
Нейросети в трейдинге: Спайково-семантический подход к пространственно-временной идентификации (S3CE-Net)

Введение
В современном мире финансов рынок уже давно перестал быть местом, где торгуют только активами. Здесь торгуют информацией, временем и вниманием. Скорость реакции становится новой валютой, а способность извлекать закономерности из непрерывного потока данных — главным преимуществом. Ежесекундно миллионы котировок, ордеров и новостных сообщений образуют бурлящий океан событий, в котором случай и закономерность переплетены так тесно, что порой границы между ними стираются. Этот поток не имеет чётких границ — он ни дискретен, ни синхронен, а потому требует моделей, способных видеть не только последовательность, но и структуру изменений, связи и напряжения внутри данных.
Традиционные методы анализа финансовых временных рядов — будь то классические статистические модели, рекуррентные сети или даже тяжёлые трансформеры — сталкиваются с рядом ограничений. Они нередко либо слишком медлительны, либо переобучаются, либо теряют контекст, пытаясь ухватить лишь поверхностные зависимости. Особенно трудно им работать с разреженными и асинхронными данными: важные события происходят редко, но именно они определяют динамику рынка. В таких случаях каждый тик, каждая вспышка объёмов, каждый аномальный перекос спроса и предложения становятся эквивалентом событий — редких, но крайне значимых импульсов, от которых зависит структура последующего движения цены.
Можно сравнить рынок с гигантским нейроморфным потоком. Он живёт вспышками активности, короткими откликами на внешние раздражители и внутренние колебания. Как нервная система, он реагирует на стимулы, передавая сигналы по сложной сети взаимосвязей. И если воспринимать его именно как систему событий, то становится очевидно, что классические подходы, основанные на равномерных временных выборках, не отражают истинной природы происходящего. Именно поэтому в последние годы исследователи обращаются к архитектурам, вдохновлённым спайковыми нейронными сетями и нейроморфным подходом к анализу данных.
На этом фоне появляется фреймворк S3CE-Net (Spike-guided Spatiotemporal Semantic Coupling and Expansion Network) — архитектура, предложенная в работе "S3CE-Net: Spike-guided Spatiotemporal Semantic Coupling and Expansion Network for Long Sequence Event Re-Identification". Данная модель была предложена для решения задачи долговременной реидентификации событий (long-sequence event re-identification) в потоках данных, получаемых с нейроморфных сенсоров. Эти сенсоры фиксируют лишь изменения — вспышки яркости, асинхронные сигналы, возникающие тогда, когда действительно что-то происходит. Модель S3CE-Net работает на пересечении пространственных и временных зависимостей, усиливая информативные сигналы и подавляя шум, сохраняя при этом высокую вычислительную эффективность.
Ключевая идея заключается в том, чтобы не просто анализировать события во времени, но и улавливать взаимосвязи между пространственными каналами — то есть, образно говоря, между участками поля зрения. В контексте финансов это можно интерпретировать как связи между различными активами, уровнями ликвидности или компонентами рыночной структуры. Когда один сектор рынка начинает движение, а другой отстаёт или опережает, это создаёт пространственно-временную корреляцию, своего рода резонанс. Именно такие резонансы и пытается уловить внимание внутри S3CE-Net — Spike-guided Spatiotemporal Attention Mechanism (SSAM). Этот механизм оценивает значимость текущего события и взвешивает его с учётом исторического контекста, не заглядывая в будущее, что принципиально важно для любых прогнозных моделей.
Ещё одна инновация фреймворка — Spatiotemporal Feature Sampling Strategy (STFS). Она позволяет модели в процессе обучения работать с подмножествами пространственно-временных признаков, избегая переобучения на фиксированных фрагментах. Проще говоря, она учит модель видеть общие закономерности, а не запоминать частные комбинации сигналов. В финансовом контексте такая стратегия особенно актуальна: рынок не терпит шаблонов, он постоянно меняется, и любое запоминание приводит к деградации результатов. STFS создаёт гибкость — она заставляет модель адаптироваться, тренировать способность видеть динамику, а не статику.
Если попытаться мысленно перенести архитектуру S3CE-Net в мир трейдинга, её аналогией может стать система, которая слушает рынок подобно тому, как слуховой нерв воспринимает звук — не фиксируя каждую ноту, а выделяя переходы, контрасты, силу и ритм. Такая модель могла бы распознавать микрособытия: вспышки объёмов, появление крупных ордеров, короткие выбросы волатильности. При этом она не просто фиксировала бы сам факт события, но и понимала его значение в контексте других активов и предыдущих всплесков — как дирижёр, который слышит не отдельную скрипку, а всю партитуру.
Финансовые рынки давно нуждаются в подобных подходах. Переход от статичных моделей к системам, способным осмысленно анализировать последовательности событий, — это не просто эволюция, а необходимость. Чем быстрее движется рынок, тем выше значение реакции, и тем важнее способность модели улавливать смысл в разреженных данных. S3CE-Net интересна тем, что она объединяет лёгкость спайковых нейронных сетей с выразительностью механизмов внимания, при этом не жертвуя скоростью и энергоэффективностью. Именно эти качества делают её концептуально близкой к потребностям финансовых моделей, особенно работающих в реальном времени или на низких таймфреймах.
Кроме того, сама философия S3CE-Net — усилить главное, отбросить лишнее — созвучна задачам трейдинга. Рынок полон ложных сигналов, шумов, случайных совпадений. И настоящее искусство анализа в том, чтобы увидеть главное.
Алгоритм S3CE-Net
Фреймворк S3CE-Net строится вокруг центральной идеи — связать динамику спайковых импульсов с пространственно-временными закономерностями потока данных, создавая модель, способную фиксировать факты событий и осмысленно выстраивает между ними связи. Если классическая нейросеть похожа на фотокамеру, которая делает равномерные кадры с постоянной частотой, то S3CE-Net ближе к слуховой системе: она слышит только то, что действительно произошло, реагирует на изменение, на переход, на контраст. В этом и состоит фундаментальная мощь спайковых моделей: они работают на уровне импульсов — единичных событий, из которых складывается целостная картина.
На вход S3CE-Net подаётся последовательность тензоров событий, сформированных из асинхронного потока. Каждый отдельный спайк, зарегистрированный сенсором, описывается координатами (x, y), временной меткой t и полярностью p, показывающей направление изменения — возрастание или спад яркости. В результате поток событий можно рассматривать как набор четырёхмерных данных: время, два пространственных измерения и полярность. Чтобы придать этому потоку регулярную форму, асинхронные события группируются в последовательность фиксированных временных окон — своеобразные мини-срезы мира, где каждый срез содержит два канала: положительные и отрицательные изменения. Совокупность таких тензоров образует структуру Xₑ ∈ RT×2×W×H, где T — число временных шагов, W×H — пространственное разрешение сцены.
Такой подход решает сразу две задачи. Во-первых, он переводит нерегулярный спайковый поток в форму, пригодную для свёрточной обработки — то есть, даёт возможность применять проверенные временем методы извлечения признаков. Во-вторых, он сохраняет саму природу событийных данных — редкость, асинхронность и направленность. Если обычное видео видит всё подряд, то здесь сеть получает лишь удары пульса, энергетические точки изменений. В финансовом контексте аналогом может быть не каждое значение цены, а только её резкие движения, выбросы объёмов, всплески ликвидности — именно те мгновения, когда рынок просыпается.
Внутренний скелет модели — SEW-ResNet, облегчённый и устойчивый к затуханию градиента спайковый резидуальный фреймворк. Его ядро — Spike-Element-Wise Residual Block. По сути, это строительный кирпич сети, который совмещает две идеи: энергоэффективную обработку событий и устойчивое распространение сигнала через глубину архитектуры. Каждый блок принимает поток спайков, аккумулирует их потенциал на уровне нейронов и передаёт преобразованный импульс вперёд, добавляя его к исходному сигналу по принципу остаточного обучения.
Классическая ResNet решала проблему затухающих градиентов в глубоких сверточных сетях. В спайковом мире задача та же, но в условиях событийного, порогового характера сигналов. SEW-ResNet изящно решает это, реализуя остаточную связь на уровне поэлементных операций, что позволяет передавать информацию без искажений, сохраняя форму импульса и стабильность потенциала.
Эта архитектура выступает в качестве фундаментального экстрактора пространственно-временных признаков. На первых уровнях она фиксирует локальные структуры — формы, контуры, переходы яркости (или, в аналогии с рынком, микро-паттерны в потоке сделок и котировок). На более глубоких слоях она агрегирует их во временные и пространственные композиции — узнаёт устойчивые конфигурации активности, закономерности в распределении импульсов. Иными словами, SEW-ResNet превращает сырую, хаотичную последовательность событий в иерархию признаков, где каждый следующий уровень всё меньше зависит от конкретных координат и всё больше отражает смысловую структуру происходящего.
Такое многоуровневое представление играет решающую роль. Оно создаёт площадку, на которой можно построить механизмы более высокого порядка — семантического взаимодействия и контекстуального внимания. Ведь чтобы модель могла осмыслять события, нужно, чтобы она сначала научилась видеть формы и ритмы этих событий. SEW-ResNet обеспечивает именно это — чистую, но выразительную основу, в которой импульсы превращаются в картины активности.
Однако, несмотря на энергоэффективность и природную способность SNN обрабатывать потоковые данные, сама по себе структура SEW-ResNet не решает ключевой проблемы — разрозненности и дискретности событийной семантики. Потоки событий, будь то сигналы нейроморфной камеры или ценовые тики на рынке, обладают высокой фрагментарностью. Каждое событие несёт локальную информацию, но не содержит связи с контекстом. В результате модель может видеть отдельные вспышки активности, но не понимать их смысла во времени и пространстве.
Именно на этом этапе возникает необходимость в механизме, способном связать отдельные спайковые импульсы в осмысленную динамическую последовательность. Здесь в игру вступает Spike-guided Spatiotemporal Attention Mechanism (SSAM) — своеобразный мост между изолированными фрагментами восприятия. Этот модуль добавляет в модель элемент внимания, формируя ассоциативные связи между событиями в пространстве и времени. По сути, SSAM превращает SEW-ResNet из просто быстрого интерпретатора событий в систему, способную к пониманию — к выделению значимых закономерностей и контекстных зависимостей в потоке данных.
В основе идеи лежит понимание, что реальный мир никогда не существует в статике. События неразрывно связаны между собой, образуя сплошную ткань времени. Однако большинство моделей, даже достаточно сложных, рассматривают данные как изолированные кадры, лишённые контекста. SSAM же стремится восполнить этот разрыв, обеспечивая семантическое сцепление между отдельными моментами, превращая дискретное восприятие в непрерывное понимание.
Главная трудность при обработке событийных данных — их фрагментарность. Каждое событие, будь то фотон, зарегистрированный сенсором, или ценовой тик, отражающий изменение котировки, существует мгновенно и не несёт в себе прошлого. Без контекста такой сигнал почти бесполезен. Именно поэтому в классических системах используют механизмы буферизации, усреднения или свёрточной агрегации. Но все они, по сути, размывают реальность, лишая модель тонкости восприятия. SSAM решает эту задачу иначе — он не сглаживает поток, а связывает события смыслом, формируя ассоциативные связи между временными состояниями.
Эти связи строятся с помощью Spike-Guided Spatiotemporal Attention, управляемого самими спайковыми импульсами. В отличие от классических моделей внимания, где каждое состояние может взаимодействовать со всеми остальными, в SSAM действует строгий принцип каузальности: событие текущего момента может опираться только на уже случившиеся события, не заглядывая в будущее. Такой принцип приближает архитектуру к реальности живых систем, где восприятие всегда запаздывает на долю мгновения, а решение принимается исходя из накопленного опыта, а не из знания будущего.
Если перевести это на язык финансовых рынков — SSAM действует как аналитик, который видит движение цены как последовательность взаимосвязанных импульсов. Каждый новый тик для него — не просто цифра, а продолжение истории, контекст которой он уже помнит и интерпретирует. Он не знает будущих цен, но способен почувствовать вероятное направление, потому что внутри него уже выстроены ассоциативные связи между прошлым и настоящим движением. Так и SSAM: каждое текущее состояние формируется как результат интеграции всех предшествующих, а не простого реагирования на текущие входные данные.
Технически механизм реализует эту концепцию через тройку Q, K и V — запросов, ключей и значений, генерируемых независимыми слоями SNN. Эти параметры выступают своеобразными координатами внимания, с помощью которых модель вычисляет, какие участки прошлого наиболее релевантны текущему моменту. Для каждого временного шага формируется собственная матрица внимания At',t, где связи между текущим временем t и всеми предшествующими состояниями t'≤t вычисляются по спайковому принципу, через операцию сглаженного произведения с нормировкой.
Важнейшая деталь — обучаемое смещение относительных позиций B, отражающее пространственные зависимости между элементами внутри каждого кадра. В классических сетях эта информация часто теряется при свёртках, но в SSAM она сохраняется и развивается, позволяя учитывать не только временные связи, но и пространственную топологию данных. Для финансовых временных рядов это можно понимать как способность модели видеть корреляцию не только между моментами времени, но и между разными участками рынка — зонами ликвидности, кластерами объёмов, структурой ордеров.
Математически внимание в SSAM реализовано с верхнетреугольной матрицей весов:
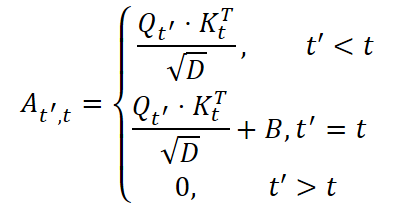
Эта простая, но фундаментально важная конструкция превращает поток спайков в причинно-организованный граф временных зависимостей. Каждое новое событие обновляет внутреннее состояние модели, добавляя в него смысловой контекст прошлого. Таким образом, сеть как бы размышляет над своим собственным опытом, формируя нечто вроде когнитивного следа.
Результирующее представление Ot после нормализации передаётся на следующую стадию обработки, где оно объединяется в финальный выход Ys = [O1; O2; …; OT]. В этом наборе каждый элемент уже несёт не только локальную информацию, но и отпечаток всей предшествующей истории — как трейдер, который, глядя на последнюю свечу, чувствует весь прошедший тренд.
Таким образом, SSAM становится для S3CE-Net тем, чем для аналитика является опыт: способностью видеть связи, которых не видно в моменте. Он обеспечивает плавное семантическое дыхание модели, создавая между её слоями устойчивую когерентность восприятия. Благодаря этому модель понимает и воспринимает смысл временных структур.
Если SSAM можно сравнить с внимательным взглядом, способным различать смысл во времени, то Spatiotemporal Feature Sampling Strategy (STFS) — это скорее умение взглянуть на ситуацию с разных ракурсов, не теряя целостности картины. Этот механизм учит модель видеть не только детали, но и контекст — то, что находится за пределами локального восприятия. В сущности, STFS является метауровнем восприятия, который противостоит одной из ключевых проблем глубоких нейросетей — склонности залипать на локальных семантиках, теряя чувство широкой, глобальной структуры.
Такое туннельное зрение свойственно не только искусственным системам. Его можно наблюдать и на финансовых рынках, где участник, сосредоточившись на коротком ценовом движении, утрачивает понимание долгосрочного тренда. Механизм STFS пытается устранить именно этот эффект. Он обучает модель воспринимать данные одновременно в нескольких масштабах (локальном, сублокальном и глобальном), формируя устойчивое многослойное восприятие динамики.
В техническом плане STFS строится на идее разбиения пространственно-временного признакового поля на подмножества: временные подпоследовательности и пространственные подрегионы. Такое разбиение выполняется не для упрощения данных, а для провокации модели к обобщению. Сеть, сталкиваясь на каждой итерации с разными комбинациями фрагментов, вынуждена искать смысл не в конкретной структуре карты признаков, а в тех инвариантах, что сохраняются при любых вариантах разбиения. Это и есть искусственно сформированный навык обобщённого восприятия.
Формально стратегия работает с глубокой картой признаков Y2, на которой последовательно выполняются три взаимосвязанных процедуры:
- выбор подпоследовательностей во времени,
- выбор подрегионов в пространстве,
- формирование глобального семантического дескриптора.
На первом уровне STFS случайным образом выбирает часть временных шагов Trandom ⊂ {1, 2, …, T}, формируя своего рода вырезку из общего потока событий. Для каждого выбранного момента вычисляется усреднённая пространственная карта признаков, которая превращается в компактный вектор Vti = Avg2d(Y2[ti,:,:,:]). Совокупность этих векторов Ytemporal = {Vti | ti ∈ Trandom} отражает суть временных подпоследовательностей — она хранит не весь поток, а его смысловые реперные точки.
Эта процедура создаёт для модели уникальный опыт. Сеть учится не полагаться на непрерывность данных, а понимать их суть даже по выборочным фрагментам. Это сродни умению опытного трейдера видеть направление рынка, взглянув лишь на несколько характерных свечей — не зная всего пути, но чувствуя его структуру.
На втором уровне STFS разбивает признаковую карту Y2 на четыре пространственные области: верхнюю левую, верхнюю правую, нижнюю левую и нижнюю правую. Для каждой из них выполняется усреднение (Avg2d) — с целью выделить наиболее устойчивые характеристики соответствующего региона. Такой подход можно трактовать как формирование локальных образов восприятия, где каждая часть сцены (или рыночной структуры) анализируется отдельно, но затем соединяется в целостную систему координат.
Случайный выбор границ подрегионов (Wrandom, Hrandom) добавляет элемент стохастичности, что особенно ценно в задачах обучения. Модель перестаёт зависеть от фиксированного положения объектов, учась распознавать смысл в любых конфигурациях. В финансовом контексте это похоже на то, как аналитик отслеживает поведение отдельных рыночных сегментов при этом сохраняя представление об их взаимной связи.
На третьем, самом важном уровне STFS восстанавливает пространственно-временное представление Y2 и извлекает из него общий дескриптор Yglobal = Avg2d(Y2[:,:,:,:]). Это — свёрнутая форма всей накопленной информации, своего рода интеллектуальное ядро опыта модели. Оно несёт в себе не детали, а смысл — квинтэссенцию восприятия, аккумулированную из множества частных наблюдений.
Именно на этой стадии формируется финальная способность модели к семантическому суждению. В финансовом анализе это эквивалентно моменту, когда множество локальных сигналов, шумов и движений складываются в единое понимание рыночного состояния. Модель больше не видит отдельных ценовых всплесков — она воспринимает общую рыночную интонацию, динамическую мелодию данных.
Для повышения устойчивости обучения STFS использует комбинированную функцию потерь: triplet loss и cross-entropy loss с label smoothing, объединённые в итоговую формулу. Первая часть учит модель различать различия между близкими и далекими семантическими состояниями (аналог человеческого контраста восприятия), а вторая стабилизирует классификационную уверенность, избегая чрезмерной категоричности.
В ходе тестирования используется лишь глобальный вектор Yglobal, что подчёркивает идею: достаточно единого, глубоко обобщённого восприятия для точной классификации или сопоставления состояния. В терминах финансовых моделей это аналог финального индикатора — лаконичного, но содержательного числа, вобравшего в себя весь многомерный анализ предшествующих событий.
STFS завершает архитектуру S3CE-Net, превращая её в систему с многоуровневым сознанием. Если SEW-ResNet формирует устойчивое течение информации, SSAM наделяет сеть вниманием и памятью, то STFS учит её видеть целое в частном, синтезировать смысл из фрагментов. Это и есть высшая форма машинного восприятия — понимание закономерности во времени и пространстве.
В применении к финансовым рынкам это открывает путь к созданию нейросетевых моделей, способных прогнозировать изменение цены и распознавать скрытые семантики рыночного поведения: смену фаз тренда, появление синергий между активами, формирование новых паттернов ликвидности. S3CE-Net с модулем STFS в этом смысле становится инструментом понимания — системой, способной увидеть структуру там, где другие видят лишь поток данных.
Авторская визуализация фреймворка S3CE-Net представлена ниже.

Реализация средствами MQL5
После того как мы подробно разобрали теоретические аспекты фреймворка S3CE-Net, пора перейти к практической части нашей работы и показать, как эти идеи можно воплотить в жизнь средствами MQL5. Стоит напомнить, что в предыдущих работах мы уже знакомились с архитектурой SEW-ResNet, которая здесь служит прочной базой. Мы реализовали предложенные подходы, интегрируя их с ResNeXt, что позволило построить гибкую платформу, способную устойчиво обрабатывать сложные временные потоки.
Теперь мы можем использовать эти наработки как фундамент и добавить к ним модули SSAM и STFS, чтобы модель не просто фиксировала события, а научилась чувствовать их взаимосвязь во времени и пространстве. В контексте финансовых рынков это сродни опыту профессионального трейдера: не достаточно видеть отдельные свечи или ценовые тики, важно ощущать их ритм, понимать, как прошлое формирует настоящее, и как текущие события влияют на динамику рынка. Именно это добавляют модули SSAM и STFS, превращая S3CE-Net из инструмента простого анализа в систему, способную к контекстному восприятию и более глубокому пониманию структуры данных.
И начнём мы свою работу с построения модуля пространственно-временного внимания SSAM. Здесь сразу бросается в глаза сходство предложенного алгоритма с казуальным Self-Attention. Однако он дополнен элементами спайковой архитектуры, что придаёт ему уникальную динамику и способность учитывать дискретные события во времени. Эта особенность требует внесения соответствующих изменений в разработанные нами ранее алгоритмы, чтобы интеграция SSAM прошла корректно и модель смогла эффективно воспринимать как пространственные, так и временные зависимости в данных.
Для формирования сущностей запросов (Q), ключей (K) и значений (V) мы будем использовать уже существующие алгоритмы сверточных слоев в сочетании со спайковыми активациями. При этом сам алгоритм внимания будет реализован на стороне OpenCL, что позволит эффективно распараллелить вычисления и существенно ускорить обработку пространственно-временных связей. Такой подход объединяет преимущества спайковых сетей и высокопроизводительных параллельных вычислений, обеспечивая одновременно точность и скорость работы модуля SSAM.
В основе реализации модуля SSAM лежит кернел OpenCL-программы SpikeMHAttention, который позволяет полностью распараллелить вычисления по всем пространственно-временным токенам и головам внимания. Иcходные данные представляют собой объединённый тензор QKV (запросы, ключи и значения), а также диагональный сдвиг diag_bias, обеспечивающий корректную обработку самих токенов при вычислении весов внимания.
__kernel void SpikeMHAttention(__global const float *qkv, __global const float *diag_bias, __global float *scores, __global float *out, const int dimension, const int mask_future ) { //--- init const int q_id = get_global_id(0); const int k_id = get_local_id(1); const int h_id = get_global_id(2); const int total_q = get_global_size(0); const int total_heads = get_global_size(2); //--- __local float temp[LOCAL_ARRAY_SIZE];
Каждое вычисление начинается с определения глобального и локального индекса для текущей головы и токена, после чего вычисляются смещения для доступа к соответствующим компонентам Q, K и V в плоском виде тензора.
//--- Shifts const int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, 3 * q_id); const int shift_k = RCtoFlat(h_id, 0, total_heads, dimension, 3 * k_id + 1); const int shift_v = RCtoFlat(h_id, 0, total_heads, dimension, 3 * k_id + 2); const int shift_s = RCtoFlat(h_id, k_id, total_heads, total_q, q_id); const int shift_out = RCtoFlat(h_id, 0, total_heads, dimension, q_id);
Основная часть алгоритма — это вычисление скалярного произведения между Q и K для формирования матрицы внимания. При этом соблюдается каузальный принцип: если флаг mask_future включен, текущий запрос не будет учитывать будущие ключи, что полностью соответствует концепции SSAM и предотвращает заглядывание в будущее.
//--- Score float score = 0; if(mask_future == 0 || q_id <= k_id) { for(int d = 0; d < dimension; d++) { float q = IsNaNOrInf(qkv[shift_q + d], 0); if(q == 0) continue; float k = IsNaNOrInf(qkv[shift_k + d], 0); if(k == 0) continue; score += q * k; } } else score = MIN_VALUE;
Здесь важно отметить, что мы работаем со спайковым представлением ключей и запросов, где велика вероятность получения нулевых значений. Чтобы сократить количество излишних операций и повысить эффективность, перед выполнением математических операций мы проверяем значения, полученные из глобальных буферов. И вычисления проводим только для тех компонентов, которые отличны от нуля. Такой подход позволяет существенно оптимизировать работу кернела, сохранив корректность вычислений и точность распределения внимания.
Далее, если текущий запрос совпадает с ключом (q_id == k_id, диагональный элемент), к score добавляется обучаемый диагональный сдвиг из diag_bias.
if(q_id == k_id) score += IsNaNOrInf(diag_bias[q_id], 0);
После этого выполняется нормализация коэффициентов внимания путем вызова функции LocalSoftMax.
//--- norm score score = LocalSoftMax(score, 1, temp); scores[shift_s] = score;
Здесь стоит отметить, что нормализация данных выполняется в рамках рабочей группы, которая соответствует одному конкретному запросуQ. То есть SoftMax применяется не по всей матрице внимания сразу, а локально для всех ключейK, относящихся к данному запросу и голове внимания. Это гарантирует, что для каждого запроса сохраняется корректное распределение внимания. При этом обеспечивается высокая параллельность вычислений на уровне OpenCL.
На последнем этапе формируется выходной тензор out. Каждый вектор значения V умножается на соответствующий вес внимания и аккумулируется с помощью LocalSum.
//--- out for(int d = 0; d < dimension; d++) { float val = 0; if(score > 0) { float v = IsNaNOrInf(qkv[shift_v + d], 0); if(v != 0) val = v * score; } val = LocalSum(val, 1, temp); if(k == 0) out[shift_out + d] = val; } }
Это позволяет получить корректное взвешенное представление для каждого токена, объединяя информацию из всех релевантных временных и пространственных позиций.
Представленный кернел реализует весь механизм Spatiotemporal Attention на низком уровне с высокой производительностью, используя возможности OpenCL для распараллеливания по токенам, головам и пространственно-временным координатам. В финансовых терминах это похоже на работу опытного аналитика, который одновременно оценивает взаимосвязь множества временных и локальных признаков, присваивая каждому вес важности в зависимости от контекста и прошлого опыта.
Для корректного обучения модели важно не только выполнять прямые вычисления внимания, но и распределять ошибки обратного прохода между всеми участниками процесса с учётом их влияния на итоговый результат. Данный функционал реализован через кернел SpikeMHAttentionGrad, который позволяет вычислять градиенты для Q, K, V и диагонального сдвига diag_bias одновременно и согласованно.
__kernel void SpikeMHAttentionGrad(__global const float *qkv, __global float *qkv_gr, __global const float *diag_bias, __global float *diag_bias_gr, __global const float *scores, __global const float *gradients, const int dimension, const int mask_future ) { //--- init const int global_id = get_global_id(0); const int local_id = get_local_id(1); const int h_id = get_global_id(2); const int total_global = get_global_size(0); const int total_local = get_local_size(1); const int total_heads = get_global_size(2); //--- __local float temp[LOCAL_ARRAY_SIZE];
Кернел начинает работу с определения глобальных и локальных индексов. Для хранения промежуточных сумм и корректного вычисления градиента функции SoftMax создаётся локальный массив, обеспечивающий эффективное взаимодействие потоков в рамках одной рабочей группы.
Сначала вычисляются градиенты для значений V, так как они напрямую влияют на выходное представление модуля. При прямом проходе каждое значение V влияет на все элементы результирующего тензора через соответствующий коэффициент внимания. Это означает, что при вычислении градиента ошибки для конкретного элемента V мы умножаем градиент на уровне выходного тензора на тот же коэффициент внимания, точно отражая, насколько данное значение V повлияло на итоговый результат.
//--- Value Gradient global_id -> v_id, local_id -> q_id { //--- Shifts const int shift_v = RCtoFlat(h_id, 0, total_heads, dimension, 3 * global_id + 2); const int shift_s = RCtoFlat(h_id, glodal_id, total_heads, total_q, local_id); const int shift_out = RCtoFlat(h_id, 0, total_heads, dimension, local_id); for(int d = 0; d < dimension; d++) { float grad = 0; if(mask_future == 0 || local_id <= global_id) { float score = IsNaNOrInf(scores[shift_s], 0); if(score > 0) grad = IsNaNOrInf(score * gradients[shift_out + d], 0); } grad = LocalSum(grad, 1, temp); if(local_id == 0) qkv_gr[shift_v + d] = grad; } }
При этом мы учитываем казуальность алгоритма. Он позволяет аналитически определить на какие элементы результирующий последовательности влияние не указывалось, и сразу исключить излишние математические операции и дорогостоящее обращение к глобальной памяти.
После этого все частичные градиенты аккумулируются с помощью локального суммирования, а итоговое значение записывается в соответствующий элемент глобального буфера qkv_gr. Таким образом, каждый компонент V получает корректный сигнал ошибки, пропорциональный его вкладу в результат, обеспечивая точное и согласованное обучение модели.
Далее наступает очередь запросов Q. Для них сначала вычисляется градиент коэффициентов внимания как произведений соответствующих векторов значений V и градиентов выхода, затем применяется локальная функция градиента SoftMax, корректирующая распределение сигналов в соответствии с нормализацией.
//--- Query Gradient global_id -> q_id, local_id -> k_id/v_id { //--- Shifts const int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, 3 * global_id); const int shift_k = RCtoFlat(h_id, 0, total_heads, dimension, 3 * local_id + 1); const int shift_v = RCtoFlat(h_id, 0, total_heads, dimension, 3 * local_id + 2); const int shift_s = RCtoFlat(h_id, local_id, total_heads, total_q, global_id); const int shift_out = RCtoFlat(h_id, 0, total_heads, dimension, global_id); //--- 1. Score grad float grad_s = 0; if(mask_future == 0 || global_id <= local_id) for(int d = 0; d < dimension; d++) { float val = IsNaNOrInf(qkv[shift_v + d], 0); if(val == 0) continue; grad_s += IsNaNOrInf(qkv[shift_v + d] * out_gr[shift_out + d], 0); } //--- 2. SoftMax grad grad_s = LocalSoftMaxGrad(scores[shift_s], grad_s, 1, temp); if(global_id == local_id) diag_bias_gr[gloval_id] = grad_s;
Наконец, градиент Q формируется как комбинация градиента score и ключей K, что позволяет каждому компоненту запроса получить взвешенный сигнал ошибки. Диагональные элементы diag_bias получают отдельный градиент, учитывая их роль в усилении влияния токена на самого себя.
//--- 3. Query grad for(int d = 0; d < dimension; d++) { float grad = 0; if(mask_future == 0 || global_id <= local_id) { float key = IsNaNOrInf(qkv[shift_k + d], 0); if(key != 0) grad = key * grad_s; } grad = LocalSum(grad, 1, temp); if(local_id == 0) qkv_gr[shift_q + d] = grad; } }
При этом мы строго учитываем каузальность, которая является ключевым принципом SSAM: модель не заглядывает в будущее, поскольку соответствующая маска применяется уже при прямом проходе. Это требует аккуратного подхода при обратном распространении ошибки: производная SoftMax возвращает ненулевой градиент даже для нулевых значений, что потенциально может создавать сигнал ошибки для элементов будущих временных шагов. В реальной временной обработке таких сигналов быть не должно, иначе нарушается принцип каузальности. Чтобы сохранить корректность обучения и избежать излишних вычислений, перед выполнением математических операций мы проверяем значения ключей и запросов и исключаем из расчёта все будущие компоненты.
Кроме того, мы учитываем спайковую природу анализируемых данных, среди которых значительная часть может быть представлена нулевыми значениями. Поэтому сначала мы проверяем полученные данные, а затем математические операции выполняются только для элементов отличных от нуля. Это позволяет не только сократить вычислительную нагрузку, но и обеспечить точное распределение градиентов только по реально существующим спайкам.
Следующим этапом рассчитываются градиенты ключей K. Для каждого ключа аккумулируется вклад всех запросов Q, учитывая их взаимодействие с соответствующими значениями V через коэффициенты внимания.
//--- Key Gradient global_id -> k_id, local_id -> score_id/v_id/dimension { //--- Shifts const int shift_k = RCtoFlat(h_id, 0, total_heads, dimension, 3 * global_id + 1); const int shift_v = RCtoFlat(h_id, 0, total_heads, dimension, 3 * local_id + 2); const int shift_out = RCtoFlat(h_id, 0, total_heads, dimension, local_id); float grad = 0; for(int q_id = 0; q_id < total_q; q_id++) { //--- 1. Score grad local_id -> score_id/v_id float grad_s = 0; const int shift_s = RCtoFlat(h_id, local_id, total_heads, total_q, q_id); int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, 3 * q_id); if(mask_future == 0 || q_id <= local_id) for(int d = 0; d < dimension; d++) { float val = IsNaNOrInf(qkv[shift_v + d], 0); if(val == 0) continue; grad_s += IsNaNOrInf(val * out_gr[shift_q + d], 0); } //--- 2. SoftMax grad grad_s = LocalSoftMaxGrad(scores[shift_s], grad_s, 1, temp); BarrierLoc; if(global_id == local_id) temp[0] = grad_s; BarrierLoc; grad_s = temp[0]; //--- 3. Key grad local_id -> dimension if(local_id < dimension) { float query = IsNaNOrInf(qkv[shift_q + local_id], 0); if(query != 0) grad += IsNaNOrInf(query * grad_s, 0); } } if(local_id < dimension) qkv_gr[shift_k + local_id] = IsNaNOrInf(grad, 0); } }
Каузальная маска обеспечивает, что будущие токены не влияют на текущий расчёт, а градиенты аккумулируются и записываются в qkv_gr. Такой подход позволяет корректно распределять ошибки и одновременно обновлять все параметры SSAM, сохраняя согласованность и точность обучения.
В результате кернел SpikeMHAttentionGrad полностью реализует механизм обратного распространения ошибки для SSAM, обеспечивая согласованное обновление Q, K, V и диагональных смещений. В контексте финансовых рынков это можно представить как процесс, когда каждая ошибка прогноза аккуратно распределяется между всеми влияющими факторами, позволяя системе постепенно учиться правильно оценивать взаимосвязи между событиями и прогнозировать динамику рынка с высокой точностью.
Сегодня мы проделали большую работу, и пришло время сделать небольшой перерыв. Дадим мыслям отдохнуть, чтобы полученная информация успела осесть и переосмыслиться. В следующей статье мы продолжим реализацию подходов фреймворка S3CE-Net средствами MQL5. Шаг за шагом приближаясь к полной интеграции всех модулей и отработке их на практике.
Заключение
В этой статье мы познакомились с фреймворком S3CE-Net и его ключевыми механизмами — пространственно-временным SSAM и стратегией выборки STFS. Модель работает со спайковыми событиями и строго соблюдает каузальность, что позволяет ей точно фиксировать важные паттерны и корректно учитывать динамику временных рядов, не заглядывая в будущее.
S3CE-Net объединяет лёгкость архитектуры, высокую параллелизацию и умение выявлять сложные временные и пространственные связи. Для финансовых рынков это значит быстрое реагирование на сигналы и точное принятие решений среди огромного потока шумных данных.
Реализация средствами MQL5 откроет путь к тестированию модели в реальных торговых сценариях. S3CE-Net показывает, как современные методы работы с разреженными событиями могут стать мощным инструментом для анализа и прогнозирования рынка. Мы лишь начали раскрывать потенциал фреймворка, и в следующей статье продолжим его практическую реализацию.
Ссылки
- S3CE-Net: Spike-guided Spatiotemporal Semantic Coupling and Expansion Network for Long Sequence Event Re-Identification
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования