
神经网络变得轻松(第四十九部分):软性扮演者-评价者

概述
我们继续精练在连续动作空间中运用强化学习解决问题的算法。在之前的文章中,我们研究了深度判定性策略梯度(DDPG)和孪生延迟深度判定性策略梯度(TD3)算法。在本文中,我们将把注意力集中在另一种算法上 — 软性扮演者-评论者(SAC)。它首次出现在 2018 年 1 月 发表的文献 “软性扮演者-评论者:随机扮演者异政策最大熵值深度强化学习” 之中。该方法几乎与 TD3 同步提出。它们有一些相似之处,但在算法上也存在差异。SAC 的主要目标是在给定策略的最大熵的情况下最大化预期回报,其能在随机环境中找到各种最优解。
1. 软性扮演者-评价者算法
在研究 SAC 算法时,我们应该能立即注意到它不是 TD3 方法的直系后代(反之亦然)。但它们有一些相似之处。特别是:
- 它们都是异政策算法
- 它们都利用 DDPG 方法
- 它们都用到 2 个评论者。
但不像之前讨论的两种方法,SAC 使用随机扮演者政策。这允许算法探索不同的策略,并找到最优解,同时考虑到扮演者动作的最大可变性。
说到环境的随机性,我们明白在 S 状态下,当执行 A 动作时,我们在 [Rmin, Rmax] 内获得 R 奖励,概率为 Psa。
软性扮演者-评价者用到的扮演者具有随机政策。这意味着处于 S 状态的扮演者能够以一定的 Pa' 概率从整个动作空间中选择 A' 动作。换言之,在每个特定状态下,扮演者的政策允许我们不一定选择特定的最优动作,而是任何可能的行动(但具有一定程度的概率)。在训练过程中,扮演者学习获得最大奖励的概率分布。
随机扮演者政策的这一属性令我们能够探索不同的策略,并发现在运用判定性策略时可能隐藏的最优解。此外,随机扮演者政策还考虑到环境中的不确定性。在出现噪声或随机因素的情况下,该种类政策可能更具弹性和适应性,因为它们可以生成各种动作,以便有效地与环境交互。
不过,训练扮演者的随机政策也会对训练进行调整。经典强化学习旨在最大化预期回报。在训练过程中,对于每个 S 动作,我们选择 A* 动作,其最有可能给我们带来更大的盈利能力。这种判定性方式建立了明确的关系 St → At → St+1 ⇒ R,并且没有给随机动作留下余地。为了训练随机政略,软性扮演者-评论者算法的作者在奖励函数当中引入了熵正则化。
![]()
在这种情况下,entropy (H) 是衡量政策不确定性或多样性的指标。ɑ>0 参数是一个温度系数,令我们能够在所研究环境和动作模型之间取得平衡。
如您所知,熵是随机变量不确定性的度量,且由方程判定
![]()
注意,我们谈论的是 [0, 1] 范围内选择动作的概率的对数。在这个可接受值的间隔内,熵函数的图形正在降低,且位于正值区域。因此,选择动作的概率越低,奖励就越高,并且鼓励模型探索环境。
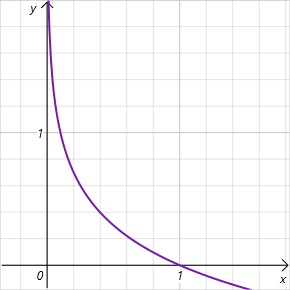
如您所见,有关于此,对 ɑ 超参数的选择提出了相当高的要求。目前,有多种选项可用于实现 SAC 算法。传统的固定参数方法就是其中之一。往往是,我们可以找到参数逐渐减少的实现。很容易就能看出,当 ɑ=0 时,我们得出了判定性强化学习。此外,在训练过程中,模型本身还有多种方式可以优化 ɑ 参数。
我们转入训练评论者。与 TD3 类似,SAC 并行训练 2 个评论者模型,并采用 MSE 作为损失函数。对于未来状态的预测值,从两个评论者目标模型中取较小值。但这里有两个关键区别。
第一个是上面讨论的奖励函数。我们对于当前和后续状态都使用熵正则化,并针对系统下一个状态的成本,参考应用一个折扣因子。
第二个区别是扮演者。SAC 不使用目标扮演者模型。若要选择当前和后续状态下的动作,会用到一个经过训练的扮演者模型。因此,我们强调,实现未来回报是利用现行政策来达成的。此外,使用单个扮演者模型可降低内存和计算资源的成本。
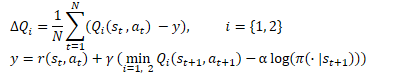
为了训练扮演者政策,我们采用 DDPG 方式。我们通过反向传播贯穿评论者模型的预测行动成本的误差梯度,来获得动作误差梯度。但不像 TD3(其中我们只用了 Critic 1 模型),SAC 的作者建议取用估算行动成本较低的模型。
此处还有一件事。在训练期间,我们更改政策,这会导致在系统特定状态下扮演者的行为发生变化。此外,随机扮演者政策的使用也有助于扮演者动作的多样性。同时,我们依据来自经验回放缓冲区的数据来训练模型,并为其它代理者动作提供奖励。在这种情况下,我们以理论假设为指导,即在训练扮演者的过程中,我们朝着最大化预测奖励的方向前进。这意味着,在任何 S 状态下,采用 π 新政策的动作成本都不低于 π 旧政策的动作成本。
![]()
这是一个非常主观的假设,但它与我们的模型训练范式完全一致。为了不累积可能的误差,我建议在训练期间更频繁地更新经验回放缓冲区,同时考虑更新扮演者政策。
使用类似于 TD3 的 τ 因子平滑目标模型的更新。
这与 TD3 方法还有一点区别。软性扮演者-评论者算法在扮演者训练和更新目标模型时不能使用延迟。在此,所有模型都会在每个训练步骤中更新。
我们总结一下软性扮演者-评论者算法:
- 在奖励函数中引入熵正则化。
- 在训练开始时,扮演者和 2 个评论者模型以随机参数进行初始化。
- 作为与环境交互的结果,将填充经验回放缓冲区。我们保持环境状态、动作、后续状态和奖励不变。
- 填满经验回放缓冲区后,我们训练模型
- 我们从经验回放缓冲区中随机提取一组数据
- 判定未来状态的动作,同时考虑扮演者的当前政策
- 使用至少 2 个目标评论者模型的当前政策来判定未来状态的预测值
- 更新评论者模型
- 更新动作政策
- 更新目标模型。
训练模型的过程是迭代的,并重复进行,直至得到所需的结果,或达到评论者损失函数图形上的最小极值。
2. 利用 MQL5 实现
在软性扮演者-评论者算法理论概述之后,我们转入利用 MQL5 实现它。我们面临的第一件事是检测特定动作的概率。实际上,对于扮演者政策的表格化实现来说,这是一个非常简单的问题。但在使用神经网络时这会造成困难。毕竟,我们不保留有关环境条件和所采取动作的统计数据。它被“硬连线”到我们模型的可定制参数之中。有关于此,我想起了分布式 Q-训练。您也许还记得,我们谈到过有关预期回报概率分布的研究。分布式 Q-学习允许我们获得给定数量的固定区间奖励值的概率分布。完全参数化的 Q-函数(FQF)模型允许我们研究区间值及其概率。
2.1创建一个新的神经层类
继承自 CNeuronFQF 类,我们将创建一个新的神经层类来实现所提出的 CNeuronSoftActorCritic 算法。新类的方法集非常标准,但它也有自己的特性。
特别是,在我们的实现中,我们决定使用自定义熵正则化参数。为此目的,添加了 cAlphas 神经层。该实现使用 CNeuronConcatenate 类型的层。为了决定比率的大小,我们将用到当前状态的嵌入,以及在输出中用到分位数分布。
此外,我们还添加了一个单独的缓冲区来记录熵值,稍后我们将在奖励函数中用到它。
添加的两个对象都声明为静态,这允许我们将类构造函数和析构函数留空。
class CNeuronSoftActorCritic : public CNeuronFQF { protected: CNeuronConcatenate cAlphas; CBufferFloat cLogProbs; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSoftActorCritic(void) {}; ~CNeuronSoftActorCritic(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcAlphaGradients(CNeuronBaseOCL *NeuronOCL); virtual bool GetAlphaLogProbs(vector<float> &log_probs) { return (cLogProbs.GetData(log_probs) > 0); } virtual bool CalcLogProbs(CBufferFloat *buffer); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronSoftActorCritic; } virtual void SetOpenCL(COpenCLMy *obj); };
首先,我们将查看类的 Init 初始化方法。方法参数完全重复父类相似方法的参数。我们立即在方法主体中调用父类方法。我们经常使用这种技术,因为所有必要的控制都已在父类中实现了。所有继承对象的初始化也一并执行。一次检查父类方法的结果取代了所提及操作的完全控制。我们所要做的就是初始化添加的对象。
首先,我们初始化 ɑ 比率计算层。如上所述,我们将向该模型的输入提交当前状态的嵌入,其大小将等于前一个神经层的大小。此外,我们将在当前层的输出中添加一个分位数分布,该分位数分布将包含在内部层 cQuantile2 当中(其在父类中声明和初始化)。在 cAlphas 层的输出端,我们将获得每个单独动作的温度系数。相应地,层的大小将等于动作的数量。
系数应为非负数。为了满足这个需求,我们将该层的激活函数定义为 Sigmoid。
在方法结束时,我们用零值初始化熵缓冲区。它的大小也等于动作的数量。马上在当前 OpenCL 关联环境中创建缓冲区。
bool CNeuronSoftActorCritic::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFQF::Init(numOutputs, myIndex, open_cl, actions, quantiles, numInputs, optimization_type, batch)) return false; //--- if(!cAlphas.Init(0, 0, OpenCL, actions, numInputs, cQuantile2.Neurons(), optimization_type, batch)) return false; cAlphas.SetActivationFunction(SIGMOID); //--- if(!cLogProbs.BufferInit(actions, 0) || !cLogProbs.BufferCreate(OpenCL)) return false; //--- return true; }
接下来,我们转入实现前向验算。在此,我们从父类借用训练分位数和概率分布的过程,不做任何修改。但我们必须加入一些过程,安排检测温度系数,以及计算熵值。甚至,虽然温度的计算涉及调用经由 cAlphas 层的直接验算,但检测熵值应从 “0” 开始实现。
我们必须计算扮演者每个动作的熵。在这个阶段,我们期望此处的动作不会太多。由于所有源数据都在 OpenCL 关联环境存储器当中,故逻辑上应将我们的操作转移到该环境。首先,我们将创建 OpenCL 内核程序 SAC_AlphaLogProbs,来实现此功能。
在内核参数中,我们将传递 5 个数据缓冲区和 2 个常量:
- outputs — 结果缓冲区包含每个动作的分位数值的概率加权总和
- quantiles — 平均分位数值(cQuantile2 内层结果缓冲区)
- probs — 概率张量(cSoftMax 内层结果缓冲区)
- alphas — 温度系数的向量
- log_probs — 熵值的向量(在本例中,记录结果的缓冲区)
- count_quants — 每个动作的分位数
- activation — 激活函数类型。
CNeuronFQF 类在输出端不使用激活函数。我甚至要说这与类背后的观点相矛盾。毕竟,在模型训练过程中,预期奖励的分位数平均值的分布是由实际奖励本身来界定的。在我们的例子中,在自层输出端,我们期望从连续分布取得扮演者动作的确定值。由于各种技术或其它境况,代理者允许的动作界域也许会受到限制。激活函数允许我们这样做。但对于我们,在判定实际动作的概率后,获得所应用激活函数的实际概率估算非常重要。因此,我们将其实现添加到此内核之中。
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float quant1 = -1e37f; float quant2 = 1e37f; float prob1 = 0; float prob2 = 0; float value = outputs[i];
我们辨别内核主体中的当前操作流。它将向我们展示正在分析的操作的序号。然后,我们将检测分位数和概率缓冲区的偏移。
接下来,我们将声明局部变量。为了检测特定动作的概率,我们需要找到 2 个最接近的分位数。在 quant1 变量中,我们将写入最低分位数的平均值。quant2 变量将包含最接近顶部的分位数的平均值。在初始阶段,我们以明显的极值来初始化指定的变量。我们将相应的概率存储在 prob1 和 prob2 变量当中,此刻我们将用零值初始化它们。确切说,在我们的理解中,获得这种极值的概率是 “0”。
我们将来自缓冲区中的所需值保存到局部变量之中。
由于 OpenCL 关联环境的特殊内存组织,访问局部变量比从全局内存缓冲区检索数据快很多倍。依据局部变量操作,我们提升了整体 OpenCL 程序的性能。
现在我们已将所需值存储在局部变量之中,我们可以 毫不费力地将激活函数应用于神经层操作结果的缓冲区。
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; break; default: break; }
接下来,我们安排循环,搜索所有平均分位数值,并寻找最接近的值。
此处应注意的是,我们并未针对平均分位数值进行排序。加权平均检测不受此影响,且我们之前已避免了执行不必要的操作。因此,在极高概率下,最接近所需值的分位数并不会位于分位数缓冲区的相邻元素当中。因此,我们要遍历所有值。
为免于将同一分位数的值写入两个变量,我们使用逻辑运算符 “>=” 作为下限,严格使用 “<” 作为上限。当一个分位数更接近先前存储的分位数时,我们将先前声明的相应变量中的值重写为分位数平均值及其概率。
for(int q = 0; q < count_quants; q++) { float quant = quantiles[shift + q]; if(value >= quant && quant1 < quant) { quant1 = quant; prob1 = probs[shift + q]; } if(value < quant && quant2 > quant) { quant2 = quant; prob2 = probs[shift + q]; } }
在完成循环的所有迭代后,我们的局部变量内将包含最接近分位数的数据。必要的值在该范围内的某处。然而,我们对动作概率分布的认知仅受所研究分布的限制。在这种情况下,我们假设两个最接近的分位数之间概率具有线性依赖性。有了足够多的分位数,考虑到实际动作区域的数值分布范围有限,我们的假设与事实相距不远。
