
Cálculos Estadísticos

Introducción
Actualmente, a menudo puede encontrar artículos y publicaciones sobre temas relacionados con econometría, pronóstico de series de precio, elección y adecuación de cálculo de un modelo, etc. Pero en la mayoría de los casos, el razonamiento se basa en la suposición de que un lector está familiarizado con los métodos de estadísticas matemáticas y puede calcular fácilmente parámetros estadísticos en una secuencia analizada.
El cálculo de parámetros estadísticos de una secuencia es muy importante, puesto que la mayoría de los modelos y métodos matemáticos se basan en suposiciones simples. Por ejemplo, la normalidad de la ley de distribución o valor de dispersión, u otros parámetros. Por tanto, al analizar y pronosticar series cronológicas necesitamos una herramienta simple y conveniente que nos permita calcular de forma rápida y clara los principales parámetros estadísticos. En este artículo, crearemos esta herramienta.
Este artículo describe brevemente los parámetros estadísticos más sencillos de secuencias aleatorias y varios métodos de su análisis visual. Ofrece además la implementación de estos métodos en MQL5 y los métodos de visualización del resultado de los cálculos usando la aplicación Gnuplot. Este artículo no pretende en absoluto ser un manual o una referencia. Por eso, puede contener ciertas familiaridades aceptadas respecto a la terminología y definiciones.
Analizar Parámetros en una Muestra
Supongamos que hay un proceso estacionario que sucede de forma infinita en el tiempo, que se puede representar como una secuencia de muestras discretas. Llamemos a esta secuencia de muestras la población general. Una parte de las muestras seleccionadas de la población general se llamará muestra de la población general, o un muestreo de N muestras. Además, supongamos que no conocemos ningún parámetro, de modo que los calcularemos en base a un muestreo infinito.
Evitar Outliers (valores atípicos)
Antes de comenzar con el cálculo estadístico de parámetros, deberíamos señalar que la precisión del cálculo podría ser insuficiente si el muestreo contiene errores grandes (outliers). La influencia de los outliers es enorme en la precisión de los cálculos si el sampleo tiene un volumen pequeño. Los outliers son los valores que divergen de forma anormal del medio de la distribución. Estas desviaciones pueden ser causadas por eventos diferentes y apenas probables, y los errores aparecen al recopilar datos estadísticos y formar la secuencia.
Es difícil tomar una decisión sobre si filtrar estos outliers o no, puesto que en la mayoría de los casos es imposible detectar claramente si un valor es un outlier, o pertenece al proceso de análisis. De modo que, si se detecta un outlier y se toma la decisión de filtrarlos, surge la pregunta: ¿qué deberíamos hacer con esos valores de error? La variante más lógica es excluirlos del muestreo, lo que podría incrementar la precisión del cálculo de características estadísticas; pero debería tener cuidado al excluir los outliers del muestreo al trabajar con secuencias cronológicas.
Para tener la posibilidad de excluir outliers de un muestreo, o al menos detectarlos, implementemos el algoritmo descrito en el libro "Statistics for Traders" ("Estadísticas para Traders"), escrito por S.V. Bulashev.
Según este algoritmo, necesitamos calcular cinco valores de cálculo del centro de la distribución:
- Mediana;
- Centro del 50% del intervalo del intercuartal (alcance cuartal medio, MQR);
- Medio aritmético del muestreo entero;
- Medio aritmético del 50% del intervalo del intercuartal (media intercuartal, IQM);
- Centro del intervalo (intervalo medio) - determinado como el valor medio del valor máximo y mínimo en un muestreo.
A continuación, los resultados del cálculo del centro de la distribución se distribuyen en orden ascendente; y después, el valor medio o el tercero en orden se elige como el centro de la distribución Xcen. Por tanto, el cálculo elegido parece estar afectado mínimamente por outliers.
Además, usando el cálculo obtenido del centro de la distribución Xcen, calcularemos las desviaciones estándar , el exceso de K y el porcentaje de censura según la fórmula empírica:
![]()
donde N es el número de muestras en el muestreo (volumen de muestreo).
Después, los valores que quedan fuera del intervalo:
![]()
se contarán como outliers, y por tanto se deberían excluir del muestreo.
Este método se describe en detalle en el libro "Statistics for Traders" ("Estadísticas para Traders"), de modo que pasemos directamente a la implementación del algoritmo. El algoritmo que permite detectar y excluir outliers se implementa en la función erremove().
Abajo puede encontrar el script escrito para poner a prueba esta función.
//---------------------------------------------------------------------------- // erremove.mq5 // Copyright 2011, MetaQuotes Software Corp. // https://www.mql5.com //---------------------------------------------------------------------------- #property copyright "Copyright 2011, MetaQuotes Software Corp." #property link "https://www.mql5.com" #property version "1.00" #import "shell32.dll" bool ShellExecuteW(int hwnd,string lpOperation,string lpFile, string lpParameters,string lpDirectory,int nShowCmd); #import //---------------------------------------------------------------------------- // Script program start function //---------------------------------------------------------------------------- void OnStart() { int i; double dat[100]; double y[]; srand(1); for(i=0;i<ArraySize(dat);i++)dat[i]=rand()/16000.0; dat[25]=3; // Make Error !!! erremove(dat,y,1); } //---------------------------------------------------------------------------- int erremove(const double &x[],double &y[],int visual=1) { int i,m,n; double a[],b[5]; double dcen,kurt,sum2,sum4,gs,v,max,min; if(!ArrayIsDynamic(y)) // Error { Print("Function erremove() error!"); return(-1); } n=ArraySize(x); if(n<4) // Error { Print("Function erremove() error!"); return(-1); } ArrayResize(a,n); ArrayCopy(a,x); ArraySort(a); b[0]=(a[0]+a[n-1])/2.0; // Midrange m=(n-1)/2; b[1]=a[m]; // Median if((n&0x01)==0)b[1]=(b[1]+a[m+1])/2.0; m=n/4; b[2]=(a[m]+a[n-m-1])/2.0; // Midquartile range b[3]=0; for(i=m;i<n-m;i++)b[3]+=a[i]; // Interquartile mean(IQM) b[3]=b[3]/(n-2*m); b[4]=0; for(i=0;i<n;i++)b[4]+=a[i]; // Mean b[4]=b[4]/n; ArraySort(b); dcen=b[2]; // Distribution center sum2=0; sum4=0; for(i=0;i<n;i++) { a[i]=a[i]-dcen; v=a[i]*a[i]; sum2+=v; sum4+=v*v; } if(sum2<1.e-150)kurt=1.0; kurt=((n*n-2*n+3)*sum4/sum2/sum2-(6.0*n-9.0)/n)*(n-1.0)/(n-2.0)/(n-3.0); // Kurtosis if(kurt<1.0)kurt=1.0; gs=(1.55+0.8*MathLog10((double)n/10.0)*MathSqrt(kurt-1))*MathSqrt(sum2/(n-1)); max=dcen+gs; min=dcen-gs; m=0; for(i=0;i<n;i++)if(x[i]<=max&&x[i]>=min)a[m++]=x[i]; ArrayResize(y,m); ArrayCopy(y,a,0,0,m); if(visual==1)vis(x,dcen,min,max,n-m); return(n-m); } //---------------------------------------------------------------------------- void vis(const double &x[],double dcen,double min,double max,int numerr) { int i; double d,yma,ymi; string str; yma=x[0];ymi=x[0]; for(i=0;i<ArraySize(x);i++) { if(yma<x[i])yma=x[i]; if(ymi>x[i])ymi=x[i]; } if(yma<max)yma=max; if(ymi>min)ymi=min; d=(yma-ymi)/20.0; yma+=d;ymi-=d; str="unset key\n"; str+="set title 'Sequence and error levels (number of errors = "+ (string)numerr+")' font ',10'\n"; str+="set yrange ["+(string)ymi+":"+(string)yma+"]\n"; str+="set xrange [0:"+(string)ArraySize(x)+"]\n"; str+="plot "+(string)dcen+" lt rgb 'green',"; str+=(string)min+ " lt rgb 'red',"; str+=(string)max+ " lt rgb 'red',"; str+="'-' with line lt rgb 'dark-blue'\n"; for(i=0;i<ArraySize(x);i++)str+=(string)x[i]+"\n"; str+="e\n"; if(!saveScript(str)){Print("Create script file error");return;} if(!grPlot())Print("ShellExecuteW() error"); } //---------------------------------------------------------------------------- bool grPlot() { string pnam,param; pnam="GNUPlot\\binary\\wgnuplot.exe"; param="-p MQL5\\Files\\gplot.txt"; return(ShellExecuteW(NULL,"open",pnam,param,NULL,1)); } //---------------------------------------------------------------------------- bool saveScript(string scr1="",string scr2="") { int fhandle; fhandle=FileOpen("gplot.txt",FILE_WRITE|FILE_TXT|FILE_ANSI); if(fhandle==INVALID_HANDLE)return(false); FileWriteString(fhandle,"set terminal windows enhanced size 560,420 font 8\n"); FileWriteString(fhandle,scr1); if(scr2!="")FileWriteString(fhandle,scr2); FileClose(fhandle); return(true); } //----------------------------------------------------------------------------
Observemos más detalladamente la función erremove(). Como primer parámetro de la función pasamos la dirección del array x[], donde se guardan los valores del muestreo analizado; el volumen de muestreo no debe ser menor de cuatro elementos. Se supone que el tamaño del array x[] es igual al tamaño del muestreo, por eso no se pasa el valor N del volumen de muestro. Los datos localizados en el array x[] no cambian como resultado de la ejecución de la función.
El siguiente parámetro es la dirección del array y[]. En caso de que la función se ejecute con éxito, este array contendrá la secuencia de entrada con los outliers excluidos. El tamaño del array y[] es menor que el tamaño del array x[] por el número de valores excluidos del muestreo. El array y[] debe declararse como dinámico, de lo contrario será imposible cambiar su tamaño en el cuerpo de la función.
El último parámetro (opcional) es la flag responsable de la visualización de los resultados del cálculo. Si su valor es igual a uno (valor por defecto), entonces, antes del final de la ejecución, el gráfico que muestra la siguiente información se dibujará en una ventana separada: la secuencia de entrada, la línea del centro de distribución y los límites del intervalo. Los valores que estén por fuera de él se considerarán outliers.
El método para dibujar gráficos se describirá más tarde. Em caso de que la ejecución tenga éxito, la función devuelve el número de valores excluidos del muestreo; en caso de error, devolverá -1. Si no se descubres valores de error (outliers), la función devolverá 0 y la secuencia en el array y[] será la misma que en x[].
Al principio de la función, la información se copia del array x[] al a[], después se ordena en orden ascendente, y a continuación se realizan cinco cálculos del centro de distribución.
La mitad del intervalo (intervalo medio) se determina como la suma de valores extremos del array a[] ordenado dividido entre dos.
La mediana se calcula para volúmenes impares del muestreo N tal y como se muestra a continuación:
![]()
y para volúmenes pares del muestreo:
![]()
Considerando que los índices del array a[] ordenado empiezan de cero, obtendremos:
m=(n-1)/2; median=a[m]; if((n&0x01)==0)b[1]=(median+a[m+1])/2.0;
La mitad del intervalo intercuartal 50% (intervalo de cuartal medio, MQR):
![]()
donde M=N/4 (división íntegra).
Para el array a[] ordenado, obtendremos:
m=n/4; MQR=(a[m]+a[n-m-1])/2.0; // Midquartile range
Medias aritméticos del intervalo intercuartal 50% (media intercuartal, IQM). El 25% de las muestras se cortan de ambas partes del muestreo, y el 50% restante se usa para el cálculo de la media aritmética:
![]()
donde M=N/4 (división íntegra).
m=n/4; IQM=0; for(i=m;i<n-m;i++)IQM+=a[i]; IQM=IQM/(n-2*m); // Interquartile mean(IQM)
La media aritmética (media) se determina para el muestreo entero.
Cada uno de los valores determinados se escriben en el array b[] , y después el array se ordena en orden ascendente. Un valor de elemento del array b[2] se elige como el centro de la distribución. Además, usando este valor, calcularemos los cálculos imparciales de la media aritmética y el coeficiente de exceso; el algoritmo de cálculo se describirá más tarde.
Los cálculos obtenidos se usan para el cálculo del coeficiente de censuración y límites del intervalo para detectar outliers (las expresiones se muestran arriba). Al final, la secuencia con outliers excluidos se forma en el array y[], y se llama a las funciones vis() para dibujar el gráfico. Echemos un vistazo al método de visualización usado en este artículo.
Visualización
Para mostrar los resultados del cálculo, yo utilizo la aplicación de freeware Gnuplot, diseñada para hacer gráficos en 2D y 3D. Gnuplot tiene la posibilidad de mostrar gráficos en la pantalla (en una ventana separada) o escribirlos en archivo en diferentes formatos gráficos. Los comandos de dibujo de gráfico se pueden ejecutar desde un archivo de texto preparado de forma preliminar. La página web oficial del proyecto gnuplot es - gnuplot.sourceforge.net. La aplicación es multi-plataforma, y se distribuye tanto en forma de archivos de código fuente como en archivos binarios compilados para una plataforma determinada.
Los ejemplos escritos para este artículo se simularon en Windows XP SP3 y en la versión 4.2.2 de Gnuplot. El archivo gp442win32.zip se puede descargar de http://sourceforge.net/projects/gnuplot/files/gnuplot/4.4.2/. No he puesto a prueba los ejemplos con otras versiones de Gnuplot.
Una vez que se ha descargado el archivo gp442win32.zip, descomprímalo. Como resultado, se creará la carpeta \gnuplot que contendrá la aplicación, el archivo de ayuda, documentación y ejemplos. Para interactuar con aplicaciones, coloque la carpeta \gnuplot entera en la carpeta raíz de su terminal de cliente MetaTrader 5.

Figura 1. Colocación de la carpeta \gnuplot
Una vez que ha movido la carpeta, puede cambiar la operabilidad de la aplicación Gnuplot. Para ello, ejecute el archivo \gnuplot\binary\wgnuplot.exe, y después, cuando aparezca la línea "gnuplot>", escriba el comando "plot sin(x)". Como resultado, debería aparecer una ventana con la función sin(x) dibujada en ella. También puede probar los ejemplos incluidos en la descarga de la aplicación. Para ello, elija la carpeta File\Demos y seleccione el archivo \gnuplot\demo\all.dem.
Ahora, al ejecutar el script erremove.mq5, el gráfico de la figura 2 se dibujará en una ventana separada:

Figura 2. El gráfico creado usando el script erremove.mq5.
Más adelante en el artículo trataremos algunas prestaciones de Gnuplot, puesto que la información sobre el programa y sus controles se puede encontrar fácilmente en la documentación que viene en la descarga, así como en varias páginas web como http://gnuplot.ikir.ru/.
Los ejemplos de programas escritos para este artículo usan el método más sencillo de interacción con Gnuplot para dibujar los gráficos. En primer lugar se crea el archivo de texto gplot.txt; contiene los comandos e información de Gnuplot que se deben mostrar. Después se inicia la aplicación wgnuplot.exe con el nombre de ese archivo pasado como argumento en la línea de comando. La aplicación wgnuplot.exe se llama usando la función ShellExecuteW() importada de la biblioteca del sistema shell32.dll; es la razón por la que la importación de dlls externos se debe permitir en el terminal de cliente.
La versión especificada de Gnuplot permite dibujar gráficos en una ventana separada para dos tipos de terminales: wxt y windows. El terminal wxt usa los algoritmos de antialiasing para dibujar gráficos, lo que nos permite obtener una mayor calidad de imagen en comparación con el terminal de windows. A pesar de ello, para los ejemplos de este artículo usamos el terminal de windows. La razón es que al trabajar con el terminal de windows, el proceso de sistema creado como resultado de la llamada "wgnuplot.exe -p MQL5\\Files\\gplot.txt" y la apertura de una ventana de gráfico se finaliza automáticamente cuando se cierra la ventana.
Si selecciona el terminal wxt, al cerrar la ventana del gráfico, el proceso del sistema wgnuplot.exe no finalizará automáticamente. Por tanto, si usa el terminal wxt y llama a wgnuplot.exe tantas veces como dijimos arriba, se acumularán muchos procesos sin signos de actividad en el sistema. Usando la llamada "wgnuplot.exe -p MQL5\\Files\\gplot.txt" y el terminal windows, puede evitar la apertura de ventanas adicionales indeseadas y la aparición de procesos de sistema no finalizados.
La ventana en la que se muestra el gráfico es interactiva, y procesa los eventos de click de ratón y de teclado. Para obtener la información sobre teclas automáticas, ejecute wgnuplot.exe, elija un tipo de terminal usando el comando "set terminal windows" y dibuje cualquier gráfico, por ejemplo usando el comando "plot sin(x)". Si la ventana de gráfico está activa (en plano), entonces verá un consejo en la ventana de texto de wgnuplot.exe en cuanto pulse la tecla "h".
Cálculo de Parámetros
Tras la breve introducción al método de dibujo de gráficos, volvamos al cálculo de parámetros de la población general en base a su muestreo finito. Suponiendo que no se conozcan parámetros estadísticos de la población general, usaremos solo cálculos imparciales de estos parámetros.
