
挖掘央行资产负债表数据,描绘全球流动性全貌

21世纪历次金融危机,从2008年次贷危机到2020年后疫情引发的市场动荡,彻底改写了金融运行规则。央行早已不再局限于单纯调控利率,政策工具箱不断扩容,新增企业债购买、定向信贷投放、货币互换、为政府支出提供融资等非常规工具。这类举措如同巨型水泵,向全球经济体投放或回笼流动性,其政策效果直观体现在作为货币政策晴雨表的央行资产负债表之中。
本文不只是央行资产负债表的分析教程,更深入讲解了如何搭建量化系统 —— 如同炼金炉一般,依托原始流动性数据推导货币对走势的精准预测。我们汇总美联储(Fed)、欧洲央行(ECB)、日本央行(BOJ)、中国人民银行(PBoC)数据编制全球流动性综合指标。结合机器学习与技术分析,捕捉传统分析难以发现的隐藏规律。此外,我们将该系统与实盘交易相结合,把抽象数据转化为具体交易决策。
传统技术分析依托K线与各类指标,好比仅凭云层预判天气;而基本面分析需要深厚的宏观功底,难以满足短线快速开仓的需求。本方案打通两种分析壁垒,依靠流动性数据研判价格短期波动与长期趋势。
理论基础:流动性是全球经济的脉搏
全球流动性并非单纯指代市场流通货币总量,而是全球经济的命脉,是由货币总量、各类金融工具、资本流转机制共同构成的复杂体系。在狭义层面,流动性代表资产无损快速变现的能力;放眼全球,它体现资本在各国、各市场、各行业间的流转难易程度。而资本流动往往催生强大的长期趋势。
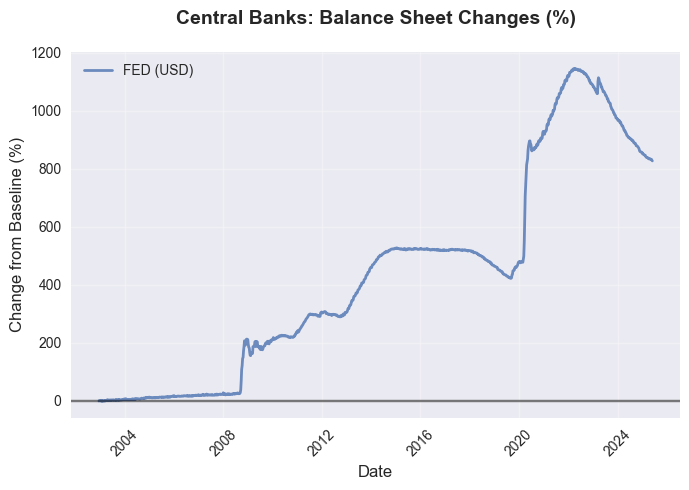
美联储、欧洲央行、日本央行、中国人民银行是全球流动性的主要调控主体。央行资产负债表不只是财务报表,而是直观反映央行通过购债、放贷等手段向市场投放的资金规模。美联储买入国债会扩表、增加市场流动性;当欧洲央行提高准备金要求时,就会回收流动性,压缩资金流动。
央行通过量化宽松、资产购置扩表,通常会拖累本币汇率。原因有两个:一是货币供应量增多,根据供需原理会压低币种价值;二是宽松政策往往伴随降息,削弱该币种的资产吸引力。
然而,汇率与扩表的逻辑并非一成不变。如果各大主要央行同步扩表,多国货币同步贬值,货币对波动幅度会显著收窄。核心在于相对扩表速度:当日央行扩表增速远超美联储时,日元大概率将相对美元走弱。
掌握流动性在金融体系的传导路径,是行情预判的关键。主要传导渠道如下:
- 利率渠道:央行降息抬升货币供给,本币计价资产收益率下行,利空汇率;
- 资产配置渠道:央行大规模购债改变投资者持仓结构,倒逼资金转向其他品类资产;
- 信贷渠道:信贷环境改善提振实体经济,进而改变跨境资金流向;
- 预期渠道:央行前瞻表态与政策指引,在落地前就提前引导市场预期。
对未来货币政策的预期,催生后续的价格趋势。让我们对此展开详述。
在信息高度透明的当下,央行已深谙预期管理。官员讲话、发布会、经济展望绝非空谈,而是左右市场预期的强力工具。当美联储主席暗示将收紧政策时,市场甚至可能在正式决议出台前就开始抛售美元。因此,流动性分析既要参考资产负债表数值,也不能忽略央行措辞,其影响力堪比实际政策落地。
系统架构:构建金融未来
我们的系统并非单一整体,而是一幅精心构建的模块化拼图,每个模块都承担着明确的功能。GlobalLiquidityMiner(全球流动性挖掘模块)负责采集并处理央行资产负债表数据,将杂乱的信息流转化为规整的时间序列。ForexLiquidityForecaster(外汇流动性预测模块)基于上述数据,结合技术指标进行特征增强,并通过机器学习算法生成精准预测。该方法支持单独更新任一组件而不影响整个系统,从而灵活适配新的数据源与市场环境。
金融市场是复杂的自适应系统,短期交易者情绪与长期宏观趋势相互交织。我们的架构体现了这种双重性,将灵敏的技术信号与深度的基本面因子相结合。
GlobalLiquidityMiner模块是数据采集系统的核心。它对接多种数据源,从美联储FRED API,到格式复杂的日本央行数据,再到信息披露相对有限的中国央行数据均能处理。其核心任务不只是加载数据,更是将数据标准化以便于分析。不同央行的数据发布频率各不相同(美联储周度报告对比中国人民银行季度数据),计价货币也存在差异。该模块会对缺失值进行插值、对指标做标准化处理,并完成多时间序列的时间对齐。
import pandas as pd import logging from typing import Dict from fredapi import Fred import yfinance as yf import requests from io import StringIO logger = logging.getLogger(__name__) class GlobalLiquidityMiner: def __init__(self, fred_api_key: str, start_date: str, end_date: str): self.fred = Fred(api_key=fred_api_key) if fred_api_key else None self.start_date = start_date self.end_date = end_date self.data_cache = {} def fetch_central_bank_balance_sheets(self) -> Dict[str, pd.DataFrame]: """Obtaining central bank balance sheet data.""" balance_sheets = {} if self.fred: logger.info("Loading Federal Reserve data...") try: fed_total_assets = self.fred.get_series('WALCL', start=self.start_date, end=self.end_date) fed_securities = self.fred.get_series('WSHOSHO', start=self.start_date, end=self.end_date) fed_loans = self.fred.get_series('WLRRAL', start=self.start_date, end=self.end_date) balance_sheets['FED'] = pd.DataFrame({ 'date': fed_total_assets.index, 'total_assets': fed_total_assets.values, 'securities_held': fed_securities.reindex(fed_total_assets.index, method='ffill').values, 'loans_and_repos': fed_loans.reindex(fed_total_assets.index, method='ffill').values, 'currency': 'USD' }) balance_sheets['FED']['assets_growth_rate'] = balance_sheets['FED']['total_assets'].pct_change(periods=52) balance_sheets['FED']['securities_share'] = balance_sheets['FED']['securities_held'] / balance_sheets['FED']['total_assets'] logger.info(f"Loaded {len(fed_total_assets)} Federal Reserve data entries") except Exception as e: logger.error(f"Error loading Fed data: {e}") self.data_cache['balance_sheets'] = balance_sheets return balance_sheets
该模块将流动性数据与技术指标相结合,为机器学习模型构建特征。通过滑动窗口的应用,我们可以同时捕捉流动性变化带来的短期与长期影响。
from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import StandardScaler from sklearn.metrics import r2_score, mean_squared_error import numpy as np class ForexLiquidityForecaster: def __init__(self, liquidity_miner: GlobalLiquidityMiner): self.liquidity_miner = liquidity_miner self.models = {} self.scalers = {} def build_prediction_model(self, symbol: str, feature_df: pd.DataFrame): """ Training a forecasting model.""" targets = { f'return_{h}d': feature_df['close'].shift(-h) / feature_df['close'] - 1 for h in [1, 5] } feature_columns = [col for col in feature_df.columns if not col.startswith(('return_', 'volatility_', 'direction_'))] X = feature_df[feature_columns].dropna() train_size = int(len(X) * 0.8) X_train, X_test = X.iloc[:train_size], X.iloc[train_size:] models = {} for target_name, target_series in targets.items(): y = target_series.dropna() common_idx = X.index.intersection(y.index) X_aligned, y_aligned = X.loc[common_idx], y.loc[common_idx] scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_aligned.iloc[:train_size]) X_test_scaled = scaler.transform(X_aligned.iloc[train_size:]) model = RandomForestRegressor(n_estimators=100, max_depth=10, random_state=42) model.fit(X_train_scaled, y_aligned.iloc[:train_size]) test_pred = model.predict(X_test_scaled) test_r2 = r2_score(y_aligned.iloc[train_size:], test_pred) models[target_name] = {'model': model, 'scaler': scaler, 'r2': test_r2} self.models[symbol] = models self.scalers[symbol] = scaler
ForexLiquidityForecaster模块是整个系统的“大脑”,负责将流动性数据与市场指标进行融合分析。它采用随机森林算法,挖掘央行资产负债表、技术指标(RSI、MACD、MA)与货币对走势之间的非线性关系。在构建特征时会引入时间滞后项,以同时捕捉流动性变化的即时效应与滞后效应。
from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import StandardScaler from sklearn.metrics import r2_score import numpy as np import pandas as pd class ForexLiquidityForecaster: def __init__(self, liquidity_miner: GlobalLiquidityMiner): self.liquidity_miner = liquidity_miner self.models = {} self.scalers = {} self.forecasts = {} def prepare_features(self, symbol: str, historical_data: pd.DataFrame) -> pd.DataFrame: """Create features for forecasting.""" df = historical_data.copy() # Technical indicators df['rsi_14'] = self.calculate_rsi(df['close'], 14) df['ema_50'] = df['close'].ewm(span=50).mean() df['volatility_20d'] = df['close'].pct_change().rolling(20).std() # Attaching liquidity data if 'balance_sheets' in self.liquidity_miner.data_cache: for bank, bs_data in self.liquidity_miner.data_cache['balance_sheets'].items(): df = df.join(bs_data[['total_assets']].rename(columns={'total_assets': f'{bank}_balance'}), how='left') df[f'{bank}_balance'].fillna(method='ffill', inplace=True) return df.dropna() def calculate_rsi(self, series: pd.Series, period: int = 14) -> pd.Series: """RSI calculation.""" delta = series.diff() gain = delta.where(delta > 0, 0).rolling(window=period).mean() loss = -delta.where(delta < 0, 0).rolling(window=period).mean() rs = gain / loss return 100 - (100 / (1 + rs)) def build_prediction_model(self, symbol: str, feature_df: pd.DataFrame): """ Training a forecasting model.""" targets = { f'return_{h}d': feature_df['close'].shift(-h) / feature_df['close'] - 1 for h in [1, 3, 5, 8] } feature_columns = [col for col in feature_df.columns if not col.startswith('return_')] X = feature_df[feature_columns].dropna() train_size = int(len(X) * 0.8) X_train, X_test = X.iloc[:train_size], X.iloc[train_size:] models = {} for target_name, target_series in targets.items(): y = target_series.dropna() common_idx = X.index.intersection(y.index) X_aligned, y_aligned = X.loc[common_idx], y.loc[common_idx] scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_aligned.iloc[:train_size]) X_test_scaled = scaler.transform(X_aligned.iloc[train_size:]) model = RandomForestRegressor(n_estimators=200, max_depth=15, random_state=42) model.fit(X_train_scaled, y_aligned.iloc[:train_size]) test_pred = model.predict(X_test_scaled) test_r2 = r2_score(y_aligned.iloc[train_size:], test_pred) models[target_name] = {'model': model, 'scaler': scaler, 'r2': test_r2} self.models[symbol] = models self.scalers[symbol] = scaler
实际落地:从数据到交易行为
FRED API是获取美联储资产负债表数据的宝库,涵盖总资产、证券持有量、贷款等多项指标。代码会处理API限制(如请求频率上限),并针对不同频率的数据进行时间同步。
def fetch_fed_data(self): """Obtaining Federal Reserve data via API FRED.""" try: fed_data = self.fred.get_series('WALCL', start=self.start_date, end=self.end_date) return pd.DataFrame({ 'date': fed_data.index, 'total_assets': fed_data.values, 'currency': 'USD' }).set_index('date') except Exception as e: logger.error(f"Error loading Fed data: {e}") return pd.DataFrame()
欧洲央行的数据通过统计数据仓库获取;如果出现服务中断,则使用欧元兑美元汇率、欧洲斯托克50指数等替代指标。对于数据获取渠道有限的日本央行与中国人民银行,则采用日经225指数、美元兑日元汇率、中国债券等市场类指标作为替代。
def fetch_boj_proxy_data(self): """Obtaining BOJ proxy data.""" try: usdjpy = yf.download('USDJPY=X', start=self.start_date, end=self.end_date, progress=False) nikkei = yf.download('^N225', start=self.start_date, end=self.end_date, progress=False) proxy_balance = pd.DataFrame(index=usdjpy.index) proxy_balance['jpy_strength'] = 1 / usdjpy['Close'] proxy_balance['equity_liquidity'] = nikkei['Close'] / nikkei['Close'].rolling(252).mean() proxy_balance['synthetic_balance'] = proxy_balance['jpy_strength'].rolling(30).mean() * proxy_balance['equity_liquidity'] * 1000000 return proxy_balance except Exception as e: logger.error(f"Error loading BOJ data: {e}") return pd.DataFrame()
流动性指数:构建金融指南针
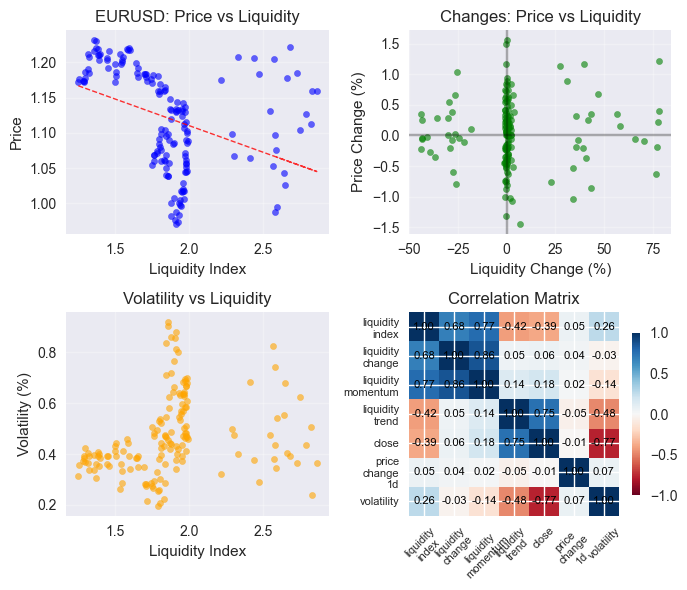
综合流动性指数将各国央行资产负债表的标准化数据按影响力权重进行整合:美联储(35%)、欧洲央行(25%)、日本央行(15%)、中国人民银行(20%)、其他央行(5%)。系统会根据数据的波动性与可靠性动态调整权重。
def calculate_liquidity_index(self) -> pd.DataFrame: """Calculation of the composite liquidity index.""" all_series = {} weights = {'FED_balance': 0.35, 'ECB_balance': 0.25, 'BOJ_balance': 0.15, 'PBOC_balance': 0.20} for bank, df in self.data_cache.get('balance_sheets', {}).items(): series_name = f'{bank}_balance' normalized = (df['total_assets'] - df['total_assets'].rolling(252).mean()) / df['total_assets'].rolling(252).std() all_series[series_name] = normalized combined_df = pd.DataFrame(all_series).fillna(method='ffill') liquidity_index = combined_df.dot(pd.Series(weights)) return pd.DataFrame({'liquidity_index': liquidity_index}, index=combined_df.index)
除主指数外,系统还会构建多项子指数:短期指数(30日)、长期指数(252日)、加速度指数以及流动性波动率指数。这些指标能帮助预测模型适配不同的市场环境。
def enhance_liquidity_index(self, base_index: pd.Series) -> pd.DataFrame: """Creating advanced liquidity indicators.""" enhanced_df = pd.DataFrame(index=base_index.index) enhanced_df['base_liquidity_index'] = base_index enhanced_df['short_term_liquidity'] = base_index.rolling(window=30).mean() enhanced_df['long_term_trend'] = base_index.rolling(window=252).mean() enhanced_df['liquidity_acceleration'] = base_index.diff().diff() enhanced_df['liquidity_volatility'] = base_index.rolling(window=60).std() return enhanced_df
与MetaTrader 5集成:通往实盘交易的桥梁
该系统与MetaTrader 5对接,用于获取行情数据并生成交易信号。输入特征同时包含技术指标与流动性指标,形成一套用于预测的独特数据集。
import MetaTrader5 as mt5 from datetime import datetime, timedelta class TradingIntegration: def __init__(self, forecaster: ForexLiquidityForecaster): self.forecaster = forecaster mt5.initialize() def fetch_forex_data(self, symbol: str, days: int = 1460) -> pd.DataFrame: """Fetching data from MetaTrader 5.""" utc_from = datetime.now() - timedelta(days=days) rates = mt5.copy_rates_from(symbol, mt5.TIMEFRAME_D1, utc_from, days) if rates is None: return pd.DataFrame() df = pd.DataFrame(rates) df['date'] = pd.to_datetime(df['time'], unit='s') df.set_index('date', inplace=True) return df def generate_trading_signals(self, symbol: str, forecasts: dict) -> dict: """Generating trading signals.""" signals = {} short_term_returns = [f['return'] for h, f in forecasts['forecasts'].items() if h in ['1d', '2d', '3d']] avg_return = np.mean(short_term_returns) if short_term_returns else 0 signals['short_term'] = { 'signal': 'BUY' if avg_return > 0.005 else 'SELL' if avg_return < -0.005 else 'HOLD', 'strength': min(abs(avg_return) * 100, 100) } return signals
可视化:通过图表呈现全球市场全貌
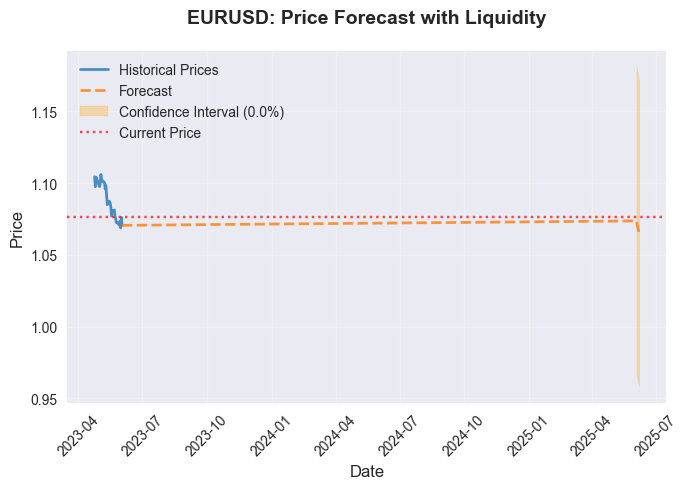
系统会生成交互式可视化图表,帮助交易者直观观察流动性与价格之间的联动关系。图表内容包括:价格预测曲线、流动性指数走势,以及特征重要性排序。
import matplotlib.pyplot as plt import numpy as np def create_comprehensive_visualization(self, symbol: str): """Building a set of visualizations.""" forecasts = self.forecaster.forecasts.get(symbol, {}) historical_data = self.fetch_forex_data(symbol, days=180) plt.figure(figsize=(15, 8)) plt.plot(historical_data.index[-60:], historical_data['close'].iloc[-60:], label='Historical prices', linewidth=2) forecast_dates = [datetime.strptime(f['date'], '%Y-%m-%d') for f in forecasts.get('forecasts', {}).values()] forecast_prices = [f['price'] for f in forecasts.get('forecasts', {}).values()] if forecast_dates: plt.plot(forecast_dates, forecast_prices, 'r--', label='Forecast', linewidth=2) plt.title(f'{symbol}: Price forecast considering liquidity', fontsize=14, fontweight='bold') plt.xlabel('Date', fontsize=12) plt.ylabel('Price', fontsize=12) plt.legend() plt.grid(True, alpha=0.3) plt.savefig(f'forecast_{symbol}.png', dpi=300) plt.close()
最终,我们可以获得全球流动性全景图:
依托数据生成的预测:
相关性矩阵:
结论
本开发系统是一款功能完备的分析工具,融合央行资产负债表研判、前沿机器学习与技术分析手段,形成一套研判汇率走势的综合分析框架。系统采用由GlobalLiquidityMiner与ForexLiquidityForecaster构成的模块化架构,具备灵活性与可拓展性,能够适配多变的市场环境。
与MetaTrader 5平台集成,交易者可将预测结果落地实盘,把繁杂的数据转化为切实可行的交易策略。交互式可视化图表与回测结果提升了系统的透明度与稳健性,帮助交易者有据可依、从容决策。
该系统突破传统分析局限,统筹基本面与技术面双重要素,构建全维度分析逻辑。使交易者不再被动跟随行情,而是依托全球流动性指标预判走势,在波动剧烈的外汇市场中,以全球流动性为指南。在全球经济波动性与不确定性持续上升的背景下,这种方法已不仅是优势,也正逐渐成为有效交易的重要工具。
但系统仍存在短板。部分央行(如中国人民银行)的公开数据有限,只能选用替代指标,一定程度上影响测算精准度。此外,机器学习虽优势突出,但无法实现预测零误差,在地缘冲突、突发经济冲击等黑天鹅事件面前预测效果受限。然而,依托算法迭代、数据源扩充与新增市场影响因子,系统能够保持其相关性和有效性。
后续优化方向可能包括:接入神经网络模型,解析新闻、社交媒体等海量非结构化数据,进一步强化预测能力;增设自适应调节机制,根据实时经济环境自动修正流动性指数权重。以上改进将助力新一代交易系统落地,提升系统抗风险能力,在各类行情环境中实现稳健收益。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/18355
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

这张照片简直太火了,简直就是网络流行语的绝配。