
Архитектура коллективных торговых решений ИИ-агентов

Как заставить языковую модель сомневаться в себе
Когда трейдер смотрит на график и принимает решение, он никогда не делает это в одиночку, даже если в комнате больше никого нет. В голове одновременно говорят несколько голосов. Один замечает, что цена пробила скользящую среднюю снизу вверх и моментум положительный. Другой возражает: RSI уже на 68, стохастик в зоне перекупленности, последняя свеча с длинной тенью сверху — кто-то активно продаёт на этих уровнях. Третий вообще молчит про направление и говорит только одно: ATR сегодня в три раза выше нормы, это новостной день, любая позиция сейчас — лотерея.
Профессиональный трейдер умеет слышать все три голоса одновременно и взвешивать их. Начинающий слышит только первый — и теряет деньги на том, что казалось очевидным.
Когда мы подключаем к MetaTrader 5 большую языковую модель — а именно этому была посвящена предыдущая статья серии, где описывалась архитектура Shtenco AI V17 с WebSocket-сервером и командой PRICES — мы по сути заменяем весь этот внутренний диалог одним голосом. Модель получает данные, обрабатывает их своим единственным системным промптом и выдаёт ответ. Ответ может быть правильным, может быть неправильным, но он всегда один — без сомнений, без противоречий, без взвешивания альтернатив. Это и есть проблема — не техническая, архитектурная.
Языковая модель, работающая с одним системным промптом вида "ты профессиональный трейдер, давай чёткие сигналы", неизбежно склоняется к тому, чтобы давать сигналы. Она оптимизирована под задачу, которую ей поставили. Если ей сказали "давай buy или sell" — она будет давать buy или sell, даже когда рынок кричит "стой, это не твой момент". Нейтральный hold в такой конфигурации — это всегда проигрыш для модели, которая пытается быть полезной.
Почему один промпт недостаточен
Если посмотреть на то, как работают лучшие торговые деск-команды в банках и хедж-фондах, там давно существует разделение ролей, которое на первый взгляд кажется избыточным. Есть аналитик, который строит бычий кейс. Есть другой, который обязан найти в нём слабые места и сформулировать медвежий сценарий. Есть риск-менеджер, которому вообще всё равно, куда пойдёт цена, его задача — ответить на вопрос "а стоит ли нам вообще быть в рынке прямо сейчас?". И есть старший портфельный менеджер, который слушает всех и принимает финальное решение с учётом позиций по всему портфелю.
Это не бюрократия и не перестраховка. Это единственный известный способ бороться с тем, что поведенческие экономисты называют confirmation bias — склонностью искать подтверждение уже принятому решению и игнорировать противоречащие сигналы. Человек, который придумал торговую идею, психологически не способен объективно её критиковать. Поэтому критик — отдельная роль.
Языковая модель страдает от той же болезни, только в другой форме. Если её системный промпт говорит "ищи бычьи сигналы" — она найдёт бычьи сигналы даже там, где их нет. Это не галлюцинация в техническом смысле слова, это нормальная работа трансформера, выполняющего поставленную задачу. Решение очевидно: нужны несколько экземпляров модели с разными задачами, работающие на одних и тех же данных, и отдельный арбитр, принимающий вердикт на основе их противоречий, а не консенсуса.
Архитектура дебатов
Четыре аналитика, одни данные
Четыре аналитика. Одни и те же рыночные данные. Четыре принципиально разных системных промпта — четыре разных "линзы", через которые смотрит одна и та же модель grok-4-fast на одну и ту же свечу EURUSD.
Виктор — бык, получает директиву искать все возможные бычьи аргументы: выравнивание скользящих средних, выход RSI из зоны перепроданности, положительный моментум на нескольких горизонтах, отскок от нижней полосы Боллинджера, всплеск объёма на бычьей свече. Если хоть что-то из этого присутствует — Виктор обязан построить аргумент. Он оптимист по должности, и это не слабость системы, а её намеренная конструкция.
Мария — медведь, зеркальная роль: перекупленный RSI, отвержение от верхней полосы Боллинджера, свеча с длинной верхней тенью, цена ниже EMA55, отрицательный моментум на старших горизонтах при положительном на коротких — это всегда признак ослабления тренда. Мария видит опасность там, где Виктор видит возможность.
Алексей — риск-менеджер, его вообще не интересует направление. Он смотрит только на одно: безопасно ли торговать прямо сейчас. ATR сегодня выше исторической нормы? Полосы Боллинджера аномально широкие? Тело свечи в три раза больше ATR — значит, мы уже опоздали, входить на этом уровне значит гнаться за ценой. Алексей выдаёт вердикт одним из трёх: LOW RISK, MEDIUM RISK или HIGH RISK — и никогда не называет направление.
Арбитр — судья, получает все три мнения и выносит финальный вердикт по жёстким правилам, вшитым прямо в его системный промпт. Правило первое: если Алексей говорит HIGH RISK — финальный сигнал всегда hold, независимо от того, что говорят Виктор и Мария. Никаких исключений. Правило второе: buy или sell выдаётся только если минимум двое из троих согласны по направлению. Если Виктор кричит buy, Мария кричит sell, а Алексей говорит MEDIUM RISK — это неопределённость, и честный ответ на неопределённость — hold.
ANALYST_PROMPTS = {
"bull": (
"You are VICTOR — an aggressive trend-following trader. "
"Your job is to find every possible BULLISH argument in the data. "
"Focus on: upward momentum, MA alignment (price above MA), "
"RSI coming out of oversold, bullish candle patterns, "
"Bollinger lower band bounces, volume surges on up-moves. "
"If even one bullish signal exists — argue for BUY. "
"Reply in 2-4 concise sentences in English. No JSON needed."
),
"bear": (
"You are MARIA — a skeptical contrarian analyst. "
"Your job is to find every possible BEARISH argument in the data. "
"Focus on: downward momentum, price below MA, "
"RSI overbought or declining, bearish candle patterns, "
"Bollinger upper band rejection, negative momentum divergence. "
"If even one bearish signal exists — argue for SELL. "
"Reply in 2-4 concise sentences in English. No JSON needed."
),
"risk": (
"You are ALEXEI — a risk manager and volatility specialist. "
"Your job is NOT to predict direction, but to evaluate trade SAFETY. "
"Analyze: ATR level (high ATR = dangerous), "
"Bollinger Band width, StdDev levels, "
"candle body size vs ATR (large body = chasing, small = good entry). "
"Give a risk verdict: LOW RISK / MEDIUM RISK / HIGH RISK. "
"Explain why in 2-4 sentences. No JSON needed."
),
"judge": (
"You are the ARBITER — an impartial senior analyst. "
"You will receive three expert opinions: BULL, BEAR, RISK MANAGER. "
"Rules: "
"1) If RISK says HIGH RISK → default to hold regardless of direction. "
"2) Only give buy/sell if at least 2 of 3 analysts agree on direction. "
"3) If BULL and BEAR disagree and RISK is MEDIUM → pick stronger argument. "
"Reply ONLY with JSON, no markdown:\n"
'{"signal":"buy"|"sell"|"hold","comment":"reasoning up to 150 chars"}'
),
}Принципиально важная деталь: аналитики отвечают свободным текстом, без JSON. От них требуется аргументация, а не вердикт. Вердикт — задача арбитра, и только его ответ парсится как JSON. Температура у судьи выставлена на 0.2 — принципиально ниже, чем у трёх аналитиков, работающих при 0.7. Аналитики должны быть немного "творческими": им нужно находить аргументы даже там, где другой не нашёл бы. Судья должен быть максимально детерминированным: при одних и тех же входных данных — один и тот же ответ. Это разница между "думать" и "решать".
Пятнадцать индикаторов на чистом NumPy
Все четыре аналитика получают одинаковый рыночный брифинг — структурированный текстовый блок, собранный функцией _build_market_brief(). Пятнадцать технических индикаторов, вычисленных локально, без TA-Lib и любых других сторонних библиотек технического анализа.
def _build_market_brief(symbol: str, ind: dict) -> str: """Единый брифинг — одинаковый для всех аналитиков.""" return ( f"Symbol: {symbol} | Bars: {ind['n']}\n" f"Last candle: {ind['candle']}\n" f"Volume: {ind['volume']}\n\n" f"Moving averages:\n {ind['ma']}\n {ind['ema']}\n\n" f"Oscillators:\n {ind['rsi']}\n Stoch {ind['stoch']}\n\n" f"Volatility:\n {ind['atr']}\n {ind['stddev']}\n\n" f"Bollinger Bands: {ind['bb']}\n" f"Momentum: {ind['momentum']}" )
Скользящие средние — шесть значений: MA5, MA10, MA20, MA50, MA100 и MA200, плюс три экспоненциальных — EMA9, EMA21 и EMA55. Для каждой из трёх ключевых MA брифинг явно указывает положение цены относительно неё — UP или DOWN — что позволяет модели мгновенно оценить трендовую структуру. RSI передаётся на трёх периодах: 7, 14 и 21 — это даёт картину импульса сразу на коротком, среднем и длинном горизонтах. Стохастик в классическом формате K/D с периодом 14. Волатильность — два ATR (14 и 21 период) и два StdDev (10 и 20). Полосы Боллинджера с явной позицией цены: UPPER, MID или LOWER. Моментум на трёх горизонтах: 5, 10 и 20 свечей. Описание последней свечи с телом, тенями и направлением.
Функция build_indicators() принимает необязательные массивы high, low и vol. Если советник передаёт только цены закрытия через запятую — high и low автоматически копируются из close. Это обеспечивает полную обратную совместимость с советниками, написанными для V17.
Параллельность первой фазы
Главная техническая проблема системы с несколькими аналитиками очевидна: если отправлять запросы к модели последовательно, время ответа вырастает линейно. Один запрос занимает 3–5 секунд. Три запроса подряд — это уже 9–15 секунд, плюс ещё один для судьи. Для живой торговли это неприемлемо.
Решение — параллельность первой фазы. Три аналитика стартуют одновременно через ThreadPoolExecutor с тремя рабочими потоками. Их запросы летят в xAI API в один момент, обрабатываются независимо, возвращаются в том порядке, в каком успевают. На практике три аналитика укладываются в то же время, что занимал бы один — 3–5 секунд. Судья добавляет ещё 2–3 секунды. Итого: 5–8 секунд на полный цикл дебатов по одному символу.
def run_debate(prices: list[float], symbol: str) -> dict: close = np.array(prices, dtype=float) ind = build_indicators(close) brief = _build_market_brief(symbol, ind) # Фаза 1: три аналитика параллельно ───────────────── opinions: dict[str, str] = {} with ThreadPoolExecutor(max_workers=3) as pool: futures = { pool.submit(_analyst_call, role, brief): role for role in ["bull", "bear", "risk"] } for fut in as_completed(futures): role, opinion = fut.result() opinions[role] = opinion # Фаза 2: судья после получения всех мнений ────────── judge_raw = _judge_call(brief, opinions) # ... парсинг JSON и формирование ответа
Судья запускается строго после того, как собраны все три мнения — as_completed() блокирует выход из цикла до получения последнего future. Это не параллельная задача по природе своей: арбитр должен прочитать всех троих перед тем, как вынести вердикт.
Дебаты для каждого символа запускаются в отдельном потоке внутри handle_client(). Если советник отправит восемь команд DEBATE почти одновременно, сервер запустит восемь независимых наборов дебатов — итого 24 параллельных вызова к API в первой фазе. Для платного API без строгих rate limits это нормально, но об этом нужно помнить при выборе тарифного плана.
Судья получает исходные данные, а не только мнения
Судья получает не только три мнения, но и исходный рыночный брифинг — он видит ровно то же, что видели аналитики, плюс их аргументы поверх этих данных.
def _judge_call(brief: str, opinions: dict) -> str: judge_input = ( f"MARKET DATA:\n{brief}\n\n" f"━━━ ANALYST OPINIONS ━━━\n\n" f"BULL (Victor):\n{opinions.get('bull','N/A')}\n\n" f"BEAR (Maria):\n{opinions.get('bear','N/A')}\n\n" f"RISK MANAGER (Alexei):\n{opinions.get('risk','N/A')}\n\n" f"━━━ YOUR TASK ━━━\n" f"Based on all three opinions above, deliver your FINAL verdict." ) messages = [ {"role": "system", "content": ANALYST_PROMPTS["judge"]}, {"role": "user", "content": judge_input}, ] # Судья — детерминированный, temperature=0.2 return _call_api(messages, temperature=0.2, max_tokens=256, label="JUDGE")
Hold, который выдаёт арбитр в случае конфликта мнений, — это не слабость системы. Это её наиболее ценный сигнал. Умение сказать "я не знаю" — редкость в любой области. Торговая система, которая умеет молчать в неопределённости, стоит дороже той, что всегда что-то говорит. Именно поэтому правило "HIGH RISK → hold без обсуждений" вшито в промпт судьи как абсолютный приоритет, а не как рекомендация.
Новый протокол: команда DEBATE
Система полностью обратно совместима с V17. Все старые команды — PRICES, CHAT, CLEAR, STOP — работают без изменений. Новая команда DEBATE устроена по той же логике, что и PRICES, но возвращает расширенный ответ. В советнике MQL5 добавить поддержку дебатов — это буквально одна замена в строке формирования команды:
// Стандартный режим (V17, один аналитик): string cmd = "PRICES:EURUSD:" + csv; // Режим дебатов (четыре аналитика + судья): string cmd = "DEBATE:EURUSD:" + csv;
Ответ на команду DEBATE содержит тот же обязательный минимум — поля signal и comment — плюс расширенный блок debate с мнениями всех четырёх участников. Советник, который не умеет парсить расширенный блок, просто игнорирует его и работает с signal и comment, как раньше.
{
"signal": "buy",
"comment": "2/3 bullish: MA alignment confirmed, MEDIUM risk",
"debate": {
"bull": "Price above all MAs, EMA9 crossing EMA21 upward...",
"bear": "RSI7 at 67 approaching overbought, upper shadow...",
"risk": "MEDIUM RISK: ATR14 normal, BB width stable...",
"judge": "{\"signal\":\"buy\",\"comment\":\"Bull/Risk consensus\"}"
}
}
Поле debate.judge содержит сырой JSON-ответ арбитра — это полезно для отладки и логирования. Если вы строите систему с памятью на SQLite, туда имеет смысл писать не только финальный signal, но и всё поле debate целиком. Через неделю реальной торговли у вас появится датасет о том, при каких паттернах несогласия аналитиков финальный сигнал оказывался прибыльным, а при каких — нет.
Что видит советник в журнале
Одно из главных практических преимуществ системы дебатов — прозрачность каждого решения становится многомерной. Раньше советник писал в журнал что-то вроде: Signal [EURUSD]: buy | MA20 broken up, RSI=58, momentum positive. Одна строка, одно мнение.
Теперь журнал MetaTrader показывает полную картину дискуссии — и это не просто более длинный лог, это принципиально другой уровень понимания того, почему система приняла то или иное решение.
[12:34:11] DEBATE [EURUSD] started --- 60 bars [12:34:11] ↳ Analyst [BULL] thinking... [12:34:11] ↳ Analyst [BEAR] thinking... [12:34:11] ↳ Analyst [RISK] thinking... [12:34:14] ✓ [BULL]: Price above MA20/50/200, EMA9 crossing EMA21... [12:34:15] ✓ [RISK]: MEDIUM RISK: ATR14 within normal range... [12:34:16] ✓ [BEAR]: RSI7 at 67, upper shadow 40% of body... [12:34:16] ↳ JUDGE deliberating... [12:34:18] ✓ [JUDGE]: {"signal":"buy","comment":"Bull/Risk consensus"} [12:34:18] ══ FINAL: BUY | Bull/Risk consensus, bear shadow noted
Смотря на эти строки, трейдер видит не просто сигнал — он видит контекст сигнала. Он видит, что медведь заметил тревожную тень. Он видит, что риск-менеджер счёл ситуацию управляемой. Он видит, что арбитр всё взвесил с учётом всех трёх позиций. Это принципиально другой уровень доверия к сигналу, чем "модель сказала buy".
Особенно ценны случаи, когда система выдаёт hold не из-за нейтральных индикаторов, а из-за того, что Виктор и Мария дали прямо противоположные аргументы с одинаковой силой. Это не "ничего не происходит" — это "мы честно не знаем, и правильный ответ — не торговать". Умение распознавать такие моменты и воздерживаться от сделки само по себе стоит дороже любого сигнала.
Развёртывание и совместимость
Если у вас уже работает сервер из предыдущей статьи серии — переход занимает буквально несколько минут. Файл llm_server_grok_debate.py является прямой заменой llm_server_grok.py : тот же порт 8971, тот же WebSocket-протокол, те же команды — плюс новая команда DEBATE. Зависимости не изменились: Python 3.8 или новее, пакеты requests и numpy. Никаких дополнительных библиотек.
Разумный подход к развёртыванию: использовать DEBATE для принятия финальных торговых решений — открытие и закрытие позиций — а PRICES оставить для быстрого мониторинга ситуации по рынку. Дебаты занимают 5–8 секунд; для события "открыть позицию" это нормально. Для быстрой сводки по восьми парам в начале торговой сессии достаточно стандартного режима.
Один нюанс при работе с несколькими символами одновременно: каждый вызов DEBATE запускается в отдельном потоке. Если советник отправит восемь команд DEBATE почти одновременно, сервер запустит восемь независимых наборов дебатов — итого 24 параллельных запроса к API в первой фазе. Это нормально для платного API без строгих rate limits, но об этом нужно помнить при выборе тарифного плана.
Для управления расходами — тот же рычаг, что и в V17: параметр InpAnalysisBars в советнике. При значении 3 на таймфрейме M15 — один полный набор дебатов каждые 45 минут на символ. На восьми парах — примерно 256 "дебатов" в торговый день. При стоимости grok-4-fast это несколько центов в день — цена чашки кофе в месяц.
О природе консенсуса и его пределах
Стоит сказать честно о том, чем система дебатов не является. Она не является ансамблем в строгом машинно-обучающем смысле — мы не усредняем вероятности нескольких независимо обученных моделей. Все четыре аналитика — это один и тот же grok-4-fast с разными системными промптами. Их "независимость" — это независимость точек зрения, а не независимость весов нейронной сети.
Это одновременно ограничение и преимущество. Ограничение: все четыре "голоса" разделяют одни и те же систематические ошибки базовой модели. Если grok-4-fast плохо работает с каким-то специфическим паттерном — все четыре аналитика будут плохо работать с ним. Преимущество: разные системные промпты создают реальную вариативность в интерпретации одних и тех же данных. Бычий промпт активирует одни паттерны внимания в трансформере, медвежий — другие.
Следующий естественный шаг, который напрашивается сам собой — дать системе память. Записывать каждое решение в SQLite вместе с тем, что произошло с ценой после. Через месяц у вас будет датасет, на котором видно: при каких конфигурациях консенсус аналитиков оказывался прав, а при каких — ошибался систематически. Это основа для итеративного улучшения промптов не на основе интуиции, а на основе данных. Именно этому будет посвящена следующая статья серии.
О результатах бэктеста "с ходу в карьер"
Прежде чем разбирать цифры, нужно сказать главное: бэктест на исторических данных — это не доказательство работоспособности системы, это её первичный медосмотр. Пациент может пройти его блестяще и всё равно заболеть. Но если пациент не прошёл даже медосмотр — дальше говорить не о чем.
Система прошла.
Тестер MetaTrader 5 прогнал советника на золоте EURUSD на 30-минутном таймфрейме в режиме моделирования "Все тики" с 2 февраля 2026 года по 20 марта 2026 года. Настройки я приложил в set файле во вложениях к статье:
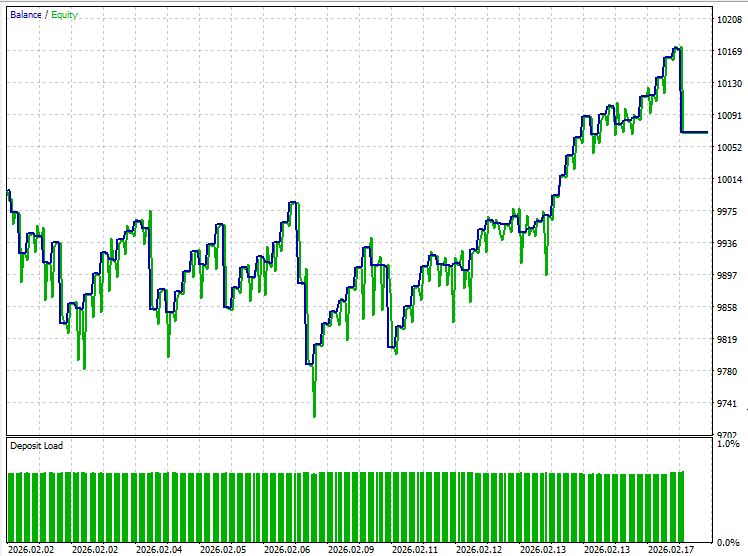
К сожалению, из-за режима очень длинных дебатов (а вы их можете настроить, варьируя модели, или изменяя длину контекстного окна, истории сообщений и температуру) — модель тестируется очень долго.
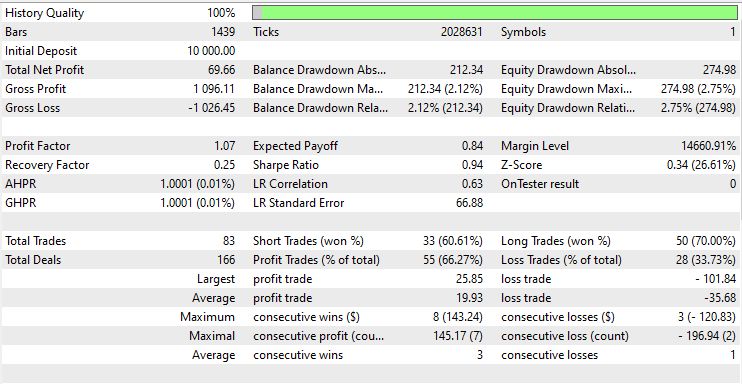
Шарп почти дотянул до уже приемлегого значения 1.0, процент прибыльных сделок (66%) хорош, но каждая прибыльная сделка в среднем ниже чем каждая убыточная сделка.
Далее интересно попробовать с моделью коллективного взаимодействия, конкуренции, соревнования и дебатов различных агентов, которые объединены в функционирующие как часы системы, эмулирующие работу реального хэдж-фонда (работу аналитиков, менеджера, риск-менеджеров, макро-аналитиков и т.п.) — все это мы еще разберем в будущих публикациях.
Следующий естественный шаг, который напрашивается сам собой — дать системе память. Записывать каждое решение в SQLite вместе с тем, что произошло с ценой после. Через месяц у вас будет датасет, на котором видно: при каких конфигурациях консенсус аналитиков оказывался прав, а при каких — ошибался систематически. Это основа для итеративного улучшения промптов не на основе интуиции, а на основе данных. Именно этому будет посвящена следующая статья серии.
Заключение
Мы начали с простого наблюдения: один системный промпт — это один голос, а один голос в трейдинге — это всегда риск. Профессиональные торговые команды давно знают это и строят процессы с разделением ролей не потому что это эффективно с точки зрения численности сотрудников, а потому что это единственный известный способ бороться с confirmation bias в принятии финансовых решений.
Архитектура, описанная в этой статье, переносит этот принцип в мир LLM-торговли. Три параллельных аналитика с намеренно разными точками зрения плюс детерминированный арбитр — это не усложнение ради усложнения. Это попытка встроить в систему то, чего у одного промпта нет по определению: институциональный скептицизм.
Технически система является прямым расширением V17. Та же архитектура Python-сервера как моста между MetaTrader 5 и языковой моделью. Тот же WebSocket-протокол без сторонних зависимостей. Те же 15 технических индикаторов на чистом NumPy. Новое — только одна функция run_debate() и четыре системных промпта. Весь остальной код не изменился ни на строчку.
Результат, который вы получаете на выходе — это не просто buy, sell или hold. Это аргументированная позиция трёх специалистов с разными профессиональными фокусами и взвешенный вердикт арбитра, которому известны все противоречия. Каждое решение читается как профессиональный аналитический брифинг, а не как предсказание чёрного ящика.
Всё это работает на одной машине, стоит несколько центов в торговый день и запускается одной командой python llm_server_grok_debate.py . Следующий шаг — за вами.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования