
Python, ONNX ve MetaTrader 5: RobustScaler ve PolynomialFeatures veri ön işleme ile bir RandomForest modeli oluşturma

Hangi çerçeveyi kullanacağız? Rastgele Orman nedir?
Rastgele Orman yönteminin gelişim tarihi uzun bir geçmişe dayanır ve makine öğrenimi ve istatistik alanında önde gelen bilim insanlarının çalışmalarıyla ilişkilidir. Bu yöntemin ilkelerini ve uygulanmasını daha iyi anlamak için, onu birlikte çalışan büyük bir insan grubu (karar ağaçları) olarak hayal edelim.
Rastgele Orman yönteminin kökleri karar ağaçlarına dayanır. Karar ağaçları, her bir düğümün özelliklerden biri üzerindeki bir testi temsil ettiği, her bir dalın bu testin sonucu olduğu ve yaprakların tahmin edilen çıktı olduğu bir karar verme algoritmasının grafiksel bir temsili olarak hizmet eder. Karar ağaçları 20. yüzyılın ortalarında geliştirilmiş ve popüler sınıflandırma ve regresyon araçları haline gelmiştir.
Bir sonraki önemli adım, 1996 yılında Leo Breiman tarafından önerilen bagging (bootstrap aggregating) kavramı olmuştur. Bagging, bir eğitim veri setinin birden fazla bootstrap örneklemine (alt örneklem) bölünmesi ve her biri üzerinde ayrı modellerin eğitilmesi anlamına gelir. Daha sonra modellerin sonuçlarının ortalaması alınır veya daha sağlam ve doğru tahminler üretmek için birleştirilir. Bu yöntem, modellerin varyansının azaltılmasını ve genelleme kabiliyetlerinin iyileştirilmesini sağlamıştır.
Rastgele Orman yöntemi 2000'li yılların başında Leo Breiman ve Adele Cutler tarafından önerilmiştir. Bagging ve ek rastgelelik kullanarak birden fazla karar ağacını birleştirme fikrine dayanır. Her ağaç, eğitim veri kümesinin rastgele bir alt örnekleminden oluşturulur ve ağaçtaki her düğüm oluşturulurken rastgele bir özellik kümesi seçilir. Bu, her ağacı benzersiz kılar ve ağaçlar arasındaki korelasyonu azaltarak genelleme yeteneğini iyileştirir.
Rastgele Orman, yüksek performansı ve hem sınıflandırma hem de regresyon problemlerini işleme yeteneği sayesinde makine öğreniminde hızla en popüler yöntemlerden biri haline gelmiştir. Sınıflandırma problemlerinde bir nesnenin hangi sınıfa ait olduğuna karar vermek için, regresyonda ise sayısal değerleri tahmin etmek için kullanılır.
Günümüzde Rastgele Orman, finans, tıp, veri analizi vb. çeşitli alanlarda yaygın olarak kullanılmaktadır. Sağlamlığı ve karmaşık makine öğrenimi problemlerini işleme yeteneği ile takdir görmektedir.
Rastgele Orman, makine öğrenimi araç setinde güçlü bir araçtır. Nasıl çalıştığını daha iyi anlamak için, onu bir araya gelen ve ortak kararlar alan büyük bir insan grubu olarak görselleştirelim. Ancak, gerçek insanlar yerine, bu gruptaki her üye mevcut durumun bağımsız bir sınıflandırıcısı veya tahmin edicisidir. Bu grup içinde bir kişi, belirli özelliklere dayalı kararlar verebilen bir karar ağacıdır. Rastgele Orman bir karar verirken demokrasi ve oylama kullanır: her ağaç kendi görüşünü ifade eder ve çoklu oylamaya dayalı bir karar verilir.
Rastgele Orman çeşitli alanlarda yaygın olarak kullanılmaktadır ve esnekliği onu hem sınıflandırma hem de regresyon problemleri için uygun hale getirmektedir. Bir sınıflandırma görevinde model, mevcut durumun önceden tanımlanmış sınıflardan hangisine ait olduğuna karar verir. Örneğin, finans piyasasında bu, çeşitli göstergelere dayalı olarak bir varlığı alma (sınıf 1) veya satma (sınıf 0) kararı anlamına gelebilir.
Ancak bu makalede regresyon problemlerine odaklanacağız. Makine öğreniminde regresyon, bir zaman serisinin geçmiş değerlerine dayanarak gelecekteki sayısal değerlerini tahmin etme girişimidir. Nesneleri belirli sınıflara atadığımız sınıflandırma yerine, regresyonda belirli sayıları tahmin etmeyi amaçlıyoruz. Bu, örneğin, hisse senedi fiyatlarını tahmin etmek, sıcaklığı tahmin etmek veya başka herhangi bir sayısal değişken olabilir.
Temel bir RF modeli oluşturma
Temel bir Rastgele Orman modeli oluşturmak için Python'daki sklearn (scikit-learn) kütüphanesini kullanacağız. Aşağıda bir Rastgele Orman regresyon modelini eğitmek için basit bir kod şablonu bulunmaktadır. Bu kodu çalıştırmadan önce, Python’daki paket yükleyici aracını kullanarak sklearn'ü çalıştırmak için gereken kütüphaneleri yüklemelisiniz.
pip install onnx
pip install skl2onnx
pip install MetaTrader5
Ardından, kütüphaneleri içe aktarmanız ve parametreleri ayarlamanız gerekir. Verilerle çalışmak için 'pandas', Google Drive'dan veri yüklemek için 'gdown' gibi gerekli kütüphanelerin yanı sıra veri işleme ve Rastgele Orman modeli oluşturma kütüphanelerini de içe aktarıyoruz. Ayrıca, özel gereksinimlere bağlı olarak belirlenen veri sekansındaki zaman adımı sayısını (n_steps) da ayarlıyoruz:
import pandas as pd import gdown import numpy as np import joblib import random import onnx import os import shutil from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.utils import shuffle from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures, PowerTransformer import MetaTrader5 as mt5 from datetime import datetime # Set the number of time steps according to requirements n_steps = 100
Bir sonraki adım veri yükleme ve işlemedir. Burada MetaTrader 5'ten fiyat verilerini yüklüyor ve işliyoruz. Zaman indeksini ayarlıyoruz ve yalnızca Kapanış fiyatlarını seçiyoruz (çalışacağımız şey bu):
İşte kodun, verilerimizi eğitim ve test kümelerine ayırmaktan ve model eğitimi için kümeyi etiketlemekten sorumlu kısmı. Verileri eğitim ve test kümelerine ayırıyoruz. Daha sonra regresyon için verileri etiketliyoruz, yani her etiket gelecekteki gerçek fiyat değerini temsil eder. Labelling_relabeling_regression fonksiyonu etiketli veri oluşturmak için kullanılır.mt5.initialize() SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2000, 1, 1) STOP_DATE = datetime(2023, 1, 1) # Set the number of time steps according to your requirements n_steps = 100 # Process data data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE), columns=['time', 'close']).set_index('time') data.index = pd.to_datetime(data.index, unit='s') data = data.dropna() data = data[['close']] # Work only with close prices
# Define train_data_initial training_size = int(len(data) * 0.70) train_data_initial = data.iloc[:training_size] test_data_initial = data.iloc[training_size:] # Function for creating and assigning labels for regression (changes made for regression, not classification) def labelling_relabeling_regression(dataset, min_value=1, max_value=1): future_prices = [] for i in range(dataset.shape[0] - max_value): rand = random.randint(min_value, max_value) future_pr = dataset['<CLOSE>'].iloc[i + rand] future_prices.append(future_pr) dataset = dataset.iloc[:len(future_prices)].copy() dataset['future_price'] = future_prices return dataset # Apply the labelling_relabeling_regression function to raw data to get labeled data train_data_labeled = labelling_relabeling_regression(train_data_initial) test_data_labeled = labelling_relabeling_regression(test_data_initial)
Ardından, belirli sekanslardan eğitim veri kümeleri oluşturuyoruz. Önemli olan, modelin sekansımızdaki tüm Kapanış fiyatlarını özellik olarak almasıdır. ONNX modeline veri girdisi büyüklüğü olarak aynı sekans büyüklüğü kullanılır. Bu aşamada normalleştirme yoktur; model veri hattı (pipeline) işleminin bir parçası olarak eğitim veri hattında gerçekleştirilecektir.
# Create datasets of features and target variables for training x_train = np.array([train_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(train_data_labeled))]) y_train = train_data_labeled['future_price'].iloc[n_steps:].values # Create datasets of features and target variables for testing x_test = np.array([test_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(test_data_labeled))]) y_test = test_data_labeled['future_price'].iloc[n_steps:].values # After creating x_train and x_test, define n_features as follows: n_features = x_train.shape[1] # Now use n_features to determine the ONNX input data type initial_type = [('float_input', FloatTensorType([None, n_features]))]
Veri ön işleme için bir veri hattı oluşturma
Bir sonraki adımımız bir Rastgele Orman modeli oluşturmaktır. Bu model bir veri hattı olarak inşa edilmelidir.
scikit-learn (sklearn) kütüphanesindeki Pipeline, veri analizi ve makine öğrenimi için sıralı bir dönüşüm ve model zinciri oluşturmanın bir yoludur. Bir veri hattı, çoklu veri işleme ve modelleme aşamasını, verilerle verimli ve sıralı bir şekilde çalışmak için kullanılabilecek tek bir nesnede birleştirmemize olanak tanır.
Kod örneğimizde, aşağıdaki veri hattını oluşturuyoruz:
# Create a pipeline with MinMaxScaler, RobustScaler, PolynomialFeatures and RandomForestRegressor
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(
n_estimators=20,
max_depth=20,
min_samples_split=5000,
min_samples_leaf=5000,
random_state=1,
verbose=2
))
])
# Train the pipeline
pipeline.fit(x_train, y_train)
# Make predictions
predictions = pipeline.predict(x_test)
# Evaluate model using R2
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}')
Gördüğünüz gibi veri hattı, tek bir zincirde birleştirilmiş bir veri işleme ve modelleme adımları sekansıdır. Bu kodda, veri hattı scikit-learn kütüphanesi kullanılarak oluşturulmuştur. Aşağıdaki adımları içerir:
-
MinMaxScaler verileri 0 ila 1 aralığında ölçeklendirir. Bu, tüm özelliklerin eşit ölçekte olmasını sağlamak için kullanışlıdır.
-
RobustScaler da veri ölçeklendirmesi yapar ancak veri kümesindeki aykırı değerlere karşı daha dayanıklıdır. Ölçeklendirme için medyan ve çeyrekler arası aralığı kullanır.
-
PolynomialFeatures, özelliklere bir polinom dönüşümü uygular. Bu, modelin verilerdeki doğrusal olmayan ilişkileri hesaba katmasına yardımcı olabilecek polinom özellikleri ekler.
-
RandomForestRegressor, bir dizi hiperparametre ile bir Rastgele Orman modeli tanımlar:
- n_estimators (ormandaki ağaç sayısı). Her biri finans piyasasındaki fiyatları tahmin etme konusunda uzmanlaşmış bir grup uzmanınız olduğunu varsayalım. Rastgele Ormandaki ağaç sayısı (n_estimators) grubunuzda kaç tane bu tür uzman olacağını belirler. Ne kadar çok ağacınız olursa, model bir karar verirken o kadar çeşitli görüş ve tahminler dikkate alınacaktır.
- max_depth (her ağacın maksimum derinliği). Bu parametre, her bir uzmanın (ağacın) veri analizine ne kadar derinlemesine "dalabileceğini" ayarlar. Örneğin, maksimum derinliği 20 olarak ayarlarsanız, her ağaç en fazla 20 özelliğe göre karar verecektir.
- min_samples_split (bir ağaç düğümünü bölmek için minimum örneklem sayısı). Bu parametre, ağacın daha küçük düğümlere bölünmeye devam etmesi için bir ağaç düğümünde kaç örneklem (gözlem) olması gerektiğini söyler. Örneğin, bölünme için minimum örneklem sayısını 5000 olarak ayarlarsanız, ağaç yalnızca düğüm başına 5000'den fazla gözlem varsa düğümleri böler.
- min_samples_leaf (bir ağaç yaprağı düğümündeki minimum örneklem sayısı). Bu parametre, ağacın bir yaprak düğümünde, o düğümün yaprak haline gelmesi ve daha fazla bölünmemesi için kaç örneklem bulunması gerektiğini belirler. Örneğin, bir yaprak düğümündeki minimum örneklem sayısını 5000 olarak ayarlarsanız, ağacın her yaprağı en az 5000 gözlem içerecektir.
- random_state (rastgele üretim için başlangıç durumunu ayarlar, tekrarlanabilir sonuçlar sağlar). Bu parametre model içindeki rastgele süreçleri kontrol etmek için kullanılır. Sabit bir değere (örneğin 1) ayarlarsanız, modeli her çalıştırdığınızda sonuçlar aynı olacaktır. Bu, sonuçların tekrarlanabilirliği açısından faydalıdır.
- verbose (model eğitim süreci hakkında bilgi çıktısı sağlar). Bir modeli eğitirken, süreçle ilgili bilgileri görmek faydalı olabilir. 'verbose' parametresi bu bilgilerin ayrıntı düzeyini kontrol etmenizi sağlar. Değer ne kadar yüksek olursa (örneğin 2), eğitim süreci sırasında o kadar fazla bilgi çıktısı alınacaktır.
Veri hattını oluşturduktan sonra, eğitim verileri üzerinde eğitmek için 'fit' metodunu kullanıyoruz. Ardından, 'predict' metodunu kullanarak, test verileri üzerinde tahminler yaparız. Son olarak, modelin kalitesini, modelin verilere uyumunu ölçen R2 metriğini kullanarak değerlendiriyoruz.
Veri hattı eğitilir ve ardından R2 metriğine göre değerlendirilir. Normalleştirme, aykırı değerleri verilerden çıkarma ve polinom özellikler oluşturma yöntemlerini kullanıyoruz. Bunlar en basit veri ön işleme yöntemleridir. Gelecek makalelerde, FunctionTransformer kullanarak kendi ön işleme fonksiyonumuzu nasıl oluşturacağımızı inceleyeceğiz.
Modelin ONNX'e aktarılması, aktarma fonksiyonunun yazılması
Veri hattını eğittikten sonra, skl2onnx kütüphanesini kullanarak ONNX formatında kaydettiğimiz joblib formatında kaydediyoruz.
# Save the pipeline
joblib.dump(pipeline, 'rf_pipeline.joblib')
# Convert pipeline to ONNX
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Connect Google Drive (if you work in Colab and this is necessary)
from google.colab import drive
drive.mount('/content/drive')
# Specify the path to Google Drive where you want to move the model
drive_path = '/content/drive/My Drive/' # Make sure the path is correct
rf_pipeline_onnx_drive_path = os.path.join(drive_path, 'rf_pipeline.onnx')
# Move ONNX model to Google Drive
shutil.move(model_onnx_path, rf_pipeline_onnx_drive_path)
print('The rf_pipeline model is saved in the ONNX format on Google Drive:', rf_pipeline_onnx_drive_path)
Modeli bu şekilde eğittik ve ONNX'e kaydettik. Eğitimi tamamladıktan sonra göreceğimiz şey budur:
Model ONNX formatında Google Drive'ın temel dizinine kaydedilir. ONNX, makine öğrenimi modelleri için bir tür "disket" olarak düşünülebilir. Bu format, eğitilmiş modelleri kaydetmenize ve onları çeşitli uygulamalarda kullanmak üzere dönüştürmenize olanak tanır. Bu, dosyaları bir flash sürücüye kaydetmenize ve daha sonra onları diğer cihazlarda okuyabilmenize benzer. Bizim durumumuzda ONNX modeli, finansal piyasa fiyatlarını tahmin etmek için MetaTrader 5 ortamında kullanılacaktır. ONNX "disketinin" kendisi üçüncü taraf bir uygulamada, örneğin MetaTrader 5'te okunabilir. Şimdi yapacağımız şey bu.
MetaTrader 5 Sınayıcıda modeli kontrol etme
ONNX modelini daha önce Google Drive'a kaydetmiştik. Şimdi, oradan indirelim. Bu modeli MetaTrader 5'te kullanmak için, alım-satım kararları vermek üzere bu modeli okuyacak ve uygulayacak bir Uzman Danışman oluşturalım. Sunulan Uzman Danışman kodunda, lot hacmi, durma emirlerinin kullanımı, Kârı Al ve Zararı Durdur seviyeleri gibi işlem parametrelerini ayarlıyoruz. İşte ONNX modelimizi "okuyacak" Uzman Danışmanın kodu:
//+------------------------------------------------------------------+ //| ONNX Random Forest.mq5 | //| Copyright 2023 | //| Evgeniy Koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com" #property version "0.90" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "Python/rf_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 100 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; CTrade ExtTrade; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Function for closing all positions void CloseAll(int type=-1) { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetInteger(POSITION_TYPE)==type || type==-1) { trade.PositionClose(PositionGetTicket(i)); } } } } // Expert Advisor initialization int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("The model should work with EURUSD, H1"); return(INIT_FAILED); } ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ",GetLastError()); return(INIT_FAILED); } const long input_shape[] = {1,100}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("Error setting the input shape OnnxSetInputShape ",GetLastError()); return(INIT_FAILED); } const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ",GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if(ExtHandle!=INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle=INVALID_HANDLE; } } // Process the tick function void OnTick() { if(TimeCurrent()<ExtNextBar) return; ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); PredictPrice(); if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; } if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } // Check position closing conditions void CheckForClose(void) { if(InpUseStops) return; bool tsignal=false; long type=PositionGetInteger(POSITION_TYPE); if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) tsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) tsignal=true; if(tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to predict prices void PredictPrice() { static vectorf output_data(1); static vectorf x_norm(SAMPLE_SIZE); double spread = GetSpreadInPips(_Symbol); if (!x_norm.CopyRates(_Symbol, _Period, COPY_RATES_CLOSE, 1, SAMPLE_SIZE)) { ExtPredictedClass = -1; return; } if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, x_norm, output_data)) { ExtPredictedClass = -1; return; } float predicted = output_data[0]; if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } }
Lütfen aşağıdaki girdi boyutuna dikkat edin:
const long input_shape[] = {1,100};
Python modelimizdeki boyutla eşleşmelidir:
# Set the number of time steps to your requirements n_steps = 100
Ardından, modeli MetaTrader 5 ortamında test etmeye başlıyoruz. Fiyat hareketlerinin yönünü belirlemek için modelin tahminlerini kullanırız. Model fiyatın yükseleceğini öngörüyorsa, bir alış pozisyon açmaya hazırlanırız ve tersine, model fiyatın düşeceğini öngörüyorsa, bir satış pozisyonu açmaya hazırlanırız. Modeli 1000 Kârı Al ve 500 Zararı Durdur ile test edelim:
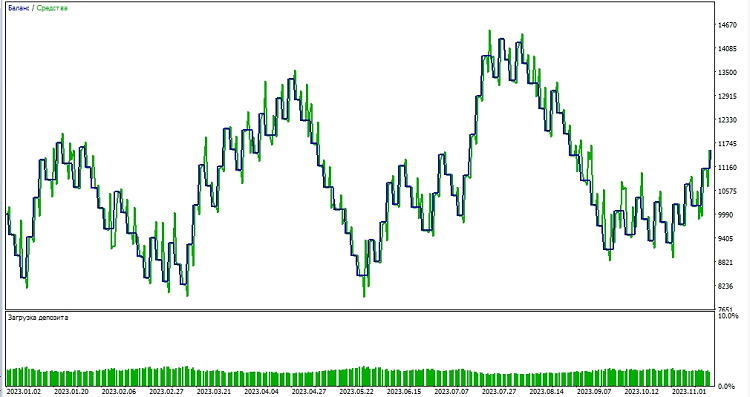
Sonuç
Bu makalede, Python'da bir Rastgele Orman modelinin nasıl oluşturulacağını ve eğitileceğini, verilere doğrudan model içinde nasıl ön işleme yapılacağını, ONNX standardına nasıl aktarılacağını ve ardından modeli MetaTrader 5'te nasıl açıp kullanacağımızı gördük.
ONNX mükemmel bir model içe aktarma-dışa aktarma sistemidir. Evrensel ve basittir. ONNX'te bir modeli kaydetmek aslında göründüğünden çok daha kolaydır. Veri ön işleme de çok kolaydır.
Elbette, sadece 20 karar ağacından oluşan modelimiz çok basittir ve Rastgele Orman modelinin kendisi zaten oldukça eski bir çözümdür. İlerleyen makalelerde, daha karmaşık veri ön işleme kullanarak daha karmaşık ve modern modeller oluşturacağız. Ayrıca, ön işleme ile eşzamanlı olarak bir sklearn veri hattı şeklinde hemen bir model topluluğu oluşturma olanağına da dikkat çekmek isterim. Bu, sınıflandırma problemleri de dahil olmak üzere yeteneklerimizi önemli ölçüde artırabilir.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/13725
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Sadece orman basit bir örnek olarak seçildi) Bir sonraki makalede Busting, şimdi biraz değiştiriyorum)
İyi)
Konveyörler ve bunların ONNX'e dönüştürülmesi ve daha sonra metatrader'da kullanılması konusunu daha da geliştirmek ilginç olacaktır. Örneğin, boru hattına özel dönüşümler eklemek mümkün mü ve böyle bir boru hattından elde edilen ONNX modeli Metatrader'da açılacak mı? Imho, konu birkaç makaleye değer.
Konveyörler ve bunların ONNX'e dönüştürülmesi ve daha sonra metatrader'da kullanılması konusunu daha da geliştirmek ilginç olacaktır. Örneğin, boru hattına özel dönüşümler eklemek mümkün mü ve böyle bir boru hattından elde edilen ONNX modeli Metatrader'da açılacak mı? Bence bu konu birkaç makale yazmaya değer.