
Die 100 besten Durchläufe der Optimierung (Teil 1). Entwicklung einer Analyse der Optimierung

- Einführung
- Struktur eines Optimierungsanalysators
- Grafiken
- Arbeiten mit der Datenbank
- Berechnungen
- Der "Presenter"
- Schlussfolgerung
Einführung
Die moderne Technologie hat sich inzwischen so tief in den Bereich des Finanzhandels eingearbeitet, dass es heute kaum noch vorstellbar ist, wie wir ohne sie auskommen könnten. Dennoch wurde noch vor sehr kurzer Zeit der Handel manuell durchgeführt, und es gab ein komplexes System von Handsprachen (die heutzutage schnell in Vergessenheit geraten), das beschreibt, wie viele Wertpapiere man kaufen oder verkaufen will.
PCs ersetzten schnell die traditionellen Handelsmethoden, indem sie den Online-Handel buchstäblich in unsere Haushalte brachten. Jetzt können wir uns die Anlagenangebote in Echtzeit ansehen und entsprechende Entscheidungen treffen. Darüber hinaus führt das Aufkommen von Online-Technologien in der Marktwirtschaft dazu, dass die Reihen der manuellen Händler immer schneller schrumpfen. Mittlerweile werden mehr als die Hälfte des Handels mit Handelsalgorithmen getätigt, und es ist anzumerken, dass MetaTrader 5 die Nummer eins unter den bequemsten Terminals dafür ist.
Aber trotz aller Vorteile dieser Plattform hat sie eine Reihe von Nachteilen, die ich mit der hier beschriebenen Anwendung zu mildern versucht habe. Der Artikel beschreibt die Entwicklung des Programms, das vollständig in MQL5 geschrieben wurde, unter Verwendung der Bibliothek EasyAndFastGUI, die zur Verbesserung der Auswahl der Parameter zur Optimierung des Handelsalgorithmus entwickelt wurde. Es erweitert auch die Analyse des retrospektiven Handels und der allgemeinen EA-Bewertung um neue Funktionen.
Erstens dauert die Optimierung von EAs ziemlich lange. Dies liegt natürlich daran, dass der Tester qualitativ hochwertige Ticks erzeugt (selbst wenn OHLC ausgewählt ist, werden vier Ticks für jede Kerze generiert), sowie an weiteren Ergänzungen, die eine bessere EA-Auswertung ermöglichen. Auf Heim-PCs, die nicht so leistungsfähig sind, kann die Optimierung jedoch mehrere Tage oder Wochen dauern. Es kommt oft vor, dass wir nach der Auswahl der EA-Parameter bald feststellen, dass sie falsch sind, und es gibt nichts verwendbares, außer den Statistiken der Optimierungsdurchläufe und ein paar Bewertungskennzahlen.
Es wäre schön, eine vollständige Statistik pro Optimierungsdurchlauf und Filtrationsfähigkeit (einschließlich bedingter Filter) für jeden von ihnen durch mehrere Parameter zu haben. Es wäre auch gut, die Handelsstatistiken mit der Strategie "Buy And Hold" zu vergleichen und alle Statistiken gegeneinander zu stellen. Darüber hinaus ist es manchmal notwendig, alle Daten der Handelsgeschichte in eine Datei hochzuladen, um die Ergebnisse der einzelnen Geschäfte weiterzuverarbeiten.
Manchmal möchten wir auch sehen, welches Ausmaß von Schlupf der Algorithmus aushalten kann und wie sich der Algorithmus in einem bestimmten Zeitintervall verhält, da einige Strategien vom Markttyp abhängen. Eine Strategie für einen Seitwärtsbewegung mag als Beispiel dienen. Sie verliert in Trendperioden und erwirtschaftet Gewinne in einem Seitwärtsmarkt. Es wäre auch gut, bestimmte Intervalle (nach Datum) als einen vollständigen Satz von Kennzahlen und anderen Ergänzungen (und nicht nur auf einem Preisdiagramm) getrennt vom allgemeinen PL-Diagramm zu betrachten.
Wir sollten auch auf die Vorwärtsprüfungen achten. Sie sind sehr informativ, aber ihre Grafiken werden als Fortsetzung der vorherigen im Standardbericht des Strategieprüfers angezeigt. Anfänger können leicht feststellen, dass ihr Roboter alle Gewinne plötzlich verloren hat und sich dann zu erholen begann (oder schlimmer noch — negativ wurde). In dem hier beschriebenen Programm werden alle Daten hinsichtlich der Optimierungsart (entweder vorwärts oder historisch) überprüft.
Es ist auch wichtig, den Handels-Gral zu erwähnen, nach dem viele EA-Entwickler so gerne suchen. Einige Roboter produzieren 1000% oder mehr pro Monat. Es mag den Anschein haben, dass sie den Markt überholen ("Buy And Hold"-Strategie), aber in der Praxis sieht alles ganz anders aus. Wie das beschriebene Programm zeigt, können diese Roboter wirklich 1000% verdienen, aber sie sind nicht schneller als der Markt.
Das Programm bietet die Trennung einer Analyse zwischen dem Handel mit einem Roboter mit einem vollen Lot (Erhöhen/Reduzieren desselben etc. ..) sowie die Nachahmung eines Handels durch den Roboter mit einem einzigen Lot (Mindestlot zum Handeln verfügbar). Beim Erstellen des "Buy and Hold"-Handelsgraphen berücksichtigt das beschriebene Programm die vom Roboter durchgeführte Volumenverwaltung (d.h. er kauft etwas mehr, wenn die Losgröße erhöht wurde, und reduziert den Betrag eines gekauften Vermögenswertes, wenn sie reduziert wurde). Wenn wir diese beiden Diagramme vergleichen, stellt sich heraus, dass mein Testroboter, der unrealistische Ergebnisse in einem seiner besten Optimierungsdurchläufe zeigte, nicht schneller als der Markt sein konnte. Für eine objektivere Bewertung der Handelsstrategien sollten wir uns daher den Handelsgraphen mit einem Lot ansehen, in dem sowohl der Roboter als auch die Strategie "Buy-and-Hold" so dargestellt werden, als ob mit dem am geringstmöglichen Handelsvolumen gehandelt würde (PL= Profit/Loss — Graph der erzielten Gewinne).
Lassen Sie uns nun einen detaillierteren Blick darauf werfen, wie das Programm entwickelt wurde.
Struktur eines Optimierungsanalysators
Die Programmstruktur sieht wie folgt aus:
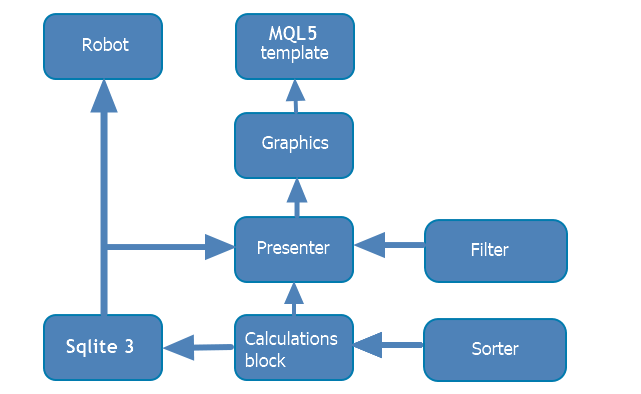
Der resultierende Optimierungsanalysator ist nicht an einen bestimmten Roboter gebunden und nicht Teil davon. Aufgrund der Besonderheiten bei der Erstellung von grafischen Oberflächen in MQL5 wurde jedoch das Entwicklungs-Template des MQL5-EAs als Grundlage für das Programm verwendet. Da sich das Programm als recht groß herausstellte (mehrere tausend Codezeilen), wurde es aus Gründen der Spezifität und Konsistenz in eine Reihe von Blöcken unterteilt (siehe Diagramm oben), die wiederum in Klassen unterteilt wurden. Das Template des Roboters ist nur der Ausgangspunkt für den Start der Anwendung. Jeder der Blöcke wird im Folgenden näher betrachtet. Hier werden wir die Beziehungen zwischen ihnen beschreiben. Um mit der Anwendung zu arbeiten, benötigen wir:
- den Handelsalgorithmus
- Dll Sqlite3
- die oben erwähnte Bibliothek des grafischen Interfaces mit den notwendigen Änderungen (beschrieben im Grafikbock unten)
Der Roboter selbst kann beliebig entwickelt werden (mit OOP, einer Funktion innerhalb der Robotervorlage, importiert aus Dll....). Am wichtigsten ist, dass er die vom MQL5 Wizard bereitgestellte Roboterentwicklungsvorlage verwendet. Sie verbindet eine Datei aus dem Datenbankblock, in dem sich die Klasse, die nach jedem Optimierungsdurchlauf die erforderlichen Daten in die Datenbank hochlädt, befindet. Dieser Teil ist unabhängig und unabhängig von der Anwendung selbst, da die Datenbank beim Start des Roboters im Strategie-Tester gebildet wird.
Der Berechnungsblock ist eine verbesserte Weiterentwicklung meines vorherigen Artikels "Individuelle Darstellung der Handelshistorie und Erstellung von Berichtsdiagrammen".
Datenbank und Berechnungsblock werden sowohl im analysierten Roboter als auch in der beschriebenen Anwendung verwendet. Daher werden sie in das Include-Verzeichnis verschoben. Diese Blöcke übernehmen den Großteil der Arbeit und sind über die Klasse Presenter mit der grafischen Oberfläche verbunden.
Die Klasse Presenter verbindet einzelne Programmblöcke. Jeder der Blöcke hat seine eigene Funktion in der grafischen Oberfläche. Es reagiert auf Tastendruck und andere Ereignisse sowie die Weiterleitung zu anderen logischen Blöcken. Die von ihnen erhaltenen Daten werden an den Präsentator zurückgegeben, wo sie verarbeitet und die entsprechenden Diagramme erstellt, Tabellen gefüllt und andere Interaktionen mit dem grafischen Teil durchgeführt werden.
Der graphische Teil des Programms führt keine konzeptionelle Logik aus. Stattdessen baut es nur ein Fenster mit der gewünschten Schnittstelle auf und ruft während des Tastendrucks die entsprechenden Funktionen des Presenters auf.
Das Programm selbst ist als MQL5-Projekt geschrieben, so dass Sie es strukturierter entwickeln und alle benötigten Dateien mit Code an einer Stelle platzieren können. Das Projekt verfügt über eine weitere Klasse, die im Berechnungsblock beschrieben wird. Diese Klasse wurde speziell für dieses Programm geschrieben. Es sortiert Optimierungsläufe nach der von mir entwickelten Methode. Tatsächlich dient es der gesamten Registerkarte "Auswahl der Optimierung", die die Datenerfassung nach bestimmten Kriterien reduziert.
Die universelle Klasse für das Sortieren ist eine unabhängige Ergänzung des Programms. Sie passt nicht in eine der Blöcke, aber sie ist dennoch ein wichtiger Teil des Programms. Deshalb betrachten wir sie kurz in diesem Teil des Artikels.
Wie der Name schon sagt, die Klasse sortiert. Ihr Algorithmus wurde von eine anderen Webseite entlehnt — Selection sort (in Russisch).
//+------------------------------------------------------------------+ //| E-num der Sortierrichtung | //+------------------------------------------------------------------+ enum SortMethod { Sort_Ascending,// steigend Sort_Descendingly// fallend }; //+------------------------------------------------------------------+ //| Klasse zur Sortierung der übergebenen Daten | //+------------------------------------------------------------------+ class CGenericSorter { public: // Standardkonstruktor CGenericSorter(){method=Sort_Descendingly;} // Sortiermethode template<typename T> void Sort(T &out[],ICustomComparer<T>*comparer); // Auswahl der Sortiermethode void Method(SortMethod _method){method=_method;} // Abfrage der Sortiermethode SortMethod Method(){return method;} private: // Sortiermethode SortMethod method; };
Die Klasse enthält die Template Sort Methode, die die Daten sortiert. Die Template-Methode ermöglicht das Sortieren beliebiger übergebener Daten, einschließlich Klassen und Strukturen. Die Datenvergleichsmethode sollte in einer eigenen Klasse beschrieben werden, die die Schnittstelle IСustomComparer<T> implementiert. Ich musste meine eigene Schnittstelle vom Typ IСomparer entwickeln, nur weil in der konventionellen IСomparer-Schnittstelle der Compare-Methode die enthaltenen Daten nicht per Referenz übergeben werden, während die Übergabe per Referenz eine der Bedingungen für die Übergabe von Strukturen an eine Methode in der Sprache MQL5 ist.
CGenericSorter::Methodenklassenmethode überlädt die Rückgabe und akzeptiert den Datensortierungstyp (in aufsteigender oder absteigender Reihenfolge). Diese Klasse wird in allen Blöcken des Programms verwendet, in denen die Daten sortiert werden.
Grafiken
| Warnung!
Bei der Entwicklung der grafischen Benutzeroberfläche wurde ein Fehler in der verwendeten Bibliothek (EasyAndFastGUI) festgestellt — das grafische Element der ComboBox löschte einige Variablen beim Nachladen nur unvollständig. Gemäß den Empfehlungen (in Russisch) des Bibliotheksentwicklers sollten folgende Änderungen vorgenommen werden, um dies zu beheben: m_item_index_focus =WRONG_VALUE; sollte der Methode CListView::Clear(const bool redraw=false) hinzugefügt werden. Die Methode findet sich in etwa bei Zeile 600 in der Datei ListView.mqh. Der Dateipfad: |
|---|
Um ein Fenster in MQL5 basierend auf der Bibliothek EasyAndFastGUI zu erstellen, wird eine Klasse benötigt, die als Container für alle nachfolgenden Fensterfüllungen dient. Die Klasse sollte von der Klasse CwindEvents abgeleitet sein. Die Methoden sollten innerhalb der Klasse neu definiert werden:
//--- Initialisierung/Deinitialisierung void OnDeinitEvent(const int reason){CWndEvents::Destroy();}; //--- Chart Event Handler virtual void OnEvent(const int id,const long &lparam,const double &dparam,const string &sparam);//
Im Allgemeinen sollte das Fenster zum Erstellen des Fensters wie folgt aussehen:
class CWindowManager : public CWndEvents { public: CWindowManager(void){presenter = NULL;}; ~CWindowManager(void){}; //=============================================================================== // Aufruf von Methoden und Ereignissen : //=============================================================================== //--- Initialisierung/Deinitialisierung void OnDeinitEvent(const int reason){CWndEvents::Destroy();}; //--- Chart Event Handler virtual void OnEvent(const int id,const long &lparam,const double &dparam,const string &sparam); //--- Erstellen des Grafischen Interfaces des Programms bool CreateGUI(void); private: //--- Hauptfenster CWindow m_window; }
Das Fenster selbst wird mit dem Typ Cwindow innerhalb der Klasse erstellt. Es sollten jedoch eine Reihe von Fenstereigenschaften definiert werden, bevor das Fenster angezeigt wird. In diesem speziellen Fall sieht die Fenstererstellungsmethode wie folgt aus:
bool CWindowManager::CreateWindow(const string text) { //--- Fensterpointer zum Array des Fensters hinzufügen CWndContainer::AddWindow(m_window); //--- Koordinaten int x=(m_window.X()>0) ? m_window.X() : 1; int y=(m_window.Y()>0) ? m_window.Y() : 1; //--- Eigenschaften m_window.XSize(WINDOW_X_SIZE+25); m_window.YSize(WINDOW_Y_SIZE); m_window.Alpha(200); m_window.IconXGap(3); m_window.IconYGap(2); m_window.IsMovable(true); m_window.ResizeMode(false); m_window.CloseButtonIsUsed(true); m_window.FullscreenButtonIsUsed(false); m_window.CollapseButtonIsUsed(true); m_window.TooltipsButtonIsUsed(false); m_window.RollUpSubwindowMode(true,true); m_window.TransparentOnlyCaption(true); //--- Festlegen der Tooltips m_window.GetCloseButtonPointer().Tooltip("Close"); m_window.GetFullscreenButtonPointer().Tooltip("Fullscreen/Minimize"); m_window.GetCollapseButtonPointer().Tooltip("Collapse/Expand"); m_window.GetTooltipButtonPointer().Tooltip("Tooltips"); //--- Erstellen der Formulars if(!m_window.CreateWindow(m_chart_id,m_subwin,text,x,y)) return(false); //--- return(true); }
Die Voraussetzungen für diese Methode sind die Zeichenkette, die das Fenster zum Array der Anwendungsfenster hinzufügt und das Formular erstellt. Später, wenn die Anwendung ausgeführt wird und das OnEvent Ereignis ausgelöst wird, läuft eine der Bibliotheksmethoden in einer Schleife über alle Fenster, die in der Anordnung der Fenster aufgelistet sind. Dann geht es über alle Elemente innerhalb des Fensters und sucht nach einem Ereignis, das sich auf das Klicken auf eine beliebige Verwaltungsoberfläche oder das Hervorheben einer Tabellenzeile usw. bezieht. Daher sollte bei der Erstellung jedes neuen Anwendungsfensters eine Referenz zu diesem Fenster im Referenz-Array hinzugefügt werden.
Die entwickelte Anwendung verfügt über eine durch Tabs gegliederte Oberfläche. Es gibt 4 Registerkarten-Container:
//--- Registerkarten CTabs main_tab; // Haupt-Tabs CTabs tab_up_1; // Tabs der Einstellungen und der Ergebnistabelle CTabs tab_up_2; // Tabs mit der Statistik und der Parameterauswahl, so wie den allgemeinen Diagrammen CTabs tab_down; // Tabs der Statistik und dem Speichern in einer Datei
Sie schauen wie auf dem Formular zu sehen ist (rot markiert auf dem Bildschirmfoto)
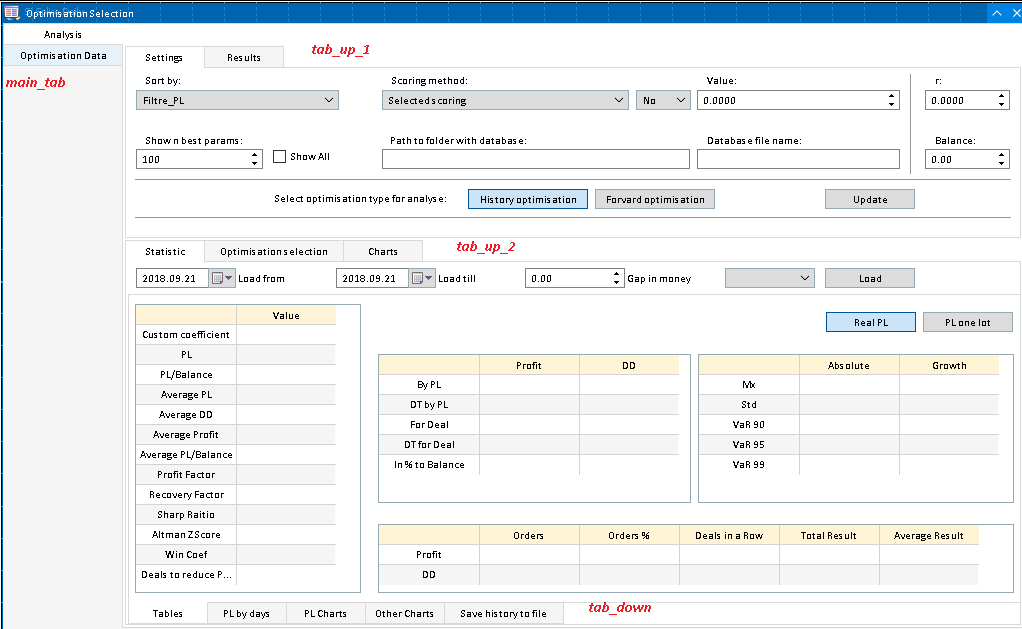
- main_tab trennt die Tabelle mit allen ausgewählten Optimierungsdurchläufen ("Optimierungsdaten") vom Rest der Programmoberfläche. Diese Tabelle enthält alle Ergebnisse, die den Filterbedingungen auf der Registerkarte Einstellungen entsprechen. Die Ergebnisse werden dann sortiert nach der Wahl in der ComboBox — Sort by. Die erhaltenen Daten werden in sortierter Form in die beschriebene Tabelle übertragen. Die Registerkarte mit dem Rest der Programmoberfläche enthält weitere 3 Tab-Container.
- tab_up_1 enthält eine Aufteilung in die Grundeinstellungen des Programms und die Tabelle mit den sortierten Ergebnissen. Zusätzlich zu den genannten bedingten Filtern dient die Registerkarte Einstellungen zur Auswahl der Datenbank und zur Eingabe zusätzlicher Daten. So können Sie beispielsweise wählen, ob Sie alle Daten, die bereits auf der Registerkarte Optimierungsdaten der Tabelle hinzugefügt wurden, in die Datenauswahltabelle eingeben möchten, oder ob nur eine bestimmte Anzahl der besten Parameter (Filterung in absteigender Reihenfolge nach ausgewähltem Verhältnis) ausreichend ist.
- tab_up_2 enthält 3 Registerkarten. Jeder von ihnen enthält die Schnittstelle, die drei verschiedene Arten von Aufgaben ausführt. Die erste Registerkarte enthält den vollständigen Bericht über einen ausgewählten Optimierungspass und ermöglicht die Simulation von Slippage sowie die Berücksichtigung der Handelsgeschichte für einen bestimmten Zeitraum. Der zweite dient als Filter für Optimierungsdurchläufe und hilft, die Empfindlichkeit der Strategie gegenüber verschiedenen Parametern zu definieren und die Anzahl der Optimierungsergebnisse durch Auswahl der geeignetsten Intervalle der interessierenden Parameter einzugrenzen. Die letzte Registerkarte dient als grafische Darstellung der Optimierungsergebnistabelle und zeigt die Gesamtzahl der ausgewählten Optimierungsparameter.
- tab_down verfügt über fünf Registerkarten, von denen vier die Darstellung des Handelsberichts eines EA während der Optimierung mit ausgewählten Parametern sind, während die letzte Registerkarte das Hochladen von Daten in eine Datei ist. Die erste Registerkarte zeigt eine Tabelle mit den geschätzten Verhältnissen. Die zweite Registerkarte enthält die Gewinn-/Verlustverteilung nach Handelstagen. Die dritte Registerkarte stellt eine Gewinn- und Verlustkurve dar, die der Kauf- und Haltestrategie zugrunde liegt (schwarze Grafik), während die vierte Registerkarte die Veränderungen einiger ausgewählter Kennzahlen im Zeitablauf sowie einige zusätzliche interessante und informative Arten von Grafiken darstellt, die durch die Analyse der EA-Handelsergebnisse erhalten werden können.
Der Prozess der Erstellung von Tabs ist ähnlich — der einzige Unterschied ist der Inhalt. Als Beispiel werde ich die Methode zur Erstellung der Hauptregisterkarte vorstellen:
//+------------------------------------------------------------------+ //| Main Tab | //+------------------------------------------------------------------+ bool CWindowManager::CreateTab_main(const int x_gap,const int y_gap) { //--- Sichern des Pointers auf das Hauptelement main_tab.MainPointer(m_window); //--- Array der Tabellenbreiten int tabs_width[TAB_MAIN_TOTAL]; ::ArrayInitialize(tabs_width,45); tabs_width[0]=120; tabs_width[1]=120; //--- string tabs_names[TAB_UP_1_TOTAL]={"Analysis","Optimisation Data"}; //--- Eigenschaften main_tab.XSize(WINDOW_X_SIZE-23); main_tab.YSize(WINDOW_Y_SIZE); main_tab.TabsYSize(TABS_Y_SIZE); main_tab.IsCenterText(true); main_tab.PositionMode(TABS_LEFT); main_tab.AutoXResizeMode(true); main_tab.AutoYResizeMode(true); main_tab.AutoXResizeRightOffset(3); main_tab.AutoYResizeBottomOffset(3); //--- main_tab.SelectedTab((main_tab.SelectedTab()==WRONG_VALUE)? 0 : main_tab.SelectedTab()); //--- Hinzufügen von Karteireitern mit den angegebenen Eigenschaften for(int i=0; i<TAB_MAIN_TOTAL; i++) main_tab.AddTab((tabs_names[i]!="")? tabs_names[i]: "Tab "+string(i+1),tabs_width[i]); //--- Erstellen eines Steuerelements if(!main_tab.CreateTabs(x_gap,y_gap)) return(false); //--- Ein Objekt in das allgemeine Array von Objektgruppen eintragen CWndContainer::AddToElementsArray(0,main_tab); return(true); }
Zusätzlich zu den Inhalten, die variieren können, sind die wichtigsten Codezeilen wie folgt:
- Hinzufügen eines Zeigers zum Hauptelement — der Tab-Container sollte das Element kennen, dem er zugeordnet ist.
- Die Zeilen zur Erstellung von Steuerelementen
- Hinzufügen eines Elements zur allgemeinen Liste der Steuerelemente.
Danach folgen die Steuerelemente, entsprechend der Hierarchie. In der Anwendung wurden 11 Typen von Steuerelementen verwendet. Sie sind alle auf ähnliche Weise erstellt worden, daher wurden die Methoden, die die Steuerelemente hinzufügen, geschrieben, um jedes von ihnen zu erstellen. Betrachten wir die Implementierung von nur einem von ihnen:
bool CWindowManager::CreateLable(const string text, const int x_gap, const int y_gap, CTabs &tab_link, CTextLabel &lable_link, int tabIndex, int lable_x_size) { //--- Sichern des Pointers auf das Hauptelement lable_link.MainPointer(tab_link); //--- Dem Tab zuweisen tab_link.AddToElementsArray(tabIndex,lable_link); //--- Einstellungen lable_link.XSize(lable_x_size); //--- Erstellen if(!lable_link.CreateTextLabel(text,x_gap,y_gap)) return false; //--- Hinzufügen des Objekts zum allg. Array der Objektgruppe CWndContainer::AddToElementsArray(0,lable_link); return true; }
Das übergebene Steuerelement (CTextLabel) sollte sich zusammen mit den Registerkarten das Element merken, dem es als Container zugeordnet ist. Der Tab-Container wiederum merkt sich die Registerkarte, auf der sich das Element befindet. Danach wird das Element mit den erforderlichen Einstellungen und Anfangsdaten gefüllt. Schließlich wird das Objekt dem allgemeinen Array von Objekten hinzugefügt.
Ähnlich wie bei Labels werden weitere Elemente, die innerhalb des Klassencontainers als Felder definiert sind, hinzugefügt. Ich habe bestimmte Elemente getrennt und einige davon in den Klassenbereich "protected" gestellt. Dies sind die Elemente, die keinen Zugriff vom Moderator erfordern. Einige andere Elemente wurden als 'public' zugänglich gemacht. Dies sind die Elemente, die bestimmte Bedingungen oder Auswahlknöpfe definieren, deren Zustand vom Presenter überprüft werden sollte. Mit anderen Worten, alle Elemente und Methoden, deren Zugriff nicht wünschenswert ist, haben ihre Header in den "protected" oder "private" Teilen der Klasse zusammen mit der Referenz auf den presenter. Das Hinzufügen der Referenz zum Presenter erfolgt in Form einer öffentlichen Methode, bei der zuerst das Vorhandensein eines bereits hinzugefügten Referenten überprüft wird und wenn der Verweis darauf noch nicht hinzugefügt wurde, wird der Referent gespeichert. Dies geschieht, um eine dynamische Presenter-Substitution während der Programmausführung zu vermeiden.
Das Fenster selbst wird in der Methode CreateGUI erstellt:
bool CWindowManager::CreateGUI(void) { //--- Fenster erstellen if(!CreateWindow("Optimisation Selection")) return(false); //--- Tabs erstellen if(!CreateTab_main(120,20)) return false; if(!CreateTab_up_1(3,44)) return(false); int indent=WINDOW_Y_SIZE-(TAB_UP_1_BOTTOM_OFFSET+TABS_Y_SIZE-TABS_Y_SIZE); if(!CreateTab_up_2(3,indent)) return(false); if(!CreateTab_down(3,33)) return false; //--- Steuerelement erstellen if(!Create_all_lables()) return false; if(!Create_all_buttons()) return false; if(!Create_all_comboBoxies()) return false; if(!Create_all_dropCalendars()) return false; if(!Create_all_textEdits()) return false; if(!Create_all_textBoxies()) return false; if(!Create_all_tables()) return false; if(!Create_all_radioButtons()) return false; if(!Create_all_SepLines()) return false; if(!Create_all_Charts()) return false; if(!Create_all_CheckBoxies()) return false; // Fenster anzeigen CWndEvents::CompletedGUI(); return(true); }
Wie aus der Implementierung ersichtlich, erzeugt es kein Steuerelement direkt selbst, sondern ruft nur andere Methoden zur Erzeugung dieser Elemente auf. Die wichtigste Zeile Codes, die als letzte in dieser Methode enthalten sein sollte, ist CWndEvents::CompletedGUI();
Diese Zeile schließt die Grafikerstellung ab und stellt sie auf dem Bildschirm eines Benutzers dar. Die Erstellung jedes Bedienelements (sei es durch Trennlinien, Beschriftungen oder Schaltflächen) wird in Methoden mit ähnlichem Inhalt implementiert und die oben genannten Ansätze zur Erstellung grafischer Bedienelemente angewendet. Die Headers der Methoden befinden sich im 'private' Teil der Klasse:
//=============================================================================== // Erstellen des Steuerelements: //=============================================================================== //--- Alle Beschriftungen bool Create_all_lables(); bool Create_all_buttons(); bool Create_all_comboBoxies(); bool Create_all_dropCalendars(); bool Create_all_textEdits(); bool Create_all_textBoxies(); bool Create_all_tables(); bool Create_all_radioButtons(); bool Create_all_SepLines(); bool Create_all_Charts(); bool Create_all_CheckBoxies();
Apropos Grafik, es ist unmöglich, den Teil des Ereignismodells zu überspringen. Für die korrekte Verarbeitung in grafischen Anwendungen, die mit EasyAndFastGUI entwickelt wurden, müssen Sie die folgenden Schritte durchführen:
Erstellen Sie die Methode zur Ereignisbehandlung (z.B. Tastendruck). Diese Methode sollte 'id' und 'lparam' als Parameter akzeptieren. Der erste Parameter gibt die Art eines grafischen Ereignisses an, während der zweite die ID eines Objekts angibt, mit dem die Interaktion stattgefunden hat. Die Implementierung der Methoden ist in allen Fällen ähnlich:
//+------------------------------------------------------------------+ //| Btn_Update_Click | //+------------------------------------------------------------------+ void CWindowManager::Btn_Update_Click(const int id,const long &lparam) { if(id==CHARTEVENT_CUSTOM+ON_CLICK_BUTTON && lparam==Btn_update.Id()) { presenter.Btn_Update_Click(); } }
Überprüfen Sie zunächst die Bedingung (ob die Schaltfläche gedrückt wurde oder das Listenelement ausgewählt wurde...). Als Nächstes überprüfen Sie lparam, wobei die an die Methode übergebene ID mit der ID des gewünschten Listenelements verglichen wird.
Alle Deklarationen von Ereignissen, die auf Knopfdruck erfolgen, befinden sich im Teil 'private' der Klasse. Das Ereignis sollte aufgerufen werden, um eine Antwort darauf zu erhalten. Deklarierte Ereignisse werden in der überladenen Methode OnEvent aufgerufen:
//+------------------------------------------------------------------+ //| OnEvent | //+------------------------------------------------------------------+ void CWindowManager::OnEvent(const int id,const long &lparam,const double &dparam,const string &sparam) { Btn_Update_Click(id,lparam); Btn_Load_Click(id,lparam); OptimisationData_inMainTable_selected(id,lparam); OptimisationData_inResults_selected(id,lparam); Update_PLByDays(id,lparam); RealPL_pressed(id,lparam); OneLotPL_pressed(id,lparam); CoverPL_pressed(id,lparam); RealPL_pressed_2(id,lparam); OneLotPL_pressed_2(id,lparam); RealPL_pressed_4(id,lparam); OneLotPL_pressed_4(id,lparam); SelectHistogrameType(id,lparam); SaveToFile_Click(id,lparam); Deals_passed(id,lparam); BuyAndHold_passed(id,lparam); Optimisation_passed(id,lparam); OptimisationParam_selected(id,lparam); isCover_clicked(id,lparam); ChartFlag(id,lparam); show_FriquencyChart(id,lparam); FriquencyChart_click(id,lparam); Filtre_click(id,lparam); Reset_click(id,lparam); RealPL_pressed_3(id,lparam); OneLotPL_pressed_3(id,lparam); ShowAll_Click(id,lparam); DaySelect(id,lparam); }
Das Verfahren wiederum wird aus dem Template des Roboters aufgerufen. Somit erstreckt sich das Ereignismodell vom Template des Roboters (siehe unten) bis zur grafischen Oberfläche. Die GUI übernimmt die gesamte Verarbeitung, Sortierung und Umleitung für die anschließende Bearbeitung im Präsentator. Das Template des Roboters selbst ist ein Ausgangspunkt des Programms. Es sieht wie folgt aus:
#include "Presenter.mqh" CWindowManager _window; CPresenter Presenter(&_window); //+------------------------------------------------------------------+ //| Initialisierungsfunktion des Experten | //+------------------------------------------------------------------+ int OnInit() { //--- if(!_window.CreateGUI()) { Print(__FUNCTION__," > Failed to create the graphical interface!"); return(INIT_FAILED); } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Deinitialisierungsfunktion des Experten | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- _window.OnDeinitEvent(reason); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OnChartEvent(const int id, const long &lparam, const double &dparam, const string &sparam) { _window.ChartEvent(id,lparam,dparam,sparam); } //+------------------------------------------------------------------+
Arbeiten mit der Datenbank
Bevor man sich mit diesem recht umfangreichen Teil des Projekts beschäftigt, lohnt es sich, ein paar Worte über die getroffene Wahl zu sagen. Eines der ersten Projektziele war es, die Arbeit mit den Optimierungsergebnissen nach Abschluss der Optimierung selbst sowie die jederzeitige Verfügbarkeit dieser Ergebnisse zu ermöglichen. Das Speichern von Daten in einer Datei wurde sofort als ungeeignet verworfen. Es würde die Erstellung mehrerer Tabellen (die tatsächlich eine einzige große Tabelle bilden, aber mit einer unterschiedlichen Anzahl von Zeilen) oder Dateien erfordern.
Beides ist nicht sehr praktisch. Außerdem ist die Methode schwieriger zu implementieren. Die zweite Methode ist das Erstellen von Optimierungsrahmen. Das Toolkit selbst ist gut, aber wir werden während des Optimierungsprozesses nicht mit Optimierungen arbeiten. Außerdem ist die Frames-Funktionalität nicht so gut wie die der Datenbank. Darüber hinaus sind die Frames für MetaTrader konzipiert, während die Datenbank bei Bedarf in jedem Analyseprogramm eines Drittanbieters verwendet werden kann.
Die Auswahl der richtigen Datenbank genügte bereits. Wir brauchten eine schnelle und beliebte Datenbank, die bequem zu vernetzen ist und keine zusätzliche Software erfordert. Die Datenbank Sqlite erfüllt alle Kriterien. Die genannten Eigenschaften machen sie so beliebt. Um sie zu verwenden, verbinden Sie die vom Anbieter bereitgestellten Datenbanken mit dem Dll-Projekt. Dll-Dateien sind in C geschrieben und lassen sich leicht mit MQL5-Anwendungen verknüpfen, was eine schöne Ergänzung ist, da Sie keine einzige Codezeile in einer dritten Sprache schreiben müssen, was das Projekt erschweren würde. Zu den Nachteilen dieses Ansatzes gehört, dass Dll Sqlite keine komfortable API für die Arbeit mit der Datenbank bereitstellt. Daher ist es erforderlich, mindestens einen minimalen Wrapper für die Arbeit mit der Datenbank zu beschreiben. Ein Beispiel für das Schreiben dieser Funktionalität wurde im Artikel "SQL und MQL5: Mit der SQLite Datenbank arbeiten". Für dieses Projekt wurde ein Teil des Codes verwendet, der sich auf die Interaktion mit WinApi und den Import einiger Funktionen von dll nach MQL5 aus dem genannten Artikel bezieht. Was den Wrapper betrifft, so habe ich mich entschieden, ihn selbst zu schreiben.
Infolgedessen besteht der Teil der Datenbank aus dem Ordner Sqlite3, in dem ein praktischer Wrapper für die Arbeit mit der Datenbank beschrieben ist, und dem Ordner OptimisationSelector, der speziell für das entwickelte Programm erstellt wurde. Beide Ordner befinden sich im Verzeichnis MQL5/Include. Wie bereits erwähnt, werden für die Arbeit mit der Datenbank eine Reihe von Funktionen der Windows-Standardbibliothek verwendet. Alle Funktionen dieses Teils der Anwendung befinden sich im WinApi-Verzeichnis. Zusätzlich zu den erwähnten 'Entlehnungen' habe ich auch den Code zur Erstellung einer gemeinsamen Ressource (Mutex) von CodeBase verwendet. Bei der Arbeit mit der Datenbank aus zwei Quellen (nämlich, wenn der Optimierungsanalysator die während der Optimierung verwendete Datenbank öffnet), sollten die vom Programm erhaltenen Daten immer vollständig sein. Aus diesem Grund ist eine gemeinsame Ressource erforderlich. Es stellt sich heraus, dass, wenn eine der Seiten (Optimierungsprozess oder Analysator) die Datenbank aktiviert, die zweite wartet, bis ihr Gegenstück ihre Arbeit beendet hat. Die Sqlite-Datenbank ermöglicht das Lesen aus mehreren Threads. Aufgrund des Themas des Artikels werden wir den resultierenden Wrapper für die Arbeit mit der sqlite3-Datenbank von MQL5 nicht im Detail betrachten. Stattdessen beschreiben wir nur einige Punkte der Implementierungs- und Anwendungsmethoden. Wie bereits erwähnt, befindet sich die Hülle für die Arbeit mit der Datenbank im Ordner Sqlite3. Es gibt drei Dateien darin. Gehen wir sie in der Reihenfolge des Schreibens durch.
- Das erste, was wir brauchen, ist, die notwendigen Funktionen für die Arbeit mit der Datenbank aus der Dll zu importieren. Da das Ziel darin bestand, einen Wrapper mit der minimal erforderlichen Funktionalität zu erstellen, habe ich nicht einmal 1% der Gesamtzahl der von den Datenbankentwicklern bereitgestellten Funktionen importiert. Alle benötigten Funktionen werden in die Datei sqlite_amalgmation.mqh importiert. Diese Funktionen sind auf der Website des Entwicklers gut kommentiert und auch in der obigen Datei beschriftet. Auf Wunsch können Sie die gesamte Header-Datei auf die gleiche Weise importieren. Das Ergebnis ist eine vollständige Liste aller Funktionen und damit die Möglichkeit, darauf zuzugreifen. Die Liste der importierten Funktionen sieht wie folgt aus:
#import "Sqlite3_32.dll" int sqlite3_open(const uchar &filename[],sqlite3_p32 &paDb);// Öffnen der Datenbank int sqlite3_close(sqlite3_p32 aDb); // Schließen der Datenbank int sqlite3_finalize(sqlite3_stmt_p32 pStmt);// Befehlsvervollständigung int sqlite3_reset(sqlite3_stmt_p32 pStmt); // Rücksetzen des Befehls int sqlite3_step(sqlite3_stmt_p32 pStmt); // Zur nächsten Zeile beim Lesen der Befehle int sqlite3_column_count(sqlite3_stmt_p32 pStmt); // Berechnen der Spaltenzahl int sqlite3_column_type(sqlite3_stmt_p32 pStmt,int iCol); // Abfrage des Typs der gewählten Spalte int sqlite3_column_int(sqlite3_stmt_p32 pStmt,int iCol);// Konvertieren des Wertes in int long sqlite3_column_int64(sqlite3_stmt_p32 pStmt,int iCol); // Konvertieren des Wertes in int64 double sqlite3_column_double(sqlite3_stmt_p32 pStmt,int iCol); // Konvertieren des Wertes in double const PTR32 sqlite3_column_text(sqlite3_stmt_p32 pStmt,int iCol);// Abfragen des Textes int sqlite3_column_bytes(sqlite3_stmt_p32 apstmt,int iCol); // Abfragen der Bytezahl, die die Zeile der übergebenen Zelle belegt int sqlite3_bind_int64(sqlite3_stmt_p32 apstmt,int icol,long a);// Kombination der Abfrage mit einem Wert (Typ int64) int sqlite3_bind_double(sqlite3_stmt_p32 apstmt,int icol,double a);// Kombination der Abfrage mit einem Wert (Typ double) int sqlite3_bind_text(sqlite3_stmt_p32 apstmt,int icol,char &a[],int len,PTRPTR32 destr);// Kombination der Abfrage mit einem Wert (Typ string (char* — in C++)) int sqlite3_prepare_v2(sqlite3_p32 db,const uchar &zSql[],int nByte,PTRPTR32 &ppStmt,PTRPTR32 &pzTail);// Vorbereiten der Abfrage int sqlite3_exec(sqlite3_p32 aDb,const char &sql[],PTR32 acallback,PTR32 avoid,PTRPTR32 &errmsg);// Sql-Ausführung int sqlite3_open_v2(const uchar &filename[],sqlite3_p32 &ppDb,int flags,const char &zVfs[]); // Öffnen der Datenbank mit den Parametern #import
Datenbanken, die von den Entwicklern bereitgestellt werden, sollten im Ordner Libraries abgelegt werden und die Namen Sqlite3_32.dll und Sqlite3_64.dll entsprechend ihrer Bitanzahl erhalten, damit der dll-Datenbank-Wrapper funktioniert. Sie können Dll-Daten aus den an den Artikel angehängten Dateien übernehmen, sie selbst aus Sqlite Amalgmation kompilieren oder sie aus der Website der Sqlite-Entwickler übernehmen. Ihre Anwesenheit ist eine Voraussetzung für das Programm. Sie müssen auch dem EA erlauben, Dll zu importieren.
- Die zweite Sache ist, einen funktionalen Wrapper für die Verbindung zur Datenbank zu schreiben. Dies sollte eine Klasse sein, die eine Verbindung zur Datenbank herstellt und diese im Destruktor freigibt (Verbindungen zur Datenbank trennt). Außerdem sollte sie in der Lage sein, einfache Zeichenketten-Sql-Befehle auszuführen, Transaktionen zu verwalten und Abfragen (Anweisungen) zu erstellen. Alle beschriebenen Funktionen wurden in der Klasse CsqliteManager implementiert — seit ihrer Erstellung beginnt der Prozess der Interaktion mit der Datenbank.
//+------------------------------------------------------------------+ //| Klasse zur Datenbank-Verbindung und -Management | //+------------------------------------------------------------------+ class CSqliteManager { public: CSqliteManager(){db=NULL;} // Leerer Konstruktor CSqliteManager(string dbName); // Pass the name CSqliteManager(string dbName,int flags,string zVfs); // Übergeben von Name und dem Verbindungsflag CSqliteManager(CSqliteManager &other) { db=other.db; } // Kopieren des Konstruktors ~CSqliteManager(){Disconnect();};// Destruktor void Disconnect(); // Abtrennen der Datenbank bool Connect(string dbName,int flags,string zVfs); // Parametrische Verbindung zur Datenbank bool Connect(string dbName); // Verbinden mit der Datenbank über den Namen void operator=(CSqliteManager &other){db=other.db;}// Zuweisungsoperator sqlite3_p64 DB() { return db; }; // Abfragen des Pointers auf die Datenbank sqlite3_stmt_p64 Create_statement(const string sql); // Erstellen des Befehls bool Execute(string sql); // Befehlsausführung void Execute(string sql,int &result_code,string &errMsg); // Befehlsausführung und Rückgabe von Fehlernummer und Nachricht void BeginTransaction(); // Übertragungsbeginn void RollbackTransaction(); // Übertragungsrücksetzung void CommitTransaction(); // Übertragungsbestätigung private: sqlite3_p64 db; // Datenbank void stringToUtf8(const string strToConvert,// Zeichenfolge, die mit utf-8-Kodierung in ein Array konvertiert werden soll uchar &utf8[],//Ein Array in der utf-8-Codierung, in dem der konvertierte String strToConvert platziert wird const bool untilTerminator=true) { // Die Anzahl der Zeichen, die in das utf8-Array kopiert und entsprechend in die utf-8-Kodierung konvertiert werden. //--- int count=untilTerminator ? -1 : StringLen(strToConvert); StringToCharArray(strToConvert,utf8,0,count,CP_UTF8); } };
Wie aus dem Code ersichtlich, hat die resultierende Klasse die Fähigkeit, zwei Arten von Verbindungen in der Datenbank zu erstellen (textuelle und spezifizierende Parameter). Die Methode Create_sttement bildet eine Anforderung an die Datenbank und gibt einen Pointer darauf zurück. Überladungen von Exequte-Methoden führen einfache Zeichenkettenabfragen durch, während Transaktionsmethoden Transaktionen erstellen und akzeptieren/abbrechen. Die Verbindung zur Datenbank selbst wird in der Variablen db gespeichert. Wenn wir die Disconnect-Methode angewendet haben oder die Klasse gerade mit dem Standardkonstruktor erstellt haben (ich hatte noch keine Zeit, mich mit der Datenbank zu verbinden), ist die Variable NULL. Wenn wir die Verbindungsmethode wiederholt aufrufen, trennen wir die Verbindung zur zuvor verbundenen Datenbank und verbinden uns mit der neuen. Da die Verbindung zur Datenbank die Übergabe einer Zeichenkette im UTF-8-Format erfordert, verfügt die Klasse über eine spezielle 'private' Methode, die die Zeichenkette in das gewünschte Datenformat konvertiert.
- Die nächste Aufgabe ist die Erstellung eines Wrappers für die komfortable Arbeit mit Anfragen (Statement). Eine Anforderung an die Datenbank sollte erstellt und vernichtet werden. Eine Anforderung wird vom CsqliteManager erstellt, aber der Speicher wird nicht überwacht. Mit anderen Worten, nach der Erstellung einer Anforderung muss sie vernichtet werden, wenn sie nicht mehr benötigt wird, andernfalls kann sie die Verbindung zur Datenbank nicht trennen, und wenn wir versuchen, die Arbeit mit der Datenbank abzuschließen, erhalten wir eine Ausnahme, die anzeigt, dass die Datenbank beschäftigt ist. Außerdem sollte eine Anweisungs-Wrapper-Klasse in der Lage sein, die Anforderung mit übergebenen Parametern zu füllen (wenn sie gebildet wurde als "INSERT INTO table_1 VALUES(@ID,@Param_1,@Param_2);"). Darüber hinaus sollte eine bestimmte Klasse in der Lage sein, die darin enthaltene Anfrage auszuführen (Exequte-Methode).
typedef bool(*statement_callback)(sqlite3_stmt_p64); // Callback, der ausgeführt wird, wenn die Anforderung ausgeführt wird, gibt bei Erfolg true zurück. If successful, a 'true' is performed //+------------------------------------------------------------------+ //| Klasse zur Datenbankabfrage | //+------------------------------------------------------------------+ class CStatement { public: CStatement(){stmt=NULL;} // Leerer Konstruktor CStatement(sqlite3_stmt_p64 _stmt){this.stmt=_stmt;} // Konstruktor mit dem Parameter — dem Pointer zum Befehl ~CStatement(void){if(stmt!=NULL)Sqlite3_finalize(stmt);} // Destruktor sqlite3_stmt_p64 get(){return stmt;} // Abfrage des Pointers zum Befehl void set(sqlite3_stmt_p64 _stmt); // Setzen des Pointers zum Befehl bool Execute(statement_callback callback=NULL); // Befehlsausführung bool Parameter(int index,const long value); // Parameter hinzufügen bool Parameter(int index,const double value); // Parameter hinzufügen bool Parameter(int index,const string value); // Parameter hinzufügen private: sqlite3_stmt_p64 stmt; };
Die Überladung der Parametermethode füllen die Anforderungsparameter. Die Methode 'set' speichert die übergebene Anweisung in der Variablen'stmt': Wird festgestellt, dass vor dem Speichern der neuen eine alte Anforderung bereits in der Klasse gespeichert wurde, wird die Methode Sqlite3_finalize für die zuvor gespeicherte Anforderung aufgerufen.
- Die abschließende Klasse in der Datenbank-Verarbeitungs-Wrapper ist CSqliteReader, der in der Lage ist, eine Antwort aus der Datenbank zu lesen. Ähnlich wie bei früheren Klassen ruft die Klasse in ihrem Destruktor die Methode sqlite3_reset auf — sie löscht die Anforderung und ermöglicht es Ihnen, mit ihr weiter zu arbeiten. In den neuen Versionen der Datenbank ist der Aufruf dieser Funktion nicht notwendig, wurde aber von den Entwicklern belassen. Ich habe es im Wrapper verwendet, für alle Fälle. Auch diese Klasse sollte ihre Hauptaufgaben erfüllen, nämlich eine Antwort aus der Datenbank Zeichenkette für Zeichenkette zu lesen mit der Möglichkeit, die gelesenen Daten in das entsprechende Format zu konvertieren.
//+------------------------------------------------------------------+ //| Klasse zum Lesen der Antworten aus der Datenbank | //+------------------------------------------------------------------+ class CSqliteReader { public: CSqliteReader(){statement=NULL;} // leerer Konstruktor CSqliteReader(sqlite3_stmt_p64 _statement) { this.statement=_statement; }; // Konstruktor mit dem Pointer zum Befehl CSqliteReader(CSqliteReader &other) : statement(other.statement) {} // Kopieren des Konstruktors ~CSqliteReader() { Sqlite3_reset(statement); } // Destruktor void set(sqlite3_stmt_p64 _statement); // Hinzufügen einer Referenz zum Befehl void operator=(CSqliteReader &other){statement=other.statement;}// Zuweisungsoperator des Readers void operator=(sqlite3_stmt_p64 _statement) {set(_statement);}// Zuweisungsoperator des Befehls bool Read(); // Lesen der Zeichenkette int FieldsCount(); // Zählen der Spaltenzahl int ColumnType(int col); // Abfrage des Spaltentyps bool IsNull(int col); // Prüfen, ob Wert == SQLITE_NULL long GetInt64(int col); // Konvertieren in 'int' double GetDouble(int col);// Konvertieren in 'double' string GetText(int col);// Konvertieren in 'string' private: sqlite3_stmt_p64 statement; // Pointer zum Befehl };
Nachdem wir nun die beschriebenen Klassen mit den Funktionen für die Arbeit mit der von Sqlite3.dll hochgeladenen Datenbank implementiert haben, ist es an der Zeit, die Klassen zu beschreiben, die mit der Datenbank aus dem beschriebenen Programm arbeiten.
Die Struktur der erstellten Datenbank ist wie folgt:
Tabelle Buy And Hold:
- Time — X-Achse (Zeitintervalltext)
- PL_total — Gewinn/Verlust, wenn wir die Losgröße im Verhältnis zum Roboter erhöhen
- PL_oneLot — Gewinn/Verlust beim Handel mit konstant einem Lot
- DD_total — Drawdown, wenn Sie viel handeln, wie ein Roboter handelt.
- DD_oneLot — Drawdown beim Handel mit konstant einem Lot
- isForvard — Eigenschaft des Vorwärtsdiagramms
Tabelle OptimisationParams:
- ID — eindeutiger Auto-Filling-Eröffnungsindex in der Datenbank
- HistoryBorder — Datum des Abschlusses der historischen Optimierung
- TF — Zeitrahmen
- Param_1....Param_n — Parameter
- InitalBalance — Erstsaldo
Tabelle ParamsCoefitients:
- ID — externer Schlüssel, Referenz auf OptimisationParams(ID)
- isForvard — Objekt der Vorwärtsoptimierung
- isOneLot — Eigenschaft des Diagramms, auf dem das Verhältnis basiert.
- DD — Drawdown
- averagePL — durchschnittlicher Gewinn/Verlust des PL-Diagramms
- averageDDD — durchschnittlicher Drawdown
- averageProfit — durchschnittlicher Gewinn
- profitFactor — Profit-Faktor
- recoveryFactor — Erholungsfaktor
- sharpRatio — Sharpe Ratio
- altman_Z_Score — Altman Z-Score
- VaR_absolute_90 — VaR 90
- VaR_absolute_95 — VaR 95
- VaR_absolute_99 — VaR 99
- VaR_Wachstum_90 — VaR 90
- VaR_Wachstum_95 — VaR 95
- VaR_Wachstum_99 — VaR 99
- winCoef — Gewinnquote
- customCoef — benutzerdefiniertes Verhältnis
Tabelle ParamType:
- ParamName — Name der Roboterparameter
- ParamType — Typ des Roboterparameters (int/doppelt/string)
Tabelle TradingHistory:
- ID — externe Schlüsselreferenz auf OptimisationParams(ID)
- isForvard — Flag des Vorwärtstests
- Symbol — Symbol
- DT_open — Eröffnungszeitpunkt
- Day_open — Tag der Eröffnung
- DT_close — Abschlusszeitpunkt
- Day_close — Tag des Abschlusszeitpunkts
- Volume — Anzahl der Lots
- isLong — Eigenschaft long/short
- Preis_in — Eröffnungspreis
- Price_out — Ausstiegspreis
- PL_oneLot — Gewinn beim Handel mit konstant einem Lot
- PL_forDeal — Gewinn beim Handeln wie vorher
- OpenComment — Kommentar zur Eröffnung
- CloseComment — Kommentar beim Ausstieg
Basierend auf der bereitgestellten Datenbankstruktur können wir sehen, dass einige Tabellen den externen Schlüssel verwenden, um auf die Tabelle OptimisationParams zu verweisen, in der wir die EA-Parameter speichern. Jede Spalte eines Eingabeparameters trägt ihren Namen (z.B. Fast/Slow — Fast/Slow — Fast/Slow Moving Average). Außerdem sollte jede Spalte ein bestimmtes Datenformat haben. Viele Sqlite-Datenbanken werden erstellt, ohne das Datenformat der Tabellenspalte zu definieren. In diesem Fall werden alle Daten als Zeilen gespeichert. Wir müssen jedoch das genaue Datenformat kennen, da wir die Verhältnisse nach einer bestimmten Eigenschaft sortieren sollten, was bedeutet, dass die aus der Datenbank hochgeladenen Daten in ihr ursprüngliches Format umgewandelt werden.
Um dies zu tun, sollten wir ihr Format kennen, bevor wir die Daten in die Datenbank eingeben. Es gibt mehrere Möglichkeiten: die Erstellung einer Template-Methode und die Übertragung des Konverters in sie oder die Erstellung einer Klasse, die in der Tat eine universelle Speicherung mehrerer Datentypen (in die jeder Datentyp konvertiert werden kann) in Kombination mit dem Namen der EA-Variablen ist. Ich habe die zweite Option ausgewählt und die Klasse CDataKeeper erstellt. Die beschriebene Klasse kann 3 Datentypen[int, double, string] speichern, während alle anderen Datentypen, die als EA-Eingabeformate verwendet werden können, auf die eine oder andere Weise in sie umgewandelt werden können.
//+------------------------------------------------------------------+ //| Typen der Daten der Eingabeparameter des EAs | //+------------------------------------------------------------------+ enum DataTypes { Type_INTEGER,// int Type_REAL,// double, float Type_Text // string }; //+------------------------------------------------------------------+ //| Vergleichsergebnis von zwei CDataKeeper | //+------------------------------------------------------------------+ enum CoefCompareResult { Coef_Different,// unterschiedliche Datentypen oder Variablennamen Coef_Equal,// Variablen sind gleich Coef_Less, // aktuelle Variable ist kleiner als die vorherige Coef_More // aktuelle Variable ist größer als die vorherige }; //+---------------------------------------------------------------------+ //| Klasse zum Speichern bestimmter Robotereingaben. | //| Es können folgende Typen gesichert werden: [int, double, string] | //+---------------------------------------------------------------------+ class CDataKeeper { public: CDataKeeper(); // Konstruktor CDataKeeper(const CDataKeeper&other); // Kopieren des Konstruktors CDataKeeper(string _variable_name,int _value); // Parametrischer Konstruktor CDataKeeper(string _variable_name,double _value); // Parametrischer Konstruktor CDataKeeper(string _variable_name,string _value); // Parametrischer Konstruktor CoefCompareResult Compare(CDataKeeper &data); // Vergleichsmethode DataTypes getType(){return variable_type;}; // Abfrage des Datentyps string getName(){return variable_name;}; // Abfrage des Parameternamens string valueString(){return value_string;}; // Parameterabfrage int valueInteger(){return value_int;}; // Parameterabfrage double valueDouble(){return value_double;}; // Parameterabfrage string ToString(); // Konvertieren eines Parameters in eine Zeichenkette. Wenn dies ein Zeichenkettenparameter ist, werden einfache Anführungszeichen von beiden Seiten zur Zeichenkette hinzugefügt <<'>> private: string variable_name,value_string; // Variablenname und Variable der Zeichenkette int value_int; // Int Variable double value_double; // Double Variable DataTypes variable_type; // Variablentyp int compareDouble(double x,double y) // Vergleich von 'Doubles' bis auf 10 Dezimalstellen { double diff=NormalizeDouble(x-y,10); if(diff>0) return 1; else if(diff<0) return -1; else return 0; } };
Drei überladene Konstruktoren akzeptieren den Variablennamen als ersten Parameter, während der zweite den entsprechenden Typ verlangt. Diese Werte werden in globalen Klassenvariablen gespeichert, die mit 'value' beginnen und von einer Typangabe gefolgt werden. Die Methode getType() gibt den Typ als eine oben angegebene Aufzählung zurück, während die Methode getName() den Variablennamen zurückgibt. Methoden, die mit 'value' beginnen, geben die Variable des gewünschten Typs zurück, aber wenn die Methode valueDouble() aufgerufen wird, während die in der Klasse gespeicherte Variable vom Typ 'int' ist, wird NULL zurückgegeben. Die Methode ToString() konvertiert den Wert einer der Variablen in eine Zeichenkette. Wenn die Variable jedoch anfangs eine Zeichenkette war, werden ihr die einfachen Anführungszeichen hinzugefügt (um SQL-Anfragen komfortabler zu gestalten). Die Methode Compare (CDataKeeper & ther) hilft beim Vergleich von zwei Objekten des CDataKeeper-Typs — Compare:
- EA-Variablenname
- Variablentyp
- Variablenwert
Wenn die ersten beiden Vergleiche fehlschlugen, dann versuchen wir, zwei verschiedene Parameter zu vergleichen (z.B. die Periode des schnelllebigen Durchschnitts mit der Periode des langsameren), und dementsprechend können wir dies nicht tun, da wir nur Daten desselben Typs vergleichen müssen. Daher geben wir den Wert Coef_Different des Typs CoefCompareResult zurück. In anderen Fällen wird ein Vergleich durchgeführt und ein gewünschtes Ergebnis zurückgegeben. Die Vergleichsmethode selbst ist wie folgt implementiert:
//+------------------------------------------------------------------+ //| Vergleich des aktuellen Parameters mit dem übergebenen | //+------------------------------------------------------------------+ CoefCompareResult CDataKeeper::Compare(CDataKeeper &data) { CoefCompareResult ans=Coef_Different; if(StringCompare(this. variable_name,data.getName())==0 && this.variable_type==data.getType()) // Vergleich von Name und Typ { switch(this.variable_type) // Wertevergleich { case Type_INTEGER : ans=(this.value_int==data.valueInteger() ? Coef_Equal :(this.value_int>data.valueInteger() ? Coef_More : Coef_Less)); break; case Type_REAL : ans=(compareDouble(this.value_double,data.valueDouble())==0 ? Coef_Equal :(compareDouble(this.value_double,data.valueDouble())>0 ? Coef_More : Coef_Less)); break; case Type_Text : ans=(StringCompare(this.value_string,data.valueString())==0 ? Coef_Equal :(StringCompare(this.value_string,data.valueString())>0 ? Coef_More : Coef_Less)); break; } } return ans; }
Die typunabhängige Darstellung von Variablen ermöglicht es, diese in einer komfortableren Form zu verwenden, wobei sowohl der Name, der Datentyp der Variablen als auch deren Wert berücksichtigt werden.
Die nächste Aufgabe ist die Erstellung der oben beschriebenen Datenbank. Dazu wird die Klasse CDatabaseWriter verwendet.
