
经典策略重构(第14部分):多策略分析

在之前《自优化智能交易系统》姊妹系列的讨论中,我们曾尝试构建多策略组合,并将它们融合为一套比单一策略更强大的综合策略。
我们决定让这些策略以"民主投票”的方式协同工作:每个策略拥有一票表决权。每一票的权重作为可调参数,交由遗传优化器自动优化,以最大化策略的整体收益。随后,我们剔除了被遗传优化器赋予最小权重的策略,只保留两套策略,作为本次分析与建模的对象。
在本次研究中,我们基于遗传优化器得出的最优结果,通过 MQL5 脚本提取历史行情数据。需要说明的是,我们只选择回测与前向测试均表现稳定的结果作为决策依据。
然而,在仔细分析遗传优化器选出的这两套策略的收益曲线后,我们发现:它们彼此高度相关。换句话说,这两套策略几乎在同一时间盈利、同一时间亏损。使用两套高度相关的交易策略,效果并不比只用一套更好;而只用一套策略,就完全失去了多策略分析的意义。
利用人工智能构建交易策略时,很多环节都可能出问题。本次的情况是:遗传优化器 “钻了框架的漏洞”,选出了相关性最高的策略组合。单纯从数学角度看,这其实是一种 “聪明” 的选择:当主要选用的策略彼此相关时,优化器更容易预判账户的整体盈亏。
我最初预期,遗传优化器会给高收益策略分配更高权重,给低收益策略分配更低权重。但由于我们只有 3 套策略可选,且优化只执行了一次,因此不能排除这一结果纯属偶然。也就是说,如果我们改用更慢速、更全面的优化算法重新优化投票权重,优化器或许就不会选出高度相关的策略。
这一发现促使我重新设计策略参数的优选方案。我们应该先将所有策略的投票权重固定为 1。这样可以强制遗传优化器只专注于寻找各指标的最优参数。后续验证会证明:这套改进方案明显优于最初的设计。使用两套相关策略进行多策略分析,无法带来真正的提升。因此,我们总结出多策略分析更合理的目标定义:如何优选收益互不相关的多策略,从而最大化账户收益?
在 MQL5 中实现
我们首先编写一段脚本,使用前序测试中收益最大化的最优参数,提取历史行情数据 —— 也就是我们目前使用的两套策略的参数。系统会沿用此前遗传优化测试中得出的若干固定参数。在数据提取阶段,这套理想策略的所有参数均保持不变。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 100 //--- Period for our moving average #define MA_TYPE MODE_EMA //--- Type of moving average we have #define RSI_PERIOD 24 //--- Period For Our RSI Indicator #define RSI_PRICE PRICE_CLOSE //--- Applied Price For our RSI Indicator #define HORIZON 38 //--- Holding period #define TF PERIOD_H3 //--- Time Frame
我们的系统将依赖几个关键的全局变量,用于记录技术指标的数值;这些数值会存储在对应的指标句柄与数据缓冲区中,供脚本运行时调用。此外,我们还会定义其他变量,例如输出文件名、需要请求的数据量等。
//--- Our handlers for our indicators int ma_handle,ma_o_handle,rsi_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],rsi_reading[]; //--- File name string file_name = Symbol() + " Market Data As Series Multiple Strategy Analysis.csv"; //--- Amount of data requested input int size = 3000;
脚本的主体部分包含我们今天要完成的核心任务。我们会初始化所有指标,并将指标数值设置为时间序列模式,确保数据按从最早到最新的时间顺序排列。这是我们组织和输出数据的统一格式。在此基础上,我们将导出全部市场数据,并利用前文遗传优化器调好的周期参数,进行一系列算术计算,以追踪市场数据的历史变化。
//+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); rsi_handle = iRSI(_Symbol,TF,RSI_PERIOD,RSI_PRICE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(rsi_handle,0,0,fetch,rsi_reading); ArraySetAsSeries(rsi_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Open","True High","True Low","True Close","True MA C","True MA O","True RSI","Open","High","Low","Close","MA Close","MA Open","RSI"); } else { FileWrite(file_handle, iTime(_Symbol,TF,i), iOpen(_Symbol,TF,i), iHigh(_Symbol,TF,i), iLow(_Symbol,TF,i), iClose(_Symbol,TF,i), ma_reading[i], ma_o_reading[i], rsi_reading[i], iOpen(_Symbol,TF,i) - iOpen(_Symbol,TF,(i + HORIZON)), iHigh(_Symbol,TF,i) - iHigh(_Symbol,TF,(i + HORIZON)), iLow(_Symbol,TF,i) - iLow(_Symbol,TF,(i + HORIZON)), iClose(_Symbol,TF,i) - iClose(_Symbol,TF,(i + HORIZON)), ma_reading[i] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_o_reading[(i + HORIZON)], rsi_reading[i] - rsi_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
在 Python 中分析数据
现在,我们准备开始利用 Python 中常用的数值分析库对市场数据进行分析。首先,我们将导入 pandas 库以读取市场数据。
#Load our libraries import pandas as pd
接下来,我们将为训练策略在特定市场条件下应执行的操作打上标签,并计算每一次操作对应的盈亏结果。
#Read in the data data = pd.read_csv("EURUSD Market Data As Series Multiple Strategy Analysis.csv") #The optimal holding period suggested by our MT5 Genetic optimizer HORIZON = 38 #Calculate the true market return data['Return'] = data['True Close'].shift(-HORIZON) - data['True Close'] #The action suggested by our first strategy, MA Cross data['Action 1'] = 0 #The action suggested by our second strategy, RSI Strategy data['Action 2'] = 0 #Buy conditions data.loc[data['True MA C'] > data['True MA O'],'Action 1'] = 1 data.loc[data['True RSI'] > 50,'Action 2'] = 1 #Sell conditions data.loc[data['True MA C'] < data['True MA O'],'Action 1'] = -1 data.loc[data['True RSI'] < 50,'Action 2'] = -1 #Perform a linear transformation of the true market return, using our trading stragies data['Return 1'] = data['Return'] * data['Action 1'] data['Return 2'] = data['Return'] * data['Action 2'] data = data.iloc[:-HORIZON,:]
这是统计建模与交易系统搭建中至关重要的一步。我们必须确保模型不会对全体数据产生过拟合;否则,由于模型已经失效,任何分析与测试都将变得毫无意义。
#Drop our back test data _ = data.iloc[-((365 * 2 * 6)):,:] data = data.iloc[:-((365 * 2 * 6)),:]
为目标变量打标签,是所有监督式机器学习项目的核心环节。为了便于可视化展示,我们会对目标变量进行标注,用以区分策略 1 的收益高于策略 2,还是策略 2 的收益高于策略 1。我们的目标变量会明确告诉我们:策略 2 是否比策略 1 产生了更高的收益。作为对比参照,我们会用模型直接预测未来市场收益的能力作为基准。
#Gether inputs X = data.iloc[:,1:15] #Both Strategies will earn equal reward data['Target 1'] = 0 data['Target 2'] = 0 #Strategy 1 is more profitable data.loc[data['Return 1'] > data['Return 2'],'Target 1'] = 1 #Strategy 2 is more profitable data.loc[data['Return 2'] > data['Return 1'],'Target 2'] = 1 #Classical Target data['Classical Target'] = 0 data.loc[data['Return'] > 0,'Classical Target'] = 1
现在,我们将导入 scikit-learn 机器学习库,用于分析我们采集到的市场数据的数值特征。
#Loading our scikit learn libraries from sklearn.model_selection import TimeSeriesSplit,cross_val_score from sklearn.linear_model import LinearRegression,LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.neural_network import MLPRegressor from sklearn.model_selection import RandomizedSearchCV
我们首先创建5折时间序列交叉验证对象,并确保间隔参数与遗传优化器找到的最优展望期一致。接下来,我们计算数据列的均值与标准差,对数据集进行标准化处理,使其均值为 0、标准差为 1。
#Prepare the data for time series modelling tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Z1 = X.mean() Z2 = X.std() X = ((X-X.mean()) / X.std())
现在我们评估模型对新定义目标的预测准确率,并与直接预测未来收益率的传统目标进行对比。通过 scikit-learn 交叉验证工具,我们使用线性分类器评估准确率。随后将结果存入数组,并绘制柱状图。可以看到,模型对传统目标的预测准确率接近 50%,而判断哪一个策略收益更高的准确率约为 90%,表现显著优于传统目标。
#Measuring our accuracy on our new target res = [] model = LinearDiscriminantAnalysis() res.append(np.mean(np.abs(cross_val_score(model,X,data['Classical Target'],cv=tscv,scoring='accuracy')))) model = LinearDiscriminantAnalysis() res.append(np.mean(np.abs(cross_val_score(model,X,data['Target 1'],cv=tscv,scoring='accuracy')))) model = LinearDiscriminantAnalysis() res.append(np.mean(np.abs(cross_val_score(model,X,data['Target 2'],cv=tscv,scoring='accuracy',n_jobs=-1)))) sns.barplot(res,color='black') plt.xticks([0,1,2],['Classical Target','MA Cross Over Target','RSI Target']) plt.axhline(res[0],linestyle=':',color='red') plt.ylabel('5-Fold Percentage Accuracy %') plt.title('Outperforming The Classical Target of Direct Price Prediction')
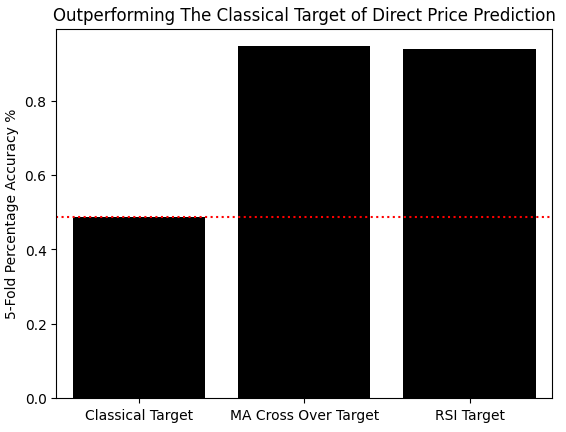
图 1:通过建模策略与市场之间的关系,我们在直接价格预测这一传统任务上实现了性能提升。
最后,我们使用 scikit-learn 随机搜索库,为市场数据构建神经网络模型。首先用固定的默认参数初始化神经网络,例如数据打乱与早停参数。
#Use random search to build a neural network for our market data #Initialize the model model = MLPRegressor(shuffle=False,early_stopping=False) distributions = {'solver':['lbfgs','adam','sgd'], 'hidden_layer_sizes':[(X.shape[1],2,10,20),(X.shape[1],30,50,10),(X.shape[1],14,14,14),(X.shape[1],5,20,2),(X.shape[1],1,2,3,4,5,6,10),(X.shape[1],1,14,14,1)], 'activation':['relu','identity','logistic','tanh'] } rscv = RandomizedSearchCV(model,distributions,n_jobs=-1,n_iter=50) rscv.fit(X,data.loc[:,['Target 1','Target 2']])现在可以将训练好的神经网络导出为 ONNX 格式。导出前,我们先导入 ONNX 库及相关转换器。ONNX 全称 Open Neural Network Exchange(开放神经网络交换),是一种开源协议,可让我们以模型无关的方式轻松构建与导出机器学习模型。
#Exporting our model to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_types = [('float_input',FloatTensorType([1,X.shape[1]]))] final_types = [('float_output',FloatTensorType([2,1]))] model = rscv.best_estimator_ model.fit(X,data.loc[:,['Target 1','Target 2']]) onnx_proto = convert_sklearn(model=model,initial_types=initial_types,final_types=final_types,target_opset=12) onnx.save(onnx_proto,'EURUSD NN MSA.onnx')
如需查看 ONNX 神经网络计算图,首先导入 Netron 库,调用 netron.start() 并传入模型路径即可。
#Viewing our ONNX graph in netron import netron netron.start('../EURUSD NN MSA.onnx')
图 2 展示了 ONNX 模型的元属性。可以看到模型包含 14 个输入、2 个输出,均为浮点型;同时显示了生成者、ONNX 版本等关键元数据。
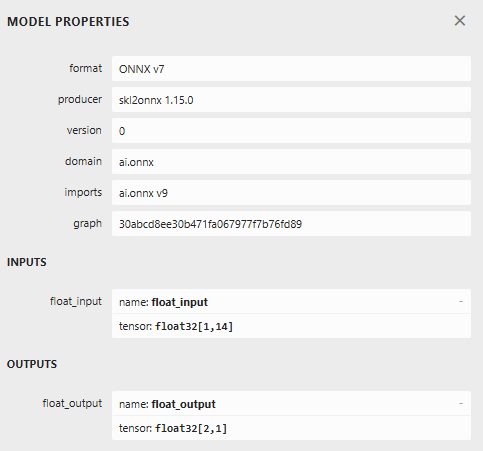
图 2:可视化 ONNX 模型元数据,验证输入输出维度是否正确
ONNX 模型将机器学习模型表示为计算节点与边构成的计算图,展示数据在节点间的传递过程。所有机器学习模型都可以转换为这种通用格式,即 ONNX 图,如图 3所示。该图代表我们通过 sklearn 随机搜索构建的神经网络。

图 3:使用 Netron 库可视化深度神经网络的计算图。
在MQL5中创建EA
构建智能交易脚本(EA)的第一步,是加载上一步生成的 ONNX 模型。
//+------------------------------------------------------------------+ //| MSA Test 1.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| ONNX Model | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD NN MSA.onnx" as uchar onnx_buffer[];
我们在 Python 中计算得到的各列均值与标准差,将分别存储到名为 Z1 和 Z2 的数组中。回想一下,我们会在从 ONNX 模型获取预测结果之前,使用这些数值对每一项输入进行缩放与标准化处理。
//+------------------------------------------------------------------+ //| ONNX Parameters | //+------------------------------------------------------------------+ double Z1[] = { 1.18932220e+00, 1.19077958e+00, 1.18786462e+00, 1.18931542e+00, 1.18994040e+00, 1.18994674e+00, 4.94395259e+01, -4.99204879e-04, -5.00701302e-04, -4.97575935e-04, -4.98995739e-04, -4.70848300e-04, -4.70289373e-04, -1.84697724e-02 }; double Z2[] = {1.09599015e-01, 1.09698934e-01, 1.09479324e-01, 1.09593123e-01, 1.09413744e-01, 1.09419007e-01, 1.00452009e+01, 1.31269558e-02, 1.31336302e-02, 1.31513465e-02, 1.31174740e-02, 6.88794916e-03, 6.89036979e-03, 1.28550006e+01 };
我们会定义关键的系统常量,并在整个程序运行周期内保持不变。请注意,这些常量均来自前文中遗传优化器筛选出的最优参数。
//+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define MA_SHIFT 0 #define MA_TYPE MODE_EMA #define RSI_PRICE PRICE_CLOSE #define ONNX_INPUTS 14 #define ONNX_OUTPUTS 2 #define HORIZON 38
关键策略参数(如移动平均周期、RSI 周期)均由遗传优化器自动优选,并在程序中保持固定。
//+------------------------------------------------------------------+ //| Strategy Parameters | //+------------------------------------------------------------------+ int MA_PERIOD = 100; //Moving Average Period int RSI_PERIOD = 24; //RSI Period ENUM_TIMEFRAMES STRATEGY_TIME_FRAME = PERIOD_H3; //Strategy Timeframe int HOLDING_PERIOD = 38; //Position Maturity Period
要让程序完整运行,我们需要引入多个依赖库。部分依赖(如交易库)对读者来说显而易见;另一些则是基于前文共同开发的自定义策略模块,如果你一直跟着学习,现在也应该很熟悉了。简单来说,我们加载的这些策略是交易程序运行的必要组件。
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> #include <VolatilityDoctor\Strategies\OpenCloseMACrossover.mqh> #include <VolatilityDoctor\Strategies\RSIMidPoint.mqh>
我们需要少量全局变量供整个程序使用,好在数量并不多。例如,用于管理自定义类(交易类、时间类、RSI 策略、均线交叉策略)的全局变量。其他全局变量则用于读取 ONNX 模型、存储模型预测结果。
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ //--- Custom Types CTrade Trade; Time *TradeTime; TradeInfo *TradeInformation; RSIMidPoint *RSIMid; OpenCloseMACrossover *MACross; long onnx_model; vectorf onnx_output; //--- Our handlers for our indicators int ma_handle,ma_o_handle,rsi_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],rsi_reading[]; //--- System Types int position_timer;
当程序首次初始化时,我们会创建所需动态对象的实例。例如,专门用于管理时间与交易信息的类。我们会实例化这些类,同时创建所需的指标句柄。接着,从加载的缓冲区中创建 ONNX 模型,并验证模型是否正确加载。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Create dynamic instances of our custom types TradeTime = new Time(Symbol(),STRATEGY_TIME_FRAME); TradeInformation = new TradeInfo(Symbol(),STRATEGY_TIME_FRAME); MACross = new OpenCloseMACrossover(Symbol(),STRATEGY_TIME_FRAME,MA_PERIOD,MA_SHIFT,MA_TYPE); RSIMid = new RSIMidPoint(Symbol(),STRATEGY_TIME_FRAME,RSI_PERIOD,RSI_PRICE); onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); onnx_output = vectorf::Zeros(ONNX_OUTPUTS); //---Setup our technical indicators ma_handle = iMA(_Symbol,STRATEGY_TIME_FRAME,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,STRATEGY_TIME_FRAME,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); rsi_handle = iRSI(_Symbol,STRATEGY_TIME_FRAME,RSI_PERIOD,RSI_PRICE); if(onnx_model != INVALID_HANDLE) { Print("Preparing ONNX model"); ulong input_shape[] = {1,ONNX_INPUTS}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Print("Failed To Specify ONNX model input shape"); return(INIT_FAILED); } ulong output_shape[] = {ONNX_OUTPUTS,1}; if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Print("Failed To Specify ONNX model output shape"); return(INIT_FAILED); } } //--- Everything was fine Print("Successfully loaded all components for our Expert Advisor"); return(INIT_SUCCEEDED); } //--- End of OnInit Scope
当程序不再使用时,我们会释放不再使用的内存与资源,确保程序安全退出。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Delete the dynamic objects delete TradeTime; delete TradeInformation; delete MACross; delete RSIMid; OnnxRelease(onnx_model); IndicatorRelease(ma_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(rsi_handle); } //--- End of Deinit Scope
每当 OnTick 或 OnExpertStart 函数收到新价格时,我们会先调用先调用 ChangeTime 类中的 NewCandle 函数,检查是否形成了新的日线 K 线。如果新 K 线已确认形成,我们会更新策略参数,再检查交易机会。若存在交易机会,就执行交易;否则,等待持仓达到持有周期后再平仓。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Check if a new daily candle has formed if(TradeTime.NewCandle()) { //--- Update strategy Update(); //--- If we have no open positions if(PositionsTotal() == 0) { //--- Reset the position timer position_timer = 0; //--- Check for a trading signal CheckSignal(); } //--- Otherwise else { //--- The position has reached maturity if(position_timer == HOLDING_PERIOD) Trade.PositionClose(Symbol()); //--- Otherwise keep holding else position_timer++; } } } //--- End of OnTick Scope
我们的更新方法接收几个关键参数,例如通过遗传优化器选定的预测展望周期。在这之后,它会更新我们正在使用的策略,以及存储在缓冲区中的技术指标数值。
//+------------------------------------------------------------------+ //| Update our technical indicators | //+------------------------------------------------------------------+ void Update(void) { int fetch = (HORIZON * 2); //--- Update the strategy RSIMid.Update(); MACross.Update(); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(rsi_handle,0,0,fetch,rsi_reading); ArraySetAsSeries(rsi_reading,true); } //--- End of Update Scope
从 ONNX 模型获取预测结果。要从 ONNX 模型获取预测结果,我们使用 ONNX 运行函数。但在调用之前,必须先更新要传入模型的输入变量,然后通过减去均值、除以标准差对数值进行缩放与标准化。
//+------------------------------------------------------------------+ //| Get A Prediction from our ONNX model | //+------------------------------------------------------------------+ void OnnxPredict(void) { vectorf input_variables = { iOpen(_Symbol,STRATEGY_TIME_FRAME,0), iHigh(_Symbol,STRATEGY_TIME_FRAME,0), iLow(_Symbol,STRATEGY_TIME_FRAME,0), iClose(_Symbol,STRATEGY_TIME_FRAME,0), ma_reading[0], ma_o_reading[0], rsi_reading[0], iOpen(_Symbol,STRATEGY_TIME_FRAME,0) - iOpen(_Symbol,STRATEGY_TIME_FRAME,(0 + HORIZON)), iHigh(_Symbol,STRATEGY_TIME_FRAME,0) - iHigh(_Symbol,STRATEGY_TIME_FRAME,(0 + HORIZON)), iLow(_Symbol,STRATEGY_TIME_FRAME,0) - iLow(_Symbol,STRATEGY_TIME_FRAME,(0 + HORIZON)), iClose(_Symbol,STRATEGY_TIME_FRAME,0) - iClose(_Symbol,STRATEGY_TIME_FRAME,(0 + HORIZON)), ma_reading[0] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_o_reading[(0 + HORIZON)], rsi_reading[0] - rsi_reading[(0 + HORIZON)] }; for(int i = 0; i < ONNX_INPUTS;i++) { input_variables[i] = ((input_variables[i] - Z1[i])/ Z2[i]); } OnnxRun(onnx_model,ONNX_DEFAULT,input_variables,onnx_output); }
使用均线交叉策略检查交易信号的第一步,是从 ONNX 模型获取预测。模型会预测它认为哪一个策略将产生最大收益。然后,我们检查该策略,看是否存在对应的有效入场信号。只有当模型预期该策略盈利,且策略本身发出有效入场信号时,我们才会入场交易。
//+------------------------------------------------------------------+ //| Check for a trading signal using our cross-over strategy | //+------------------------------------------------------------------+ void CheckSignal(void) { OnnxPredict(); //--- MA Strategy is profitable if((onnx_output[0] > 0.5) && (onnx_output[1] < 0.5)) { //--- Long positions when the close moving average is above the open if(MACross.BuySignal()) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } //--- Otherwise short else if(MACross.SellSignal()) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),0,0,""); return; } } //--- RSI strategy is profitable else if((onnx_output[0] < 0.5) && (onnx_output[1] > 0.5)) { if(RSIMid.BuySignal()) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } //--- Otherwise short else if(MACross.SellSignal()) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),0,0,""); return; } } } //--- End of CheckSignal Scope
在程序的最后部分,我们会解除宏定义所有在程序开头声明的系统常量。
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_SHIFT #undef RSI_PRICE #undef MA_TYPE #undef ONNX_INPUTS #undef ONNX_OUTPUTS #undef HORIZON //+------------------------------------------------------------------+
选择合适的回测周期天数其实很简单。我们希望在前向测试阶段对新程序进行验证,该阶段已在之前的测试中使用。因此,测试日期已做相应调整。
图 4:选择回测天数,使其与我们此前执行的前向测试周期保持一致
我们始终希望采用最贴近实盘的参数设置,因此选择随机延迟模式。
图 5:将建模条件设置为 “随机延迟”,以实现尽可能贴近实盘的效果
出乎意料的是,在程序中加入统计模型后采用的新设置,导致策略表现大幅下滑。这通常强烈表明我们的方案中存在问题。
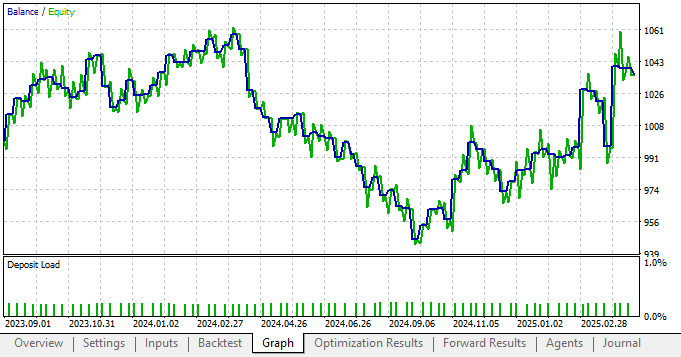
图 6:与未使用统计建模的表现相比,新生成的资金曲线状态很差
通过深入分析程序表现细节可以发现,总净利润与夏普比率均出现下降,这并非积极信号。这表明我们选用的统计建模工具,并未给程序带来预期效果。
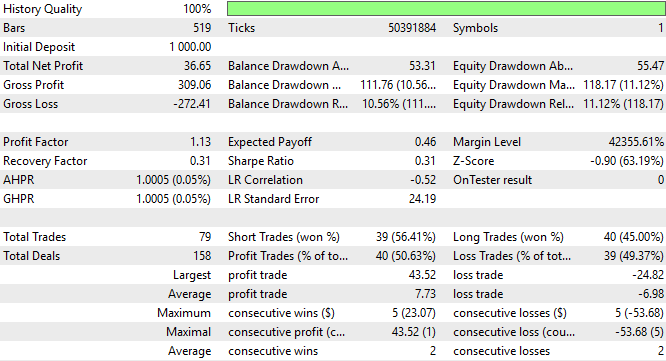
图 7:基于统计模型的新交易策略表现详情分析
在 Python 中重新检查市场数据
在进一步用 Python 修正行情数据时,我希望更细致地排查问题根源。于是,我先导入用于可视化行情数据的标准库,随后绘制两种策略所产生收益的累计和曲线,问题立刻清晰显现。import numpy as np import seaborn as sns import matplotlib.pyplot as plt
从下方图表可以明显看出,两套策略的走势特征与斜率高度相似。两种策略涨跌基本同步,表现近乎一致,几乎等同于只运行了一套策略。
fig , axs = plt.subplots(2,1,sharex=True) fig.suptitle('Visualizing The Individual Cumulative Return of our 2 Strategies') sns.lineplot(data['Return 1'].cumsum(),ax=axs[0],color='black') sns.lineplot(data['Return 2'].cumsum(),ax=axs[1],color='black')
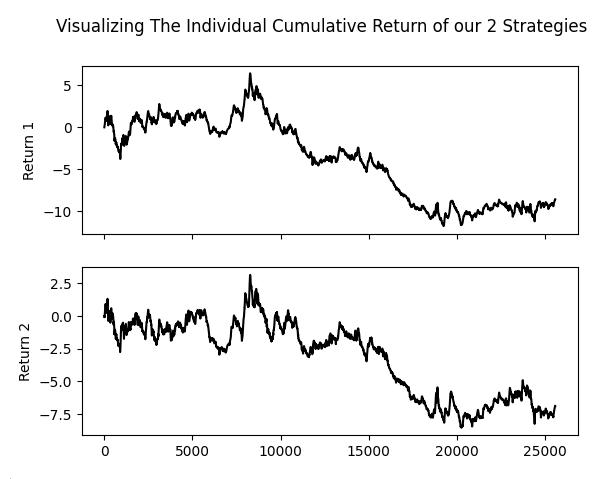
图 8:遗传优化器似乎选出了高度相关的策略,并为其分配了最大投票权重。
除此之外,当我们绘制策略收益的滚动风险值时,又发现了另一个隐患。两套策略的风险特征走势,与市场本身的风险走势几乎毫无差别。这再次说明,我们实际上只是在用同一种策略。如果不在图表栏目上做标注,根本无法区分策略一和策略二。
fig , axs = plt.subplots(3,1,sharex=True) fig.suptitle('Visualizing The Risk In Our 2 Strategies') sns.lineplot(data['Return'].rolling(window=HORIZON).var(),ax=axs[0],color='black') axs[0].axhline(data['Return'].var(),color='red',linestyle=':') sns.lineplot(data['Return 1'].rolling(window=HORIZON).var(),ax=axs[1],color='black') axs[1].axhline(data['Return 1'].var(),color='red',linestyle=':') sns.lineplot(data['Return 2'].rolling(window=HORIZON).var(),ax=axs[2],color='black') axs[2].axhline(data['Return 2'].var(),color='red',linestyle=':')
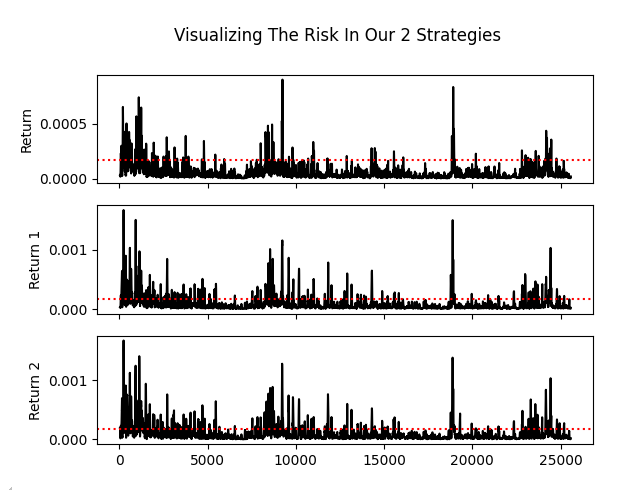
图 9:两套策略的风险与收益水平几乎完全趋同,这使得多策略分析的设计初衷失去意义
最终让我们彻底确认问题所在的,是对三类收益数据计算出的相关系数矩阵:市场收益、均线交叉策略收益、RSI 策略收益。可以清晰看到,均线交叉策略与 RSI 策略的相关系数约为 0.75,属于高度正相关。这一最终发现让我确定:遗传优化器并非以最大化盈利为目标去调整投票权重。相反,看起来它更像是在调整权重,以筛出高度相关的策略——因为这样会让优化过程更容易。
plt.title('Correlation Between Market Return And Strategy Returns')
sns.heatmap(data.loc[:,['Return','Return 1','Return 2']].corr(),annot=True)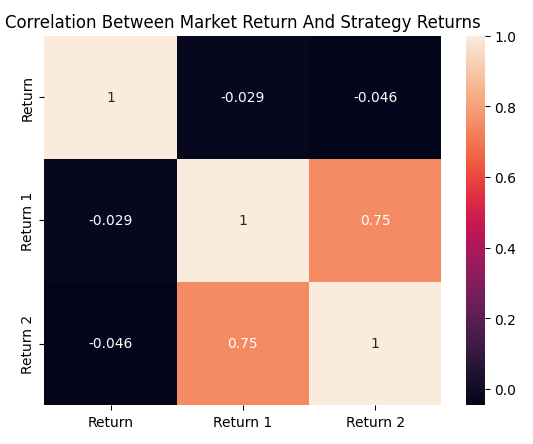
图 10:各交易策略与欧元兑美元市场的相关系数热力矩阵
策略优化改进
掌握以上问题根源后,我们可以重新对交易程序进行优化改进。首先,回退至早期版本的交易策略,恢复启用全部三套目标策略。
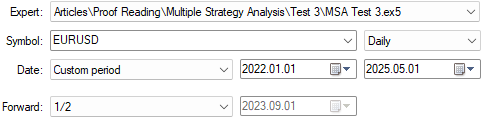
图 11:为优化流程选定回测周期天数
和以往一样,本次回测依旧采用随机延迟设置。
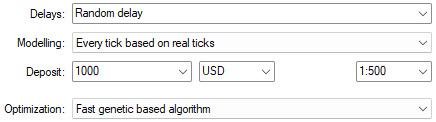
图 12:如需复刻本次实操流程,务必勾选 “随机延迟” 选项
但与此前测试不同的是,我们将所有策略投票权重固定为 1,以此约束遗传优化器,使其只能朝着提升整体策略盈利性的方向迭代。同时强制优化器必须启用全部三套策略,不能擅自筛选高度相关的策略组合,避免违背多策略组合的设计初衷。
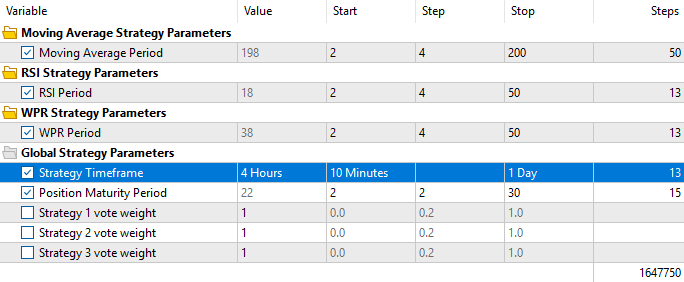
图 13:本次需将所有投票权重固定设为 1;原因在于我们发现遗传优化器会自作聪明、绕开优化目标走捷径
查看优化结果后可以发现,相较于初始策略向量,性能已有明显改善。最初同时启用三套策略时,盈利水平仅维持在 40 至 50 美元区间。而如今策略盈利性已出现显著提升。
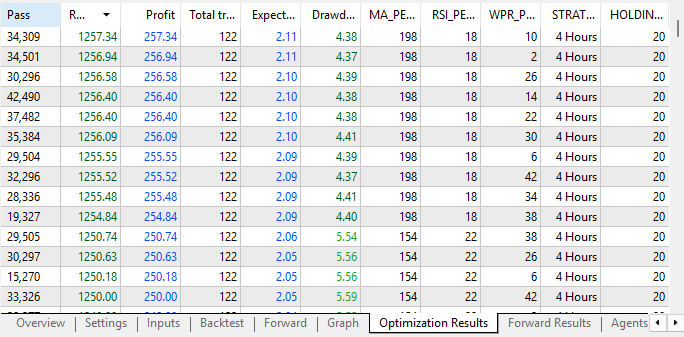
图 14:本次优化结果较上一轮迭代有大幅改善
此外,从前向测试结果来看,盈利水平同样有所提升。当前策略在回测与前向测试中双双实现盈利,这是策略配置稳定性极强的信号。最重要的是,遗传优化器现已能批量生成在两类测试中均稳定盈利的策略配置组合。而在此前放任优化器自由调整权重时,我们始终无法得到这类优质结果。这也进一步印证:当前参数配置下,交易程序具备良好稳定性。
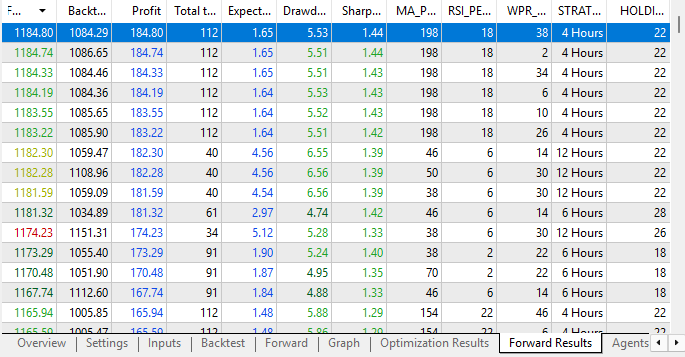
图 15:前向测试结果呈现出极强的稳定性与盈利性特征
最后,我们选用从前向测试中筛选出的最优参数组合进行回测,可以清晰看到:新参数配置在回测和前向测试中均实现盈利,且资金曲线保持上行趋势,这正是我们期望的理想表现。
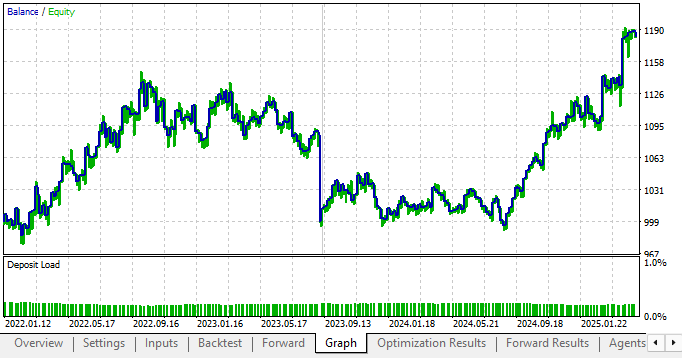
图 16:采用固定投票权重后的新交易策略,资金曲线盈利能力大幅增强
结论
通过本次分析实操,我们总结出多条深刻的经验教训。第一,奖励作弊问题普遍存在,无论我们是否察觉,都有可能发生。遗传优化器这类智能算法工具运算速度快、逻辑推演能力极强,甚至往往超出人类预判。我们必须时刻保持审慎,避免算法钻规则漏洞、生成无效的优化方案 —— 仅满足我们设定的成功条件,却违背实际交易优化目标。
通过仔细复盘优化器筛选出的策略收益表现,我们明确了一条原则:切勿选用高度相关的策略进行组合,否则将彻底失去多策略分散配置的意义。
读者需要注意:遗传优化器的运算边界,仅受限于我们愿意投入的优化时间成本。同时,本文并不足以证明 MT5 遗传优化器一定会刻意进行奖励作弊。由于本次仅选取少量策略、且只完成一轮优化迭代,重复运行流程仍有可能得出完全不同的结果。
更客观地说,本次问题根源更多在于:我本人在给遗传优化器设定求解问题框架时,考虑得不够周全。更合理的做法应当是:先强制优化器启用全部可用策略,再以更严谨的逻辑微调各策略投票权重。
最重要的是,本次实操也为后续研究定下方向:在下一篇文章中,我们需要研究如何突破权重统一设为 1时的盈利上限。统一权重下的策略表现,已成为一个坚实的基准参照;后续我们将引入本文原定的统计模型,力求实现盈利水平的进一步超越。
| 文件名 | 文件描述 |
|---|---|
| Fetch Data MSA.mq5 | 我们用于获取遗传优化器所选两套策略数据的 MQL5 脚本。 |
| MSA Test 2.1.mq5 | 基于优化器选出的两套策略,结合 ONNX 模型联合构建的EA。 |
| Analyzing Multiple Strategies I.ipynb | 我们共同编写的 Jupyter 笔记本,用于分析通过 MQL5 脚本获取的行情数据。 |
| EURUSD NN MSA.onnx | 基于 sklearn 随机搜索库构建的深度神经网络模型。 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/18847
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
