
Adicionando um LLM personalizado a um robô investidor (Parte 5): Desenvolvimento e teste de estratégia de trading com LLM (I) - Ajuste fino

Conteúdo
- Conteúdo
- Introdução
- Ajuste fino de modelos de linguagem grandes
- Estratégia de negociação
- Criação de um conjunto de dados
- Ajuste fino do modelo
- Testes
- Considerações finais
- Referências
Introdução
No artigo anterior, explicamos como usar a aceleração por GPU para treinar grandes modelos de linguagem, mas não a utilizamos para formular estratégias de trading ou realizar testes em dados históricos. A partir deste artigo, usaremos um modelo de linguagem treinado passo a passo para formular estratégias de trading e testá-las em pares de moedas. É claro que esse não é um processo simples.
Todo o trabalho pode levar vários artigos.
- O primeiro passo é formular uma estratégia de trading;
- O segundo passo é criar um conjunto de dados de acordo com a estratégia e ajustar finamente o modelo (ou treiná-lo) para que os dados de entrada e saída do grande modelo de linguagem correspondam à nossa estratégia formulada. Existem várias abordagens para resolver essa tarefa. Apresentarei o máximo de exemplos possível;
- O terceiro passo é a inferência do modelo e a integração dos resultados à estratégia de trading, além da criação de um EA conforme nossa estratégia. Claro, ainda precisamos realizar alguns ajustes na etapa de inferência do modelo, como a escolha da estrutura de saída adequada e dos métodos de otimização (atenção instantânea, quantização do modelo, aceleração etc.).
- O quarto passo é usar o teste em dados históricos para validar nosso EA no lado do cliente.
Você pode dizer: "Você já treinou o modelo com seus próprios dados. Por que ajustá-lo finamente?" A resposta a essa pergunta será dada no artigo.
Obviamente, os métodos disponíveis não se limitam ao ajuste fino de um grande modelo de previsão. Outros métodos também podem ser utilizados, como o RAG (que usa informações de busca para ajudar o grande modelo de linguagem a gerar conteúdo) e o Agent (um objeto inteligente criado a partir da inferência do grande modelo de linguagem). Se fôssemos descrever todos esses métodos em um único artigo, ele seria muito longo e desorganizado. Por isso, o material foi dividido em várias partes. Neste artigo, discutiremos principalmente nossos primeiros e segundos passos, ou seja, como formular estratégias de trading e como apresentar um exemplo de ajuste fino de um grande modelo de linguagem (GPT-2).
Ajuste fino de modelos de linguagem grandes
Antes de começar, precisamos entender o que significa esse ajuste fino. Já treinamos o modelo nos artigos anteriores. Por que precisaríamos ajustá-lo? Por que não usar diretamente o modelo treinado? Para responder a essa pergunta, primeiro devemos analisar a diferença entre grandes modelos de linguagem e modelos tradicionais de redes neurais. Atualmente, os grandes modelos de linguagem são baseados principalmente na arquitetura Transformer, que inclui mecanismos complexos de atenção. O modelo é altamente sofisticado e possui um grande número de parâmetros, de modo que, ao treinar grandes modelos de linguagem, geralmente é necessário um grande volume de dados, além de um computador de alto desempenho. O tempo de treinamento costuma variar de dezenas de horas a vários dias ou até semanas. Assim, para desenvolvedores individuais, treinar um modelo de linguagem do zero é relativamente difícil (claro, se você tiver uma mina de ouro em casa, a história muda).
Nesse momento, o uso do nosso próprio conjunto de dados para o ajuste fino de um grande modelo de linguagem já treinado nos dá mais opções. Um grande modelo de linguagem, treinado com um vasto volume de dados em infraestruturas computacionais de grande escala, possui melhor compatibilidade e capacidade de generalização. Isso não significa que um modelo treinado diretamente em dados específicos seja inadequado. Se o volume e a qualidade dos dados forem suficientemente bons e o hardware for poderoso o bastante, é totalmente viável treinar um modelo do zero com um conjunto de dados próprio, e o resultado pode ser até melhor.
No entanto, o ajuste fino nos dá mais flexibilidade. Assim, a principal abordagem para grandes modelos de linguagem envolve o pré-treinamento do modelo em um grande conjunto de dados genéricos, seguido de um ajuste fino para resolver tarefas específicas dentro de um domínio específico. O ajuste fino mencionado aqui é essencialmente o mesmo que o aprendizado por transferência ou o ajuste fino de redes neurais tradicionais, mas com diferenças significativas. A seguir, descrevemos em detalhes os métodos mais comuns de ajuste fino em grandes modelos de linguagem.
O ajuste fino de grandes modelos pode ser dividido em três abordagens principais: ajuste fino com aprendizado supervisionado, ajuste fino com aprendizado não supervisionado e ajuste fino com aprendizado por reforço:
- Ajuste fino com aprendizado supervisionado: é o método mais comum para treinar um modelo utilizando dados rotulados. Por exemplo, é possível coletar conjuntos de dados de perguntas e respostas em diálogos. Aqui, é necessário definir os dados de entrada e saída-alvo como pares de exemplos para otimizar o modelo.
- Ajuste fino com aprendizado não supervisionado: quando há uma quantidade insuficiente de texto rotulado, a grande linguagem modelo pode continuar o pré-treinamento em um grande volume de texto não rotulado. Isso ajuda o modelo a compreender melhor a estrutura do idioma.
- Ajuste fino com japrendizado por reforço: assim como no aprendizado por reforço tradicional, primeiro criamos um modelo para comparar a qualidade do texto (equivalente ao Critic) como um modelo de recompensa. Esse modelo avalia a qualidade de várias saídas diferentes geradas pelo modelo previamente treinado a partir do mesmo prompt. Além disso, a função de recompensa pode usar um modelo de classificação binária para avaliar prós e contras entre dois resultados de entrada. Com base nesses dados, utilizamos o modelo de recompensa para fornecer uma avaliação qualitativa dos resultados gerados pelo modelo pré-treinado, ajudando a obter melhores respostas na linguagem-alvo. O ajuste fino com aprendizado por reforço permite aprimorar os textos gerados pela grande linguagem modelo. Os métodos mais utilizados para esse tipo de treinamento incluem DPO, ORPO, PPO, entre outros.
Os métodos mais comuns de ajuste fino para grandes modelos geralmente se dividem em duas categorias principais: Model-Tuning (ajuste fino do modelo) e Prompt-Tuning (ajuste fino de prompts):
1. Ajuste fino completo dos parâmetros
A abordagem mais direta é o ajuste fino de todos os parâmetros do grande modelo de linguagem. Isso significa que todos os parâmetros do modelo são atualizados para se adaptar ao novo conjunto de dados. No entanto, esse método não é eficiente, pois, à medida que o número de parâmetros nos grandes modelos de linguagem atuais aumenta, os requisitos de hardware crescem exponencialmente. Por exemplo, para ajustar finamente um grande modelo de linguagem utilizando parâmetros com escala de 8 bits, pode ser necessário um total de 160 GB de memória de vídeo, distribuídos em duas GPUs com 80 GB cada. Logicamente, esse alto custo de hardware desencoraja a maioria dos desenvolvedores.
2. Adapter-Tuning (ajuste fino com adaptadores)
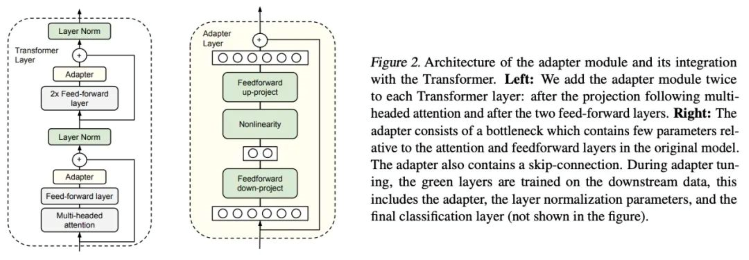
Adapter-Tuning é um método de ajuste fino PEFT (Parameter-Efficient Fine-Tuning, ajuste fino eficiente em parâmetros) aplicado ao modelo de linguagem BERT (Bidirectional Encoder Representations from Transformers, representações bidirecionais de codificadores para transformadores), inicialmente proposto por pesquisadores do Google. Esse método também deu início às pesquisas sobre PEFT. Ao resolver uma tarefa específica de fluxo descendente (downstream task), o ajuste fino completo (modificação de todos os parâmetros do modelo pré-treinado) é altamente ineficiente. Por outro lado, quando se usa um modelo pré-treinado fixo, ajustando apenas algumas camadas de parâmetros próximas à tarefa downstream, pode ser difícil obter um desempenho otimizado. Para contornar esse problema, o Google projetou a estrutura de adaptadores (Adapter structure) e a incorporou à arquitetura Transformer. Durante o treinamento, os parâmetros do modelo original (pré-treinado) são mantidos inalterados, enquanto apenas a estrutura do adaptador adicionada é refinada. Além disso, para garantir a eficiência do treinamento (ou seja, introduzir o menor número possível de parâmetros adicionais), o adaptador foi projetado da seguinte forma: primeiro, uma camada de projeção descendente (down-project layer) reduz a dimensionalidade das características de alta dimensão, passando-as para uma camada não linear. Em seguida, uma estrutura de projeção ascendente (up-project structure) reconstrói as características de baixa dimensão para objetos de alta dimensão originais. Ao mesmo tempo, a estrutura de conexões residuais (skip-connection structure) foi desenvolvida de modo que, no pior dos casos, o modelo possa regredir à identidade original (degrade to identity).
Artigo: Parameter-Efficient Transfer Learning for NLP (Ajuste fino eficiente em parâmetros para Processamento de Linguagem Natural) -https://arxiv.org/pdf/1902.00751
3. Parameter-Efficient Prompt-Tuning (Ajuste de Prompt com eficiência de parâmetros)

Um método eficaz e prático para ajuste fino de modelos. Antes de inserir os dados para treinamento, é possível reduzir a carga computacional e o número de parâmetros, além de acelerar o processo de treinamento, adicionando vetores contínuos de incorporação relacionados à tarefa (task-related embedding vectors). Esse método permite um ajuste fino eficiente com uma quantidade relativamente pequena de dados, reduzindo a dependência de um grande volume de dados rotulados. Além disso, diferentes prompts podem ser ajustados para tarefas distintas, garantindo um alto grau de adaptação às necessidades específicas. Na prática, o ajuste fino eficiente de prompts pode nos ajudar a nos adaptar rapidamente a diferentes exigências e a melhorar o desempenho do modelo. Para implementar esse tipo de ajuste, normalmente são seguidos os seguintes passos:
- Definição dos vetores contínuos de incorporação (continuous task-related embedding vectors), que podem ser projetados manualmente ou aprendidos automaticamente com outros métodos.
- Modificação do prefixo de entrada: o vetor de incorporação definido é usado como um prefixo antes dos dados de entrada. Esses prefixos são passados para o modelo junto com os dados originais durante o treinamento.
- Ajuste fino do modelo: os dados de entrada com prefixo são utilizados no ajuste fino, onde apenas os parâmetros da parte do prefixo são atualizados, enquanto os parâmetros do modelo pré-treinado permanecem inalterados.
- Avaliação e otimização: a eficácia do modelo é testada em um conjunto de validação, e ajustes são feitos para otimização. Com iterações contínuas e ajustes, conseguimos um modelo ajustado para tarefas específicas.
Artigo: The Power of Scale for Parameter-Efficient Prompt Tuning Official (O poder da escala no ajuste fino eficiente de prompts) - https://arxiv.org/pdf/2104.08691.pdf
4. Prefix-Tuning (ajuste fino de prefixo)

Esse método propõe a adição de um vetor contínuo de incorporação relacionado à tarefa a cada entrada de treinamento. O modelo base continua fixo, mas, além da adição de um ou mais vetores de incorporação específicos para cada tarefa, um perceptron multicamadas é usado para codificar o prefixo (sendo o perceptron multicamadas o codificador do prefixo). Assim, ao contrário do ajuste fino de prompts, esse método não introduz modificações diretas na grande linguagem modelo.
Aqui, "contínuo" (continuous) refere-se ao fato de que os tokens de texto do prompt (que normalmente são valores discretos definidos manualmente) são substituídos por vetores de incorporação. Por exemplo, considere um conjunto de tokens definidos manualmente como [‘The’, ‘movie’, ‘is’, ‘[MASK]’]. Se um token for substituído por um vetor de incorporação para servir como entrada do modelo, essa incorporação será contínua. Durante o ajuste fino para tarefas de fluxo descendente (downstream tasks), todos os parâmetros do modelo original são mantidos fixos, enquanto apenas o vetor de prefixo específico da tarefa é ajustado (prefix embedding). Para grandes modelos self-regressive (como o GPT-2, usado no nosso exemplo), o prefixo é adicionado antes do prompt original (z = [PREFIX; x; y]). Para um grande modelo de codificador + decodificador (como o BART), o prefixo é adicionado tanto aos dados de entrada do codificador quanto do decodificador (z = [PREFIX; x; PREFIX’; y]).
Artigo: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks (Ajuste de prefixo: otimizando prompts contínuos para geração, P-Tuning v2: O ajuste de prompts pode ser comparável ao ajuste fino universalmente em diferentes escalas e tarefas) - https://aclanthology.org/2021.acl-long.353
5. P-Tuning e P-Tuning V2

P-Tuning pode melhorar significativamente o desempenho dos modelos de linguagem em ambientes multitarefa com baixo consumo de recursos. Ele aprimora as características de entrada ao incorporar uma pequena sub-rede de interface de baixa complexidade computacional, aumentando assim o desempenho do modelo base. O método P-Tuning mantém os parâmetros do grande modelo de linguagem fixos, enquanto utiliza um perceptron multicamadas e uma rede LSTM (Long Short-Term Memory) para codificar os prompts. Após essa codificação, os prompts normalmente são concatenados com outros vetores e alimentados como entrada no grande modelo de linguagem. Vale ressaltar que, após o treinamento, apenas o vetor resultante da codificação do prompt é preservado, enquanto o codificador em si não é mantido. Esse método não apenas melhora a precisão e a confiabilidade do modelo em diferentes tarefas, mas também reduz significativamente a necessidade de dados e os custos computacionais envolvidos no ajuste fino. No entanto, a desvantagem do P-Tuning é seu baixo desempenho em modelos com um número reduzido de parâmetros. Para resolver essa limitação, foi desenvolvida a segunda versão (V2), semelhante ao LoRA, na qual novos parâmetros são incorporados a cada camada do modelo (Deep FT).
P-Tuning v2 é uma versão aprimorada. Sua principal melhoria está na introdução de um método mais eficiente de redução de parâmetros, permitindo diminuir ainda mais o volume de ajustes necessários. Estritamente falando, P-Tuning v2 não é um novo método, mas sim uma versão otimizada do Deep Prompt Tuning (Li e Liang, 2021; Qin e Eisner, 2021).
P-Tuning v2 foi projetado para geração de texto e pesquisa, mas uma de suas melhorias mais significativas é a aplicação de prompts contínuos em todas as camadas do modelo pré-treinado, em vez de apenas na camada de entrada. Esse método requer o ajuste fino de apenas 0,1% a 3% dos parâmetros, alcançando um desempenho comparável ao ajuste fino convencional da totalidade do modelo.
Artigo sobre P-Tuning: GPT Understands, Too (GPT também entende) - https://arxiv.org/pdf/2103.10385.
6. LoRA

O método LoRA (Low-Rank Adapter, adaptador de baixo nível) inicialmente congela os parâmetros do modelo pré-treinado e adiciona parâmetros adicionais (dropout + Linear + Conv1d) em cada camada do decodificador. Essencialmente, o LoRA não alcança o mesmo desempenho que o ajuste fino completo dos parâmetros. De acordo com experimentos, o ajuste fino completo supera significativamente o LoRA, mas em cenários de recursos limitados, LoRA se torna a melhor opção. LoRA permite treinar indiretamente algumas camadas densas da rede neural, otimizando a matriz de decomposição de baixa ordem das mudanças nas camadas densas durante a adaptação, mantendo os pesos pré-treinados congelados.
Características do LoRA:
- Um modelo bem treinado pode ser reutilizado e servir para a criação de vários pequenos módulos LoRA para diferentes tarefas. Podemos congelar o modelo base e alternar tarefas de forma eficiente, substituindo as matrizes A e B (ver Figura 1 no artigo), reduzindo significativamente os requisitos de armazenamento e os custos de alternância entre tarefas.
- O LoRA torna o treinamento mais eficiente. Com otimizadores adaptativos, os requisitos de hardware podem ser reduzidos em até três vezes, pois não há necessidade de calcular gradientes ou armazenar o estado do otimizador para a maioria dos parâmetros. Em vez disso, apenas uma pequena matriz de baixa ordem é otimizada.
- Sua estrutura linear simples permite que a matriz treinada seja mesclada com os pesos congelados durante a implantação, sem adicionar latência na inferência em comparação com um modelo totalmente ajustado.
- O LoRA é independente de muitos métodos anteriores e pode ser combinado com eles.
Artigo: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (LoRA: adaptação de baixa ordem para grandes modelos de linguagem) - https://arxiv.org/pdf/2106.09685.pdf.
Código: https://github.com/microsoft/LoRA.
7. AdaLoRA

Existem várias maneiras de determinar quais parâmetros do LoRA são mais importantes. AdaLoRA é uma dessas abordagens, e os autores desse método sugerem considerar o valor singular da matriz LoRA como um indicador de sua importância.
Uma diferença crucial em relação ao LoRA-drop é que, no LoRA-drop, os adaptadores da camada intermediária são completamente treinados ou não são treinados de forma alguma. O AdaLoRA, por sua vez, permite que diferentes adaptadores tenham diferentes ranks (enquanto no LoRA original todos os adaptadores possuem o mesmo rank).
O AdaLoRA mantém o mesmo número total de parâmetros que o LoRA padrão com o mesmo rank, mas distribui esses parâmetros de maneira diferente. No LoRA convencional, todas as matrizes possuem o mesmo rank, enquanto no AdaLoRA algumas matrizes têm ranks mais altos e outras mais baixos. Dessa forma, o número total de parâmetros permanece inalterado. Experimentos demonstraram que o AdaLoRA apresenta melhores resultados do que os métodos LoRA padrão, o que sugere uma distribuição mais eficiente dos parâmetros treináveis dentro do modelo. Isso é particularmente importante para a tarefa em questão, já que os layers mais próximos do final da rede neural tendem a ter um rank maior. Isso indica que a adaptação nessas camadas é mais relevante.
O AdaLoRA decompõe a matriz de pesos em uma matriz incremental usando decomposição por valores singulares (Singular Value Decomposition – SVD) e ajusta dinamicamente o tamanho dos valores singulares em cada matriz incremental. Durante o ajuste fino, apenas os parâmetros que contribuem mais significativamente para o desempenho do modelo são atualizados, resultando em uma melhor eficiência dos parâmetros e em um aumento no desempenho geral do modelo.
Artigo: ADALORA: ADAPTIVE BUDGET ALLOCATION FOR PARAMETER-EFFICIENT FINE-TUNING (ADALORA: Alocação Adaptativa de Orçamento para Ajuste Fino Eficiente em Parâmetros) (https://arxiv.org/pdf/2303.10512).
Código: https://github.com/QingruZhang/AdaLoRA.
8. QLoRA

O QLoRA propaga o gradiente de volta para o adaptador de baixa ordem (LoRA) utilizando um modelo de linguagem pré-treinado congelado e quantizado em 4 bits. Esse processo reduz significativamente o uso de memória e o custo computacional, ao mesmo tempo em que mantém o desempenho de um ajuste fino tradicional de 16 bits.
Principais características do QLoRA:
- Propagação reversa de gradientes para adaptadores de baixa ordem (LoRA) utilizando um modelo de linguagem pré-treinado congelado e quantizado em 4 bits.
- Introdução do NormalFloat 4-bit (NF4), um tipo de dado teoricamente otimizado para quantização de informações normalmente distribuídas. Esse formato supera os resultados empíricos de números inteiros de 4 bits e números de ponto flutuante de 4 bits.
- Aplicação de quantização dupla, um método que reduz a precisão das constantes de quantização para economizar, em média, cerca de 0,37 bits por parâmetro.
- Uso de um otimizador de páginas com NVIDIA Unified Memory, que previne picos no consumo de memória durante a gravação de estados em pontos de verificação (checkpoints). Isso é particularmente útil no processamento de pequenos batches com sequências de grande comprimento. Redução significativa nos requisitos de memória, permitindo ajustar um modelo com 65 bilhões de parâmetros em uma única GPU de 48 GB, sem comprometer o tempo de execução ou a precisão em relação a um ajuste fino tradicional de 16 bits.
Artigo: QLORA: Efficient Finetuning of Quantized LLMs (QLORA: Ajuste fino eficiente de grandes modelos de linguagem quantizados) - https://arxiv.org/pdf/2305.14314.pdf.
Código: https://github.com/artidoro/qlora.
Neste artigo, listamos apenas alguns dos métodos mais utilizados e representativos, além de algumas variantes baseadas na tecnologia LoRA: LoRA+, VeRA, LoRA-fa, LoRA-drop, DoRA e Delta-LoRA, entre outros. No entanto, não abordaremos cada um deles separadamente. Caso precise de mais informações, consulte a literatura correspondente.
Obviamente, também existem outros métodos para processamento de prompts que podem atender às nossas necessidades técnicas, como a tecnologia RAG. Vamos explorá-los em artigos futuros.
A seguir, apresentarei um exemplo de ajuste fino do GPT-2 com todos os parâmetros.
Estratégia de negociação
Para a estratégia de negociação, utilizaremos um exemplo simples para demonstrar o ajuste fino de um grande modelo de linguagem, sem incluir temporariamente a implementação de um EA. A implementação completa do EA será realizada apenas após finalizarmos a estratégia completa de inferência do grande modelo de linguagem. Somente então poderemos estruturar o EA dentro de um prazo razoável. Inicialmente, obtemos do cliente os últimos 20 preços de fechamento de um par de moedas em um determinado período e calculamos sua média, que chamaremos de A. Em seguida, usamos o grande modelo de linguagem para prever os próximos 40 preços de fechamento para o mesmo período e calculamos sua média, que chamaremos de B. A decisão de compra ou venda será baseada na comparação desses valores:
- Se a média B dos 40 preços previstos for maior que a média A dos 20 últimos preços reais, então compramos.
- Se a média B dos 40 preços previstos for menor que a média A dos 20 últimos preços reais, então vendemos.
- Se os valores A e B forem iguais ou muito próximos, nenhuma operação será realizada.
Formulamos uma estratégia de trading. Essa estratégia é bastante simples e serve apenas como uma demonstração, sem a intenção de idealizá-la. Você pode modificá-la conforme necessário, por exemplo, tornando os parâmetros de entrada dinâmicos, de modo que o comprimento total das previsões seja 60 menos o comprimento dos parâmetros de entrada. Também é possível usar outras lógicas de trading diretamente, como estabelecer regras baseadas em estratégias como a estratégia de ondas, a estratégia do crocodilo ou a estratégia da tartaruga. Naturalmente, seu modelo precisará ser ajustado de acordo com essas mudanças. Agora, vamos criar um conjunto de dados conforme a estratégia definida e realizar o ajuste fino do modelo de linguagem grande.
Criação de um conjunto de dados
Já criamos um conjunto de dados ao discutir o treinamento de grandes modelos de linguagem. Ele está armazenado no arquivo llm_data.csv. Esse conjunto contém apenas as cotações de um par de moedas ao longo de um ciclo de 5 meses e foi devidamente processado, resultando em 2442 linhas de dados, cada uma contendo 64 colunas. Para mais detalhes sobre o processo de preparação dos dados, consulte a seção sobre treinamento de grandes modelos de linguagem usando CPU ou GPU nesta série de artigos (Integre seu próprio LLM no EA (Parte 3): Treinando seu próprio LLM com CPU "). Claro, você também pode usar o script mencionado no artigo para ajustar o conjunto de dados ou transformar suas próprias ideias em um novo conjunto (por exemplo, criar um conjunto de dados que correlacione dados fiscais governamentais com taxas de câmbio). Em resumo, esse conjunto de dados pode assumir qualquer forma, não estando restrito apenas a cotações numéricas.
1. Pré-processamentoPrimeiro, importamos as bibliotecas necessárias.
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments import torch
Depois, lemos o arquivo de dados.
df = pd.read_csv('llm_data.csv') Atualizei esse conjunto de dados, e agora ele contém 60 preços de fechamento do par de moedas ao longo de 5 meses em cada linha, substituindo o formato anterior de 64 colunas. Além disso, os dados foram convertidos para formato textual.
sentences = [' '.join(map(str, prices)) for prices in df.iloc[:-10,1:].values]
Esta linha de código basicamente lê todo o arquivo DataFrame, percorre seus elementos e converte cada linha em uma string de código, tratando-a como uma sentença. Cada sentença contém 60 preços de fechamento. Em outras palavras, convertemos a linha para o seguinte formato: "0.6119 0.61197 0.61201…0.61196" em vez de: "0.6119" "0.61197" … "0.61196". Isso é feito para que o modelo de linguagem memorize o comprimento da sequência especificado. Por exemplo, se inserirmos 20 valores de entrada, o modelo completará automaticamente os 40 valores restantes, em vez de gerar conteúdo que não podemos controlar.
Nesta linha de código, há um ponto específico que precisa ser explicado: df.iloc[:-10,1:].values ":-10" significa que pegamos todas as linhas do início do arquivo CSV, exceto as últimas 10, que serão reservadas para teste. "1:" significa que removemos a primeira coluna de cada linha. Essa coluna representa o índice do CSV, que não é necessário para o modelo.
Em seguida, combinamos todas as sequências em um único conjunto de dados e o salvamos como train.txt, para que, da próxima vez, possamos simplesmente carregar o arquivo CSV processado diretamente, em vez de repetir o processamento várias vezes.
with open('train.txt', 'w') as f: for sentence in sentences: f.write(sentence + '\n')
2. Carregamos os dados como uma classe Dataset
Após concluir a pré-processamento dos dados, ainda precisamos aplicar um tokenizador para realizar um processamento adicional e carregar os dados no formato Dataset do PyTorch. Atualmente, a biblioteca Transformers já integra classes que facilitam essa tarefa. No exemplo desta seção, podemos usar diretamente a classe TextDataset, o que torna esse processo muito mais simples. No entanto, primeiro precisamos instanciar um tokenizador para o GPT-2. Se você ainda não baixou o GPT-2, ao utilizá-lo pela primeira vez, a biblioteca Transformers fará o download do modelo pré-treinado automaticamente a partir do Hugging Face. Certifique-se de que sua conexão de rede esteja desbloqueada. Para usuários de Docker ou WSL, verifique se sua configuração de rede está correta, caso contrário, o download poderá falhar.
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
train_dataset = TextDataset(tokenizer=tokenizer,
file_path="train.txt",
block_size=60) 3. Carregamos os dados na linguagem modelo
Aqui, usamos diretamente a classe DataCollatorForLanguageModeling, da biblioteca Transformers, para preparar os dados. Isso elimina a necessidade de pré-processamento adicional.
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
Agora, podemos carregar o modelo pré-treinado e configurar seus parâmetros.
Ajuste fino do modelo
Já preparamos o conjunto de dados necessário para o ajuste fino. Agora, podemos iniciar o ajuste fino do nosso grande modelo de linguagem.
1. Carregamos o modelo pré-treinado
O primeiro passo é carregar o modelo pré-treinado. Como já carregamos o tokenizador, agora só precisamos carregar o modelo em si:
model = GPT2LMHeadModel.from_pretrained('gpt2') Em seguida, definimos os parâmetros de treinamento. A biblioteca Transformers fornece uma classe conveniente para essa função, eliminando a necessidade de arquivos de configuração adicionais.
training_args = TrainingArguments(output_dir="./gpt2_stock", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, load_best_model_at_end=True, )
2. Inicializamos os parâmetros do ajuste fino
Ao instanciar a classe TrainingArguments, utilizamos os seguintes parâmetros:
- output_dir – Diretório onde os resultados das previsões e os pontos de verificação (checkpoints) serão armazenados. Definimos a pasta gpt2_stock no diretório atual como o caminho de saída.
- overwrite_output_dir – Indica se devemos sobrescrever os arquivos de saída. Optamos por sobrescrever.
- num_train_epochs – Número de épocas de treinamento. Escolhemos 3 épocas.
- per_device_train_batch_size – Tamanho do lote de treinamento por dispositivo. Definimos 32. Como mencionado anteriormente, é recomendável que esse valor seja uma potência de 2.
- save_steps=10_000 – Número de passos de atualização antes de salvar dois pontos de verificação, caso save_strategy="steps". Deve ser um número inteiro ou um valor decimal no intervalo [0,1). Se for menor que 1, será interpretado como uma fração do total de passos de treinamento.
- save_total_limit – Quando definido, limita o número total de pontos de verificação armazenados. Os pontos mais antigos serão removidos do output_dir.
- load_best_model_at_end – Define se a melhor versão do modelo deve ser carregada no final do treinamento, em vez de usar os pesos da última iteração.
Existem muitos outros parâmetros que não configuramos, pois usamos seus valores padrão para manter o exemplo simples. Alguns deles incluem:
- deepspeed – Indica se Deepspeed será utilizado para acelerar o treinamento.
- eval_steps – Define o número de passos entre duas avaliações do modelo.
- dataloader_pin_memory – Indica se a memória deve ser fixada nos carregadores de dados.
A classe TrainingArguments é extremamente poderosa, pois inclui a maior parte dos parâmetros de treinamento, tornando-a muito conveniente. Recomendo fortemente que os leitores consultem a documentação oficial para explorar todos os seus recursos.
3. Ajuste fino
Agora, retornemos ao nosso processo de ajuste fino e formalizemos sua definição. No artigo anterior, discutimos detalhadamente o treinamento de um grande modelo de linguagem. O ajuste fino não difere muito desse processo. Suponho que os leitores já estejam familiarizados com ele, então, em vez de explicar o passo a passo, este exemplo utilizará diretamente a classe Trainer, da biblioteca Transformers, para realizar o ajuste fino. Agora, passamos os seguintes parâmetros para a classe Trainer, criando uma instância desse objeto:
trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset,)
A classe Trainer também possui outros parâmetros que não definimos, como os callbacks. Os callbacks permitem personalizar o comportamento do ciclo de treinamento. Eles podem: Monitorar o estado do ciclo de treinamento (para geração de relatórios, registro no TensorBoard ou outras plataformas de aprendizado de máquina). Tomar decisões automaticamente (por exemplo, interromper o treinamento antecipadamente caso um critério seja atendido). A razão pela qual não os utilizamos neste artigo é que este é apenas um exemplo e as configurações dos parâmetros do modelo no ajuste fino foram feitas de forma conservadora. Se você deseja que seu modelo desempenhe melhor, não ignore essa opção. Para iniciar o processo de ajuste fino, basta chamar o método:
trainer.train()
Após concluir o treinamento, salvamos o modelo para que possamos carregá-lo diretamente usando o método from_pretrained() durante a inferência:
trainer.save_model("./gpt2_stock") Agora, realizamos a inferência para verificar a eficácia do ajuste fino:
prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1]))
generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt').to("cuda"),
do_sample=True,
max_length=200)[0],
skip_special_tokens=True)
print(f"test the model:{generated}") No trecho de código abaixo, a linha prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) converte a última linha do nosso conjunto de dados para o formato de string. A linha tokenizer.encode(prompt, return_tensors='pt') transforma o texto de entrada (prompt) em um formato que a LLM pode processar, convertendo o texto em uma sequência de tokens. O parâmetro return_tensors='pt' especifica que os dados de saída serão tensores do PyTorch. Além disso, o parâmetro do_sample=True habilita amostragem aleatória no processo de geração, enquanto max_length=200 define o comprimento máximo do texto gerado. Agora, vejamos os resultados do código completo:

Podemos observar que a LLM ajustada corretamente gerou os resultados esperados.
O código completo pode ser encontrado no arquivo anexo: Fin-tuning.py.
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments import torch dvc='cuda' if torch.cuda.is_available() else 'cpu' print(dvc) df = pd.read_csv('llm_data.csv') sentences = [' '.join(map(str, prices)) for prices in df.iloc[:-10,1:].values] with open('train.txt', 'w') as f: for sentence in sentences: f.write(sentence + '\n') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') train_dataset = TextDataset(tokenizer=tokenizer, file_path="train.txt", block_size=60) data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False) model = GPT2LMHeadModel.from_pretrained('gpt2') training_args = TrainingArguments(output_dir="./gpt2_stock", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, load_best_model_at_end=True, ) trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset,) trainer.train() trainer.save_model("./gpt2_stock") prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt').to(dvc), do_sample=True, max_length=200)[0], skip_special_tokens=True) print(f"test the model:{generated}")
Testes
Após concluir o ajuste fino, precisamos testar a precisão do modelo. Para isso, comparamos os resultados da LLM com os valores reais. O método mais simples para medir essa diferença é calcular o erro quadrático médio (MSE, Mean Squared Error) entre os valores reais e os valores previstos.
Agora, recriamos um script de teste para esse processo. Primeiro, importamos as bibliotecas necessárias, carregamos o modelo GPT-2 ajustado e os dados:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from sklearn.metrics import mean_squared_error import torch import numpy as np df = pd.read_csv('llm_data.csv') dvc='cuda' if torch.cuda.is_available() else 'cpu' model = GPT2LMHeadModel.from_pretrained('./gpt2_stock') tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
Esse processo não difere muito do ajuste fino, exceto pelo fato de que o caminho do modelo agora se refere ao local onde salvamos os pesos do modelo durante o ajuste fino. Após carregar o modelo e o tokenizador, processamos os valores reais e os valores previstos. Essa etapa é idêntica ao que fizemos no script de ajuste fino:
prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt'), do_sample=True, max_length=200)[0], skip_special_tokens=True)
Agora, extraímos os últimos 40 preços de fechamento da última linha do conjunto de dados como valores reais, e os convertamos para uma lista do tamanho adequado:
true_prices= df.iloc[-1:,21:].values.tolist()[0] generated_prices=generated.split('\n')[0] generated_prices=list(map(float,generated_prices.split())) generated_prices=generated_prices[0:len(true_prices)] def trim_lists(a, b): min_len = min(len(a), len(b)) return a[:min_len], b[:min_len] true_prices,generated_prices=trim_lists(true_prices,generated_prices)
Para garantir que os valores reais e os valores previstos tenham o mesmo comprimento, ajustamos o tamanho das listas, usando a função trim_lists(a, b). Então, imprimimos os valores reais e os previstos para verificar se correspondem às expectativas.
print(f"true_prices:{true_prices}") print(f"generated_prices:{generated_prices}")
Os resultados são os seguintes:
true_prices: [0.6119, 0.61197, 0.61201, 0.61242, 0.61237, 0.6123, 0.61229, 0.61242, 0.61212, 0.61197, 0.61201, 0.61213, 0.61212,
0.61206, 0.61203, 0.61206, 0.6119, 0.61193, 0.61191, 0.61202, 0.61197, 0.6121, 0.61211, 0.61214, 0.61203, 0.61203, 0.61213, 0.61218,
0.61227, 0.61226, 0.61227, 0.61231, 0.61228, 0.61227, 0.61233, 0.61211, 0.6121, 0.6121, 0.61195, 0.61196]
generated_prices:[0.61163, 0.61162, 0.61191, 0.61195, 0.61209, 0.61231, 0.61224, 0.61207, 0.61187, 0.61184, 0.6119, 0.61169, 0.61168,
0.61162, 0.61181, 0.61184, 0.61184, 0.6118, 0.61176, 0.61169, 0.61191, 0.61195, 0.61204, 0.61188, 0.61205, 0.61188, 0.612, 0.61208,
0.612, 0.61192, 0.61168, 0.61165, 0.61164, 0.61179, 0.61183, 0.61192, 0.61168, 0.61175, 0.61169, 0.61162]
Agora, calculamos o erro quadrático médio (MSE) e imprimimos os resultados para análise:
mse = mean_squared_error(true_prices, generated_prices)
print('MSE:', mse) Resultado: MSE: 2.1906250000000092e-07.
Como pode ser observado, a erro quadrático médio (MSE) é muito pequeno, mas isso significa que nossa modelo é altamente preciso? Por favor, não se esqueça de que os valores originais do nosso conjunto de dados eram muito pequenos! Portanto, embora o MSE seja baixo, isso ocorre porque os valores originais também são relativamente pequenos. Isso significa que o MSE não reflete com precisão o modelo neste momento. Para uma avaliação mais precisa, precisamos calcular: O erro quadrático médio raiz (RMSE, Root Mean Square Error) O erro quadrático médio raiz normalizado (NRMSE, Normalized Root Mean Square Error) Esses cálculos nos permitirão determinar o tamanho do erro de previsão em relação ao intervalo de valores observados, ajudando-nos a avaliar com maior precisão o modelo:
rmse=np.sqrt(mse) nrmse=rmse/(np.max(true_prices)-np.min(generated_prices)) print(f"RMSE:{rmse},NRMSE:{nrmse}")
Resultado:
- RMSE:0.00046804113067122735
- NRMSE:0.5850514133390986

Podemos notar que, apesar dos valores de MSE e RMSE serem pequenos, o NRMSE é 5850514133390986, o que indica que o erro de previsão corresponde a aproximadamente 58,5% do intervalo observado. Isso nos mostra que, embora o valor absoluto do RMSE seja pequeno, o erro de previsão ainda é relativamente alto quando comparado ao intervalo de valores observados.
Como melhorar a precisão do modelo? Aqui estão algumas opções:
- Aumentar o número de épocas no ajuste fino.
- Expandir o conjunto de dados para fornecer mais informações ao modelo.
- Otimizar corretamente os parâmetros de ajuste fino.
- Substituir o modelo por uma versão maior, capaz de capturar padrões mais complexos.
Esses métodos são relativamente simples de implementar. Neste artigo, não testamos cada um deles individualmente, mas você pode escolher um ou mais e aplicá-los conforme suas próprias necessidades. Tenho certeza de que os resultados serão muito melhores do que os apresentados neste exemplo!
O código completo do teste do modelo pode ser encontrado no arquivo anexo: test.py.
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from sklearn.metrics import mean_squared_error import torch import numpy as np df = pd.read_csv('llm_data.csv') dvc='cuda' if torch.cuda.is_available() else 'cpu' model = GPT2LMHeadModel.from_pretrained('./gpt2_stock') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt'), do_sample=True, max_length=200)[0], skip_special_tokens=True) true_prices= df.iloc[-1:,21:].values.tolist()[0] generated_prices=generated.split('\n')[0] generated_prices=list(map(float,generated_prices.split())) generated_prices=generated_prices[0:len(true_prices)] def trim_lists(a, b): min_len = min(len(a), len(b)) return a[:min_len], b[:min_len] true_prices,generated_prices=trim_lists(true_prices,generated_prices) print(f"true_prices:{true_prices}") print(f"generated_prices:{generated_prices}") mse = mean_squared_error(true_prices, generated_prices) print('MSE:', mse) rmse=np.sqrt(mse) nrmse=rmse/(np.max(true_prices)-np.min(generated_prices)) print(f"RMSE:{rmse},NRMSE:{nrmse}")
Considerações finais
Neste artigo, discutimos os princípios fundamentais para usar grandes modelos de linguagem em estratégias de trading. Ou seja, os resultados da LLM devem estar alinhados com os requisitos da estratégia de trading. Exploramos alguns métodos técnicos que possibilitam essa integração. Devido à limitação de espaço, não incluímos exemplos de código para todos os métodos, apresentando apenas um exemplo de ajuste fino do GPT-2 com todos os seus parâmetros. Naturalmente, o conjunto de dados utilizado não é aplicável a todas as técnicas de ajuste fino mencionadas. No entanto, artigos futuros apresentarão exemplos detalhados sobre como criar conjuntos de dados adequados para cada método. Nas próximas publicações, abordarei métodos representativos com exemplos de código mais completos, além de apresentar a implementação de EAs. Quanto às tecnologias RAG e Agent, que foram apenas mencionadas, exploraremos seus detalhes em artigos futuros, incluindo exemplos de código e suas implementações práticas.
Vejo você no próximo artigo!
Referências
https://alexqdh.github.io/posts/2183061656/
http://note.iawen.com/note/llm/finetune
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13497
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá
Olá, com base nos exemplos deste artigo:
1. Os pesos do modelo GPT2 pré-treinado que usamos neste exemplo não têm nenhum conteúdo relacionado aos nossos dados, e a série temporal de entrada não será reconhecida sem o ajuste fino, mas o conteúdo correto pode ser gerado de acordo com nossas necessidades após o ajuste fino.
2. Como dissemos em nosso artigo, é muito demorado treinar um modelo de linguagem do zero para fazê-lo convergir, mas o ajuste fino fará um modelo pré-treinado convergir rapidamente, economizando muito tempo e poder de computação. Como o modelo usado em nosso exemplo é relativamente pequeno, esse processo não é muito óbvio.
3. O processo de ajuste fino requer muito menos dados do que o processo de pré-treinamento. Se a quantidade de dados não for suficiente, o ajuste fino do modelo com a mesma quantidade de dados é muito melhor do que o treinamento direto de um modelo.
Olá, obrigado pelos artigos incríveis.
Estou ansioso para ver como integraremos o modelo ajustado ao MT5