

If you found this blog post it implies you've been bombarded with maths , every lecture and every tutorial you watch has a giant black (or white) board full of equations and zero screens with source code.
You keep hearing about the chain rule and the quotient rule and the derivative because it is so and the algebra and the maths , and mid lecture you are wondering "does professor bro even code ? i know he smarter but do he code ? 😂 😭 " . Well , at this moment in time i think i understood how it all ties together so here is my attempt at bridging the gap between the whiteboard and your source code.
So , let us take this beautifully designed neural network ...what a masterpiece 😍
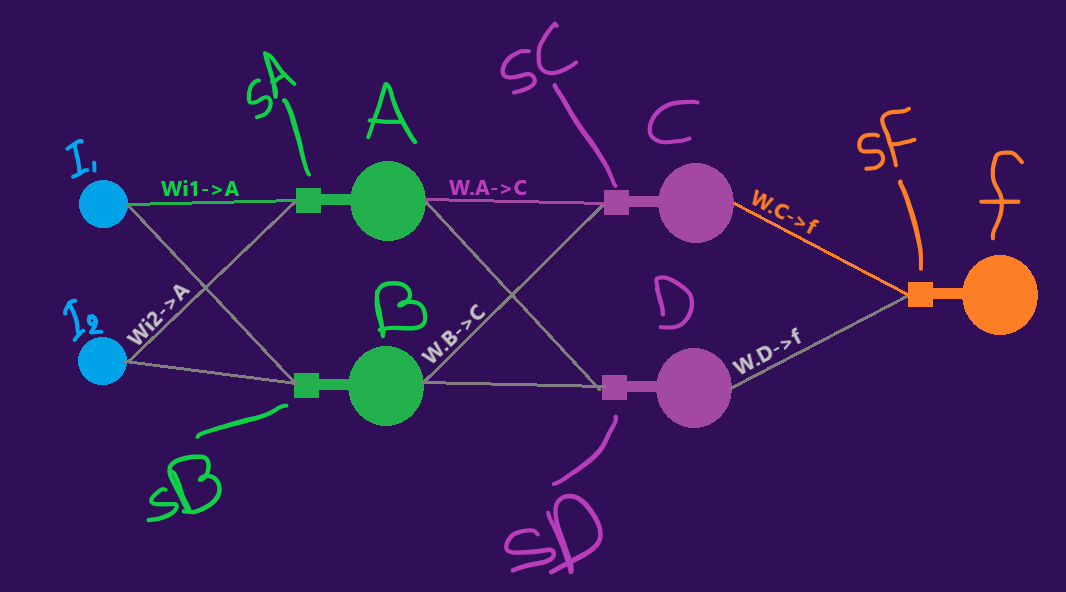
So what do we have here ?
- One input layer in blue with nodes I1 and I2
- One hidden layer in green with nodes A and B
- One hidden layer in pink with nodes C and D
- One output layer in orange with node f
If this is your first neural net you are wondering what sA ,sB sC , sD sF are . You'll see
So a bit of code , not how it looks on the final network but to bridge the gap:
sA is calculated like this :
double sA=I1*w_I1_A+I2*w_I2_A; "damn what is that ? " , this is the value of I1 times the weight Wi1->A plus the value of I2 times the weight Wi2->A. Look at the network .
Got it ? that is the value of sA.
Similarly you can assume what the value of sB is , but the weights that we won't use are not displayed to avoid clutter.
Next , we take the value of sA and pass it through the activation function at node A and the value we get is the value of A from now on.
double A=activation_function(sA); Ignore what the activation function is for now.
So we move along and we calculate value of A and value of B respectively . Neat , now we can move forward and calculate stuff
all the way till we get value f (which is the activation value of sF which is the sum of C*W.c->f+D*W.d->f and so on)
Of course you are thinking , yeah , that makes sense . Right about here the funny stuff starts . The lecturer pulls out a loss function and starts reciting math.
So , here is what they mean : (get coffee first ☕️ ☕️ ☕️)
- We have a sample with 2 inputs for which we know the correct answer
- We have the forecast of our network f for these 2 inputs
- We need to know how the weights must change in our layers so that we come closer to the correct answer
Cool , but why do we need the derivative(s) ?
Imagine you want to go to a bar in Mykonos . You meet a lady and ask "where is this bar?" . You are given directions but the lady makes a mistake.
The lady is the random initialization of weights !
So you follow the directions , you are not at the bar , you pull out a GPS and you can see where the bar is and where you are , so you can see how far
and wrong the directions you followed were .
(Allow a simplification) If you end up to the left of the bar you will need to go right and if you end up to the right of the bar you will need to go left. So if you know the direction you are heading and how "wrong" it was you can figure out how to adjust your course .
That is what the derivative does .
The derivative , in the blackboard of the professor and all the books , is the slope of the function of the entire network , or in the example, the derivative is the slope(direction) of all the steps you took.
So you are at the left of the bar , you know that you went too much to the left .
Will it be fixed if you turn back and go too much to the right ?
No , you also need the direction of the solution and the size of the step.
Knowing where the bar is from you and how far as well.(in your field of view that is , to be precise!)
That is where the other derivative comes in.
What other derivative you ask , where was this mentioned ?
It was ,but, -just like me- you were thunderstruck by the math and did not see it !
So , let's get into what we've seen and did not understand as coders :
Let's assume L is the Loss of one sample .
You think ow easy ,i'll take the correct value minus the forecasted value right ?
Nope. Why nope ?
Because the slope of correct value minus forecast value , with respect to the forecast , is always -1 , correct me if i'm wrong , so if :
L=correct-forecast;
derivativeLwrt_forecast=-1; Right ?
You know what that means ? We cannot see where the "bar" is directionwise but we can get an estimate of the step if we go about it this way.
What will that do ? your network will step around and if it lands on the correct spot by accident it will work. (again , correct me if i'm wrong , i failed math in high school)
Hence the dreaded Loss function L=(correct-forecast)^2
double Loss=MathPow((correct-forecast),2.0);

But why ? Because the derivative of the Loss with respect to the forecast is :
double dL_wrt_f=2*(forecast-correct);
This is a beautiful slope , your network can ski all day on that ! 🏂🏻
Okay ? So far so good so remember that equation . , more coffee ( ☕️ ☕️ ☕️ )
Take a break and go look at the network schematic again .
Ready ? sco
What in the name of earth's flat a** is the chain rule and how does it relate to the network ?
Consider what we have so far , the direction of the solution right ? Our task (the coders) is to take that and adjust the weights of the network so that the buyers of our EA can go to Dubai . So the question you are asking , and you probably had that idea for a veeery long time , is , if i change this ,or any of these weights , the result of the network changes . Right , it does so you thought at some point , hmm , "why don't i find the value that is supposed to go in the activation function and then distribute this backwards and change the weights ? Why do i need all this math ?" Well you could -i think , i'll try it later - but guess what , you'd need the chain rule again ! You'd need to relate how one weight at the start of the network affects the whole thing and if you go by just adjusting for the "would" be values , without the chain rule , you would be jumping around the solution constantly.
That is what the chain rule does , if you design a network , or rather , when you design your network and you decide to print out the weight adjustment matrix you will see it cascading backwards and usually being reduced from the front layers till the back of the network.
Okay, i know that words and equations don't cut it at the beginning so let's dive in :
You are told : "If we want to calculate the adjustment needed for the weight that goes from C to f (W.c->f) we need the partial derivative of the Loss function with respect to that weight."
What they mean : "For every sample that the network forecast was wrong or not 100% right , how wrong was this weight?"
If you answer that for all the weights you move closer to the network being right next time with each iteration.
Cool , so what is the "derivative of the Loss with respect to (wrt) the weight?" . To answer that you need to look at the schematic again .
What is the weight W.C->f going through :
- The summer (that sums not the season) sF because its part of the sF calculation
- The activation function on f
Great so let's deconstruct this :
1.Take the last item on the list and add the derivative of the loss with respect to that ,hmm we have that already ! it is the slope of the solution!
double dL_wrt_f=2*(forecast-correct);
2.Take the second to last item on the list and derive the last item with respect to that , so the derivative of f with respect to sF! And what is that ? that is the derivative of the activation function ! Ignore the calculation inside the function for now , mql5 takes care of that, keep the formula!
double df_wrt_sF=activation_function_derivative(f); 3.We run out of list items so then we take the weight W.C->f and derive the second to last item with respect to it! and what do we find ? C!
double dsF_wrt_Wc_to_f=C; So what is all that telling you ? that to find how wrong the weight W.C->f is you can multiply all of the above , so let's see it again from another viewpoint , what are we multiplying ?
- the effect f has on the loss
- the effect sF has on f
- the effect W.C->f has on sF
So that is what the chain rule means . Let's see the complete formula :
double dL_wrt_Wc_to_f=dL_wrt_f*df_wrt_sF*dsF_wrt_Wc_to_f; double dL_wrt_Wc_to_f=(2*forecast-2*correct)*(activation_function_derivative(f))*C;
I hope this "clicks" , let's re-look at the formula like this :
where the correct direction is x the direction we took x what the weight got multiplied by
or like this :
we know the correct direction , we know the direction we took , we measure how big the adjustment must be on this weight
Cool . I hope it makes sense , but , you are hoping i don't stop at layer one like most lectures , and i wont !
Let's see what happens at the back of the network and try to relate things .
You are probably wondering : "Do i need to calculate a new loss at the previous nodes ? for example on C and D and B and A ?"
No , you can send back the equivalent of the loss that each node is responsible for , and , guess what you can use to prove that .... the chain rule!
So , let's see how node C affects the network , or in other words , let's calculate the loss at point C of the network :
Coffee ( ☕️ ☕️ ☕️) ... look at the schematic again :

[do you need to always do that for each network? no , the following proofs will reveal how you can just distribute things backwards and frankly that is what all this lectures do but we get lost in the math of it all.]
- What is C going through ? (generally , when you think about networks and the chain rule always ask what is x going through in the network)
- Why do we want to see what C is going through ? because we want to calculate the derivative of the Loss with respect to C.
- Why do we need this derivative ? because we want to see how C affects the network
- Why do we need to see how C (lol) affects the network ? because we want to send the error backwards to adjust all the weights
- Will we always die doing math for each network ? no
So , What is C going through ?
- the summer sF
- the activation f
(wait isn't it going through the weight too? yes but the weight is not a function !)
That sounds familiar right ?
We start from the bottom again :
1.Take the derivative of the Loss with respect to f , we have it , good
2.Take the derivative of f with respect to sF , we have it , good
3.No more items on the list so take the derivative of sF with respect to C , we don't have it ! but wait , its the weight !
double dsF_wrt_C=Wc_to_f; Magical
So , does that mean our equation changes only in one place ? yes
double dL_wrt_C_to_f=dL_wrt_f*df_wrt_sF*dsF_wrt_C; double dL_wrt_C_to_f=(2*forecast-2*correct)*(activation_function_derivative(f))*Wc_to_f;
And what is this equation ? this is the loss at point C ! this is how you send back the error to work with on the previous layers.

And now you are asking , of course , wait but then the equation will exponentially grow ?
Let's see what happens , lets go for the weight behind node C , the weight W.A->C
So let's look at the schematic again : ...
And ask ... what is W.A->C going through ?
- the summer sC
- the activation on C
- the summer sF
- the activation on f
oof that is a lot of steps , let's go from the bottom up :
1.Take the derivative of the Loss with respect to f , we have it
2.Take the derivative of f with respect to sF , we have it
3.Take the derivative of sF with respect to C , we have it
4.Take the derivative of C with respect to sC , we don't have it , but its the derivative of the activation function on C!
double dC_wrt_sC=activation_function_derivative(C); 5.No more items on the list so take the derivative of sC with respect to W.A->C and that is A!
double dsC_wrt_Wa_to_c=A; So we have all the components , let's construct the equation and see what happens :
double dL_wrt_Wa_to_c=dL_wrt_f * df_wrt_sF * dsF_wrt_C * dC_wrt_sC * dsC_wrt_Wa_to_c; double dL_wrt_Wa_to_c=(2*forecast-2*correct)*(activation_function_derivative(f))*(Wc_to_f)*(activation_function_derivative(C))*(A);
What is all that ? well if we look closely we will discover that the highlighted portion :
double dL_wrt_Wa_to_c=(2*forecast-2*correct)*(activation_function_derivative(f))*(Wc_to_f)*(activation_function_derivative(C))*(A);
! is the error we sent back to node C ! from this equation :
double dL_wrt_C_to_f=(2*forecast-2*correct)*(activation_function_derivative(f))*Wc_to_f;
Interesting , does that mean we can automate this sh*t ? Yes . You just proved that we can use the "loss" that we send back to each node in order to adjust the weights , and also send the "loss" further back to the previous layers .
That is the chain rule .
If i have any mistakes please let me know . Thanks
<!> Caution , you will notice once you reach to the calculation of the loss at point A that it receives 2 losses . You just sum them up . I made the mistake of dividing by the amount of inbound losses or weights . Don't do it too 😊 <!>
<?> What about nets that have 2 output nodes ? How is the loss calculated there and do we go per output node ? (i'm studying this now and will update when i understand it as well)


















")