//+---------------------------------------------------------------------------------+ //| Call-back berechnen des Nutzerverhältnisses | //| historische Daten und die Flags der historischen Typen der Verhältnisberechnung | //| werden übergeben | //+---------------------------------------------------------------------------------+ typedef double(*customScoring_1)(const DealDetales &history[],bool isOneLot); //+---------------------------------------------------------------------------------+ //| Call-back berechnen des Nutzerverhältnisses | //| Verbindung zur Datenbank (nur lesen), Historie und verlangtes Flag des | //| Verhältnistyps werden übergeben | //+---------------------------------------------------------------------------------+ typedef double(*customScoring_2)(CSqliteManager *dbManager,const DealDetales &history[],bool isOneLot); //+---------------------------------------------------------------------------------+ //| Klasse zur Datensicherung in der Datenbank und Erstellen der Datenbank davor | //+---------------------------------------------------------------------------------+ class CDBWriter { public: // Aufruf einer der Rücksetzungen OnInit void OnInitEvent(const string DBPath,const CDataKeeper &inputData_array[],customScoring_1 scoringFunction,double r,ENUM_TIMEFRAMES TF=PERIOD_CURRENT); // Call-back 1 void OnInitEvent(const string DBPath,const CDataKeeper &inputData_array[],customScoring_2 scoringFunction,double r,ENUM_TIMEFRAMES TF=PERIOD_CURRENT); // Call-back 2 void OnInitEvent(const string DBPath,const CDataKeeper &inputData_array[],double r,ENUM_TIMEFRAMES TF=PERIOD_CURRENT);// Kein Call-back und kein Nutzerverhältnis (ist gleich Null) double OnTesterEvent();// Aufruf von OnTester void OnTickEvent();// Aufruf von OnTick private: CSqliteManager dbManager; // Verbinder zur Datenbank CDataKeeper coef_array[]; // Eingabeparameter datetime DT_Border; // Zeitpunkt der letzten Kerze (berechnet in OnTickEvent) double r; // risikofreien Rate customScoring_1 scoring_1; // Call-back customScoring_2 scoring_2; // Call-back int scoring_type; // Call-back Typ [1,2] string DBPath; // Pfad zur Datenbank double balance; // Saldo ENUM_TIMEFRAMES TF; // Zeitrahmen void CreateDB(const string DBPath,const CDataKeeper &inputData_array[],double r,ENUM_TIMEFRAMES TF);// Erstellen der Datenbank und alles Zugehörige bool isForvard();// Definieren des aktuellen Optimierungstyps (Historie/Vorwärts) void WriteLog(string s,string where);// Eintrag in der Logdatei int setParams(bool IsForvard,CReportCreator *reportCreator,DealDetales &history[],double &customCoef);// Ausfüllen der Eingabetabelle void setBuyAndHold(bool IsForvard,CReportCreator *reportCreator);// Ausfüllen der Historie von "Buy And Hold" bool setTraidingHistory(bool IsForvard,DealDetales &history[],int ID);// Ausfüllen der Handelshistorie bool setTotalResult(TotalResult &coefData,bool isOneLot,long ID,bool IsForvard,double customCoef);// Ausfüllen der Tabelle mit den Verhältnissen bool isHistoryItem(bool IsForvard,DealDetales &item,int ID); // Prüfen, ob die aktuellen Parameter bereits in der Handelshistorie existieren };
Die Klasse wird nur im benutzerdefinierten Roboter selbst verwendet. Ziel ist es, einen Eingabeparameter für ein beschriebenes Programm zu erstellen, nämlich die Datenbank mit der erforderlichen Struktur und dem gewünschten Inhalt. Wie wir sehen können, hat es 3 'public' Methoden (die überladene Methode wird als eine betrachtet):
- OnInitEvent
- OnTesterEvent
- OnTickEvent
Jeder von ihnen wird in den entsprechenden Call-Backs der Robotervorlage aufgerufen, wo die erforderlichen Parameter an sie übergeben werden. Die Methode OnInitEvent wurde entwickelt, um die Klasse auf die Arbeit mit der Datenbank vorzubereiten. Die Überlastungen sind wie folgt implementiert:
//+------------------------------------------------------------------+ //| Erstellen der Datenbank und Verbinden | //+------------------------------------------------------------------+ void CDBWriter::OnInitEvent(const string _DBPath,const CDataKeeper &inputData_array[],customScoring_2 scoringFunction,double _r,ENUM_TIMEFRAMES _TF) { CreateDB(_DBPath,inputData_array,_r,_TF); scoring_2=scoringFunction; scoring_type=2; } //+------------------------------------------------------------------+ //| Erstellen der Datenbank und Verbinden | //+------------------------------------------------------------------+ void CDBWriter::OnInitEvent(const string _DBPath,const CDataKeeper &inputData_array[],customScoring_1 scoringFunction,double _r,ENUM_TIMEFRAMES _TF) { CreateDB(_DBPath,inputData_array,_r,_TF); scoring_1=scoringFunction; scoring_type=1; } //+------------------------------------------------------------------+ //| Erstellen der Datenbank und Verbinden | //+------------------------------------------------------------------+ void CDBWriter::OnInitEvent(const string _DBPath,const CDataKeeper &inputData_array[],double _r,ENUM_TIMEFRAMES _TF) { CreateDB(_DBPath,inputData_array,_r,_TF); scoring_type=0; }
Wie wir in der Methodenimplementierung sehen können, weist sie den Feldern der Klasse die erforderlichen Werte zu und erstellt die Datenbank. Die Call-Back-Methoden sollten von einem Benutzer persönlich implementiert werden (wenn ein benutzerdefiniertes Verhältnis berechnet werden soll) oder eine Überlastung ohne Call-Back verwendet wird — in diesem Fall ist ein benutzerdefiniertes Verhältnis gleich Null. Das nutzerdefinierte Verhältnis ist eine nutzerdefinierte Methode zur Beurteilung des EA-Optimierungsdurchlaufs. Um dies zu realisieren, wurden die Zeiger auf zwei Funktionen mit zwei Arten von möglichen erforderlichen Daten erstellt.
- Der Erste (customScoring_1) empfängt die Handelshistorie und das Flag, das den Optimierungspass definiert, für den die Berechnung erforderlich ist (tatsächlich gehandelter Lot oder Handel mit einem einzelnen Lot — alle Daten für Berechnungen sind im übergebenen Array vorhanden).
- Der zweite Call-Back-Typ (customScoring_2) erhält Zugriff auf die Datenbank, aus der die Arbeit ausgeführt wird, jedoch nur mit schreibgeschützten Rechten, um unerwartete Änderungen durch den Nutzer zu vermeiden.
- Zuweisung der Werte von Saldo, Zeitrahmen und risikofreien Rate.
- Verbindung zur Datenbank herstellen und eine gemeinsame Ressource belegen (Mutex)
- Erstellen der Tabellendatenbank, falls noch nicht angelegt.
Die 'public' Methode speichert bei jedem Tick das Datum der Kerze. Beim Testen einer Strategie ist es unmöglich zu definieren, ob der aktuelle Durchlauf weitergeleitet wird oder nicht, während die Datenbank einen ähnlichen Parameter hat. Aber wir wissen, dass der Tester vorwärts läuft, nachdem er historische Läufe durchgeführt hat. Während wir also die Variable bei jedem Tick mit einem Datum überschreiben, finden wir das letzte Datum am Ende des Optimierungsprozesses heraus. Die Tabelle OptimisationParams enthält den Parameter HistoryBorder. Es ist gleich dem gespeicherten Datum. Die Zeilen werden nur bei der historischen Optimierung in diese Tabelle eingefügt. Beim ersten Durchlauf mit diesen Parametern (wie beim historischen Optimierungslauf) wird das Datum in das erforderliche Feld auf der Datenbank eingefügt. Wenn wir bei einem der nächsten Durchläufe sehen, dass der Eintrag mit diesen Parametern bereits in der Datenbank vorhanden ist, gibt es zwei Möglichkeiten:
- entweder hat ein Nutzer aus irgendeinem Grund die historische Optimierung gestoppt und dann neu gestartet,
- oder das ist eine Vorwärtsoptimierung.
Um die einen von den andern zu trennen, vergleichen wir das letzte im aktuellen Durchgang gespeicherte Datum mit dem Datum aus der Datenbank. Wenn das aktuelle Datum größer als das in der Datenbank ist, dann ist dies ein Durchlauf des Vorwärtstests, wenn es kleiner oder gleich ist, haben Sie es mit einem historischen zu tun. Da die Optimierung zweimal mit den gleichen Verhältnissen gestartet werden sollte, geben wir nur die neuen Daten in die Datenbank ein oder verwerfen alle Änderungen, die während des aktuellen Durchlaufs vorgenommen wurden. Die Methode OnTesterEvent() speichert Daten in der Datenbank. Es wird wie folgt implementiert:
//+------------------------------------------------------------------+ //| Sichern aller Daten in der Datenbank und Rückgabe | //| eines Nutzerverhältnisses | //+------------------------------------------------------------------+ double CDBWriter::OnTesterEvent() { DealDetales history[]; CDealHistoryGetter historyGetter; historyGetter.getDealsDetales(history,0,TimeCurrent()); // Abfrage der Handelshistorie CMutexSync sync; // Synchronisieren des Objekts if(!sync.Create(getMutexName(DBPath))) { Print(Symbol()+" MutexSync create ERROR!"); return 0; } CMutexLock lock(sync,(DWORD)INFINITE); // Sperren des Segments in Klammern bool IsForvard=isForvard(); // Prüfen ob die aktuelle Iteration vorwärts läuft CReportCreator rc; string Symb[]; rc.Get_Symb(history,Symb); // Abfrage der Liste der Symbole rc.Create(history,Symb,balance,r); // Erstellen des Berichts ("Buy And Hold"-Bericht wird automatisch erstellt) double ans=0; dbManager.BeginTransaction(); // Start der Transaktion CStatement stmt(dbManager.Create_statement("INSERT OR IGNORE INTO ParamsType VALUES(@ParamName,@ParamType);")); // Aufforderung die Liste der Typen der Parameter des EAs zu sichern if(stmt.get()!=NULL) { for(int i=0;i<ArraySize(coef_array);i++) { stmt.Parameter(1,coef_array[i].getName()); stmt.Parameter(2,(int)coef_array[i].getType()); stmt.Execute(); // Sichern der Parametertypen und Namen } } int ID=setParams(IsForvard,&rc,history,ans); // Sichern der EA-Parameter und Verhältniswerte und ID-Abfrage if(ID>0)// Wenn ID > 0, wurden die Parameter erfolgreich gesichert { if(setTraidingHistory(IsForvard,history,ID)) // Sichern der Handelshistorie und Prüfen, ob gesichert wurde { setBuyAndHold(IsForvard,&rc); // Sichern der Historie von "Buy And Hold" (nur einmal, beim ersten Sichern) dbManager.CommitTransaction(); // Bestätigung des Endes der Transaktion } else dbManager.RollbackTransaction(); // Sonst löschen der Transaktion } else dbManager.RollbackTransaction(); // Sonst löschen der Transaktion return ans; }
Das erste, was die Methode tut, ist, die Handelshistorie mit der in meinem vorherigen Artikel beschriebenen Klasse zu bilden. Dann nimmt es die gemeinsame Ressource (Mutex) und speichert die Daten. Um dies zu erreichen, definieren Sie zunächst, ob der aktuelle Optimierungsdurchlauf ein Vorwärtstest ist (nach der oben beschriebenen Methode), und dann erhalten Sie die Liste der Symbole (alle Symbole, die gehandelt wurden).
Dementsprechend wird, wenn beispielsweise ein Spread-Trading EA getestet wurde, die Handelshistorie auf beide Symbole hochgeladen, mit denen der Handel durchgeführt wurde. Danach wird ein Bericht erstellt (mit der unten geprüften Klasse) und auf die Datenbank geschrieben. Es wird eine Transaktion für den richtigen Datensatz angelegt. Die Transaktion wird abgebrochen, wenn beim Füllen einer der Tabellen ein Fehler aufgetreten ist oder falsche Daten erhalten wurden. Zuerst werden die Kennzahlen gespeichert, und wenn alles reibungslos verlief, speichern wir die Handelsgeschichte, gefolgt von der Kauf- und Haltehistorie. Letzteres wird bei der ersten Dateneingabe nur einmal gespeichert. Im Falle eines Datenspeicherungsfehlers wird die Protokolldatei im Ordner Common/Files erzeugt.
Nach der Erstellung der Datenbank sollte diese gelesen werden. Die Datenbankklasse zum Lesen wird im beschriebenen Programm bereits verwendet. Es ist einfacher und sieht wie folgt aus:
//+------------------------------------------------------------------+ //| Klasse zum Lesen der Daten aus der Datenbank | //+------------------------------------------------------------------+ class CDBReader { public: void Connect(string DBPath);// Method connecting to the database bool getBuyAndHold(BuyAndHoldChart_item &data[],bool isForvard);// Berechnungsmethode für die Historie von "Buy And Hold" bool getTraidingHistory(DealDetales &data[],long ID,bool isForvard);// Berechnungsmethode der Handelshistorie des EAs bool getRobotParams(CoefData_item &data[],bool isForvard);// Berechnungsmethode der Parameter und Verhältnisse des EAs private: CSqliteManager dbManager; // Datenbankmanager string DBPath; // Pfad zur Datenbank bool getParamTypes(ParamType_item &data[]);// Berechnen der Typen und Namen der Eingaben. };
Es werden 3 'public' Methoden implementiert, die 4 Tabellen lesen, an denen wir interessiert sind, und Struktur-Arrays mit Daten aus diesen Tabellen erstellen.
- Die erste Methode (getBuyAndHold) gibt die BuyAndHold Historie als Referenz für Vorwärts- und historische Zeiträume zurück, abhängig vom übergebenen Flag. Wenn der Upload erfolgreich ist, gibt die Methode 'true', ansonsten 'false' zurück. Der Upload erfolgt aus der Tabelle Buy And Hold.
- Die Methode getTradingHistory gibt auch die Handelshistorie für übergebene ID und das isForvard-Flag entsprechend zurück. Der Upload erfolgt aus der Tabelle TradingHistory.
- Die Methode getRobotParams kombiniert Uploads aus den beiden Tabellen: ParamsCoefitients — von wo aus die Roboterparameter übernommen werden und OptimisationParams, wo berechnete Bewertungskennzahlen liegen.
Somit können Sie mit den geschriebenen Klassen nicht mehr direkt mit der Datenbank arbeiten, sondern mit den Klassen, die die erforderlichen Daten liefern, die den gesamten Algorithmus für die Arbeit mit der Datenbank verbergen. Diese Klassen wiederum arbeiten mit dem geschriebenen Wrapper für die Datenbank, was die Arbeit ebenfalls vereinfacht. Der erwähnte Wrapper arbeitet mit der Datenbank über die von den Datenbankentwicklern bereitgestellte Dll. Die Datenbank selbst erfüllt alle erforderlichen Bedingungen und ist in der Tat eine Datei, die den Transport und die Verarbeitung sowohl in diesem Programm als auch in anderen analytischen Anwendungen erleichtert. Ein weiterer Vorteil dieses Ansatzes ist die Tatsache, dass der langfristige Betrieb eines einzelnen Algorithmus es Ihnen ermöglicht, Datenbanken aus jeder Optimierung zu sammeln, wodurch die Historie angesammelt und die Parameteränderungsmuster verfolgt werden.
Berechnungen
Der Block besteht aus zwei Klassen. Die erste ist für die Erstellung eines Handelsberichts gedacht und ist eine verbesserte Version der Klasse, die einen im vorherigen Artikel beschriebenen Handelsbericht erstellt.
Die zweite ist eine Filterklasse. Er sortiert Optimierungsproben in einem durchlaufenen Bereich und ist in der Lage, ein Diagramm zu erstellen, das für jeden einzelnen Wert des Optimierungsverhältnisses eine Häufigkeit von profitablen und verlustbringenden Geschäften anzeigt. Ein weiteres Ziel dieser Klasse ist die Erstellung eines Normalverteilungsgraphen für den tatsächlich gehandelten PL am Ende der Optimierung (d.h. PL für den gesamten Optimierungszeitraum). Mit anderen Worten, wenn es 1000 Optimierungsdurchläufe gibt, haben wir 1000 Optimierungsergebnisse (PL zum Zeitpunkt des Optimierungsendes). Die Distribution, an der wir interessiert sind, basiert auf ihnen.
Diese Verteilung zeigt, in welche Richtung sich die Asymmetrie der erhaltenen Werte verschiebt. Wenn sich die größere Seite und das Zentrum der Verteilung in der Gewinnzone befinden, erzeugt der Roboter meist profitable Optimierungsläufe und ist dementsprechend gut, ansonsten erzeugt er meist unrentable Durchläufe. Wird die Definitionsasymmetrie auf die Verlustzone verlagert, bedeutet dies auch, dass die ausgewählten Parameter meist eher Verluste als Gewinne verursachen.
Lassen Sie uns einen Blick auf diesen Block werfen, beginnend mit der Klasse, die einen Handelsbericht erstellt. Die beschriebene Klasse befindet sich im Verzeichnis Include des Ordners "History manager" und hat den folgenden Header:
//+------------------------------------------------------------------+ //| Klasse zum Erstellen der Statistik der Handelshistorie | //+------------------------------------------------------------------+ class CReportCreator { public: //============================================================================================================================================= // (Neu-) Berechnung: //============================================================================================================================================= void Create(DealDetales &history[],DealDetales &BH_history[],const double balance,const string &Symb[],double r); void Create(DealDetales &history[],DealDetales &BH_history[],const string &Symb[],double r); void Create(DealDetales &history[],const string &Symb[],const double balance,double r); void Create(DealDetales &history[],double r); void Create(const string &Symb[],double r); void Create(double r=0); //============================================================================================================================================= // Abfragen (Getters): //============================================================================================================================================= bool GetChart(ChartType chart_type,CalcType calc_type,PLChart_item &out[]); // Abfrage der PL-Diagramme bool GetDistributionChart(bool isOneLot,DistributionChart &out); // Abfrage der Verteilungsdiagramme bool GetCoefChart(bool isOneLot,CoefChartType type,CoefChart_item &out[]); // Abfrage der Verhältnis-Diagramme bool GetDailyPL(DailyPL_calcBy calcBy,DailyPL_calcType calcType,DailyPL &out); // Abfrage der PL-Diagramme nach Tagen bool GetRatioTable(bool isOneLot,ProfitDrawdownType type,ProfitDrawdown &out); // Abfrage der Tabelle der Extrema bool GetTotalResult(TotalResult &out); // Abfrage der Tabelle von des TotalResult bool GetPL_detales(PL_detales &out); // Abfrage der Tabelle PL_detales void Get_Symb(const DealDetales &history[],string &Symb[]); // Abfrage des Arrays der gehandelten Symbole void Clear(); // Statistik löschen private: //============================================================================================================================================= // 'private' Datentypen: //============================================================================================================================================= // Struktur der Typen der PL-Diagramme struct PL_keeper { PLChart_item PL_total[]; PLChart_item PL_oneLot[]; PLChart_item PL_Indicative[]; }; // Types structure of daily Profit/Loss graph struct DailyPL_keeper { DailyPL avarage_open,avarage_close,absolute_open,absolute_close; }; // Struktur der Tabelle mit den Extrema struct RatioTable_keeper { ProfitDrawdown Total_max,Total_absolute,Total_percent; ProfitDrawdown OneLot_max,OneLot_absolute,OneLot_percent; }; // Struktur zur Berechnung von Gewinn und Verlust in einer Zeile struct S_dealsCounter { int Profit,DD; }; struct S_dealsInARow : public S_dealsCounter { S_dealsCounter Counter; }; // Struktur zur Berechnung der Hilfsdaten struct CalculationData_item { S_dealsInARow dealsCounter; int R_arr[]; double DD_percent; double Accomulated_DD,Accomulated_Profit; double PL; double Max_DD_forDeal,Max_Profit_forDeal; double Max_DD_byPL,Max_Profit_byPL; datetime DT_Max_DD_byPL,DT_Max_Profit_byPL; datetime DT_Max_DD_forDeal,DT_Max_Profit_forDeal; int Total_DD_numDeals,Total_Profit_numDeals; }; struct CalculationData { CalculationData_item total,oneLot; int num_deals; bool isNot_firstDeal; }; // Struktur zum Erstellen des Verhältnisdiagramms struct CoefChart_keeper { CoefChart_item OneLot_ShartRatio_chart[],Total_ShartRatio_chart[]; CoefChart_item OneLot_WinCoef_chart[],Total_WinCoef_chart[]; CoefChart_item OneLot_RecoveryFactor_chart[],Total_RecoveryFactor_chart[]; CoefChart_item OneLot_ProfitFactor_chart[],Total_ProfitFactor_chart[]; CoefChart_item OneLot_AltmanZScore_chart[],Total_AltmanZScore_chart[]; }; // Klasse für das Sortieren der Handelshistorie nach dem Schlussdatum class CHistoryComparer : public ICustomComparer<DealDetales> { public: int Compare(DealDetales &x,DealDetales &y); }; //============================================================================================================================================= // Keepers: //============================================================================================================================================= CHistoryComparer historyComparer; // Vergleich von Klassen CChartComparer chartComparer; // Vergleich von Klassen // Hilfsstrukturen PL_keeper PL,PL_hist,BH,BH_hist; DailyPL_keeper DailyPL_data; RatioTable_keeper RatioTable_data; TotalResult TotalResult_data; PL_detales PL_detales_data; DistributionChart OneLot_PDF_chart,Total_PDF_chart; CoefChart_keeper CoefChart_data; double balance,r; // Anfangskapital und risikofreien Rate // Sortierklasse CGenericSorter sorter; //============================================================================================================================================= // Berechnungen: //============================================================================================================================================= // Berechnen von PL void CalcPL(const DealDetales &deal,CalculationData &data,PLChart_item &pl_out[],CalcType type); // Berechnen des PL-Histogramms void CalcPLHist(const DealDetales &deal,CalculationData &data,PLChart_item &pl_out[],CalcType type); // Berechnen der Hilfsstrukturen für das Zeichnen void CalcData(const DealDetales &deal,CalculationData &out,bool isBH); void CalcData_item(const DealDetales &deal,CalculationData_item &out,bool isOneLot); // Berechnen des täglichen Gewinns/Verlusts void CalcDailyPL(DailyPL &out,DailyPL_calcBy calcBy,const DealDetales &deal); void cmpDay(const DealDetales &deal,ENUM_DAY_OF_WEEK etalone,PLDrawdown &ans,DailyPL_calcBy calcBy); void avarageDay(PLDrawdown &day); // Vergleich der Symbole bool isSymb(const string &Symb[],string symbol); // Berechnen des Profit-Faktors void ProfitFactor_chart_calc(CoefChart_item &out[],CalculationData &data,const DealDetales &deal,bool isOneLot); // Berechnen des Erholungsfaktors void RecoveryFactor_chart_calc(CoefChart_item &out[],CalculationData &data,const DealDetales &deal,bool isOneLot); // Berechnen des Gewinnverhältnisses void WinCoef_chart_calc(CoefChart_item &out[],CalculationData &data,const DealDetales &deal,bool isOneLot); // Berechnen des Sharpe-Ratio double ShartRatio_calc(PLChart_item &data[]); void ShartRatio_chart_calc(CoefChart_item &out[],PLChart_item &data[],const DealDetales &deal); // Berechnen der Verteilung void NormalPDF_chart_calc(DistributionChart &out,PLChart_item &data[]); double PDF_calc(double Mx,double Std,double x); // Berechnen von VaR double VaR(double quantile,double Mx,double Std); // Berechnen von Z-Score void AltmanZScore_chart_calc(CoefChart_item &out[],double N,double R,double W,double L,const DealDetales &deal); // Berechnen der Struktur von TotalResult_item void CalcTotalResult(CalculationData &data,bool isOneLot,TotalResult_item &out); // Berechnen der Struktur von PL_detales_item void CalcPL_detales(CalculationData_item &data,int deals_num,PL_detales_item &out); // Abfrage des Tages vom Datum ENUM_DAY_OF_WEEK getDay(datetime DT); // Daten löschen void Clear_PL_keeper(PL_keeper &data); void Clear_DailyPL(DailyPL &data); void Clear_RatioTable(RatioTable_keeper &data); void Clear_TotalResult_item(TotalResult_item &data); void Clear_PL_detales(PL_detales &data); void Clear_DistributionChart(DistributionChart &data); void Clear_CoefChart_keeper(CoefChart_keeper &data); //============================================================================================================================================= // Kopieren: //============================================================================================================================================= void CopyPL(const PLChart_item &src[],PLChart_item &out[]); // Kopieren der PL-Diagramme void CopyCoefChart(const CoefChart_item &src[],CoefChart_item &out[]); // Kopieren der Verhältnisdiagramme };
Diese Klasse berechnet im Gegensatz zu ihrer Vorgängerversion zweimal mehr Daten und erstellt mehr Arten von Diagrammen. Die Überladung der Methode "Create" berechnen auch den Bericht.
Tatsächlich wird der Bericht nur einmal generiert — zum Zeitpunkt des Methodenaufrufs Create. Später werden in den Methoden, die mit dem Get-Wort beginnen, nur die zuvor berechneten Daten erhalten. Die Hauptschleife, die einmal über die Eingabeparameter läuft, befindet sich in der Methode Create mit den meisten Argumenten. Diese Methode iteriert über Argumente und berechnet sofort eine Reihe von Daten, auf deren Grundlage alle erforderlichen Daten in der gleichen Iteration aufgebaut werden.
Dies ermöglicht es, alles, was uns interessiert, in einem einzigen Durchgang zu erstellen, während die vorherige Version dieser Klasse, um das Diagramm wieder über die Ausgangsdaten zu iterieren. Dadurch dauert die Berechnung aller Verhältnisse Millisekunden, während die Beschaffung der benötigten Daten noch zeitsparender ist. Im 'private' Teil der Klasse gibt es eine Reihe von Strukturen, die nur innerhalb dieser Klasse als komfortablere Datencontainer verwendet werden. Die Sortierung der Handelshistorie erfolgt mit der oben beschriebenen generischen Sortierungsmethode.
Lassen Sie uns die Daten beschreiben, die beim Aufruf der einzelnen 'Getter' erhalten wurden:
| Methode | Parameter | Charttyp |
|---|---|---|
| GetChart | chart_type = _PL, calc_type = _Total | PL-Diagramm — gemäß der aktuellen Handelshistorie |
| GetChart | chart_type = _PL, calc_type = _OneLot | PL-Diagramm — beim Handel mit nur einem Lot |
| GetChart | chart_type = _PL, calc_type = _Indicative | PL-Diagramm — bezeichnend |
| GetChart | chart_type = _BH, calc_type = _Total | BH-Diagramm — beim Handel mit der Losgröße des Roboters |
| GetChart | chart_type = _BH, calc_type = _OneLot | BH-Diagramm — beim Handel mit nur einem Lot |
| GetChart | chart_type = _BH, calc_type = _Indicative | BH-Diagramm — bezeichnend |
| GetChart | chart_type = _Hist_PL, calc_type = _Total | PL-Histogramm — gemäß der aktuellen Handelshistorie |
| GetChart | chart_type = _Hist_PL, calc_type = _OneLot | PL-Histogramm — beim Handel mit nur einem Lot |
| GetChart | chart_type = _Hist_PL, calc_type = _Indicative | PL-Histogramm — bezeichnend |
| GetChart | chart_type = _Hist_BH, calc_type = _Total | BH-Histogramm — beim Handel mit der Losgröße des Roboters |
| GetChart | chart_type = _Hist_BH, calc_type = _OneLot | BH-Histogramm — beim Handel mit nur einem Lot |
| GetChart | chart_type = _Hist_BH, calc_type = _Indicative | BH-Histogramm — bezeichnend |
| GetDistributionChart | isOneLot = true | Verteilung und VaR beim Handel mit nur einem Lot |
| GetDistributionChart | isOneLot = false | Verteilung und VaR beim Handel wie vorher |
| GetCoefChart | isOneLot = true, type=_ShartRatio_chart | Sharpe Ratio beim Handel mit konstant einem Lot |
| GetCoefChart | isOneLot = true, type=_WinCoef_chart | Gewinnverhältnis beim Handel mit nur einem Lot |
| GetCoefChart | isOneLot = true, type=_RecoveryFactor_chart | Erholungsfaktor beim Handel mit nur einem Lot |
| GetCoefChart | isOneLot = true, type=_ProfitFactor_chart | Profit-Faktor beim Handel mit nur einem Lot |
| GetCoefChart | isOneLot = true, type=_AltmanZScore_chart | Altman Z-Score beim Handel mit nur einem Lot |
| GetCoefChart | isOneLot = false, type=_ShartRatio_chart | Sharpe ratio beim Handel wie vorher |
| GetCoefChart | isOneLot = false, type=_WinCoef_chart | Gewinnverhältnis für die Zeit, in der gehandelt wird |
| GetCoefChart | isOneLot = false, type=_RecoveryFactor_chart | Erholungsfaktor für die Zeit, in der gehandelt wird |
| GetCoefChart | isOneLot = false, type=_ProfitFactor_chart | Profit-Faktor für die Zeit, in der gehandelt wird |
| GetCoefChart | isOneLot = false, type=_AltmanZScore_chart | Altman Z-Score für die Zeit, in der gehandelt wird |
| GetDailyPL | calcBy=CALC_FOR_CLOSE, calcType=AVERAGE_DATA | Durchschnittlicher PL in Tagen nach dem Zeitpunkt des Schließens |
| GetDailyPL | calcBy=CALC_FOR_CLOSE, calcType=ABSOLUTE_DATA | Gesamt PL in Tagen nach dem Zeitpunkt des Schließens |
| GetDailyPL | calcBy=CALC_FOR_OPEN, calcType=AVERAGE_DATA | Durchschnitts-PL in Tagen nach dem Zeitpunkt der Eröffnung |
| GetDailyPL | calcBy=CALC_FOR_OPEN, calcType=ABSOLUTE_DATA | Gesamt-PL in Tagen nach dem Zeitpunkt der Eröffnung |
| GetRatioTable | isOneLot = true, type = _Max | Beim Handel von einem Lot — Maximalgewinn/-verlust je Position |
| GetRatioTable | isOneLot = true, type = _Absolute | Beim Handel von einem Lot — total profit/loss |
| GetRatioTable | isOneLot = true, type = _Percent | Beim Handel von einem Lot — Gewinn/Verlust in % |
| GetRatioTable | isOneLot = false, type = _Max | Beim Handel wie vorher — Maximalgewinn/-verlust je Position |
| GetRatioTable | isOneLot = false, type = _Absolute | Beim Handel wie vorher — Gesamtgewinn/-verlust |
| GetRatioTable | isOneLot = false, type = _Percent | Beim Handel wie vorher — Gewinn/Verlust in % |
| GetTotalResult | Tabelle der Verhältnisse | |
| GetPL_detales | PL-Kurve kurz zusammengefasst | |
| Get_Symb | Array der Symbole der Handelshistorie |
PL-Diagramm — gemäß der aktuellen Handelshistorie
Das Diagramm entspricht dem gewöhnlichen PL-Diagramm Wir können das nach allen Durchläufen sehen.
PL-Diagramm — when trading a single lot:
Diese Grafik ähnelt der zuvor beschriebenen Grafik, die sich in einem gehandelten Volumen unterscheidet. Sie wird so berechnet, als würden wir die ganze Zeit nur ein einziges Lot handeln. Ein- und Ausstiegspreise werden als gemittelte Preise über die Gesamtzahl der EA-Marktein- und -austritte berechnet. Ein Handelsergebnis wird ebenfalls auf der Grundlage des vom EA gehandelten Gewinns berechnet, aber es wird in den erzielten Gewinn umgewandelt, als ob es sich um einen einzelnen Lot über die Quote handelt.
PL-Diagramm — indicative:
Normalisiertes PL-Diagramm. Wenn PL > 0, wird PL durch das zu diesem Zeitpunkt erreichte maximale Verlustgeschäft geteilt, ansonsten wird PL durch die bisher bekannte maximale profitable Position geteilt.
Die Histogramme sind in ähnlicher Weise aufgebaut.
Verteilung und VaR
Parametrischer VaR wird sowohl mit absoluten Daten als auch mit Wachstum aufgebaut.
Das Gleiche gilt für das Diagramm der Verteilung.
Verhältnisdiagramm:
Erstellt bei jeder Schleifeniteration gemäß den entsprechenden Gleichungen über die gesamte für diese spezielle Iteration verfügbare Historie.
Tägliche Gewinnkurven:
Erstellt aus 4 möglichen Gewinnkombinationen, die in der Tabelle aufgeführt sind. Sieht aus wie ein Histogramm.
Die Methode, die alle erwähnten Daten erstellt, sieht wie folgt aus:
//+------------------------------------------------------------------+ //| Ratio calculation/re-calculation | //+------------------------------------------------------------------+ void CReportCreator::Create(DealDetales &history[],DealDetales &BH_history[],const double _balance,const string &Symb[],double _r) { Clear(); // Löschen der Daten // Sichern des Saldos this.balance=_balance; if(this.balance<=0) { CDealHistoryGetter dealGetter; this.balance=dealGetter.getBalance(history[ArraySize(history)-1].DT_open); } if(this.balance<0) this.balance=0; // Sichern der risikofreien Rate if(_r<0) _r=0; this.r=r; // Hilfsstrukturen CalculationData data_H,data_BH; ZeroMemory(data_H); ZeroMemory(data_BH); // Sortieren der Handelshistorie sorter.Method(Sort_Ascending); sorter.Sort<DealDetales>(history,&historyComparer); // Schleife durch die Handelshistorie for(int i=0;i<ArraySize(history);i++) { if(isSymb(Symb,history[i].symbol)) CalcData(history[i],data_H,false); } // Sortieren der Historie von "Buy And Hold" und die entsprechende Schleife sorter.Sort<DealDetales>(BH_history,&historyComparer); for(int i=0;i<ArraySize(BH_history);i++) { if(isSymb(Symb,BH_history[i].symbol)) CalcData(BH_history[i],data_BH,true); } // täglicher Durchschnitts-PL (Durchschnittstyp) avarageDay(DailyPL_data.avarage_close.Mn); avarageDay(DailyPL_data.avarage_close.Tu); avarageDay(DailyPL_data.avarage_close.We); avarageDay(DailyPL_data.avarage_close.Th); avarageDay(DailyPL_data.avarage_close.Fr); avarageDay(DailyPL_data.avarage_open.Mn); avarageDay(DailyPL_data.avarage_open.Tu); avarageDay(DailyPL_data.avarage_open.We); avarageDay(DailyPL_data.avarage_open.Th); avarageDay(DailyPL_data.avarage_open.Fr); // Füllen der Tabelle mit den Gewinn-/Verlust-Verhältnissen RatioTable_data.data_H.oneLot.Accomulated_Profit; RatioTable_data.data_H.oneLot.Accomulated_DD; RatioTable_data.data_H.oneLot.Max_Profit_forDeal; RatioTable_data.data_H.oneLot.Max_DD_forDeal; RatioTable_data.data_H.oneLot.Total_Profit_numDeals/data_H.num_deals; RatioTable_data.data_H.oneLot.Total_DD_numDeals/data_H.num_deals; RatioTable_data.Total_absolute.Profit=data_H.total.Accomulated_Profit; RatioTable_data.Total_absolute.Drawdown=data_H.total.Accomulated_DD; RatioTable_data.Total_max.Profit=data_H.total.Max_Profit_forDeal; RatioTable_data.Total_max.Drawdown=data_H.total.Max_DD_forDeal; RatioTable_data.Total_percent.Profit=data_H.total.Total_Profit_numDeals/data_H.num_deals; RatioTable_data.Total_percent.Drawdown=data_H.total.Total_DD_numDeals/data_H.num_deals; // Berechnen der Normalverteilung NormalPDF_chart_calc(OneLot_PDF_chart,PL.PL_oneLot); NormalPDF_chart_calc(Total_PDF_chart,PL.PL_total); // TotalResult CalcTotalResult(data_H,true,TotalResult_data.oneLot); CalcTotalResult(data_H,false,TotalResult_data.total); // PL_detales CalcPL_detales(data_H.oneLot,data_H.num_deals,PL_detales_data.oneLot); CalcPL_detales(data_H.total,data_H.num_deals,PL_detales_data.total); }
Wie aus der Implementierung ersichtlich, wird ein Teil der Daten berechnet, während die Schleife durch die Historie geht, während einige Daten berechnet werden, nachdem alle Schleifen auf der Grundlage von Daten aus den Strukturen durchlaufen wurden: CalculationData data_H, data_BH.
Die Methode CalcData ist ähnlich wie die Methode Create implementiert. Dies ist die einzige Methode, die die Methoden aufruft, die bei jeder Iteration Berechnungen durchführen sollen. Alle Methoden zur Berechnung der endgültigen Daten werden auf der Grundlage der in den oben genannten Strukturen enthaltenen Informationen berechnet. Das Füllen/Nachfüllen der beschriebenen Strukturen erfolgt nach dem folgenden Verfahren:
//+------------------------------------------------------------------+ //| Berechnen von Hilfsdaten | //+------------------------------------------------------------------+ void CReportCreator::CalcData_item(const DealDetales &deal,CalculationData_item &out, bool isOneLot) { double pl=(isOneLot ? deal.pl_oneLot : deal.pl_forDeal); // PL int n=0; // Umfang von Gewinn und Verlust if(pl>=0) { out.Total_Profit_numDeals++; n=1; out.dealsCounter.Counter.DD=0; out.dealsCounter.Counter.Profit++; } else { out.Total_DD_numDeals++; out.dealsCounter.Counter.DD++; out.dealsCounter.Counter.Profit=0; } out.dealsCounter.DD=MathMax(out.dealsCounter.DD,out.dealsCounter.Counter.DD); out.dealsCounter.Profit=MathMax(out.dealsCounter.Profit,out.dealsCounter.Counter.Profit); // Abfolge von Gewinn und Verlust int s=ArraySize(out.R_arr); if(!(s>0 && out.R_arr[s-1]==n)) { ArrayResize(out.R_arr,s+1,s+1); out.R_arr[s]=n; } out.PL+=pl; // Total PL // Max Profit / DD if(out.Max_DD_forDeal>pl) { out.Max_DD_forDeal=pl; out.DT_Max_DD_forDeal=deal.DT_close; } if(out.Max_Profit_forDeal<pl) { out.Max_Profit_forDeal=pl; out.DT_Max_Profit_forDeal=deal.DT_close; } // Akkumulierter Profit / DD out.Accomulated_DD+=(pl>0 ? 0 : pl); out.Accomulated_Profit+=(pl>0 ? pl : 0); // Extrema des Gewinns double maxPL=MathMax(out.Max_Profit_byPL,out.PL); if(compareDouble(maxPL,out.Max_Profit_byPL)==1/* || !isNot_firstDeal*/)// nur eine weitere notwendige Prüfung zur Datumssicherung { out.DT_Max_Profit_byPL=deal.DT_close; out.Max_Profit_byPL=maxPL; } double maxDD=out.Max_DD_byPL; double DD=0; if(out.PL>0)DD=out.PL-maxPL; else DD=-(MathAbs(out.PL)+maxPL); maxDD=MathMin(maxDD,DD); if(compareDouble(maxDD,out.Max_DD_byPL)==-1/* || !isNot_firstDeal*/)// nur eine weitere notwendige Prüfung zur Datumssicherung { out.Max_DD_byPL=maxDD; out.DT_Max_DD_byPL=deal.DT_close; } out.DD_percent=(balance>0 ?(MathAbs(DD)/(maxPL>0 ? maxPL : balance)) :(maxPL>0 ?(MathAbs(DD)/maxPL) : 0)); }
Dies ist die grundlegende Methode, die alle Eingabedaten für jede der Berechnungsmethoden berechnet. Dieser Ansatz (Verschieben der Berechnung der Eingabedaten auf diese Methode) ermöglicht es, übermäßige Anzahl von Durchläufen in den Historienschleifen zu vermeiden, wie sie in der Vorgängerversion der Klasse zur Erstellung eines Handelsberichts aufgetreten sind. Diese Methode wird innerhalb der Methode CalcData aufgerufen.
Die Klasse des Ergebnisfilters für den Optimierungsdurchlauf hat die folgende Header:
//+--------------------------------------------------------------------------+ //| Klasse zum Sortieren der Optimierungsdurchläufe nach dem Laden | //+--------------------------------------------------------------------------+ class CParamsFiltre { public: CParamsFiltre(){sorter.Method(Sort_Ascending);} // Standardkonstruktor int Total(){return ArraySize(arr_main);}; // Gesamtzahl der entladenen Parameter (entsprechend der Tabelle Optimisation Data) void Clear(){ArrayFree(arr_main);ArrayFree(arr_result);}; // Freigeben aller Arrays void Add(LotDependency_item &customCoef,CDataKeeper ¶ms[],long ID,double total_PL,bool addToResult); // Hinzufügen neuer Werte zum Array double GetCustomCoef(long ID,bool isOneLot);// Abfrage der Nutzerverhältnisse nach ID void GetParamNames(CArrayString &out);// Abfrage der Parameternamen des EAs void Get_UniqueCoef(UniqCoefData_item &data[],string paramName,CArrayString &coefValue); // Abfrage der eindeutigen Verhältnisse void Filtre(string Name,string from,string till,long &ID_Arr[]);// Sortieren des Arrays arr_result void ResetFiltre(long &ID_arr[]);// Rücksetzen der Filter bool Get_Distribution(Chart_item &out[],bool isMainTable);// Erstellen der Verteilungen für beide Arrays bool Get_Distribution(Chart_item &out[],string Name,string value);// Erstellen der Verteilung der gewählten Daten private: CGenericSorter sorter; // Sortierer CCoefComparer cmp_coef;// Vergleich der Verhältnisse CChartComparer cmp_chart;// Vergleich der Diagramme bool selectCoefByName(CDataKeeper &_input[],CDataKeeper &out,string Name);// Auswahl der Verhältnisse nach Namen double Mx(CoefStruct &_arr[]);// Arithmetisches Mittel double Std(CoefStruct &_arr[],double _Mx);// Standardabweichung CoefStruct arr_main[]; // Äquivalent der Tabelle Optimisation data CoefStruct arr_result[];// Äquivalent der Ergebnistabelle };
Analysieren wir die Struktur der Klasse und erläutern einige der Methoden im Detail. Wie wir sehen können, hat die Klasse zwei globale Arrays: arr_main und arr_result. Die Arrays speichern die Daten der Optimierung. Nach dem Entfernen der Optimierungsdurchläufe aus der Tabelle von der Datenbank wird sie in zwei Tabellen unterteilt:
- main — alle entfernten Daten bleiben erhalten, mit Ausnahme der Daten, die bei einer bedingten Sortierung verworfen wurden.
- result — n zunächst ausgewählte beste Daten. Danach sortiert die beschriebene Klasse diese Tabelle und reduziert oder setzt entsprechend die Anzahl ihrer Einträge zurück.
Die beschriebenen Arrays speichern die ID und die Parameter des EA sowie einige andere Daten aus den obigen Tabellen entsprechend den Array-Namen. Im Wesentlichen führt diese Klasse zwei Funktionen aus — eine komfortable Datenspeicherung für Operationen mit Tabellen und das Sortieren der Ergebnistabelle der ausgewählten Optimierungsläufe. Die Sortierklasse und zwei Komparatorklassen sind am Sortierprozess der genannten Arrays sowie an der Sortierung der nach den beschriebenen Tabellen aufgebauten Verteilungen beteiligt.
Da diese Klasse mit den EA-Verhältnissen, d.h. deren Darstellung in Form der Klasse CdataKeeper, arbeitet, wird eine 'private' Methode selectCoefByName erstellt. Es wählt ein notwendiges Verhältnis aus und gibt das Ergebnis als Referenz aus dem Array der übergebenen EA-Verhältnisse eines bestimmten Optimierungsdurchgangs zurück.
Die Add-Methode fügt die in die Datenbank hochgeladene Zeile (beide Arrays) hinzu, wenn man bedenkt, dass addToResult ==true, oder nur zum Array arr_main, wenn addToResult ==false. ID ist ein eindeutiger Parameter jedes Optimierungsdurchgangs, daher basiert die gesamte Arbeit an der Definition eines bestimmten ausgewählten Durchgangs darauf. Wir holen das vom Benutzer berechnete Verhältnis für diesen Parameter aus den bereitgestellten Arrays. Das Programm selbst kennt die Gleichung zur Berechnung einer benutzerdefinierten Bewertung nicht, da die Bewertung während der EA-Optimierung ohne die Programmteilnahme berechnet wird. Aus diesem Grund müssen wir eine benutzerdefinierte Bewertung für diese Arrays speichern. Wenn das verlangt wird, erhalten wir es mit der Methode GetCustomCoef über die übergebene ID.
Die wichtigsten Klassenmethoden sind die folgenden:
- Filter — sortiert die Ergebnistabelle so, dass sie die Werte eines ausgewählten Verhältnisses in einem übergebenen Bereich (von/bis) enthält.
- ResetFiltre — setzt die gesamte sortierte Information zurück.
- Get_Distribution(Chart_item &out[],bool isMainTable) — erstellt die Verteilung durch einen tatsächlich gehandelten PL gemäß der ausgewählten Tabelle, die mit dem isMainTable-Parameter angegeben wurde.
