Diskussion zum Artikel "Die Anwendung der Monte Carlo Methode beim Reinforcement-Learning"
Ich möchte gerne zu den Beobachtungen beitragen:
Vorteile dieser Version:
*************************************
1. Im Gegensatz zu früheren Versionen wird bei dieser Version nicht ständig gehandelt. Es wird selektiv gehandelt, wenn das Signal gut ist. Dies ist ein großer Vorteil, um Ihre Bedürfnisse zu erfüllen. Ansonsten ist es eine gute Sache.))) ..
2. Er kann schnell und einfach optimiert werden.
3. Die Größe des Trainermodells ist klein, so dass wir große Datenmengen trainieren können.
Die Nachteile dieser Version:
*******************************************
1. In vielen Fällen dauert es sehr lange, bis der Optimierungsprozess abgeschlossen ist, und wir müssen ihn daher manuell abbrechen.
2. Aus einigen Gründen ist es nicht so einfach, die Tests auszuführen. Ich muss mein MT5-Terminal neu starten und manchmal funktioniert es trotzdem nicht.
Meine Vorschläge zur Verbesserung:
*************************************
1. Versuchen Sie, mindestens 4 bis 5 Eingabefunktionen für das Training zu verwenden, wie z.B. open, close, high, low.
2. versuchen Sie, die "MathMoments ()" -Funktionen richtig zu verwenden, wenn Sie die Handelssignale optimieren wollen:
h ttps:// www.mql5.com/en/docs/standardlibrary/mathematics/stat/mathsubfunctions/statmathmoments
3. Versuchen Sie, einen iterativen Trainingskurs auf täglicher oder wöchentlicher Basis zu implementieren.
Dies ist ein zufälliges Ergebnis.
4. Versuchen Sie mehrere Zeiträume.
Ich muss das tun. Wie können wir es besser machen :))))

- www.mql5.com
Die Monte-Carlo-Methode ist sicherlich eine wirksame Methode zur Untersuchung von Zufallsprozessen. Allerdings sollte bei der Anwendung dieser Methode (wie auch bei jeder anderen) die Art des Prozesses (bei uns sind es die Finanzmärkte) berücksichtigt werden.
Das Problem der modernen Analytik besteht darin, dass bisher weder die traditionelle TA noch andere Methoden in der Lage waren, die elementare Struktur der Marktpreisbewegungen (wie ein Atom in der Physik) aufzudecken, und die verfügbaren Strukturen (TA-Muster, Elliott-Wellen und andere) sind nicht elementar, da sie für die Analyse nicht kontinuierlich sind (sie erscheinen mehrdeutig oder selten). Daher ist die Anwendung moderner Methoden fast eine blinde Suche nach dem so genannten "besten Modell" mittels Brute-Force-Methode (in diesem Fall mittels Monte-Carlo-Methode).
Dies ist jedoch ein Problem für die gesamte Analytikbranche. Und der Autor hat im Rahmen der Methode originelle Lösungen aufgezeigt - danke für die Arbeit!
Respekt an den Autor, für einen weiteren interessanten Artikel, für ein offenes und konstruktives Herangehen an die MO, trotz der heimlichen, mausartigen Fummelei anderer Teilnehmer des Themas und des Zugunders der Verwaltung:)
Speziell zum Thema - ich verstehe nicht ganz den Sinn des Monte-Carlo-Schießens, um Ziele zu finden, denn sie sind fast eindeutig deterministisch und können eine Größenordnung schneller gefunden werden, je nach den Scheitelpunkten des Zickzacks oder den Werten der gleichen Erträge.
Meines Erachtens wäre es sinnvoller, diese Methode auf ein viel unsichereres und mehrdimensionales Problem anzuwenden, wie z. B. die Auswahl und Einstufung von Prädiktoren. Idealerweise sollten die Prädiktoren bei der Lösung dieses Problems in einem Komplex bewertet werden, und die im Artikel beschriebene Suche und das alternative Training für jeden einzelnen Prädiktor sieht aus wie ein Gleichungssystem mit einer Unbekannten.
Respekt an den Autor, für einen weiteren interessanten Artikel, für eine offene und konstruktive Herangehensweise an die MO, trotz der geheimen, Mausfummelei anderer Teilnehmer des Themas und der Verwaltung zugunder:)
Speziell zum Thema - ich verstehe nicht ganz den Sinn des Monte-Carlo-Schießens, um Ziele zu finden, denn sie sind fast eindeutig deterministisch und können eine Größenordnung schneller gefunden werden, in Übereinstimmung mit den Scheitelpunkten des Zickzacks oder den Werten der gleichen Erträge.
Meines Erachtens wäre es sinnvoller, diese Methode auf ein viel unsichereres und mehrdimensionales Problem anzuwenden, wie z. B. die Auswahl und Einstufung von Prädiktoren. Idealerweise sollten die Prädiktoren bei der Lösung dieses Problems in einem Komplex bewertet werden, und die im Artikel beschriebene Suche und das alternative Training für jeden einzelnen Prädiktor sieht aus wie die Erstellung von Gleichungssystemen mit einer Unbekannten.
Respekt an den Autor, für einen weiteren interessanten Artikel, für eine offene und konstruktive Herangehensweise an die MO, trotz der geheimen, Mausfummelei anderer Teilnehmer des Themas und der Verwaltung zugunder:)
Speziell zum Thema - ich verstehe nicht ganz den Sinn des Monte-Carlo-Schießens, um Ziele zu finden, denn sie sind fast eindeutig deterministisch und können eine Größenordnung schneller gefunden werden, in Übereinstimmung mit den Scheitelpunkten des Zickzacks oder den Werten der gleichen Erträge.
Meines Erachtens wäre es sinnvoller, diese Methode auf ein viel unsichereres und mehrdimensionales Problem anzuwenden, wie z. B. die Auswahl und Einstufung von Prädiktoren. Idealerweise sollten die Prädiktoren bei der Lösung dieses Problems in einem Komplex bewertet werden, und die im Artikel beschriebene Suche und das alternative Training für jeden einzelnen Prädiktor sieht aus wie die Erstellung von Gleichungssystemen mit einer Unbekannten.
Was "eindeutig deterministisch" betrifft, so ist dies nicht korrekt, da TA-Zahlen und "Renditen" sehr mehrdeutig und unzuverlässig zu analysieren sind.
Deshalb verwendet der Autor sie nicht, sondern experimentiert mit der Monte-Carlo-Methode.
Hallo Maxim.
eine Frage.
"shift_probab" und "regularisation" Die Werte werden nur zur Optimierung verwendet und NICHT im Zuge des Live-Handels. Liege ich da richtig?
Oder ist es notwendig, die optimierten Werte für shift_probab und regularisation nach jeder Optimierung für den Live-Handel auf dem Chart zu setzen?
Vielen Dank!
Hallo, durch Monte Carlo gibt es eine zufällige Aufzählung von Zielen, nach allen Kanons des RL. Das heißt, es gibt viele Strategien (Schritte), der Agent sucht nach der optimalen, durch den minimalen Fehler auf der oos. Die Konstruktion neuer Merkmale ist ebenfalls in einer der Bibliotheken über MSUA implementiert (siehe Codobase). In diesem Papier wird nur eine Brute-Force-Suche von bestehenden Fiches implementiert, ohne neue zu konstruieren. Siehe Rekursive Eliminierungsmethode. Das heißt, sowohl Fiches als auch Ziele werden rekursiv eliminiert. Später kann ich andere Varianten vorschlagen, davon gibt es tatsächlich eine Menge. Aber vergleichende Tests sind sehr zeitaufwändig.
Hi, natürlich ist die zufällige Auswahl von Aktionen der Kanon des RL, außerdem kann sie notwendig sein, weil verschiedene Aktionen des Agenten die Umgebung verändern können, was eine gegen unendlich tendierende Anzahl von Varianten erzeugt, und natürlich kann man Monte Carlo anwenden, um die Reihenfolge solcher Aktionen zu optimieren.
Aber in unserem Fall hängt die Umgebung - die Marktkurse - nicht von den Handlungen des Agenten ab, vor allem nicht in der betrachteten Implementierung, in der historische, im Voraus bekannte Daten verwendet werden, und daher kann die Wahl der Reihenfolge der Handlungen (Trades) des Agenten ohne stochastische Methoden erfolgen.
P.S. Es ist z.B. möglich, die Zielsequenz von Trades mit dem maximal möglichen Gewinn durch Notierungen zu finden https://www.mql5.com/de/code/9234.

- www.mql5.com
Hallo Maxim.
eine Frage.
"shift_probab" und "regularisation" Die Werte werden nur zur Optimierung verwendet und NICHT im Zuge des Live-Handels. Liege ich da richtig?
Oder ist es notwendig, die optimierten Werte für shift_probab und regularisation nach jeder Optimierung für den Live-Handel auf dem Chart zu setzen?
Ja, danke.
Hi, natürlich ist die zufällige Auswahl von Aktionen der Kanon von RL, außerdem kann es notwendig sein, weil verschiedene Aktionen des Agenten die Umgebung verändern können, was eine Anzahl von Optionen erzeugt, die gegen unendlich tendieren, und natürlich kann Monte Carlo gut angewandt werden, um die Sequenz solcher Aktionen zu optimieren.
Aber in unserem Fall hängt die Umgebung - die Marktkurse - nicht von den Handlungen des Agenten ab, vor allem nicht in der betrachteten Implementierung, in der historische, im Voraus bekannte Daten verwendet werden, und daher kann die Wahl der Reihenfolge der Handlungen (Trades) des Agenten ohne stochastische Methoden erfolgen.
P.S. Es ist z.B. möglich, die Zielsequenz von Trades mit dem maximal möglichen Gewinn durch Notierungen zu finden https://www.mql5.com/de/code/9234.
Die Aussage "eindeutig deterministisch" ist falsch, da TA-Zahlen und "Renditen" sehr vieldeutig und unzuverlässig zu analysieren sind.
Daher verwendet der Autor sie nicht, sondern experimentiert mit der Monte-Carlo-Methode.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Die Anwendung der Monte Carlo Methode beim Reinforcement-Learning :
Im Artikel werden wir das Reinforcement-Learning (Verstärkungslernen) anwenden, um selbstlernende Expert Advisors zu entwickeln. Im vorherigen Artikel haben wir den Algorithmus Random Decision Forest betrachtet und einen einfachen, selbstlernenden EA geschrieben, der auf dem Reinforcement-Learning basiert. Die Hauptvorteile eines solchen Ansatzes (Einfachheit der Entwicklung von Handelsalgorithmen und hohe "Trainings"-Geschwindigkeit) wurden erläutert. Reinforcement-Learning (RL) lässt sich leicht in jedes Trading EA integrieren und beschleunigt dessen Optimierung.
Nach Beendigung der Optimierung aktivieren Sie einfach den Einzeltestmodus (da das beste Modell in die Datei geschrieben wird und nur dieses Modell hochgeladen werden soll):
Lassen Sie uns die Historie für zwei Monate zurückblättern und sehen, wie das Modell für die vollen vier Monate funktioniert:
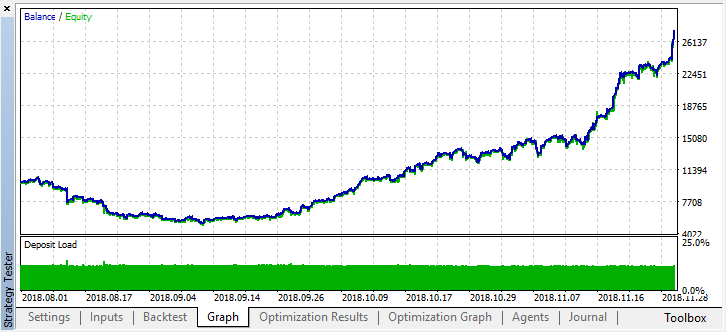
Wir sehen, dass das resultierende Modell einen weiteren Monat (fast den gesamten September) dauerte, während es im August zusammenbrach.Autor: Maxim Dmitrievsky