float prob = fabs(value - quant1) / fabs(quant2 - quant1); prob = clamp((1-prob) * prob1 + prob * prob2, 1.0e-3f, 1.0f); log_probs[i] = -alphas[i] * log(prob); }
在检测动作概率之后,我们检测动作的熵,并将结果值乘以温度系数。为了避免熵值过高,我将概率的下限限制在 0.001。
现在我们转入主程序。在此,我们为该类创建一个前向验算方法 CNeuronSoftActorCritic::feedForward。
如您所记,在此,我们广泛利用了继承对象中虚拟方法的能力。因此,方法参数完全重复了前面讨论过的所有类的相似方法。
在方法主体中,我们为了计算温度系数,首先调用父类的前向验算方法,和相似层方法。在此,我们只需检查这些方法的执行结果。
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false;
接下来,我们必须计算奖励函数的熵分量。为此,我们安排了启动上面讨论的内核的过程。我们将根据正在分析的动作数量在一维任务空间中运行它。
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
与往常一样,在将内核放入执行队列之前,我们将初始数据传递给其参数。
if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
请注意,我们不检查任何缓冲区。事实是,在父类的直接验算方法,以及该层计算温度比率的阶段,所有用到的缓冲区均已通过检查。唯一尚未检查的是记录内核操作结果的内部缓冲区。但这是一个内部对象。其创建是在类对象的初始化阶段控制的。无法从外部程序访问该对象。这里出错的概率非常低。因此,我们冒着这样的风险来加快我们的程序。
在方法结束时,我们将内核放入执行队列,并检查操作结果。
if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
我想再次指出,在这种情况下,我们检查的是将内核放入执行队列的结果,而非在内核内部执行操作的结果。为了获得结果,我们需要将 cLogProbs 缓冲区数据加载到主内存之中。此功能是在 GetAlphaLogProbs 方法中实现的。该方法代码只有一行,且是在类结构描述模块中提供。
我们转入创建反向验算功能。该功能的主要部分已在父类方法中实现。尽管看起来很奇怪,但我们不至于重新定义贯穿神经层的误差梯度分配方法。事实是,熵正则化的误差梯度分布并不完全符合我们的一般结构。我们从评论者模型的最后一层按动作获得误差梯度。我们在奖励函数之中包含熵正则化本身。相应地,它的误差也将在奖励预测的级别上,即在评论者结果层的级别上。在此,我们遇到 2 个问题:
- 引入额外的梯度缓冲区将破坏反向验算方法的虚拟化模型。
- 在扮演者反向验算阶段,我们根本没有关于评论者的误差数据。有必要为整个模型构建一个新流程。
为了简化起见,我创建了一个新的并行过程,仅用于熵正则化误差的梯度,且无需彻底修改模型中的反向验算过程。
首先,我们将在 OpenCL 程序中创建一个内核。它的代码非常简单。我们只需将得到的误差梯度乘以熵即可。然后,我们通过层的激活函数的导数来调整结果值,以便计算温度比率。
__kernel void SAC_AlphaGradients(__global float *outputs, __global float *gradient, __global float *log_probs, __global float *alphas_grad, const int activation ) { const int i = get_global_id(0); float out = outputs[i]; //--- float grad = -gradient[i] * log_probs[i]; switch(activation) { case 0: out = clamp(out, -1.0f, 1.0f); grad = clamp(grad + out, -1.0f, 1.0f) - out; grad = grad * max(1 - pow(out, 2), 1.0e-4f); break; case 1: out = clamp(out, 0.0f, 1.0f); grad = clamp(grad + out, 0.0f, 1.0f) - out; grad = grad * max(out * (1 - out), 1.0e-4f); break; case 2: if(out < 0) grad = grad * 0.01f; break; default: break; } //--- alphas_grad[i] = grad; }
于此我们应当注意,为了简化计算,我们只需将梯度乘以来自 log_probs 缓冲区中的值即可。如您所记,在前向验算期间,我们在此设置熵值,同时考虑温度比率。从数学角度来看,我们需要将来自缓冲区的值除以该值。但对于温度,我们使用 sigmoid 作为激活函数。因此,其值始终在 [0,1] 范围内。除以小于 1 的正数只会增加误差梯度。在这种情况下,我们故意不这样做。
在完成 SAC_AlphaGradients 内核的工作后,我们把工作转入主程序,并创建 CNeuronSoftActorCritic::calcAlphaGradients 方法。在这个阶段,我们首先将内核放入执行队列中,然后调用内部对象的方法。因此,我们在开始该过程之前安排了一个控制单元。
bool CNeuronSoftActorCritic::calcAlphaGradients(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL || !NeuronOCL.getGradient() || !NeuronOCL.getGradientIndex()<0) return false;
接下来,我们定义内核的任务空间,并将输入数据传递给其参数。
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_outputs, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_alphas_grad, cAlphas.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_gradient, NeuronOCL.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaGradients, def_k_sac_alg_activation, (int)cAlphas.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
之后,我们将内核放入执行队列,并监视操作的执行。
if(!OpenCL.Execute(def_k_SAC_AlphaGradients, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
在方法的最后,我们调用内部温度系数计算层的反向验算方法。
return cAlphas.calcHiddenGradients(GetPointer(cQuantile0), cQuantile2.getOutput(), cQuantile2.getGradient()); }
此外,我们将覆盖 CNeuronSoftActorCritic::updateInputWeights 神经层更新参数的方法。该方法算法十分简单。它只调用父类和内部对象的相似方法。该方法的完整代码可在附件中找到。您还可从中找到本文中所用的所有方法和类的完整代码,包括操控新类文件的方法,这些我现在都不会赘述。
2.2修改 CNet 类
新类完成后,我们声明一些常量,它们都服务于所创建的内核。我们还要把新内核添加到上下关联对象的初始化过程、以及 OpenCL 程序之中。在创建每个新内核时,我都讲解过该功能,50 多次了,故我不会再啰嗦。
我们的函数库功能不允许用户直接访问特定的神经层。整个交互过程都经由 CNet 类层次的整体模型功能构建的。为了获取熵分量的值,我们将创建 CNet::GetLogProbs 方法。
在参数中,该方法接收指向设置值的向量指针。
在方法主体中,我们安排了一个控件模块,并逐步降低对象的级别。首先,我们检查神经层的动态数组对象是否存在。然后我们去往下一层,检查指向最后一个神经层对象的指针。接下来,我们再往下走,检查最后一个神经层的类型。这应该是我们新的 CNeuronSoftActorCritic 层。
bool CNet::GetLogProbs(vectorf &log_probs) { //--- if(!layers) return false; int total = layers.Total(); if(total <= 0 || !layers.At(total - 1)) return false; CLayer *layer = layers.At(total - 1); if(!layer.At(0) || layer.At(0).Type() != defNeuronSoftActorCritic) return false; //--- CNeuronSoftActorCritic *neuron = layer.At(0);
仅当所有控制级别都成功通过之后,我们才会转向神经层的相似方法。
return neuron.GetAlphaLogProbs(log_probs);
}
请注意,在此阶段,我们仅限于模型中的最后一层。这意味着该层只能用作扮演者的最后一层。
此外,该方法仅从缓冲区读取数据,且不会启动计算。因此,仅当扮演者直接验之后调用它才有意义。事实上,这并非是一项限制。确切说,熵正则化仅用于在收集原始数据和训练模型时形成奖励。在这些过程中,扮演者依据生成动作执行前向验算才是主要的。
对于反向验算的需要,我们将创建 CNet::AlphasGradient 方法。正如我们上面所说,梯度的熵分布超出了我们之前所构建过程的界域。这也反映在方法算法当中。我们按这样一种方式构建了这种方法,我们将它称为评论者。在方法参数中,我们将传递指向扮演者对象的指针。
该方法的控制单元算法也要相应构建。首先,我们检查指向扮演者对象的指针是在有效期,并且它包含最新的 CNeuronSoftActorCritic 层。
bool CNet::AlphasGradient(CNet *PolicyNet) { if(!PolicyNet || !PolicyNet.layers) return false; int total = PolicyNet.layers.Total(); if(total <= 0) return false; CLayer *layer = PolicyNet.layers.At(total - 1); if(!layer || !layer.At(0)) return false; if(layer.At(0).Type() != defNeuronSoftActorCritic) return true; //--- CNeuronSoftActorCritic *neuron = layer.At(0);
控制模块的第二部分针对最后一个评论者层运作相似的检查。此处对于神经层的类型没有限制。
if(!layers) return false; total = layers.Total(); if(total <= 0 || !layers.At(total - 1)) return false; layer = layers.At(total - 1);
所有控制成功通过之后,我们转向新神经层梯度的分配方法。
return neuron.calcAlphaGradients((CNeuronBaseOCL*) layer.At(0)); }
公平而言,使用完全参数化的模型可以让我们检测独立动作的概率。但它不允许创建真正的随机扮演者政策。扮演者随机性涉及从学习的分布中抽取动作,这在 OpenCL 关联环境端是无法做到的。在变分自动编码器中,为了解决类似的问题,我们曾用过一个重新参数化的技巧,并在主程序一端生成了一个随机值的向量。但在这种情况下,我们需要加载概率分布以便进行抽样。取而代之,在收集样本数据库阶段,我们将在某个环境中对计算出的值进行抽样(类似于 TD3),然后询问模型此类动作的熵。出于这些目的,我们将创建 CNet::CalcLogProbs 方法。它的算法类似于 GetLogProbs 方法的构造,但不像前一个,在参数中,我们将收到一个指向含有样本值的数据缓冲区指针。方法在同一缓冲区中进行操作的结果,我们将得到它们的概率。
附件中提供了所有类及其方法的完整代码。
2.3创建模型训练 EA
在完成为模型创建新对象的工作后,我们转入编排其创建和训练的过程。如前,将用到 3 个 EA:
- 研究 — 收集样本数据库
- 学习 — 模型训练
- 测试 ― 检查得到的结果。
为了减少文章的篇幅,并节省您的时间,我将重点放在针对上一篇文章中相似智能系统版本所做的修改,按问题编排算法。
首先是模型架构。在此,我们只修改了最后一个扮演者层,将其替换为新的 CNeuronSoftActorCritic 类。我们按照动作数量、及每个动作的 32 个分位数来指定层大小(正如 FQF 方法的作者所建议的那样)。
我们用 sigmoid 作为激活函数,类似于上一篇文章中的实验。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- Actor ......... ......... //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftActorCritic; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- Critic ......... ......... //--- return true; }
“...\SoftActorCritic\Research.mq5” EA 算法已从上一篇文章中转移而来,几乎没做任何修改。历史数据收集模块和交易操作模块均未发生任何变化。仅在环境奖励方面修改了 OnTick 函数。如上所述,软性扮演者-评论者算法将熵正则化添加到奖励函数当中。
如前,我们采用账户余额的相对变化作为补偿。我们还针对缺乏持仓增加了处罚。但接下来我们需要添加熵正则化。我为此创建了上面提到的 CalcLogProbs 方法。但有一处细微差别。我们类的分位数分布存储的值直至激活函数起作用。在制定决策过程中,我们使用扮演者模型的激活结果。我们使用 sigmoid 作为扮演者输出端的激活函数。
![]()
通过数学变换,我们得出
![]()
我们用此属性,并将抽样动作调整为所需的形式。然后,我们将数据从向量传输到数据缓冲区,如果可能,将信息传输到 OpenCL 关联环境内存。
在完成这样的准备工作后,我们询问扮演者所执行动作的熵。
注意,考虑到温度比率,我们得到了 6 个动作的熵。但我们的奖励是一个数字来评估当前状态和动作的整体。在这个实现中,我们使用了总熵值,它非常适合概率和对数的上下文,因为复杂事件的概率等于其组成部分事件的概率的乘积。乘积的对数等于各个因子的对数之和。不过,可能还有其它方法。在训练期间可以检查它们与每个个案的相适度。不要害怕实验。
void OnTick() { //--- ......... ......... //--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; temp.Clip(0.001f, 0.999f); temp = MathLog((temp - 1.0f) * (-1.0f) / temp) * (-1); Result.AssignArray(temp); if(Result.GetIndex() >= 0) Result.BufferWrite(); if(Actor.CalcLogProbs(Result)) { Result.GetData(temp); reward += temp.Sum(); } if(!Base.Add(sState, reward)) ExpertRemove(); }
最重要的修改是针对 “...\SoftActorCritic\Study.mq5” EA 中的模型训练。我们来仔细看看指定 EA 的 Train 函数。这是安排整个模型训练过程的地方。
在函数开始时,我们从经验回放缓冲区中抽样一组数据,就像之前一样。
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
接下来,我们检测未来状态的预测值。该算法重复了在 TD3 方法中实现的类似过程。唯一的区别是没有目标扮演者模型。在此,我们使用可训练的扮演者模型来判定未来状态下的动作。
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
填充源数据缓冲区,调用扮演者的前向验算方法和 2 个评论者 目标模型。
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
如 TD3 方法一样,我们使用最低的预测状态成本值来训练评论者。但在这种情况下,我们添加了一个熵分量。
vector<float> log_prob; if(!Actor.GetLogProbs(log_prob)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) + log_prob.Sum() - Buffer[tr].Revards[i + 1]);
此处需要注意的是,在保存轨迹的过程中,考虑到折扣因素,我们保存了累计奖励额度,直到验算结束。在这种情况下,每次向新状态转换的独立奖励都包括熵正则化。为了训练评论者模型,我们调整了存储的累积奖励,考虑更新政策所用。为此,我们取后续状态的最低预测成本之间的差值,考虑到熵分量与保存在回放缓冲区中的该状态的累积奖励经验。按折扣系数调整结果值,并将其加到当前状态的保存值之中。在这种情况下,我们假设在优化模型的过程中动作成本不会降低。
接下来,我们将面对训练评论者模型阶段。为此,我们用系统的当前状态填充数据缓冲区。
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); //--- Account.BufferWrite();
请注意,在这种情况下,我们不再检查 OpenCL 关联环境中是否存在帐户状态描述缓冲区。保存数据后,我们立即调用将数据传输到关联环境的方法。因为我们所有的模型都在同一个 OpenCL 关联环境中工作,故这成为可能。我们之前已探讨过这种方式的优点。在目标模型上调用前向验算方法时,缓冲区已在关联环境中创建好了。否则,我们在执行时会收到错误。因此,我们现阶段不再将时间和资源浪费在不必要的验证上。
加载数据后,我们调用扮演者的前向验算方法,并加载奖励的熵分量。
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Actor.GetLogProbs(log_prob);
在此阶段,我们掌握了评论者的正向和反向验算的所有必要数据。但在此阶段,我们略微偏离了作者的算法。事实上,该方法的作者在更新了评论者的参数后,建议采用具有最低分数的评论者来更新扮演者的政策。根据我们的观察,尽管估算值存在偏差,但动作误差的梯度几乎没有变化。故此,我决定简单地轮换评论者模型。在偶数迭代中,我们根据经验回放缓冲区中的动作更新 Critic2 模型。我们基于第一位评论者的评估来训练扮演者的政策。
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if((iter % 2) == 0) { if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Clear(); Result.Add(reward-log_prob.Sum()); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Critic1.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Update(0,Buffer[tr].Revards[i]); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
在奇数迭代中更改 Critic1 模型。
else { if(!Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Clear(); Result.Add(reward); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Critic2.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Update(0,Buffer[tr].Revards[i]); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
注意调用反向验算方法的顺序。首先,我们执行评论者反向验算。然后我们通过熵分量传递梯度。接下来,我们通过扮演者的主数据处理模块执行反向验算。这令我们能够根据评论者的需求定制卷积层。做完所有之后,我们针对扮演者执行彻底的反向验算,从而优化其动作政策。
在函数操作结束时,我们更新目标模型,并向用户显示信息消息,从而直观地监控训练过程。
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
完整的智能系统代码可在文后附件中找到。在那里,您还可以找到测试 EA 代码。针对它所做的更改类似于主要数据收集 EA 中的更改,我们不再详述它们。
3. 测试
该模型依据 EURUSD H1 自 2023 年 1 月至 5 月期间的历史数据进行了训练和测试。指标参数和所有超参数均设置为默认值。
我深表遗憾,我必须承认,在撰写本文时,我没能训练出一个能够在训练集上产生盈利的模型。根据测试结果,我的模型在 5 个月的训练期间亏损了 3.8%。

从积极的一面来看,最大的盈利交易高于最大亏损交易的 3.6 倍。平均盈利交易仅略高于平均亏损交易。但可盈利交易份额为 49%。本质上,这 1% 不足以达到 “0”。
对于训练集之外的数据,形势几乎没有变化。甚至盈利交易的份增加到了 51%。但平均盈利交易的规模下降,再次造成亏损。

模型在训练集之外的稳定性是一个积极因素。但问题仍然是我们如何摆脱亏损。也许,原因在于算法的变化,或膨胀的温度比率刺激了更多的市场研究。
此外,原因可能是抽样动作值过于分散。当抽样动作概率接近 “0” 时,高熵会令其奖励膨胀,这会扭曲扮演者政策。为了找到原因,我们需要额外的测试。我将与您分享他们的结果。
结束语
在本文中,我们介绍了软性扮演者-评论者(SAC)算法,该算法旨在解决连续动作空间中的问题。它基于最大化政策熵的思想,它允许代理者探索不同的策略,并在随机环境中找到最优解,同时考虑到最大化行动变数。
该方法的作者建议利用熵正则化,将其添加到训练标的物函数之中。这令算法能够鼓励对新动作的探索,防止它过于僵化、并固守在某些策略上。
我们利用 MQL5 实现了该方法,但不幸的是,我们未能训练出一个可盈利的策略。不过,经过训练的模型在训练集内外都表现出稳定的性能。这表明该方法能够普适所获得的经验,并将其转移到未知的环境条件下。
我给自己设定了一个目标,即寻找机会来训练可盈利的扮演者政策。结果将在稍后公布。
参考文献列表
本文中用到的程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | 智能交易系统 | 样本收集 EA |
| 2 | Study.mq5 | 智能交易系统 | 代理者训练 EA |
| 3 | Test.mq5 | 智能交易系统 | 模型测试 EA |
| 4 | Trajectory.mqh | 类库 | 系统状态定义结构 |
| 5 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 6 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/12941
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

我发现了一个新的 NN 序列:请欣赏 <3
也可以简单地将图片拖入文本,或使用Ctrl+V 粘贴图片