- Get_Distribution(Chart_item &out[],string Name,string value) — erstellt ein neues Array, in dem ein ausgewählter Parameter (Name) gleich dem übergebenen Wert (Wert) ist. Mit anderen Worten, der Durchlauf entlang des Arrays arr_result wird in einer Schleife durchgeführt. Bei jeder Iteration der Schleife wird der Parameter, für den wir uns interessieren, durch seinen Namen (mit der Funktion selectCoefByName) aus allen EA-Parametern ausgewählt. Außerdem wird geprüft, ob sein Wert gleich dem gewünschten (Wert) ist. Wenn ja, wird der Wert des Arrays arr_result dem temporären Array hinzugefügt. Anschließend wird eine Verteilung durch das temporäre Array erstellt und zurückgegeben. Mit anderen Worten, so wählen wir alle Optimierungsdurchläufe aus, bei denen der Wert des durch den Namen ausgewählten Parameters ermittelt wurde, der gleich dem übergebenen Wert ist. Dies ist notwendig, um abzuschätzen, wie stark sich dieser spezielle Parameter auf das EA als Ganzes auswirkt. Die Implementierung der beschriebenen Klasse ist im Code ausreichend kommentiert, und deshalb werde ich hier nicht auf die Implementierung dieser Methoden eingehen.
Der "Presenter"
Der Presenter dient als Verbinder. Dies ist eine Art Verknüpfung zwischen der grafischen Ebene der Anwendung und ihrer oben beschriebenen Logik. In dieser Anwendung wird der presenter mit Hilfe von Abstraktionen implementiert — der Schnittstelle IPresenter. Dieses Interface enthält den Namen der benötigten Callback-Methoden; sie wiederum sind in der Presenter-Klasse implementiert, die das gewünschte Interface erben soll. Dieser Teil wurde geschaffen, um die Anwendung abzuschließen. Wenn Sie den Block presenter neu schreiben müssen, kann dies problemlos geschehen, ohne den Grafikblock oder die Anwendungslogik zu beeinträchtigen. Die beschriebene Schnittstelle ist wie folgt dargestellt:
//+------------------------------------------------------------------+ //| Presenter Schnittstelle | //+------------------------------------------------------------------+ interface IPresenter { void Btn_Update_Click(); // Laden der Daten und Aufbau des Formulars void Btn_Load_Click(); // Erstellen des Berichts void OptimisationData(bool isMainTable);// Auswahl der Optimierungszeile in der Tabelle void Update_PLByDays(); // Hochladen von Gewinn und Verlust nach Tagen void DaySelect();// Auswahl eines Tages aus der PL-Tabelle nach Wochen void PL_pressed(PLSelected_type type);// Erstellen des PL-Diagramms ausgewählt nach der Historie void PL_pressed_2(bool isRealPL);// Erstellen der Diagramme "Andere Charts" void SaveToFile_Click();// Sichern der Datendatei (in der "Sandbox") void SaveParam_passed(SaveParam_type type);// Auswahl der in der Datei zu sichernden Daten void OptimisationParam_selected(); // Auswahl der Optimierungsparameter und der Tabelle "Optimisation selection" void CompareTables(bool isChecked);// Erstellen der Verteilung aus der tabelle mit den Ergebnissen (für die Korrelation mit der allgemeinen (Haupt-) Tabelle) void show_FriquencyChart(bool isChecked);// Darstellung des Häufigkeitsdiagramms von Gewinn/Verlust void FriquencyChart_click();// Auswahl einer Zeile der Tabelle der Verhältnisse und Erstellen der Verteilung void Filtre_click();// Sortieren nach den gewählten Bedingungen void Reset_click();// Rücksetzen des Filters void PL_pressed_3(bool isRealPL);// Erstellen des Diagramms Gewinn/Verlust mit allen Daten der Tabelle Result void PL_pressed_4(bool isRealPL);// Erstellen der Tabelle der Statistik void setChartFlag(bool isPlot);// Bedingung für das Erstellen (oder eben nicht) des Diagramms mit der Methode PL_pressed_3(bool isRealPL); };
Die Klasse presenter implemntiert die benötigte Schnittstelle und schaut folgendermaßen aus:
class CPresenter : public IPresenter { public: CPresenter(CWindowManager *_windowManager); // Konstruktor void Btn_Update_Click();// Laden der Daten und Aufbau des Formulars void Btn_Load_Click();// Berichtserstellung void OptimisationData(bool isMainTable);// Auswahl der Optimierungszeile in der Tabelle void Update_PLByDays(); // Hochladen von Gewinn und Verlust nach Tagen void PL_pressed(PLSelected_type type);// Erstellen des PL-Diagramms ausgewählt nach der Historie void PL_pressed_2(bool isRealPL);// Erstellen der Diagramme "Andere Charts" void SaveToFile_Click();// Sichern der Datendatei (in der "Sandbox") void SaveParam_passed(SaveParam_type type);// Auswahl der in der Datei zu sichernden Daten void OptimisationParam_selected(); // Auswahl der Optimierungsparameter und der Tabelle "Optimisation selection" void CompareTables(bool isChecked);// Erstellen der Verteilung aus der tabelle mit den Ergebnissen (für die Korrelation mit der allgemeinen (Haupt-) Tabelle) void show_FriquencyChart(bool isChecked);// Darstellung des Häufigkeitsdiagramms von Gewinn/Verlust void FriquencyChart_click();// Auswahl einer Zeile der Tabelle der Verhältnisse und Erstellen der Verteilung void Filtre_click();// Sortieren nach den gewählten Bedingungen void PL_pressed_3(bool isRealPL);// Erstellen des Diagramms Gewinn/Verlust mit allen Daten der Tabelle Result void PL_pressed_4(bool isRealPL);// Erstellen der Tabelle der Statistik void DaySelect();// Auswahl eines Tages aus der PL-Tabelle nach Wochen void Reset_click();// Rücksetzen des Filters void setChartFlag(bool isPlot);// Bedingung für das Erstellen (oder eben nicht) des Diagramms mit der Methode PL_pressed_3(bool isRealPL); private: CWindowManager *windowManager;// Referenz zur Fensterklasse CDBReader dbReader;// Klasse für die Arbeit mit der Datenbank CReportCreator reportCreator; // Klasse der Datenverarbeitung CGenericSorter sorter; // Klasse zum Sortieren CoefData_comparer coefComparer; // Klasse der Vergleiche void loadData();// Laden der Daten aus der Datenbank und eintragen in die Tabelle void insertDataTo_main_Table(bool isResult,const CoefData_item &data[]); // Einfügen der Daten in die Ergebnistabelle und in die "Main"-Tabelle (Tabelle mit den Verhältnissen der Optimierungsdurchläufe) void insertRowTo_main_Table(CTable *tb,int n,const CoefData_item &data); // Direktes Dateneintragen in die Tabelle der Optimierungsdurchläufe void selectChartByID(long ID,bool recalc=true);// Diagrammauswahl nach der ID void createReport();// Berichtserstellung string getCorrectPath(string path,string name);// Abfrage des Dateipfads bool getPLChart(PLChart_item &data[],bool isOneLot,long ID); bool curveAdd(CGraphic *chart_ptr,const PLChart_item &data[],bool isHist);// Hinzufügen des Diagramms zu "Other Charts" bool curveAdd(CGraphic *chart_ptr,const CoefChart_item &data[],double borderPoint);// Hinzufügen des Diagramms zu "Other Charts" bool curveAdd(CGraphic *chart_ptr,const Distribution_item &data);//Hinzufügen des Diagramms zu "Other Charts" void setCombobox(CComboBox *cb_ptr,CArrayString &arr,bool isFirstIndex=true);// Setzen der Parameter der Combobox void addPDF_line(CGraphic *chart_ptr,double &x[],color clr,int width,string _name=NULL);// Hinzufügen der geglätteten Linie zum Diagramms der Verteilung void plotMainPDF();// Erstellen der Verteilung durch die "Main"-Tabelle (Optimisation Data) void updateDT(CDropCalendar *dt_ptr,datetime DT);// Aktualisieren der Dropdown-Kalenders CParamsFiltre coefKeeper;// Sortieren der Optimierungsdurchläufe (nach den Verteilungen) CArrayString headder; // Kopfzeile der Tabelle der Verhältnisse bool _isUpbateClick; // Flag des Aktualisierungsschaltfläche und Laden der Daten aus der Datenbank long _selectedID; // ID der ausgewählten Serie von allen PL-Diagrammen (rot bei Verlusten, grün bei Gewinnen) long _ID,_ID_Arr[];// Array der IDs, ausgewählt für die Tabelle Result nach dem Laden der Daten bool _IsForvard_inTables,_IsForvard_inReport; // Flag des Typs der Optimierungsdaten in der Tabelle der Optimierungsdurchläufe datetime _DT_from,_DT_till; double _Gap; // Gesicherter Typ der hinzugefügten Gapy (simulierte Ausweitung der Spreizung / oder Schlupfes...) des vorher gewählten Optimierungsdiagramms };
Jeder der Call-Backs ist recht gut kommentiert, so dass es nicht nötig ist, hier auf sie einzugehen. Es ist nur zu sagen, dass dies genau der Teil der Anwendung ist, in dem das gesamte Formularverhalten implementiert ist. Er enthält das Erstellen der Diagramme, das Ausfüllen von Comboboxen, Aufrufmethoden zum Hochladen und Behandeln von Daten aus der Datenbank sowie andere Operationen, die verschiedene Klassen verbinden.
Schlussfolgerung
Wir haben die Anwendung entwickelt, die die Tabelle mit allen möglichen Optimierungsparametern behandelt, die durch den Tester geleitet werden, sowie die Ergänzung zum EA zum Speichern aller Optimierungsübergaben an die Datenbank. Zusätzlich zu dem detaillierten Handelsbericht, den wir bei der Auswahl eines für uns interessanten Parameters erhalten, ermöglicht uns das Programm auch eine gründliche Anzeige eines Intervalls aus der gesamten Optimierungshistorie, ausgewählt nach Zeit, sowie aller Kennzahlen für ein bestimmtes Zeitintervall. Es ist auch möglich, Schlupf zu simulieren, indem man den Gap-Parameter erhöht und sieht, wie sich dies auf das Verhalten von Graphen und Verhältnissen auswirkt. Eine weitere Ergänzung ist die Möglichkeit, Optimierungsergebnisse in einem bestimmten Intervall von Verhältniswerten zu sortieren.
Der einfachste Weg, um 100 beste Optimierungsdurchläufe zu erhalten, besteht darin, die Klasse CDBWriter mit Ihrem Roboter zu verbinden, genau wie mit dem Beispiel EA (in den angehängten Dateien), den bedingten Filter zu setzen (z.B. Profit Factor >= 1 schließt sofort alle verlustbringenden Kombinationen aus) und auf Aktualisieren zu klicken und den Parameter "Show n params" gleich 100 zu lassen. In diesem Fall werden in der Ergebnistabelle die 100 beste Optimierungsdurchläufe (entsprechend Ihrem Filter) angezeigt. Jede der Optionen der resultierenden Anwendung sowie verfeinerte Methoden zur Auswahl der Kennzahlen werden im nächsten Artikel näher erläutert.
Die folgenden Dateien sind dem Artikel beigefügt:
Experts/2MA_Martin — Test-EA Projekt
- 2MA_Martin.mq5 — EA-Template Code. Die Datei DBWriter.mqh, die die Daten der Optimierung sichert, ist hier inkludiert.
- Robot.mq5 — EA-Logik
- Robot.mqh — Headerdatei implementiert in der Datei Robot.mq5
- Trade.mq5 — EA-Handelslogik
- Trade.mqh — Headerdatei implementiert in der Datei Trade.mq5
Experts/OptimisationSelector — beschrieben im Anwendungsprojekt
- OptimisationSelector.mq5 — Template eines EAs, der das ganze Projekt aufruft
- ParamsFiltre.mq5 — Filter und Verteilungen nach den Ergebnissen der Tabellen
- ParamsFiltre.mqh — Headerdatei implementiert in der Datei ParamsFiltre.mq5
- Presenter.mq5 — presenter
- Presenter.mqh — Headerdatei implementiert in der Datei Presenter.mq5
- Presenter_interface.mqh — presenter Schnittstelle
- Window_1.mq5 — Grafik
- Window_1.mqh — Headerdatei implementiert in der Datei Window_1.mq5
Include/CustomGeneric
- GenericSorter.mqh — Sortieren der Daten
- ICustomComparer.mqh — ICustomSorter Schnittstelle
Include/History manager
- DealHistoryGetter.mqh — Laden der Handelshistorie des Terminals und Konvertieren in die geforderte Darstellung
- ReportCreator.mqh — Klasse zum Erstellen der Handelshistorie
Include/OptimisationSelector
- DataKeeper.mqh — Klasse zum Sichern der Verhältnisse des EAs gemäß des Verhältnisnamens
- DBReader.mqh — Klasse zum Lesen der benötigten Tabelle aus der Datenbank
- DBWriter.mqh — Klasse zum Schreiben der Datenbank
Include/Sqlite3
- sqlite_amalgmation.mqh — Importfunktionen zur Arbeit mit der Datenbank
- SqliteManager.mqh — Verbinder zur Datenbank und zur Klasse der Befehle
- SqliteReader.mqh — Klasse zum Lesen der Antworten aus der Datenbank
Include/WinApi
- memcpy.mqh — Importieren der Funktion memcpy
- Mutex.mqh — Importieren der Funktion zum Erstellen von Mutex
- strcpy.mqh — Importieren der Funktion strcpy
- strlen.mqh — Importieren der Funktion strlen
Libraries
- Sqlite3_32.dll — Dll Sqlite für 32-bit Terminals
- Sqlite3_64.dll — Dll Sqlite für 64-bit Terminals
Test database
- 2MA_Martin optimisation data — Sqlite Datenbank
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/5214
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Methoden zur Fernsteuerung von EAs
Methoden zur Fernsteuerung von EAs
 Modell der Bewegungsfortsetzung - Suche im Chart und Ausführungsstatistik
Modell der Bewegungsfortsetzung - Suche im Chart und Ausführungsstatistik
 Modellierung von Zeitreihen unter Verwendung nutzerdefinierter Symbole nach festgelegten Verteilungsgesetzen
Modellierung von Zeitreihen unter Verwendung nutzerdefinierter Symbole nach festgelegten Verteilungsgesetzen
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Vielen Dank für Ihre Hilfe. Das Projekt erschien, aber gab einen Fehler.
Vielen Dank für Ihre Hilfe. Das Projekt erschien, aber gab einen Fehler.
Vielen Dank für Ihr Feedback. Sie müssen die EasyAndFast-Grafikbibliothek herunterladen und die entsprechenden Änderungen vornehmen (es gibt einen Link im Artikel, der beschreibt, welche Änderungen wo vorzunehmen sind).
Das ganze Projekt ist sehr interessant, aber es wäre eine Freude zu wissen, wie können wir die auf mt4/mql4 Version, um dies zu versuchen, wenn möglich?
Das ganze Projekt ist sehr interessant, aber es wäre eine Freude zu wissen, wie können wir die auf mt4/mql4 Version, um dies zu versuchen, wenn möglich?
Mt4 ist nicht unterstützt, sorry.