
Переосмысливаем классические стратегии (Часть III): Прогнозирование более высоких максимумов и более низких минимумов

Введение
Искусственный интеллект предлагает практически безграничные возможности для улучшения наших торговых возможностей. Однако маловероятно, что все стратегии окажутся эффективными. Наша цель — помочь трейдерам определить стратегии, которые наилучшим образом соответствуют их потребностям, предоставляя необходимую информацию для принятия обоснованных решений.
Учитывая огромное количество потенциальных комбинаций стратегий, ни один трейдер не может оценить их все в комплексе, прежде чем принять важные решения. Поэтому в этой серии статей мы будем исследовать пространство поиска торговых стратегий, сравнивая точность популярных стратегий с простейшими моделями.
В этой статье мы подробно рассмотрим классическую стратегию торговли на основе ценового действия, основанную на "более высоких максимумах" или "более низких минимумах". Мы обучили различные модели прогнозировать две различные цели. Первая цель — самая простая из возможных - включала прогнозирование изменений цен. Вторая заключалась в определении того, будет ли будущая цена закрытия выше текущего максимума, ниже текущего минимума или будет находиться между этими двумя значениями.
Для сравнения моделей разной сложности мы использовали перекрестную проверку временных рядов без случайного перемешивания. Мы проанализировали изменения точности по обеим целям. Наши результаты показывают, что более простые модели, прогнозирующие изменения уровня цен, могут быть более эффективными.
Обзор торговой стратегии
Обычно, когда трейдеры, использующие стратегии ценового действия, анализируют ценную бумагу, они ищут признаки формирования или затухания сильных трендов. Известным признаком формирования сильного тренда является ситуация, когда уровни цен закрываются выше предыдущих экстремальных значений и продолжают двигаться дальше все большими шагами. В этих случаях обычно говорят о "более высоких максимумах" или "более низких минимумах" в зависимости от направления цены.
На протяжении многих поколений трейдеры использовали эту простую стратегию для определения точек входа и выхода. Точки выхода обычно определяются, когда цена не может преодолеть свои экстремальные значения, что указывает на то, что тренд теряет силу и потенциально может развернуться. За долгие годы в эту стратегию были добавлены различные незначительные расширения, но ее основа осталась прежней.
Одним из самых больших недостатков этой стратегии является ситуация, когда цена неожиданно опускается ниже своего экстремума. Эти неблагоприятные изменения цен известны как "коррекции", и их трудно предсказать. В результате большинство трейдеров не открывают позицию немедленно, когда цена достигает нового экстремума. Вместо этого они ждут, чтобы увидеть, как долго цена сможет удерживаться на этих уровнях, прежде чем принять решение, — по сути, позволяя тренду проявить себя. Однако такой подход порождает несколько вопросов: как долго следует ждать, прежде чем делать вывод о том, что тренд себя оправдал? И наоборот, сколько времени пройдет, прежде чем тренд развернется? Именно с такими вопросами сталкиваются аналитики ценового действия.
Обзор методологии
Теперь, когда мы знакомы со слабыми сторонами торговой стратегии, мы понимаем желание многих трейдеров использовать ИИ для преодоления этих ограничений. Как упоминалось ранее, мы обучили разнообразную группу классификаторов прогнозировать, закроется ли цена за пределами текущих экстремальных значений или останется в пределах диапазона. Для этой задачи мы выбрали различные классификаторы, включая AdaBoost, деревья решений и нейронные сети. Перед сравнением ни для одной из моделей не проводилась настройка гиперпараметров.
Мы сопоставили три потенциальных результата с тремя категориальными уровнями: 1, 2 и 3 соответственно:
- 1 означает, что цена закрытия в будущем будет выше, чем максимальная цена сейчас
- 2 означает, что цена закрытия в будущем будет ниже минимальной цены на данный момент
- 3 означает, что 1 и 2 не оправдались, будущая цена будет находиться между текущим максимумом и минимумом.
Стоит отметить, что созданную нами новую цель сложнее интерпретировать. Если наша модель прогнозирует переход в состояние 3, мы не всегда можем ответить на вопрос, повысятся или понизятся уровни цен, в зависимости от цены на тот момент. Это делает нашу модель не только менее прозрачной, но и, по-видимому, менее точной, чем самая простая модель.
