
Добавляем пользовательскую LLM в торгового робота (Часть 5): Разработка и тестирование торговой стратегии с помощью LLM (I) - Тонкая настройка

Содержание
- Содержание
- Введение
- Тонкая настройка больших языковых моделей
- Торговая стратегия
- Создание набора данных
- Тонкая настройка модели
- Тестирование
- Заключение
- Ссылки
Введение
В предыдущей статье мы рассказали, как использовать ускорение GPU для обучения больших языковых моделей, но мы не использовали его для формулирования торговых стратегий или проведения тестирования на истории. Начиная с этой статьи, мы шаг за шагом будем использовать обученную языковую модель для формулирования торговых стратегий и их тестирования на валютных парах. Конечно, это не простой процесс.
Вся работа может занять несколько статей.
- Первый шаг — сформулировать торговую стратегию;
- Вторым шагом является создание набора данных в соответствии со стратегией и тонкая настройка модели (или обучение модели) таким образом, чтобы входные и выходные данные большой языковой модели соответствовали нашей сформулированной торговой стратегии. Существует множество различных подходов для решения этой задачи. Я приведу как можно больше примеров;
- Третий шаг — вывод модели и объединение результатов с торговой стратегией, а также создание советника в соответствии с нашей торговой стратегией. Конечно, нам еще предстоит проделать определенную работу на этапе вывода модели (выбор подходящей структуры вывода и методов оптимизации: например, мгновенное внимание, квантование модели, ускорение и т. д.);
- Четвертый шаг — использование тестирование на истории для проверки нашего советника на стороне клиента.
Вы можете сказать: "Ты уже обучил модель на собственных данных. Зачем ее настраивать?" Ответ на этот вопрос будет дан в статье.
Конечно, доступные методы не ограничиваются тонкой настройкой большой модели прогнозирования. Также могут использоваться и другие методы, такие как RAG (метод, который использует поисковую информацию для помощи большой языковой модели в генерации контента) и Agent (интеллектуальный объект, созданный путем вывода большой языковой модели). Если описывать все эти методы в одной статье, то она получится слишком длинной и хаотичной. Поэтому раздел материал на несколько частей. В этой статье мы в основном обсудим наши первый и второй шаги, сформулируем торговые стратегии и приведем пример тонкой настройки большой языковой модели (GPT2).
Тонкая настройка больших языковых моделей
Прежде чем начать, мы должны сначала понять эту тонкую настройку. Мы уже обучили модель в предыдущих статьях. Зачем нам ее настраивать? Почему бы не использовать обученную модель напрямую? Чтобы ответить на этот вопрос, мы должны сначала посмотреть на разницу между большими языковыми моделями и традиционными моделями нейронных сетей. На текущем этапе большие языковые модели в основном основаны на архитектуре трансформера, которая включает в себя сложные механизмы внимания. Модель сложна и имеет большое количество параметров, поэтому при обучении больших языковых моделей, как правило, требуется большой объем данных для обучения, а также высокопроизводительный компьютер, а время обучения обычно составляет от десятков часов до нескольких дней или даже десятков дней. Таким образом, для индивидуальных разработчиков относительно сложно обучить языковую модель с нуля (конечно, если у вас дома есть золотая жила, это меняет дело).
На данный момент использование нашего собственного набора данных для точной настройки уже обученной большой языковой модели дает нам больше возможностей выбора. Большая языковая модель, обученная с использованием большого объема данных на крупномасштабных кластерных вычислениях, обладает лучшей совместимостью и способностью к обобщению. Это не означает, что модель, обученная непосредственно на конкретных данных, недостаточно хороша. Если объем и качество данных достаточно хороши и велики, а аппаратное обеспечение достаточно мощное, вы можете полностью использовать свой собственный набор данных для обучения модели с нуля, и эффект может быть лучше.
Однако тонкая настройка дает нам больше выбора. Таким образом, основная парадигма больших языковых моделей заключается в предварительном обучении языковой модели на большом объеме общих данных, а затем в ее тонкой настройке для решения конкретных задач в рамках доменной адаптации. Упомянутая здесь тонкая настройка по сути та же самая, что и трансферное обучение или тонкая настройка традиционных нейронных сетей, но есть и весьма существенные различия. Далее подробно описаны наиболее часто используемые методы тонкой настройки в больших языковых моделях.
Тонкую настройку больших моделей можно разделить на методы тонкой настройки с обучением с учителем, методы тонкой настройки с обучением без учителя и методы тонкой настройки с обучением с подкреплением:
- Тонкая настройка с обучением с учителем: Наиболее распространенный способ обучения модели с использованием размеченных данных. Например, вы можете собрать наборы данных по вопросам и ответам в диалогах. Необходимо задать целевые выходные и входные данные в виде пары примеров для оптимизации модели.
- Тонкая настройка с обучением без учителя: При недостаточном количестве размеченного текста большая языковая модель может продолжить предварительное обучение на большом объеме неразмеченного текста, что помогает модели лучше понять структуру языка.
- Тонкая настройка с обучением с подкреплением: Как и в традиционном обучении с подкреплением, сначала построим модель сравнения качества текста (эквивалентную Critor) в качестве модели вознаграждения и оценим качество нескольких различных выходных данных, предоставленных предварительной обучающей моделью для одного и того же слова-подсказки. В то же время эта модель вознаграждения может использовать модель бинарной классификации для оценки плюсов и минусов между двумя входными результатами. Затем, в соответствии с данными на основе слова-подсказки, используем модель вознаграждения, чтобы дать качественную оценку результата подсказок пользователю в модели предварительного обучения и получить лучшие результаты с целевой языковой моделью. Тонкая настройка с обучением с подкреплением позволит улучшить результаты текста, сгенерированного большой языковой моделью на основе модели предварительного обучения. К наиболее часто используемым методам обучения с подкреплением относятся DPO, ORPO, PPO и другие.
Наиболее часто используемые методы тонкой настройки больших моделей в основном делятся на две категории: Model-Tuning (настройка модели) и Prompt-Tuning (настройка подсказок):
1. Полная тонкая настройка параметров
Самый прямой способ — тонкая настройка всей большой языковой модели, что означает, что все параметры будут обновлены для адаптации к новому набору данных. Этот метод считается неэффективным, поскольку по мере того, как объем параметров текущей большой языковой модели становится все больше и больше, требуемые аппаратные ресурсы экспоненциально увеличиваются. Например, для точной настройки большой языковой модели со шкалой параметров в 8 бит может потребоваться 2 видеопамяти по 80 Гб или в общей сложности около 160 Гб видеопамяти. Логично предположить, что потенциальная стоимость оборудования отпугнет большинство рядовых разработчиков.
2. Adapter-Tuning (настройка адаптера)
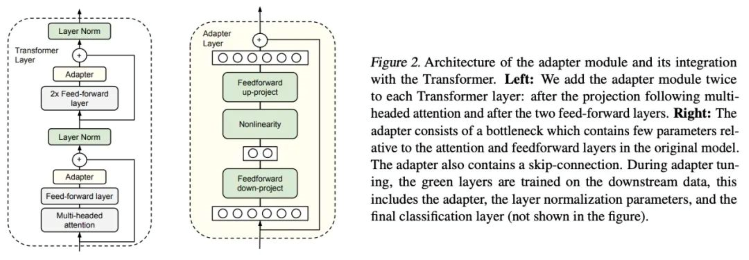
Adapter-Tuning - это метод тонкой настройки PEFT (Parameter-Efficient Fine-Tuning, параметрически эффективная тонкая настройка) для языковой модели BERT (Bidirectional Encoder Representations from Transformers, двунаправленные презентации кодировщика для трансформеров), впервые предложенный исследователями Google. Он также положил начало исследованиям PEFT. При решении конкретной задачи нисходящего потока (downstream task) полная тонкая настройка (все параметры модели предварительного обучения настраиваются точно) слишком неэффективна. Если же используется фиксированная модель предварительного обучения, то настраиваются только несколько слоев параметров, близких к задаче нисходящего потока, и добиться лучшего эффекта сложно. Google спроектировал структуру адаптера (Adapter structure), встроил ее в структуру трансформера, во время обучения зафиксировал параметры исходной (предтренировочной модели) и только доработал вновь добавленную структуру адаптера. В то же время, чтобы обеспечить эффективность обучения (то есть ввести как можно меньше дополнительных параметров), Адаптер был спроектирован следующим образом: сначала слой более низкого уровня (down-project layer) отображает высокоразмерные признаки на низкоразмерных, а затем передает нелинейный слой. После этого используется структура более высокого уровня (up-project structure) для сопоставления низкоразмерных признаков с исходными высокоразмерными объектами. В то же время структура пропускных соединений (skip-connection structure) также спроектирована таким образом, чтобы гарантировать, что в худшем случае она может откатиться до тождественной (degrade to identity).
Статья: Parameter-Efficient Transfer Learning for NLP (параметрически эффективное трансферное обучение для обработки естественного языка) -https://arxiv.org/pdf/1902.00751
Код: https://github.com/google-research/adapter-bert
3. Parameter-Efficient Prompt-Tuning (параметрически эффективная быстрая настройка)

Действенный и практичный метод точной настройки модели. Перед вводом данных для обучения, можно сократить объем вычислений и параметров, а также ускорить процесс обучения, добавляя непрерывные векторы внедрения, связанные с задачей (task-related embedding vectors). При этом для эффективной тонкой настройки требуется лишь небольшой объем данных, что снижает зависимость от большого объема размеченных данных. Кроме того, различные подсказки (prompts) можно настраивать для разных задач, что обеспечивает высокую степень адаптации к задачам. В приложениях параметрически эффективная быстрая настройка может помочь нам быстро адаптироваться к различным потребностям и улучшить производительность модели. Для реализации такой настройки подсказок обычно требуются следующие шаги:
- В соответствии с задачей определяются непрерывные векторы внедрения (continuous task-related embedding vectors). Эти векторы можно спроектировать вручную или автоматически изучить с помощью других методов.
- Изменяется входной префикс: Заданный вектор внедрения определяется в качестве префикса перед входными данными. Эти префиксы будут переданы в модель для обучения вместе с исходными входными данными.
- Тонкая настройка модели: Входные данные с префиксом используются для тонкой настройки. При этом будут обновлены только параметры префиксной части, а параметры исходной предобучающей модели останутся неизменными.
- Оценка и оптимизация: Оценивается эффективность модели на проверочном наборе и вносятся коррективы в оптимизацию. Благодаря непрерывной итерации и оптимизации мы можем получить точно настроенную модель, подходящую для конкретных задач.
Статья: The Power of Scale for Parameter-Efficient Prompt Tuning Official (степень масштабирования для параметрически эффективной настройки подсказок) - https://arxiv.org/pdf/2104.08691.pdf
Код: https://github.com/google-research/prompt-tuning
4. Prefix-Tuning (настройка префикса)

Метод предлагает добавлять непрерывный вектор внедрения, связанный с задачей, к каждому входу обучения. Метод по-прежнему является фиксированным предварительным параметром обучения, но, в дополнение к добавлению одного или нескольких вложений для каждой задачи, он использует многослойный перцептрон для кодирования префикса (обратите внимание, что многослойный перцептрон является кодировщиком префикса) и больше не вводит большую языковую модель, как при настройке подсказок.
Здесь "непрерывный" (continuous) относится к дискретному значению (discrete) токенов текстовых подсказок, определенных вручную. Например, рассмотрим вручную определенный массив токенов подсказок [‘The’, ‘movie’, ‘is’, ‘[MASK]’]. Если токен заменить вектором внедрения в качестве входного параметра, внедрение будет непрерывным. При переобучении задачи нисходящего потока фиксируются все параметры исходной большой модели и переобучается только префиксный вектор (встраивание префикса), относящийся к задаче. Для саморегрессивных (self-regressive) больших моделей (таких как GPT-2, которая используется в нашем примере) префикс добавляется перед исходной подсказкой (z = [PREFIX; x; y]); Для большой модели кодировщика+декодировщика (такой как BART), префикс будет добавлен к входным данным кодировщика и декодировщика соответственно (z = [PREFIX; x; PREFIX’; y],).
Статья: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks (Настройка префиксов: оптимизация непрерывных подсказок для генерации, P-Tuning v2: Настройка подсказок может быть сопоставима с тонкой настройкой универсально для всех масштабов и задач) - https://aclanthology.org/2021.acl-long.353
Код: https://github.com/XiangLi1999/PrefixTuning
5. P-Tuning и P-Tuning V2

P-Tuning может значительно улучшить производительность языковых моделей в многозадачных средах с низким потреблением ресурсов. Он улучшает входные характеристики за счет внедрения небольшой, простой в вычислении интерфейсной подсети, тем самым повышая производительность базовой модели. P-tuning по-прежнему фиксирует параметры большой языковой модели, использует многослойный перцептрон и LSTM (long short-term memory, долгую краткосрочную память) для кодирования подсказки. После этого она обычно подается на вход большой языковой модели после конкатенации с другими векторами. Обратите внимание, что после обучения сохраняется только вектор после кодирования подсказки, а кодировщик больше не сохраняется. Этот метод позволяет не только повысить точность и надежность модели в различных задачах, но и значительно сократить объем данных и вычислительных затрат, необходимых при тонкой настройке. Проблема p-tuning заключается в том, что он плохо работает на моделях с небольшим числом параметров, поэтому существует вторая версия (V2), похожая на LoRA, в которой новые параметры встроены в каждый слой (Deep FT).
P-Tuning v2 — это усовершенствованная версия. Основным улучшением является внедрение более эффективного метода обрезки, который может дополнительно сократить объем параметров тонкой настройки модели. Строго говоря, P-tuning V2 — это не новый метод, это оптимизированная версия Deep Prompt Tuning (Li and Liang,2021; Qin and Eisner,2021).
P-tuning v2 предназначен для генерации и исследования, но одним из наиболее важных улучшений является применение непрерывных подсказок к каждому слою модели предварительного обучения, а не только к входному слою. Метод требует точной настройки всего лишь 0,1–3% параметров. Его эффективность сопоставима с точностью настройки модели.
Статья о P-Tuning: GPT Understands, Too (GPT тоже понимает) - https://arxiv.org/pdf/2103.10385.
6. LoRA

Метод LoRA (low-rank adapter, низкоуровневый адаптер) сначала замораживает параметры модели предварительного обучения и добавляет дополнительные параметры dropout+Linear+Conv1d в каждом слое декодера. По сути, LoRA не может достичь производительности полной точной настройки параметров. Согласно экспериментам, полная тонкая настройка параметров намного лучше метода LoRA, но в ситуациях с нехваткой ресурсов LoRA становится лучшим выбором. LoRA позволяет нам косвенно обучать некоторые плотные слои нейронной сети, оптимизируя матрицу рангового разложения изменений в плотном слое во время адаптации, сохраняя при этом предтренировочные веса замороженными.
Особенности LoRA:
- Хорошо обученную модель можно использовать совместно и использовать для создания множества небольших модулей LoRA для различных задач. Мы можем заморозить общую модель и эффективно переключать задачи, заменив матрицы A и B на рисунке 1, тем самым значительно сокращая требования к хранилищу и расходы на переключение задач.
- LoRA делает обучение более эффективным. При использовании адаптивных оптимизаторов порог аппаратных требований снижается в 3 раза, поскольку нам не нужно рассчитывать градиенты или поддерживать статус оптимизатора большинства параметров. Напротив, мы оптимизируем только введенную, гораздо меньшую матрицу низкого ранга.
- Наша простая линейная конструкция позволяет нам объединять обучаемую матрицу с замороженными весами во время развертывания и не вносит задержку вывода в структуру по сравнению с полностью настроенной моделью.
- LoRA не имеет отношения ко многим предыдущим методам и может использоваться в сочетании с ними.
Статья: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (LORA: низкоранговая адаптация больших языковых моделей) - https://arxiv.org/pdf/2106.09685.pdf.
Код: https://github.com/microsoft/LoRA.
7. AdaLoRA

Существует много способов решить, какие параметры LoRA важнее других. AdaLoRA — один из них, и авторы AdaLoRA рекомендуют рассматривать сингулярное значение матрицы LoRA как индикатор ее важности.
Важным отличием от LoRA-drop является то, что адаптеры в среднем слое LoRA-drop либо полностью обучены, либо не обучены вообще. AdaLoRA может решить, что разные адаптеры имеют разные ранги (в оригинальном методе LoRA все адаптеры имеют одинаковый ранг).
AdaLoRA имеет в общей сложности такое же количество параметров, как и стандартная LoRA того же ранга, но распределение этих параметров иное. В LoRA ранг всех матриц одинаков, в то время как в AdaLoRA некоторые матрицы имеют более высокий ранг, а некоторые — более низкий, поэтому итоговое общее число параметров одинаково. Эксперименты показали, что AdaLoRA дает лучшие результаты, чем стандартные методы LoRA, что свидетельствует о лучшем распределении обучаемых параметров по частям модели, что особенно важно для решаемой задачи, а слои, расположенные ближе к концу модели, обеспечивают более высокий ранг, что указывает на то, что адаптация к ним более важна.
AdaLoRA разлагает матрицу весов на инкрементальную матрицу посредством разложения по сингулярным значениям и динамически корректирует размер сингулярных значений в каждой инкрементальной матрице, так что в процессе тонкой настройки обновляются только те параметры, которые вносят больший вклад или необходимы для производительности модели, что позволяет улучшить производительность модели и эффективность параметров.
Статья: ADALORA: ADAPTIVE BUDGET ALLOCATION FOR PARAMETER-EFFICIENT FINE-TUNING (ADALORA: Адаптивное распределение бюджета для параметрически эффективной точной настройки) (https://arxiv.org/pdf/2303.10512).
Код: https://github.com/QingruZhang/AdaLoRA.
8. QLoRA

QLoRA передает градиент обратно к адаптеру низкого ранга (LoRA) с помощью замороженной 4-битной квантованной предварительно обученной языковой модели, что позволяет значительно сократить использование памяти и сэкономить вычислительные ресурсы, сохраняя при этом производительность полной 16-битной задачи тонкой настройки.
Технические характеристики QLoRA:
- Обратное распространение градиентов в адаптеры низкого уровня (LoRA) с помощью замороженной, 4-битной квантованной предварительно обученной языковой модели.
- Введен 4-битный NormalFloat (NF4), который является теоретически оптимальным типом данных для квантования информации для нормально распределенных данных, который может давать лучшие эмпирические результаты, чем 4-битные целые числа и 4-битные числа с плавающей точкой.
- Применяется двойное квантование — метод количественной оценки констант квантификации, позволяющий сэкономить в среднем около 0,37 бита на параметр.
- Используется оптимизатор страниц с NVIDIA Unified Memory, чтобы избежать скачков памяти во время фиксации состояния в контрольных точках при обработке небольших пакетов с большой длиной последовательностей. Значительно снижены требования к памяти, что позволяет выполнять тонкую настройку модели с 65 байтами параметров на одном графическом процессоре объемом 48 ГБ без ухудшения времени выполнения или прогнозирования производительности по сравнению с полностью настроенным 16-битным тестом.
Статья: QLORA: Efficient Finetuning of Quantized LLMs (QLORA: эффективная тонкая настройка квантованных больших языковых моделей) - https://arxiv.org/pdf/2305.14314.pdf.
Код: https://github.com/artidoro/qlora.
В этой статье перечислены лишь несколько наиболее часто используемых репрезентативных методов, а также некоторые варианты, основанные на технологии LoRA: LoRA+, VeRA, LoRA-fa, LoRA-drop, DoRA и Delta-LoRA и т. д. В этой статье мы не будем знакомить вас с ними по отдельности. Вы можете обратиться к необходимой литературе.
Конечно, существуют и другие методы обработки подсказок, которые также отвечают нашим техническим потребностям (например, технология RAG). Я познакомлю вас с ними в последующих статьях.
Далее я покажу пример тонкой настройки GPT2 со всеми параметрами.
Торговая стратегия
Что касается торговой стратегии, мы используем простой пример для руководства по тонкой настройке большой языковой модели, временно не включающей реализацию советника (конкретная реализация должна подождать, пока не будет завершена наша полная стратегия вывода большой языковой модели, прежде чем мы сможем в разумных сроках создать советник). Сначала получим от клиента последние 20 цен закрытия котировок за определенный период по определенной валютной паре и определим их среднее значение как A. Затем используем большую языковую модель для прогнозирования цен закрытия следующих 40 котировок за тот же период и определим их среднее значение как B. Затем решим, покупать или продавать дальше, в соответствии с прогнозируемым значением:
- Если среднее значение B из 40 прогнозируемых значений больше среднего значения A из 20 последних текущих цен закрытия, покупаем.
- Если среднее значение B из 40 прогнозируемых значений меньше среднего значения A из 20 последних текущих цен закрытия, продаем.
- Если значения A и B равны или очень близки, то операция не выполняется.
Мы сформулировали торговую стратегию. Это довольно простая торговая стратегия для демонстрации, которую не следует идеализировать. Вы также можете заменить эту стратегию по своему усмотрению, например, изменив входные параметров на динамические, при этом общая длина результатов прогнозирования составит 60 минус длина входных параметров. Также можно напрямую использовать другие торговые логики, такие как формулирование правил на основе волновой стратегии, стратегии крокодила или стратегии черепахи. Конечно, ваша модель также должна внести соответствующие коррективы. Далее мы приступаем к созданию набора данных в соответствии со стратегией и тонкой настройке большой языковой модели.
Создание набора данных
Мы уже создали набор данных, когда ранее обсуждали обучение больших языковых моделей, — это содержимое файла llm_data.csv. Этот набор данных содержит только котировки валютной пары за 5-месячный цикл и был обработан соответствующим образом, в результате чего получилось 2442 строки данных, каждая из которых содержит 64 столбца. Для получения подробной информации о процессе обработки обратитесь к разделу об обучении больших языковых моделей с использованием CPU или GPU в этой серии статей ("Добавляем пользовательскую LLM в торгового робота (Часть 3): Обучение собственной LLM с помощью CPU "). Конечно, вы также можете использовать скрипт, представленный в статье, чтобы повторно настроить набор данных или превратить свою собственную превосходную идею в набор данных (например, создать набор данных с корреляцией между государственными фискальными данными и обменным курсом и т. д.). Короче говоря, этот набор данных может быть в любой форме, а не только в виде числовых котировок.
1. Предварительная обработкаСначала импортируем необходимые нам библиотеки:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments import torch
Читаем файл данных:
df = pd.read_csv('llm_data.csv') Я обновил этот набор данных, теперь он содержит 60 цен закрытия валютной пары в 5-месячном цикле на каждой строке вместо исходных 64, и данные преобразованы в текстовый формат:
sentences = [' '.join(map(str, prices)) for prices in df.iloc[:-10,1:].values]
Эта строка кода в основном считывает весь файл Dataframe, просматривает его элементы и преобразует каждую строку в строку кода, рассматривая их как предложение. Каждое предложение содержит 60 цен закрытия. Другими словами, мы преобразуем ее в: “0.6119 0.61197 0.61201…0.61196”, а не в: “0.6119” “0.61197”…“0.61196”. Это делается для того, чтобы языковая модель запомнила заданную нами длину последовательности. Например, если мы введем 20 данных, модель завершит обработку оставшихся 40 данных за нас, вместо того чтобы выводить содержание, который мы не можем контролировать.
В строке кода есть также особое место, которое необходимо пояснить: “df.iloc[:-10,1:].values”. ":-10" означает, что нужно взять начало CSV-файла до последних 10 строк, а оставшиеся 10 строк оставить для тестирования; "1:" означает удалить первый столбец каждой строки. Этот столбец является значением индекса в CSV-файле, оно нам не нужно.
Затем мы объединяем все последовательности в набор данных и сохраняем его как train.txt, чтобы в следующий мы просто напрямую считали обработанный CSV-файл вместо того, чтобы обрабатывать его несколько раз.
with open('train.txt', 'w') as f: for sentence in sentences: f.write(sentence + '\n')
2. Загрузим данные как класс Dataset
После завершения предварительной обработки данных нам все еще необходимо использовать токенизатор для дальнейшей обработки данных и загрузки их в формат данных Dataset в pytorch. Теперь некоторые часто используемые классы интегрированы в библиотеку Transformers для непосредственного выполнения этой работы. В примере в этой статье вы можете напрямую использовать TextDataset для реализации этой функции, что очень просто, но сначала нам нужно использовать GPT2 для создания экземпляра токенизатора. Если вы ранее не загружали GPT2, то при первом использовании библиотека Transformers загрузит файл предварительной подготовки с Huggingface. Убедитесь, что сеть разблокирована. Для пользователей docker или wsl: пожалуйста, убедитесь, что ваша сетевая конфигурация правильная, в противном случае загрузка не удастся.
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
train_dataset = TextDataset(tokenizer=tokenizer,
file_path="train.txt",
block_size=60) 3. Загружаем данные для языковой модели
Здесь мы напрямую используем класс DataCollatorForLanguageModeling в библиотеке Transformer для создания экземпляра данных, и нам больше не нужно выполнять дополнительную работу.
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
Далее загрузим предварительно обученную модель и настроим ее.
Тонкая настройка модели
Мы подготовили набор данных для тонкой настройки. Теперь можно начать тонкую настройку нашей большой языковой модели.
1. Загрузка предварительно обученной модели
Первый шаг - загрузка предварительно обученной модели. Мы уже загрузили токенизатор, поэтому нам осталось только загрузить модель:
model = GPT2LMHeadModel.from_pretrained('gpt2') Далее необходимо задать параметры обучения. Библиотека Transformers также предоставляет нам очень удобный класс для реализации этой функции без необходимости использования дополнительных файлов конфигурации:
training_args = TrainingArguments(output_dir="./gpt2_stock", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, load_best_model_at_end=True, )
2. Инициализация параметров тонкой настройки
При создании экземпляра TrainingArguments мы использовали следующие параметры:
- output_dir - место сохранения результатов прогнозирования и контрольных точек. Мы определили папку gpt2_stock в текущем каталоге в качестве выходного пути.
- overwrite_output_dir - нужно ли перезаписывать выходной файл. Мы решили перезаписать.
- num_train_epochs - количество эпох обучения. Мы выбрали 3 эпохи.
- per_device_train_batch_size - размер пакета обучения. Мы выбрали число 32. Как я уже писал ранее, лучше всего представлять в виде степени числа 2.
- save_steps=10_000 - число шагов обновления перед сохранением двух контрольных точек, если save_strategy="steps". Должно быть целым числом или числом с плавающей точкой в диапазоне [0,1). Если меньше 1, значение будет интерпретироваться как коэффициент общего количества шагов обучения.
- save_total_limit - при передаче значения будет ограничено общее количество контрольных точек. Удаляет старые контрольные точки в output_dir.
- load_best_model_at_end - нужно ли загружать лучшую модель в процессе обучения вместо использования веса модели на последнем этапе обучения.
Существует много параметров, которые мы не устанавливали и использовали значения по умолчанию, поскольку это всего лишь пример, в частности:
- deepspeed - нужно ли использовать Deepspeed для ускорения обучения.
- eval_steps - количество шагов обновления между двумя оценками.
- dataloader_pin_memory - нужно ли закреплять память в загрузчиках данных или нет.
Мы видим, что класс TrainingArguments очень мощный, он включает в себя большую часть параметров обучения, его очень удобно использовать. Читателям настоятельно рекомендуется ознакомиться с официальной документацией.
3. Тонкая настройка
Теперь давайте вернемся к нашему процессу тонкой настройки и дадим ему определение. Процесс обучения языковой модели мы подробно описали в предыдущей статье. Тонкая настройка не сильно отличается от обучения. Я полагаю, что читатели уже хорошо с ним знакомы, поэтому пример в этой статье больше не описывает подробно процесс тонкой настройки языковой модели, а напрямую использует класс Trainer, предоставленный в библиотеке Transformer, для его реализации. Теперь мы передаем model, training_args, data_collator и train_dataset, которые мы определили как параметры, в класс Trainer для создания экземпляра Trainer:
trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset,)
Класс Trainer также имеет другие параметры, которые мы не задавали, такие как важные обратные вызовы (callbacks): вы можете использовать обратные вызовы для настройки поведения цикла обучения. Они могут проверять состояние цикла обучения (для отчетов о ходе выполнения, регистрации на TensorBoard или других платформах машинного обучения и т. д.) и принимать решения (например, о ранней остановке и т. д.). Причина, по которой мы не задали их в этой статье, заключается в том, что это всего лишь пример, а настройки параметров модели в процессе тонкой настройки относительно консервативны. Если вы хотите, чтобы ваша модель работала лучше, помните, что эту опцию нельзя игнорировать. Вызовите метод tran() созданного класса Trainer, чтобы напрямую запустить процесс тонкой настройки:
trainer.train()
После завершения обучения сохраните модель, чтобы напрямую использовать метод from_pretrained() для загрузки точно настроенной модели при выводе:
trainer.save_model("./gpt2_stock") Далее сделаем вывод, чтобы проверить эффективность тонкой настройки:
prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1]))
generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt').to("cuda"),
do_sample=True,
max_length=200)[0],
skip_special_tokens=True)
print(f"test the model:{generated}") В этой части кода "prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1]))" преобразует последнюю строку нашего набора данных в строковый формат. "tokenizer.encode(prompt, return_tensors=‘pt’)" Эта часть кода преобразует входной текст (подсказку) в форму, понятную модели, то есть преобразует текст в серию токенов. "return_tensors=‘pt’" указывает, что возвращаемый тип данных является тензором PyTorch. "do_sample=True" указывает, что в процессе генерации используется случайная выборка, а "max_length=200" ограничивает максимальную длину генерируемого текста. Теперь давайте посмотрим на результаты работы всего кода:

Видно, что точно настроенная предобученная модель успешно выдала желаемые результаты.
Полный код выглядит следующим образом, имя скрипта во вложении — Fin-tuning.py:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments import torch dvc='cuda' if torch.cuda.is_available() else 'cpu' print(dvc) df = pd.read_csv('llm_data.csv') sentences = [' '.join(map(str, prices)) for prices in df.iloc[:-10,1:].values] with open('train.txt', 'w') as f: for sentence in sentences: f.write(sentence + '\n') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') train_dataset = TextDataset(tokenizer=tokenizer, file_path="train.txt", block_size=60) data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False) model = GPT2LMHeadModel.from_pretrained('gpt2') training_args = TrainingArguments(output_dir="./gpt2_stock", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, load_best_model_at_end=True, ) trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset,) trainer.train() trainer.save_model("./gpt2_stock") prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt').to(dvc), do_sample=True, max_length=200)[0], skip_special_tokens=True) print(f"test the model:{generated}")
Тестирование
После завершения процесса тонкой настройки нам все еще необходимо протестировать модель, проверить разницу между выходными данными модели и исходным истинным значением, и самый простой метод — вычислить среднеквадратичную ошибку (MSE) между истинным значением и прогнозируемым значением.
Теперь воссоздадим скрипт для реализации процесса тестирования, сначала импортируем необходимые библиотеки, загрузим настроенную нами модель GPT2 и данные:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from sklearn.metrics import mean_squared_error import torch import numpy as np df = pd.read_csv('llm_data.csv') dvc='cuda' if torch.cuda.is_available() else 'cpu' model = GPT2LMHeadModel.from_pretrained('./gpt2_stock') tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
Этот процесс не сильно отличается от тонкой настройки, за исключением того, что путь модели изменяется на путь, по которому мы сохранили вес модели во время тонкой настройки. После загрузки модели и токенизатора нам необходимо обработать истинное значение и прогнозируемое значение после вывода. Эта часть также совпадает с шагами в нашем скрипте тонкой настройки:
prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt'), do_sample=True, max_length=200)[0], skip_special_tokens=True)
Теперь мы берем последние 40 цен закрытия последней строки набора данных в качестве истинного значения и преобразуем истинное и прогнозируемое значения в форму списка с необходимой длиной:
true_prices= df.iloc[-1:,21:].values.tolist()[0] generated_prices=generated.split('\n')[0] generated_prices=list(map(float,generated_prices.split())) generated_prices=generated_prices[0:len(true_prices)] def trim_lists(a, b): min_len = min(len(a), len(b)) return a[:min_len], b[:min_len] true_prices,generated_prices=trim_lists(true_prices,generated_prices)
Чтобы сохранить одинаковую длину истинного и прогнозируемого значений, нам необходимо обрезать еще один список в соответствии с длиной наименьшего списка, поэтому мы определяем trim_lists(a, b) для выполнения этой задачи. Затем мы выводим истинное и прогнозируемое значения, чтобы проверить, соответствуют ли они ожиданиям:
print(f"true_prices:{true_prices}") print(f"generated_prices:{generated_prices}")
Результаты следующие:
true_prices: [0.6119, 0.61197, 0.61201, 0.61242, 0.61237, 0.6123, 0.61229, 0.61242, 0.61212, 0.61197, 0.61201, 0.61213, 0.61212,
0.61206, 0.61203, 0.61206, 0.6119, 0.61193, 0.61191, 0.61202, 0.61197, 0.6121, 0.61211, 0.61214, 0.61203, 0.61203, 0.61213, 0.61218,
0.61227, 0.61226, 0.61227, 0.61231, 0.61228, 0.61227, 0.61233, 0.61211, 0.6121, 0.6121, 0.61195, 0.61196]
generated_prices:[0.61163, 0.61162, 0.61191, 0.61195, 0.61209, 0.61231, 0.61224, 0.61207, 0.61187, 0.61184, 0.6119, 0.61169, 0.61168,
0.61162, 0.61181, 0.61184, 0.61184, 0.6118, 0.61176, 0.61169, 0.61191, 0.61195, 0.61204, 0.61188, 0.61205, 0.61188, 0.612, 0.61208,
0.612, 0.61192, 0.61168, 0.61165, 0.61164, 0.61179, 0.61183, 0.61192, 0.61168, 0.61175, 0.61169, 0.61162]
Далее мы можем рассчитать их среднюю квадратическую ошибку (mean square error, MSE), а затем распечатать результаты для проверки:
mse = mean_squared_error(true_prices, generated_prices)
print('MSE:', mse) Результат: MSE: 2.1906250000000092e-07.
Как видите, среднеквадратическая ошибка (MSE) очень мала, но означает ли это, что наша модель очень точна? Пожалуйста, не забывайте, что наши исходные данные имели очень небольшую ценность! Таким образом, хотя MSE очень мала, поскольку наши исходные значения также относительно малы, MSE не может точно отражать точность модели на данный момент. Нам необходимо дополнительно рассчитать квадратный корень среднеквадратической ошибки (root mean square error, RMSE) и нормализованную среднеквадратическую ошибку (normalized root mean square error, NRMSE) между прогнозируемым значением и исходным значением, чтобы дополнительно определить размер ошибки прогноза относительно диапазона наблюдаемых значений, чтобы дополнительно определить точность модели:
rmse=np.sqrt(mse) nrmse=rmse/(np.max(true_prices)-np.min(generated_prices)) print(f"RMSE:{rmse},NRMSE:{nrmse}")
Результат:
- RMSE:0.00046804113067122735
- NRMSE:0.5850514133390986

Мы можем заметить, что хотя значения MSE и RMSE очень малы, значение NRMSE составляет 0,5850514133390986, что означает, что ошибка прогнозирования составляет около 58,5% от диапазона наблюдаемых значений. Это показывает, что хотя абсолютное значение RMSE очень мало по сравнению с диапазоном наблюдаемых значений, ошибка прогнозирования все еще относительно велика.
Как сделать нашу модель более точной? Вот несколько вариантов:
- Увеличение количества эпох во время тонкой настройки
- Увеличение объема данных
- Правильная оптимизация параметров тонкой настройки
- Замена на модель большего масштаба
Эти методы несложны в реализации. В этой статье мы не будем проверять их по одному, вы можете выбрать один или несколько из них в соответствии со своими собственными идеями и применить на практике. Я считаю, что результаты определенно будут намного лучше, чем в примере в этой статье!
Полный код, имя скрипта во вложении — test.py:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from sklearn.metrics import mean_squared_error import torch import numpy as np df = pd.read_csv('llm_data.csv') dvc='cuda' if torch.cuda.is_available() else 'cpu' model = GPT2LMHeadModel.from_pretrained('./gpt2_stock') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt'), do_sample=True, max_length=200)[0], skip_special_tokens=True) true_prices= df.iloc[-1:,21:].values.tolist()[0] generated_prices=generated.split('\n')[0] generated_prices=list(map(float,generated_prices.split())) generated_prices=generated_prices[0:len(true_prices)] def trim_lists(a, b): min_len = min(len(a), len(b)) return a[:min_len], b[:min_len] true_prices,generated_prices=trim_lists(true_prices,generated_prices) print(f"true_prices:{true_prices}") print(f"generated_prices:{generated_prices}") mse = mean_squared_error(true_prices, generated_prices) print('MSE:', mse) rmse=np.sqrt(mse) nrmse=rmse/(np.max(true_prices)-np.min(generated_prices)) print(f"RMSE:{rmse},NRMSE:{nrmse}")
Заключение
В статье в основном рассматривались предпосылки использования больших языковых моделей для торговых стратегий, то есть выходные данные большой языковой модели должны соответствовать требованиям нашей торговой стратегии. Мы обсудили некоторые технические методы, которые могут выполнить эту задачу. Из-за ограничений по объему мы не привели соответствующие примеры кода для всех методов, приведен только пример тонкой настройки GPT2 с полными параметрами (конечно, этот набор данных не применим ко всем методам тонкой настройки, упомянутым в тексте, но подробные примеры в последующих статьях дадут метод создания набора данных, соответствующий этому методу). В следующих статьях я выберу несколько репрезентативных методов, чтобы предоставить соответствующие примеры кода и советников. Что касается технологий RAG и Agent, которые просто упоминаются в тексте, то в следующих статьях мы рассмотрим их подробнее, включая реализацию в коде.
Увидимся в следующей статье!
Ссылки
https://alexqdh.github.io/posts/2183061656/
http://note.iawen.com/note/llm/finetune
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13497
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Эволюционный торговый алгоритм обучения с подкреплением и вымиранием убыточных особей (ETARE)
Эволюционный торговый алгоритм обучения с подкреплением и вымиранием убыточных особей (ETARE)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте
Здравствуйте, из примеров в этой статье:
1. Веса предварительно обученной модели GPT2, которую мы используем в этом примере, не имеют никакого содержания, связанного с нашими данными, и входной временной ряд не будет распознан без тонкой настройки, но правильное содержание может быть выведено в соответствии с нашими потребностями после тонкой настройки.
2. Как мы уже говорили в нашей статье, очень трудоемко обучать языковую модель с нуля, чтобы она сходилась, но тонкая настройка позволяет быстро сходиться предварительно обученной модели, что экономит много времени и вычислительных мощностей. Поскольку модель, используемая в нашем примере, относительно небольшая, этот процесс не очень очевиден.
3. Процесс тонкой настройки требует гораздо меньше данных, чем процесс предварительного обучения. Если количество данных недостаточно, то тонкая настройка модели с тем же количеством данных гораздо лучше, чем прямое обучение модели.
Здравствуйте, спасибо за замечательные статьи.
С нетерпением ждем, как мы интегрируем доработанную модель в MT5