
MQL4 语言入门。简单词组中的难题。
简介
这是“MQL4 语言入门”系列的第二篇文章。第一篇文章“MQL4 语言入门简介”描述了 MQL4 的功能,我们学习编写简单脚本,了解变量含义,学习使用变量,分析函数、数组、内置数组和变量、循环“for”以及简单和复杂的条件。现在我们将探讨该语言更复杂、更高级的构造,学习新内容,并了解如何将它们应用到日常实践中。您将了解新循环类型“while”,新条件类型“switch”,运算符“break”和“continue”。此外,我们将学习编写您自己的函数和使用多维数组。作为餐前甜点,我还准备了一份有关预处理器的说明。
建议
请在充分理解上一篇文章之后,再来阅读本文。否则您会犯很多错误,同时也学不到什么。本文要以上一篇文章为基础,所以别太心急!放轻松 - 学习这些新东西时碰到的难题都不过是纸老虎。总有那么一天,您无需再三考虑循环怎么编写,要放上哪些条件等等问题,所有东西都会按部就班地完成。多多使用 MQL4 语言,它就会变得越来越简单。
新的循环类型 - while
我想提一下,上一篇文章中讲到的循环“for”是一个通用循环,可以替代我们现在要学的任何其他循环类型。但它也并不是适用于所有情况的。有时用 while 会更高效。。很快您就会知道使用哪种循环类型会比较合理。我们用两种方式做一个任务:使用两种循环找出所有条柱的总成交量,看看有什么区别:
// using the cycle for double sum = 0.0; for(int a = 0; a < Bars; a++) sum += Volume[a]; // now using while, the result is the same double sum = 0.0; int a = 0; while(a < Bars) { sum += Volume[a]; a++; }
while(condition of cycle fulfillment)
{
code;
}更简单的示例如下:
while(I havent eaten up the apple) // condition { // what to do, if the condition is not fulfilled bite more; }
新的循环类型 - switch
在使用循环的案例中,应注意switch可替代为一组您熟悉的“if”和“else”条件。当您需要根据变量值执行一些操作时,就可以使用“switch”结构。这就像微波炉上常见的模式开关。例如,假设您在编写一个 EA,它的行为会根据市场情况进行变化。就用变量int marketState来执行这个任务。它可拥有以下含义:
- 1 - 上升趋势
- 2 - 下跌趋势
- 3 - 平盘趋势
无论这个价位是怎么定义的,我们的任务是实现某种机制,以便 EA 根据市场情况执行对应的操作。您知道该怎么做。以下是最明显的变体:
if(marketState == 1) { // trading strategy for an uptrend } else if(marketState == 2) { // strategy for a downtrend } else if(marketState == 3) { // strategy for a flat } else { // error: this state is not supported! }
这里有一些特性:
- 所有条件采用的是同一个变量;
- 所有条件都在将该变量与其可接受的意义之一进行比较。
因此,所有这些还都涉及到 switch 结构。以下是使用 switch 的一个代码,结果是相同的:
switch(marketState) { case 1: // trading strategy for an uptrend break; case 2: // strategy for a downtrend break; case 3: // strategy for a flat break; default: // error: this state is not supported! break; }
注意,我们首先定义要比较的变量:
// switch - key word, marketState - // a variable for comparison switch(marketState)
然后指示特定情况下应执行的操作:
case 1: // case - key word; // trading strategy // if marketState is equal to 1, then // for an uptrend // perform this code break; // key word that indicates // the end of actions in this case case 2: // if marketState is equal to 2, then // startegy for // perform this // a downtrend break; // end case 3: // identical // strategy for flat break; default: // otherwise, perform this // error: this // state is not // supported! break;
在一般视图中,switch采用以下格式:
switch(a variable for comparison) { case [a variable value]: // a code for this case break; case [another value of the variable] // a code for this case break; default: // a code for all other cases break; }
在将switch进行比较,和将特定代码块与一个值进行比较时,使用 switch。其他情况下,使用“if”和“else”条件的常用组合。有时您需要根据某个变量的多个值执行一个代码。例如,如果 marketState == 1 或 2,则执行某个特定代码。以下就是这个任务中 switch:
switch(marketState) { case 1: // if marketState is equal to 1 case 2: // or if marketState is equal to 2, then // perform this break; default: // in any other case perform // this code break; }
运算符:continue 和 break
我们刚才就看到了这个 break 运算符。它用于跳出 switch。除此以外,您可用它跳出一个循环。例如在某些条件下您不需要执行某个循环时就能用到。假设我们需要找出第一批条柱的金额,这批条柱需要包括 1000 个点。我们可以编写以下代码:
int a = 0; double volume = 0.0; while(volume < 1000.0) { volume += Volume[a]; // equivalent to volume = volume + Volume[a]; a++; } // now variable "a" includes the amount of bars, the volume of their sums // is no less than 1000 points
现在让我们用break 运算符:
int a = 0; double volume = 0.0; while(a < Bars) { // if the volume is exceeds 1000 points, then if(volume > 1000.0) // exit the cycle break; volume += Volume[a]; a++; }
你看,break 运算符运算符很好用,可以避免不需要的循环迭代。还有一个很有用的操作符continue,它主要用于“忽略”不需要的迭代。假设我们需要计算一个总金额,但我们必须把出现重大消息时的交易量排除在外。如你所知,重大消息的出现总是伴随着大量的点。举个简单的例子,假设条柱金额包括 50 个点,超过这 50 个点的都是针对消息的。要解决这个任务,让我们使用 continue 运算符:
int a = -1; double volume = 0.0; while(a < Bars) { a++; // if the volume exceeds 50 points, then it must // be news, omit it if(Volume[a] > 50.0) continue; volume += Volume[a]; }
你看,使用continue操作符相当繁琐,但某些时候是很有用的。很明显,此脚本主要用于小时间框架。
编写自己的函数
但我们为何需要它们?事实上,您经常会发现重复的代码。也就是说,您会在不同的案例中使用同一套指令。要节省时间和精力,您可将这种重复的代码编写成一个单独的函数。需要时,只要写下该函数的名称,它就会帮你搞定一切。让我们看看它们是怎么工作的。假设您需要找出某个烛台的颜色。已知一根白色烛台的收盘价高于开盘价,一根黑色烛台的收盘价低于开盘价。我们来编写一段代码,确定烛台的颜色。
bool color; // as there are only 2 variants // (white or black candlestick), // then suppose that the velue // false corresponds to a black // candlestick, and true - white if(Close[0] > Open[0]) color = true; // white candlestick if(Open[0] > Close[0]) color = false; // black candlestick
好了,现在变量颜色包含最后一根烛台的颜色。要确定另一根烛台的颜色,例如倒数第二根,您需要将指数 0 更改为 1。但难道您每次需要查找烛台的颜色,就要编一次这些代码?如果出现大量这种情况呢?所以我们需要函数。想想看应该怎么做。此类函数应接受一个参数 - 需要确定其颜色的烛台的指数,并返回该颜色 - 一个布尔型变量。想象一下,我们编写了这个函数并激活它:
bool color; // here will be the color of a wanted candlestick color = GetColor(0);
如您预料的那样,我们的函数名为 GetColor。我们调用此函数是为了查找最后一根烛台的颜色。所以这个唯一的参数等于 0。此函数返回一根烛台的颜色,以便我们立即进行分配。这是一个非常重要的时刻!将在函数内部创建一个变量,然后该变量值将取代此函数调用。最终,上述的函数调用和函数确定代码会产生相同的结果 - 变量颜色将包含最后一根烛台的颜色,但使用函数我们会更省力。
现在我们回头说说空脚本的代码。实际上,空脚本的代码已经包含了函数 start() 的完整说明。最有趣的一点是,您其实一直是在这个函数中编写代码。当您打开脚本时,终端就会激活函数 start()。我们来看看空脚本的代码:
int start()
这一行非常关键!它包括函数名称,即一个用于激活此函数的关键字。在我们的示例中,它是“start”。它还包含返回值类型- int。它的意思是,执行此函数之后,此函数将向我们返回一些 int 类型的值。括号中包含参数列表,但在我们的实例中,此函数不接受任何参数。
然后在大括号中可以看到函数描述,即在函数调用时执行的代码。
{
//----
// a code that will be performed
// at the function call.
//----
return(0);
}
很明显,我们是在 start() 函数的主体内编写代码。在函数末尾,我们看到运算符return,它返回函数值。在我们的示例中,它返回 0。
以下是编写一个函数时的常用格式:
[type of return value] [function name] ([list of arguments]) { // function code return([a value, which the function returns]); }
现在返回到我们的烛台和GetColor 函数。看看此函数的代码:
bool GetColor(int index) { bool color; if(Close[index] > Open[index]) color = true; // white candlestick if(Open[index] > Close[index]) color = false; // black candlestick return(color); }
我们仔细想想第一行:
bool GetColor(int index)
里面有:bool - 返回值的类型;GetColor- 函数名称;int- 参数类型;index- 参数名称。注意,我们在函数主体内使用index,但在函数调用时,不会再提到此名称。例如:
bool lastColor = GetColor(0);
然后:
{
bool color;
if(Close[index]>Open[index])
color=true; // white candlestick
if(Open[index]>Close[index])
color=false; // black candlestick
此函数主体是一个通用代码,每次函数调用时都可执行此代码。之后:
return(color); }
运算符 return。返回值应与最开头确定的类型相对应。必要时,可以在一个函数中使用多个运算符“return”,例如:
bool GetColor(int index) { if(Close[index] > Open[index]) return(true); // white candlestick if(Open[index] > Close[index]) return(false); // black candlestick }
很明显,使用多个return运算符可避免使用变量color。此外,在运算符 return中,您甚至可以使用逻辑表达式:
return(Close[index] > Open[index]);
这是可行的,因为比较运算符也会像一些其他常用函数一样返回布尔型的变量(true 或 false)。看上去有点难,但用用就很快习惯了。
现在让我们返回参数列表。我们的函数中仅使用了参数 int index 。如果您需要使用多个参数,列举它们,并用逗号隔开:
bool SomeСomplicatedFunction(int fistArgument, int secondArgument, sting stringArgument)
要参考参数,像在上一个函数中那样使用其名称。调用使用多个参数的名称时,注意参数顺序序列:切勿混淆任何东西!如果函数不应返回任何值,使用关键字 void 指示这一点。注意,这种情况下不使用 return运算符:
void function() { // code }
还有个细节:您可设置函数参数默认值。。这是什么?假设您编写了一个复杂函数,其中包括 5 个影响函数行为的参数。但最后几个参数几乎总是使用相同的值。只有在二三十个函数调用中才需要使用不同的值。为了不必每次都指示最后几个参数几乎总是相同的值,我们使用参数的默认值。在这种情况下,您只是忽略了最后几个参数,就像它们不存在一样,尽管实际上使用了这些参数,但它们的值是默认分配的。碰到特殊情况时,您还是需要指示所有函数。让我们看看如何声明使用默认值的函数:
void someFunction(int argument1, int argument2, int specialArgument = 1) { // code }
你看,一些都很简单:我们向需要的参数分配一个需要的值,现在可以在调用函数时忽略这个参数:
someFunction(10,20); // we omitted the last argument, but // actually it is assigned a value by default someFunction(10,20,1); // this activation is fully identical to the previous one someFunction(10,20,2); // here we indicate another value, // it is a rare case
对于参数默认值,您想要分配多少就可以分配多少。但记住一条重要的规则:它们都要放在末尾。例如:
void someFunction(int argument1, int argument2, int specialArgument = 1) // all right void someFunction(int argument1, int argument2 = 10, int specialArgument=1) // all right void someFunction(int argument1, int argument2 = 10, int specialArgument) // wrong! default // values must stay // at the end of the // list of arguments void someFunction(int argument1 = 0, int argument2 = 10, int specialArgument = 1) // you can assign // default values // to all arguments
多维数组
编程期间常常会用到数组,大部分情况下,一维数组就够用了。但在某些情况下,您需要二维数组、三维数组。现在我们来学习如何使用它们。
我们先来看看一维数组、修改声明、初始化、指数和值的相关图片:

任何一维数组都可显示为一个类型的一行值。以下是一维数组的不同参考的处理方式:
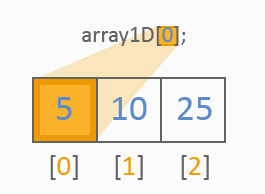
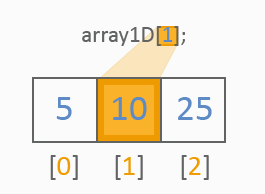
二维数组就像一般的表格,如下:
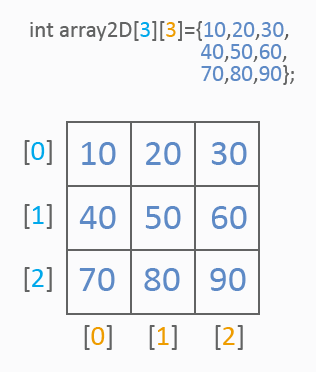
从图片上来看,二维数组已有两个指数用于值的参考:第一个指数确定一行,第二个指数确定一列。像在一维数组中那样,使用值列表进行初始化。以下是参考表格单元的值的方式:
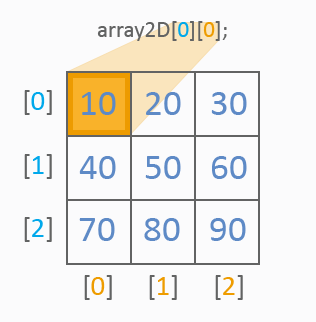
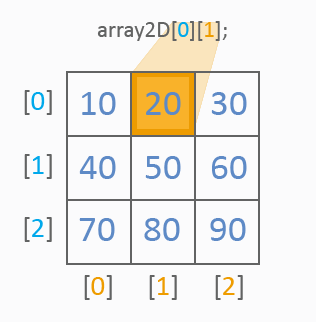
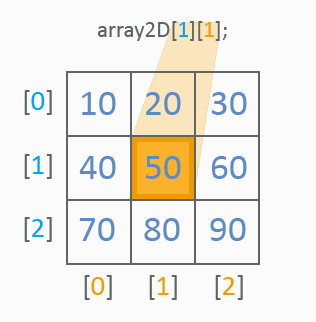
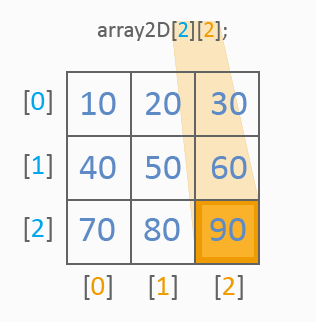
一切都很清楚。我们来看看如何遍历一个二维数组的所有值。应使用 2 个循环:
int array2D[3][3]={10,20,30, 40,50,60, 70,80,90}; for(int y=0;y<3;y++) for(int x=0;x<3;x++) MessageBox("array2D["+y+"]["+x+"]="+array2D[y][x]);
此例中,参考是从上到下,从左到右进行的。可以做个练习,试着更改方向,例如从下到上。
三维数组的区别仅在于多了一个指数用于参考单元值。一个三维数组可以轻松呈示为几个表格(二维数组)。我们来看看如何遍历一个三维数组的所有元素:
int array3D[3][3][3] = {11, 12, 13, 14, 15, 16, 17, 18, 19, 21, 22, 23, 24, 25, 26, 27, 28, 29, 31, 32, 33, 34, 35, 36, 37, 38, 39}; for(int z = 0; z < 3; z++) for(int y = 0; y < 3; y++) for(int x = 0; x < 3; x++) MessageBox("array3D["+z+"]["+y+"]["+x+"]=" + array3D[z][y][x]);
彻底理解二维和三维数组 - 这一点非常重要。再次非常认真地浏览说明图片。很多不同的任务都可以用数组解决,所以请投入足够时间理解这些数组,将来它们会给你带来极大的帮助。如果您理解了数组的工作原理,那么任何多维数组都可以手到擒来。
使用数组时所用的一些函数
我们从简单的函数开始说起。
int ArraySize(object array[]);
此函数返回该数组包含的元素数量。它适用于所有类型。例如:
// create two different arrays int arrayInt[] = {1, 2, 3, 4}; double arrayDouble[] = {5.9, 2.1, 4.7}; // here store the amount of elements int amount; amount = ArraySize(arrayInt); // note: // to define a specific // array, you need to indicate // only its name. // Now amount is equal to 4 amount = ArraySize(arrayDouble); // amount is equal to 3
下一个函数:
int ArrayInitialize(object array[],double value);ArrayInitialize
分配一个值到所有数组元素,返回所有分配到值的元素的数量。将此函数用于 int 和 double 类型的数组。
下一对函数:
int ArrayMaximum(double array[], int count = WHOLE_ARRAY, int start = 0); int ArrayMinimum(double array[], int count = WHOLE_ARRAY, int start = 0);
这两个函数返回最大和最小单元值的指数。要使用它们,只需指示应在什么数组中查找它们:
int array[] = {10, 100, 190, 3, 1}; // will be returned 1, because array[1] - maximal value ArrayMaximum(array); // will be returned 4, because array[4] - minimal value ArrayMinimum(array);
下一对函数:
int ArrayDimension(object array[]);
使用这些函数,您可确定数组的维数,即您可确定它是一维、二维还是 n 维数组。使用这些函数,您可确定数组的维数,即您可确定它是一维、二维还是 n 维数组。例如:
int array1D[15]; int array4D[3][3][3]; ArrayDimension(array1D); // get 1 ArrayDimension(array3D); // 3
以下还有更多复杂而有用的函数:
int ArraySort(double&array[], int count = WHOLE_ARRAY, int start = 0, int sort_dir = MODE_ASCEND);
此函数对元素进行排序。如果没有直接指示参数的默认值,如下例:
int array[5] = {1, 10, 5, 7, 8}; ArraySort(array);
元素将按升序排序。您可使用其他参数指定此函数行为:
- int count - 要排序的元素数量。
- int start - 排序起始元素的指数
- int sort_dir - 排序方向(升序 - MODE_ASCEND 或降序 - MODE_DESCEND)
这里您可能会问:什么是 MODE_ASCEND 和 MODE_DESCEND??根据 int,它必须是一个整数!别紧张,所有问题都会在下一部分“预处理器”中得到解答。例如,如果您需要从第 2 个元素开始对 5 个元素进行升序排序,进行如下指示:
ArraySort(array, 5, 1, MODE_DESCEND);
今天的最后一个函数:
int ArrayCopy(object&dest[], object source[], int start_dest = 0, int start_source=0, int count=WHOLE_ARRAY);
它用于将一个数组复制到另一个数组。我们来看必要的参数:
- dest[] - 目的地数组
- dest[] - 复制的数组
可选参数:
- start_dest - 复制到的目的地数组元素的指数
- start_source - 开始复制的数组元素的指数
- int count - 要复制的元素数量
此函数返回复制元素的数量。非常小心地使用 ArrayCopy:确保目的地数组有足够的容量容纳复制的数组。
预处理器
这是什么?预处理器是一种特殊的机制,旨在用于处理源代码。也就是说,首先是由预处理器准备代码,然后传达此代码用于编译。今天我们再学一个有用的选项 - 常数。
它主要讲什么?要了解这个选项,我们回忆一下 switch 部分中的一个示例:
switch(marketState) { case 1: // trading strategy for an uptrend break; case 2: // strategy for a downtrend break; case 3: // strategy for a flat break; default: // error: this state is not supported! break; }
这里我们激活了一个机制,它会根据市场状态进行不同的操作。还记得吗?那么,我们只需编写诸如 TREND_UP、TREND_DOWN、FLAT 的项目来取代 1、 2 、3,非常简单,只是更具描述性而已。
switch(marketState) { case TREND_UP: // trading strategy for an uptrend break; case TREND_DOWN: // strategy for a downtrend break; case FLAT: // strategy for a flat break; default: // error: this state is not supported! break; }
在这种情况下,源代码看起来更易读也更生动,不是吗?所以,在编译之前,常数允许将 TREND_UP、TREND_DOWN 和 FLAT 用对应的值 1、2 和 3 替代。您要做的只是指示预处理器应更改的内容。这个工作可通过预处理器指令来完成,此指令以特殊符号“#”开头。预处理器指令应放在源文件的开头,与其他指令放在一起。来看一个完整的常数示例:
//+------------------------------------------------------------------+ //| preprocessor.mq4 | //| Copyright © 2007, Antonio Banderass. All rights reserved | //| banderassa@ukr.net | //+------------------------------------------------------------------+ #property copyright "Copyright © 2007, Antonio Banderass. All rights reserved" #property link "banderassa@ukr.net" #define TREND_UP 1 #define TREND_DOWN 2 #define FLAT 3 //+------------------------------------------------------------------+ //| script program start function | //+------------------------------------------------------------------+ int start() { MessageBox("TREND_UP=" + TREND_UP + " TREND_DOWN=" + TREND_DOWN + " FLAT=" + FLAT); return(0); }
注意,我们将常数声明放在文件开头的其他预处理器指令之下。让我们更进一步检查该声明:
#define TREND_UP 1
首先我们编写关键字#define.它向预处理器表明,之后的内容是常数声明。然后我们编写常数名称(标识符),即一个可通过其参考常数值的词。在我们的示例中,它是“TREND_UP”。值 - 1紧跟其后。现在,当预处理器看到源代码中的 TREND_UP 时,它会将其替换为 1,并对所有其他常数执行相同的操作。以下是被预处理器处理前的源代码示例:处理前
int start() { MessageBox("TREND_UP=" + TREND_UP + " TREND_DOWN=" + TREND_DOWN + " FLAT=" + FLAT); return(0); }
与处理后的源代码示例::
int start() { MessageBox("TREND_UP=" + 1 + " TREND_DOWN=" + 2 + " FLAT=" + 3); return(0); }
现在您应该理解上一部分中 MODE_ASCEND 和 MODE_DESCEND 所代表的含义了。它们是带相应值的常数。
总结
您已在本文中学习了很多新知识:新循环类型 - while;新条件类型 - switch;运算符 break 和 continue。您学习编写自己的函数和使用多维数组,了解如何使用常数。所有这些都是您的主要工具,是您编写更高级代码(例如用户的指标和 EA)的基础。所以,您要确保完全掌握本文的内容,因为它非常重要,在将来会经常用到。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/1483
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 使用神经网络预测价格
使用神经网络预测价格

 MQL5 初学者: 图形对象的防破坏保护
MQL5 初学者: 图形对象的防破坏保护