
Predicción de series de tiempo usando el ajuste exponencial (continuación)

Introducción
El artículo "Predicción de series de tiempo usando el ajuste exponencial" [1] proporcionó un breve resumen de los modelos de ajuste exponencial, mostrando uno de los posibles enfoques en la optimización de los parámetros del modelo y propuso el indicador de predicción desarrollado en base al modelo de crecimiento lineal con amortiguación. El artículo representa un intento de incrementar de alguna forma la precisión de este indicador de predicción.
Es complicado predecir cotizaciones de divisas o conseguir una predicción fiable incluso para tres o cuatro pasos en el futuro. No obstante, como en el artículo anterior de esta serie, realizaremos predicciones de 12 pasos hacia el futuro, dándonos cuenta claramente que será imposible obtener resultados satisfactorios sobre tan largo horizonte. Los primeros pasos de la predicción con los intervalos de confianza más reducidos son los que deben recibir mayor atención.
Una predicción con 10 a 12 pasos hacia el futuro pretende principalmente mostrar las características de comportamiento de los distintos modelos y métodos de predicción. En cualquier caso, la precisión de la predicción obtenida para cualquier horizonte puede evaluarse usando los límites del intervalo de confianza. Este artículo está destinado esencialmente a la demostración de algunos métodos que pueden ayudar a actualizar el indicador según se establece en el artículo [1].
El algoritmo para encontrar el mínimo de una función de varias variables que es aplicado al desarrollo de indicadores fue tratado en el artículo anterior y por tanto no se volverá a describir aquí. Para no sobrecargar el artículo, las entradas teóricas serán mínimas.
1. Indicador inicial
El indicador IndicatorES.mq5 (ver artículo [1]) se usará como punto de partida.
Para la compilación del indicador necesitaremos IndicatorES.mq5, CIndicatorES.mqh y PowellsMethod.mqh, todos ubicados en el mismo directorio. Los archivos se encuentran en el archivo files2.zip al final del artículo.
Vamos a recordar las ecuaciones que definen el modelo de ajuste exponencial usado al desarrollar este indicador: el modelo de crecimiento lineal con amortiguación.
![]()
![]()
![]()
Donde:
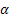 – parámetro de ajuste para el nivel de la serie, [0,1];
– parámetro de ajuste para el nivel de la serie, [0,1];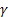 – parámetro de ajuste para la tendencia, [0,1];
– parámetro de ajuste para la tendencia, [0,1];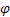 – parámetro de amortiguación, [0,1];
– parámetro de amortiguación, [0,1];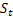 – nivel ajustado de la serie calculado en el momento t después de que
– nivel ajustado de la serie calculado en el momento t después de que 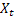 ha sido observado;
ha sido observado;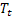 – tendencia aditiva ajustada calculada en el momento t;
– tendencia aditiva ajustada calculada en el momento t;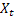 – valor de la serie en el momento t;
– valor de la serie en el momento t;
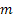 m – número de pasos en el futuro para los que se realiza la predicción;
m – número de pasos en el futuro para los que se realiza la predicción;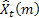 – predicción en m pasos en el futuro en el momento t;
– predicción en m pasos en el futuro en el momento t;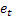 – predicción en un paso en el futuro en el momento t,
– predicción en un paso en el futuro en el momento t, 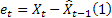 .
.
El único parámetro de entrada del indicador es el valor que determina la longitud del intervalo según el cual se optimizarán los parámetros del modelo y se elegirán los valores iniciales (intervalo de estudio). Después de la determinación de los valores óptimos de los parámetros del modelo en un intervalo determinado y de los cálculos necesarios, se genera la predicción, el intervalo de confianza y la línea correspondiente a la predicción a un paso en el futuro. Con cada nueva barra, se optimizan los parámetros y se realiza la predicción.
Como el indicador en cuestión va a ser actualizado, el efecto de los cambios que produciremos será evaluado usando las series de prueba del archivo Files2.zip que se encuentra al final del artículo. El directorio del archivo contiene los archivos con las cotizaciones guardadas EURUSD, USDCHF, USDJPY y el U.S. Dollar Index DXY. Cada uno de ellos se proporciona para los tres periodos de tiempo, siendo M1, H1 y D1. Los valores "abierto" guardados se ubican de forma que el valor más reciente esté al final del archivo. Cada archivo contiene 1.200 elementos.
Los errores de predicción se estimarán calculando el coeficiente de "Error porcentual absoluto medio" (MAPE).
![]()
Vamos a dividir cada una de las 12 series de prueba en 50 secciones superpuestas con 80 elementos cada una y calcularemos el valor MAPE para cada uno de ellos. La media de las estimaciones así obtenidas se usará como índice del error de predicción con relación a los indicadores comparados. Los valores de MAPE para los errores de predicción con dos y tres pasos en el futuro se calcularán de la misma forma. Dichas estimaciones promedio se indicarán posteriormente de la siguiente forma:
- MAPE1 – estimación promedio del error a un paso en el futuro;
- MAPE2 – estimación promedio del error a dos pasos en el futuro;
- MAPE3 – estimación promedio del error a tres pasos en el futuro;
- MAPE1-3 – media (MAPE1+MAPE2+MAPE3)/3.
Al calcular el valor MAPE, el valor del error de predicción absoluto en cada paso se divide por el valor actual de la serie. Para evitar la división por cero u obtener resultados negativos, las series de entrada deberán tomar solo valores positivos distintos a cero, como en nuestro caso.
Los valores de la estimación para nuestro indicador inicial se muestran en la Tabla 1.
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicatorES |
0,2099 |
0,2925 |
0,3564 |
0,2863 |
Tabla 1. Estimaciones del error de predicción del indicador iniciales
Los datos mostrados en la Tabla 1 se obtienen usando el script Errors_IndicatorES.mq5 (a partir del archivo files2.zip al final del artículo). Para compilar y ejecutar el script es necesario que los archivos CIndicatorES.mqh y PowellsMethod.mqh se encuentren en el mismo directorio que el archivo Errors_IndicatorES.mq5, y que las series de entrada estén en el directorio Files\Dataset2\.
Después de obtener las estimaciones iniciales de los errores de predicción, podemos proceder a actualizar el indicador en cuestión.
2. Criterio de optimización
Los parámetros del modelo en el indicador inicial tal y como se establece en el artículo "Predicción de series de tiempo usando el ajuste exponencial" se determinaron minimizando la suma de los cuadrados del error de predicción con un paso hacia el futuro. Parece lógico pensar que el óptimo de los parámetros del modelo para una predicción un paso hacia el futuro pueda no dar errores mínimos para una predicción a más pasos hacia el futuro. Sería deseable, por supuesto, minimizar errores de predicción de 10 a 12 pasos hacia el futuro, pero obtener una predicción satisfactoria sobre el rango dado para las series en cuestión sería una misión imposible.
Siendo realistas, al optimizar los parámetros del modelo, usaremos la suma de los cuadrados de los errores de predicción a uno, dos y tres pasos hacia el futuro como primera actualización de nuestro indicador. El número promedio de errores puede esperarse que sea algo inferior con respecto al rango de los primeros tres pasos de la predicción.
Claramente, dicha actualización del indicador inicial no implica a sus principios estructurales sino que solo cambia el criterio de optimización del parámetro. Por tanto, no podemos esperar que la precisión de la predicción se incremente varias veces, aunque el número de errores de predicción de dos y tres pasos hacia el futuro debería caer un poco.
Para comparar los resultados de la predicción hemos creado la clase CMod1 similar a la clase CIndicatorES presentada en el artículo anterior con la función objetivo func modificada.
La función func de la clase CIndicatorES inicial:
double CIndicatorES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 sse=0; for(i=0;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(Dlen*MathLog(k1*k2*k3*sse)); }
Después de algunas modificaciones la función func aparece ahora de la siguiente forma:
double CMod1::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95; // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*k3*err); }
Ahora, cuando calculamos la función objetivo, se utiliza la suma de los cuadrados de los errores de predicción a uno, dos y tres pasos hacia el futuro.
Además, en base a esta clase se desarrollo el script Errors_Mod1.mq5 permitiendo estimar los errores de predicción, al igual que hace el mencionado script Errors_IndicatorES.mq5. CMod1.mqh y Errors_Mod1.mq5 se encuentran en el archivo files2.zip al final del artículo.
La Tabla 2 muestra las estimaciones del error de predicción para las versiones inicial y actualizada.
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicatorES |
0,2099 |
0,2925 |
0,3564 |
0,2863 |
| Mod1 |
0,2144 |
0,2898 |
0,3486 |
0,2842 |
Tabla 2. Comparación de las estimaciones del error de predicción
Como puede verse, los coeficientes de error MAPE2 y MAPE3 y el valor medio MPA1-3 realmente resultaron ser ligeramente más bajos para las series en cuestión. Por tanto, vamos a guardar esta versión y a proceder con la modificación de nuestro indicador.
3. Adaptación de los parámetros en el proceso de ajuste
La idea de cambiar los parámetros de ajuste en función de los valores actuales de la serie de entrada no es nueva ni original y surge del deseo de adaptar los coeficientes de ajuste para que sigan siendo óptimos frente a cualquier cambio en la naturaleza de la serie de entrada. Algunas formas de adaptación de los coeficientes de ajuste se describen en la bibliografía [2] y [3].
Para actualizar más el indicador, usaremos el modelo con coeficiente de ajuste variable dinámicamente, esperando que la utilización del modelo de ajuste exponencial adaptativo nos permita incrementar la precisión de predicción de nuestro indicador.
Por desgracia, al usarlo en los algoritmos de predicción, la mayoría de los métodos adaptativos no siempre dan los resultados deseados. La elección del método adaptativo adecuado puede parecer molesto y consumir mucho tiempo. Por tanto en nuestro caso haremos uso de las experiencias disponibles en la literatura [4] e intentaremos emplear el enfoque "Ajuste exponencial de transición suave" (STES) que se describe en el artículo [5].
La esencia del enfoque se describe claramente en el artículo indicado, por lo que lo dejaremos aquí y procederemos directamente con las ecuaciones de nuestro modelo (véase el principio del artículo indicado), teniendo en cuenta el uso del coeficiente de ajuste adaptativo.
![]()
![]()
![]()
![]()
Como podemos ver ahora, el valor del coeficiente de ajuste alfa se calcula en cada paso del algoritmo y depende del error de predicción al cuadrado. Los valores de los coeficientes b y g determinan el efecto del error de predicción sobre el valor alfa. Respecto a todo lo demás, las ecuaciones para el modelo utilizado permanecen sin cambios. Puede encontrarse información adicional sobre el uso del enfoque STES en al artículo [6].
Como en las primeras versiones, tuvimos que determinar el valor óptimo del coeficiente alfa sobre la secuencia de entrada dada, ahora hay dos coeficientes adaptativos b y g que están sujetos a optimización y el valor alfa será determinado dinámicamente en el proceso de ajuste de la serie de entrada.
Esta actualización se implementa mediante la clase CMod2. Los mayores cambios afectaron principalmente a la función func que ahora es como se muestra a continuación.
double CMod2::func(const double &p[]) { int i; double s,t,alp,gam,phi,sb,sg,k1,k2,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; gam=p[2]; phi=p[3]; sb=p[4]; sg=p[5]; k1=1; k2=1; if (gam>0.95){k1+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k1+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k2+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k2+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*err); }
Al desarrollar esta función, se modificó ligeramente la ecuación que define el valor del coeficiente alfa. Esto se hizo para establecer el límite del valor permisible máximo y mínimo de este coeficiente en 0,05 y 0,95 respectivamente.
Para estimar los errores de predicción, como se hizo anteriormente, escribimos el script Errors_Mod2.mq5 basándonos en la clase CMod2. CMod2.mqh y Errors_Mod2.mq5 se encuentran en el archivo files2.zip al final del artículo.
Los resultados del script se muestran en la Tabla 3.
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicatorES |
0,2099 |
0,2925 |
0,3564 |
0,2863 |
| Mod1 |
0,2144 |
0,2898 |
0,3486 |
0,2842 |
| Mod2 |
0,2145 |
0,2832 |
0,3413 |
0,2797 |
Tabla 3. Comparación de las estimaciones del error de predicción
Como sugiere la Tabla 3, el uso del coeficiente de ajuste adaptativo sobre la media permitió disminuir ligeramente los errores de predicción para nuestra serie de prueba. De esta forma, después de dos actualizaciones, conseguimos disminuir el coeficiente de error MAPE1-3 en aproximadamente un 2%.
A pesar de un resultado de la actualización bastante modesto, seguiremos con la versión resultante y dejaremos las actualizaciones posteriores fuera del alcance de este artículo. Como paso siguiente, sería interesante intentar usar la transformación Box-Cox. Esta transformación se usa principalmente para aproximar la distribución de la serie inicial a la distribución normal.
En nuestro caso, podría utilizarse para transformar la serie inicial, computar la predicción y transformar a la inversa la predicción. El coeficiente de transformación aplicado debe elegirse de forma que se minimice el error de predicción obtenido. Un ejemplo del uso de la transformación Box-Cox en la predicción de series pueden consultarse en el artículo [7].
4. Intervalo de confianza de la predicción
El intervalo de confianza de la predicción en el indicador inicial IndicatorES.mq5 (descrito en el artículo anterior) se calculó según las expresiones analíticas derivadas del modelo de ajuste exponencial elegido. Los cambios realizados en nuestro caso han provocado cambios en el modelo considerado. El coeficiente de ajuste de la variable hace que sea inadecuado usar las expresiones analíticas mencionadas para la estimación de intervalos de confianza.
El hecho de que las expresiones analíticas usadas anteriormente se obtuvieran en base a la suposición de que la distribución del error de predicción era simétrica y normal puede constituir una razón adicional para cambiar el método de estimación del intervalo de confianza. Estos requisitos no se cumplen para nuestra clase de series y la distribución del error de predicción puede no ser normal ni simétrica.
Al estimar el intervalo de confianza en el indicador inicial, la varianza del error de predicción a un paso hacia el futuro se calculó en la primera posición en la serie de entrada, seguido por el cálculo de la varianza para una predicción de dos, tres y más pasos hacia el futuro en base al valor de la varianza del error de predicción de un paso hacia adelante obtenido usando las expresiones analíticas.
Para evitar el uso de expresiones analíticas, hay una salida simple donde la varianza para la predicción a dos, tres y más pasos hacia el futuro se calcula directamente a partir de la serie de entrada así como la varianza para una predicción a un paso hacia el futuro. Sin embargo, este enfoque tiene una desventaja significativa: en series de entrada cortas, las estimaciones del intervalo de confianza se dispersarán ampliamente y el cálculo de la varianza y el error cuadrado medio no permitirá evitar las restricciones sobre la normalidad esperada de los errores.
Una solución en este caso consiste en el uso de la inicialización (bootstrap) no paramétrica (resampling) [9]. La columna vertebral de la idea mencionada es simple: en el muestreo aleatorio (distribución uniforme) con sustitución desde la serie inicial, la distribución de la serie artificial generada será la misma que la de la inicial.
Supongamos que tenemos una serie de entrada de N miembros. Generando una serie seudo-aleatoria distribuida uniformemente sobre el rango de [0,N-1] y usando estos valores como índices al hacer el muestreo a partir de la matriz inicial, podemos generar una serie artificial de una longitud sustancialmente mayor que la de la inicial. Dicho esto, la distribución de la serie generada será la misma (o casi la misma) que la de la inicial.
El procedimiento de bootstrap para la estimación de los intervalos del coeficiente puede ser este:
- Determinamos los valores iniciales óptimos de los parámetros del modelo, sus coeficientes y coeficientes adaptativos a partir de la serie de entrada para el modelo de ajuste exponencial obtenido como resultado de la modificación. Los parámetros óptimos se determinan, como antes, usando el algoritmo que utiliza el método de búsqueda de Powell;
- Usamos los parámetros del modelo óptimo calculados, "vamos" a través de la serie inicial y formamos una matriz de errores de predicción de un paso hacia el futuro. El número de elementos de la matriz será igual a la longitud de la serie de entrada N.
- Alineamos los errores restando de cada elemento de la matriz de errores el valor medio;
- Usando el generador de serie seudo-aleatorio, generamos los índices dentro del rango de [0,N-1] y los usamos para formar una serie artificial de errores de 9.999 elementos de longitud (resampling).
- Formamos una matriz con 9.999 valores de la serie de seudo-entrada insertando los valores de la matriz de errores generada artificialmente en las ecuaciones que definen el modelo actualmente usado. En otras palabras, como previamente tuvimos que insertar los valores de la serie de entrada en las ecuaciones del modelo calculando el error de predicción, ahora ya están hechos los cálculos inversos. Para cada elemento de la matriz el valor del error se introduce para calcular el valor de entrada. Como resultado, obtenemos la matriz de 9.999 elementos con la serie con la misma distribución que la serie de entrada al tiempo que es de longitud suficiente para estimar directamente los intervalos de confianza de la predicción.
Posteriormente, estimamos los intervalos de confianza usando la serie generada de longitud adecuada. Para esta finalidad, haremos uso del hecho de que si la matriz de errores de predicción generada se ordena en orden ascendente, las celdas de la matriz con índices 149 y 9.749 para la matriz de 9.999 valores tendrán los valores correspondientes a los límites del intervalo de confianza del 95% [10].
Para conseguir una estimación más exacta de los intervalos de predicción, la longitud de la matriz debe ser impar. En nuestro caso, los límites de los intervalos de confianza de la predicción se estiman de la siguiente forma:
- Usamos los parámetros del modelo óptimo como se calculó antes, "vamos" a través de la serie inicial y formamos una matriz de 9.999 errores de predicción de un paso hacia el futuro.
- Ordenamos la matriz resultante;
- A partir de la matriz de errores ordenada seleccionamos los valores con índices 249 y 9.749 que representan los límites del intervalo de confianza del 95%.
- Repetimos los pasos 1, 2 y 3 para los errores de predicción de 3 y más pasos hacia el futuro.
Este enfoque para estimar los intervalos de confianza tiene sus ventajas y desventajas.
Entre sus ventajas se encuentra la ausencia de suposiciones en relación a la naturaleza de la distribución de los errores de la predicción. No tienen que ser normales o estar simétricamente distribuidos. Además, este enfoque puede ser útil cuando es imposible derivar analíticamente las expresiones para el modelo en uso.
Como desventaja puede citarse un incremento drástico en el alcance requerido de los cálculos y la dependencia de las estimaciones de la calidad del generador de series seudo-aleatorio usado.
El enfoque propuesto para estimar los intervalos de confianza usando el resampling y los cuantiles es bastante primitivo y debe haber formas de mejorarlo. Pero como los intervalos de confianza en nuestro caso solo pretenden una evaluación visual, la precisión que proporciona el enfoque anterior puede parecer suficiente.
5. Versión modificada del indicador
Teniendo en cuenta las actualizaciones presentadas en el artículo, se desarrolló el indicador ForecastES.mq5. Para el resampling, usamos el generador de series seudo-aleatorio propuesto antes en el artículo [11]. El generador MathRand() estándar dio unos resultados ligeramente más pobres debido, probablemente, al hecho de que el rango de valores que generó [0,32767] no fue lo suficientemente amplio.
Al compilar el indicador ForecastES.mq5 deben ubicarse en el mismo directorio que él los archivos PowellsMethod.mqh, CForeES.mqh y RNDXor128.mqh. Todos los archivos se encuentran en el archivo fore.zip.
A continuación se muestra el código fuente del indicador ForecastES.mq5.
//+------------------------------------------------------------------+ //| ForecastES.mq5 | //| Copyright 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg." #property link "https://www.mql5.com" #property version "1.02" #property description "Forecasting based on the exponential smoothing." #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" // Forecast #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "ConfUp" // Confidence interval #property indicator_type3 DRAW_LINE #property indicator_color3 clrCrimson #property indicator_style3 STYLE_DOT #property indicator_width3 1 #property indicator_label4 "ConfDn" // Confidence interval #property indicator_type4 DRAW_LINE #property indicator_color4 clrCrimson #property indicator_style4 STYLE_DOT #property indicator_width4 1 input int nHist=80; // History bars, nHist>=24 #include "CForeES.mqh" #include "RNDXor128.mqh" #define NFORE 12 #define NBOOT 9999 double Hist[],Fore[],Conf1[],Conf2[]; double Data[],Err[],BSDat[],Damp[NFORE],BSErr[NBOOT]; int NDat; CForeES Es; RNDXor128 Rnd; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { NDat=nHist; if(NDat<24)NDat=24; MqlRates rates[]; CopyRates(NULL,0,0,NDat,rates); // Load missing data ArrayResize(Data,NDat); ArrayResize(Err,NDat); ArrayResize(BSDat,NBOOT+NFORE); SetIndexBuffer(0,Hist,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,Fore,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFORE); SetIndexBuffer(2,Conf1,INDICATOR_DATA); // Confidence interval PlotIndexSetString(2,PLOT_LABEL,"ConfUp"); PlotIndexSetInteger(2,PLOT_SHIFT,NFORE); SetIndexBuffer(3,Conf2,INDICATOR_DATA); // Confidence interval PlotIndexSetString(3,PLOT_LABEL,"ConfDN"); PlotIndexSetInteger(3,PLOT_SHIFT,NFORE); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,j,k,start; double s,t,alp,gam,phi,sb,sg,e,f,a,a1,a2; if(rates_total<NDat){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated==rates_total)return(rates_total); // New tick but not new bar start=rates_total-NDat; //----------------------- PlotIndexSetInteger(0,PLOT_DRAW_BEGIN,rates_total-NDat); PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFORE); for(i=0;i<NDat;i++)Data[i]=open[rates_total-NDat+i]; // Input data Es.CalcPar(Data); // Optimization of parameters s=Es.GetPar(0); t=Es.GetPar(1); gam=Es.GetPar(2); phi=Es.GetPar(3); sb=Es.GetPar(4); sg=Es.GetPar(5); //---- a=phi; Damp[0]=phi; for(j=1;j<NFORE;j++){a=a*phi; Damp[j]=Damp[j-1]+a;} // Phi table //---- f=s+phi*t; for(i=0;i<NDat;i++) // History { e=Data[i]-f; Err[i]=e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); Hist[start+i]=f; // History } for(j=0;j<NFORE;j++)Fore[rates_total-NFORE+j]=s+Damp[j]*t; // Forecast //---- a=0; for(i=0;i<NDat;i++)a+=Err[i]; a/=NDat; for(i=0;i<NDat;i++)Err[i]-=a; // alignment of the array of errors //---- f=Es.GetPar(0)+phi*Es.GetPar(1); for(i=0;i<NBOOT+NFORE;i++) // Resampling { j=(int)(NDat*Rnd.Rand_01()); if(j>NDat-1)j=NDat-1; e=Err[j]; BSDat[i]=f+e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=s+phi*t; } //---- for(j=0;j<NFORE;j++) // Prediction intervals { s=Es.GetPar(0); t=Es.GetPar(1); f=s+phi*t; for(i=0,k=0;i<NBOOT;i++,k++) { BSErr[i]=BSDat[i+j]-(s+Damp[j]*t); e=BSDat[i]-f; a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); } ArraySort(BSErr); Conf1[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[249]; Conf2[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[9749]; } return(rates_total); } //-----------------------------------------------------------------------------------
Para poder mostrarlo mejor se ejecutó el indicador, en la medida de lo posible, como una línea recta de código . No se pretendía ninguna optimización al escribir el código.
Las Figuras 1 y 2 muestran los resultados de la operación del indicador para dos casos diferentes.

Figura 1. Primer ejemplo de operación del indicador ForecastES.mq5

Figura 2. Segundo ejemplo de operación del indicador ForecastES.mq5
La Figura 2 muestra claramente que el intervalo de confianza del 95% es asimétrico. Esto es debido al hecho de que la serie de entrada contiene un gran número de valores atípicos que originaron una distribución asimétrica de los errores de predicción.
Los sitios web anteriores www.mql4.com y www.mql5.com proporcionaron los indicadores del extrapolador. Vamos a coger uno de esos, ar_extrapolator_of_price.mq5, y a establecer sus parámetros como se muestra en la Figura 3 para comparar sus resultados con los resultados obtenidos usando el indicador que hemos desarrollado.

Figura 3. Ajustes del indicador ar_extrapolator_of_price.mq5
La operación de estos dos indicadores se comparó visualmente en los distintos periodos de tiempo para EURUSD y USDCHF. Sobre la superficie, parece que la dirección de la predicción de ambos indicadores coincide en la mayoría de casos. Sin embargo, en observaciones más prolongadas uno puede encontrarse con serias divergencias. Dicho esto, ar_extrapolator_of_price.mq5 producirá siempre una línea de predicción más quebrada.
En la Figura 4 se muestra un ejemplo de la operación simultanea de los indicadores IndicatorES.mq5 y ForecastES.mq5.

Figura 4. Comparación de los resultados de la predicción
La predicción generada por el indicador ar_extrapolator_of_price.mq5 se muestra en la Figura 4 como una línea sólida naranja-roja.
Conclusión
Resumen de los resultados relativos a este y al anterior artículo:
- Se han presentado los modelos de ajuste exponencial usados en la predicción de series de tiempo;
- Se han propuesto las soluciones de programación para la implementación de los modelos;
- Se ha dado una rápida visión de las cuestiones relacionadas con la elección de los valores iniciales óptimos y los parámetros del modelo;
- Se ha proporcionado una implementación de la programación del algoritmo para encontrar el mínimo de una función para varias variables usando el método de Powell;
- Se han mostrado las soluciones de programación para la optimización del parámetro del modelo de predicción usando la serie de entrada;
- Se mostraron algunos ejemplos simples de la actualización del algoritmo de predicción;
- Se ha descrito brevemente un método para estimar los intervalos de confianza de la predicción usando bootstrapping y cuantiles;
- Se ha desarrollado el indicador de predicción ForecastES.mq5 que contiene todos los métodos y algoritmos descritos en los artículos;
- Se proporcionan algunos enlaces a los artículos, revistas y libros sobre esta materia.
Con relación al indicador ForecastES.mq5, debe señalarse que el algoritmo de optimización que utiliza el método Powell puede en algunos casos fallar a la hora de calcular el mínimo de la función objetivo con una precisión dada. Si este es el caso, se alcanzará el número máximo permisible de iteraciones y aparecerá en el registro el correspondiente mensaje. Sin embargo, esta situación no es procesada de ninguna forma en el código del indicador que es bastante aceptable para mostrar los algoritmos descritos en el artículo. No obstante, cuando se trata de aplicaciones serias, dichas instancias deben ser supervisadas y procesadas de una u otra forma.
Para desarrollar y mejorar más el indicador de predicción, podríamos sugerir varios modelos de predicción distintos simultáneamente en cada paso con vistas a elegir posteriormente uno de ellos usando, p.ej. el criterio de información de Akaike. O en nuestro caso, usar varios modelos de similar naturaleza para calcular el valor promedio ponderado de los resultados de la predicción. Los coeficientes de ponderación en este caso pueden elegirse en función del coeficiente de error de predicción de cada modelo.
La temática de predicción de series de tiempo están amplia que por desgracia estos artículos apenas han rayado la superficie del algunas de las cuestiones relacionadas. Se espera que estas publicaciones ayuden a atraer la atención del lector en relación a las cuestiones sobre predicción y los futuros trabajos en este área.
Bibliografía
- "Predicción de series de tiempo usando el ajuste exponencial".
- Yu. P. Lukashin. Adaptive Methods for Short-Term Forecasting of Time Series: Textbook. - М.: Finansy i Statistika, 2003.-416 pp.
- S.V. Bulashev. Statistics for Traders. - М.: Kompania Sputnik +, 2003. - 245 pp.
- Everette S. Gardner Jr., Exponential Smoothing: The State of the Art – Part II. // June 3, 2005.
- James W. Taylor, Smooth Transition Exponential Smoothing. Journal of Forecasting, 2004, Vol. 23, pp. 385-394.
- James W. Taylor, Volatility Forecasting with Smooth Transition Exponential Smoothing. International Journal of Forecasting, 2004, Vol. 20, pp. 273-286.
- Alysha M De Livera. Automatic Forecasting with a Modified Exponential Smoothing State Space Framework. 28 April 2010, Department of Econometrics and Business Statistics, Monash University, VIC 3800 Australia.
- Rob J Hyndman et al. Prediction Intervals for Exponential Smoothing Using Two New Classes of State Space Models. 30 January 2003.
- The Quantile Journal. issue No. 3, September 2007.
- http://ru.wikipedia.org/wiki/Квантиль
- "Analysis of the Main Characteristics of Time Series".
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/346
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Crear asesores expertos usando el Expert Advisor Visual Wizard
Crear asesores expertos usando el Expert Advisor Visual Wizard
 Uso del análisis discriminante para desarrollar sistemas de trading
Uso del análisis discriminante para desarrollar sistemas de trading
 Trademinator 3: el auge de las máquinas de trading
Trademinator 3: el auge de las máquinas de trading
 Analizando los parámetros estadísticos de los indicadores
Analizando los parámetros estadísticos de los indicadores
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Victor, ¿no tienes ninguna modificación de indicadores con cambio de historia? No sólo para la última barra. Me gustaría estimar aproximadamente la eficiencia de los métodos que has implementado.
No, no he hecho indicadores con desplazamiento.
En el archivo ForecastES. mq5 se han corregido los errores detectados. El archivo ForecastES.m q5 actualizado se encuentra en el archivo Fore.zip como antes.
Nuevo artículo Time Series Forecasting Using Exponential Smoothing (continuación) publicado:
Autor: Victor
He intentado muchas veces buscar este nuevo indicador modificado en la sección de código base de MT5 pero no lo he encontrado.
¿Puedes por favor añadirlo en la base de código de MT5 para que pueda descargarlo fácilmente y probarlo? ¿O por favor me proporcionan el indicador modificado y cómo descargarlo en mi MT5?
¿Tiene el mismo para MT4?
Cualquiera puede ayudar por favor/
Thank you
Foro sobre negociación, sistemas automatizados de negociación y ensayo de estrategias de negociación
Discusión del artículo "Predicción de series temporales mediante suavizado exponencial"
newdigital, 2014.06.06 21:48
Cómo convertirse en un trader de Forex sin miedo
- Debes Saber Lo Que Sucederá Después?
- ¿Existe una mejor manera?
- Estrategias cuando se sabe que no se sabe
"La buena inversión es un equilibrio peculiar entre la convicción de seguir tus ideas y la flexibilidad para reconocer cuándo te has equivocado".-Michael Steinhardt
"El 95% de los errores de trading que probablemente cometa se derivarán de su actitud ante la posibilidad de equivocarse, perder dinero, fallar y dejar dinero sobre la mesa: los cuatro miedos del trading"
-Mark Douglas, Trading In the Zone
Muchos traders se enamoran de la idea de hacer previsiones. La necesidad de prever parece inherente al éxito en el trading. Después de todo, razonan, debo saber lo que va a ocurrir a continuación para ganar dinero, ¿verdad? Afortunadamente, eso no es cierto y este artículo le explicará cómo puede operar bien sin saber qué ocurrirá a continuación.
¿Debe saber qué ocurrirá a continuación?
Aunque sería útil saber qué ocurrirá a continuación, nadie puede saberlo con certeza. La razón por la que el uso de información privilegiada es un delito que a menudo se pone a prueba en los mercados de valores puede ayudarle a ver que algunos operadores están tan desesperados por conocer el futuro que están dispuestos a hacer trampas y pagar una fuerte multa cuando se les pilla. En resumen, es peligroso pensar en términos de un futuro cierto cuando su dinero está en juego y es mejor pensar en las aristas que en las certezas a la hora de realizar una operación.
El problema de pensar que debe saber lo que depara el futuro para su operación es que, cuando ocurre algo adverso para su operación respecto a sus expectativas, aparece el miedo. El miedo en sí mismo no es malo. Sin embargo, la mayoría de los operadores con su dinero en juego, a menudo se congelan y no logran cerrar la operación.
Si no necesita saber qué ocurrirá a continuación, ¿qué necesita? La lista es sorprendentemente corta y sencilla, pero lo más importante es que no crea que sabe lo que va a pasar, porque si lo hace, es probable que se apalanque en exceso y reste importancia a los riesgos que siempre están presentes en el mundo del trading.
- Una ventaja clara con la que se sienta cómodo al entrar en una operación
- Un punto de invalidación bien definido en el que la configuración de su operación deje de ser
- Un punto de entrada de reversión potencial
- Un tamaño de operación / gestión monetaria adecuados
¿Hay una forma mejor?Ayer, el Banco Central Europeo decidió recortar su tasa de refinanciamiento y su tasa de depósito. Muchos operadores entraron en corto en esta reunión, pero el EURUSD cubrió el ~250% de su rango diario ATR y cerró cerca de los máximos, lo que indica la fortaleza del EURUSD. En pocas palabras, el resultado estaba fuera del ámbito de posibilidades de la mayoría de los operadores y si usted se puso corto y fue golpeado por el miedo, es probable que no cerrara ese corto y fuera otra "víctima del mercado", que es otra forma de decir una víctima de sus propios miedos a perder.
Entonces, ¿cuál es la mejor manera? Lo crea o no, es acercarse al mercado, entendiendo lo emocionales que pueden ser los mercados y que es mejor no atarse a la dirección en la que el mercado "tiene que ir". Muchos operadores se aferran a una operación perdedora, no en beneficio de su cuenta, sino más bien para proteger su ego. Por supuesto, el mejor camino para operar es centrarse en proteger el capital de su cuenta y dejar su ego en la puerta de su sala de operaciones para que no afecte negativamente a sus operaciones.
Estrategias cuando sabe que no sabe
Hay algo en común con los operadores que pueden operar sin miedo. Construyen operaciones perdedoras en su enfoque. Es similar a un gambito de ajedrez y elimina la ventaja y el fuerte control que el miedo ejerce sobre muchos operadores. Para quienes no juegan al ajedrez, un gambito es una jugada en la que se sacrifica una pieza de poco valor, como un peón, para obtener una ventaja. En el trading, el gambito puede ser la primera operación que le permita conocer mejor la ventaja que está percibiendo en el momento de iniciar la operación.
El USD Hedge de James Stanley es un gran ejemplo de una estrategia que funciona bajo el supuesto de que una operación será perdedora. ¿Qué significa esto? Asume de antemano la pérdida y le permitirá operar sin el miedo que atormenta a tantos operadores. Otra herramienta que puede utilizar para ayudarle a definir si la tendencia se mantiene a su favor o va en su contra es un fractal.
Si mira fuera del mundo del trading y del ajedrez, hay otros negocios que suponen una pérdida y, por lo tanto, son capaces de actuar con la cabeza despejada cuando se produce una pérdida. Son los casinos y las compañías de seguros. Ambos negocios asumen una pérdida y trabajan sólo en línea con un riesgo calculado, operan libres de miedo y tú también puedes hacerlo si asumes pequeñas pérdidas como parte de tu estrategia.
Otra gran cita de Mark Douglas:
"Cuanto menos me importaba si me equivocaba o no, más claras se volvían las cosas, lo que hacía mucho más fácil entrar y salir de posiciones, acortando mis pérdidas para estar mentalmente disponible para aprovechar la siguiente oportunidad." -Mark Douglas
¡Feliz trading!
La fuente