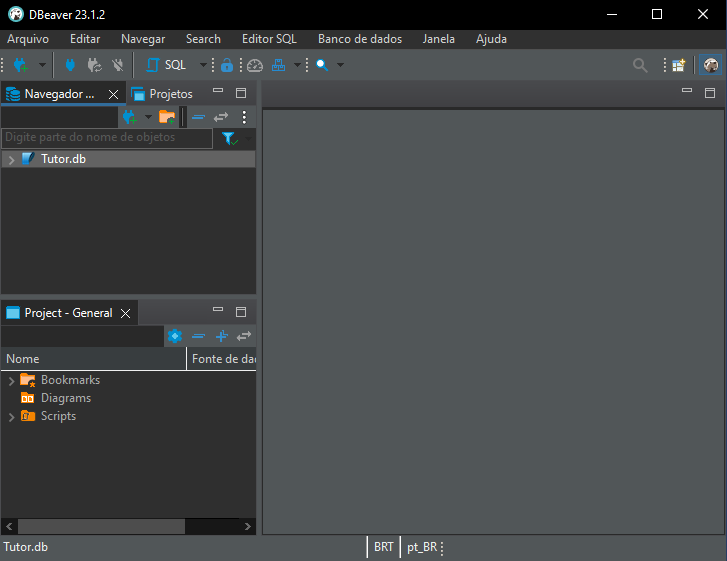
Bild 07
Wenn alles korrekt ausgeführt wurde, sieht das Ergebnis wie in Abbildung 07 aus, und unsere Datenbank ist einsatzbereit. Wir können das Diagramm nun öffnen, indem wir auf die unten hervorgehobenen Elemente klicken:
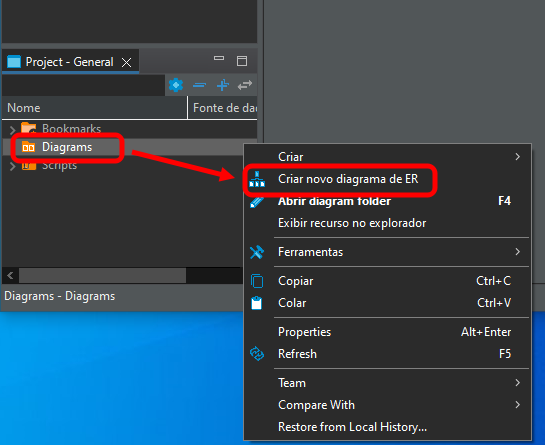
Bild 08
Es öffnet sich das unten abgebildete Fenster:
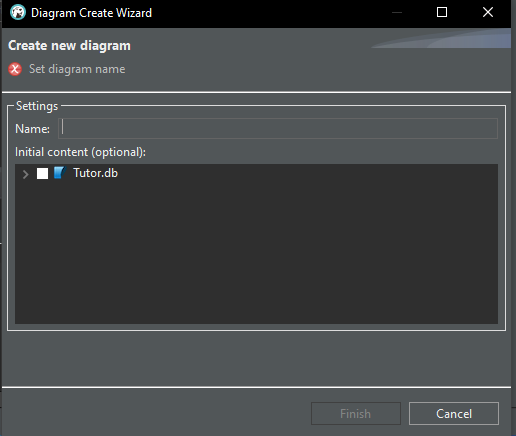
Bild 09
Geben Sie dem neuen Diagramm nun einen Namen, wie in der Abbildung gezeigt. Sie können sich einen beliebigen Namen aussuchen.
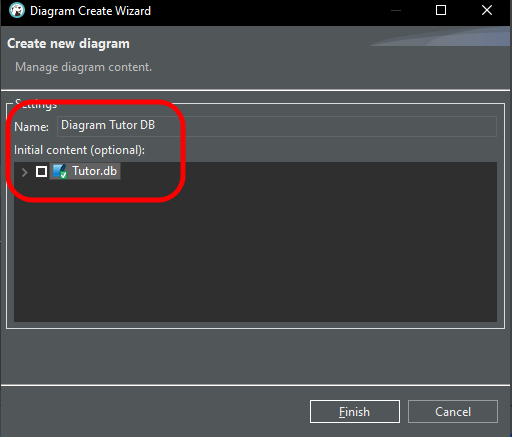
Bild 10
Nachdem wir auf die Schaltfläche „Finish“ geklickt haben, erhalten wir schließlich folgendes Ergebnis:
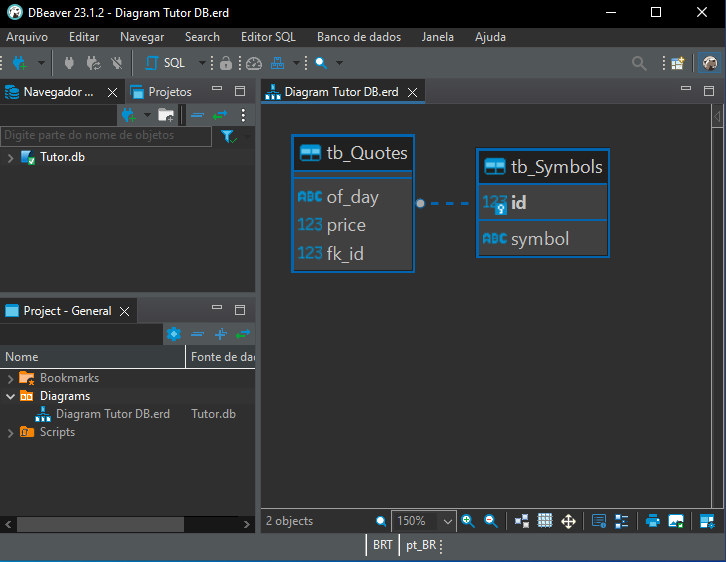
Bild 11
Das Diagramm interpretieren
Abbildung 11 veranschaulicht deutlich die Beziehung zwischen den Tabellen „tb_Quotes“ und „tb_Symbols“. Auf den ersten Blick könnte man meinen, es handele sich um eine Eins-zu-eins-Beziehung, was bedeuten würde, dass jeder Datensatz in „tb_Symbols“ einem entsprechenden Datensatz in „tb_Quotes“ entspricht. Das kann in manchen Fällen vorkommen. Beachten Sie jedoch ein Detail in der Abbildung. Es ist eine kleine, aber wichtige Sache, und das Bild unten zeigt genau, worauf Sie achten sollten.
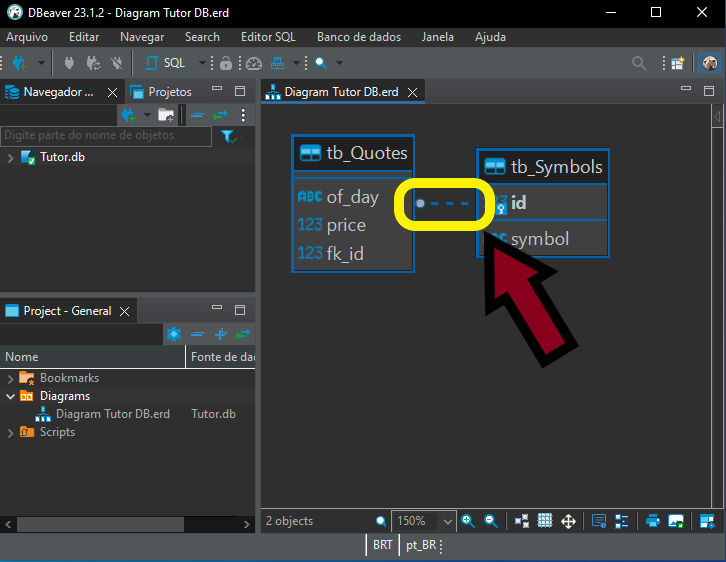
Bild 12
Beachten Sie, dass auf der einen Seite ein kleiner Kreis zu sehen ist, während die andere Seite keine solche Markierung aufweist. Achten Sie genau darauf. Was bedeutet das? Dies weist auf eine Eins-zu-Viele-Beziehung hin. Die Tabelle auf der Seite mit dem Kreis kann zu jedem Datensatz der anderen, über diese Linie verbundenen Tabelle mehrere Datensätze enthalten. Wenn wir wissen, wie man dies richtig interpretiert, können wir bessere Abfragen erstellen. Außerdem lassen sich Datenbankänderungen so viel einfacher und fehlerfreier vornehmen.
Dies ist von Bedeutung, denn wenn ein Datensatz in einer Tabelle mehrfach in einer oder mehreren anderen Tabellen referenziert werden kann, können wir Trigger zum Hinzufügen neuer Daten, zum Löschen von Datensätzen oder zum Aktualisieren von Datenbankinformationen besser verstehen und entwerfen. Aber das ist ein Thema für eine andere Diskussion. An dieser Stelle müssen wir verstehen, wie uns diese Art von Beziehung dabei hilft, den Inhalt der Datenbank korrekt darzustellen.
Arbeiten mit Daten in SQL
Bisher haben wir uns nur mit der Erstellung des Datenbankdiagramms befasst. Nun kehren wir zum DB Browser zurück. Beachten Sie, dass Sie das hier gezeigte Ergebnis auch mit dem MetaEditor erzielen können, auch wenn sich der Code für die Datenbankabfrage geringfügig unterscheidet. Der betreffende Code ist unten aufgeführt:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes, tb_Symbols;
Code 02
Wenn dieses Skript ausgeführt wird, gibt SQL 24 Datensätze zurück. Warum? Schauen wir mal, was passiert ist. Sehen Sie sich die Ausgabe an, die der Code im folgenden Bild erzeugt:
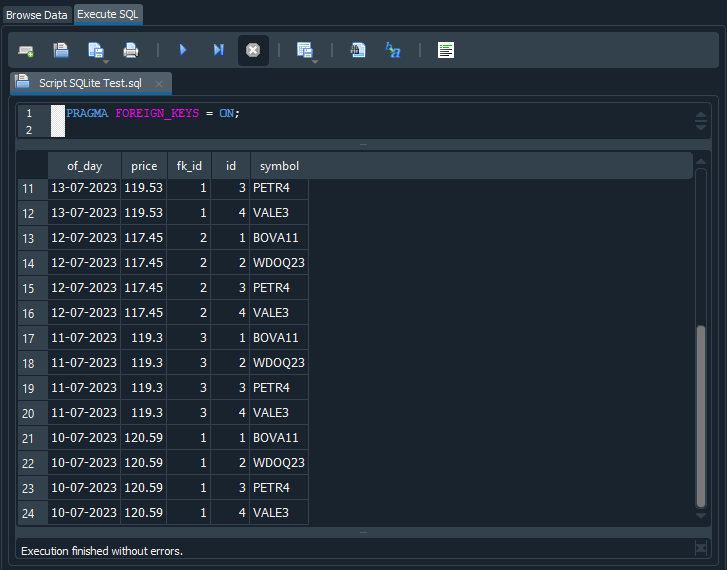
Abbildung 13
Sie können sehen, dass sich derselbe Kurswert und dasselbe Datum in den Zeilen 17 bis 20 wiederholen. Mit anderen Worten: SQL hat die SELECT-Anweisung als Aufforderung interpretiert, den Inhalt von tb_Quotes und tb_Symbols zu kombinieren. Infolgedessen werden die Werte aus „tb_Quotes“ wiederholt, während sich die Werte aus „tb_Symbols“ ändern. Da die Tabelle „tb_Quotes“ sechs Datensätze und die Tabelle „tb_Symbols“ vier Datensätze enthält, ergibt die Zusammenführung der beiden Tabellen 24 Datensätze. Ist nun klar, warum SQL 24 Datensätze zurückgibt?
Schauen Sie sich nun Bild 13 genau an. In manchen Fällen stimmt der Wert von „fk_id“ mit dem Wert von „id“ überein. Interessant, nicht wahr? Warum ist das so? Der in fk_id gespeicherte Wert gibt an, welchen Wert wir nachschlagen sollen. Wenn wir uns noch einmal das Diagramm in Abbildung 12 ansehen, stellen wir fest, dass „id“ zur Tabelle „tb_Symbols“ gehört, während „fk_id“ zur Tabelle „tb_Quotes“ gehört.
Nun müssen wir einen sogenannten Alias verwenden. Mit anderen Worten: Wir weisen den Tabellen Aliasnamen zu, damit wir eine Tabelle mit einer anderen verknüpfen können. Dadurch wird SQL mitgeteilt, wie die Ergebnismenge korrekt zusammengestellt werden soll. Vermeiden Sie bei der Verwendung von Aliasen reservierte Wörter. Manche Implementierungen unterstützen dies zwar, doch generell sollten reservierte Wörter im SQL-Code nicht als Aliase verwendet werden, um Verwirrung bei anderen SQL-Programmierern zu vermeiden. Der neue Code ist unten abgebildet:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * 32. FROM tb_Quotes AS tq, tb_Symbols AS ts 33. WHERE tq.fk_id = ts.id;
Code 03
Wenn dieser Code ausgeführt wird, erhalten wir das in der folgenden Abbildung gezeigte Ergebnis:
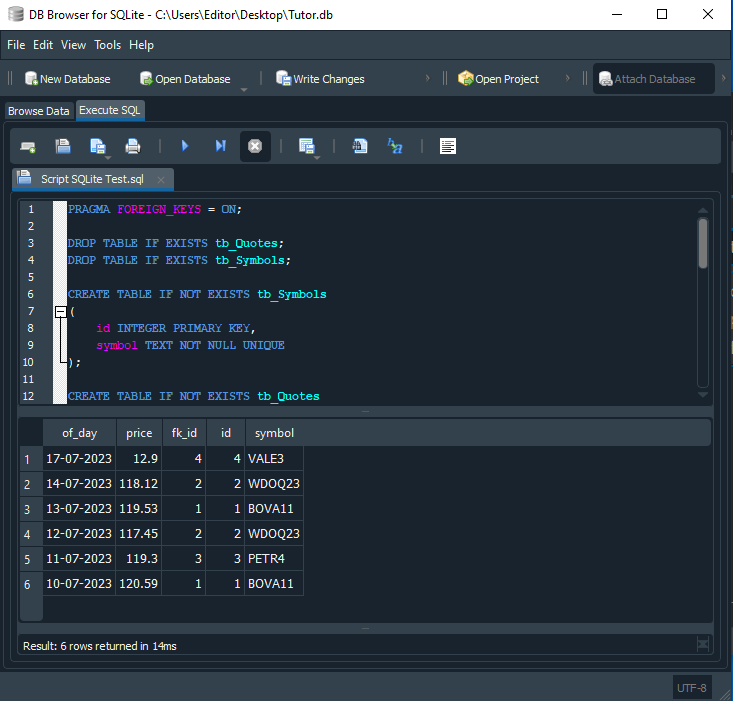
Abbildung 14
Wie durch Zauberei erhalten wir nun genau das, was wir erwartet haben: sechs Kursdatensätze, die das Symbol, das Datum und den Kurs des Wertpapiers enthalten. Schauen wir uns nun an, warum das so ist. In Zeile 32 des Skripts fügen wir hinter jedem Tabellennamen einen Alias ein.
Zeile 33 teilt SQL mit, wie die beiden Tabellen miteinander verknüpft werden sollen, und liefert das richtige Ergebnis. Hier definiert die WHERE-Klausel die Kriterien, nach denen die Ergebnismenge gefiltert wird. In diesem Fall sollte die Zeile in die Ausgabe aufgenommen werden, sobald der Wert von „fk_id“ in der Tabelle „tb_Quotes“ mit dem Wert von „id“ in der Tabelle „tb_Symbols“ übereinstimmt. Der SELECT-Befehl kann daher die zuvor gezeigten Kombinationen berücksichtigen, doch dank des WHERE-Filters gibt SQL nur die Zeilen zurück, die wir tatsächlich angefordert haben.
Eine kleine Präzisierung zur obigen Erklärung: Streng genommen durchläuft SQL nicht unbedingt physisch jede mögliche Zeilenkombination. Die Datenbank wählt einen effizienteren Ausführungsplan für die Abfrage aus. Würde man dies ohne weitere Überlegungen tun, würde dies sehr schnell zu einer Verschlechterung der Gesamtleistung des Systems führen. In der Praxis beginnt SQL bei einer der Tabellen und sucht dann die erforderlichen Felder in der anderen Tabelle, um die Vergleiche und Abgleiche durchzuführen. Dadurch wird die Abfrage wesentlich effizienter.
Wir können die Ergebnisse der SQL-Abfrage noch weiter verbessern. Spaltennamen sehen oft etwas seltsam aus, und manchmal, wie Sie in Abbildung 14 gesehen haben, gibt SQL Spalten zurück, die wir nicht benötigen. Wie können wir diese überflüssigen Informationen entfernen? Es ist ganz einfach: Man teilt SQL mit, welche Spalten man haben möchte und wie sie heißen sollen. Damit kommen wir zu dem unten gezeigten Skript:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Quote Date', 32. tq.price AS 'Current Price', 33. ts.symbol AS 'Asset Name' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id;
Code 04
Das Ergebnis ist unten dargestellt:
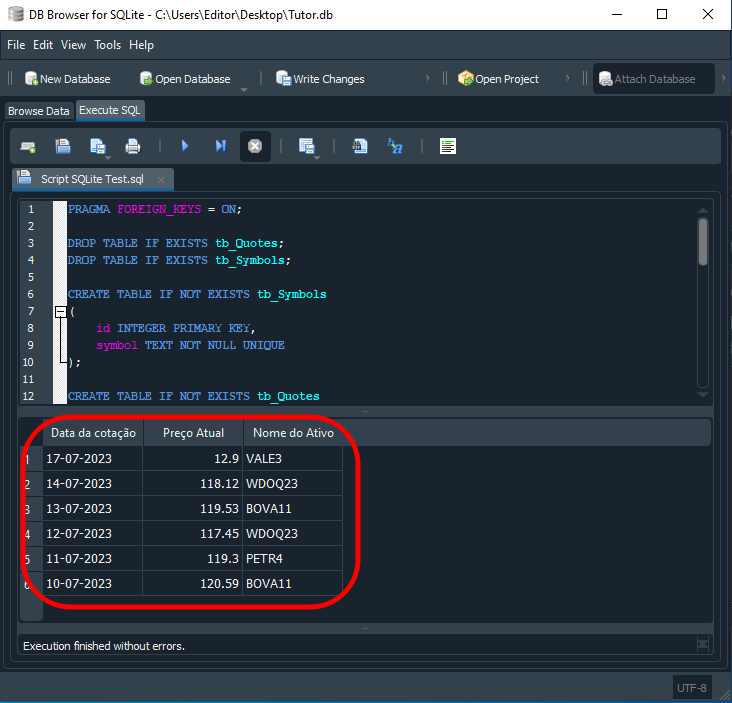
Bild 15
„Wow! SQL ist also nicht ganz das, was ich mir vorgestellt habe. Ich dachte immer, es handele sich nur um eine Reihe bedeutungsloser Anweisungen, aber jetzt sehe ich, dass es tatsächlich sehr interessant sein kann.“ Und das ist erst der Anfang. Viele glauben, dass zur weiteren Verarbeitung der zurückgegebenen Daten externe Programme erforderlich sind, doch dies lässt sich direkt in SQL erledigen. Nehmen wir zum Beispiel an, wir möchten, dass die Daten so sortiert werden, dass die höchsten Preise zuerst und die niedrigsten Preise zuletzt kommen. Dazu können wir folgenden Code verwenden:
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Quote Date', 32. tq.price AS 'Current Price', 33. ts.symbol AS 'Asset Name' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id 36. ORDER BY price DESC;
Code 05
Das Ergebnis der Ausführung von Code 05 in SQL ist unten dargestellt:
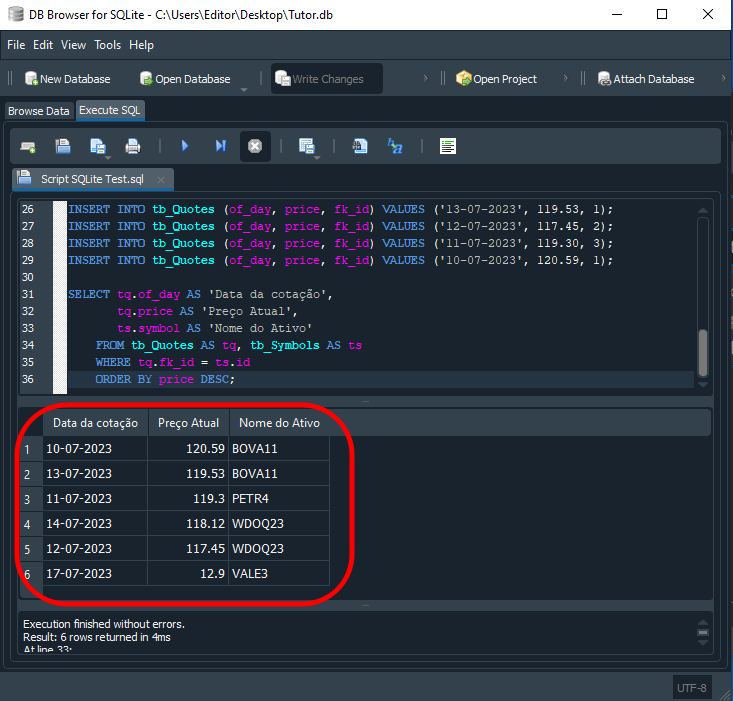
Bild 16
Seien Sie vorsichtig beim Arbeiten mit Datensätzen
In dem Artikel „Marktsimulation (Teil 19): Erste Schritte mit SQL (II)“ haben wir erläutert, wie Datensätze mithilfe der Befehle UPDATE und DELETE geändert oder gelöscht werden können. Das funktioniert zwar, ist aber nicht die beste Vorgehensweise beim Umgang mit einer relationalen Datenbank, da dieser Ansatz fehleranfällig ist, wenn mehrere Tabellen miteinander verknüpft sind. Um das Problem zu verstehen, kehren wir zu Code 05 zurück und machen etwas ganz Einfaches. Bis Zeile 29 erstellen wir die Datenbank und fügen Daten ein. Ob die Daten korrekt sind, spielt hier keine Rolle; wir wollen lediglich die Datenbank anlegen. Wenn wir die SELECT-Abfrage in Zeile 31 ausführen, erhalten wir das unten gezeigte Ergebnis:
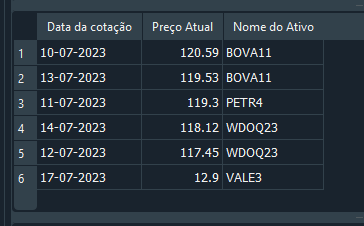
Bild 17
An dieser Stelle stellen wir fest, dass ein Datensatz falsche Angaben enthält. Anstatt die gesamte Datenbank neu zu erstellen oder den Datensatz zu löschen, entscheiden wir uns dafür, den Wert mit dem UPDATE-Befehl zu korrigieren. Dies geschieht wie folgt:
1. UPDATE tb_Quotes SET price = 29.58 WHERE fk_id = 3; 2. 3. SELECT tq.of_day AS 'Quote Date', 4. tq.price AS 'Current Price', 5. ts.symbol AS 'Asset Name' 6. FROM tb_Quotes AS tq, tb_Symbols AS ts 7. WHERE tq.fk_id = ts.id 8. ORDER BY price DESC;
Code 06
Und wir erhalten das unten gezeigte Ergebnis:
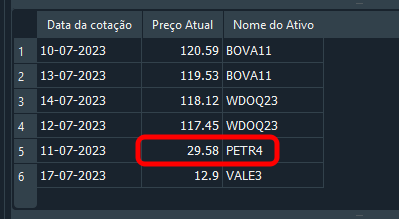
Bild 18
Gut. Der Datensatz wurde aktualisiert, und vielleicht freuen Sie sich darüber und denken, dass Sie bereits wissen, wie man mit SQL umgeht. Wenn man sich jedoch Code 05 ansieht, wo wir Daten in die Datenbank einfügen, sieht man, dass es nur einen Datensatz für PETR4 gibt. In diesem Fall können die Daten problemlos geändert oder sogar gelöscht werden. Denken wir mal kurz darüber nach. Was wäre, wenn wir statt PETR4 den Datensatz für WDOQ23 ändern müssten? Wie würden wir das tun? Man könnte sofort sagen: „Es ist ganz einfach; ich würde den folgenden Befehl verwenden“:
01. UPDATE tb_Quotes 02. SET price = 119 03. WHERE fk_id = 2 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Quote Date', 07. tq.price AS 'Current Price', 08. ts.symbol AS 'Asset Name' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
Code 07
Sie haben wieder einmal Recht: Das Ergebnis ist unten zu sehen. Das hat funktioniert, weil wir die Zeilen sowohl nach „fk_id“ als auch nach „of_day“ gefiltert haben.
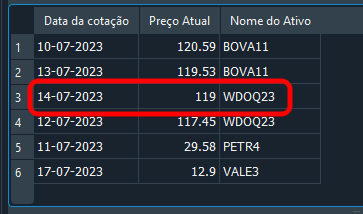
Bild 19
Einen Datensatz in einer relationalen Datenbank aktualisieren
Eine gute, wenn auch nicht die einzige Möglichkeit, eine relationale Datenbank zu bearbeiten, besteht darin, genau zu verstehen, was jeder SQL-Befehl bewirkt. Anders ausgedrückt: Wenn man SQL-Befehle nicht versteht, könnte man zu dem Schluss kommen, dass SQL äußerst begrenzt ist. Aber sobald man es verstanden hat, kann man eine Menge erreichen. Und mit „sehr viel“ meine ich wirklich sehr viel. Ich habe schon erlebt, dass Leute externen Code geschrieben haben, um Aufgaben zu lösen, die direkt in SQL hätten erledigt werden können. Meistens tun sie das, weil sie nicht ganz verstehen, wie SQL funktioniert. Schauen wir uns vor diesem Hintergrund an, wie man dieselbe Änderung wie im vorigen Abschnitt vornimmt, dieses Mal jedoch ohne den Wert für „fk_id“ manuell einzugeben.
Vielleicht denken Sie jetzt: „Also, werden wir eine nicht-relationale Tabellenstruktur verwenden?“ Nein, lieber Leser. Wir werden das relationale Modell beibehalten. Um dasselbe Ziel wie im vorigen Abschnitt zu erreichen, werden wir Code 07 wie folgt anpassen.
01. UPDATE tb_Quotes 02. SET price = 4985.5 03. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Quote Date', 07. tq.price AS 'Current Price', 08. ts.symbol AS 'Asset Name' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
Code 08
„Mann, was für ein Wahnsinn ist das denn? Sind Sie sicher, dass das klappt? Ich habe noch nie jemanden gesehen, der so etwas Verrücktes gemacht hat.“ Ihre Skepsis ist verständlich, lieber Leser. Aber sehen Sie sich das Ergebnis unten an:
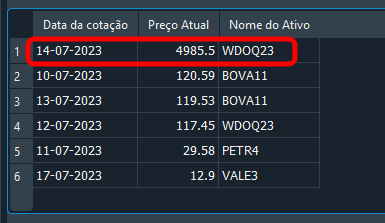
Bild 20
Beachten Sie, dass wir bewusst einen etwas anderen Wert verwendet haben, um zu zeigen, dass es funktioniert. Die Frage lautet also: Wie funktioniert der obige Code? Wir geben zu keinem Zeitpunkt die fk_id oder die zu verwendende Kennung an. Dennoch wird der richtige Datensatz geändert. Wir geben den Symbolnamen und das entsprechende Datum an. Das ist wichtig: Auch wenn jeder Datensatz ein eigenes Datum hat, sollten wir realistischer denken. Am selben Tag kann die Datenbank unterschiedliche Symbole mit unterschiedlichen Kursen enthalten. Daher erhöht die Filterung sowohl nach Datum als auch nach Symbol die Genauigkeit der Abfrage erheblich und liefert genau den gewünschten Datensatz.
Vielleicht ist es Ihnen gar nicht aufgefallen, aber wir haben gerade erklärt, wie der obige Code funktioniert. Wenn Sie die Idee nicht verstanden oder nicht ganz erfasst haben, lassen Sie sich davon nicht entmutigen. Das ist anfangs schwer zu verstehen. Schauen wir uns einmal genauer an, was in Code 08 geschieht. Beachten Sie, dass der UPDATE-Befehl auf mehrere Zeilen verteilt ist. Wir haben das bewusst so gemacht, damit wir erklären können, was gerade passiert.
In Zeile 01 geben wir an, dass wir einen Datensatz in der Tabelle „tb_Quotes“ aktualisieren möchten. Hätten wir statt UPDATE die Anweisung DELETE verwendet, wäre der Datensatz aus der Tabelle gelöscht worden. Daher gilt diese Erklärung auch für das Löschen von Datensätzen. In Zeile 02 legen wir fest, welche Spalte aktualisiert wird und welchen Wert sie nach der Aktualisierung enthalten soll. Ich denke, die Argumentation ist bis hierhin klar. In Zeile 03 definieren wir mithilfe des Schlüsselworts WHERE die Filterkriterien, damit SQL weiß, wie der gewünschte Datensatz gefunden werden kann. Pass jetzt gut auf, denn genau hier geraten viele Anfänger ins Straucheln.
Jeder dieser Befehle verhält sich gewissermaßen wie eine Funktion: Er gibt Werte zurück. Der Rückgabewert kann ein einzelner Wert sein oder ein zusammengesetztes Ergebnis, das mehrere Werte oder Felder enthält. Daher kann ein SELECT-Befehl, wie hier, nur einen Wert zurückgeben. Sie kann auch mehrere Werte in einer tabellenartigen Struktur zurückgeben, genau wie bei der Ausführung des SELECT-Befehls in Zeile 06.
Wenn die Filterkriterien spezifisch genug sind und auf die richtige Tabelle angewendet werden, gibt der SELECT-Befehl einen eindeutigen Wert zurück, was bedeutet, dass das Ergebnis fast wie eine Variable behandelt werden kann. „Aber warte mal kurz. In SQLite kann man keine Variablen verwenden, oder?“ Na ja, mehr oder weniger. Wenn wir wissen, wie man mit SQL arbeitet – und nicht nur mit SQLite –, können wir Werte im SQL-Code praktisch wie Variablen verwenden. Dieser Punkt wird später noch deutlicher werden, da wir bei der Verwendung verwandter Tabellen zusätzliche Maßnahmen ergreifen müssen, um die Konsistenz der Datenbank zu gewährleisten.
Um auf die Erläuterung zurückzukommen: Beachten Sie, dass wir in Zeile 03 den Symbolnamen angeben, in diesem Fall WDOQ23. Dadurch sucht SQL in „tb_Symbols“, der im SELECT-Befehl angegebenen Tabelle. Wonach sucht es? Der Wert ts.id. Mit anderen Worten: Sobald die Abfrage ausgeführt wurde, gibt SELECT den ID-Wert der Zeile zurück, deren Symbolname WDOQ23 lautet. SQL verwendet dann den in einer Tabelle gefundenen Wert, um zu bestimmen, welcher Datensatz in einer anderen Tabelle aktualisiert werden soll. Ist das alles? Ja, lieber Leser, genau das tun wir hier. Und die Wahrscheinlichkeit, einen Fehler zu machen, ist viel geringer.
Aber nicht alles ist perfekt. Möglicherweise geben wir den Namen eines Symbols an, dessen Bezeichner nicht gefunden werden kann. Auch wenn dies ungewöhnlich erscheinen mag, sind solche Situationen in der Praxis durchaus üblich. Folglich wird Code 08 diese Situation nicht ordnungsgemäß bewältigen. Um es deutlicher zu sagen: Wir können versuchen, etwas zu tun, und SQL teilt uns nicht unbedingt mit, dass ein Fehler aufgetreten ist oder der Befehl anders interpretiert wurde, als wir es beabsichtigt hatten. Wir können einfach davon ausgehen, dass alles funktioniert hat, da die einzige Ausgabe, die wir sehen, das Ergebnis des SELECT-Befehls in Zeile 06 ist.
Zum jetzigen Zeitpunkt ist vielleicht noch nicht ganz klar, warum das ein Problem ist. Wenn die Implementierung keine Fehler meldet, könnten wir der Illusion erliegen, dass alles in Ordnung ist. Später, wenn wir versuchen, die Daten zu finden oder zu verwenden, von denen wir dachten, dass sie vorhanden seien, erleben wir möglicherweise eine unangenehme Überraschung: Die Informationen befinden sich nicht im erwarteten Zustand. Oftmals stehen die für die Diagnose und Behebung des Problems erforderlichen Informationen dann nicht mehr zur Verfügung.
Prüfen, ob ein Datensatz aktualisiert wurde
SQLite bietet eine relativ einfache Möglichkeit, um zu überprüfen, ob der Datensatzwert, den wir aktualisieren wollten, tatsächlich aktualisiert wurde. Dazu benötigen wir ein kleines Stück Code. Bevor wir jedoch zum Code übergehen, sollten wir uns über etwas Gedanken machen. Man hört oft, dass man nach dem Aktualisieren oder sogar Hinzufügen eines Datensatzes zu einer Datenbank eine SELECT-Anweisung ausführen sollte, um zu überprüfen, ob alles erfolgreich war. Dieser Ansatz hat jedoch einen kleinen Haken. Wenn wir mit einer kleinen Datenbank arbeiten oder mit einer, an der nur wenige Änderungen vorgenommen wurden, ist es durchaus sinnvoll, mit einem SELECT-Befehl zu überprüfen, ob die Aktualisierung tatsächlich erfolgt ist. Insbesondere bei gemeinsam genutzten Datenbanken ist es jedoch nicht immer einfach, mehrere aktualisierte Datensätze mit SELECT zu überprüfen.
Glücklicherweise laufen gemeinsam genutzte Datenbanken in der Regel auf Servern, sodass SQLite normalerweise nicht unter diese Kategorie fällt. Dennoch kann es vorkommen, dass in einer SQLite-Datenbank Hunderte oder sogar Tausende Datensätze aktualisiert werden müssen. Stellen Sie sich nur einmal vor, wie viel Arbeit es wäre, jeden einzelnen Eintrag mit SELECT zu überprüfen, um sicherzustellen, dass die Datenbank korrekt aktualisiert wurde. Deshalb brauchen wir einen etwas anderen Ansatz. Das individuelle Überprüfen jedes aktualisierten Datensatzes ist nur dann sinnvoll, wenn nur geringfügige Änderungen an der Datenbank vorgenommen werden.
Da jedoch die Arbeitslast und die Anzahl der Vorgänge zunehmen, benötigen wir einen anderen Ansatz. Neben der gleich vorgestellten Methode gibt es noch eine weitere, fast gleichwertige Methode, auf die wir jedoch später eingehen werden. Konzentrieren wir uns zunächst auf die erste Aufgabe: Wie können wir mithilfe von SQLite herausfinden, ob die angeforderten Datensatzaktualisierungen ausgeführt wurden?
Es gibt eine recht einfache Lösung. Verwenden Sie es jedoch mit Bedacht, um Probleme durch eine falsche Anwendung zu vermeiden. Der Beispielcode ist unten aufgeführt:
1. UPDATE tb_Quotes 2. SET price = 4987.5 3. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 4. AND of_day = '14-07-2023'; 5. 6. SELECT changes() 'Updated Records';
Code 09
Wenn dieser Code ausgeführt wird, erhalten wir folgendes Ergebnis:
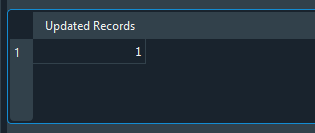
Bild 21
Beachten Sie, dass das Ergebnis der Wert Eins ist. Warum? Weil die UPDATE-Anweisung eine Aktualisierung bzw. eine Änderung in der Datenbank vorgenommen hat. Wenn wir Hunderte oder sogar Tausende Aktualisierungen durchführen würden, entspräche der angezeigte Wert der Anzahl der Zeilen, die durch die UPDATE-Anweisung geändert wurden. Bedenken Sie jedoch Folgendes: Würde derselbe Code wie in der Abbildung unten gezeigt geändert, wäre das Ergebnis ein anderes, wie Sie auf demselben Bild sehen können:
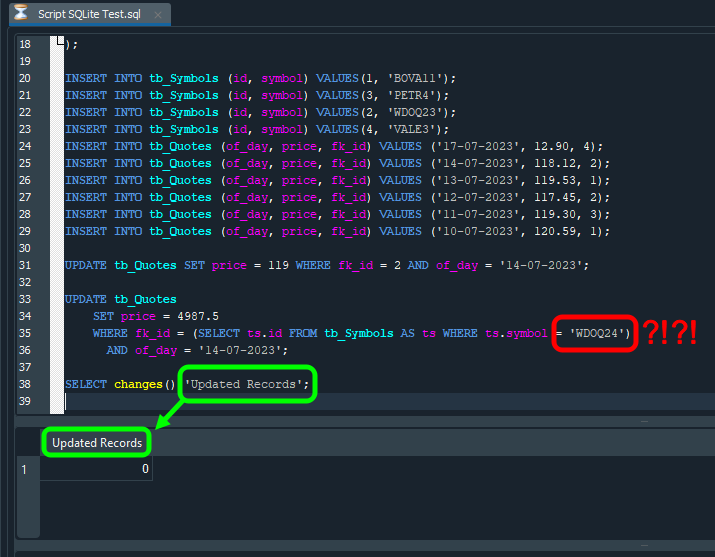
Bild 22
In dieser Abbildung sind die Änderungen gegenüber der vorherigen Version rot markiert. Beachten Sie, dass lediglich der Symbolname geändert wurde. Da kein solches Symbol existiert, kann der SELECT-Befehl nicht feststellen, welcher Bezeichner verwendet werden soll. Daher werden durch den UPDATE-Befehl keine Zeilen geändert. Wenn wir dann mit SELECT überprüfen, wie viele Zeilen geändert wurden, wird ein Wert zurückgegeben, der von unseren Erwartungen abweicht. In diesem Fall ist der Wert null: Wir hatten erwartet, dass ein UPDATE-Befehl ausgeführt wird, doch da wir einen Symbolnamen angegeben haben, der in der Tabelle nicht existiert, wurde die UPDATE-Anweisung zwar ausgeführt, betraf jedoch keine Zeilen.
Auf dem Bild oben ist noch ein weiteres Detail zu sehen, das grün markiert ist. Die von SQL zurückgegebene Spaltenüberschrift entspricht genau den im SELECT-Befehl angegebenen Informationen. Wenn wir das nicht wissen, könnten wir versucht sein, etwas Komplizierteres zu tun. Aber wie Sie sehen, lassen sich manche Dinge ganz einfach in den Griff bekommen.
Wie bereits erwähnt, dient der von uns verwendete Befehl jedoch lediglich dazu, zu überprüfen, wie viele Zeilen durch die letzte UPDATE-Anweisung geändert wurden. Da SQLite es uns ermöglicht, lokale, benutzerverwaltete Datenbanken zu erstellen, können wir das Problem auch auf ganz andere Weise angehen.
Für alle, die es noch nicht wussten: SQLite kann direkt aus dem GitHub-Repository heruntergeladen werden, und der Quellcode lässt sich so anpassen, dass es sich etwas anders verhält als die Standardversion. Da es in dieser Artikelserie nicht darum geht, zu zeigen, wie das funktioniert, werden wir dies lediglich erwähnen. Je nach verwendeter SQLite-Implementierung können Fehler bei Aktualisierungen oder Einfügungen ganz anders behandelt werden als in der hier gezeigten Methode. Mit anderen Worten: Um den besten Ansatz zu finden, sollten Sie die Dokumentation der von Ihnen geplanten Implementierung lesen.
Bevor wir zum nächsten Thema übergehen, wollen wir uns die Methode, mit der wir eine Datenbankaktualisierung überprüft haben, genauer ansehen. In diesem Fall zeigt SELECT changes() nur das Ergebnis des letzten UPDATE-Befehls an. Nehmen wir an, wir verwenden das unten gezeigte Codefragment:
1. UPDATE tb_Quotes SET price = 119 WHERE fk_id = 2 AND of_day = '14-07-2023'; 2. 3. UPDATE tb_Quotes SET price = 4987.5 WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ24') AND of_day = '14-07-2023'; 4. 5. SELECT changes() 'Updated Records';
Code 10
Beachten Sie, dass wir nun zwei UPDATE-Befehle ausführen. Natürlich könnte man ein kumulatives Ergebnis oder zumindest einen repräsentativen Wert erwarten, da beide Befehle im selben Skript enthalten sind. Aber so funktioniert das nicht. Wenn wir Zeile 03 genau betrachten, stellen wir fest, dass sie mit dem in Abbildung 22 gezeigten Code übereinstimmt. Der einzige neue Teil in Code 10 ist Zeile 01. Auch wenn die UPDATE-Anweisung in Zeile 03 zwar ausgeführt wird, aber keine Zeilen betrifft – was sicherlich der Fall sein wird –, ist bei der Ausführung von Zeile 05 dennoch mit einem Wert ungleich Null zu rechnen. Wenn wir den Code jedoch ausführen, gibt SQL den Wert Null zurück. Was ist schiefgelaufen? Wiesen beide Zeilen, 01 und 03, Fehler auf? In Zeile 01 wurde eine Tabellenzeile geändert, während die UPDATE-Anweisung in Zeile 03 zwar ausgeführt wurde, jedoch keine Tabellenzeile betraf.
