
Python, ONNX et MetaTrader 5 : Création d'un modèle RandomForest avec RobustScaler et PolynomialFeatures pour le pré-traitement des données

Quelle base allons-nous utiliser ? Qu'est-ce que la Forêt Aléatoire (Random Forest) ?
L'histoire du développement de la méthode Random Forest remonte à loin et est associée aux travaux d'éminents scientifiques dans le domaine de l'apprentissage automatique et des statistiques. Pour mieux comprendre les principes et l'application de cette méthode, imaginons un grand groupe de personnes (arbres de décision) qui travaillent ensemble.
La méthode de la forêt aléatoire trouve son origine dans les arbres de décision. Les arbres de décision servent de représentation graphique d'un algorithme de prise de décision, où chaque nœud représente un test sur l'un des attributs, chaque branche est le résultat de ce test et les feuilles sont la sortie prédite. Les arbres de décision ont été développés au milieu du 20e siècle et sont devenus des outils de classification et de régression populaires.
La prochaine étape importante a été le concept de bagging (Bootstrap Aggregating), proposé par Leo Breiman en 1996. Le bagging consiste à diviser un ensemble de données de formation en plusieurs échantillons bootstrap (sous-échantillons) et à former des modèles distincts sur chacun d'entre eux. Les résultats des modèles sont ensuite moyennés ou combinés pour produire des prévisions plus robustes et plus précises. Cette méthode a permis de réduire la variance des modèles et d'améliorer leur capacité de généralisation.
La méthode Random Forest a été proposée par Leo Breiman et Adele Cutler au début des années 2000. Elle est basée sur l'idée de combiner plusieurs arbres de décision à l'aide d'une méthode d'échantillonnage et d'un caractère aléatoire supplémentaire. Chaque arbre est construit à partir d'un sous-échantillon aléatoire de l'ensemble de données d'apprentissage et un ensemble aléatoire de caractéristiques est sélectionné lors de la construction de chaque nœud de l'arbre. Cela rend chaque arbre unique et réduit la corrélation entre les arbres, ce qui améliore la capacité de généralisation.
Random Forest est rapidement devenu l'une des méthodes les plus populaires dans le domaine de l'apprentissage automatique en raison de ses performances élevées et de sa capacité à traiter les problèmes de classification et de régression. Dans les problèmes de classification, elle est utilisée pour décider de la classe à laquelle un objet appartient, et dans la régression, elle est utilisée pour prédire des valeurs numériques.
Aujourd'hui, Random Forest est largement utilisé dans divers domaines, notamment la finance, la médecine, l'analyse de données et bien d'autres. Cette méthode est appréciée pour sa robustesse et sa capacité à traiter des problèmes complexes d'apprentissage automatique.
Random Forest est un outil puissant dans la boîte à outils de l'apprentissage automatique. Pour mieux comprendre son fonctionnement, imaginons un immense groupe de personnes se réunissant et prenant des décisions collectives. Mais au lieu de personnes réelles, chaque membre de ce groupe est un classificateur indépendant ou un prédicteur de la situation actuelle. Au sein de ce groupe, une personne est un arbre de décision capable de prendre des décisions sur la base de certains attributs. Lorsque la forêt aléatoire prend une décision, elle utilise la démocratie et le vote : chaque arbre exprime son opinion et la décision est prise sur la base de votes multiples.
Random Forest est largement utilisé dans une variété de domaines, et sa flexibilité le rend adapté à la fois aux problèmes de classification et de régression. Dans une tâche de classification, le modèle décide à quelle classe prédéfinie appartient l'état actuel. Par exemple, sur le marché financier, il peut s'agir d'une décision d'achat (classe 1) ou de vente (classe 0) d'un actif sur la base d'une série d'indicateurs.
Toutefois, dans cet article, nous nous concentrerons sur les problèmes de régression. La régression dans l'apprentissage automatique est une tentative de prédire les valeurs numériques futures d'une série temporelle sur la base de ses valeurs passées. Au lieu de la classification, qui consiste à classer les objets dans certaines catégories, la régression vise à prédire des nombres spécifiques. Il peut s'agir, par exemple, de prévoir le cours des actions, la température ou toute autre variable numérique.
Création d'un modèle RF de Base
Pour créer un modèle Random Forest de base, nous utiliserons la bibliothèque sklearn (Scikit-learn) en Python. Vous trouverez ci-dessous un modèle de code simple pour l'entraînement d'un modèle de régression Random Forest. Avant d'exécuter ce code, vous devez installer les bibliothèques nécessaires à l'exécution de sklearn en utilisant l'outil Python Package Installer.
pip install onnx
pip install skl2onnx
pip install MetaTrader5
Ensuite, il est nécessaire d'importer des bibliothèques et de définir des paramètres. Nous importons les bibliothèques nécessaires, notamment "pandas" pour travailler avec des données, "gdown" pour charger des données depuis Google Drive, ainsi que des bibliothèques pour le traitement des données et la création d'un modèle Random Forest. Nous définissons également le nombre de pas de temps (n_steps) dans la séquence de données, qui est déterminé en fonction des besoins spécifiques :
import pandas as pd import gdown import numpy as np import joblib import random import onnx import os import shutil from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.utils import shuffle from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures, PowerTransformer import MetaTrader5 as mt5 from datetime import datetime # Set the number of time steps according to requirements n_steps = 100
L'étape suivante consiste à charger et à traiter les données. Dans notre exemple spécifique, nous chargeons les données de prix de MetaTrader 5 et nous les traitons. Nous définissons l'indice de temps et sélectionnons uniquement les prix de clôture (c'est ce avec quoi nous allons travailler) :
Voici la partie du code responsable de la division de nos données en ensembles d'entraînement et de test, ainsi que de l'étiquetage de l'ensemble pour l'entraînement du modèle. Nous divisons les données en ensembles de formation et de test. Nous étiquetons ensuite les données pour la régression, ce qui signifie que chaque étiquette représente la valeur réelle du prix futur. La fonction labelling_relabeling_regression est utilisée pour créer des données étiquetées.mt5.initialize() SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2000, 1, 1) STOP_DATE = datetime(2023, 1, 1) # Set the number of time steps according to your requirements n_steps = 100 # Process data data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE), columns=['time', 'close']).set_index('time') data.index = pd.to_datetime(data.index, unit='s') data = data.dropna() data = data[['close']] # Work only with close prices
# Define train_data_initial training_size = int(len(data) * 0.70) train_data_initial = data.iloc[:training_size] test_data_initial = data.iloc[training_size:] # Function for creating and assigning labels for regression (changes made for regression, not classification) def labelling_relabeling_regression(dataset, min_value=1, max_value=1): future_prices = [] for i in range(dataset.shape[0] - max_value): rand = random.randint(min_value, max_value) future_pr = dataset['<CLOSE>'].iloc[i + rand] future_prices.append(future_pr) dataset = dataset.iloc[:len(future_prices)].copy() dataset['future_price'] = future_prices return dataset # Apply the labelling_relabeling_regression function to raw data to get labeled data train_data_labeled = labelling_relabeling_regression(train_data_initial) test_data_labeled = labelling_relabeling_regression(test_data_initial)
Nous créons ensuite des ensembles de données de formation à partir de certaines séquences. Ce qui importe, c'est que le modèle prenne comme caractéristiques tous les prix proches dans notre séquence. La même taille de séquence est utilisée comme taille des données d'entrée du modèle ONNX. Il n'y a pas de normalisation à ce stade ; elle sera effectuée dans le pipeline de formation, dans le cadre de l’exécution du pipeline du modèle.
# Create datasets of features and target variables for training x_train = np.array([train_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(train_data_labeled))]) y_train = train_data_labeled['future_price'].iloc[n_steps:].values # Create datasets of features and target variables for testing x_test = np.array([test_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(test_data_labeled))]) y_test = test_data_labeled['future_price'].iloc[n_steps:].values # After creating x_train and x_test, define n_features as follows: n_features = x_train.shape[1] # Now use n_features to determine the ONNX input data type initial_type = [('float_input', FloatTensorType([None, n_features]))]
Création d'un pipeline pour le pré-traitement des données
L'étape suivante consiste à créer un modèle Random Forest. Ce modèle doit être construit comme un pipeline.
Le Pipeline de la bibliothèque scikit-learn (sklearn) permet de créer une chaîne séquentielle de transformations et de modèles pour l'analyse de données et l'apprentissage automatique. Un pipeline vous permet de combiner plusieurs étapes de traitement et de modélisation des données en un seul objet qui peut être utilisé pour exploiter les données de manière efficace et séquentielle.
Dans notre exemple de code, nous créons le pipeline suivant :
# Create a pipeline with MinMaxScaler, RobustScaler, PolynomialFeatures and RandomForestRegressor
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(
n_estimators=20,
max_depth=20,
min_samples_split=5000,
min_samples_leaf=5000,
random_state=1,
verbose=2
))
])
# Train the pipeline
pipeline.fit(x_train, y_train)
# Make predictions
predictions = pipeline.predict(x_test)
# Evaluate model using R2
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}')
Comme vous pouvez le constater, un pipeline est une séquence d'étapes de traitement des données et de modélisation combinées en une seule chaîne. Dans ce code, le pipeline est créé à l'aide de la bibliothèque scikit-learn. Il comprend les étapes suivantes :
-
MinMaxScaler met les données à l'échelle dans une fourchette de 0 à 1. Cela permet de s'assurer que toutes les caractéristiques sont de même grandeur.
-
RobustScaler effectue également une mise à l'échelle des données, mais il est plus résistant aux valeurs aberrantes de l'ensemble de données. Il utilise la médiane et l'intervalle inter-quartile pour la mise à l'échelle.
-
PolynomialFeatures applique une transformation polynomiale aux caractéristiques. Cela ajoute des caractéristiques polynomiales qui peuvent aider le modèle à prendre en compte les relations non linéaires dans les données.
-
RandomForestRegressor définit un modèle de forêt aléatoire avec un ensemble d'hyper-paramètres :
- n_estimators (nombre d'arbres dans la forêt). Supposons que vous disposiez d'un groupe d'experts, chacun d'entre eux étant spécialisé dans la prévision des prix sur le marché financier. Le nombre d'arbres dans la forêt aléatoire (n_estimators) détermine le nombre d'experts dans votre groupe. Plus il y a d'arbres, plus le modèle prendra en compte des opinions et des prédictions diverses lorsqu'il prendra une décision.
- max_depth (profondeur maximale de chaque arbre). Ce paramètre définit la profondeur à laquelle chaque expert (arbre) peut "plonger" dans l'analyse des données. Par exemple, si vous fixez la profondeur maximale à 20, chaque arbre prendra des décisions basées sur un maximum de 20 caractéristiques.
- min_samples_split (nombre minimum d'échantillons pour diviser un nœud de l'arbre). Ce paramètre indique le nombre d'échantillons (observations) que doit contenir un nœud de l'arbre pour que l'arbre continue à le diviser en nœuds plus petits. Par exemple, si vous fixez le nombre minimum d'échantillons à diviser à 5.000, l'arbre ne divisera les nœuds que s'il y a plus de 5.000 observations par nœud.
- min_samples_leaf (nombre minimum d'échantillons dans un nœud feuille de l'arbre). Ce paramètre détermine le nombre d'échantillons qui doivent être présents dans un nœud feuille de l'arbre pour que ce nœud devienne une feuille et ne soit plus divisé. Par exemple, si vous fixez le nombre minimum d'échantillons dans un nœud feuille à 5.000, chaque feuille de l'arbre contiendra au moins 5.000 observations.
- random_state (définit l'état initial de la génération aléatoire, ce qui garantit des résultats reproductibles). Ce paramètre est utilisé pour contrôler les processus aléatoires dans le modèle. Si vous le fixez à une valeur fixe (par exemple, 1), les résultats seront les mêmes chaque fois que vous exécuterez le modèle. Ceci est utile pour la reproductibilité des résultats.
- verbose (permet d'afficher des informations sur le processus d'apprentissage du modèle). Lors de l'apprentissage d'un modèle, il peut être utile de disposer d'informations sur le processus. Le paramètre "verbose" vous permet de contrôler le niveau de détail de ces informations. Plus la valeur est élevée (par exemple, 2), plus le nombre d'informations produites au cours du processus de formation est important.
Après avoir créé le pipeline, nous utilisons la méthode "fit" pour l'entraîner sur les données d'entraînement. Ensuite, à l'aide de la méthode "predict", nous faisons des prédictions sur les données de test. Enfin, nous évaluons la qualité du modèle à l'aide de la métrique R2, qui mesure l'adéquation du modèle aux données.
Le pipeline est formé puis évalué par rapport à la métrique R2. Nous utilisons la normalisation, la suppression des données aberrantes et la création de caractéristiques polynomiales. Il s'agit des méthodes de pré-traitement des données les plus simples. Dans les prochains articles, nous verrons comment créer votre propre fonction de pré-traitement à l'aide de Function Transformer.
Export du modèle vers ONNX, écriture de la fonction d'export
Après avoir formé le pipeline, nous le sauvegardons dans le format joblib, que nous sauvegardons dans le format ONNX à l'aide de la bibliothèque skl2onnx.
# Save the pipeline
joblib.dump(pipeline, 'rf_pipeline.joblib')
# Convert pipeline to ONNX
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Connect Google Drive (if you work in Colab and this is necessary)
from google.colab import drive
drive.mount('/content/drive')
# Specify the path to Google Drive where you want to move the model
drive_path = '/content/drive/My Drive/' # Make sure the path is correct
rf_pipeline_onnx_drive_path = os.path.join(drive_path, 'rf_pipeline.onnx')
# Move ONNX model to Google Drive
shutil.move(model_onnx_path, rf_pipeline_onnx_drive_path)
print('The rf_pipeline model is saved in the ONNX format on Google Drive:', rf_pipeline_onnx_drive_path)
C'est ainsi que nous avons formé le modèle et que nous l'avons enregistré dans ONNX. C'est ce que nous verrons à l'issue de la l’entraînement du modèle :
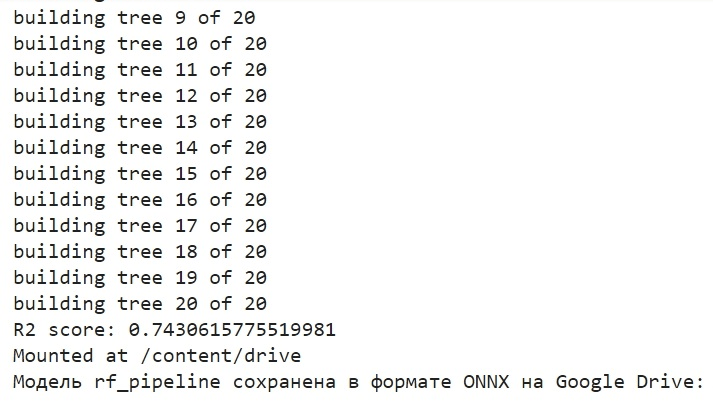
Le modèle est enregistré au format ONNX dans le répertoire de base de Google Drive. ONNX peut être considéré comme une sorte de "disquette" pour les modèles d'apprentissage automatique. Ce format permet d'enregistrer les modèles formés et de les convertir pour les utiliser dans diverses applications. Cela s'apparente à la façon dont vous enregistrez des fichiers sur une clé USB pour les lire ensuite sur d'autres appareils. Dans notre cas, le modèle ONNX sera utilisé dans l'environnement MetaTrader 5 pour prédire les prix des marchés financiers. La "disquette" ONNX elle-même peut être lue dans une application tierce, par exemple dans MetaTrader 5. C'est ce que nous allons faire maintenant.
Vérification du modèle dans le Testeur MetaTrader 5
Nous avons précédemment sauvegardé le modèle ONNX sur Google Drive. Nous allons maintenant le télécharger à partir de là. Pour utiliser ce modèle dans MetaTrader 5, créons un Expert Advisor qui lira et appliquera ce modèle pour prendre des décisions de trading. Dans le code de l’Expert Advisor présenté, définissez les paramètres de trading, tels que le volume des lots, l'utilisation d'ordres stop, les niveaux de Take Profit et de Stop Loss. Voici le code de l'EA qui va "lire" notre modèle ONNX :
//+------------------------------------------------------------------+ //| ONNX Random Forest.mq5 | //| Copyright 2023 | //| Evgeniy Koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com" #property version "0.90" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "Python/rf_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 100 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; CTrade ExtTrade; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Function for closing all positions void CloseAll(int type=-1) { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetInteger(POSITION_TYPE)==type || type==-1) { trade.PositionClose(PositionGetTicket(i)); } } } } // Expert Advisor initialization int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("The model should work with EURUSD, H1"); return(INIT_FAILED); } ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ",GetLastError()); return(INIT_FAILED); } const long input_shape[] = {1,100}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("Error setting the input shape OnnxSetInputShape ",GetLastError()); return(INIT_FAILED); } const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ",GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if(ExtHandle!=INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle=INVALID_HANDLE; } } // Process the tick function void OnTick() { if(TimeCurrent()<ExtNextBar) return; ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); PredictPrice(); if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; } if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } // Check position closing conditions void CheckForClose(void) { if(InpUseStops) return; bool tsignal=false; long type=PositionGetInteger(POSITION_TYPE); if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) tsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) tsignal=true; if(tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to predict prices void PredictPrice() { static vectorf output_data(1); static vectorf x_norm(SAMPLE_SIZE); double spread = GetSpreadInPips(_Symbol); if (!x_norm.CopyRates(_Symbol, _Period, COPY_RATES_CLOSE, 1, SAMPLE_SIZE)) { ExtPredictedClass = -1; return; } if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, x_norm, output_data)) { ExtPredictedClass = -1; return; } float predicted = output_data[0]; if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } }
Veillez à ce que la dimension d'entrée suivante soit respectée :
const long input_shape[] = {1,100};
doit correspondre à la dimension de notre modèle Python :
# Set the number of time steps to your requirements n_steps = 100
Ensuite, nous commençons à tester le modèle dans l'environnement MetaTrader 5. Nous utilisons les prédictions du modèle pour déterminer la direction des mouvements de prix. Si le modèle prédit que le prix va augmenter, nous nous préparons à ouvrir une position longue (achat). Et inversement, si le modèle prédit que le prix va baisser, nous nous préparons à ouvrir une position courte (vente). Testons le modèle avec un take profit de 1000 et un stop loss de 500 :
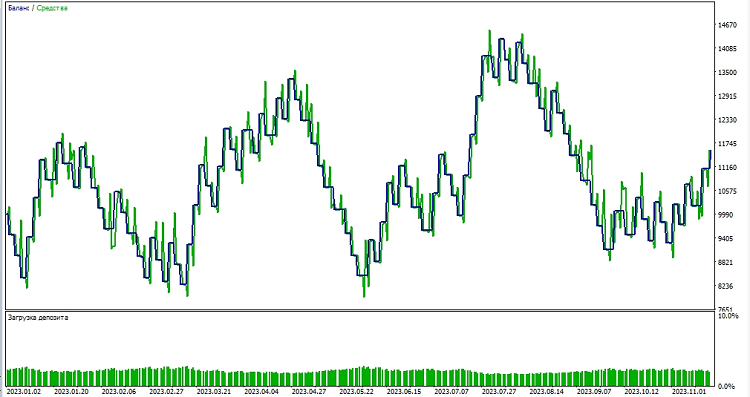
Conclusion
Dans cet article, nous avons étudié comment créer et entraîner un modèle Random Forest en Python, comment pré-traiter les données directement dans le modèle, ainsi que comment l'exporter vers le standard ONNX, puis ouvrir et utiliser le modèle dans MetaTrader 5.
ONNX est un excellent modèle de système d'import-export. Il est universel et simple. Sauvegarder un modèle dans ONNX est en fait beaucoup plus facile qu'il n'y paraît. Le pré-traitement des données est également très simple.
Bien sûr, notre modèle de seulement 20 arbres de décision est très simple, et le modèle de forêt aléatoire lui-même est déjà une solution assez ancienne. Dans les prochains articles, nous créerons des modèles plus complexes et plus modernes, en utilisant un pré-traitement des données plus complexe. J'aimerais également souligner la possibilité de créer immédiatement un ensemble de modèles sous la forme d'un pipeline sklearn, en même temps que le pré-traitement. Cela peut considérablement élargir nos capacités, y compris pour les problèmes de classification.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/13725
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
La forêt a été choisie comme exemple simple)Busting dans le prochain article, je suis en train de le peaufiner un peu)
Bon)
Il serait intéressant de développer davantage le sujet des convoyeurs et de leur conversion en ONNX avec une utilisation ultérieure dans Metatrader. Par exemple, est-il possible d'ajouter des transformations personnalisées au pipeline et le modèle ONNX obtenu à partir d'un tel pipeline sera-t-il ouvert dans Metatrader ? Je pense que ce sujet mérite plusieurs articles.
Il serait intéressant de développer davantage le sujet des convoyeurs et de leur conversion en ONNX avec une utilisation ultérieure dans Metatrader. Par exemple, est-il possible d'ajouter des transformations personnalisées au pipeline et le modèle ONNX obtenu à partir d'un tel pipeline sera-t-il ouvert dans Metatrader ? Je pense que ce sujet mérite plusieurs articles.