
Упрощение работы с базами данных в MQL5 (Часть 1): Введение в базы данных и SQL

Введение
Когда мы говорим об MQL5, большинство разговоров вертится вокруг индикаторов, советников, торговых стратегий и бэктестов. Но в какой-то момент каждый трейдер или разработчик, который серьезно работает с автоматизацией, понимает, что сохранение данных имеет решающее значение. И вот тут-то на помощь приходят базы данных. Вы, возможно, даже подумаете: «Но я уже сохраняю результаты в CSV или TXT файлах, зачем усложнять себе жизнь с помощью базы данных?» Ответ кроется в организации, эффективности и надежности, которые обеспечивает база данных, особенно при работе с большими объемами информации или сложными операциями.
В контексте MQL5 разговоры о базах данных на первый взгляд могут показаться преувеличением. Ведь этот язык сильно ориентирован на торговлю, индикаторы и роботов для автоматического исполнения. Но когда начинаешь работать со стратегиями, которые включают в себя большие объемы данных, сложные бэктесты или подробные записи об ордерах, простота стандартных файлов быстро оказывается недостаточной. Именно здесь понимание того, как создавать базу данных, получать доступ к ней и работать с ней, становится инструментом, способным преобразовать ваш торговый процесс.
Трейдер, начинающий изучать базы данных на MQL5, найдет десятки встроенных функций и отдельных примеров. Достаточно сохранять записи и запрашивать их, но вскоре возникает вопрос: *как организовать все это удобным для повторного использования способом в реальных проектах?* В этой серии статей мы выходим за рамки документации. Мы начнём с основных функций SQLite и шаг за шагом перейдём к созданию **мини-ORM на языке MQL5 (TickORM)**. Идея заключается в преобразовании прямых вызовов в хорошо продуманные слои, вдохновленные Java-технологиями JDBC и JPA, но адаптированные к экосистеме MetaTrader.
В этой статье я демонстрирую основы работы с базами данных на языках MQL5 и SQL. Это открывает путь для последующих статей, в которых эти функции будут инкапсулированы в классы, интерфейсы и, наконец, ORM.
Что такое база данных и чем она полезна?
Технически база данных - это организованный способ структурирования информации, позволяющий хранить сохраненные данные, запрашивать их и управлять ими. Она гарантирует целостность, создает взаимосвязи между различными наборами информации и обеспечивает скорость выполнения операций.
Практическая разница между сохранением данных в файлах и использованием базы данных заключается в ее организации и простоте доступа. В простых файлах, таких как CSV или TXT, для каждого чтения или изменения требуется просмотреть все содержимое, манипулировать строками, устранять ошибки форматирования и надеяться, что файл не будет поврежден. В базе данных эти операции абстрагированы: можно выполнять поиск конкретных записей, обновлять сразу несколько значений и обеспечивать выполнение полных транзакций без потери данных.
Но как эта организация устроена внутри? Представьте себе базовую структуру базы данных в виде электронной таблицы, вот пример:

- Каждая таблица в базе данных эквивалентна вкладке в электронной таблице, посвященной определенному набору информации (например, Trades).
- Внутри каждой таблицы у нас есть столбцы, как в электронной таблице, которые представляют атрибуты каждого элемента (например, идентификатор, символ, цена и т.д.).
- И каждая строка в таблице соответствует одной записи, то есть конкретной сделке или исполненному ордеру.
Эта простая архитектура с таблицами, столбцами и строками является основой для быстрых, хорошо структурированных запросов. Это похоже на то, как если бы у вас было бесконечное количество организованных и взаимосвязанных электронных таблиц, но с тем преимуществом, что вы можете сопоставлять данные, применять расширенные фильтры и работать с большими объемами информации без головной боли.
Именно отсюда проистекает мотивация к созданию нашего собственного ORM на MQL5. Идея проста: вместо того, чтобы каждый раз вручную писать SQL-запросы для работы с таблицей (создание записей, получение результатов, обновление значений), мы создадим слой, который будет рассматривать таблицы как сущности, а столбцы — как атрибуты класса. Это станет ядром проекта, который мы будем разрабатывать на протяжении всей серии, и послужит основой для более надежных и масштабируемых торговых систем. Названием ORM будет TickORM .
Вкратце, базы данных являются основой для создания надежных и гибких решений, а наш ORM станет связующим звеном между этой основой и кодом на языке MQL5.
Чтобы упростить ваше тестирование, весь пример кода прилагается в конце. Таким образом, вы можете ссылаться на него, копировать и адаптировать по мере необходимости, не собирая фрагменты вручную заново.
Примечание: С этого момента некоторые примеры кода будут выводить записи лога на консоль. Для этого я использую свою библиотеку Logify, разработанную специально для упрощения трассировки и отладки в MQL5. Если вы хотите узнать больше о том, как она работает, или проследить за её пошаговой реализацией, я написал целую серию статей, объясняющих её разработку.Нативные функции SQL и MQL5
Работа с базами данных не требует многого. К счастью, этот язык предлагает набор нативных функций, позволяющих создавать, обращаться к данным и манипулировать ими непосредственно в рамках языка. Эти функции служат связующим звеном между вашим кодом и базой данных.
Связь с SQL прямая: эти функции выступают в качестве уровня выполнения запросов. Иными словами, вы пишете SQL-команды в MQL5, а нативные функции обрабатывают подготовку, выполнение и чтение результатов. Это означает, что даже без использования внешних библиотек вы можете выполнять сложные операции, такие как SELECT, INSERT, UPDATE, DELETE и даже создавать таблицы.
Это отправная точка для понимания каждой функции и ее возможностей, прежде чем переходить к практической реализации. Для получения полной информации обо всех доступных функциях я перечислю все нативные функции базы данных, поскольку мы рассмотрим использование каждой из них:
- DatabaseOpen(string filename, uint flags): Открывает или создает базу данных в указанном файле.
- DatabaseClose(int database): Закрывает базу данных
- DatabaseImport(int database,const string table,const string filename,uint flags,const string separator,ulong skip_rows,const string skip_comments): Импортирует данные из файла в таблицу.
- DatabaseExport(int database,const string table_or_sql,const string filename,uint flags,const string separator): Экспортирует таблицу или результат выполнения SQL-запроса в CSV-файл.
- DatabasePrint(int database,const string table_or_sql,uint flags): Отображает таблицу или результат выполнения SQL-запроса в журнале эксперта
- DatabaseTableExists(int database,string table): Проверяет наличие таблицы в базе данных.
- DatabaseExecute(int database, string sql): Выполняет запрос к указанной базе данных
- DatabasePrepare(int database, string sql): Создает идентификатор для запроса, который затем может быть выполнен с помощью DatabaseRead()
- DatabaseReset(int request): Сбрасывает запрос, например, после вызова DatabasePrepare()
- DatabaseBind(int request,int index,T value): Устанавливает значение параметра в запросе
- DatabaseRead(int request): Переходит к следующей записи в результате запроса
- DatabaseFinalize(int request): Удаляет запрос, созданный в функции DatabasePrepare()
- DatabaseTransactionBegin(int database): Начинает транзакцию
- DatabaseTransactionCommit(int database): Подтверждает транзакцию
- DatabaseTransactionRollback(int database): Откатывает транзакцию
- DatabaseColumnsCount(int request): Получает количество полей в запросе
- DatabaseColumnName(int request,int column,string& name): Получает имя поля по индексу
- DatabaseColumnType(int request,int column): Получает тип поля по индексу
- DatabaseColumnSize(int request,int column): Получает размер поля в байтах
- DatabaseColumnText(int request,int column,string& value): Получает строковое значение поля из текущей записи
- DatabaseColumnInteger(int request,int column,int& value): Получает значение типа int из текущей записи
- DatabaseColumnLong(int request,int column,long& value): Получает значение типа long из текущей записи
- DatabaseColumnDouble(int request,int column,double& value): Получает значение типа double из текущей записи
Подробную информацию обо всех доступных функциях, параметрах и примерах можно найти в официальной документации MetaQuotes по адресу MQL5 Database Functions.
1. Открытие и закрытие баз данных
Начнём с основ, а именно с установления соединения с базой данных. Это делается с помощью функции DatabaseOpen, которая принимает имя файла базы данных и необязательные флаги, определяющие режим открытия, который может принимать следующие возможные значения:
| Значение | Описание |
|---|---|
| DATABASE_OPEN_READONLY | Только чтение |
| DATABASE_OPEN_READWRITE | Открытие для чтения и записи |
| DATABASE_OPEN_CREATE | При необходимости, создание файла на диске |
| DATABASE_OPEN_MEMORY | Создание базы данных в ОЗУ |
| DATABASE_OPEN_COMMON | Файл находится в общей папке всех терминалов. |
int OnInit() { //--- Open connection int handler = DatabaseOpen("database.sqlite",DATABASE_OPEN_CREATE|DATABASE_OPEN_READWRITE); if(handler == INVALID_HANDLE) { logs.Error("Failed to open database","TickORM"); return(INIT_FAILED); } logs.Info("Open database","TickORM"); //--- Here you would perform queries, inserts or updates //--- Close connection logs.Info("Closed database","TickORM"); DatabaseClose(handler); return(INIT_SUCCEEDED); }
В первом параметре мы определяем название базы данных, в данном случае я использовал "database". В конце просто добавим расширение файла ".sqlite", поскольку это база данных, хранящаяся в файле. Но это не проблема. Способ получения данных и выполнения запросов соответствует стандарту SQL.
В этом примере DATABASE_OPEN_READWRITE разрешает чтение и запись, а DATABASE_OPEN_CREATE гарантирует создание файла, если он еще не существует. После завершения операций просто закройте соединение с DatabaseClose, чтобы освободить ресурсы.
При выполнении этого кода база данных автоматически создается в папке <MQL5/Files>, которую можно просмотреть в метаредакторе:
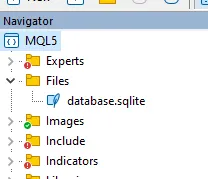
2. Создание таблицы
Первым шагом после подключения к базе данных является определение структуры, в которой будут храниться данные. В SQL это делается с помощью команды CREATE TABLE. В ней указывается название таблицы и поля, которые она должна содержать.
В MQL5 создание таблиц включает в себя две основные функции:
- DatabaseTableExists(handler, table_name): проверяет, существует ли уже таблица в базе данных, и возвращает true или false.
- DatabaseExecute(handler, sql): непосредственно выполняет SQL-инструкцию.
Наиболее распространенный алгоритм действий: проверить, существует ли таблица → если нет, создать таблицу. Вот практический пример:
//--- Create table if(!DatabaseTableExists(handler,"trades")) { logs.Info("Creating user table...","TickORM"); if(DatabaseExecute(handler,"CREATE TABLE trades (id INTEGER PRIMARY KEY AUTOINCREMENT,symbol TEXT, price FLOAT, takeprofit FLOAT, stoploss FLOAT, volume FLOAT);")) { logs.Info("'Trades' table created","TickORM"); } else { logs.Error("Failed to create table",GetLastError(),"TickORM"); } }
В этом фрагменте кода мы используем команду CREATE TABLE trades (...) для создания таблицы с именем trades, содержащей основную информацию о сделке: id (автоматически генерируемый уникальный идентификатор), инструмент, цена, тейк-профит, стоп-лосс и объем.
Если таблица уже существует, функция DatabaseTableExists предотвращает повторное выполнение команды. Всегда следуйте этому шаблону проверки наличия и создания таблиц по требованию.
На этом этапе структура базы данных выглядит так:
Метаредактор поддерживает просмотр этой базы данных, просто дважды щелкните по файлу просмотра таблиц, он автоматически изменит вкладку браузера:
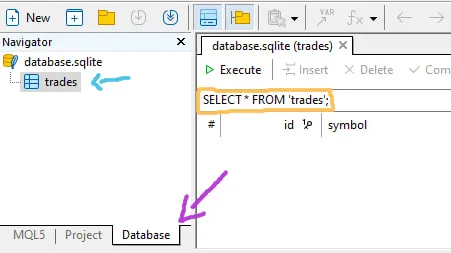
- Синяя стрелка указывает на таблицы базы данных
- Желтый цвет указывает, где вы вводите SQL-команду (это можно сделать вручную или с помощью кода, примеры мы увидим на следующем шаге).
- Фиолетовая стрелка показывает вкладку "Database" браузера, если вы хотите вернуться к просмотру файлов (с расширением .mqh или другие файлы исходного кода MQL5), просто вернитесь на вкладку "MQL5".
3. Вставка данных в таблицу
Следуя алгоритму, давайте вставим данные в таблицу, которую мы только что создали. В SQL мы используем команду INSERT INTO для добавления записей. Она следует этой структуре:
INSERT INTO table_name (column1,column2,...) VALUES (value1,value2,...)
В значениях мы передаем данные в необработанном виде, если это строка, просто заключаем ее в одинарные кавычки ('example'). Мы используем ту же функцию DatabaseExecute и проверяем, что выполнение было успешным:
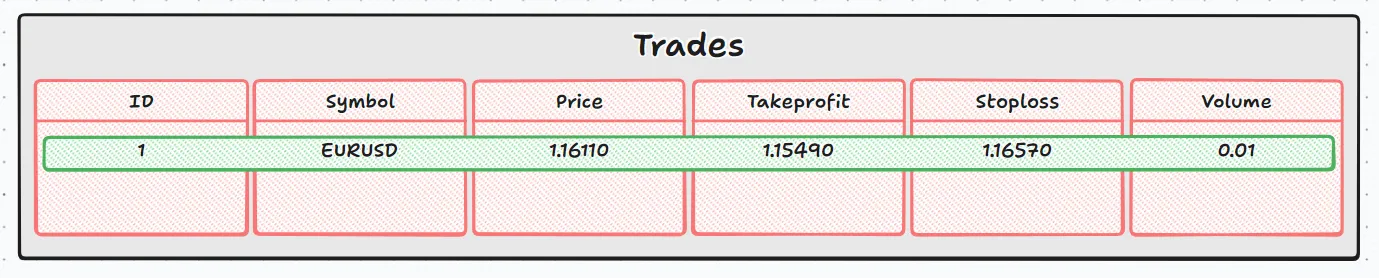
//--- Insert data ResetLastError(); if(DatabaseExecute(handler,"INSERT INTO trades (symbol,price,takeprofit,stoploss,volume) VALUES ('EURUSD',1.16110,1.15490,1.16570,0.01);")) { logs.Info("Data saved to the trades table","TickORM"); } else { logs.Error("Failed to save data to the trade table",GetLastError(),"TickORM"); }
Здесь мы добавляем запись в таблицу сделок, каждому столбцу присваивается значение:
- id: Генерируется базой данных автоматически
- инструмент: 'EURUSD'
- цена: 1.16110
- тейк-профит: 1.15490
- стоп-лосс: 1.16570
- объём: 0.01
Если представлять текущий этап, он выглядит следующим образом:
4. Считывание данных из таблицы
Сохранение данных в базе данных - это только половина работы, реальный потенциал открывается, когда мы можем запрашивать и извлекать эти данные структурированным способом. В MQL5 этот процесс протекает по четко определенной схеме:
- Подготовка запроса с помощью DatabasePrepare, передавая команду SQL.
- Чтение данных построчно с помощью DatabaseRead, прокручивая результаты.
- Завершение выполнения запроса с помощью DatabaseFinalize, освобождая ресурсы памяти.
Простой пример:
//--- Data reading int request = DatabasePrepare(handler,"SELECT * FROM trades;"); //--- Number of table columns that were read int size_cols = DatabaseColumnsCount(request); //--- While data is available for reading (reading each line) while(DatabaseRead(request)) { //--- Scan across all columns of the current line of reading for(int j=0;j<size_cols;j++) { string name = ""; DatabaseColumnName(request,j,name); logs.Info(name,"TickORM"); } } //--- Reset query DatabaseFinalize(request);
После выполнения в логе появляется следующее:
2025.08.21 10:14:51 [INFO]: Open database 2025.08.21 10:14:51 [INFO]: id 2025.08.21 10:14:51 [INFO]: symbol 2025.08.21 10:14:51 [INFO]: price 2025.08.21 10:14:51 [INFO]: takeprofit 2025.08.21 10:14:51 [INFO]: stoploss 2025.08.21 10:14:51 [INFO]: volume 2025.08.21 10:14:51 [INFO]: Closed database
Здесь запрос SELECT * FROM trades; извлекает все записи из таблицы "сделки". Каждый вызов DatabaseRead(request) перемещает курсор на следующую строку, а внутренний цикл проходит по всем столбцам, выводя только имена.
Если сравнить это с изображением, вид будет примерно следующим:
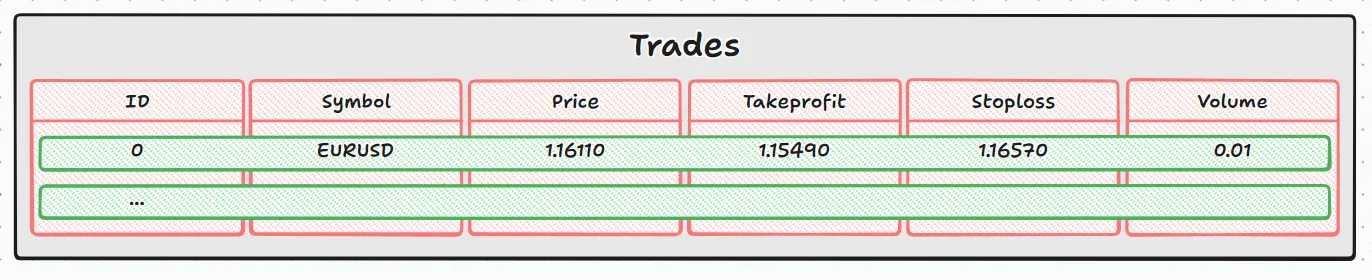
- Внешний цикл (while(DatabaseRead(request)) проходит построчно (зеленые прямоугольники).
- Внутренний цикл (for(int j=0;j<size_cols;j++) ) проходит столбец за столбцом в текущей строке (красные прямоугольники).
Вместе они позволяют перемещаться по базе данных от ячейки к ячейке, как если бы вы прокручивали электронную таблицу.
Переходя к чтению значений столбцов, следует отметить, что в предыдущем примере были перечислены только названия столбцов. Нам нужны сохраненные значения, поэтому мы используем определенные функции в соответствии с типом столбца:
- DatabaseColumnType → позволяет нам динамически определять тип столбца.
- DatabaseColumnText → тексты (например, символы или имена).
- DatabaseColumnDouble → числа с плавающей запятой (например, цены).
- DatabaseColumnLong или DatabaseColumnInteger → целочисленные значения (например, идентификаторы).
