
Анализ статистических характеристик индикаторов

Введение
Использующие в своей работе трейдеры широко используют
индикаторы, которые преобразовывают исходные котировки в некоторую, «более
ясную», форму, по которой трейдер проводит анализ и дает прогноз движения цен
на рынке. Вопросы о допустимости проводимого в индикаторе преобразования, а также
доверия к полученному результату, обычно не рассматриваются, и, в лучшем случае, заменяются тестированием построенных на базе
индикаторов торговых систем.
Для меня очевидно, что без ответа на вопрос допустимости преобразования исходных котировок, а также доверия к полученному результату, бессмысленно использовать индикаторы и, тем более, строить на их основе торговые системы. В данной статье покажем, что для такого вывода имеются серьезные основания. Покажем возникающие проблемы на трех индикаторах: прямая трендовая линия, экспоненциальная скользящая средняя и фильтр Ходрика-Прескотта.
1. Немного
теории
Для удобства читателя приведу некоторые понятия из теории
вероятности и математической статистики, которые будут использоваться в
дальнейшем по тексту статьи. Ссылок не привожу, так как используемые мною
понятия ничем не отличаются от соответствующих понятий в учебниках.
Наблюдаемые нами котировки являются косвенными выборочными
измерениями (генеральная совокупность нам не известна) некоторого
стохастического процесса на фундаментальном уровне, в котором имеются:
- точно измеряемые детерминированные компоненты, например, исполненные сделки по покупке-продаже валюты;
- детерминированные компоненты, измеряемые с ошибкой, например, количество валюты, проданной за промежуток времени, например, за один день;
- стохастическая компонента, измерить которую вообще невозможно – настроение толпы. В течение большей части времени основной характеристикой этой компоненты является случайное блуждание с дрейфом.
В результате взаимодействия этих компонент мы имеем стохастический процесс, в котором имеется:
- тренды (детерминированные и стохастические);
- циклы с фиксированными и стохастическими длинами периодов;
- случайное блуждание с дрейфом.
Нестационарность является общей характеристикой стохастического процесса, отражением которого являются котировки валют. Для нас понятие нестационарности стохастического процесса интересно только в том смысле, что нестационарный процесс, для которого практически отсутствуют средства анализа, необходимо разложить на совокупность процессов, для каждого из которых имеются средства анализа. При применении индикаторов трейдер не задумывается о применимости индикатора к конкретной котировке того или иного актива. Вместе с тем существуют средства статистики, а точнее, эконометрики, которые позволяют оценить возможность применения индикатора и результат этого применения.
1.2. Случайное событие. Вероятность
Случайным событием (в нашем случае, сделки по покупке - продаже валюты) называется такое событие, которое может как произойти, так и не произойти. Мы знаем, что количество сделок в разные дни и в разное время суток различается и является случайным, но по общепринятой практике принимаются во внимание только события в дискретные моменты времени – минута, час, день и т.д.
Относительной частотой случайного события называется отношение количества случаев появления этого события M к общему числу проведенных наблюдений N. При росте числа наблюдений, в теории до бесконечности, частота стремится к числу, называемому вероятностью случайного события. По определению, вероятность – это величина от нуля до единицы. Обычно и в данной статье, вместо относительной частоты будет употребляться слово вероятность.
Случайной величиной называется такая величина, которая принимает те или иные значения с определенными вероятностями.
Генеральной совокупностью будем называть все возможные значения, которые может принимать случайная величина. На рынке мы всегда имеем дело с выборкой из генеральной совокупности – обычно берем котировки за некоторый промежуток времени. Естественно, что статистика, вычисленная по выборке, отличается от статистики, вычисленной на генеральной совокупности, так как относительная частота отличается от вероятности и смыслом дальнейших вычислений является оценка отличий статистик, вычисленных на выборке, от статистик, вычисленных на генеральной совокупности. Такая постановка вопроса невозможна в случае индикаторов, так как цены, например, close, принимаются в вычисления индикатором как детерминированные величины.
Еще одно любопытное замечание. Так как мы по выборке
пытаемся судить о генеральной совокупности, то мы можем игнорировать различия в
котировках, которые имеются у разных дилинговых центров, так как легко поменять
значения котировок, но крайне сложно изменить их статистические характеристики.
1.3.
Характеристики случайных величин
1.3.1. Описательные статистики
Совокупности случайных величин, в нашем случае котировки валюты, характеризуются целым набором показателей, часть из которых будет использоваться в дальнейшем.
Гистограмма – график, показывающий частоту значения случайной величины. В предельном случае – это график плотности распределения вероятности.
Арифметическое среднее – сумма значений всех наблюдений, деленная на число наблюдений (в нашем случае, на число периодов). Применимо не для всех распределений и наиболее популярно для нормальных распределений, для которых совпадает с медианой. Отсюда следует, что любимейший индикатор скользящей средней, строго говоря, применим только в случае, если котировки имеют закон распределения, для которого существует средняя.
Медиана делит все наблюдения в выборке на две части: с одной стороны все наблюдения меньше по значению медианы, а с другой – больше. Медиана существует для любого распределения и не чувствительна к выбросам. Если средняя равна (близка по значению) медиане, то это один из признаков нормального закона распределения.
Интересным вопросом является отклонение от среднего. Дисперсия - это среднее значение квадратов отклонений случайной величины от ее математического ожидания. Корень квадратный из дисперсии – это среднеквадратичное (стандартное) отклонение.
Стандартное отклонение и дисперсия не устойчивы к выбросам.
Показателем степени несимметричности кривой плотности распределения является безразмерная величина, называемая коэффициентом асимметрии (скосом – skewness). Если величина скоса меньше, чем «шесть, деленное на число наблюдений», то распределение вероятности случайной величины подчинено нормальному закону.
Другой величиной, характеризующей плотность распределения, является куртосиз. Для нормального закона он равен 3. Если куртосиз больше трех, то вершина острая и полого спадают «тяжелые» хвосты.
Как видим, целый ряд понятий применим к случайным величинам, имеющим нормальный закон распределения. Не все так плохо, так как большое количество законов распределения сходится по вероятности к нормальному при росте числа наблюдений.
1.3.2. Нормальное
распределение
Нормальное распределение (распределение Гаусса) является
предельным случаем почти всех реальных распределений вероятности.
Теоретической основой является предельная теорема Ляпунова, утверждающая, что распределение суммы независимых случайных величин с любым исходным распределением будет нормальным, если наблюдений много и их вклад мал. Поэтому оно используется в очень большом числе реальных приложений теории вероятностей.
Нормальное распределение имеет вид симметричной колоколообразной кривой, распространяющейся по всей числовой оси. Распределение Гаусса зависит от двух параметров: μ (математическое ожидание) и σ (среднеквадратичное отклонение).
Математическое ожидание и медиана данного распределения равны μ, а дисперсия σ2. Кривая плотности вероятности симметрична относительно математического ожидания. Коэффициент асимметрии и эксцесс равны γ = 0, ε = 3 .
Часто плотность нормального распределения записывают не как функцию переменной х, а как функцию переменной z = (x − μ ) /σ, которая имеет нулевое математическое ожидание и дисперсию, равную 1.
Распределение с μ = 0 и σ = 1 называют стандартным нормальным распределением(i.i.i).

Рисунок 1. Нормальное распределение
1.3.3. Распределение Стьюдента (t -распределение)
Основной параметр – степень свободы (число элементов в выборке). При этом с увеличением числа степеней свободы распределение Стьюдента приближается к стандартизированному нормальному, причем при n > 30 распределение Стьюдента практически можно заменить нормальным распределением. При n<30 распределение Стьюдента имеет более тяжелые хвосты.
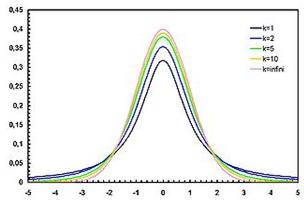
Рисунок 2. Распределение Стьюдента
t-статистика широко используется при проверке статистических гипотез.
1.3.4. Хи-квадрат (распределение Пирсона)
Если Хi - независимые случайные величины, имеющие i.i.i, то сумма их квадратов подчиняется χ2-распределению. Плотность зависит от единственного параметра ν, который принято называть числом степеней свободы, равного числу независимых случайных величин. При числе степеней свободы ν →∞, χ2 - распределение стремится к нормальному распределению с центром ν и дисперсией 2ν. Плотность распределения асиметрична, унимодальна и с ростом степеней свободы становится более пологой и симметричной.

Рисунок 3. Распределение Пирсона (хи-квадрат)
1.3.5. F -распределение
Фишера
F-распределение Фишера называют распределением дисперсионного отношения, т.е. отношением дисперсий двух рядов.
Если две независимые случайные величины имеют распределение хи-квадрат со степенями свободы (V1, V2), то их отношение имеет распределение Фишера

Рисунок 4. Распределение Фишера
1.3.6.
Коэффициент детерминации R-квадрат
Коэффициент детерминации показывает, какая доля дисперсии результата объясняется влиянием независимых переменных. В случае двух переменных это квадрат корреляции Пирсона. Он выражает количество дисперсии, общей между двумя переменными.
Значимость коэффициента корреляции зависит от количества наблюдений или F-статистики Фишера. При количестве свечей в котировке свыше 100 даже весьма малые отклонения наблюдаемого значения от нуля оказываются достаточными для того, чтобы признать значимость индикатора.
1.4. Определение гипотез
Какие выводы о некотором параметре генеральной совокупности мы можем сделать, имея выборочное значение этого параметра? Ответ на этот вопрос зависит от того, имеем ли мы априорную информацию о величине генерального параметра.
Если априорная информация о величине генерального параметра отсутствует, то мы можем по выборочному значению оценить этот параметр, задав для него доверительный интервал, то есть границы, в которых его величина лежит с определенной доверительной вероятностью.
На практике обычно требуется проверить какую-то конкретную и,
как правило, простую гипотезу Hо. Такую гипотезу принято называть нулевой. Для
проверки гипотезы используют критерии, позволяющие принять или опровергнуть
гипотезу. Наиболее часто в качестве критериев используются перечисленные выше статистики: t-статистика, F-статистика и статистика хи-квадрат. При использовании пакетов статистики, например, STATISTICA, или эконометрики, например, EViews, вычисленный критерий
сопровождается величиной значимости этого критерия - р-значением. Например, р-значение, равное 0,02 (2%) означает, что соответствующий критерий не значим на 1% уровне значимости, и значим на 5% уровне значимости. Эквивалентно можно считать, что с вероятностью, равной "1 - р-значение" нулевая гипотеза не справедлива.
Выбор р-значения является субъективным и определяется тяжестью последствий в ошибочной оценке конкретного критерия.
1.5.
Статистические характеристики котировок
1.5.1. Описательные статистики
К описательным статистикам относят:
- Гистограмму, которая при росте числа свечей в котировке должна приблизиться к закону распределения;
- Меры центральной тенденции: среднее, медиана;
- Мера разброса: стандартное отклонение;
- Меры формы: скос и куртосиз;
- Критерий нормальности Жарка Бера.
Критерий Жарка Бера (Jarque-Bera). Нулевая гипотеза Hо: распределение нормально. Например, вероятность, сопровождающая значение критерия, равна 0.04. Казалось бы, что можно сделать следующий вывод: вероятность принятия нулевой гипотезы равна 4%. Однако это не совсем точно, так как вычисленная величина является р-значением критерия и вероятность принятия нулевой гипотезы равна 96%.
1.5.2. Автокорреляции и Q-статистика
Корреляция - это мера связи между двумя переменными. Коэффициент корреляции может изменяться от -1.00 до +1.00. Значение -1.00 означает полностью отрицательную корреляцию, значение +1.00 означает полностью положительную корреляцию. Значение 0.00 означает отсутствие корреляции.
Корреляция между элементами одной котировки называется автокорреляцией. По ней очень удобно выявлять тренды. Наличие автокорреляций делает сомнительными любые выводы о котировках как о случайных величинах, так как существенным в определении случайной величины является независимость разных цен в разное время.
В пакетах статистического анализа автокорреляция сопровождается Q-статистикой Льюнга-Бокса с р-значением. Нулевой гипотезой является: автокорреляция отсутствует, т.е. при р-значении равном нулю можно сделать вывод об отсутствии корреляции до определенной свечки в котировке.
Исключение автокорреляций (трендов) из котировок является первым шагом на пути получения возможности применения методов математической статистики.
1.5.3.
Стационарность котировок
Котировки будем считать стационарными,
если их математическое ожидание и
дисперсия не зависят от времени. Даже это определение стационарности является слишком строгим и малопригодным при практическом применении. Очень часто приходится считать котировки стационарными, если в течение времени отклонения математического ожидания и/или дисперсии составляет несколько процентов, обычно не более 5%.
Реальные котировки на рынке Форекс не являются стационарными, а имеют следующие отклонения:
- Наличие тренда, порождаемого зависимостью между наблюдениями во времени. Наличие зависимости является характерной чертой, в частности, котировок валют, и вообще экономических наблюдений;
- Наличие цикличности;
- Наличие переменной дисперсии (гетероскедастичности).
Котировки с отклонениями от стационарных называют нестационарными, анализ которых состоит в последовательном разложении на составляющие. Процесс разложения заканчивается при получении в остатке стационарного ряда с практически постоянным математическим ожиданием и/или дисперсией.
Существует несколько тестов на стационарность котировок, основными из которых являются тесты единичного корня (unit root test). Наиболее известным из тестов единичного корня является тест Дикки-Фуллера. Нулевая гипотеза Но: котировки не стационарны (или, говорят, котировки имеют единичный корень), т.е. среднее и дисперсия зависят от времени. Так как практически всегда имеется очевидная зависимость от времени – это тренд, то при проведении теста следует указывать на наличие тренда в котировках, которые на данном этапе определяются на глаз.
1.6. Спецификация индикаторов (регрессия)
Поверхностный взгляд на тексты индикаторов на исходном языке, например, MQL5, позволяет выявить две формы их задания: аналитическая (наиболее распространенная) и табличная (применяется к индикаторам, которые называют фильтрами, например, индикаторы Кравчука).
Мы же будем использовать термин регрессия – общепринятый термин в математической статистике и эконометрике.
Имея идею, что же мы хотим выделить из котировок, для формулирования регрессии (индикатора) необходимо задать:
- Перечень независимых переменных, по которым вычисляется индикатор;
- Коэффициенты при независимых переменных;
- Формулу вычисления индикатора, по которой будет вычисляться зависимая переменная.
Если при построении мультивалютных индикаторов имеются сложности, то в регрессии таких ограничений нет.
Имея эти три позиции, в дальнейшем следует подогнать регрессию к котировке. В отличие от трейдерских форумов в эконометрике слово «подгонка – fit, fitting» не является ругательным, а является стандартной процедурой, в ходе которой с помощью одного из многочисленных методов оценки вычисляется соответствие регрессии (индикатора) котировкам. Наиболее известным из методов оценки является метод наименьших квадратов (МНК).
В результате оценки нас интересует два вопроса:
- Соответствие индикатора котировкам – величина остающейся ошибки;
- Стабильность вычисленных параметров регрессии в будущем.
Ответы на эти вопросы даются в ходе диагностики индикаторов.
1.7. Диагностика индикаторов
Диагностика индикаторов (регрессий) разделена на три группы:
- Диагностика коэффициентов;
- Диагностика остатков;
- Диагностика стабильности.
Каждая процедура проверки, описанная ниже, включает
спецификацию нулевой гипотезы, которая является гипотезой при тесте. Результат
теста состоит из выборки значений одной или более статистик и их присоединенных
р-значений. Последние указывают на
вероятность выполнения условия нулевой гипотезы, на которой построена тестовая статистика.
Таким образом, малые р-значения приводят к отклонению нулевой гипотезы. Например, если р-значение лежит между 0.05 и 0.01, то нулевая гипотеза отклонена на пяти процентном уровне, но не на однопроцентном уровне.
Следует учесть, что имеются различные предположения и результаты распределения, связанные с каждым тестом. Например, у некоторых из статистик есть точные, конечные тестовые распределения (обычно t или F-распределения). Другие являются большими выборками тестовой статистики с асимптотическими χ2 распределениями.
1.7.1. Диагностика коэффициентов
Диагностики коэффициентов предоставляют информацию и оценивают ограничения на оцененные коэффициенты, включая частный случай тестов на пропущенные и избыточные переменные. Будут использоваться следующие тесты коэффициентов уравнения регрессии:
- Доверительные эллипсы, позволяют выявить коррелированность между коэффициентами уравнений;
- Тест пропущенных переменных позволяет определить необходимость дополнительных переменных в уравнении регрессии;
- Тест избыточных переменных позволяет выявить лишние переменные;
- Тест излома позволяет реакцию уравнения регрессии на изменение тренда. Желательно создать такое уравнение регрессии, которое бы одинаково хорошо отражало котировки на растущем, падающем и боковом участках котировок.
1.7.2. Диагностика остатков
При обсуждении понятия стационарности котировок мы уже останавливались на важности изучения остатков при попытке преобразовать нестационарные котировки в стационарные.
Проводимый тест единичного корня может показать, что остатки гораздо ближе распределены к нормальному закону, чем исходные котировки. Использованное слово "ближе" отражает тот факт, что остатки имеют среднее и дисперсию, зависящую от времени, что приводит к нестабильности коэффициентов уравнения регрессии.
В терминологии трейдерских форумов: оптимизация торговой
системы, причем надо "не переоптимизировать (вот она подгонка!)", т.е. чтобы на
следующих участках торговая система не теряла своих характеристик. В понимании данной статьи торговая система оказывается не пригодной для будущих участков котировок из-за изменяющихся во времени математического ожидания и дисперсии.
В дальнейшем будут проведены тесты для остатков на корреляцию рядов, нормальность, гетероскедастичность и авторегрессивную условную гетероскедастичность остатков.
Коррелограммы - Q-статистики показывает автокорреляции остатков и вычисляют Q-статистику Ljung-Box для соответствующих лагов с указанием р-значения.
Гистограмма - тест нормальности показывает гистограмму и описательную статистику остатков, включая статистику Жарка-Бера (Jarque-Bera) при тестировании на нормальность. Если остатки нормально распределены, гистограмма должна быть колоколообразной, и статистика Жарка-Бера не должна быть значимой.
Тесты гетероскедастичности проверяет гетероскедастичности остатков уравнения. Если имеется доказательство гетероскедастичности, то следует или изменить спецификацию регрессии (изменить индикатор), или следует смоделировать гетероскедастичность.
Используем тест на гетероскедастичность White с нулевой гипотезой об отсутствии гетероскедастичности против теста об гетероскедастичности неизвестной, общей формы.
White описывает свой подход как общий тест на ошибочную спецификацию модели, так как нулевая гипотеза, лежащая в основе теста, предполагает, что ошибки и гомоскедастичны и независимы от независимых переменных, и что линейная спецификация модели правильна. Отказ от любого из этих параметров мог привести к значимой тестовой статистике. Наоборот, незначащая тестовая статистика подразумевает, что ни один из этих трех параметров не нарушен.
1.7.3. Диагностика стабильности
Диагностика стабильности является наиболее интересной и важной, так как результаты этой диагностики дают сведения о прогнозных возможностях индикатора. В рамках МТ4 или МТ5 диагностировать стабильность пытаются с помощью тестера стратегий. Далее покажем, что тестер стратегий не может диагностировать будущую стабильность торговой системы, построенной на индикаторах, а дает лишь некоторую оценку торговой системы на исторических данных.
Как и при тестировании торговых систем общий подход диагностики стабильности состоит в том, что Т баров котировки делится на наблюдения Т1, которые будут использоваться для оценки, и Т2 = Т – Т1 баров, которые будут использоваться для тестирования и оценки.
В случае тестирования торговой системы на двух участках проблема ее будущей стабильности не решается, так как тест на втором участке лишь говорит о том, что этот новый участок неизвестными статистическими характеристиками похож на предыдущий участок. При этом остаются не известны те статистические проблемы, которые удалось решить при построении торговой системы.
Конечно, при тестировании торговых систем подбирают разные участки котировок, но невозможно на глаз выделить участки, например, с гетероскедастичностью, или же участки котировок, на которых коэффициенты регрессии будут вести себя не стабильно.
Ниже перечислен ряд тестов (это не все существующие тесты стабильности), при прохождении которых можно быть уверенным, что при появлении в будущем в котировке условий теста торговая система будет показывать стабильный результат.
Например, изменение тренда с падающего на растущий или наоборот - это тест на точку излома. Если тест индикатора на точку излома не нашел таковую, то можно быть уверенным, что в будущем индикатор будет давать стабильный результат при любых изменениях тренда.
Тест точки излома Quandt-Andrews
Нулевая гипотеза: отсутствие точек излома между двумя наблюдениями, отстоящими от концов выборки на 15%.
Тест точки излома Quandt-Andrews проверяет на одну или более неизвестных структурных точек излома в выборке для указанного уравнения. Идея, на которой основан тест Quandt-Andrews, состоит в том, что отдельный тест точки излома Chow выполнен для каждого наблюдения между двумя датами, или наблюдениями t1 и t2. k тестовых статистик из тестов Chow затем суммируются в одну тестовую статистику для теста против нулевой гипотезы об отсутствии точек излома между t1 и t2.
Тест Ramsey RESET
Нулевая гипотеза: ошибка в уравнении регрессии является нормально распределенной величиной с нулевым средним.
Корреляция ряда, гетероскедастичность или ненормальный закон распределения для всех нарушают предположение, что шумы распределены нормально.
RESET - общий тест на следующие типы ошибок спецификации:
- Пропущенные переменные; Х не включает все соответствующие переменные;
- Неправильная функциональная форма: некоторые или все переменные в y и X должны быть преобразованы логарифмом, степенью, обратной величиной, или некоторым другим способом;
- Корреляция между Х и e, которая может быть вызвана, между прочим, ошибкой измерения Х, одновременно, или присутствием лагового значения и корреляцией в ряде шума.
При таких ошибках спецификации оценки МНК окажутся смещенными (системная ошибка не равна нулю) и не состоятельными (при увеличении числа наблюдений не сходится по вероятности к оцениваемой величине), и обычные процедуры вывода будут лишены законной силы.
Рекурсивные остатки
Тесты рекурсивных остатков основаны на многократных оценках регрессии с постепенным увеличением числа баров.
Тест прогноза на один шаг
Если посмотреть на определение рекурсивных остатков, данных выше, то можно увидеть, что каждый рекурсивный остаток – это ошибка прогноза на один шаг вперед. Чтобы проверить, может ли значение зависимой переменной за время t дойти из подогнанной модели по всем данным до той точки, то каждую ошибку следует сравнить с ее стандартным отклонением из полной выборки.
Рекурсивные оценки коэффициента
Этот вид позволяет проследить изменение оценок для любого коэффициента при увеличении количества данных в выборке, используемых при оценке. Рисунок показывает выбранные коэффициенты в уравнении для всех выполнимых рекурсивных оценок. На рисунках показывается два стандартных интервала вокруг оцененных коэффициентов.
Если коэффициент показывает значимое изменение при
добавлении данных к уравнению оценки, то это - верный признак неустойчивости.
Рисунки коэффициента могут иногда указывать драматические скачки, поскольку
постулированное уравнение пытается преодолеть структурный излом.
В техническом анализе довольно широко представлено направление так называемых "адаптивных" индикаторов, при этом не делается попытка ответить на вопрос о необходимости такой адаптации. Рекурсивные оценки коэффициентов дают ответ на такой вопрос.
2.
Подготовка исходных данных
Для анализа возьмем цены close дневных котировок EURUSD с 11 ноября 2010 года по 23 марта 2011 года. Котировки получены из терминала MT4 по F2 и экспортированы в Excel.
Линейный график котировок выглядит следующим образом:

Рисунок 5. График котировок EURUSD
Данный пример показывает, что в индикаторах необходим контроль на пропущенные данные. Не надо думать, что приведенные котировки являются частным случаем некачественных котировок. Пропуски данных могут возникнуть всегда по разным причинам. Кроме этого, приходится отвечать на вопрос по пропущенным данным в праздники в США. Особенно остро проблема пропущенных данных возникает при построении торговых систем на разных по экономической природе данных, например, на корреляции валютных котировок и фондовых индексов, которые не торгуются круглосуточно.
В нашем простом случае можно провести линейную интерполяцию и хоть как-то уменьшить влияние пропущенных данных на вычисления.
Кроме пропущенных данных существует проблема выбросов. Вопрос выбросов более сложен, чем пропущенных данных. Прежде, чем искать выбросы, следует для себя ответить на вопрос: что считать выбросом? Я считаю выбросом движение цены свыше трех стандартных отклонений, причем этот выброс не продолжился в виде сильного движения цены.
Выбросы будем определять не по котировкам, а по их остаткам: вычислим ряд путем вычитания предыдущего значения цены из последующей – eurusd(i) – eurusd(i+1) (в нотации MQL). В английской нотации для этой величины имеется несколько названий. На графике – это differenced (дифференцировано). Наиболее часто применяется слово returns. Далее по тексту я буду применять слово «остаток» - это величина, получаемая в результате удаления тренда в котировках. График остатков от EURUSD имеет следующий вид:
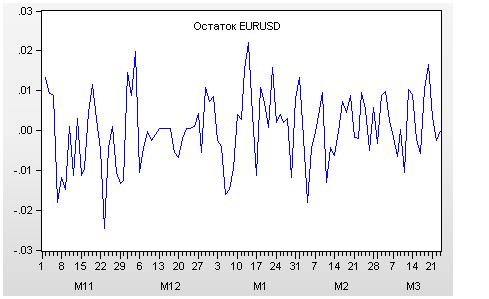
Рисунок 6. Остаток EURUSD
Стандартное отклонение для котировок EURUSD равно 0.033209. Следовательно, на основе сформулированных критериев выбросов в наших котировках выбросов не имеется.
В случае наличия выбросов их можно заменить, например, значениями для пропущенных данных, а затем интерполировать.
Приведенный способ удаления выбросов не является единственным, а самое главное, правильным. Если остаток – это то, что осталось от котировок в результате удаления тренда, то очевидно, что величина выбросов зависит от способа определения тренда, т.е. проблему выбросов необходимо решать после решения проблемы выделения тренда.
На этом будем считать законченной подготовку исходных данных для последующего анализа.3.
Анализ статистических характеристик
Целью анализа статистических характеристик котировок на рынке FOREX, и, в частности, котировок EURUSD, является проверка возможности использования индикаторов для анализа и построения торговых систем.
Типичная схема построения торговой системы выглядит следующим образом:
- Берется индикатор, например, скользящая средняя, и на его основе строится торговая система;
- Поскольку практически всегда невозможно построить торговую систему на одном индикаторе, то в торговую систему встраивают дополнительные индикаторы, которые призваны фильтровать ложные входы в рынок.
При этом обязательно произнесение мантры: "главное не переподогнать".
3.1. Описательные статистики
Из статистики известно, что если бы котировка, как случайная величина, подчинялась бы нормальному закону распределения, то значение ошибка вычисления средней менялась бы при изменении числа периодов и в бесконечности совпала бы с математическим ожиданием, которое для нормального закона является константой. Котировки можно было бы заменить прямой горизонтальной линии, стоп лоссы и тэйк профиты выставить на уровне стандартных отклонений. Но так не бывает. Посмотрим почему.
Проверим на соответствие закона распределения котировок нормальному закону распределения.
Построим гистограмму котировок EURUSD, которая имеет следующий вид:

Рисунок 7. Гистограмма котировок EURUSD
Гистограмма показывает, какое количество раз встретилась конкретная цена в выбранном нами интервале.
По внешнему виду распределение не является нормальным, очень портит
картину две вершины. Проведем тест на нормальность Жарка Бера с нулевой
гипотезой Н0: распределение является нормальным. Результат приведен ниже:
| Характеристика | Значение (факт) | Теоретическое значение |
|---|---|---|
| Средняя | 1.3549 | Средняя должна быть равна медиане |
| Медиана | 1.3580 | Медиана должна быть равна средней |
| Стандартное отклонение | 0.0332 | - |
| Ассиметрия (скос) | 0.0909 | 0.0 |
| Куртосиз | 2.1052 | 3.0 |
| Жарк-Бера | 3.5773 | 0.0 |
| Вероятность | 0.1671 | 1.0 |
Таблица 1. Результат теста на нормальность распределения
По критерию Жарка-Бера вывод о не соответствии нормальности не так категоричен, так как:
- Почти совпадает средняя и медиана
- Ассиметрия близка к нулю
- Куртосиз близок к трем
- Имеющиеся неточности хорошо отражает последняя строка «вероятность», которая говорит, что распределение является нормальным с вероятностью 16,7186%.
Можно по-разному относиться к этой цифре. С одной стороны, нельзя отвергнуть нулевую гипотезу (котировка распределена нормально) на общепринятом уровне значимости, например, 95%. С другой стороны, утверждать о нормальности распределения также не приходится при 16%.
Так как средняя практически совпадает с медианой (один из признаков нормальности распределения), то проверим, а можем ли мы доверять вычисленному значению средней. Проведем тест равенства средней путем разбивки котировок на участки.
Результат следующий:
| EURUSD | Кол-во | Среднее | С.К.О. | Ошибка средней |
|---|---|---|---|---|
| [1.25, 1.3) | 4 | 1.2951 | 0.0034 | 0.0017 |
| [1.3, 1.35) | 42 | 1.3262 | 0.0125 | 0.0019 |
| [1.35, 1.4) | 48 | 1.3740 | 0.0133 | 0.0019 |
| [1.4, 1.45) | 9 | 1.4131 | 0.0083 | 0.0027 |
| Все | 103 | 1.3549 | 0.0332 | 0.0032 |
Таблица 2. Сравнение средних на участках
Как показывает этот тест, средняя вычисляется с ошибкой с наиболее типичной величиной 19 пипсов и доходит до 32 пипсов.
Из выше изложенного следует вывод: пользоваться средней нельзя.
Очень подозрительной выглядит значение стандартного отклонения, равное 0.033209. Это 332 пипса! Вообще говоря, столь большая величина стандартного отклонения очевидна: котировка EURUSD имеет тренд, по идее, это регулярная детерминированная составляющая и она искажает любые статистические характеристики котировок.
3.2. Тестирование автокорреляции котировок
Основой понятия "случайности" является независимость значений случайной величины между собой. По внешнему виду котировок можно выделить участки направленного движения – трендов.
Детерминированность (наличие тренда) предполагает зависимость
соседних значений EURUSD,
что может быть проверено вычислением автокорреляции (АКФ), т.е. корреляции
между соседними величинами EURUSD.
Результаты ниже:

Рисунок 8. Автокорреляционная функция котировок EURUSD
Присоединенная вероятность к Q-статистике везде одинакова и равна нулю.
Из выполненных расчетов видно:
- Значение автокорреляционной функции плавно убывает, причем убывание имеет явный регулярный характер.
Вычисленная вероятность относится к тесту с нулевой гипотезой Но : нет корреляции до лага 16 (в нашем случае). Так как эта вероятность равна нулю для всех лагов, то мы строго отклоняем нулевую гипотезу об отсутствии автокорреляции (отсутствия тренда) в котировках.
3.3. Анализ стационарности котировок
Анализ стационарности котировок EURUSD проведем с помощью теста
Дикки-Фуллера в его трех вариантах: со смещением, с трендом, без смещения и без
тренда.
Результат теста состоит из двух частей: для EURUSD и для дифференцированных
котировок EURUSD, обозначим как D(EURUSD).
Нулевой гипотезой этого теста является: EURUSD не стационарен (имеет единичный корень). Вычисления проведем не только единичного корня, но и статистических характеристик результатов дифференцирования EURUSD, график которого представлен ниже:

Рисунок 9. Остаток котировок EURUSD
Визуально можно сделать вывод, что дифференцированные котировки EURUSD представляют собой случайные колебания примерно около нуля.
Итак, рассмотрим три варианта вычисления теста на стационарность котировок EURUSD.
1. Котировки без смещения (константы) и без тренда, для которой регрессия имеет вид:
D(EURUSD) = С(1) * EURUSD(1) + С(2) * D(EURUSD(1))
Вероятность принятия нулевой гипотезы (ряд не стационарен): 0.6961
| Переменная | Коэффициент | t-статистика | Вероятность равенства нулю |
|---|---|---|---|
| EURUSD(1) | 3.09E-05 | 0.0488 | 0.9611 |
| D(EURUSD(1)) | 0.2747 | 2.8759 | 0.0049 |
Таблица 3. Результаты теста на стационарность без учета смещения и тренда
Оценка подгонки регрессии к D(EURUSD) по R-квадрат: 0.07702.
Из приведенных данных можно сделать следующие выводы:
- С большой вероятностью (69%) котировки EURUSD следует признать не стационарными - мы строго не отклоняем нулевую гипотезу;
- Приращение D(EURUSD) с вероятностью 99.5% не зависит от предыдущего значения цены EURUSD;
- Приращение D(EURUSD) полностью зависит от предыдущего приращения D(EURUSD(1));
- Значение коэффициента детерминации Rквадрат = 0.077028 говорит о полном не соответствии регрессии дифференцированным котировкам D(EURUSD).
2. Котировка EURUSD со смещением (константой), для которой регрессия имеет вид:
| Переменная | Коэффициент | t-статистика | Вероятность равенства нулю |
|---|---|---|---|
| EURUSD(1) | -0.0445 | -1.6787 | 0.0964 |
| D(EURUSD(1)) | 0.3049 | 3.1647 | 0.0021 |
| С | 0.0603 | 1.6803 | 0.0961 |
Таблица 4. Результаты теста на стационарность с учетом смещения
Вероятность принятия нулевой гипотезы (ряд не стационарен): 0.4389
Оценка подгонки регрессии к D(EURUSD) по R-квадрат: 0.1028
Из приведенных данных можно сделать следующие выводы:
- С достаточно большой вероятностью (43%) котировки EURUSD следует признать не стационарными - мы строго не отклоняем нулевую гипотезу;
- Следует остерегаться включать в уравнение регрессии для приращения D(EURUSD) предыдущее значение цены EURUSD и константу (смещение), так как для 5% уровня значимости мы признаем эти коэффициенты равными нулю;
- Приращение D(EURUSD) полностью зависит от предыдущего приращения D(EURUSD(1));
- Значение коэффициента детерминации R-квадрат = 0.102876 говорит о полном не соответствии регрессии дифференцированным котировкам D(EURUSD).
3. Котировка EURUSD со смещением (константой) и трендом, для которой регрессия имеет вид:
D(EURUSD) = С(1) * EURUSD(1) + С(2) * D(EURUSD(1)) + С(3) + С(4) * TREND
Вероятность принятия нулевой гипотезы (ряд не стационарен): 0.2541
| Переменная | Коэффициент | t-статистика | Вероятность равенства нулю |
|---|---|---|---|
| EURUSD(-1) | -0.0743 | -2.6631 | 0.0091 |
| D(EURUSD(-1)) | 0.2717 | 2.8867 | 0.0048 |
| C | 0.0963 | 2.5891 | 0.0111 |
| TREND(11/01/2010) | 8.52E-05 | 2.7266 | 0.0076 |
Таблица 5. Результаты теста на стационарность с учетом смещения и тренда
Оценка подгонки регрессии к D(EURUSD) по R-квадрат: 0.1667
Из приведенных данных можно сделать следующие выводы:
- С достаточно большой вероятностью (25%) котировки EURUSD следует признать не стационарными - мы строго не отклоняем нулевую гипотезу;
- Хотя вероятность равенства нулю коэффициента при тренде менее 1%, но значение этого коэффициента крайне мало, т.е. тренд представляет собой горизонтальную линию;
- Значение коэффициента детерминации R-квадрат = 0.166742 говорит о полном не соответствии регрессии дифференцированным котировкам D(EURUSD).
Из приведенных расчетов можно сделать итоговый вывод: если
исходные котировки EURUSD
не являются стационарными, то их первая разность, полученная путем вычитания из
каждой последующего значения цены предыдущей, вероятно, является стационарной.
При этом из котировок был удален тренд и смещение, которые можно описать уравнением:
eurusd = c(1) * trend + c(2),
где с(1) и с(2) некоторые константы, которые можно оценить методом наименьших квадратов.
Приведенная формула является обычным уравнением регрессии и полностью совпадает с инструментом "регрессия" в терминале МТ4. То есть, исходную котировку мы заменили прямой – это широко используемый прием в техническом анализе, так как можно вспомнить широко используемый набор инструментов, представляющий собой прямые линии: каналы, уровни поддержки-сопротивления, уровни Фиббоначи, Ганна и т.д.
Прямые линии – это самый первый инструмент, используемый любым трейдером. А на каком основании мы доверяем этому инструменту и насколько можно доверять прямым линиям? Далее в статье ответим на этот вопрос.
Кроме прямых линий в техническом анализе используют индикаторы, которые заменяют исходные котировки некоторыми кривыми. Поступим аналогично и для анализа возьмем два известных индикатора: экспоненциальная скользящая средняя и фильтр Ходрика-Прескотта.
4.
Детрендирование котировок
Использование термина «детрендирование» призвано подчеркнуть связь данного раздела с соответствующим понятием эконометрики. Более точно и в соответствии с ранее декларированной моделью финансового рынка следует говорить об удалении - детрендировании, из котировок регулярной составляющей.
В нашем случае мы выделили три регулярных составляющих: линейный тренд, экспоненциальная скользящая средняя и фильтр Ходрика-Прескотта.
Все регулярные составляющие зададим в виде временных рядов.
4.1. Линейный тренд
Линейный тренд зададим путем добавления единицы к предыдущему значению.
Проведем оценку коэффициентов линейной регрессии:
eurusd = c(1) * trend + c(2),
Получаем совмещенный график исходной котировки eurusd, прямой линии регрессии, сдвинутой по вертикали на константу и остаток, полученный путем вычитания линии регрессии из котировки:

Рисунок 10. График котировок EURUSD, линейная регрессия и остаток
Оцениваем методом наименьших квадратов следующее уравнение:
EURUSD = С(1)*TREND + С(2)
Процесс оценки уравнения регрессии сопровождается следующими сведениями:
| Переменная | Коэффициент | t-статистика | Вероятность равенства нулю |
|---|---|---|---|
| TREND | 0.0004 | 4.4758 | 0.0000 |
| C | 1.3318 | 223.3028 | 0.0000 |
Таблица 6. Результаты теста на стационарность линейного тренда
Оценка подгонки регрессии к котировке R-квадрат = 0.1655
Из результата можно сделать следующие выводы:
- В соответствии с коэффициентом детерминации R-квадрат прямая линия только в 16% случаев объясняет изменения в котировках;
- Остаток от вычитания линейного тренда из котировки мало чем отличается от самой котировки и, по-видимому, будет иметь те же статистические недостатки, как и сама котировка.
4.2. Экспоненциальное сглаживание
Для экспоненциального сглаживания будем использовать алгоритм Холта-Винтерса (Holt-Winters) без сезонной составляющей с параметрами сглаживания для котировки (уровня) и тренда.
Основная идея метода:
- Убрать тренд из временного ряда путем разделения уровня от тренда;
- Сгладить уровень (параметр a);
- Сгладить прогноз тренда (параметр b).
Полученный результат представлен на рисунке.

Рисунок 11. Экспоненциальная скользящая средняя
Получили обычную экспоненциальную скользящую среднюю, немного запаздывающую, но вполне хорошо отражающую котировку. Параметры сглаживания указаны вверху, подбор параметров не осуществлялся.
В оцениваем методом наименьших квадратов следующее уравнение:EURUSD = С(1)*EURUSD_EX +С(2)
Процесс оценки уравнения регрессии сопровождается следующими сведениями:
| Переменная | Коэффициент | t-статистика | Вероятность равенства нулю |
|---|---|---|---|
| EURUSD_EX | 0.9168 | 24.3688 | 0.0000 |
| C | 0.1145 | 2.2504 | 0.0266 |
Таблица 7. Результаты оценки линейной регрессии
Оценка подгонки регрессии к котировке R-квадрат = 0.8546
Из результата можно сделать следующие выводы:
- В соответствии с коэффициентом детерминации R-квадрат экспоненциальная скользящая средняя в 84% случаев объясняет изменения в котировках;
- Остаток от вычитания экспоненциальной средней из котировки по внешнему виду похож на случайный процесс с нормальным распределением. Будем считать, что имеется смысл дальнейшего анализа этого остатка.
4.3. Фильтр Ходрика-Прескотта
Фильтр Ходрика-Прескотта имеет параметр лямбда.
Не будем заниматься подбором этого параметра и примем его равным 8162.
Результат показан ниже:

Рисунок 12. Фильтр Ходрика-Прескотта
В оцениваем методом наименьших квадратов следующее уравнение:
EURUSD = С(1)*EURUSD_HP + С(2)
Процесс оценки уравнения регрессии сопровождается следующими сведениями:
| Переменная | Коэффициент | t-статистика | Вероятность равенства нулю |
|---|---|---|---|
| EURUSD_HP | 1.0577 | 23.9443 | 0.0000 |
| C | -0.0782 | -1.3070 | 0.1942 |
Таблица 8. Результаты оценки подгонки регрессии к котировкам
Оценка подгонки регрессии к котировке R-квадрат = 0.8502
Из результата можно сделать следующие выводы:
- Вероятность равенства нулю второго коэффициента (константы) равна 19%, что ставит под сомнение использование константы в уравнении регрессии;
- В соответствии с коэффициентом детерминации R-квадрат фильтр Ходрика-Прескотта в 85% случаев объясняет изменения в котировках;
- Остаток от вычитания фильтра Ходрика-Прескотта из котировки по внешнему виду похож на случайный процесс с нормальным распределением, и имеет смысл его дальнейший анализ.
5.
Диагностика коэффициентов
Диагностика коэффициентов включает следующие тесты:
- Доверительный эллипс – определяет корреляцию между коэффициентами уравнения регрессии: чем ближе эллипс к окружности, тем меньше корреляция;
- Доверительный интервал – определяет границы изменения коэффициентов уравнения. В техническом анализе коэффициенты являются константами, которые обычно можно менять с помощью параметра «период» или каким-либо другим способом. Но в любом случае коэффициенты не рассматриваются как случайные величины. Проверим, так ли это;
- Тест пропущенных переменных – рассматривается нулевая гипотеза: дополнительная независимая переменная не значима.
- Тест избыточных переменных - нулевая гипотеза: коэффициент дополнительной переменной равен нулю;
- Тест излома (breakpoints) – определяет наличие точек изменения статистических характеристик котировок. Проверим в качестве таких точек точки изменения трендов в понимании технического анализа. В исследуемой нами котировке EURUSD, как минимум, может быть выделено два тренда – падающий, а затем (с возможностью выделения боковика пренебрежем) растущий тренд.
5.1. Доверительный эллипс
Построим доверительные эллипсы для каждого из уравнений регрессии:

Рисунок 13. Доверительный эллипс для уравнения регрессии 1

Рисунок 14. Доверительный эллипс для уравнения регрессии 2

Рисунок 15. Доверительный эллипс для уравнения регрессии 3
Из приведенных рисунков можно сделать следующие выводы:
- Корреляция коэффициентов для регрессии линейного тренда имеется и на глаз ее можно оценить примерно в 0.5;
- Корреляция для регрессий с экспоненциальной средней и фильтром Ходрика-Прескотта практически равна единице, что требует исключения константы из уравнений регрессии. В пользу исключения константы из уравнения регрессии с фильтром Ходрика-Прескотта говорит значимая вероятность равенства нулю этой константы.
5.2. Доверительный интервал
Проверим предположение, что константы в уравнениях регрессии являются
случайными величинами.
Для этого построим доверительные интервалы:
| Переменная | Коэффициент | Доверительный интервал 90% | Доверительный интервал 95% | ||||
|---|---|---|---|---|---|---|---|
| Нижняя граница |
Верхняя граница |
% интервала |
Нижняя граница |
Верхняя граница | % интервала |
||
| TREND | 0.0004 | 0.0002 | 0.0006 | 74.3362 | 0.0002 | 0.0006 | 88.7168 |
| C | 1.3318 | 1.3219 | 1.3417 | 1.4868 | 1.3200 | 1.3436 | 1.7767 |
| EURUSD_EX | 0.9168 | 0.8543 | 0.9793 | 13.6247 | 0.8422 | 0.9914 | 16.2810 |
| C | 0.1145 | 0.0300 | 0.1991 | 147.5336 | 0.0135 | 0.2155 | 176.2960 |
| EURUSD_HP | 1.0577 | 0.9844 | 1.1310 | 13.8661 | 0.9701 | 1.1453 | 16.5694 |
| C | -0,0782 | -0.1776 | 0.0211 | 254.0276 | -0.1970 | 0.0405 | 303.5529 |
Таблица 9. Доверительные интервалы коэффициентов регрессии
Из представленных доверительных интервалов видно, что коэффициент является случайной величиной, которая ведет себя в соответствии со своим статусом – при увеличении доверия (уменьшения ширины коридора) ширина интервала растет.
Большой интерес представляет колонка «% интервала», которая представляет собой отношение в процентах ширины интервала значения коэффициента к значению коэффициента. Мы видим, что эта величина для констант регрессий с экспоненциальной средней и с фильтром принимает совершенно неприемлемые величины свыше 100%! Вспомним, что коэффициенты корреляции между двумя коэффициентами этих уравнений практически равны единице.
Удалим константу из уравнений и произведем повторную оценку коэффициентов регрессий.
Получаем следующий результат:
| Переменная | Коэффициент | Доверительный интервал 90% | Доверительный интервал 95% | ||||
|---|---|---|---|---|---|---|---|
| Нижняя граница |
Верхняя граница |
% интервала |
Нижняя граница |
Верхняя граница | % интервала |
||
| EURUSD_EX | 1.0014 | 0.9999 | 1.0030 | 0.3131 | 0.9996 | 1.0033 | 0.3742 |
| EURUSD_HP | 1.0000 | 0.9984 | 1.0015 | 0.3127 | 0.9981 | 1.0018 | 0.3737 |
Таблица 10. Доверительные интервалы пересчитанных коэффициентов регрессии
Приводить новые расчеты для регрессий с экспоненциальной
средней и фильтром я не буду с целью экономии места.
Отмечу, что в дальнейшем будут использоваться следующие уравнения регрессии:
EURUSD = 1.00149684612*EURUSD_EX
EURUSD = 1.00002609628*EURUSD_HP
5.3. Пропущенные и избыточные переменные (индикаторы)
Типовой алгоритм разработки торговой системы состоит в следующем. Берется какой-либо индикатор и тестируется торговая система на этом индикаторе. Затем добавляется дополнительный индикатор, который отфильтрует ложные срабатывания торговой системы и т.д.
В описанном алгоритме не ясно, когда надо остановиться? Нужно ли добавить дополнительные индикаторы или же надо исключать уже включенные в торговую систему? На эти вопросы в рамках существующей теории построения торговых систем нет ответа, но ответ имеется в рамках теста на пропущенные и избыточные переменные (индикаторы).
Тест пропущенных переменных - рассматривается нулевая гипотеза: дополнительная независимая переменная не значима.
Из имеющихся у нас трех индикаторов составим комплексный индикатор, включающий все три:
EURUSD = C(1)*TREND + C(2) + C(3)*EURUSD_EX + C(4)*EURUSD_HP
Оценивая коэффициенты этого интегрального индикаторы (регрессии), получаем:
EURUSD = 1.41879198369e-05*TREND - 0.00319950161771 + 0.50111527265*EURUSD_EX + 0.501486719095*EURUSD_HP
При этом вероятность того, что соответствующие коэффициенты равны нулю, представлены следующей таблицей:
| Переменная | Коэффициент | Вероятность равенства нулю |
|---|---|---|
| TREND | 1.42E-05 | 0.7577 |
| C | -0.0032 | 0.9608 |
| EURUSD_EX | 0.5011 | 0.0000 |
| EURUSD_HP | 0.5014 | 0.0004 |
Таблица 11. Оценка вероятности равенства нулю коэффициентов индикатора
Из таблицы следует, что мы зря включили индикатор TREND и константу, так как можно с уверенностью утверждать, что коэффициенты при них равны нулю.
Добавим к нашему интегральному индикатору еще один: квадрат экспоненциальной средней eurusd_ex^2, и проведем тест пропущенной переменной (eurusd_ex^2) с нулевой гипотезой: дополнительная переменная eurusd_ex^2 не значима.
В соответствии с вычисленной t-статистикой и F-статистикой вероятность того, что дополнительная переменная (eurusd_ex^2) не значима, равна 44.87%. На этом основании можно утверждать, что дополнительные индикаторы в нашей торговой системе не нужны.
Но еще более интересной является оценка совокупного индикатора с дополнением eurusd_ex^2, которая приведена в таблице:
| Переменная | Коэффициент | Вероятность равенства нулю |
|---|---|---|
| TREND | 1.69E-05 | 0.7154 |
| C | 1.9682 | 0.4496 |
| EURUSD_EX | -2.3705 | 0.5317 |
| EURUSD_HP | 0.4641 | 0.0020 |
| EURUSD_EX^2 | 1.0724 | 0.4487 |
Таблица 12. Оценка вероятности равенства нулю коэффициентов совокупного индикатора с дополнением eurusd_ex^2
Из таблицы следует, что интерес представляется только индикатор на основе фильтра Ходрика-Прескотта.
Тест избыточных переменных - нулевая гипотеза: коэффициент дополнительной переменной равен нулю.
Зайдем с другой стороны для чего проведем тест избыточных переменных с нулевой гипотезой: коэффициент избыточной переменной равен нулю. В качестве избыточных переменных в нашем комплексном индикаторе укажем trend c.
В соответствии с вычисленной t-статистикой и F-статистикой вероятность того, что коэффициенты избыточных переменных trend и с равны нулю, равна 92.95%. На этом основании можно утверждать, что в нашей торговой системе имеются избыточные переменные trend и с, что хорошо согласовывается с предыдущими результатами.
Оценка совокупного индикатора, состоящего из экспоненциальной средней и фильтра Ходрика-Прескотта имеет следующий вид:
| Переменная | Коэффициент | Вероятность равенства нулю |
|---|---|---|
| EURUSD_EX | 0.4992 | 0.00 |
| EURUSD_HP | 0.5015 | 0.00 |
Таблица 13. Оценка вероятности равенства нулю коэффициентов совокупного индикатора из экспоненциальной средней и фильтра Ходрика-Прескотта
т.е. мы строго отклоняем сомнения в полезности использования этих индикаторов в торговой системе.
6.
Диагностика остатков
6.1. Автокорреляция - Q - статистика

Рисунок 16. Автокорреляционная функция после вычитания линейного тренда
Из коррелограммы следует, что вычитание линейного тренда из исходной котировки не исключило наличие тренда, о чем говорит АКФ. Вероятность того, что отсутствует корреляция, равна нулю, т.е. мы строго отвергаем нулевую гипотезу на всех уровнях значимости.
Рисунок 17. Автокорреляционная функция после вычитания экспоненциального сглаживания
Из коррелограммы следует, что вычитание экспоненциальной
кривой из исходной котировки исключило тренд на всех свечах свыше второй, о чем
говорит АКФ.
По расчетам вероятность того, что отсутствует корреляция, равна
нулю, т.е. мы строго отвергаем нулевую гипотезу на всех уровнях значимости.
Однако, если некоторыми дополнительными усилиями исключить корреляцию на первых двух свечах, то можно будет получить остаток без корреляций.

Рисунок 18. Автокорреляционная функция после вычитания фильтра Ходрика-Прескотта
Из коррелограммы следует, что вычитание фильтра Ходрика-Прескотта из исходной котировки исключило тренд на всех свечах свыше третьей, о чем говорит АКФ. Вероятность того, что отсутствует корреляция, равна нулю, т.е. мы строго отвергаем нулевую гипотезу на всех уровнях значимости. Однако, если некоторыми дополнительными усилиями исключить корреляцию на первых двух свечах, то можно будет получить остаток без корреляций.
Вывод. Попытка удалить детерминированную составляющую путем вычитания наших индикаторов из исходной котировки EURUSD полностью провалилась для линейного тренда и удалась частично для экспоненциальной скользящей средней и фильтра Ходрик-Прескотта.
Из-за автокорреляции (детерминированной составляющей) в остатках дальнейшее изучение наших индикаторов становится бессмысленным. Необходимо найти такой индикатор, который позволит исключить автокорреляцию в остатках. Сделаем это в следующем разделе.
7. Конструирование и анализ индикатора с учетом анализа
В настоящее время отсутствует формальная теория для создания набора индикаторов. Единственный способ - это прямой перебор с выбором некоторого набора по результатам анализа.
Из предыдущего анализа по автокорреляции был сделан вывод, что после детрендирования осталась автокорреляция на первых свечах котировок.
С учетом этого проанализируем следующее уравнение регрессии:
EURUSD = C(1)*EURUSD_HP(1) + C(2)*D(EURUSD_HP(1)) + C(3)*D(EURUSD_HP(2))
D(EURUSD_HP(1)) - означает остаток между котировкой и сглаживанием фильтром Ходрика-Прескотта, первый лаг (второй бар, а не первый, считая бары с единицы).
Оценка коэффициентов этого уравнения методом наименьших квадратов приводит к следующим результатам:
| Переменная | Коэффициент | Вероятность равенства нулю |
|---|---|---|
| EURUSD_HP(1) | 1.0001 | 0.0000 |
| D(EURUSD(1)) | 0.8262 | 0.0000 |
| D(EURUSD(-2)) | -0.4881 | 0.0000 |
Таблица 14. Результаты оценки коэффицентов методом МНК
По тесту избыточных переменных в соответствии с вычисленной по t-статистикой и F-статистикой вероятность того что коэффициенты при переменных eurusd(1) eurusd(2) равны нулю, равна нулю, т.е. эти две переменные не являются избыточными.
Автокорреляция показывает отсутствие зависимостей до лага 16 с вероятностью свыше 70% (первая строка подписи):

Рисунок 19. Автокорреляция остатка
Тест на гетероскедастичность White дает результат по F-статистике, что с вероятностью 80% гетероскедастичность отсутствует.
Исследование на точки излома по тесту Quandt-Andrews с нулевой гипотезой: «точки излома отсутствуют» дает результат: нулевая гипотеза с вероятностью 71% принимается (точки излома отсутствуют).
Еще раз хотелось бы подчеркнуть, что с точки зрения классического технического анализа, рассматриваемые котировки имеют, по крайней мере, одну точку излома (один разворот тренда). Однако наш индикатор имеет одинаковые статистические характеристики как для падающего тренда, и для растущего и поэтому инвариантен к характеру рынка.
Интегральный тест Ramsey с нулевой гипотезой: «ошибки в уравнении регрессии является нормально распределенной величиной» с вероятностью 48% по t-статистике и F-статистике принимается. На этом основании можно пренебречь автокорреляцией остатка и его гетероскедастичностью.
Также это означает, оценки линейных квадратов не являются смещенными (математическое ожидание оцениваемой величины совпадает с оцениваемой величиной) и можно провести тесты рекурсивных остатков.
Сделаем тест прогноза рекурсивных остатков на один шаг вперед. Верхняя часть рисунка приводит рекурсивные остатки и ограничительные линии в два стандартных отклонения. Кроме этого (левая ось) показано значение вероятности для тех свечей котировок, где гипотеза постоянства коэффициента индикатора была бы отклонена на 5%, 10% и 15% уровне значимости. Этих точек не много, но их существование фактически означает ложное срабатывание стоп лоссов и тэйк профитов.

Рисунок 20. Тест прогноза рекуривных остатков
Приведем рекурсивные оценки коэффициентов уравнения регрессии. График формируется следующим образом: вычисляются значения коэффициентов для крайне левого бара. Затем добавляется один бар и снова вычисляются значения коэффициентов и т.д. до самого последнего бара. Естественно, что на малом количестве баров слева, значения коэффициентов крайне не устойчивы. Однако с увеличением количества баров, на которых ведется расчет, устойчивость (неизменность) возрастает.
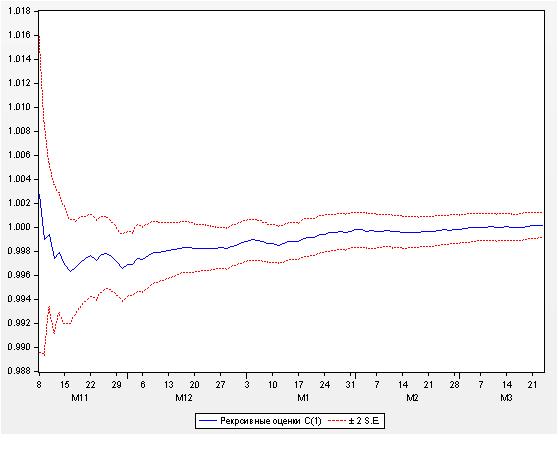
Рисунок 21. Рекурсивные оценки коэффициента С(1)
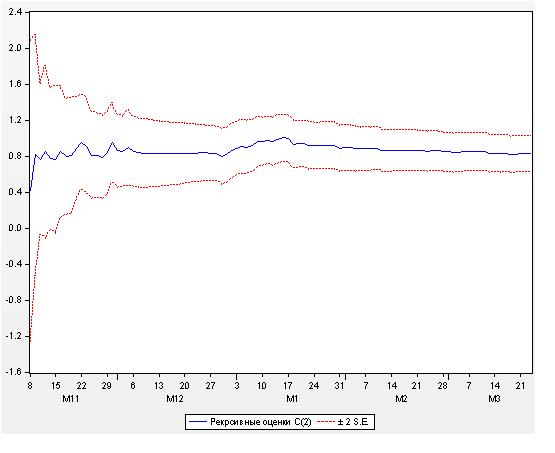
Рисунок 22. Рекурсивные оценки коэффициента С(2)
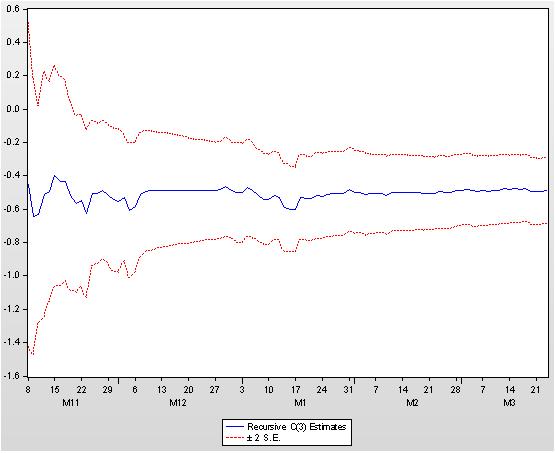
Рисунок 23. Рекурсивные оценки коэффициента С(3)
Из приведенных рисунков следует, что определенная
неустойчивость была в начале интервала котировок, но затем можно считать, что значения коэффициентов
приняли устойчивый характер. Тем не менее, строго говоря, коэффициенты нашего уравнения регрессии не являются константами.
Заключение
В данной статье было получено очередное доказательство, что финансовые данные не являются стационарными. В статье использовался стандартный прием разложения нестационарных данных на сумму данных с целью получения стационарного остатка.
Имея стационарный остаток исходных котировок можно получить ответ на главный вопрос о стабильности полученного индикатора.
Приведенные в статье сведения представляют собой лишь начало построения торговой системы, которая может и должна быть построена на основе прогноза котировок.
Литература
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Интервью с Матушем Германом (ATC 2011)
Интервью с Матушем Германом (ATC 2011)
 Синтетические бары – новое слово в отображении ценовой графической информации
Синтетические бары – новое слово в отображении ценовой графической информации
 Интервью с Антонио Морилласом (ATC 2011)
Интервью с Антонио Морилласом (ATC 2011)
 Прогнозирование временных рядов при помощи экспоненциального сглаживания
Прогнозирование временных рядов при помощи экспоненциального сглаживания
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Вышла новая статья Статистические параметры для анализа метрик:
Вышла новая статья Статистические параметры для анализа метрик:
Автор: alex Я не могу читать
Форум о трейдинге, автоматизированных торговых системах и тестировании торговых стратегий
Обзор прессы
newdigital, 2014.02.13 15:46
3 вида анализа Форекс (по материалам статьи на dailyfx)
Фундаментальный
Фундаментальный анализ Форекс в основном сосредоточен вокруг процентной ставки валюты. Также учитываются и другие фундаментальные факторы, такие как валовой внутренний продукт, инфляция, производственная активность, экономический рост. Однако то, хороши или плохи эти другие фундаментальные релизы, имеет меньшее значение, чем то, как эти релизы влияют на процентную ставку в данной стране.
Изучая фундаментальные данные, не забывайте о том, как они могут повлиять на будущую динамику процентных ставок. Когда инвесторы стремятся к риску, деньги следуют за доходностью, и повышение ставок может означать увеличение инвестиций. Когда инвесторы настроены негативно по отношению к риску, деньги уходят от доходности к валютам-убежищам.
Технический
Технический анализ Форекс включает в себя изучение моделей в истории цен, чтобы определить время и место входа и выхода из сделки с большей вероятностью. В результате технический анализ Форекс является одним из наиболее широко используемых видов анализа.
Поскольку валютный рынок является одним из крупнейших и наиболее ликвидных, движения на графике ценового действия обычно дают подсказки о скрытых уровнях спроса и предложения. Другие модели поведения, например, какие валюты имеют наиболее сильный тренд, могут быть получены путем анализа ценового графика.
Другие технические исследования можно проводить с помощью индикаторов. Многие трейдеры предпочитают использовать индикаторы, потому что сигналы легко читаются, и это делает торговлю на Форекс простой.
Сентимент
Сентимент на Форекс - еще одна широко распространенная форма анализа. Когда вы видите, что настроения в подавляющем большинстве случаев направлены в одну сторону, это означает, что подавляющее большинство трейдеров уже заняли эту позицию.
Поскольку мы знаем, что существует большой пул трейдеров, которые уже покупают, то эти покупатели становятся будущими продавцами. Мы знаем это, потому что в конечном итоге они захотят закрыть сделку. Это делает курс евро к доллару уязвимым для резкого отката, если эти покупатели развернутся и начнут продавать, чтобы закрыть сделку.
Фильтр Ходрика-Прескотта
Фильтр Ходрика-Прескотта используется в макроэкономике, особенно в теории реального делового цикла, для выделения циклической составляющей временного ряда из исходных данных. Он имеет нулевой лаг. Есть общий недостаток таких фильтров с нулевым лагом - последние значения пересчитываются.
Больше информации об одностороннем фильтре HP вы можете найти здесь : статистика - фильтр Ходрика-Прескотта (односторонняя версия) - Mathematica Stack Exchange или здесь time series - Формула для одностороннего фильтра Ходрика-Прескотта - Cross Validated и в pdf файле, прикрепленном к этому сообщению.
Темы форума (спасибо mladen)
- goertzel_browser_5.2.1 indicator - пост,
- goertzel_browser_5.3 индикатор - пост
- goertzel_browser_5.4 индикатор - пост
- goertzel_browser_5.4_nrp индикатор - пост
- goertzel_browser_5.5 индикатор - пост (отдельный индикатор)
- goertzel_browser_5.51 индикатор - пост
- goertzel_browser_5.52 индикатор - пост
- goertzel_browser_5.53 индикатор - пост
- goertzel_browser_5.1_cs_detrendampsmooth_1 индикатор - пост
Статьи
CodeBase
============