
OpenCL: da semplice verso una programmazione più perspicace

Introduzione
Il primo articolo "OpenCL: il ponte verso mondi paralleli" è stata un'introduzione all'argomento di OpenCL. Ha affrontato i problemi di base dell'interazione tra il programma in OpenCL (chiamato anche kernel, sebbene non sia del tutto corretto) e il programma esterno (host) in MQL5. Alcune capacità di prestazione del linguaggio (ad esempio l'uso di tipi di dati vettoriali) sono state esemplificate dal calcolo di pi = 3,14159265...
L'ottimizzazione delle prestazioni del programma è stata in alcuni casi considerevole. Tuttavia, tutte queste ottimizzazioni erano troppo semplici in quanto non tenevano conto delle specifiche hardware utilizzate per eseguire tutti i nostri calcoli. La conoscenza di queste specifiche può, nella maggior parte dei casi, consentirci di raggiungere consapevolmente accelerazioni che sono significativamente oltre le capacità della CPU.
Per dimostrare queste ottimizzazioni, l'autore ha dovuto ricorrere ad un esempio non più originale, che è probabilmente uno dei più studiati nella letteratura su OpenCL. È la moltiplicazione di due grandi matrici.
Cominciamo con la cosa principale: il modello di memoria OpenCL insieme alle peculiarità della sua implementazione sull'architettura hardware reale.
1. Gerarchia della memoria nei moderni dispositivi di elaborazione
1.1. Il modello di memoria OpenCL
In generale, i sistemi di memoria differiscono notevolmente l'uno dall'altro a seconda delle piattaforme del computer. Ad esempio, tutte le moderne CPU supportano la memorizzazione automatica dei dati nella cache al contrario delle GPU, dove questo non è sempre il caso.
Per garantire la portabilità del codice, in OpenCL viene adottato un modello di memoria astratto che i programmatori e i fornitori che hanno bisogno di implementare questo modello su hardware reale possono seguire. La memoria come definita in OpenCL può essere teoricamente illustrata nella Figura seguente:

Fig.1. Il modello di memoria OpenCL
Una volta che i dati vengono trasferiti dall'host al dispositivo, vengono archiviati nella memoria globale del dispositivo. Tutti i dati trasferiti nella direzione opposta vengono anche archiviati nella memoria globale (ma questa volta, nella memoria host globale). La parola chiave __global (due trattini bassi!) è un modificatore che indica che i dati associati a un determinato puntatore sono archiviati nella memoria globale:
__kernel void foo( __global float *A ) { /// kernel code }
La memoria globale è accessibile a tutte le unità di calcolo all'interno del dispositivo come la RAM nel sistema host.
La memoria costante, contrariamente al suo nome, non memorizza necessariamente dati di sola lettura. Questo tipo di memoria è progettato per i dati in cui ogni elemento è accessibile contemporaneamente da tutte le unità di lavoro. Naturalmente, rientrano in questa categoria anche le variabili con valori costanti. La memoria costante nel modello OpenCL è una parte della memoria globale e gli oggetti di memoria trasferiti nella memoria globale possono quindi essere specificati come __costante.
La memoria locale è la memoria degli appunti in cui lo spazio degli indirizzi è univoco per ciascun dispositivo. Nell'hardware, spesso si presenta sotto forma di memoria su chip, ma non vi è alcun requisito speciale per essere esattamente lo stesso per OpenCL.
L'accesso a questo tipo di memoria comporta una latenza molto inferiore e la larghezza di banda della memoria è quindi molto maggiore di quella della memoria globale. Cercheremo di sfruttare la sua minore latenza per l'ottimizzazione delle prestazioni del kernel.
La specifica OpenCL dice che una variabile nella memoria locale può essere dichiarata sia nell'intestazione del kernel:
__kernel void foo( __local float *sharedData ) { }e nel suo corpo:
__kernel void foo( __global float *A ) { __local float sharedData[ 64 ]; }Nota che un array dinamico non può essere dichiarato nel corpo del kernel; devi sempre specificare la sua dimensione.
Di seguito, nell'ottimizzazione del kernel per la moltiplicazione di due grandi matrici, vedrai come gestire i dati locali e quali peculiarità implementative comporta su MetaTrader 5, come sperimentato dall'autore.
Le variabili locali e gli argomenti del kernel che non contengono puntatori sono privati per impostazione predefinita (se specificati senza il modificatore __local). In pratica, queste variabili si trovano solitamente nei registri. E viceversa, gli array privati e qualsiasi registro “versato” si trovano solitamente nella memoria off-chip, ovvero memoria a latenza più elevata. Permettimi di citare le informazioni rilevanti da Wikipedia:
In molti linguaggi di programmazione, il programmatore ha l'illusione di allocare arbitrariamente molte variabili. Tuttavia, durante la compilazione, il compilatore deve decidere come allocare queste variabili a un piccolo insieme finito di registri. Non tutte le variabili sono in uso (o "live") contemporaneamente, quindi alcuni registri possono essere assegnati a più di una variabile. Tuttavia, due variabili in uso contemporaneamente non possono essere assegnate allo stesso registro senza alterarne il valore.
Le variabili che non possono essere assegnate a qualche registro devono essere mantenute nella RAM e caricate in/out per ogni lettura/scrittura, un processo chiamato spilling. L'accesso alla RAM è significativamente più lento dell'accesso ai registri e rallenta la velocità di esecuzione del programma compilato, quindi un compilatore ottimizzatore mira ad assegnare quante più variabili possibili ai registri. Pressione di registro è il termine utilizzato quando sono disponibili meno registri hardware di quanto sarebbe stato ottimale; una pressione più alta di solito significa che sono necessari più versamenti e ricariche.
Il modello di memoria OpenCL come descritto è molto simile alla struttura di memoria delle moderne GPU. La figura seguente mostra una correlazione tra il modello di memoria OpenCL e il modello di memoria GPU AMD Radeon HD 6970.

Fig.2. La correlazione tra la struttura della memoria della Radeon HD 6970 e il modello di memoria OpenCL astratto
Passiamo a una considerazione più dettagliata dei problemi relativi a una specifica implementazione della memoria GPU.
1.2. Memoria nelle moderne GPU discrete
1.2.1. Richieste di memoria coalescenti
Queste informazioni sono importanti anche per l'ottimizzazione delle prestazioni del kernel poiché l'obiettivo principale è ottenere un'elevata larghezza di banda della memoria.
Dai un'occhiata alla figura seguente per comprendere meglio il processo di indirizzamento della memoria:

Fig.3. Schema di indirizzamento dei dati nella memoria globale del dispositivo
Supponiamo che il puntatore a un array di variabili intere int sia l'indirizzo di Х = 0x00001232. Ogni int occupa 4 byte di memoria. Supponiamo che un thread (che è un analogo software di un'unità di lavoro che esegue il codice del kernel) indirizzi i dati a Х[ 0 ]:
int tmp = X[ 0 ];
Supponiamo che la larghezza del bus di memoria sia 32 byte (256 bit). Questa larghezza del bus è tipica delle GPU potenti, come la Radeon HD 5870. In alcune altre GPU, la larghezza del bus dati può essere diversa, ad esempio 384 bit o addirittura 512 in alcuni modelli NVidia.
L'indirizzamento del bus di memoria dovrebbe corrispondere alla sua struttura, cioè prima di tutto alla sua larghezza. In altre parole, i dati in memoria vengono archiviati in blocchi di 32 byte (256 bit) ciascuno. Indipendentemente da ciò che affrontiamo nell'intervallo da 0x00001220 a 0x0000123F (ci sono esattamente 32 byte in questo intervallo, puoi vederlo tu stesso), otterremo comunque l'indirizzo 0x00001220 come indirizzo iniziale per la lettura.
L'accesso all'indirizzo 0x00001232 restituirà tutti i dati agli indirizzi compresi nell'intervallo da 0x00001220 a 0x0000123F, ovvero 8 numeri int. Pertanto, ci saranno solo 4 byte (un numero int) di dati utili, mentre i restanti 28 byte (7 numeri int) saranno inutili:
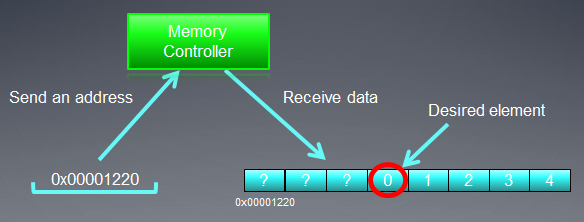
Fig.4. Schema per ottenere i dati richiesti dalla memoria
Il numero di cui abbiamo bisogno, situato all'indirizzo specificato in precedenza - 0x00001232 - è cerchiato nello schema.
Per massimizzare l'uso del bus, la GPU cerca di unire gli accessi alla memoria da diversi thread in un'unica richiesta di memoria; meno memoria accede, meglio è. Il motivo è che l'accesso alla memoria globale del dispositivo ci costa tempo e quindi riduce notevolmente la velocità di esecuzione del programma. Considera la seguente riga del codice del kernel:
int tmp = X[ get_global_id( 0 ) ];
Supponiamo che il nostro array Х sia l'array dell'esempio precedente dato sopra. Quindi, i primi 16 thread (kernel) accederanno agli indirizzi da 0x00001232 a 0x00001272 (ci sono 16 numeri int all'interno di questo intervallo, ovvero 64 byte). Se ogni richiesta fosse inviata dai kernel in modo indipendente, senza essere preventivamente coalizzata in una sola, ciascuna delle 16 richieste conterrebbe 4 byte di dati utili e 28 byte di dati inutili, per un totale di 64 utilizzati e 448 inutilizzati.
Questo calcolo si basa sul fatto che ogni accesso a un indirizzo situato all'interno di uno stesso blocco di memoria a 32 byte restituirà dati assolutamente identici. Questo è il punto chiave. Sarebbe più corretto unire più richieste in richieste singole e coerenti per risparmiare su richieste inutili. Tale operazione sarà di seguito denominata coalescente e le richieste coalizzate in quanto tali verranno indicate come coerenti.

Fig.5. Sono necessarie solo tre richieste di memoria per ottenere i dati richiesti
Ogni cella nella figura sopra è di 4 byte. Nel nostro esempio, sarebbero sufficienti 3 richieste. Se l'inizio dell'array fosse allineato all'indirizzo dell'inizio di ogni blocco di memoria a 32 byte, sarebbero sufficienti anche 2 richieste.
Nella GPU AMD 64, i thread fanno parte di un fronte d'onda e devono quindi eseguire la stessa istruzione dell'esecuzione SIMD. 16 thread organizzati da get_global_id( 0 ), essendo esattamente un quarto del fronte d'onda, sono riuniti in una richiesta coerente per un uso efficiente del bus.
Di seguito viene illustrata la larghezza di banda di memoria necessaria per richieste coerenti rispetto a richieste incoerenti, ovvero "spontanee". Riguarda Radeon HD 5870. Un risultato simile si può osservare per le schede NVidia.
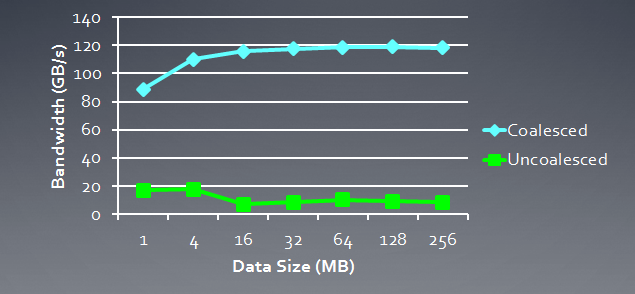
Fig.6. Analisi comparativa della larghezza di banda di memoria richiesta per richieste coerenti e incoerenti
Si vede chiaramente che una richiesta di memoria coerente consente di aumentare la larghezza di banda della memoria di circa un ordine di grandezza.
1.2.2. Banche di memoria
La memoria è costituita da banche in cui i dati sono effettivamente memorizzati. Nelle GPU moderne, queste sono solitamente parole a 32 bit (4 byte). I dati seriali sono memorizzati in banche di memoria adiacenti. Un gruppo di thread che accedono a elementi seriali non produrrà alcun conflitto di banca.
Il massimo effetto negativo dei conflitti di banca si osserva solitamente nella memoria GPU locale. È quindi consigliabile che gli accessi ai dati locali dai thread vicini abbiano come target diverse banche di memoria.
Sull'hardware AMD, il fronte d'onda che genera i conflitti di banca si blocca fino al completamento di tutte le operazioni sulla memoria locale. Ciò porta alla serializzazione, in base alla quale i blocchi di codice che devono essere eseguiti in parallelo vengono eseguiti in sequenza. Ha un effetto estremamente negativo sulle prestazioni del kernel.
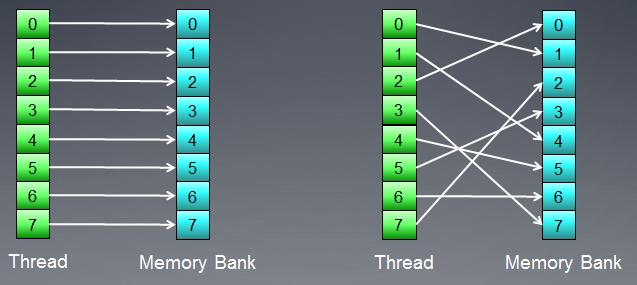
Fig.7. Schemi di accesso alla memoria senza conflitti di banca
La figura sopra mostra l'accesso alla memoria senza conflitti di banca poiché tutti i thread accedono a dati diversi.
Illustriamo l'accesso alla memoria con conflitti di banca:
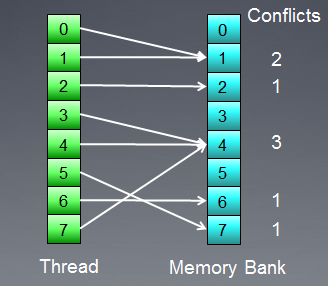
Fig.8. Accesso alla memoria con conflitti di banca
Questa situazione ha però un'eccezione: se tutti gli accessi sono allo stesso indirizzo, la banca può effettuare un broadcast per evitare il ritardo:
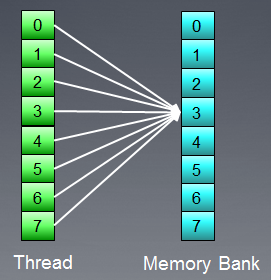
Fig.9. Tutti i thread accedono allo stesso indirizzo
Eventi simili si verificano anche quando si accede alla memoria globale, ma l'impatto di tali conflitti è notevolmente inferiore.
- La memoria della GPU è diversa dalla memoria della CPU. L'obiettivo principale dell'ottimizzazione delle prestazioni del programma utilizzando OpenCL è garantire la massima larghezza di banda invece di ridurre la latenza, come sarebbe sulla CPU.
- La natura dell'accesso alla memoria ha un grande impatto sull'efficienza dell'uso del bus. Bassa efficienza di utilizzo del bus significa bassa velocità di marcia.
- Per migliorare le prestazioni del codice, è consigliabile che l'accesso alla memoria sia coerente. Inoltre, è altamente preferibile evitare conflitti di banca.
- Le specifiche hardware (larghezza del bus, numero di banche di memoria e numero di thread che possono essere uniti per un singolo accesso coerente) possono essere trovate nella documentazione fornita dal fornitore.
Le specifiche di alcune schede video della serie Radeon 5xxx sono riportate di seguito come esempio:
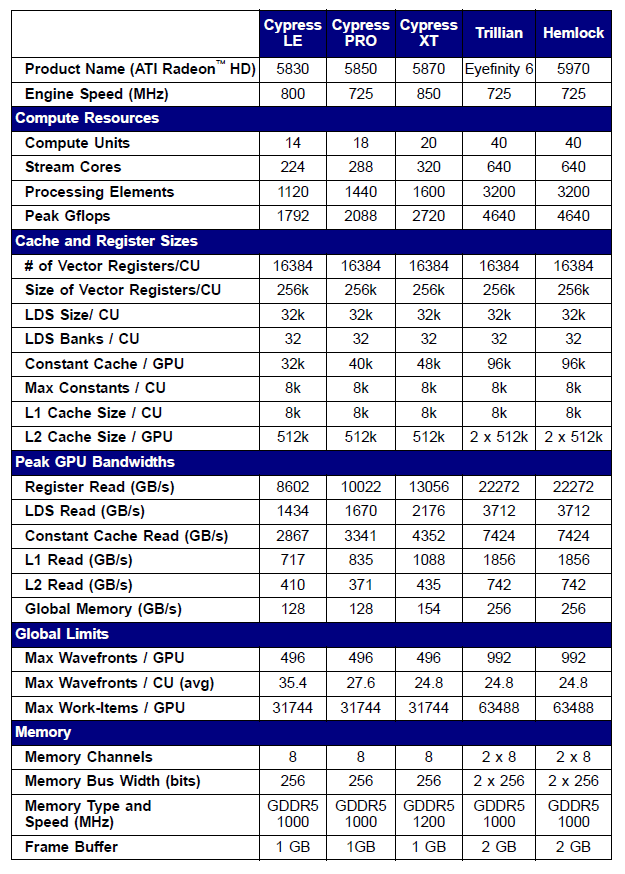
Fig.10. Specifiche tecniche delle schede video Radeon HD 58xx di fascia media e alta
Passiamo ora alla programmazione.
2. Moltiplicazione di matrici quadrate grandi: Dal codice della CPU seriale al codice della GPU parallela
2.1. Codice MQL5
Il compito a portata di mano, in contrasto con il precedente articolo "OpenCL: The Bridge to Parallel Worlds", è standard, ovvero occorre moltiplicare due matrici. Viene scelto principalmente per il fatto che molte informazioni sull'argomento possono essere trovate in diverse fonti. La maggior parte di esse, in un modo o nell'altro, offre soluzioni più o meno coordinate. Questa è la strada che percorreremo, fornendo chiarimenti passo passo sul significato delle strutture del modello, tenendo presente che stiamo lavorando su un hardware reale.
Di seguito è riportata una formula di moltiplicazione matriciale ben nota nell'algebra lineare, modificata per i calcoli al computer. Il primo indice è il numero di riga della matrice, il secondo indice è il numero di colonna. Ogni elemento della matrice di output viene calcolato sommando sequenzialmente ciascun prodotto successivo di elementi nella prima e nella seconda matrice alla somma accumulata. Alla fine, questa somma accumulata è l'elemento della matrice di output calcolato:
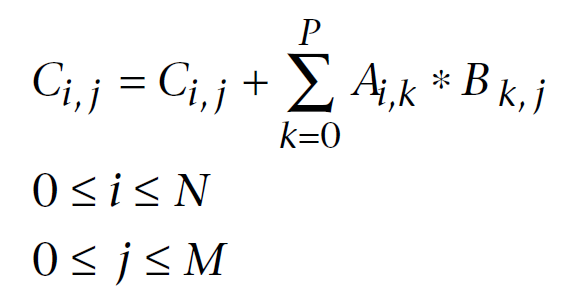
Fig.11. Formula di moltiplicazione della matrice
Può essere schematicamente rappresentato come segue:
 rappresentato schematicamente")
Fig.12. Algoritmo di moltiplicazione della matrice (esemplificato dal calcolo di un elemento della matrice di output) rappresentato schematicamente
Si può facilmente vedere che dove entrambe le matrici hanno le stesse dimensioni pari a N, il numero di addizioni e moltiplicazioni può essere stimato dalla funzione O(N^3): per calcolare ogni elemento di matrice di output, è necessario ottenere il prodotto scalare di una riga nella prima matrice e di una colonna nella seconda matrice. Richiede circa 2*N addizioni e moltiplicazioni. Una stima richiesta si ottiene moltiplicando per il numero di elementi della matrice N^2. Pertanto, il tempo di esecuzione approssimativo del codice dipende in modo abbastanza considerevole da N cubi.
Il numero di righe e colonne per le matrici è qui di seguito fissato a 2000 solo per comodità; potrebbero essere arbitrari, ma non troppo grandi.
Il codice in MQL5 non è molto complicato:
//+------------------------------------------------------------------+ //| matr_mul_2dim.mq5 | //+------------------------------------------------------------------+ #define ROWS1 1000 // rows in the first matrix #define COLSROWS 1000 // columns in the first matrix = rows in the second matrix #define COLS2 1000 // columns in the second matrix float first[ ROWS1 ][ COLSROWS ]; // first matrix float second[ COLSROWS ][ COLS2 ]; // second matrix float third[ ROWS1 ][ COLS2 ]; // product //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { MathSrand(GetTickCount()); Print("======================================="); Print("ROWS1 = "+i2s(ROWS1)+"; COLSROWS = "+i2s(COLSROWS)+"; COLS2 = "+i2s(COLS2)); genMatrices(); ArrayInitialize(third,0.0f); //--- execution on the CPU uint st1=GetTickCount(); mul(); double time1=(double)(GetTickCount()-st1)/1000.; Print("CPU: time = "+DoubleToString(time1,3)+" s."); return; } //+------------------------------------------------------------------+ //| i2s | //+------------------------------------------------------------------+ string i2s(int arg) { return IntegerToString(arg); } //+------------------------------------------------------------------+ //| genMatrices | //| generate initial matrices; this generation is not reflected | //| in the final runtime calculation | //+------------------------------------------------------------------+ void genMatrices() { for(int r=0; r<ROWS1; r++) for(int c=0; c<COLSROWS; c++) first[r][c]=genVal(); for(int r=0; r<COLSROWS; r++) for(int c=0; c<COLS2; c++) second[r][c]=genVal(); return; } //+------------------------------------------------------------------+ //| genVal | //| generate one value of the matrix element: | //| uniformly distributed value lying in the range [-0.5; 0.5] | //+------------------------------------------------------------------+ float genVal() { return(float)(( MathRand()-16383.5)/32767.); } //+------------------------------------------------------------------+ //| mul | //| Main matrix multiplication function | //+------------------------------------------------------------------+ void mul() { // r-cr-c: 10.530 s for(int r=0; r<ROWS1; r++) for(int cr=0; cr<COLSROWS; cr++) for(int c=0; c<COLS2; c++) third[r][c]+=first[r][cr]*second[cr][c]; return; }
Elenco 1. Programma sequenziale iniziale sull'host
Risultati delle prestazioni utilizzando diversi parametri:
2012.05.19 09:39:11 matr_mul_2dim (EURUSD,H1) CPU: time = 10.530 s. 2012.05.19 09:39:00 matr_mul_2dim (EURUSD,H1) ROWS1 = 1000; COLSROWS = 1000; COLS2 = 1000 2012.05.19 09:39:00 matr_mul_2dim (EURUSD,H1) ======================================= 2012.05.19 09:41:04 matr_mul_2dim (EURUSD,H1) CPU: time = 83.663 s. 2012.05.19 09:39:40 matr_mul_2dim (EURUSD,H1) ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.19 09:39:40 matr_mul_2dim (EURUSD,H1) =======================================
Come si può vedere, la nostra dipendenza stimata del tempo di esecuzione dalle dimensioni della matrice lineare è sembrata essere vera: un aumento di due volte in tutte le dimensioni della matrice ha comportato un aumento di circa 8 volte nel tempo di esecuzione.
Qualche parola sull'algoritmo: l'ordine del ciclo può essere modificato arbitrariamente nella funzione di moltiplicazione mul(). Si scopre che ha un effetto considerevole sul runtime: il rapporto tra la variante di runtime più lenta e quella più veloce è di circa 1,73.
L'articolo mostra solo la variante più veloce; le restanti varianti testate si trovano nel codice allegato a fine articolo (file matr_mul_2dim.mq5). A questo proposito, OpenCL Programming Guide (Aaftab Munshi, Benedict R. Gaster, Timothy G. Mattson, James Fung, Dan Ginsburg) dice quanto segue (p. 512):
Queste, ovviamente, non sono tutte ottimizzazioni del codice "non parallelo" iniziale che possiamo implementare. Alcuni di essi sono relativi all'hardware (istruzioni (S)SSEx), mentre altri sono puramente algoritmici, ad esempio l’algoritmo Strassen, l’algoritmo Coppersmith–Winograd, ecc. Da notare che la dimensione delle matrici moltiplicate per l'algoritmo di Strassen, il quale porta a una notevole accelerazione rispetto all'algoritmo classico, è piuttosto piccola, essendo solo 64х64. In questo articolo impareremo a moltiplicare rapidamente matrici la cui dimensione lineare è fino a poche migliaia (approssimativamente fino a 5000).
2.2. La prima implementazione dell'algoritmo in OpenCL
Portiamo ora questo algoritmo su OpenCL, creando il thread ROWS1 * COLS2, ovvero eliminando entrambi i loop esterni dal kernel. Ogni thread eseguirà le iterazioni COLSROWS in modo che il ciclo interno rimanga parte del kernel.
Poiché dovremo creare tre buffer lineari per il kernel OpenCL, sarebbe ragionevole rielaborare l'algoritmo iniziale in modo che sia il più simile possibile all'algoritmo del kernel. Insieme al codice del kernel verrà fornito il codice del programma "non parallelo" su una "CPU single core" con buffer lineari. L'ottimalità del codice con array bidimensionali non comporta che il suo analogo sarà ottimale anche per buffer lineari: tutti i test dovranno essere ripetuti. Pertanto, optiamo ancora per c-r-cr come variante iniziale, la quale corrisponde alla logica standard della moltiplicazione matriciale in algebra lineare.
Detto questo, per evitare un possibile elemento matrice/buffer che indirizza la confusione, rispondi alla domanda principale: se una matrice Matr( M righe per N colonne ) è disposta nella memoria GPU globale come un buffer lineare, come possiamo calcolare uno spostamento lineare di un elemento Matr[ row ][ column ]?
Non esiste infatti un ordine fisso di disposizione di una matrice nella memoria della GPU poiché è determinato dalla sola logica del problema. Ad esempio, gli elementi di entrambe le matrici potrebbero essere disposti diversamente nei buffer perché, per quanto riguarda l'algoritmo di moltiplicazione delle matrici, le matrici sono asimmetriche, cioè le righe della prima matrice vengono moltiplicate per le colonne della seconda matrice. Tale riarrangiamento può influenzare notevolmente le prestazioni di calcolo nella lettura sequenziale degli elementi della matrice dalla memoria GPU globale in ogni iterazione del kernel.
La prima implementazione dell'algoritmo presenterà matrici disposte nello stesso modo, in ordine di riga. I primi elementi della riga saranno i primi ad essere inseriti nel buffer, seguiti da tutti gli elementi della seconda riga e così via. La formula per appiattire una rappresentazione bidimensionale di una matrice Matr[ M (rows) ][ N (columns) ] sulla memoria lineare è la seguente:

Fig.13. Algoritmo per convertire uno spazio indice bidimensionale in lineare per disporre la matrice nel buffer della GPU
La figura sopra fornisce anche un esempio di come una rappresentazione matriciale bidimensionale viene appiattita sulla memoria lineare in ordine di colonna.
Di seguito è riportato un codice leggermente ridotto della nostra prima implementazione del programma eseguita sul dispositivo OpenCL:
//+------------------------------------------------------------------+ //| matr_mul_1dim.mq5 | //+------------------------------------------------------------------+ #property script_show_inputs #define ROWS1 2000 // rows in the first matrix #define COLSROWS 2000 // columns in the first matrix = rows in the second matrix #define COLS2 2000 // columns in the second matrix #define REALTYPE float REALTYPE first[]; // first linear buffer (matrix) rows1 * colsrows REALTYPE second[]; // second buffer colsrows * cols2 REALTYPE thirdGPU[ ]; // product - also a buffer rows1 * cols2 REALTYPE thirdCPU[ ]; // product - also a buffer rows1 * cols2 input int _device=1; // here is the device; it can be changed (now 4870) string d2s(double arg,int dig) { return DoubleToString(arg,dig); } string i2s(long arg) { return IntegerToString(arg); } //+------------------------------------------------------------------+ const string clSrc= "#define COLS2 "+i2s(COLS2)+" \r\n" "#define COLSROWS "+i2s(COLSROWS)+" \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " int c = get_global_id( 1 ); \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " out[ r * COLS2 + c ] += \r\n" " in1[ r * COLSROWS + cr ] * in2[ cr * COLS2 + c ]; \r\n" "} \r\n"; //+------------------------------------------------------------------+ //| Main matrix multiplication function; | //| Input matrices are already generated, | //| the output matrix is initialized to zeros | //+------------------------------------------------------------------+ void mulCPUOneCore() { //--- c-r-cr: 11.544 s //st = GetTickCount( ); for(int c=0; c<COLS2; c++) for(int r=0; r<ROWS1; r++) for(int cr=0; cr<COLSROWS; cr++) thirdCPU[r*COLS2+c]+=first[r*COLSROWS+cr]*second[cr*COLS2+c]; return; } //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { initAllDataCPU(); //--- start working with non-parallel version ("bare" CPU, single core) //--- calculate the output matrix on a single core CPU uint st=GetTickCount(); mulCPUOneCore(); //--- output total calculation time double timeCPU=(GetTickCount()-st)/1000.; Print("CPUTime = "+d2s(timeCPU,3)); //--- start working with OCL int clCtx; // context handle int clPrg; // handle to the program on the device int clKrn; // kernel handle int clMemIn1; // first (input) buffer handle int clMemIn2; // second (input) buffer handle int clMemOut; // third (output) buffer handle //--- start calculating the program runtime on GPU //st = GetTickCount( ); initAllDataGPU(clCtx,clPrg,clKrn,clMemIn1,clMemIn2,clMemOut); //--- start calculating total OCL code runtime st=GetTickCount(); executeGPU(clKrn); //--- create a buffer for reading and read the result; we will need it later REALTYPE buf[]; readOutBuf(clMemOut,buf); //--- stop calculating the total program runtime //--- together with the time required for retrieval of data from GPU and transferring it back to RAM double timeGPUTotal=(GetTickCount()-st)/1000.; Print("OpenCL total: time = "+d2s(timeGPUTotal,3)+" sec."); destroyOpenCL(clCtx,clPrg,clKrn,clMemIn1,clMemIn2,clMemOut); //--- calculate the time elapsed Print("CPUTime / GPUTotalTime = "+d2s(timeCPU/timeGPUTotal,3)); //--- debugging: random checks. Multiplication accuracy is checked directly //--- on the initial and output matrices using a few dozen examples for(int i=0; i<10; i++) checkRandom(buf,ROWS1,COLS2); Print("________________________"); return; } //+------------------------------------------------------------------+ //| initAllDataCPU | //+------------------------------------------------------------------+ void initAllDataCPU() { //--- initialize random number generator MathSrand(( int) TimeLocal()); Print("======================================="); Print("1st OCL martices mul: device = "+i2s(_device)+"; ROWS1 = " +i2s(ROWS1)+ "; COLSROWS = "+i2s(COLSROWS)+"; COLS2 = "+i2s(COLS2)); //--- set the required sizes of linear representations of the input and output matrices ArrayResize(first,ROWS1*COLSROWS); ArrayResize(second,COLSROWS*COLS2); ArrayResize(thirdGPU,ROWS1*COLS2); ArrayResize(thirdCPU,ROWS1*COLS2); //--- generate both input matrices and initialize the output to zeros genMatrices(); ArrayInitialize( thirdCPU, 0.0 ); ArrayInitialize( thirdGPU, 0.0 ); return; } //+------------------------------------------------------------------+ //| initAllDataCPU | //| lay out in row-major order, Matr[ M (rows) ][ N (columns) ]: | //| Matr[row][column] = buff[row * N(columns in the matrix) + column]| //| generate initial matrices; this generation is not reflected | //| in the final runtime calculation | //| buffers are filled in row-major order! | //+------------------------------------------------------------------+ void genMatrices() { for(int r=0; r<ROWS1; r++) for(int c=0; c<COLSROWS; c++) first[r*COLSROWS+c]=genVal(); for(int r=0; r<COLSROWS; r++) for(int c=0; c<COLS2; c++) second[r*COLS2+c]=genVal(); return; } //+------------------------------------------------------------------+ //| genVal | //| generate one value of the matrix element: | //| uniformly distributed value lying in the range [-0.5; 0.5] | //+------------------------------------------------------------------+ REALTYPE genVal() { return(REALTYPE)((MathRand()-16383.5)/32767.); } //+------------------------------------------------------------------+ //| initAllDataGPU | //+------------------------------------------------------------------+ void initAllDataGPU(int &clCtx, // context int& clPrg, // program on the device int& clKrn, // kernel int& clMemIn1, // first (input) buffer int& clMemIn2, // second (input) buffer int& clMemOut) // third (output) buffer { //--- write the kernel code to a file WriteCLProgram(); //--- create context, program and kernel clCtx = CLContextCreate( _device ); clPrg = CLProgramCreate( clCtx, clSrc ); clKrn = CLKernelCreate( clPrg, "matricesMul" ); //--- create all three buffers for the three matrices //--- first matrix - input clMemIn1=CLBufferCreate(clCtx,ROWS1 *COLSROWS*sizeof(REALTYPE),CL_MEM_READ_WRITE); //--- second matrix - input clMemIn2=CLBufferCreate(clCtx,COLSROWS*COLS2 *sizeof(REALTYPE),CL_MEM_READ_WRITE); //--- third matrix - output clMemOut=CLBufferCreate(clCtx,ROWS1 *COLS2 *sizeof(REALTYPE),CL_MEM_READ_WRITE); //--- set arguments to the kernel CLSetKernelArgMem(clKrn,0,clMemIn1); CLSetKernelArgMem(clKrn,1,clMemIn2); CLSetKernelArgMem(clKrn,2,clMemOut); //--- write the generated matrices to the device buffers CLBufferWrite(clMemIn1,first); CLBufferWrite(clMemIn2,second); CLBufferWrite(clMemOut,thirdGPU); // 0.0 everywhere return; } //+------------------------------------------------------------------+ //| WriteCLProgram | //+------------------------------------------------------------------+ void WriteCLProgram() { int h=FileOpen("matr_mul_OCL_1st.cl",FILE_WRITE|FILE_TXT|FILE_ANSI); FileWrite(h,clSrc); FileClose(h); } //+------------------------------------------------------------------+ //| executeGPU | //+------------------------------------------------------------------+ void executeGPU(int clKrn) { //--- set the workspace parameters for the task and execute the OpenCL program uint offs[ 2 ] = { 0, 0 }; uint works[ 2 ] = { ROWS1, COLS2 }; bool ex=CLExecute(clKrn,2,offs,works); return; } //+------------------------------------------------------------------+ //| readOutBuf | //+------------------------------------------------------------------+ void readOutBuf(int clMemOut,REALTYPE &buf[]) { ArrayResize(buf,COLS2*ROWS1); //--- buf - a copy of what is written to the buffer thirdGPU[] uint read=CLBufferRead(clMemOut,buf); Print("read = "+i2s(read)+" elements"); return; } //+------------------------------------------------------------------+ //| destroyOpenCL | //+------------------------------------------------------------------+ void destroyOpenCL(int clCtx,int clPrg,int clKrn,int clMemIn1,int clMemIn2,int clMemOut) { //--- destroy all that was created for calculations on the OpenCL device in reverse order CLBufferFree(clMemIn1); CLBufferFree(clMemIn2); CLBufferFree(clMemOut); CLKernelFree(clKrn); CLProgramFree(clPrg); CLContextFree(clCtx); return; } //+------------------------------------------------------------------+ //| checkRandom | //| random check of calculation accuracy | //+------------------------------------------------------------------+ void checkRandom(REALTYPE &buf[],int rows,int cols) { int r0 = genRnd( rows ); int c0 = genRnd( cols ); REALTYPE sum=0.0; for(int runningIdx=0; runningIdx<COLSROWS; runningIdx++) sum+=first[r0*COLSROWS+runningIdx]* second[runningIdx*COLS2+c0]; //--- element of the buffer m[] REALTYPE bufElement=buf[r0*COLS2+c0]; //--- element of the matrix not calculated in OpenCL REALTYPE CPUElement=thirdCPU[r0*COLS2+c0]; Print("sum( "+i2s(r0)+","+i2s(c0)+" ) = "+d2s(sum,8)+ "; thirdCPU[ "+i2s(r0)+","+i2s(c0)+" ] = "+d2s(CPUElement,8)+ "; buf[ "+i2s(r0)+","+i2s(c0)+" ] = "+d2s(bufElement,8)); return; } //+------------------------------------------------------------------+ //| genRnd | //+------------------------------------------------------------------+ int genRnd(int max) { return(int)(MathRand()/32767.*max); }
Elenco 2. La prima implementazione del programma in OpenCL
Le ultime due funzioni sono utili per verificare l'accuratezza dei calcoli. Il codice completo lo trovate allegato alla fine dell'articolo (matr_mul_1dim.mq5). Da notare che le dimensioni non devono necessariamente corrispondere solo alle matrici quadrate.
Ulteriori modifiche riguarderanno quasi sempre solo il codice del kernel e, pertanto, di seguito verranno riportati solo i codici di modifica del kernel.
Il tipo REALTYPE è stato introdotto per la comodità di cambiare la precisione di calcolo da float a double. Va detto che il tipo REALTYPE è dichiarato non solo nel programma host, ma anche all'interno del kernel. Se necessario, eventuali modifiche relative a questo tipo dovranno essere apportate in due punti contemporaneamente, sia in #define del programma host che nel codice del kernel.
I risultati delle prestazioni del codice (di seguito, tipo di dati float ovunque):
CPU (OpenCL, _device = 0):
2012.05.20 22:14:57 matr_mul_1dim (EURUSD,H1) CPUTime / GPUTotalTime = 12.479 2012.05.20 22:14:57 matr_mul_1dim (EURUSD,H1) OpenCL total: time = 9.266 sec. 2012.05.20 22:14:57 matr_mul_1dim (EURUSD,H1) read = 4000000 elements 2012.05.20 22:14:48 matr_mul_1dim (EURUSD,H1) CPUTime = 115.628 2012.05.20 22:12:52 matr_mul_1dim (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.20 22:12:52 matr_mul_1dim (EURUSD,H1) =======================================
Se eseguito su Radeon HD 4870 (_device = 1):
2012.05.27 01:40:50 matr_mul_1dim (EURUSD,H1) CPUTime / GPUTotalTime = 9.002 2012.05.27 01:40:50 matr_mul_1dim (EURUSD,H1) OpenCL total: time = 12.729 sec. 2012.05.27 01:40:50 matr_mul_1dim (EURUSD,H1) read = 4000000 elements 2012.05.27 01:40:37 matr_mul_1dim (EURUSD,H1) CPUTime = 114.583 2012.05.27 01:38:42 matr_mul_1dim (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 01:38:42 matr_mul_1dim (EURUSD,H1) =======================================
Come si può notare, l'esecuzione del kernel sulla GPU è molto più lenta. Tuttavia non abbiamo ancora affrontato l'ottimizzazione specifica per la GPU.
Alcune conclusioni:
- La modifica della rappresentazione matriciale da bidimensionale a lineare (corrispondente alla rappresentazione nel programma eseguito sul dispositivo) non ha avuto un effetto notevole sul tempo di esecuzione totale della versione sequenziale del programma.
- L'algoritmo di calcolo più intuitivo che corrisponde alla definizione di moltiplicazione matriciale in algebra lineare è stato selezionato come variante iniziale per un'ulteriore ottimizzazione. È un po' più lento del più veloce, ma in vista della futura accelerazione della GPU questo fattore non è essenziale.
- Il runtime deve essere calcolato solo dopo aver letto i buffer nella RAM piuttosto che dopo il comando CLExecute(). La ragione di ciò, indicata da MetaDriver all'autore, è probabilmente la seguente: MetaDriver: Prima di leggere dal buffer, CLBufferRead() attende semplicemente il completamento effettivo del programma. CLExecute() è infatti una funzione di accodamento asincrona. Restituisce il risultato immediatamente, molto prima che l'operazione sul codice cl sia completata.
- Le guide al GPU Computing di solito non calcolano il runtime del kernel, ma piuttosto il throughput relativo a vari oggetti: memoria, aritmetica, ecc. Possiamo e faremo in seguito lo stesso.
Sappiamo che il calcolo di una matrice della dimensione di 2000 richiede circa 2 * 2000 addizioni/moltiplicazioni per ogni elemento. Moltiplicando per il numero degli elementi della matrice (2000 * 2000), troviamo che il numero totale di operazioni sui dati di tipo float è 16 miliardi. Detto questo, l'esecuzione sulla CPU richiede 115,628 sec, il che corrisponde a una velocità di streaming dei dati pari a
D'altra parte, ricorda che il calcolo più veloce finora su una "CPU single core" con la dimensione della matrice di 2000 ha richiesto solo 83.663 secondi per essere completato (vedi il nostro primo codice senza OpenCL). Quindi
Prendiamo questa figura come riferimento, punto di partenza per le nostre ottimizzazioni.
Allo stesso modo, il calcolo utilizzando OpenCL sulla CPU produce:
Infine, calcola il throughput sulla GPU:
2.3. Eliminazione degli accessi ai dati incoerenti
Guardando il codice del kernel, puoi facilmente notare alcune non ottimalità.
Dai un'occhiata al corpo del ciclo all'interno del kernel:
for( int cr = 0; cr < COLSROWS; cr ++ ) out[ r * COLS2 + c ] += in1[ r * COLSROWS + cr ] * in2[ cr * COLS2 + c ];
È facile vedere che quando il contatore del ciclo (cr++) è in esecuzione, i dati contigui vengono presi dal primo buffer in1[]. Mentre i dati dal secondo buffer in2[] sono presi con "gaps" pari a COLS2. In altre parole, la maggior parte dei dati prelevati dal secondo buffer sarà inutile in quanto le richieste di memoria saranno incoerenti (vedi 1.2.1. Coalescing Memory Requests). Per risolvere questa situazione è sufficiente modificare il codice in tre punti cambiando la formula per il calcolo dell'indice dell'array in2[], nonché il suo modello di generazione:
for( int cr = 0; cr < COLSROWS; cr ++ ) out[ r * COLS2 + c ] += in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ];Ora, quando i valori del contatore di loop (cr++) cambiano, i dati di entrambi gli array verranno presi in sequenza, senza "lacune".
- Codice di riempimento del buffer in genMatrices(). Ora deve essere compilato in ordine di colonna anziché in ordine di riga utilizzato all'inizio:
for( int r = 0; r < COLSROWS; r ++ ) for( int c = 0; c < COLS2; c ++ ) /// second[ r * COLS2 + c ] = genVal( ); second[ r + c * COLSROWS ] = genVal( );- Codice di verifica nella funzione checkRandom():
for( int runningIdx = 0; runningIdx < COLSROWS; runningIdx ++ ) ///sum += first[ r0 * COLSROWS + runningIdx ] * second[ runningIdx * COLS2 + c0 ]; sum += first[ r0 * COLSROWS + runningIdx ] * second[ runningIdx + c0 * COLSROWS ];Risultati delle prestazioni sulla CPU:
2012.05.24 02:59:22 matr_mul_1dim_coalesced (EURUSD,H1) CPUTime / GPUTotalTime = 16.207 2012.05.24 02:59:22 matr_mul_1dim_coalesced (EURUSD,H1) OpenCL total: time = 5.756 sec. 2012.05.24 02:59:22 matr_mul_1dim_coalesced (EURUSD,H1) read = 4000000 elements 2012.05.24 02:59:16 matr_mul_1dim_coalesced (EURUSD,H1) CPUTime = 93.289 2012.05.24 02:57:43 matr_mul_1dim_coalesced (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.24 02:57:43 matr_mul_1dim_coalesced (EURUSD,H1) =======================================Radeon HD 4870:
2012.05.27 01:50:43 matr_mul_1dim_coalesced (EURUSD,H1) CPUTime / GPUTotalTime = 7.176 2012.05.27 01:50:43 matr_mul_1dim_coalesced (EURUSD,H1) OpenCL total: time = 12.979 sec. 2012.05.27 01:50:43 matr_mul_1dim_coalesced (EURUSD,H1) read = 4000000 elements 2012.05.27 01:50:30 matr_mul_1dim_coalesced (EURUSD,H1) CPUTime = 93.133 2012.05.27 01:48:57 matr_mul_1dim_coalesced (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 01:48:57 matr_mul_1dim_coalesced (EURUSD,H1) =======================================
Come puoi vedere, l'accesso coerente ai dati non ha avuto quasi alcun effetto sul runtime della GPU; tuttavia, ha chiaramente migliorato l'autonomia della CPU. È molto probabile che abbia a che fare con fattori che verranno ottimizzati in seguito, in particolare con una latenza molto elevata di accesso alle variabili globali di cui dovremmo liberarci al più presto.
throughput_arithmetic_CPU_OCL = 16 000000000 / 5.756 ~ 2.780 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 12.979 ~ 1.233 GFlops.
Il nuovo codice del kernel può essere trovato in matr_mul_1dim_coalesced.mq5 alla fine dell'articolo.
Il codice del kernel è riportato di seguito:
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " int c = get_global_id( 1 ); \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " out[ r * COLS2 + c ] += \r\n" " in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ]; \r\n" "} \r\n";
Elenco 3. Kernel con accesso ai dati della memoria globale coalizzato
Passiamo ad ulteriori ottimizzazioni.
2.4. Rimozione dell'accesso alla memoria GPU globale "dispendioso" dalla matrice di output
È noto che la latenza dell'accesso alla memoria globale della GPU è estremamente elevata (circa 600-800 cicli). Ad esempio, la latenza dell'esecuzione di un'aggiunta di due numeri è di circa 20 cicli. L'obiettivo principale delle ottimizzazioni durante il calcolo sulla GPU è nascondere la latenza aumentando il throughput dei calcoli. Nel ciclo del kernel sviluppato in precedenza, accediamo costantemente a elementi di memoria globale che ci costano tempo.
Introduciamo ora nel kernel la variabile locale sum (a cui si accede molte volte più velocemente in quanto è una variabile privata del kernel situata nel registro dell'unità di lavoro) e al termine del ciclo assegniamo singolarmente il valore di somma ottenuto all’elemento dell'array di output:
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " int c = get_global_id( 1 ); \r\n" " REALTYPE sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " sum += in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ]; \r\n" " out[ r * COLS2 + c ] = sum; \r\n" "} \r\n" ;
Elenco 4. Presentazione della variabile privata per calcolare la somma cumulativa nel ciclo di calcolo del prodotto scalare
Il file del codice sorgente completo, matr_mul_sum_local.mq5, è allegato alla fine dell'articolo.
CPU:
2012.05.24 03:28:17 matr_mul_sum_local (EURUSD,H1) CPUTime / GPUTotalTime = 24.863 2012.05.24 03:28:16 matr_mul_sum_local (EURUSD,H1) OpenCL total: time = 3.759 sec. 2012.05.24 03:28:16 matr_mul_sum_local (EURUSD,H1) read = 4000000 elements 2012.05.24 03:28:12 matr_mul_sum_local (EURUSD,H1) CPUTime = 93.460 2012.05.24 03:26:39 matr_mul_sum_local (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000GPU HD 4870:
2012.05.27 01:57:30 matr_mul_sum_local (EURUSD,H1) CPUTime / GPUTotalTime = 69.541 2012.05.27 01:57:30 matr_mul_sum_local (EURUSD,H1) OpenCL total: time = 1.326 sec. 2012.05.27 01:57:30 matr_mul_sum_local (EURUSD,H1) read = 4000000 elements 2012.05.27 01:57:28 matr_mul_sum_local (EURUSD,H1) CPUTime = 92.212 2012.05.27 01:55:56 matr_mul_sum_local (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 01:55:56 matr_mul_sum_local (EURUSD,H1) =======================================Questo è un vero aumento della produttività!
throughput_arithmetic_CPU_OCL = 16 000000000 / 3.759 ~ 4.257 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 1.326 ~ 12.066 GFlops.
Il principio fondamentale che cerchiamo di rispettare nelle ottimizzazioni sequenziali è il seguente: è necessario prima riorganizzare la struttura dei dati nel modo più completo possibile, in modo che sia appropriata per un determinato compito e, in particolare, per l'hardware sottostante e solo dopo procedere alle ottimizzazioni fini utilizzando algoritmi di calcolo veloci, come mad() o fma(). Tieni presente che le ottimizzazioni sequenziali non sempre comportano necessariamente un aumento delle prestazioni - questo non può essere garantito.
2.5. Aumentare le operazioni eseguite dal kernel
Nella programmazione parallela, è importante organizzare i calcoli in modo da ridurre al minimo l'overhead (tempo impiegato) per l'organizzazione delle operazioni parallele. Nelle matrici con dimensione 2000, un'unità di lavoro che calcola un elemento della matrice di output esegue una quantità di lavoro pari a 1/4000000 del compito totale.
Questo è ovviamente troppo lontano dal numero effettivo di unità che eseguono calcoli sull'hardware. Ora, nella nuova versione del kernel, calcoleremo l'intera riga della matrice invece di un elemento.
È importante che lo spazio delle attività venga ora modificato da bidimensionale a unidimensionale poiché l'intera dimensione - l'intera riga, anziché un singolo elemento della matrice - viene ora calcolata in ogni attività del kernel. Pertanto, lo spazio delle attività si trasforma nel numero di righe della matrice.
Fig.14. Schema di calcolo dell'intera riga della matrice di output
Il codice del kernel diventa più complicato:
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE sum; \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " sum += in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ]; \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
Elenco 5. Il kernel per il calcolo dell'intera riga della matrice di output
void executeGPU( int clKrn ) { //--- set parameters of the task workspace and execute the OpenCL program uint offs[ 1 ] = { 0 }; uint works[ 1 ] = { ROWS1 }; bool ex = CLExecute( clKrn, 1, offs, works ); return; }
Risultati delle prestazioni (il codice sorgente completo può essere trovato in matr_mul_row_calc.mq5):
CPU:
2012.05.24 15:56:24 matr_mul_row_calc (EURUSD,H1) CPUTime / GPUTotalTime = 17.385 2012.05.24 15:56:24 matr_mul_row_calc (EURUSD,H1) OpenCL total: time = 5.366 sec. 2012.05.24 15:56:24 matr_mul_row_calc (EURUSD,H1) read = 4000000 elements 2012.05.24 15:56:19 matr_mul_row_calc (EURUSD,H1) CPUTime = 93.288 2012.05.24 15:54:45 matr_mul_row_calc (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.24 15:54:45 matr_mul_row_calc (EURUSD,H1) =======================================
GPU 4870:
2012.05.27 02:24:10 matr_mul_row_calc (EURUSD,H1) CPUTime / GPUTotalTime = 55.119 2012.05.27 02:24:10 matr_mul_row_calc (EURUSD,H1) OpenCL total: time = 1.669 sec. 2012.05.27 02:24:10 matr_mul_row_calc (EURUSD,H1) read = 4000000 elements 2012.05.27 02:24:08 matr_mul_row_calc (EURUSD,H1) CPUTime = 91.994 2012.05.27 02:22:35 matr_mul_row_calc (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 02:22:35 matr_mul_row_calc (EURUSD,H1) =======================================
Possiamo vedere che l'autonomia della CPU è nettamente peggiorata ed è peggiorata leggermente, anche se non di molto, sulla GPU. Non è tutto così male: questo cambiamento strategico che aggrava temporaneamente la situazione a livello locale è qui solo per aumentare ulteriormente e drasticamente le prestazioni.
throughput_arithmetic_CPU_OCL = 16 000000000 / 5.366 ~ 2.982 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 1.669 ~ 9.587 GFlops.
2.6. Trasferimento della riga del primo array nella memoria privata
La principale particolarità dell'algoritmo di moltiplicazione di matrici è un gran numero di moltiplicazioni con concomitante accumulo dei risultati. Un'ottimizzazione adeguata e di alta qualità di questo algoritmo deve implicare la minimizzazione dei trasferimenti di dati. Ma finora, nei calcoli all'interno del ciclo principale di accumulo del prodotto scalare, tutte le nostre modifiche al kernel hanno memorizzato due matrici su tre nella memoria globale.
Ciò significa che tutti i dati di input per ogni prodotto scalare (essendo di fatto ogni elemento della matrice di output) vengono costantemente trasmessi attraverso l'intera gerarchia di memoria, da globale a privata, con latenze associate. Questo traffico può essere ridotto assicurando che ogni unità di lavoro riutilizzi una e la stessa riga della prima matrice per ogni riga calcolata della matrice di output.
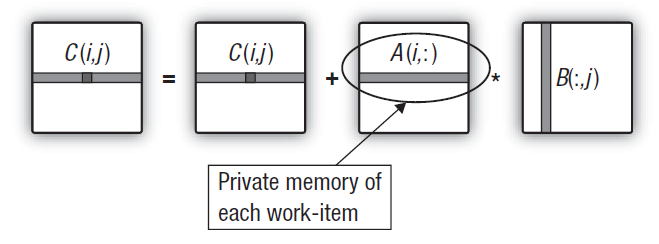
Fig.15. Trasferimento della riga della prima matrice nella memoria privata dell'unità di lavoro
Ciò non comporta alcuna modifica al codice del programma host. E i cambiamenti nel kernel sono minimi. A causa del fatto che un array privato unidimensionale intermedio viene generato all'interno del kernel, la GPU cerca di posizionarlo nella memoria privata dell'unità che esegue il kernel. La riga richiesta della prima matrice viene semplicemente copiata da global nella memoria privata. Detto questo, va notato che anche questa copia sarà relativamente veloce. Il trucco sta nel fatto che la copia più "dispendiosa" degli elementi riga del primo array dalla memoria globale in quella privata viene eseguita in modo coerente e l'overhead sulla copia è piuttosto modesto rispetto al tempo di esecuzione del doppio ciclo principale, il quale calcola la riga della matrice di output.
Il codice del kernel (il codice commentato nel ciclo principale è quello presente nella versione precedente):
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE rowbuf[ COLSROWS ]; \r\n" " for( int col = 0; col < COLSROWS; col ++ ) \r\n" " rowbuf[ col ] = in1[ r * COLSROWS + col ]; \r\n" " REALTYPE sum; \r\n" " \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " ///sum += in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ]; \r\n" " sum += rowbuf[ cr ] * in2[ cr + c * COLSROWS ]; \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
Elenco 6. Un kernel con la riga della prima matrice nella memoria privata dell'unità di lavoro.
CPU:2012.05.27 00:51:46 matr_mul_row_in_private (EURUSD,H1) CPUTime / GPUTotalTime = 18.587 2012.05.27 00:51:46 matr_mul_row_in_private (EURUSD,H1) OpenCL total: time = 4.961 sec. 2012.05.27 00:51:46 matr_mul_row_in_private (EURUSD,H1) read = 4000000 elements 2012.05.27 00:51:41 matr_mul_row_in_private (EURUSD,H1) CPUTime = 92.212 2012.05.27 00:50:08 matr_mul_row_in_private (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 00:50:08 matr_mul_row_in_private (EURUSD,H1) =======================================GPU:
2012.05.27 02:28:49 matr_mul_row_in_private (EURUSD,H1) CPUTime / GPUTotalTime = 69.242 2012.05.27 02:28:49 matr_mul_row_in_private (EURUSD,H1) OpenCL total: time = 1.327 sec. 2012.05.27 02:28:49 matr_mul_row_in_private (EURUSD,H1) read = 4000000 elements 2012.05.27 02:28:47 matr_mul_row_in_private (EURUSD,H1) CPUTime = 91.884 2012.05.27 02:27:15 matr_mul_row_in_private (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 02:27:15 matr_mul_row_in_private (EURUSD,H1) =======================================
throughput_arithmetic_CPU_OCL = 16 000000000 / 4.961 ~ 3.225 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 1.327 ~ 12.057 GFlops.
Il throughput della CPU è rimasto circa allo stesso livello dell'ultima volta, mentre il throughput della GPU è tornato al livello più alto raggiunto, ma nella nuova capacità. Da notare che il throughput della CPU è come se si fosse bloccato sul posto, essendo solo leggermente instabile, mentre il throughput della GPU aumenta (non sempre, però) con salti abbastanza ampi.
Segnaliamo che il throughput effettivo aritmetico deve essere un po' più alto in quanto, a causa della copia della riga della prima matrice nella memoria privata, vengono eseguite più operazioni rispetto a prima. Tuttavia, ha scarso effetto sulla stima del throughput finale.
Il codice sorgente può essere trovato in matr_mul_row_in_private.mq5.
2.7. Trasferimento della colonna del secondo array nella memoria locale
Ora è facile intuire quale sarà il prossimo passo. Abbiamo già provveduto a nascondere le latenze associate all'output e alle prime matrici di input. C'è ancora la seconda matrice.
Uno studio più attento dei prodotti scalari utilizzati nella moltiplicazione di matrici mostra che durante il calcolo della riga della matrice di output tutte le unità di lavoro nel gruppo ritrasmettono i dati dalle stesse colonne della seconda matrice moltiplicata attraverso il dispositivo. Ciò è illustrato nello schema seguente:
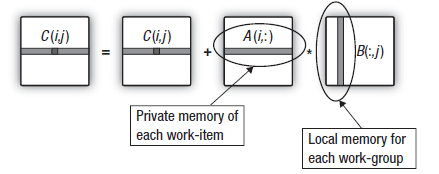
Fig.16. Trasferimento della colonna della seconda matrice al Local Data Share del gruppo di lavoro
L'overhead sul trasferimento dei dati dalla memoria globale può essere ridotto se le unità di lavoro che compongono il gruppo di lavoro copiano le colonne della seconda matrice nella memoria del gruppo di lavoro prima che inizi il calcolo delle righe della matrice di output.
Ciò richiederà modifiche da apportare nel kernel, così come nel programma host. Il cambiamento più importante è l'impostazione della memoria locale per ogni kernel. Deve essere esplicito poiché l'allocazione della memoria dinamica non è supportata in OpenCL. Pertanto, un oggetto di memoria di dimensioni adeguate deve essere prima posizionato nell'host per essere ulteriormente elaborato all'interno del kernel.
E solo allora, durante l'esecuzione del kernel, le unità di lavoro copiano la colonna della seconda matrice nella memoria locale. Questo viene fatto in parallelo utilizzando la distribuzione ciclica delle iterazioni del ciclo tra tutte le unità di lavoro del gruppo di lavoro. Tuttavia, tutte le copie devono essere completate prima che l'unità di lavoro inizi la sua operazione principale (calcolo della riga della matrice di output).
Ecco perché il seguente comando viene inserito dopo il ciclo incaricato di copiare:
barrier(CLK_LOCAL_MEM_FENCE);
Questa è una "barriera di memoria locale" che garantisce che ogni unità di lavoro all'interno del gruppo possa "vedere" la memoria locale in un certo stato coordinato con altre unità. Tutte le unità di lavoro nel gruppo di lavoro devono eseguire comandi fino alla barriera, prima che qualcuno di loro possa procedere con l'esecuzione del kernel. In altre parole, la barriera è uno speciale meccanismo di sincronizzazione tra le unità di lavoro all'interno del gruppo di lavoro.
In OpenCL non sono previsti meccanismi di sincronizzazione tra gruppi di lavoro.
Di seguito, l'illustrazione della barriera in azione:

Fig.17. Illustrazione della barriera in azione
In effetti, sembra solo che le unità di lavoro all'interno del gruppo di lavoro eseguano il codice rigorosamente contemporaneamente. Questa è semplicemente un'astrazione del modello di programmazione OpenCL.
Finora, i nostri codici del kernel eseguiti su diverse unità di lavoro non hanno richiesto la sincronizzazione delle operazioni, in quanto non vi era alcuna comunicazione esplicita tra di loro che sarebbe stata impostata a livello di codice nel kernel; inoltre, non era nemmeno necessario. Tuttavia, in questo kernel è necessaria la sincronizzazione poiché il processo di riempimento dell'array locale è distribuito in parallelo tra tutte le unità del gruppo di lavoro.
In altre parole, ogni unità di lavoro scrive i propri valori nella condivisione dati locale (qui, l'array) senza sapere a che punto si trovano le altre unità di lavoro in questo processo di scrittura. La barriera esiste affinché una certa unità di lavoro non proceda all'esecuzione del kernel prima che sia necessario, cioè prima che un array locale sia stato completamente generato.
Devi capire che questa ottimizzazione difficilmente sarà vantaggiosa per le prestazioni della CPU: La Guida all'ottimizzazione OpenCL di Intel afferma che quando si esegue un kernel sulla CPU, tutti gli oggetti di memoria OpenCL vengono memorizzati nella cache dall'hardware, quindi la memorizzazione nella cache esplicita mediante l'uso della memoria locale introduce solo un sovraccarico (moderato) non necessario.
C'è un altro punto importante che vale la pena notare qui e che è costato molto tempo all'autore dell'articolo. Ha a che fare con il fatto che una variabile locale non può essere passata nell'intestazione della funzione del kernel, cioè in fase di compilazione, nell'attuale implementazione costruita dagli sviluppatori del terminale. Il motivo è che per allocare memoria a un oggetto di memoria come argomento della funzione del kernel, dovremmo prima creare esplicitamente tale oggetto nella memoria della CPU utilizzando la funzione CLBufferCreate() e specificarne esplicitamente la dimensione come parametro di funzione. Questa funzione restituisce un handle di oggetto di memoria che verrà ulteriormente archiviato nella memoria GPU globale poiché questo è l'unico posto in cui può stare.
La memoria locale, invece, è la memoria diversa da quella globale e, di conseguenza, un oggetto di memoria creato non può essere collocato nella memoria locale del gruppo di lavoro.
L'API OpenCL completa consente di assegnare esplicitamente la memoria della dimensione richiesta con il puntatore NULL all'argomento del kernel, anche senza creare l'oggetto memoria in quanto tale (funzione CLSetKernelArg()). Tuttavia, la sintassi della funzione CLSetKernelArgMem(), essendo l'analogo MQL5 della funzione API completa, non ci consente di passare in essa la dimensione della memoria allocata all'argomento senza creare l'oggetto memoria stesso. Quello che possiamo passare alla funzione CLSetKernelArgMem() è solo l'handle del buffer già generato nella memoria globale della CPU e destinato al trasferimento nella memoria globale della GPU. Ecco il paradosso.
Fortunatamente, esiste un modo equivalente di lavorare con i buffer locali nel kernel. Dichiari semplicemente tale buffer con il modificatore __local nel corpo del kernel. La memoria locale allocata al gruppo di lavoro verrà così determinata in fase di Runtime anziché in fase di compilazione.
I comandi che vengono dopo la barriera nel kernel (la linea della barriera nel codice è contrassegnata in rosso) sono, in sostanza, gli stessi dell'ottimizzazione precedente. Il codice del programma host è rimasto lo stesso (il codice sorgente può essere trovato in matr_mul_col_local.mq5).
Quindi, ecco il nuovo codice del kernel:
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE rowbuf[ COLSROWS ]; \r\n" " for( int col = 0; col < COLSROWS; col ++ ) \r\n" " rowbuf[ col ] = in1[ r * COLSROWS + col ]; \r\n" " \r\n" " int idlocal = get_local_id( 0 ); \r\n" " int nlocal = get_local_size( 0 ); \r\n" " __local REALTYPE colbuf[ COLSROWS ] ; \r\n" " \r\n" " REALTYPE sum; \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " for( int cr = idlocal; cr < COLSROWS; cr = cr + nlocal ) \r\n" " colbuf[ cr ] = in2[ cr + c * COLSROWS ]; \r\n" " barrier( CLK_LOCAL_MEM_FENCE ); \r\n" " \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " sum += rowbuf[ cr ] * colbuf[ cr ]; \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
Elenco 7. La colonna del secondo array trasferita nella memoria locale del gruppo di lavoro
2012.05.27 06:31:46 matr_mul_col_local (EURUSD,H1) CPUTime / GPUTotalTime = 17.630 2012.05.27 06:31:46 matr_mul_col_local (EURUSD,H1) OpenCL total: time = 5.227 sec. 2012.05.27 06:31:46 matr_mul_col_local (EURUSD,H1) read = 4000000 elements 2012.05.27 06:31:40 matr_mul_col_local (EURUSD,H1) CPUTime = 92.150 2012.05.27 06:30:08 matr_mul_col_local (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 06:30:08 matr_mul_col_local (EURUSD,H1) =======================================GPU:
2012.05.27 06:21:36 matr_mul_col_local (EURUSD,H1) CPUTime / GPUTotalTime = 58.069 2012.05.27 06:21:36 matr_mul_col_local (EURUSD,H1) OpenCL total: time = 1.592 sec. 2012.05.27 06:21:36 matr_mul_col_local (EURUSD,H1) read = 4000000 elements 2012.05.27 06:21:34 matr_mul_col_local (EURUSD,H1) CPUTime = 92.446 2012.05.27 06:20:01 matr_mul_col_local (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 06:20:01 matr_mul_col_local (EURUSD,H1) =======================================
Entrambi i casi mostrano un degrado delle prestazioni che tuttavia non può essere definito significativo. Può darsi che le prestazioni possano essere migliorate anziché degradate modificando le dimensioni del gruppo di lavoro. L'esempio precedente servirebbe piuttosto a uno scopo diverso: mostrare come utilizzare gli oggetti di memoria locale.
C'è un'ipotesi che spiega una diminuzione delle prestazioni quando viene utilizzata la memoria locale. L'articolo Confronto tra OpenCL e CUDA, GLSL e OpenMP (in russo) pubblicato su habrahabr.ru circa 2 anni fa dice:
In altre parole, significa che la memoria locale dei prodotti rilasciati 2 anni fa non è più veloce della memoria globale? Il momento in cui è stato pubblicato quanto sopra suggerisce che due anni fa le schede video della serie Radeon HD 58xx erano già state rilasciate, ma la situazione, secondo l'autore, era tutt'altro che ottimistica. Lo trovo difficile da credere, soprattutto considerando la sensazionale serie Evergreen di AMD. Sarebbe interessante verificarlo utilizzando schede più moderne, ad esempio la serie HD 69xx.
Aggiunta: avvia GPU Caps Viewer e vedrai quanto segue nella scheda OpenCL:

Fig.18. Principali parametri OpenCL supportati da HD 4870
CL_DEVICE_LOCAL_MEM_TYPE: Globale
La spiegazione di questo parametro fornita nella Specifica del linguaggio (Tabella 4.3, p. 41) è la seguente:
Tipo di memoria locale supportata. Questo può essere impostato su CL_LOCAL implicando un'archiviazione di memoria locale dedicata come SRAM o CL_GLOBAL.
Pertanto, la memoria locale dell'HD 4870 è in realtà una parte della memoria globale e qualsiasi manipolazione della memoria locale in questa scheda video è quindi inutile e non si tradurrà in qualcosa di più veloce della memoria globale. Ecco un altro link dove uno specialista AMD chiarisce questo punto per la serie HD 4xxx. Non significa necessariamente che sarà altrettanto dannoso per la scheda video che hai; era solo per mostrare dove si possono trovare tali informazioni riguardanti l'hardware. In questo caso, nel GPU Caps Viewer.
throughput_arithmetic_CPU_OCL = 16 000000000 / 5.227 ~ 3.061 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 1.592 ~ 10.050 GFlops.
Infine, aggiungiamo alcuni ritocchi finali vettorizzando esplicitamente il kernel. Il kernel derivato nella fase di trasferimento della riga del primo array nella memoria privata (matr_mul_row_in_private.mq5) fungerà da kernel iniziale poiché è sembrato essere il più veloce.
2.8. Vettorizzazione del kernel
Questa operazione deve essere suddivisa in più fasi, per evitare confusione. Nella modifica iniziale, non cambiamo i tipi di dati dei parametri esterni del kernel e vettorializziamo solo i calcoli nel ciclo interno:
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" "#define REALTYPE4 float4 \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE rowbuf[ COLSROWS ]; \r\n" " for( int col = 0; col < COLSROWS; col ++ ) \r\n" " { \r\n" " rowbuf[ col ] = in1[r * COLSROWS + col ]; \r\n" " } \r\n" " \r\n" " REALTYPE sum; \r\n" " \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr += 4 ) \r\n" " sum += dot( ( REALTYPE4 ) ( rowbuf[ cr ], \r\n" " rowbuf[ cr + 1 ], \r\n" " rowbuf[ cr + 2 ], \r\n" " rowbuf[ cr + 3 ] ), \r\n" " ( REALTYPE4 ) ( in2[c * COLSROWS + cr ], \r\n" " in2[c * COLSROWS + cr + 1 ], \r\n" " in2[c * COLSROWS + cr + 2 ], \r\n" " in2[c * COLSROWS + cr + 3 ] ) ); \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
Elenco 8. Vettorizzazione parziale del kernel tramite float4 (solo ciclo interno)
CPU:
2012.05.27 21:28:16 matr_mul_vect (EURUSD,H1) CPUTime / GPUTotalTime = 18.657 2012.05.27 21:28:16 matr_mul_vect (EURUSD,H1) OpenCL total: time = 4.945 sec. 2012.05.27 21:28:16 matr_mul_vect (EURUSD,H1) read = 4000000 elements 2012.05.27 21:28:11 matr_mul_vect (EURUSD,H1) CPUTime = 92.259 2012.05.27 21:26:38 matr_mul_vect (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 21:26:38 matr_mul_vect (EURUSD,H1) =======================================
GPU:
2012.05.27 21:21:30 matr_mul_vect (EURUSD,H1) CPUTime / GPUTotalTime = 78.079 2012.05.27 21:21:30 matr_mul_vect (EURUSD,H1) OpenCL total: time = 1.186 sec. 2012.05.27 21:21:30 matr_mul_vect (EURUSD,H1) read = 4000000 elements 2012.05.27 21:21:28 matr_mul_vect (EURUSD,H1) CPUTime = 92.602 2012.05.27 21:19:55 matr_mul_vect (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 21:19:55 matr_mul_vect (EURUSD,H1) =======================================
Sorprendentemente, anche una vettorizzazione così primitiva ha prodotto buoni risultati sulla GPU; anche se non molto significativo, il guadagno è apparso di circa il 10%.
Continua a vettorizzare all'interno del kernel: trasferisci le operazioni "dispendiose" di conversione del tipo vettoriale REALTYPE4 insieme alla specifica dei componenti vettoriali espliciti al ciclo ausiliario esterno che riempie la variabile privata rowbuf[]. Non ci sono ancora cambiamenti nel kernel.
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" "#define REALTYPE4 float4 \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE4 rowbuf[ COLSROWS / 4 ]; \r\n" " for( int col = 0; col < COLSROWS / 4; col ++ ) \r\n" " { \r\n" " rowbuf[ col ] = ( REALTYPE4 ) ( in1[r * COLSROWS + 4 * col ], \r\n" " in1[r * COLSROWS + 4 * col + 1 ], \r\n" " in1[r * COLSROWS + 4 * col + 2 ], \r\n" " in1[r * COLSROWS + 4 * col + 3 ] ); \r\n" " } \r\n" " \r\n" " REALTYPE sum; \r\n" " \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS / 4; cr ++ ) \r\n" " sum += dot( rowbuf[ cr ], \r\n" " ( REALTYPE4 ) ( in2[c * COLSROWS + 4 * cr ], \r\n" " in2[c * COLSROWS + 4 * cr + 1 ], \r\n" " in2[c * COLSROWS + 4 * cr + 2 ], \r\n" " in2[c * COLSROWS + 4 * cr + 3 ] ) ); \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
Elenco 9. Sbarazzarsi di operazioni "dispendiose" di tipo conversione nel ciclo principale del kernel
Da notare che il valore di conteggio massimo del contatore del ciclo interno (oltre che ausiliario) è diventato 4 volte inferiore poiché le operazioni di lettura che ora sono richieste per il primo array sono 4 volte inferiori rispetto a prima: la lettura è chiaramente diventata un'operazione vettoriale.
2012.05.27 22:41:43 matr_mul_vect_v2 (EURUSD,H1) CPUTime / GPUTotalTime = 24.480 2012.05.27 22:41:43 matr_mul_vect_v2 (EURUSD,H1) OpenCL total: time = 3.791 sec. 2012.05.27 22:41:43 matr_mul_vect_v2 (EURUSD,H1) read = 4000000 elements 2012.05.27 22:41:39 matr_mul_vect_v2 (EURUSD,H1) CPUTime = 92.805 2012.05.27 22:40:06 matr_mul_vect_v2 (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 22:40:06 matr_mul_vect_v2 (EURUSD,H1) =======================================GPU:
2012.05.27 22:35:28 matr_mul_vect_v2 (EURUSD,H1) CPUTime / GPUTotalTime = 185.605 2012.05.27 22:35:28 matr_mul_vect_v2 (EURUSD,H1) OpenCL total: time = 0.499 sec. 2012.05.27 22:35:28 matr_mul_vect_v2 (EURUSD,H1) read = 4000000 elements 2012.05.27 22:35:27 matr_mul_vect_v2 (EURUSD,H1) CPUTime = 92.617 2012.05.27 22:33:54 matr_mul_vect_v2 (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 22:33:54 matr_mul_vect_v2 (EURUSD,H1) =======================================Rendimento aritmetico:
throughput_arithmetic_CPU_OCL = 16 000000000 / 3.791 ~ 4.221 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 0.499 ~ 32.064 GFlops.
Come si può vedere, i cambiamenti nelle prestazioni per la CPU sono notevoli, pur essendo quasi rivoluzionari per la GPU. Il codice sorgente può essere trovato in matr_mul_vect_v2.mq5.
Eseguiamo le stesse operazioni rispetto all'ultima variante del kernel, utilizzando solo la larghezza del vettore di 8. La decisione dell'autore può essere spiegata dal fatto che la larghezza di banda della memoria della GPU è di 256 bit, cioè 32 byte o 8 numeri di tipo float; quindi, l'elaborazione simultanea di 8 float, che equivale all'uso simultaneo di float8, appare del tutto naturale.
Tieni presente che, in questo caso, il valore di COLSROWS deve essere integralmente divisibile per 8. Questo è un requisito naturale in quanto ottimizzazioni più precise impostano requisiti più specifici per i dati.
