
Redes neuronales en el trading: Previsión probabilística de series temporales (K2VAE)

Introducción
En los últimos años, el análisis de series temporales ha experimentado avances significativos. Ahora, las tareas de detección de anomalías, así como la clasificación y la reconstrucción de valores faltantes se resuelven con mayor precisión y rapidez. Sin embargo, para los mercados financieros, la previsión probabilística es mucho más importante: no se trata solo de predecir el precio de un activo, sino de evaluar la gama de escenarios posibles. Estas evaluaciones ayudan a los tráders y analistas a desarrollar estrategias flexibles, gestionar riesgos y tomar decisiones informadas.
Los modelos clásicos son muy eficaces para realizar pronósticos a corto plazo. Pero si analizamos con más detenimiento, los errores comienzan a acumularse, la volatilidad aumenta las imprecisiones y los costos computacionales se disparan. Especialmente en los mercados financieros, donde cada acontecimiento (un informe empresarial o una sorpresa geopolítica) puede introducir no linealidad y cambia las reglas del juego.
Como posible solución a este tipo de problema, en el artículo "K²VAE: A Koopman-Kalman Enhanced Variational AutoEncoder for Probabilistic Time Series Forecasting" se propuso un nuevo framework basado en dos ideas fundamentales. En primer lugar, la teoría de Koopman traduce los procesos no lineales a una forma lineal. Imagine mirar un gráfico de precios de acciones a través de una lente especial, y que se convierta en una línea recta: este enfoque facilita la comprensión de la dinámica. En segundo lugar, el filtro de Kalman clásico procesa cuidadosamente los nuevos datos, ajustando la previsión cada vez que llega nueva información: un informe de ganancias, un cambio en las tasas de interés o un evento inesperado.Los autores del trabajo combinaron estas ideas en el framework K²VAE, un sistema ligero y rápido basado en un autoencoder variacional. Primero, KoopmanNet impone una estructura lineal a las cotizaciones e indicadores históricos. A continuación, KalmanNet, basado en los métodos del filtro de Kalman, refina paso a paso la estimación de los posibles movimientos y su incertidumbre. Esta arquitectura permite realizar pronósticos a corto y largo plazo, manteniendo una alta precisión y estabilidad.
Principales ventajas del framework K²VAE :
- transparencia del modelo. La parte lineal proporciona a los tráders señales claras, no una caja negra;
- flexibilidad de las previsiones. Podemos obtener rápidamente escenarios para diferentes activos: pares de divisas, índices, materias primas;
- gestión de riesgos. El ajuste adaptativo del intervalo de confianza ayuda a reducir a tiempo el riesgo de grandes pérdidas.
Como resultado, K²VAE se convierte en una solución universal para pronósticos a corto y largo plazo, lo cual le permite no limitarse a un solo escenario, sino evaluar de inmediato todo el espectro de posibles movimientos del mercado. Esto mejora significativamente la eficiencia de la gestión de carteras y la fiabilidad de las estrategias comerciales automatizadas: no solo se ve una previsión puntual, sino una imagen completa de los riesgos y oportunidades potenciales.
El algoritmo K²VAE
En la dinámica de los mercados financieros, con frecuencia encontramos un aparente caos: fluctuaciones de precios, aumentos repentinos de la volatilidad, el impacto de las noticias. La teoría de Koopman ofrece una perspectiva interna: en lugar de intentar controlar la no linealidad directamente, trasladamos nuestro sistema a un espacio dimensional especial. Aquí, cada vector de estado xₖ (por ejemplo, una cesta de cotizaciones o un conjunto de indicadores económicos) se transforma mediante la función ψ en una dimensión donde la evolución se describe mediante el operador lineal 𝒦. En pocas palabras, extendemos un gráfico de precios complejo de manera que se sitúe sobre una línea recta, lo que facilita considerablemente el análisis y la previsión de la dinámica subyacente de la serie temporal. Esta técnica ayuda a separar la tendencia a largo plazo del ruido a corto plazo.
No obstante, incluso con una representación lineal, seguimos atrapados en la incertidumbre: las cotizaciones cambian cada segundo, se publican nuevos informes económicos y los bancos centrales ajustan los tipos de interés. Y aquí es donde entra en juego el filtro de Kalman. Este algoritmo funciona según un principio simple pero potente de Previsión-Ajuste: primero pronosticamos el estado actual del sistema y evaluamos nuestra confianza en el pronóstico (matriz Pₖ), y luego, tras recibir una medición real (precio, volumen comercial o indicador macroeconómico), calculamos el coeficiente de Kalman Kₖ. Con su ayuda, ajustamos la previsión inicial a la realidad y actualizamos la evaluación de la incertidumbre. Para un tráder, esto equivale a entrenar rápidamente un modelo con datos recientes: los informes de las empresas, los cambios en la liquidez o los acontecimientos geopolíticos repentinos se integran instantáneamente en la previsión, minimizando el retraso del modelo con respecto al mercado en tiempo real.
Al combinar el despliegue de sistemas lineales y el filtrado adaptativo, obtenemos una base sólida para la previsión probabilística. Pero para ir más allá de un solo escenario, debemos añadir la potencia de un autoencoder variacional. El VAE transforma el problema en una generación condicional: la entrada son datos históricos X (T últimas observaciones para N activos), la salida no es un único vector de valores futuros, sino una distribución de posibles trayectorias Y. El punto clave es la variable latente Z, responsable de los factores ocultos del mercado: correlaciones, ciclos, choques inesperados. La optimización se realiza utilizando el límite inferior de la log-verosimilitud. El primer componente penaliza el modelo por una mala generación, mientras que el segundo lo penaliza por la distribución latente que se desplaza a regiones extremas alejadas de nuestras expectativas a priori.
En el framework K²VAE, estos tres elementos (KoopmanNet, KalmanNet y VAE) no solo coexisten uno al lado del otro, sino que se complementan orgánicamente entre sí. En general, la arquitectura K²VAE se basa en un esquema claro de varias etapas, en el que cada componente es responsable de su propia etapa de transformación de los datos analizados en un modelo dinámico comprensible.
En primer lugar, el módulo Input Token Embedding divide la serie temporal original en tokens: pequeños fragmentos de la historia de precios o indicadores de liquidez. Esta técnica es similar a la forma en que un analista divide un gráfico de precios en secciones con niveles clave de soporte y resistencia: hace que los datos sean más significativos.
Luego, KoopmanNet traduce estos tokens a lo que se denomina un espacio de observación. En este caso, la compleja no linealidad de las series temporales (correlaciones entre activos, picos de volatilidad a corto plazo) se descompone en componentes lineales simples. Usando el procedimiento de aprendizaje, seleccionamos un operador de Koopman lineal que, al iterar sobre el primer token, construye un modelo de evolución. Por supuesto, no existe un espacio de medición ideal que haga que el sistema resulte completamente lineal, de ahí el sesgo en las predicciones.
Después de esto, entra en juego KalmanNet. Por analogía con el filtro de Kalman, obtiene una predicción lineal y se entrena posteriormente con nuevos datos, refinando la covarianza del estado multidimensional y formando así una distribución posterior variacional Q(Z|X) con semántica transparente. Esto es de vital importancia para las finanzas: no solo trazamos una trayectoria básica de precios, sino que evaluamos directamente el rango de sus posibles desviaciones, desde brechas repentinas hasta reversiones en respuesta a noticias importantes.
Finalmente, el decodificador realiza la función de medición inversa (ψ⁻¹), devolviendo las muestras obtenidas del espacio latente al formato habitual de series temporales. También es responsable de modelar la distribución final de P(Y|Z,X) durante el horizonte de planificación. De este modo, obtenemos un escenario listo para usar de cotizaciones futuras, y no solo una, sino muchas trayectorias probabilísticas, cada una con su propia evaluación de riesgo y confianza.
En definitiva, el K²VAE transforma los datos financieros brutos en un modelo dinámico lineal robusto con ajuste adaptativo de la incertidumbre y una generación de toda la gama de posibles movimientos del mercado. Supone una herramienta poderosa para la planificación de carteras, la evaluación de riesgos y la creación de estrategias algorítmicas sólidas.
Dividir una serie temporal en parches (patches) resulta mucho más que un truco técnico. En el análisis financiero, esto es similar a pasar de cotizaciones individuales a gráficos de velas de cinco minutos o de media hora, que muestran de inmediato tanto la tendencia como los picos clave de volatilidad. En el framework K²VAE, el preprocesamiento de datos se basa en una idea similar, pero va más allá de la arquitectura tradicional independiente de canales, donde cada canal se procesa por separado. En cambio, los autores del framework combinan todas las variables (precios de diferentes activos, volúmenes comerciales, indicadores técnicos) en un único conjunto, lo que permite que el modelo tenga en cuenta de forma natural las influencias cruzadas entre ellas.
Inicialmente, la serie temporal de contexto X, que es una matriz de N variables a lo largo de T pasos de tiempo, se divide en varios fragmentos iguales no superpuestos de longitud s. Cada uno de estos fragmentos contiene datos de los N indicadores para s puntos temporales simultáneamente, lo cual ofrece una instantánea de la situación del mercado durante un periodo determinado. Después de esto, estiramos cada fragmento en un vector de dimensión N·s y lo pasamos a través de una proyección lineal que comprime la información obtenida en una representación de incorporación compacta de tamaño d. Gracias a esta operación, el modelo no solo aprende a analizar cada segmento dentro de él, sino que también identifica automáticamente las combinaciones de variables más significativas: ya sea una correlación entre las acciones tecnológicas y las acciones de semiconductores, o aumentos sincronizados en los volúmenes comerciales en diferentes segmentos del mercado.
Esta transición casi explosiva de canales dispares a tokens multidimensionales ofrece varias ventajas a la vez. En primer lugar, el modelo capta instantáneamente los fenómenos de clusterización que se producen cuando la volatilidad o las tendencias de precios afectan a varios activos simultáneamente. En segundo lugar, se ecualizan el ruido local y la fluctuación aleatoria dentro de un mismo parche, lo cual reduce significativamente el número de señales falsas. En tercer lugar, gracias a la mayor cobertura de variables, los ciclos ocultos y los patrones a largo plazo se hacen más visibles dentro de cada token, que de otro modo podrían pasar desapercibidos o distorsionarse mediante el procesamiento independiente de canales usando un enfoque tradicional.
De este modo, el K²VAE recibe como entrada no un conjunto de características individuales, sino una sección transversal compleja de la situación del mercado para cada intervalo s, lista para su análisis. Este se convierte en el punto de partida para las etapas posteriores.
En las series temporales financieras reales, encontramos varias manifestaciones de no linealidad: las fases del ciclo de precios pueden variar entre sí, las características estadísticas cambian con la publicación de informes importantes y las noticias repentinas rompen los patrones tradicionales. Para controlar dicha complejidad, los autores del framework K²VAE aplicaron lentes de Koopman; es decir, trasladaron los tokens de una zona de fluctuaciones caóticas a un espacio donde su evolución es simple y directa.
En la práctica, se ve así. Primero, cada vector de incorporación suavizado del parche X′ᴾ se pasa a través de una MLP pequeña pero potente, que desempeña el papel de una función de medición ψ. En pocas palabras, procesamos las relaciones complejas entre precios e indicadores en un nuevo vector xᴾᵢ*, donde la dinámica subyacente se vuelve más discernible.
Tras recopilar todos esos vectores, obtenemos una matriz X*ᴾ, en la que cada fila es ya una proyección legible linealmente de un parche. Pero con solo mirar no basta. Para comprender cómo el sistema se mueve paso a paso, utilizamos el método eDMD (extended Dynamic Mode Decomposition), extrayendo el par anterior-siguiente de X*ᴾ y calculando el operador 𝒦 loc que minimiza la discrepancia entre ellos. Este se entrena a sí mismo de manera que la primera columna de X*ᴾ, multiplicada por 𝒦 loc, reproduzca la segunda con la mayor precisión posible, y así sucesivamente, hasta el final de la fila. Esta técnica permite construir localmente reglas de transición paso a paso.
