
初心者向け MQL4 言語シンプルなフレーズにおける難しい質問
はじめに
本稿は『初心者向け MQL4 言語』シリーズの第2弾です。1番目の記事『初心者向け MQL4 言語:序章』では、MQL4 を用いて何をすることができるのか、を説明しています。また、シンプルなスクリプトの書き方を学習し、変数とは何かを見、変数を処理する方法を学び、関数、配列、内蔵配列、と変数、サイクル 'for' 、シンプルな条件と複雑な条件を分析しました。 より複雑で高度な言語構成を考察し、新しいオプションを学習し、日々の実践にそれらが応用されるか見ていきます。新しいサイクルタイプである 'while' と、新しい条件タイプ 'switch'、演算子 'break' と 'continue' を取得します。また、自分の関数を書き、多次元配列を処理する方法を学習します。そして仕上げには、プリプロセッサの説明です。
アドバイス
最初の記事を完全に理解しないまま本稿を読み始めることはしないでください。エラーを多く出し、それでもまだ何も理解できていない、ということになります。本稿はこれまでの内容を基にしていますから、急ぐことはありません。そして私はみなさんに安心していただきたいのです。新しいことを学ぶときに出会うむつかしさは本物の困難ではありません。サイクルがどのように書かれているのだろう、どんな条件を入れるべきだろうなどと考えず、すべてを機械的に行えるときはやってきます。MQL4 言語で作業をすればするほど、使いこなすのは簡単になっていきます。
サイクルの新タイプ-while
先行記事で説明したサイクル 'for' はユニバーサルなサイクルで、ここで学習するほかのどのようなサイクルタイプとも置き換えが可能です。ただしそれが必ずしも便利で適しているとは限りません。while を使用する方が効率的なこともあります。どのサイクルタイプを使用するのがより合理的かはすぐにわかるようになります。あるタスクを2とおりの方法で作成します。:サイクルを両方使用して全バーのボリューム合計を求め、違いを確認するのです。
// using the cycle for double sum = 0.0; for(int a = 0; a < Bars; a++) sum += Volume[a]; // now using while, the result is the same double sum = 0.0; int a = 0; while(a < Bars) { sum += Volume[a]; a++; }
while(condition of cycle fulfillment)
{
code
}
以下はより簡単な例です。
while(I haven't eaten up the apple) // condition
{
// what to do, if the condition is not fulfilled
bite more;
}
サイクル 'while' がサイクル 'for' と異なるのはカウンターがないことだけです。カウンターが不要であれば、その必要がなくても while を使用します。たとえば、私はカウンターと共に while を頻繁に使用します。それは好みの問題です。for の場合のように、サイクルの本体が命令を1つしか持たない場合、括弧は省略可能です。また、ご自分が作成するときのために 反復という語の意味を覚えておいてください。それは複数処理(繰り返し)の一つで、サイクルで行われます。すなわち、サイクル本体を1回実行することは反復が1度行われることを意味します。
条件の新タイプ- switch
サイクル同様、switch はなじみある条件 'if' と 'else' の組み合わせと置き換え可能であることに留意します。この構造 'switch' は変数値に依存するなんらかのアクションを行う必要があるとき使用されます。これはオーブンに付いているふつうのスイッチのようなものです。たとえば Expert Advisor を書き、市況よりその動きが変化する、ということを想像します。変数 int marketState がそれを行うようにします。それは以下の意味を持ちます。
- 1 -上昇トレンド
- 2 -下降トレンド
- 3 -フラット
このポジションがどのように定義されていようと、われわれのタスクは、市況に応じて Expert Advisor がふさわしい処理を行うようになんらかのメカニズムを実行することです。どうすればいいかはおわかりですね。もっとも判り切ったバリアントは以下です。
if(marketState == 1) { // trading strategy for an uptrend } else if(marketState == 2) { // strategy for a downtrend } else if(marketState == 3) { // strategy for a flat } else { // error: this state is not supported! }
ここには多少の特殊な点があります。
- 条件はすべて1つの同じ変数が作成し実行する。
- 条件はすべて変数が受け入れる意味の一つに対して変数を比較する。
よって、これはすべて switch ストラクチャを参照します。以下が switch を使用したコードで結果は同様です。
switch(marketState) { case 1: // trading strategy for an uptrend break; case 2: // strategy for a downtrend break; case 3: // strategy for a flat break; default: // error: this state is not supported! break; }
まずどの変数が比較されるかも明確にすることに注意が必要です。
// switch - key word, marketState - // a variable for comparison switch(marketState)
そして、特殊な場合には何をおこなうか指示します。
case 1: // case - key word; // trading strategy // if marketState is equal to 1, then // for an uptrend // perform this code break; // key word that indicates // the end of actions in this case case 2: // if marketState is equal to 2, then // startegy for // perform this // a downtrend break; // end case 3: // identical // strategy for flat break; default: // otherwise, perform this // error: this // state is not // supported! break;
一般的にはswitch は以下の形式となっています。
switch(a variable for comparison) { case [a variable value]: // a code for this case break; case [another value of the variable] // a code for this case break; default: // a code for all other cases break; }
ある変数を複数の値と比較し、特定のコードブロックがある値に対応するとき switch を使います。その他の場合には、条件 'if' と 'else' の組み合わせを使います。ときとして、1つの変数の複数値でコードを実行する必要があります。たとえば、marketState == 1 または 2 であれば、特定のコードを実行します。以下は switch を使用してそれを行う方法です。
switch(marketState) { case 1: // if marketState is equal to 1 case 2: // or if marketState is equal to 2, then // perform this break; default: // in any other case perform // this code break; }
演算子:continue および break
演算子 break はさきほど見たばかりです。それは switch の本体から出るために使用されています。また、サイクルから出るのに使用することもできます。たとえば、条件の一部でサイクルの実行が必要ない場合です。1000 ポイントを囲い込むために、最初のバー本数を求める必要があるとします。そこで以下のコードを書きます。
int a = 0; double volume = 0.0; while(volume < 1000.0) { volume += Volume[a]; // equivalent to volume = volume + Volume[a]; a++; } // now variable "a" includes the amount of bars, the volume of their sums // is no less than 1000 points
演算子 break を使って、ここで類似のコードを書きます。
int a = 0; double volume = 0.0; while(a < Bars) { // if the volume is exceeds 1000 points, then if(volume > 1000.0) // exit the cycle break; volume += Volume[a]; a++; }
演算子 break は使い勝手がよく、それにより不必要なサイクルの反復を避けることができます。もう一つ便利な演算子 continue は不要な反復を「飛ばします」。ボリュームのトータルを計算する必要がありますが、重要なニュースの瞬間のバーのボリュームは考慮しないとします。ご存じのように、重要なニュースは大容量のポイントを持つものです。無邪気な子供のふりをして、50ポイント以上のバーボリュームがニュースであるとします。このタスクを遂行するのに、演算子 continue を利用します。
int a = -1; double volume = 0.0; while(a < Bars) { a++; // if the volume exceeds 50 points, then it must // be news, omit it if(Volume[a] > 50.0) continue; volume += Volume[a]; }
演算子 continue の使用はひじょうに他愛ないものですが、ときとして役に立つのがおわかりでしょう。このスクリプトは小さなタイムフレーム向けであることは明らかです。
自分の関数の書き込み
しかし、なぜそれらが必要なのでしょうか?コードに重複が見られることが非常に頻繁におこるのです。すなわち、異なる場合に1つ同じセットの命令を使用するのです。時間と労力の節約のために、この重複しているコードを別の関数内に書きます。そしてそれが必要なときは、関数名を書くだけでみなさんに代わってそれがすべてを行います。どのように動作するか見直します。あるろうそく足の色を求める必要があるとします。白のろうそく足は始値ほりも高く終了し、黒のろうそく足は逆であることはわかっています。ろうそく足の色を決定するコードを書きます。
bool color; // as there are only 2 variants // (white or black candlestick), // then suppose that the velue // false corresponds to a black // candlestick, and true - white if(Close[0] > Open[0]) color = true; // white candlestick if(Open[0] > Close[0]) color = false; // black candlestick
