Aprendizaje automático y Data Science (Parte 43): Detección de patrones ocultos en datos de indicadores con modelos de mezcla gaussiana latente (LGMM)

Contenido
- Introducción
- ¿Qué es un modelo de mezcla gaussiana latente?
- Las matemáticas detrás de LGMM
- Entrenamiento de LGMM en datos de indicadores
- Un indicador MQL5 basado en LGMM
- Cómo encontrar el número óptimo de componentes para LGMM
- Modelo de mezcla gaussiana latente junto con un modelo clasificador
- Robot de negociación basado en LGMM
- Conclusión
Introducción
Casi todas las estrategias de trading disponibles que utilizamos como operadores se basan en la identificación y detección de algún patrón. Analizamos indicadores en busca de patrones y confirmaciones, e incluso a veces dibujamos objetos y líneas, como líneas de soporte y resistencia, para identificar el estado del mercado.
Si bien la detección de patrones es una tarea sencilla para los humanos en los mercados financieros, resulta difícil programar y automatizar este proceso debido a la naturaleza de los mercados (ruidosos y caóticos).
Algunos operadores han adoptado el uso de la Inteligencia Artificial (IA) y el aprendizaje automático para esta tarea en particular, utilizando diversas técnicas basadas en visión artificial que procesan datos de imágenes de manera similar a como lo hacen los humanos, como lo comentamos en uno de los artículos anteriores..
En este artículo, hablaremos de un modelo probabilístico llamado Modelo de Mezcla Gaussiana Latente (LGMM, por sus siglas en inglés), que es capaz de detectar patrones. En función de los datos de los indicadores, analizaremos la eficacia de este modelo para detectar patrones ocultos y realizar predicciones precisas en los mercados financieros.

¿Qué es un modelo de mezcla gaussiana latente (LGMM)?
El modelo de mezcla gaussiana latente es un modelo probabilístico que supone que los datos se generan a partir de una mezcla de varias distribuciones gaussianas, cada una de ellas asociada a una variable latente (oculta).
Se trata de una extensión del Modelo de Mezcla Gaussiana (GMM) que incorpora variables latentes que explican la asignación de clústeres para cada observación.
Los modelos gaussianos latentes se utilizan para analizar datos cuyos procesos subyacentes que los generan no son directamente observables y se supone que tienen una distribución gaussiana (normal).
La parte "latente" se refiere a estas variables no observadas, muy parecidas a las señales eléctricas invisibles en un circuito, que influyen en el comportamiento del sistema pero que no se miden directamente.
En los mercados financieros, estas variables latentes pueden representar patrones de negociación subyacentes en los datos que a menudo malinterpretamos o pasamos por alto.
En pocas palabras, la base de LGMM consiste en:
- Variables latentes
Se trata de variables no observadas que se suponen gaussianas, y que representan factores subyacentes que afectan a los datos observados. - Observaciones
Los datos reales recopilados, que normalmente no son gaussianos y pueden seguir cualquier distribución vinculada a las variables latentes a través de una función conocida. - Parámetros
Estos parámetros rigen la relación entre las variables latentes y las observaciones, incluyendo las medias y las varianzas de las distribuciones.
Las matemáticas detrás de LGMM
LGMM es un modelo generativo probabilístico que se basa en una técnica de agrupamiento. Tiene:
Variables latentes
- Estos no se observan directamente.
- Representan el componente (grupo) del que se extrae un punto de datos.
- A menudo se modelan como una distribución categórica (discreta), por ejemplo:
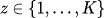
El modelo de mezcla
La distribución de probabilidad de los datos es una suma ponderada de varias distribuciones gaussianas.
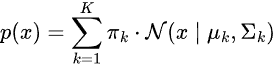
Donde:
-
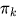 es el coeficiente de mezcla (probabilidad previa) de un componente
es el coeficiente de mezcla (probabilidad previa) de un componente 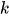 ,
, 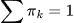
-
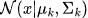 = Distribución gaussiana con media
= Distribución gaussiana con media 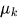 y covarianza
y covarianza 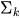
Representación de variables latentes
En lugar de modelar p(x) directamente, consideramos:
![]()
Donde:
El objetivo de este modelo es estimar las variables latentes y los parámetros ![]() .
.
El método más habitual para determinar estas variables es el algoritmo de expectativa-maximización (EM).
Método de maximización de expectativas (EM) para LGMM
Esto implica dos pasos: Expectativa y Minimización.
Paso 01, Expectativas.
Esto implica estimar la probabilidad posterior de que cada punto de datos pertenezca a cada distribución gaussiana.
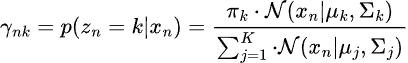
Paso 02, Maximización
Este paso consiste en actualizar los parámetros mediante el elemento ![]() .
.
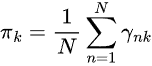
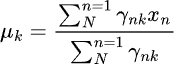
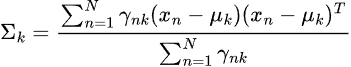
Durante el entrenamiento, se repiten tanto el paso 01 como el paso 02 hasta que el modelo converge.
LGMM se ha utilizado en diversas aplicaciones del mundo real, como la agrupación de datos con incertidumbre (agrupación suave), la detección de anomalías, la estimación de densidad y tareas relacionadas con el reconocimiento de voz.
Entrenamiento de LGMM en datos de indicadores
Sabemos que dentro de los datos de los indicadores existen patrones que, como operadores, utilizamos para tomar decisiones de inversión informadas. Nuestro objetivo es utilizar LGMM para detectar esos patrones en primer lugar.
Comenzamos recopilando datos de indicadores de MetaTrader 5 utilizando primero el lenguaje MQL5.
- Símbolo = XAUUSD.
- Periodo de tiempo = DIARIO.
Nombre del archivo: Get XAUUSD Data.mq5
#include <Arrays\ArrayString.mqh> #include <Arrays\ArrayObj.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 input datetime start_date = D'2005.01.01'; input datetime end_date = D'2023.01.01'; input string symbol = "XAUUSD"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; struct indicator_struct { long handle; CArrayString buffer_names; //buffer_names array }; indicator_struct indicators[15]; //Structure for keeping indicator handle alongside its buffer names //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector time, open, high, low, close; if (!SymbolSelect(symbol, true)) { printf("%s failed to select symbol %s, Error = %d",__FUNCTION__,symbol,GetLastError()); return; } //--- time.CopyRates(symbol, timeframe, COPY_RATES_TIME, start_date, end_date); open.CopyRates(symbol, timeframe, COPY_RATES_OPEN, start_date, end_date); high.CopyRates(symbol, timeframe, COPY_RATES_HIGH, start_date, end_date); low.CopyRates(symbol, timeframe, COPY_RATES_LOW, start_date, end_date); close.CopyRates(symbol, timeframe, COPY_RATES_CLOSE, start_date, end_date); CDataFrame df; df.insert("Time", time); df.insert("Open", open); df.insert("High", high); df.insert("Low", low); df.insert("Close", close); //--- Oscillators indicators[0].handle = iATR(symbol, timeframe, 14); indicators[0].buffer_names.Add("ATR"); indicators[1].handle = iBearsPower(symbol, timeframe, 13); indicators[1].buffer_names.Add("BearsPower"); indicators[2].handle = iBullsPower(symbol, timeframe, 13); indicators[2].buffer_names.Add("BullsPower"); indicators[3].handle = iChaikin(symbol, timeframe, 3, 10, MODE_EMA, VOLUME_TICK); indicators[3].buffer_names.Add("Chainkin"); indicators[4].handle = iCCI(symbol, timeframe, 14, PRICE_OPEN); indicators[4].buffer_names.Add("CCI"); indicators[5].handle = iDeMarker(symbol, timeframe, 14); indicators[5].buffer_names.Add("Demarker"); indicators[6].handle = iForce(symbol, timeframe, 13, MODE_SMA, VOLUME_TICK); indicators[6].buffer_names.Add("Force"); indicators[7].handle = iMACD(symbol, timeframe, 12, 26, 9, PRICE_OPEN); indicators[7].buffer_names.Add("MACD MAIN_LINE"); indicators[7].buffer_names.Add("MACD SIGNAL_LINE"); indicators[8].handle = iMomentum(symbol, timeframe, 14, PRICE_OPEN); indicators[8].buffer_names.Add("Momentum"); indicators[9].handle = iOsMA(symbol, timeframe, 12, 26, 9, PRICE_OPEN); indicators[9].buffer_names.Add("OsMA"); indicators[10].handle = iRSI(symbol, timeframe, 14, PRICE_OPEN); indicators[10].buffer_names.Add("RSI"); indicators[11].handle = iRVI(symbol, timeframe, 10); indicators[11].buffer_names.Add("RVI MAIN_LINE"); indicators[11].buffer_names.Add("RVI SIGNAL_LINE"); indicators[12].handle = iStochastic(symbol, timeframe, 5, 3,3,MODE_SMA,STO_LOWHIGH); indicators[12].buffer_names.Add("StochasticOscillator MAIN_LINE"); indicators[12].buffer_names.Add("StochasticOscillator SIGNAL_LINE"); indicators[13].handle = iTriX(symbol, timeframe, 14, PRICE_OPEN); indicators[13].buffer_names.Add("TEMA"); indicators[14].handle = iWPR(symbol, timeframe, 14); indicators[14].buffer_names.Add("WPR"); //--- Get buffers for (uint ind=0; ind<indicators.Size(); ind++) //Loop through all the indicators { for (uint buffer_no=0; buffer_no<(uint)indicators[ind].buffer_names.Total(); buffer_no++) //Their buffer names resemble their buffer numbers { string name = indicators[ind].buffer_names.At(buffer_no); //Get the name of the buffer, it is helpful for the DataFrame and CSV file vector buffer = {}; if (!buffer.CopyIndicatorBuffer(indicators[ind].handle, buffer_no, start_date, end_date)) //Copy indicator buffer { printf("func=%s line=%d | Failed to copy %s indicator buffer, Error = %d",__FUNCTION__,__LINE__,name,GetLastError()); continue; } df.insert(name, buffer); //Insert a buffer vector and its name to a dataframe object } } df.to_csv(StringFormat("Oscillators.%s.%s.csv",symbol,EnumToString(timeframe)), true); //Save all the data to a CSV file }
Resultados:
Fíjate en que hemos recopilado prácticamente todos los indicadores de oscilador integrados en MQL5, la mayoría de los cuales resultan generar datos estacionarios, ya que suelen tener valores mínimos y máximos. Por ejemplo, el indicador RSI produce valores entre 0 y 100.
A pesar de que el LGMM es capaz de trabajar con datos de diferentes propiedades estadísticas, como datos no estacionarios. Los datos estacionarios facilitan que el modelo LGMM encuentre estructuras y patrones significativos, ya que las propiedades estadísticas de los datos estacionarios permanecen constantes a lo largo del tiempo.
Puedes utilizar cualquier tipo de datos que prefieras.
Recopilamos variables de Apertura, Máximo, Mínimo, Cierre y Tiempo (OHLCT) junto con datos de indicadores para su uso en aprendizaje automático. Esta información puede utilizarse en la visualización y para definir la variable objetivo en modelos predictivos de aprendizaje automático distintos del LGMM.
Dentro de un script de Python (Jupyter Notebook), lo primero que hacemos es cargar estos datos poco después de importar las dependencias e inicializar la aplicación de escritorio MetaTrader 5.
Nombre del archivo: main.ipynb
import pandas as pd import numpy as np import MetaTrader5 as mt5 import os from Trade.TerminalInfo import CTerminalInfo import matplotlib.pyplot as plt import seaborn import warnings warnings.filterwarnings("ignore") seaborn.set_style("darkgrid") if not mt5.initialize(): print("Failed to Initialize MetaTrade5, Error = ",mt5.last_error()) mt5.shutdown() terminal = CTerminalInfo() # similarly to CTerminalInfo from MQL5. For getting information about the MetaTrader5 app
Importamos los datos desde la ruta (carpeta) común, que es donde los guardamos utilizando MQL5.
common_path = os.path.join(terminal.common_data_path(), "Files") symbol = "XAUUSD" timeframe = "PERIOD_D1" df = pd.read_csv(os.path.join(common_path, f"Oscillators.{symbol}.{timeframe}.csv")) # the same naming pattern as the one used in the MQL5 script # Identify max float value max_float = np.finfo(float).max # Replace all max float (double) values with NaN produced by preliminary indicator calculations df = df.replace(max_float, np.nan) df.dropna(inplace=True) df["Time"] = pd.to_datetime(df["Time"], unit="s") df.head()
Resultados:
Time Open High Low Close ATR BearsPower BullsPower Chainkin CCI ... MACD SIGNAL_LINE Momentum OsMA RSI RVI MAIN_LINE RVI SIGNAL_LINE StochasticOscillator MAIN_LINE StochasticOscillator SIGNAL_LINE TEMA WPR 0 2005-01-03 438.45 438.71 426.72 429.55 5.481429 -12.314215 -0.324215 -1079.046551 -51.013015 ... 0.175727 99.870165 -0.582169 46.666555 -0.082596 0.018515 26.976532 32.920132 -0.000089 -85.144357 1 2005-01-04 429.52 430.18 423.71 427.51 5.450000 -13.677899 -7.207899 -1129.324384 -235.622347 ... -0.000779 98.615544 -1.252741 37.393138 -0.158362 -0.048541 22.158658 27.150101 -0.000190 -82.774252 2 2005-01-05 427.50 428.77 425.10 426.58 5.162143 -10.743913 -7.073913 -1496.644248 -196.837418 ... -0.247283 97.044402 -1.816758 35.666584 -0.227422 -0.119850 17.070979 22.068723 -0.000325 -86.990027 3 2005-01-06 426.31 427.85 420.17 421.37 5.234286 -13.606211 -5.926211 -3349.884147 -164.038728 ... -0.576309 97.480164 -2.194161 34.651526 -0.269634 -0.187300 14.096364 17.775334 -0.000482 -95.312500 4 2005-01-07 421.39 425.48 416.57 419.02 5.605000 -15.098181 -6.188181 -4970.426959 -168.301515 ... -1.015433 95.440750 -2.669414 30.754440 -0.305796 -0.243045 11.442611 14.203318 -0.000670 -91.609589
Preparemos la variable objetivo para un problema de clasificación, para su posterior uso en modelos de aprendizaje automático de clasificación. Eliminamos las funciones que no son indicadores a lo largo del proceso.
lookahead = 1 df["future_close"] = df["Close"].shift(-lookahead) new_df = df.dropna() new_df["Direction"] = np.where(new_df["future_close"]>new_df["Close"], 1, -1) # if a the close value in the next bar(s)=lookahead is above the current close price, thats a long signal otherwise that's a short signal
from sklearn.model_selection import train_test_split X = new_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "future_close", "Direction" ]) y = new_df["Direction"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=42)
Tenemos que comprobar que disponemos de los «datos de los indicadores» que necesitamos.
X_train.head()
Resultados:
ATR BearsPower BullsPower Chainkin CCI Demarker MACD MAIN_LINE MACD SIGNAL_LINE Momentum OsMA RSI RVI MAIN_LINE RVI SIGNAL_LINE StochasticOscillator MAIN_LINE StochasticOscillator SIGNAL_LINE TEMA WPR 1057 30.139286 34.958195 62.858195 16280.794393 268.371098 251356.076923 -1.759289 -15.645899 107.768519 13.886610 62.077386 0.229591 0.108028 92.301971 83.886543 -0.002663 -8.048595 3806 3.096429 0.724299 3.314299 -1279.189840 69.806094 696.923077 -0.121217 -0.952863 100.299538 0.831645 52.157089 0.096237 0.080054 67.031250 71.466497 -0.000077 -21.325052 38884 5.927143 -8.488258 -3.858258 -2005.866698 -213.672289 -3333.080000 -0.049837 0.496440 99.774916 -0.546277 39.550361 -0.022395 0.035070 28.046540 49.606252 0.000012 -73.130342 10351 2.060714 -0.491108 1.158892 723.246254 40.384615 2508.735385 1.293179 0.953618 100.533084 0.339561 58.791715 0.217352 0.294053 57.239819 69.770534 0.000123 -19.070322 38170 5.632143 -5.682364 -3.262364 -1321.008995 -109.039933 -1673.607692 -0.609996 0.785433 99.712893 -1.395429 41.917705 -0.062258 -0.053202 13.322009 9.490964 0.000035 -77.826942
Vamos a entrenar por fin el LGMM.
from sklearn.mixture import GaussianMixture from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType components = 3 gmm = GaussianMixture(n_components=components, covariance_type="full", random_state=42) gmm.fit(X_train) latent_features_train = gmm.predict_proba(X_train) latent_features_test = gmm.predict_proba(X_test)
Estoy utilizando tres componentes para el modelo de mezcla gaussiana, con la esperanza de que permita agrupar los patrones observados en los indicadores en tres clústeres. Supuestamente, un grupo correspondería a una tendencia alcista (señal), otro a una señal bajista y el tercero a una consolidación o a una señal de oscilación lateral. De nuevo, esto no es más que una suposición.
Al igual que ocurre con otras técnicas de aprendizaje automático no supervisado y técnicas de agrupación, resulta difícil interpretar los componentes resultantes (resultados) generados por el modelo. Por ahora, solo podemos suponer que cada uno de los componentes pertenece a las tres clases que acabo de describir.
Quizá te preguntes por qué denomino al modelo Modelo de mezcla gaussiana latente (LGMM), pero al final acabo utilizando un modelo llamado GaussianMixture de Scikit-Learn?
El modelo GaussianMixture importado tiene una funcionalidad equivalente a la del LGMM, tal y como se describe en la sección de matemáticas de esta entrada. En teoría, estas dos cosas son lo mismo.
Vamos a imprimir el array latent_features_train.
latent_features_train
Resultados:
array([[9.48947877e-13, 1.08107288e-62, 1.00000000e+00], [9.71935407e-01, 2.80542130e-02, 1.03801388e-05], [5.35722226e-03, 9.94642667e-01, 1.10916653e-07], ..., [7.72441751e-08, 8.80712550e-41, 9.99999923e-01], [9.99975623e-01, 1.07924534e-33, 2.43771745e-05], [1.91968188e-01, 8.08030586e-01, 1.22621110e-06]], shape=(3760, 3))
LGMM ha generado una matriz de 3 elementos en cada fila de predicciones, donde cada columna representa la probabilidad de que los datos de entrada recibidos pertenezcan a uno de los 3 clústeres. La suma de probabilidades para las 3 columnas es igual a 1 en cada fila.
Dado que su interpretación es compleja tal como está planteada, vamos a convertir este modelo al formato ONNX, visualizar los clústeres en MQL5 y ver qué conclusiones podemos extraer de los resultados producidos por este modelo probabilístico.
Un indicador MQL5 basado en el modelo de mezcla gaussiana latente (LGMM)
Comenzamos guardando LGMM en formato ONNX.
# Define input type (shape should match your training data) initial_type = [("float_input", FloatTensorType([None, X_train.shape[1]]))] # Convert the pipeline to ONNX format onnx_model = convert_sklearn(gmm, initial_types=initial_type) # Save the model to a file with open(os.path.join(common_path, f"LGMM.{symbol}.{timeframe}.onnx"), "wb") as f: f.write(onnx_model.SerializeToString())
A continuación se muestra la arquitectura del modelo al abrirlo en Netron.
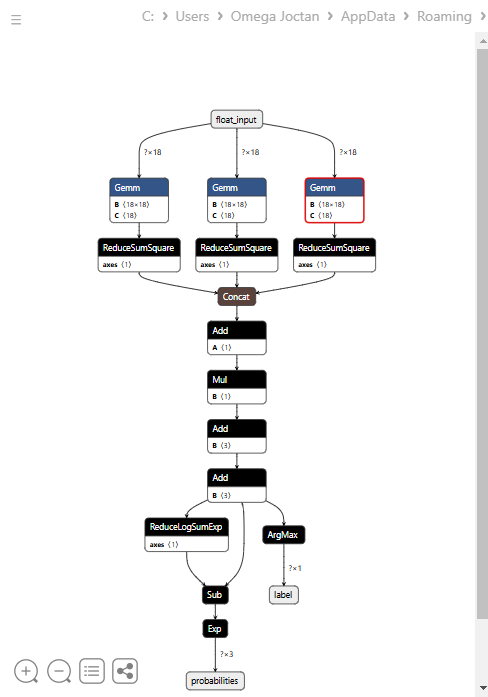
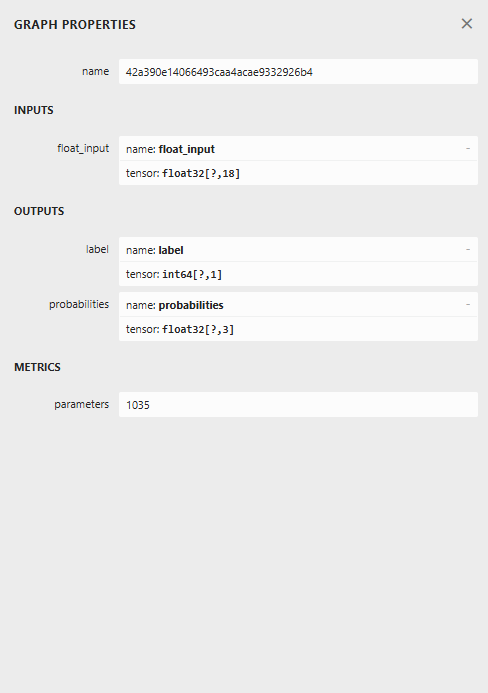
Este modelo tiene una arquitectura peculiar, con dos salidas en el nodo final: una para la etiqueta predicha y otra para las probabilidades. Debemos tener esto en cuenta a la hora de implementar el código para cargar este modelo en MQL5.
Carga de LGMM en MQL5
Nombre del archivo:Gaussian Mixture.mqh
Necesitamos una estructura de salida que admita múltiples matrices de valores para dar cabida a dos nodos de salida, cada uno con una matriz de salidas.
class CGaussianMixture { protected: bool initialized; long onnx_handle; void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info); ulong inputs[]; //Inputs of a model in dimensions [nxn] struct outputs_struct { ulong outputs[]; } model_output_structure[]; //Outputs of the model structure array
Entonces.
bool CGaussianMixture::OnnxLoad(long &handle) { //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",output_count," output(s)"); ArrayResize(model_output_structure, (int)output_count); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"output",type_info); ArrayCopy(model_output_structure[i].outputs, type_info.tensor.dimensions); } //--- Set the output shape replace(model_output_structure); if(!OnnxSetOutputShape(handle, i, model_output_structure[i].outputs)) { if (MQLInfoInteger(MQL_DEBUG)) { printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError()); DebugBreak(); } return false; } } //--- replace(inputs); //--- Setting the input size for (long i=0; i<input_count; i++) if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape { if (MQLInfoInteger(MQL_DEBUG)) printf("Failed to set the input shape Err=%d",GetLastError()); DebugBreak(); return false; } initialized = true; if (MQLInfoInteger(MQL_DEBUG)) Print("ONNX model Initialized"); return true; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CGaussianMixture::Init(string onnx_filename, uint flags=ONNX_DEFAULT) { onnx_handle = OnnxCreate(onnx_filename, flags); if (onnx_handle == INVALID_HANDLE) return false; return OnnxLoad(onnx_handle); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CGaussianMixture::Init(const uchar &onnx_buff[], ulong flags=ONNX_DEFAULT) { onnx_handle = OnnxCreateFromBuffer(onnx_buff, flags); //creating onnx handle buffer if (onnx_handle == INVALID_HANDLE) return false; return OnnxLoad(onnx_handle); }
Hemos hecho que el método «predict» de esta clase devuelva dos variables: la etiqueta predicha y un vector de probabilidades en una estructura.
struct pred_struct { vector proba; long label; };
pred_struct CGaussianMixture::predict(const vector &x) { pred_struct res; if (!this.initialized) { if (MQLInfoInteger(MQL_DEBUG)) printf("%s The model is not initialized yet to make predictions | call Init function first",__FUNCTION__); return res; } //--- vectorf x_float; //Convert inputs from a vector of double values to those float values x_float.Assign(x); vector label = vector::Zeros(model_output_structure[0].outputs[1]); //outputs[1] we get the second shape (columns) from an array vector proba = vector::Zeros(model_output_structure[1].outputs[1]); //outputs[1] we get the second shape (columns) from an array if (!OnnxRun(onnx_handle, ONNX_DATA_TYPE_FLOAT, x_float, label, proba)) //Run the model and get the predicted label and probability { if (MQLInfoInteger(MQL_DEBUG)) printf("Failed to get predictions from Onnx err %d",GetLastError()); DebugBreak(); return res; } //--- res.label = (long)label[label.Size()-1]; //Get the last item available at the label's array res.proba = proba; return res; }
Llamemos a la función «predict» dentro de la función principal de un indicador para que nos proporcione características latentes.
Nombre del archivo: LGMM Indicator.mq5
int OnCalculate(const int32_t rates_total, const int32_t prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int32_t &spread[]) { //--- Main calculation loop int lookback = 20; for (int i = prev_calculated; i < rates_total && !IsStopped(); i++) { if (i+1<lookback) //prevent data not found errors during copy buffer continue; int reverse_index = rates_total - 1 - i; //--- Get the indicators data vector x = getX(reverse_index, lookback); if (x.Size()==0) continue; pred_struct res = lgmm.predict(x); vector proba = res.proba; long label = res.label; ProbabilityBuffer[i] = proba.Max(); // Determine color based on histogram value if (label == 0) ColorBuffer[i] = 0; else if (label == 1) ColorBuffer[i] = 1; else ColorBuffer[i] = 2; Comment("bars [",i+1,"/",rates_total,"]"," Proba: ",proba," label: ",label); } //--- return(rates_total); }
Dentro de la función getX(), tenemos que recopilar todos los búferes de indicadores del mismo modo que lo hicimos en el script al recopilar los datos para el entrenamiento.
vector getX(uint start=0, uint count=10) { //--- Get buffers CDataFrame df; for (uint ind=0; ind<indicators.Size(); ind++) //Loop through all the indicators { uint buffers_total = indicators[ind].buffer_names.Total(); for (uint buffer_no=0; buffer_no<buffers_total; buffer_no++) //Their buffer names resemble their buffer numbers { string name = indicators[ind].buffer_names.At(buffer_no); //Get the name of the buffer, it is helpful for the DataFrame and CSV file vector buffer = {}; if (!buffer.CopyIndicatorBuffer(indicators[ind].handle, buffer_no, start, count)) //Copy indicator buffer { printf("func=%s line=%d | Failed to copy %s indicator buffer, Error = %d",__FUNCTION__,__LINE__,name,GetLastError()); continue; } df.insert(name, buffer); //Insert a buffer vector and its name to a dataframe object } } return df.iloc(-1); //Return the latest information from the dataframe which is the most recent buffer }
Nota: Todos los indicadores se inicializaron dentro de la función Init justo después de que el modelo se inicializara desde la carpeta común, que es donde lo guardamos utilizando Python.
#include <Gaussian Mixture.mqh> #include <Arrays\ArrayString.mqh> #include <MALE5\Pandas\pandas.mqh> CGaussianMixture lgmm; input string symbol = "XAUUSD"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; struct indicator_struct { long handle; CArrayString buffer_names; }; indicator_struct indicators[15]; //--- Indicator buffers double ProbabilityBuffer[]; double ColorBuffer[]; double MaBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- indicator buffers mapping Comment(""); // Setting indicator properties SetIndexBuffer(0, ProbabilityBuffer, INDICATOR_DATA); SetIndexBuffer(1, ColorBuffer, INDICATOR_COLOR_INDEX); // Setting histogram drawing style PlotIndexSetInteger(0, PLOT_DRAW_TYPE, DRAW_COLOR_HISTOGRAM); // Set indicator labels IndicatorSetString(INDICATOR_SHORTNAME, "3-Color Histogram"); IndicatorSetInteger(INDICATOR_DIGITS, _Digits); //--- string filename = StringFormat("LGMM.%s.%s.onnx",symbol, EnumToString(timeframe)); if (!lgmm.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s Failed to initialize the GaussianMixture model (LGMM) in ONNX format file={%s}, Error = %d",__FUNCTION__,filename,GetLastError()); } //--- Oscillators indicators[0].handle = iATR(symbol, timeframe, 14); indicators[0].buffer_names.Add("ATR"); //... //... //... indicators[14].handle = iWPR(symbol, timeframe, 14); indicators[14].buffer_names.Add("WPR"); for (uint i=0; i<indicators.Size(); i++) if (indicators[i].handle==INVALID_HANDLE) { printf("%s Invalid %s handle, Error = %d",__FUNCTION__,indicators[i].buffer_names[0],GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Por último, aplicamos este indicador al gráfico del XAUUSD y al mismo intervalo de tiempo con el que se entrenó el modelo.
Este indicador sigue siendo difícil de interpretar, pero parece haber una tendencia predominante, y es el componente que aparece en color rojo. Parece que este patrón se da cuando el mercado es volátil (la volatilidad es alta), tanto en una tendencia alcista como en una bajista. Los componentes restantes aún no están claros; esto podría deberse a que no estamos seguros del número de componentes que hemos utilizado para este modelo, así que vamos a determinar cuál es el número óptimo de componentes para este modelo.
Determinación del número óptimo de componentes para el LGMM
Dado que el modelo de mezcla que ofrece Scikit-Learn genera valores de criterios de información, como el criterio de información de Akaike (AIC) y el criterio de información bayesiano (BIC). Representemos gráficamente estos valores en función del rango de sus componentes en un único gráfico y localicemos el punto o puntos de inflexión.
El punto de inflexión en un gráfico es aquel en el que añadir más componentes al modelo solo supone una mejora marginal en el rendimiento, es decir, la curva se aplana.
Nombre del archivo: main.ipynb
lowest_bic = np.inf bic = [] aic = [] n_components_range = range(1, 10) for n_components in n_components_range: gmm = GaussianMixture(n_components=n_components, random_state=42) gmm.fit(X) bic.append(gmm.bic(X_train)) aic.append(gmm.aic(X_train)) if bic[-1] < lowest_bic: best_gmm = gmm lowest_bic = bic[-1] # Plot the BIC and AIC scores plt.figure(figsize=(8, 5)) plt.plot(n_components_range, bic, label='BIC', marker='o') plt.plot(n_components_range, aic, label='AIC', marker='o') plt.xlabel('Number of components') plt.ylabel('Score') plt.title('LGMM selection: AIC vs BIC') plt.legend() plt.grid(True) plt.show()
Resultados:

Tanto la curva AIC como la curva BIC descienden bruscamente al pasar de 1 a 2 componentes y siguen disminuyendo, pero el ritmo de mejora se ralentiza notablemente a partir del quinto componente en ambos casos. Esto significa que el número óptimo de componentes que deberíamos utilizar para este modelo es 5.
Volvamos atrás, reentrenemos el modelo y actualicemos el indicador.
Nombre del archivo: main.ipynb
components = 5 # according to the elbow point gmm = GaussianMixture(n_components=components, covariance_type="full", random_state=42) gmm.fit(X_train) latent_features_train = gmm.predict_proba(X_train) latent_features_test = gmm.predict_proba(X_test)
Ahora que tenemos 5 componentes en lugar de 3, lo que significa que el modelo produce 5 probabilidades que podemos representar, tenemos que aumentar a 5 el número de colores del indicador para el histograma coloreado y manejar 5 casos distintos para las etiquetas predichas.
Nombre del archivo: LGMM Indicator.mq5
#property indicator_color1 clrDodgerBlue, clrLimeGreen, clrCrimson, clrOrange, clrYellow
Dentro de la función OnCalculate.
int OnCalculate(const int32_t rates_total, const int32_t prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int32_t &spread[]) { //--- Main calculation loop int lookback = 20; for (int i = prev_calculated; i < rates_total && !IsStopped(); i++) { if (i+1<lookback) //prevent data not found errors during copy buffer continue; //... //... //... // Determine color based on predicted label if (label == 0) ColorBuffer[i] = 0; else if (label == 1) ColorBuffer[i] = 1; else if (label == 2) ColorBuffer[i] = 2; else if (label == 3) ColorBuffer[i] = 3; else ColorBuffer[i] = 4; Comment("bars [",i+1,"/",rates_total,"]"," Proba: ",proba," label: ",label); }
El nuevo aspecto del indicador.
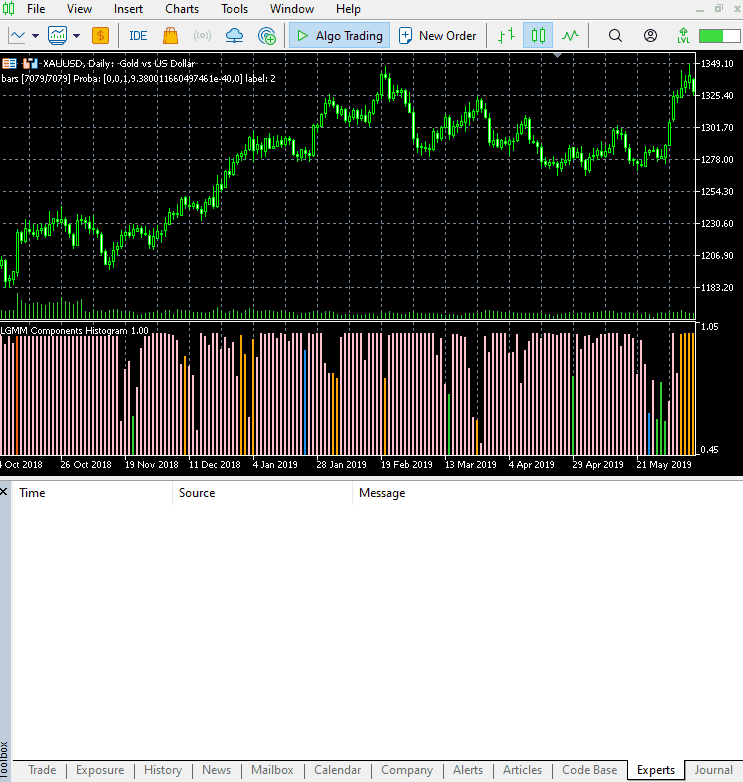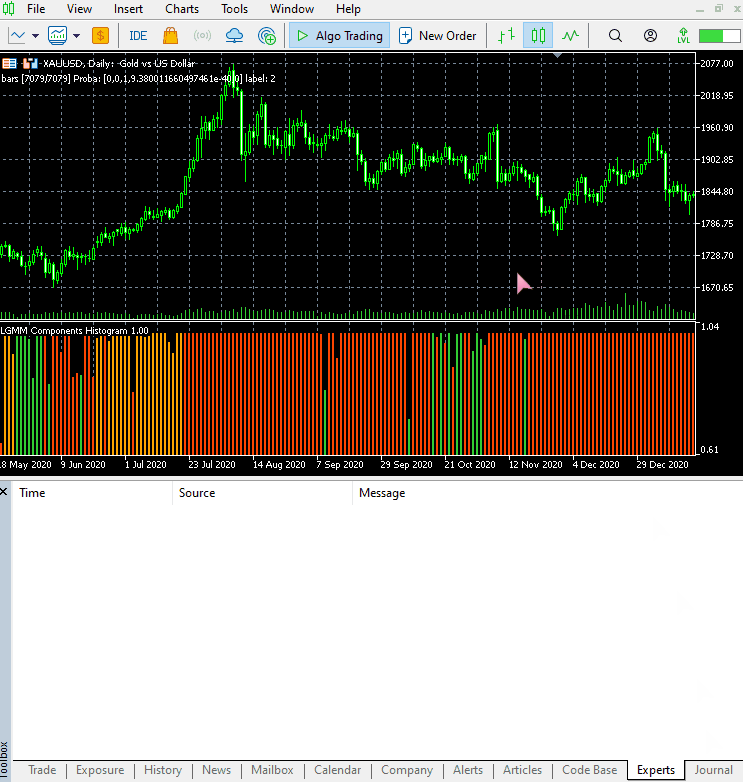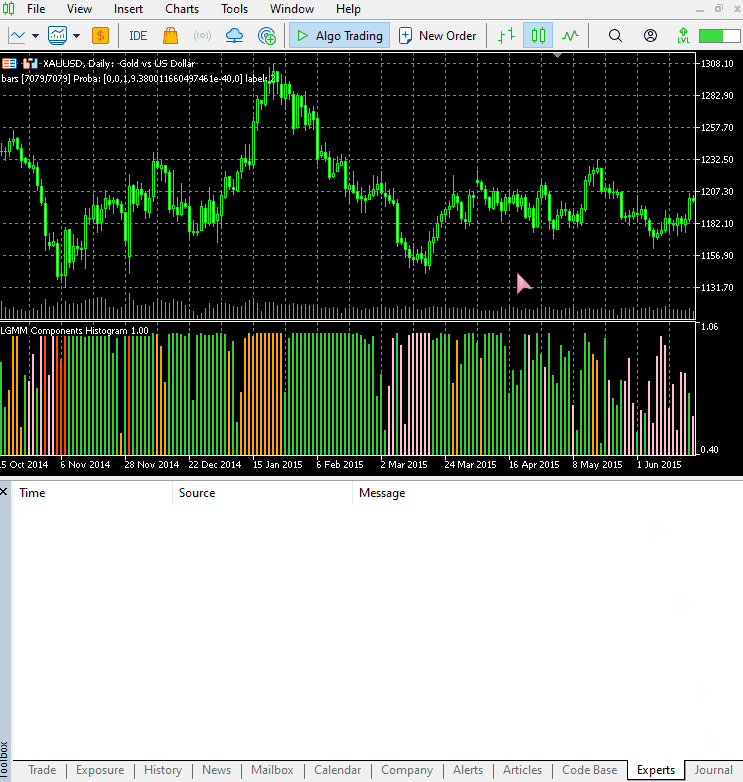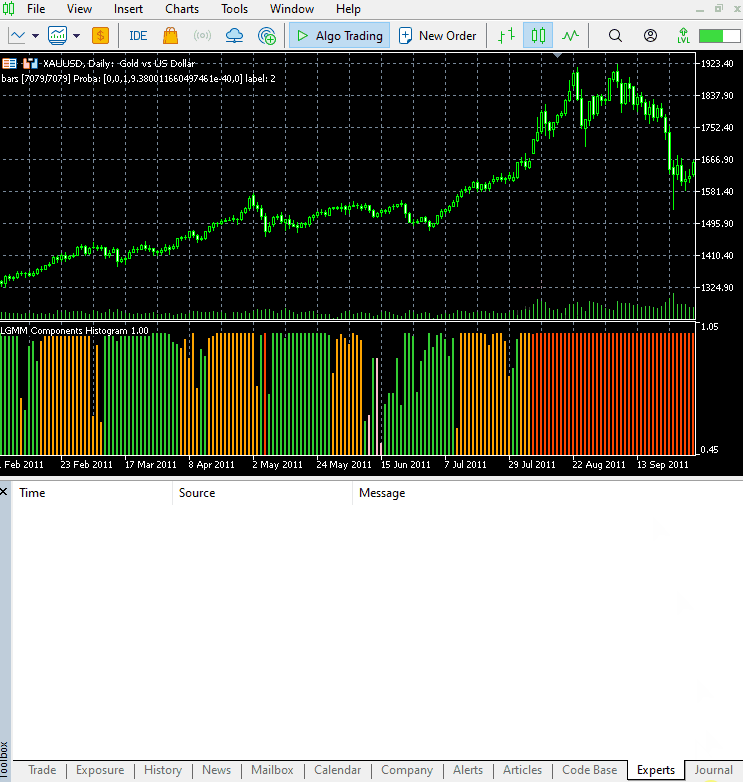
Tiene muy buena pinta, pero sigue siendo difícil de interpretar, ya que solemos estar acostumbrados a trabajar con osciladores sencillos que a menudo muestran zonas de sobreventa y sobrecompra. No dudes en explorar este indicador y compartir tus opiniones en la sección de comentarios.
Ahora, usemos el LGMM junto con un modelo de aprendizaje automático.
Modelo de mezcla gaussiana latente junto con un modelo clasificador.
Ahora hemos visto cómo podemos utilizar LGMM para generar características latentes que representan la probabilidad de que una etiqueta pertenezca a un clúster determinado, ya que resulta difícil comprender estas características. Utilicémoslas en un modelo Random forest classifier junto con las características indicadoras, con la esperanza de que este modelo de aprendizaje automático pueda determinar cómo las características latentes afectan a las señales de negociación.
Nombre del archivo: main.ipynb
Ya habíamos creado la variable objetivo anteriormente, al dividir los datos de entrenamiento y de prueba; aquí la volvemos a incluir a modo de referencia.
from sklearn.model_selection import train_test_split X = new_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "future_close", "Direction" ]) y = new_df["Direction"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=42)
Tras entrenar el LGMM, lo utilizamos para realizar predicciones sobre los datos de entrenamiento y de prueba.
latent_features_train = gmm.predict_proba(X_train) latent_features_test = gmm.predict_proba(X_test)
Dado que estos datos son difíciles de interpretar, vamos a añadirles algunos nombres de características, para que estas sean más fáciles de identificar.
latent_features_train_df = pd.DataFrame(latent_features_train, columns=[f"LATENT_FEATURE_{i}" for i in range(latent_features_train.shape[1])]) latent_features_test_df = pd.DataFrame(latent_features_test, columns=[f"LATENT_FEATURE_{i}" for i in range(latent_features_test.shape[1])])
latent_features_train_df
Resultados:
| LATENT_FEATURE_0 | LATENT_FEATURE_1 | LATENT_FEATURE_2 | LATENT_FEATURE_3 | LATENT_FEATURE_4 | |
|---|---|---|---|---|---|
| 0 | 0.000000e+00 | 5.368039e-08 | 9.999999e-01 | 1.566000e-57 | 8.541983e-37 |
| 1 | 3.316692e-124 | 8.262106e-01 | 2.931424e-06 | 1.725415e-01 | 1.244990e-03 |
| 2 | 6.572730e-49 | 7.441120e-08 | 3.481699e-08 | 9.461818e-01 | 5.381811e-02 |
| 3 | 0.000000e+00 | 1.165057e-126 | 1.413762e-05 | 4.101964e-16 | 9.999859e-01 |
| 4 | 0.000000e+00 | 4.446778e-289 | 1.000000e+00 | 1.717945e-36 | 4.234123e-21 |
Vamos a combinar estas características con los datos de los indicadores primarios.
all_columns = X_train.columns.tolist() + latent_features_train_df.columns.tolist() X_latent_train_arr = np.hstack([X_train, latent_features_train_df]) X_latent_test_arr = np.hstack([X_test, latent_features_test_df]) X_Train_latent = pd.DataFrame(X_latent_train_arr, columns=all_columns) X_Test_latent = pd.DataFrame(X_latent_test_arr, columns=all_columns) X_Train_latent.columns
Resultados:
Index(['ATR', 'BearsPower', 'BullsPower', 'Chainkin', 'CCI', 'Demarker', 'Force', 'MACD MAIN_LINE', 'MACD SIGNAL_LINE', 'Momentum', 'OsMA', 'RSI', 'RVI MAIN_LINE', 'RVI SIGNAL_LINE', 'StochasticOscillator MAIN_LINE', 'StochasticOscillator SIGNAL_LINE', 'TEMA', 'WPR', 'LATENT_FEATURE_0', 'LATENT_FEATURE_1', 'LATENT_FEATURE_2', 'LATENT_FEATURE_3', 'LATENT_FEATURE_4'], dtype='object')
Vamos a pasar estos datos combinados a un clasificador de bosque aleatorio.
from sklearn.ensemble import RandomForestClassifier from sklearn.utils.class_weight import compute_class_weight classes = np.unique(y_train) weights = compute_class_weight(class_weight='balanced', classes=classes, y=y_train) class_weights_dict = dict(zip(classes, weights)) params = { "n_estimators": 100, "min_samples_split": 2, "max_depth": 10, "max_leaf_nodes": 10, "criterion": "gini", "random_state": 42 } model = RandomForestClassifier(**params, class_weight=class_weights_dict) model.fit(X_Train_latent, y_train)
Evaluación del modelo.
y_train_pred = model.predict(X_Train_latent) print("Train classification report\n", classification_report(y_train, y_train_pred)) y_test_pred = model.predict(X_Test_latent) print("Test classification report\n", classification_report(y_test, y_test_pred))
Resultados:
Train classification report precision recall f1-score support -1 0.60 0.67 0.63 1766 1 0.68 0.61 0.64 1994 accuracy 0.64 3760 macro avg 0.64 0.64 0.64 3760 weighted avg 0.64 0.64 0.64 3760 Test classification report precision recall f1-score support -1 0.45 0.47 0.45 445 1 0.50 0.48 0.49 495 accuracy 0.47 940 macro avg 0.47 0.47 0.47 940 weighted avg 0.47 0.47 0.47 940
El modelo resultante tiene un rendimiento deficiente en la muestra de validación; hay mucho que podemos hacer para mejorarlo, pero por ahora, observemos el gráfico de importancia de las características producido por el modelo.
importances = model.feature_importances_ feature_names = X_Train_latent.columns if hasattr(X_Train_latent, 'columns') else [f'feature_{i}' for i in range(X_Train_latent.shape[1])] # Create DataFrame and sort importance_df = pd.DataFrame({'feature': all_columns, 'importance': importances}) importance_df = importance_df.sort_values('importance', ascending=False) # Plot plt.figure(figsize=(8, 6)) plt.barh(importance_df['feature'], importance_df['importance'], color='red') plt.title('RFC Feature Importance (Gini Importance)') plt.xlabel('Importance Score') plt.gca().invert_yaxis() # Most important on top plt.show()
Resultados:
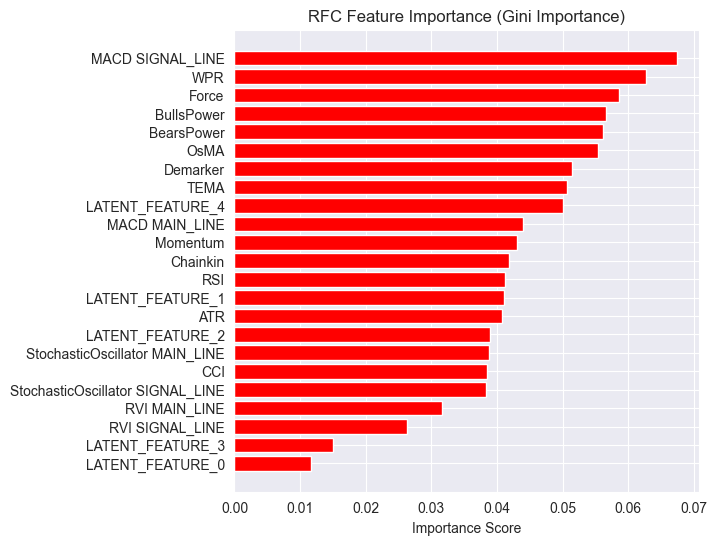
Las características latentes están demostrando ser importantes para el modelo, lo que significa que contienen ciertos patrones e información que contribuyen a las predicciones del modelo.
La razón de este modelo de bajo rendimiento podría deberse a la naturaleza de la variable objetivo utilizada. El valor de anticipación de 1 podría ser incorrecto.
Cuando utilizamos estos indicadores para tomar decisiones de inversión informadas, no solemos usarlos para predecir la siguiente vela. Por ejemplo, si el valor del RSI está por debajo del umbral de 30 (sobreventa), podemos decir que el mercado podría experimentar una tendencia alcista durante un par de barras más. No en la siguiente barra, solo como en la forma en que estamos entrenando nuestro modelo actualmente.
Así que vamos a recrear la variable objetivo usando el valor de anticipación de 5.
lookahead = 5 df["future_close"] = df["Close"].shift(-lookahead) new_df = df.dropna() new_df["Direction"] = np.where(new_df["future_close"]>new_df["Close"], 1, -1) # if a the close value in the next bar(s)=lookahead is above the current close price, thats a long signal otherwise that's a short signal
Ahora bien, evaluar el modelo tanto con los datos de entrenamiento como con los de validación produce un resultado diferente.
Train classification report precision recall f1-score support -1 0.56 0.70 0.62 1706 1 0.69 0.54 0.61 2050 accuracy 0.61 3756 macro avg 0.62 0.62 0.61 3756 weighted avg 0.63 0.61 0.61 3756 Test classification report precision recall f1-score support -1 0.46 0.61 0.52 392 1 0.63 0.48 0.55 548 accuracy 0.54 940 macro avg 0.55 0.55 0.53 940 weighted avg 0.56 0.54 0.54 940
Y un gráfico diferente que muestra la importancia de las características.
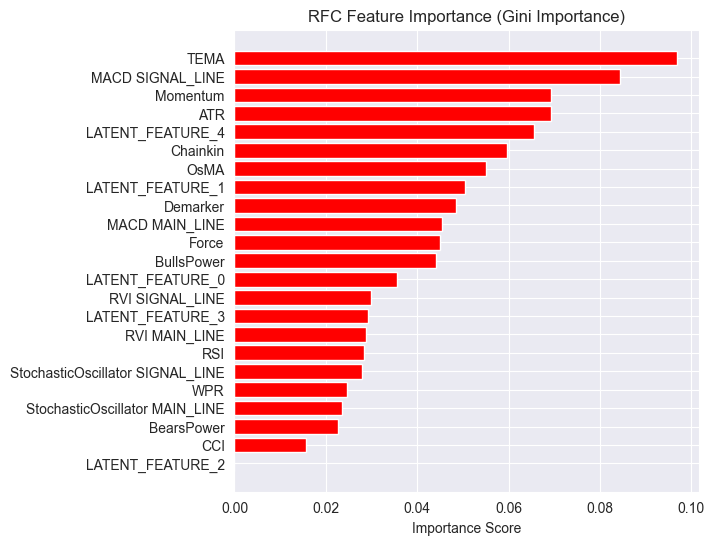
El modelo tuvo una precisión general del 54%, no es muy buena, pero sí lo suficientemente decente como para hacernos creer lo que vemos en el gráfico de importancia de las características.
Algunas de las características latentes producidas por el LGMM llegaron a estar entre las características más predictivas del modelo.
Siendo LATENT_FEATURE_4 la quinta característica importante para el clasificador de bosque aleatorio, las características latentes restantes, como LATENT_FEATURE_0 y LATENT_FEATURE_1, funcionaron bastante bien y superaron algunos indicadores brutos.
En general, la mayoría de las características producidas por LGMM presentan patrones beneficiosos para el modelo clasificador.
Con esta información, ya tienes un punto de partida para comprender el indicador.
La disposición de los colores se asemeja a los rasgos latentes.
Robot de trading basado en LGMM
Dentro del Asesor Experto (EA), comenzamos importando las bibliotecas necesarias.
Nombre del archivo: LGMM BASED EA.mq5
#include <Random Forest.mqh> #include <Arrays\ArrayString.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> #include <Trade\SymbolInfo.mqh> #include <errordescription.mqh> CSymbolInfo m_symbol; CTrade m_trade; CPositionInfo m_position; CRandomForestClassifier rfc;
Una vez más, debemos asegurarnos de utilizar el mismo símbolo y el mismo período de tiempo que se usaron en los datos de entrenamiento.
#define MAGICNUMBER 11062025 input string SYMBOL = "XAUUSD"; input ENUM_TIMEFRAMES TIMEFRAME = PERIOD_D1; input uint LOOKAHEAD = 5; input uint SLIPPAGE = 100;
Inicializamos ambos modelos, el LGMM y el clasificador de bosque aleatorio, dentro de la función OnInit.
int OnInit() { if (!MQLInfoInteger(MQL_DEBUG) && !MQLInfoInteger(MQL_TESTER)) { ChartSetSymbolPeriod(0, SYMBOL, TIMEFRAME); if (!SymbolSelect(SYMBOL, true)) { printf("%s failed to select SYMBOL %s, Error = %s",__FUNCTION__,SYMBOL,ErrorDescription(GetLastError())); return INIT_FAILED; } } //--- Loading the Gaussian Mixture model string filename = StringFormat("LGMM.%s.%s.onnx",SYMBOL, EnumToString(TIMEFRAME)); if (!lgmm.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s Failed to initialize the GaussianMixture model (LGMM) in ONNX format file={%s}, Error = %s",__FUNCTION__,filename,ErrorDescription(GetLastError())); } //--- Loading the RFC model filename = StringFormat("rfc.%s.%s.onnx",SYMBOL,EnumToString(TIMEFRAME)); Print(filename); if (!rfc.Init(filename, ONNX_COMMON_FOLDER)) { printf("func=%s line=%d, Failed to Load the RFC in ONNX file={%s}, Error = %s",__FUNCTION__,__LINE__,filename,ErrorDescription(GetLastError())); return INIT_FAILED; } //... //... other lines of code //... }
Dentro de la función getX, llamamos a LGMM para preparar las características latentes que se pueden utilizar junto con los datos de los indicadores como entradas finales del modelo clasificador «Random Forest».
vector getX(uint start=0, uint count=10) { //--- Get buffers CDataFrame df; for (uint ind=0; ind<indicators.Size(); ind++) //Loop through all the indicators { uint buffers_total = indicators[ind].buffer_names.Total(); for (uint buffer_no=0; buffer_no<buffers_total; buffer_no++) //Their buffer names resemble their buffer numbers { string name = indicators[ind].buffer_names.At(buffer_no); //Get the name of the buffer, it is helpful for the DataFrame and CSV file vector buffer = {}; if (!buffer.CopyIndicatorBuffer(indicators[ind].handle, buffer_no, start, count)) //Copy indicator buffer { printf("func=%s line=%d | Failed to copy %s indicator buffer, Error = %d",__FUNCTION__,__LINE__,name,GetLastError()); continue; } df.insert(name, buffer); //Insert a buffer vector and its name to a dataframe object } } if ((uint)df.shape()[0]==0) return vector::Zeros(0); //--- predict the latent features vector indicators_data = df.iloc(-1); //index=-1 returns the last row from the dataframe which is the most recent buffer from all indicators //--- Given the indicators let's predict the latent features vector latent_features = lgmm.predict(indicators_data).proba; if (latent_features.Size()==0) return vector::Zeros(0); return hstack(indicators_data, latent_features); //Return indicators data stacked alongside latent features }
Por último, elaboramos una estrategia de negociación sencilla que se basa en las señales de negociación generadas por el modelo clasificador de bosque aleatorio.
void OnTick() { //--- Close trades after AI predictive horizon is over CloseTradeAfterTime(MAGICNUMBER, PeriodSeconds(TIMEFRAME)*LOOKAHEAD); //--- Refresh tick information if (!m_symbol.RefreshRates()) { printf("func=%s line=%s. Failed to copy rates, Error = %s",__FUNCTION__,ErrorDescription(GetLastError())); return; } //--- vector x = getX(); //Get all the input for the model if (x.Size()==0) return; long signal = rfc.predict(x).cls; //the class predicted by the random forest classifier double proba = rfc.predict(x).proba; //probability of the predictions double volume = m_symbol.LotsMin(); if (!PosExists(POSITION_TYPE_SELL, MAGICNUMBER) && !PosExists(POSITION_TYPE_BUY, MAGICNUMBER)) //no position is open { if (signal == 1) //If a model predicts a bullish signal m_trade.Buy(volume, SYMBOL, m_symbol.Ask()); //Open a buy trade else if (signal == -1) // if a model predicts a bearish signal m_trade.Sell(volume, SYMBOL, m_symbol.Bid()); //open a sell trade } }
Cerramos las operaciones una vez que han transcurrido un número «LOOKAHEAD» de barras en el marco temporal con el que se entrenó el modelo. El valor de LOOKAHEAD debe coincidir con el utilizado para crear la variable de destino en el script de entrenamiento.
Configuraciones del probador.
Entradas.

Resultados de las pruebas
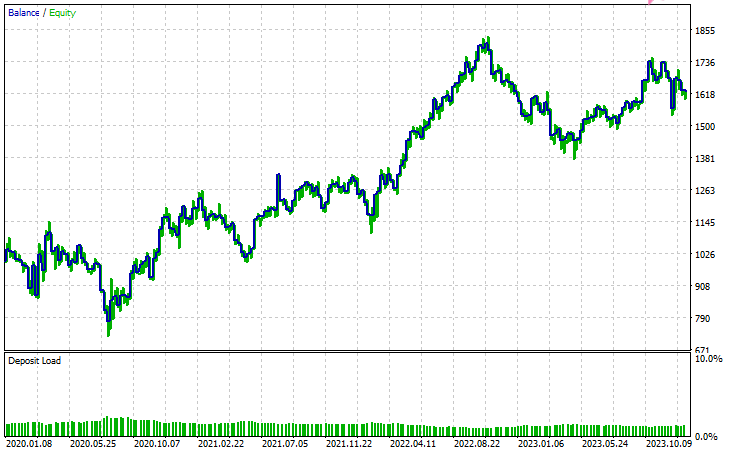
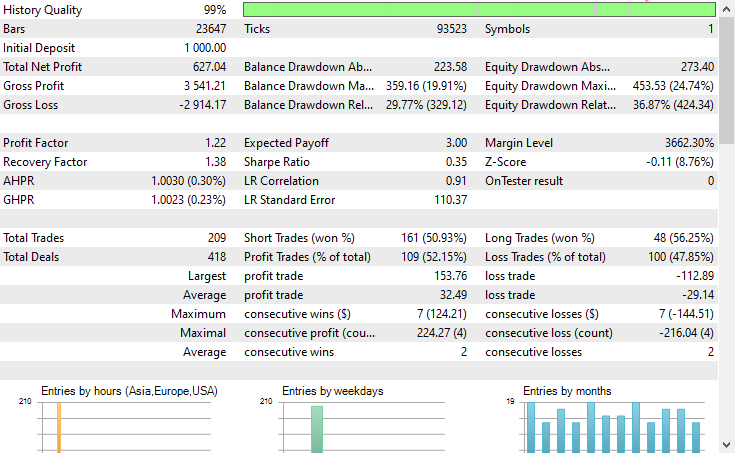
Conclusión
El modelo de mezcla gaussiana latente (LGMM) es una técnica decente que nos proporciona características significativas que comprenden patrones no observables que a menudo son útiles para los modelos de aprendizaje automático. Sin embargo, al igual que cualquier otro modelo de aprendizaje automático y técnica predictiva, tiene algunas desventajas.
Modelo de mezcla gaussiana latente (LGMM): Descripción general
| Aspecto | Descripción |
|---|---|
| ¿Qué es LGMM? | Un método para extraer características latentes (ocultas) que representan patrones no observables en los datos. Estas características pueden resultar útiles para los modelos de aprendizaje automático. |
| Ventaja principal | Captura estructuras ocultas significativas en los datos que pueden mejorar el rendimiento del modelo. |
Limitaciones del modelo LGMM
| Limitación | Explicación |
|---|---|
| Se asume una distribución gaussiana. | El modelo LGMM asume que cada punto de datos sigue una distribución normal multivariada, lo cual rara vez ocurre en los datos financieros, que tienden a ser caóticos y no lineales. |
| Sensible a la inicialización | El modelo requiere una cuidadosa selección del número de componentes. Una inicialización deficiente o una selección incorrecta de parámetros pueden reducir significativamente su eficacia. |
| Resultados difíciles de interpretar | Las características latentes que genera son difíciles de comprender o explicar. Al ser un método no supervisado, no etiqueta los patrones que detecta, solo los agrupa. |
| Sensible a los valores atípicos | Las distribuciones gaussianas no son robustas ante los valores atípicos. Unos pocos valores extremos pueden sesgar la media e inflar la varianza, distorsionando los resultados del modelo. |
Este modelo resulta muy útil para la reducción de dimensionalidad (reducir el número de características a unas pocas que sean significativas) y para introducir nuevas características que enriquezcan el modelo con información más útil. Creo que es mejor usarlo de esta manera.
Atentamente.
No te pierdas las novedades y colabora en el desarrollo de algoritmos de aprendizaje automático para el lenguaje MQL5 en este repositorio de GitHub.
Tabla de archivos adjuntos
| Nombre del archivo | Descripción y uso |
|---|---|
| Include\errordescription.mqh | Contiene la descripción de todos los códigos de error generados por MetaTrader 5 en lenguaje MQL5. |
| Include\Gaussian Mixture.mqh | Una biblioteca que contiene la clase para inicializar y desplegar el modelo de mezcla gaussiana almacenado en formato ONNX. |
| Include\pandas.mqh | Contiene una clase para el almacenamiento y la manipulación de datos similar a Pandas, que se ofrece en el lenguaje de programación Python. |
| Include\Random Forest.mqh | Una biblioteca que contiene la clase para inicializar y desplegar el clasificador de bosque aleatorio almacenado en formato ONNX. |
| Indicators\LGMM Indicator.mq5 | Un indicador para mostrar características latentes producidas por el Modelo de Mezcla Gaussiana Latente (LGMM). |
| Scripts\Get XAUUSD Data.mq5 | Un script para recopilar indicadores de osciladores junto con valores OHLCT de MetaTrader 5 y almacenarlos en un archivo CSV. |
| Experts\LGMM BASED EA.mq5 | Un Asesor Experto (EA) que abre y cierra operaciones basándose en las predicciones que ofrece el clasificador de bosque aleatorio utilizando los datos, que son la combinación de características latentes producidas por LGMM e indicadores osciladores. |
| Python Code\main.ipynb | Un cuaderno Jupyter (script de Python) para análisis de datos, entrenamiento de modelos de aprendizaje automático, etc. |
| Python Code\Trade\TerminalInfo.py | Dispone de una clase similar a CTerminalInfo, proporcionada en MQL5, para obtener información sobre la aplicación de escritorio MetaTrader 5 seleccionada. |
| Python\requirements.txt | Incluye todas las dependencias de Python y sus números de versión utilizados en este proyecto. |
| Common\Files\* | Incluye un archivo CSV de ejemplo que contiene datos de entrenamiento y un par de archivos de modelos ONNX utilizados en este artículo, solo a modo de referencia. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/18497
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Utilizando redes neuronales en MetaTrader
Utilizando redes neuronales en MetaTrader
 Particularidades del trabajo con números del tipo double en MQL4
Particularidades del trabajo con números del tipo double en MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso