
통계의 기초

개요
통계란 무엇인가? 위키백과는 통계를 다음과 같이 정의합니다. '통계학은 산술적 방법을 기초로 하여, 주로 다량의 데이터를 관찰하고 정리 및 분석하는 방법을 연구하는 수학의 한 분야이다.'(통계학). 정의를 통해 통계의 세 가지 기본 요소를 알 수 있죠. 바로 데이터 수집, 평가 및 분석입니다. 특히 거래 터미널 또는 브로커로부터 이미 평가된 정보를 수신하는 우리 투자자들에게 데이터 분석은 아주 유용합니다.
대부분의 투자자들은 기술적 분석을 통해 매매를 결정합니다. 특정 인디케이터를 이용하거나 미래의 가격을 예측하는 것도 모두 통계와 관련이 있습니다. 가격 변동 차트 자체가 주식 또는 통화에 대한 통계를 나타내죠. 따라서 투자자의 의사결정 과정에 매우 중요한 기반이 되는 통계학의 기본 원리를 이해할 필요가 있습니다.
확률 이론과 통계
모든 통계는 한 개체의 상태 변화의 결과입니다. 시간 별 EURUSD 가격 차트를 이용하겠습니다.

이 경우 개체는 두 통화의 상관 관계가 되고 통계는 매 순간 해당 통화쌍의 가격이 됩니다. 두 통화 간의 상관 관계가 가격에 어떤 영향을 미치는가? 왜 다른 가격 차트가 아닌 특정 가격 차트가 해당 기간에 나타나나? 왜 가격이 하락하고 있나? 위의 세 가지 질문에 대한 답은 바로 '확률'에 있습니다. 각 객체는 확률에 따라 하나의 값 또는 다른 값을 가질 수 있는데요.
간단한 실험을 해 보죠. 동전을 몇 번 던져 봅니다. 던질 때마다 어느 면이 나오는지 기록합니다. 앞뒤가 공평하게 나왔다고 가정할게요. 다음과 같은 표가 작성됩니다.
| 결과 | 확률 |
|---|---|
| 앞면 | 0.5 |
| 뒷면 | 0.5 |
앞면과 뒷면이 나올 확률이 각각 0.5로 동일하죠. 발생 가능한 사건(모서리로 떨어지는 경우 제외)에 대한 확률의 합이 1이므로 다른 결과는 나올 수 없습니다.
동전을 10번 던집니다. 결과를 다시 볼까요?
| 결과 | 횟수 |
|---|---|
| 앞면 | 8 |
| 뒷면 | 2 |
각 면으로 떨어질 확률이 같은데 왜 이런 결과가 발생하는 걸까요? 어느 쪽으로나 떨어질 확률이 같다는 것이 몇 번의 반복 후에도 동전이 양 쪽으로 떨어질 확률이 같다는 것을 의미하지는 않습니다. 해당 확률은 특정 시도에서 동전이 앞면 또는 뒷면으로 떨어질 것이며 두 경우의 수가 같음을 의미하죠.
이제 동전을 100번 던져 보죠. 다음의 결과가 나옵니다.
| 결과 | 횟수 |
|---|---|
| 앞면 | 53 |
| 뒷면 | 47 |
이번에도 각 면이 나온 횟수가 상이하네요. 하지만 53:47은 첫 번째 결과와 동일하다고 봐도 무방합니다. 앞면과 뒷면이 골고루 나온 것이죠.
이제 반대로 해보겠습니다. 어느 쪽으로 떨어질지 모르는 동전이 있다고 생각합시다. 앞면과 뒷면이 나올 확률이 같은지 판단하는 것이 우리의 목표입니다.
첫 번째 실험의 데이터를 이용할게요. 각 면이 나온 수를 전체 결과 수로 나눕니다. 다음의 확률이 나옵니다.
| 결과 | 확률 |
|---|---|
| 앞면 | 0.8 |
| 뒷면 | 0.2 |
첫 번째 실험으로 앞면과 뒷면이 나올 확률이 동일하다고 결론을 내리기는 힘들겠네요. 두 번째 실험을 해봅시다.
| 결과 | 횟수 |
|---|---|
| 앞면 | 0.53 |
| 뒷면 | 0.47 |
높은 정확도로 앞면과 뒷면이 나올 확률이 같다고 말할 수 있습니다.
위의 예시에서 실험 횟수가 많을수록 객체의 특성이 보다 정확하게 통계에 반영된다는 결론을 얻을 수 있죠.
따라서 통계와 확률은 아주 밀접하게 연결되어 있습니다. 통계는 한 객체에 대한 실험의 결과이며 해당 객체의 상태를 나타내는 확률에 따라 달라집니다. 반대로, 해당 객체의 상태에 대한 확률은 통계를 통해 측정할 수 있습니다. 이를 이용한 투자자의 주 목표는 일정 기간 동안 이루어진 거래에 대한 데이터를 가지고(통계), 미래의 일정 기간 동안의 가격 움직임(확률)을 예측하여 매매에 대한 결정을 내리는 것입니다 .
따라서 통계와 확률 간의 관계를 이해하고, 위험 평가 및 위험 상황에 대한 인식을 갖는 것이 중요합니다. 마지막 두 주제는 이번 글에서 다루지 않습니다.
기본 통계 변수
이제 기본 통계 변수를 살펴보겠습니다. 10명으로 이루어진 그룹 내 각 구성원의 키에 대한 데이터가 있다고 가정하죠.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 키 | 173 | 162 | 194 | 181 | 186 | 159 | 173 | 178 | 168 | 171 |
위 표의 데이터는 표본, 데이터의 수는 표본 크기가 됩니다. 해당 표본에 대한 매개 변수를 살펴볼게요. 모든 매개 변수는 임의의 데이터가 아닌 표본 데이터의 결과이므로 표본 변수가 됩니다.
1. 표본 평균
표본 평균은 표본의 평균입니다. 우리의 경우 그룹에 속한 사람들의 평균 키가 되겠죠?
평균은 다음과 같이 계산합니다.
- 우선 표본 값을 모두 더합니다.
- 그렇게 나온 결과 값을 표본의 개수로 나눕니다.
공식
![]()
읽는 법
- 표본 평균 M
- 표본 요소 a[i]
- 표본 크기 n
연산을 통해 평균값 174.5cm를 얻습니다.
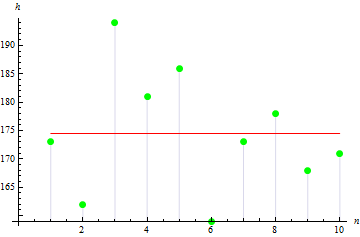
2. 표본 편차
표본 편차는 표본 평균에서 표본 값이 얼마나 떨어져 있는지를 나타냅니다. 값이 클수록 데이터가 넓게 분산되죠.
다음의 방법으로 편차를 계산합니다.
- 우선 표본 평균을 계산합니다.
- 각 표본 요소에서 평균을 뺀 값을 제곱합니다.
- 제곱된 편차를 모두 더합니다.
- 제곱된 편차의 합을 표본 집단의 자료 개수에서 하나를 뺀 값으로 나눕니다.
공식
![]()
읽는 법
- 표본 편차 D
- 표본 평균 M
- 표본 요소 a[i]
- 표본 크기 n
우리의 경우 표본 편차는 113.611이 됩니다.
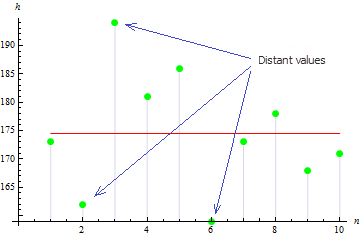
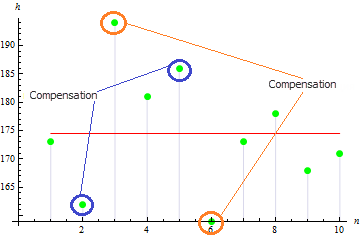
위 그림에는 3개의 값이 평균에서 크게 떨어져 편차 값을 올립니다.
3. 표본 왜도
표본 왜도는 표본 변수 분포의 비대칭도를 나타냅니다. 왜도의 값이 0에 가까울수록 표본의 분포가 대칭을 이룹니다.
다음의 방법으로 왜도를 계산합니다.
- 우선 표본 평균을 계산합니다.
- 표본 편차를 계산합니다.
- 각 표본과 평균의 차이의 3 제곱을 모두 더합니다.
- 결과 값을 편차*3/2으로 나눕니다.
- 결과 값을 표본 개수를 (표본 개수-1)*(표본 개수-2)로 나눕니다.
공식
![]()
읽는 법
- 표본 왜도 A
- 표본 편차 D
- 표본 평균 M
- 표본 요소 a[i]
- 표본 크기 n
해당 표본의 왜도는 0.372981로 꽤 작은 편입니다. 발산 값이 서로 상쇄되기 때문입니다.
분포의 비대칭도가 클수록 왜도 값이 증가합니다. 예를 들어 아래 그림의 데이터에 대한 왜도 값은 1.384651입니다.
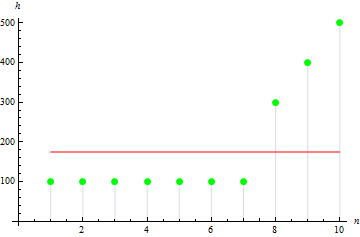
4. 표본 첨도
표본 첨도는 표본 분포의 뾰족한 정도를 나타냅니다.
다음의 방법으로 첨도를 계산합니다.
- 우선 표본 평균을 계산합니다.
- 표본 편차를 계산합니다.
- 각 표본과 평균의 차이의 4 제곱을 모두 더합니다.
- 편차의 제곱으로 나눕니다.
- (표본 개수)*(표본 개수+1)/(표본 개수-1)*(표본 개수-2)*(표본 개수-3)을 곱합니다.
- 3*(표본 개수-1)^2/(표본 개수-2)(표본 개수-3)을 뺍니다.
공식
![]()
읽는 법
- 표본 첨도 E
- 표본 편차 D
- 표본 평균 M
- 표본 요소 a[i]
- 표본 크기 n
해당 키 데이터를 이용하면 -0.1442285가 나옵니다.
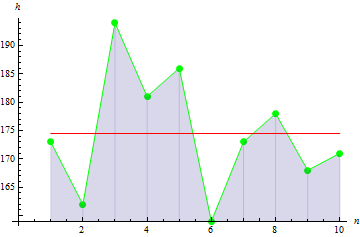
다음의 경우 첨도 값은 10이 됩니다.
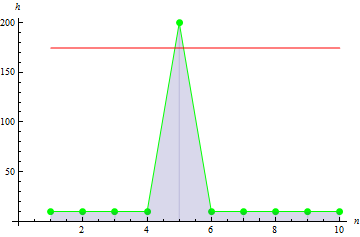
5. 표본 공분산
표본 공분산은 2개의 표본 변수 사이의 선형 관계를 나타냅니다. 두 변수의 선형 관계가 없는 경우 공분산은 0이 됩니다.
설명을 위해 10명에 대한 몸무게 데이터를 추가하겠습니다.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 몸무게 | 65 | 70 | 83 | 60 | 105 | 58 | 69 | 90 | 78 | 65 |
다음의 방법으로 두 표본의 공분산을 계산합니다.
- 첫 번째 표본의 평균을 계산합니다.
- 두 번째 표본의 평균을 계산합니다.
- 두 값의 차이를 곱한 값을 모두 더합니다. (첫 번째 표본 요소1-첫 번째 표본 평균)(두 번째 표본 요소1-두 번째 표본 평균)+(첫 번째 표본 요소2-첫 번째 표본 평균)(두 번째 표본 요소2-두 번째 표본평균)+...식으로 반복합니다.
- (표본 개수-1)로 나눕니다.
공식
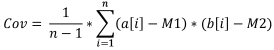
읽는 법
- 표본 공분산 Cov
- 첫 번째 표본 요소 a[i]
- 두 번째 표본 요소 b[i]
- 첫 번째 표본 평균 M1
- 두 번째 표본 평균 M2
- 표본 크기 n
두 표본으로 공분산을 계산하면 91.2778이 나오네요. 아래 차트에서 두 표본의 의존성을 확인할 수 있습니다.
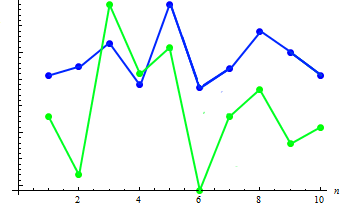
키가 클수록 몸무게가 감소하고 몸무게가 증가할수록 키가 작아지죠.
6. 표본 상관 계수
표본 상관 계수 또한 두 표본 변수 사이의 선형 관계의 정도를 나타냅니다. 상관 계수 값의 범위는 -1부터 +1까지입니다.
다음의 방법으로 두 표본의 상관 계수를 계산합니다.
- 첫 번째 표본의 편차를 계산합니다.
- 두 번째 표본의 편차를 계산합니다.
- 두 표본의 공분산을 계산합니다.
- 공분산을 두 편차의 곱의 제곱근으로 나눕니다.
공식
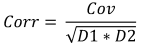
읽는 법
- 표본 상관 계수 Corr
- 표본 공분산 Cov
- 첫 번째 표본의 표본 편차 D1
- 두 번째 표본의 표본 편차 D2
위의 키와 몸무게 데이터에 대한 상관 계수는 0.579098이 됩니다.
거래에 통계 적용하기
거래에 적용된 통계 변수를 나타내는 가장 간단한 예는 MovingAverage 인디케이터입니다. 일정 기간에 대한 데이터를 가지고 가격의 산술적 평균을 계산하기 때문이죠.
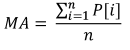
읽는 법
- 인디케이터 값 MA
- 가격 P[i]
- MA 측정 기간 n
표본 변수와 동일한 방법으로 작동하죠. 간단하긴 하지만 해당 인디케이터는 이동 평균 지수(EMA)를 계산할 때 사용되며 추세 강도와 가격 변동의 방향을 예측하는 대표적 인디케이터인 MACD 인디케이터의 기본 요소가 됩니다.

MQL5 통계
앞서 설명한 기본 통계 변수를 MQL5로 구현해 보겠습니다. 통계 함수 라이브러리인 statistics.mqh 파일에 위의 통계 분석 방법을 포함해 여러가지 통계 분석 방법이 들어 있습니다.코드를 한번 살펴보죠.
1. 표본 평균
표본 평균을 구하는 라이브러리 함수의 이름은 Average입니다.

인풋: 데이터 표본 아웃풋: 평균
2. 표본 편차
표본 편차를 구하는 라이브러리 함수의 이름은 Variance입니다.

인풋: 데이터 표본 및 표본 평균 아웃풋: 편차
3. 표본 왜도
표본 왜도를 구하는 라이브러리 함수의 이름은 Asymmetry입니다.

인풋: 데이터 표본, 표본 평균 및 표본 편차/아웃풋: 왜도
4. 표본 첨도
표본 첨도를 구하는 라이브러리 함수의 이름은 Excess(Excess2)입니다.

인풋: 데이터 표본, 표본 평균 및 표본 편차/아웃풋: 첨도
5. 표본 공분산
표본 공분산을 구하는 라이브러리 함수의 이름은 Cov입니다.

인풋: 두 개의 데이터 표본 및 각 데이터 표본 평균/아웃풋: 표본 공분산
6. 표본 상관 계수
표본 상관 계수를 구하는 라이브러리 함수의 이름은 Corr입니다.

인풋: 두 개의 표본에 대한 공분산, 첫 번째 표본 변수 및 두 번째 표본 변수 아웃풋: 상관 계수
키와 몸무게로 나타난 표본 데이터를 적용해 라이브러리를 실행해 보겠습니다.#include <Statistics.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- specify two data samples. double arrX[10]={173,162,194,181,186,159,173,178,168,171}; double arrY[10]={65,70,83,60,105,58,69,90,78,65}; //--- calculate the mean double mx=Average(arrX); double my=Average(arrY); //--- to calculate the variance, use the mean value double dx=Variance(arrX,mx); double dy=Variance(arrY,my); //--- skewness and kurtosis values double as=Asymmetry(arrX,mx,dx); double exc=Excess(arrX,mx,dx); //--- covariance and correlation values double cov=Cov(arrX,arrY,mx,my); double corr=Corr(cov,dx,dy); //--- print results in the log file PrintFormat("mx=%.6e",mx); PrintFormat("dx=%.6e",dx); PrintFormat("as=%.6e",as); PrintFormat("exc=%.6e",exc); PrintFormat("cov=%.6e",cov); PrintFormat("corr=%.6e",corr); }
스크립트를 실행하면 터미널에 다음과 같은 결과가 나타납니다.
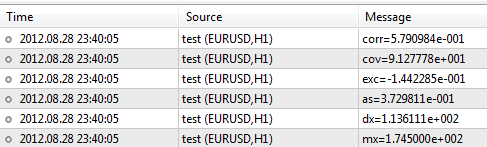
해당 라이브러리에 포함된 함수에 대한 설명은 코드베이스 https://www.mql5.com/ko/code/866에서 찾아볼 수 있습니다.
결론
통계와 확률에 대해 배웠습니다. 통계학은 기초부터 배워야 한다는 걸 추가로 알려드리고 싶네요. 아주 기본적인 요소도 투자에 필요한 복잡한 메커니즘이나 패턴을 이해하는 데에 도움을 줄 수 있거든요.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/387
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

 미지의 확률 밀도 함수에 대한 커널 밀도 추정
미지의 확률 밀도 함수에 대한 커널 밀도 추정
 MQL5.community 회원 활동 기록
MQL5.community 회원 활동 기록
 알고리즘 트레이딩 기사를 작성하고 200달러를 받으세요!
알고리즘 트레이딩 기사를 작성하고 200달러를 받으세요!
 DLL 생성이 불필요한 이유
DLL 생성이 불필요한 이유
모드를 결정하기 위한 알고리즘이 많아야 하므로 범용 자전거는 여기서 유용하지 않습니다.
오히려 원하는 것과 원하지 않는 것의 예를 살펴봐야 합니다.
기사가 마음에 들었습니다.
이해하기 쉽고 충분한 정보를 담고 있습니다.
그리고 제목으로 판단하면 그 이상을 가장하지 않습니다.
이 글은 쓸모가 없습니다. TV에서 나온 수많은 미사여구. 그리고이 기사가 전문적이고 반 거래자 웹 사이트에 인쇄되지 않았다면 침묵을 지킬 수있을 것입니다. 그러나 사이트를 고려할 때 다음 사항에 유의하고 싶습니다.
경제 데이터를 측정, 분석, 예측하는 과학이 있습니다. 이를 계량경제학이라고 합니다. 통계와 가까운 혈육이지만 상당한 차이점이 있습니다.
1. 트레이더의 경우 분석에서 예측이 따르지 않으면 분석 자체는 가치가 없습니다. 이 기사에서는 예측에 대해 전혀 언급하지 않습니다.
계량경제학은 처음에 경제계열의 비정형성에서 출발합니다. 그리고 적어도 그것에 대해 기억한다면, 말하자면 기본 통계에 대한 이야기가 그렇게 장밋빛이 아닐 것입니다. 비고정 계열의 경우 모수, 분산 등의 기본 개념을 많은 예약과 함께 적용 할 수 있습니다. 어쨌든 항상 의심해야 합니다. 예를 들어, 비고정 계열의 경우 평균이 반드시 모수에 수렴하는 것은 아닙니다. 저는 상관관계에 대해 전혀 이야기하고 있지 않습니다.
계량경제학은 수십 개의 관측치라는 매우 짧은 표본을 기반으로 합니다. 이러한 평균은 또한 수년간의 포즈를 의미하기 때문에 수년간의 평균에는 관심이 없습니다. 위기 상황에서는 계산 결과의 추정이 중요해집니다. TV를 통계, 특히 계량 경제학에서 근본적으로 구별하는 것은 추정치입니다.
학교 기사. 기관의 주니어 과정이 아닌 특수 학교의 수준.
"이 간단한 예에서 우리는 중요한 결론을 도출할 수 있습니다. 시도 횟수가 증가할수록 통계는 이를 생성하는 대상의 속성을 더 정확하게 반영합니다."
고정된 프로세스(진공 상태의 구형 말)의 경우 - 예.
실제 데이터의 시계열의 경우 이 진술은 말도 안 되는 소리입니다.
외환이 고정된 시계열이라면 이를 추정하는 데 MQL5가 필요하지 않으며 식료품점의 간단한 나무 브러시로 충분할 것입니다.
나방에 혼란스러운 순서와 혼란스러운 시간 간격으로 구멍을 뚫는다면
전체 기간에 대한 통계는 RosStat 보고서 또는 미친 사람의 호언장담과 비슷할 것입니다.
" 트레이더의 주요 임무는 특정 기간의 거래 데이터를 파악 (통계)하고, 다음 기간의 가격(환율) 움직임을예측 (확률 구하기)하며, 이를 바탕으로 매수 또는 매도 결정을 내리는 것입니다."
의미 측면에서 또 다른 진술은 넌센스와 크게 다르지 않습니다. 무언가를 예측하려면 먼저 그 시리즈가 무작위가 아니며 예측할 수 있다는 것을 스스로 증명해야 합니다. 무작위 시리즈에 대한 수입을 가질 수 있습니다. 예측할 수는 없지만 확률 비대칭 및 긍정적 / 부정적 기대.
.