
Нейросети в трейдинге: Адаптивное масштабирование представлений (Окончание)

Введение
Финансовый рынок не статичен — он меняет темп, рисунок и логику быстрее, чем большинство моделей успевает подстроиться. Для трейдера это знакомая история: на одном участке алгоритм работает уверенно, на другом — начинает буксовать, а при смене режима и вовсе теряет опору. Проблема здесь не только в качестве данных, проблема еще и в том, как именно модель эти данные видит. Если представление слишком жесткое, рынок уходит из-под него, а если слишком общее, то сигнал растворяется в шуме.
Именно поэтому интерес вызывает фреймворк Adaptive Domain Scaling. В его основе лежит простая, но сильная идея о том, что представление данных должно быть не фиксированным, а адаптивным. Модель не обязана смотреть на последовательность одним и тем же взглядом, она может перестраивать его в зависимости от контекста. Для исходной области применения это позволяет учитывать различия между доменами и точнее интерпретировать поведение последовательностей. Для финансовых данных такая логика особенно ценна, потому что рынок редко дает прямые подсказки. Чаще он говорит намеками, и эти намеки меняются от режима к режиму.
Переход от идеи к практике оказался поэтапным. В первой статье мы не пытались сразу собрать всю систему целиком. Такой путь обычно красив только на бумаге. В реальной же разработке он быстро превращается в тяжеловесную конструкцию, которую трудно проверять и еще труднее доводить до стабильной работы. Поэтому было принято другое решение: архитектура была разложена на отдельные блоки, и реализация началась с базового механизма динамической генерации параметров. Этот шаг закреплял главный принцип ADS: параметры модели могут зависеть от контекста, а не только от входа как такового.
Во второй статье работа была продолжена, но уже в более сложной постановке. Здесь особенно отчетливо проявилась разница между рекомендательными системами и финансовыми данными. В рынке нет явных маркеров, по которым можно удобно разрезать последовательность, нет готовых границ, нет очевидных событий, на которые можно опереться. Есть непрерывная история, которую приходится читать целиком и при этом одновременно рассматривать через набор возможных сценариев. И вот тут вычислительная нагрузка растет очень быстро. Для длинной истории нужно пересчитывать представления сценариев, а это уже серьезные расходы.
Ответом на эту проблему стала оптимизация в стиле Stacked Target-to-History Cross Attention. Она позволила изменить порядок вычислений и снизить стоимость работы с длинными последовательностями. Это важный инженерный ход. Он ускоряет модель и делает подход пригодным для практики.
Одновременно была переработана внутренняя логика фреймворка. Часть функций, которые раньше были распределены между разными модулями, была перенесена в более компактную схему. В результате архитектура стала проще, а поведение — более управляемым. Это как убрать лишние звенья из хорошо настроенного механизма — движение не теряется, но ход становится чище.
К текущему моменту у нас уже есть не абстрактная идея, а рабочая основа. Реализован ключевой компонент, адаптированный к финансовым данным и к длинной истории рынка. Он умеет учитывать сценарии, работать с ними без лишней тяжести и сохранять вычислительную эффективность. Но на этом этапе компонент все еще существует сам по себе. Он показывает направление, но еще не отвечает на главный прикладной вопрос: как все это поведет себя в настоящей торговой модели?
Именно это и становится задачей данной статьи. Мы выходим из режима локальной реализации и переходим к уровню целой системы. Появляется объект верхнего уровня, который объединяет уже реализованные решения и организует их совместную работу. Это важный переход. Речь идет о создании полноценной торговой конструкции, в которой каждый элемент работает в общей логике модели.
Дальше задача становится практической. Нужно показать, как система ведет себя на реальных исторических данных. Здесь важен результат. Нас интересует, насколько хорошо реализованные подходы удерживают устойчивость. Как они работают при смене режима. И способны ли дать трейдеру прикладную полезную модель.
Объект верхнего уровня
До этого момента мы сознательно двигались медленно и последовательно. Каждый элемент создавался отдельно. Такой подход позволил избежать накопления скрытых ошибок и сохранить управляемость модели. Но у него есть естественное ограничение. Отдельные компоненты, какими бы аккуратно реализованными они ни были, не дают ответа на главный практический вопрос: как система ведет себя в целом?
Чтобы получить ответ на этот вопрос, необходимо изменить точку зрения. Мы больше не рассматриваем компоненты изолированно. Нас интересует, как они взаимодействуют с другими частями модели, как передаются данные между уровнями, и каким образом формируется итоговое решение. Именно здесь появляется необходимость в объекте верхнего уровня.
Этот объект выполняет роль связующего звена. Он определяет архитектурную логику всей системы. Через него задается структура модели, порядок прохождения данных и правила взаимодействия между компонентами. Фактически он превращает набор реализованных механизмов в единую вычислительную схему.
При этом сам объект верхнего уровня остается максимально прозрачным. Его задача — не усложнять систему, а структурировать уже существующие решения. Он задает каркас, в котором каждый компонент занимает свое место и выполняет строго определенную функцию.
Но прежде чем переходить к практической части, важно зафиксировать одну вещь. В рамках данного проекта мы не воспроизводим архитектуру фреймворка в том виде, в котором она представлена в авторской работе. Это уже можно было заметить по изменениям, внесенным в модуль PCRG. И это не единичный случай, а осознанный подход.
В то же время мы не начинаем с чистого листа. Задача стоит иначе — аккуратно собрать рабочую систему, опираясь на сильные стороны уже существующих решений. В этом проекте мы фактически объединяем несколько архитектурных подходов в единую модель, адаптированную под специфику финансовых данных.
Базу для работы с исходными данными формирует фреймворк OneTrans. Его подходы позволяют связать представления временных последовательностей и контекстных признаков в рамках одной модели. В результате мы получаем не разрозненные признаки, а согласованное пространство представлений, с которым уже можно работать дальше.
Поверх этой основы накладываются идеи Adaptive Domain Scaling. Они позволяют преобразовать полученные представления в сценарно-зависимую форму. Это ключевой момент. Мы больше не рассматриваем данные как единый поток, мы интерпретируем их через набор возможных сценариев, что делает модель чувствительной к контексту и меняющимся условиям рынка.
Отдельного внимания заслуживает выбор механизма внимания. В оригинальной работе авторы фреймворка ADS прямо указывают, что предложенный подход не привязан к конкретной реализации механизма внимания и может быть интегрирован с различными его вариантами. В данном проекте мы используем Stacked Target-to-History Cross Attention. Его многоуровневая структура позволяет извлекать сложные зависимости в длинных временных рядах и при этом сохранять вычислительную эффективность.
Именно на этой основе построен объект верхнего уровня CNeuronADS. Он не является прямым переносом оригинальной архитектуры, но аккуратно объединяет ключевые идеи, обсуждавшиеся ранее. В его структуре уже можно увидеть композицию подходов, о которой шла речь: подготовка данных, формирование представлений, генерация адаптивных запросов и их дальнейшая обработка.
class CNeuronADS : public CNeuronSpikeConvBlock { protected: CLayer cPrepare; CNeuronBaseOCL cLastSequence; CNeuronBaseOCL cLastNonSequence; CNeuronAddToStack cStackSequence; CNeuronPCGR cQuerys; CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronADS(void) {}; ~CNeuronADS(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint units_out, uint heads, uint scenarios, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronADS; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual bool Clear(void) override; };
Поток исходных данных сначала проходит через блок подготовки cPrepare. На этом этапе формируется базовое представление, согласованное по размерностям и пригодное для дальнейшей обработки.
Далее поток разделяется на две части — последовательность и контекст. Элементы последовательности аккумулируются в cStackSequence. Это позволяет сохранить историю и использовать ее на последующих шагах без повторных вычислений.
Контекстная часть передается в модуль cQuerys, где формируются адаптивные запросы. Именно здесь сосредоточена логика, заимствованная от подхода ADS и переработанная с учетом оптимизаций, рассмотренных во второй статье.
Дальнейшая обработка осуществляется в блоке cFlow. Это уже последовательность слоев, в которых реализуется взаимодействие запросов с историей. Здесь применяется механизм кросс-внимания, и именно на этом уровне раскрывается потенциал выбранного подхода. Поток данных проходит через несколько стадий преобразования, постепенно уточняя представление и извлекая зависимости.
Важно, что вся эта структура собрана как единое целое. Отдельные элементы больше не существуют изолированно, они работают в связке, передавая данные и градиенты через общий вычислительный граф. При этом сама архитектура остается управляемой — каждый блок выполняет свою функцию и может быть проанализирован отдельно.
Непосредственно архитектура класса формируется в методе инициализации. Здесь задается полный вычислительный граф модуля. Каждый шаг инициализации определяет, как именно будут обрабатываться данные: где будет происходить адаптация, и каким образом контролируется сложность.
bool CNeuronADS::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint units_out, uint heads, uint scenarios, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { uint count = dimensions.Size(); if(units_s <= 0 || units_out <= 0 || count < (units_s + 2)) ReturnFalse; uint dimension_out = dimensions[count - 1]; uint units_ns = count - units_s - 1; uint bottleneck = uint(0.5 * embed_size * log(topK + 1)); if(bottleneck < 8 * heads || (bottleneck % heads) != 0) bottleneck = MathMax((bottleneck + heads - 1) / heads, 4) * heads;
В самом начале проверяется конфигурация входа и рассчитывается размер bottleneck. Он зависит от параметров embed_size и topK, после чего приводится к кратности числу голов внимания. Это задает базовую размерность внутреннего представления. Фактически здесь фиксируется баланс между выразительностью модели и ее вычислительной стоимостью. Если этот уровень выбран неверно, дальнейшая архитектура уже не сможет это компенсировать.
Затем управление передается одноименному методу родительского класса для формирования всех унаследованных интерфейсов.
if(!CNeuronSpikeConvBlock::Init(numOutputs, myIndex, open_cl, bottleneck * topK, bottleneck * topK, dimension_out, units_out, 1, optimization_type, batch)) ReturnFalse;
Далее формируется входной тракт cPrepare. Сначала применяется BatchNorm. Его задача — стабилизировать распределение исходных данных.
//--- Prepare arrays cPrepare.Clear(); cFlow.Clear(); cPrepare.SetOpenCL(OpenCL); cFlow.SetOpenCL(OpenCL); //--- CNeuronBaseOCL* neuron = NULL; CNeuronBatchNormOCL* norm = NULL; CNeuronMultiWindowsConvOCL* mwc = NULL; CNeuronFieldPatternEmbedding* emb = NULL; CNeuronAutoToken* select = NULL; CNeuronSwiGLUOCL* swiglu = NULL; CNeuronSpikeConvBlock* conv = NULL; CNeuronMHTHCrossAttention* attention = NULL; //--- Prepare inputs uint windows[]; if(ArrayCopy(windows, dimensions, 0, 0, count - 1) < int(count - 1)) ReturnFalse; uint index = 0; norm = new CNeuronBatchNormOCL(); uint total_windows = 0; for(uint i = 0; i < windows.Size(); i++) total_windows += windows[i]; if(!norm || !norm.Init(0, index, OpenCL, total_windows, iBatch, optimization) || !cPrepare.Add(norm)) DeleteObjAndFalse(norm); norm.SetActivationFunction(None);
В финансовых рядах это особенно важно, так как сами признаки могут иметь разную шкалу и динамику. Нормализация выравнивает их и задает устойчивую точку отсчета для последующей обработки.
Следующим шагом идет многооконная свертка. В данном случае она не используется для извлечения признаков на разных масштабах. Окна не перекрываются, поэтому повторного анализа одних и тех же данных не происходит. Основная задача этого слоя — привести мультимодальные входные данные к единому пространству. На вход поступают векторы различной размерности, описывающие разные аспекты рынка. Многооконная свертка обрабатывает каждый из них в своем окне и проецирует в общее пространство фиксированной размерности. Это выравнивание критично. Без него дальнейшие слои работали бы с несогласованными представлениями.
index++; mwc = new CNeuronMultiWindowsConvOCL(); if(!mwc || !mwc.Init(0, index, OpenCL, windows, embed_size, 1, 1, optimization, iBatch) || !cPrepare.Add(mwc)) DeleteObjAndFalse(mwc); mwc.SetActivationFunction(SIGMOID);
Далее подключается FieldPatternEmbedding. Здесь происходит уже не просто проекция, а структурирование признаков. Слой формирует набор кандидатов и выделяет устойчивые комбинации входных факторов. Это промежуточный этап между сырыми признаками и сценарным представлением. Он подготавливает данные к тому, чтобы их можно было интерпретировать через различные гипотезы поведения рынка.
index++; emb = new CNeuronFieldPatternEmbedding(); if(!emb || !emb.Init(0, index, OpenCL, embed_size, windows.Size(), embed_size, candidates, topK, optimization, iBatch) || !cPrepare.Add(emb)) DeleteObjAndFalse(emb); emb.SetActivationFunction(TANH);
После этого поток разделяется на две части. Последовательная компонента передается в cStackSequence. Этот блок отвечает за накопление и повторное использование истории. Он позволяет не пересчитывать уже обработанные участки и тем самым снижает вычислительную нагрузку. В условиях длинных временных рядов это принципиально важно.
//--- Sequence/NonSequence index++; if(!cLastSequence.Init(0, index, OpenCL, units_s * embed_size, optimization, iBatch)) ReturnFalse; cLastSequence.SetActivationFunction(None); index++; if(!cLastNonSequence.Init(0, index, OpenCL, units_ns * embed_size, optimization, iBatch)) ReturnFalse; cLastNonSequence.SetActivationFunction(None); index++; if(!cStackSequence.Init(0, index, OpenCL, stack_size, embed_size, units_s, optimization, iBatch)) ReturnFalse;
Контекстная часть поступает в cQuerys. Здесь реализуется механизм генерации адаптивных запросов. Это центральный элемент всей архитектуры. Запрос формируется с учетом текущего представления данных и набора сценариев.
index++; if(!cQuerys.Init(0, index, OpenCL, embed_size, bottleneck, units_ns, scenarios, bottleneck, candidates, topK, optimization_type, batch)) ReturnFalse;
После переноса логики адаптации внутрь этого модуля, он фактически берет на себя роль формирования контекстно-зависимого взгляда на данные. Это делает архитектуру компактнее и устраняет избыточные преобразования.
Далее инициализируется блок cFlow. Именно здесь модель приобретает глубину. Каждый слой представляет собой повторяющуюся структуру: SwiGLUFFN → Cross-Attention → SwiGLUFFN. Эти компоненты выполняют разные функции, но работают как единый механизм. SwiGLUFFN обеспечивает гибкую нелинейность и позволяет модели адаптивно усиливать значимые сигналы.
//--- Flow for(uint l = 0; l < layers; l++) { index++; swiglu = new CNeuronSwiGLUOCL(); if(!swiglu || !swiglu.Init(0, index, OpenCL, bottleneck, bottleneck, bottleneck, scenarios, units_ns, optimization, iBatch) || !cFlow.Add(swiglu)) DeleteObjAndFalse(swiglu); index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, swiglu.GetWindowOut(), swiglu.GetWindowOut(), bottleneck, scenarios, units_ns, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv);
Cross-Attention связывает сценарно-зависимые запросы с накопленной историей, извлекая релевантные зависимости.
index++; attention = new CNeuronMHTHCrossAttention(); if(!attention || !attention.Init(0, index, OpenCL, bottleneck, units_ns * scenarios, heads, embed_size, stack_size, bottleneck, candidates, topK, optimization, iBatch) || !cFlow.Add(attention)) DeleteObjAndFalse(attention);
За ним следует еще один SwiGLUFFN.
index++; swiglu = new CNeuronSwiGLUOCL(); if(!swiglu || !swiglu.Init(0, index, OpenCL, bottleneck, bottleneck, bottleneck, scenarios, units_ns, optimization, iBatch) || !cFlow.Add(swiglu)) DeleteObjAndFalse(swiglu); index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, swiglu.GetWindowOut(), swiglu.GetWindowOut(), bottleneck, units_ns, scenarios, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv);
Если слой не последний, в архитектуру добавляется дополнительный контур. Через CNeuronBaseOCL происходит накопление представлений.
if(l < layers - 1) { index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, bottleneck * (l + 2) * units_ns * scenarios, optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
Затем AutoToken выполняет мягкую группировку сценариев по Top-K.
index++; select = new CNeuronAutoToken(); if(!select || !select.Init(0, index, OpenCL, bottleneck, bottleneck, neuron.Neurons() / bottleneck, units_ns * scenarios, candidates, topK, optimization, iBatch) || !cFlow.Add(select)) DeleteObjAndFalse(select);
Важно, что это не жесткий отбор, а взвешенное объединение.
Далее результат снова сжимается через SpikeConv до размера bottleneck.
index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, bottleneck * topK, bottleneck * topK, bottleneck, scenarios, units_ns, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv); } }
Этот шаг играет ключевую роль в контроле сложности. Без него количество сценариев и размер представлений росли бы на каждом уровне, что быстро привело бы к перегрузке модели.
Финальная часть cFlow завершает агрегацию. Накопленные представления объединяются.
index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, bottleneck * layers * units_ns * scenarios, optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
И проходят еще один этап выбора через AutoToken.
index++; select = new CNeuronAutoToken(); if(!select || !select.Init(0, index, OpenCL, bottleneck, bottleneck, neuron.Neurons() / bottleneck, units_out, candidates, topK, optimization, iBatch) || !cFlow.Add(select)) DeleteObjAndFalse(select);
А затем применяется нелинейное преобразование.
index++; swiglu = new CNeuronSwiGLUOCL(); if(!swiglu || !swiglu.Init(0, index, OpenCL, bottleneck, bottleneck, bottleneck, units_out * topK, 1, optimization, iBatch) || !cFlow.Add(swiglu)) DeleteObjAndFalse(swiglu); //--- return true; }
В результате формируется компактное выходное представление, готовое для дальнейшего использования.
Алгоритм прямого прохода реализован в методе feedForward, и именно здесь статическая архитектура, заданная при инициализации, превращается в динамический процесс обработки данных.
bool CNeuronADS::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; CNeuronBaseOCL* stack_querys = NULL; //--- Inputs for(int i = 0; i < cPrepare.Total(); i++) { curr = cPrepare[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Входной поток сначала последовательно проходит через блок cPrepare. Здесь происходит первичное приведение данных к рабочему виду. Нормализация стабилизирует распределение, многооконная свертка выравнивает мультимодальные признаки, а Field-Aware Embedding формирует согласованное пространство представлений. На выходе этого блока данные уже готовы к интерпретации, а не просто к обработке.
Далее следует ключевой момент — разделение потока на последовательную и контекстную части.
uint embedding_size = cStackSequence.GetDimension(); uint units_s = cLastSequence.Neurons() / embedding_size; uint units_ns = cLastNonSequence.Neurons() / embedding_size; uint scenarios = cQuerys.GetCount(); uint bottleneck = cQuerys.GetDimension(); uint units_out = GetUnits(); //--- Sequence/NonSequence if(!DeConcat(cLastSequence.getOutput(), cLastNonSequence.getOutput(), prev.getOutput(), embedding_size * units_s, embedding_size * units_ns, 1)) ReturnFalse;
Это точка, где модель явно фиксирует различие между историей и текущим контекстом.
Последовательная часть отправляется в cStackSequence. Здесь она включается в накопительную память модели. Это позволяет использовать историю повторно и обеспечивает устойчивость при работе с длинными рядами.
if(!cStackSequence.FeedForward(cLastSequence.AsObject()))
ReturnFalse;
Параллельно контекстная часть поступает в cQuerys. На этом шаге формируются адаптивные запросы.
//--- PCRG if(!cQuerys.FeedForward(cLastNonSequence.AsObject())) ReturnFalse;
Это не статическая проекция, а контекстно-зависимое преобразование. Запросы уже на этом этапе настроены на сценарии, которые модель считает релевантными. Фактически здесь задается направление дальнейшего анализа.
Далее начинается основной цикл обработки — блок cFlow. Начальное состояние задается выходом cQuerys, и одновременно сохраняется указатель в локальной переменной stack_querys, которая начинает играть роль накопителя представлений.
//--- Flow
prev = cQuerys.AsObject();
stack_querys = prev;
Это важный механизм, он позволяет не терять информацию между слоями, а последовательно ее накапливать.
При проходе по слоям возникает два типа операций. Если текущий слой — это CNeuronBaseOCL, то выполняется конкатенация текущего состояния с накопленным в stack_querys.
for(int i = 0; i < cFlow.Total(); i++) { curr = cFlow[i]; if(!curr) ReturnFalse; if(curr.Type() == defNeuronBaseOCL) { if(!stack_querys || !prev || !Concat(prev.getOutput(), stack_querys.getOutput(), curr.getOutput(), bottleneck, curr.Neurons() / (units_ns * scenarios) - bottleneck, units_ns * scenarios)) ReturnFalse; stack_querys = curr; }
Это означает, что модель не забывает предыдущие представления, а расширяет их. Здесь реализуется эффект наращивания контекста. Каждый такой шаг увеличивает информативность представления, но при этом требует последующего контроля размерности.
Во всех остальных случаях выполняется стандартный вызов метода FeedForward с передачей текущего состояния и накопленной исторической последовательности cStackSequence.
else if(!curr.FeedForward(prev, cStackSequence.getOutput())) ReturnFalse; prev = curr; }
Это принципиально важно. Каждый слой в cFlow работает с доступом к истории. Таким образом, внимание и локальные преобразования всегда опираются на полный контекст, а не только на текущий слой.
Механизм stack_querys обновляется только в точках расширения. Это создает четкую структуру. Накопление происходит дискретно. А между этими точками модель занимается переработкой и уточнением представлений. В результате достигается баланс между ростом информации и ее контролем.
После завершения прохода по cFlow управление передается одноименному методу родительского класса. Он выполняет роль агрегатора. Здесь представление приводится к выходному формату, нормализуется и стабилизируется.
if(!CNeuronSpikeConvBlock::feedForward(prev)) ReturnFalse; //--- return true; }
Этот шаг замыкает вычислительный цикл и подготавливает данные к использованию на уровне модели.
Вся логика построена вокруг двух идей. Первая — не терять информацию, а аккуратно ее накапливать. Вторая — не позволять этой информации выйти из-под контроля. Именно сочетание накопления через stack_querys и регулярной переработки через слои cFlow делает модель одновременно выразительной и устойчивой.
На данном этапе у нас реализован алгоритм прямого прохода. Модель принимает исходные данные, формирует представления, уточняет их через последовательность слоев и на выходе выдает некоторую оценку текущего состояния. Однако при случайной инициализации параметров такая оценка носит формальный характер. Она отражает структуру вычислений, но не содержит практической ценности.
Чтобы модель начала работать осмысленно, ее необходимо обучить, а значит — организовать корректный процесс обратного распространения ошибки. Именно на этом этапе архитектура начинает проявлять свои особенности. И если прямой проход реализован как последовательность согласованных преобразований, то обратный требует гораздо более аккуратной логики. Обратное распространение ошибки в данной архитектуре упирается в два узких места.
Первое — это общая историческая последовательность cStackSequence, которая используется во всех модулях кросс-внимания. Один и тот же набор данных участвует в вычислениях на каждом уровне. В результате градиент к этой последовательности формируется сразу из нескольких источников. Без дополнительного контроля он начинает накапливаться и искажать обучение.
Второе — это стек контекста, формируемый в процессе прямого прохода через механизм stack_querys. Он последовательно расширяется на каждом уровне cFlow. В прямом проходе это выглядит как накопление информации, в обратном — превращается в цепочку разветвлений. Градиент необходимо не просто передать назад, а корректно разделить и распределить между всеми этапами его формирования.
Метод calcInputGradients решает обе задачи одновременно. В начале задается точка входа обратного прохода. Последний элемент cFlow[-1] передается в одноименный метод родительского класса. Это восстанавливает градиент на выходе всей конструкции и формирует исходный сигнал ошибки для дальнейшего распространения.
bool CNeuronADS::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- if(!CNeuronSpikeConvBlock::feedForward(cFlow[-1])) ReturnFalse;
Далее инициализируются рабочие параметры и указатели. Ключевым является next, который всегда указывает на слой, уже обработанный на предыдущем шаге. Это позволяет последовательно двигаться в обратном направлении, не теряя связность цепочки.
uint embedding_size = cStackSequence.GetDimension(); uint units_s = cLastSequence.Neurons() / embedding_size; uint units_ns = cLastNonSequence.Neurons() / embedding_size; uint scenarios = cQuerys.GetCount(); uint bottleneck = cQuerys.GetDimension(); uint units_out = GetUnits(); //--- CNeuronBaseOCL* next = cFlow[-1]; CNeuronBaseOCL* curr = NULL; CNeuronBaseOCL* stack_querys = NULL;
Основной цикл проходит по cFlow в обратном порядке. Здесь начинается разбор сложных мест.
Если следующий слой (next) является точкой конкатенации контекста, то для передачи градиента сначала выполняется деконкатенация.
//--- Flow for(int i = cFlow.Total() - 2; i >= 0; i--) { curr = cFlow[i]; if(!curr) ReturnFalse; if(next.Type() == defNeuronBaseOCL) { if(!DeConcat(curr.getGradient(), next.getPrevOutput(), next.getGradient(), bottleneck, next.Neurons() / (units_ns * scenarios) - bottleneck, units_ns * scenarios)) ReturnFalse; Deactivation(curr); }
Это принципиальный момент. Градиент не передается напрямую. Он разбивается на части, соответствующие текущему слою и накопленному контексту. Тем самым мы восстанавливаем исходную топологию представления. Только после этого применяется деактивация. Такой порядок позволяет избежать смешивания градиентов и сохранить их привязку к конкретным компонентам модели.
Во всех остальных случаях используется стандартный вызов CalcHiddenGradients, но с важным дополнением. В него передается выход cStackSequence.
else if(!curr.CalcHiddenGradients(next, cStackSequence.getOutput(), (!stack_querys ? cStackSequence.getGradient() : cStackSequence.getPrevOutput()), (ENUM_ACTIVATION)cStackSequence.Activation())) ReturnFalse;
Это означает, что каждый слой при обратном проходе работает с той же исторической последовательностью, что и при прямом. Тем самым устраняется разрыв между использованием истории и распространением градиента.
Особое внимание уделяется слоям кросс-внимания. Здесь градиенты от разных уровней сходятся в общую историческую последовательность.
if(curr.Type() == defNeuronMHTHCrossAttention && !!stack_querys) { if(!SumAndNormilize(cStackSequence.getGradient(), cStackSequence.getPrevOutput(), cStackSequence.getGradient(), embedding_size, false, 0, 0, 0, 0.5f)) ReturnFalse; }
Чтобы не допустить их неконтролируемого накопления, используется суммирование с понижающим коэффициентом. Это позволяет учитывать вклад каждого слоя, но удерживать общий сигнал в разумных пределах. История продолжает обучаться, но не начинает доминировать.
Аналогичный подход применяется и к стеку контекста. При прохождении узлов конкатенации градиенты не просто разделяются, но и дополнительно балансируются относительно накопленного состояния stack_querys.
if(curr.Type() == defNeuronBaseOCL) { if(!!stack_querys && !SumAndNormilize(curr.getGradient(), stack_querys.getPrevOutput(), curr.getGradient(), bottleneck, false, 0, 0, 0, 0.5f)) ReturnFalse; stack_querys = curr; } next = curr; }
Это предотвращает перекос в сторону отдельных уровней и делает вклад каждого шага сопоставимым. В результате стек контекста остается устойчивым даже при увеличении глубины модели.
После завершения обработки cFlow градиент передается в модуль генерации адаптивных запросов cQuerys. Здесь вновь выполняется декомпозиция градиента с последующей деактивацией и балансировкой.
//--- PCRG if(!cQuerys.CalcHiddenGradients(cFlow[0])) ReturnFalse; if(!!stack_querys) { if(!DeConcat(stack_querys.getPrevOutput(), cQuerys.getPrevOutput(), stack_querys.getGradient(), bottleneck, bottleneck, units_ns * scenarios)) ReturnFalse; if(cQuerys.Activation() != None && !DeActivation(cQuerys.getOutput(), cQuerys.getPrevOutput(), cQuerys.getPrevOutput(), cQuerys.Activation())) ReturnFalse; if(!SumAndNormilize(cQuerys.getGradient(), cQuerys.getPrevOutput(), cQuerys.getGradient(), bottleneck, false, 0, 0, 0, 0.5f)) ReturnFalse; }
Это необходимо, чтобы корректно восстановить вклад сценариев и не смешать его с накопленным контекстом.
Далее поток разделяется на последовательную и контекстную части. Каждая из них обрабатывается независимо через соответствующие блоки.
//--- Sequence/NonSequence if(!cLastNonSequence.CalcHiddenGradients(cQuerys.AsObject())) ReturnFalse; if(!cLastSequence.CalcHiddenGradients(cStackSequence.AsObject())) ReturnFalse;
Это сохраняет различие между историей и текущим состоянием. Только после этого градиенты объединяются и передаются в блок подготовки исходных данных.
next = cPrepare[-1]; if(!next || !Concat(cLastSequence.getGradient(), cLastNonSequence.getGradient(), next.getGradient(), embedding_size * units_s, embedding_size * units_ns, 1)) ReturnFalse;
Финальный этап — обратный проход через блок cPrepare. Здесь уже нет сложных зависимостей, все ключевые проблемы были решены ранее, и градиент распространяется линейно через Field-Aware Embedding, свертку и нормализацию.
//--- Inputs for(int i = cPrepare.Total() - 2; i >= 0; i--) { curr = cPrepare[i]; if(!curr || !curr.CalcHiddenGradients(next)) ReturnFalse; next = curr; } //--- if(!NeuronOCL.CalcHiddenGradients(next)) ReturnFalse; //--- return true; }
В итоге метод calcInputGradients восстанавливает структуру вычислений и одновременно контролирует два критических источника нестабильности — повторное использование истории и накопление контекста. Благодаря этому модель сохраняет баланс между глубиной, выразительностью и устойчивостью обучения.
Построение объекта верхнего уровня играет прикладную роль. Оно позволяет радикально упростить интеграцию всей разработанной логики в торговую модель и, что не менее важно, снизить издержки на внедрение и отладку.
Фактически мы получаем замкнутый архитектурный блок с четко определенным интерфейсом. Внутри него уже инкапсулированы механизмы работы со сценариями, адаптивные запросы, стек исторической последовательности и вся логика многоуровневого внимания. Снаружи же он ведет себя как обычный слой, принимающий исходные данные и формирующий выход фиксированной размерности. Это снимает необходимость перестраивать всю модель под новую архитектуру.
В практическом плане это означает, что для внедрения нам не требуется проектировать модель с нуля. Достаточно взять проверенное архитектурное решение из предыдущего проекта и заменить один из ключевых нейронных слоев на реализованный объект верхнего уровня. Вся остальная структура может быть сохранена без изменений.
Тестирование
Как и прежде, итогом проекта должна стать торговая модель, способная анализировать рынок и самостоятельно совершать торговые операции. Обучение мы выстроили в два этапа. Так проще сохранить контроль над процессом и увидеть, как именно модель накапливает знания.
На этапе офлайн-обучения модель проходит по всей истории EURUSD за период 2024-2025 гг и постепенно выстраивает собственное представление о рынке. В процессе обучения модель изучает целостные структуры: последовательности, контекстные признаки, эмбеддинги сценариев. Все это собирается в единый поток и аккуратно раскладывается по внутренним стекам модели. Модуль PCRG формирует контекстно-зависимые запросы. AutoToken отбирает наиболее значимые сочетания сценариев. Блоки кросс-внимания и SwiGLU последовательно проходят по истории, извлекают устойчивые зависимости и превращают их в рабочие сигналы.
Затем модель переходит к онлайн-обучению в тестере стратегий MetaTrader 5. Здесь она уже работает в более живой среде. Новые данные поступают непрерывно, и каждый новый бар может влиять на текущее состояние модели. Параметры корректируются почти в реальном времени. Стеки обновляются. Сценарии уточняются. А накопленный опыт сразу включается в новые прогнозы. На этом этапе модель учится отличать краткий импульс от более крупного движения. Распознавать коррекцию и менять поведение в зависимости от контекста.
Финальная проверка становится логичным завершением этого процесса. На данных за январь–февраль 2026 года модель уже сталкивается с новыми условиями, где прежние шаблоны не могут быть просто повторены. Именно здесь и проверяется, насколько хорошо она научилась понимать рынок.
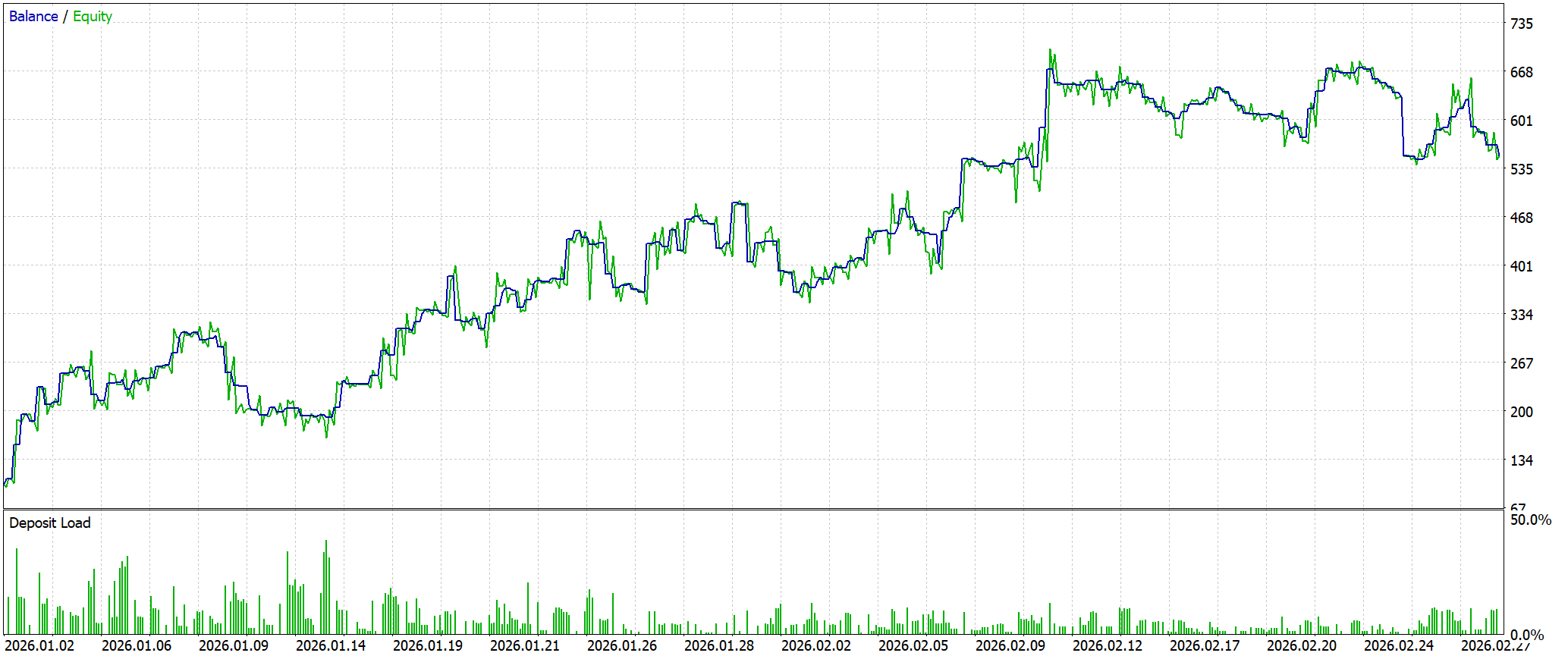
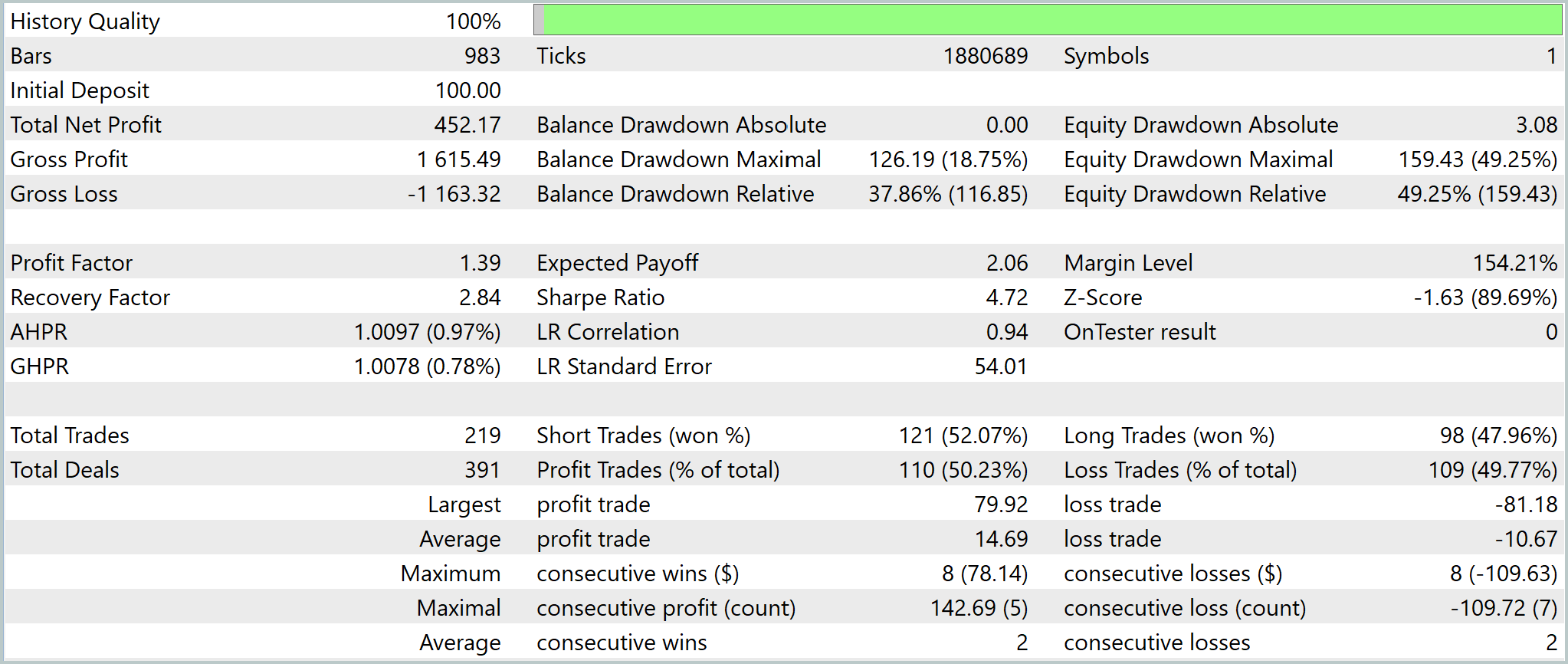
Результаты тестирования показывают, что модель действительно умеет зарабатывать на рыночной истории. Однако делает это не без напряжения. Начальный депозит в 100.0 USD был увеличен до 552.17 USD. То есть капитал вырос более чем в пять раз. Кривая баланса в целом направлена вверх, и это важный сигнал. Система сумела удержать положительную динамику на протяжении всего теста. Но вместе с ростом хорошо видна и другая сторона — заметная волатильность, особенно во второй половине периода.
По ключевым метрикам стратегия остается прибыльной, но запас прочности у нее пока небольшой. Profit Factor на уровне 1.39 говорит о положительном математическом ожидании. Однако оставляет ограниченный люфт для ухудшения рыночных условий. При этом средняя прибыль на сделку выше среднего убытка, а это означает, что система компенсирует почти равное число прибыльных и убыточных сделок за счет структуры результата.
Более тревожным выглядит риск-профиль. Просадка по эквити достигает почти половины баланса, что указывает на высокую нагрузку на депозит и достаточно агрессивное управление позицией. Это подтверждается и статистикой по сделкам. Серии выигрышей и проигрышей могут доходить до восьми подряд, а значит, модель способна длительное время находиться в неблагоприятной фазе. Формально она остается устойчивой, но в практическом применении такая динамика требует аккуратного риск-контроля.
В целом результат можно оценить как прибыльный, но рискованный. Сама архитектурная логика показывает свою состоятельность. Модель умеет извлекать положительное ожидание и поддерживать рост баланса. Следующий шаг здесь очевиден — снижение просадки, более строгий фильтр входов и проверка на других участках истории.
Заключение
В рамках данного проекта мы последовательно перевели теоретические положения фреймворка ADS в прикладную плоскость и довели их до уровня полноценной торговой модели. Архитектура, ранее рассмотренная на уровне отдельных компонентов, была собрана в единый объект верхнего уровня и встроена в существующую инфраструктуру без необходимости ее пересборки.
Ключевым результатом стало формирование воспроизводимого инженерного подхода. Читатель получает готовое решение, которое можно напрямую интегрировать в собственные торговые системы. Важнее того, он получает понимание, как сложные механизмы сценарного анализа, адаптивного внимания и накопления контекста могут быть реализованы в рамках ограничений прикладной среды и использованы для анализа финансовых временных рядов.
Проведенное тестирование показало, что предложенный подход способен генерировать положительное математическое ожидание и демонстрировать устойчивый рост на исторических данных. При этом были выявлены и слабые места. Прежде всего связанные с уровнем риска и глубиной просадок. Это не является недостатком реализации, а, скорее, естественным следствием высокой адаптивности модели, которая требует более точной настройки управления позицией.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен по ссылке.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования