
Gescheites "Marktgedächtnis" durch Differentiation und Entropieuntersuchung
Grund für die Vorgehensweise und ein kurzer Hintergrund
Eine große Anzahl von Teilnehmern an liquiden Märkten, die mit unterschiedlichen Anlagehorizonten operieren, erzeugen viel Unruhe im Markt. Somit haben die Märkte einen niedrigen Signal-Rausch-Abstand. Die Situation kann durch Versuche der ganzzahligen Zeitreihendifferenzierung verschärft werden, die das verbleibende Gedächtnis löscht und Kurse in eine durch Stationarität gekennzeichnete Reihe umwandelt.
Preisreihen haben ein Gedächtnis, da jeder Wert von einer langen Geschichte der Preise abhängt. Zeitreihentransformationen, wie z.B. der Logarithmus von Inkrementen, beschneiden das Gedächtnis, da sie auf der Grundlage einer begrenzten Fensterlänge erstellt werden. Wenn Transformationen zur Stationarität das Marktgedächtnis beseitigen, verwenden Statistiker komplexe mathematische Methoden, um das verbleibende Gedächtnis zu extrahieren. Deshalb führen viele der damit verbundenen klassischen, statistischen Ansätze zu falschen Ergebnissen.
Das Konzept der Langzeitkorrelation
Die Langzeitkorrelation, auch Langzeitpersistenz, Erhaltungsneigung oder Memory-Effekt genannt, ist ein Phänomen, das bei der Analyse finanzieller Zeitreihen auftreten kann. Dies drückt sich in der Zerfallsrate der statistischen Abhängigkeit zwischen zwei Preisen mit einer Erhöhung des Zeitintervalls (oder des Abstands zwischen ihnen) aus. Ein Phänomen gilt als eine langfristige Abhängigkeit, wenn die Abhängigkeit langsamer abklingt als der exponentielle Zerfall. Die Langzeitkorrelation ist oft auch mit selbstähnlichen Prozessen verbunden. Für Details zur Langzeitkorrelation lesen Sie bitte den Wikipedia-Artikel.
Das Problem der Stationarität und der Existenz eines Gedächtnisses
Ein gemeinsames Merkmal von Preisdiagrammen ist die Unstationarität: Sie haben eine lange Preisgeschichte, die den Durchschnittspreis über die Zeit verschieben. Um eine statistische Analyse durchführen zu können, müssen Forscher mit Preisinkrement (oder Logarithmen des Inkrements), Veränderungen der Rentabilität oder Volatilität arbeiten. Diese Transformationen machen die Zeitreihen stationär, indem sie das Gedächtnis aus den Preisreihen entfernen. Obwohl die Stationarität eine notwendige Eigenschaft für statistische Schlussfolgerungen ist, ist es nicht immer notwendig, das gesamte Gedächtnis zu löschen, da das Gedächtnis die Grundlage für die prädiktiven Eigenschaften von Modellen ist. Beispielsweise müssen Gleichgewichtsmodelle (stationäre) Modelle etwas Gedächtnis aufweisen, um beurteilen zu können, wie weit sich der Preis von seinem erwarteten Wert entfernt hat.
Das Problem ist, dass die Preisinkremente stationär sind, aber kein Gedächtnis der Vergangenheit enthalten, während die Preisreihen die gesamte verfügbare Menge im Gedächtnis behalten, aber nicht stationär sind. Es stellt sich die Frage, wie man eine Zeitreihe behandelt, um sie stationär zu machen und gleichzeitig das größtmögliche Gedächtnis zu erhalten. Daher möchten wir das Konzept die Preisinkremente für die Berücksichtigung stationärer Reihen, bei denen nicht das gesamte Gedächtnis gelöscht wird, verallgemeinern. In diesem Fall sind Preisinkremente neben anderen verfügbaren Methoden nicht die optimale Lösung für die Preistransformation.
Zu diesem Zweck wird das Konzept der Fraktionalen Differenziation (Fraktionale Infinitesimalrechnung) eingeführt. Zwischen den beiden Extremen gibt es eine Vielzahl von Möglichkeiten: einfache und nullte Differenziation. Auf der einen Seite gibt es völlig differenzierte Preise. Nicht differenzierte Preise sind am anderen Ende.
Der Anwendungsbereich der Fraktionalen Differenziation ist breit genug. Beispielsweise wird in der Regel eine differenzierte Zeitreihe in maschinelle Lernalgorithmen eingegeben. Das Problem ist, dass es notwendig ist, neue Daten entsprechend der verfügbaren Historie anzuzeigen, die das Modell des maschinellen Lernens erkennen kann. Im Falle einer nicht stationären Zeitreihe können neue Daten außerhalb des bekannten Wertebereichs liegen, wodurch das Modell möglicherweise falsch funktioniert.
Die Geschichte der Fraktionalen Differenziation
Fast alle Methoden zur Analyse und Prognose von Finanzzeitreihen, die in verschiedenen wissenschaftlichen Artikeln beschrieben werden, stellen die Idee der ganzzahligen Differenziation dar.
In diesem Zusammenhang stellen sich die folgenden Fragen:
- Warum ist die ganzzahlige Differenziation (z.B. mit einer einheitlichen Verzögerung) optimal?
- Ist eine solche Überdifferenziation nicht einer der Gründe, warum die Wirtschaftstheorie anfällig für die Hypothese effizienter Märkte ist?
Das Konzept der fraktionierten Differenziation, wie es auf die Analyse und Prognose von Zeitreihen angewendet wird, geht mindestens auf Hosking zurück. In seinem Artikel wurde die Familie der ARIMA-Prozesse verallgemeinert, so dass der Differenzieationsgrad einen Bruchteil ausmacht. Dies war sinnvoll, da der fraktionierte Differenziationsprozess eine langfristige Persistenz oder Antipersistenz aufwies und damit die Vorhersagefähigkeit im Vergleich zu Standard-ARIMA erhöhte. Dieses Modell wurde ARFIMA (autoregressive fractionally integrated moving average) oder FARIMA genannt. Danach wurde die fraktionierte Differenziation manchmal in Artikeln anderer Autoren erwähnt, hauptsächlich im Zusammenhang mit der Beschleunigung der Berechnungsmethode.
Solche Modelle können für die Modellierung von Zeitreihen mit langem Gedächtnis nützlich sein, d.h. in Fällen, in denen Abweichungen vom langfristigen durchschnittlichen Verfall langsamer sind als der exponentielle Verfall.
Das Konzept der fraktionierten Differenziation
Betrachten wir den Rückschaltoperator (oder einen Verzögerungsoperator) B, angewendet auf die Matrix der Realwerte {Xt}, wobei B^kXt = Xt-k, für jede ganze Zahl k ≥ 0. Zum Beispiel, (1 − B)^2 = 1 − 2B + B^2, wobei B^2Xt = Xt−2, ergo, (1 − B)^2Xt = Xt − 2Xt−1 + Xt−2.
Es gilt (x + y)^n =
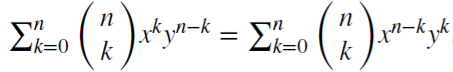 für
jede positive, ganze Zahl
n. Für eine reelle Zahl d,
für
jede positive, ganze Zahl
n. Für eine reelle Zahl d,
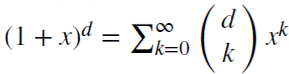 ist
das eine Binomialreihe. Im fraktionellen Modell kann
d eine reelle Zahl mit folgender formaler Erweiterung der Binomialreihe:
ist
das eine Binomialreihe. Im fraktionellen Modell kann
d eine reelle Zahl mit folgender formaler Erweiterung der Binomialreihe:
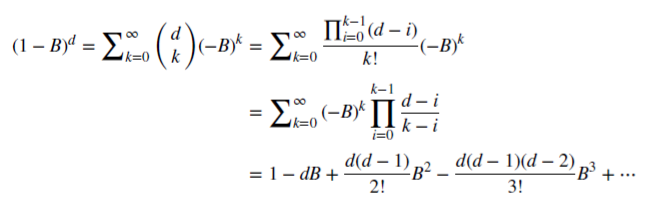
Erhalten des Marktgedächtnisses bei fraktionierter Differenziation
Mal sehen, wie ein rationales, nicht-negatives d das Gedächtnis bewahren kann. Diese arithmetische Reihe besteht aus einem skalaren Produkt:
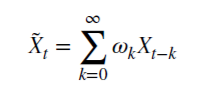
mit den Gewichten 𝜔
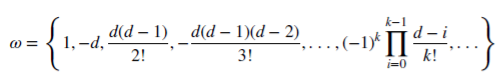
und den Werten X
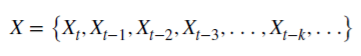
Wenn d eine positive, ganze Zahl ist,
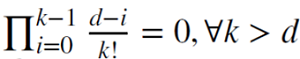 ,
wird in diesem Fall das Gedächtnis verkleinert.
,
wird in diesem Fall das Gedächtnis verkleinert.
Zum Beispiel wird d = 1für die Berechnung des Inkrements berechnet, wobei
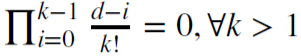 und 𝜔
= {1,−1, 0, 0,…}.
und 𝜔
= {1,−1, 0, 0,…}.
Fraktionale Differenziation für ein fixes Betrachtungsfenster
Die fraktionierte Differenziation wird in der Regel auf die gesamte Sequenz einer Zeitreihe angewendet. Die Komplexität der Berechnung ist in diesem Fall höher, während die Verschiebung der transformierten Reihe negativ ist. Marcos Lopez De Prado hat in seinem Buch Advances in Financial Machine Learning eine Methode für ein Fenster mit fester Breite vorgeschlagen, bei der die Reihenfolge der Koeffizienten verworfen wird, wenn ihr Modul (|𝜔k|) unter dem angegebenen Schwellenwert (𝜏) liegt. Dieses Verfahren hat gegenüber der klassischen, sich weitende Fenstermethode folgenden Vorteil: Es ermöglicht gleiche Gewichte für jede Sequenz der Originalreihe, reduziert die Rechenkomplexität und eliminiert die Verzögerung. Diese Umwandlung ermöglicht es, Speicherplatz der Preise und des Rauschens zu sparen. Die Verteilung dieser Transformation ist nicht normalverteilt (gaußförmig) aufgrund des Vorhandenseins von Gedächtnis, Asymmetrie und Überschusskurtose, kann aber stationär sein.
Demonstration des fraktionierten Differenziationsprozesses
Erstellen wir ein Skript, mit dem wir den Effekt der fraktionierten Differenziation der Zeitreihen visuell bewerten können. Wir werden zwei Funktionen erstellen: eine zum Erhalt der Gewichte 𝜔 und die andere zum Berechnen neuer Werte der Reihe:
//+------------------------------------------------------------------+ void get_weight_ffd(double d, double thres, int lim, double &w[]) { ArrayResize(w,1); ArrayInitialize(w,1.0); ArraySetAsSeries(w,true); int k = 1; int ctr = 0; double w_ = 0; while (ctr != lim - 1) { w_ = -w[ctr] / k * (d - k + 1); if (MathAbs(w_) < thres) break; ArrayResize(w,ArraySize(w)+1); w[ctr+1] = w_; k += 1; ctr += 1; } } //+------------------------------------------------------------------+ void frac_diff_ffd(double &x[], double d, double thres, double &output[]) { double w[]; get_weight_ffd(d, thres, ArraySize(x), w); int width = ArraySize(w) - 1; ArrayResize(output, width); ArrayInitialize(output,0.0); ArraySetAsSeries(output,true); ArraySetAsSeries(x,true); ArraySetAsSeries(w,true); int o = 0; for(int i=width;i<ArraySize(x);i++) { ArrayResize(output,ArraySize(output)+1); for(int l=0;l<ArraySize(w);l++) output[o] += w[l]*x[i-width+l]; o++; } ArrayResize(output,ArraySize(output)-width); }
Zeige wir ein animiertes Diagramm, das sich je nach Parameter 0<d<1: ändert.
