
Datenwissenschaft und ML (Teil 47): Marktprognosen mithilfe des DeepAR-Modells in Python

Inhalt
- Einführung
- Was ist DeepAR?
- Funktionsprinzipien von DeepAR
- Aufbereitung der Daten für das DeepAR-Modell
- Training des DeepAR-Modells in Python
- Marktprognosen in Echtzeit mit dem DeepAR-Modell
- Ein Mehrwährungsansatz auf Basis des DeepAR-Modells
- Schlussfolgerung
Einführung
Die Vorhersage von Zeitreihen war noch nie eine einfache Aufgabe im Bereich des maschinellen Lernens; verschiedene Techniken und Modelle wurden eingeführt, um dieses Problem anzugehen, meist ohne endgültigen Erfolg. Auch lineare und nichtlineare Modelle sind oft nicht in der Lage, diese Aufgabe zu bewältigen, obwohl sie durchaus brauchbare Vorhersagen für Zeitreihendaten liefern.
Um die Zeitreihenprognose zu bewältigen, haben Händler eine Zuflucht in auf neuronalen Netzen basierenden Modellen wie den rekurrenten neuronalen Netzen (RNNs) gefunden.
RNNs sind jedoch eher nichtlineare Modelle und weniger Zeitreihenmodelle. Diejenigen, die mit dem Auto Regressive Integrated Moving Average (ARIMA) und dem Vector AutoRegressive (AR) vertraut sind, haben dies vielleicht bemerkt. Sie erfordern zusätzliche Schritte zur Aufbereitung der Daten in Fenstern, damit das neuronale Netz Zeitreihenmuster erkennen kann, obwohl sie noch immer nicht auf saisonale Muster programmiert sind, die von traditionellen Modellen für Zeitreihenprognosen erkannt werden.

In diesem Artikel werden wir das DeepAR-Modell erörtern. Ein autoregressives neuronales Netzmodell. Es verhält sich wie ein nichtlineares Modell, da es über ein neuronales Netz verfügt, während es die autoregressive Eigenschaft besitzt, die in klassischen Zeitreihenmodellen wie ARIMA zu finden ist.
Was ist DeepAR?
In der Dokumentation heißt es dazu.
Der Amazon SageMaker DeepAR-Prognosealgorithmus ist ein überwachter Lernalgorithmus zur Vorhersage skalarer (eindimensionaler) Zeitreihen unter Verwendung rekurrenter neuronaler Netze (RNN). Klassische Prognosemethoden wie autoregressive integrierte gleitende Durchschnitte (ARIMA) oder exponentielle Glättung (ETS) passen ein einziges Modell an jede einzelne Zeitreihe an. Mit diesem Modell extrapolieren sie dann die Zeitreihe in die Zukunft.
In vielen Anwendungen gibt es jedoch viele ähnliche Zeitreihen in einer Reihe von Querschnittseinheiten. So können Sie beispielsweise Zeitreihen für die Nachfrage nach verschiedenen Produkten, die Serverauslastung und die Abrufe von Webseiten gruppieren. Für diese Art von Anwendung kann es von Vorteil sein, ein einziges Modell für alle Zeitreihen gemeinsam zu trainieren. DeepAR verfolgt diesen Ansatz. Wenn Ihr Datensatz Hunderte von zusammenhängenden Zeitreihen enthält, übertrifft DeepAR die Standardmethoden ARIMA und ETS. Sie können das trainierte Modell auch verwenden, um Prognosen für neue Zeitreihen zu erstellen, die denjenigen ähnlich sind, auf die es trainiert wurde.
Schauen wir uns also die wichtigsten Grundsätze dieses Modells an.
Arbeitsprinzipien von DeepAR
Nachfolgend werden einige wichtige Funktionsprinzipien des DeepAR-Modells erläutert.
01: Probabilistische Zeitreihenvorhersage
Deep AR erzeugt nicht nur eine einzelne „Punktschätzung“ für zukünftige Werte, sondern lernt die Ausgaben und eine vollständige Verteilung über zukünftige Punkte.
Dies ermöglicht es dem Modell, die Unsicherheit auszudrücken und Vorhersageintervalle oder Quantile zu erzeugen (z. B. P10, P50, P90). Diese Vorhersagen sind wertvoll für risikobewusste Entscheidungen.
02: Globale Modellierung über viele Serien hinweg
Im Gegensatz zu traditionellen Prognosemodellen wie ARIMA und ETS, die für jede Zeitreihe ein eigenes Modell erstellen, trainiert DeepAR ein einziges Modell für viele zusammenhängende Zeitreihen.
Dieses globale Modell erlernt gemeinsame Muster und verbessert die Leistung, insbesondere wenn einzelne Reihen nur über begrenzte Daten verfügen. Dieses Modell kann sogar auf neue, aber ähnliche Serien verallgemeinern, die es noch nicht gesehen hat.
03: Autoregressive rekurrente neuronale Netzarchitektur
DeepAR verwendet ein auf einem rekurrenten neuronalen Netz (RNN) basierendes Design (typischerweise mit LSTM-Zellen in autoregressiver Weise). Das bedeutet, dass das Modell die Vorhersagen auf seine eigenen, zuvor vorhergesagten Werte und auf frühere Beobachtungen stützt.
Dadurch können zeitliche Abhängigkeiten wie Trends, Saisonalität und nichtlineare Dynamik in den Daten erfasst werden.
04: Verwendung von statischen und dynamischen Merkmalen
Dieses Modell ist sowohl für dynamische als auch für kategoriale Merkmale geeignet.
- Statische/kategoriale Merkmale wie Produktkategorie oder Region.
- Dynamische/zeitabhängige Merkmale wie Preise.
Diese Fähigkeit unterscheidet es von nichtlinearen Modellen wie XGBoost und neuronalen Netzen.
05: Zeitbewusstes Feature Engineering
DeepAR leitet Zeitmerkmale wie Wochentag, Monat usw. aus einer Zeitreihe ab und unterstützt das Modell bei der Erfassung von Saisonalität und periodischem Verhalten ohne aufwändiges manuelles Feature Engineering.
Dies erspart uns viel Zeit bei der Erstellung der zeitbasierten Merkmale, die wir normalerweise für die Zeitreihenprognose benötigen.
In der folgenden Tabelle sind die abgeleiteten Merkmale für die unterstützten Basiszeitfrequenzen aufgeführt.
| Häufigkeit der Zeitreihe | Abgeleitete Merkmale |
|---|---|
| Minute | Stundenminute, Tagesstunde, Wochentag, Tag des Monats, Tag des Jahres. |
| Stunde | Stunde des Tages, Tag der Woche, Tag des Monats, Tag des Jahres. |
| Tag | Tag der Woche, Tag des Monats, Tag des Jahres. |
| Woche | Tag des Monats, Woche des Jahres. |
| Monat | Monat des Jahres. |
06: Sampling von Kontext und Vorhersagefenster
Mit diesem Modell können wir steuern, wie weit wir in die Vergangenheit zurückschauen und die Zukunft vorhersagen wollen.
Mit den Hyperparametern context_length und prediction_length wird gesteuert, wie weit das Modell in die Vergangenheit bzw. in die Zukunft vorausschaut.
07: Umgang mit fehlenden Werten
DeepAR kann von Haus aus mit fehlenden Werten in den Zeitreihen umgehen. Externe Ergänzungen sind nicht erforderlich, um die Prognosegenauigkeit auch bei unvollständigen Daten zu erhalten.
Aufbereitung der Daten für das DeepAR-Modell
Nachdem wir nun die Grundprinzipien dieses Modells verstanden haben, wollen wir es in Python implementieren und sehen, ob der Hype echt ist.
Laden Sie zunächst alle in der Datei requirements.txt (am Ende dieses Artikels angehängt) aufgeführten Abhängigkeiten in Ihre virtuelle Python-Umgebung herunter.
pip install -r requirements.txt
In main.py importieren wir zunächst alle erforderlichen Module.
import pandas as pd import torch import lightning.pytorch as pl import matplotlib.pyplot as plt import pytorch_forecasting from pytorch_forecasting import Baseline, DeepAR, TimeSeriesDataSet, GroupNormalizer from lightning.pytorch.callbacks import EarlyStopping from pytorch_forecasting.metrics import SMAPE, MultivariateNormalDistributionLoss, QuantileLoss from pytorch_forecasting import DeepAR import MetaTrader5 as mt5 import warnings
Da alle maschinellen Lernmodelle Daten benötigen, aus denen sie lernen können, importieren wir die Daten aus dem MetaTrader 5.
if not mt5.initialize(): # initialize MetaTrader 5 print(f"failed to initialize MetaTrader5, Error = {mt5.last_error()}") exit() symbol = "EURUSD" df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 1, 1000)) print(df.head())
Ausgabe:
time open high low close tick_volume spread real_volume 0 1760598000 1.16621 1.16623 1.16559 1.16563 1209 0 0 1 1760601600 1.16561 1.16615 1.16541 1.16602 2113 0 0 2 1760605200 1.16602 1.16680 1.16521 1.16539 3925 0 0 3 1760608800 1.16539 1.16569 1.16431 1.16521 4533 0 0 4 1760612400 1.16518 1.16599 1.16487 1.16591 3948 0 0
Wir müssen die Zeit von Sekunden in datetime-Objekt(e) formatieren.
df['time'] = pd.to_datetime(df['time'], unit='s')
Anschließend sortieren wir die Werte nach der Zeitspalte.
df = df.sort_values("time").reset_index(drop=True)
Ausgabe:
time open high low close tick_volume spread real_volume 0 2025-10-16 07:00:00 1.16621 1.16623 1.16559 1.16563 1209 0 0 1 2025-10-16 08:00:00 1.16561 1.16615 1.16541 1.16602 2113 0 0 2 2025-10-16 09:00:00 1.16602 1.16680 1.16521 1.16539 3925 0 0 3 2025-10-16 10:00:00 1.16539 1.16569 1.16431 1.16521 4533 0 0 4 2025-10-16 11:00:00 1.16518 1.16599 1.16487 1.16591 3948 0 0
Um ein TimeSeriesDataset-Objekt zu erstellen (ein Objekt, das zur Vorbereitung eines Zeitreihen-Datensatzes für pytortch_forecasting-Modelle nützlich ist), benötigen wir zwei Spalten: time_idx und group_id (optional).
df["time_idx"] = (df["time"] - df["time"].min()).dt.total_seconds().astype(int) // 3600 df["symbol"] = symbol
Die Spalte time_idx gibt die zeitliche Reihenfolge aller Zeilen im Datenrahmen an.
Das Spaltensymbol wird verwendet, um die verschiedenen im Datenrahmen vorhandenen Instrumente zu gruppieren. In diesem Fall haben wir eine Gruppe namens EURUSD.
Bei der Visualisierung sieht der Datenrahmen wie folgt aus:
time open high low close tick_volume spread real_volume time_idx symbol 0 2025-10-16 07:00:00 1.16621 1.16623 1.16559 1.16563 1209 0 0 0 EURUSD 1 2025-10-16 08:00:00 1.16561 1.16615 1.16541 1.16602 2113 0 0 1 EURUSD 2 2025-10-16 09:00:00 1.16602 1.16680 1.16521 1.16539 3925 0 0 2 EURUSD 3 2025-10-16 10:00:00 1.16539 1.16569 1.16431 1.16521 4533 0 0 3 EURUSD 4 2025-10-16 11:00:00 1.16518 1.16599 1.16487 1.16591 3948 0 0 4 EURUSD
Auch hier ist das DeepAR-Modell eindimensional, d. h. ein Modell wird auf eine einzige Variable trainiert, die es lernt, das zukünftige Selbst der Variable anhand ihrer Vergangenheit vorherzusagen.
Da wir normalerweise nach Möglichkeiten zur Vorhersage des Schlusskurses suchen, ist die Variable des Schlusskurses das einzige Merkmal, das wir benötigen.
Der Schlusskurs ist jedoch eine kontinuierliche Variable; der Versuch, ihn vorherzusagen, könnte sich selbst für dieses Modell als schwierig erweisen. Bei der Zeitreihenprognose haben wir es in der Regel mit stationären Daten zu tun, da diese einen konstanten Mittelwert und eine konstante Varianz über die Zeit aufweisen.
Erstellen der Zielvariablen
Zu diesem Zweck trainieren wir unser Modell zur Vorhersage der Renditen;
df["returns"] = (df["close"].shift(-1) - df["close"]) / df["close"] df = df.dropna().reset_index(drop=True)
Anschließend wird der Datenrahmen in 3 Spalten gefiltert, die für das Zeitreihen-Datenobjekt erforderlich sind.
ts_df = df[["time_idx", "returns", "symbol"]]
In gedruckter Form sieht es so aus.
time_idx returns symbol 0 0 0.000335 EURUSD 1 1 -0.000540 EURUSD 2 2 -0.000154 EURUSD 3 3 0.000601 EURUSD 4 4 -0.000069 EURUSD
Mit einem geeigneten Dataframe in der Hand, lassen Sie uns zunächst ein TimeSeriesDataset-Objekt für das Training erstellen.
max_encoder_length = 24 max_prediction_length = 6 training_cutoff = df["time_idx"].max() - max_prediction_length training = TimeSeriesDataSet( data=ts_df[ts_df.time_idx <= training_cutoff], time_idx="time_idx", target="returns", group_ids=["symbol"], max_encoder_length=max_encoder_length, max_prediction_length=max_prediction_length, min_encoder_length=1, allow_missing_timesteps=True, time_varying_known_reals=["time_idx"], time_varying_unknown_reals=["returns"], target_normalizer=GroupNormalizer(groups=["symbol"], transformation="log1p") )
max_encoder_length, teilt dem Modell mit, wie weit es in die Vergangenheit schauen soll.
max_prediction_lengh, stellt den Vorhersagehorizont des Modells dar.
Wir bereiten ein ähnliches Objekt für die Validierungsdaten vor, das dem für die Trainingsdaten ähnelt.
validation = TimeSeriesDataSet.from_dataset(training, ts_df, min_prediction_idx=training_cutoff + 1) Wie in den Grundsätzen beschrieben, verfügt das DeepAR-Modell über eine eingebaute Möglichkeit zur Erstellung zusätzlicher zeitbasierter Merkmale in Abhängigkeit von der gegebenen Datumszeit aus dem Datensatz.
Dies ist der Fall, wenn Sie explizit das DeepAR-Modell von Amazon SageMaker AI. verwenden. Leider konnte ich keine gute Dokumentation dafür finden, daher werden wir das Prognosemodul Pytorch mit manuell hinzugefügten Zeitmerkmalen implementieren.
df["hour"] = df["time"].dt.hour.astype(str) df["day_of_week"] = df["time"].dt.dayofweek.astype(str) df["month"] = df["time"].dt.month.astype(str) ts_df = df[["time_idx", "returns", "symbol", "hour", "day_of_week", "month"]]
Training des DeepAR-Modells in Python
Wir benötigen Datenlieferanten für unser Modell (eine gängige Praxis in PyTorch Forecasting).
batch_size = 64 train_dataloader = training.to_dataloader(train=True, batch_size=batch_size, num_workers=0, batch_sampler="synchronized") val_dataloader = validation.to_dataloader(train=False, batch_size=batch_size, num_workers=0, batch_sampler="synchronized")
Wir benötigen einen Trainer für unser Modell. Wir werden dafür das Modul Lightning verwenden.
# create trainer trainer = pl.Trainer( max_epochs=100, accelerator="gpu" if torch.cuda.is_available() else "cpu", gradient_clip_val=0.1, callbacks=[EarlyStopping(monitor="val_loss", patience=10, mode="min")], )
Wir trainieren das Modell für maximal 100 Epochen und überwachen den Validierungsverlust, um das Training frühzeitig abzubrechen (d. h. das Training zu beenden, wenn sich das Modell nicht verbessert).
Außerdem passen wir das DeepAR-Modell mithilfe des soeben erstellten Trainerobjekts an.
trainer.fit( model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, )
Ausgabe:
┏━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃Mode ┃FLOPs ┃ ┡━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━━┩ │ 0 │ loss │ MultivariateNormalDistributionLoss │ 0 │ train │ 0 │ │ 1 │ logging_metrics │ ModuleList │ 0 │ train │ 0 │ │ 2 │ embeddings │ MultiEmbedding │ 245 │ train │ 0 │ │ 3 │ rnn │ LSTM │ 22.9 K │ train │ 0 │ │ 4 │ distribution_projector │ Linear │ 1.3 K │ train │ 0 │ └───┴────────────────────────┴────────────────────────────────────┴────────┴───────┴───────┘ Trainable params: 24.4 K Non-trainable params: 0 Total params: 24.4 K Total estimated model params size (MB): 0 Modules in train mode: 14 Modules in eval mode: 0 Total FLOPs: 0 Epoch 10/99 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 933/933 0:00:23 • 0:00:00 40.63it/s v_num: 38.000 train_loss_step: -7.305 val_loss: -60.929 train_loss_epoch: -44.401
Nachdem der Trainingsprozess abgeschlossen ist, wird das beste Modell aus dem Trainer extrahiert.
best_model_path = trainer.checkpoint_callback.best_model_path
best_model = DeepAR.load_from_checkpoint(best_model_path, weights_only=False) Erstellen der Vorhersagen für die Bewertung.
raw_predictions = best_model.predict(val_dataloader, mode="raw", return_x=True)
Abschließend werden die Vorhersagen zu Bewertungszwecken grafisch dargestellt.
for idx in range(len(raw_predictions.x["decoder_time_idx"])): best_model.plot_prediction( raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True ) plt.show()
Ergebnisse (Vorhersagen und tatsächliche Werte auf der gleichen Achse).
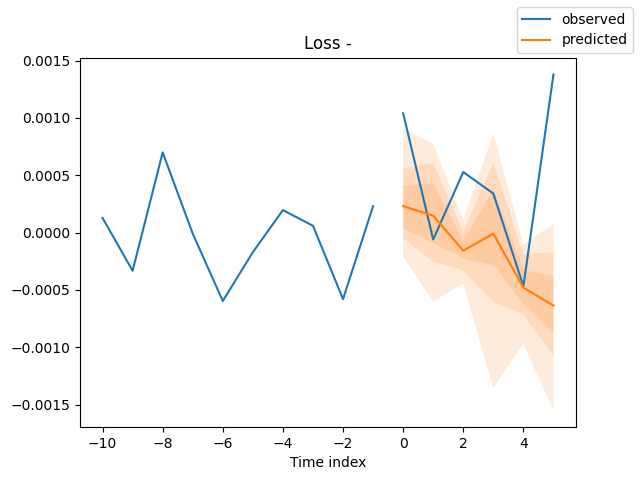
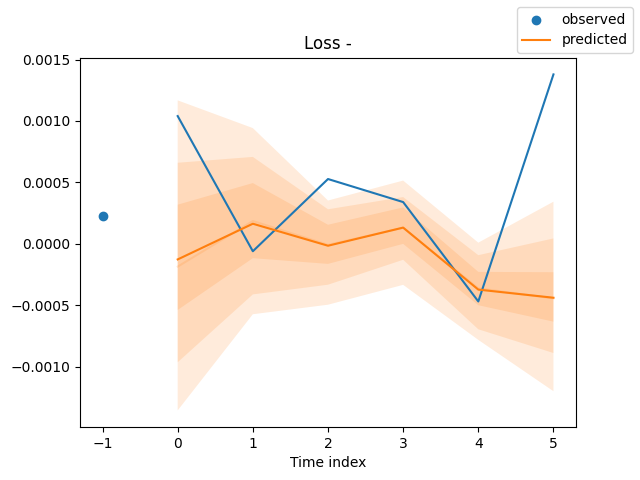
Da wir nun eine Möglichkeit haben, das/die Modell(e) zu trainieren, können wir ein Modell verwenden, um nützliche Vorhersagen zu treffen.
Vorhersage des Marktes in Echtzeit mit dem DeepAR-Modell
Um uns das Leben zu erleichtern, müssen wir den Trainingsprozess in eine separate Datei aufteilen und dann eine separate Funktion für die Merkmalsverarbeitung und das Engineering haben.
Innerhalb der Datei train.py
import torch import lightning.pytorch as pl import matplotlib.pyplot as plt import pytorch_forecasting from pytorch_forecasting import DeepAR, TimeSeriesDataSet from lightning.pytorch.callbacks import EarlyStopping, ModelCheckpoint from pytorch_forecasting.metrics import MultivariateNormalDistributionLoss from pytorch_forecasting import DeepAR # from lightning.pytorch.tuner import Tuner import os import config import warnings warnings.filterwarnings("ignore") torch.serialization.add_safe_globals([pytorch_forecasting.data.encoders.GroupNormalizer]) torch.serialization.safe_globals([pytorch_forecasting.data.encoders.GroupNormalizer]) pl.seed_everything(config.random_seed) # set random seed for the lightning module def run(training: TimeSeriesDataSet, train_dataloader: any, val_dataloader: any, loss: pytorch_forecasting.metrics = MultivariateNormalDistributionLoss(rank=30), best_model_name: str=config.best_model_name) -> DeepAR: # model's checkpoint checkpoint_callback = ModelCheckpoint( dirpath=config.models_path, filename=best_model_name, save_top_k=1, mode="min", monitor="val_loss" ) # create trainer trainer = pl.Trainer( max_epochs=config.num_epochs, accelerator="gpu" if torch.cuda.is_available() else "cpu", gradient_clip_val=config.grad_clip, callbacks=[EarlyStopping(monitor="val_loss", patience=config.patience, mode="min"), checkpoint_callback], logger=False, ) # create DeepAR model model = DeepAR.from_dataset( training, learning_rate=config.learning_rate, hidden_size=config.hidden_size, rnn_layers=config.rnn_layers, dropout=config.dropout, # --- probabilistic forecasting --- loss=loss, log_interval=config.log_interval, log_val_interval=config.log_val_interval, ) res = None try: # find the optimal learning rate """ res = Tuner(trainer).lr_find( model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, early_stop_threshold=1000.0, max_lr=0.3, ) # and plot the result - always visually confirm that the suggested learning rate makes sense print(f"suggested learning rate: {res.suggestion()}") fig = res.plot(show=True, suggest=True) fig.savefig(os.path.join(config.images_path, "lr_finder.png")) """ # fit the model trainer.fit( model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, ) except Exception as e: raise RuntimeError(e) best_model_path = checkpoint_callback.best_model_path best_model = DeepAR.load_from_checkpoint(best_model_path, weights_only=False) # make probabilistic forecasts raw_predictions = best_model.predict(val_dataloader, mode="raw", return_x=True) # plot predictions # for idx in range(config.max_prediction_length): for idx in range(len(raw_predictions.x["decoder_time_idx"])): best_model.plot_prediction( raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True ) plt.savefig(os.path.join(config.images_path, "deepar_forecast_{}.png".format(idx+1))) # plt.show() return model
Da das Training eines Modells ein ressourcenintensiver Prozess ist, ist es sicherlich nicht das Richtige, dies häufig zu tun. Wir benötigen eine Funktion zum Laden eines vortrainierten (gespeicherten) Modells.
Innerhalb von main.py
def load_model(): global model try: model = DeepAR.load_from_checkpoint( checkpoint_path=os.path.join(config.models_path, config.best_model_name+".ckpt"), weights_only=False, ) except Exception as e: print(f"Failed to load model from checkpoint: {e}") model = None return False return True
Denn wir müssen dieselbe Merkmalserfassung und Technik auf die Daten anwenden, bevor wir sie an das Inferenzmodell weitergeben. Es ist ratsam, alle erforderlichen Prozesse in eine eigenständige Funktion zu verpacken.
def feature_engineering(df: pd.DataFrame) -> pd.DataFrame: # convert time in seconds to datetime df['time'] = pd.to_datetime(df['time'], unit='s') df = df.sort_values("time").reset_index(drop=True) # print(df.head()) df["time_idx"] = np.arange(len(df)) df["symbol"] = symbol # print(df.head()) # instead of using close price, which is very hard to predict, let's use close price returns df["returns"] = (df["close"].shift(-1) - df["close"]) / df["close"] df = df.dropna().reset_index(drop=True) df["hour"] = df["time"].dt.hour.astype(str) df["day_of_week"] = df["time"].dt.dayofweek.astype(str) df["month"] = df["time"].dt.month.astype(str) return df[["time_idx", "returns", "symbol", "hour", "day_of_week", "month"]]
Innerhalb einer Funktion training_job,, die auf einen Zeitplan gesetzt wird. Für ein geplantes Training, werden zunächst die Daten gesammelt und die Merkmale entwickelt.
Innerhalb der Datei main.py
def training_job(): global model # ----- feature engineering ----- try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, config.train_start_bar, config.train_total_bars)) ts_df = feature_engineering(df) except Exception as e: print(f"Failed to get historical data from MetaTrader 5: {e}") return print(ts_df.head())
Nachdem wir die Rohdaten in pandas.DataFrame erhalten haben, müssen wir TimeSeriesData-Objekte und Ladeprogramme ähnlich wie zuvor erstellen.
def training_job(): global model # ----- feature engineering ----- try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, config.train_start_bar, config.train_total_bars)) ts_df = feature_engineering(df) except Exception as e: print(f"Failed to get historical data from MetaTrader 5: {e}") return print(ts_df.head()) # ----- create timeseries datasets and dataloaders ----- training_cutoff = ts_df["time_idx"].max() - config.max_prediction_length training = TimeSeriesDataSet( data=ts_df[ts_df.time_idx <= training_cutoff], time_idx="time_idx", target="returns", group_ids=["symbol"], max_encoder_length=config.max_encoder_length, max_prediction_length=config.max_prediction_length, min_encoder_length=config.min_encoder_length, # min_prediction_length=1, allow_missing_timesteps=True, time_varying_known_categoricals=["hour", "day_of_week", "month"], time_varying_known_reals=["time_idx"], time_varying_unknown_reals=["returns"], target_normalizer=GroupNormalizer(groups=["symbol"], transformation="log1p") ) validation = TimeSeriesDataSet.from_dataset(training, ts_df, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, batch_size=config.batch_size, num_workers=config.num_workers, batch_sampler="synchronized") val_dataloader = validation.to_dataloader(train=False, batch_size=config.batch_size, num_workers=config.num_workers, batch_sampler="synchronized") model = train.run(training=training, train_dataloader=train_dataloader, val_dataloader=val_dataloader, loss=MultivariateNormalDistributionLoss(rank=30), best_model_name=config.best_model_name)
Schließlich planen wir den Trainingsvorgang nach einem bestimmten Zeitintervall in Minuten mit dem Modul Schedule.
import schedule #.... #.... schedule.every(config.train_interval_minutes).minutes.do(training_job)
Beachten Sie, dass die meisten Variablen das Muster (config.some_variable) haben. Das liegt daran, dass die meisten Variablen in einer Datei namens config.py gespeichert sind
Nachdem alle Trainingsmaßnahmen durchgeführt wurden, benötigen wir eine abschließende Funktion, um die neuesten Ticks und Kurse vom MetaTrader 5 zu erhalten und diese Informationen für die Ausführung der endgültigen Handelsentscheidungen zu verwenden.
def trading_loop(): global model if model is None: if not load_model(): print("Model not loaded, skipping trading loop.") return False
Zunächst muss sichergestellt werden, dass eine globale Variable mit dem Namen model ein Objekt enthält. Ist dies nicht der Fall, wird das beste Modell für das jeweilige Instrument und den jeweiligen Zeitrahmen geladen.
Nach erfolgreichem Lesen des Modells erhalten wir Echtzeitdaten und führen das Feature-Engineering auf ähnliche Weise durch wie beim Training.
try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, 1, config.max_encoder_length + config.max_prediction_length)) ts_df = feature_engineering(df) except Exception as e: print(f"Failed to get realtime data from MetaTrader 5: {e}") return False
Anschließend übergeben wir die Daten an ein Modellobjekt und erhalten die Vorhersagen.
Da wir eine einzige Gruppe in den Trainingsdaten haben, reduzieren wir das 2-dimensionale Array auf ein 1-dimensionales NumPy-Array.
predictions = model.predict(data=ts_df, mode="prediction")
predictions = np.array(predictions).ravel() Da wir das Modell mit der Variablen max_prediction_length auf die Vorhersage von 6 Schritten trainiert haben, wird das Modell immer 6 vorhergesagte Werte für 6 aufeinanderfolgende Balken nach der letzten bekannten Beobachtung liefern.
Wir müssen auswählen, für welchen Balken wir die Vorhersage verwenden wollen, was auch immer wir wollen (in diesem Fall für die Festlegung unserer Stop-Loss- und Take-Profit-Werte).
forecast_index = -1 # last-step forecast predicted_return = predictions[forecast_index]
Wir müssen darauf achten, wie wir die Zielvariable während des Trainings gestaltet haben, denn das sagt uns, wie wir die vorhergesagten Werte behandeln und verwenden sollten.
In diesem Fall haben wir das Modell so trainiert, dass es die täglichen Teilrenditen vorhersagt. Um einen geschätzten Marktwert zu erhalten, müssen wir den Wert mit dem letzten Schlusskurs multiplizieren (zur Erinnerung: die Renditen wurden auf der Grundlage der Schlusskurse berechnet).
price_delta = predicted_return * df["close"].iloc[-1]
Wir verwenden diesen Kurswert des Marktes, um den Stop-Loss und den Take-Profit für unseren Handel festzulegen, während wir gleichzeitig die vorhergesagte Rendite als Handelssignal verwenden (d.h. wenn die vorhergesagte Rendite negativ ist, ist das ein Abwärtssignal, und das Gegenteil für ein Aufwärtssignal).
# ------------ sl and tp according to model predictions ------------ if predicted_return > 0: tp = round(ask + price_delta, digits) sl = round(ask - abs(price_delta), digits) if not is_valid_sl_tp(sl=sl, tp=tp, price=ask): return if not pos_exists(magic_number=m_trade.magic_number, symbol=symbol, pos_type=mt5.POSITION_TYPE_BUY): if not m_trade.buy(symbol=symbol, volume=min_lotsize, price=ask, sl=sl, tp=tp): print(f"Buy order failed, Error = {mt5.last_error()} | price= {ask}, sl= {sl}, tp= {tp}") else: tp = round(bid - abs(price_delta), digits) sl = round(bid + abs(price_delta), digits) if not is_valid_sl_tp(sl=sl, tp=tp, price=bid): return if not pos_exists(magic_number=m_trade.magic_number, symbol=symbol, pos_type=mt5.POSITION_TYPE_SELL): if not m_trade.sell(symbol=symbol, volume=min_lotsize, price=bid, sl=sl, tp=tp): print(f"Sell order failed, Error = {mt5.last_error()} | price= {bid}, sl= {sl}, tp= {tp}")
Kommt Ihnen etwas bekannt vor?
Die Module m_trade, m_symbol und andere sind MQL5-ähnliche Module, die uns das Leben in Python wie in MQL5 erleichtern sollen.
Nachfolgend wird gezeigt, wie sie in main.py deklariert wurden.
import MetaTrader5 as mt5 from Trade.PositionInfo import CPositionInfo from Trade.SymbolInfo import CSymbolInfo from Trade.Trade import CTrade # --------------- configure metatrader5 modules ------------------- if not mt5.initialize(): # initialize MetaTrader 5 print(f"failed to initialize MetaTrader5, Error = {mt5.last_error()}") exit() m_position = CPositionInfo(mt5_instance=mt5) m_trade = CTrade(mt5_instance=mt5, magic_number=123456, filling_type_symbol=symbol, deviation_points=100) m_symbol = CSymbolInfo(mt5_instance=mt5) m_symbol.name(symbol_name=symbol) # set symbol name
Wenn die Datei main.py ausgeführt wird, kann unser einfacher Bot seine allererste Handelsoperation auslösen.
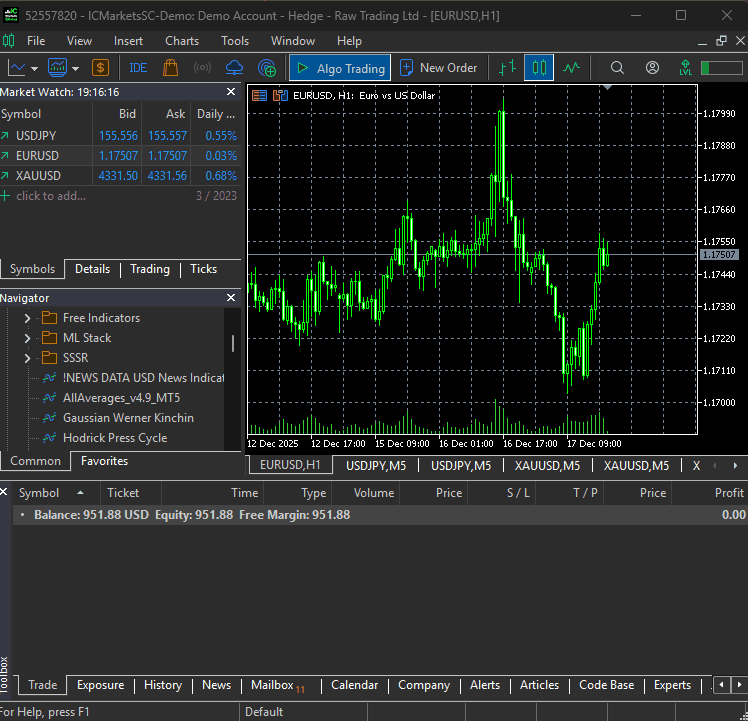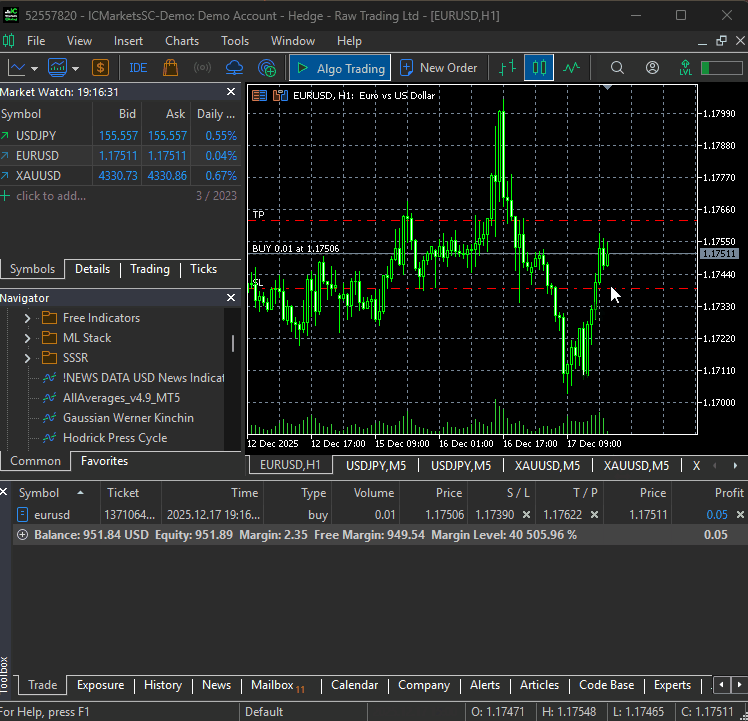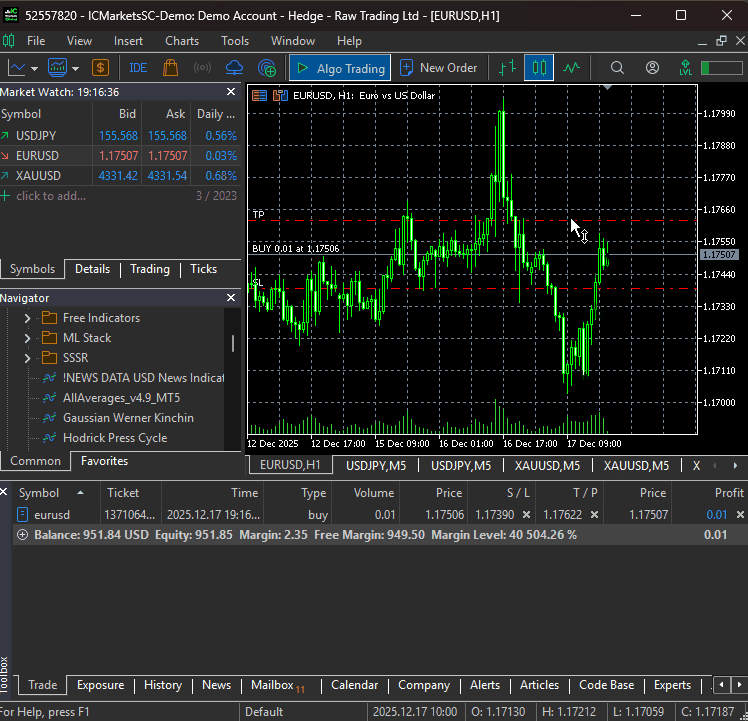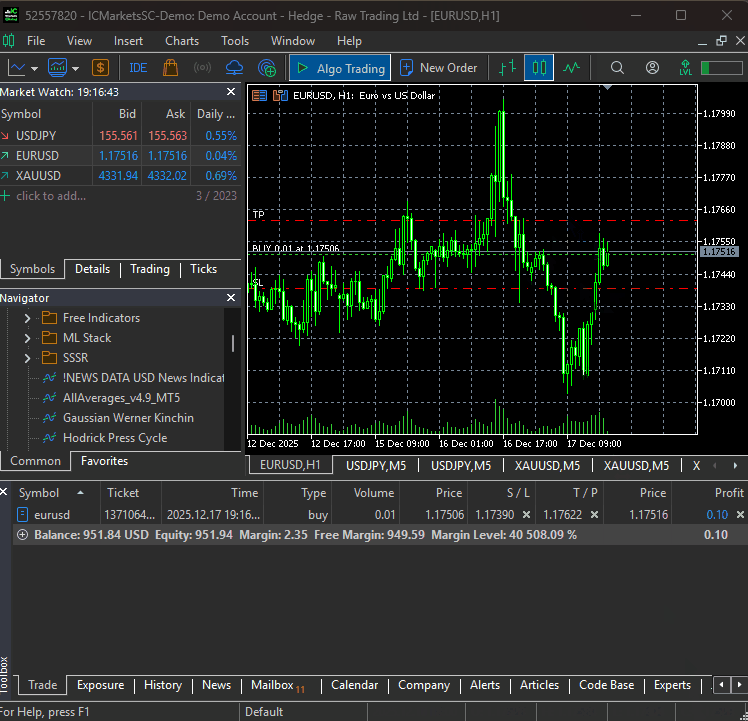
Ein Multiwährungsansatz im DeepAR-Modell
Wie bei den Kernprinzipien des DeepAR-Modells erörtert, ist es in der Lage, verschiedene Zeitreihen zu modellieren. Manche sagen, dass es sogar noch besser ist, wenn dieses Modell verschiedene Serien erhält, die ähnliche Muster aufweisen, da die gelernten Muster weitergegeben und das Modell dadurch besser verallgemeinert werden kann.
Um es mehrwährungsfähig zu machen, müssen wir unser Modell mit Daten aus allen gewünschten Instrumenten füttern.
Wir werden denselben Ansatz verfolgen, wobei wir die Datenerfassung und den Umgang mit zweidimensionalen Vorhersagen, die das Modell für verschiedene Zeitreihen und Zeitfenster (Vorhersagehorizonte) liefert, optimieren.
Anstelle einer einzelnen Variablen für ein bestimmtes Symbol haben wir jetzt ein Array mit mehreren Symbolen.
symbols = [ "EURUSD", "GBPUSD", "USDJPY", "USDCHF", "AUDUSD", "USDCAD", "NZDUSD" ] timeframe = mt5.TIMEFRAME_D1
Dieses Mal sammeln wir Daten (Kurse) von MetaTrader 5 über verschiedene Symbole.
Wir fügen alle neuen Zeilen am Ende eines großen Datenrahmens namens ts_df an.
def training_job(): global model # -------- feature engineering --------- ts_df = pd.DataFrame() for symbol in symbols: try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, config.train_start_bar, config.train_total_bars)) temp_df = feature_engineering(df, symbol) ts_df = pd.concat([ts_df, temp_df], axis=0, ignore_index=True) except Exception as e: print(f"Failed to get historical data from MetaTrader 5: {e} for symbol {symbol}") continue print(ts_df.head()) print(ts_df.tail())
Ausgabe:
time_idx returns symbol hour day_of_week month 0 0 0.023229 EURUSD 0 2 4 1 1 0.013703 EURUSD 0 3 4 2 2 -0.000493 EURUSD 0 4 4 3 3 -0.006018 EURUSD 0 0 4 4 4 0.010389 EURUSD 0 1 4 time_idx returns symbol hour day_of_week month 1248 174 0.006002 NZDUSD 0 1 12 1249 175 -0.001272 NZDUSD 0 2 12 1250 176 -0.001670 NZDUSD 0 3 12 1251 177 -0.002759 NZDUSD 0 4 12 1252 178 0.000017 NZDUSD 0 0 12
Innerhalb der Funktion trading_loop sammeln wir Daten ähnlich wie beim Training (diesmal innerhalb einer for-Schleife).
# ----------- get realtime data from MetaTrader 5 ----------- ts_df = pd.DataFrame() for symbol in symbols: try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, 1, config.max_encoder_length + config.max_prediction_length)) temp_df = feature_engineering(df, symbol) ts_df = pd.concat([ts_df, temp_df], axis=0, ignore_index=True) except Exception as e: print(f"Failed to get realtime data from MetaTrader 5: {e} for symbol {symbol}") continue
Wir benötigen eine weitere Schleife für mehrere Symbole (Mehr-Währung).
# ---------- use the model to make predictions ---------- predictions = model.predict(data=ts_df, mode="prediction") predictions = np.array(predictions) # print("Predictions: ", predictions) forecast_index = -1 # last-step forecast for idx, (symbol, m_trade, m_symbol) in enumerate(zip(symbols, m_trades, m_symbols)): # get latest symbol info if not m_symbol.refresh_rates(): print(f"failed to refresh rates for symbol {symbol}, Error = {mt5.last_error()}") return min_lotsize = m_symbol.lots_min() ask = m_symbol.ask() bid = m_symbol.bid() # ------------ Get a corresponding prediction ----------- predicted_return = predictions[idx][forecast_index] price_delta = predicted_return * df["close"].iloc[-1] digits = m_symbol.digits() # ------------ sl and tp according to model predictions ------------ if predicted_return > 0: tp = round(ask + price_delta, digits) sl = round(ask - abs(price_delta), digits) if not is_valid_sl_tp(sl=sl, tp=tp, price=ask, m_symbol=m_symbol): return if not pos_exists(magic_number=m_trade.magic_number, symbol=symbol, pos_type=mt5.POSITION_TYPE_BUY, m_symbol=m_symbol): if not m_trade.buy(symbol=symbol, volume=min_lotsize, price=ask, sl=sl, tp=tp): print(f"Buy order failed, Error = {mt5.last_error()} | price= {ask}, sl= {sl}, tp= {tp}") else: tp = round(bid - abs(price_delta), digits) sl = round(bid + abs(price_delta), digits) if not is_valid_sl_tp(sl=sl, tp=tp, price=bid, m_symbol=m_symbol): return if not pos_exists(magic_number=m_trade.magic_number, symbol=symbol, pos_type=mt5.POSITION_TYPE_SELL, m_symbol=m_symbol): if not m_trade.sell(symbol=symbol, volume=min_lotsize, price=bid, sl=sl, tp=tp): print(f"Sell order failed, Error = {mt5.last_error()} | price= {bid}, sl= {sl}, tp= {tp}")
Wenn unserem Modell während des Trainings mehrere Gruppen zugewiesen werden, erzeugt das Inferenzmodell ein 2-dimensionales Array von Vorhersagen in der Form (group_ids, predictions).
predicted_return = predictions[idx][forecast_index] price_delta = predicted_return * df["close"].iloc[-1]
Da dieser Bot nun mehrere Währungen umfasst, müssen wir die Klassen SymbolInfo und CTrade für jedes Instrument anders behandeln.
m_trades = [CTrade(mt5_instance=mt5, magic_number=123456, filling_type_symbol=symbol, deviation_points=100) for symbol in symbols] m_symbols = [] for symbol in symbols: s = CSymbolInfo(mt5_instance=mt5) s.name(symbol) m_symbols.append(s)
Nach dem Training des Modells sollten wir in der Lage sein, Handelsgeschäfte von allen angegebenen Instrumenten zu erhalten.
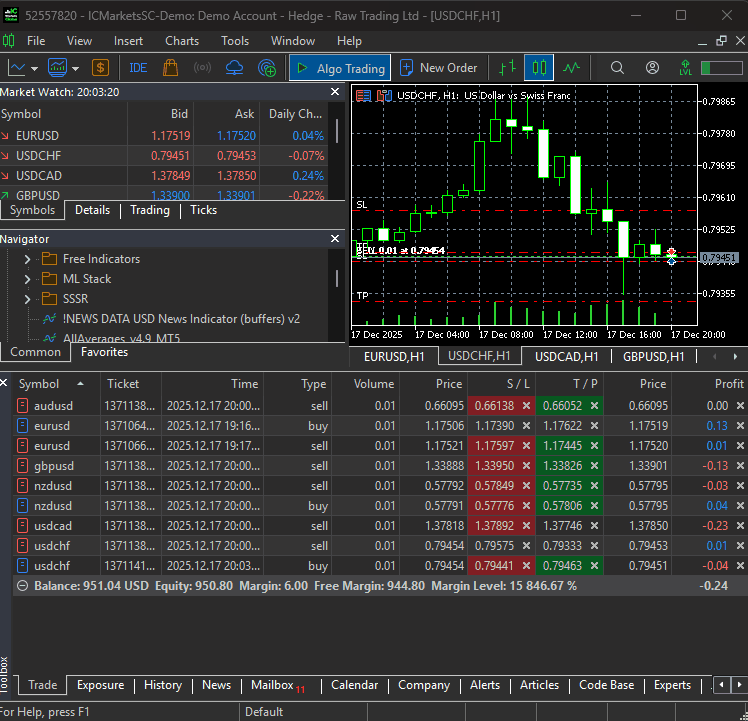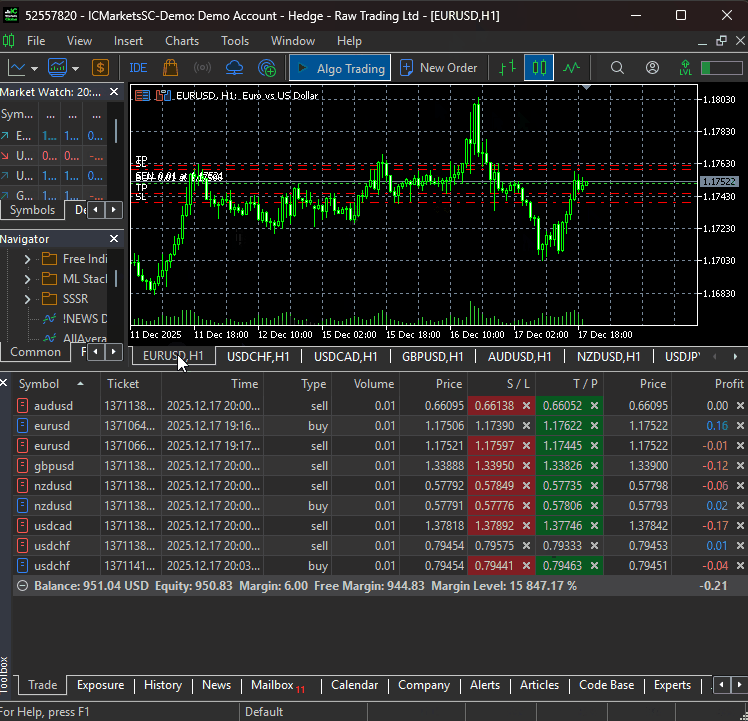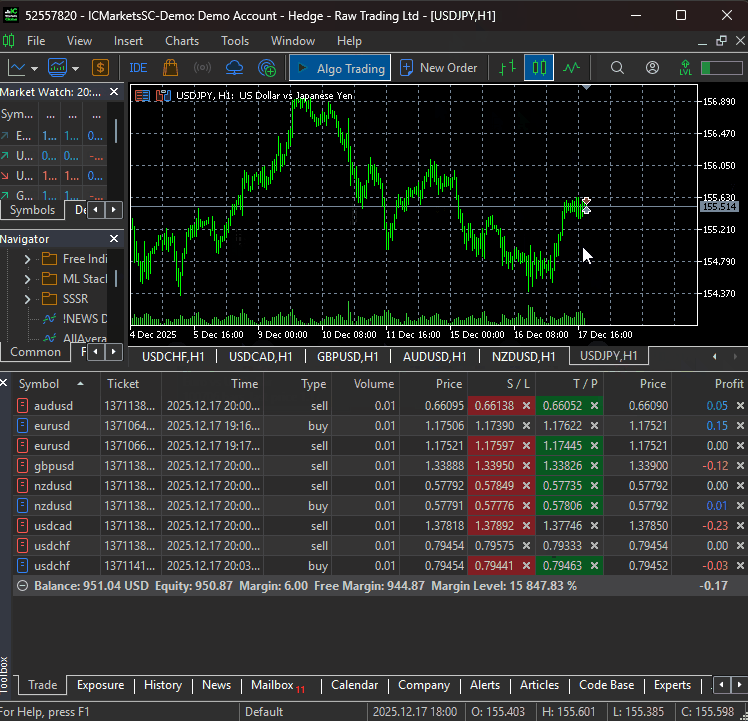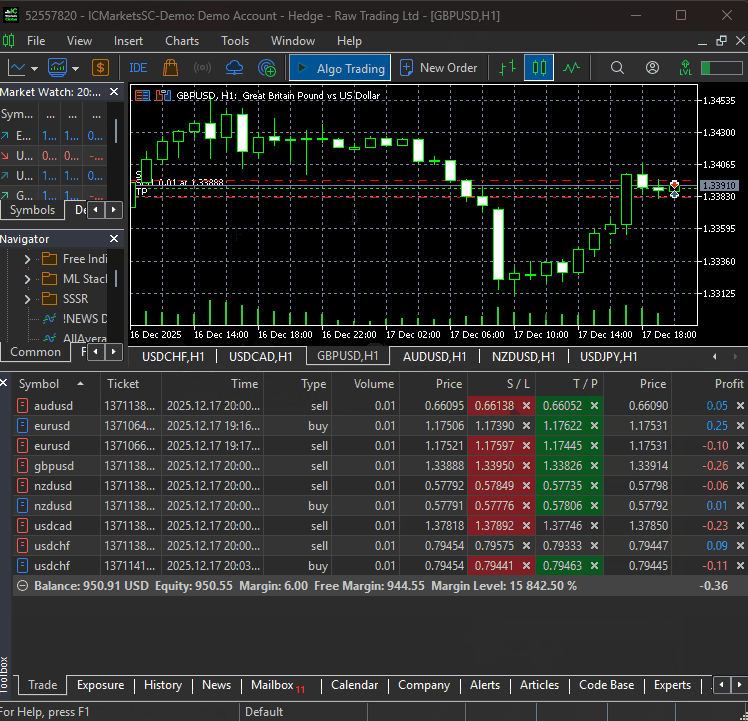
Die Quintessenz
Das DeepAR-Modell ist eine solide Wahl für probabilistische Zeitreihenprognosen, aber es hat einige Nachteile, die anerkannt werden müssen, einschließlich der Annahme, dass zukünftige Werte hauptsächlich von der Vergangenheit abhängen (was nicht immer der Fall ist).
Wie die klassischen Modelle für die Zeitreihenprognose hängt es von der Stationarität der Daten ab und geht davon aus, dass sich ähnliche Dynamiken in den Daten im Laufe der Zeit wiederholen. Wie wir alle wissen, ändern sich die Finanzmärkte schnell, und so etwas wie Stationarität gibt es die meiste Zeit über nicht.
Im Moment gibt es keine Möglichkeit, die Effektivität dieses speziellen Modells in einer realen Handelsumgebung zu testen; wir können uns nur auf die vorhergesagten Plots verlassen, um zu prüfen, wie nahe die Prognosen des Modells an den wahren Werten des Marktes liegen.
Tschüss.
Tabelle der Anhänge
| Dateiname | Beschreibung und Verwendung |
|---|---|
| main.py | Die wichtigste Python-Datei für die Zusammenstellung aller Module, das Training von Machine-Learning-Modellen und die Eröffnung von Handelsgeschäften in MetaTrader 5. |
| configs.py | Eine Python-Konfigurationsdatei, die alle notwendigen Variablen enthält. Sie gibt unserem Projekt einen globalen Raum zur Abstimmung. |
| train.py | Enthält eine Funktion und Module für das Training des DeepAR-Modells. |
| error_description.py | Es verfügt über Funktionen zur Interpretation von MetaTrader 5-Fehlercodes in menschenlesbare Meldungen (Fehler). |
| Trade/ | Ein ähnliches Verzeichnis wie MQL5/Include/Trade. Dieser Pfad enthält Python-Module, die den Standard-Klassenbibliotheken ähneln. |
| requirements.txt | Enthält alle Python-Abhängigkeiten und ihre Version(en), die in diesem Projekt verwendet werden. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/20571
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Sehr interessanter Artikel!
Haben Sie irgendwelche Bücher, die ich einsehen kann, um diese Themen zu vertiefen?
Ich habe über ARIMAS, GARCH und VAR gelesen, aber ich weiß nicht, wo ich mehr über ARIMAs und ML-Modelle erfahren kann!