Обычно мы рассматриваем любую стратегию, которая может превзойти самую простую модель. Сложная стратегия, которая не способна превзойти простую модель, может не оправдать дополнительных затрат ресурсов, таких как время.
Исследовательский анализ данных в Python
Для начала нужно экспортировать рыночные данные из MetaTrader 5. Откройте терминал и выберите иконку "Символ". Затем выберите бары в контекстном меню, найдите интересующий вас символ и нажмите "Экспортировать бары".

Рис. 1. Подготовка к экспорту рыночных данных
Теперь, когда наши данные готовы, начнем визуализацию для оценки того, могут ли существовать какие-либо взаимосвязи между рассматриваемыми переменными.
Начнем с импорта необходимых нам библиотек.
#import libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Затем считываем данные, подготовленные ранее. Обратите внимание, что терминал MetaTrader 5 выдает нам CSV-файлы, разделенные табуляцией. Поэтому при чтении файла мы передаем параметр \t.
gbpusd = pd.read_csv("/home/volatily/market_data/GBPUSD_Daily_20160103_20240131.csv",sep="\t")
Переименуем столбцы в нашем фрейме данных.
#Rename the columns
gbpusd.rename(columns={"<DATE>":"Date","<OPEN>":"Open","<HIGH>":"High","<LOW>":"Low","<CLOSE>":"Close","<TICKVOL>":"TickVol","<VOL>":"Vol","<SPREAD>":"Spread"},inplace=True)
Определим, насколько далеко в будущее мы хотим заглянуть в нашем прогнозе.
#Define how far into the future we want to forecast look_ahead = 20
Теперь определим наши метки уже рассмотренным способом.
#This column will help us with our plots gbpusd["Future Close"] = gbpusd["Close"].shift(-look_ahead) #Let's mark the normal target #If price rises, our target will be 1 #If price falls, our target will be 0 gbpusd["Price Target"] = 0 #Let's mark the new target #If price makes a higher high, we will label 1 #If price makes a lower low, we will label 2 #If price fails to make either, we will label 3 gbpusd["New Target"] = 0
Маркировка данных.
#Labeling the data #If the future close was less than the current close, price depreciated, label 0 gbpusd.loc[gbpusd["Close"] > gbpusd["Close"].shift(-look_ahead),"Price Target"] = 0 #If the future close was greater than the current close, price depreciated, label 1 gbpusd.loc[gbpusd["Close"] < gbpusd["Close"].shift(-look_ahead),"Price Target"] = 1 #If price makes a higher high our label will be 1 gbpusd.loc[gbpusd["Close"].shift(-look_ahead) > gbpusd["High"],"New Target"] = 1 #If price makes a lower low our label will be 2 gbpusd.loc[gbpusd["Close"].shift(-look_ahead) < gbpusd["Low"],"New Target"] = 2 #Otherwise our label will be 3 gbpusd.loc[gbpusd["Close"].shift(-look_ahead) < gbpusd["Low"],"New Target"] = 3
Мы можем удалить все строки с отсутствующими значениями.
#Drop the last look ahead rows
gbpusd = gbpusd[:-look_ahead] Торговая стратегия подразумевает, что между закрытием и максимумом существует взаимосвязь. Давайте визуализируем, существует ли какая-либо взаимосвязь между закрытием и максимумом.
#Plot a scattor plot so we can see if there may be any relationship between the close and the high sns.scatterplot(data=gbpusd,x="Close",y="High",hue="Price Target")

Рис. 2. Графическое сопоставление закрытия и максимума
Графики рассеяния позволяют нам визуализировать взаимосвязи между любой парой переменных в моделируемой системе.
Наблюдая за данными, мы можем сразу увидеть, что существует сильная, почти линейная связь между ценой закрытия и максимальной ценой. Мы добавили цвет к графику, чтобы отличить случаи, когда цена росла, от случаев, когда она падала. Как было отмечено, четкого разграничения между этими двумя случаями не существует. Единственные заметные точки разделения появляются при экстремальных значениях. Например, когда цена закрывается ниже уровня 1,1, она всегда как будто отскакивает назад.
Построим ту же самую диаграмму рассеяния, однако на этот раз поместим самую низкую цену на ось Y.
#Plot a scattor plot so we can see if there may be any relationship between the close and the low sns.scatterplot(data=gbpusd,x="Close",y="Low",hue="Price Target")

Рис. 3. Визуализация взаимосвязи между ценой закрытия и минимумом
Как и ожидалось, естественного разделения не наблюдается. Такое естественное разделение желательно, поскольку оно помогает нашим моделям быстрее усваивать границы принятия решений. Давайте посмотрим, поможет ли нам наша новая цель лучше разделить набор данных.