Полный пример:
//--- Data reading int request = DatabasePrepare(handler,"SELECT * FROM trades;"); //--- Number of table columns that were read int size_cols = DatabaseColumnsCount(request); //--- While data is available for reading (reading each line) while(DatabaseRead(request)) { //--- Scan across all columns of the current line of reading for(int j=0;j<size_cols;j++) { string name = ""; DatabaseColumnName(request,j,name); ENUM_DATABASE_FIELD_TYPE type = DatabaseColumnType(request,j); if(type == DATABASE_FIELD_TYPE_TEXT) { string data = ""; DatabaseColumnText(request,j,data); logs.Info(name + " | "+data,"TickORM"); } else if(type == DATABASE_FIELD_TYPE_FLOAT) { double data = 0; DatabaseColumnDouble(request,j,data); logs.Info(name + " | "+DoubleToString(data,5),"TickORM"); } else if(type == DATABASE_FIELD_TYPE_INTEGER) { long id = 0; DatabaseColumnLong(request,j,id); logs.Info(name + " | "+IntegerToString(id),"TickORM"); } } } //--- Reset query DatabaseFinalize(request);
После выполнения в логе появляется следующее:
2025.08.21 10:18:04 [INFO]: Open database 2025.08.21 10:18:04 [INFO]: id | 1 2025.08.21 10:18:04 [INFO]: symbol | EURUSD 2025.08.21 10:18:04 [INFO]: price | 1.16110 2025.08.21 10:18:04 [INFO]: takeprofit | 1.15490 2025.08.21 10:18:04 [INFO]: stoploss | 1.16570 2025.08.21 10:18:04 [INFO]: volume | 0.01000 2025.08.21 10:18:04 [INFO]: Closed database
В этом случае, помимо прокрутки строк и столбцов, мы также получаем доступ к содержимому каждой ячейки. Возвращаясь к аналогии с дидактическим образом:
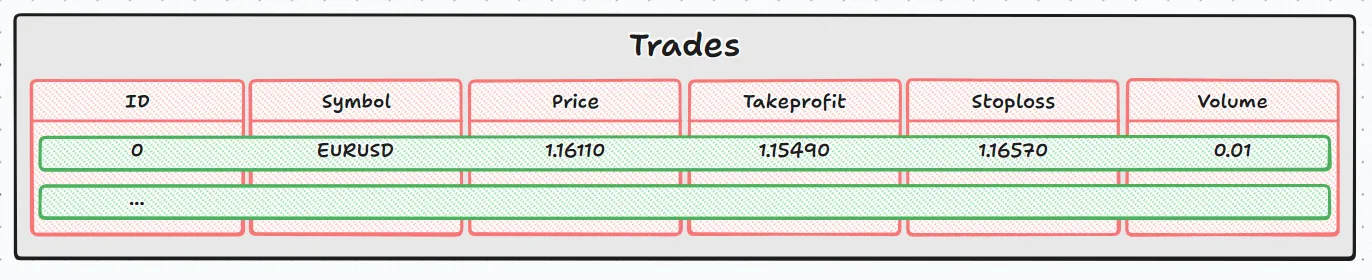
- Серый прямоугольник - это полная таблица (trades ).
- Каждый зеленый прямоугольник - это строка, возвращаемая DatabaseRead .
- Каждый красный прямоугольник представляет собой столбец, значением которого может быть текст (строка), десятичное число (double) или целое число (int).
- При использовании DatabaseColumnType это выглядит так, как если бы мы спрашивали: "Какой тип данных находится внутри этого красного прямоугольника?".
- Затем соответствующая функция (DatabaseColumnText , DatabaseColumnDouble , DatabaseColumnLong ) получает значение.
5. Обновление данных таблицы
В реальной жизни нам нередко приходится корректировать имеющуюся информацию. Именно здесь появляется команда UPDATE, которая позволяет изменять значения одного или нескольких столбцов в определенных строках таблицы.
В SQL базовая структура команды выглядит следующим образом:
UPDATE table_name SET column1=value1, column2=value2, ... WHERE condition;
В MQL5 обновление записей происходит с помощью функции DatabaseExecute, которая отправляет SQL-команду непосредственно в базу данных. Приведем пример:
//--- Update data ResetLastError(); if(DatabaseExecute(handler,"UPDATE trades SET volume=0.1 WHERE id=1")) { logs.Info("Trades table data updated","TickORM"); } else { logs.Error("Failed to update trades table data",GetLastError(),"TickORM"); }
Здесь мы имеем классический случай: мы указываем базе данных найти в таблице сделок запись с идентификатором, равным 1, и, найдя её, изменить значение столбца volume на 0,1.
Этот паттерн чрезвычайно полезен в трейдинге. Представьте, что вы сохранили сделку с начальным объемом 0,01 лота, но после корректировки стратегии вам нужно изменить его до 0,1. С помощью простой команды UPDATE информация надежно синхронизируется в базе данных без необходимости удаления и повторного создания записей.
6. Удаление данных из таблицы
Для удаления данных мы используем команду SQL DELETE, которая отвечает за удаление строк из таблицы. Общая форма команды выглядит следующим образом:
DELETE FROM table_name WHERE condition;
Она следует тому же паттерну, мы используем функцию DatabaseExecute для отправки SQL-команды:
//--- Delete data ResetLastError(); if(DatabaseExecute(handler,"DELETE FROM trades WHERE id=1")) { logs.Info("Deleted trades table data","TickORM"); } else { logs.Error("Failed to delete data to the trade table",GetLastError(),"TickORM"); }
В этом примере мы просим базу данных удалить из таблицы сделок запись, поле идентификатора которой равно 1. Одноразовое, контролируемое и безопасное удаление.
Важная деталь: Как и в случае с UPDATE, использование WHERE важно для предотвращения случайного удаления всей таблицы целиком.С помощью этой команды мы завершили основной цикл обработки данных: создание, вставка, обновление и удаление. Теперь у нас есть все основы для следующего шага.
7. Удаление таблицы
Если таблица больше не нужна, можно её удалить.
//--- Delete table ResetLastError(); if(DatabaseExecute(handler,"DROP TABLE trades")) { logs.Info("Trades table deleted","TickORM"); } else { logs.Error("Failed to delete trades table",GetLastError(),"TickORM"); }
Стоит подчеркнуть: удаление таблицы (DROP TABLE) необратимо. В отличие от команды DELETE FROM trades, которая удаляет только записи, но сохраняет структуру, команда DROP TABLE удаляет как таблицу, так и данные. Если вы выполните эту инструкцию, таблицу необходимо будет пересоздать, прежде чем она сможет принимать новые записи.
8. Транзакции и целостность данных
Теперь давайте перейдем к важному вопросу, а именно к целостности базы данных. В любом приложении, работающем с данными, целостность данных является критически важным моментом. Представьте себе ситуацию, когда нам нужно записать несколько записей. Если одна из этих вставок не удастся, а остальные уже выполнены, база данных может оказаться в несогласованном состоянии. Транзакции существуют для того, чтобы избежать эту проблему.
Транзакция — это блок SQL-операций, который следует рассматривать как атомарную единицу:
- Либо все содержащиеся в нем операторы будут применены**(commit**),
- Либо ни один не сохраняется**(rollback**).
В MQL5 у нас есть нативные функции, которые позволяют нам управлять этим процессом:
- DatabaseTransactionBegin(handler) → Начинает транзакцию.
- DatabaseTransactionCommit(handler) → Подтверждает и применяет изменения.
- DatabaseTransactionRollback(handler) → Отменяет все изменения с момента начала транзакции.
В приведенном ниже примере показано, как их использовать:
//--- Insert with transaction string sql="INSERT INTO trades (symbol,price,takeprofit,stoploss,volume) VALUES ('EURUSD',1.16110,1.15490,1.16570,0.01);"; DatabaseTransactionBegin(handler); logs.Info("Inserting data, preparing transaction","TickORM"); if(!DatabaseExecute(handler,sql)) { logs.Error("Transaction failed, reverting to previous state",GetLastError(),"TickORM"); DatabaseTransactionRollback(handler); } else { logs.Info("Transaction complete, changes saved","TickORM"); DatabaseTransactionCommit(handler); }
В этом фрагменте:
- Начинаем транзакцию с помощью DatabaseTransactionBegin .
- Мы пытаемся выполнить вставку (DatabaseExecute ).
- Если что-то пойдет не так, мы используем DatabaseTransactionRollback, чтобы все отменить.
- В противном случае мы подтверждаем изменения с помощью DatabaseTransactionCommit.
Это полезно, поскольку гарантирует, что не останется неполных данных. Это обеспечивает больший контроль, вы можете сгруппировать несколько операций вместе и применять их только тогда, когда будете уверены, что все они сработали. И, следовательно, это повышает безопасность: в случае непредвиденных сбоев (сеть, сбой питания, ошибка выполнения) база данных возвращается в прежнее состояние без ущерба для данных.
Представьте, что вы записываете десять различных операций на разных таблицах. Если восьмая завершится неудачей, то без транзакции у вас будет зарегистрировано семь операций и три пропущенных, что приведет к несогласованному состоянию. С транзакцией же все, что вам нужно сделать, это выполнить откат, и база данных вернется в предыдущее состояние.
9. Импорт и экспорт данных
Помимо транзакций, еще одним уровнем безопасности и практичности является возможность импорта и экспорта данных. Это позволяет создавать периодические резервные копии базы данных, обеспечивая не только защиту от потери данных, но и мобильность и простоту восстановления. Для этого существуют функции DatabaseExport и DatabaseImport, позволяющие извлекать данные в формате CSV и, при необходимости, восстанавливать их обратно в базе данных.
В приведенном ниже примере показан экспорт таблицы сделок в файл с именем backup_trades.csv:
//--- Export table ResetLastError(); long data = DatabaseExport(handler,"trades","backup_trades.csv",DATABASE_EXPORT_HEADER,";"); if(data > 0) { logs.Info("Backup of the 'trades' table created successfully","TickORM"); } else { logs.Error("Failed to create backup of table 'trades'",GetLastError(),"TickORM"); }
Ниже указаны некоторые важные моменты:
-
Имя файла: относится к папке MQL5\\Files. Это означает, что при желании вы можете организовать резервные копии во вложенных папках.
-
Формат CSV: общепринятый, может быть открыт в Excel, Google Sheets, Python, R и т.д.
-
Флаги: в примере мы использовали DATABASE_EXPORT_HEADER, который включает имена столбцов в первой строке. Это облегчает задачу, когда кому-то позже потребуется интерпретировать данные.
Значение Описание DATABASE_EXPORT_HEADER Отображает названия полей в первой строке DATABASE_EXPORT_INDEX Отображает номера рядов DATABASE_EXPORT_NO_BOM Не вставляет тег BOM в начало файла (BOM вставляется по умолчанию) DATABASE_EXPORT_CRLF Для переноса строк используется CRLF (по умолчанию — LF) DATABASE_EXPORT_APPEND Добавляет данные в конец существующего файла (по умолчанию файл перезаписывается). Если файла не существует, он будет создан. DATABASE_EXPORT_QUOTED_STRINGS Отображает строковые значения в двойных кавычках. DATABASE_EXPORT_COMMON_FOLDER CSV-файл будет создан в общей папке всех терминалов: \Terminal\Common\File. -
Разделитель: мы используем ";", но это может быть "," , "\\t" и т. д., в зависимости от ваших предпочтений или системы, которая будет обрабатывать файл.
В возвращаемых данных указано, сколько записей было экспортировано. Если значение отрицательное, произошла ошибка, и функция GetLastError() укажет, какая именно.
Теперь представьте обратный случай: восстановление или загрузка данных в таблицу сделок:
//--- Import table ResetLastError(); long data = DatabaseImport(handler,"trades","backup_trades.csv",DATABASE_IMPORT_HEADER|DATABASE_IMPORT_APPEND,";",0,NULL); if(data > 0) { logs.Info("'trades' table imported successfully","TickORM"); } else { logs.Error("Failed to import 'trades' table",GetLastError(),"TickORM"); }
Ниже указаны некоторые ценные подробности:
-
Комбинированные флаги: мы используем DATABASE_IMPORT_HEADER (система распознает первую строку как заголовок) и DATABASE_IMPORT_APPEND (импортированные данные будут добавлены к существующей таблице, без удаления уже имеющихся данных).
Значение Описание DATABASE_IMPORT_HEADER Первая строка содержит названия полей таблицы. DATABASE_IMPORT_CRLF Перенос строки - CRLF (по умолчанию — LF) DATABASE_IMPORT_APPEND Добавляет данные в конец существующей таблицы DATABASE_IMPORT_QUOTED_STRINGS Строковые значения заключены в двойные кавычки DATABASE_IMPORT_COMMON_FOLDER Файл находится в общей папке всех клиентских терминалов \Terminal\Common\File. -
Разделитель: должен совпадать с использованным при экспорте.
-
skip_rows: позволяет пропускать начальные строки (например, если вы хотите игнорировать комментарии или старые данные).
-
skip_comments: определяет символы, которые отмечают строки, подлежащие пропуску. Очень полезно при работе с CSV-файлами, аннотированными вручную.
В возвращаемых данных отображается количество импортированных записей.
С помощью функций DatabaseExport и DatabaseImport мы завершили базовый цикл работы с данными: импорт и экспорт. Теперь мы знаем, как создавать таблицы, вставлять данные, выполнять запросы, обновлять, удалять и даже сохранять внешние копии или восстанавливать информацию при необходимости.
Однако обратите внимание на одну деталь: каждая операция требует прямой работы с SQL и специфических вызовов нативных функций. Этот подход хорошо работает на небольших примерах, но по мере роста системы сложность возрастает, а вместе с ней и риск ошибок. Именно здесь неизбежно возникает следующий вопрос: действительно ли нам нужно всё фиксировать?
Именно здесь вступает в дело идея ORM. В следующем разделе мы разберемся, что это такое, почему это может радикально изменить способ взаимодействия с базами данных в MQL5 и как это вписывается в создаваемый нами путь.
Что такое ORM и зачем он нам нужен?
До сих пор мы изучали использование SQL непосредственно в MQL5, работая с таблицами и записями "на лету". Этот подход работает, но по мере роста системы увеличивается количество SQL, разбросанного по всему коду, а вместе с этим возникают проблемы с обслуживанием, повторением и риском ошибок. Вот тут-то и пригодится ORM (объектно-реляционное отображение).
ORM - это уровень, который устраняет разрыв между объектно-ориентированным миром и реляционным миром баз данных. Вместо того чтобы писать SQL вручную, мы описываем наши сущности как классы и позволяем ORM преобразовать их в команды SQL. Иными словами: вместо того, чтобы иметь дело с INSERT INTO trades (...) VALUES (...) , достаточно создать объект Trade и вызвать что-то вроде repository.save(trade).
К основным характеристикам ORM относятся:
- Автоматическое отображение: преобразует классы и атрибуты в таблицы и столбцы.
- Абстракция SQL: вы работаете с объектами и методами, а не со строками SQL.
- Согласованность: уменьшает дублирование логики, поскольку общие операции, такие как сохранение, поиск или удаление, централизованы.
- Портативность: в некоторых ORM одна и та же логика может работать в разных базах данных без изменения исходного кода.
В MQL5 эта идея приобретает еще больший смысл, поскольку написание SQL-запросов, встроенных в код, быстро превращается в кошмар. Представьте себе советник, содержащий десятки сущностей (сделки, ордера, логи, показатели эффективности). Каждая операция INSERT, SELECT или UPDATE, разбросанная по всему коду, означает больше точек отказа, больше трудностей в развитии логики и больше шансов на несогласованность.
"Проблема", которую решает ORM, заключается в следующем:
- Позволяет избежать дублирования SQL в различных частях советника.
- Упрощает обслуживание, поскольку изменения в структуре таблицы отражаются в одном месте (классе сущностей).
- Позволяет писать более читаемый и естественный код, мысля с точки зрения объектов предметной области (например, Торговля, Пользователь, Ордер), а не таблиц и столбцов.
- Это открывает простор для расширенных функций, таких как автоматическое создание таблиц, версионирование схемы и еще более простая интеграция с библиотеками ведения лога и аудита.
Вкратце: без ORM каждая операция представляет собой блок SQL в коде; с ORM SQL становится скрытой деталью, а вы сосредотачиваетесь на том, что действительно важно, - на логике торговли.
Наш ORM-проект в MQL5
Теперь, когда мы понимаем полезность ORM, необходимо визуализировать, как это отражается на экосистеме MQL5. В отличие от более традиционных языков в мире ORMS (Java, C#, Python), здесь у нас нет надежных фреймворков, готовых к использованию. Это означает, что нам придется создавать собственное решение, адаптированное к ограничениям и особенностям языка.
Цель этого проекта очевидна: создать уровень, который позволит разработчику работать с объектами вместо прямого SQL, но без потери простоты и производительности, необходимых в торговой среде.
Планируемые функциональные возможности включают в себя:
- Сущности: Каждая таблица в базе данных будет представлена классом MQL5, содержащим метаданные, описывающие ее столбцы (тип, первичный ключ, является ли он автоинкрементным, является ли он null и т.д.). Таким образом, класс Trade будет напрямую отражать таблицу сделок, но будет обрабатываться как нативный объект.
- Репозитории: Вместо того чтобы вручную писать команды INSERT, UPDATE или SELECT, для каждой сущности будет создан репозиторий, отвечающий за операции сохранения и восстановления данных. Например, TradeRepository централизует такие методы, как Save(trade), FindById(id) или Delete(trade). Таким образом, код советника становится чистым и свободным от разрозненных SQL-запросов.
- Конструктор запросов: Для случаев, когда нам потребуются более сложные запросы (фильтрация, сортировка, объединения), будет предусмотрен конструктор запросов. Это позволит вам программно и безопасно создавать запросы, избегая ошибок конкатенации строк и уменьшая прямое взаимодействие с SQL.
- Автоматическое создание таблиц: На основе метаданных сущности ORM сможет автоматически сгенерировать соответствующую таблицу. Прежде чем создавать таблицу, ORM проверит, не создана ли она ранее. Эта функциональность устраняет необходимость в написании SQL-скриптов вручную на начальном этапе проекта и гарантирует, что база данных будет соответствовать эволюции сущностей.
- Интеграция с логами и аудит: Каждая операция, выполняемая ORM (вставка, обновление, удаление), может быть записана в логи с использованием уже разработанных на MQL5 библиотек. Это упрощает аудит происходящего в базе данных и помогает выявлять проблемы.
- Расширяемость: Архитектура будет спроектирована таким образом, чтобы развиваться: сегодня мы начинаем с базовых операций CRUD, но ничто не мешает нам добавить поддержку миграции схем, связей между сущностями (одна со многим, многие со многими) или даже кэширования в памяти для оптимизации запросов.
Цель состоит не в том, чтобы воссоздать фреймворк Hibernate в MQL5, а в том, чтобы обеспечить минималистичный и эффективный уровень абстракции, отвечающий реальным потребностям тех, кто работает с алгоритмической торговлей и нуждается в структурированном сохранении данных.
Заключение и следующие шаги
Мы подошли к концу первой части этой серии, и картина начинает проясняться: базы данных в MQL5 - это не просто файлы для хранения информации, а мощные структуры, которые при надлежащем использовании позволяют записывать, запрашивать данные и работать с ними организованным и надежным способом. Мы увидели, как работает SQL на практике, от создания таблиц, вставки и чтения записей до работы со столбцами и типами данных с использованием нативных функций MQL5, таких как DatabaseOpen, DatabaseExecute, DatabasePrepare и DatabaseRead.
Что еще более важно, мы понимаем, что написание SQL вручную в каждом проекте быстро становится повторяющимся, подверженным ошибкам и сложным в обслуживании. Именно здесь появляется концепция ORM: уровень абстракции, который превращает таблицы в объекты, а SQL-запросы в простые методы, давая возможность работать с сущностями естественным образом, сохраняя при этом чистоту и централизованность кода.
В качестве следующих шагов в этой серии мы приступим к созданию этого уровня абстракции. Нашей целью будет создание минималистичного и эффективного ORM с классами сущностей, репозиториями, конструктором запросов и механизмом автоматического создания таблиц. Таким образом, такие операции, как сохранение, извлечение или удаление данных, больше не будут зависеть от SQL, разбросанного по всему коду, а от интуитивно понятных методов, которые непосредственно отражают домен торговли, который мы моделируем.
Осваивая эти инструменты, вы не только повышаете эффективность и безопасность работы с данными, но и создаете прочную основу для разработки сложных торговых систем, позволяющих проводить более углубленный анализ, надежные тесты на истории и подробные истории ордеров и стратегий.
На этом первый этап подходит к концу. Следующая часть серии будет практической: мы начнем с определения начальных классов ORM и реализации персистентности объектов, соединяя всю теорию, которую мы здесь рассмотрели, с функциональным кодом на MQL5.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/19285
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
В этой первой статье я показал лишь верхушку айсберга. TickORM идет гораздо дальше: идея заключается в том, чтобы полностью изменить способ работы с базами данных на MQL5. Цель - добиться чего-то прямолинейного, простого и мощного, когда открытие базы данных, создание хранилища и работа с сущностями будут так же естественны, как работа с массивами. К концу серии статей использование базы данных будет напоминать приведенный ниже пример, где вы сохраняете, ищете, обновляете и удаляете записи, не написав ни одного ручного запроса. Именно этот путь я прокладываю с помощью TickORM.
К сведению: В книге представлена реализация ORM для MQL5.