
Redes neuronales en el trading: Segmentación periódica adaptativa (Final)

Introducción
En artículos anteriores, analizamos paso a paso cómo el framework LightGTS convierte series temporales en partituras musicales. En primer lugar, en el módulo Period Patching, los datos analizados se dividen automáticamente en ciclos completos definidos por FFT. Cada uno de estos ciclos se proyecta luego en un token usando una Flex Projection Layer, que permite un manejo flexible de fragmentos de diferentes longitudes. En el Codificador, estos tokens se enriquecen con Rotary Positional Encoding (RoPE), una forma compacta de incorporar cambios de fase y posiciones relativas, tras lo cual los bloques del Transformer clásicos con atención multi-cabeza fusionan patrones locales en un contexto unificado. La previsión se genera utilizando Periodical Parallel Decoding, que crea instantáneamente toda la secuencia de salida sin autorregresión. El resultado se ajusta en el módulo Flex-resize, que mantiene la consistencia periódica.

Llegados a este punto, hemos implementado con éxito las ideas clave de LightGTS en código: hemos aprendido a dividir automáticamente una serie temporal en fragmentos periódicos mediante parcheo adaptativo y a convertir cada fragmento en un token informativo. Asimismo, hemos añadido nuestros propios toques a los algoritmos originales, hemos perfeccionado la lógica de proyección flexible y también obtenido representaciones ya listas de los ciclos locales del mercado. Hoy daremos un paso más en la construcción de nuestra propia visión de los enfoques propuestos por los autores del framework LightGTS.
El mecanismo RoPE
Una vez que la convolución adaptativa ha extraído un conjunto concentrado de tokens informativos de la serie temporal original, es hora de pasarlos por el potente filtro de bloques del Transformer. En una arquitectura convencional Encoder–Decoder, a estos tokens simplemente se les añaden vectores de codificación posicional sinusoidales o entrenables, tras lo cual se introducen en el mecanismo de atención. Los autores del framework LightGTS proponen utilizar un método mucho más elegante y flexible: el Rotary Positional Encoding (RoPE). En lugar de vectores de codificación de posición fija, cada token rota en el espacio de incorporación.
La idea principal de RoPE consiste en introducir un desplazamiento de fase vectorial proporcional a la posición del token y sus dimensionalidades, sin recurrir a parámetros adicionales. Cabe decir que esta técnica fue presentada por primera vez en el artículo "RoFormer: Enhanced Transformer with Rotary Position Embedding", donde los autores demostraron que rotar los pares de coordenadas de las entidades Query y Key utilizando una matriz de rotación permite que el modelo capture de manera confiable los cambios relativos a lo largo del tiempo.
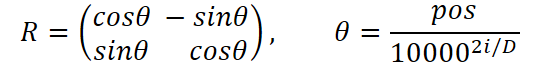
El método se puede generalizar fácilmente a espacios multidimensionales dividiendo la dimensionalidad en pares de valores. Y aquí surge una limitación: la dimensionalidad del espacio debe ser par.

Gracias a esta rotación, incluso con tamaños de ventana variables y un paso dinámico, el modelo comprende con precisión qué tokens se encuentran más cerca en el tiempo y cuáles están más lejos. Como resultado, el mecanismo de Self‑Attention se convierte en un detector altamente sensible de patrones temporales: no solo compara el contenido de Query y Key, sino que también tiene en cuenta las diferencias de fase entre los tokens. Como resultado, tras varias capas de atención multi-cabeza y Feed‑Forward, los tokens emergen profundamente contextualizados.
Ahora que nos hemos adentrado en los fundamentos matemáticos y conceptuales del Rotary Positional Encoding, es hora de pasar a la implementación y ver cómo traducir todo esto a código de programa OpenCL. Ya disponemos de tokens predefinidos: un array de vectores, cada uno de los cuales tiene D dimensiones. Además, prepararemos con antelación tablas de senos y cosenos para cada posición. Nuestra tarea consiste en rotar cada vector en el espacio de incorporación de manera que la fase refleje la marca temporal, sin perder la velocidad general del proceso. Para lograrlo, creamos un kernel RoPE que opera en un espacio de tareas tridimensional. La primera dimensión es responsable del índice del par de coordenadas dentro del vector. Su dimensionalidad es igual a la mitad de la longitud del vector. La segunda dimensión indica la longitud de la secuencia (número de tokens). Y la tercera es el número de secuencias unitarias.
Tenga en cuenta que, para facilitar el trabajo con pares de valores, usamos el tipo de representación de datos vectoriales float2.
__kernel void RoPE(__global const float2* __attribute__((aligned(8))) inputs, __global const float2* __attribute__((aligned(8))) position_emb, __global float2* __attribute__((aligned(8))) outputs ) { const size_t id_d = get_global_id(0); // dimension const size_t id_u = get_global_id(1); // unit const size_t id_v = get_global_id(2); // variable const size_t dimension = get_global_size(0); const size_t units = get_global_size(1); const size_t variables = get_global_size(2);
En el cuerpo del kernel, primero identificamos las coordenadas del flujo actual de operaciones en el espacio de tareas tridimensional. Esto es necesario para que cada flujo sepa exactamente con qué dato va a trabajar: qué par de coordenadas vectoriales procesar, a qué token se refiere y de qué variable (o canal) proviene.
Una vez que se conocen las coordenadas de flujo, el siguiente paso es calcular los desplazamientos en los búferes lineales de OpenCL. A pesar de la estructura multidimensional de la lógica, todos los datos en OpenCL se almacenan de forma lineal, por lo que es necesario calcular manualmente la ubicación exacta en la memoria del elemento de interés.
const int shift_in = (id_v * units + id_u) * dimension + id_d; const int shift_pos = id_u * dimension + id_d; const float2 inp = inputs[shift_in]; const float2 pe = position_emb[shift_pos];
Para minimizar accesos costosos a la memoria global, cargamos inmediatamente el par de coordenadas original y los factores seno/coseno correspondientes en variables vectoriales locales, una especie de variables registrales del kernel. Al fin y al cabo, cada acceso a los búferes de memoria global es sustancialmente más costoso que trabajar con vectores locales. Esto nos permite eliminar casi por completo las descargas repetidas de la memoria global y mantener los datos de uso frecuente en los registros o en la memoria local de la GPU, lo que acelera significativamente todo el proceso de rotación de tokens y hace que la ejecución del kernel resulte lo más eficiente posible.
Una vez tengamos todos los ingredientes (los datos de origen y los valores sin/cos) a mano, estaremos listos para pasar a la acción principal: el cambio de fase. Es esto lo que confiere a los tokens una noción del tiempo y garantiza el correcto funcionamiento del mecanismo de atención.
float2 result = 0; result.s0 = inp.s0 * pe.s0 - inp.s1 * pe.s1; result.s1 = inp.s0 * pe.s1 + inp.s1 * pe.s0; //--- outputs[shift_in] = result; }
Aquí usamos operaciones aritméticas sencillas sobre variables locales: cuatro multiplicaciones y dos sumas por cada par de valores. Al precargar los datos, este paso se completa casi instantáneamente.
Después de esto, escribimos inmediatamente el par de coordenadas ajustadas en el búfer de resultados.
Aquí está el truco: simplemente multiplicando por los cos y sin preparados de antemano, le damos a cada token información sobre la fase y el tiempo relativo, sin agregar un solo parámetro nuevo. Como resultado, este kernel muestra:
- Un máximo paralelismo — cada flujo de operaciones funciona de forma independiente.
- Sobrecargas de entrenamiento nulas — la codificación posicional no contiene parámetros entrenables.
- Una integración perfecta con los módulos de atención posteriores: las incorporaciones tienen en cuenta no solo el contenido de los tokens, sino también sus diferencias de fase.
Aunque RoPE no introduce ningún parámetro entrenable en el modelo, para nosotros es importante que los gradientes puedan fluir correctamente a través de esta capa, volviendo a los datos de origen. Para ello, creamos un kernel especial de pasada inversa , CalcHiddenGradRoPE, que realiza la rotación inversa de los vectores.
La idea es simple: el kernel de pasada directa ha multiplicado los datos de origen (x, y) por una matriz de rotación. En la dirección opuesta, necesitamos aplicar su versión transpuesta, es decir, una rotación de −θ, donde cos(−θ)=cosθ y sin(−θ)=−sinθ.
El algoritmo del kernel de pasada inversa es casi idéntico al que hemos descrito antes para la pasada directa. Se utiliza el mismo espacio de tareas y los desplazamientos hacia los búferes de datos globales se definen de forma similar. La única pequeña diferencia radica en la rotación de los vectores. Y los datos de origen para realizar las operaciones son los gradientes de error a nivel de resultado.
__kernel void CalcHiddenGradRoPE(__global float2* __attribute__((aligned(8))) inputs_gr, __global const float2* __attribute__((aligned(8))) position_emb, __global const float2* __attribute__((aligned(8))) outputs_gr ) { const size_t id_d = get_global_id(0); // dimension const size_t id_u = get_global_id(1); // unit const size_t id_v = get_global_id(2); // variable const size_t dimension = get_global_size(0); const size_t units = get_global_size(1); const size_t variables = get_global_size(2); //--- const int shift_in = (id_v * units + id_u) * dimension + id_d; const int shift_pos = id_u * dimension + id_d; const float2 grad = outputs_gr[shift_in]; const float2 pe = position_emb[shift_pos]; //--- float2 grad_x; grad_x.s0 = grad.s0 * pe.s0 + grad.s1 * pe.s1; grad_x.s1 = grad.s1 * pe.s0 - grad.s0 * pe.s1; //--- inputs_gr[shift_in] = grad_x; }
Sin saltos condicionales ni fórmulas complejas: solo cuatro multiplicaciones y un par de sumas. Gracias a esto, los gradientes de la capa RoPE se desenroscan con la misma rapidez y economía con la que se rotaron los tokens en la pasada directa.
Como resultado, CalcHiddenGradRoPE convierte la capa RoPE en un participante de pleno derecho en el proceso de aprendizaje: podemos incluirla en cualquier nivel de la red y retornará los gradientes a los tensores de entrada sin pérdidas, manteniendo la velocidad y el paralelismo.
Ahora que nuestros kernels OpenCL para Rotary Positional Encoding están pulidos a la perfección, es hora de transferir esta potencia al mundo MQL5 y conectarla a un robot de trading. Ya disponemos de un mecanismo preparado para rotar tokens en la GPU; lo único que queda es crear una capa de abstracción ligera que se adapte a la estructura familiar de los expertos MQL5. Precisamente por eso crearemos la clase CNeuronRoPE, cuya estructura presentamos a continuación.
class CNeuronRoPE : public CNeuronPositionEncoder { protected: uint iWindow; uint iVariables; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL)override; public: CNeuronRoPE(void) : iWindow(0), iVariables(0) {}; ~CNeuronRoPE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronRoPE; } };
En la clase CNeuronRoPE, todo está organizado de la forma más sencilla posible; solo tiene dos variables: iWindow, que determina el tamaño del vector de un token, y iVariables, que especifica el número de canales. Toda la demás funcionalidad pesada relacionada con los búferes y la comprobación de parámetros se hereda de CNeuronPositionEncoder, por lo que el constructor y el destructor aquí se encuentran vacíos. La base para el funcionamiento de toda la capa se encuentra en el método Init.
bool CNeuronRoPE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(window % 2 > 0) return false; if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window * variables, optimization_type, batch)) return false;
Al inicio del método, realizamos una comprobación sencilla pero extremadamente importante: la dimensionalidad de cada token debe ser par, ya que RoPE opera con pares de coordenadas. Sin este postulado condicional, sencillamente no podremos avanzar; no podremos relacionar pares de valores de forma inequívoca. Y tras superar con éxito el punto de control, transferimos el control al método homónimo de la clase padre, en el que ya están organizados los puntos de control restantes y el algoritmo para inicializar las interfaces heredadas.
Luego guardamos los parámetros del tensor de datos original en variables internas.
iWindow = window; iVariables = variables;
Y pasamos a construir el array de incorporación clave para RoPE, un array bidimensional, en cuyas las columnas pares estará cos(θ), y en las impares, sin(θ).
Primero, creamos una matriz pe del tamaño requerido. Este será el lienzo que llenaremos inmediatamente con los valores de los senos y cosenos. Para entender cómo responderá cada columna de la matriz a su paso de la serie temporal, formamos un vector de posiciones al inicio: del vector unitario hacemos la suma de los prefijos y restamos uno, obteniendo [0, 1, 2, …, count –1]. Precisamente este vector nos indica qué paso estamos codificando actualmente.
matrix<float> pe = matrix<float>::Zeros(count, iWindow); vector<float> position = vector<float>::Ones(count); position = position.CumSum() - 1;
Ahora llega el acto principal: iterar todos los pares de dimensionalidades, ya que cada par de coordenadas de token requiere sus propios ángulos. Para cada par de estos, tomamos el vector de posición y lo dividimos por un denominador creciente igual a pow(10000, 2 * i / iWindow) para ralentizar la velocidad de rotación de las dimensionalidades superiores y acelerar las inferiores. Como resultado, en la salida obtenemos un array de ángulos: no un conjunto de números escalares, sino un vector θ para todas las posiciones.
for(uint i = 0; i < iWindow / 2; i++) { vector<float> temp = position / MathPow(10000.0f, 2.0f * i / window); pe.Col(MathCos(temp), i * 2); pe.Col(MathSin(temp), i * 2 + 1); }
Así pues, en cada columna par de la matriz pe escribimos los cosenos de los ángulos obtenidos, y en la columna impar adyacente, los senos. Como resultado, la matriz se convierte en una verdadera fábrica, donde cada columna está equipada con su propio par de valores [cos(θ), sin(θ)], listos para rotar cualquier token. Realizamos todos estos cálculos una sola vez en el código de la CPU y, a continuación, pasamos un conjunto de funciones predefinidas a los kernels de la GPU.
Luego transmitimos la matriz rellena al búfer de datos y finalizamos el método, devolviendo el resultado lógico de las operaciones al programa que realiza la llamada.
PositionEncoder.BufferFree(); if(!PositionEncoder.AssignArray(pe)) return false; SetActivationFunction(None); //--- return PositionEncoder.BufferCreate(open_cl); }
Gracias a este enfoque, nuestros núcleos OpenCL reciben como entrada una tabla de senos y cosenos ya preparada y pueden funcionar a pleno rendimiento sin distraerse con operaciones matemáticas innecesarias.
Como resultado, toda la configuración inicial se concentra en un solo método: basta con cambiar los parámetros window o variables, y la capa se adapta instantáneamente a las nuevas condiciones. Este enfoque garantiza que el código siga siendo estricto y comprensible, y que obtengamos un control total sobre el comportamiento del módulo RoPE.
Cuando llega la etapa de pasada directa, basta con llamar al método feedForward, pasándole un puntero al objeto de datos de origen que ya contiene los tokens. Internamente, el método presta atención a los detalles: comprueba la relevancia del puntero recibido, pone el kernel RoPE en la cola de ejecución con los tamaños de grupo de trabajo necesarios, espera a que finalice y devuelve el control. El resultado es un búfer de tokens rotados listos para ser pasados al módulo de atención.
Durante el proceso de entrenamiento, entra en juego el método calcInputGradients. Este método ejecuta el kernel CalcHiddenGradRoPE. La lógica en sí es casi inversa a la pasada directa: las mismas coordenadas, los mismos desplazamientos, pero la rotación se realiza en la dirección opuesta para devolver el gradiente a su representación original. El resultado final encaja perfectamente en el búfer de gradiente de entrada y fluye sin obstáculos hacia las capas anteriores del modelo.
Ambos métodos son esencialmente envoltorios de los kernels correspondientes y se construyen utilizando el algoritmo con el que usted ya estará familiarizado. Por lo tanto, no profundizaremos en su análisis en el marco de este artículo. El código completo de la clase presentada y todos sus métodos se pueden encontrar en el archivo adjunto.
Ahora que los tokens han pasado por el filtro de fase RoPE, están listos para entrar en el núcleo del modelo: el módulo de atención. El framework LightGTS basa su lógica por defecto en el esquema clásico Codificador-Decodificador, por lo que no tenemos que reinventar la rueda: todos los componentes necesarios ya están en nuestra biblioteca. Basta con pasar los tokens rotados a uno de los módulos de Self‑Attention existentes, donde la atención multi-cabeza funcionará a la perfección, vinculando los patrones locales con el contexto global de la serie temporal.
En la versión original de LightGTS los autores proponen tomar el último token oculto después del Codificador y multiplicarlo exactamente tantas veces como sea necesario para cubrir el horizonte de planificación dado, de modo que el Decodificador pueda generar inmediatamente toda la secuencia de salida. Hemos dado un paso audaz hacia la simplificación: la replicación no es necesaria. En primer lugar, nuestra tarea no consiste en obtener cifras ultraprecisas, sino en extraer de la representación latente toda la información valiosa para el Agente, que tomará las decisiones comerciales. En segundo lugar, realizamos cálculos en cada nueva barra, que siempre es más corta que el ciclo completo del mercado. Y esto significa que un último token para cada secuencia unitaria es suficiente para nosotros.
Así pues, evitando las copias múltiples, enviamos esta última incorporación por la tubería principal hasta el Decodificador. Allí se encuentra con la misma atención multicabeza y la misma Feed‑Forward, pero sin repeticiones innecesarias: el modelo se basa en una presentación clara y concisa que contiene toda la información relevante sobre los últimos movimientos del mercado. Este enfoque ahorra recursos, simplifica la lógica y permite que el Agente actúe lo más rápido posible; al fin y al cabo, cada barra requiere una respuesta inmediata, y no necesitamos mil copias del token, sino una única señal potente lista para generar beneficios.
Arquitectura de los modelos
Finalmente, llegamos a la culminación: el momento en que todos los módulos cuidadosamente ajustados se unen para formar un sistema único que funciona a la perfección. En nuestro proyecto MQL5, esto ocurre en la función CreateDescriptions, donde construimos siete ramas de red neuronal paso a paso: Codificador, 3 flujos de predicción y tres componentes de Agente: el Actor, el Director y el Crítico.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&forecast1, CArrayObj *&forecast2, CArrayObj *&forecast3, CArrayObj *&actor, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!forecast1) { forecast1 = new CArrayObj(); if(!forecast1) return false; } if(!forecast2) { forecast2 = new CArrayObj(); if(!forecast2) return false; } if(!forecast3) { forecast3 = new CArrayObj(); if(!forecast3) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En primer lugar, comprobamos la validez de los punteros a los arrays dinámicos de cada uno de los contenedores. Si alguno de ellos aún no se ha creado, asignamos cuidadosamente memoria para un nuevo array dinámico. Estos contenedores se convertirán en el esqueleto sobre el que se ensamblarán las descripciones de las capas neuronales de nuestro modelo.
En el Codificador, todo comienza con una capa básica totalmente conectada que recibe datos de entrada sin procesar: una secuencia de barras históricas, cada una de las cuales se describe mediante un conjunto de características.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, introducimos la normalización por lotes con adición de ruido, que iguala suavemente la distribución de las activaciones. Luego pasamos a la primera operación sobre los datos de origen, donde se extraen las diferencias entre puntos adyacentes de la serie. Esto nos permite destacar la dinámica del cambio.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatDiff; prev_count = descr.count = HistoryBars; descr.layers = BarDescr; descr.step = 1; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
La siguiente capa añade armónicos de marca temporal a los datos de origen, convirtiendo cada barra no solo en un conjunto de características de precio y volumen, sino en un punto en la línea de tiempo.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = 2 * BarDescr; uint prev_out = descr.window_out = NSkills; { uint temp[] = {PeriodSeconds(PERIOD_H1), PeriodSeconds(PERIOD_D1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count;
Luego transponemos el resultado para prepararlo para su entrada en la convolución adaptativa CNeuronAdaptConv. A primera vista, esto puede parecer una simple operación técnica, pero aquí es donde se produce un cambio clave, pues reestructuramos los datos para que cada secuencia unitaria pueda dividirse en parches adaptativos: fragmentos compactos y localizados de series temporales que contienen patrones locales.
Esto permite que CNeuronAdaptConv se adapte de forma flexible a la naturaleza de los datos de origen: algunos fragmentos capturan movimientos impulsivos, mientras que otros capturan áreas de estabilidad u oscilaciones. En esencia, lo que le estamos transmitiendo al modelo no es simplemente un array plano de valores, sino una representación estructurada con una jerarquía espacio-temporal claramente definida. Esto permite al Codificador preservar tanto el contexto a corto plazo como identificar patrones profundos y ocultos en series temporales complejas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAdaptConv; descr.count = Segments; descr.window = 2*prev_out/Segments; descr.variables = prev_count; prev_out = descr.window_out = EmbeddingSize; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_count = descr.count; uint prev_var = descr.variables;
El siguiente paso es RoPE (Rotary Positional Encoding), un mecanismo que a primera vista puede parecer redundante, dado que ya se han añadido etiquetas temporales a los datos de origen. La diferencia clave aquí, sin embargo, radica en el nivel de aplicación.
Las etiquetas temporales añadidas hacen referencia a barras individuales, es decir, a los datos de origen sin procesar. Sirven para registrar las coordenadas temporales absolutas de cada observación antes del inicio del procesamiento estructural.
Posteriormente, los datos pasan por una etapa de parcheo, mediante la cual cada grupo de barras consecutivas se combina en segmentos. Este segmento se convierte luego en un único token: una representación agregada de un segmento de tiempo local. Y RoPE se aplica a los tokens recibidos.
Por lo tanto, RoPE no codifica las posiciones dentro de un parche, ya que en esta etapa ya quedaron agregadas en una sola representación. En cambio, incorpora información sobre la posición del propio parche en la secuencia general. En otras palabras, RoPE permite que el modelo comprenda el orden en que aparecen los parches en relación unos con otros, lo cual resulta fundamental para analizar la estructura global de la serie temporal que se está analizando.
Esta ubicación de RoPE lo convierte en un complemento ideal: cuando se combina con etiquetas temporales a nivel de barra, proporciona una conciencia temporal jerárquica, desde valores granulares a nivel de barra hasta las posiciones relativas de los bloques agregados.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRoPE; descr.count = prev_count; descr.window = prev_out; descr.variables = prev_var; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Tras aplicar RoPE, volvemos a realizar la transposición de datos, esta vez con el objetivo de garantizar que el módulo Multi-Head Self-Attention posterior pueda leer de forma eficiente el array de vectores de tokens en orden cronológico. Este es un paso puramente técnico pero importante: la atención debe ver los datos en el formato correcto, de lo contrario solo obtendremos caos y no una comparación equilibrada de los tokens.
A continuación, entra en juego la Self‑Attention configurada con parámetros de 4 cabezas de atención y 3 capas secuenciales. Esta arquitectura permite que el modelo analice diferentes aspectos de las relaciones entre los tokens en paralelo; cada cabeza se centra en su propio subespacio de características. Es como tener cuatro expertos, cada uno con su propia opinión sobre la importancia de las conexiones entre los parches.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeRCDOCL; descr.count = prev_var; descr.window = prev_count; descr.step = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronComplexMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_out / 2 * prev_var; descr.window_out = descr.window / 4; descr.layers = 3; descr.step = 4; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Aquí cabe destacar que el mecanismo RoPE no es simplemente una forma de añadir información ordinal. Este realiza la rotación de vectores de tokens en el plano complejo utilizando elementos de matemáticas complejas. Este enfoque nos permite considerar explícitamente la posición relativa de los tokens mediante la incorporación de cambios de fase en las incorporaciones.
Por eso, a diferencia de la implementación del framework LightGTS del autor, donde se utilizaba la Self‑Attention habitual, nosotros utilizamos deliberadamente una versión compleja del módulo de atención CNeuronComplexMLMHAttentionOCL. Esto garantiza la coherencia matemática: si la codificación posicional se realiza en un dominio complejo, entonces la capa de atención también debe ser capaz de operar con cantidades complejas.
Como resultado, el modelo adquiere la capacidad no solo de ver las relaciones entre los tokens, sino también de tener en cuenta su desfase, lo cual resulta fundamental al trabajar con estructuras periódicas y ondulatorias de series temporales financieras. Las tres capas de atención proporcionan profundidad de procesamiento, lo que permite modelar tanto las dependencias locales como las más distantes en la serie temporal. Esto crea una representación rica en contexto, una especie de resumen condensado de toda la secuencia, lista para los siguientes pasos del modelo.
Como decodificador, usamos el módulo CNeuronTimeMoEAttention, que combina el poder de la atención multi-cabeza con la elegante mecánica de una mezcla dispersa de expertos (MoE). Este módulo está diseñado específicamente para el análisis eficiente de series temporales y la creación de representaciones latentes expresivas, lo que resulta especialmente importante en aplicaciones financieras donde cada detalle de la dinámica temporal importa.
Una innovación importante es la sustitución del clásico bloque FeedForward por un bloque de mezcla dispersa de expertos: CNeuronTimeMoESparseExperts. Este enfoque permite una distribución flexible y eficiente de los recursos informáticos entre diferentes especialistas, cada uno de los cuales analiza su propia parte de las características, mejorando así la calidad del procesamiento y reduciendo la redundancia.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTimeMoEAttention; descr.window_out = EmbeddingSize; { uint temp[] = {prev_out, prev_out, 8, TopK}; //Window Main, Window Cross, Experts dimension, TopK if(ArrayCopy(descr.windows, temp) < ArraySize(temp)) return false; } { uint temp[] = {prev_var, prev_var * prev_count, NExperts}; //Units Main, Units Cross, Experts if(ArrayCopy(descr.units, temp) < ArraySize(temp)) return false; } descr.layers = 3; descr.step = 4; // Attention heads descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }//--- CLayerDescription *latent = descr;
Como resultado del trabajo del Codificador de estado del entorno, obtenemos una representación latente, comprimida pero expresiva, de los datos analizados.
Esta representación no es simplemente un conjunto de vectores. Se trata de una descripción verificada y exhaustiva de la situación actual del mercado, que conserva todas las características esenciales de la dinámica, la estacionalidad y las anomalías a corto plazo. El Codificador absorbe el comportamiento del mercado, filtra el ruido y concentra la esencia, transmitiéndola en forma de tokens compactos.
Estos tokens no almacenan toda la historia; en cambio, acumulan significado, agregan relaciones de causa y efecto y aíslan los factores más importantes. Y son estos tokens los que se convierten en una fuente universal de conocimiento para todos los demás componentes del sistema: las unidades de pronóstico, el módulo de toma de decisiones (el Actor) y los evaluadores (el Director y el Crítico).
De hecho, el Codificador en nuestra arquitectura es el único canal de compresión semántica a través del cual pasa toda la información histórica y actual del mercado. El resultado de su funcionamiento puede compararse con una fotografía de alta calidad de una escena compleja: comprimida, pero enfocada, rica en detalles importantes para un análisis y una toma de decisiones posteriores.
Durante el proceso de entrenamiento, para formar un espacio latente rico y estable, usamos tres modelos predictivos paralelos, cada uno de los cuales opera con un horizonte de planificación diferente. Este enfoque permite que nuestro Codificador capture tanto los impulsos a corto plazo como las tendencias del mercado a largo plazo sin perder su capacidad de generalización.
Cada uno de estos modelos accede a la misma salida Codificador, pero se entrena con su propio objetivo correspondiente a un horizonte de planificación específico. Durante la propagación inversa, los gradientes de los tres modelos se agregan, lo que permite al Codificador entrenar simultáneamente en un problema multidimensional:
- siendo rápido y preciso a corto plazo;
- manteniéndose resistente al ruido del mercado;
- sin perder la orientación estratégica.
De este modo, ya en la fase de entrenamiento, obligamos al espacio latente a absorber diversos niveles de lógica de mercado, lo que posteriormente confiere una ventaja significativa a todos los demás componentes del sistema. El estado generado por dicho Codificador es igualmente adecuado tanto para generar decisiones comerciales (Actor) como para evaluar su calidad (Crítico y Director).
La arquitectura de los modelos predictivos se ha transferido íntegramente de nuestros trabajos anteriores sin modificaciones. Como ya ha demostrado su valía en diversas tareas, no tiene sentido detenerse en sus detalles en el marco de este artículo.
Sin embargo, la arquitectura del Actor (Actor) ha experimentado mejoras significativas destinadas a aumentar la adaptabilidad y la expresividad de la política. La estructura actualizada incluye siete niveles, cada uno de los cuales añade capacidades específicas al modelo. En primer lugar, como antes, usamos una capa básica totalmente conectada, a la que transmitimos información sobre el estado actual de la cuenta y las posiciones abiertas.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, se aplica la normalización por lotes para estabilizar el entrenamiento e igualar la escala de las características obtenidas de distintas fuentes.
La capa de atención cruzada multicabeza permite que el modelo haga coincidir el estado actual de la cuenta con el contexto de la situación de mercado analizada, obtenida a partir del codificador de estado del entorno.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { uint temp[] = {AccountDescr, // Inputs window latent.windows[0] // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {1, // Inputs units latent.units[0] // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 8; descr.batch = 1e4; descr.layers = 2; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Gracias a una arquitectura de atención de dos capas y cuatro cabezas, el modelo puede seleccionar aspectos relevantes del contexto para generar acciones.
Luego tenemos un MLP de decisión de tres capas. Aquí, cada capa utiliza su propia función de activación. La tangente hiperbólica permite comprimir los tokens en un espacio continuo y compacto con una mayor sensibilidad a los límites.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = BatchSize; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A esto le sigue una no linealidad suave que mantiene valores positivos. Esto resulta importante para generar parámetros de acción.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = BatchSize; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y genera logits para el muestreo de acciones posterior. El doble número de resultados puede relacionarse con la parametrización de la media y la varianza, en consonancia con las políticas probabilísticas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SoftPlus; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
La introducción de una capa variacional permite generar acciones de forma estocástica manteniendo el control sobre la distribución. Esto aumenta la capacidad de investigación del Agente.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El último paso es la convolución, que se aplica a las acciones ya generadas. Esto nos permite fortalecer las dependencias locales entre parámetros y acciones e introducir filtros probabilísticos suaves que transforman la acción en el rango [0, 1].
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
En general, la nueva arquitectura del módulo del Actor demuestra una interacción más profunda con el contexto, una alta variabilidad de comportamiento y la capacidad de tener en cuenta las dependencias históricas a la hora de tomar decisiones comerciales.
Los modelos de valoración del Director (Director) y el Crítico (Critic) al igual que los componentes predictivos, se han mantenido sin cambios con respecto a trabajos anteriores. Esta parte de la arquitectura ya ha superado la prueba del tiempo y ha demostrado su valía en el entrenamiento de Agentes. La arquitectura completa de todos los componentes entrenables se presenta en el archivo adjunto.
Simulación
El proceso de entrenamiento del modelo se ha dividido en dos etapas, lo que ha permitido construir el sistema de forma consistente, fiable y sin prisas.
En primer lugar, hemos realizado el entrenamiento offline. Para ello, hemos usado 15 años de datos históricos del par EURUSD en el marco temporal M1. Este volumen de datos abarca una enorme variedad de situaciones de mercado: desde periodos prolongados de estancamiento hasta tendencias rápidas, desde periodos estables hasta periodos de alta volatilidad. El modelo ha tenido la oportunidad única de observar cómo se comporta el mercado en una amplia variedad de condiciones. El Codificador ha aprendido a reconocer patrones, extraer los más significativos y codificar las condiciones del mercado en un vector de características compacto y completo. Este vector se convierte en la base de todas las decisiones que el Agente tome en el futuro. Durante el proceso de entrenamiento, el Actor ha dominado una estrategia de comportamiento basada en las señales de retroalimentación del Crítico y el Director, lo que le ha permitido formar un modelo de comportamiento estable y lógico.
A continuación, pasamos a la segunda fase: el ajuste online del modelo utilizando datos históricos desde 2024. En este caso, el entrenamiento se ha trasladado a un entorno casi en tiempo real: el modelo interactúa con el mercado vela por vela, encontrándose con ruido de mercado, fluctuaciones aleatorias y distorsiones temporales. Esto nos ha permitido no solo seguir entrenando el modelo, sino también adaptar su comportamiento a la dinámica real del mercado, ajustar la estrategia y aumentar la resiliencia en condiciones de incertidumbre.
Tras completar el entrenamiento, hemos realizado una prueba a gran escala utilizando datos nuevos: cotizaciones correspondientes al periodo de enero a marzo de 2025. Todos los ajustes se han fijado de antemano y no se han modificado durante la prueba. Esto garantiza la objetividad y la transparencia de la evaluación, excluyendo cualquier tipo de ajuste o interferencia. Los resultados de la prueba se muestran a continuación.
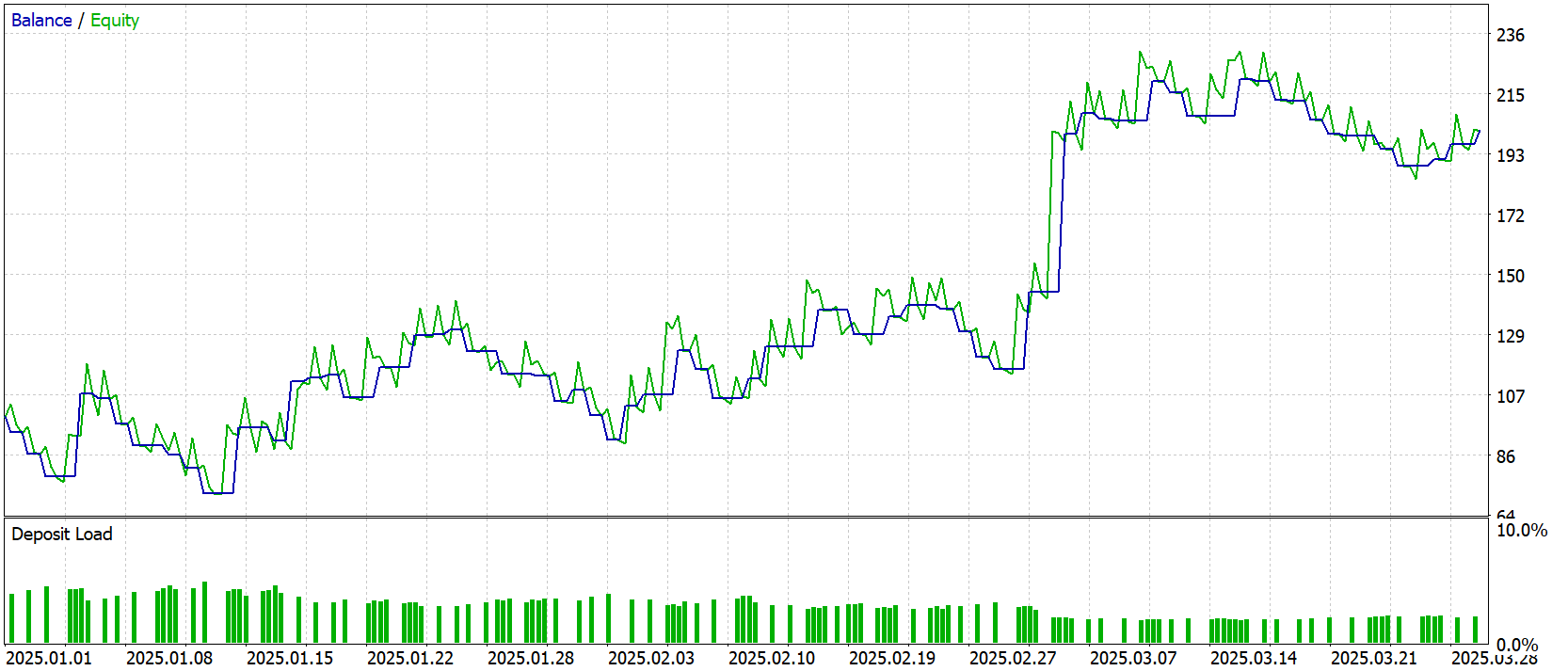
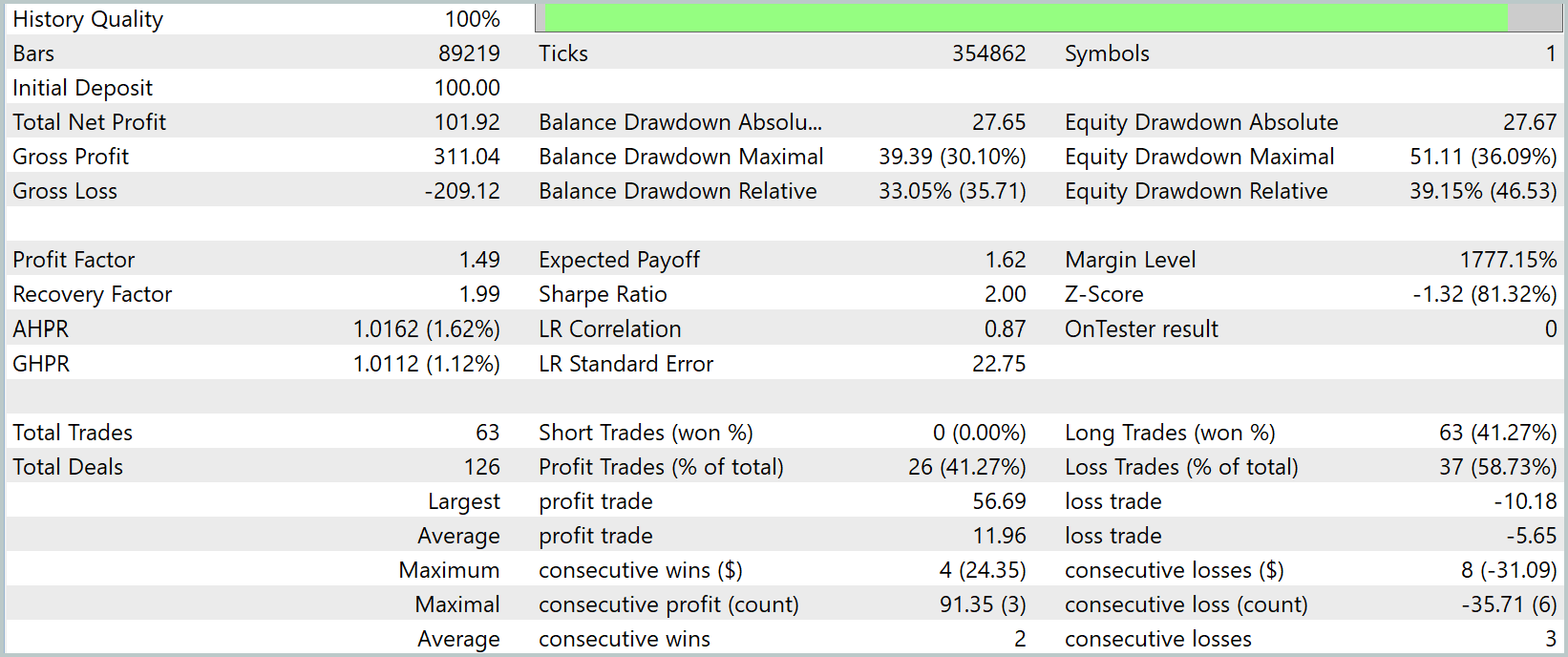
Tras tres meses de pruebas en un gráfico de un minuto (M1), nuestro modelo ha demostrado un impresionante crecimiento del capital: de 100 dólares a casi 202 dólares, duplicando claramente el depósito. Solo alrededor del 41% de las operaciones han sido rentables, pero la ganancia promedio de 12 dólares ha sido muchas veces mayor que la pérdida promedio de 5,6 dólares, lo que ha redundado en un factor de beneficio de 1,49. El gráfico de equidad muestra claramente fuertes aumentos después de cada caída, y el factor de recuperación de casi dos puntos confirma una rápida recuperación desde la caída máxima del 36%.
Sin embargo, a pesar de todo el optimismo, se evidencia un sesgo importante: el modelo abre sistemáticamente solo posiciones largas, siguiendo la tendencia alcista global. En el ámbito temporal de los minutos, esto resulta especialmente evidente: mientras las cotizaciones suben, el agente obtiene beneficios, pero ante el menor indicio de un retroceso, pierde la oportunidad de ganar dinero con una venta en corto.
Para que la estrategia sea verdaderamente universal, todavía tenemos que trabajar para optimizarla.
Conclusión
Durante nuestro trabajo, hemos creado una arquitectura de red neuronal flexible: desde parcheo adaptativo y RoPE hasta módulos complejos de Time‑MoEAttention y Actor–Director–Critic. El sistema es capaz de capturar tanto los impulsos a corto plazo como las tendencias a largo plazo, y su triple pronóstico en múltiples horizontes temporales lo hace resistente a las fluctuaciones del mercado. La siguiente tarea consiste en optimizar la estrategia para el trading bidireccional, añadiendo soporte tanto para posiciones largas como cortas, y ajustando la gestión de riesgos para ambas direcciones. Solo mediante pruebas exhaustivas y ajustes precisos con datos reales podremos conseguir un sistema de negociación automatizado verdaderamente competitivo.
Enlaces
- LightGTS: A Lightweight General Time Series Forecasting Model
- RoFormer: Enhanced Transformer with Rotary Position Embedding
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 2 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18686
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso