
データサイエンスとML(第47回):DeepARモデルによるPythonでの市場予測

内容
- はじめに
- DeepARとは
- DeepARの動作原理
- DeepARモデルのためのデータ準備
- PythonによるDeepARモデルの学習
- DeepARモデルを用いたリアルタイム市場予測
- DeepARモデルにおける複数通貨アプローチ
- 結論
はじめに
時系列予測は、機械学習において容易な課題ではありません。この問題に対処するために、これまで多くの手法やモデルが提案されてきましたが、その多くは決定的な成功を収めているとは言えません。線形モデルや非線形モデルも、時系列データの予測においてある程度の精度を示すことはありますが、多くの場合、このタスクに十分適しているとは言えません。
こうした時系列予測に取り組むため、トレーダーはリカレントニューラルネットワーク(RNN)などのニューラルネットワークベースのモデルに頼るようになりました。
しかしながら、RNNは時系列モデルというよりも、むしろ非線形モデルに近い性質を持っています。自己回帰和分移動平均モデル(ARIMA)や自己回帰モデル(AR)に詳しい方であれば、その違いに気づいているかもしれません。これらの手法では、ニューラルネットワークが時系列パターンを学習できるようにするために、データをウィンドウ形式に変換する追加の前処理が必要になります。それにもかかわらず、従来の時系列予測モデルが考慮するような季節性パターンには、依然として十分に対応できていません。

本記事では、DeepARモデルについて解説します。DeepARは自己回帰型ニューラルネットワークモデルです。ニューラルネットワークを用いるため非線形モデルのように振る舞う一方で、ARIMAのような古典的な時系列モデルに見られる自己回帰的な性質も備えています。
DeepARとは
公式ドキュメントによると:
Amazon SageMakerのDeepAR予測アルゴリズムは、リカレントニューラルネットワーク(RNN)を用いてスカラー値の時系列を予測するための教師あり学習アルゴリズムです。 ARIMAや指数平滑化(ETS)といった従来の予測手法では、個々の時系列ごとに単一のモデルを構築し、そのモデルを用いて将来へ外挿します。
しかし多くのアプリケーションでは、横断的に互いに類似した時系列が多数存在します。たとえば、製品ごとの需要、サーバーの負荷、ウェブページへのリクエストなどが挙げられます。このようなケースでは、すべての時系列に対して個別にモデルを作るのではなく、単一のモデルを一括で学習させることで性能向上が期待できます。DeepARはまさにこのアプローチを採用しています。データセットに数百もの関連する時系列が含まれている場合、DeepARは標準的なARIMAやETSよりも優れた性能を示します。また、学習済みモデルを用いて、学習に使ったものと類似した新しい時系列に対しても予測を生成できます。
それでは、このモデルの主要な原理について見ていきましょう。
DeepARの動作原理
DeepARモデルの主要な動作原理は以下のとおりです。
01:確率的時系列予測
DeepARは、将来の値に対する単一の点推定を出力するだけではなく、将来の各時点における出力の確率分布全体を学習します。
これにより、モデルは不確実性を表現でき、予測区間や分位数(例:P10、P50、P90など)を生成することができます。これらの予測は、リスクを考慮した意思決定において非常に有用です。
02:複数系列にわたるグローバルモデリング
ARIMAやETSといった従来の予測モデルが各時系列ごとに個別のモデルを構築するのに対し、DeepARは関連する多数の時系列をまとめて単一のモデルとして学習します。
このグローバルモデルは共通のパターンを学習し、特に個々の時系列データ量が限られている場合に性能を向上させます。未観測の類似時系列にも一般化できます。
03:自己回帰型ニューラルネットワークアーキテクチャ
DeepARはRNNベースの設計を採用しており、通常はLSTMセルを自己回帰的な形で使用します。これは、モデルの予測が過去の観測値だけでなく、これまでに生成した予測値にも依存することを示します。
その結果、トレンド、季節性、非線形な変動といった時系列データの時間的依存関係を捉えることが可能になります。
04:静的特徴量と動的特徴量の利用
静的(カテゴリ)特徴量と動的(時間依存)特徴量の両方を扱います。
- 静的(カテゴリ)特徴量:製品カテゴリや地域など
- 動的(時間依存)特徴量:価格など
この点は、XGBoostや一般的なニューラルネットワークのような非線形モデルとの大きな違いの一つです。
05:時間情報を考慮した特徴量エンジニアリング
DeepARは、曜日や月などの時間的特徴量を時系列データから自動的に導出し、明示的な特徴量設計を大幅に減らしながら、季節性や周期的パターンを学習できるようにします。
これによって、通常の時系列予測で必要となる時間ベースの特徴量作成にかかる手間を大きく削減できます。
以下は、基本的な時間頻度ごとの派生特徴量の一覧です。
| 時系列の頻度 | 派生特徴量 |
|---|---|
| 分 | minute-of-hour、hour-of-day、day-of-week、day-of-month、day-of-year |
| 時間 | hour-of-day、day-of-week、day-of-month、day-of-year |
| 日 | day-of-week、day-of-month、day-of-year |
| 週 | day-of-month、week-of-year |
| 月 | month-of-year |
06:コンテキスト長と予測ウィンドウのサンプリング
このモデルでは、過去のどの程度の期間を参照し、将来のどこまでを予測するかを制御できます。
ハイパーパラメータであるcontext_lengthとprediction_lengthによって、それぞれモデルが参照する過去の履歴の長さと、予測する将来の期間を調整します。
07:欠損値の処理
DeepARは時系列データに含まれる欠損値をネイティブに処理できます。そのため、データが不完全であっても、外部で補完処理をおこなう必要はなく、予測精度を維持することが可能です。
DeepARモデルのためのデータ準備
モデルの基本原理を理解したところで、次にPythonで実装し、その性能を確認していきます。
まず、この記事の末尾にあるrequirements.txtに記載された依存ライブラリを仮想環境にインストールします。
pip install -r requirements.txt
その後、main.py内で必要なモジュールをインポートします。
import pandas as pd import torch import lightning.pytorch as pl import matplotlib.pyplot as plt import pytorch_forecasting from pytorch_forecasting import Baseline, DeepAR, TimeSeriesDataSet, GroupNormalizer from lightning.pytorch.callbacks import EarlyStopping from pytorch_forecasting.metrics import SMAPE, MultivariateNormalDistributionLoss, QuantileLoss from pytorch_forecasting import DeepAR import MetaTrader5 as mt5 import warnings
すべての機械学習モデルは学習のためのデータを必要とするため、ここではMetaTrader 5からデータを取得します。
if not mt5.initialize(): # initialize MetaTrader 5 print(f"failed to initialize MetaTrader5, Error = {mt5.last_error()}") exit() symbol = "EURUSD" df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 1, 1000)) print(df.head())
出力結果は以下のとおりです。
time open high low close tick_volume spread real_volume 0 1760598000 1.16621 1.16623 1.16559 1.16563 1209 0 0 1 1760601600 1.16561 1.16615 1.16541 1.16602 2113 0 0 2 1760605200 1.16602 1.16680 1.16521 1.16539 3925 0 0 3 1760608800 1.16539 1.16569 1.16431 1.16521 4533 0 0 4 1760612400 1.16518 1.16599 1.16487 1.16591 3948 0 0
まず、time列を秒単位からdatetime型のオブジェクトに変換します。
df['time'] = pd.to_datetime(df['time'], unit='s')
次に、値を時間列に基づいて並べ替えます。
df = df.sort_values("time").reset_index(drop=True)
出力結果は以下のとおりです。
time open high low close tick_volume spread real_volume 0 2025-10-16 07:00:00 1.16621 1.16623 1.16559 1.16563 1209 0 0 1 2025-10-16 08:00:00 1.16561 1.16615 1.16541 1.16602 2113 0 0 2 2025-10-16 09:00:00 1.16602 1.16680 1.16521 1.16539 3925 0 0 3 2025-10-16 10:00:00 1.16539 1.16569 1.16431 1.16521 4533 0 0 4 2025-10-16 11:00:00 1.16518 1.16599 1.16487 1.16591 3948 0 0
TimeSeriesDatasetオブジェクト(pytorch_forecastingモデルのための時系列データを準備するのに役立つオブジェクト)を作成するには、time_idx列とgroup_id(任意)が必要です。
df["time_idx"] = (df["time"] - df["time"].min()).dt.total_seconds().astype(int) // 3600 df["symbol"] = symbol
time_idx列は、データフレーム内のすべての行における時間の順序を表します。
symbol列は、データフレーム内に存在する異なる金融商品をグループ化するために使用されます。この場合、グループはEURUSDの1つだけです。
可視化すると、データフレームは次のようになります。
time open high low close tick_volume spread real_volume time_idx symbol 0 2025-10-16 07:00:00 1.16621 1.16623 1.16559 1.16563 1209 0 0 0 EURUSD 1 2025-10-16 08:00:00 1.16561 1.16615 1.16541 1.16602 2113 0 0 1 EURUSD 2 2025-10-16 09:00:00 1.16602 1.16680 1.16521 1.16539 3925 0 0 2 EURUSD 3 2025-10-16 10:00:00 1.16539 1.16569 1.16431 1.16521 4533 0 0 3 EURUSD 4 2025-10-16 11:00:00 1.16518 1.16599 1.16487 1.16591 3948 0 0 4 EURUSD
改めて、DeepARモデルは1次元のモデルであり、単一の変数に対して学習をおこない、その変数の過去の値から将来の値を予測するようになっています。
通常、私たちは終値を予測することを目的とするため、close列だけが必要な特徴量になります。
しかしながら、終値は連続値であり、そのまま予測することはこのモデルにとっても容易ではない場合があります。時系列予測では、その性質上、平均や分散が時間によって変化しない定常データを扱うことが一般的です。
目的変数の作成
このタスクでは、モデルに収益率を予測させるようにします。
df["returns"] = (df["close"].shift(-1) - df["close"]) / df["close"] df = df.dropna().reset_index(drop=True)
その後、時系列データオブジェクトに必要な3つの列だけをデータフレームから抽出します。
ts_df = df[["time_idx", "returns", "symbol"]]
出力は以下のようになります。
time_idx returns symbol 0 0 0.000335 EURUSD 1 1 -0.000540 EURUSD 2 2 -0.000154 EURUSD 3 3 0.000601 EURUSD 4 4 -0.000069 EURUSD
適切なデータフレームが用意できたので、まず学習用のTimeSeriesDatasetオブジェクトを作成します。
max_encoder_length = 24 max_prediction_length = 6 training_cutoff = df["time_idx"].max() - max_prediction_length training = TimeSeriesDataSet( data=ts_df[ts_df.time_idx <= training_cutoff], time_idx="time_idx", target="returns", group_ids=["symbol"], max_encoder_length=max_encoder_length, max_prediction_length=max_prediction_length, min_encoder_length=1, allow_missing_timesteps=True, time_varying_known_reals=["time_idx"], time_varying_unknown_reals=["returns"], target_normalizer=GroupNormalizer(groups=["symbol"], transformation="log1p") )
max_encoder_lengthは、モデルが過去をどれだけ参照するかを指定します。
max_prediction_lenghは、モデルの予測の先読みの長さ(予測ホライズン)を表します。
その後、学習データと同様に、検証データ用のオブジェクトを作成します。
validation = TimeSeriesDataSet.from_dataset(training, ts_df, min_prediction_idx=training_cutoff + 1) 原理の説明でも述べたように、DeepARモデルには、データセット内のdatetimeに基づいて時間関連の追加特徴量を自動的に生成する仕組みがあります。
これは、Amazon SageMaker AIが提供するDeepARモデルを明示的に使用する場合に該当します。ただし、十分なドキュメントを見つけることができなかったため、本記事ではPyTorch Forecastingモジュールを用い、時間特徴量を手動で追加する形でモデルを実装していきます。
df["hour"] = df["time"].dt.hour.astype(str) df["day_of_week"] = df["time"].dt.dayofweek.astype(str) df["month"] = df["time"].dt.month.astype(str) ts_df = df[["time_idx", "returns", "symbol", "hour", "day_of_week", "month"]]
PythonによるDeepARモデルの学習
DeepARモデルの学習には、PyTorch Forecastingで一般的に用いられるデータローダーが必要です。
batch_size = 64 train_dataloader = training.to_dataloader(train=True, batch_size=batch_size, num_workers=0, batch_sampler="synchronized") val_dataloader = validation.to_dataloader(train=False, batch_size=batch_size, num_workers=0, batch_sampler="synchronized")
次に、モデルを学習させるためのTrainerを用意します。ここではLightningモジュールを使用します。
# create trainer trainer = pl.Trainer( max_epochs=100, accelerator="gpu" if torch.cuda.is_available() else "cpu", gradient_clip_val=0.1, callbacks=[EarlyStopping(monitor="val_loss", patience=10, mode="min")], )
この設定では、最大100エポックまで学習をおこない、検証損失(val_loss)を監視します。そして、改善が見られない場合は早期停止によって学習を自動的に終了します。
その後、先ほど作成したTrainerオブジェクトを用いてDeepARモデルを学習させます。
trainer.fit( model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, )
出力結果は以下のとおりです。
┏━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━┳━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃Mode ┃FLOPs ┃ ┡━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━╇━━━━━━━━┩ │ 0 │ loss │ MultivariateNormalDistributionLoss │ 0 │ train │ 0 │ │ 1 │ logging_metrics │ ModuleList │ 0 │ train │ 0 │ │ 2 │ embeddings │ MultiEmbedding │ 245 │ train │ 0 │ │ 3 │ rnn │ LSTM │ 22.9 K │ train │ 0 │ │ 4 │ distribution_projector │ Linear │ 1.3 K │ train │ 0 │ └───┴────────────────────────┴────────────────────────────────────┴────────┴───────┴───────┘ Trainable params: 24.4 K Non-trainable params: 0 Total params: 24.4 K Total estimated model params size (MB): 0 Modules in train mode: 14 Modules in eval mode: 0 Total FLOPs: 0 Epoch 10/99 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 933/933 0:00:23 • 0:00:00 40.63it/s v_num: 38.000 train_loss_step: -7.305 val_loss: -60.929 train_loss_epoch: -44.401
学習プロセスが完了した後、trainerから最良のモデルを抽出します。
best_model_path = trainer.checkpoint_callback.best_model_path
best_model = DeepAR.load_from_checkpoint(best_model_path, weights_only=False) 評価のために予測を立てます。
raw_predictions = best_model.predict(val_dataloader, mode="raw", return_x=True)
最後に、評価のために予測結果をグラフ化します。
for idx in range(len(raw_predictions.x["decoder_time_idx"])): best_model.plot_prediction( raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True ) plt.show()
以下が出力(予測値と実測値を同じ軸上にプロットしたもの)です。
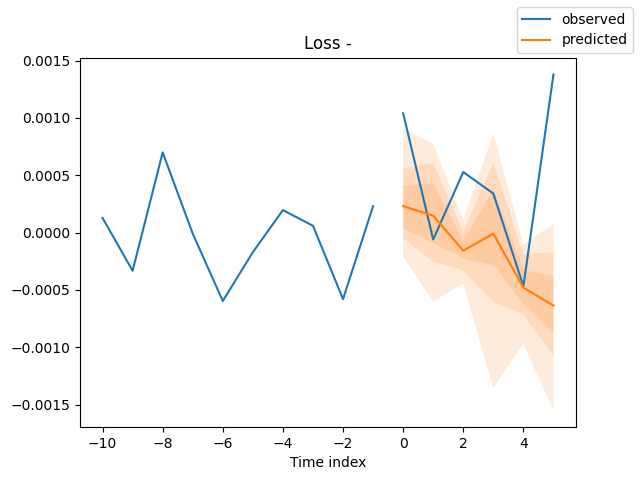
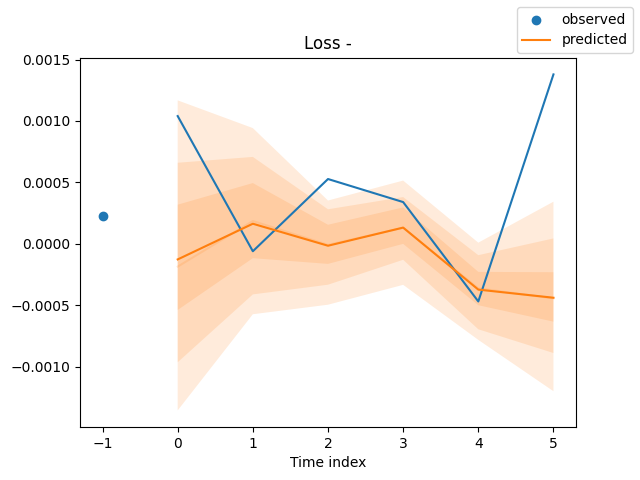
モデルを訓練する方法がわかったので、今度はモデルを使って有用な予測をしてみましょう。
DeepARモデルを用いたリアルタイム市場予測
作業を簡単にするために、学習処理は別ファイルに分離し、さらに特徴量の処理およびエンジニアリング専用の関数も別途用意する必要があります。
以下がtrain.pyファイルです。
import torch import lightning.pytorch as pl import matplotlib.pyplot as plt import pytorch_forecasting from pytorch_forecasting import DeepAR, TimeSeriesDataSet from lightning.pytorch.callbacks import EarlyStopping, ModelCheckpoint from pytorch_forecasting.metrics import MultivariateNormalDistributionLoss from pytorch_forecasting import DeepAR # from lightning.pytorch.tuner import Tuner import os import config import warnings warnings.filterwarnings("ignore") torch.serialization.add_safe_globals([pytorch_forecasting.data.encoders.GroupNormalizer]) torch.serialization.safe_globals([pytorch_forecasting.data.encoders.GroupNormalizer]) pl.seed_everything(config.random_seed) # set random seed for the lightning module def run(training: TimeSeriesDataSet, train_dataloader: any, val_dataloader: any, loss: pytorch_forecasting.metrics = MultivariateNormalDistributionLoss(rank=30), best_model_name: str=config.best_model_name) -> DeepAR: # model's checkpoint checkpoint_callback = ModelCheckpoint( dirpath=config.models_path, filename=best_model_name, save_top_k=1, mode="min", monitor="val_loss" ) # create trainer trainer = pl.Trainer( max_epochs=config.num_epochs, accelerator="gpu" if torch.cuda.is_available() else "cpu", gradient_clip_val=config.grad_clip, callbacks=[EarlyStopping(monitor="val_loss", patience=config.patience, mode="min"), checkpoint_callback], logger=False, ) # create DeepAR model model = DeepAR.from_dataset( training, learning_rate=config.learning_rate, hidden_size=config.hidden_size, rnn_layers=config.rnn_layers, dropout=config.dropout, # --- probabilistic forecasting --- loss=loss, log_interval=config.log_interval, log_val_interval=config.log_val_interval, ) res = None try: # find the optimal learning rate """ res = Tuner(trainer).lr_find( model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, early_stop_threshold=1000.0, max_lr=0.3, ) # and plot the result - always visually confirm that the suggested learning rate makes sense print(f"suggested learning rate: {res.suggestion()}") fig = res.plot(show=True, suggest=True) fig.savefig(os.path.join(config.images_path, "lr_finder.png")) """ # fit the model trainer.fit( model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, ) except Exception as e: raise RuntimeError(e) best_model_path = checkpoint_callback.best_model_path best_model = DeepAR.load_from_checkpoint(best_model_path, weights_only=False) # make probabilistic forecasts raw_predictions = best_model.predict(val_dataloader, mode="raw", return_x=True) # plot predictions # for idx in range(config.max_prediction_length): for idx in range(len(raw_predictions.x["decoder_time_idx"])): best_model.plot_prediction( raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True ) plt.savefig(os.path.join(config.images_path, "deepar_forecast_{}.png".format(idx+1))) # plt.show() return model
モデルの学習は計算資源を多く消費する処理であり、頻繁におこなうべきものではありません。そのため、あらかじめ学習済み(保存済み)のモデルを読み込むための関数が必要になります。
以下がmain.pyです。
def load_model(): global model try: model = DeepAR.load_from_checkpoint( checkpoint_path=os.path.join(config.models_path, config.best_model_name+".ckpt"), weights_only=False, ) except Exception as e: print(f"Failed to load model from checkpoint: {e}") model = None return False return True
推論モデルにデータを渡す前に、学習時と同じ特徴量の収集および特徴量エンジニアリングを適用する必要があります。そのため、必要な処理をすべてスタンドアロンの関数としてまとめておくのが適切です。
def feature_engineering(df: pd.DataFrame) -> pd.DataFrame: # convert time in seconds to datetime df['time'] = pd.to_datetime(df['time'], unit='s') df = df.sort_values("time").reset_index(drop=True) # print(df.head()) df["time_idx"] = np.arange(len(df)) df["symbol"] = symbol # print(df.head()) # instead of using close price, which is very hard to predict, let's use close price returns df["returns"] = (df["close"].shift(-1) - df["close"]) / df["close"] df = df.dropna().reset_index(drop=True) df["hour"] = df["time"].dt.hour.astype(str) df["day_of_week"] = df["time"].dt.dayofweek.astype(str) df["month"] = df["time"].dt.month.astype(str) return df[["time_idx", "returns", "symbol", "hour", "day_of_week", "month"]]
スケジュールに基づいて実行されるtraining_jobという関数の中では、まずデータの取得と特徴量エンジニアリングから処理を開始します。
以下はmain.pyファイルです。
def training_job(): global model # ----- feature engineering ----- try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, config.train_start_bar, config.train_total_bars)) ts_df = feature_engineering(df) except Exception as e: print(f"Failed to get historical data from MetaTrader 5: {e}") return print(ts_df.head())
生データをpandas.DataFrameとして取得した後は、以前と同様にTimeSeriesDataオブジェクトとデータローダーを作成する必要があります。
def training_job(): global model # ----- feature engineering ----- try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, config.train_start_bar, config.train_total_bars)) ts_df = feature_engineering(df) except Exception as e: print(f"Failed to get historical data from MetaTrader 5: {e}") return print(ts_df.head()) # ----- create timeseries datasets and dataloaders ----- training_cutoff = ts_df["time_idx"].max() - config.max_prediction_length training = TimeSeriesDataSet( data=ts_df[ts_df.time_idx <= training_cutoff], time_idx="time_idx", target="returns", group_ids=["symbol"], max_encoder_length=config.max_encoder_length, max_prediction_length=config.max_prediction_length, min_encoder_length=config.min_encoder_length, # min_prediction_length=1, allow_missing_timesteps=True, time_varying_known_categoricals=["hour", "day_of_week", "month"], time_varying_known_reals=["time_idx"], time_varying_unknown_reals=["returns"], target_normalizer=GroupNormalizer(groups=["symbol"], transformation="log1p") ) validation = TimeSeriesDataSet.from_dataset(training, ts_df, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, batch_size=config.batch_size, num_workers=config.num_workers, batch_sampler="synchronized") val_dataloader = validation.to_dataloader(train=False, batch_size=config.batch_size, num_workers=config.num_workers, batch_sampler="synchronized") model = train.run(training=training, train_dataloader=train_dataloader, val_dataloader=val_dataloader, loss=MultivariateNormalDistributionLoss(rank=30), best_model_name=config.best_model_name)
最後に、Scheduleモジュールを使用して、指定した時間間隔(分単位)ごとに学習処理を実行するようスケジューリングします。
import schedule #.... #.... schedule.every(config.train_interval_minutes).minutes.do(training_job)
ここで注目すべき点は、ほとんどの変数がconfig.some_variableという形になっていることです。 これは、多くの設定値がconfig.pyというファイルにまとめて保存されているためです。
すべての学習プロセスが整ったら、最後に必要となるのは、MetaTrader 5から最新のティックおよびレート情報を取得し、その情報を用いて最終的な取引判断を実行するための関数です。
def trading_loop(): global model if model is None: if not load_model(): print("Model not loaded, skipping trading loop.") return False
まず、modelという名前のグローバル変数にオブジェクトが存在していることを確認します。存在していない場合は、その特定の銘柄および時間足に対応する最良のモデルを読み込みます。
モデルの読み込みが正常に完了したら、リアルタイムデータを取得し、学習時と同様の手順で特徴量エンジニアリングを実行します。
try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, 1, config.max_encoder_length + config.max_prediction_length)) ts_df = feature_engineering(df) except Exception as e: print(f"Failed to get realtime data from MetaTrader 5: {e}") return False
次に、そのデータをモデルオブジェクトに渡し、予測結果を取得します。
単一グループのデータで学習しているため、予測結果は2次元配列として返されます。これを1次元のNumPy配列に変換してフラット化します。
predictions = model.predict(data=ts_df, mode="prediction")
predictions = np.array(predictions).ravel() 変数max_prediction_lengthを6に設定して学習しているため、モデルは常に直近の観測値の先にある6本分の連続したバーに対する予測値を返します。
そのため、どの時点の予測を使うかを選択する必要があります(たとえば、ストップロスやテイクプロフィットの設定などに利用)。
forecast_index = -1 # last-step forecast predicted_return = predictions[forecast_index]
学習時に目的変数をどのように設計したかを常に意識する必要があります。それによって、予測値の解釈方法も決まります。
今回のケースでは、日次のリターン(収益率)を予測するように学習させています。そのため、実際の市場価格として解釈するには、最新の終値に予測リターンを掛ける必要があります(リターンは終値ベースで計算されているためです)。
price_delta = predicted_return * df["close"].iloc[-1]
この価格変動量を用いて、ストップロスやテイクプロフィットの水準を構築します。また、予測されたリターンの符号そのものもトレードシグナルとして利用します(予測リターンが負であれば弱気シグナル、正であれば強気シグナルとなります)。
# ------------ sl and tp according to model predictions ------------ if predicted_return > 0: tp = round(ask + price_delta, digits) sl = round(ask - abs(price_delta), digits) if not is_valid_sl_tp(sl=sl, tp=tp, price=ask): return if not pos_exists(magic_number=m_trade.magic_number, symbol=symbol, pos_type=mt5.POSITION_TYPE_BUY): if not m_trade.buy(symbol=symbol, volume=min_lotsize, price=ask, sl=sl, tp=tp): print(f"Buy order failed, Error = {mt5.last_error()} | price= {ask}, sl= {sl}, tp= {tp}") else: tp = round(bid - abs(price_delta), digits) sl = round(bid + abs(price_delta), digits) if not is_valid_sl_tp(sl=sl, tp=tp, price=bid): return if not pos_exists(magic_number=m_trade.magic_number, symbol=symbol, pos_type=mt5.POSITION_TYPE_SELL): if not m_trade.sell(symbol=symbol, volume=min_lotsize, price=bid, sl=sl, tp=tp): print(f"Sell order failed, Error = {mt5.last_error()} | price= {bid}, sl= {sl}, tp= {tp}")
ここで、何か見覚えのあるものに気づくはずです。
m_trade、m_symbolなどのモジュールは、MQL5風に設計されたモジュールであり、Python上でもMQL5と同様に扱いやすくするためのものです。
以下は、それらがmain.py内でどのように宣言されているかの例です。
import MetaTrader5 as mt5 from Trade.PositionInfo import CPositionInfo from Trade.SymbolInfo import CSymbolInfo from Trade.Trade import CTrade # --------------- configure metatrader5 modules ------------------- if not mt5.initialize(): # initialize MetaTrader 5 print(f"failed to initialize MetaTrader5, Error = {mt5.last_error()}") exit() m_position = CPositionInfo(mt5_instance=mt5) m_trade = CTrade(mt5_instance=mt5, magic_number=123456, filling_type_symbol=symbol, deviation_points=100) m_symbol = CSymbolInfo(mt5_instance=mt5) m_symbol.name(symbol_name=symbol) # set symbol name
そのようなわけで、main.pyファイルを実行すると、シンプルなボットが初めての取引を実際に実行することができました。
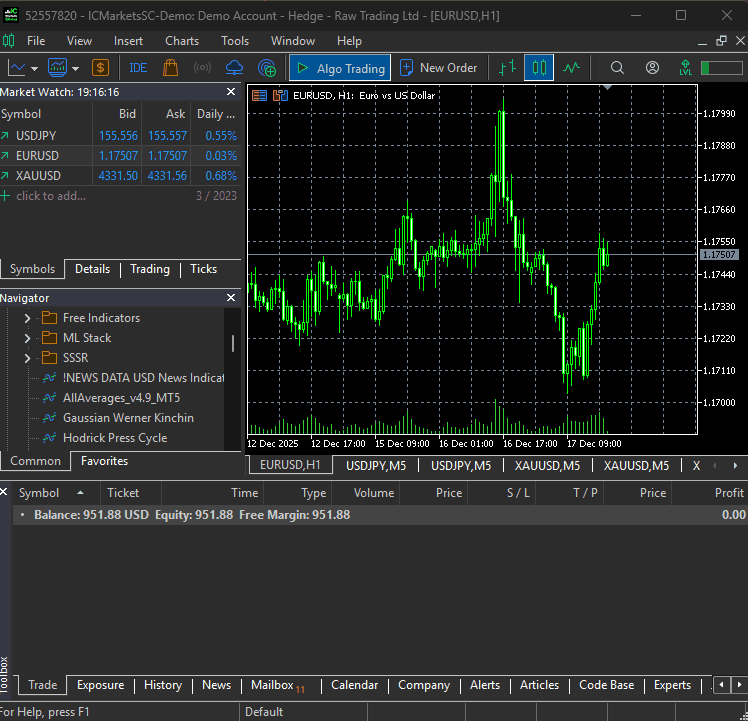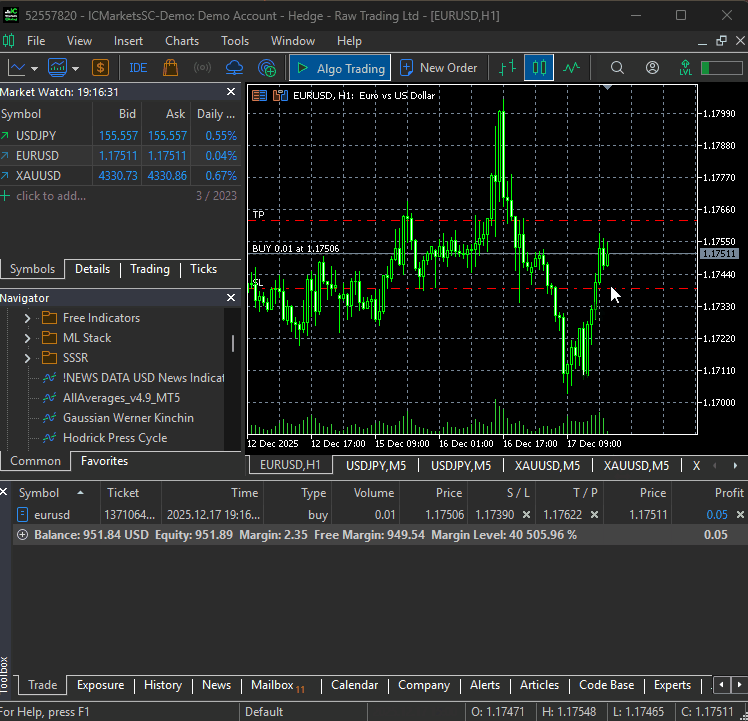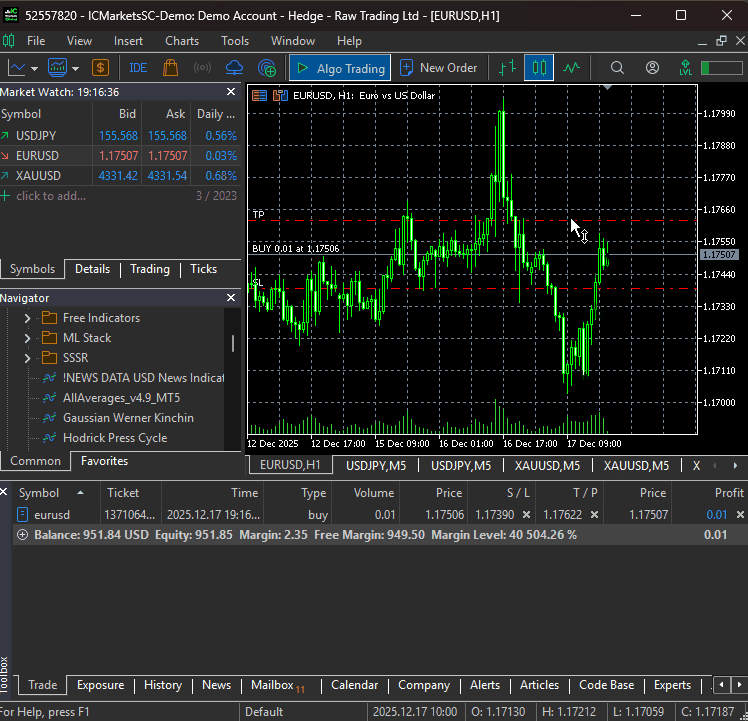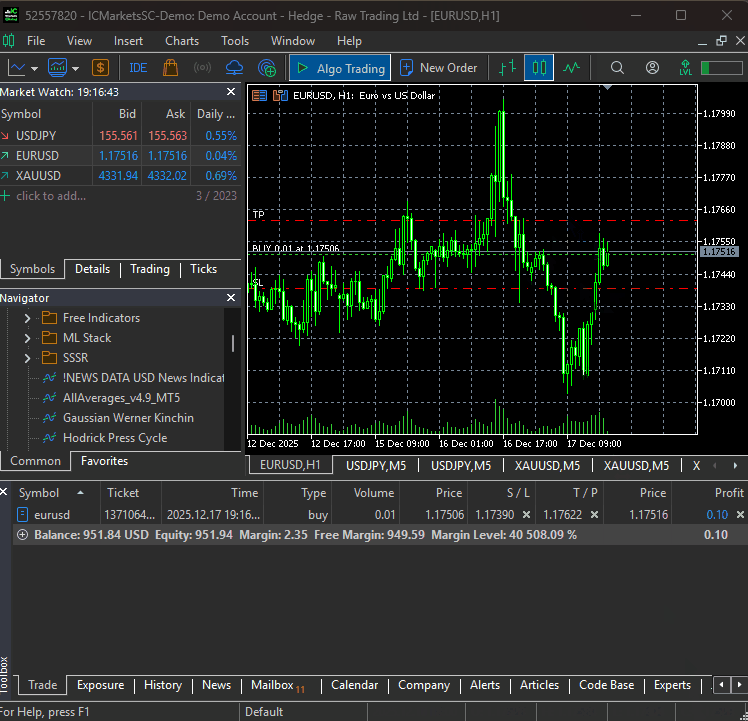
DeepARモデルにおける複数通貨アプローチ
DeepARモデルの基本原理でも述べたように、このモデルは異なる時系列をまたいだモデリングが可能です。むしろ、似たようなパターンを持つ複数の時系列データを同時に学習させることで、学習されたパターンが共有され、モデルの汎化性能が向上すると言われています。
通貨対応にするためには、モデルに複数の銘柄データをまとめて入力する必要があります。
基本的なアプローチは同じですが、データ収集の方法と、複数の時系列および予測ウィンドウ(予測ホライズン)に対応する2次元予測の扱いに若干の調整が必要になります。
これまでは単一の銘柄に対する単一変数を扱っていましたが、これが、複数銘柄を含む配列としてデータを扱う形になります。
symbols = [ "EURUSD", "GBPUSD", "USDJPY", "USDCHF", "AUDUSD", "USDCAD", "NZDUSD" ] timeframe = mt5.TIMEFRAME_D1
今回は、MetaTrader 5から複数の銘柄にわたってレートデータを収集します。
そして、新しく取得したすべての行を、大きなデータフレームであるts_dfの末尾に追加していきます。
def training_job(): global model # -------- feature engineering --------- ts_df = pd.DataFrame() for symbol in symbols: try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, config.train_start_bar, config.train_total_bars)) temp_df = feature_engineering(df, symbol) ts_df = pd.concat([ts_df, temp_df], axis=0, ignore_index=True) except Exception as e: print(f"Failed to get historical data from MetaTrader 5: {e} for symbol {symbol}") continue print(ts_df.head()) print(ts_df.tail())
出力結果は以下のとおりです。
time_idx returns symbol hour day_of_week month 0 0 0.023229 EURUSD 0 2 4 1 1 0.013703 EURUSD 0 3 4 2 2 -0.000493 EURUSD 0 4 4 3 3 -0.006018 EURUSD 0 0 4 4 4 0.010389 EURUSD 0 1 4 time_idx returns symbol hour day_of_week month 1248 174 0.006002 NZDUSD 0 1 12 1249 175 -0.001272 NZDUSD 0 2 12 1250 176 -0.001670 NZDUSD 0 3 12 1251 177 -0.002759 NZDUSD 0 4 12 1252 178 0.000017 NZDUSD 0 0 12
trading_loop関数の中では、学習時と同様の方法でデータを収集します。ただし今回は、それをforループの中で繰り返し実行する形になります。
# ----------- get realtime data from MetaTrader 5 ----------- ts_df = pd.DataFrame() for symbol in symbols: try: df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, timeframe, 1, config.max_encoder_length + config.max_prediction_length)) temp_df = feature_engineering(df, symbol) ts_df = pd.concat([ts_df, temp_df], axis=0, ignore_index=True) except Exception as e: print(f"Failed to get realtime data from MetaTrader 5: {e} for symbol {symbol}") continue
風数銘柄(複数通貨)に対応するためには、もう一つ別のループが必要になります。
# ---------- use the model to make predictions ---------- predictions = model.predict(data=ts_df, mode="prediction") predictions = np.array(predictions) # print("Predictions: ", predictions) forecast_index = -1 # last-step forecast for idx, (symbol, m_trade, m_symbol) in enumerate(zip(symbols, m_trades, m_symbols)): # get latest symbol info if not m_symbol.refresh_rates(): print(f"failed to refresh rates for symbol {symbol}, Error = {mt5.last_error()}") return min_lotsize = m_symbol.lots_min() ask = m_symbol.ask() bid = m_symbol.bid() # ------------ Get a corresponding prediction ----------- predicted_return = predictions[idx][forecast_index] price_delta = predicted_return * df["close"].iloc[-1] digits = m_symbol.digits() # ------------ sl and tp according to model predictions ------------ if predicted_return > 0: tp = round(ask + price_delta, digits) sl = round(ask - abs(price_delta), digits) if not is_valid_sl_tp(sl=sl, tp=tp, price=ask, m_symbol=m_symbol): return if not pos_exists(magic_number=m_trade.magic_number, symbol=symbol, pos_type=mt5.POSITION_TYPE_BUY, m_symbol=m_symbol): if not m_trade.buy(symbol=symbol, volume=min_lotsize, price=ask, sl=sl, tp=tp): print(f"Buy order failed, Error = {mt5.last_error()} | price= {ask}, sl= {sl}, tp= {tp}") else: tp = round(bid - abs(price_delta), digits) sl = round(bid + abs(price_delta), digits) if not is_valid_sl_tp(sl=sl, tp=tp, price=bid, m_symbol=m_symbol): return if not pos_exists(magic_number=m_trade.magic_number, symbol=symbol, pos_type=mt5.POSITION_TYPE_SELL, m_symbol=m_symbol): if not m_trade.sell(symbol=symbol, volume=min_lotsize, price=bid, sl=sl, tp=tp): print(f"Sell order failed, Error = {mt5.last_error()} | price= {bid}, sl= {sl}, tp= {tp}")
学習時にモデルへ複数グループを割り当てている場合、推論モデルは(group_ids, predictions))の形状を持つ2次元配列として予測結果を出力します。
predicted_return = predictions[idx][forecast_index] price_delta = predicted_return * df["close"].iloc[-1]
ボットが複数通貨対応になっているため、各銘柄ごとにSymbolInfoおよびCTradeクラスを個別に適切に扱う必要があります。
m_trades = [CTrade(mt5_instance=mt5, magic_number=123456, filling_type_symbol=symbol, deviation_points=100) for symbol in symbols] m_symbols = [] for symbol in symbols: s = CSymbolInfo(mt5_instance=mt5) s.name(symbol) m_symbols.append(s)
モデルの学習が完了した後は、指定したすべての銘柄から売買シグナルを受け取れるようになります。
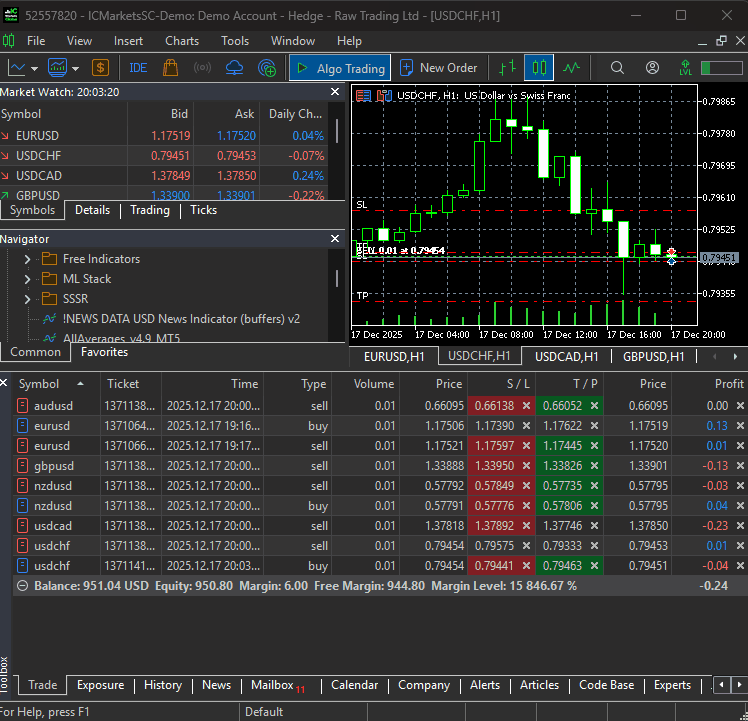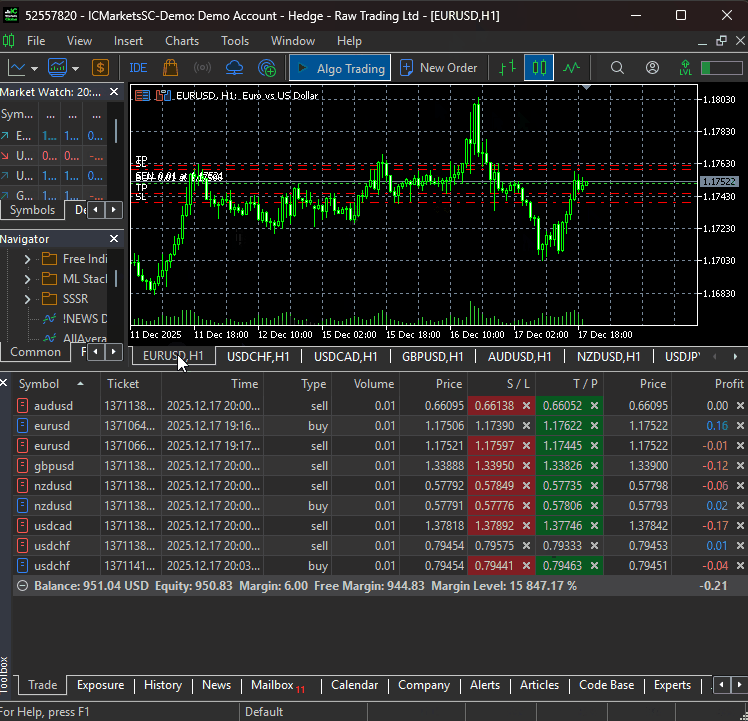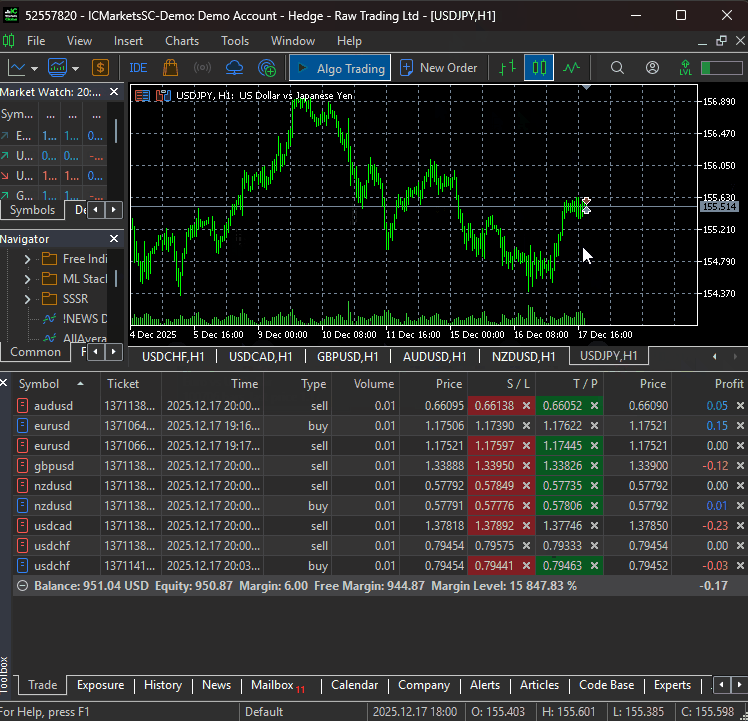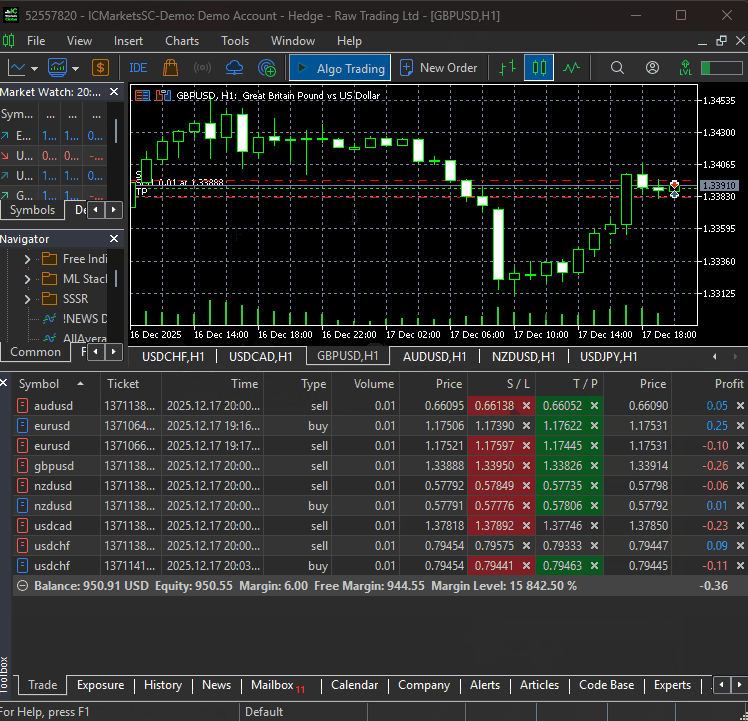
まとめ
DeepARモデルは確率的な時系列予測において非常に優れた選択肢ですが、いくつかの欠点も存在することを理解しておく必要があります。その一つは、将来の値が主に過去の値に依存するという前提を置いている点です(これは常に正しいとは限りません)。
時系列予測の古典的なモデルと同様に、このモデルもデータの定常性に依存しており、データ内の類似したダイナミクスが時間とともに繰り返されると仮定しています。しかし周知の通り、金融市場は急速に変化するため、実際には定常性が成り立たないことが多くあります。
現時点では、このモデルが実際のトレーディング環境でどれほど有効かを直接検証する方法はなく、市場の真の値とどれだけ予測が近いかを示す予測プロットに頼るしかありません。
では、また。
添付ファイルの表
| ファイル名 | 説明と使用法 |
|---|---|
| main.py | すべてのモジュールを統合し、機械学習モデルの学習およびMetaTrader 5での取引実行をおこなうメインPythonファイル |
| configs.py | 必要なすべての変数を管理する設定ファイル。プロジェクト全体のチューニング用のグローバル空間を提供する |
| train.py | DeepARモデルの学習処理を行う関数および関連モジュールを含む |
| error_description.py | MetaTrader 5のエラーコードを人間が読める形式に変換する関数を含む |
| Trade/ | MQL5/Include/Tradeと同様のディレクトリ。標準取引クラスのライブラリに相当するPythonモジュール |
| requirements.txt | このプロジェクトで使用するPython依存ライブラリとそのバージョン一覧 |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/20571
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
とても興味深い記事だ!
このトピックについてもっと深く知りたいのですが、調べられる本はありますか?
ARIMAS、GARCH、VARについては読んだことがあるのですが、ARIMAとMLモデルについてもっと詳しく知りたいのですが!