Artikel über Datenanalyse und Statistik in MQL5
Artikel über mathematische Modelle und die Gesetze der Wahrscheinlichkeit können für viele Börsenhändler interessant sein. Denn Mathematik liegt technischer Indikatoren zugrunde, und Kenntnisse in Statistik braucht man, um die Ergebnisse des Handels zu analysieren und Strategien zu entwickeln.
Lesen Sie über die Fuzzylogik, digitale Filter, Marktprofil, Kohonenkarten, neuronales Gas und andere Werkzeuge, die man für den Handel verwenden kann.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Vom Neuling zum Experten: Synchronisieren der Zeitrahmen des Marktes
In dieser Diskussion stellen wir ein Synchronisierungsinstrument der Zeitrahmen von länger zu kürzer vor, das das Problem der Analyse von Marktmustern lösen soll, die sich über höhere Zeitrahmen bilden. Die eingebauten Periodenmarker in MetaTrader 5 sind oft begrenzt, starr und lassen sich nicht ohne weiteres an nicht standardisierte Zeitrahmen anpassen. Unsere Lösung nutzt die MQL5-Sprache, um einen Indikator zu entwickeln, der eine dynamische und visuelle Möglichkeit bietet, Strukturen mit höherem Zeitrahmen in Charts mit niedrigerem Zeitrahmen auszurichten. Dieses Instrument kann für eine detaillierte Marktanalyse sehr wertvoll sein. Um mehr über die Funktionen und die Umsetzung zu erfahren, lade ich Sie ein, sich an der Diskussion zu beteiligen.

Statistische Arbitrage durch kointegrierte Aktien (Teil 6): Bewertungssystem
In diesem Artikel schlagen wir ein Bewertungssystem für die Strategien der Rückkehr zum Mittelwert vor, das auf der statistischen Arbitrage von kointegrierten Aktien basiert. In dem Artikel werden Kriterien vorgeschlagen, die von der Liquidität und den Transaktionskosten bis zur Anzahl der Kointegrationsränge und der Zeit bis zur Umkehrung des Mittelwerts reichen, wobei die strategischen Kriterien der Datenhäufigkeit (Zeitrahmen) und des Rückblickzeitraums für die Kointegrationstests berücksichtigt werden, die vor der Bewertung der Rangfolge richtig bewertet werden. Die für die Reproduktion des Backtests erforderlichen Dateien werden zur Verfügung gestellt, und ihre Ergebnisse werden ebenfalls kommentiert.

Statistische Arbitrage durch kointegrierte Aktien (Teil 5): Screening
In diesem Artikel wird ein Verfahren zum Screening von Vermögenswerten für eine statistische Arbitragestrategie durch kointegrierte Aktien vorgeschlagen. Das System beginnt mit der regulären Filterung nach wirtschaftlichen Faktoren, wie z. B. Vermögensbereich und Branche, und endet mit einer Liste von Kriterien für ein Scoring-System. Für jeden statistischen Test, der beim Screening verwendet wurde, wurde eine entsprechende Python-Klasse entwickelt: Pearson-Korrelation, Engle-Granger-Kointegration, Johansen-Kointegration und ADF/KPSS-Stationarität. Diese Python-Klassen werden zusammen mit einer persönlichen Anmerkung des Autors über den Einsatz von KI-Assistenten für die Softwareentwicklung bereitgestellt.

Vom Neuling zum Experten: Entmystifizierung versteckter Fibonacci-Retracement-Levels
In diesem Artikel untersuchen wir einen datengestützten Ansatz zur Ermittlung und Validierung von nicht standardmäßigen Fibonacci-Retracement-Levels, die von den Märkten möglicherweise respektiert werden. Wir stellen einen kompletten Arbeitsablauf vor, der auf die Implementierung in MQL5 zugeschnitten ist, beginnend mit der Datenerfassung und der Balken- oder Swing-Erkennung, bis hin zum Clustering, statistischen Hypothesentests, Backtesting und der Integration in ein MetaTrader 5 Fibonacci-Tool. Das Ziel ist es, eine reproduzierbare Pipeline zu erstellen, die anekdotische Beobachtungen in statistisch vertretbare Handelssignale umwandelt.

Entwicklung des Price Action Analysis Toolkit (Teil 46): Entwicklung eines interaktiven Fibonacci Retracement EA mit intelligenter Visualisierung in MQL5
Die Fibonacci-Instrumente gehören zu den beliebtesten Instrumenten der technischen Analysten. In diesem Artikel erstellen wir einen interaktiven Fibonacci-EA, der Retracement- und Extension-Ebenen zeichnet, die dynamisch auf Kursbewegungen reagieren und Echtzeitwarnungen, stilvolle Linien und eine scrollende Schlagzeile im Nachrichtenstil liefern. Ein weiterer wichtiger Vorteil dieses EAs ist die Flexibilität: Sie können die Werte für den höchsten (A) und den niedrigsten (B) Umkehrpunkt direkt im Chart manuell eingeben und haben so die genaue Kontrolle über den Marktbereich, den Sie analysieren möchten.
Entwicklung des Price Action Analysis Toolkit (Teil 47): Verfolgen von Forex-Sitzungen und Ausbrüchen in MetaTrader 5
Globale Marktsitzungen prägen den Rhythmus des Handelstages, und die Kenntnis ihrer Überschneidungen ist entscheidend für das Timing von Ein- und Ausstiegen. In diesem Artikel werden wir einen interaktiven EA für Handelssitzungen erstellen, der diese globalen Stunden direkt auf Ihrem Chart zum Leben erweckt. Der EA zeichnet automatisch farbcodierte Rechtecke für die Sitzungen in Asien, Tokio, London und New York, die in Echtzeit aktualisiert werden, sobald der jeweilige Markt eröffnet oder geschlossen wird. Sie verfügt über Schaltflächen auf dem Chart, ein dynamisches Informationspanel und eine Laufschrift, die Status- und Ausbruchsmeldungen live überträgt. Dieser bei verschiedenen Brokern getestete EA kombiniert Präzision mit Stil und hilft Händlern, Volatilitätsübergänge zu erkennen, sitzungsübergreifende Ausbrüche zu identifizieren und visuell mit dem Puls des globalen Marktes verbunden zu bleiben.

Bivariate Copulae in MQL5 (Teil 1): Implementierung von Gauß- und Studentische t-Copulae für die Modellierung von Abhängigkeiten
Dies ist der erste Teil einer Artikelserie, in der die Implementierung von bivariaten Copulae in MQL5 vorgestellt wird. Dieser Artikel enthält Code zur Implementierung der Gauß‘schen und Studentischen t-Copulae. Außerdem werden die Grundlagen der statistischen Copulae und verwandte Themen behandelt. Der Code basiert auf dem Python-Paket Arbitragelab von Hudson und Thames.

Entwicklung des Price Action Analysis Toolkit (Teil 44): Aufbau eines VWMA Crossover Signal EA in MQL5
In diesem Artikel wird ein VWMA-Crossover-Signal für den MetaTrader 5 vorgestellt, das Händlern helfen soll, potenzielle Aufwärts- und Abwärtsbewegungen zu erkennen, indem es Preisbewegungen mit dem Handelsvolumen kombiniert. Der EA generiert klare Kauf- und Verkaufssignale direkt auf dem Chart, verfügt über ein informatives Panel und lässt sich vollständig an den Nutzer anpassen, was ihn zu einer praktischen Ergänzung Ihrer Handelsstrategie macht.

Entwicklung des Price Action Analysis Toolkit (Teil 45): Erstellen eines dynamischen Level-Analyse-Panels in MQL5
In diesem Artikel stellen wir Ihnen ein leistungsstarkes MQL5-Tool vor, mit dem Sie jedes gewünschte Preisniveau mit nur einem Klick testen können. Geben Sie einfach das von Ihnen gewählte Niveau ein und drücken Sie auf „Analyze“. Der EA scannt sofort die historischen Daten, hebt jede Berührung und jeden Durchbruch im Chart hervor und zeigt die Statistiken in einem übersichtlichen Dashboard an. Sie werden genau sehen, wie oft der Kurs Ihr Niveau respektiert oder durchbrochen hat und ob es sich eher wie eine Unterstützung oder ein Widerstand verhielt. Lesen Sie weiter, um das genaue Verfahren zu erfahren.
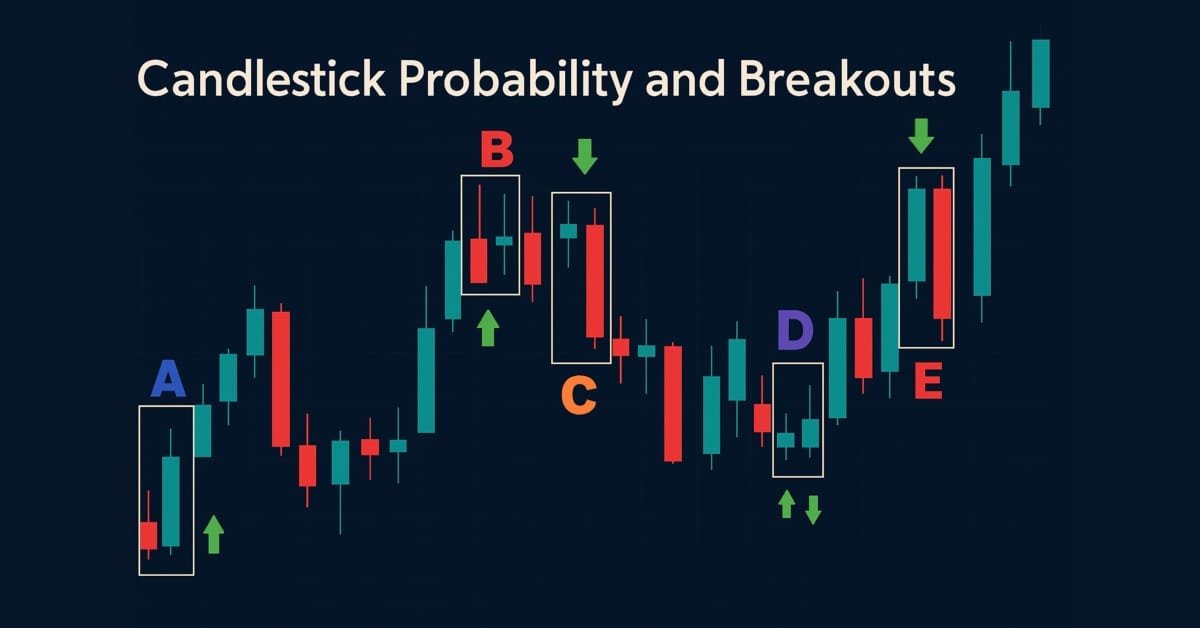
Entwicklung des Price Action Analysis Toolkit (Teil 43): Wahrscheinlichkeit und Ausbrüche von Kerzen
Verbessern Sie Ihre Marktanalyse mit dem Candlestick Probability EA in MQL5, einem leichtgewichtigen Tool, das rohe Preisbalken in Echtzeit in instrumentenspezifische Wahrscheinlichkeiten umwandelt. Es klassifiziert Pinbars, Engulfing und Doji-Muster, wenn der Balken schließt, verwendet ATR-fähige Filterung und optionale Ausbruchsbestätigung. Der EA berechnet rohe und volumengewichtete Follow-Through-Prozentsätze, die Ihnen helfen, das typische Ergebnis jedes Musters für bestimmte Symbole und Zeitrahmen zu verstehen. Markierungen auf dem Chart, ein kompaktes Dashboard und interaktive Kippschalter ermöglichen eine einfache Validierung und Fokussierung. Exportieren Sie detaillierte CSV-Protokolle für Offline-Tests. Nutzen Sie es, um Wahrscheinlichkeitsprofile zu entwickeln, Strategien zu optimieren und Mustererkennung in einen messbaren Vorteil zu verwandeln.

Aufbau eines Handelssystems (Teil 5): Verwaltung von Gewinnen durch strukturierte Handelsausstiege
Für viele Händler ist es ein vertrauter Schmerzpunkt: zu sehen, wie ein Handel bis auf einen Hauch an Ihr Gewinnziel herankommt, nur um dann umzukehren und ihren Stop-Loss zu treffen. Oder noch schlimmer: Sie sehen, dass ein Trailing-Stop Sie an der Gewinnschwelle stoppt, bevor der Markt auf Ihr ursprüngliches Ziel zusteuert. Dieser Artikel befasst sich mit dem Einsatz mehrerer Einstiege zu unterschiedlichen Rendite-Risiko-Verhältnissen, um systematisch Gewinne zu sichern und das Gesamtrisiko zu reduzieren.

Aufbau eines Handelssystems (Teil 4): Wie zufällige Ausstiege die Handelserwartung beeinflussen
Viele Händler haben diese Erfahrung gemacht, sie halten sich oft an ihre Einstiegskriterien, aber sie haben Probleme mit dem Handelsmanagement. Selbst bei den richtigen Setups können emotionale Entscheidungen – wie z. B. panische Ausstiege vor Erreichen des Take-Profit- oder Stop-Loss-Niveaus – zu einer fallenden Kapitalkurve führen. Wie können Händler dieses Problem lösen und ihre Ergebnisse verbessern? Dieser Artikel geht auf diese Fragen ein, indem er zufällige Gewinnraten untersucht und anhand von Monte-Carlo-Simulationen aufzeigt, wie Händler ihre Strategien verfeinern können, indem sie bei angemessenen Niveaus Gewinne mitnehmen, bevor das ursprüngliche Ziel erreicht ist.
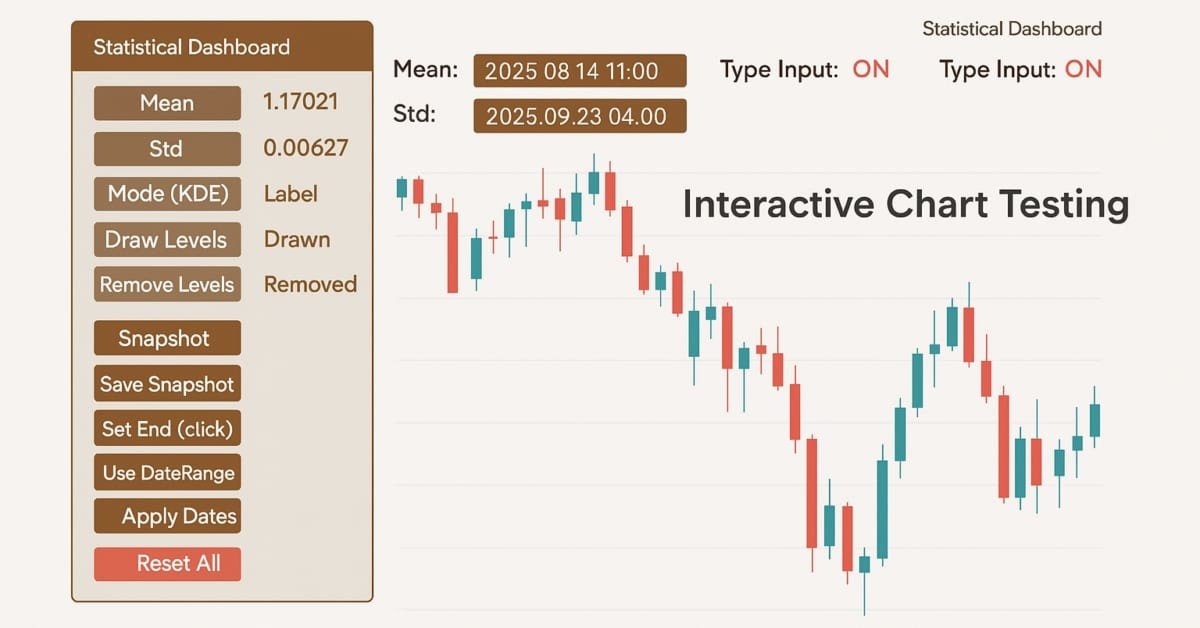
Entwicklung des Price Action Analysis Toolkit (Teil 42): Interaktive Chart-Prüfung mit Schaltflächenlogik und statistischen Ebenen
In einer Welt, in der es auf Geschwindigkeit und Präzision ankommt, müssen die Analysetools so intelligent sein wie die Märkte, auf denen wir handeln. In diesem Artikel wird ein EA vorgestellt, der auf der Logik von Schaltflächen basiert – ein interaktives System, das rohe Kursdaten sofort in aussagekräftige statistische Werte umwandelt. Mit einem einzigen Klick werden Mittelwert, Abweichung, Perzentile und vieles mehr berechnet und angezeigt, sodass fortschrittliche Analysen zu klaren Signalen auf dem Chart werden. Es hebt die Zonen hervor, in denen der Preis am wahrscheinlichsten abprallen, zurückgehen oder durchbrechen wird, was die Analyse sowohl schneller als auch praktischer macht.

Wie man ein zyklusbasiertes Handelssystem aufbaut und optimiert (Detrended Price Oscillator – DPO)
Dieser Artikel erklärt, wie man ein Handelssystem mit dem Detrended Price Oscillator (DPO) in MQL5 entwickelt und optimiert. Er umreißt die Kernlogik des Indikators und zeigt, wie er kurzfristige Zyklen erkennt, indem er langfristige Trends herausfiltert. Anhand einer Reihe von Schritt-für-Schritt-Beispielen und einfachen Strategien lernen die Leser, wie man den Code erstellt, Ein- und Ausstiegssignale definiert und Backtests durchführt. Schließlich werden praktische Optimierungsmethoden vorgestellt, um die Leistung zu verbessern und das System an die sich ändernden Marktbedingungen anzupassen.

Pipelines in MQL5
In diesem Beitrag befassen wir uns mit einem wichtigen Schritt der Datenaufbereitung für das maschinelle Lernen, der zunehmend an Bedeutung gewinnt. Pipelines für die Datenvorverarbeitung. Dabei handelt es sich im Wesentlichen um eine rationalisierte Abfolge von Datenumwandlungsschritten, mit denen Rohdaten aufbereitet werden, bevor sie in ein Modell eingespeist werden. So uninteressant dies für den Laien auch erscheinen mag, diese „Datenstandardisierung“ spart nicht nur Trainingszeit und Ausführungskosten, sondern trägt auch zu einer besseren Generalisierung bei. In diesem Artikel konzentrieren wir uns auf einige SCIKIT-LEARN Vorverarbeitungsfunktionen, und während wir den MQL5-Assistenten nicht ausnutzen, werden wir in späteren Artikeln darauf zurückkommen.
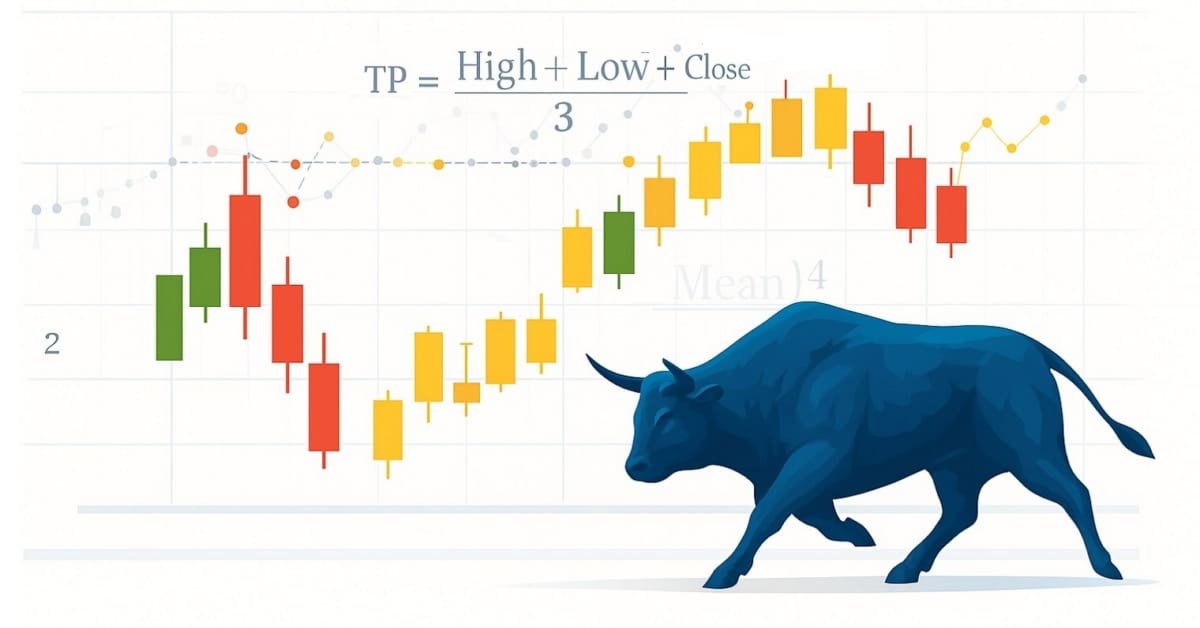
Entwicklung des Price Action Analysis Toolkit (Teil 41): Aufbau eines statistischen Preis-Level EA in MQL5
Die Statistik war schon immer das Herzstück der Finanzanalyse. Laut Definition ist Statistik die Disziplin, die sich mit dem Sammeln, Analysieren, Interpretieren und Darstellen von Daten auf sinnvolle Weise befasst. Stellen Sie sich nun vor, dasselbe Rahmenwerk auf Kerzen anzuwenden – und die rohe Preisbewegung in messbare Erkenntnisse zu verdichten. Wie hilfreich wäre es, für einen bestimmten Zeitraum die zentrale Tendenz, die Streuung und die Verteilung des Marktverhaltens zu kennen? In diesem Artikel stellen wir genau diesen Ansatz vor und zeigen, wie statistische Methoden Kerzendaten in klare, umsetzbare Signale verwandeln können.

Beherrschung der Fair Value Gaps: Bildung, Logik und automatisierter Handel von Ausbrüchen und Marktstrukturverschiebungen
Dies ist ein Artikel, den ich geschrieben habe, um Fair Value Gaps, ihre Entstehungslogik und den automatisierten Handel von Ausbrüchen und Marktstrukturverschiebungen zu erläutern und zu erklären.

Entwicklung des Price Action Analysis Toolkit (Teil 40): Markt-DNA-Pass
In diesem Artikel wird die einzigartige Identität der einzelnen Währungspaare anhand ihrer historischen Kursentwicklung untersucht. Inspiriert vom Konzept der genetischen DNA, die den individuellen Bauplan eines jeden Lebewesens kodiert, wenden wir einen ähnlichen Rahmen auf die Märkte an, indem wir die Kursentwicklung als „DNA“ eines jeden Paares betrachten. Durch die Aufschlüsselung struktureller Verhaltensweisen wie Volatilität, Schwankungen, Rückschritte, Ausschläge und Sitzungsmerkmale zeigt das Tool das zugrunde liegende Profil, das ein Paar von einem anderen unterscheidet. Dieser Ansatz bietet einen tieferen Einblick in das Marktverhalten und gibt Händlern eine strukturierte Methode an die Hand, um ihre Strategien auf die natürlichen Tendenzen der einzelnen Instrumente abzustimmen.

Dynamic Mode Decomposition angewandt auf univariate Zeitreihen in MQL5
Die Dynamic Mode Decomposition (DMD) ist eine Technik, die in der Regel auf hochdimensionale Datensätze angewendet wird. In diesem Artikel demonstrieren wir die Anwendung der DMD auf univariate Zeitreihen und zeigen, dass sie in der Lage ist, sowohl eine Reihe zu charakterisieren als auch Prognosen zu erstellen. Dabei werden wir die in MQL5 eingebaute Implementierung der Dynamic Mode Decomposition untersuchen und dabei besonderes Augenmerk auf die neue Matrixmethode DynamicModeDecomposition() legen.

Entwicklung des Price Action Analysis Toolkit (Teil 38): Tick Buffer VWAP und Short-Window Imbalance Engine
In Teil 38 bauen wir ein produktionsreifes MT5-Überwachungspanel, das rohe Ticks in umsetzbare Signale umwandelt. Der EA puffert Tick-Daten, um VWAP auf Tick-Ebene, eine Ungleichgewichtsmetrik (Flow) in einen kurzzeitigen Fenster und ATR-basierte Positionsgrößen zu berechnen. Anschließend werden Spread, ATR und Flow mit flimmerarmen Balken visualisiert. Das System berechnet eine vorgeschlagene Losgröße und einen 1R-Stopp und gibt konfigurierbare Warnungen bei engen Spreads, starkem Flow und Randbedingungen aus. Der automatische Handel ist absichtlich deaktiviert; der Schwerpunkt liegt weiterhin auf einer robusten Signalgenerierung und einer sauberen Nutzererfahrung.

Aufbau eines Handelssystems (Teil 3): Bestimmung des Mindestrisikoniveaus für realistische Gewinnziele
Das oberste Ziel eines jeden Händlers ist die Rentabilität. Deshalb setzen sich viele Händler bestimmte Gewinnziele, die sie innerhalb einer bestimmten Handelsperiode erreichen wollen. In diesem Artikel werden wir Monte-Carlo-Simulationen verwenden, um den optimalen Risikoprozentsatz pro Handel zu bestimmen, der erforderlich ist, um die Handelsziele zu erreichen. Die Ergebnisse helfen den Händlern zu beurteilen, ob ihre Gewinnziele realistisch oder zu ehrgeizig sind. Schließlich werden wir erörtern, welche Parameter angepasst werden können, um einen praktischen Risikoprozentsatz pro Handel festzulegen, der mit den Handelszielen übereinstimmt.

Entwicklung des Price Action Analysis Toolkit (Teil 39): Automatisierung der BOS- und ChoCH-Erkennung in MQL5
Dieser Artikel stellt das Fractal Reaction System vor, ein kompaktes MQL5-System, das fraktale Pivots in umsetzbare Marktstruktursignale umwandelt. Der EA verwendet eine geschlossene Balkenlogik, um ein erneutes Zeichnen zu vermeiden, erkennt Change-of-Character-Warnungen (ChoCH) und bestätigt Breaks-of-Structure (BOS), zeichnet persistente Chartobjekte und protokolliert/meldet jedes bestätigte Ereignis (Desktop, Mobile und Sound). Lesen Sie weiter, um den Algorithmusentwurf, Implementierungshinweise, Testergebnisse und den vollständigen EA-Code zu erfahren, damit Sie den Detektor selbst kompilieren, testen und einsetzen können.

Vom Neuling zum Experten: Detaillierte Handelsberichte mit Reporting EA beherrschen
In diesem Artikel befassen wir uns mit der Verbesserung der Details von Handelsberichten und der Übermittlung des endgültigen Dokuments per E-Mail im PDF-Format. Dies stellt eine Weiterentwicklung unserer bisherigen Arbeit dar, da wir weiterhin erforschen, wie wir die Leistungsfähigkeit von MQL5 und Python nutzen können, um Handelsberichte in den bequemsten und professionellsten Formaten zu erstellen und zu planen. Nehmen Sie an dieser Diskussion teil und erfahren Sie mehr über die Optimierung der Erstellung von Handelsberichten innerhalb des MQL5-Ökosystems.

MetaTrader trifft auf Google Sheets mit Pythonanywhere: Ein Leitfaden für einen sicheren Datenfluss
Dieser Artikel zeigt einen sicheren Weg, um MetaTrader-Daten in Google Sheets zu exportieren. Google Sheet ist die wertvollste Lösung, da es cloudbasiert ist und die dort gespeicherten Daten jederzeit und von überall abgerufen werden können. So können Händler jederzeit und von jedem Ort aus auf die in Google Sheet exportierten Handels- und zugehörigen Daten zugreifen und weitere Analysen für den zukünftigen Handel durchführen.

Statistische Arbitrage durch kointegrierte Aktien (Teil 4): Modellaktualisierung in Echtzeit
Dieser Artikel beschreibt eine einfache, aber umfassende statistische Arbitrage-Pipeline für den Handel mit einem Korb von kointegrierten Aktien. Es enthält ein voll funktionsfähiges Python-Skript zum Herunterladen und Speichern von Daten, Korrelations-, Kointegrations- und Stationaritätstests sowie eine Beispielimplementierung des Metatrader 5 Service zur Aktualisierung der Datenbank und des entsprechenden Expert Advisors. Einige Designentscheidungen werden hier zu Referenzzwecken und als Hilfe bei der Reproduktion des Experiments dokumentiert.

Automatisieren von Handelsstrategien in MQL5 (Teil 28): Erstellen eines Price Action Bat Harmonic Patterns mit visuellem Feedback
In diesem Artikel entwickeln wir ein Bat-Pattern-System in MQL5, das Auf- und Abwärtsmuster von Bat-Harmonic unter Verwendung von Umkehrpunkten und Fibonacci-Verhältnissen identifiziert und Handelsgeschäfte mit präzisen Einstiegs-, Stop-Loss- und Take-Profit-Levels auslöst, ergänzt durch visuelles Feedback durch Chart-Objekte

Statistische Arbitrage durch kointegrierte Aktien (Teil 3): Datenbank-Einrichtung
In diesem Artikel wird ein Beispiel für die Implementierung eines MQL5-Dienstes zur Aktualisierung einer neu erstellten Datenbank vorgestellt, die als Quelle für die Datenanalyse und für den Handel mit einem Korb kointegrierter Aktien dient. Der Grundgedanke des Datenbankentwurfs wird ausführlich erläutert und das Datenwörterbuch wird als Referenz dokumentiert. MQL5- und Python-Skripte werden für die Erstellung der Datenbank, die Initialisierung des Schemas und die Eingabe der Marktdaten bereitgestellt.

MetaTrader 5 Machine Learning Blueprint (Teil 2): Kennzeichnung von Finanzdaten für maschinelles Lernen
In diesem zweiten Teil der MetaTrader 5 Machine Learning Blueprint-Serie erfahren Sie, warum einfache Bezeichnungen Ihre Modelle in die Irre führen können und wie Sie fortgeschrittene Techniken wie die Triple-Barrier- und Trend-Scanning-Methode anwenden, um robuste, risikobewusste Ziele zu definieren. Dieser praktische Leitfaden ist vollgepackt mit praktischen Python-Beispielen, die diese rechenintensiven Techniken optimieren, und zeigt Ihnen, wie Sie verrauschte Marktdaten in zuverlässige Kennzeichnungen umwandeln können, die die realen Handelsbedingungen widerspiegeln.

Statistische Arbitrage durch kointegrierte Aktien (Teil 2): Expert Advisor, Backtests und Optimierung
In diesem Artikel wird eine Beispielimplementierung eines Expert Advisors für den Handel mit einem Korb von vier Nasdaq-Aktien vorgestellt. Die Aktien wurden zunächst anhand von Pearson-Korrelationstests gefiltert. Die gefilterte Gruppe wurde dann mit Johansen-Tests auf Kointegration geprüft. Schließlich wurde der kointegrierte Spread mit dem ADF- und dem KPSS-Test auf Stationarität geprüft. Hier sehen wir einige Anmerkungen zu diesem Prozess und die Ergebnisse der Backtests nach einer kleinen Optimierung.

Selbstoptimierende Expert Advisors in MQL5 (Teil 12): Aufbau von linearen Klassifikatoren durch Matrixfaktorisierung
Dieser Artikel befasst sich mit der leistungsfähigen Rolle der Matrixfaktorisierung im algorithmischen Handel, insbesondere in MQL5-Anwendungen. Von Regressionsmodellen bis hin zu Multi-Target-Klassifikatoren gehen wir durch praktische Beispiele, die zeigen, wie einfach diese Techniken mit Hilfe von integrierten MQL5-Funktionen integriert werden können. Ganz gleich, ob Sie die Kursrichtung vorhersagen oder das Verhalten von Indikatoren modellieren wollen, dieser Leitfaden schafft eine solide Grundlage für den Aufbau intelligenter Handelssysteme mit Hilfe von Matrixmethoden.

Automatisieren von Handelsstrategien in MQL5 (Teil 27): Erstellen eines Price Action Harmonic Pattern der Krabbe mit visuellem Feedback
In diesem Artikel entwickeln wir ein Crab Harmonic Pattern System in MQL5, das harmonische Auf- und Abwärtsmuster der Krabbe oder „crab“ mit Hilfe von Umkehrpunkten und Fibonacci-Verhältnisse identifiziert und Handelsgeschäfte mit präzisen Einstiegs-, Stop-Loss- und Take-Profit-Levels auslöst. Wir integrieren visuelles Feedback durch Chart-Objekte wie Dreiecke und Trendlinien, um die Struktur des XABCD-Musters und die Handelsniveaus anzuzeigen.

Aufbau eines Handelssystems (Teil 2): Die Wissenschaft der Positionsbestimmung
Selbst bei einem System mit positiver Erwartungshaltung entscheidet die Positionsgröße darüber, ob Sie Erfolg haben oder zusammenbrechen. Das ist der Dreh- und Angelpunkt des Risikomanagements – die Umsetzung statistischer Erkenntnisse in reale Ergebnisse bei gleichzeitigem Schutz Ihres Kapitals.

Entwicklung des Price Action Analysis Toolkit (Teil 37): Sentiment Tilt Meter
Die Marktstimmung ist eine der am meisten übersehenen, aber dennoch mächtigen Kräfte, die die Kursentwicklung beeinflussen. Während sich die meisten Händler auf nachlaufende Indikatoren oder Vermutungen verlassen, verwandelt der Sentiment Tilt Meter (STM) EA rohe Marktdaten in klare, visuelle Hinweise, die in Echtzeit anzeigen, ob der Markt nach oben oder unten tendiert oder neutral bleibt. Dies erleichtert die Bestätigung von Geschäften, die Vermeidung von Fehleinstiegen und eine bessere Zeitplanung der Marktteilnahme.

MetaTrader Tick-Info-Zugang von MQL5-Diensten zur Python-Anwendung über Sockets
Manchmal ist nicht alles in der MQL5-Sprache programmierbar. Und selbst wenn es möglich wäre, bestehende fortgeschrittene Bibliotheken in MQL5 zu konvertieren, wäre dies sehr zeitaufwändig. Dieser Artikel versucht zu zeigen, dass wir die Abhängigkeit vom Windows-Betriebssystem umgehen können, indem wir Tick-Informationen wie Bid, Ask und Time mit MetaTrader-Diensten über Sockets an eine Python-Anwendung übertragen.
MQL5-Handelswerkzeuge (Teil 8): Verbessertes informatives Dashboard mit verschiebbaren und minimierbaren Funktionen
In diesem Artikel entwickeln wir ein erweitertes Informations-Dashboard, das den vorigen Teil durch die Hinzufügung von verschiebbaren und minimierbaren Funktionen für eine verbesserte Nutzerinteraktion aufwertet, während die Echtzeitüberwachung von Multi-Symbol-Positionen und Kontometrien beibehalten wird.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 78): Gator- und AD-Oszillator-Strategien für Marktresilienz
Der Artikel stellt die zweite Hälfte eines strukturierten Ansatzes für den Handel mit dem Gator Oscillator und der Akkumulation/Distribution vor. Durch die Einführung von fünf neuen Mustern zeigt der Autor, wie man falsche Bewegungen herausfiltert, frühe Kehrtwendungen erkennt und Signale über verschiedene Zeitrahmen hinweg abgleicht. Mit klaren Programmierbeispielen und Leistungstests verbindet das Material Theorie und Praxis für MQL5-Entwickler.

Aufbau eines Handelssystems (Teil 1): Ein quantitativer Ansatz
Viele Händler bewerten Strategien auf der Grundlage kurzfristiger Ergebnisse und geben profitable Systeme oft zu früh auf. Die langfristige Rentabilität hängt jedoch von einer positiven Erwartungshaltung durch eine optimierte Gewinnrate und ein optimiertes Risiko-Ertrags-Verhältnis ab, zusammen mit einer disziplinierten Positionsgröße. Diese Grundsätze können mit Hilfe von Monte-Carlo-Simulationen in Python mit bewährten Metriken validiert werden, um zu beurteilen, ob eine Strategie robust ist oder im Laufe der Zeit wahrscheinlich scheitern wird.
Implementierung von praktischen Modulen aus anderen Sprachen in MQL5 (Teil 03): Zeitplan-Modul von Python, das OnTimer-Ereignis auf Steroiden
Das Schedule-Modul in Python bietet eine einfache Möglichkeit, wiederkehrende Aufgaben zu planen. Während MQL5 kein eingebautes Äquivalent hat, werden wir in diesem Artikel eine ähnliche Bibliothek implementieren, um die Einrichtung von zeitgesteuerten Ereignissen in MetaTrader 5 zu erleichtern.

Vom Neuling zum Experten: Reporting EA – Einrichten des Arbeitsablaufs
Makler stellen oft in regelmäßigen Abständen nach einem vordefinierten Zeitplan Berichte über Handelskonten zur Verfügung. Diese Firmen haben über ihre API-Technologien Zugang zu Ihren Kontoaktivitäten und Ihrer Handelshistorie, sodass sie in Ihrem Namen Performanceberichte erstellen können. Ebenso speichert das MetaTrader 5-Terminal detaillierte Aufzeichnungen Ihrer Handelsaktivitäten, die mit MQL5 genutzt werden können, um vollständig angepasste Berichte zu erstellen und personalisierte Liefermethoden zu definieren.

Selbstoptimierende Expert Advisors in MQL5 (Teil 11): Eine sanfte Einführung in die Grundlagen der linearen Algebra
In dieser Diskussion werden wir die Grundlagen für die Verwendung leistungsstarker linearer Algebra-Werkzeuge schaffen, die in der MQL5-Matrix- und Vektor-API implementiert sind. Damit wir diese API sachkundig nutzen können, müssen wir die Grundsätze der linearen Algebra, die den intelligenten Einsatz dieser Methoden bestimmen, genau kennen. Dieser Artikel zielt darauf ab, dem Leser ein intuitives Verständnis einiger der wichtigsten Regeln der linearen Algebra zu vermitteln, die wir als algorithmische Händler in MQL5 benötigen, um mit der Nutzung dieser leistungsstarken Bibliothek zu beginnen.