El cálculo de expectativas matemáticas o el medio de muestreo se pueden considerar como el parámetro que determina la distribución de una secuencia. El muestreo se calcula usando la siguiente fórmula:
![]()
donde N es el número de muestras en el muestreo.
El valor principal es un cálculo del centro de distribución, y se usa para el cálculo de otros parámetros conectados con momentos centrales que hacen este parámetro especialmente importante. Además del valor de media, usaremos el cálculo de dispersion (dispersión, diferencia), la desviación estándar, el coeficiente de oblicuidad (skewness), y el coeficiente de exceso (kurtosis) como parámetros estadísticos.
![]()
donde m son momentos centrales.
Los momentos centrales son características numéricas de distribución de una población general.
Los segundos, terceros y cuartos momentos centrales selectivos se determinan por las siguientes expresiones:
![]()
Pero esos valores son imparciales. Aquí deberíamos mencionar k-Statistic y h-Statistic. Bajo ciertas condiciones permiten obtener cálculos imparciales de momentos centrales, de modo que se pueden usar para el cálculo de cálculos imparciales de dispersión, desviación estándar, oblicuidad y kurtosis.
Note que el cálculo del cuarto momento en los cálculos k y h se realiza de diferentes formas. Esto resulta en la obtención de diferentes expresiones para el cálculo de kurtosis al usar k o h. Por ejemplo, en Microsoft Excel, el exceso se calcula usando la fórmula que se corresponde con el uso de cálculos k, y en el libro "Statistics for Traders" ("Estadísticas para Traders") el cálculo imparcial de kurtosis se hace usando los cálculos h.
Escojamos los cálculos h, y después calcularemos los parámetros necesarios sustituyéndolos en lugar de 'm' en la expresión dada anteriormente.
Dispersión y Desviación Estándar
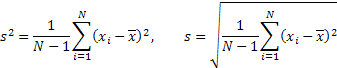
Oblicuidad:
![]()
Kurtosis:
![]()
El coeficiente de exceso (kurtosis) calculado de acuerdo con la expresión dada para la secuencia con ley de distribución normal es igual a 3.
Preste atención al hecho de que el valor obtenido restando 3 del valor calculado se usa a menudo como valor de kurtosis; por tanto, el valor obtenido se normaliza en relación a la ley de distribución normal. En el primer caso, este coeficiente se llama kurtosis; en el segundo caso, se llama "exceso de kurtosis".
El cálculo de parámetros según la expresión dada se lleva a cabo en la función dStat():
struct statParam { double mean; double median; double var; double stdev; double skew; double kurt; }; //---------------------------------------------------------------------------- int dStat(const double &x[],statParam &sP) { int i,m,n; double a,b,sum2,sum3,sum4,y[]; ZeroMemory(sP); // Reset sP n=ArraySize(x); if(n<4) // Error { Print("Function dStat() error!"); return(-1); } sP.kurt=1.0; ArrayResize(y,n); ArrayCopy(y,x); ArraySort(y); m=(n-1)/2; sP.median=y[m]; // Median if((n&0x01)==0)sP.median=(sP.median+y[m+1])/2.0; sP.mean=0; for(i=0;i<n;i++)sP.mean+=x[i]; sP.mean/=n; // Mean sum2=0;sum3=0;sum4=0; for(i=0;i<n;i++) { a=x[i]-sP.mean; b=a*a;sum2+=b; b=b*a;sum3+=b; b=b*a;sum4+=b; } if(sum2<1.e-150)return(1); sP.var=sum2/(n-1); // Variance sP.stdev=MathSqrt(sP.var); // Standard deviation sP.skew=n*sum3/(n-2)/sum2/sP.stdev; // Skewness sP.kurt=((n*n-2*n+3)*sum4/sum2/sum2-(6.0*n-9.0)/n)* (n-1.0)/(n-2.0)/(n-3.0); // Kurtosis return(1);Cuando se llama a dStat(), la dirección del array x[] pasa a la función. Contiene los datos iniciales y el enlace a la estructura statParam structure, que contendrá valores calculados de los parámetros. En caso de que se de un error cuando hay menos de cuatro elementos en el array, la función devuelve -1.
Histograma
Además de los parámetros calculados en la función dStat(), la ley de distribución de la población general es de gran interés para nosotros. Para calcular visualmente la ley de distribución en el muestreo finito, podemos dibujar un histograma. Al dibujar el histograma, el intervalo de valores del muestreo se divide en varias secciones similares. Y después se calcula el número de elementos en cada sección (frecuencias de grupo).
Además se dibuja un diagrama de barras en base a las frecuencias de grupo. Esto se llama histograma. Tras la normalización para la anchura del intervalo, el histograma representará una densidad empírica de distribución de un valor aleatorio. Usemos la expresión empírica descrita en "Statistics for Traders" ("Estadísticas para Traders") para determinar un número óptimo de secciones para dibujar el histograma:
![]()
donde L es el número requerido de secciones, N es el volumen de muestreo y e es la kurtosis.
Abajo puede encontrar el dHist(), que determina el número de secciones, calcula el número de elementos en cada uno de ellos y normaliza las frecuencias de grupo obtenidas.
struct statParam { double mean; double median; double var; double stdev; double skew; double kurt; }; //---------------------------------------------------------------------------- int dHist(const double &x[],double &histo[],const statParam &sp) { int i,k,n,nbar; double a[],max,s,xmin; if(!ArrayIsDynamic(histo)) // Error { Print("Function dHist() error!"); return(-1); } n=ArraySize(x); if(n<4) // Error { Print("Function dHist() error!"); return(-1); } nbar=(sp.kurt+1.5)*MathPow(n,0.4)/6.0; if((nbar&0x01)==0)nbar--; if(nbar<5)nbar=5; // Number of bars ArrayResize(a,n); ArrayCopy(a,x); max=0.0; for(i=0;i<n;i++) { a[i]=(a[i]-sp.mean)/sp.stdev; // Normalization if(MathAbs(a[i])>max)max=MathAbs(a[i]); } xmin=-max; s=2.0*max*n/nbar; ArrayResize(histo,nbar+2); ArrayInitialize(histo,0.0); histo[0]=0.0;histo[nbar+1]=0.0; for(i=0;i<n;i++) { k=(a[i]-xmin)/max/2.0*nbar; if(k>(nbar-1))k=nbar-1; histo[k+1]++; } for(i=0;i<nbar;i++)histo[i+1]/=s; return(1); }
La dirección del array x[] se pasa a la función. Contiene la secuencia inicial. El contenido del array no cambia como resultado de la ejecución de la función. El siguiente parámetro es el enlace al array dinámico histo[], donde se almacenarán los valores calculados. El número de elementos de ese array se corresponderá con el número de secciones usadas para el cálculo más dos elementos.