Al pasar de lo local a lo global, agregamos un segundo componente entrenable 𝒦glo. Juntos forman el operador completo de Koopman 𝒦 = 𝒦 loc + 𝒦 glo. Precisamente esto nos permite no solo reconstruir fragmentos históricos, sino también mirar audazmente hacia el futuro multiplicando la primera proyección x₁ᴾ* por 𝒦ⁿ, 𝒦ⁿ⁺¹, y así sucesivamente. En este caso, los parches m = L/s en el espacio de medición se corresponden de forma única con L pasos en la serie original.
Como resultado, incluso las interacciones más complejas entre los precios de las acciones, los volúmenes comerciales y los indicadores técnicos se simplifican. El K²VAE adquiere la capacidad de generar pronósticos de forma rápida y precisa para cualquier horizonte temporal, desde los próximos minutos hasta los meses venideros. Al mismo tiempo, se mantiene la transparencia del modelo: podemos observar tanto las reglas de transición locales como las tendencias globales, mientras que el envoltorio lineal permite a los tráders y gestores de riesgos comprender cómo se forma un escenario en particular.
Una vez que KoopmanNet ha corregido las tendencias principales y reconstruido la secuencia de contexto, inevitablemente quedan pequeños errores: la diferencia entre las proyecciones de parches reales y su aproximación lineal. Los autores del framework K²VAE no ignoran estos residuos, sino que, por el contrario, los recopilan en un único flujo de información de diferencias que muestran dónde y en qué medida el modelo lineal se ha quedado corto.
![]()
Esta lista matricial de quejas tiene en cuenta cualquier evento inesperado: brechas repentinas, picos de volumen bruscos o noticias impactantes que aún no se hayan reflejado en el operador de Koopman.
Entonces, el integrador del Transformer ligero asume el papel de un sabio asesor: analiza toda esta no linealidad acumulada y la convierte en una serie de pulsos de control U = [u₁, …, uₘ]. Cada vector uₖ indica en qué dirección debe ajustarse el pronóstico en el paso k. Gracias a la capacidad del Transformer para tener en cuenta las relaciones entre diferentes momentos temporales, el modelo aprende a redistribuir la información de error y corregirla de la manera más eficiente.
Una vez recibidas las instrucciones de gestión, construiremos un modelo de proceso clásico.
![]()
Donde A es responsable de la transición básica paso a paso, B es para el efecto de impulso y wₖ agrega un toque de ruido aleatorio que refleja factores de mercado impredecibles. El estado inicial z₀ lo tomamos del último parche verdadero para que el modelo comience desde el punto más preciso.
A continuación, analizamos la previsión resultante a través del prisma del modelo de observación.
![]()
Aquí, H traduce el estado interno a un formato de predicción, mientras que vₖ agrega ruido de medición, lo que sirve como recordatorio de las imprecisiones de la parte lineal del modelo en sí. Tomaremos como observación prioritaria la previsión de KoopmanNet generada previamente para el horizonte.
El ciclo tradicional de pronóstico y ajuste permite a KalmanNet encontrar un equilibrio dinámico entre los pronósticos lineales y la información de error. Primero obtenemos una previsión previa ẑₖ y una matriz de covarianza P̂ₖ, que estima la confianza del modelo.
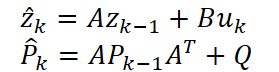
Luego, comparándolo con la observación, calculamos el coeficiente de Kalman Kₖ. Después de ello, especificamos el estado y la covarianza.
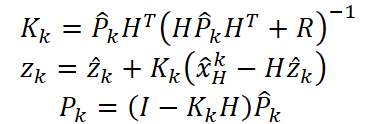
De esta manera, el modelo no solo reestructura la previsión, sino que también muestra claramente en cada paso hasta qué punto comprende el mercado y dónde todavía necesita confirmación adicional.
Para evitar la pérdida de información de errores acumulada, los autores del framework conectan los estados finales con los pulsos mediante skip‑connection.
![]()
Esto garantiza que, hasta que KoopmanNet y KalmanNet dominen todos los matices, el modelo usará toda la información disponible. A medida que avanza el aprendizaje, el valor de U tenderá a cero, lo que significa que la dinámica lineal se vuelve cada vez más autosuficiente.
Como resultado, el framework K²VAE recibe no solo una previsión de precios, sino dos evaluaciones relacionadas a la vez: el valor en sí mismo y el grado de confianza en él. Para un tráder y un gestor de riesgos, esta es una señal doble de gran valor: la previsión permite planificar las operaciones, mientras que la covarianza indica dónde se debe actuar con más cautela y dónde se pueden asumir riesgos. Este enfoque transforma el trading algorítmico, pasando de ser una carrera a ciegas por predicciones precisas a una estrategia equilibrada de gestión de riesgos.
Finalmente, vamos a pasar a la etapa final de generación de una previsión probabilística. En este punto, ya tenemos dos resultados clave: los estados latentes ajustados Z' y las matrices de covarianza P, que describen nuestra confianza en cada etapa del pronóstico. Son ellos los que definen la distribución variacional de la que extraeremos muestras aleatorias de los escenarios futuros.
![]()
Para permitir que los gradientes atraviesen una muestra aleatoria, los autores del framework utilizan un truco conocido relacionado con la reparametrización. En lugar de extraer directamente Z de N (Z',P), generan ruido normal estándar ϵ∈N(0,1) y construyen:
![]()
Donde L es una matriz triangular inferior de la descomposición P = LLᵀ. Por lo tanto, el proceso en sí es diferenciable, y los gradientes fluyen libremente desde la función de pérdida hacia los parámetros tanto de KalmanNet como de KoopmanNet.
A continuación, los autores de K²VAE devuelven los vectores latentes Z sample obtenidos al formato habitual de series temporales utilizando un decodificador: dos MLP simétricos que reflejan el codificador de Koopman original ψ. El primer MLP, que denotamos por ψ⁻¹μ, predice un vector de medias μ, y el segundo, ψ⁻¹σ, predice un vector de desviaciones estándar σ.
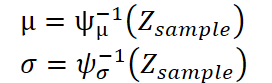
Como resultado, cada muestra recibida genera un vector de valores futuros junto con una estimación de la dispersión; es decir, vemos inmediatamente no solo la trayectoria más probable, sino también los límites del intervalo de confianza.
Para fortalecer aún más la calidad de la transformación inversa, los autores del framework también introducen ψ⁻¹μ en secuencia reconstruida X̂C.
![]()
Obtenemos XRec, a partir del cual calculamos el error de reconstrucción LRec. Esto fomenta que la función de medición ψ construya un sistema verdaderamente lineal y que el decodificador retorne con precisión los datos al espacio original de precios e indicadores.
Finalmente, reuniendo toda la información, determinamos la distribución de la previsión.
![]()
Para cada muestra, el Decodificador produce un vector μ y un vector σ, a partir de los cuales se construye una previsión probabilística completamente funcional: mediana, intervalos de confianza y escenarios extremos.
En la práctica, esto significa que un tráder o gestor de riesgos recibe de inmediato una visión completa de los posibles movimientos del mercado, desde movimientos conservadores en un rango mínimo hasta movimientos bruscos acompañados de una mayor volatilidad. Al reparar y entrenar sincrónicamente todos los componentes (KoopmanNet, KalmanNet y Decoder), K²VAE proporciona un proceso fluido y diferenciable donde cada iteración mejora no solo la precisión promedio del pronóstico, sino también la robustez de la evaluación de riesgos.
En el núcleo del entrenamiento K²VAE se encuentra un dúo de dos funciones de pérdida complementarias que juntas forman un poderoso mecanismo de auto-mejora para el modelo. El primero de ellos es el objetivo clásico ELBO (Evidence Lower Bound), donde el modelo pretende lograr dos cosas simultáneamente: asegurar que las trayectorias generadas Y sigan la distribución esperada y evitar que el espacio latente Z se aleje demasiado de nuestras probabilidades a priori.
![]()
El primer término es una penalización por la mala generación de escenarios futuros: cuanto peor reproduzca el decodificador la distribución Y a partir de las muestras Z, más nos penalizará. El segundo término es la divergencia KL entre nuestra distribución posterior variacional Q (Z|X) y la distribución previa simple cero P(Z|X)= N (0, I). Gracias a esto, conseguimos que el espacio latente no se acelere más allá de límites razonables y converja suavemente a un estado estable, donde el sistema lineal en el espacio de medición se vuelve estable.
Pero ELBO en sí mismo no garantiza que nuestro espacio de medición se comporte realmente de forma lineal. Aquí es donde entra en juego el segundo componente más importante: el error de reconstrucción.
![]()
Los autores del framework comparan la secuencia original real X con su reconstrucción XRec, transformada a través del Decodificador a partir de la cadena de salida de Koopman reconstruida. Cuanto mayor sea la precisión con la que un modelo puede devolver los datos al espacio original, más correcta y limpiamente construirá la dinámica lineal en la capa de medición. Esta función de pérdida actúa como soporte para la base del modelo, evitando que la función de medición ψ se desvíe de la trayectoria lineal.
En definitiva, el objetivo general de aprendizaje es simplemente la suma de sus dos partes.
![]()
ELBO es responsable de la correcta generación y del espacio latente ordenado, mientras que el error de reconstrucción es responsable del rigor de la aproximación lineal y de la calidad de la transformada inversa. En conjunto, permiten que K²VAE no solo aprenda a generar escenarios de mercado plausibles, sino también a formar un envoltorio lineal-dinámico legible e interpretable que sea robusto ante picos de volatilidad y aumentos inesperados del mercado. Esto proporciona a los tráders y gestores de riesgos no solo una previsión, sino una herramienta completa, transparente y fiable para la toma de decisiones.
A continuación le presentamos la visualización del framework K²VAE realizada por el autor.

Implementación con MQL5
Ahora que hemos cubierto con detalle todos los componentes clave del framework K²VAE, desde la rectificación lineal de la dinámica de KoopmanNet hasta el refinamiento adaptativo de la incertidumbre de KalmanNet y el decodificador VAE final, es hora de poner la teoría en práctica. En la parte práctica de nuestro trabajo, demostraremos sucesivamente cómo implementar cada uno de estos módulos directamente en el entorno MQL5 : desde la preparación de los datos de origen y la generación de parches hasta el entrenamiento de los parámetros del modelo y la visualización del resultado final. Esta guía práctica le permitirá implementar K²VAE paso a paso en sus propias estrategias algorítmicas, manteniendo toda la flexibilidad y transparencia de la arquitectura propuesta.
Como habrá podido observar, el núcleo de K²VAE se basa en unas pocas matrices clave: el operador de Koopman, las matrices de transición y control en KalmanNet, y las proyecciones de pesos en el codificador y el decodificador. Y a diferencia de la jerarquía habitual de Convolución → Activación → Convolución en las redes neuronales estándar, aquí se utilizan los mismos parámetros en varios puntos del proceso a la vez. Si simplemente copiáramos esta idea tal cual, tendríamos que declarar capas MLP separadas para cada paso y, por lo tanto, duplicar los pesos, lo que no solo ralentizaría y complicaría el código, sino que también distorsionaría la intención de un único operador lineal.
Por lo tanto, necesitamos hallar una solución alternativa que preserve el concepto de parámetros compartidos, pero que al mismo tiempo los integre en el mecanismo de aprendizaje existente. Y aquí vale la pena recordar el enfoque antiguo y probado al que ya hemos recurrido en otros proyectos cuando nos hemos enfrentado a la necesidad de matrices entrenables fuera de la jerarquía estándar de capas neuronales.
La idea es implementar la matriz de aprendizaje como un MLP (perceptrón multicapa) de dos capas. La primera capa ofrece un valor fijo (1,0), mientras que la segunda revela a partir de él la matriz completa de parámetros requerida. Esta ingeniosa construcción permite el uso de herramientas estándar de retropropagación y actualización de pesos incluso para parámetros no estructurales como estos.
Es decir, en esencia, estamos creando una pseudocapa cuya tarea no consiste en procesar los datos de origen, sino simplemente generar una matriz paramétrica. En una primera aproximación, es inútil desde un punto de vista computacional, pero precisamente a través de ella fluye el gradiente que entrena la segunda capa, y estas ya son nuestras matrices A, B, K, H o, digamos, ψ.
La ventaja de este enfoque es que permite mantener la compatibilidad con la estructura general del entrenamiento de redes neuronales. No necesitamos crear un mecanismo de optimización por separado ni actualizar los pesos manualmente. Todo funciona según las reglas del mecanismo estándar: pasada directa → error → distribución del gradiente → actualización de parámetros.
De este modo, incluso características especiales como los operadores de Koopman o las matrices de covarianza de KalmanNet pueden integrarse en la arquitectura con soporte completo para el aprendizaje.
Cuando un problema requiere solo una matriz parametrizada, implementar una pequeña red neuronal multicapa (MLP) dentro de un solo objeto es bastante apropiado. Simplemente añadimos un par de capas internas a la estructura, ofrecemos una constante como entrada y obtenemos la matriz deseada como salida, que luego utilizamos en los cálculos. Todo es sencillo, transparente y no requiere arquitectura adicional.
Sin embargo, en el marco de los algoritmos KoopmanNet y KalmanNet, la situación es diferente: aquí necesitamos todo un arsenal de estas matrices. Usar implementaciones separadas para cada una implica el riesgo de sobrecargar la arquitectura y perder legibilidad.
Por consiguiente, vamos a adoptar una solución más universal y escalable: es decir, a trasladar la lógica para generar matrices entrenables a una clase separada, que llamaremos CParams. Dicha clase se encarga de todo el trabajo de inicialización, almacenamiento y actualización de los pesos, así como de emitir la matriz requerida en el momento adecuado. Esto nos permite:
- gestionar parámetros de forma centralizada,
- escalar fácilmente la arquitectura al agregar nuevas matrices,
- utilizar una interfaz de generación única,
- simplifica la depuración y la visualización.
A continuación le presentamos la estructura del nuevo objeto, que incluye un marco mínimo, pero funcionalmente completo, para su integración en cualquier esquema de red neuronal.
class CParams : public CNeuronBaseOCL { protected: CNeuronBaseOCL cOne; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return FeedForward(); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return UpdateInputWeights(); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return true; } virtual bool calcHiddenGradients(CNeuronBaseOCL *NeuronOCL) override { return true; } public: CParams(void) {}; ~CParams(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) override; virtual bool Identity(const int rows, const int cols); //--- virtual bool FeedForward(void); virtual bool UpdateInputWeights(void); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defParams; } virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
La característica clave de la implementación es el uso de una entrada ficticia cOne rellena con valores individuales, que se introduce en la capa de entrenamiento. De este modo, la matriz resultante que se forma a la salida se convierte en el único objeto que contiene los parámetros necesarios y que es apto para su uso directo.
Internamente, CParams hereda de la capa de red neuronal CNeuronBaseOCL, lo que la hace totalmente compatible con el resto del framework. La lógica principal del trabajo se concentra en los métodos FeedForward y UpdateInputWeights, que se implementan llamando a los métodos homónimos heredados con entrada de cOne.
El objeto se inicializa llamando al método Init en el que se crean las interfaces necesarias y se configuran las conexiones entre los componentes.
bool CParams::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; if(!cOne.Init(numNeurons, 0, OpenCL, 1, optimization, iBatch)) return false; cOne.SetActivationFunction(None); if(!cOne.getOutput().Fill(1)) return false; //--- return true; }
Una implementación sencilla nos permite ocultar por completo todas las complejidades asociadas con la compatibilidad con pasadas directa y inversa, la optimización de parámetros y búferes en el contexto de OpenCL, dejando al usuario únicamente con una indicación declarativa de la forma y el propósito de la matriz.
El resultado final es un bloque de parámetros entrenables, escalable, reutilizable y de propósito general, adecuado para grafos de computación complejos. En otras palabras, obtenemos un análogo flexible de nn.Parameter de PyTorch, solo que en condiciones MQL5 con soporte para OpenCL.
Cabe destacar un detalle importante: las operaciones de pasada directa (FeedForward) en el objeto CParams se realizan exclusivamente durante el proceso de entrenamiento. Esto es lógico, ya que es precisamente en este punto donde la matriz de pesos debe adaptarse a los errores del modelo y ajustarse para tener en cuenta la propagación inversa.
bool CParams::FeedForward(void) { if(!bTrain) return true; //--- return CNeuronBaseOCL::feedForward(cOne.AsObject()); }
Sin embargo, en el modo de inferencia, es decir, cuando se utiliza un modelo entrenado para la previsión o la toma de decisiones, no es necesario recalcular la matriz. La matriz obtenida mediante el entrenamiento se convierte en un parámetro estático: ya no cambia y no requiere operaciones adicionales, especialmente llamadas a kernels de OpenCL que consumen muchos recursos.
De este modo, al pasar al modo real, fijaremos los parámetros y podremos desactivar de forma segura la pasada directa, evitando así cálculos innecesarios al sistema. Esto reduce la carga sobre los recursos informáticos, acelera el funcionamiento del modelo y aumenta su estabilidad.
Este enfoque es un ejemplo clásico de separación de fases computacionales, donde el entrenamiento y el uso están estrictamente separados por la lógica y la carga. Esto hace que la arquitectura no solo sea más comprensible y flexible, sino también más predecible en su funcionamiento, lo que resulta especialmente importante en sistemas en tiempo real.
El código completo del objeto CParams y todos sus métodos se proporciona en el archivo adjunto.
Ya hemos realizado una cantidad ingente de trabajo: hemos abarcado los fundamentos teóricos del framework K²VAE, hemos examinado sus módulos clave con detalle e incluso hemos implementado el objeto CParams, un generador de matrices parametrizadas universal, indispensable en la arquitectura del modelo. Ahora nos enfrentamos a un reto mayor: construir una lógica clara y coherente para todo el framework, donde cada detalle sea un componente importante en un mecanismo que funcione a la perfección.
Pero no hay necesidad de apresurarse. Para configurar un sistema de este tipo se requiere una mente despejada, atención al detalle y una perspectiva novedosa. Por eso, nos tomaremos un descanso hasta el próximo artículo y regresaremos con energías renovadas e inspiración fresca.
Conclusión
En este artículo, hemos presentado el potente y prometedor framework K²VAE, que combina las ventajas de la dinámica lineal, la inferencia variacional y el filtrado entrenable. Su principal fortaleza reside en su capacidad para aproximar linealmente procesos no lineales complejos en un espacio de medición latente, al tiempo que se mantiene robusta frente al ruido y las desviaciones sistémicas. Esto proporciona no solo un modelo, sino una herramienta con un alto grado de interpretabilidad, flexibilidad y precisión, especialmente relevante para el análisis de series temporales y la previsión de la dinámica del mercado.
Apenas hemos comenzado a desentrañar la intrincada red de ideas que sustentan el framework K²VAE. En este artículo hemos dado los primeros pasos, desde los fundamentos teóricos hasta la implementación de componentes clave como las matrices parametrizadas y la clase universal CParams, que ha asumido toda la responsabilidad de gestionar los pesos fuera de la arquitectura estándar de la red neuronal. Esto se ha convertido en un paso importante en la preparación para la construcción de la lógica completa del modelo.
Sin embargo, aún queda mucho trabajo por hacer. Tenemos que combinar elementos dispares en un único sistema coherente: implementar mecanismos de filtrado, organizar la dinámica probabilística en el espacio latente y ensamblar la arquitectura del Codificador, el Integrador, la red de Kalman y el Decodificador en un todo único. La tarea no es fácil, pero precisamente esto permitirá que el modelo se convierta en un sistema de toma de decisiones verdaderamente inteligente.
No estamos resumiendo los resultados; simplemente estamos describiendo la trayectoria. El desarrollo principal de los acontecimientos aún está por llegar. Por lo tanto, será lógico tomar un breve descanso para continuar el viaje en la siguiente etapa con fuerzas renovadas.
Enlaces
- K²VAE: A Koopman-Kalman Enhanced Variational AutoEncoder for Probabilistic Time Series Forecasting
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 2 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18734
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso