
Fondamenti di Statistica

Introduzione
Cos'è la statistica? Ecco la definizione che si trova su Wikipedia: "La statistica è lo studio della raccolta, dell'organizzazione, dell'analisi, dell'interpretazione e della presentazione dei dati." (Statistiche). Questa definizione suggerisce tre componenti principali della statistica: raccolta, dati,misurazione e analisi. L'analisi dei dati sembra essere particolarmente utile per un trader, in quanto le informazioni ricevute sono fornite dal broker o tramite un terminale di trading e sono già misurate.
I trader moderni (per lo più) l’analisi tecnica per decidere se acquistare o vendere. Si occupano di statistiche praticamente in tutto ciò che fanno quando utilizzano un determinato indicatore o cercano di prevedere il livello dei prezzi per il prossimo periodo. In effetti, un grafico di fluttuazione dei prezzi rappresenta di per sé alcune statistiche di un'azione o di una valuta nel tempo. È quindi molto importante comprendere i principi di base delle statistiche alla base della maggior parte dei meccanismi che facilitano il processo decisionale per un trader.
Teoria e statistica della probabilità
Qualsiasi statistica è il risultato del cambiamento degli stati dell'oggetto che la genera. Consideriamo un grafico dei prezzi EURUSD su intervalli di tempo orari:

In questo caso, l'oggetto è la correlazione tra due valute, mentre le statistiche sono i loro prezzi in ogni momento. In che modo la correlazione tra due valute influisce sui loro prezzi? Perché abbiamo questo grafico dei prezzi e non uno diverso all'intervallo di tempo dato? Perché i prezzi attualmente stanno scendendo e non salendo? La risposta a queste domande è la parola "probabilità". Ogni oggetto, a seconda della probabilità, può assumere l'uno o l'altro valore.
Facciamo un semplice esperimento: prendi una moneta e lanciala un certo numero di volte, ogni volta registrando il risultato del lancio. Supponiamo di avere una moneta equa. Quindi la sua tabella può essere la seguente:
| Risultato | Probabilità |
|---|---|
| Teste | 0,5 |
| Code | 0,5 |
La tabella suggerisce che la moneta ha uguale probabile di dare testa o croce. Qualsiasi altro risultato non è possibile qui (l'atterraggio sul bordo della moneta è stato escluso a priori) in quanto la somma delle probabilità di tutti i possibili eventi deve essere uguale a uno.
Lancia la moneta 10 volte. Ora diamo un'occhiata ai risultati del lancio:
| Risultato | Numero |
|---|---|
| Teste | 8 |
| Code | 2 |
Perché abbiamo questi risultati se la moneta ha la stessa probabilità di atterrare su uno dei lati? La probabilità che la moneta atterri su uno dei lati è infatti uguale, il che tuttavia non significa che dopo pochi lanci la moneta atterrerà su un lato tante volte quante volte sull'altro lato. La probabilità mostra solo che in questo particolare tentativo (lancio) la moneta atterrerà come testa o in croce ed entrambi gli eventi hanno le stesse possibilità.
Lanciamo ora la moneta 100 volte. Otteniamo la nuova tabella dei risultati:
| Risultato | Numero |
|---|---|
| Teste | 53 |
| Code | 47 |
Come si può vedere, il numero di risultati non è di nuovo uguale. Tuttavia, da 53 a 47 è il risultato che dimostra le ipotesi di probabilità iniziali. La moneta è atterrata sulle teste in quasi tanti lanci quanti ne ha fatto sulle croci.
Ora facciamo lo stesso nell'ordine inverso. Supponiamo di avere una moneta, ma la probabilità di atterrare sui suoi lati è sconosciuta. Dobbiamo determinare se si tratta di una moneta equa, cioè una moneta per cui è altrettanto probabile che venga fuori testa o croce.
Prendiamo i dati del primo esperimento. Dividi il numero di risultati per lato per il numero totale di risultati. Otteniamo le seguenti probabilità:
| Risultato | Probabilità |
|---|---|
| Teste | 0,8 |
| Code | 0,2 |
Possiamo vedere che è molto difficile concludere dal primo esperimento che la moneta è giusta. Facciamo lo stesso per il secondo esperimento:
| Risultato | Numero |
|---|---|
| Teste | 0,53 |
| Code | 0,47 |
Avendo questi risultati a portata di mano, possiamo dire con un alto grado di precisione che questa è una moneta equa.
Questo semplice esempio ci consente di trarre una conclusione importante: maggiore è il numero di esperimenti, più accuratamente le proprietà dell'oggetto sono riflesse dalle statistiche generate dall'oggetto.
Pertanto, statistiche e probabilità sono inestricabilmente intrecciate. La statistica rappresenta i risultati sperimentali con un oggetto ed è direttamente dipendente dalla probabilità degli stati dell'oggetto. Al contrario, la probabilità degli stati dell'oggetto può essere stimata utilizzando le statistiche. Ecco dove si trova la sfida principale per un trader: avere dati sulle negoziazioni in un certo periodo di tempo (statistiche), prevedere il comportamento dei prezzi per il seguente periodo di tempo (probabilità) e sulla base di queste informazioni per prendere una decisione di acquisto o vendita.
Pertanto, tornando ai punti citati nell’Introduzione, è anche importante conoscere e comprendere la relazione tra statistica e probabilità, nonché avere conoscenza della valutazione del rischio e delle situazioni di rischio. Gli ultimi due sono tuttavia al di fuori dell'ambito di applicazione di questo articolo.
Parametri statistici di base
Esaminiamo ora i parametri statistici di base. Supponiamo di avere i dati sull'altezza in cm per quanto riguarda 10 persone in un gruppo:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Altezza | 173 | 162 | 194 | 181 | 186 | 159 | 173 | 178 | 168 | 171 |
I dati indicati nella tabella sono chiamati campione, mentre la quantità di dati è la dimensione del campione. Daremo un'occhiata ad alcuni parametri del campione dato. Tutti i parametri saranno parametri di esempio come risultano dai dati di esempio, piuttosto che dati variabili casuali.
1. Media del campione
La media del campione è il valore medio nel campione. Nel nostro caso, è l'altezza media delle persone nel gruppo.
Per calcolare la media, dovremmo:
- Sommare tutti i valori di esempio.
- Dividere il valore risultante per la dimensione del campione.
Formula:
![]()
Dove:
- M è la media del campione,
- a[i] è l'elemento campione,
- n è la dimensione del campione.
Seguendo i calcoli, otteniamo il valore medio di 174,5 cm
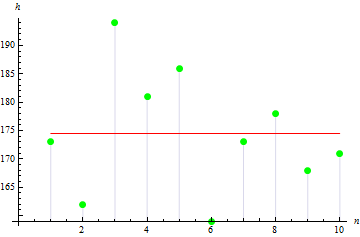
2. Varianza del campione
La varianza del campione descrive la distanza tra i valori del campione e la media del campione. Maggiore è il valore, più ampiamente i dati sono distribuiti.
Per calcolare la varianza, dovremmo:
- Calcolare la media del campione.
- Sottrarre la media da ciascun elemento campione e quadrare la differenza.
- Sommare i valori risultanti ottenuti sopra.
- Dividere la somma per la dimensione del campione meno 1.
Formula:
![]()
Dove:
- D è la varianza del campione,
- M è la media del campione,
- a[i] è l'elemento campione,
- n è la dimensione del campione.
La varianza del campione nel nostro caso è 113.611.
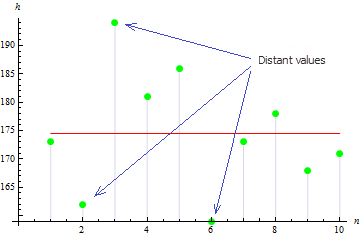
La figura suggerisce che 3 valori sono ampiamente distribuiti dalla media,la quale porta al grande valore di varianza.
3. Asimmetria del campione
L'asimmetria del campione viene utilizzata per descrivere il grado di asimmetria dei valori del campione attorno alla sua media. Più il valore di inclinazione è vicino a zero, più simmetrici sono i valori del campione.
Per calcolare l'asimmetria, dovremmo:
- Calcolare la media del campione.
- Calcolare la varianza del campione.
- Sommare le differenze cubiche di ciascun elemento campione e la media.
- Dividere la risposta per il valore di varianza elevato alla potenza di 2/3.
- Moltiplicare la risposta per il coefficiente uguale alla dimensione del campione diviso per il prodotto della dimensione del campione meno 1 e la dimensione del campione meno 2.
Formula:
![]()
Dove:
- A è l'asimmetria del campione,
- D è la varianza del campione,
- M è la media del campione,
- a[i] è l'elemento campione,
- n è la dimensione del campione.
Otteniamo un valore piuttosto piccolo di asimmetria per questo campione: 0,372981. Ciò è dovuto al fatto che valori divergenti si compensano a vicenda.
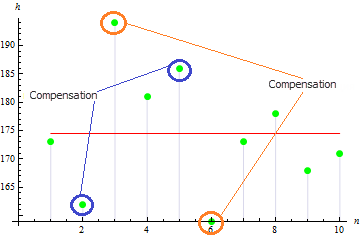
Il valore sarà maggiore per il campione asimmetrico. Ad esempio, il valore per i dati come di seguito sarà 1,384651.
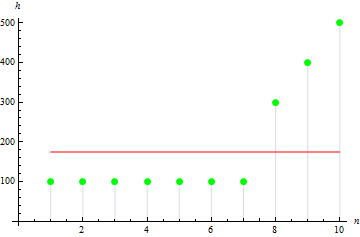
4. Esempio di curtosi
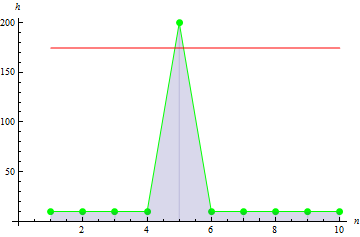
La curtosi del campione descrive il picco del campione.
Per calcolare la curtosi, dovremmo:
- Calcolare la media del campione.
- Calcolare la varianza del campione.
- Sommare le differenze di quarta potenza di ciascun elemento campione e la media.
- Dividere la risposta per la varianza al quadrato.
- Moltiplicare il valore risultante per il coefficiente uguale al prodotto della dimensione del campione e la dimensione del campione più 1, diviso per il prodotto della dimensione del campione meno 1, la dimensione del campione meno 2 e la dimensione del campione meno 3.
- Sottrarre dal valore risultante il prodotto di 3 e la differenza al quadrato della dimensione del campione e 1, divisa per il prodotto della dimensione del campione meno 1 e la dimensione del campione meno 2.
Formula:
![]()
Dove:
- E è la curtosi campione,
- D è la varianza del campione,
- M è la media del campione,
- a[i] è l'elemento campione,
- n è la dimensione del campione.
Per i dati di altezza dati, otteniamo il valore di -0,1442285.
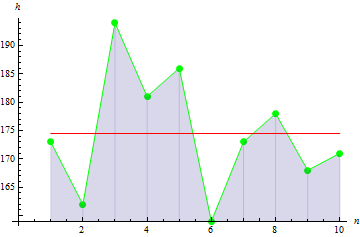
Per un picco di dati più nitido, otteniamo un valore maggiore: 10.
5. Covarianza del campione
La covarianza del campione è una misura che indica il grado di dipendenza lineare tra due campioni di dati. La covarianza tra dati linearmente indipendenti sarà 0.
Per illustrare questo parametro, aggiungeremo i dati di peso per ciascuna delle 10 persone:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Peso | 65 | 70 | 83 | 60 | 105 | 58 | 69 | 90 | 78 | 65 |
Per calcolare la covarianza di due campioni, dovremmo:
- Calcolare la media del primo campione.
- Calcolare la media del secondo campione.
- Sommare tutti i prodotti di due differenze: la prima differenza, un elemento del primo campione meno la media del primo campione; la seconda differenza, un elemento del secondo campione (corrispondente all'elemento del primo campione) meno la media del secondo campione.
- Dividere la risposta per la dimensione del campione meno 1.
Formula:
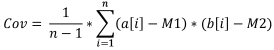
Dove:
- Cov è la covarianza del campione,
- a[i] è l'elemento del primo campione,
- b[i] è l'elemento del secondo campione,
- M1 è la media del campione del primo campione,
- M2 è la media del campione del secondo campione,
- n è la dimensione del campione.
Calcoliamo il valore di covarianza dei due campioni: 91,2778. La dipendenza esistente può essere mostrata nel grafico combinato:
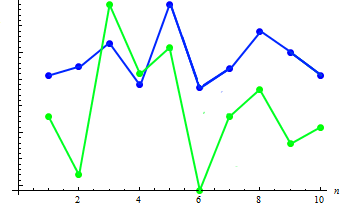
Come si può vedere, l'aumento di altezza (di regola) corrisponde alla diminuzione del peso e viceversa.
6. Correlazione di esempio
La correlazione del campione viene anche utilizzata per descrivere il grado di dipendenza lineare tra due campioni di dati, ma il suo valore si trova sempre nell'intervallo da -1 a 1.
Per calcolare la correlazione di due campioni, dovremmo:
- Calcolare la varianza del primo campione.
- Calcolare la varianza del secondo campione.
- Calcola la covarianza di questi campioni.
- Dividere la covarianza per la radice quadrata del prodotto delle varianze.
Formula:
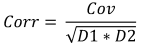
Dove:
- Corr è la correlazione del campione,
- Cov è la covarianza del campione,
- D1 è la varianza del campione del primo campione,
- D2 è la varianza del campione del secondo campione,
Per i dati di altezza e peso indicati, la correlazione sarà pari a 0,579098.
Come utilizzare le statistiche nel trading
L'esempio più semplice che illustra l'uso dei parametri statistici nel trading è l'indicatore MovingAverage. Il suo calcolo richiede dati su un certo periodo di tempo e fornisce il valore medio aritmetico del prezzo:
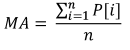
Dove:
- MA è il valore dell'indicatore,
- P[i] è il prezzo,
- n è il periodo di misurazione MA
Possiamo vedere che l'indicatore è un analogo completo della media del campione. Nonostante la sua semplicità, questo indicatore viene utilizzato per calcolare l'EMA, la media mobile esponenziale che, a sua volta, è un elemento di base richiesto per l'indicatore MACD, uno strumento classico per determinare la forza e la direzione del trend.

Statistiche in MQL5
Esamineremo l'implementazione MQL5 dei parametri statistici di base sopra descritti. I metodi statistici esaminati sopra (e molto altro) sono implementati nella libreria di funzioni statistiche statistics.mqh. Esaminiamo i loro codici.
1. Media del campione
La funzione di libreria che calcola la media del campione è chiamata Media:

Dati di input: campione di dati. Dati di uscita: media.
2. Varianza del campione
La funzione di libreria che calcola la varianza del campione è chiamata Varianza:

Dati di input: campione di dati e relativa media. Dati di output: varianza.
3. Asimmetria del campione
La funzione di libreria che calcola l'asimmetria del campione è chiamata asimmetria:

Dati di input: campione di dati, media e varianza. Dati di output: asimmetria.
4. Esempio di curtosi
La funzione di libreria che calcola la curtosi del campione è chiamata Excess (Excess2):

Dati di input: campione di dati, media e varianza. Dati di uscita: curtosi.
5. Covarianza del campione
La funzione di libreria che calcola la covarianza del campione è chiamata Cov:

Dati di input: due campioni di dati e i rispettivi mezzi. Dati di uscita: covarianza.
6. Correlazione di esempio
La funzione di libreria che calcola la correlazione del campione è chiamata Corr:

Dati di input: covarianza di due campioni, varianza del primo campione e varianza del secondo campione. Dati di output: correlazione.
Inseriamo ora i dati del campione di altezza e peso ed elaboriamoli utilizzando la libreria.#include <Statistics.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- specify two data samples. double arrX[10]={173,162,194,181,186,159,173,178,168,171}; double arrY[10]={65,70,83,60,105,58,69,90,78,65}; //--- calculate the mean double mx=Average(arrX); double my=Average(arrY); //--- to calculate the variance, use the mean value double dx=Variance(arrX,mx); double dy=Variance(arrY,my); //--- skewness and kurtosis values double as=Asymmetry(arrX,mx,dx); double exc=Excess(arrX,mx,dx); //--- covariance and correlation values double cov=Cov(arrX,arrY,mx,my); double corr=Corr(cov,dx,dy); //--- print results in the log file PrintFormat("mx=%.6e",mx); PrintFormat("dx=%.6e",dx); PrintFormat("as=%.6e",as); PrintFormat("exc=%.6e",exc); PrintFormat("cov=%.6e",cov); PrintFormat("corr=%.6e",corr); }
Dopo aver eseguito lo script, il terminale produrrà i risultati come segue:
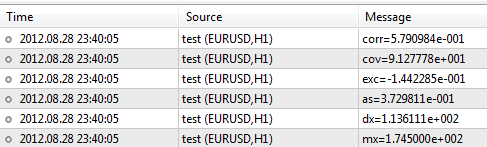
La libreria contiene molte più funzioni le cui descrizioni possono essere trovate nella CodeBase: https://www.mql5.com/it/code/866.
Conclusione
Alcune conclusioni sono già state tratte alla fine della sezione "Teoria e statistica della probabilità". Oltre a quanto sopra, vale la pena ricordare che la statistica, come qualsiasi altra branca della scienza, deve essere studiata a partire dal suo ABC. Anche i suoi elementi di base possono facilitare la comprensione di una grande quantità di cose, meccanismi e schemi complessi che alla fine della giornata possono essere estremamente necessari nel lavoro del trader.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/387
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

 La stima kernel di densità della funzione di densità di probabilità
La stima kernel di densità della funzione di densità di probabilità
 Chi è chi nella MQL5.community?
Chi è chi nella MQL5.community?
 Ottieni 200 USD per il tuo articolo per il trading algoritmico!
Ottieni 200 USD per il tuo articolo per il trading algoritmico!
 Sbarazzarsi delle DLL auto-prodotte
Sbarazzarsi delle DLL auto-prodotte
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Dovrebbero esserci molti algoritmi per determinare le mod, quindi una bicicletta universale non è utile in questo caso.
Si dovrebbe piuttosto guardare agli esempi, a ciò che si vuole ottenere e a ciò che non si vuole ottenere.
Mi è piaciuto l'articolo.
È molto facile da capire e contiene informazioni sufficienti.
E, a giudicare dal titolo, non pretende di essere più di questo.
Non vedo l'utilità di questo articolo. Una serie di luoghi comuni della TV. E se questo articolo non fosse stampato su un sito web specializzato e mezzo commerciante, sarebbe possibile tacere. Ma considerando il sito, vorrei far notare quanto segue.
Esiste una scienza che misura, analizza e prevede i dati economici. Si chiama econometria. È una parente stretta e consanguinea della statistica, ma presenta differenze significative.
1. Per i trader, l'analisi in sé non ha valore se la previsione non deriva dall'analisi. L'articolo non parla affatto di previsioni.
2. L'econometria si basa inizialmente sulla non stazionarietà delle serie economiche. E se ci si ricordasse almeno di questo, se lo si tenesse a mente, per così dire, la storia della statistica di base non sarebbe così rosea: per le serie non stazionarie i concetti di base di mo, varianza, ecc. possono essere applicati con molte riserve. In ogni caso, bisogna sempre avere dei dubbi. Ad esempio, per le serie non stazionarie, la media non convergerà necessariamente al mo. Non parlo affatto di correlazione.
3. L'econometria si basa su campioni molto brevi - poche decine di osservazioni. Non è interessata alla media di molti anni, poiché tale media implica anche la presenza di una posa per diversi anni. Nelle crisi, le stime dei risultati del calcolo diventano importanti. Sono le stime che distinguono radicalmente la TV dalla statistica e soprattutto dall'econometria.
Articolo sulla scuola. Il livello di una scuola speciale, nemmeno i corsi junior di un istituto.
"Da questo semplice esempio possiamo trarre un'importante conclusione: all'aumentare del numero di prove, la statistica riflette più accuratamente le proprietà dell'oggetto che le genera".
Per un processo stazionario (Cavallo sferico nel vuoto) - Sì.
Per le serie temporali di dati reali questa affermazione è più che altro un'assurdità.
Se il Forex fosse una serie temporale stazionaria - non sarebbe necessario MQL5 per stimarlo - basterebbero delle semplici spazzole di legno del negozio di alimentari.
Se i fori vengono praticati nella falena in un ordine caotico e a intervalli di tempo caotici.
allora le statistiche per l'intero periodo saranno più simili a un rapporto RosStat - o alle farneticazioni di un pazzo.
"È qui che sorge il compito principale di un trader: conoscere i dati sugli scambi per un certo periodo di tempo (statistiche), prevedere il comportamento dei prezzi (tasso) per il periodo di tempo successivo (ottenere la probabilità) e, sulla base di questo, prendere una decisione di acquisto o di vendita".
un'altra affermazione in termini di significato non è lontana dal nonsenso. Per prevedere qualcosa, bisogna prima dimostrare a se stessi che la serie non è casuale e può essere prevista. È possibile avere delle entrate su serie casuali. non si possono prevedere, ma se ne può uscire. asimmetria delle probabilità e aspettativa positiva/negativa.
.