#Plot a scattor plot so we can see if there may be any relationship between the close and the low sns.scatterplot(data=gbpusd,x="Close",y="Low",hue="New Target")

Рис. 4. Наша новая цель не обеспечивает большего разделения
Как видим, разделение по-прежнему плохое. Самые темные точки, представляющие состояние 3, проходят почти по всей длине нашего графика. То есть в наших данных есть случаи, когда одни и те же входные данные приводят к разным результатам.
Чтобы продемонстрировать, как выглядит хорошее разделение, давайте визуализируем текущую цену на оси X, а будущую цену - на оси Y. Окрасим точки в оранжевый цвет при повышения цен и в синий цвет - при понижении.
#Plot a scattor plot so we can see if there may be any relationship between the close and the low sns.scatterplot(data=gbpusd,x="Close",y="Future Close",hue="Price Target")

Рис. 5. Искусственный пример того, как выглядит хорошее разделение
Здесь мы видим четкое разделение между двумя классами. Этого следовало ожидать, поскольку мы используем саму цель на графике, наша цель как специалистов по машинному обучению — обнаружить признак или цель, которая дает нам уровень разделения, близкий к тому, что мы видим на рисунке 4.
Если мы сделаем то же самое, используя нашу новую цель, мы увидим нечто странное.
#Plot a scattor plot so we can see if there may be any relationship between the close and the low sns.scatterplot(data=gbpusd,x="Close",y="Future Close",hue="New Target")

Рис. 6. Визуализация разделения с новой целью
Обратите внимание, что темные и светлые точки хорошо разделены между верхней и нижней половинами графика, представляя собой случаи, когда цена росла и падала соответственно. Между этими двумя группами имеются точки, классифицированные как состояние 3, обозначенные темными пятнами вдоль центра, показывающими случаи, когда цена колебалась.
Обучение моделей
Теперь импортируем необходимые нам модели и другие инструменты предварительной обработки.
#Let's get a group of different models from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import BaggingClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.neural_network import MLPClassifier from sklearn.svm import LinearSVC #Import cross validation libraries from sklearn.model_selection import TimeSeriesSplit #Import accuracy metrics from sklearn.metrics import accuracy_score #Import preprocessors from sklearn.preprocessing import RobustScaler
Определим параметры для перекрестной проверки наших временных рядов. Помните, что разрыв должен быть как минимум равен нашему горизонту прогнозирования.
#Splits splits = 10 gap = look_ahead
Давайте сохраним каждую из нужных нам моделей в списке, чтобы мы могли программно подогнать все имеющиеся у нас модели.
#Store each of the models we need cols = ["AdaBoostClassifier","Linear DiscriminantAnalysis","Bagging Classifier","Random Forest Classifier","KNeighborsClassifier","Neural Network Small","Neural Network Large"] models = [AdaBoostClassifier(),LinearDiscriminantAnalysis(),BaggingClassifier(n_jobs=-1),RandomForestClassifier(n_jobs=-1),KNeighborsClassifier(n_jobs=-1),MLPClassifier(hidden_layer_sizes=(5,2),early_stopping=True,max_iter=1000),MLPClassifier(hidden_layer_sizes=(20,10),early_stopping=True,max_iter=1000)] #Create data frames to store our accuracy with different models on different targets index = np.arange(0,splits) price_target = pd.DataFrame(columns=cols,index=index) new_target = pd.DataFrame(columns=cols,index=index)
Создадим объект разделения временного ряда для перекрестной проверки.
#Create the tscv splits
tscv = TimeSeriesSplit(n_splits=splits,gap=gap)
Определим предикторы и цели для наших моделей.
#Define the predictors and target predictors = ["Open","High","Low","Close"] target = "New Target"
Проведем перекрестную проверку.
#Now we perform cross validation for j in (np.arange(len(models))): #We need to train each model model = models[j] for i,(train,test) in enumerate(tscv.split(gbpusd)): #Scale the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(gbpusd.loc[train[0]:train[-1],predictors]) scaler = RobustScaler() X_test_scaled = scaler.fit_transform(gbpusd.loc[test[0]:test[-1],predictors]) #Train the model model.fit(X_train_scaled,gbpusd.loc[train[0]:train[-1],target]) #Measure the accuracy new_target.iloc[i,j] = accuracy_score(gbpusd.loc[test[0]:test[-1],target],model.predict(X_test_scaled))
Рассмотрим эффективность каждой из наших моделей на максимально простой цели.
