
インディケータの統計パラメータ分析

はじめに
トレーダーは基本クオートを「より明確に」示し、トレーダーがマーケット価格動向を分析し推定することのできるインディケータを幅広く使用します。変換の有効性および取得した結果の信頼性に関わる問題は考慮されず 、よくてインディケータを基にトレーディングシステムを検証することに置き換えられる程度です。
私にとってはインディケータを使用することに意味はなく、言うまでもなく最初のクオート変換と取得した結果の信頼性に関する問題を解決できないかぎり、インディケータを特定のトレーディングシステム作成に適用することにも意味がありません。本稿ではそのような結論について確たる理由があることを示していきます。ここでは3つのインディケータを使用して潜在的問題を考察します。それらは、トレンド直線、指数移動平均、ホドリック・プレスコット フィルターです。
1. セオリー断片
読者のみなさんに解りやすいようにのちに使用する確率論と数学統計の用語について少しお話します。リンクは提供しません。というのもここで使われている用語はテキストにあるものと完全に同じだからです。
1.1. 経済観測の確率的記述
われわれが観測するクオートは、基本レベルで以下を含むなんらかの確率過程の間接的な選択的測定(一般集団は未知です)です。
- 正確に測定される決定論的要素。たとえば売買取り引きの実行通貨
- たとえば1日などの時間区間で売られる通貨量など、エラーが観測される決定論的要素
- 確率論的要素。これは計測されないもので、集団のムードです。たいていの場合、この要素の主要な特性はドリフトを伴うランダムな変動です。
こういった要素の相互作用により以下を含む確率過程が導かれます。
- トレンド(決定論的および確率論的)
- 固定および確率論的期間サイクル
- ドリフトを伴うランダムな変動
非定常性は確率過程の一般的特性で、それは通貨クオートに反映されます。非定常確率過程プロセスのコンセプトは重要です。なぜならそれはそれを分析する手段をほとんどもたらさず、よって分析可能な個別処理セットとに分けられる必要があります。インディケータを適用するとき、トレーダーは特定のシンボルのクオートにそのインディケータを適用することは考えません。ただし、インディケータ適用可能性とそこから得られる結果を判定することのできる計量経済学的ツールがあります。
1.2. ランダム事象確率
ランダム事象(この場合は通貨の売買)は起こるかもしれないし起こらないかもしれない出来事を言います。異なる日で一日のうち異なる時刻におけるディール数が異なりその数がランダム値であり、通常時間の離散点(分、時間、日など)におけるイベントだけが考慮されることはわかっています。
ランダム事象の相対頻度は行われる観測の一般数 N に対するそのような事象 M の発生数の割合です。観測数(理論的には無限大まで)が増えるに従い、頻度はランダム事象確率と呼ばれる数値になる傾向にあります。定義によると、確率はゼロから1までの値です。本稿では『確率』という語は通常、相対頻度の代わりに使用します。
乱数値は一定の確率で異なる値を取る量です。
一般集合はランダム集合が取りうるあらゆる可能な値を表します。マーケットでは通常、ある期間に対するクオートを用いて一般集合サンプルを扱います。サンプルを用いて取得される統計が一般集合で計算される統計と異なるのはあたりまえです。相対頻度は確率とは異なるからです。のちにサンプルを用いて取得される統計と一般集合で計算される統計の差を判定するための計算を行います。インディケータの場合、そのような方法は使えません。それはたとえば終値が計算中インディケータによって決定論的値とみなされるためです。
別のおもしろい観測一般集合を観測しようとしているので、異なるディールセンターによって提出されるクオートの差は無視することができます。クオート値を変更することは簡単ですが、その統計的プロパティを変更するのは難しいからです。
1.3. ランダム変数の特性
1.3.1. 記述統計
ランダム数量の集合(ここでは通貨クオート)はパラメータ数によって特色づけられます。その中にはのちに使うパラメータもあります。
ヒストグラムは乱数頻度を示すグラフです。その極端なケースでは、確率分布の密度を示しているのがグラフです。
算術平均値 (average)は観測数で割った観測値の合計です。(われわれの場合は期間数です。)それはすべての分布に適用可能とは限りません。また中央値を考慮するとき正規分布に対して最もよく利用されるとは限りません。厳密に言えば、もっともよく利用される移動平均インディケータは、クオートに分布法則があり、それに対して平均値が存在する場合に適用可能だということです。
中央値 はサンプル内のすべての観測を二分します。最初のケースではすべての観測は中央値を下回り、二番目のケースでは観測地は中央値を超えます。中央値はあらゆる分布に存在し、異常値に対して敏感です。平均値が中央値に等しければ(または近ければ)、それは正規分布法則特性だと言えます。
平均値からの分散はおもしろいテーマです。分散 は数学的期待値からの乱数偏向の二乗の平均値です。分散の平方根は平均二乗 (一般)偏差です。
標準偏差と分散は異常値に対してレジスタントではありません。
非対称比率(歪度)と呼ばれる無次元量は、分布密度曲線の非対称度のインディケータとしての機能を果たします。歪度値が«6÷観測数»より小さければ、乱数確率分布は正規法則に依存します。
分布密度を特徴づける別の値は尖度です。それは通常の条件では3です。尖度が3より大きければ、てっぺんが鋭く、『重い』尾部が小さい角度で落ちています。
ここに見るように、正規分布法則のランダム変数には多数のコンセプトが適用できます。それはそう悪いことではありません。なぜなら多数の分布法則は観測数が増えると標準的なもの一つまで減るからです。
1.3.2. 正規分布
正規(ガウス)分布は実際の確率分布のほとんどすべてにおいて極端なケースです。
リアプノフの極限定理は、あらゆる初期分布を持つ個別の乱数の合計分布は多数の観測がありその貢献が小さい場合、標準であることを述べる理論的基礎の役割をします。よってそれは、確率論の現実のアプリケーションで広く利用されています。
正規分布は左右対称な釣鐘型の曲線で、数値軸全体に伸びています。ガウス分布は2つのパラメータに依存します。それは μ (数学的期待値)および σ (標準偏差)です。
数学的期待値と既定の分布の中央値は μ に等しく、一方分散は, σ2に等しくなっています。確率密度曲線は数学的期待値について対称です。非対称比率と過剰値は γ = 0、 ε = 3です。
正規分布密度はしばしば x 変数関数ではなく数学的期待値ゼロ、分散値1を取る z = (x − μ) / σ 変数関数として記載されます。
μ = 0 および σ = 1 を取る分布は標準正規分布 (i.i.i)と呼ばれます。

図1 正規分布
1.3.3. ストゥーデントの分布(t 分布)
主なパラメータは自由度です(サンプル内のエレメント数)。自由度の数値が増えるに従い、ストゥーデント分布は標準化された正規分布に近づき、n > 30のときストゥーデント分布は正規分布と置き換え可能です。n < 30の場合、ストゥーデント分布の尾部はより重くなります。

図2 ストゥーデント分布
t 統計は統計的仮説を検証するために広く利用されます。
1.3.4. カイ二乗(ピアソン)分布
Хi が i.i.i を持つ独立な乱数であれば、その二乗の合計は χ2分布に依存します。密度は、自立ランダム変数の数値に等しいシングルパラメータ ν (通常自由度数と呼ばれます) に依存します。自由度数 ν →∞ であれば、χ2分布は中央値 v と分散値 2νを持つ正規分布と言えます。分布密度は非対称、単一モードで、それはまた自由度の増加に伴いより平坦で対象になります。
")
図3 ピアソン分布(カイ二乗)
1.3.5. F -フィッシャー分布
フィッシャー F 分布は分散関連の分布です。たとえば2系統の分散の比率
2つの独立ランダム変数が自由度 (V1, V2)を取る カイ二乗分布であれば、その比率はフィッシャー分布であると言えます

図4 フィッシャー分布
1.3.6. Rの2乗決定比率
決定比率は、分散結果のどの比率が独立変数の影響により説明されているのを示します。ピアソン相関の二乗の2つの変数の場合それは2つの変数間トータルである分散の総量を示します。
相関比率の有意性は観測数またはフィッシャーF統計に依存します。1クオートのろうそく足数が100を超えると、ゼロから観測される小さな分散でさえインディケータの有意性を確認するには十分です。
1.4. 仮説の決定
パラメータの一般集団についてどのような結論が導き出せるでしょうか?このパラメータの選択的値を持っているとした場合です。この質問に対する答えは、一般パラメータのゼロについて事前に情報を得ているかどうかによります。
パラメータの一般的大きさについての事前情報がなければ、それにたとえばその値が一定の信頼確率を伴って配置される信頼区間を設定し、このパラメータを選択的値で判定することができます。
実践では通常いくつか指定の、そしてほとんどの場合シンプルな仮説Butをチェックする必要があります。この仮説は null 仮説とみなされます。この仮説を検証するためにはいくらかの基準が使用され、それで仮説が受け付けられるか却下されます。 以下にリストアップされている統計タイプがたいてい基準として使用されます。:t-統計、F-統計、カニ二乗統計。統計用(たとえばSTATISTICA)または計量経済学用(EViewsのような)の特定ソフトウェアを使用する場合、計算された基準はこの基準の有意の値p 値を伴います。たとえば 0.02 (2%) の p 値は対応する基準が 1% の有意性レベルでは有意でない、また 5% の有意性レベルでは有意であることを意味します。最終的に null 仮説は「1 - p 値」の確率では有効でないと推測できます。
p 値の選択は主観的で指定の基準の誤った判定結果の重大性により判断されます。
1.5. クオートの統計的特性
1.5.1. 記述統計
記述統計には以下が含まれます。
- クオートのろうそく足数量が増加するとき、分布法則に近づくヒストグラム
- 主要トレンド計測:平均値、中央値
- 分散計測:標準偏差
- 形式測定:歪度と尖度
- ジャック・ベラ正規化基準
ジャック・ベラ基準Null 仮説But:分布は正常です。たとえば、基準値を伴う確率は 0.04です。そうすると次の結論が導かれます。:null 仮説支持確率は 4%である。ただし、これは全体的に正しいとは言えません。なぜなら計算された値は基準 p 値で null 仮説支持確率は 96%だからです。
1.5.2. 自己相関および Q 統計
相関関係は2つの変数間の関係の尺度です。 相関関係比率は -1.00 ~ +1.00と変化する可能性があります。値 -1.00 は完全に負の相関で、値+1.00 は完全に正の相関を意味します。値 0.00 は相関関係がないことを意味します。
1クオートの複数エレメントの相関関係を自己相関関係と呼びます。それはトレンドを見つけるのに有用です。自己相関の存在はランダム変数としてのクオートに関する結論疑いを呈します。というのは、乱数を決めるのにもっとも顕著な要因は異なる期間における独立した多様な価格だからです。
統計分析ソフトウェアでは、自己相関は p 値を取るリュングボックスの Q 統計を伴います。null 仮説は:自己相関はありません。たとえば p 値がゼロの場合、他に確定されたろうそく足がクオートに出現する前、相関はないと結論して差し支えないでしょう。
クオートから自己相関関係(トレンド)を除外するのは数学的統計手法を使用する機能を得る第一のステップです。
1.5.3. クオートの定常性
数学的期待値と分散が時間に依存しない 場合、クオートは定常とみなします。定常性のこの定義は厳格過ぎ、実践での適応にはあまり適していないかもしれません。クオートは、いくらかの時間内で数学的期待値の偏差および/または分散が数パーセント(通常は5%を越えません)であれば、しばしば 定常とみなされます。
外為マーケットでの実際のクオートは定常ではありません。それらは以下の偏差を持ちます。
- 時間内の観測間の独立性によって生成されるトレンドの存在依存性は通貨クオートと経済観測に共通する特性です。
- 循環性
- 分散を多様化します (異分散性)。
安定しているクオートから外れるクオートは非定常であると呼ばれます。それらは要素に連続分解することによって分析されます。分解処理はほとんど一定の期待値および/または分散を持つ定常系列のバランスを受け取る時終了します。
クオートの定常性検定は複数あります。基本の検定は単位根検定です。単位根検定のもっとも有名なものは Dickey-Fuller 検定です。null 仮説But:クオートは定常(単位根を持ちます)ではない。たとえば、平均値および分散値は時間に依存します。ほとんど常に時間依存(トレンド)なので、クオート内のトレンドの存在は検定が実行されるときに指示される必要があります。この段階でそれらは目で判断されます。
1.6. インディケータ仕様(回帰)
MQL5のような言語を使用して書かれているインディケータのテキストを一瞥すると、たとえば設定形式が2つ特定できます。それらは解析(もっとも一般的)と 表計算(インディケータに適用され、それはフィルターと呼ばれます。たとえば Kravchuk インディケータです。)
ここでは「回帰」という語を使いますが、これは数学的統計や計量経済学の一般用語です。
クオートから何を得たいのか考えると、回帰(インディケータ)を形成するために次のパラメータを設定する必要があります。
- インディケータ計算に使用される独立変数のリスト
- 独立変数比率
- 依存変数計算に使用するインディケータ計算式
複数通貨対応インディケータの作成に困難があっても、回帰にはそのような難しさはありません。
以上のポイント3点をもって、回帰をクオートに当てはめる必要があります。トレーダーフォーラムと反対に、『当てはめる、当てはまる』という言葉は、計量経済学では悪意ある言葉ではなく、その間複数の判定メソッドから一つを使ってクオートに対する(インディケータ)回帰 適合が計算される標準手続きです。最小二乗(OLS) は最も有名な判定手法です。
判定は興味を引くことが2点あります。
- インディケータのクオートとの適合 – 残されているエラーの値
- 計算された回帰パラメータの将来的安定性
これら課題に対する答えはインディケータ診断中にもたらされます。
1.7. インディケータ診断
インディケータ(回帰)診断は3つのグループに分けられます。
- 比率診断
- 余剰診断
- 安定性診断
下記に述べられる検証手順には検証仮説として利用される null 仮説の使用が含まれます。検証結果は1つ以上の統計値とそのアタッチされた p 値の選択によって構成されます。後者は null 仮説条件の実行確率を表します。それは検証統計の基本となるものです。
よって小さい p 値は null 仮説の却下につながります。たとえば p 値が 0.05 ~ 0.01にあれば null 仮説は1%ではなく 5% レベルに偏差します。
各検証に関連した提案や分布結果は多様であることに注意が必要です。たとえば統計の中には正確で有限な検定分布を持つものがあります。(通常 t または F 分布です。)その他は漸近的な χ2 分布を持つ径庭統計の大きいサンプルです。
1.7.1. 比率診断
比率診断は情報を与え、欠損変数や留数変数といった検証の特殊なケースを含む判定比率の欠点を判断します。以下の回帰式比率の検証が使用されます。
- 信頼楕円によって式比率間の相関関係が判ります。
- 欠損変数の検定により、回帰式に追加変数の必要性が判断できます。
- 留数変数検定により過剰な変数が判ります。
- ブレーク検定によりトレンド変化の回帰式の反応を判断することができます。昇順、降順、平坦クオートセグメントでクオートをよく反映するそのような回帰式を作成することが望まれます。
1.7.2. 留数診断
非定常クオートを定常クオートに変換しようとするとき余剰を調査するのが重要であることはすでに述べました。
単位根検定により留数が基本クオートに比べると正規法則にずっと近い分布をしていることが示されます。「近く」という言葉は留数 が平均値を持ち、時間に依存する分散をすることを反映しています。それは回帰式比率を不安定にするものです。
トレーダーフォーラムの用語を使用すると、トレーディングシステムを「最適化しすぎる(ここにあまり有名でないフィッティングです!)」ことは避けるべきだと言えます。たとえば次のセグメントでその特性を緩めてはいけないということです。数学的期待と時間とともに変化する分散が理由で、システムは将来的なクオートセグメントには適していません。
留数に対しては以下の検定が行なわれます。系列相関、正規性、 異分散性 、自己回帰条件、自己回帰条件付留数不均一分散です。
相対曲線- Q 統計は留数 自己相関を示し、p値インディケーションを持つ適切なラグに対しリュング・ボックス Q 統計を計算します。
ヒストグラム-正規化検定はヒストグラムと、正規化検定時、ジャック・ベラ統計を含む記述的留数統計を示します。留数が正常に分布されていれば、ヒストグラムは釣鐘型となり、ジャック・ベラ統計は有意です。
異分散性の検定は均等留数異分散性を検証します。異分散性の証拠がひとつでもあれば、回帰仕様を変更する(インディケータを変更する)か、 異分散性をモデル化するかいずれかの必要があります。
未知の異分散性検定に対する異分散性不在に関するnull 仮説を伴うホワイトの異分散性検定の一般形式を利用します。
ホワイトは自己の手法をモデルのエラー仕様についての一般検定と述べています。それは null 仮説によると検定はエラーは独立変数から不均一で独立しており、線形モデル仕様は正しいという考えに基づいています。これらパラメータを除外すると有意な検定統計量に導かれる可能性があります。逆に有意でない検定統計量はこれら3つのパラメータはひとつも 違反ではないと示します。
1.7.3. 安定性診断
安定性診断はこの場合、もっともおもしろく重要なものです。というのも診断の結果インディケータの予測能力が明らかになるからです。MT4 または MT5 では安定性はストラテジーテスタを用いて診断することができます。もっと先で、インディケータを使用して作成されるトレーディングシステムの将来的安定性はストラテジーテスタでは診断できないことを示します。ストラテジーテスタは履歴データに基づきなんらかのトレーディングシステム判定をすることしかできません。
トレーディングシステム検証中のように、安定性診断の一般的手法はТクオートバーが判定に使用される観測値Т1に分割され、Т2 = Т は検証および判定に使用される Т1バーに分割される、というものです。
トレーディングシステムが2つのセグメントで検証される場合、将来的安定性の問題は解決されません。なぜなら二番目のセグメントでの検証はこの新しいセグメントは未知の統計パラメータによって一番目のセグメントに似ていることを示すだけだからです。同時に、トレーディングシステム作成中に解決される統計的問題は知られないまま残ります。
異なるクオートのセグメントがトレーディングシステム検証中に選択されますが、目で見つけるのは不可能です。たとえば、回帰比率が不安定な異分散性領域、またクオートセグメントです。
いくつかの検定(すべてが安定性検定ではありませんが)を以下にリストアップします。検定条件が将来、クオートに表示される場合、この検定はトレーディングシステムが安定している結果を示します。
たとえばトレンド方向を降順から昇順に変える、またその逆はブレークポイント検定です。この検定でブレークポイントが見つからなければ、そのインディケータはトレンドがどのように変化しようと安定した結果を示すと確信することができます。
Quandt-Andrews ブレークポイント検定
null 仮説:サンプルの終わりから 15% 間隔があると、2件の観測の間にブレークポイントがない。
Quandt-Andrews ブレークポイント検定は、所定の式に対するサンプル内で1つ以上の未知のストラクチャのブレークポイントを検証します。Quandt-Andrews 検定の基本的考えは2つの日付または観測t1 および t2の間の各観測に対して別のチャウの構造変化検定が実行される、というものです。t1 と t2の間にブレークポイントがないことに関する null仮説に対する検定統計量にチャウ検定からの検定統計量である k が合計されます。
Ramseyの RESET 検定
null 仮説:回帰操作内のエラーは通常ゼロ平均を持って分布される値である。
すべてに対する系列相関、異分散性、異常分布法則はノイズが普通に分布する仮定を覆すものです。
RESET - 以下の仕様エラータイプについての一般的検定です。
- 欠損変数; X はすべての適切な変数をインクルードするわけではありません。
- 不正な関数形式; y および X におけるいくつかまたはすべての変数は対数、乗数、逆数、その他別の方法で変換される必要があります。
- X 、e 間の相関関係 は、 X測定エラーまたはラグ値およびノイズ系列内の相関関係などいくつかの要因によって生じる可能性があります。
そのような指定誤差を伴い、OSL 判定は変わり(システムエラーはゼロではありません。)、無効となり(観測数が増えるとき確率によって判定される数量と一致しません。)、そのため通常の出力プロシージャは不当となります。
再帰留数
再帰留数検定はバー数が次第に増加するに伴う複数の回帰判定に基づきます。
一歩先の予測検定
先に挙げた再帰留数の定義を見ると、それぞれの再帰留数が一歩先の観測エラーであることが判るでしょう。時刻 t のポイントまでのすべてのデータについてフィットなモデルによって渡される独立変数値の機能をチェックしたければ、サンプルすべてからの各エラーをその標準偏差と比較する必要があります。
比率再帰推定
このタイプはサンプルの推定値データ数量が増加するときあらゆる比率に対する推定値の変化を追跡することを可能にします。図に示されているのは、実行可能な再帰推定のすべての式に選択された比率です。図は推定された比率の周辺にある2つの標準区間を表しています。
比率が判定式にデータを加えるとき有意な変化を示す場合、それは確実に不安的な前ぶれです。比率画像は急激な上昇を示すことがありますが、これは想定された式がストラクチャの破壊を克服しようとするためです。
テクニカル分析はいわゆる「適応型」インディケータを幅広くそろえています。それにもかかわらず、そのような適応への実際的なニーズを判断する試みはありません。比率再帰推定によりこの問題を解決することができるのです。
2. 初期データの準備
分析のため、2010年11月11日~2011年3月23日のEURUSD の日次クオートを詳しく見ていきます。クオートは F2 によってMT4 ターミナルから受け取られ Excelにエクスポートされます。
クオートの折れ線グラフは以下のようなものです。

図5 EURUSD グラフ
この例はインディケータ内で欠けているデータ管理の必要性を示しています。表示されているクオートがただ低品質クオートの特別なケースだと思ってはいけません。データ損失は様々な理由で起こります。その上、データがUSA の祝日に失われたことに注意が必要です。損失データの問題は通貨レートの相関関係、株式インデックスなど24時間取り引きされてるのではない多様な経済要因に基づいてトレーディングシステムを構築する際は特に重要です。
われわれのシンプルなケースでも線形補間を実行し、すくなくとも多少は計算上損失データの影響を減らすことが可能です。
また異常値の問題もあります。異常値問題は損失データ問題よりも複雑です。異常値を見る前に、次の質問に答える必要があります。異常値とは?私は異常値を後に強い価格変動を伴わない3つの標準偏差を超える価格変動と考えます。
異常値はクオートではなく留数によって決まります。次の価格値から前回の価格値を引いて系列を計算します。 – eurusd(i) – eurusd(i+1)(MQL 定理において)英語ではこの値に対して複数の名前があります。グラフ上、それは「異なっています」。「戻り値」が最も頻繁に使用されます。ここで、また以下で私は「留数」という言葉を使います。それはクオート内からトレンドを除去した後取得される値です。EURUSD留数グラフは以下です。

図6 EURUSD 留数
EURUSD クオートの標準偏差は 0.033209です。よって公式化された異常値基準によるとわれわれのクオートには異常値はありません。
異常値がある場合、それらはいわゆる欠損データと置き換え、その後補間することができます。
提供されている異常値を消去する手法は唯一の方法ではなく、重要なのはそれは正しくないということです。トレンドが除去されたあと、留数がクオート留数と一致すれば異常値サイズがトレンドが判断されるメソッドに依存していることは明らかです。すなわち、異常値問題はトレンド判断問題が解決されてから考えられるべきです
この時点でさらなる分析に必要な基本データは出そろったと考えられます。
3. 統計的パラメータ分析
インディケータの分析とトレーディングシステム基準に適用する可能性を確認するため、外為クオート統計パラメータの分析および特に EURUSD クオートの分析を行います。
以下はトレーディングシステム作成の典型的なアルゴリズムです。
- インディケータが選択され(たとえば移動平均)、それを基にトレーディングシステムが作成されます。
- ひとつのインディケータだけに基づくトレーディングシステム構築は通常不可能なので、別のインディケータを実装し、誤ったマーケットエントリーを避けます。
また、この段階では「フィットしすぎない、フィットしすぎない」を唱えることです。
3.1. 記述統計
われわれは統計から、クオートが乱数のような正規化分布を表していれば平均値計算エラーの値は期間数変更の場合変化し、正規化法則に対する定数である数学的期待値に一致することを理解しています。クオートは水平な直線と置き換えられ、ストップロスおよびテイクプロフィットは標準偏差レベルに設定可能だったはずです。ただ、それは今の場合ではありません。その理由を調査します。
クオートが正規分布法則に従っているか確認します。
以下のようなEURUSD クオートヒストグラムを作成します。

図7 EURUSD ヒストグラム
ヒストグラムには選択した範囲内に一定の価格が何度現れるかが示されています。
それを見ると、分布は正常ではなく2つの最大値がグラフ全体を損ねています。H0 null 仮説でジャック・ベラ検定を行います。:分布は正常です。以下が結果です。
| パラメータ | 値 (実) | 理論値 |
|---|---|---|
| 平均値 | 1.3549 | 平均値は中央値に等しい |
| 中央値 | 1.3580 | 中央値は平均値に等しい |
| 標準偏差 | 0.0332 | - |
| 非対称(偏向) | 0.0909 | 0.0 |
| 尖度 | 2.1052 | 3.0 |
| ジャック・ベラ | 3.5773 | 0.0 |
| 確率 | 0.1671 | 1.0 |
表1 分布正規化検定結果
ジャック・ベラ基準によると、正規化に対する違反についての結論はそれほど独断的ではありません。それは以下の理由によります。
- 平均値と中央値がほとんど一致している
- 非対称がゼロに近い
- 尖度が3に近い
- 既存の不一致は最後の『確率』線によってよく表されています。それは分布は16.7186%の確率で正常だということを表しています。
このグラフに対しては異なる考え方があることでしょう。一方で95%という有意性の一般的レベル においてnull 仮説を(クオートは正常分布である)却下することはできません。また一方で、16%で分布が正常とみなすわけにはいきません。
平均値がほとんど中央値(正規分布の一特性)と一致しているので、平均値の計算を信頼できるか確認します。クオートをセクションに分割して平均式に対する検証を行います。
結果は以下です。
| EURUSD | 数量 | 平均値 | 標準偏差 | 平均値エラー |
|---|---|---|---|---|
| [1.25, 1.3) | 4 | 1.2951 | 0.0034 | 0.0017 |
| [1.3, 1.35) | 42 | 1.3262 | 0.0125 | 0.0019 |
| [1.35, 1.4) | 48 | 1.3740 | 0.0133 | 0.0019 |
| [1.4, 1.45) | 9 | 1.4131 | 0.0083 | 0.0027 |
| All | 103 | 1.3549 | 0.0332 | 0.0032 |
表2 セグメントにおける平均値比較
この検証が示すように、平均値計算にはエラーがあります。それはももっとも典型的な値 19 pipsを伴い、それは 32 pipsに達する可能性のあるものです。
そのことを考慮すると、平均値は使用できないという結論にいたります。
標準偏差値 0.033209 はかなり疑わしい値です。これは 332 pipsにもなります!一般的に言うと、そのような大きい標準偏差からは次のことが明らかです。:EURUSD クオートはトレンドである。それは実際一般的な決定論的要素でクオートの統計的特性をすべて歪めてしまう。
3.2. クオートの相関関係検定
「無作為性」の概念は互いに関連する無作為な数量の自立性に基づきます。クオートの表示によりセクションの方向性ある動き、すなわちトレンドを見つけることができます。
決定論(トレンドの存在)は自己相関(ACF)を計算することで確認できるEURUSD の隣接する値の依存性を示します。すなわち隣接する EURUSD 値の相関関係です。
結果は以下に示します。

図8 EURUSD クオートの自己相関関数
Q 統計に関わる確率はどこでも同じでゼロです。
この計算が示すものは以下です。
- 自己相関関数値はなめらかに減少し、その減少はおそらく不変である。
計算された確率は null 仮説の検定を参照するが、ラグ 16(われわれのケースで)まで相関関係はない。この確率はすべてのラグに対してゼロに等しいので、ここではクオート内に自己相関関係(トレンド)がないとするnull 仮説は厳格に却下します。
3.3. クオートの定常性分析
Dickey-Fuller検定の3バージョン:動きを伴う、トレンドを伴う、動きおよびトレンドなし、を利用し EURUSD クオートの定常性分析を行います。
検定結果は2つのパートで構成されます。すなわち EURUSD に対するものと、EURUSD とは異なる、D(EURUSD)と表記されるのに対するものです。
この検定の null 仮説はEURUSD は定常ではない(単位根を持つ)というものです。単位根計算だけでなく、 EURUSD分化結果の統計的特性も計算します。差別化グラフは以下に示します。

図9 EURUSDクオート留数
視覚的に EURUSD 分化クオートはゼロ付近に位置するランダムなオシレーションであるという結論が導かれます。
EURUSD クオート定常化検定の3つの計算手法を確認します。
1. 変動のないクオート(定数)および回帰が以下のようなトレンド:
D(EURUSD) = С(1) * EURUSD(1) + С(2) * D(EURUSD(1))
null 仮説支持率(系列は定常的ではない)は 0.6961 です。
| 変数 | 比率 | t 統計 | ゼロになる確率 |
|---|---|---|---|
| EURUSD(1) | 3.09E-05 | 0.0488 | 0.9611 |
| D(EURUSD(1)) | 0.2747 | 2.8759 | 0.0049 |
表3 変動とトレンドを考慮しない定常性検定結果
決定係数により D(EURUSD) に対する回帰フィット判定:0.07702
このデータから以下の結論が導かれます。
- EURUSD クオートは高確率 (69%)で定常的ではないと認められる。null 仮説は厳密には却下しません。
- D(EURUSD) のインクリメントは確 99.5%で前のEURUSD価格に依存しない。
- D(EURUSD) は完全に前回の D(EURUSD(1)) インクリメントに依存する。
- 決定係数判断比率値- = 0.077028 は 分化したクオートD(EURUSD) に対し回帰に完全に違反であることを示します。
2. 変化を伴うEURUSD クオート(定数)。これに対する回帰は以下です。
| 変数 | 比率 | t 統計 | ゼロになる確率 |
|---|---|---|---|
| EURUSD(1) | -0.0445 | -1.6787 | 0.0964 |
| D(EURUSD(1)) | 0.3049 | 3.1647 | 0.0021 |
| С | 0.0603 | 1.6803 | 0.0961 |
表4 変化を考慮した定常化検定結果
null 仮説指示率(系列は定常的ではない)は 0.4389 です。
決定係数により D(EURUSD) に対する回帰フィット判定:0.1028
このデータから以下の結論が導かれます。
- EURUSD クオートは高確率 (43%)で定常的ではないと認められる。null 仮説は厳密には却下しません。
- 前回 EURUSD 価格、D(EURUSD) インクリメントに対する回帰式への定数(変化)は含みません。というのもこういった比率は 5% の有意レベルに対してゼロとみなすためです。
- D(EURUSD) は完全に前回の D(EURUSD(1)) インクリメントに依存する。
- 決定係数判断比率値 = 0.102876 は 分化したクオートD(EURUSD)に対し回帰が完全に違反であることを示します。
3.変化とトレンドを伴うEURUSD クオート(定数)。これに対する回帰は以下です。
D(EURUSD) = С(1) * EURUSD(1) + С(2) * D(EURUSD(1)) + С(3) + С(4) * TREND
null 仮説指示率(系列は定常的ではない)は 0.2541 です。
| 変数 | 比率 | t 統計 | ゼロになる確率 |
|---|---|---|---|
| EURUSD(-1) | -0.0743 | -2.6631 | 0.0091 |
| D(EURUSD(-1)) | 0.2717 | 2.8867 | 0.0048 |
| C | 0.0963 | 2.5891 | 0.0111 |
| TREND(11/01/2010) | 8.52E-05 | 2.7266 | 0.0076 |
表5 変動とトレンドを考慮する定常性検定結果
決定係数により D(EURUSD) に対する回帰フィット判定:0.1667
このデータから以下の結論が導かれます。
- EURUSD クオートは高確率 (25%)で定常的ではないと認められる。null 仮説は厳密には却下しません。
- トレンドの間比率がゼロになる確率が 1%未満であっても、この比率値は極端に小さいと言えます。すなわちトレンドは平坦な線です。
- 決定係数判断比率値 = 0.166742 は 分化したクオートD(EURUSD)に対し回帰が完全に違反であることを示します。
これら計算から以下の結論が導かれます。:基本 EURUSD クオートは定常でない場合、次の価格から前回価格を引いたその最初の分化はおそらく定常的なものである。
この場合、トレンドと変動を除去します。それにより次の式ができます。
eurusd = c(1) * trend + c(2),
ここでwhere c(1) と c(2) は最小二乗法で判定される定数です。
この式はMT4ターミナルの「回帰」ツールに適合している一般的回帰式です。これで直線によって基本クオートを置き換えました。これはテクニカル分析では広く利用されている手法です。直線:チャネル、サポートとレジスタンスレベル、フィボナッチレベル、ジェン等、で構成される幅広いインスツルメントを思い出すことができます。
直線はトレーダーが最初に使うツールです。しかし、このツールを信用する理由は何でしょうか?直線が信頼できると考える根拠は何でしょうか?これら質問には本稿でのちに答えることにします。
直線に加え、基本クオートをなんらかの曲線と置き換えるインディケータもテクニカル分析では利用されます。同じ方法で有名なインディケータを2つ取得します。それは指数移動平均と Hodrick-Prescott フィルターです。.
4. クオートのトレンド除去
«トレンド除去»という言葉を使うことで計量経済学の記述に対応するこの項 との関係を強調しようとしています。より正確にまたファイナンシャルマーケットの前述モデルに従って述べると、クオートからの一定コンポーネントの除去(トレンド除去)について話す必要があります。
われわれのケースでは3つの通常成分を決めました。線形トレンド、指数移動平均、 Hodrick-Prescott フィルターです。
すべての通常成分は時系列として設定されます。
4.1.線形トレンド
前回値に1を加えることで線形トレンドを設定します。
線形回帰比率を判定します。
eurusd = c(1) * trend + c(2),
eurusd基本クオート、縦方向に変化する回直線帰、クオートから回帰線を減らすことで取得する留数を組み合わせたグラフを取得します。

図10 EURUSD グラフ:線形回帰および留数
これで最小二乗解析法を用いて以下の式を判定します。
EURUSD = С(1)*TREND + С(2)
回帰式の判定には次のデータが伴います。
| 変数 | 比率 | t 統計 | ゼロになる確率 |
|---|---|---|---|
| トレンド | 0.0004 | 4.4758 | 0.0000 |
| C | 1.3318 | 223.3028 | 0.0000 |
表6 線形トレンド定常性検定結果
決定係数クオートにフィットする回帰判定 = 0.1655.
結果から以下の結論が導かれます。
- 決定係数判断比率によると、指数移動平均はケースの16% でのみクオートにおける変化を説明しうる。
- クオートから線形トレンドを除いた留数はクオートとは大きく異なる。そこには明らかにクオートと同様の統計的流れがあります。.
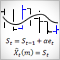
4.2. 指数平滑化
指数平滑化にはクオート(レベル)およびトレンドに対する平滑化パラメータを持つ季節要素を伴わないHolt-Winters アルゴリズムが選択されます。
この手法の主要な考え方:
- トレンドからレベルを分離することで時系列からトレンドを取り除く。
- レベルの平滑化(a パラメータ)
- トレンド予測の平滑化(b パラメータ)
取得された結果は以下のグラフに示されています。

図11 指数移動平均
ラグは少ないがクオートは十分よく表示する標準的な指数移動平均を取得しました。平滑化パラメータは一番上に表示され、パラメータ選択がすでに行われています。
これで最小二乗解析法を用いて以下の式を判定します。
EURUSD = С(1)*EURUSD_EX +С(2)
回帰式の判定には次のデータが伴います。
| 変数 | 比率 | t 統計 | ゼロになる確率 |
|---|---|---|---|
| EURUSD_EX | 0.9168 | 24.3688 | 0.0000 |
| C | 0.1145 | 2.2504 | 0.0266 |
表7 線形回帰判定結果
決定係数クオートにフィットする回帰判定 = 0.8546
結果から以下の結論が導かれます。
- 決定係数判断比率によると、指数移動平均はケースの84% でクオートにおける変化を説明しうる。
- クオートから指数移動平均を除いた留数は正規分布のランダム処理に似ている。ではここから留数をこれ以上分析することに意味があるのか考察します。
4.3. Hodrick-Prescott フィルター
Hodrick-Prescott フィルターはラムダパラメータを持ちます。
パラメータ選択については取り上げません。それは 8162とします。
以下が結果です。

図12 Hodrick-Prescott フィルター
これで最小二乗解析法を用いて以下の式を判定します。
EURUSD = С(1)*EURUSD_HP + С(2)
回帰式の判定には次のデータが伴います。
| 変数 | 比率 | t 統計 | ゼロになる確率 |
|---|---|---|---|
| EURUSD_HP | 1.0577 | 23.9443 | 0.0000 |
| C | -0.0782 | -1.3070 | 0.1942 |
Table 8. 回帰がクオートにフィットする判定結果
決定係数クオートにフィットする回帰判定 = 0.8502
結果から以下の結論が導かれます。
- 二番目の比率(定数)がゼロになる確率は 19%です。それは回帰式に定数を使うことに疑問を投げます。
- 決定係数判断比率によると、Hodrick-Prescottフィルターはケースの85% のみでクオートにおける変化を説明しうる。
- クオートからHodrick-Prescottフィルターを除いた留数は正規分布のランダム処理に似ており、それをさらに分析する意味がある。
5. 比率診断
比率診断には以下の検定が含まれます。
- 信頼楕円の 回帰式比率間の相関関係を定義します。:楕円が円に近いほど相関関係が少ない。
- 信頼楕円は式比率のバリエーションを制限します。テクニカル分析では比率は通常「期間」パラメータを使うかまたは別のいくつかの方法で変更することができます。しかしどの場合においても、比率は乱数とはみなされません。それが真であるか確認します。
- 欠損変数検定– null 仮説が考慮されます。他の独立変数は有意ではない。
- 冗長変数検定 – null 仮説:追加の変数比率はゼロである。
- ブレークポイント検定はクオートの統計的特性が変化するポイントの有無を判断します。述べられている変更ポイントの役割におけるテクニカル分析に関連する変更ポイントのトレンド変化を確認します。分析された EURUSD クオートに、降順および昇順の(ここでは平坦な動きは無視します。)最低2種類のトレンドを割り当てることができます。
5.1. 信頼楕円
各回帰式に対して信頼楕円を作成します。

図13 回帰式1 についての信頼楕円

図14 回帰式 2 についての信頼楕円

図15 回帰式 3 についての信頼楕円
図から以下の結論を導くことができます。
- 線形トレンド回帰に対する比率間の相関関係が存在し、だいたい0.5と判定できる。
- 指数移動平均、 Hodrick-Prescott フィルターの回帰に対する相関関係は実際には1で、それは回帰式の定数排除を要求する。ゼロの定数の有意性確率は Hodrick-Prescott フィルターを用いた回帰式かあの例外についての考えを支持します。
5.2. 信頼区間
回帰式内の定数は乱数であるという仮定を確認します。
これを行うには信頼区間を作成する必要があります。
| 変数 | 比率 | 信頼区間 90% | 信頼区間 95% | ||||
|---|---|---|---|---|---|---|---|
| 下方境界 |
上方境界 |
区間からの% |
下方境界 | 上方境界 | 区間からの% | ||
| トレンド | 0.0004 | 0.0002 | 0.0006 | 74.3362 | 0.0002 | 0.0006 | 88.7168 |
| C | 1.3318 | 1.3219 | 1.3417 | 1.4868 | 1.3200 | 1.3436 | 1.7767 |
| EURUSD_EX | 0.9168 | 0.8543 | 0.9793 | 13.6247 | 0.8422 | 0.9914 | 16.2810 |
| C | 0.1145 | 0.0300 | 0.1991 | 147.5336 | 0.0135 | 0.2155 | 176.2960 |
| EURUSD_HP | 1.0577 | 0.9844 | 1.1310 | 13.8661 | 0.9701 | 1.1453 | 16.5694 |
| C | -0.0782 | -0.1776 | 0.0211 | 254.0276 | -0.1970 | 0.0405 | 303.5529 |
表9 回帰比率の信頼レベル
信頼区間を観察すると、比率は状況に応じて変化する乱数で、信頼性が高まる(チャネル幅が増える)と区間幅は広がることが判ります。
«区間から% » 欄にはたいへん興味を引かれます。それは比率値と比率値区間幅の関係をパーセンテージで表しているからです。見てのとおり、この指数平均とフィルターにとっての回帰定数に対する数量は100%を超える完全に受け入れられない値です。これら式の2つのレシオ間の相関比率はほとんどゼロであることを再度述べる必要があります。
式から定数を除去し、回帰比率を再判定します。
すると以下の結果下を得ます。
| 変数 | 比率 | 信頼区間 90% | 信頼区間 95% | ||||
|---|---|---|---|---|---|---|---|
| 下方境界 | 上方境界 | 区間からの% | 下方境界 | 上方境界 | 区間からの% | ||
| EURUSD_EX | 1.0014 | 0.9999 | 1.0030 | 0.3131 | 0.9996 | 1.0033 | 0.3742 |
| EURUSD_HP | 1.0000 | 0.9984 | 1.0015 | 0.3127 | 0.9981 | 1.0018 | 0.3737 |
表10 再計算された回帰比率の信頼区間
本稿の誌面節約のため、指数平均とフィルターのの新しい回帰計算は表示しません。
以下の回帰式はこれから先使用されることのみ述べておきます。
EURUSD = 1.00149684612*EURUSD_EX
EURUSD = 1.00002609628*EURUSD_HP
5.3. 欠損または余剰変数(インディケータ)
典型的なトレーディングシステム作成のためのアルゴリズムは以下のステップで構成されます。インディケータがいくつか取られ、トレーディングシステム検証に使用されます。その後別のインディケータが追加されトレーディングシステムの誤ったトリガーを検出するなどします。
このアルゴリズムはトレーダーが停止するべき時を表示しません。それは、追加のインディケータが必要か、またトレーディングシステムからインディケータを除外する必要があるか指示しません。既存のトレーディングシステム作成理論はこういった疑問に答えてくれませんが、答えは欠損変数または過剰変数(インディケータ)に対する検証を実行することで見つけ出せます。
欠損変数検定– null 仮説が考慮されます。他の独立変数は有意ではない。
入手済みの3つのインディケータすべてから複合的なインディケータを作成します。
EURUSD = C(1)*TREND + C(2) + C(3)*EURUSD_EX + C(4)*EURUSD_HP
この統合インディケータ(回帰)のレシオを判定すると、以下の結果を得ます。
EURUSD = 1.41879198369e-05*TREND - 0.00319950161771 + 0.50111527265*EURUSD_EX + 0.501486719095*EURUSD_HP
適切なレシオの確率はゼロでそれは以下の表に示されます。
| 変数 | 比率 | ゼロになる確率 |
|---|---|---|
| トレンド | 1.42E-05 | 0.7577 |
| C | -0.0032 | 0.9608 |
| EURUSD_EX | 0.5011 | 0.0000 |
| EURUSD_HP | 0.5014 | 0.0004 |
表611 インディケータレシオ確率判定はゼロ
表では TREND インディケータと定数は含んでいないことが示されています。というのはそれらのレシオはゼロだからです。
前のものにもうひとつ統合インディケータ(指数平均eurusd_ex^2の二乗)を追加します。そしてnull仮説を伴う欠損変数の検定を行います。もう一つの変数(eurusd_ex^2)eurusd_ex^2 は有意ではありません。
計算され t および F統計によると、有意ではない追加の変数 (eurusd_ex^2) の確率は 44.87%です。これを基に追加のインディケータはわれわれのトレーディングシステムには必要ないと言えます。
ただ、より興味深いことは表に示されているとおり追加のeurusd_ex^2を伴うインディケータ全体の推定です。
| 変数 | 比率 | ゼロになる確率 |
|---|---|---|
| トレンド | 1.69E-05 | 0.7154 |
| C | 1.9682 | 0.4496 |
| EURUSD_EX | -2.3705 | 0.5317 |
| EURUSD_HP | 0.4641 | 0.0020 |
| EURUSD_EX^2 | 1.0724 | 0.4487 |
Table 12. インディケータレシオ全体の確率判定はゼロ with eurusd_ex^2
表は Hodrick-Prescott フィルターに基づくインディケータだけはいくらか興味を引かれることを示しています。
冗長変数検定 – null 仮説:追加変数レシオはゼロ
別の面からそれを検証し、null 仮説:追加変数レシオはゼロ、を伴って冗長変数検定を行います。トレンド c をわれわれの複合冗長変数とします。
計算され t および F統計によると、ゼロであるトレンドと c 冗長変数 の確率は 92.95%です。これを基にわれわれのトレーディングシステムにはトレンドとc 冗長変数があることが言えます。前回結果との対応は十分よいものです。
指数平均と Hodrick-Prescott フィルターで構成される全体のインディケータ判定は以下のようなものです。
| 変数 | 比率 | ゼロになる確率 |
|---|---|---|
| EURUSD_EX | 0.4992 | 0.00 |
| EURUSD_HP | 0.5015 | 0.00 |
表13 このインディケータが指数平均と Hodrick-Prescott フィルターで構成されテイル場合、全体のインディケータレシオの確率判定はゼロです。以下のようなものです。
すなわち、トレーディングシステムでこれらインディケータは無用であることに疑いはありません。
6. 留数診断
6.1. 自己相関関数 - Q 統計

図16 形トレンド除去後の自己相関関数
相関曲線は基本クオートからの線形トレンド除去は、ACFで示されるとおりトレンドの存在を否定するものではないことを表示しています。相関関係不在の確率はゼロです。厳密にあらゆる有意性レベルにおいて null 仮説は排除します。

図17 指数平滑化除去後の自己相関関数
相関曲線は基本クオートからの指数平滑化除去は、ACFで示されるとおり二番目より高いすべてのろうそく足でトレンドを除外していることを表示しています。
相関関係不在の確率はゼロです。厳密にあらゆる有意性レベルにおいて null 仮説は排除します。
ただし、もうすこし労力を使い、最初の2本のろうそく足で相関関係を除外するなら、相関関係のない留数を取得することが可能です。

図18 Hodrick-Prescottフィルター除去後の自己相関関
相関曲線は基本クオートからのHodrick-Prescottフィルター除去は、ACFで示されるとおり三番目より高いすべてのろうそく足でトレンドを除外していることを表示しています。相関関係不在の確率はゼロです。厳密にあらゆる有意性レベルにおいて null 仮説は排除します。ただし、もうすこし労力を使い、最初の2本のろうそく足で相関関係を除外するなら、相関関係のない留数を取得することが可能です。
結論EURUSD の基本クオートからわれわれのインディケータにより決定論的成分を除去する試みは線形トレンドに対してはまったく失敗に終わりました。また指数移動平均、 Hodrick-Prescott フィルターに対しては部分的に成功でした。
これ以上のインディケータ分析は自己相関関係(決定論的成分)のために意味がありません。留数において自己相関を除去するようなインディケータを見つける必要があります。次の項でそれを行います。
7. 分析を考慮したインディケータ作成および検証
現時点では、インディケータセットを作成する形式的理論は持ち合わせていません。唯一の方法は分析結果に応じたいくつかの設定を選択して直接調べてみることです。
以前の自己相関分析から、最初のクオートのろうそく足における自己相関はトレンド除去後も残るという結論に至りました。
述べられた事実に配慮しつつ次の式を検証します。
EURUSD = C(1)*EURUSD_HP(1) + C(2)*D(EURUSD_HP(1)) + C(3)*D(EURUSD_HP(2))
D(EURUSD_HP(1)) はクオートと最初のラグを平滑化するHodrick-Prescott フィルタ間の留数(二番目のバー。1から始まるバーを計算するときは最初のバーではない)を意味します。
最小二乗法を用いたその式のレシオ判定は次のような結果となります。
| 変数 | 比率 | ゼロになる確率 |
|---|---|---|
| EURUSD_HP(1) | 1.0001 | 0.0000 |
| D(EURUSD(1)) | 0.8262 | 0.0000 |
| D(EURUSD(-2)) | -0.4881 | 0.0000 |
表14 最小二乗法を用いたレシオ判定結果
余剰変数検定と計算された t および F 統計によると、変数 eurusd(1) と eurusd(2) のレシオがゼロの確率は nullです。すなわちこれら2つの変数は余剰ではないということです。
自己相関は70%以上の確率でラグ 16 まで依存性がないと示しています。(最初のシグネチャライン)

図19 留数自己相関関係
ホワイト異分散性検定から F 統計に関し異分散性は 80%の確率で存在しないと確認する結果が出ています。
null仮説:«ブレークポイントなし»の Quandt-Andrews 検定によるブレークポイント検証は結果を出しました。確率71%の確率でnull 仮説は支持される(ブレークポイントなし)というものです。
標準テクニカル分析によると、検証されたクオートには最低1つのブレークポイントがある(1トレンド逆)ことを再度述べる必要があります。しかし、われわれのインディケータは昇順、降順どちらに対しても似た統計パラメータを持ち、そのためマーケット状況に対しては不変です。
null 仮説: «回帰操作におけるエラーは正規分布値である» を伴うRamseyの積分検定は t および F 統計により48%の確率で支持されます。これを基に、留数自己相関とその異分散性は否定することができます。
また、それは線形二乗判定は変化せず(検証値の数学的期待値は検証値に一致する)再帰留数検定を行うことは可能であることを意味します。
一歩先の再帰留数予測の検定を行います。グラフの上部には2つの標準偏差において再帰留数と限界線が示されています。それだけでなく、左側の軸はろうそく足クオートに対する確率が示されています。そこではインディケータレシオ不変性仮説は有意性レベル 5%、10% 、15% で外れています。この点についてはたいしてありませんがその存在はストップロスとテイクプロフィットの誤ったトリガーを意味します。

図20 再帰留数予測検定
回帰式レシオの帰納的推定値に名前をつけます。グラフはつぎのように作成されます。最も左にあるバーに対するレシオ値が計算されます。そしてバーが1本追加され、レシオ値が最後のバーまで再度計算されます。左側の小さな数量のバーではレシオ値はもちろんひじょうに不安定なものとなります。ただし、計算に使用されるバー数が増えると安定性(不変性)も高まります。
 レシオ 帰納的推定値")
図21 С(1) レシオ帰納的 推定値
 レシオ 帰納的推定値")
図22 С(2) レシオ帰納的推定値
 レシオ帰納的推定値")
図23 С(3) レシオ帰納的推定値
図では、クオート区間の最初に特定の不安定性が観測され、その後それはレシオ値が安定したとみなされますただし、厳密に言えば、ここでの回帰式のレシオは定数ではありません。
おわりに
本稿ではファイナンシャルデータは定常である事実の証拠をもうひとつ提示しました。本稿では非定常データをデータ合計に分割する標準メソッドを使用して定常留数を取得しています。
基本クオートの定常留数を得ることで、取得したインディケータの安定性に関する主な疑問に答えることができます。
本稿で紹介している情報はクオート予測の基となるトレーディングシステム作成のほんのとっかかりにしかすぎません。
参照資料リスト
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/320
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 指数平滑法を用いた時系列予測
指数平滑法を用いた時系列予測
 トレーディングシステム作成のための判別分析の利用
トレーディングシステム作成のための判別分析の利用
 高度適応インディケータ理論および MQL5への実装
高度適応インディケータ理論および MQL5への実装
 Expert Advisor ビジュアルウィザードを用いたExpert Advisorsの作成
Expert Advisor ビジュアルウィザードを用いたExpert Advisorsの作成
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事 メトリックスを分析するための統計パラメータが リリースされました:
新しい記事 分析指標の統計パラメータが リリースされました:
著者:アレックス 私は読むことができない
取引、自動取引システム、取引戦略のテストに関するフォーラム
プレスレビュー
ニューデジタル, 2014.02.13 15:46
外国為替分析の3つのタイプ (dailyfxの記事に基づいて)
ファンダメンタル
外国為替ファンダメンタルでは、主に通貨の金利が中心となります。その他のファンダメンタル要因としては、国内総生産、インフレ、製造業、経済成長活動などがあります。しかし、他のファンダメンタルズの発表が良いか悪いかは、それらの発表がその国の金利にどのように影響するかよりも重要ではありません。
ファンダメンタル・リリースを確認する際には、それが将来の金利の動きにどのような影響を与えるかを念頭に置いてください。投資家がリスクを求めるモードにある場合、資金は利回りを追い求め、金利の上昇は投資の増加を意味する。投資家がリスク回避の心理にあるときは、資金は利回りから安全な通貨に向かいます。
テクニカル
外国為替テクニカル分析では、価格履歴のパターンを見て、より高い確率で取引を開始・終了する時間と場所を決定します。その結果、FXのテクニカル分析は、最も広く使用されている分析の種類の1つです。
FXは最大かつ最も流動性の高い市場の1つであるため、プライスアクションからのチャート上の動きは、一般的に隠れた需要と供給のレベルについての手がかりを与えます。どの通貨が最も強いトレンドを示しているかなど、その他のパターン化された動きは、価格チャートを確認することで得ることができます。
その他のテクニカル分析は、インジケーターを使用して行うことができます。シグナルが読みやすく、FX取引がシンプルになるため、多くのトレーダーがインジケータの使用を好んでいます。
センチメント
FXのセンチメントは、広く普及しているもう一つの分析形式です。センチメントが圧倒的に一方向に位置している場合、大多数のトレーダーがすでにそのポジションにコミットしていることを意味します。
すでに買いを入れているトレーダーが大勢いることがわかっているので、これらの買い手は将来の売り手の供給源になります。なぜなら、最終的に彼らは取引を決済したいと考えるからである。そのため、これらの買い手が取引を決済するために売りに転じれば、EUR対USDは急反落する可能性がある。
ホドリック・プレスコット・フィルター
ホドリック・プレスコット・フィルターは、マクロ経済学、特に実質景気循環理論において、生データから時系列の循環成分を分離するために使用される。ラグがゼロである。このようなゼロラグフィルタには,最近の値が再計算されるという共通の欠点があります.
片側HPフィルタに関するより詳しい情報は,こちらをご覧ください:statistics - Hodrick-Prescott filter (one-sided version) - Mathematica Stack Exchange または こちらtime series - Formula for one-sided Hodrick-Prescott filter - Cross Validated and in pdf file attached tothis post.
フォーラムスレッド(mladenに 感謝します)
- goertzel_browser_5.2.1 インジケータ -投稿,
- goertzel_browser_5.3 インジケータ -投稿
- goertzel_browser_5.4 インジケータ -投稿
- goertzel_browser_5.4_nrp インジケータ -投稿
- goertzel_browser_5.5 インジケータ -投稿(スタンドアロン・インジケータ)
- goertzel_browser_5.51 インジケータ -投稿
- goertzel_browser_5.52 インジケーター -投稿
- goertzel_browser_5.53 インジケーター -投稿
- goertzel_browser_5.1_cs_detrendampsmooth_1 インジケーター -投稿
記事
コードベース
============