
Erstellen von selbstoptimierenden Expertenberatern in MQL5 (Teil 7): Handel mit mehreren Periodenlängen gleichzeitig

Technische Indikatoren stellen den modernen Anleger vor viele Möglichkeiten und entsprechende Herausforderungen. Es gibt viele bekannte Einschränkungen technischer Indikatoren, wie z. B. die ihnen innewohnende Verzögerung, die bereits ausführlich erörtert wurde.
In dieser Diskussion wollen wir uns auf die differenzierteren Herausforderungen konzentrieren, die mit der Ermittlung des richtigen Periodenlänge für Ihren Indikator verbunden sind. Die Periodenlänge eines Indikators ist ein gemeinsamer Parameter für die meisten technischen Indikatoren, der bestimmt, wie viele historische Daten der Indikator für seine Berechnungen benötigt.
Im Allgemeinen führt die Wahl einer zu kleinen Periodenlänge dazu, dass der technische Indikator ein beträchtliches Marktrauschen aufnimmt, während zu große Periodenwerte oft Signale erzeugen, lange nachdem die Marktbewegung bereits stattgefunden hat. In beiden Fällen werden Handelschancen verpasst und das Leistungsniveau sinkt.
Unsere in diesem Artikel vorgeschlagene Lösung ermöglicht es uns, die Komplexität der Ermittlung der optimalen Periodenlänge zu beseitigen und stattdessen alle verfügbaren Periodenlängen auf einmal zu nutzen. Um dieses Ziel zu erreichen, wird der Leser in eine Familie von Algorithmen des maschinellen Lernens eingeführt, die als Dimensionsreduktionsalgorithmen bekannt sind, wobei ein besonderer Schwerpunkt auf einem relativ neuen Algorithmus liegt, der als Uniform Manifold Approximation And Projection (UMAP) bekannt ist. Anschließend werden wir zeigen, dass diese Familie von Algorithmen es uns ermöglicht, alle verfügbaren Daten, die ein Problem beschreiben, in einer aussagekräftigen Darstellung zu verwenden, die mehr Erkenntnisse liefert als der Datensatz in seiner ursprünglichen Form.
Darüber hinaus werden wir auch relevante Prinzipien der objektorientierten Programmierung (OOP) in MQL5 betrachten, die notwendig sind, um nützliche Klassen zu erstellen, die uns helfen, den Namensraum, die Speichernutzung und andere Routineoperationen, die für unsere Handelsanwendungen benötigt werden, effizient zu verwalten. Unter den 4 Klassen, die wir gemeinsam schreiben werden, werden wir eine spezielle Klasse erstellen, die es uns ermöglicht, schnell Anwendungen zu entwickeln, die auf ONNX-Modellen basieren. Es gibt viel zu berichten, beginnen wir.
Die benötigten Klassen in MQL5 erstellen
In unserer letzten Diskussion über selbstoptimierende Expert Advisors haben wir eine RSI-Klasse erstellt, die uns eine sinnvolle und organisierte Möglichkeit bietet, Indikatordaten über viele verschiedene Periodenlängen des RSI abzurufen. Leser, die mit dieser Diskussion nicht vertraut sind, können sich schnell informieren, indem sie diesem Link folgen. Für diese Diskussion werden wir jedoch vom RSI abweichen und ihn stattdessen durch Indikator Williams Percent Range (WPR) ersetzen.
Der WPR wird im Allgemeinen als Momentum-Oszillator betrachtet, und seine mögliche Gesamtspanne reicht von 0 bis -100. Werte zwischen 0 und -20 stehen für fallend, während Werte zwischen -80 und -100 als ansteigend angesehen werden. Der Indikator funktioniert im Wesentlichen durch den Vergleich des aktuellen Kurses eines bestimmten Symbols mit dem höchsten Wert, der innerhalb des vom Nutzer ausgewählten Periodenlänge festgestellt wurde. Unser erstes Ziel wird es sein, eine neue Klasse mit dem Namen „SingleBufferIndicator“ zu erstellen, die sowohl von der RSI- als auch von der WPR-Klasse genutzt wird. Dadurch, dass unsere RSI- und WPR-Klassen ein gemeinsames übergeordnetes Element haben, erhalten wir eine einheitliche Funktionalität beider Indikatorklassen. Wir beginnen mit der Definition der Klasse „SingleBufferIndicator“ und der Auflistung ihrer Klassenmitglieder.
Dieser Entwurfsansatz bietet uns viele Vorteile. Wenn wir zum Beispiel neue Funktionen realisieren, die alle Indikatorklassen in Zukunft haben sollen, müssen wir nur eine Klasse aktualisieren, die übergeordnete Klasse „SingleBufferIndicator.mqh“, und von dort aus müssen wir nur noch die untergeordneten Klassen kompilieren, damit die Aktualisierungen verfügbar sind. Die Vererbung ist ein unverzichtbares Merkmal der objektorientierten Programmierung, weil wir viele Klassen effektiv kontrollieren können, indem wir nur eine Klasse ändern.
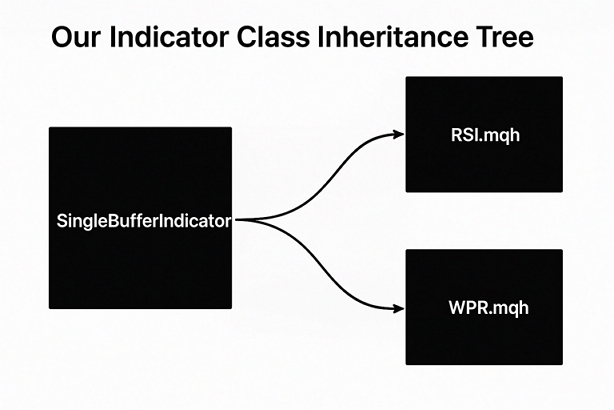
Abb. 1: Visualisierung des Vererbungsbaums unserer Indikatorfamilie von Einzelpuffern
Um den Ball ins Rollen zu bringen, werden wir die Funktionalität, die wir bei der Entwicklung der RSI-Klasse verwendet haben, so verallgemeinern, dass sie für jeden Indikator geeignet ist, der nur einen Puffer hat. Der Leser sollte beachten, dass MetaTrader 5 eine umfassende Reihe von Indikatoren bietet, aus denen der Leser wählen kann. Die Tatsache, dass wir eine Klasse für Indikatoren mit einem einzigen Puffer bauen, sollte den Leser darüber informieren, dass es Indikatoren gibt, die mehr als einen Puffer haben. Wenn wir Klassen entwerfen, wollen wir im Allgemeinen, dass die Klasse einen klaren und eindeutigen Zweck hat.
Der Versuch, eine einzige Klasse zu entwerfen, die alle Indikatoren behandelt, unabhängig davon, wie viele Puffer sie haben, könnte sich als zu schwierig erweisen, um sie auf einmal zu erreichen. Außerdem kann Ihr Code logische Fehler und andere unbeabsichtigte Bugs enthalten, wenn Sie bei der Entwicklung nicht vorsichtig sind. Wenn wir also den Umfang des Kurses begrenzen, schaffen wir die Voraussetzungen für den Erfolg.
//+------------------------------------------------------------------+ //| SingleBufferIndicator.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class SingleBufferIndicator { public: //--- Class methods bool SetIndicatorValues(int buffer_size,bool set_as_series); double GetReadingAt(int index); bool SetDifferencedIndicatorValues(int buffer_size,int differencing_period,bool set_as_series); double GetDifferencedReadingAt(int index); double GetCurrentReading(void); //--- Have the indicator values been copied to the buffer? bool indicator_values_initialized; bool indicator_differenced_values_initialized; //--- How far into the future we wish to forecast int forecast_horizon; //--- The buffer for our indicator double indicator_reading[]; vector indicator_differenced_values; //--- The current size of the buffer the user last requested int indicator_buffer_size; int indicator_differenced_buffer_size; //--- The handler for our indicator int indicator_handler; //--- The time frame our indicator should be applied on ENUM_TIMEFRAMES indicator_time_frame; //--- The price should the indicator be applied on ENUM_APPLIED_PRICE indicator_price; //--- Give the user feedback string user_feedback(int flag); //--- The Symbol our indicator should be applied on string indicator_symbol; //--- Our period int indicator_period; //--- Is our indicator valid? bool IsValid(void); //---- Testing the Single Buffer Indicator Class //--- This method should be deleted in production virtual void Test(void); }; //+------------------------------------------------------------------+
Wir brauchen nun eine Methode, die die Indikatorwerte aus unserem Indikator-Handler in den Indikatorpuffer kopiert. Die Methode hat 2 Parameter, von denen einer die Menge der zu kopierenden Daten angibt und der andere, wie die Daten geordnet werden sollen. Wenn der zweite Parameter wahr ist, werden die Daten von der Vergangenheit zur Gegenwart hin geordnet.
//+------------------------------------------------------------------+ //| Set our indicator values and our buffer size | //+------------------------------------------------------------------+ bool SingleBufferIndicator::SetIndicatorValues(int buffer_size,bool set_as_series) { //--- Buffer size indicator_buffer_size = buffer_size; CopyBuffer(this.indicator_handler,0,0,buffer_size,indicator_reading); //--- Should the array be set as series? if(set_as_series) ArraySetAsSeries(this.indicator_reading,true); indicator_values_initialized = true; //--- Did something go wrong? vector indicator_test; indicator_test.CopyIndicatorBuffer(indicator_handler,0,0,buffer_size); if(indicator_test.Sum() == 0) return(false); //--- Everything went fine. return(true); }
Beim maschinellen Lernen kann die Aufzeichnung der Veränderung einer Variablen aufschlussreicher sein als der Rohwert. Deshalb wollen wir auch eine eigene Methode erstellen, die die Änderung des Indikatorwertes berechnet und in einen Indikatorpuffer kopiert.
//+--------------------------------------------------------------+ //| Let's set the conditions for our differenced data | //+--------------------------------------------------------------+ bool SingleBufferIndicator::SetDifferencedIndicatorValues(int buffer_size,int differencing_period,bool set_as_series) { //--- Internal variables indicator_differenced_buffer_size = buffer_size; indicator_differenced_values = vector::Zeros(indicator_differenced_buffer_size); //--- Prepare to record the differences in our RSI readings double temp_buffer[]; int fetch = (indicator_differenced_buffer_size + (2 * differencing_period)); CopyBuffer(indicator_handler,0,0,fetch,temp_buffer); if(set_as_series) ArraySetAsSeries(temp_buffer,true); //--- Fill in our values iteratively for(int i = indicator_differenced_buffer_size;i > 1; i--) { indicator_differenced_values[i-1] = temp_buffer[i-1] - temp_buffer[i-1+differencing_period]; } //--- If the norm of a vector is 0, the vector is empty! if(indicator_differenced_values.Norm(VECTOR_NORM_P) != 0) { Print(user_feedback(2)); indicator_differenced_values_initialized = true; return(true); } indicator_differenced_values_initialized = false; Print(user_feedback(3)); return(false); }
Nachdem wir nun Methoden zum Kopieren von Indikatorwerten in Puffer definiert haben, benötigen wir Methoden zum Abrufen der Daten in diesen Puffern. Man beachte, dass wir den Indikatorpuffer einfach als öffentliches Mitglied der Klasse hätten deklarieren können, sodass wir die gewünschten Werte schnell abrufen können. Das Problem bei diesem Ansatz ist, dass er den Zweck des Aufbaus einer Klasse verfehlt, der darin besteht, eine einheitliche Methode zum Lesen und Schreiben von Objekten zu haben.
//--- Get a differenced value at a specific index double SingleBufferIndicator::GetDifferencedReadingAt(int index) { //--- Make sure we're not trying to call values beyond our index if(index > indicator_differenced_buffer_size) { Print(user_feedback(4)); return(-1e10); } //--- Make sure our values have been set if(!indicator_differenced_values_initialized) { //--- The user is trying to use values before they were set in memory Print(user_feedback(1)); return(-1e10); } //--- Return the differenced value of our indicator at a specific index if((indicator_differenced_values_initialized) && (index < indicator_differenced_buffer_size)) return(indicator_differenced_values[index]); //--- Something went wrong. return(-1e10); }
Die vorherige Methode gab den differenzierten Indikatorwert zurück. Sie benötigt eine Gegenmethode, die die tatsächlichen Indikatorwerte zurückgibt, wie sie auf dem Indikator erscheinen.
//+------------------------------------------------------------------+ //| Get a reading at a specific index from our RSI buffer | //+------------------------------------------------------------------+ double SingleBufferIndicator::GetReadingAt(int index) { //--- Is the user trying to call indexes beyond the buffer? if(index > indicator_buffer_size) { Print(user_feedback(4)); return(-1e10); } //--- Get the reading at the specified index if((indicator_values_initialized) && (index < indicator_buffer_size)) return(indicator_reading[index]); //--- User is trying to get values that were not set prior else { Print(user_feedback(1)); return(-1e10); } }
Ich dachte auch, es wäre nützlich, eine Funktion zu haben, die den Indikatorwert bei Index 0 zurückgibt, d.h. den aktuellen Indikatorwert.
//+------------------------------------------------------------------+ //| Get our current reading from the RSI indicator | //+------------------------------------------------------------------+ double SingleBufferIndicator::GetCurrentReading(void) { double temp[]; CopyBuffer(this.indicator_handler,0,0,1,temp); return(temp[0]); }
Diese Funktion informiert uns, ob unser Handler korrekt geladen wurde. Es ist ein nützliches Sicherheitsmerkmal für uns.
//+------------------------------------------------------------------+ //| Check if our indicator handler is valid | //+------------------------------------------------------------------+ bool SingleBufferIndicator::IsValid(void) { return((this.indicator_handler != INVALID_HANDLE)); }
Während der Nutzer mit der Indikatorklasse interagiert, möchten wir ihm Hinweise auf Fehler geben, die er möglicherweise gemacht hat, und ihm die entsprechende Lösung zur Behebung des Fehlers anbieten.
//+------------------------------------------------------------------+ //| Give the user feedback on the actions he is performing | //+------------------------------------------------------------------+ string SingleBufferIndicator::user_feedback(int flag) { string message; //--- Check if the indicator loaded correctly if(flag == 0) { //--- Check the indicator was loaded correctly if(IsValid()) message = "Indicator Class Loaded Correcrtly \nSymbol: " + (string) indicator_symbol + "\nPeriod: " + (string) indicator_period; return(message); //--- Something went wrong message = "Error loading Indicator: [ERROR] " + (string) GetLastError(); return(message); } //--- User tried getting indicator values before setting them if(flag == 1) { message = "Please set the indicator values before trying to fetch them from memory, call SetIndicatorValues()"; return(message); } //--- We sueccessfully set our differenced indicator values if(flag == 2) { message = "Succesfully set differenced indicator values."; return(message); } //--- Failed to set our differenced indicator values if(flag == 3) { message = "Failed to set our differenced indicator values: [ERROR] " + (string) GetLastError(); return(message); } //--- The user is trying to retrieve an index beyond the buffer size and must update the buffer size first if(flag == 4) { message = "The user is attempting to use call an index beyond the buffer size, update the buffer size first"; return(message); } //--- The class has been deactivated by the user if(flag == 5) { message = "Goodbye."; return(message); } //--- No feedback else return(""); }
Damit können wir nun unsere WPR-Klasse erstellen, die von der übergeordneten Klasse SingleBufferIndicator abgeleitet wird. Alles in allem sollte Ihr Abhängigkeitsbaum in etwa so aussehen wie in Abbildung 1, wenn Sie dem Artikel folgen wollen.
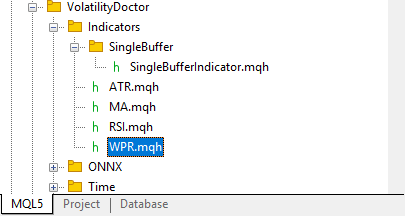
Abb. 2: Unser Abhängigkeitsbaum für unsere Indikatorklassen
Kommen wir nun zum ersten Schritt, den wir in unserer WPR-Klasse machen werden, nämlich die Einbindung der SingleBufferIndicator-Klasse in die WPR-Klasse.
//+------------------------------------------------------------------+ //| WPR.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the parent class | //+------------------------------------------------------------------+ #include <VolatilityDoctor\Indicators\SingleBuffer\SingleBufferIndicator.mqh>
Bevor wir die Klassenmitglieder der WPR-Klasse definieren, geben wir diesmal an, dass die Klasse die SingleBufferIndicator-Klasse erweitert, indem wir die Syntax des Doppelpunkts : verwenden. So erweitern wir Klassen in MQL5. Für Leser, die mit den Konzepten der OOP nicht vertraut sind: Die Erweiterung einer Klasse ermöglicht es uns, die Methoden, die wir in der SingleBufferIndicator-Klasse geschrieben haben, innerhalb der WPR-Klasse aufzurufen. Dadurch, dass unsere WPR- und RSI-Klasse beide die SingleBufferIndicator-Klasse erweitern, erhalten wir eine einheitliche Funktionalität für beide Klassen. Mit anderen Worten: Alle öffentlichen Klassenmitglieder in unserer SingleBufferIndicator-Klasse sind in jeder Klasse, die sie erweitert, ohne weiteres verfügbar.
//+------------------------------------------------------------------+ //| This class will provide us with usefull functionality for the WPR| //+------------------------------------------------------------------+ class WPR : public SingleBufferIndicator { public: WPR(); WPR(string user_symbol,ENUM_TIMEFRAMES user_time_frame,int user_period); ~WPR(); };
Die WPR- und RSI-Indikatoren haben beide nur einen Puffer; die Indikatoren benötigen jedoch unterschiedliche Parameter, um initialisiert zu werden. Daher ist es sinnvoller, dass der Konstruktor für jede Indikatorinstanz spezifisch ist, da die Konstruktorsignaturen von Indikator zu Indikator sehr unterschiedlich sein können.
//+------------------------------------------------------------------+ //| Our default constructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::WPR() { indicator_values_initialized = false; indicator_symbol = "EURUSD"; indicator_time_frame = PERIOD_D1; indicator_period = 5; indicator_handler = iWPR(indicator_symbol,indicator_time_frame,indicator_period); //--- Give the user feedback on initilization Print(user_feedback(0)); //--- Remind the user they called the default constructor Print("Default Constructor Called: ",__FUNCSIG__," ",&this); }
Mit dem parametrischen Konstruktor kann der Nutzer angeben, mit welchem Symbol, Zeitrahmen und Periodenlänge der WPR-Indikator initialisiert werden soll.
//+------------------------------------------------------------------+ //| Our parametric constructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::WPR(string user_symbol,ENUM_TIMEFRAMES user_time_frame,int user_period) { indicator_values_initialized = false; indicator_symbol = user_symbol; indicator_time_frame = user_time_frame; indicator_period = user_period; indicator_handler = iWPR(indicator_symbol,indicator_time_frame,indicator_period); //--- Give the user feedback on initilization Print(user_feedback(0)); }
Der Destruktor der Klasse setzt unsere wichtigen Flags zurück und gibt den Indikator für uns frei. Es ist eine gute MQL5-Praxis, hinter sich selbst aufzuräumen. Durch die Erstellung einer eigenen Klasse für diesen Zweck wird die kognitive Belastung des Entwicklers reduziert, da Sie nicht ständig den Überblick behalten und den Aufräumprozess wiederholen müssen, wenn die Klasse dies für Sie erledigt.
//+------------------------------------------------------------------+ //| Our destructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::~WPR() { //--- Free up resources we don't need and reset our flags if(IndicatorRelease(indicator_handler)) { indicator_differenced_values_initialized = false; indicator_values_initialized = false; Print(user_feedback(5)); } } //+------------------------------------------------------------------+
Eine weitere Funktion, die wir benötigen, ist die Fähigkeit zu erkennen, wann eine neue Kerze vollständig ausgebildet ist. Wann immer dies der Fall ist, möchten wir bestimmte Aufgaben erfüllen. Daher werden wir diesem Ziel eine eigene Klasse widmen, da es für uns von wesentlicher Bedeutung ist und wir in manchen Fällen die Bildung von Kerzen auf verschiedenen Zeitrahmen gleichzeitig verfolgen wollen. Wir beginnen mit der Deklaration der Klassenmitglieder, die unsere Klasse Time benötigt.
//+------------------------------------------------------------------+ //| Time.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class Time { private: datetime time_stamp; datetime current_time; string selected_symbol; ENUM_TIMEFRAMES selected_time_frame; public: Time(string user_symbol,ENUM_TIMEFRAMES user_time_frame); bool NewCandle(void); ~Time(); };
Beachten Sie, dass die Klasse keinen Standardkonstruktor hat, dies wurde bewusst so gemacht. Standardkonstrukteure wären in diesem speziellen Fall nicht sehr sinnvoll.
//+------------------------------------------------------------------+ //| Create our time object | //+------------------------------------------------------------------+ Time::Time(string user_symbol,ENUM_TIMEFRAMES user_time_frame) { selected_time_frame = user_time_frame; selected_symbol = user_symbol; current_time = iTime(user_symbol,selected_time_frame,0); time_stamp = iTime(user_symbol,selected_time_frame,0); }
Derzeit ist der Destruktor der Klasse leer.
//+------------------------------------------------------------------+ //| Our destructor is currently empty | //+------------------------------------------------------------------+ Time::~Time() { } //+------------------------------------------------------------------+
Schließlich benötigen wir eine Methode, die uns informiert, wenn sich eine neue Kerze gebildet hat. Diese Methode gibt true zurück, wenn sich eine neue Kerze gebildet hat, sodass wir unsere Routinen periodisch durchführen können.
//+------------------------------------------------------------------+ //| Check if a new candle has fully formed | //+------------------------------------------------------------------+ bool Time::NewCandle(void) { current_time = iTime(selected_symbol,selected_time_frame,0); //--- Check if a new candle has formed if(time_stamp != current_time) { time_stamp = current_time; return(true); } //--- No new candle has completely formed return(false); }
Im weiteren Verlauf benötigen wir auch eine eigene Klasse für den Umgang mit unseren ONNX-Objekten. Da unsere Projekte immer größer und komplizierter werden, wollen wir bestimmte Schritte nicht mehrfach wiederholen. Letztendlich ist es vielleicht besser, eine Klasse ONNXFloat für alle ONNX-Modelle zu haben, die Float-Datentypen akzeptieren. Zum Zeitpunkt der Erstellung dieses Dokuments ist der Datentyp float weithin als stabiler Datentyp für ONNX-Modelle anerkannt. Beginnen wir mit der ONNX-Float-Klasse, indem wir ihre Klassenmitglieder definieren.
//+------------------------------------------------------------------+ //| ONNXFloat.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| This class will help us work with ONNX Float models. | //+------------------------------------------------------------------+ class ONNXFloat { private: //--- Our ONNX model handler long onnx_model; int onnx_outputs; public: //--- Is our Model Valid? bool OnnxModelIsValid(void); //--- Define the input shape of our model bool DefineOnnxInputShape(int n_index,int n_stacks,int n_input_params); //--- Define the output shape of our model bool DefineOnnxOutputShape(int n_index,int n_stacks, int n_output_params); vectorf Predict(const vectorf &model_inputs); //--- ONNXFloat class constructor ONNXFloat(const uchar &user_proto[]); //---- ONNXFloat class destructor ~ONNXFloat(); };
Der Konstruktor für unsere Klasse akzeptiert einen ONNX-Modellprototyp und erstellt das ONNX-Modell aus dem vom Nutzer übergebenen Puffer. Beachten Sie, dass ONNX-Modellpuffer nur als Referenz und nicht als Wert übergeben werden können. Das kaufmännische Und-Zeichen „&“, das dem Namen des ONNX-Modellpuffers „&user_proto“ vorangestellt ist, gibt ausdrücklich an, dass dieser Parameter ein Verweis auf ein Objekt im Speicher ist. Wenn eine Funktion einen Parameter hat, der als Referenz übergeben wird, wird vom Nutzer erwartet, dass er versteht, dass jede Änderung des Parameters innerhalb der Funktion auch den ursprünglichen Parameter außerhalb der Funktion ändert.
In unserem Fall beabsichtigen wir nicht, den ONNX-Prototyp zu bearbeiten; daher ändern wir den Parameter in „const“, um dem Programmierer und dem Compiler anzuzeigen, dass keine Änderungen vorgenommen werden sollen. Wenn der Programmierer also unsere Richtlinien ignoriert, wird der Compiler dies nicht akzeptieren.
//+------------------------------------------------------------------+ //| Parametric Constructor For Our ONNXFloat class | //+------------------------------------------------------------------+ ONNXFloat::ONNXFloat(const uchar &user_proto[]) { onnx_model = OnnxCreateFromBuffer(user_proto,ONNX_DATA_TYPE_FLOAT); if(OnnxModelIsValid()) Print("Volatility Doctor ONNXFloat Class Loaded Correctly: ",__FUNCSIG__," ",&this); else Print("Failed To Create The specified ONNX model: ",GetLastError()); }
Der Destruktor der Klasse ONNXFloat wird den Speicher, den wir unserem ONNX-Modell zugewiesen haben, automatisch für uns freigeben.
//+------------------------------------------------------------------+ //| Our ONNXFloat class destructor | //+------------------------------------------------------------------+ ONNXFloat::~ONNXFloat() { OnnxRelease(onnx_model); } //+------------------------------------------------------------------+
Wir benötigen auch eine spezielle Funktion, die uns darüber informiert, ob unser ONNX-Modell gültig ist, indem sie ein boolesches Flag zurückgibt, das nur wahr ist, wenn das Modell gültig ist.
//+------------------------------------------------------------------+ //| A method that returns true if our ONNXFloat model is valid | //+------------------------------------------------------------------+ bool ONNXFloat::OnnxModelIsValid(void) { //--- Check if the model is valid if(onnx_model != INVALID_HANDLE) return(true); //--- Something went wrong return(false); }
Das Einrichten der Eingabeform eines jeden ONNX-Modells ist ein notwendiger vorbereitender Schritt, den wir wahrscheinlich häufig benötigen werden.
//+------------------------------------------------------------------+ //| Set the input shape of our ONNXFloat model | //+------------------------------------------------------------------+ bool ONNXFloat::DefineOnnxInputShape(int n_index,int n_stacks,int n_input_params) { const ulong model_input_shape[] = {n_stacks,n_input_params}; if(OnnxSetInputShape(onnx_model,n_index,model_input_shape)) { Print("Succefully specified ONNX model output shape: ",__FUNCTION__," ",&this); return(true); } //--- Something went wrong Print("Failed to set the passed ONNX model output shape: ",GetLastError()); return(false); }
Das Gleiche gilt für die Ausgabeform des ONNX-Modells.
//+------------------------------------------------------------------+ //| Set the output shape of our model | //+------------------------------------------------------------------+ bool ONNXFloat::DefineOnnxOutputShape(int n_index,int n_stacks,int n_output_params) { const ulong model_output_shape[] = {n_output_params,n_stacks}; onnx_outputs = n_output_params; if(OnnxSetOutputShape(onnx_model,n_index,model_output_shape)) { Print("Succefully specified ONNX model input shape: ",__FUNCSIG__," ",&this); return(true); } //--- Something went wrong Print("Failed to set the passed ONNX model input shape: ",GetLastError()); return(false); }
Schließlich brauchen wir noch eine Vorhersagefunktion. Diese Funktion nimmt die Eingabedaten des ONNX-Modells als Referenz, und da wir nicht vorhaben, die Eingabedaten zu ändern, haben wir diesen Parameter als Konstante festgelegt. Dadurch wird verhindert, dass unbeabsichtigte Seiteneffekte die Eingabedaten verfälschen. Vor allem aber wird unser Compiler angewiesen, uns vor unbedachten Fehlern zu bewahren, die die Modelleingaben verändern würden. Solche Sicherheitsfunktionen sind von unschätzbarem Wert, und dass sie in Ihre Programmiersprache eingebaut sind, qualifiziert MQL5 als erstklassige Programmiersprache.
//+------------------------------------------------------------------+ //| Get a prediction from our model | //+------------------------------------------------------------------+ vectorf ONNXFloat::Predict(const vectorf &model_inputs) { vectorf model_output(onnx_outputs); if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_output)) { vectorf res = model_output; return(res); } Comment("Failed to get a prediction from our ONNX model"); Print("ONNX Run Failed: ",GetLastError()); vectorf res = {10e8}; return(res); }
Die letzte Klasse, die wir benötigen, ist dafür zuständig, nützliche Handelsinformationen für uns abzurufen, wie das Mindesthandelsvolumen oder den aktuellen Briefkurs.
//+------------------------------------------------------------------+ //| TradeInfo.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class TradeInfo { private: string user_symbol; ENUM_TIMEFRAMES user_time_frame; double min_volume,max_volume,volume_step; public: TradeInfo(string selected_symbol,ENUM_TIMEFRAMES selected_time_frame); double MinVolume(void); double MaxVolume(void); double VolumeStep(void); double GetAsk(void); double GetBid(void); double GetClose(void); string GetSymbol(void); ~TradeInfo(); };
Der Konstruktor der parametrischen Klasse benötigt 2 Parameter, die das gewünschte Symbol und den Zeitrahmen angeben.
//+------------------------------------------------------------------+ //| The constructor will load our symbol information | //+------------------------------------------------------------------+ TradeInfo::TradeInfo(string selected_symbol,ENUM_TIMEFRAMES selected_time_frame) { //--- Which symbol are you interested in? user_symbol = selected_symbol; user_time_frame = selected_time_frame; if(SymbolSelect(user_symbol,true)) { //--- Load symbol details min_volume = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_MIN); max_volume = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_MAX); volume_step = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_STEP); Print("Trade Info Loaded Successfully: ",__FUNCSIG__); } else { Print("Error Symbol Information Could Not Be Found For: ",selected_symbol," ",GetLastError()); } }
Wir werden auch Methoden definieren, um die aktuellen Werte jedes der 4 primären Preisfeeds zu erhalten, d.h. jede dieser Methoden liefert die aktuellen Eröffnungs-, Hoch-, Tief- und Schlusskurse.
//+------------------------------------------------------------------+ //| Return the close of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetClose(void) { double res = iClose(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the open of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetOpen(void) { double res = iOpen(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the high of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetHigh(void) { double res = iHigh(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the low of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetLow(void) { double res = iLow(user_symbol,user_time_frame,0); return(res); }
Wenn Sie mit mehreren Symbolen arbeiten, ist es hilfreich, eine Erinnerung daran zu haben, welchem Symbol die aktuelle Instanz der Klasse zugewiesen wurde.
//+------------------------------------------------------------------+ //| Return the selected symbol | //+------------------------------------------------------------------+ string TradeInfo::GetSymbol(void) { string res = user_symbol; return(res); }
Unsere Klasse bietet auch Wrapper, um schnell wichtige Informationen über die zulässigen Lautstärkepegel des aktuellen Symbols abzurufen.
//+------------------------------------------------------------------+ //| Return the volume step allowed | //+------------------------------------------------------------------+ double TradeInfo::VolumeStep(void) { double res = volume_step; return(res); } //+------------------------------------------------------------------+ //| Return the minimum volume allowed | //+------------------------------------------------------------------+ double TradeInfo::MinVolume(void) { double res = min_volume; return(res); } //+------------------------------------------------------------------+ //| Return the maximum volume allowed | //+------------------------------------------------------------------+ double TradeInfo::MaxVolume(void) { double res = max_volume; return(res); }
Außerdem muss uns die Klasse die aktuellen Geld- und Briefkurse bereitstellen.
//+------------------------------------------------------------------+ //| Return the current ask | //+------------------------------------------------------------------+ double TradeInfo::GetAsk(void) { return(SymbolInfoDouble(GetSymbol(),SYMBOL_ASK)); } //+------------------------------------------------------------------+ //| Return the current bid | //+------------------------------------------------------------------+ double TradeInfo::GetBid(void) { return(SymbolInfoDouble(GetSymbol(),SYMBOL_BID)); }
Derzeit ist der Destruktor der Klasse Time leer.
//+------------------------------------------------------------------+ //| Destructor is currently empty | //+------------------------------------------------------------------+ TradeInfo::~TradeInfo() { } //+------------------------------------------------------------------+
Alles in allem sollte Ihr Abhängigkeitsbaum in etwa so aussehen wie in Abbildung 3 unten.
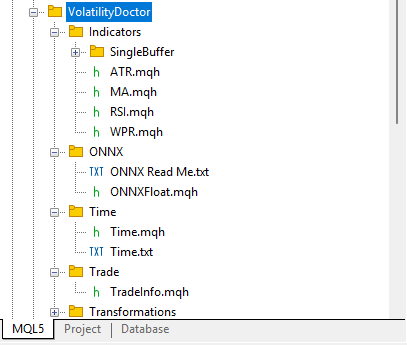
Abb. 3: Diese Klassen sollten in einem Abhängigkeitsbaum gehalten werden, der unserem ähnelt, für Leser, die mitlesen
Lassen Sie uns nun das Skript definieren, das die benötigten Marktdaten abruft. Wir wollen zunächst die vier primären Preisfeeds (OHLC) abrufen, dann das Wachstum in diesen 4 Preisfeeds und schließlich die Indikatordaten aus unseren 14 WPR-Indikatoren ausschreiben.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 10 //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <VolatilityDoctor\Indicators\WPR.mqh> //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ WPR *my_wpr_array[14]; string file_name = Symbol() + " WPR Algorithmic Input Selection.csv"; //+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //--- How much data should we store in our indicator buffer? int fetch = size + (2 * HORIZON); //--- Store pointers to our WPR objects for(int i = 0; i <= 13; i++) { //--- Create an WPR object my_wpr_array[i] = new WPR(Symbol(),PERIOD_CURRENT,((i+1) * 5)); //--- Set the WPR buffers my_wpr_array[i].SetIndicatorValues(fetch,true); my_wpr_array[i].SetDifferencedIndicatorValues(fetch,HORIZON,true); } //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Open","True High","True Low","True Close","Open","High","Low","Close","WPR 5","WPR 10","WPR 15","WPR 20","WPR 25","WPR 30","WPR 35","WPR 40","WPR 45","WPR 50","WPR 55","WPR 60","WPR 65","WPR 70","Diff WPR 5","Diff WPR 10","Diff WPR 15","Diff WPR 20","Diff WPR 25","Diff WPR 30","Diff WPR 35","Diff WPR 40","Diff WPR 45","Diff WPR 50","Diff WPR 55","Diff WPR 60","Diff WPR 65","Diff WPR 70"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(Symbol(),PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(Symbol(),PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(Symbol(),PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(Symbol(),PERIOD_CURRENT,i + HORIZON), my_wpr_array[0].GetReadingAt(i), my_wpr_array[1].GetReadingAt(i), my_wpr_array[2].GetReadingAt(i), my_wpr_array[3].GetReadingAt(i), my_wpr_array[4].GetReadingAt(i), my_wpr_array[5].GetReadingAt(i), my_wpr_array[6].GetReadingAt(i), my_wpr_array[7].GetReadingAt(i), my_wpr_array[8].GetReadingAt(i), my_wpr_array[9].GetReadingAt(i), my_wpr_array[10].GetReadingAt(i), my_wpr_array[11].GetReadingAt(i), my_wpr_array[12].GetReadingAt(i), my_wpr_array[13].GetReadingAt(i), my_wpr_array[0].GetDifferencedReadingAt(i), my_wpr_array[1].GetDifferencedReadingAt(i), my_wpr_array[2].GetDifferencedReadingAt(i), my_wpr_array[3].GetDifferencedReadingAt(i), my_wpr_array[4].GetDifferencedReadingAt(i), my_wpr_array[5].GetDifferencedReadingAt(i), my_wpr_array[6].GetDifferencedReadingAt(i), my_wpr_array[7].GetDifferencedReadingAt(i), my_wpr_array[8].GetDifferencedReadingAt(i), my_wpr_array[9].GetDifferencedReadingAt(i), my_wpr_array[10].GetDifferencedReadingAt(i), my_wpr_array[11].GetDifferencedReadingAt(i), my_wpr_array[12].GetDifferencedReadingAt(i), my_wpr_array[13].GetDifferencedReadingAt(i) ); } } //--- Close the file FileClose(file_handle); //--- Delete our WPR object pointers for(int i = 0; i <= 13; i++) { delete my_wpr_array[i]; } } //+------------------------------------------------------------------+ #undef HORIZON
Analysieren unserer Daten mit Python
Sobald Sie fertig sind, wenden Sie das Skript auf den von Ihnen gewählten Markt an, damit wir Marktdaten zur Analyse erhalten. Wir wenden das Skript in dieser Diskussion auf das EURGBP-Paar an. Da unsere Daten nun fertig sind, können wir unsere Python-Bibliotheken für die Analyse laden.
#Load the libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Wir lesen die Daten ein,
#Read in the data data = pd.read_csv("..\EURGBP WPR Algorithmic Input Selection.csv") #Label the data HORIZON = 10 data['Target'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last 10 rows data = data.iloc[:-HORIZON,:]
erstellen Kopien der Eingabe und des Ziels,
#Define inputs and target X = data.iloc[:,1:-1].copy() y = data.iloc[:,-1].copy()
skalieren und zentrieren jede numerische Spalte des Datensatzes,
#Store Z-scores Z1 = X.mean() Z2 = X.std() #Scale the data X = ((X - Z1)/ Z2)
laden die numerischen Bibliotheken, die wir zur Überprüfung unserer Genauigkeit benötigen,
from sklearn.model_selection import cross_val_score,TimeSeriesSplit from sklearn.linear_model import Ridge
erstellen ein Objekt für die Kreuzvalidierung von Zeitreihen und
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)sdvdsvds definieren eine Methode, die immer unsere kreuzvalidierten Genauigkeitsstufen zurückgibt.
#Return our cross validated accuracy def score(f_model,f_X,f_y): return(np.mean(np.abs(cross_val_score(f_model,f_X,f_y,scoring='neg_mean_squared_error',cv=tscv,n_jobs=-1))))
Wir brauchen auch eine eigene Methode, um ein neues Modell zurückzugeben, um sicherzustellen, dass wir keine Daten an die Modelle weitergeben, die wir verwenden.
def get_model(): return(Ridge())
Wenn Sie eine Spalte komplett mit Nullen füllen, können Sie die Genauigkeit der Vorhersage der durchschnittlichen Marktrendite messen.
X['Null'] = 0
Erfassen wir den Fehler, der sich ergibt, wenn wir immer die durchschnittliche Marktrendite vorhersagen (Gesamtsumme der Quadrate/TSS). Nachdem wir nun die Fehlerschwelle erfasst haben, die dadurch definiert ist, dass wir immer die durchschnittliche Marktrendite vorhersagen, können wir nun getrost behaupten, dass jedes Modell, das eine Fehlerquote von mehr als 0,000324 aufweist, keine Fähigkeiten besitzt, die uns im Rahmen dieser Diskussion beeindrucken.
#This will be the last entry in our list of results #Record our error if we always predict the average market return (total sum of squares/TSS) tss = score(get_model(),X[['Null']],y) tss
0.00032439931180771236
Wir werden nun ein Array erstellen, das uns hilft, unsere Ergebnisse im Auge zu behalten.
res = []
Das erste Ergebnis, das wir festhalten wollen, sind unsere Fehlerquoten bei der Verwendung von OHLC-Marktdaten in ihrer ursprünglichen Form.
#This will be our first entry in our list of results #Record our error using OHLC price data res.append(score(get_model(),X.iloc[:,:8],y))
Als Nächstes möchten wir unsere Fehlerquoten nur anhand der 14 von uns ausgewählten Periodenlängen für den WPR-Indikator ermitteln.
#Second #Record our error using just indicators res.append(score(get_model(),X.iloc[:,8:-1],y))
Abschließend wollen wir unsere Fehlerquoten mit allen uns zur Verfügung stehenden Daten erfassen.
#Third #Record our error using all the data we have res.append(score(get_model(),X.iloc[:,:-1],y))
Laden wir nun die UMAP-Bibliothek. Unsere Originaldaten haben 36 Spalten. Mit Hilfe der UMAP-Bibliothek können wir diese Daten mit einer beliebigen Anzahl von Spalten darstellen, die größer oder gleich 1 und kleiner als die ursprüngliche Anzahl von Spalten ist. Diese neue Darstellung der Daten kann informativer sein, als die Daten in ihrer ursprünglichen Form waren. In diesem Sinne können die Algorithmen zur Dimensionsreduktion auch als eine Familie von Methoden betrachtet werden, die es uns ermöglichen, alle Daten, die wir zur Beschreibung unseres Problems haben, effektiv zu nutzen.
import umap
Wir wollen nach einer Anzahl von Einbettungen suchen, die höchstens 2 weniger als die ursprüngliche Anzahl von Spalten beträgt.
EPOCHS = X.iloc[:,:-1].shape[1] - 2
Iteratives Einbetten der Daten mit UMAP. Die Anzahl der zu erzeugenden eingebetteten Spalten wird von 1 an in Schritten von 1 erhöht, bis die in der vorherigen Codezeile festgelegte Obergrenze erreicht ist.
for i in range(EPOCHS): reducer = umap.UMAP(n_components=(i+1),metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(X.iloc[:,:-1])) res.append(score(get_model(),X_embedded,y))
Fügen wir unsere Ergebnisse hinzu.
res.append(tss)
Die rote durchgezogene Linie ist unsere kritische Fehler-Benchmark, also der Fehler, der sich ergibt, wenn man immer die durchschnittliche Marktrendite (TSS) vorhersagt. Die rot gestrichelte Linie ist die niedrigste Fehlerquote, die wir erreichen konnten. Dies entspricht dem Modell, das erstellt wurde, als unsere ursprünglichen Daten durch unseren UMAP-Algorithmus in zwei Spalten eingebettet wurden. Es ist zu beachten, dass dieses Fehlerniveau die TSS um ein Vielfaches übertrifft, was wir bei der Verwendung der Marktdaten in ihrer ursprünglichen Form erreichen konnten. Wir nutzen im Wesentlichen alle WPR-Zeiträume auf einmal, und zwar in einer Weise, die sinnvoller ist als das, was wir sonst hätten erreichen können.
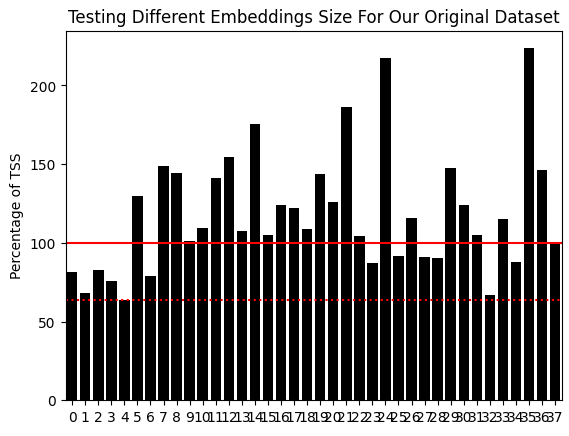
Abb. 4: Unter Verwendung von 2 eingebetteten UMAP-Komponenten haben wir ein gleichwertiges Modell, das alle Marktdaten in ihrer ursprünglichen Form verwendet, übertroffen
Transformieren wir die Daten unter Verwendung der von uns ermittelten idealen UMAP-Einstellungen.
reducer = umap.UMAP(n_components=2,metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(X.iloc[:,:-1]))
Kennzeichnen wir unsere 2 Klassen. Dies wird uns später dabei helfen, zu visualisieren, was UMAP mit unseren Daten macht.
data['Class'] = 0 data.loc[data['Target'] > 0,'Class'] = 1
Bereiten wir ein Dataset vor, um die transformierten Daten zu speichern.
umap_data =pd.DataFrame(columns=['UMAP 1','UMAP 2'])
Speichern wir die eingebetteten Preisniveaus.
umap_data['UMAP 1'] = X_embedded.iloc[:,0] umap_data['UMAP 2'] = X_embedded.iloc[:,1]
Ohne UMAP ist es schwierig, unsere Daten aufgrund der hohen Anzahl von Dimensionen sinnvoll zu visualisieren. Das Beste, was wir tun können, ist, Paare von Streudiagrammen zu erstellen; andernfalls gibt es keine Möglichkeit, 36 Dimensionen auf einmal effektiv zu visualisieren. In den Abbildungen 5 und 6 unten zeigen die roten Punkte eine steigende und die schwarzen Punkte eine fallende Preisentwicklung an.
fig , axs = plt.subplots(2,2) fig.suptitle('Visualizing EURGBP 2002-2025 Daily Price Data') axs[0,0].scatter(data.loc[data['Target']>0 ,'Open'],data.loc[data['Target']>0 ,'Close'],color='red') axs[0,0].scatter(data.loc[data['Target']<0 ,'Open'],data.loc[data['Target']<0 ,'Close'],color='black') axs[0,1].scatter(data.loc[data['Target']>0 ,'True Open'],data.loc[data['Target']>0 ,'True Close'],color='red') axs[0,1].scatter(data.loc[data['Target']<0 ,'True Open'],data.loc[data['Target']<0 ,'True Close'],color='black') axs[1,1].scatter(data.loc[data['Target']>0 ,'WPR 5'],data.loc[data['Target']>0 ,'WPR 50'],color='red') axs[1,1].scatter(data.loc[data['Target']<0 ,'WPR 5'],data.loc[data['Target']<0 ,'WPR 50'],color='black') axs[1,0].scatter(data.loc[data['Target']>0 ,'WPR 15'],data.loc[data['Target']>0 ,'WPR 25'],color='red') axs[1,0].scatter(data.loc[data['Target']<0 ,'WPR 15'],data.loc[data['Target']<0 ,'WPR 25'],color='black')
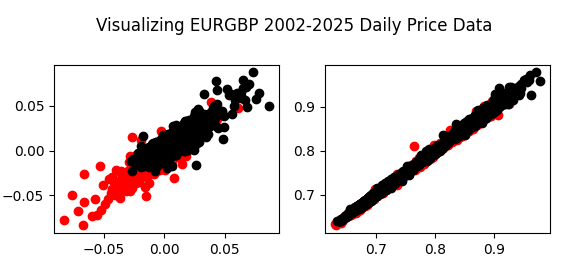
Abb. 5: Auf der linken Seite haben wir die Veränderung des Eröffnungskurses gegen die Veränderung des Schlusskurses aufgetragen. Auf der rechten Seite haben wir den wahren Eröffnungs- und Schlusskurs eingezeichnet.
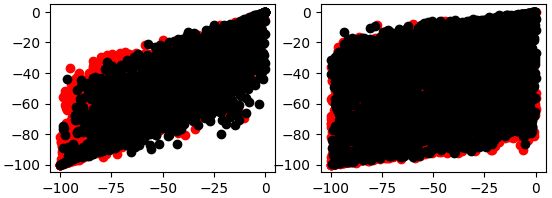
Abb. 6: Das linke Streudiagramm zeigt die Beziehung zwischen der 5 und 50 Perioden-WPR, während das rechte die 15 und 25 Perioden-WPR darstellt.
Wie wir sehen, sind Abb. 5 und Abb. 6 schwer sinnvoll zu interpretieren, da die Daten keine klaren Muster aufweisen. Außerdem kann es gefährlich sein, 2-dimensionale Streudiagramme von Phänomenen zu erstellen, die in mehr als 2 Dimensionen stattfinden. Dies liegt daran, dass das, was als Beziehung zwischen den beiden Variablen erscheint, durch andere Dimensionen erklärt werden kann, die wir nicht in eine Darstellung aufnehmen können. Dies kann uns zu falschen Entdeckungen oder zu unangemessenem Vertrauen in Beziehungen führen, die nicht so stabil sind, wie sie scheinen.
Nach der Anwendung von UMAP können wir jedoch alle Daten, die wir haben, problemlos in nur 2 Dimensionen darstellen. Im Allgemeinen ist zu erkennen, dass niedrige und hohe Werte der ersten Einbettung mit fallenden bzw. steigenden Kursen verbunden sind.
sns.scatterplot(x=X_embedded.iloc[:,0],y=X_embedded.iloc[:,1],hue=data['Class']) plt.grid() plt.ylabel('Second UMAP Embedding') plt.xlabel('First UMAP Embedding') plt.title('Visualizing The Most Effective Embedding We Found')
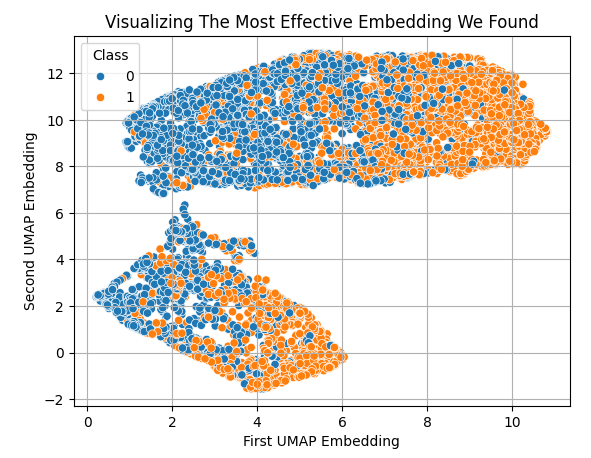
Abb. 7: Visualisierung unserer UMAP-Einbettungen der ursprünglichen Marktdaten
Bereiten wir nun unsere Modelle für die Backtests vor. Importieren der benötigten Bibliothek.
from sklearn.model_selection import train_test_split
Aufteilen der Marktdaten. Unsere Trainingsstichproben liefen von November 2002 bis August 2018, sodass unser Rückprüfungszeitraum im September 2018 beginnen wird.
train , test = train_test_split(data,test_size=0.3,shuffle=False) train
Abb. 8: Ansicht unserer Marktdaten in ihrer ursprünglichen Form
Lassen Sie uns nun unser statistisches Modell laden.
from sklearn.neural_network import MLPRegressor
Skalieren der Trainingsdaten.
#Sample mean Z1 = train.iloc[:,1:-2].mean() #Sample standard deviation Z2 = train.iloc[:,1:-2].std() train_scaled = train.copy() train_scaled.iloc[:,1:-2] = ((train.iloc[:,1:-2] - Z1) / Z2)
Betten wir die Trainingsdaten ein.
reducer = umap.UMAP(n_components=2,metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(train_scaled.iloc[:,1:-2],columns=['UMAP 1','UMAP 2']))
Unser Rahmenwerk folgt einem 2-stufigen Prozess. Zunächst passen wir ein Modell an, das lernt, den UMAP-Algorithmus zu approximieren. Dies ersetzt die Notwendigkeit, den UMAP-Algorithmus in MQL5 von Grund auf neu zu schreiben. Der UMAP-Algorithmus ist ziemlich ausgeklügelt und wurde von einem Team von promovierten Forschern implementiert. Es ist für die Forscher ein erheblicher Aufwand, eine numerisch stabile Implementierung eines Algorithmus zu schreiben. Daher wird es im Allgemeinen nicht als sinnvoll erachtet, solche Algorithmen selbst zu implementieren.
#Learn To Estimate UMAP Embeddings From The Data umap_model = MLPRegressor(shuffle=False,hidden_layer_sizes=(train.iloc[:,1:-2].shape[1],10,20,100,20,10,2),random_state=0,solver='lbfgs',activation='relu',learning_rate='constant',learning_rate_init=1e-4,power_t=1e-1) np.mean(np.abs(cross_val_score(umap_model,train.iloc[:,1:-2],X_embedded,scoring='neg_mean_squared_error',n_jobs=-1)))
11.2489992665160363
Lernen wir die UMAP-Funktion kennen.
umap_model.fit(train.iloc[:,1:-2],X_embedded) predictions = umap_model.predict(train.iloc[:,1:-2])
Jetzt brauchen wir ein Modell, das die EURGBP-Marktrendite vorhersagt, wenn die UMAP-Einbettungen des Marktes gegeben sind. In scikit-learn haben unsere neuronalen Netzmodelle einen wichtigen Parameter namens „random_state“. Dieser Parameter beeinflusst die anfänglichen Gewichte und Verzerrungen, mit denen das neuronale Netz startet. Je nach Problemstellung kann das mehrmalige Trainieren des Modells mit unterschiedlichen Ausgangszuständen zu erheblichen Leistungsunterschieden führen, wie in Abb. 9 unten zu sehen ist.
EPOCHS = 100 res = [] for i in range(EPOCHS): #Try different random states model = MLPRegressor(shuffle=False,early_stopping=False,hidden_layer_sizes=(2,1,10,20,1),activation='identity',solver='lbfgs',random_state=i,max_iter=int(2e5)) res.append(score(model,predictions,train['Target']))
Visualisierung unserer Ergebnisse.
plt.plot(res,color='black') plt.axhline(np.min(res),color='red',linestyle=':') plt.scatter(res.index(np.min(res)),np.min(res),color='red') plt.grid() plt.ylabel('Cross Validated RMSE') plt.xlabel('Neural Network Random State') plt.title('Our Neural Network Performance With Different Initial Conditions')
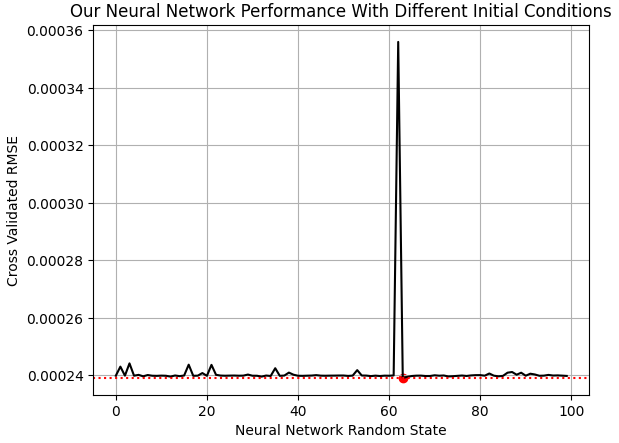
Abb. 9: Visualisierung des optimalen Ausgangszustands für unser neuronales Netz bei diesem Problem
Das von uns gewählte neuronale Netz prognostiziert die 10-Tage-Rendite des EURGBP mit einem um 38 % geringeren Fehler als bei der Vorhersage der durchschnittlichen Marktrendite.
tss = score(Ridge(),train[['Close']]*0,train['Target']) 1-(np.min(res)/tss)
0.3822093585025088
Passen wir das Modell mit dem optimalen Zufallszustand an, den wir in Abb. 9 ermittelt haben.
embedded_model = MLPRegressor(shuffle=False,early_stopping=False,hidden_layer_sizes=(2,1,10,20,1),activation='identity',solver='lbfgs',random_state=res.index(np.min(res)),max_iter=int(2e5)) embedded_model.fit(predictions,train['Target'])
Laden wir die Bibliotheken, die wir für die Konvertierung des Modells in das ONNX-Format benötigen.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Definieren wir die Parameterformen unserer Modelle.
umap_model_input_shape = [("float_input",FloatTensorType([1,train.iloc[:,1:-2].shape[1]]))] umap_model_output_shape = [("float_output",FloatTensorType([X_embedded.iloc[:,:].shape[1],1]))] embedded_model_input_shape = [("float_input",FloatTensorType([1,X_embedded.iloc[:,:].shape[1]]))] embedded_model_output_shape = [("float_output",FloatTensorType([1,1]))]
Konvertieren wir die ONNX-Modelle in ihre Prototypen.
umap_proto = convert_sklearn(umap_model,initial_types=umap_model_input_shape,final_types=umap_model_output_shape,target_opset=12) embeded_proto = convert_sklearn(embedded_model,initial_types=embedded_model_input_shape,final_types=embedded_model_output_shape,target_opset=12)
Speichern wir die Prototypen auf der Festplatte.
onnx.save(umap_proto,"EURGBP WPR Ridge UMAP.onnx") onnx.save(embeded_proto,"EURGBP WPR Ridge EMBEDDED.onnx")
Aufbau unserer Anwendung in MQL5
Beginnen wir nun mit der Erstellung unserer Anwendung. Zunächst müssen wir Systemkonstanten angeben, die sich in unserem Programm nicht ändern werden.
//+------------------------------------------------------------------+ //| EURGBP Multiple Periods Analysis.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| REMINDER: | //| These ONNX models were trained with Daily EURGBP data ranging | //| from 24 November 2002 until 12 August 2018. Test the strategy | //| outside of these time periods, on the Daily Time-Frame for | //| reliable results. | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ //--- ONNX Model I/O Parameters #define UMAP_INPUTS 36 #define UMAP_OUTPUTS 2 #define EMBEDDED_INPUTS 2 #define EMBEDDED_OUTPUTS 1 //--- Our forecasting periods #define HORIZON 10 //--- Our desired time frame #define SYSTEM_TIMEFRAME_1 PERIOD_D1
Laden wir nun unsere ONNX-Modelle.
//+------------------------------------------------------------------+ //| Load our ONNX models as resources | //+------------------------------------------------------------------+ //--- ONNX Model Prototypes #resource "\\Files\\EURGBP WPR UMAP.onnx" as const uchar umap_proto[]; #resource "\\Files\\EURGBP WPR EMBEDDED.onnx" as const uchar embedded_proto[];
Dann werden wir die Bibliotheken laden, die wir für unsere Anwendung benötigen.
//+------------------------------------------------------------------+ //| Libraries We Need | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Indicators\WPR.mqh> #include <VolatilityDoctor\ONNX\OnnxFloat.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh>
Wir definieren die globalen Variablen, die wir in unserem Programm verwenden werden. Beachten Sie, dass wir nur eine Handvoll globaler Variablen definieren müssen. Das haben wir in der Einleitung unserer Diskussion gemeint, als wir sagten, dass OOP uns hilft, den Namensraum unserer Anwendungen zu kontrollieren. Die meisten Variablen und Objekte, die wir verwenden, wurden ordentlich in die von uns geschriebenen Klassen verpackt.
//+------------------------------------------------------------------+ //| Global varaibles | //+------------------------------------------------------------------+ CTrade Trade; TradeInfo *TradeInformation; //--- Our time object let's us know when a new candle has fully formed on the specified time-frame Time *eurgbp_daily; //--- All our different Williams Percent Range Periods will be kept in a single array WPR *wpr_array[14]; //--- Our ONNX class objects have usefull functions designed for rapid ONNX development ONNXFloat *umap_onnx,*embedded_onnx; //--- Model forecast double expected_return; int position_timer;
Wir haben auch die Z1- und Z2-Werte kopiert, die wir zur Skalierung unserer Trainingsdaten in Python verwendet haben.
//--- The average column values from the training set double Z1[] = {7.84311120e-01, 7.87104135e-01, 7.81713516e-01, 7.84343731e-01, 5.23887980e-04, 5.26022077e-04, 5.25382257e-04, 5.25688880e-04, -5.08398234e+01, -5.07130228e+01, -5.05834313e+01, -5.04425081e+01, -5.02709031e+01, -5.01349627e+01, -5.00653250e+01, -5.01661938e+01, -5.03082375e+01, -5.04550339e+01, -5.05861939e+01, -5.06434696e+01, -5.07286211e+01, -5.07819768e+01, 1.96979782e-02, 5.29204133e-02, 4.12732506e-02, 3.20037455e-02, 2.61762719e-02, 2.34184127e-02, 2.62342592e-02, 3.32894491e-02, 3.81853070e-02, 3.85464026e-02, 3.85499926e-02, 3.94004124e-02, 4.02388908e-02, 4.02388908e-02 }; //--- The column standard deviation from the training set double Z2[] = {8.29473604e-02, 8.35406090e-02, 8.23981331e-02, 8.28950223e-02, 1.21995172e-02, 1.22880295e-02, 1.20471133e-02, 1.21798952e-02, 3.00742110e+01, 3.05948913e+01, 3.05244154e+01, 3.03776475e+01, 3.02862706e+01, 3.00844693e+01, 2.98788650e+01, 2.97182936e+01, 2.95133008e+01, 2.93983475e+01, 2.92679071e+01, 2.91072869e+01, 2.90154368e+01, 2.89821474e+01, 4.32293242e+01, 4.43537714e+01, 4.02730688e+01, 3.66106699e+01, 3.41930128e+01, 3.21743917e+01, 3.03647897e+01, 2.87462989e+01, 2.73771066e+01, 2.63857585e+01, 2.54625376e+01, 2.43656339e+01, 2.33983568e+01, 2.26334633e+01 };
Bei der Initialisierung werden wir unsere Indikatoren einrichten und unsere nutzerdefinierten Klassen initialisieren. Wenn unsere Klassen nicht korrekt geladen werden können, unterbrechen wir die Initialisierungsprozedur und geben dem Nutzer eine Rückmeldung, was schief gelaufen ist.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Do no display the indicators, they will clutter our view TesterHideIndicators(true); //--- Setup our pointers to our WPR objects update_indicators(); //--- Get trade information on the symbol TradeInformation = new TradeInfo(Symbol(),SYSTEM_TIMEFRAME_1); //--- Create our ONNXFloat objects umap_onnx = new ONNXFloat(umap_proto); embedded_onnx = new ONNXFloat(embedded_proto); //--- Create our Time management object eurgbp_daily = new Time(Symbol(),SYSTEM_TIMEFRAME_1); //--- Check if the models are valid if(!umap_onnx.OnnxModelIsValid()) return(INIT_FAILED); if(!embedded_onnx.OnnxModelIsValid()) return(INIT_FAILED); //--- Reset our position timer position_timer = 0; //--- Specify the models I/O shapes if(!umap_onnx.DefineOnnxInputShape(0,1,UMAP_INPUTS)) return(INIT_FAILED); if(!embedded_onnx.DefineOnnxInputShape(0,1,EMBEDDED_INPUTS)) return(INIT_FAILED); if(!umap_onnx.DefineOnnxOutputShape(0,1,UMAP_OUTPUTS)) return(INIT_FAILED); if(!embedded_onnx.DefineOnnxOutputShape(0,1,EMBEDDED_OUTPUTS)) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
Bei der Deinitialisierung räumen wir hinter uns auf und löschen die Zeiger, die wir für unsere Objekte erstellt haben. Dies ist eine gute Programmierpraxis in MQL5 und verhindert Probleme wie Speicherlecks oder Pufferüberläufe, wenn mehrere Instanzen dieser Anwendung auf einem Rechner laufen, aber keine von ihnen nach sich selbst aufräumt. Ein weiterer wichtiger Hinweis: Entwickler mit Erfahrung außerhalb von MQL5, insbesondere mit Sprachen wie C, sind möglicherweise bereits mit Zeigern als Speicheradresse vertraut.
Hier muss ein wichtiger Unterschied gemacht werden: Die in MQL5 eingebetteten Sicherheitsfunktionen erlauben keinen direkten Zugriff auf den Speicher. Stattdessen haben die cleveren Entwickler des MetaQuotes-Teams eine Lösung gefunden, die für jedes Objekt einen eindeutigen Bezeichner erstellt und dann jeden eindeutigen Bezeichner auf intelligente Weise mit dem zugehörigen Objekt verknüpft. Daher sollten Leser, die bereits mit Zeigern aus ihren unabhängigen Studien vertraut sind, beachten, dass die MQL5-Implementierung eines Zeigers dem Entwickler buchstäblich keine Speicheradressen gibt, da die Entwickler von MQL5 dies als Sicherheitslücke betrachteten.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Delete the pointers for our custom objects delete umap_onnx; delete embedded_onnx; delete eurgbp_daily; //--- Delete all pointers to our WPR objects for(int i = 0; i <= 13; i++) { delete wpr_array[i]; } }
Jedes Mal, wenn wir aktualisierte Kurse erhalten, rufen wir die Klasse Time auf, um zu prüfen, ob sich eine neue Tageskerze gebildet hat. Ist dies der Fall, aktualisieren wir unsere Indikatorwerte und suchen anschließend nach einer Handelsmöglichkeit, wenn wir keine offenen Geschäfte haben, oder verwalten die von uns eröffneten Geschäfte.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Do we have a new daily candle? if(eurgbp_daily.NewCandle()) { static int i = 0; Print(i+=1); update_indicators(); if(PositionsTotal() == 0) { position_timer =0; find_setup(); } else if((PositionsTotal() > 0) && (position_timer < HORIZON)) position_timer += 1; else if((PositionsTotal() > 0) && (position_timer >= (HORIZON -1))) Trade.PositionClose(Symbol()); Comment("Position Timer: ",position_timer); } }
Um ein Handels-Setup zu finden, müssen wir lediglich die relevanten Marktdaten abrufen und sie als Inputs für unser ONNX-Modell aufbereiten. Beachten Sie, dass wir den Mittelwert jeder Spalte subtrahieren und durch die Standardabweichung der Spalte dividieren, bevor wir die Eingabedaten schließlich in einer Konstante vom Typ vectorf speichern. Anschließend übergeben wir diesen konstanten Vektor an unsere Methode ONNXFloat.Predict() und erhalten eine Prognose von unserem Modell. Die Erstellung dieser Klassen hat uns geholfen, die Gesamtzahl der Codezeilen, die wir schreiben müssen, um einen beträchtlichen Faktor zu reduzieren.
//+------------------------------------------------------------------+ //| Find A Trading Setup For Us | //+------------------------------------------------------------------+ void find_setup(void) { //--- Update our indicators update_indicators(); //--- Prepare our input vector vectorf market_state(UMAP_INPUTS); //--- Fill in the Market Data that has to embedded into UMAP form market_state[0] = (float) iOpen(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[1] = (float) iHigh(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[2] = (float) iLow(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[3] = (float) iClose(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[4] = (float)(iOpen(_Symbol,SYSTEM_TIMEFRAME_1,0) - iOpen(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[5] = (float)(iHigh(_Symbol,SYSTEM_TIMEFRAME_1,0) - iHigh(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[6] = (float)(iLow(_Symbol,SYSTEM_TIMEFRAME_1,0) - iLow(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[7] = (float)(iClose(_Symbol,SYSTEM_TIMEFRAME_1,0) - iClose(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[8] = (float) wpr_array[0].GetReadingAt(0); market_state[9] = (float) wpr_array[1].GetReadingAt(0); market_state[10] = (float) wpr_array[2].GetReadingAt(0); market_state[11] = (float) wpr_array[3].GetReadingAt(0); market_state[12] = (float) wpr_array[4].GetReadingAt(0); market_state[13] = (float) wpr_array[5].GetReadingAt(0); market_state[14] = (float) wpr_array[6].GetReadingAt(0); market_state[15] = (float) wpr_array[7].GetReadingAt(0); market_state[16] = (float) wpr_array[8].GetReadingAt(0); market_state[17] = (float) wpr_array[9].GetReadingAt(0); market_state[18] = (float) wpr_array[10].GetReadingAt(0); market_state[19] = (float) wpr_array[11].GetReadingAt(0); market_state[20] = (float) wpr_array[12].GetReadingAt(0); market_state[21] = (float) wpr_array[13].GetReadingAt(0); market_state[22] = (float) wpr_array[0].GetDifferencedReadingAt(0); market_state[23] = (float) wpr_array[1].GetDifferencedReadingAt(0); market_state[24] = (float) wpr_array[2].GetDifferencedReadingAt(0); market_state[25] = (float) wpr_array[3].GetDifferencedReadingAt(0); market_state[26] = (float) wpr_array[4].GetDifferencedReadingAt(0); market_state[27] = (float) wpr_array[5].GetDifferencedReadingAt(0); market_state[27] = (float) wpr_array[6].GetDifferencedReadingAt(0); market_state[29] = (float) wpr_array[7].GetDifferencedReadingAt(0); market_state[30] = (float) wpr_array[8].GetDifferencedReadingAt(0); market_state[31] = (float) wpr_array[9].GetDifferencedReadingAt(0); market_state[32] = (float) wpr_array[10].GetDifferencedReadingAt(0); market_state[33] = (float) wpr_array[11].GetDifferencedReadingAt(0); market_state[34] = (float) wpr_array[12].GetDifferencedReadingAt(0); market_state[35] = (float) wpr_array[13].GetDifferencedReadingAt(0); //--- Standardize and scale each input for(int i =0; i < UMAP_INPUTS;i++) { market_state[i] = (float)((market_state[i] - Z1[i]) / Z2[i]); }; const vectorf onnx_inputs = market_state; const vectorf umap_predictions = umap_onnx.Predict(onnx_inputs); Print("UMAP Model Returned Embeddings: ",umap_predictions); const vectorf expected_eurgbp_return = embedded_onnx.Predict(umap_predictions); Print("Embeddings Model Expects EURGBP Returns: ",expected_eurgbp_return); expected_return = expected_eurgbp_return[0]; vector o,c; o.CopyRates(Symbol(),SYSTEM_TIMEFRAME_1,COPY_RATES_OPEN,0,HORIZON); c.CopyRates(Symbol(),SYSTEM_TIMEFRAME_1,COPY_RATES_CLOSE,0,HORIZON); bool bullish_reversal = o.Mean() < c.Mean(); bool bearish_reversal = o.Mean() > c.Mean(); if(bearish_reversal) { if(expected_return > 0) { Trade.Buy((TradeInformation.MinVolume()*2),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } else if(bullish_reversal) { if(expected_return < 0) { Trade.Sell((TradeInformation.MinVolume()*2),Symbol(),TradeInformation.GetBid(),0,0,""); } Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),0,0,""); return; } }
Dies ist die Implementierung der Methode, die wir zur Aktualisierung unserer technischen Indikatoren aufrufen.
//+------------------------------------------------------------------+ //| Update our indicator readings | //+------------------------------------------------------------------+ void update_indicators(void) { //--- Store pointers to our WPR objects for(int i = 0; i <= 13; i++) { //--- Create an WPR object wpr_array[i] = new WPR(Symbol(),SYSTEM_TIMEFRAME_1,((i+1) * 5)); //--- Set the WPR buffers wpr_array[i].SetIndicatorValues(60,true); wpr_array[i].SetDifferencedIndicatorValues(60,HORIZON,true); } }
Vergessen Sie nicht, die von Ihnen erstellten Systemkonstanten am Ende Ihres Programms wieder zu deklarieren.
//+------------------------------------------------------------------+ //| Undefine system constants we no longer need | //+------------------------------------------------------------------+ #undef EMBEDDED_INPUTS #undef EMBEDDED_OUTPUTS #undef UMAP_INPUTS #undef UMAP_OUTPUTS #undef HORIZON #undef SYSTEM_TIMEFRAME_1 //+------------------------------------------------------------------+
Wenn Sie Ihre Anwendung starten, sollte sie ungefähr so aussehen wie in Abbildung 10 unten. Dies ist zu erwarten, und wir müssen lediglich eine weitere Codezeile in unsere Initialisierungsprozedur schreiben, die unser Terminal anweist, während der Prüfung keine Indikatoren anzuzeigen.
//--- Do no display the indicators, they will clutter our view TesterHideIndicators(true);
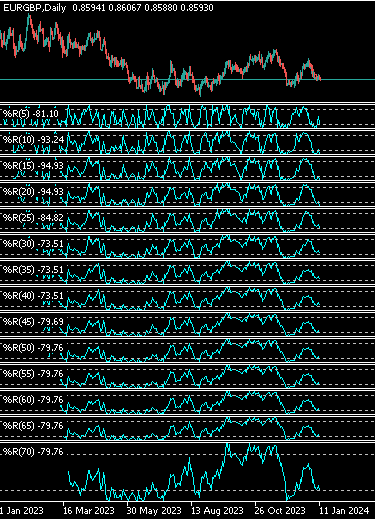
Abb. 10: Aufgrund der großen Anzahl von Indikatoren, die wir verwenden, wird unsere Ansicht zunächst unübersichtlich sein
Sobald dies geschehen ist, können wir mit dem Rückentest beginnen. Wir erinnern daran, dass unsere Trainingsstichproben von November 2002 bis August 2018 liefen; daher sollte unser Backtest-Zeitraum im September 2018 beginnen und bis zum heutigen Tag dauern. Leider war meine Internetverbindung nicht zuverlässig, und ich konnte die historischen Daten nicht sicher von meinem Broker herunterladen. Deshalb musste ich den Test stattdessen von Anfang 2023 bis heute durchführen.
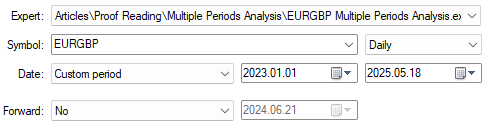
Abb. 11: Die Daten für unseren Backtest-Zeitraum
Wir ziehen es immer vor, alle Ticks auf der Basis von Real-Ticks zu verwenden, um eine realistische Nachbildung der vergangenen Marktentwicklung zu erhalten. Dies kann Ihr Netz stark beanspruchen, da das angeforderte Datenvolumen sehr groß ist.
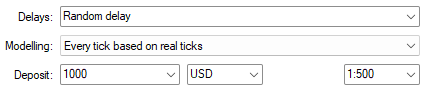
Abb. 12: Wichtig sind auch die Einstellungen, die wir für unseren Backtest verwendet haben
Die von uns erstellten Klassen geben Ihnen beim Backtest ein ständiges Feedback. Durch das Lesen der ausgedruckten Meldungen können wir überprüfen, ob Fehler vorliegen. Wie in Abb. 13 zu sehen ist, laufen unsere Klassen wie erwartet, ohne dass irgendwelche Fehlermeldungen protokolliert werden.
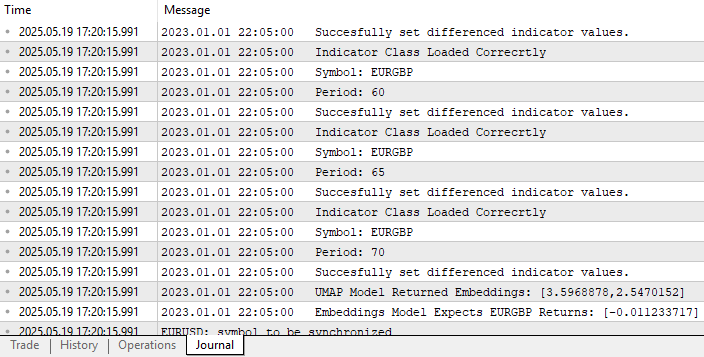
Abb. 13: Die von uns erstellten Klassen werden Ihnen beim Backtest Feedback geben. Das Feedback sollte positiv sein und immer mit der Modellprognose enden, wenn Sie keine offenen Positionen haben.
Wir können auch die durch unsere Strategie erzeugte Kapitalkurve visualisieren. Die Kapitalkurve weist einen positiven langfristigen Aufwärtstrend auf, was uns ermutigt, die Strategie weiterzuentwickeln und nach weiteren Sicherheitsmerkmalen zu suchen, um die Verluste nach Möglichkeit zu begrenzen.
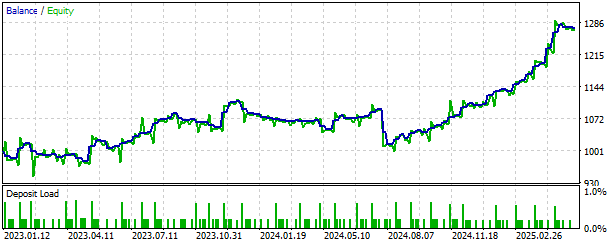
Abb. 14: Visualisierung der durch unsere Handelsstrategie erzeugten Kapitalkurve
Schließlich können wir auch eine detaillierte Analyse der Leistung unserer Handelsstrategie visualisieren. Wie wir sehen können, hatte unsere Strategie einen Genauigkeitsgrad von 58% bei allen von ihr platzierten Handelsgeschäfte, mit einer Sharpe Ratio von 0,90.
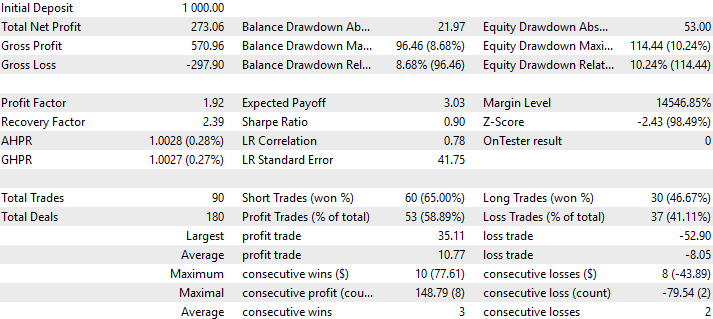
Abb. 15: Eine detaillierte Analyse der Leistung unserer Handelsstrategie anhand von Daten, die sie bisher nicht gesehen hat
Schlussfolgerung
Durch diese Diskussion erhält der Leser praktische Einblicke in die Vorteile der statistischen Modellierung, die über die gewöhnliche Aufgabe der Preisvorhersage hinausgehen. Das haben wir dem Leser veranschaulicht:
- Maschinelles Lernen kann für die Geldverwaltung eingesetzt werden: Indem wir unsere Losgröße erhöhen, wenn unser Modell mit unserem Handelssignal übereinstimmt, geben wir dem statistischen Modell effektiv die Kontrolle über das Handelsvolumen und erlauben unserem Computer, größere Geschäfte zu tätigen, wenn er sich „sicher fühlt“.
- Das maschinelle Lernen kann auch eingesetzt werden, um aussagekräftigere Wege zur Betrachtung von Daten zu finden: Wir können eine Familie von Algorithmen des maschinellen Lernens verwenden, die als Methoden zur Dimensionsreduktion bekannt sind, um unsere Daten zu verdichten und so die wichtigen Muster in großen Datensätzen zu erkennen.
Das bedeutet, dass der Leser den WPR-Indikator durch eine Kombination seiner Lieblingsindikatoren ersetzen kann. Durch die Anwendung von Dimensionsreduktionstechniken, wie sie in diesem Artikel demonstriert werden, können Sie neuartige Darstellungen Ihrer privaten Strategien finden, die Ihre Handelsleistung verbessern können, wie wir zuvor gesehen haben, als wir mit einer UMAP-Darstellung von nur 2 Spalten der ursprünglichen 36 Spalten alle uns zur Verfügung stehenden Marktdaten übertroffen haben.
Die Verwendung des in diesem Artikel vorgeschlagenen UMAP-Algorithmus bietet dem Leser zudem viele Vorteile gegenüber gängigen Verfahren wie der PCA (Principal Components Analysis). Wir werden einige wesentliche Vorteile hervorheben:
- UMAP ist eine nichtlineare Methode: Gängige Verfahren zur Dimensionsreduktion wie PCA gehen von vornherein von einer linearen Beziehung in den Daten aus. Die Algorithmen versagen, wenn diese Annahme nicht zutrifft. UMAP hingegen ist ausdrücklich auf die Suche nach nicht-linearen Beziehungen ausgerichtet. Der Leser sollte nicht sagen, dass UMAP „leistungsfähiger“ ist als PCA, sondern es ist eher angebracht zu sagen, dass UMAP „flexibler“ ist als PCA.
- UMAP ist geometrisch und nicht euklidisch: Das heißt, UMAP sieht Formen, nicht nur gerade Strecken. Im Gegensatz zu Methoden wie PCA, die Daten mit geraden Linien zerschneiden, biegt sich UMAP mit Ihren Daten. Es geht nicht davon aus, dass die Welt flach ist, sondern dass sich Ihre Daten auf einer gekrümmten Oberfläche befinden, die als Riemannsche Mannigfaltigkeit bezeichnet wird, ein Konzept aus dem mathematischen Studium der Topologie, das zur Beschreibung komplexer, nichtlinearer Räume dient. Auf diese Weise kann UMAP die wahre Geometrie Ihrer Daten bewahren, indem es sie nicht platt macht, sondern mit ihnen fließt.
Schließlich hat der Leser davon profitiert, dass er den Wert der objektorientierten Programmierung in MQL5 schätzen gelernt hat. OOP mag zwar als alte Technologie gelten, ist aber nach wie vor von unschätzbarem Wert, da es uns erlaubt, die Kontrolle und alle Fehler in einer einzigen Datei zu zentralisieren. Es erspart uns die Wiederholung von Standardcode und ermöglicht uns die schnelle Umsetzung unserer Ideen mit vorhersehbaren Ergebnissen.
| Dateiname | Beschreibung der Datei |
|---|---|
| Use_All_Data.ipynb | Das Jupyter-Notebook, das wir für die Analyse unserer Marktdaten verwendet haben. |
| Fetch_Data_Algorithmic_Input_Selection.mq5 | Das MQL5-Skript, das wir zum Abrufen der benötigten Marktdaten verwendet haben. |
| EURGBP_Multiple_Periods_Analysis.mq5 | Der Expert Advisor, den wir gemeinsam entwickelt haben und der 14 verschiedene WPR-Perioden auf einmal verwendet. |
| EURGBP_WPR_Algorithmic_Input_Selection.csv | Die historischen Marktdaten haben wir von unserem Broker geholt. |
| EURGBP_WPR_EMBEDDED.onnx | Das ONNX-Modell, das für die Annäherung unserer 36 Datenspalten bis hin zu 2 UMAP-Einbettungen verantwortlich ist. |
| EURGBP_WPR_UMAP.onnx | Das ONNX-Modell, das für die Prognose der EURGBP-Marktrendite verantwortlich ist, bei 2 UMAP-Einbettungen. |
| EURGBP_Multiple_Periods_Analysis.ex5 | Eine kompilierte Version unseres Expert Advisors. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/18187
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.