Un elemento que contenga un valor de cero se añade al comienzo y al final del array histo[]. El último parámetro es la dirección de la estructura statParam que debería contener los valores previamente calculados de los parámetros almacenados en él. Si el array histo[] que pasa a la función no es un array dinámico, o el array de entrada array x[] contiene menos de cuatro elementos, la función detiene su ejecución y devuelve -1.
Una vez que ha dibujado un histograma de valores obtenidos, puede calcular visualmente si el muestreo se corresponde con la ley normal de distribución. Para una representación gráfica más visual de la correspondencia con la ley normal de distribución, podemos dibujar un gráfico con la escala de probabilidad normal (Normal Probability Plot, o Dibujo de Probabilidad Normal), además del histograma.
Dibujo de Probabilidad Normal
La idea principal de dibujar este gráfico es que el eje X debería limitarse para que los valores mostrados de una secuencia con distribución normal queden en la misma línea. De esta forma, la hipótesis de normalidad se puede comprobar gráficamente. Puede encontrar más información detallada sobre este tipo de gráficos aquí: "Normal probability plot" ("Dibujo de probabilidad normal") o "e-Handbook of Statistical Methods" ("Manual Electrónico de Métodos Estadísticos").
Para calcular los valores requeridos para dibujar el gráfico de probabilidad normal, se usa la función dRankit(), tal y como se muestra a continuación.
struct statParam { double mean; double median; double var; double stdev; double skew; double kurt; }; //---------------------------------------------------------------------------- int dRankit(const double &x[],double &resp[],double &xscale[],const statParam &sp) { int i,n; double np; if(!ArrayIsDynamic(resp)||!ArrayIsDynamic(xscale)) // Error { Print("Function dHist() error!"); return(-1); } n=ArraySize(x); if(n<4) // Error { Print("Function dHist() error!"); return(-1); } ArrayResize(resp,n); ArrayCopy(resp,x); ArraySort(resp); for(i=0;i<n;i++)resp[i]=(resp[i]-sp.mean)/sp.stdev; ArrayResize(xscale,n); xscale[n-1]=MathPow(0.5,1.0/n); xscale[0]=1-xscale[n-1]; np=n+0.365; for(i=1;i<(n-1);i++)xscale[i]=(i+1-0.3175)/np; for(i=0;i<n;i++)xscale[i]=ltqnorm(xscale[i]); return(1); } //---------------------------------------------------------------------------- double A1 = -3.969683028665376e+01, A2 = 2.209460984245205e+02, A3 = -2.759285104469687e+02, A4 = 1.383577518672690e+02, A5 = -3.066479806614716e+01, A6 = 2.506628277459239e+00; double B1 = -5.447609879822406e+01, B2 = 1.615858368580409e+02, B3 = -1.556989798598866e+02, B4 = 6.680131188771972e+01, B5 = -1.328068155288572e+01; double C1 = -7.784894002430293e-03, C2 = -3.223964580411365e-01, C3 = -2.400758277161838e+00, C4 = -2.549732539343734e+00, C5 = 4.374664141464968e+00, C6 = 2.938163982698783e+00; double D1 = 7.784695709041462e-03, D2 = 3.224671290700398e-01, D3 = 2.445134137142996e+00, D4 = 3.754408661907416e+00; //---------------------------------------------------------------------------- double ltqnorm(double p) { int s=1; double r,x,q=0; if(p<=0||p>=1){Print("Function ltqnorm() error!");return(0);} if((p>=0.02425)&&(p<=0.97575)) // Rational approximation for central region { q=p-0.5; r=q*q; x=(((((A1*r+A2)*r+A3)*r+A4)*r+A5)*r+A6)*q/(((((B1*r+B2)*r+B3)*r+B4)*r+B5)*r+1); return(x); } if(p<0.02425) // Rational approximation for lower region { q=sqrt(-2*log(p)); s=1; } else //if(p>0.97575) // Rational approximation for upper region { q = sqrt(-2*log(1-p)); s=-1; } x=s*(((((C1*q+C2)*q+C3)*q+C4)*q+C5)*q+C6)/((((D1*q+D2)*q+D3)*q+D4)*q+1); return(x); }
La dirección del array x[] se introduce en la función. El array contiene la secuencia inicial. Los siguientes parámetros son referencias a los arrays de salidas resp[] y xscale[]. Tras la ejecución de la función, los valores usados para dibujar el gráfico en los ejes X e Y respectivamente se escriben en los arrays. A continuación, la dirección de la estructura statParam se pasa a la función. Debe contener valores previamente calculados de los parámetros estadísticos de la secuencia de entrada. En caso de error, la función devuelve -1.
Al formar valores para el eje X, se llama a la función ltqnorm(). Calcula la función íntegra inversa de distribución normal. El algoritmo usado para el cálculo se toma de "An algorithm for computing the inverse normal cumulative distribution function" ("Un algoritmo para computar la función de distribución acumulativa normal inversa").
Cuatro Gráficos
Anteriormente mencioné la función dStat() donde se calculan los valores de los parámetros estadísticos. Repitamos su significado brevemente.
Dispersión (diferencia) – el valor medio de cuadrados de desviación de un valor aleatorio de su expectativa matemática (valor medio). El parámetro que muestra lo grande que es la desviación de un valor aleatorio de su centro de distribución. Cuanto mayor sera el valor de este parámetro, mayor será la desviación.
Desviación estándar – puesto que la dispersión se mide como el cuadrado de un valor aleatorio, la desviación estándar se usa a menudo como una característica más obvia de dispersión. Es igual a la raíz cuadrada de la dispersión.
Oblicuidad – si dibujamos una curva de distribución de un valor aleatorio, la oblicuidad mostrará lo asimétrica que es la curva de densidad de probabilidad en relación con el centro de distribución. Si el valor de la oblicuidad es mayor que cero, la curva de densidad de probabilidad tendrá una pendiente empinada a la izquierda, y una pendiente plana a la derecha. Si el valor de la oblicuidad es negativo, entonces la pendiente izquierda será plana, y la derecha será empinada. Cuando la curva de densidad de probabilidad es simétrica al centro de distribución, la oblicuidad será igual a cero.
El coeficiente de exceso (kurtosis) – describe lo afilado que es el pico de la curva de densidad de probabilidad y lo escarpado de las pendientes de las colas de distribución. Cuanto más afilado sea el pico de la curva cerca del centro de distribución, mayor será el valor de la kurtosis.
A pesar del hecho de que los parámetros estadísticos mencionados describen una secuencia en detalle, a menudo puede caracterizar una secuencia más fácilmente, en base al resultado de cálculos representados de forma gráfica. Por ejemplo, un gráfico ordinario de una secuencia puede completar en gran medida una visualización obtenida al analizar los parámetros estadísticos.
Anteriormente en el artículo mencioné las funciones dHist() y dRankit(), que nos permiten preparar datos para dibujar un histograma o un gráfico con la escala de probabilidad normal. La posibilidad mostrar el histograma y el gráfico de distribución normal junto con el gráfico ordinario en la misma hoja le permitirá determinar visualmente las principales prestaciones de la secuencia analizada.
Estos tres gráficos alistados deberían ser complementados con un cuarto: el gráfico con los valores actuales de la secuencia en el que Y su sus valores previos en el eje X. Este gráfico se llama "Lag Plot". Si hay una correlación fuerte entre indicaciones adyacentes, los valores del muestreo se extenderán en línea recta. Y si no hay correlación entre indicaciones adyacentes, por ejemplo al analizar una secuencia aleatoria, entonces los valores se dispersarán por todo el gráfico.
Para un cálculo rápido de un muestreo inicial, sugiero dibujar cuatro gráficos en una misma hoja y mostrar en ella los valores calculados del parámetro estadístico. Esta no es una idea nueva; puede leer sobre el uso del análisis de los cuatro gráficos mencionados aquí: "4-Plot".
Al final del artículo podrá encontrar la sección "Archivos", donde se encuentra el script s4plot.mq5, que dibuja los cuatro gráfico en una sola hoja. El array dat[] se crea dentro de la función OnStart() del script. Contiene la secuencia inicial. Después, las funciones dStat(), dHist() y dRankit() se llaman consecuentemente para el cálculo de datos requeridos para dibujar los gráficos. La función vis4plot() se llama a continuación. Crea un archivo de texto con los comandos de Gnuplot en base a los datos calculados, y después llama a la aplicación para dibujar los gráficos en una ventana separada.
No tiene sentido mostrar el código entero del script en el artículo, puesto que las funciones dStat(), dHist() y dRankit() ya se describieron antes, la función vis4plot(), que crea una secuencia de comandos Gnuplot, no tiene peculiaridad significativa alguna, y la descripción del comando de Gnuplot va más allá del tema del artículo. Además de ello, puede usar otro método para dibujar los gráficos en lugar de la aplicación Gnuplot.
De modo que mostremos solo una parte de s4plot.mq5 - su función OnStart().
//---------------------------------------------------------------------------- // Script program start function //---------------------------------------------------------------------------- void OnStart() { int i; double dat[128],histo[],rankit[],xrankit[]; statParam sp; MathSrand(1); for(i=0;i<ArraySize(dat);i++) dat[i]=MathRand(); if(dStat(dat,sp)==-1)return; if(dHist(dat,histo,sp)==-1)return; if(dRankit(dat,rankit,xrankit,sp)==-1)return; vis4plot(dat,histo,rankit,xrankit,sp,6); }
En este ejemplo se usa una secuencia aleatoria para llenar el array dat[] con información inicial usando la función MathRand(). La ejecución del script debería dar el siguiente resultado:

Figura 3. Cuatro gráficos. Script s4plot.mq5
Preste atención al último parámetro de la función vis4plot(). Es responsable del formato de los valores numéricos producidos. En este ejemplo, los valores se producen con seis cifras decimales. Este parámetro es el mismo que el que determina el formato en la función DoubleToString().
Si los valores de la secuencia de entrada son demasiado pequeños o demasiado grandes, puede usar el formato científico para una visualización más obvia. Para ello, configure el parámetro a -5, por ejemplo. El valor -5 se configura por defecto para la función vis4plot().
Para demostrar la obviedad del método de los cuatro gráficos para mostrar las peculiaridades de una secuencia, necesitaremos un generador de estas secuencias.
Generador de una Secuencia Pseudo-Aleatoria
La clase RNDXor128 está diseñada para generar secuencias pseudo-aleatorias.
Debajo tiene el código fuente del archivo incluido que describe esta clase.
//----------------------------------------------------------------------------------- // RNDXor128.mqh // 2011, victorg // https://www.mql5.com //----------------------------------------------------------------------------------- #property copyright "2011, victorg" #property link "https://www.mql5.com" #include <Object.mqh> //----------------------------------------------------------------------------------- // Generation of pseudo-random sequences. The Xorshift RNG algorithm // (George Marsaglia) with the 2**128 period of initial sequence is used. // uint rand_xor128() // { // static uint x=123456789,y=362436069,z=521288629,w=88675123; // uint t=(x^(x<<11));x=y;y=z;z=w; // return(w=(w^(w>>19))^(t^(t>>8))); // } // Methods: // Rand() - even distribution withing the range [0,UINT_MAX=4294967295]. // Rand_01() - even distribution within the range [0,1]. // Rand_Norm() - normal distribution with zero mean and dispersion one. // Rand_Exp() - exponential distribution with the parameter 1.0. // Rand_Laplace() - Laplace distribution with the parameter 1.0 // Reset() - resetting of all basic values to initial state. // SRand() - setting new basic values of the generator. //----------------------------------------------------------------------------------- #define xor32 xx=xx^(xx<<13);xx=xx^(xx>>17);xx=xx^(xx<<5) #define xor128 t=(x^(x<<11));x=y;y=z;z=w;w=(w^(w>>19))^(t^(t>>8)) #define inidat x=123456789;y=362436069;z=521288629;w=88675123;xx=2463534242 class RNDXor128:public CObject { protected: uint x,y,z,w,xx,t; uint UINT_half; public: RNDXor128() {UINT_half=UINT_MAX>>1;inidat;}; double Rand() {xor128;return((double)w);}; int Rand(double& a[],int n) {int i;if(n<1)return(-1); if(ArraySize(a)<n)return(-2); for(i=0;i<n;i++){xor128;a[i]=(double)w;} return(0);}; double Rand_01() {xor128;return((double)w/UINT_MAX);}; int Rand_01(double& a[],int n) {int i;if(n<1)return(-1); if(ArraySize(a)<n)return(-2); for(i=0;i<n;i++){xor128;a[i]=(double)w/UINT_MAX;} return(0);}; double Rand_Norm() {double v1,v2,s,sln;static double ra;static uint b=0; if(b==w){b=0;return(ra);} do{ xor128;v1=(double)w/UINT_half-1.0; xor128;v2=(double)w/UINT_half-1.0; s=v1*v1+v2*v2; } while(s>=1.0||s==0.0); sln=MathLog(s);sln=MathSqrt((-sln-sln)/s); ra=v2*sln;b=w; return(v1*sln);}; int Rand_Norm(double& a[],int n) {int i;if(n<1)return(-1); if(ArraySize(a)<n)return(-2); for(i=0;i<n;i++)a[i]=Rand_Norm(); return(0);}; double Rand_Exp() {xor128;if(w==0)return(DBL_MAX); return(-MathLog((double)w/UINT_MAX));}; int Rand_Exp(double& a[],int n) {int i;if(n<1)return(-1); if(ArraySize(a)<n)return(-2); for(i=0;i<n;i++)a[i]=Rand_Exp(); return(0);}; double Rand_Laplace() {double a;xor128; a=(double)w/UINT_half; if(w>UINT_half) {a=2.0-a; if(a==0.0)return(-DBL_MAX); return(MathLog(a));} else {if(a==0.0)return(DBL_MAX); return(-MathLog(a));}}; int Rand_Laplace(double& a[],int n) {int i;if(n<1)return(-1); if(ArraySize(a)<n)return(-2); for(i=0;i<n;i++)a[i]=Rand_Laplace(); return(0);}; void Reset() {inidat;}; void SRand(uint seed) {int i;if(seed!=0)xx=seed; for(i=0;i<16;i++){xor32;} xor32;x=xx;xor32;y=xx; xor32;z=xx;xor32;w=xx; for(i=0;i<16;i++){xor128;}}; int SRand(uint xs,uint ys,uint zs,uint ws) {int i;if(xs==0&&ys==0&&zs==0&&ws==0)return(-1); x=xs;y=ys;z=zs;w=ws; for(i=0;i<16;i++){xor128;} return(0);}; }; //-----------------------------------------------------------------------------------
El algoritmo usado para generar una secuencia aleatoria se describe en detalle en el artículo "Xorshift RNGs" de George Marsaglia (vea el archivo xorshift.zip al final del artículo). Los métodos de la clase RNDXor128 se describen en el archivo RNDXor128.mqh. Usando esta clase podrá obtener secuencias con distribución uniforme, normal o exponencial, o con distribución Laplace (exponencial doble).
Note que, cuando se crea una instancia de la clase RNDXor128, los valores básicos de la secuencia vuelven a su estado inicial. Por tanto, en lugar de llamar a la función MathRand() en cada nueva ejecución del script o indicador que use RNDXor128, se generará una sola secuencia, al igual que al llamar MathSrand() y después MathRand().
Ejemplos de Secuencia
Debajo, como ejemplo, puede ver los resultados obtenidos al analizar secuencias que son extremadamente diferentes entre ellas con sus propiedades.
Ejemplo 1. Una Secuencia Aleatoria con la Ley de Distribución Uniforme.
#include "RNDXor128.mqh" RNDXor128 Rnd; //---------------------------------------------------------------------------- void OnStart() { int i; double dat[512]; for(i=0;i<ArraySize(dat);i++) dat[i]=Rnd.Rand_01(); ... }

Figura 4. Distribución uniforme
Ejemplo 2. Una Secuencia Aleatoria con la Ley de Distribución Normal.
#include "RNDXor128.mqh" RNDXor128 Rnd; //---------------------------------------------------------------------------- void OnStart() { int i; double dat[512]; for(i=0;i<ArraySize(dat);i++) dat[i]=Rnd.Rand_Norm(); ... }

Figura 5. Distribución normal
Ejemplo 3. Una Secuencia Aleatoria con la Ley de Distribución Exponencial.
#include "RNDXor128.mqh" RNDXor128 Rnd; //---------------------------------------------------------------------------- void OnStart() { int i; double dat[512]; for(i=0;i<ArraySize(dat);i++) dat[i]=Rnd.Rand_Exp(); ... }

Figura 6. Distribución exponencial
Ejemplo 4. Una Secuencia Aleatoria con la Ley Distribución Laplace.
#include "RNDXor128.mqh" RNDXor128 Rnd; //---------------------------------------------------------------------------- void OnStart() { int i; double dat[512]; for(i=0;i<ArraySize(dat);i++) dat[i]=Rnd.Rand_Laplace(); ... }

Figura 7. Distribución Laplace
Ejemplo 5. Secuencia Sinusoidal
//---------------------------------------------------------------------------- void OnStart() { int i; double dat[512]; for(i=0;i<ArraySize(dat);i++) dat[i]=MathSin(2*M_PI/4.37*i); ... }

Figura 8. Secuencia sinusoidal
Ejemplo 6. Una Secuencia con Correlación Visible Entre Indicaciones Adyacentes.
#include "RNDXor128.mqh" RNDXor128 Rnd; //---------------------------------------------------------------------------- void OnStart() { int i; double dat[512],a; for(i=0;i<ArraySize(dat);i++) {a+=Rnd.Rand_Laplace();dat[i]=a;} ... }

Figura 9. Correlación entre indicaciones adyacentes
Conclusión
El desarrollo de algoritmos de programa que implementan cualquier tipo de cálculos siempre es un trabajo duro. La razón es una necesidad de considerar una gran cantidad de requisitos para minimizar errores que pueden surgir al redondear, truncar y desbordar variables.
Al escribir los ejemplos para el artículo no llevé a cabo ningún análisis de algoritmos de programa. Al escribir la función, los algoritmos matemáticos se implementaron "directamente". Por tanto, si va a usarlo en aplicaciones "serias", debería analizar su estabilidad y precisión.
El artículo no describe las prestaciones de la aplicación Gnuplot. Estas preguntas van más allá del alcance de este artículo. En cualquier caso, me gustaría mencionar que Gnuplot se puede adaptar para usarse en conjunto con MetaTrader 5. Para ello deberá hacer algunas correcciones en su código fuente y recompilarlo. Además de ello, la forma de pasar comandos a Gnuplot usando un archivo seguramente no es la forma más óptima, puesto que la interacción con Gnuplot se organiza a través de un interfaz de programación.
Archivos
- erremove.mq5 – ejemplo de script que excluye errores de un muestreo.
- function_dstat.mq5 – función para el cálculo de parámetros estadísticos.
- function_dhist.mq5 - función para el cálculo de valores del histograma.
- function_drankit.mq5 – función para el cálculo de valores usados al dibujar un gráfico con la escala de distribución normal.
- s4plot.mq5 – ejemplo de script que dibuja cuatro gráficos en una sola hoja.
- RNDXor128.mqh – clase del generador de una secuencia aleatoria.
- xorshift.zip - George Marsaglia. "Xorshift RNGs".
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/273
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Utilizar Mapas con Función de Auto-Organización (Mapas Kohonen) en MetaTrader 5
Utilizar Mapas con Función de Auto-Organización (Mapas Kohonen) en MetaTrader 5
 Rastreo, Depuración y Análisis Estructural de Código Fuente
Rastreo, Depuración y Análisis Estructural de Código Fuente
 Crear Criterios Personalizados de Optimización de Asesores Expertos
Crear Criterios Personalizados de Optimización de Asesores Expertos
 Distribuciones de Probabilidad Estadística en MQL5
Distribuciones de Probabilidad Estadística en MQL5
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
"Eliminación de valores atípicos
Antes de proceder a la estimación de los parámetros estadísticos, hay que tener en cuenta que la precisión de la estimación puede ser insuficiente si la muestra contiene errores groseros (valores atípicos). El impacto de los valores atípicos en la precisión de las estimaciones es especialmente fuerte cuando el tamaño de la muestra es pequeño. Los valores atípicos son valores que se desvían de forma anómala del centro de la distribución. Tales desviaciones pueden deberse a diversos tipos de sucesos improbables y errores ocurridos durante la recogida de estadísticas y la generación de secuencias.
Es bastante difícil decidir si filtrar o no los valores atípicos, porque en la mayoría de los casos es imposible determinar sin ambigüedad si un valor dado es un valor atípico o pertenece al proceso considerado. Si se detectan valores atípicos y se decide filtrarlos, surge la pregunta de qué hacer con esos valores erróneos. Lo más lógico es simplemente excluirlos de la muestra, y la precisión de la estimación de las características estadísticas de la población general puede aumentar, pero no hay que olvidar que, cuando se trata de secuencias temporales, hay que tener cuidado al excluir muestras de la secuencia."
Es mejor no hacerlo.
Sí, todos los datos deben validarse, y sí, la validación debe automatizarse.
Pero es mejor descartar una fuente de datos que manipular los datos originales, manual o automáticamente.
En la vida real, aceptar o excluir grandes riesgos basándose en su "baja probabilidad" es la causa de muchas tragedias y catástrofes.
Victor, este es el tipo de pregunta.
¿Crees que Kurtosis puede ser inferior a 1?
Si es así.
sería igual a -1.:-)
¡Gran artículo!
Victor, este es el tipo de pregunta.
¿Crees que Kurtosis puede ser inferior a 1?
Si es así.
sería igual a -1. :-)
¡Gran artículo!
Lo más probable es que, teóricamente, la curtosis no pueda ser inferior a uno. Probablemente se obtendría un valor igual a uno para una secuencia formada por muestras rectilíneas. Por ejemplo, 1,2,3,4,5.
Si debido a errores, el algoritmo utilizado en el artículo puede dar un valor de curtosis menor que uno, no lo sé. Al final del artículo se menciona que no se ha investigado el comportamiento del algoritmo de cálculo del coeficiente.
De hecho, al calcular estimaciones insesgadas, la curtosis puede tomar un valor inferior a uno. Por ejemplo, para la secuencia de entrada 4,7,13,16.
Gracias por su observación. Voy a hacer cambios.