
Analyse der Bilanzdaten von Zentralbanken zur Einschätzung der globalen Liquidität

Die Finanzkrisen des 21. Jahrhunderts – von der Hypothekenkrise 2008 bis hin zu den Turbulenzen infolge der Pandemie in den 2020er Jahren – haben die Spielregeln grundlegend verändert. Die Zentralbanken sind nicht länger auf die vergleichsweise begrenzte Rolle als Zinsregulatoren angewiesen. Ihr Instrumentarium hat sich um exotische Instrumente erweitert: Unternehmensanleihekäufe, direkte Kredite an Banken, Währungsswaps und sogar die Finanzierung staatlicher Ausgaben. Diese Maßnahmen pumpen – ähnlich wie leistungsstarke Pumpen – Liquidität in die Weltwirtschaft hinein oder entziehen ihr diese, und ihre Auswirkungen zeigen sich in den Bilanzen der Zentralbanken, den Spiegeln der Geldpolitik.
Dieser Artikel ist nicht nur eine Anleitung zur Analyse von Zentralbankbilanzen. Es handelt sich um eine eingehende Untersuchung der Frage, wie man ein System aufbaut, das – ähnlich wie ein alchemistischer Kessel – Liquiditätsrohdaten in wertvolle Prognosen transformiert. Wir werden Daten der US-Notenbank (Fed), der Europäischen Zentralbank (EZB), der Bank of Japan (BOJ) und der Volksbank von China (PBoC) zusammenführen, um einen Gesamtindex für die globale Liquidität zu erstellen. Wir werden untersuchen, wie maschinelles Lernen und technische Analyse zusammenwirken können, um verborgene Muster aufzudecken, die mit herkömmlichen Methoden oft nicht erkannt werden. Darüber hinaus werden wir zeigen, wie man dieses System in den realen Handel integriert und abstrakte Daten in konkrete Handelsentscheidungen umsetzt.
Die klassische technische Analyse mit ihren Charts und Indikatoren ähnelt oft dem Versuch, das Wetter allein anhand der Wolken vorherzusagen. Die Fundamentalanalyse hingegen erfordert ein fundiertes Verständnis der Makroökonomie, was für schnelle Handelsentscheidungen nicht immer geeignet ist. Unser Ansatz schlägt eine Brücke zwischen zwei Welten, wobei Liquiditätsdaten zum Schlüssel für das Verständnis kurzfristiger Bewegungen und langfristiger Trends werden.
Theoretische Grundlagen: Liquidität als Puls der Weltwirtschaft
Die globale Liquidität ist nicht einfach nur die im Umlauf befindliche Geldmenge. Sie ist das Lebenselixier der Weltwirtschaft, ein komplexes System, das Geldmengenaggregate, Finanzinstrumente und Mechanismen vereint, die den freien Kapitalfluss gewährleisten. Im engeren Sinne ist Liquidität die Fähigkeit eines Vermögenswerts, schnell und ohne Wertverlust in Geld umgewandelt zu werden. Auf globaler Ebene zeigt dies jedoch, wie leicht sich Kapital zwischen Ländern, Märkten und Sektoren bewegt. Kapitalflüsse können selbst starke langfristige Trends auslösen.
Die Zentralbanken – die Fed, die EZB, die BOJ und die PBoC – sind die Dirigenten dieses Orchesters. Ihre Bilanzen sind nicht nur buchhalterische Berichte, sondern Indikatoren dafür, wie viel Geld sie durch den Ankauf von Vermögenswerten, die Vergabe von Krediten oder andere Maßnahmen in die Wirtschaft gepumpt haben. Wenn die Fed Staatsanleihen kauft, schafft sie neue Liquidität, indem sie ihre Bilanz ausweitet. Wenn die EZB die Mindestreserveanforderungen erhöht, entzieht sie dem Markt Liquidität und reduziert damit die Geldströme.
Eine Ausweitung der Bilanzsumme der Zentralbank durch quantitative Lockerung oder Wertpapierkäufe führt in der Regel zu einer Schwächung der Landeswährung. Dafür gibt es zwei Gründe. Erstens führt die Ausweitung der Geldmenge gemäß den Gesetzen von Angebot und Nachfrage zu einer Wertminderung der Währung. Zweitens gehen solche Maßnahmen oft mit niedrigeren Zinssätzen einher, was die Währung für renditeorientierte Anleger weniger attraktiv macht.
Dieser Zusammenhang ist jedoch nicht so einfach. Wenn alle großen Zentralbanken gleichzeitig ihre Bilanzen ausweiten, sind die Auswirkungen auf die Währungspaare möglicherweise minimal – alle Währungen werden gewissermaßen gleichzeitig verwässert. Der entscheidende Faktor ist dabei die relative Dynamik: Wenn die BOJ ihre Bilanz schneller ausweitet als die Fed, dürfte der JPY gegenüber dem USD an Wert verlieren.
Für Prognosen ist es entscheidend, zu verstehen, wie sich Liquidität im Finanzsystem auswirkt. Es gibt mehrere Kanäle:
- Zinskanal: Zinssenkungen der Zentralbank erhöhen die Geldmenge, was die Rendite von auf diese Währung lautenden Vermögenswerten senkt und die Währung schwächt.
- Portfolio-Kanal: Umfangreiche Wertpapierkäufe durch die Zentralbanken verändern die Zusammensetzung der Anlegerportfolios und zwingen diese dazu, nach alternativen Anlagemöglichkeiten zu suchen.
- Kreditkanal: Bessere Kreditbedingungen kurbeln die Wirtschaftstätigkeit an und wirken sich auf die Währungsströme aus.
- Erwartungskanal: Die Kommunikation und die vorlaufenden Signale der Zentralbanken prägen die Erwartungen des Marktes bereits vor dem Ergreifen konkreter Maßnahmen.
Erwartungen hinsichtlich der künftigen Geldpolitik prägen zukünftige Trends. Schauen wir uns das nun genauer an.
Im Zeitalter der Informationstransparenz sind die Zentralbanken zu Meistern der Kommunikation geworden. Ihre Erklärungen, Pressekonferenzen und Prognosen sind nicht nur Worte, sondern wirkungsvolle Instrumente, die die Markterwartungen prägen. Wenn der Fed-Vorsitzende eine Straffung der Geldpolitik andeutet, könnten die Märkte bereits vor der offiziellen Entscheidung beginnen, USD zu verkaufen. Bei der Liquiditätsanalyse müssen nicht nur die Zahlen in den Bilanzen berücksichtigt werden, sondern auch die Äußerungen der Verantwortlichen, die ebenso wichtig sein können wie deren tatsächliches Handeln.
Systemarchitektur: Konstruktion der finanziellen Zukunft
Unser System ist kein Monolith, sondern ein sorgfältig zusammengestelltes Mosaik, in dem jedes Modul eine klar definierte Funktion erfüllt. GlobalLiquidityMiner sammelt und verarbeitet Daten zu den Bilanzen der Zentralbanken und wandelt chaotische Informationsströme in schlüssige Zeitreihen um. ForexLiquidityForecaster nutzt diese Daten, ergänzt sie um technische Indikatoren und wertet sie mit Algorithmen des maschinellen Lernens aus, um präzise Prognosen zu erstellen. Dieser Ansatz ermöglicht es, einzelne Komponenten zu aktualisieren, ohne das gesamte System zu beeinträchtigen, und es an neue Datenquellen oder Marktbedingungen anzupassen.
Finanzmärkte sind komplexe adaptive Systeme, in denen die kurzfristige Stimmung der Händler mit langfristigen makroökonomischen Trends verflochten ist. Unsere Architektur spiegelt diese Dualität wider, indem sie schnelle technische Signale mit tiefgreifenden fundamentalen Faktoren verbindet.
Das Modul GlobalLiquidityMiner ist das Herzstück des Datenerfassungssystems. Es funktioniert mit einer Vielzahl von Quellen, von der FRED-API der Fed über komplexe Datenformate der BOJ bis hin zu begrenzten Informationen der PBoC. Die Hauptaufgabe besteht nicht nur darin, die Daten zu laden, sondern sie für die Analyse zu standardisieren. Verschiedene Banken veröffentlichen Daten in unterschiedlichen Zeitabständen (wöchentliche Berichte der Fed gegenüber vierteljährlichen Daten der PBoC) und in unterschiedlichen Währungen. Das Modul interpoliert fehlende Werte, normiert Indikatoren und synchronisiert Zeitreihen.
import pandas as pd import logging from typing import Dict from fredapi import Fred import yfinance as yf import requests from io import StringIO logger = logging.getLogger(__name__) class GlobalLiquidityMiner: def __init__(self, fred_api_key: str, start_date: str, end_date: str): self.fred = Fred(api_key=fred_api_key) if fred_api_key else None self.start_date = start_date self.end_date = end_date self.data_cache = {} def fetch_central_bank_balance_sheets(self) -> Dict[str, pd.DataFrame]: """Obtaining central bank balance sheet data.""" balance_sheets = {} if self.fred: logger.info("Loading Federal Reserve data...") try: fed_total_assets = self.fred.get_series('WALCL', start=self.start_date, end=self.end_date) fed_securities = self.fred.get_series('WSHOSHO', start=self.start_date, end=self.end_date) fed_loans = self.fred.get_series('WLRRAL', start=self.start_date, end=self.end_date) balance_sheets['FED'] = pd.DataFrame({ 'date': fed_total_assets.index, 'total_assets': fed_total_assets.values, 'securities_held': fed_securities.reindex(fed_total_assets.index, method='ffill').values, 'loans_and_repos': fed_loans.reindex(fed_total_assets.index, method='ffill').values, 'currency': 'USD' }) balance_sheets['FED']['assets_growth_rate'] = balance_sheets['FED']['total_assets'].pct_change(periods=52) balance_sheets['FED']['securities_share'] = balance_sheets['FED']['securities_held'] / balance_sheets['FED']['total_assets'] logger.info(f"Loaded {len(fed_total_assets)} Federal Reserve data entries") except Exception as e: logger.error(f"Error loading Fed data: {e}") self.data_cache['balance_sheets'] = balance_sheets return balance_sheets
Das Modul kombiniert Liquiditätsdaten mit technischen Indikatoren und erstellt so Merkmale für Modelle des maschinellen Lernens. Durch die Verwendung von beweglichen Fenstern können wir die kurz- und langfristigen Auswirkungen von Liquiditätsveränderungen berücksichtigen.
from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import StandardScaler from sklearn.metrics import r2_score, mean_squared_error import numpy as np class ForexLiquidityForecaster: def __init__(self, liquidity_miner: GlobalLiquidityMiner): self.liquidity_miner = liquidity_miner self.models = {} self.scalers = {} def build_prediction_model(self, symbol: str, feature_df: pd.DataFrame): """ Training a forecasting model.""" targets = { f'return_{h}d': feature_df['close'].shift(-h) / feature_df['close'] - 1 for h in [1, 5] } feature_columns = [col for col in feature_df.columns if not col.startswith(('return_', 'volatility_', 'direction_'))] X = feature_df[feature_columns].dropna() train_size = int(len(X) * 0.8) X_train, X_test = X.iloc[:train_size], X.iloc[train_size:] models = {} for target_name, target_series in targets.items(): y = target_series.dropna() common_idx = X.index.intersection(y.index) X_aligned, y_aligned = X.loc[common_idx], y.loc[common_idx] scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_aligned.iloc[:train_size]) X_test_scaled = scaler.transform(X_aligned.iloc[train_size:]) model = RandomForestRegressor(n_estimators=100, max_depth=10, random_state=42) model.fit(X_train_scaled, y_aligned.iloc[:train_size]) test_pred = model.predict(X_test_scaled) test_r2 = r2_score(y_aligned.iloc[train_size:], test_pred) models[target_name] = {'model': model, 'scaler': scaler, 'r2': test_r2} self.models[symbol] = models self.scalers[symbol] = scaler
Das Modul ForexLiquidityForecaster ist das Gehirn des Systems, in dem Liquiditätsdaten auf Marktindikatoren treffen. Das Modell nutzt Random Forest, um nichtlineare Zusammenhänge zwischen den Bilanzen der Zentralbanken, technischen Indikatoren (RSI, MACD, gleitende Durchschnitte) und den Kursbewegungen von Währungspaaren zu ermitteln. Bei der Erstellung der Merkmale werden zeitliche Verzögerungen berücksichtigt, um sowohl unmittelbare als auch verzögerte Auswirkungen von Liquiditätsveränderungen zu erfassen.
from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import StandardScaler from sklearn.metrics import r2_score import numpy as np import pandas as pd class ForexLiquidityForecaster: def __init__(self, liquidity_miner: GlobalLiquidityMiner): self.liquidity_miner = liquidity_miner self.models = {} self.scalers = {} self.forecasts = {} def prepare_features(self, symbol: str, historical_data: pd.DataFrame) -> pd.DataFrame: """Create features for forecasting.""" df = historical_data.copy() # Technical indicators df['rsi_14'] = self.calculate_rsi(df['close'], 14) df['ema_50'] = df['close'].ewm(span=50).mean() df['volatility_20d'] = df['close'].pct_change().rolling(20).std() # Attaching liquidity data if 'balance_sheets' in self.liquidity_miner.data_cache: for bank, bs_data in self.liquidity_miner.data_cache['balance_sheets'].items(): df = df.join(bs_data[['total_assets']].rename(columns={'total_assets': f'{bank}_balance'}), how='left') df[f'{bank}_balance'].fillna(method='ffill', inplace=True) return df.dropna() def calculate_rsi(self, series: pd.Series, period: int = 14) -> pd.Series: """RSI calculation.""" delta = series.diff() gain = delta.where(delta > 0, 0).rolling(window=period).mean() loss = -delta.where(delta < 0, 0).rolling(window=period).mean() rs = gain / loss return 100 - (100 / (1 + rs)) def build_prediction_model(self, symbol: str, feature_df: pd.DataFrame): """ Training a forecasting model.""" targets = { f'return_{h}d': feature_df['close'].shift(-h) / feature_df['close'] - 1 for h in [1, 3, 5, 8] } feature_columns = [col for col in feature_df.columns if not col.startswith('return_')] X = feature_df[feature_columns].dropna() train_size = int(len(X) * 0.8) X_train, X_test = X.iloc[:train_size], X.iloc[train_size:] models = {} for target_name, target_series in targets.items(): y = target_series.dropna() common_idx = X.index.intersection(y.index) X_aligned, y_aligned = X.loc[common_idx], y.loc[common_idx] scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_aligned.iloc[:train_size]) X_test_scaled = scaler.transform(X_aligned.iloc[train_size:]) model = RandomForestRegressor(n_estimators=200, max_depth=15, random_state=42) model.fit(X_train_scaled, y_aligned.iloc[:train_size]) test_pred = model.predict(X_test_scaled) test_r2 = r2_score(y_aligned.iloc[train_size:], test_pred) models[target_name] = {'model': model, 'scaler': scaler, 'r2': test_r2} self.models[symbol] = models self.scalers[symbol] = scaler
Praktische Implementierung: Von Daten zu konkretem Handeln
Die FRED-API ist eine wahre Fundgrube an Daten zur Bilanz der Federal Reserve, darunter Gesamtvermögen, Wertpapiere und Kredite. Der Code berücksichtigt API-Beschränkungen wie beispielsweise Anforderungslimits und synchronisiert Daten in unterschiedlichen Intervallen.
def fetch_fed_data(self): """Obtaining Federal Reserve data via API FRED.""" try: fed_data = self.fred.get_series('WALCL', start=self.start_date, end=self.end_date) return pd.DataFrame({ 'date': fed_data.index, 'total_assets': fed_data.values, 'currency': 'USD' }).set_index('date') except Exception as e: logger.error(f"Error loading Fed data: {e}") return pd.DataFrame()
Für die EZB werden die Daten über das Statistical Data Warehouse abgerufen; bei Ausfällen kommen Ersatzindikatoren wie der EURUSD und der Euro Stoxx 50 zum Einsatz. Für die BOJ und die PBoC, bei denen der Zugang zu Daten eingeschränkt ist, werden Marktindikatoren (Nikkei 225, USDJPY, chinesische Anleihen) herangezogen.
def fetch_boj_proxy_data(self): """Obtaining BOJ proxy data.""" try: usdjpy = yf.download('USDJPY=X', start=self.start_date, end=self.end_date, progress=False) nikkei = yf.download('^N225', start=self.start_date, end=self.end_date, progress=False) proxy_balance = pd.DataFrame(index=usdjpy.index) proxy_balance['jpy_strength'] = 1 / usdjpy['Close'] proxy_balance['equity_liquidity'] = nikkei['Close'] / nikkei['Close'].rolling(252).mean() proxy_balance['synthetic_balance'] = proxy_balance['jpy_strength'].rolling(30).mean() * proxy_balance['equity_liquidity'] * 1000000 return proxy_balance except Exception as e: logger.error(f"Error loading BOJ data: {e}") return pd.DataFrame()
Liquiditätsindex: Einen finanziellen Kompass erstellen
Der Composite Liquidity Index kombiniert normalisierte Daten aus den Bilanzen der Zentralbanken mit Gewichtungen, die deren Einfluss widerspiegeln: Fed (35 %), EZB (25 %), BOJ (15 %), PBoC (20 %), sonstige (5 %). Die dynamische Anpassung berücksichtigt die Schwankungen und die Zuverlässigkeit der Daten.
def calculate_liquidity_index(self) -> pd.DataFrame: """Calculation of the composite liquidity index.""" all_series = {} weights = {'FED_balance': 0.35, 'ECB_balance': 0.25, 'BOJ_balance': 0.15, 'PBOC_balance': 0.20} for bank, df in self.data_cache.get('balance_sheets', {}).items(): series_name = f'{bank}_balance' normalized = (df['total_assets'] - df['total_assets'].rolling(252).mean()) / df['total_assets'].rolling(252).std() all_series[series_name] = normalized combined_df = pd.DataFrame(all_series).fillna(method='ffill') liquidity_index = combined_df.dot(pd.Series(weights)) return pd.DataFrame({'liquidity_index': liquidity_index}, index=combined_df.index)
Neben dem Hauptindex erstellt das System Teilindizes: einen kurzfristigen (30 Tage), einen langfristigen (252 Tage), einen Beschleunigungsindex und einen Liquiditätsvolatilitätsindex. Diese Indikatoren helfen dabei, Prognosen an unterschiedliche Marktbedingungen anzupassen.
def enhance_liquidity_index(self, base_index: pd.Series) -> pd.DataFrame: """Creating advanced liquidity indicators.""" enhanced_df = pd.DataFrame(index=base_index.index) enhanced_df['base_liquidity_index'] = base_index enhanced_df['short_term_liquidity'] = base_index.rolling(window=30).mean() enhanced_df['long_term_trend'] = base_index.rolling(window=252).mean() enhanced_df['liquidity_acceleration'] = base_index.diff().diff() enhanced_df['liquidity_volatility'] = base_index.rolling(window=60).std() return enhanced_df
Integration mit MetaTrader 5: Eine Brücke zum realen Handel
Das System lässt sich an MetaTrader 5 einbinden, um Marktdaten abzurufen und Handelssignale zu generieren. Zu den Merkmalen gehören sowohl technische Indikatoren als auch Liquiditätskennzahlen, wodurch ein einzigartiger Datensatz für Prognosen entsteht.
import MetaTrader5 as mt5 from datetime import datetime, timedelta class TradingIntegration: def __init__(self, forecaster: ForexLiquidityForecaster): self.forecaster = forecaster mt5.initialize() def fetch_forex_data(self, symbol: str, days: int = 1460) -> pd.DataFrame: """Fetching data from MetaTrader 5.""" utc_from = datetime.now() - timedelta(days=days) rates = mt5.copy_rates_from(symbol, mt5.TIMEFRAME_D1, utc_from, days) if rates is None: return pd.DataFrame() df = pd.DataFrame(rates) df['date'] = pd.to_datetime(df['time'], unit='s') df.set_index('date', inplace=True) return df def generate_trading_signals(self, symbol: str, forecasts: dict) -> dict: """Generating trading signals.""" signals = {} short_term_returns = [f['return'] for h, f in forecasts['forecasts'].items() if h in ['1d', '2d', '3d']] avg_return = np.mean(short_term_returns) if short_term_returns else 0 signals['short_term'] = { 'signal': 'BUY' if avg_return > 0.005 else 'SELL' if avg_return < -0.005 else 'HOLD', 'strength': min(abs(avg_return) * 100, 100) } return signals
Visualisierung: Die Welt in Diagrammen
Das System erstellt interaktive Visualisierungen, die Händlern helfen, den Zusammenhang zwischen Liquidität und Kursen zu erkennen. Die Diagramme enthalten Kursprognosen, die Entwicklung des Liquiditätsindexes und die Wichtigkeit der Merkmale (Feature Importance).
import matplotlib.pyplot as plt import numpy as np def create_comprehensive_visualization(self, symbol: str): """Building a set of visualizations.""" forecasts = self.forecaster.forecasts.get(symbol, {}) historical_data = self.fetch_forex_data(symbol, days=180) plt.figure(figsize=(15, 8)) plt.plot(historical_data.index[-60:], historical_data['close'].iloc[-60:], label='Historical prices', linewidth=2) forecast_dates = [datetime.strptime(f['date'], '%Y-%m-%d') for f in forecasts.get('forecasts', {}).values()] forecast_prices = [f['price'] for f in forecasts.get('forecasts', {}).values()] if forecast_dates: plt.plot(forecast_dates, forecast_prices, 'r--', label='Forecast', linewidth=2) plt.title(f'{symbol}: Price forecast considering liquidity', fontsize=14, fontweight='bold') plt.xlabel('Date', fontsize=12) plt.ylabel('Price', fontsize=12) plt.legend() plt.grid(True, alpha=0.3) plt.savefig(f'forecast_{symbol}.png', dpi=300) plt.close()
Daraus ergibt sich ein Bild der globalen Liquidität:
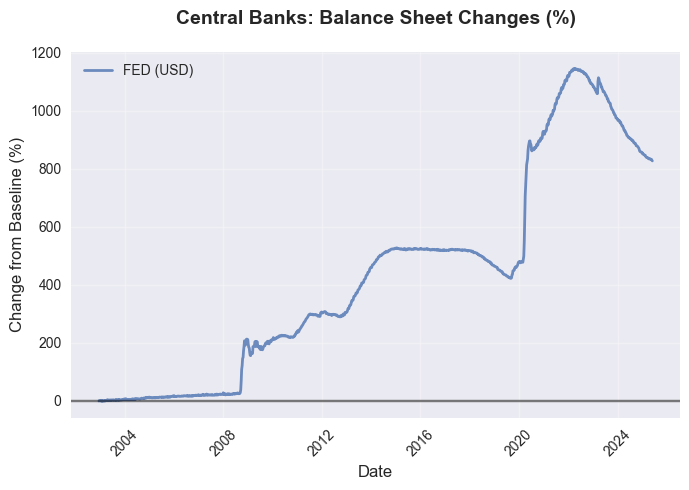
Daraus abgeleitete Prognosen:
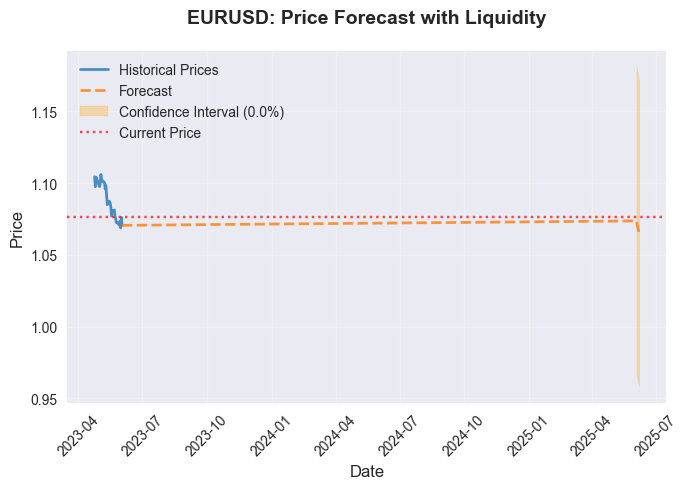
Und die Korrelationsmatrix:
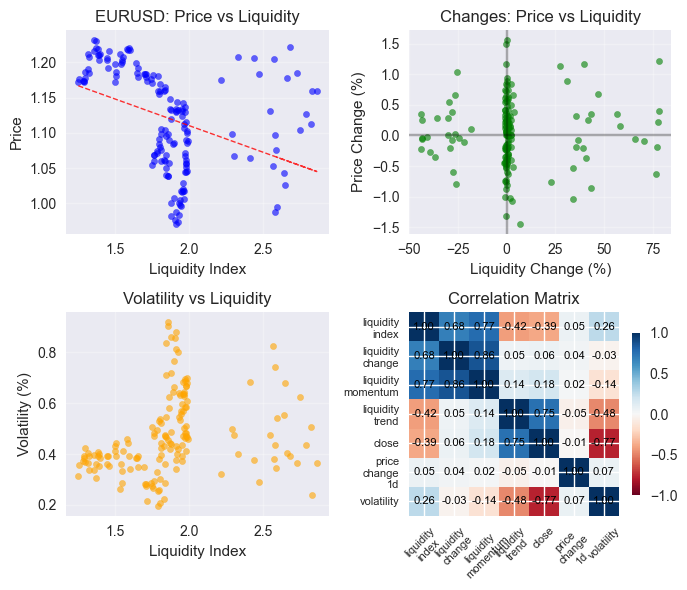
Schlussfolgerung
Das entwickelte System ist ein leistungsstarkes Werkzeug, das die Analyse der Zentralbankbilanzen mit fortschrittlichen Methoden des maschinellen Lernens und der technischen Analyse verbindet und so einen umfassenden Ansatz für die Prognose von Währungsschwankungen bietet. Die modulare Systemarchitektur, zu der GlobalLiquidityMiner und ForexLiquidityForecaster gehören, bietet Flexibilität, Skalierbarkeit und die Möglichkeit, sich an veränderte Marktbedingungen anzupassen.
Die Integration mit MetaTrader 5 ermöglicht es Händlern, Prognosen auf den realen Handel anzuwenden und so abstrakte Daten in konkrete Handelsentscheidungen umzusetzen. Interaktive Visualisierungen und Backtest-Ergebnisse erhöhen die Transparenz und Robustheit des Systems und ermöglichen es Händlern, fundierte Entscheidungen mit hoher Sicherheit zu treffen.
Dieses System geht über herkömmliche Analysen hinaus und bietet einen ganzheitlichen Ansatz, der sowohl fundamentale als auch technische Faktoren berücksichtigt. Damit können Händler nicht nur auf Marktveränderungen reagieren, sondern diese auch vorhersehen, indem sie die globale Liquidität als Kompass in den stürmischen Gewässern des Devisenmarktes nutzen. Angesichts der zunehmenden Volatilität und Unsicherheit in der Weltwirtschaft wird dieser Ansatz nicht nur zu einem Vorteil, sondern zu einer Notwendigkeit für den erfolgreichen Handel.
Das System ist nicht ohne Einschränkungen. Da der Zugang zu Daten einiger Zentralbanken, wie beispielsweise der PBoC, eingeschränkt ist, müssen Ersatzindikatoren herangezogen werden, was die Genauigkeit beeinträchtigen kann. Zudem garantiert maschinelles Lernen trotz seiner Leistungsfähigkeit keine absolute Prognosegenauigkeit, insbesondere angesichts unerwarteter geopolitischer oder wirtschaftlicher Schocks. Durch die kontinuierliche Verbesserung der Algorithmen, die Erweiterung der Datenquellen und die Berücksichtigung neuer Marktfaktoren wird das System jedoch weiterhin relevant und effektiv bleiben.
Zukünftige Weiterentwicklungen des Systems könnten die Integration von neuronalen Netzwerken umfassen, um große Mengen unstrukturierter Daten wie Nachrichten und Inhalte aus sozialen Medien zu verarbeiten, was die Vorhersagekraft des Systems verbessern wird. Es ist auch möglich, adaptive Mechanismen zu implementieren, die die Gewichtung des Liquiditätsindexes automatisch an die aktuellen wirtschaftlichen Rahmenbedingungen anpassen. Dies ebnet den Weg für die Entwicklung einer neuen Generation von Handelssystemen, die noch widerstandsfähiger gegenüber Unsicherheiten sind und unter allen Marktbedingungen stabile Ergebnisse liefern können.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/18355
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Das Bild ist einfach der Hammer, genau das Richtige für Internet-Memes.