以上です。変数 color が最終のろうそく足の色を持っています。別のろうそく足、たとえば最終のろうそく足、の色を決めるには、インデックス 0 を 1 に変える必要があります。ですが、ろうそく足の色を求める必要があるたびにこのコードを入れるつもりですか?何十とそのような場合が発生したらどうしますか?関数が必要なのはそのためです。それがどのように動作すべきか考えます。そのような関数は引数-色を決める必要があるろうそく足のインデックス、を1つ受け取ります。そして、色-bool タイプの変数を返します。関数が書かれ、それをアクティブにすることをイメージします。
bool color; // here will be the color of a wanted candlestick color = GetColor(0);
お察しのとおり、われわれの関数は GetColor という名前です。この関数呼出しでは、最終ろうそく足の色を求めたかったのです。唯一の引数がゼロなのはそのためです。この関数はろうそく足の色を返します。そのためすぐに割り当てをします。ひじょうに重要な場面です。変数は関数内に作成され、それからその値が関数呼び出しを置き換えます。最終的に、上に記述されているこの関数呼び出しと関数決定のコードは同じ結果を出します。-変数 color は最終ろうそく足の色を持ちますが、関数を使うことで労力が少なくて済むのです。
ここで予想外に空のスクリプトに戻ります。何かといえば、そこにはすでに関数 start() の完全な記述が入っているのです。もっとも興味深いことは、今までこの関数内にスクリプトを書いてきたということです。スクリプトを開始するとき、ターミナルは関数 start() をアクティブにします。空スクリプトのコードを考察します。
int start()
この行はひじょうに重要です!そこには関数名があります。すなわち、この関数を起動するために書くキーワードです。われわれの場合、それは 'start' です。それにはまた戻り値のタイプ -int も入っています。それは、関数実行のあと、int タイプの値を返してくるということです。括弧には引数リストが入っていますが、われわれの場合、関数はパラメータをひとつも受けつけません。
そして括弧内には関数記述、すなわち関数呼び出し時実行されるコード、があります。
{
//----
// a code that will be performed
// at the function call.
//----
return(0);
}
start() 関数本文にコードを書いたのは明白です。関数の末尾では、関数値を返す演算子 return があるのがわかります。われわれの場合、それはゼロを返します。
関数書き込みの一般的形式を見ます。
[type of return value] [function name] ([list of arguments]) { // function code return([a value, which the function returns]); }
ここでひとまずろうそく足と GetColor 関数に戻ります。この関数のコードを見ます。
bool GetColor(int index) { bool color; if(Close[index] > Open[index]) color = true; // white candlestick if(Open[index] > Close[index]) color = false; // black candlestick return(color); }
1行目を詳しく説明します。
bool GetColor(int index)
ここにあるのは以下です:bool -戻り値のタイプ、GetColor -関数名、int -引数タイプ、index -引数名。関数本文でindexを使用していますが、関数呼び出しではこの名前はまったく述べられていないことに注意が必要です。例:
bool lastColor = GetColor(0);
そうすると
{
bool color;
if(Close[index]>Open[index])
color=true; // white candlestick
if(Open[index]>Close[index])
color=false; // black candlestick
この関数本文は大きなコードで、関数呼び出しごとに実行されます。その後、
return(color); }
演算子の戻り値は、関数が何を返すのか指示します。戻り値はタイプに対応し、それは一番最初に決定されたものです。必要に応じ、1つの関数内で複数の演算子 'return' を使用することができます。以下がその例です。
bool GetColor(int index) { if(Close[index] > Open[index]) return(true); // white candlestick if(Open[index] > Close[index]) return(false); // black candlestick }
複数の演算子 return を使用することで明らかに変数 color を避けることができます。また、演算子 return 内では、論理式も使用可能です。
return(Close[index] > Open[index]);
他の一般的な関数同様、比較の演算子も bool タイプ(真か偽)の変数を返すためそれが可能なのです。むつかしく見えますが、すぐに使いこなせるようになります。
ここで引数リストに戻ります。われわれの関数では、引数 int index だけが使われます。複数の引数を使用する必要があれば、それらをコンマで区切って列挙します。
bool SomeСomplicatedFunction(int fistArgument, int secondArgument, sting stringArgument)
引数を参照するためには、前出の関数のようにその名前を使います。関数が複数の引数で呼び出す場合、連続した引数の順序に注意が必要です。混ざってしまわないようにします。関数が値を何も返さない場合、それを指示するのにキーワードvoidを使用します。この場合、演算子return は使用しないことに留意します。
void function() { // code }
もうひとつ細かな点があります。関数の引数 on default に値を設定することがあるかもしれません。これは何でしょうか?引数を5個持つ複雑な関数を書き、その引数が関数の動作に影響を与えると仮定します。ただし、最後の数個の引数はほとんどつねに同じ値で使用されます。ただ24の関数呼び出しに対しては異なる値が必要です。ほとんどつねに同じである最終引数の値を毎回指示しなくてすむように、引数のデフォルト値が使用されます。そのような場合は、実際には使用されていても最終引数が存在しないかのように省略します。ですが、その値はデフォルトで割り当てられているのです。そのような特殊な場合に出会ったときは、引数をすべて指示します。デフォルトの引数を持つ関数の宣言方法を確認します。
void someFunction(int argument1, int argument2, int specialArgument = 1) { // code }
すべて簡単なのがおわかりでしょう。必要な引数に必要な値を割り当て、これで関数呼び出し時には省略できます。
someFunction(10,20); // we omitted the last argument, but // actually it is assigned a value by default someFunction(10,20,1); // this activation is fully identical to the previous one someFunction(10,20,2); // here we indicate another value, // it is a rare case
引数のデフォルト値はお好きなだけ指示することが可能です。ただ一つ重要なルールを覚えておきます。それは、その値はすべて末尾に設定しなければならない、ということです。例:
void someFunction(int argument1, int argument2, int specialArgument = 1) // all right void someFunction(int argument1, int argument2 = 10, int specialArgument=1) // all right void someFunction(int argument1, int argument2 = 10, int specialArgument) // wrong! default // values must stay // at the end of the // list of arguments void someFunction(int argument1 = 0, int argument2 = 10, int specialArgument = 1) // you can assign // default values // to all arguments
多次元配列
プログラミング中配列を使用することは頻繁にありますが、大半の場合は一次元配列で十分です。ただ二次元配列、三次元配列が必要となる場合もあります。ここでそれらの使用法を学習します。
まず最初に、一次元配列を視覚的に提示し、宣言、初期化、インデックス、値を変更します。

一次元配列はどんなものでも1タイプの値の行として書かれます。一次元配列に対する異なる参照がどのように処理されるか見ます。
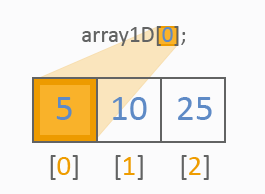
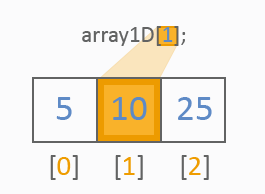
二次元配列は一般的なテーブルのようなものです。以下を見ます。
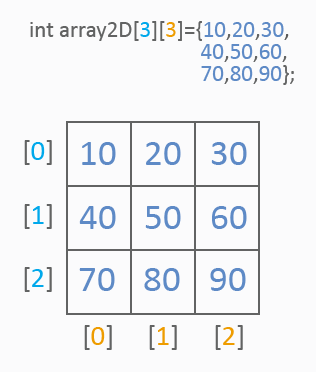
画像からわかるように、二次元配列は常に値の参照にインデックスを2つ持ちます。1番目のインデックスは行を、2番目のインデックスは列を決定します。一次元配列同様、初期化には値リストが使用されます。以下はテーブルセルの値がどのように参照されるかを表しています。
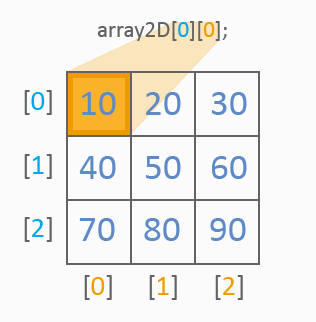
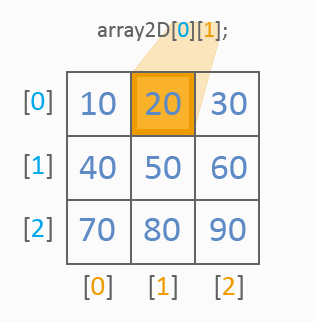
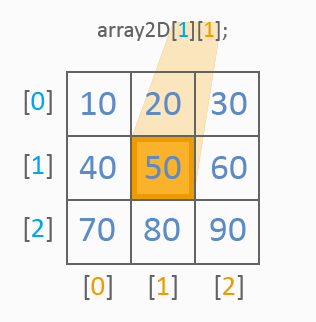
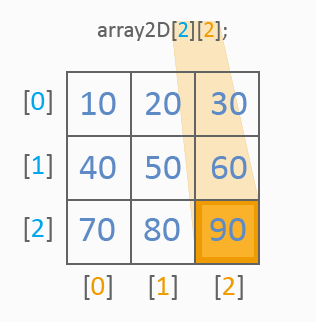
すべて明確ですね。二次元配列の値をすべてどのように処理するのか見ていきます。それにはサイクルが2つ使用されます。
int array2D[3][3]={10,20,30, 40,50,60, 70,80,90}; for(int y=0;y<3;y++) for(int x=0;x<3;x++) MessageBox("array2D["+y+"]["+x+"]="+array2D[y][x]);
この例では、参照は左から右に下りていきます。練習のために、上向きなど方向を変えてみます。
三次元配列は、セル値を参照するのにもう一つインデックスがあることだけが違いです。三次元配列は複数テーブル(二次元配列)として簡単に書くことができます。以下は三次元配列の全エレメントを網羅する方法です。
int array3D[3][3][3] = {11, 12, 13, 14, 15, 16, 17, 18, 19, 21, 22, 23, 24, 25, 26, 27, 28, 29, 31, 32, 33, 34, 35, 36, 37, 38, 39}; for(int z = 0; z < 3; z++) for(int y = 0; y < 3; y++) for(int x = 0; x < 3; x++) MessageBox("array3D["+z+"]["+y+"]["+x+"]=" + array3D[z][y][x]);
二次元配列、三次元配列を完全に学ぶ。それはひじょうに重要なことです。再びひじょうに注意して説明画像を見ます。配列を利用して数多くの異なるタスクが推敲されています。配列に十分な時間を注ぎ込むと、今後とても役立つものとなるのです。配列を扱う原則を理解すれば、何次元配列を扱ってもなんの問題もないのです。
配列を扱う関数
簡単な関数から始めます。
int ArraySize(object array[]);
この関数は配列が持つエレメント数を返します。どんなタイプにも対応します。例:
// create two different arrays int arrayInt[] = {1, 2, 3, 4}; double arrayDouble[] = {5.9, 2.1, 4.7}; // here store the amount of elements int amount; amount = ArraySize(arrayInt); // note: // to define a specific // array, you need to indicate // only its name. // Now amount is equal to 4 amount = ArraySize(arrayDouble); // amount is equal to 3
次の関数です。
int ArrayInitialize(object array[],double value);
ArrayInitialize
は配列エレメントに値を割り当て、値が割り当てられたエレメント数を返します。この関数は int や double タイプの配列に使います。
次に:
int ArrayMaximum(double array[], int count = WHOLE_ARRAY, int start = 0); int ArrayMinimum(double array[], int count = WHOLE_ARRAY, int start = 0);
この 2 つの関数は最大、最小セル値のインデックスを返します。それらを使うには、どの配列を検索するかを指示するだけです。
int array[] = {10, 100, 190, 3, 1}; // will be returned 1, because array[1] - maximal value ArrayMaximum(array); // will be returned 4, because array[4] - minimal value ArrayMinimum(array);
次に:
int ArrayDimension(object array[]);
こういった関数を使用することで、配列の次元 を決定することができます。すなわち、一次元か二次元か、何次元かを決めることができるのです。例:
int array1D[15]; int array4D[3][3][3]; ArrayDimension(array1D); // get 1 ArrayDimension(array3D); // 3
以下はより複雑で便利な関数です。
int ArraySort(double&array[], int count = WHOLE_ARRAY, int start = 0, int sort_dir = MODE_ASCEND);
この関数はエレメントをソートします。たとえば以下のように、引数をデフォルトで直接指示しなければ、
int array[5] = {1, 10, 5, 7, 8}; ArraySort(array);
エレメントは昇順でソートされます。関数の動作を指定するために追加のパラメータを使用することもできます。
- int count -ソートされるエレメントのメンバー
- int start -エレメントのインデックスで、それからソートが開始します。
- int sort_dir -ソート方向(昇順-MODE_ASCEND 、降順-MODE_DESCEND)
ここで疑問に思われることでしょう。MODE_ASCEND と MODE_DESCEND は何か?と。int に従えばそれは 整数です。緊張しなくて大丈夫です。すべては次の『プリプロセッサ』ではっきりします。たとえば、2番目から始めて5個のエレメントを降順でソートする必要がある場合、以下のようなことを指定するのです。
ArraySort(array, 5, 1, MODE_DESCEND);
そして本日最後の関数です。
int ArrayCopy(object&dest[], object source[], int start_dest = 0, int start_source=0, int count=WHOLE_ARRAY);
これはある配列を別の配列にコピーするのに使用されます。必須パラメータを見ます。
- dest[] -配列のコピー先
- source[] -配列のコピー元
オプション パラメータ
- start_dest -配列エレメントのインデックスで、そこへコピーが行われます。
- start_source -配列エレメントのインデックスで、そこからコピーが行われます。
- int count -コピー対象エレメント数
この関数はコピーされたエレメント数を返します。ArrayCopy はひじょうに注意して使用します。そこにコピーするときは配列に 十分なキャパがあることを確認します。
プリプロセッサ
これは何でしょうか?プリプロセッサとはソースコードを処理する特殊なメカニズムです。すなわち、まずプリプロセッサがコードを準備し、それからそれをコンパイルのために伝達するのです。今日はもう一つ便利なオプションである定数について学びます。
主要な点は何でしょうか?これを理解するためにswitch の箇所で出た例を思い出します。
switch(marketState) { case 1: // trading strategy for an uptrend break; case 2: // strategy for a downtrend break; case 3: // strategy for a flat break; default: // error: this state is not supported! break; }
このとき、市況に応じて異なる方法で対処するメカニズムを起動しました。覚えていますか?よって、1、2、3の代わりにTREND_UP、TREND_DOWN、 FLAT のようなものを書く方が簡単でより良く表現できるでしょう。
switch(marketState) { case TREND_UP: // trading strategy for an uptrend break; case TREND_DOWN: // strategy for a downtrend break; case FLAT: // strategy for a flat break; default: // error: this state is not supported! break; }
この場合、ソースコードはより理解しやすく明白であるように思えませんか?よって、定数によりコンパイル前に対応する値1、2、3 で TREND_UP、TREND_DOWN、FLAT を置き換えることができるのです。必要なことは、プリプロセッサが何を変更するか指示することだけです。それは プリプロセッサ指令によって行われます。それは特別な記号 "#" から始まるものです。プリプロセッサ指令はその他の指令とともにソースファイルの冒頭に設定します。定数を使用した複雑な例を見ていきます。
//+------------------------------------------------------------------+ //| preprocessor.mq4 | //| Copyright © 2007, Antonio Banderass. All rights reserved | //| banderassa@ukr.net | //+------------------------------------------------------------------+ #property copyright "Copyright © 2007, Antonio Banderass. All rights reserved" #property link "banderassa@ukr.net" #define TREND_UP 1 #define TREND_DOWN 2 #define FLAT 3 //+------------------------------------------------------------------+ //| script program start function | //+------------------------------------------------------------------+ int start() { MessageBox("TREND_UP=" + TREND_UP + " TREND_DOWN=" + TREND_DOWN + " FLAT=" + FLAT); return(0); }
定数宣言を他のプリプロセッサ指令の下で、ファイルの冒頭に入れたことに注意します。この宣言をより詳しく考察します。
#define TREND_UP 1
まず、キーワードの #define を書きます。それはプリプロセッサに対しそのあとに 定数宣言が来ることを示します。そして定数名、その識別子、すなわち定数値を参照するのに用いる語、を書きます。われわれの場合それは TREND_UP です。それに値-1 が続きます。プリプロセッサがコード内に TREND_UP を確認したら、その他定数すべてと同様にそれを1で置き換えます。以下はプリプロセッサによる処理前のわれわれのコード例です。
int start() { MessageBox("TREND_UP=" + TREND_UP + " TREND_DOWN=" + TREND_DOWN + " FLAT=" + FLAT); return(0); }
そして処理後です。
int start() { MessageBox("TREND_UP=" + 1 + " TREND_DOWN=" + 2 + " FLAT=" + 3); return(0); }
ここで理解しておくことは、以前の箇所にあった MODE_ASCEND および MODE_DESCEND の意味です。それらは対応する値を持つ定数です。
おわりに
本稿では数多くの新しい内容を学習しました。新しいサイクルタイプとしてwhile、新しい条件対タイプとして switch、演算子 break と continue です。自分の関数を書き多次元配列を扱う方法、定数の使用法も学びました。これらはすべて主要な主題、ユーザーのインディケータや expert advisor のような、より高度なものを書くための基本です。本稿の内容を完全に身に着けたことを確認するのはそのためです。本稿の内容はひじょうに重要で、今後常に活用するものであるからです。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/1483
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 ヘッジ Expert Advisor コーディングの基礎
ヘッジ Expert Advisor コーディングの基礎

 初心者向け MQL4 言語はじめに
初心者向け MQL4 言語はじめに
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索