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" "#define REALTYPE4 float4 \r\n" "#define REALTYPE8 float8 \r\n" " \r\n" "inline REALTYPE dot8( REALTYPE8 a, REALTYPE8 b ) \r\n" "{ \r\n" " REALTYPE8 c = a * b; \r\n" " REALTYPE4 _1 = ( REALTYPE4 ) 1.; \r\n" " return( dot( c.lo + c.hi, _1 ) ); \r\n" "} \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE8 rowbuf[ COLSROWS / 8 ]; \r\n" " for( int col = 0; col < COLSROWS / 8; col ++ ) \r\n" " { \r\n" " rowbuf[ col ] = ( REALTYPE8 ) ( in1[r * COLSROWS + 8 * col ], \r\n" " in1[r * COLSROWS + 8 * col + 1 ], \r\n" " in1[r * COLSROWS + 8 * col + 2 ], \r\n" " in1[r * COLSROWS + 8 * col + 3 ], \r\n" " in1[r * COLSROWS + 8 * col + 4 ], \r\n" " in1[r * COLSROWS + 8 * col + 5 ], \r\n" " in1[r * COLSROWS + 8 * col + 6 ], \r\n" " in1[r * COLSROWS + 8 * col + 7 ] ); \r\n" " } \r\n" " \r\n" " REALTYPE sum; \r\n" " \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS / 8; cr ++ ) \r\n" " sum += dot8( rowbuf[ cr ], \r\n" " ( REALTYPE8 ) ( in2[c * COLSROWS + 8 * cr ], \r\n" " in2[c * COLSROWS + 8 * cr + 1 ], \r\n" " in2[c * COLSROWS + 8 * cr + 2 ], \r\n" " in2[c * COLSROWS + 8 * cr + 3 ], \r\n" " in2[c * COLSROWS + 8 * cr + 4 ], \r\n" " in2[c * COLSROWS + 8 * cr + 5 ], \r\n" " in2[c * COLSROWS + 8 * cr + 6 ], \r\n" " in2[c * COLSROWS + 8 * cr + 7 ] ) ); \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
Elenco 10. Vettorizzazione del kernel utilizzando la larghezza del vettore di 8
Abbiamo dovuto inserire nel codice del kernel la funzione inline dot8(), la quale permette di calcolare il prodotto scalare per vettori con larghezza 8. In OpenCL, la funzione standard dot() può calcolare il prodotto scalare solo per vettori fino a larghezza 4. Il codice sorgente può essere trovato in matr_mul_vect_v3.mq5.
2012.05.27 23:11:47 matr_mul_vect_v3 (EURUSD,H1) CPUTime / GPUTotalTime = 45.226 2012.05.27 23:11:47 matr_mul_vect_v3 (EURUSD,H1) OpenCL total: time = 2.200 sec. 2012.05.27 23:11:47 matr_mul_vect_v3 (EURUSD,H1) read = 4000000 elements 2012.05.27 23:11:45 matr_mul_vect_v3 (EURUSD,H1) CPUTime = 99.497 2012.05.27 23:10:05 matr_mul_vect_v3 (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 23:10:05 matr_mul_vect_v3 (EURUSD,H1) =======================================GPU:
2012.05.27 23:20:05 matr_mul_vect_v3 (EURUSD,H1) CPUTime / GPUTotalTime = 170.115 2012.05.27 23:20:05 matr_mul_vect_v3 (EURUSD,H1) OpenCL total: time = 0.546 sec. 2012.05.27 23:20:05 matr_mul_vect_v3 (EURUSD,H1) read = 4000000 elements 2012.05.27 23:20:04 matr_mul_vect_v3 (EURUSD,H1) CPUTime = 92.883 2012.05.27 23:18:31 matr_mul_vect_v3 (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 23:18:31 matr_mul_vect_v3 (EURUSD,H1) =======================================
I risultati sono inaspettati: l'autonomia della CPU è quasi il doppio rispetto a prima, mentre è leggermente aumentata per la GPU, nonostante float8 sia una larghezza di bus adeguata per HD 4870 (pari a 256 bit). E qui ricorriamo di nuovo a GPU Caps Viewer.
La spiegazione può essere trovata nella Fig.18, nella penultima riga dell'elenco dei parametri:
CL_DEVICE_PREFERRED_VECTOR_WIDTH_FLOAT: 4
Consulta le specifiche OpenCL e vedrai il testo seguente, relativo a questo parametro, nell'ultima colonna della Tabella 4.3 a pagina 37:
Dimensione della larghezza del vettore nativa preferita per i tipi scalari incorporati che possono essere inseriti nei vettori. La larghezza del vettore è definita come il numero di elementi scalari che possono essere memorizzati nel vettore.
Pertanto, per HD 4870, la larghezza del vettore preferita del vettore floatN è float4 invece di float8.
Concludiamo qui il ciclo di ottimizzazione del kernel. Potremmo andare avanti per ottenere molto di più, ma la lunghezza di questo articolo non consente una tale profondità di discussione.
Conclusione
L'articolo ha dimostrato alcune capacità di ottimizzazione che si aprono quando si tiene conto almeno dell'hardware sottostante su cui viene eseguito il kernel.
Le cifre ottenute sono lungi dall'essere valori limite, ma anche loro suggeriscono che avere le risorse esistenti disponibili qui e ora (l'API OpenCL implementata dagli sviluppatori del terminale non consente di controllare alcuni parametri importanti per l'ottimizzazione - - in particolare, il gruppo di lavoro dimensioni), il guadagno di prestazioni rispetto all'esecuzione del programma host è molto consistente: il guadagno in esecuzione sulla GPU rispetto al programma sequenziale sulla CPU (sebbene non molto ottimizzato) è di circa 200:1.
La mia sincera gratitudine va a MetaDriver per i preziosi consigli e l'opportunità di utilizzare la GPU discreta mentre la mia non era disponibile.
Contenuto dei file allegati:
- matr_mul_2dim.mq5 - il programma sequenziale iniziale sull'host con rappresentazione dei dati bidimensionali;
- matr_mul_1dim.mq5 - la prima implementazione del kernel con rappresentazione lineare dei dati e relativo binding per l'API MQL5 OpenCL;
- matr_mul_1dim_coalesced - il kernel con accesso globale alla memoria coalescente;
- matr_mul_sum_local - una variabile privata introdotta per il calcolo del prodotto scalare, invece di accedere a una cella calcolata dell'array di output memorizzato nella memoria globale;
- matr_mul_row_calc - il calcolo dell'intera riga di array di output nel kernel;
- matr_mul_row_in_private - la riga del primo array trasferito nella memoria privata;
- matr_mul_col_local.mq5 -la colonna del secondo array trasferita nella memoria locale;
- matr_mul_vect.mq5 - la prima vettorizzazione del kernel (usando float4, solo subloop interno del ciclo principale);
- matr_mul_vect_v2.mq5 - sbarazzarsi di operazioni "costose" di conversione dei dati nel ciclo principale;
- matr_mul_vect_v3.mq5 - vettorizzazione utilizzando la larghezza del vettore di 8.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/407
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

 Programmazione basata su automi come nuovo approccio alla creazione di sistemi di trading automatizzati
Programmazione basata su automi come nuovo approccio alla creazione di sistemi di trading automatizzati
 I membri più attivi della MQL5.community hanno ricevuto un iPhone!
I membri più attivi della MQL5.community hanno ricevuto un iPhone!
 Perché il Market di MQL5 è il posto migliore per la vendita di strategie di trading e indicatori tecnici
Perché il Market di MQL5 è il posto migliore per la vendita di strategie di trading e indicatori tecnici
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
È necessario sincronizzare anche le quotazioni?
P.S. Ho letto la guida, vedo che è necessario.
Ho ricalcolato i risultati dell'articolo tenendo conto dell'aggiornamento hardware.
Un anno fa: CPU Intel Pentium G840 (2 core @ 2,8 GHz) + scheda video AMD HD4870.
Recentemente: CPU Intel Xeon E3-1230v2 (4 core/8 thread @ 3,3 GHz; leggermente inferiore all'i7-3770) + scheda video AMD HD.6 870.
I risultati dei calcoli in OpenCL sono mostrati nel grafico (in orizzontale - il numero di ottimizzazioni applicate nell'articolo):
Il tempo di calcolo è mostrato verticalmente in secondi. Il tempo di esecuzione dello script "in un colpo solo sulla CPU" (su un core, senza OpenCL) variava a seconda delle modifiche dell'algoritmo entro 95 più o meno 25 secondi.
Come possiamo vedere, tutto sembra chiaro, ma ancora non molto evidente.
L'ovvio outsider è il G840 dual-core. Beh, c'era da aspettarselo. Ulteriori ottimizzazioni non hanno modificato troppo il tempo di esecuzione, che è variato da 4 a 5,5 secondi. Si noti che anche in questo caso l'accelerazione dell'esecuzione degli script ha raggiunto valori superiori a 20 volte.
Nella competizione tra due schede video di generazioni diverse - la vecchia HD4870 e la più moderna HD6870 - possiamo quasi considerare la 6870 come la vincitrice. Tranne che nell'ultima fase di ottimizzazione, dove il mostro antico 4870 ha comunque strappato una vittoria nominale (anche se è rimasto indietro per quasi tutto il tempo). I motivi, francamente, non sono chiari: gli shader sono più piccoli e la loro frequenza è inferiore, ma ha comunque vinto.
Supponiamo che si tratti dei capricci dello sviluppo delle generazioni di schede video. O di un errore nel mio algoritmo :)
Sono stato francamente soddisfatto dello Xeon, che è riuscito a essere migliore dell'antica 4870 con tutte le ottimizzazioni, e ha combattuto con la 6870 quasi alla pari, e alla fine è riuscito persino a batterli tutti. Non sto dicendo che sarà sempre così per qualsiasi compito. Ma il compito era computazionalmente molto difficile: dopo tutto, si trattava della moltiplicazione di due matrici di dimensioni 2000 x 2000!
La conclusione è semplice: se si dispone già di una CPU decente come l'i7, e le computazioni OpenCL non sono troppo lunghe, allora forse non è necessario un riscaldatore potente aggiuntivo (scheda video). D'altra parte, caricare la pietra al 100% per decine di secondi (durante i calcoli lunghi) non è molto piacevole, perché il computer "perde reattività" per questo tempo.
Ciao a tutti,
Puoi fornire un esempio di come OpenCL possa accelerare il backtesting di un EA in modalità EveryTick? Attualmente mi ci vogliono 18 minuti per eseguire 14 anni di dati in modalità EveryTick. Credo che molti trader saranno interessati se OpenCL può ridurre il tempo di test del 50%.
Ottimo articolo, ma non ho capito come lo spostamento del trasferimento della riga dall'interno del ciclo all'esterno della memoria privata lo velocizzi.
La stessa operazione di trasferimento avviene comunque, ho un impatto nullo sul mio codice ma ovviamente ogni caso è diverso. (ma d'altra parte 0 impatto dopo l'aggiunta di qualcosa significa che qualcosa si è velocizzato ma senza alcun guadagno).
Questa parte è nel sorgente OpenCL:
Dove si sposta al di fuori del ciclo di crunch
Grazie