//+------------------------------------------------------------------+ //| Script Programm Start Funktion | //+------------------------------------------------------------------+ void OnStart() { for(double i=0.05; i<1.0; plotFFD(i+=0.05,1e-5)) } //+------------------------------------------------------------------+ void plotFFD(double fd, double thresh) { double prarr[], out[]; CopyClose(_Symbol, 0, 0, hist, prarr); for(int i=0; i < ArraySize(prarr); i++) prarr[i] = log(prarr[i]); frac_diff_ffd(prarr, fd, thresh, out); GraphPlot(out,1); Sleep(500); }
Hier ist das Ergebnis:
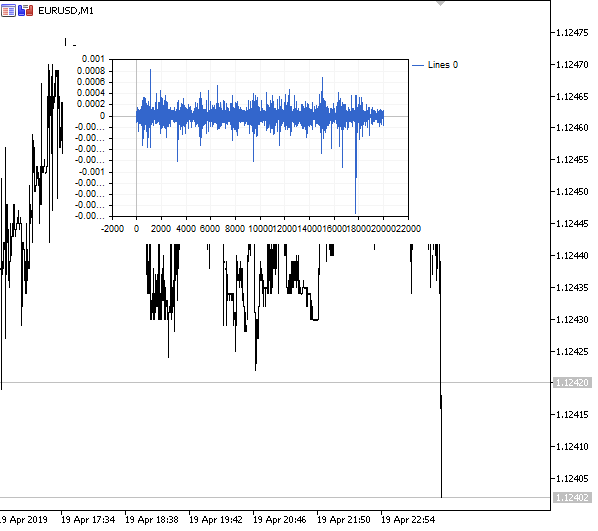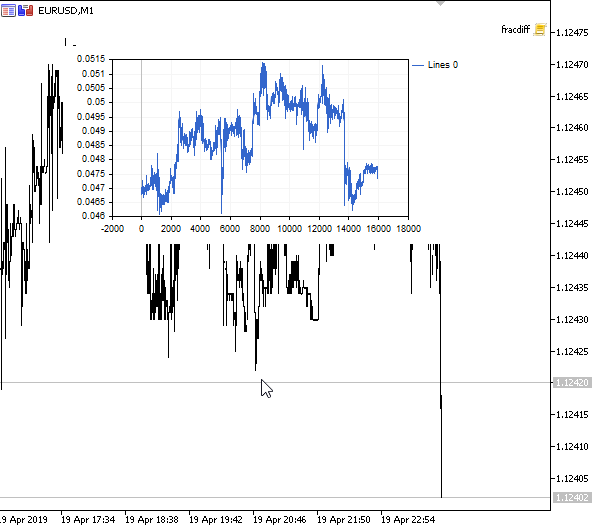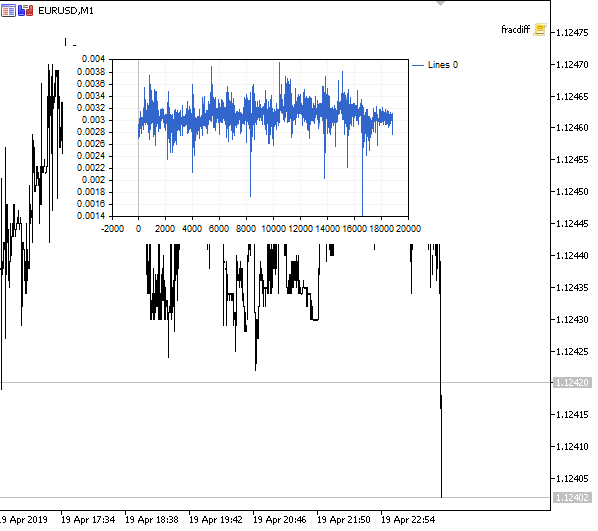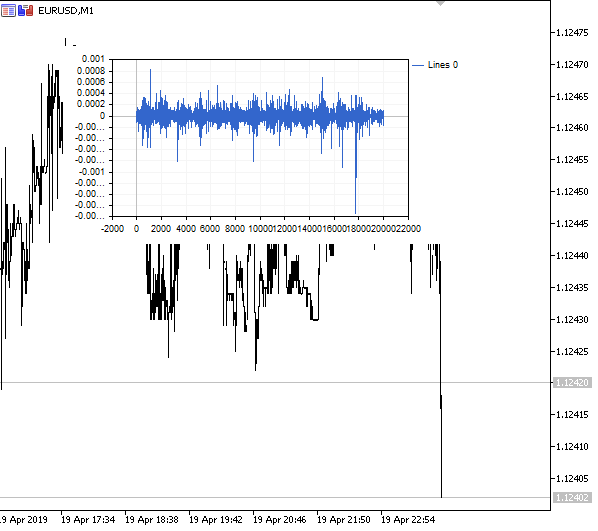
Abb. 1. Fraktionale Differenziation 0<d<1
Wie erwartet, mit einem Anstieg des Differenziationsgrades d, werden die Diagramme stationärer, während sie allmählich das "Gedächtnis" vergangener Preise verlieren. Die Gewichte für die Reihe (die Funktion des Skalarprodukts aus Gewichten nach Preiswerten) bleiben während der gesamten Sequenz unverändert und müssen nicht neu berechnet werden.
Erstellung eines Indikators auf Basis der fraktionierten Differenziation
Für die komfortable Verwendung in Expert Advisors erstellen wir einen Indikator, den wir einbeziehen können, indem wir verschiedene spezifizierte Parameter angeben: den Grad der Differenziation, die Größe des Schwellenwerts für das Entfernen von Übergewichten und die Tiefe der angezeigten Historie. Ich werde hier nicht den vollständigen Indikatorcode veröffentlichen, so dass Sie ihn in der Quelldatei ansehen können.
Ich möchte nur darauf hinweisen, dass die Funktion zur Gewichtsberechnung die gleiche ist. Die folgende Funktion wird zur Berechnung der Werte des Indikatorpuffers verwendet:
frac_diff_ffd(weights, price, ind_buffer, hist_display, prev_calculated !=0);
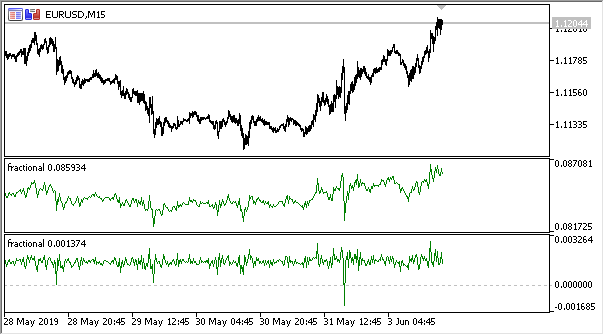
Abb. 2. Fraktionale Differenziation mit den Potenzen 0,3 und 0,9
Jetzt haben wir einen Indikator, der die Dynamik der Informationsmengenänderung in einer Zeitreihe ziemlich genau erklärt. Wenn der Differenziationsgrad zunimmt, gehen Informationen verloren und die Reihe wird stationärer. Es gehen jedoch nur Preis-Daten verloren. Was übrig bleiben könnte, sind die periodischen Zyklen, die der Bezugspunkt für die Prognose sein werden. Wir nähern uns also den informationstheoretischen Methoden, nämlich der Informationsenropie, die bei der Beurteilung der Datenmenge helfen wird.
Das Konzept der Informationsentropie
Die Informationsenropie ist ein Konzept, das sich auf die Informationstheorie bezieht und zeigt, wie viel Information in einem Ereignis enthalten ist. Im Allgemeinen gilt: Je spezifischer oder deterministischer das Ereignis, desto weniger Informationen enthält es. Genauer gesagt, sind Informationen mit einer Zunahme der Unsicherheit verbunden. Dieses Konzept wurde von Claude Shannon eingeführt.
Die Entropie eines Zufallswertes kann durch Einführung des Verteilungskonzepts eines zufälligen Wertes X bestimmt werden, der eine endliche Anzahl von Werten annimmt:
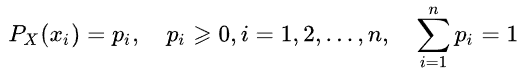
Dann werden die spezifischen Informationen des Ereignisses (oder der Zeitreihe) wie folgt definiert:
![]()
Die Schätzung der Entropie kann wie folgt berechnet werden:
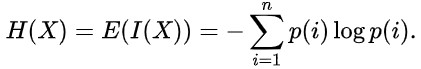
Die Maßeinheit der Informationsmenge und der Entropie hängt von der Basis des Logarithmus ab. Dies können z.B. Bits, Nats, Trits oder Hartleys sein.
Wir werden die Entropie Shannons nicht im Detail beschreiben. Es ist jedoch zu beachten, dass diese Methode für die Auswertung kurzer und verrauschter Zeitreihen schlecht geeignet ist. Deshalb schlugen Steve Pincus und Rudolf Kalman eine Methode namens " ApEn" (Approximate Entropy) für finanzielle Zeitreihen vor. Die Methode wurde im Artikel "Irregularity, volatility, risk and financial market time series" ausführlich beschrieben.
In diesem Artikel haben sie zwei Formen der Preisabweichung von der Konstanz (Beschreibung der Volatilität) betrachtet, die sich grundlegend unterscheiden:
- Die erste beschreibt eine große Standardabweichung.
- Die zweite zeigt extreme Unregelmäßigkeiten und Unvorhersehbarkeiten.
Diese beiden Formen sind völlig unterschiedlich und daher ist eine solche Trennung notwendig: Die Standardabweichung bleibt eine gute Schätzung der Abweichung von einem Zentrum, während ApEn eine Schätzung der Unregelmäßigkeit liefert. Außerdem ist der Grad der Variabilität nicht sehr kritisch, während Unregelmäßigkeiten und Unvorhersehbarkeiten wirklich ein Problem darstellen.
Hier ist ein einfaches Beispiel mit zwei Zeitreihen:
- Reihe (10,20,10,20,20,10,10,20,20,10,20,20,10,10,20....) mit abwechselnd 10 und 20
- Reihe (10,10,20,10,20,20,20,20,10,10,10,10,20,10,20,10,20,20...), wobei 10 und 20 zufällig ausgewählt werden, mit einer Wahrscheinlichkeit von 1/2
Die statistischen Momente, wie der Mittelwert und die Varianz, zeigen keinen Unterschied zwischen den beiden Zeitreihen. Gleichzeitig ist die erste Reihe vollkommen gleichmäßig. Das bedeutet, dass man, wenn man den vorherigen Wert kennt, immer den nächsten vorhersagen kann. Die zweite Reihe ist absolut zufällig, so dass jeder Versuch, etwas vorherzusagen, fehlschlägt.
Joshua Richman und Randall Moorman kritisierten die ApEn Methode in ihrem Artikel "Physiological time-analysis analysis using approximate entropy and sample entropy". Stattdessen schlugen sie eine verbesserte Methode " SampEn" vor. Insbesondere kritisierten sie die Abhängigkeit des Entropiewertes von der Stichprobenlänge sowie die Inkonsistenz von Werten für verschiedene, aber verwandte Zeitreihen. Auch ist die neu vorgeschlagene Berechnungsmethode weniger komplex. Wir werden diese Methode anwenden und die Merkmale ihrer Anwendung beschreiben.
Die Methode "Sample Entropy" zur Bestimmung der Regelmäßigkeit von Preisinkrement
SampEn ist eine Modifikation der Methode ApEn. Sie wird verwendet, um die Komplexität (Unregelmäßigkeit) eines Signals (Zeitreihe) zu bewerten. Für die angegebene Größe von m Punkten werden die Toleranz r und die Werte N berechnet, SampEn ist der Logarithmus der Wahrscheinlichkeit, dass, wenn zwei Reihen von gleichzeitigen Punkten mit der Länge m den Abstand < r haben, dann haben die beiden Reihen von gleichzeitigen Punkten der Länge m + 1 auch den Abstand r.
Angenommen, wir haben einen Datensatz von Zeitreihen mit der Länge von
![]() ,
mit einem konstanten Zeitintervall zwischen ihnen. Definieren wir die Vektorvorlage der Länge m so, dass
,
mit einem konstanten Zeitintervall zwischen ihnen. Definieren wir die Vektorvorlage der Länge m so, dass
![]() und
die Abstandsfunktion
und
die Abstandsfunktion
![]() (i≠j)
durch Chebyshev, das ist der maximale Modul der Differenz zwischen den Komponenten dieser Vektoren (aber das kann auch
eine andere Abstandsfunktion sein). Dann wird
SampEn wie folgt definiert:
(i≠j)
durch Chebyshev, das ist der maximale Modul der Differenz zwischen den Komponenten dieser Vektoren (aber das kann auch
eine andere Abstandsfunktion sein). Dann wird
SampEn wie folgt definiert:
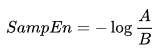
Wobei:
- A ist die Anzahl der Paare von Vorlagenvektoren, für die gilt:
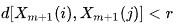
- B ist die Anzahl der Paare von Vorlagenvektoren, für die gilt:
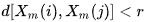
Aus dem Obenstehenden ist ersichtlich, dass A immer <= B ist und somit ist SampEn immer Null oder ein positiver Wert. Je niedriger der Wert, desto größer die Selbstähnlichkeit im Datensatz und desto geringer das Rauschen.
Es werden hauptsächlich die folgenden Werte verwendet: m = 2 and r = 0.2 * std, wobei std die Standardabweichung ist, die für einen sehr großen Datensatz ermittelt werden sollte.
Ich fand die schnelle Implementierung der im folgenden Code vorgeschlagenen Methode und schrieb sie in MQL5 neu:
double sample_entropy(double &data[], int m, double r, int N, double sd) { int Cm = 0, Cm1 = 0; double err = 0.0, sum = 0.0; err = sd * r; for (int i = 0; i < N - (m + 1) + 1; i++) { for (int j = i + 1; j < N - (m + 1) + 1; j++) { bool eq = true; //m - length series for (int k = 0; k < m; k++) { if (MathAbs(data[i+k] - data[j+k]) > err) { eq = false; break; } } if (eq) Cm++; //m+1 - length series int k = m; if (eq && MathAbs(data[i+k] - data[j+k]) <= err) Cm1++; } } if (Cm > 0 && Cm1 > 0) return log((double)Cm / (double)Cm1); else return 0.0; }
Darüber hinaus schlage ich eine Option zur Berechnung der Kreuzprobe-Entropie (cross-SampEn) für Fälle vor, in denen es notwendig ist, eine Entropie-Schätzung für zwei Reihen (zwei Eingangsvektoren) zu ermitteln. Es kann aber auch zur Berechnung der Entropie einer Stichprobe verwendet werden:
// Calculate the cross-sample entropy of 2 signals // u : signal 1 // v : signal 2 // m : length of the patterns that compared to each other // r : tolerance // return the cross-sample entropy value double cross_SampEn(double &u[], double &v[], int m, double r) { double B = 0.0; double A = 0.0; if (ArraySize(u) != ArraySize(v)) Print("Error : lenght of u different than lenght of v"); int N = ArraySize(u); for(int i=0;i<(N-m);i++) { for(int j=0;j<(N-m);j++) { double ins[]; ArrayResize(ins, m); double ins2[]; ArrayResize(ins2, m); ArrayCopy(ins, u, 0, i, m); ArrayCopy(ins2, v, 0, j, m); B += cross_match(ins, ins2, m, r) / (N - m); ArrayResize(ins, m+1); ArrayResize(ins2, m+1); ArrayCopy(ins, u, 0, i, m + 1); ArrayCopy(ins2, v, 0, j, m +1); A += cross_match(ins, ins2, m + 1, r) / (N - m); } } B /= N - m; A /= N - m; return -log(A / B); } // calculation of the matching number // it use in the cross-sample entropy calculation double cross_match(double &signal1[], double &signal2[], int m, double r) { // return 0 if not match and 1 if match double darr[]; for(int i=0; i<m; i++) { double ins[1]; ins[0] = MathAbs(signal1[i] - signal2[i]); ArrayInsert(darr, ins, 0, 0, 1); } if(darr[ArrayMaximum(darr)] <= r) return 1.0; else return 0.0; }
Die erste Berechnungsmethode ist ausreichend und wird daher weiterverwendet.
Persistenz und fraktioniertes Brownsches Bewegungsmodell
Wenn der Wert des Preisinkrements derzeit steigt, wie hoch ist dann die Wahrscheinlichkeit eines weiteren Wachstums im nächsten Moment? Betrachten wir nun die Persistenz. Die Messung der Persistenz kann eine große Hilfe sein. In diesem Abschnitt werden wir die Methode SampEn zur Bewertung der Persistenz von Inkrementen in einem gleitenden Fenster betrachten. Diese Bewertungsmethode wurde im oben genannten Artikel " Irregularity, volatility, risk and financial market time series" vorgeschlagen.
Wir haben bereits eine differenzierte Reihe nach der fraktionierten Brownschen Bewegungstheorie (daher kommt der Begriff "fraktionierte Differenziation"). Definieren wir eine grobkörnige, binäre, inkrementelle Reihe.
BinInci:= +1, wenn di+1 – di > 0, –1. Einfach ausgedrückt, machen wir aus den Inkrementen +1 und -1. So schätzen wir direkt die Verteilung von vier möglichen Varianten des Inkrementverhaltens, nach:
- oben, oben
- unten, unten
- oben, unten
- unten, oben
Die Unabhängigkeit der Schätzungen und die statistische Leistungsfähigkeit der Methode sind mit folgendem Merkmal verbunden: Fast alle Prozesse haben extrem kleine SampEn-Fehler für die Binlnci-Reihe. Eine wichtigere Tatsache ist, dass die Schätzung nicht impliziert und nicht verlangt, dass die Daten einer Markov-Kette entsprechen, und dass sie keine Vorkenntnisse über andere Merkmale außer der Stationarität erfordert. Wenn die Daten die Markov-Eigenschaft erster Ordnung erfüllen, dann ist SampEn(1) = SampEn(2), die das Zeichnen zusätzlicher Schlussfolgerungen ermöglichen.
Das Modell der fraktionierten brownschen Bewegung geht auf Benoit Mandelbrot zurück, der Phänomene modellierte, die sowohl Langzeitkorrelation oder "Gedächtnis" als auch "schwere Schwänze" zeigten. Dies führte auch zur Entwicklung neuer statistischer Anwendungen wie dem Hurst-Index und der R/S-Analyse. Wie wir bereits wissen, weisen Preisinkremente manchmal eine langfristige Abhängigkeit und starke Schwänze auf.
So können wir die Persistenz einer Zeitreihe direkt auswerten: Die niedrigsten Werte von SampEn entsprechen den größten Persistenzwerten und umgekehrt.
Implementierung einer Persistenzbewertung für eine differenzierte Reihe
Lassen Sie uns den Indikator neu schreiben und die Möglichkeit hinzufügen, im Persistenz-Auswertungsmodus zu laufen. Da die Entropie-Schätzung für diskrete Werte funktioniert, müssen wir die Inkrementwerte mit einer Genauigkeit von bis zu 2 Stellen normieren.
Die vollständige Implementierung ist im beigefügten Indikator "Fraktionsentropie" verfügbar. Die Indikatoreinstellungen werden im Folgenden beschrieben:
input bool entropy_eval = true; // show entropy or increment values input double diff_degree = 0.3; // the degree of time series differentiation input double treshhold = 1e-5; // threshold to cut off excess weight (the default value can be used) input int hist_display = 5000; // depth of the displayed history input int entropy_window = 50; // sliding window for the process entropy evaluation
Die folgende Abbildung zeigt den Indikator in zwei Modi (der obere Teil zeigt die Entropie, der untere Teil die standardisierten Inkremente):
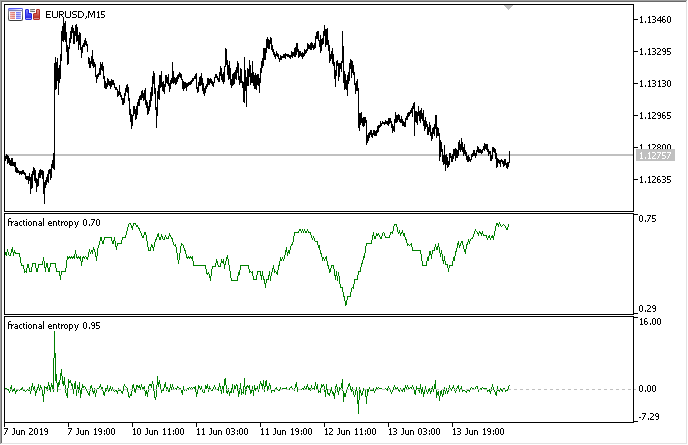
Abb. 3. Entropiewerte für das gleitende Fenster 50 (oben) und Fraktionale Differenziation mit dem Grad 0,8
Es zeigt sich, dass die Werte dieser beiden Schätzungen nicht korreliert sind, was ein gutes Zeichen für das Modell des maschinellen Lernens (Fehlen von Multikollinearität) ist, das im nächsten Abschnitt betrachtet wird.
"On-the-fly" Optimierung eines Expert Advisors durch maschinelles Lernen: logit Regression
Damit haben wir eine geeignete differenzierte Zeitreihe, die zur Erzeugung von Handelssignalen verwendet werden kann. Es wurde bereits erwähnt, dass die Zeitreihe stationärer ist und für Modelle des maschinellen Lernens besser geeignet ist. Wir haben auch die Reihe der Persistenzauswertungen. Nun müssen wir einen optimalen, maschinellen Lernalgorithmus auswählen. Da der EA in sich selbst optimiert werden muss, ist eine Anforderung an die Lerngeschwindigkeit gegeben, die sehr schnell und mit minimalen Verzögerungen erfolgen muss. Aus diesen Gründen habe ich mich für die logistische Regression entschieden.
Die logistische Regression wird verwendet, um die Wahrscheinlichkeit eines Ereignisses basierend auf den Werten einer Reihe von Variablen x1, x2, x3... xN, vorherzusagen, die auch Prädiktoren oder Regressoren genannt werden. In unserem Fall sind die Variablen die Indikatorwerte. Es ist auch notwendig, die abhängige Variable y einzuführen, die normalerweise entweder 0 oder 1 ist. So kann das als Signal zum Kauf oder Verkauf dienen. Berechnen Sie auf der Grundlage der Werte der Regressoren die Wahrscheinlichkeit, dass die abhängige Variable zu einer bestimmten Klasse gehört.
Es wird davon ausgegangen, dass die Eintrittswahrscheinlichkeit von y = 1 gleich ist:
![]() wobei
wobei
![]() die
Vektoren von Werten unabhängiger Variablen
1, x1, x2 sind... xN bzw. die Regressionskoeffizienten, und f(z) die logistische Funktion oder das Sigmoid
ist:
die
Vektoren von Werten unabhängiger Variablen
1, x1, x2 sind... xN bzw. die Regressionskoeffizienten, und f(z) die logistische Funktion oder das Sigmoid
ist:
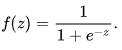 Dadurch
kann die Verteilungsfunktion
y für die gegebenen x wie folgt beschrieben werden:
Dadurch
kann die Verteilungsfunktion
y für die gegebenen x wie folgt beschrieben werden:
![]()
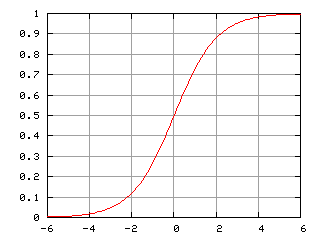
Abb. 4. Logistische Kurve (Sigmoid). Quelle: Wikipedia.
Wir werden den logistischen Regressionsalgorithmus nicht im Detail beschreiben, da er allgemein bekannt ist. Verwenden wir die fertige Klasse CLogitModel aus der Bibliothek Alglib.
Erstellen einer sich selbst optimierenden Klasse
Lassen Sie uns eine separate Klasse CAuto_optimizer erstellen, die eine Kombination aus dem einfachen virtuellen Tester und der Logit-Regression darstellt:
//+------------------------------------------------------------------+ //|Auto optimizer class | //+------------------------------------------------------------------+ class CAuto_optimizer { private: // Logit regression model ||||||||||||||| CMatrixDouble LRPM; CLogitModel Lmodel; CLogitModelShell Lshell; CMNLReport Lrep; int Linfo; double Lout[]; //|||||||||||||||||||||||||||||||||||||||| int number_of_samples, relearn_timout, relearnCounter; virtual void virtual_optimizer(); double lVector[][2]; int hnd, hnd1; public: CAuto_optimizer(int number_of_sampleS, int relearn_timeouT, double diff_degree, int entropy_window) { this.number_of_samples = number_of_sampleS; this.relearn_timout = relearn_timeouT; relearnCounter = 0; LRPM.Resize(this.number_of_samples, 5); hnd = iCustom(NULL, 0, "fractional entropy", false, diff_degree, 1e-05, number_of_sampleS, entropy_window); hnd1 = iCustom(NULL, 0, "fractional entropy", true, diff_degree, 1e-05, number_of_sampleS, entropy_window); } ~CAuto_optimizer() {}; double getTradeSignal(); };
Im Abschnitt //Logit regression model// wird folgendes erstellt: eine Matrix für die Werte x und y, das Logitmodell Lmodel und seine Hilfsklassen. Nach dem Training des Modells empfängt das Array Lout[] die Wahrscheinlichkeiten des Signals, das zu einer der Klassen gehört, 0:1.
Der Konstruktor erhielt die Größe des Lernfensters number_of_samples, den Zeitraum, nach dem das Modell erneut optimiert wird relearn_timout, und den fraktionierten Differenziationsgrad für den Indikator diff_degree sowie das Entropieberechnungsfenster entropy_window.
Betrachten wir die Methode virtual_optimizer() im Detail:
//+------------------------------------------------------------------+ //|Virtual tester | //+------------------------------------------------------------------+ CAuto_optimizer::virtual_optimizer(void) { double indarr[], indarr2[]; CopyBuffer(hnd, 0, 1, this.number_of_samples, indarr); CopyBuffer(hnd1, 0, 1, this.number_of_samples, indarr2); ArraySetAsSeries(indarr, true); ArraySetAsSeries(indarr2, true); for(int s=this.number_of_samples-1;s>=0;s--) { LRPM[s].Set(0, indarr[s]); LRPM[s].Set(1, indarr2[s]); LRPM[s].Set(2, s); if(iClose(NULL, 0, s) > iClose(NULL, 0, s+1)) { LRPM[s].Set(3, 0.0); LRPM[s].Set(4, 1.0); } else { LRPM[s].Set(3, 1.0); LRPM[s].Set(4, 0.0); } } CLogit::MNLTrainH(LRPM, LRPM.Size(), 3, 2, Linfo, Lmodel, Lrep); double profit[], out[], prof[1]; ArrayResize(profit,1); ArraySetAsSeries(profit, true); profit[0] = 0.0; int pos = 0, openpr = 0; for(int s=this.number_of_samples-1;s>=0;s--) { double in[3]; in[0] = indarr[s]; in[1] = indarr2[s]; in[2] = s; CLogit::MNLProcess(Lmodel, in, out); if(out[0] > 0.5 && !pos) {pos = 1; openpr = s;}; if(out[0] < 0.5 && !pos) {pos = -1; openpr = s;}; if(out[0] > 0.5 && pos == 1) continue; if(out[0] < 0.5 && pos == -1) continue; if(out[0] > 0.5 && pos == -1) { prof[0] = profit[0] + (iClose(NULL, 0, openpr) - iClose(NULL, 0, s)); ArrayInsert(profit, prof, 0, 0, 1); pos = 0; } if(out[0] < 0.5 && pos == 1) { prof[0] = profit[0] + (iClose(NULL, 0, s) - iClose(NULL, 0, openpr)); ArrayInsert(profit, prof, 0, 0, 1); pos = 0; } } GraphPlot(profit); }
Die Methode ist offensichtlich sehr einfach und daher schnell. Die erste Spalte der LRPM-Matrix wird in einer Schleife mit den Indikatorwerten + linearem Trendwert gefüllt (sie wurde hinzugefügt). In der nächsten Schleife wird der aktuelle Schlusskurs mit dem vorherigen verglichen, um die Wahrscheinlichkeit eines Deals zu klären: Kaufen oder Verkaufen. Ist der aktuelle Wert größer als der vorherige, dann war das ein Kaufsignal. Ansonsten war dies ein Verkaufssignal. Dementsprechend wird in die folgenden Spalten die Werte 0 und 1eingetragen.
Es handelt sich also um einen sehr einfachen Tester, der nicht darauf abzielt, Signale optimal auszuwählen, sondern sie einfach auf jeder Bar abliest. Der Tester kann durch Methodenüberladung verbessert werden, was jedoch den Rahmen dieses Artikels sprengt.
Danach wird die Logit-Regression mit der Methode MNLTrain() trainiert, die die Matrix, ihre Größe, die Anzahl der Variablen x (hier wird jeweils nur eine Variable übergeben), das Klassenobjekt Lmodel zum Speichern des trainierten Modells und Hilfsklassen akzeptiert.
Nach dem Training wird das Modell getestet und im Optimierungsfenster als Saldenkurve angezeigt. Dies ist visuell effizient, um zu zeigen, wie das Modell an der Lernprobe trainiert wurde. Aber die Leistung wird nicht aus algorithmischer Sicht analysiert.
Der virtuelle Optimierer wird von der folgenden Methode aufgerufen:
//+------------------------------------------------------------------+ //|Get trade signal | //+------------------------------------------------------------------+ double CAuto_optimizer::getTradeSignal() { if(this.relearnCounter==0) this.virtual_optimizer(); relearnCounter++; if(this.relearnCounter>=this.relearn_timout) this.relearnCounter=0; double in[], in1[]; CopyBuffer(hnd, 0, 0, 1, in); CopyBuffer(hnd1, 0, 0, 1, in1); double inn[3]; inn[0] = in[0]; inn[1] = in1[0]; inn[2] = relearnCounter + this.number_of_samples - 1; CLogit::MNLProcess(Lmodel, inn, Lout); return Lout[0]; }
Sie überprüft die Anzahl der Bars, die seit dem letzten Training entstanden sind. Wenn der Wert den angegebenen Schwellenwert überschreitet, sollte das Modell neu trainiert werden. Danach wird der letzte Wert der Indikatoren entlang der Zeiteinheiten kopiert, die seit dem letzten Training vergangen sind. Diese wird mit der Methode MNLProcess() in das Modell eingegeben, die das Ergebnis zurückgibt, das anzeigt, ob der Wert zu einer Klasse 0:1, d.h. dem Handelssignal, gehört.
Erstellen eines Expertenberaters zum Testen der Bibliotheksverwendung
Jetzt müssen wir die Bibliothek in einem handelnden Expert Advisor einbinden und den Signalhandler hinzufügen:
#include <MT4Orders.mqh> #include <Math\Stat\Math.mqh> #include <Trade\AccountInfo.mqh> #include <Auto optimizer.mqh> input int History_depth = 1000; input double FracDiff = 0.5; input int Entropy_window = 50; input int Recalc_period = 100; sinput double MaximumRisk=0.01; sinput double CustomLot=0; input int Stop_loss = 500; //Stop loss, positions protection input int BreakEven = 300; //Break even sinput int OrderMagic=666; static datetime last_time=0; CAuto_optimizer *optimizer = new CAuto_optimizer(History_depth, Recalc_period, FracDiff, Entropy_window); double sig1;
Die Einstellungen des Expert Advisors sind einfach und beinhalten die Fenstergröße History_depth, d.h. die Anzahl der Trainingsbeispiele für den Selbstoptimierer. Der Differenziationsgrad FracDiff und die Anzahl der erhaltenen Bars Recalc_period, danach wird das Modell neu trainiert. Außerdem wurde die Einstellung Entropy_window zur Anpassung des Entropieberechnungsfensters hinzugefügt.
Die letzte Funktion empfängt ein Signal von einem trainierten Modell und führt das Handeln aus:
void placeOrders(){ if(countOrders(0)!=0 || countOrders(1)!=0) { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) { if(OrderType()==0 && sig1 < 0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {}; if(OrderType()==1 && sig1 > 0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {}; } } if(countOrders(0)!=0 || countOrders(1)!=0) return; if(sig1 > 0.5 && (OrderSend(Symbol(),OP_BUY,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { return; } if(sig1 < 0.5 && (OrderSend(Symbol(),OP_SELL,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN)>0)) {} }
Wenn die Wahrscheinlichkeit des Kaufs größer als 0,5 ist, dann ist dies ein Kaufsignal und/oder ein Signal zum Schließen einer Verkaufsposition. Und umgekehrt.
Test des selbstoptimierenden EA und Schlussfolgerungen
Kommen wir zum interessantesten Teil, nämlich zum Test.
Der Expert Advisor wurde mit den spezifizierten Hyperparametern ohne genetische Optimierung, d.h. nahezu zufällig, auf dem EURUSD-Paar mit dem 15-minütigen Zeitrahmen zu Open-Preisen durchgeführt.
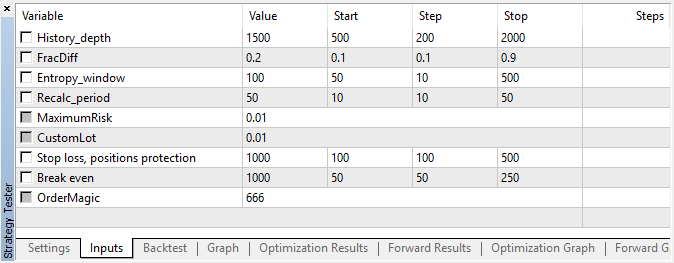
Abb. 5. Einstellungen des getesteten Expert Advisors
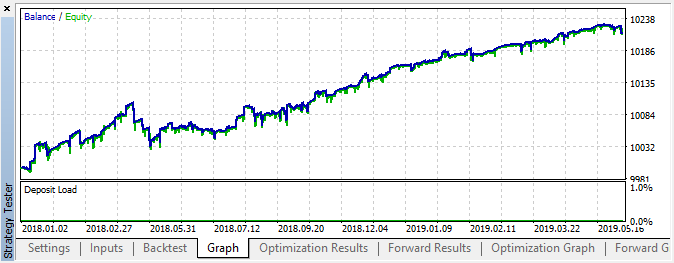
Abb. 6. Testergebnisse mit den angegebenen Einstellungen
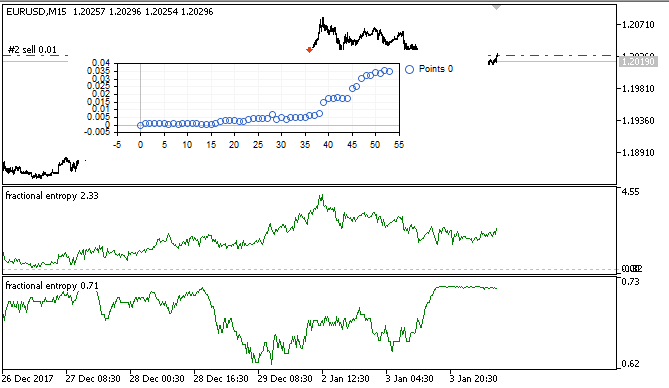
Abb. 7. Virtuelle Testergebnisse in der Trainingsstichprobe
In diesem Zeitraum zeigte die Implementierung ein stabiles Wachstum, so dass der Ansatz für weitere Analysen interessant sein kann.
Schlussendlich haben wir versucht, folgende drei Ziele mit diesem Artikel zu erreichen:
- Verständnis für das "Gedächtnis" des Marktes,
- Bewertung des Gedächtnisses im Hinblick auf die Entropie,
- Entwicklung eine sich selbstoptimierenden Expert Advisors.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/6351
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Entwicklung eines plattformübergreifenden Grider-EAs (Teil II): Kursspannenbasiertes Raster in Trendrichtung
Entwicklung eines plattformübergreifenden Grider-EAs (Teil II): Kursspannenbasiertes Raster in Trendrichtung
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich verstehe, dass im Indikator die Normalisierung der unterschiedlichen Preise auf der Grundlage des einmal berechneten Mittelwerts/Std. erfolgt. Aber wie korrekt ist es, das Modell anhand eines vorher unbekannten Mittelwerts des gesamten hist_display Bereichs zu trainieren? Ist die Verwendung eines gleitenden Fensters für die Normalisierung nicht plausibler?