Warum? Denn bevor wir das Ergebnis von Zeile 01 überprüft haben, haben wir in Zeile 03 eine weitere Anfrage an SQL gesendet. Wenn wir also SQL fragen, was passiert ist, gibt es nur das Ergebnis der letzten UPDATE-Anweisung aus, nämlich dass Zeile 03 ausgeführt wurde, aber keine Zeilen betraf. Manche Menschen verbringen viel Zeit damit, herauszufinden, warum ein Skript wie erwartet funktioniert oder nicht. Letztendlich liegt das Problem meist darin, dass wir Vermutungen anstellen. In der Programmierung führen Annahmen selten zu guten Ergebnissen: Sie bedeuten, dass wir davon ausgehen, dass etwas passiert, anstatt zu überprüfen, ob es tatsächlich passiert ist. Verlassen Sie sich also niemals auf Vermutungen. Vergewissern Sie sich erst, dass alles funktioniert, bevor Sie alles um sich herum dafür verantwortlich machst.
Abschließende Überlegungen
So oder so gibt es noch einen weiteren Punkt, den wir bei der Verwendung miteinander verbundener Datenbanken oder Tabellen berücksichtigen müssen – wie beispielsweise in unserem System, in dem eine Tabelle Symbolnamen und eine andere Kursdaten speichert. Ein solches Schema könnte wesentlich komplexer sein und mehrere Beziehungen zwischen verschiedenen, eng miteinander verbundenen Tabellen umfassen. All dies wird über Primär- und Fremdschlüssel geregelt.
Um das Ausmaß des Problems oder die Komplexität der vor uns liegenden Aufgabe zu verstehen, stellen Sie sich folgendes Szenario vor: Irgendwann in der Zukunft beschließen wir, ein bestimmtes Symbol nicht mehr zu verwenden, da es sich nicht mehr lohnt, es zu speichern oder zu überwachen. Eine solche Entscheidung könnte früher oder später getroffen werden. Das Hauptproblem – und genau hier beginnt die Schwierigkeit – ist folgendes: Wie löschen wir die Datensätze des Symbols aus der Datenbank? Viele werden sagen, dass die Lösung ganz einfach ist: Man erstellt eine Schleife oder führt eine SQL-Abfrage aus, die die Datensätze für uns löscht. Ja, das wäre in etwa der Gedanke, wenn wir mit einer Datenbank arbeiten würden, die aus einer einzigen riesigen Tabelle mit Datensätzen besteht – was meiner Meinung nach völliger Wahnsinn ist. Aber das ist in Ordnung; jeder weiß – oder sollte wissen –, was er tut.
Eine SQL-Abfrage zu schreiben, um alle Datensätze für ein bestimmtes Symbol zu löschen, wäre ganz einfach. Man bräuchte lediglich einen DELETE-Befehl, und dieser Befehl würde dem UPDATE-Befehl fast identisch aussehen. Das ist nur ein kleines Detail, daher werden wir hier nicht weiter darauf eingehen. Was aber, wenn die Datenbank nicht nur eine Tabelle, sondern mehrere miteinander verknüpfte Tabellen verwendet? Wie löscht man alle Datensätze, die sich auf ein bestimmtes Symbol beziehen? Jetzt wird es ein bisschen komplizierter, nicht wahr?
Denken Sie nun einmal über das Schema nach, das wir verwenden. Wenn Sie einen Symbolnamen aus „tb_Symbols“ löschen, wirkt sich dies zwangsläufig auf das Ergebnis aus, das bei einer Abfrage der Datenbank mit dem unten gezeigten Befehl zurückgegeben wird.
SELECT tq.of_day AS 'Quote Date', tq.price AS 'Current Price', ts.symbol AS 'Asset Name' FROM tb_Quotes AS tq, tb_Symbols AS ts WHERE tq.fk_id = ts.id ORDER BY price DESC;
Code 11
| Datei | Beschreibung |
|---|---|
| Experts\Expert Advisor.mq5 | Veranschaulicht die Interaktion zwischen Chart Trade und dem Expert Advisor. Für die Interaktion ist eine Mausstudie erforderlich. |
| Indicators\Chart Trade.mq5 | Erstellt ein Fenster zur Konfiguration der zu sendenden Order. Für die Interaktion ist eine Mausstudie erforderlich. |
| Indicators\Market Replay.mq5 | Erstellt Steuerelemente für die Interaktion mit dem Wiedergabe-/Simulationsdienst. Für die Interaktion ist eine Mausstudie erforderlich. |
| Indicators\Mouse Study.mq5 | Ermöglicht die Interaktion zwischen grafischen Steuerelementen und dem Benutzer. Dies ist sowohl für das Wiedergabe-/Simulationssystem als auch für den Live-Marktbetrieb erforderlich. |
| Services\Market Replay.mq5 | Erstellt und pflegt den Markt-Replay-/Simulationsdienst, die zentrale Datei des gesamten Systems. |
| Code VS C++\Servidor.cpp | Erstellt und verwaltet einen in C++ geschriebenen Server-Socket für die Mini-Chat-Version. |
| Code in Python\Server.py | Erstellt und verwaltet einen Python-Socket, der für die Kommunikation zwischen MetaTrader 5 und Excel verwendet wird. |
| Indicators\Mini Chat.mq5 | Ermöglicht die Implementierung eines Mini-Chats über eine Schaltfläche. Für den Betrieb ist ein Server erforderlich. |
| Experts\Mini Chat.mq5 | Ermöglicht die Implementierung eines Mini-Chats mithilfe eines Expert Advisors. Für den Betrieb ist ein Server erforderlich. |
| Scripts\SQLite.mq5 | Zeigt, wie man ein SQL-Skript mit MQL5 verwendet. |
| Files\Script 01.sql | Zeigt, wie man eine einfache Tabelle mit einem Fremdschlüssel erstellt. |
| Files\Script 02.sql | Zeigt, wie man Werte in eine Tabelle einträgt. |
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/12987
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.