#Calculate the mean for each column when predicting price for i in np.arange(0,len(models)): print(f"{cols[i]} achieved accuracy: {price_target.iloc[:,i].mean()}")
Linear Discriminant Analysis achieved accuracy: 0.5579646017699115
Bagging Classifier achieved accuracy: 0.5075221238938052
Random Forest Classifier achieved accuracy: 0.5349557522123894
KNeighborsClassifier achieved accuracy: 0.536283185840708
Neural Network Small achieved accuracy: 0.45309734513274336
Neural Network Large achieved accuracy: 0.5446902654867257
Линейный дискриминантный анализ (Linear Discriminant Analysis) показал наилучшие результаты на этом конкретном наборе данных, достигнув почти 56% точности. Давайте посмотрим, какие будут результаты с новой целью.
#Calculate the mean for each column when predicting price for i in np.arange(0,len(models)): print(f"{cols[i]} achieved accuracy: {new_target.iloc[:,i].mean()}")
Linear DiscriminantAnalysis achieved accuracy: 0.4668141592920355
Bagging Classifier achieved accuracy: 0.4393805309734514
Random Forest Classifier achieved accuracy: 0.45929203539823016
KNeighborsClassifier achieved accuracy: 0.465929203539823
Neural Network Small achieved accuracy: 0.3920353982300885
Neural Network Large achieved accuracy: 0.4606194690265487
Линейный дискриминантный анализ по-прежнему возглавляет список. Все модели продемонстрировали более слабые результаты на новой цели, но наибольшее падение производительности наблюдалось у малой нейронной сети.
| Модель | Изменение производительности |
|---|---|
| AdaBoostClassifier | -14.32748538011695% |
| Линейный дискриминантный анализ (Linear Discriminant Analysis) | -19.526066350710863% |
| Бэггинг (Bagging Classifier) | -22.09660842754366% |
| Случайный лес (Random Forest Classifier) | -16.730769230769248% |
| Ближайшие соседи (KNeighborsClassifier) | -15.099715099715114% |
| Малая нейронная сеть (Neural Network Small) | -41.04193138500632% |
| Большая нейронная сеть (Neural Network Large) | -21.1502782931354% |
Давайте проанализируем матрицу ошибок нашей наиболее эффективной модели.
#Let's continue analysing the performance of our best model Linear Discriminant Analysis from mlxtend.evaluate import confusion_matrix from mlxtend.plotting import plot_confusion_matrix model = LinearDiscriminantAnalysis() model.fit(gbpusd.loc[0:1000,predictors],gbpusd.loc[0:1000,"New Target"]) cm = confusion_matrix(y_target=gbpusd.loc[1000:,"New Target"],y_predicted=model.predict(gbpusd.loc[1000:,predictors]),binary=True) fig , ax = plot_confusion_matrix(cm)

Рис. 7. Матрица путаницы для нашей модели линейно-дискриминантного анализа
Матрица ошибок помогает нам определить, какие классы представляют сложность для нашей модели. Как видно на рисунке выше, наша модель показала наихудшие результаты при прогнозировании класса 3. Однако этот класс имеет небольшой набор наблюдений. Для решения этой проблемы нам, возможно, придется использовать данные, которые лучше представляют всю популяцию. Этого можно добиться, извлекая больше исторических данных или анализируя более короткие таймфреймы.
Выбор признаков
Иногда мы можем улучшить производительность, исключив ненужные признаки из наших моделей. Давайте сосредоточимся на нашей самой эффективной модели - линейно-дискриминантном анализе (LDA) - и выявим ее наиболее важные особенности, чтобы посмотреть, можем ли мы еще больше повысить ее производительность.#Now let us perform feature selection
from mlxtend.feature_selection import SequentialFeatureSelector
Существует множество алгоритмов выбора признаков. В этой статье мы использовали алгоритм прямого выбора признаков. Хотя существуют различные версии этого алгоритма, общий процесс начинается с нулевой модели, которая служит эталоном. Затем алгоритм оценивает каждый из доступных признаков p один за другим, выбирая в качестве первого тот, который обеспечивает наибольшее улучшение производительности. Этот процесс повторяется для оставшихся p-1 предикторов. Благодаря последним достижениям в области параллельных вычислений такие алгоритмы стали более доступными.
Уменьшая наши предикторы от p до k, где k<p и разумно выбирая признаки k, мы можем либо превзойти изначальную модель или создать модель с той же надежностью, но более быстрой в обучении. Кроме того, сокращение числа предикторов, используемых в модели, может снизить дисперсию коэффициентов нашей модели.
Однако есть два существенных ограничения этого алгоритма, которые стоит обсудить. Во-первых, новая модель может быть немного более предвзятой из-за ограниченной информации, которую мы используем для ее обучения. Более того, выбор первого признака влияет на последующий выбор. Если изначально выбранный признак имеет слабую связь с целевым, последующие признаки могут оказаться неинформативными из-за изначально неудачного выбора.
В нашем анализе мы позволили селектору признаков выбрать столько переменных, сколько он посчитает важным, но он выбрал только один - цену открытия.
#Forward feature selection forward_feature_selection = SequentialFeatureSelector(LinearDiscriminantAnalysis(), k_features =(1,4), forward=True, verbose=2, scoring="accuracy", cv=5, n_jobs=-1).fit(gbpusd.loc[:,predictors],gbpusd.loc[:,"New Target"])
Теперь мы хотим увидеть лучший признак.
#Best feature
forward_feature_selection.k_feature_names_ Давайте посмотрим на наши новые уровни точности.
#Update the predictors and target predictors = ["Open"] target = "New Target" best_features_for_new_target = pd.DataFrame(columns=["Linear Discriminant Analysis"],index=index)
Проведем перекрестную проверку, используя лучший выявленный нами признак.
#Now we perform cross validation for i,(train,test) in enumerate(tscv.split(gbpusd)): #First initialize the model model = LogisticRegression() #Train the model model.fit(gbpusd.loc[train[0]:train[-1],predictors],gbpusd.loc[train[0]:train[-1],target]) #Measure the accuracy best_features_for_new_target.iloc[i,0] = accuracy_score(gbpusd.loc[test[0]:test[-1],target],model.predict(gbpusd.loc[test[0]:test[-1],predictors]))
Рассмотрим наши новые уровни точности.
#New accuracy only using the open price best_features_for_new_target.iloc[:,0].mean()
И наконец, рассмотрим изменение эффективности между моделью, которая использовала все предикторы, и моделью, которая использовала только один.
Как видим, изменение производительности составляет около -0,2%. Это значит, что мы потеряли очень мало информации, отказавшись от трех других предикторов.
Реализация стратегии на MQL5
Начнем с импорта необходимых нам библиотек.
//+------------------------------------------------------------------+ //| Forecasting Highs And Lows.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //|Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> //Trade class CTrade Trade; //Initialize the class
Then we define input variables, so our end user can customize his experience.
//+------------------------------------------------------------------+ //| Input variables | //+------------------------------------------------------------------+ input int fetch = 10; //How much data should we fetch? input int look_ahead = 2; //Forecst horizon. input int rsi_period = 20; //Forecst horizon. int input lot_multiple = 1; //How many times bigger than minimum lot? input double stop_loss_values = 1; //How large should our stop loss be?
Нам нужны некоторые глобальные переменные, которые будут использоваться в разных частях нашего приложения.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ vector state = vector::Zeros(3);//This vector will store the state of the system using binary mapping double minimum_volume;//The smallest contract size allowed vector input_data;//Input data vector output_data;//Output data vector rsi_data;//RSI output data double variance;//This is the variance of our input data int classes = 3;//The total number of output classes we have vector mean_values = vector::Zeros(classes);//This vector will store the mean value for each class vector probability_values = vector::Zeros(classes);//This vector will store the prior probability the target will belong each class vector total_class_count = vector::Zeros(classes);//This vector will count the number of times each class was the target int rsi_handler;//This will store our RSI handler int forecast = 0;//Our model's forecast double discriminant_values[3];//The discriminant function
Затем определим процедуру инициализации нашего советника. Сначала проверяем, что пользователь передал допустимые входные данные, а затем приступаем к настройке нашего технического индикатора и инициализируем состояние нашей торговой системы.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Validate inputs if(!valid_inputs()) { //User passed invalid inputs Print("Invalid inputs were received!"); return(INIT_FAILED); } //--- Load input data rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,rsi_period,PRICE_CLOSE); //--- Market data minimum_volume = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); //--- Update system state update_system_state(0); //--- End of initialization return(INIT_SUCCEEDED); }
Нам также необходимо определить процедуру деинициализации для нашего приложения.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Remove indicators IndicatorRelease(rsi_handler); //--- Detach the Expert Advisor ExpertRemove(); //--- End of deinitialization }
Мы построим функцию, которая поможет нам проанализировать, есть ли у нас какие-либо сигналы на вход. Наши сигналы на вход считаются действительными, если прогноз модели совпадает с трендом на более длинных таймфреймах, например, недельном. Если эти два показателя совпадают, мы будем рассчитывать время входа, используя индикатор RSI.
//+------------------------------------------------------------------+ //| This function will analyse our entry signals | //+------------------------------------------------------------------+ void analyse_entry(void) { Print("Higher Time Frame Trend"); Print(iClose(_Symbol,PERIOD_W1,12) - iClose(_Symbol,PERIOD_CURRENT,0)); if(iClose(_Symbol,PERIOD_W1,12) < iClose(_Symbol,PERIOD_CURRENT,0)) { if(forecast == 1) { bullish_sentiment(); } } if(iClose(_Symbol,PERIOD_W1,12) > iClose(_Symbol,PERIOD_CURRENT,0)) { if(forecast == 2) { bearish_sentiment(); } } }
Нам нужны две специальные функции для интерпретации нашего индикатора RSI: одна функция будет анализировать индикатор на предмет потенциальной продажи, а другая — покупки.
//+------------------------------------------------------------------+ //| This function will analyze our RSI for sell signals | //+------------------------------------------------------------------+ void bearish_sentiment(void) { rsi_data.CopyIndicatorBuffer(rsi_handler,0,0,1); if(rsi_data[0] < 50) { Trade.Sell(minimum_volume * lot_multiple,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_BID),(SymbolInfoDouble(_Symbol,SYMBOL_BID) + stop_loss_values),(SymbolInfoDouble(_Symbol,SYMBOL_BID) - stop_loss_values)); update_system_state(2); } } //+------------------------------------------------------------------+ //| This function will analyze our RSI for buy signals | //+------------------------------------------------------------------+ void bullish_sentiment(void) { rsi_data.CopyIndicatorBuffer(rsi_handler,0,0,1); if(rsi_data[0] > 50) { Trade.Buy(minimum_volume * lot_multiple,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_ASK),(SymbolInfoDouble(_Symbol,SYMBOL_ASK) - stop_loss_values),(SymbolInfoDouble(_Symbol,SYMBOL_ASK) +stop_loss_values)); update_system_state(2); } }
Теперь мы определим функцию, которая будет проверять входные данные, переданные нашим пользователем при инициализации.
//+------------------------------------------------------------------+ //|This function will check the inputs the user passed | //+------------------------------------------------------------------+ bool valid_inputs(void) { //--- For the inputs to be valid: //--- The forecast horizon must be less than the data fetched return((fetch > look_ahead)); }
Теперь разработаем функцию, которая инициализирует нашу модель LDA.
//+------------------------------------------------------------------+
//| This function will initialize our model |
//+------------------------------------------------------------------+
void initialize_model(void)
{
//--- First fetch the input data
fetch_input_data(look_ahead,fetch);
fetch_output_data(0,fetch);
//--- Update the system state
update_system_state(1);
//--- Fit the model
fit_model();
}
Чтобы инициализировать модель, нам сначала необходимо получить входные данные для модели. За это и отвечает наша функция. Обратите внимание, что функция просто извлекает цену открытия, поскольку наш анализ показал, что это самый важный признак, который у нас есть.
//+------------------------------------------------------------------+ //| This function will fetch our input data | //+------------------------------------------------------------------+ void fetch_input_data(int start,int size) { //--- Fetching input data Print("Fetching input data"); input_data = vector::Zeros(fetch); input_data.CopyRates(_Symbol,PERIOD_CURRENT,COPY_RATES_OPEN,start,size); input_data.Resize(size); Print("Input data fetched"); }
Затем нам нужно извлечь наши выходные данные и маркировать их. Также обратите внимание, что мы отслеживаем, сколько раз каждый класс появлялся в качестве целевого. Эта информация будет использоваться позже, когда мы будем подгонять модель LDA.
//+------------------------------------------------------------------+ //| This function will fetch our output data | //+------------------------------------------------------------------+ void fetch_output_data(int start,int size) { //--- Fetching output data vector historic_high = vector::Zeros(size); vector historic_low = vector::Zeros(size); vector historic_close = vector::Zeros(size); historic_close.CopyRates(_Symbol,PERIOD_CURRENT,COPY_RATES_CLOSE,start,size+look_ahead); historic_low.CopyRates(_Symbol,PERIOD_CURRENT,COPY_RATES_HIGH,start,size+look_ahead); historic_high.CopyRates(_Symbol,PERIOD_CURRENT,COPY_RATES_LOW,start,size+look_ahead); output_data = vector::Zeros(size); output_data.Resize(size); //--- Reset class counts total_class_count[0] = 0; total_class_count[1] = 0; total_class_count[2] = 0; //--- Label the data for(int i = 0; i < size; i++) { //--- Price broke into a higher high if(historic_close[i + look_ahead] > historic_high[i]) { output_data[i] = 1; total_class_count[0] += 1; } //--- Price broke into a lower low else if(historic_close[i + look_ahead] < historic_low[i]) { output_data[i] = 2; total_class_count[1] += 1; } //--- Price was stuck in a range else if((historic_close[i + look_ahead] > historic_low[i]) && (historic_close[i + look_ahead] < historic_high[i])) { output_data[i] = 3; total_class_count[2] += 1; } } //--- We fetched output data succesfully Print("Output data fetched"); Print("Total class counts"); Print(total_class_count); }
Теперь определим процедуру подгонки модели LDA. На первом этапе мы рассчитываем среднее значение цены открытия в каждом из трех классов. На втором этапе нам необходимо рассчитать начальное распределение вероятностей того, что каждый класс является целевым. Мы можем просто оценить это значение, используя подсчеты классов, которые мы выполнили на предыдущем этапе. Наконец, нам необходимо рассчитать дисперсию цены открытия для каждого из трех классов.
//+------------------------------------------------------------------+ //| This function will fit the LDA algorithm | //+------------------------------------------------------------------+ //--- Fit the model void fit_model(void) { //--- To fit the LDA model, we first need to know the mean value of X for each of our 3 classes double sum_class_one = 0; double sum_class_two = 0; double sum_class_three = 0; //--- In this case we only have 1 input for(int i = 0; i < fetch;i++) { //--- Class 1 if(output_data[i] == 1) { sum_class_one += input_data[i]; } //--- Class 2 else if(output_data[i] == 2) { sum_class_two += input_data[i]; } //--- Class 3 else if(output_data[i] == 3) { sum_class_three += input_data[i]; } } //--- Calculate the mean value for each class mean_values[0] = sum_class_one / total_class_count[0]; mean_values[1] = sum_class_two / total_class_count[1]; mean_values[2] = sum_class_three / total_class_count[2]; Print("Mean values"); Print(mean_values); //--- Now we need to calculate class probabilities for(int i=0;i<classes;i++) { probability_values[i] = total_class_count[i] / fetch; } Print("Class probability values"); Print(probability_values); //--- Calculating the variance Print("Calculating the variance"); //--- Next we need to calculate the variance of the inputs within each class of y. //--- This process can be simplified into 2 steps //--- First we calculate the difference of each instance of x from the group mean. double squared_difference[3]; for(int i =0; i < fetch;i++) { //--- If the output value was 1, find the input value that created the output //--- Calculate how far that value is from it's group mean and square the difference if(output_data[i] == 1) { squared_difference[0] = MathPow((input_data[i]-mean_values[0]),2); } else if(output_data[i] == 2) { squared_difference[1] = MathPow((input_data[i]-mean_values[1]),2); } else if(output_data[i] == 3) { squared_difference[2] = MathPow((input_data[i]-mean_values[2]),2); } } //--- Show the squared difference values Print("Squared difference value for each output value of y"); ArrayPrint(squared_difference); //--- Next we calculate the variance as the average squared difference from the mean variance = (1.0/(fetch - 3.0)) * (squared_difference[0] + squared_difference[1] + squared_difference[2]); Print("Variance: ",variance); }
Теперь нам нужна функция для извлечения прогнозов из нашей модели. Модель будет прогнозировать дискриминантное значение для каждого из трех возможных классов. Класс с наибольшим значением дискриминанта является прогнозным.
//+-------------------------------------------------------------------+ //| This model will fetch our model's prediction | //+-------------------------------------------------------------------+ void model_forecast(void) { //--- Obtain a forecast from our model //--- First we need to fetch the most recent input data fetch_input_data(0,1); //--- We need to calculate the discriminant function for each class //--- The predicted class is the one with the largest discriminant function Print("Calculating discriminant values."); for(int i = 0; i < classes; i++) { discriminant_values[i] = (input_data[0] * (mean_values[i]/variance) - (MathPow(mean_values[i],2)/(2*variance)) + (MathLog(probability_values[i]))); } //--- Show the LDA prediction forecast = (ArrayMaximum(discriminant_values) +1); Print("LDA Forecast: ",forecast); ArrayPrint(discriminant_values); }
Нам нужна функция для обновления состояния нашей системы, чтобы наша функция OnTick всегда знала, что делать дальше.
//+-------------------------------------------------------------------+ //| This function will be used to update the state of the system | //+-------------------------------------------------------------------+ void update_system_state(int index) { //--- Each column vector is set to 0 except column 0, the first column. //--- If the first column is set to 1, then our model has not been trained //--- If the second column is set to 1, then our model has been trained but we have no positions //--- If the third column is set to 1, then we have a position we need to manage //--- Update the system state state = vector::Zeros(3); state[index] = 1; Print("Updating system state"); Print(state); }
Теперь определим функцию OnTick, которая обеспечит вызов всех наших функций в нужное время.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- The model has not been trained if(state.ArgMax() == 0) { Print("Training the model."); initialize_model(); } //--- The model has been trained, but we have no positions else if(state.ArgMax() == 1) { Print("Finding An Entry."); model_forecast(); analyse_entry(); } } //+------------------------------------------------------------------+

Рис. 8. Наш советник

Рис. 9. Наш советник на основе LDA
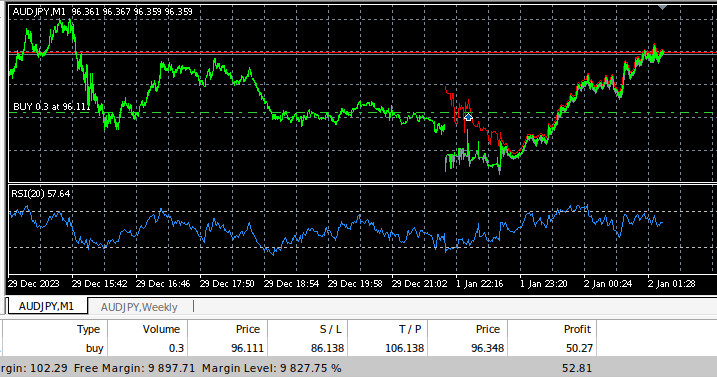
Рис. 10. Наш советник на исторических данных
Заключение
В статье мы продемонстрировали, почему трейдерам, по-видимому, лучше прогнозировать изменения цен, чем более высокие максимумы и более низкие минимумы. Надеюсь, что после прочтения этой статьи у вас появится больше уверенности в принятии решения о том, подходит ли вам эта торговая стратегия, учитывая ваш личный уровень толерантности к риску и ваши финансовые цели.
Алгоритм линейного дискриминантного анализа (LDA) моделирует распределение входных переменных внутри каждого класса, используя теорему Байеса для оценки вероятностей и предполагая нормальное распределение со специфическими для класса средними значениями и общей дисперсией. Это помогает LDA эффективно различать характеристики классов, вычисляя дискриминантные значения, которые максимизируют разделение классов и минимизируют внутриклассовую дисперсию. Однако допущения LDA могут ограничить прозрачность и интерпретируемость. Модель может оказаться хуже более простых моделей без обширной настройки параметров. Наши тесты с использованием настроек по умолчанию для ежедневных данных выявили потенциальные проблемы с производительностью, что позволяет предположить, что лучших результатов можно достичь при наличии большего объема данных и вычислительных ресурсов.
Повторение анализа с более крупными наборами данных может дать больше информации, хотя такой подход осуществим только при наличии достаточной вычислительной мощности. Мы использовали 10-кратную перекрестную проверку временных рядов, то есть каждая модель обучалась 10 раз. По мере увеличения размера набора данных можно ожидать, что время обучения модели будет расти экспоненциально.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15388
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования