
Kategorientheorie in MQL5 (Teil 7): Mehrere, relative und indizierte Domänen
Einführung
Im vorangegangenen Artikel haben wir untersucht, wie sich Änderungen der Kegel und der Zusammensetzungen auf die Ergebnisse der Sensitivitätsanalyse auswirken können, sodass sich je nach den Indikatoren und Wertpapieren, mit denen gehandelt werden könnte, Möglichkeiten für die Systemgestaltung ergeben. In diesem Kapitel werden wir uns die verschiedenen Arten von speziellen/einzigartigen Bereichen genauer ansehen und untersuchen, wie ihre Beziehungen genutzt werden können, um die Erwartungen an die Preisvolatilität zu dämpfen.
Multi-Domains
In der Kategorientheorie ist ein Multimenge (auch engl. Multiset oder Bag genannt) eine Verallgemeinerung einer Domäne, die ein mehrfaches Vorkommen desselben Elements zulässt. Wie in Artikel eins beschrieben, musste nach der strengen Definition eines Bereichs jedes Element eindeutig sein. Eine Multi-Domain eignet sich für Situationen, in denen die Wiederholung von Elementen innerhalb einer Domain notwendig ist, um alle Metadaten dieser Elemente innerhalb dieser Domain korrekt zu erfassen. Betrachten Sie zum Beispiel einen Bereich, der aus den Wörtern dieses Satzes besteht:
„Die Mengenlehre befasst sich mit Mengen, die Kategorientheorie mit Mengen von Mengen, Mengen von Mengen von Mengen und so weiter.“
Typischerweise würde dies in einer Domäne wie folgt dargestellt werden:
{sets, theory, deals, with, while, category, of, and, so, on}
Wie Sie sehen können, geht jedoch der volle Sinn des Satzes verloren. Um diese zusätzlichen Informationen zu erfassen, wird eine Multidomäne X formell definiert als
X := (N, π)
- N ist die typische Bereichsdarstellung von X, da sie nur die Elemente in X ohne Wiederholung aufzählt.
- Und π ist der Homomorphismus von X nach N.
π: X → N,
N wird oft als die Menge der Namen in X bezeichnet, und π ist die Benennungsfunktion für X. Gegeben ein Name x ∈ N, mit π -1(x) ∈ X, als das preimage; die Anzahl der Elemente in π -1(x) wird multiplicity (Multiplizität) von x genannt.
Setzt man dies alles zusammen, ergibt sich das folgende Diagramm.
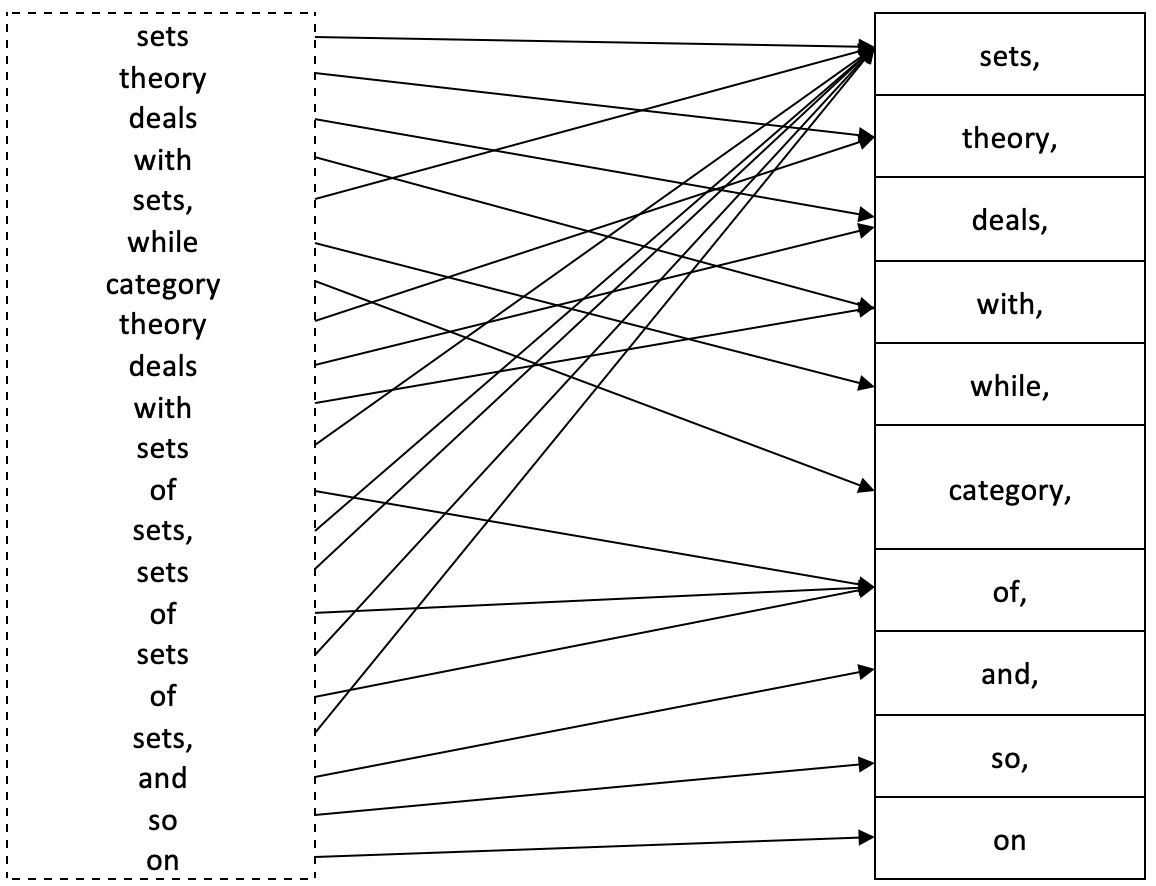
So wäre die Multiplizität von „sets“ 8, die von „deals“ 2, für „category“ ist es 1, und so weiter.
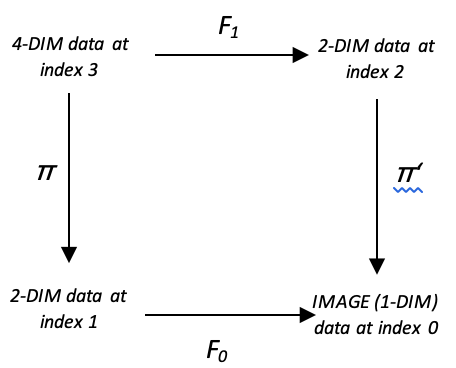
Um dies für einen Händler weiter zu veranschaulichen, betrachten wir eine Zeitreihe von Preisen. Wenn wir an Veränderungen in der Preisspanne interessiert sind und diese Veränderungen anhand früherer Preisspannen vorhersagen wollen, könnten wir 2 Bereiche finden, die diese Beziehung erklären.
Wenn wir frühere Kursbewegungen als mehrdimensionalen Datensatz und die Veränderungen, die wir vorhersagen wollen, als eindimensionalen Datensatz betrachten, verbindet der Homomorphismus zwischen den beiden Bereichen beide Bereiche über eine Trainingsverzögerung (lag), beispielsweise einen Kursbalken. Das nachstehende Diagramm kann zur Verdeutlichung beitragen.

Dieser Homomorphismus-Satz stellt einen mehrdimensionalen Bereich dar, da bei der Bearbeitung mehrerer Datenpunkte (oder in manchen Fällen sogar nur eines einzigen) zwangsläufig Wiederholungen im Ausgangsbereich auftreten. Für die Kodomäne können wir alle Datenpunkte als ganze Zahlen normalisieren, die von -100 bis +100 reichen, als prozentuale Darstellung des Ausmaßes der resultierenden Veränderung der Preisspanne. Diese Normalisierung bedeutet, dass es keine Wiederholungen gibt, sodass die Elemente in der Codomäne wie folgt vermutet werden können.
{-100, -80, -60, -40, -20, 0, 20, 40, 60, 80, 100}
Bei einer Gesamtgröße von 11. Wir können diese Homomorphismenmenge noch einen Schritt weiterführen, indem wir Domänendaten mit mehr als zwei Dimensionen berücksichtigen. Angenommen, wir berücksichtigen bei der Vorhersage von Veränderungen in der Preisspanne mehr als eine Verzögerung? Schauen wir uns das folgende Diagramm an:

Sie ähnelt der obigen, mit dem einzigen Unterschied, dass die Datenpunkte hinzugefügt wurden. Idealerweise müssten wir unser Modell trainieren, um genügend Datenpunkte in den Domänen und Codomänen zu sammeln, und um es zu verwenden, könnten wir bei der Zuordnung zur Codomäne eine Reihe von Methoden anwenden. Für diesen Artikel könnten wir einen „Winner takes all“-Ansatz für die Auswahl der Codomain-Vorhersage in Betracht ziehen. Der Gewinner ist also derjenige mehrdimensionale Datenpunkt (der einfach als Vektor oder Array dargestellt wird, da die Elementklasse ein Array ist), der mit seinem Abstand zu den neuen oder aktuellen Eingabedaten am nächsten von allen im Bereich liegt. Dies würde wie im nachstehenden Code gezeigt erfasst werden.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int CTrailingCT::Morphisms_A(CHomomorphism<double,double> &H,CDomain<double> &D,CElement<double> &E,int CardinalCheck=4) { int _domain_index=-1,_codomain_index=-1; if(E.Cardinality()!=CardinalCheck){ return(_domain_index); } double _least_radius=DBL_MAX; for(int c=0;c<D.Cardinality();c++) { double _radius=0.0; m_element_a.Let(); if(D.Get(c,m_element_a)) { for(int cc=0;cc<E.Cardinality();cc++) { double _e=0.0,_d=0.0; if(E.Get(cc,_e) && m_element_a.Get(cc,_d)) { _radius+=pow(_e-_d,2.0); } } } _radius=sqrt(_radius); if(_least_radius>_radius) { _least_radius=_radius; _domain_index=c; } } // for(int m=0;m<H.Morphisms();m++) { m_morphism_ab.Let(); if(H.Get(m,m_morphism_ab)) { if(m_morphism_ab.Domain()==_domain_index) { _codomain_index=m_morphism_ab.Codomain(); break; } } } return(_codomain_index); }
Um die Kategorientheorie in diesem Modell anzuwenden, würden wir das Konzept der Kommutation, das bereits in früheren Artikeln angesprochen wurde. Wenn wir das unten gezeigte Diagramm anpassen, hätten wir bei den Homomorphismen π und π' eine Mehrbereichskonstellation, und die Möglichkeit des Pendelns bedeutet einfach, dass wir zwei Möglichkeiten haben, Veränderungen in der Preisspanne zu projizieren.
Wie wir dies nutzen, um unsere Vorhersage zu erhalten, könnte dadurch erreicht werden:
- Der Mittelwert der beiden Projektionen wird gebildet
- Die Einnahme ihrer maximalen oder
- Unter Verwendung ihres Minimums
Für den gemeinsam genutzten Code haben wir eine Option für die Auswahl zwischen Minimum, Mittelwert und Maximum vorgesehen, wie im folgenden Codeschnipsel gezeigt.
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for short position. | //+------------------------------------------------------------------+ bool CTrailingCT::CheckTrailingStopShort(CPositionInfo *position,double &sl,double &tp) { //--- check if(position==NULL) return(false); Refresh(); m_element_a.Let(); m_element_b.Let(); m_element_c.Let(); m_element_bd.Let(); m_element_cd.Let(); SetElement_A(StartIndex(),m_element_a); int _b_index=Morphisms_A(m_multi_domain.ab,m_multi_domain.ab.domain,m_element_a,4); int _c_index=Morphisms_A(m_multi_domain.ac,m_multi_domain.ac.domain,m_element_a,2); SetElement_B(StartIndex(),m_element_b); SetElement_C(StartIndex(),m_element_c); int _b_d_index=Morphisms_D(m_multi_domain.bd,m_multi_domain.bd.domain,m_element_b,2); int _c_d_index=Morphisms_D(m_multi_domain.cd,m_multi_domain.cd.domain,m_element_c,2); int _bd=0,_cd=0; if(m_multi_domain.bd.codomain.Get(_b_d_index,m_element_bd) && m_element_bd.Get(0,_bd) && m_multi_domain.cd.codomain.Get(_c_d_index,m_element_cd) && m_element_cd.Get(0,_cd)) { m_high.Refresh(-1); m_low.Refresh(-1); int _x=StartIndex(); double _type=0.5*((_bd+_cd)/100.0); //for mean if(m_type==0){ _type=fmin(_bd,_cd)/100.0; } //for minimum else if(m_type==2){ _type=fmax(_bd,_cd)/100.0; } //for maximum double _atr=fmax(2.0*m_spread.GetData(_x)*m_symbol.Point(),m_high.GetData(_x)-m_low.GetData(_x))*(_type); double _sl=m_high.GetData(_x)+(m_step*_atr); double level =NormalizeDouble(m_symbol.Ask()+m_symbol.StopsLevel()*m_symbol.Point(),m_symbol.Digits()); double new_sl=NormalizeDouble(_sl,m_symbol.Digits()); double pos_sl=position.StopLoss(); double base =(pos_sl==0.0) ? position.PriceOpen() : pos_sl; sl=EMPTY_VALUE; tp=EMPTY_VALUE; if(new_sl<base && new_sl>level) sl=new_sl; } //--- return(sl!=EMPTY_VALUE); }
Wenn wir Tests für EURGBP auf dem täglichen Zeitrahmen vom 2022.01.01 bis 2022.08.01 durchführen und ein einfaches Signal wie den eingebauten Awesome Oscillator ('SignalAO.mqh') verwenden, erhalten wir den folgenden Bericht.

Wenn wir dasselbe Signal in ähnlicher Weise ausführen, aber eine der eingebauten Trailing-Klassen verwenden, die den gleitenden Durchschnitt über denselben Zeitraum und denselben täglichen Zeitrahmen mit derselben Positionsgrößenklasse (feste Marge) verwenden, erhalten wir den folgenden Bericht.

Dies spricht für das Potenzial der Verwendung mehrerer Domänen, nicht nur bei der Projektion von Veränderungen in der Preisspanne, um Trailing-Stop-Entscheidungen zu treffen, sondern möglicherweise auch bei Signal- oder Geldmanagemententscheidungen. Wir haben in diesem Artikel nur die Trailing-Stops behandelt, sodass der Leser vielleicht die anderen beiden Anwendungen in Ruhe erkunden kann.
Relativ-Domains
Relative Domains sind eine Erweiterung der obigen Konzepte zu Multi-Domains, allerdings hat Wikipedia noch keine Referenzseite zu diesem Thema. Wenn wir jedoch auf unser erstes Beispiel oben zurückkommen, bei dem ein einfacher Satz zur Definition von Multidomänen verwendet wurde, würden wir einen Schritt weiter gehen, indem wir die Codomäne N als Wörterbuch aller englischen Wörter verwenden. Dies würde bedeuten, dass jeder englische Satz einen Homomorphismus mit N hat. Ein Homomorphismus von Satz A zu Satz B würde jedes Wort, das irgendwo in A vorkommt, zu demselben Wort schicken, das irgendwo in B vorkommt.
Formal gesehen ist eine Abbildung von relativen Bereichen über N, dargestellt als f: (E,π) à (E',π'), ist eine Funktion f: E à E’' so, dass das folgende Dreieck kommutiert
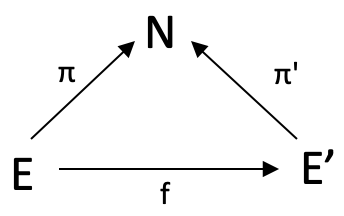
Um dies für Händler zu veranschaulichen, würden wir den Morphismus f ausnutzen, indem wir unser oben verwendetes Pendelquadrat so abändern, dass es ein einfaches Dreieck ohne D-Bereich ist. Bei der Nutzung von f würden wir Morphismusgewichte zwischen zwei Bereichen E & E' suchen, die für unsere Demonstrationszwecke, wie oben, mehrdimensionale Daten mit dem Index Null und dem Index 1 sind. Die „Mehrdimensionalität“ bedeutet einfach, dass wir mehr als einen Datenpunkt messen und aufzeichnen. In unserem Fall handelt es sich um Veränderungen der Höchst- und Tiefststände. Da wir also die eventuelle Änderung der Preisspanne für den Balken bei Index 1 (unsere Verzögerung) bereits kennen, würden wir den Morphismus f verwenden, um unseren aktuellen Datenpunkt, dessen eventuelle Änderung wir noch nicht kennen, umzuwandeln und herauszufinden, welchem der Elemente in E' er am ehesten entspricht. Das nächstgelegene Codomain-Element über π' ergibt unsere voraussichtliche Änderung.
Wenn wir die Tests wie zuvor durchführen, erhalten wir den folgenden Bericht.

Wie Sie feststellen können, ist der Bericht identisch mit unserem ersten, aber es gab einige leichte Verbesserungen in zusätzlichen Tests, die ich durchgeführt habe, obwohl diese hier nicht mitgeteilt werden. Beachten Sie, dass alle diese Experten dasselbe Einstiegssignal verwenden (integriertes Awesome Oscillator Signal), wobei die einzige Änderung in der Implementierung des Trailing-Stops besteht.
Indizierte Domains
Indizierte Domänen (indexed-domains) sind äquivalent zu relativen Domänen, indem sie die Elemente der obigen Domäne N nehmen und sie in solche Domänen verwandeln, dass jede dieser neuen Domänen eine Beziehung zu den Elementen in E und E' hat. Ein kurzes Beispiel, um dies zu veranschaulichen, ist eine Schule mit einer Reihe von Klassen (N). Jede Klasse hat einen Bereich von Schülern, die sie besuchen (E), und jede Klasse hat auch einen Bereich von Lehrern (E'). Die Bereiche E und E' werden daher aufgrund ihrer Beziehung zur Klasse als N-Indexed Domains bezeichnet.
Für Händler würden wir unseren Bereich N, der bisher 11 Werte hatte, auf 11 Bereiche hochskalieren. Jeder Bereich würde feinere Abstufungen bei der Veränderung der Preisspanne erfassen. Zum Beispiel könnten wir anstelle des Elements 40 (40 % Änderung) 9 neue Änderungen in dem Bereich haben:
{32.5, 35.0, 37.5, 40.0, 42.5, 45.0, 47.5, 50.0}
Dieser Bereich wird dann auf alle Elemente in E und E' abgebildet, wobei es sich in unserem Fall im letzten Beispiel um mehrdimensionale Daten handelte, die Änderungen mit einer Verzögerung und Änderungen mit zwei Verzögerungen erfassten. Wenn wir einen Schritt zurücktreten und allgemeinere Anwendungen von indexierten Domänen für Händler betrachten, könnten wir eine ganze Liste erstellen. Hier sind fünf mögliche Verwendungszwecke.
Gleitende Durchschnitte, ein beliebter Indikator, der von Händlern verwendet wird, um kurzfristige Schwankungen der Marktdaten zu glätten und Trends bei den Preisen von Vermögenswerten zu erkennen. Bei dieser Technik wird der Durchschnittspreis eines Vermögenswerts in einem bestimmten Zeitfenster ermittelt und dann in einem Diagramm dargestellt, um Muster und Trends zu erkennen.
Indizierte Mengen und die Kategorientheorie können eine Möglichkeit bieten, gleitende Durchschnitte anders zu betrachten. Wie bereits erwähnt, ist eine indizierte Menge eine Sammlung von Elementen, die durch einen anderen Bereich indiziert sind. Im Zusammenhang mit gleitenden Durchschnitten könnte der indizierte Bereich verschiedene Perioden für die Berechnung des gleitenden Durchschnitts darstellen, da jede Periode einen Puffer von gleitenden Durchschnittsperioden darstellt, die als Bereich betrachtet werden können.
Unser E und E' könnten ein gleitender Durchschnitt sein, der nach dem typischen Preis berechnet wird, bzw. ein gleitender Durchschnitt, der nach dem Medianpreis berechnet wird. Neben den beiden in diesem Artikel betrachteten Bereichen könnte es noch weitere geben, z. B. den Durchschnitt der Schlusskurse oder den gewichteten Durchschnittskurs usw. Es genügt zu sagen, dass diese Unterbereichsklassifizierung auch außerhalb der Kategorientheorie untersucht werden kann. Was die Kategorientheorie jedoch zu dieser Studie beiträgt, ist die Konzentration auf die Relativitäts-Domänen-Beziehungen. Die Morphismen zwischen E und E' (f), z. B. zwischen dem Medianpreis MA im Zeitraum von 21 und dem Medianpreis MA im Zeitraum von 34, können vielseitig verwendet werden. So könnte man z. B. ein gleitendes Durchschnittsband abbilden. Wenn wir die Veränderungen der Gewichte in diesen Morphismen verfolgen, könnten wir quantifizieren, wie viel von einem Trend noch übrig ist oder ob bald eine Umkehrung eintritt.
Neben der Anwendung bei der Nachverfolgung offener Positionen durch Klassifizierung und Vorhersage der Preisvolatilität kann es hilfreich sein, einige andere Anwendungen von Multi-Domains und indizierten Domains in der Kategorientheorie für Händler aufzulisten. Hier sind einige davon, was die Auswahl der Einstiegssignale betrifft.
- Analyse des Orderbuchs. Wenn Kauf- und Verkaufsaufträge in einem Orderbuch als Multi-Domains protokolliert werden (da ein bestimmtes Wertpapier zu unterschiedlichen Zeiten und mit unterschiedlichen Zuteilungen ge- oder verkauft werden kann, was bedeutet, dass die Domain der Wertpapiere „Wiederholungen“ aufweist), kann ein Händler feststellen, wo sich Angebot und Nachfrage für ein Wertpapier konzentrieren. Ist die Kauf-Multi-Domäne größer als die Verkaufs-Multi-Domäne, kann dies ein Kaufsignal sein, ist die Verkaufs-Multi-Domäne größer, kann dies ein Verkaufssignal sein.
- Portfolio-Analyse. Multi-Domains können das Portfolio eines Händlers darstellen, wobei jedes Element ein bestimmtes Wertpapier oder einen bestimmten Vermögenswert repräsentiert (warum? Da jedes Wertpapier durch Optionskontrakte oder andere derivative Instrumente abgesichert sein kann, d.h. sie erscheinen mehr als einmal). Durch die Analyse einer solchen Vielzahl von Wertpapieren und die Fokussierung auf ihre Performance kann ein Händler entscheiden, mehr von den gut abschneidenden Wertpapieren zu kaufen und Positionen zu schließen oder sogar Leerverkäufe auf die schlecht abschneidenden zu tätigen.
- Risikomanagement. Multi-Domains können die Risikoverteilung im Portfolio eines Händlers darstellen, wenn man sich beispielsweise die Performance-Drawdowns in vergangenen Handelssitzungen ansieht (jeder normalisierte Drawdown-Bereich könnte in den verschiedenen Sitzungen mehrfach auftreten, was zur Anwendung von Multi-Domains führt). Wenn die Multi-Domain der risikoreichen Wertpapiere größer ist als die Multi-Domain der risikoarmen Wertpapiere, kann dies ein Signal sein, einige der risikoreichen Wertpapiere zu verkaufen und einige risikoarme Wertpapiere zu kaufen.
- Handelsstrategien. Multi-Domains können Handelsstrategien darstellen, wobei jedes Element eine bestimmte Handelsentscheidung repräsentiert, z. B. die Platzierung von Marktaufträgen, schwebenden Aufträgen, Stopps oder Gewinnmitnahmen (solche Entscheidungen wiederholen sich zwangsläufig, und die Reihenfolge, in der sie getroffen werden, ist von Bedeutung, sodass eine Multi-Domain dabei helfen würde, diese Sequenzinformationen zu erfassen und die eigene Analyse zu unterstützen). Durch die Analyse des Mehrbereichs erfolgreicher Trades kann ein Händler entscheiden, eine ähnliche Long-Strategie für diese Trades zu implementieren.
- Technische Indikatoren. Multi-Domains können technische Indikatoren wie gleitende Durchschnitte oder Bollinger-Bänder darstellen, indem ihre normalisierten Werte über einen zu untersuchenden Zeitraum aufgezeichnet werden (normalisierte Werte über jedes Intervall wiederholen sich zwangsläufig über das gesamte Untersuchungsintervall, und durch die Aufzeichnung der Reihenfolge dieser Wiederholungen innerhalb einer Multi-Domain wird die Analyse vollständiger). Liegt der Mehrbereich der Werte für einen bestimmten technischen Indikator über oder unter einem bestimmten Schwellenwert, kann dies als Kauf- oder Verkaufssignal verwendet werden.
- Korrelationen. Multi-Domain kann Korrelationen zwischen verschiedenen Wertpapieren oder Vermögenswerten darstellen. Die Korrelationswerte liegen in der Regel zwischen -1,0 und +1,0, und wenn diese Werte auf die erste Dezimalstelle normiert werden, ergeben sich Werte wie {1,0, 0,4, -0,7, 0,1,...} usw. Solche Korrelationen können über verschiedene Vermögenswerte oder Zeitfenster desselben Vermögenswerts hinweg gemessen werden, was bedeutet, dass Wiederholungen zwangsläufig auftreten. Indem man diese Wiederholungen in einer Multidomäne unterbringt, die beispielsweise eine Beziehung zu einer Codomäne hat, in der die Namen von Wertpapieren aufgeführt sind, entgeht einem bei der Analyse nicht die Bedeutung der einzelnen Korrelationswerte. Wenn ein Mehrfachbereich von Wertpapieren, die stark mit einem Titel mit einem Aufwärtsmomentum korreliert sind, größer ist als der von Titeln mit einem Abwärtsmomentum, kann dies ein Kaufsignal sein, während eine umgekehrte Situation einen Verkauf signalisiert.
- Zeitreihenanalyse. Multi-Domains können Zeitreihendaten darstellen, sodass Händler Trends und Muster im Zeitverlauf analysieren können. Auch hier wiederholen sich im Laufe der Zeit zwangsläufig dieselben Trendmuster, weshalb die bloße Auflistung jedes einzelnen Musters in einem Bereich nichts darüber aussagt, welcher Abfolge innerhalb der Zeitreihe jedes Muster folgte. Wenn die Werte für einen bestimmten Zeitraum über oder unter dem Durchschnitt liegen, könnte dies auf eine überverkaufte Situation hindeuten und ein Kauf- oder Verkaufssignal sein, wenn sich die Situation umkehrt oder zusätzliche Faktoren berücksichtigt werden, je nach der von Ihnen gewählten Strategie.
- Stimmungsanalyse. Multi-Domains können die Stimmung der Marktteilnehmer anzeigen. Wenn wir uns an der Mehrheitsstimmung der Teilnehmer orientieren, ist dieser Wert, wenn er richtig quantifiziert und normalisiert wird (wie der CBOE Volatility Index (VIX)), dazu verpflichtet, sich über einen analysierten Zeitraum zu wiederholen. Wenn eine Multi-Domain alle diese Werte in ihrer Reihenfolge erfasst und die aktuelle positive Stimmung größer ist als die negative, könnte dies aufgrund der zusätzlichen protokollierten Informationen innerhalb der Multi-Domain ein stärkeres Kaufsignal sein, als wenn nur einzelne Werte verwendet würden.
- Handelssignale. Multi-Domains können Handelssignale darstellen, wenn Sie mehr als ein Demo-Konto haben, von dem jedes für den Empfang von Signalen im Rahmen einer Abonnementvereinbarung eingerichtet ist. Die Aktionen jedes Signals, ob Kauf oder Verkauf, in den verschiedenen Volumenbeträgen, wenn sie tabellarisch dargestellt werden, haben zwangsläufig Wiederholungen. Eine typische Domäne, die solche Wiederholungen auslässt, verliert Informationen wie das Handelsvolumen, das mit jeder Signalentscheidung verbunden ist, und dies könnte die Analyse der relativen Leistung dieser Signale verfälschen.
- Marktdaten. Multi-Domains können Marktdaten wie z.B. das Volumen in festgelegten Zeitintervallen darstellen, insbesondere wenn die Volumen-Kontrakt-Beträge zur einfachen Interpretation in Quartile normalisiert werden. Diese normalisierten Beträge werden sich während des Untersuchungszeitraums eines Wertpapiers zwangsläufig wiederholen. Da mehrere Domänen diese Wiederholung zulassen, wird es einfach, eine präzisere Analyse mit einer beliebigen Kodomäne zu erstellen, die Sie mit dieser Volumendomäne verbinden.
In ähnlicher Weise kann es nützlich sein, mögliche Verwendungszwecke von indexierten Domains für das Geldmanagement von Händlern aufzulisten, daher hier eine Liste:
- Gewichtung der Marktkapitalisierung. Indexierte Domains können die Marktkapitalisierungen verschiedener Aktien in einem Portfolio darstellen. In unserem obigen Diagramm würde dies im Bereich N liegen, wobei die Bereiche E, E' und der Rest Aktien innerhalb einer bestimmten Marktkapitalisierung darstellen. Die Funktion f würde die relative Größe der Aktien innerhalb eines Portfolios bestimmen.
- Faktorinvestitionen. In indexierten Bereichen können verschiedene Faktoren untersucht werden, die die Wertentwicklung einer Aktie oder eines Portfolios beeinflussen, z. B. Value, Momentum und Wachstum. Nach unserem obigen Diagramm würden die normalisierten Leistungsbenchmarks in N liegen, wobei E, E' und andere Bereiche die Faktoren darstellen. Der Morphismus f würde die relative Bedeutung der einzelnen Faktoren festlegen.
- Risikoparität. Der Ansatz der Risikoparität bei der Portfoliokonstruktion zielt auf eine risikogewichtete Allokation des Anlagekapitals ab, um die Anlagen optimal zu diversifizieren, wobei Risiko und Ertrag des gesamten Portfolios als Einheit betrachtet werden. In diesem Fall würde unsere Risikogewichtung in N erfolgen, wobei die einzelnen Vermögenswerte E, E',... einnehmen und die Funktion f die relative Gewichtung zwischen den Vermögenswerten definiert.
- Smart beta. Smart Beta versucht, die Vorteile des passiven Investierens mit den Vorteilen aktiver Anlagestrategien zu kombinieren, indem es alternative Indexkonstruktionsregeln zu den traditionellen marktkapitalisierungsbasierten Indizes verwendet. Der Schwerpunkt liegt auf der Beseitigung von Marktineffizienzen auf regelbasierte und transparente Weise. Der Bereich N würde normalisierte Performance-Rendite-Benchmarks enthalten, während E und E' aktive bzw. passive börsengehandelte Fonds sein könnten. Die Funktion f dient als Leitfaden für die relative Gewichtung.
- Value at Risk (VaR). Der Value-at-Risk (VaR) ist eine Methode zur Quantifizierung des Risikos potenzieller Verluste aus einer offenen Handelsposition. Diese Metrik kann entweder historisch unter Verwendung von Varianz-Kovarianz- oder Monte-Carlo-Methoden berechnet werden. Investmentbanken wenden in der Regel VaR-Modelle für das unternehmensweite Risiko an, da unabhängige Handelsabteilungen das Unternehmen ungewollt hoch korrelierten Vermögenswerten aussetzen können. Das Ausmaß des maximalen Verlustes würde im Bereich N liegen, E, E' wären Vermögenswerte unterschiedlicher Art, z. B. Aktien und Anleihen, während f die relative Portfoliogewichtung sein könnte, die sich aus der vergangenen Handelsperformance ergibt.
Schlussfolgerung
Abschließend haben wir uns mit Multi-Sets, relativen Sets und indexierten Sets und ihrer möglichen Anwendung bei der Klassifizierung und Vorhersage der Preisvolatilität beschäftigt. Wir haben es bisher vermieden, Domänen als Mengen zu bezeichnen, aber vielleicht werden wir sie in den nächsten Artikeln als Mengen bezeichnen, da diese besser verstanden werden, während Domänen, obwohl sie angemessener sind, da sie ein Oberbegriff für andere „Arten von Mengen“ wie Topologien, einfache Komplaxität und andere Formate sind, wir werden solche Anwendungen und Beispiele in dieser Reihe von Artikeln nicht haben. Daher werde ich im Folgenden den Begriff "Menge" verwenden, um auf das zu verweisen, was ich in diesem und früheren Artikeln als Domänen bezeichnet habe.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/12470
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Gute Arbeit.
Freut mich, dass es dir gefallen hat. Prost!
Schade, dass Topologien und vereinfachte Komplexe nicht berücksichtigt werden.