
OpenCL: 기본에서 통찰력 있는 프로그래밍으로 향하여

개요
첫 번째 기사 "OpenCL: 병렬 세계로의 다리" 는 OpenCL에 대한 소개였습니다. 또한 OpenCL(아주 정확하지는 않지많 커널이라고도 합니다.)의 프로그램과 MQL5의 외부(호스트) 프로그램 간의 기본적인 상호 작용 문제를 다루었습니다. 일부 언어 성능 능력(예: 벡터 데이터 유형 사용)은 pi = 3.14159265의 계산으로 예시되었습니다...
프로그램 성능 최적화는 경우에 따라 상당한 수준이었습니다. 그러나 이러한 모든 최적화는 당사의 모든 계산을 수행하는 데 사용된 하드웨어 사양을 고려하지 않았기 때문에 순진한 것이었습니다. 대부분의 경우 이러한 사양에 대한 지식을 통해 CPU의 기능을 훨씬 뛰어넘는 속도 향상을 의도적으로 달성할 수 있습니다.
이러한 최적화를 입증하기 위해 저자는 OpenCL 관련 문헌에서 가장 철저하게 연구한 사례 중 하나인 더 이상 독창적이지 않은 사례를 사용해야 했습니다. 이것은 두 개의 큰 행렬의 곱입니다.
먼저 OpenCL 메모리 모델과 실제 하드웨어 아키텍처 구현의 특징부터 살펴보겠습니다.
1. 최신 컴퓨팅 장치의 메모리 계층
1.1. The OpenCL 메모리 모델
일반적으로, 메모리 시스템은 컴퓨터 플랫폼에 따라 서로 큰 차이가 납니다. 예를 들어, GPU와는 달리 현대의 모든 CPU는 자동 데이터 캐슁을 지원합니다.
코드 이식성을 보장하기 위해 OpenCL에서는 프로그래머뿐만 아니라 실제 하드웨어에서 이 모델을 구현해야 하는 공급업체도 사용할 수 있는 추상 메모리 모델이 채택됩니다. OpenCL에 정의된 메모리는 아래 그림에서 개념적으로 설명할 수 있습니다.

그림 1. The OpenCL 메모리 모델
데이터가 호스트에서 장치로 전송되면 글로벌 장치 메모리에 저장됩니다. 반대 방향으로 전송된 모든 데이터는 글로벌 메모리에도 저장됩니다(그러나 이번에는 글로벌 호스트 메모리에 저장됨). keyword __global (밑줄 두 개!)은 특정 포인터와 관련된 데이터가 글로벌 메모리에 저장되었음을 나타내는 수식어입니다:
__kernel void foo( __global float *A ) { /// kernel code }
Global memory는 호스트 시스템의 RAM과 같은 디바이스 내의 모든 컴퓨팅 유닛에서 액세스할 수 있습니다.
이름과 달리 상수 메모리에는 읽기 전용 데이터가 저장되지 않습니다. 이 메모리 유형은 모든작업 유닛에서 각 요소에 동시에 액세스할 수 있는 데이터를 위해 설계되었습니다. 상수 값을 갖는 변수도 이 범주에 속합니다. OpenCL 모델의 상수 메모리는 글로벌 메모리의 일부이므로 글로벌 메모리로 전송되는 메모리 개체를 __constant로 지정할 수 있습니다.
로컬 메모리는 주소 공간이 장치마다 고유한 스크래치패드 메모리입니다. 하드웨어에서는 종종 온칩 메모리 형태로 제공되지만 OpenCL과 정확히 동일해야 하는 특별한 요구사항은 없습니다.
이러한 유형의 메모리에 액세스하면 대기 시간이 훨씬 짧아지므로 메모리 대역폭이 글로벌 메모리보다 훨씬 큽니다. 커널 성능 최적화를 위해 지연 시간이 짧은 점을 활용하겠습니다.
OpenCL 규격에 따르면 로컬 메모리의 변수는 커널 헤더에서 모두 선언될 수 있습니다.
__kernel void foo( __local float *sharedData ) { }그자체에서도 그렇습니다:
__kernel void foo( __global float *A ) { __local float sharedData[ 64 ]; }동적 배열은 커널 본문에 선언할 수 없습니다; 항상 크기를 지정해야 합니다.
아래에서는 두 개의 큰 행렬의 곱셈에 대한 커널 최적화에서 로컬 데이터를 처리하는 방법과 작성자가 경험한 MetaTrader 5에서 수반하는 구현 특성을 볼 수 있습니다.
포인터를 포함하지 않는 로컬 변수 및 커널 인수는 기본적으로 전용입니다 (__local 한정자 없이 지정된 경우). 실제로 이러한 변수는 일반적으로 레지스터에 위치합니다. 그 반대로, 프라이빗 어레이와 유출된 레지스터는 대개 오프칩 메모리(예: 대기 시간이 긴 메모리)에 위치합니다. 위키백과의 관련 정보를 인용하겠습니다.
많은 프로그래밍 언어에서 프로그래머는 임의로 많은 변수를 할당하는 착각을 가지고 있습니다. 그러나 컴파일하는 동안 컴파일러는 이러한 변수를 작고 유한한 레지스터 집합에 할당하는 방법을 결정해야 합니다. 일부 변수는 동시에 사용 중(또는 라이브)이 아니므로 일부 레지스터는 둘 이상의 변수에 할당될 수 있습니다. 그러나 동시에 사용 중인 두 변수를 동일한 레지스터에 할당하면 해당 값이 손상됩니다.
일부 레지스터에 할당할 수 없는 변수는 RAM에 보관하고 모든 읽기/쓰기(stread/write)에 대해 로드해야 합니다(spilling이라는 프로세스). RAM에 액세스하는 것은 레지스터에 액세스하는 것보다 훨씬 느리고 컴파일된 프로그램의 실행 속도도 느리기 때문에 최적화 컴파일러는 가능한 한 많은 변수를 레지스터에 할당하는 것을 목표로 합니다. 레지스터 압력은 사용 가능한 하드웨어 레지스터 수가 최적 수준보다 적을 때 사용하는 용어입니다. 압력이 높을수록 더 많은 유출이 있고 리로드가 필요합니다.
설명된 OpenCL 메모리 모델은 최신 GPU의 메모리 구조와 매우 유사합니다. 아래 그림은 OpenCL 메모리 모델과 GPU AMD Radeon HD 6970 메모리 모델 간의 상관 관계를 보여줍니다.

그림. 2. Radeon HD 6970 메모리 구조와 추상 OpenCL 메모리 모델 간의 상관 관계
특정 GPU 메모리 구현과 관련된 문제에 대해 좀 더 자세히 고려해 보겠습니다.
1.2. 최신 이산 GPU의 메모리
1.2.1. 메모리 요청 병합
이 정보는 높은 메모리 대역폭을 달성하는 것이 주요 목표이므로 커널 성능 최적화에도 중요합니다.
메모리 주소 지정 프로세스를 더 잘 이해하려면 아래 그림을 참조하십시오.

그림 3. 글로벌 장치 메모리의 데이터 주소 지정 체계
int 정수 변수 배열에 대한 포인터가 X = 0x00001232의 주소라고 가정합니다. 모든 int는 4바이트의 메모리를 소모합니다. thread(커널 코드를 실행하는 작업 단위의 소프트웨어 아날로그)가 Х[ 0 ]에서 데이터를 처리한다고 가정합니다.
int tmp = X[ 0 ];
메모리 버스 폭은 32바이트(256비트)라고 가정합니다. 이 버스 폭은 Radeon HD 5870과 같은 강력한 GPU의 전형적인 형태입니다. 일부 다른 GPU에서는 데이터 버스 폭이 다를 수 있습니다(예: 384비트 또는 일부 NVidia 모델의 경우 512).
메모리 버스의 주소 지정은 구조, 즉 가장 먼저 폭과 일치해야 합니다. 즉, 메모리에 있는 데이터는 각각 32바이트(256비트)의 블록에 저장됩니다. 0x00001220에서 0x0000123F 사이의 범위 내에서 어떤 주소를 사용하든 상관없이(이 범위에는 정확히 32바이트가 있으므로 직접 확인할 수 있음), 읽기의 시작 주소로 주소 0x00001220을 계속 사용할 수 있습니다.
주소 0x00001232에 액세스하면 0x00001220 ~ 0x00123F 범위의 주소(즉, 8인치 숫자)에 있는 모든 데이터가 반환됩니다. 따라서 유용한 데이터는 4바이트(인트 수)뿐이고 나머지 28바이트(7인트 수)는 무용지물이 됩니다.
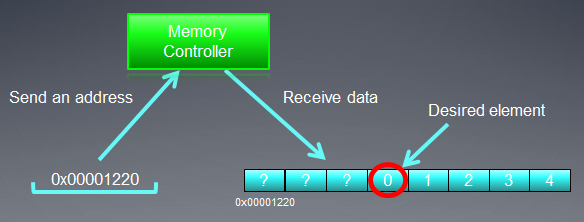
그림 4. 메모리에서 필요한 데이터를 가져오는 방법
이전에 지정한 주소(0x00001232)에 필요한 번호가 체계에 동그라미 쳐져 있습니다.
버스 사용을 극대화하기 위해 GPU는 서로 다른 스레드의 메모리 액세스를 단일 메모리 요청으로 병합하려고 시도합니다. 메모리 액세스 횟수가 적을수록 좋습니다. 그 이유는 글로벌 장치 메모리에 액세스하는 데 시간이 많이 소요되어 프로그램 실행 속도가 크게 저하되기 때문입니다. 커널 코드의 다음 줄을 고려하십시오:
int tmp = X[ get_global_id( 0 ) ];
어레이 X가 위에 제공된 이전 예제의 어레이라고 가정합니다. 그런 다음 처음 16개의 스레드(커널)가 0x00001232부터 0x00001272까지의 주소(이 범위 내에 16인치 숫자(예: 64바이트)가 있음)에 액세스합니다. 모든 요청을 커널에서 독립적으로 보낸 경우, 이전에 단일 요청으로 병합하지 않고 16개의 요청 각각에 4바이트의 유용한 데이터와 28바이트의 쓸모 없는 데이터가 포함되어 총 64바이트와 448바이트의 사용되지 않은 바이트가 생성됩니다.
이 계산은 하나의 주소와 동일한 32바이트 메모리 블록에 있는 주소에 대한 모든 액세스가 완전히 동일한 데이터를 반환한다는 사실에 기초합니다. 이것이 핵심입니다. 불필요한 요청을 절약하기 위해 여러 요청을 일관성 있는 단일 요청으로 통합하는 것이 더 정확할 것입니다. 이 작업을 이하에서는 병합 및 병합 요청이라고 합니다. 이러한 작업을 coherent(일관)이라고 합니다.

그림 5. 필요한 데이터를 얻으려면 메모리 요청이 3개만 필요합니다.
위 그림의 각 셀은 4바이트입니다. 이 예에서는 3개의 요청으로 충분합니다. 어레이의 시작이 각 32바이트 메모리 블록의 시작 주소에 맞춰져 있다면 2개의 요청만으로도 충분합니다.
AMD GPU 64에서 스레드는 wavefront(파장)의 일부이므로 SIMD 실행에서와 동일한 명령을 실행해야 합니다. 정확히 파장의 1/4인 get_global_id(0)로 배열된 16개의 스레드는 버스를 효율적으로 사용하기 위한 일관된 요청으로 통합됩니다.
아래는 일관성 없는 요청(예: "자발적" 요청)과 비교하여 일관성 있는 요청에 필요한 메모리 대역폭을 보여줍니다. 그것은 Radeon HD 5870에 관한 것입니다. NVidia 카드에서도 유사한 결과를 확인할 수 있습니다.
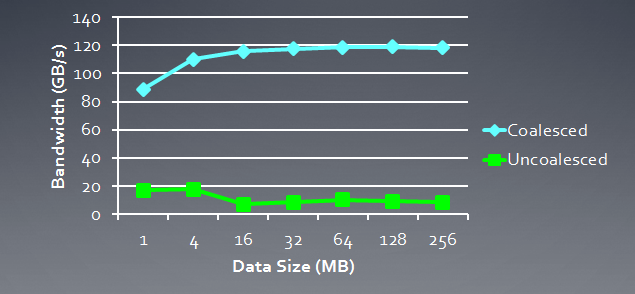
그림 6. 일관성 있는 것과 일관성 없는 요청에 필요한 메모리 대역폭을 비교 분석
일관성 있는 메모리 요청을 통해 메모리 대역폭을 약 1자릿수 크기까지 늘릴 수 있음을 분명히 알 수 있습니다.
1.2.2. 메모리 뱅크
메모리는 데이터가 실제로 저장되는 뱅크로 구성됩니다. 최신 GPU에서는 일반적으로 32비트(4바이트) 워드입니다. 직렬 데이터는 인접한 메모리 뱅크에 저장됩니다. 직렬 요소에 액세스하는 스레드 그룹은 뱅크 충돌을 생성하지 않습니다.
뱅크 충돌의 최대 부정적 영향은 일반적으로 로컬 GPU 메모리에서 관찰됩니다. 따라서 인접 스레드로부터의 로컬 데이터 액세스는 서로 다른 메모리 뱅크를 대상으로 하는 것이 좋습니다.
AMD 하드웨어에서 뱅크를 생성하는 파장은 모든 로컬 메모리 작업이 완료될 때까지 중지됩니다. 따라서 병렬로 실행되어야 하는 코드 블록이 순차적으로 실행되는 직렬화로 이어집니다. 커널 성능에 매우 부정적인 영향을 미칩니다.
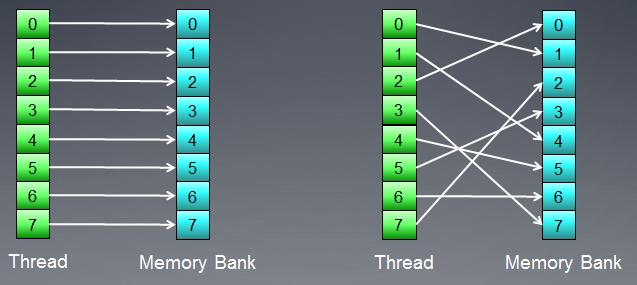
그림 7. 뱅크 충돌이 없는 메모리 액세스 체계
위의 그림은 모든 스레드가 서로 다른 데이터에 액세스하기 때문에 뱅크 충돌이 없는 메모리 액세스를 보여줍니다.
뱅크 충돌 시 메모리 액세스를 보여 드리겠습니다.
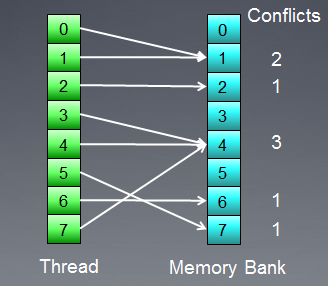
그림 8. 뱅크 충돌이 있는 메모리 액세스
그러나 이 상황에서는 예외가 있습니다. 모든 액세스가 동일한 주소에 있는 경우 은행은 지연을 방지하기 위해 브로드캐스트를 수행할 수 있습니다.
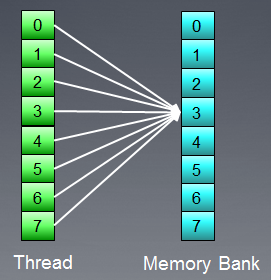
그림 9. 모든 스레드가 동일한 주소에 액세스하고 있습니다.
글로벌 메모리에 액세스할 때도 유사한 이벤트가 발생하지만 이러한 충돌의 영향은 상당히 낮습니다.
- GPU 메모리는 CPU 메모리와 다릅니다. OpenCL을 사용하여 프로그램 성능을 최적화하는 주요 목적은 CPU에서처럼 대기 시간을 줄이는 대신 최대 대역폭을 보장하는 것입니다.
- 메모리 액세스의 특성은 버스 사용 효율성에 큰 영향을 미칩니다. 버스 사용 효율성이 낮다는 것은 실행 속도가 낮다는 것을 의미합니다.
- 코드 성능을 향상시키려면 메모리 액세스를 일관되게 유지하는 것이 좋습니다. 또한, 뱅크 충돌을 피하는 것이 매우 바람직합니다.
- 하드웨어 사양(버스 폭, 메모리 뱅크 수 및 단일 일관성 액세스를 위해 통합할 수 있는 스레드 수)은 벤더 제공 문서에서 확인할 수 있습니다.
일부 Radeon 5xxx 시리즈 비디오 카드의 사양은 다음과 같습니다:
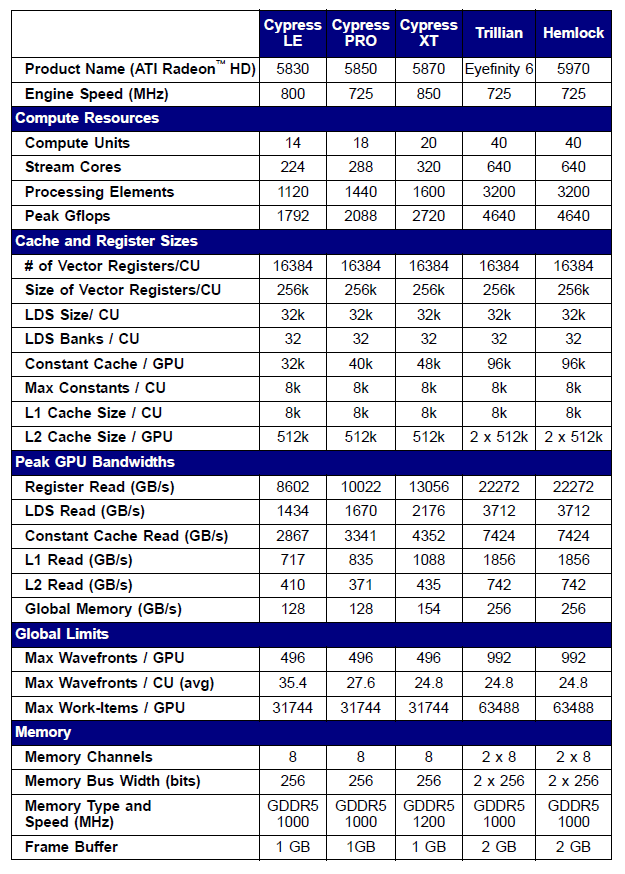
그림 10. 중급 및 고급 Radeon HD 58xx 비디오 카드의 기술 사양
이제 프로그래밍을 진행하겠습니다.
2. 큰 정사각형 행렬의 곱: 직렬 CPU 코드에서 병렬 GPU 코드
2.1. MQL5 코드
현재 작업은 이전 문서 "OpenCL: 병렬 세계로의 다리"와는 대조적으로, 즉, 두 행렬을 곱하는 표준입니다. 주로 주제에 대한 많은 정보를 다른 출처에서 찾을 수 있기 때문에 선택됩니다. 이들 대부분은 어느 쪽이든 어느 정도 조정된 솔루션을 제공합니다. 이것은 우리가 실제 하드웨어에 대해 작업하고 있다는 점을 염두에 두고 모델 구조의 의미를 단계적으로 명확하게 설명하면서 내려갈 길입니다.
다음은 선형대수학에서 잘 알려진 컴퓨터 계산을 위해 수정된 행렬 곱셈 공식입니다. 첫 번째 인덱스는 행렬 행 번호이고 두 번째 인덱스는 열 번호입니다. 모든 출력 행렬 요소는 첫 번째 및 두 번째 행렬에서 요소의 연속 곱을 누적 합계에 순차적으로 추가하여 계산됩니다. 결국 이 누적 합계는 계산된 출력 매트릭스 요소가 됩니다.
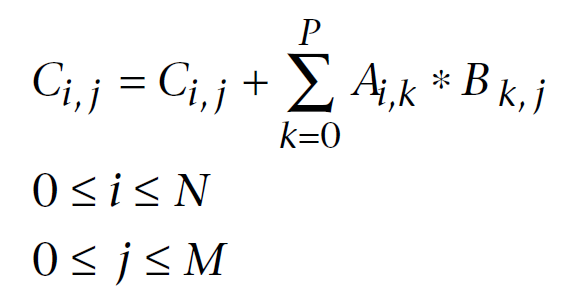
그림 11. 행렬 곱셈 공식
이는 다음과 같이 개략적으로 나타낼 수 있습니다:
이 도식으로 표현됩니다.")
그림 12. 매트릭스 곱셈 알고리즘(출력 매트릭스 요소의 계산으로 예시화)이 도식으로 표현됩니다.
두 행렬의 치수가 모두 N과 같은 경우 함수 O(N^3)로 덧셈과 곱셈 수를 추정할 수 있습니다. 모든 출력 행렬 요소를 계산하려면 첫 번째 행렬의 행과 두 번째 행렬의 열의 스칼라 곱을 구해야 합니다. 약 2*N개의 추가 및 곱셈이 필요합니다. 필요한 추정치는 행렬 요소 N^2의 수에 곱하여 구합니다. 따라서, 대략적인 코드 런타임은 N입방형에 따라 상당히 달라집니다.
매트릭스의 행 및 열 수는 편의상 2000으로 설정되며 임의일 수 있지만 너무 크지는 않습니다.
MQL5의 코드는 그다지 복잡하지 않습니다.
//+------------------------------------------------------------------+ //| matr_mul_2dim.mq5 | //+------------------------------------------------------------------+ #define ROWS1 1000 // rows in the first matrix #define COLSROWS 1000 // columns in the first matrix = rows in the second matrix #define COLS2 1000 // columns in the second matrix float first[ ROWS1 ][ COLSROWS ]; // first matrix float second[ COLSROWS ][ COLS2 ]; // second matrix float third[ ROWS1 ][ COLS2 ]; // product //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { MathSrand(GetTickCount()); Print("======================================="); Print("ROWS1 = "+i2s(ROWS1)+"; COLSROWS = "+i2s(COLSROWS)+"; COLS2 = "+i2s(COLS2)); genMatrices(); ArrayInitialize(third,0.0f); //--- execution on the CPU uint st1=GetTickCount(); mul(); double time1=(double)(GetTickCount()-st1)/1000.; Print("CPU: time = "+DoubleToString(time1,3)+" s."); return; } //+------------------------------------------------------------------+ //| i2s | //+------------------------------------------------------------------+ string i2s(int arg) { return IntegerToString(arg); } //+------------------------------------------------------------------+ //| genMatrices | //| generate initial matrices; this generation is not reflected | //| in the final runtime calculation | //+------------------------------------------------------------------+ void genMatrices() { for(int r=0; r<ROWS1; r++) for(int c=0; c<COLSROWS; c++) first[r][c]=genVal(); for(int r=0; r<COLSROWS; r++) for(int c=0; c<COLS2; c++) second[r][c]=genVal(); return; } //+------------------------------------------------------------------+ //| genVal | //| generate one value of the matrix element: | //| uniformly distributed value lying in the range [-0.5; 0.5] | //+------------------------------------------------------------------+ float genVal() { return(float)(( MathRand()-16383.5)/32767.); } //+------------------------------------------------------------------+ //| mul | //| Main matrix multiplication function | //+------------------------------------------------------------------+ void mul() { // r-cr-c: 10.530 s for(int r=0; r<ROWS1; r++) for(int cr=0; cr<COLSROWS; cr++) for(int c=0; c<COLS2; c++) third[r][c]+=first[r][cr]*second[cr][c]; return; }
목록 1. 호스트의 초기 순차적 프로그램
다양한 매개 변수를 사용한 성능 결과입니다:
2012.05.19 09:39:11 matr_mul_2dim (EURUSD,H1) CPU: time = 10.530 s. 2012.05.19 09:39:00 matr_mul_2dim (EURUSD,H1) ROWS1 = 1000; COLSROWS = 1000; COLS2 = 1000 2012.05.19 09:39:00 matr_mul_2dim (EURUSD,H1) ======================================= 2012.05.19 09:41:04 matr_mul_2dim (EURUSD,H1) CPU: time = 83.663 s. 2012.05.19 09:39:40 matr_mul_2dim (EURUSD,H1) ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.19 09:39:40 matr_mul_2dim (EURUSD,H1) =======================================
보시다시피, 선형 매트릭스 크기에 대한 런타임의 추정 의존도는 사실로 나타났습니다. 즉, 모든 매트릭스 차원이 2배 증가하면 런타임이 약 8배 증가합니다.
알고리즘에 대한 몇 가지 단어: 곱셈 함수 mul()에서 루프 순서를 임의로 변경할 수 있습니다. 런타임에 상당한 영향을 미치는 것으로 나타났습니다. 즉, 가장 느린 런타임 변종과 가장 빠른 런타임 변종의 비율은 약 1.73입니다.
이 문서는 가장 빠른 변형 모델만 보여주며, 나머지 테스트된 변형 모델은 문서 끝에 부착된 코드(file matr_mul_2dim.mq5)에서 찾을 수 있습니다. 이와 관련하여 OpenCL 프로그래밍 가이드(Aaftab Munshi, Benedict R. Gaster, Timothy G. Mattson, James Fung, Dan Ginsburg)는 다음과 같이 말합니다. 512쪽:
이러한 것들이 우리가 구현할 수 있는 초기 "비병렬" 코드의 모든 최적화는 아닙니다. 이들 중 일부는 하드웨어(S) SSEx 지침과 관련이 있으며, 다른 일부는 순수 알고리즘(예: Strassen 알고리즘, Coppersmith-Winograd 알고리즘, 등)과 같습니다. Strassen 알고리즘에 대한 곱셈 행렬의 크기는 기존 알고리즘에 비해 상당히 작으며 64x64에 불과합니다. 이 기사에서는 선형 크기가 최대 수천(최대 5000)인 행렬을 빠르게 곱하는 방법에 대해 알아보겠습니다.
2.2. OpenCL에서 알고리즘의 첫 번째 구현
이제 이 알고리즘을 OpenCL로 포팅하여 ROWS1 * COLS2 스레드를 만듭니다. 즉, 커널에서 두 외부 루프를 모두 삭제합니다. 내부 루프가 커널의 일부로 유지되도록 각 스레드는 COLSROWS 반복을 실행합니다.
OpenCL 커널용 선형 버퍼를 3개 만들어야 하므로 초기 알고리즘을 최대한 커널 알고리즘과 비슷하게 재작업하는 것이 합리적입니다. 선형 버퍼가 있는 "단일 코어 CPU"의 "비병렬" 프로그램 코드는 커널 코드와 함께 제공됩니다. 2차원 배열을 사용하는 코드의 최적성은 아날로그가 선형 버퍼에도 최적임을 의미하는 것은 아닙니다: 모든 테스트를 반복해야 합니다. 따라서, 우리는 선형대수학에서 행렬 곱셈의 표준 논리에 해당하는 초기 변종으로 다시 c-r-cr을 선택합니다.
즉, 혼란을 해결하기 위해 주요 질문에 답하십시오. 매트릭스 Matr(M행 N열 기준)가 글로벌 GPU 메모리에 선형 버퍼로 배치되어 있는 경우 Matr[행][열 ] 요소의 선형 이동을 계산하려면 어떻게 해야 합니까?
사실 GPU 메모리에는 문제의 논리만으로 결정되기 때문에 매트릭스를 배치하는 순서가 정해져 있지 않습니다. 예를 들어, 행렬 곱하기 알고리즘에 관한 한 행렬이 비대칭이기 때문에, 첫 번째 행렬의 행에 두 번째 행렬의 열을 곱하기 때문에 두 행렬의 요소는 버퍼에서 다르게 배치될 수 있습니다. 이러한 재배열은 커널의 모든 반복에서 글로벌 GPU 메모리에서 매트릭스 요소를 순차적으로 읽을 때 계산 성능에 큰 영향을 미칠 수 있습니다.
알고리즘의 첫 번째 구현에서는 동일한 방식으로 - 행 주요 순서로 - 행렬이 배치됩니다. 첫 번째 행 요소는 먼저 버퍼에 배치되고 그 다음에 두 번째 행의 모든 요소가 배치됩니다. 행렬 Matr[ M(행) ][ N(열) ]의 2차원 표현을 선형 메모리로 평탄화하는 공식은 다음과 같습니다.

그림 13. 2차원 인덱스 공간을 선형으로 변환하여 GPU 버퍼에서 행렬을 배치하는 알고리즘입니다.
위의 그림에서는 2차원 행렬 표현이 주요 순서로 선형 메모리에 평탄화되는 방법에 대한 예도 제공합니다.
다음은 OpenCL 장치에서 실행된 첫 번째 프로그램 구현의 코드를 약간 줄인 것입니다.
//+------------------------------------------------------------------+ //| matr_mul_1dim.mq5 | //+------------------------------------------------------------------+ #property script_show_inputs #define ROWS1 2000 // rows in the first matrix #define COLSROWS 2000 // columns in the first matrix = rows in the second matrix #define COLS2 2000 // columns in the second matrix #define REALTYPE float REALTYPE first[]; // first linear buffer (matrix) rows1 * colsrows REALTYPE second[]; // second buffer colsrows * cols2 REALTYPE thirdGPU[ ]; // product - also a buffer rows1 * cols2 REALTYPE thirdCPU[ ]; // product - also a buffer rows1 * cols2 input int _device=1; // here is the device; it can be changed (now 4870) string d2s(double arg,int dig) { return DoubleToString(arg,dig); } string i2s(long arg) { return IntegerToString(arg); } //+------------------------------------------------------------------+ const string clSrc= "#define COLS2 "+i2s(COLS2)+" \r\n" "#define COLSROWS "+i2s(COLSROWS)+" \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " int c = get_global_id( 1 ); \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " out[ r * COLS2 + c ] += \r\n" " in1[ r * COLSROWS + cr ] * in2[ cr * COLS2 + c ]; \r\n" "} \r\n"; //+------------------------------------------------------------------+ //| Main matrix multiplication function; | //| Input matrices are already generated, | //| the output matrix is initialized to zeros | //+------------------------------------------------------------------+ void mulCPUOneCore() { //--- c-r-cr: 11.544 s //st = GetTickCount( ); for(int c=0; c<COLS2; c++) for(int r=0; r<ROWS1; r++) for(int cr=0; cr<COLSROWS; cr++) thirdCPU[r*COLS2+c]+=first[r*COLSROWS+cr]*second[cr*COLS2+c]; return; } //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { initAllDataCPU(); //--- start working with non-parallel version ("bare" CPU, single core) //--- calculate the output matrix on a single core CPU uint st=GetTickCount(); mulCPUOneCore(); //--- output total calculation time double timeCPU=(GetTickCount()-st)/1000.; Print("CPUTime = "+d2s(timeCPU,3)); //--- start working with OCL int clCtx; // context handle int clPrg; // handle to the program on the device int clKrn; // kernel handle int clMemIn1; // first (input) buffer handle int clMemIn2; // second (input) buffer handle int clMemOut; // third (output) buffer handle //--- start calculating the program runtime on GPU //st = GetTickCount( ); initAllDataGPU(clCtx,clPrg,clKrn,clMemIn1,clMemIn2,clMemOut); //--- start calculating total OCL code runtime st=GetTickCount(); executeGPU(clKrn); //--- create a buffer for reading and read the result; we will need it later REALTYPE buf[]; readOutBuf(clMemOut,buf); //--- stop calculating the total program runtime //--- together with the time required for retrieval of data from GPU and transferring it back to RAM double timeGPUTotal=(GetTickCount()-st)/1000.; Print("OpenCL total: time = "+d2s(timeGPUTotal,3)+" sec."); destroyOpenCL(clCtx,clPrg,clKrn,clMemIn1,clMemIn2,clMemOut); //--- calculate the time elapsed Print("CPUTime / GPUTotalTime = "+d2s(timeCPU/timeGPUTotal,3)); //--- debugging: random checks. Multiplication accuracy is checked directly //--- on the initial and output matrices using a few dozen examples for(int i=0; i<10; i++) checkRandom(buf,ROWS1,COLS2); Print("________________________"); return; } //+------------------------------------------------------------------+ //| initAllDataCPU | //+------------------------------------------------------------------+ void initAllDataCPU() { //--- initialize random number generator MathSrand(( int) TimeLocal()); Print("======================================="); Print("1st OCL martices mul: device = "+i2s(_device)+"; ROWS1 = " +i2s(ROWS1)+ "; COLSROWS = "+i2s(COLSROWS)+"; COLS2 = "+i2s(COLS2)); //--- set the required sizes of linear representations of the input and output matrices ArrayResize(first,ROWS1*COLSROWS); ArrayResize(second,COLSROWS*COLS2); ArrayResize(thirdGPU,ROWS1*COLS2); ArrayResize(thirdCPU,ROWS1*COLS2); //--- generate both input matrices and initialize the output to zeros genMatrices(); ArrayInitialize( thirdCPU, 0.0 ); ArrayInitialize( thirdGPU, 0.0 ); return; } //+------------------------------------------------------------------+ //| initAllDataCPU | //| lay out in row-major order, Matr[ M (rows) ][ N (columns) ]: | //| Matr[row][column] = buff[row * N(columns in the matrix) + column]| //| generate initial matrices; this generation is not reflected | //| in the final runtime calculation | //| buffers are filled in row-major order! | //+------------------------------------------------------------------+ void genMatrices() { for(int r=0; r<ROWS1; r++) for(int c=0; c<COLSROWS; c++) first[r*COLSROWS+c]=genVal(); for(int r=0; r<COLSROWS; r++) for(int c=0; c<COLS2; c++) second[r*COLS2+c]=genVal(); return; } //+------------------------------------------------------------------+ //| genVal | //| generate one value of the matrix element: | //| uniformly distributed value lying in the range [-0.5; 0.5] | //+------------------------------------------------------------------+ REALTYPE genVal() { return(REALTYPE)((MathRand()-16383.5)/32767.); } //+------------------------------------------------------------------+ //| initAllDataGPU | //+------------------------------------------------------------------+ void initAllDataGPU(int &clCtx, // context int& clPrg, // program on the device int& clKrn, // kernel int& clMemIn1, // first (input) buffer int& clMemIn2, // second (input) buffer int& clMemOut) // third (output) buffer { //--- write the kernel code to a file WriteCLProgram(); //--- create context, program and kernel clCtx = CLContextCreate( _device ); clPrg = CLProgramCreate( clCtx, clSrc ); clKrn = CLKernelCreate( clPrg, "matricesMul" ); //--- create all three buffers for the three matrices //--- first matrix - input clMemIn1=CLBufferCreate(clCtx,ROWS1 *COLSROWS*sizeof(REALTYPE),CL_MEM_READ_WRITE); //--- second matrix - input clMemIn2=CLBufferCreate(clCtx,COLSROWS*COLS2 *sizeof(REALTYPE),CL_MEM_READ_WRITE); //--- third matrix - output clMemOut=CLBufferCreate(clCtx,ROWS1 *COLS2 *sizeof(REALTYPE),CL_MEM_READ_WRITE); //--- set arguments to the kernel CLSetKernelArgMem(clKrn,0,clMemIn1); CLSetKernelArgMem(clKrn,1,clMemIn2); CLSetKernelArgMem(clKrn,2,clMemOut); //--- write the generated matrices to the device buffers CLBufferWrite(clMemIn1,first); CLBufferWrite(clMemIn2,second); CLBufferWrite(clMemOut,thirdGPU); // 0.0 everywhere return; } //+------------------------------------------------------------------+ //| WriteCLProgram | //+------------------------------------------------------------------+ void WriteCLProgram() { int h=FileOpen("matr_mul_OCL_1st.cl",FILE_WRITE|FILE_TXT|FILE_ANSI); FileWrite(h,clSrc); FileClose(h); } //+------------------------------------------------------------------+ //| executeGPU | //+------------------------------------------------------------------+ void executeGPU(int clKrn) { //--- set the workspace parameters for the task and execute the OpenCL program uint offs[ 2 ] = { 0, 0 }; uint works[ 2 ] = { ROWS1, COLS2 }; bool ex=CLExecute(clKrn,2,offs,works); return; } //+------------------------------------------------------------------+ //| readOutBuf | //+------------------------------------------------------------------+ void readOutBuf(int clMemOut,REALTYPE &buf[]) { ArrayResize(buf,COLS2*ROWS1); //--- buf - a copy of what is written to the buffer thirdGPU[] uint read=CLBufferRead(clMemOut,buf); Print("read = "+i2s(read)+" elements"); return; } //+------------------------------------------------------------------+ //| destroyOpenCL | //+------------------------------------------------------------------+ void destroyOpenCL(int clCtx,int clPrg,int clKrn,int clMemIn1,int clMemIn2,int clMemOut) { //--- destroy all that was created for calculations on the OpenCL device in reverse order CLBufferFree(clMemIn1); CLBufferFree(clMemIn2); CLBufferFree(clMemOut); CLKernelFree(clKrn); CLProgramFree(clPrg); CLContextFree(clCtx); return; } //+------------------------------------------------------------------+ //| checkRandom | //| random check of calculation accuracy | //+------------------------------------------------------------------+ void checkRandom(REALTYPE &buf[],int rows,int cols) { int r0 = genRnd( rows ); int c0 = genRnd( cols ); REALTYPE sum=0.0; for(int runningIdx=0; runningIdx<COLSROWS; runningIdx++) sum+=first[r0*COLSROWS+runningIdx]* second[runningIdx*COLS2+c0]; //--- element of the buffer m[] REALTYPE bufElement=buf[r0*COLS2+c0]; //--- element of the matrix not calculated in OpenCL REALTYPE CPUElement=thirdCPU[r0*COLS2+c0]; Print("sum( "+i2s(r0)+","+i2s(c0)+" ) = "+d2s(sum,8)+ "; thirdCPU[ "+i2s(r0)+","+i2s(c0)+" ] = "+d2s(CPUElement,8)+ "; buf[ "+i2s(r0)+","+i2s(c0)+" ] = "+d2s(bufElement,8)); return; } //+------------------------------------------------------------------+ //| genRnd | //+------------------------------------------------------------------+ int genRnd(int max) { return(int)(MathRand()/32767.*max); }
목록 2. OpenCL에서 프로그램 첫 구현
마지막 두 기능은 계산 정확도를 확인하는 데 유용합니다. 전체 코드는 문서 끝에 첨부되어 있습니다(matr_mul_1dim.mq5). 치수가 반드시 정사각형 행렬에만 해당할 필요는 없습니다.
추가 변경은 거의 항상 커널 코드만 포함하므로 커널 수정 코드만 여기에 명시됩니다.
REALTYPE은 계산 정밀도를 플로트에서 더블로 변경할 수 있는 편의를 위해 도입되었습니다. REALTYPE 유형은 호스트 프로그램뿐만 아니라 커널 내에서 선언됩니다. 필요한 경우 호스트 프로그램의 #define과 커널 코드 두 위치에서 동시에 이 유형에 대한 모든 변경을 수행해야 합니다.
코드 성능 결과(이하, 모든 곳에 플로트 데이터 유형):
CPU (OpenCL, _device = 0) :
2012.05.20 22:14:57 matr_mul_1dim (EURUSD,H1) CPUTime / GPUTotalTime = 12.479 2012.05.20 22:14:57 matr_mul_1dim (EURUSD,H1) OpenCL total: time = 9.266 sec. 2012.05.20 22:14:57 matr_mul_1dim (EURUSD,H1) read = 4000000 elements 2012.05.20 22:14:48 matr_mul_1dim (EURUSD,H1) CPUTime = 115.628 2012.05.20 22:12:52 matr_mul_1dim (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.20 22:12:52 matr_mul_1dim (EURUSD,H1) =======================================
Radeon HD 4870(_device = 1)에서 실행되는 경우:
2012.05.27 01:40:50 matr_mul_1dim (EURUSD,H1) CPUTime / GPUTotalTime = 9.002 2012.05.27 01:40:50 matr_mul_1dim (EURUSD,H1) OpenCL total: time = 12.729 sec. 2012.05.27 01:40:50 matr_mul_1dim (EURUSD,H1) read = 4000000 elements 2012.05.27 01:40:37 matr_mul_1dim (EURUSD,H1) CPUTime = 114.583 2012.05.27 01:38:42 matr_mul_1dim (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 01:38:42 matr_mul_1dim (EURUSD,H1) =======================================
보시다시피 GPU의 커널 실행 속도가 훨씬 느립니다. 그러나 GPU에 대한 최적화에 대해서는 아직 구체적으로 다루지 않았습니다.
몇 가지 결론:
- 매트릭스 표현을 2차원에서 선형(장치에서 실행되는 프로그램의 표현에 해당)으로 변경하는 것은 프로그램의 순차적 버전의 총 런타임에 큰 영향을 미치지 않았습니다.
- 선형 대수의 행렬 곱셈 정의와 일치하는 가장 직관적인 계산 알고리즘이 추가 최적화를 위한 초기 변종으로 선택되었습니다. 가장 빠른 속도보다 다소 느리지만 향후 GPU 속도 향상에 있어 이 요소가 반드시 필요한 것은 아닙니다.
- 런타임은 버퍼를 RAM으로 읽은 후에만 계산해야 하며 CLExecute() 명령 다음에 계산해야 합니다. MetaDriver가 저자에게 지적한 그 이면의 이유는 아마도 다음과 같습니다:MetaDriver: 버퍼에서 읽기 전에, CLBufferRead()는 프로그램의 실제 완료를 기다립니다. CLExecute()는 사실 비동기 큐 함수입니다. cl 코드 작업이 완료되기 바로 전에 결과를 반환합니다.
- GPU 컴퓨팅 가이드는 일반적으로 커널 런타임을 계산하지 않고 메모리, 산술 등 다양한 개체와 관련된 처리량을 계산합니다. 우리는 할 수 있고 앞으로도 그렇습니다.
우리는 2000 크기의 행렬을 계산하려면 각 원소에 대해 약 2 * 2000의 덧셈/곱셈이 필요하다는 것을 알고 있습니다. 행렬 요소 수(2000 * 2000)를 곱하면 플로트 유형 데이터에 대한 총 작업 수가 160억 개임을 알 수 있습니다. 즉, CPU 실행에는 115.628초가 소요되며 이는 다음과 같은 데이터 스트리밍 속도에 해당합니다.
반면에, 지금까지의 "단일 코어 CPU"의 매트릭스 크기가 2000인 가장 빠른 계산은 83.663초밖에 걸리지 않았습니다(OpenCL이 없는 첫 번째 코드 참조). 따라서
이 수치를 최적화의 출발점으로 삼겠습니다.
마찬가지로 CPU에서 OpenCL을 사용하여 계산하면 다음과 같은 결과를 얻을 수 있습니다:
마지막으로 GPU의 처리량을 계산합니다:
2.3. 일관성 없는 데이터 액세스 제거
커널 코드를 보면 몇 가지 비최적성을 쉽게 알 수 있습니다.
커널 내의 루프 본문을 살펴봅니다:
for( int cr = 0; cr < COLSROWS; cr ++ ) out[ r * COLS2 + c ] += in1[ r * COLSROWS + cr ] * in2[ cr * COLS2 + c ];
루프 카운터(cr++)가 실행 중일 때 1[]의 첫 번째 버퍼에서 연속 데이터가 수집됨을 쉽게 알 수 있습니다. 반면 2[]의 두 번째 버퍼의 데이터는 COLS2와 동일한 "갭"으로 수집됩니다. 즉, 메모리 요청이 일관되지 않기 때문에 두 번째 버퍼에서 가져온 데이터의 주요 부분은 무용지물이 됩니다(1.2.1 참조). (메모리 요청을 병합). 이 상황을 해결하려면 2[]의 배열 색인 계산 공식과 생성 패턴을 변경하여 코드를 세 곳에서 수정하면 됩니다.
for( int cr = 0; cr < COLSROWS; cr ++ ) out[ r * COLS2 + c ] += in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ];이제 루프 카운터(cr++) 값이 변경되면 "갭" 없이 두 어레이의 데이터가 순차적으로 수집됩니다.
- genMatrices() 버퍼 채우기 코드 이제 처음에 사용된 행-주요 순서 대신 열-주요 순서로 채워야 합니다:
for( int r = 0; r < COLSROWS; r ++ ) for( int c = 0; c < COLS2; c ++ ) /// second[ r * COLS2 + c ] = genVal( ); second[ r + c * COLSROWS ] = genVal( );- checkRandom() 함수의 확인 코드:
for( int runningIdx = 0; runningIdx < COLSROWS; runningIdx ++ ) ///sum += first[ r0 * COLSROWS + runningIdx ] * second[ runningIdx * COLS2 + c0 ]; sum += first[ r0 * COLSROWS + runningIdx ] * second[ runningIdx + c0 * COLSROWS ];CPU 성능 결과:
2012.05.24 02:59:22 matr_mul_1dim_coalesced (EURUSD,H1) CPUTime / GPUTotalTime = 16.207 2012.05.24 02:59:22 matr_mul_1dim_coalesced (EURUSD,H1) OpenCL total: time = 5.756 sec. 2012.05.24 02:59:22 matr_mul_1dim_coalesced (EURUSD,H1) read = 4000000 elements 2012.05.24 02:59:16 matr_mul_1dim_coalesced (EURUSD,H1) CPUTime = 93.289 2012.05.24 02:57:43 matr_mul_1dim_coalesced (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.24 02:57:43 matr_mul_1dim_coalesced (EURUSD,H1) =======================================Radeon HD 4870:
2012.05.27 01:50:43 matr_mul_1dim_coalesced (EURUSD,H1) CPUTime / GPUTotalTime = 7.176 2012.05.27 01:50:43 matr_mul_1dim_coalesced (EURUSD,H1) OpenCL total: time = 12.979 sec. 2012.05.27 01:50:43 matr_mul_1dim_coalesced (EURUSD,H1) read = 4000000 elements 2012.05.27 01:50:30 matr_mul_1dim_coalesced (EURUSD,H1) CPUTime = 93.133 2012.05.27 01:48:57 matr_mul_1dim_coalesced (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 01:48:57 matr_mul_1dim_coalesced (EURUSD,H1) =======================================
보시다시피 데이터에 대한 일관성 있는 액세스는 GPU의 런타임에 거의 영향을 미치지 않았지만 CPU의 런타임은 확실히 개선되었습니다. 나중에 최적화될 요소, 특히 글로벌 변수에 대한 액세스 지연 시간이 매우 길기 때문에 가능한 한 빨리 제거해야 합니다.
throughput_arithmetic_CPU_OCL = 16 000000000 / 5.756 ~ 2.780 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 12.979 ~ 1.233 GFlops.
새 커널 코드는 문서 끝에 있는 matr_mul_1dim_coalesced.mq5에서 찾을 수 있습니다.
커널 코드는 아래에 명시되어 있습니다.
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " int c = get_global_id( 1 ); \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " out[ r * COLS2 + c ] += \r\n" " in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ]; \r\n" "} \r\n";
목록 3. 통합 글로벌 메모리 데이터 액세스가 있는 커널
다음 최적화로 넘어가겠습니다.
2.4. 출력 매트릭스에서 '비용이 많이 드는' 글로벌 GPU 메모리 액세스 제거
글로벌 GPU 메모리 액세스 지연 시간이 매우 긴 것으로 알려져 있습니다(약 600~800 사이클). 예를 들어, 두 숫자를 추가하는 데 걸리는 지연 시간은 약 20주기입니다. GPU에서 계산할 때 최적화의 주요 목적은 계산 처리량을 늘려 대기 시간을 숨기는 것입니다. 앞서 개발된 커널의 루프에서 글로벌 메모리 요소에 지속적으로 액세스하여 시간이 소요됩니다.
이제 커널에 로컬 변수 합계를 소개하고(작업 단위 레지스터에 위치한 커널의 개인 변수이므로 몇 배 더 빠르게 액세스할 수 있음) 루프가 완료되면 얻은 합계 값을 출력 어레이의 요소에 각각 할당합니다.
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " int c = get_global_id( 1 ); \r\n" " REALTYPE sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " sum += in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ]; \r\n" " out[ r * COLS2 + c ] = sum; \r\n" "} \r\n" ;
목록 4. 스칼라 제품 계산 루프에서 누적 합계를 계산하기 위해 개인 변수를 도입합니다.
전체 소스 코드 파일, matr_mul_sum_local.mq5는 문서 끝에 첨부되어 있습니다.
CPU:
2012.05.24 03:28:17 matr_mul_sum_local (EURUSD,H1) CPUTime / GPUTotalTime = 24.863 2012.05.24 03:28:16 matr_mul_sum_local (EURUSD,H1) OpenCL total: time = 3.759 sec. 2012.05.24 03:28:16 matr_mul_sum_local (EURUSD,H1) read = 4000000 elements 2012.05.24 03:28:12 matr_mul_sum_local (EURUSD,H1) CPUTime = 93.460 2012.05.24 03:26:39 matr_mul_sum_local (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000GPU HD 4870:
2012.05.27 01:57:30 matr_mul_sum_local (EURUSD,H1) CPUTime / GPUTotalTime = 69.541 2012.05.27 01:57:30 matr_mul_sum_local (EURUSD,H1) OpenCL total: time = 1.326 sec. 2012.05.27 01:57:30 matr_mul_sum_local (EURUSD,H1) read = 4000000 elements 2012.05.27 01:57:28 matr_mul_sum_local (EURUSD,H1) CPUTime = 92.212 2012.05.27 01:55:56 matr_mul_sum_local (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 01:55:56 matr_mul_sum_local (EURUSD,H1) =======================================이것은 진정한 생산성 향상입니다!
throughput_arithmetic_CPU_OCL = 16 000000000 / 3.759 ~ 4.257 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 1.326 ~ 12.066 GFlops.
순차적 최적화에서 우리가 고수하고자 하는 주요 원칙은 다음과 같습니다: 먼저 데이터 구조가 주어진 작업, 특히 기본 하드웨어에 적합하도록 가능한 가장 완전한 방식으로 재정렬하고 나서 mad() 또는 fma()와 같은 빠른 계산 알고리즘을 사용하는 미세 최적화를 진행해야 합니다. 순차적 최적화가 반드시 성능 향상을 가져오지는 않는다는 점을 명심하십시오. 이는 보장할 수 없습니다.
2.5. 커널에서 실행되는 작업 증가하기
병렬 프로그래밍에서는 병렬 운영 조직에 대한 오버헤드(시간)를 최소화하기 위해 계산을 구성하는 것이 중요합니다. 치수가 2000인 행렬에서 하나의 출력 매트릭스 요소를 계산하는 하나의 작업 장치는 전체 작업의 1/4000000에 해당하는 작업량을 수행합니다.
이는 하드웨어에 대한 계산을 수행하는 실제 장치 수와는 분명 너무 많고 거리가 너무 멉니다. 이제 새로운 버전의 커널에서는 하나의 요소가 아닌 전체 행렬 행을 계산합니다.
이제 매트릭스의 단일 요소가 아닌 전체 행이 커널의 모든 작업에서 계산되므로 작업 공간을 2차원에서 1차원으로 변경하는 것이 중요합니다. 따라서 태스크 공간이 행렬 행의 수로 바뀝니다.
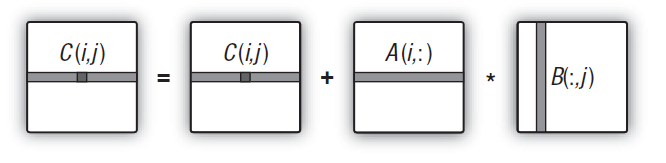
그림 14. 출력 매트릭스의 전체 행을 계산하는 방식
커널 코드가 더 복잡해집니다:
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE sum; \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " sum += in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ]; \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
목록 5. 출력 매트릭스의 전체 행을 계산하기 위한 커널
void executeGPU( int clKrn ) { //--- set parameters of the task workspace and execute the OpenCL program uint offs[ 1 ] = { 0 }; uint works[ 1 ] = { ROWS1 }; bool ex = CLExecute( clKrn, 1, offs, works ); return; }
성능 결과(전체 소스 코드는 matr_mul_row_calc.mq5에서 찾을 수 있습니다):
CPU:
2012.05.24 15:56:24 matr_mul_row_calc (EURUSD,H1) CPUTime / GPUTotalTime = 17.385 2012.05.24 15:56:24 matr_mul_row_calc (EURUSD,H1) OpenCL total: time = 5.366 sec. 2012.05.24 15:56:24 matr_mul_row_calc (EURUSD,H1) read = 4000000 elements 2012.05.24 15:56:19 matr_mul_row_calc (EURUSD,H1) CPUTime = 93.288 2012.05.24 15:54:45 matr_mul_row_calc (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.24 15:54:45 matr_mul_row_calc (EURUSD,H1) =======================================
GPU 4870:
2012.05.27 02:24:10 matr_mul_row_calc (EURUSD,H1) CPUTime / GPUTotalTime = 55.119 2012.05.27 02:24:10 matr_mul_row_calc (EURUSD,H1) OpenCL total: time = 1.669 sec. 2012.05.27 02:24:10 matr_mul_row_calc (EURUSD,H1) read = 4000000 elements 2012.05.27 02:24:08 matr_mul_row_calc (EURUSD,H1) CPUTime = 91.994 2012.05.27 02:22:35 matr_mul_row_calc (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 02:22:35 matr_mul_row_calc (EURUSD,H1) =======================================
CPU의 실행 시간이 크게 악화되지는 않았지만 GPU의 실행 시간이 약간 악화되었다는 것을 알 수 있습니다. 이 모든 것이 나쁜 것은 아닙니다: 이 전략적인 변화가 일시적으로 현지 상황을 악화시키는 것은 단지 성과를 극적으로 증가시키기 위해서입니다.
throughput_arithmetic_CPU_OCL = 16 000000000 / 5.366 ~ 2.982 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 1.669 ~ 9.587 GFlops.
2.6. 첫 번째 어레이의 행을 전용 메모리로 전송
행렬 곱하기 알고리즘의 주요 특이점은 결과의 누적에 따른 많은 곱하기입니다. 이 알고리즘의 적절한 고품질 최적화는 데이터 전송의 최소화를 의미해야 합니다. 그러나 지금까지는 스칼라 제품 축적의 주요 루프 내 계산에서 모든 커널 수정사항의 3가지 매트릭스 중 2가 글로벌 메모리에 저장되었습니다.
즉, 모든 스칼라 제품(사실 모든 출력 매트릭스 요소)에 대한 모든 입력 데이터가 글로벌에서 프라이빗으로 연결된 대기 시간으로 전체 메모리 계층을 통해 지속적으로 스트리밍됩니다. 이 트래픽은 모든 작업 장치가 출력 매트릭스의 계산된 모든 행에 대해 첫 번째 매트릭스의 동일한 행을 재사용하도록 함으로써 줄일 수 있습니다.
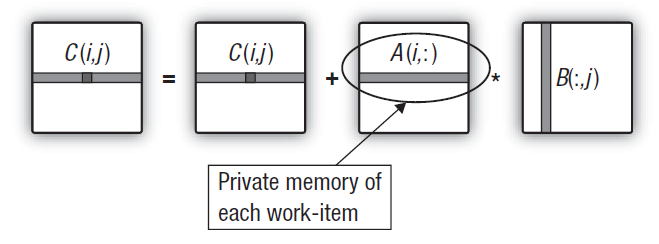
그림 15. 첫 번째 매트릭스의 행을 작업 단위의 개인 메모리로 전송
여기에는 호스트 프로그램 코드가 변경되지 않습니다. 커널의 변경도 최소화됩니다. 커널 내에 중간 1차원 개인 배열이 생성되기 때문에 GPU는 커널을 실행하는 장치의 개인 메모리에 배치하려고 합니다. 첫 번째 매트릭스의 필수 행은 글로벌 메모리에서 개인 메모리로 복사됩니다. 그렇기는 하지만, 이 복사 작업도 상대적으로 빠를 것이라는 점에 유의해야 합니다. 요령은 첫 번째 어레이의 행 요소를 전역 메모리에서 개인 메모리로 '비용이 많이 드는' 복사 작업이 일관성 있게 수행되고 복사 시 오버헤드가 출력 매트릭스 행을 계산하는 메인 이중 루프의 런타임에 비해 상당히 낮다는 점입니다.
커널 코드(메인 루프에 코멘트가 지정된 코드는 이전 버전에 있는 코드):
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE rowbuf[ COLSROWS ]; \r\n" " for( int col = 0; col < COLSROWS; col ++ ) \r\n" " rowbuf[ col ] = in1[ r * COLSROWS + col ]; \r\n" " REALTYPE sum; \r\n" " \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " ///sum += in1[ r * COLSROWS + cr ] * in2[ cr + c * COLSROWS ]; \r\n" " sum += rowbuf[ cr ] * in2[ cr + c * COLSROWS ]; \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
목록 6. 작업 단위의 개인 메모리에 있는 첫 번째 매트릭스의 행을 특징으로 하는 커널입니다
CPU:2012.05.27 00:51:46 matr_mul_row_in_private (EURUSD,H1) CPUTime / GPUTotalTime = 18.587 2012.05.27 00:51:46 matr_mul_row_in_private (EURUSD,H1) OpenCL total: time = 4.961 sec. 2012.05.27 00:51:46 matr_mul_row_in_private (EURUSD,H1) read = 4000000 elements 2012.05.27 00:51:41 matr_mul_row_in_private (EURUSD,H1) CPUTime = 92.212 2012.05.27 00:50:08 matr_mul_row_in_private (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 00:50:08 matr_mul_row_in_private (EURUSD,H1) =======================================GPU:
2012.05.27 02:28:49 matr_mul_row_in_private (EURUSD,H1) CPUTime / GPUTotalTime = 69.242 2012.05.27 02:28:49 matr_mul_row_in_private (EURUSD,H1) OpenCL total: time = 1.327 sec. 2012.05.27 02:28:49 matr_mul_row_in_private (EURUSD,H1) read = 4000000 elements 2012.05.27 02:28:47 matr_mul_row_in_private (EURUSD,H1) CPUTime = 91.884 2012.05.27 02:27:15 matr_mul_row_in_private (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 02:27:15 matr_mul_row_in_private (EURUSD,H1) =======================================
throughput_arithmetic_CPU_OCL = 16 000000000 / 4.961 ~ 3.225 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 1.327 ~ 12.057 GFlops.
CPU 처리량은 지난 번과 거의 동일한 수준을 유지한 반면 GPU 처리량은 다시 최고 수준에 도달했지만 새로운 용량으로 변경되었습니다. CPU 처리량은 즉석에서 정지된 것처럼 약간 불안정할 뿐 GPU 처리량은 상당히 크게 증가(항상 그렇지는 않음)합니다.
첫 번째 매트릭스의 행을 개인 메모리에 복사하기 때문에 이전보다 더 많은 연산이 실행되기 때문에 실제 산술 처리량이 조금 더 높아져야 한다는 점을 지적합니다. 그러나 최종 처리량 추정치에는 거의 영향을 미치지 않습니다.
소스 코드는 matr_mul_row_in_private.mq5에서 찾을 수 있습니다.
2.7. 두 번째 배열의 열을 로컬 메모리로 전송합니다.
이제, 다음 단계가 무엇일지 쉽게 짐작할 수 있습니다. 우리는 이미 출력 및 첫 번째 입력 매트릭스와 관련된 지연 시간을 숨기기 위한 조치를 취했습니다. 두 번째 매트릭스가 아직 남아 있습니다.
행렬 곱셈에 사용되는 스칼라 곱셈에 대한 보다 세심한 연구를 통해 출력 행렬 행을 계산하는 과정에서 그룹의 모든 작업 단위가 두 번째 곱셈 행렬의 동일한 열에서 장치를 통해 데이터를 다시 스트리밍한다는 것을 알 수 있습니다. 이는 아래 계획에 설명되어 있습니다.
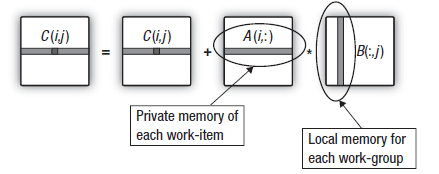
그림 16. 두 번째 매트릭스의 열을 작업 그룹의 로컬 데이터 공유(Local Data Share)로 전송합니다.
출력 매트릭스 행 계산이 시작되기전에 두 번째 매트릭스의 작업 그룹 복사 열을 구성하는 작업 장치가 작업 그룹 메모리로 데이터를 전송하는 데 따른 오버헤드를 줄일 수 있습니다.
이렇게 하려면 호스트 프로그램뿐만 아니라 커널도 변경해야 합니다. 가장 중요한 변경 사항은 각 커널의 로컬 메모리 설정입니다. OpenCL에서는 동적 메모리 할당이 지원되지 않으므로 명시적이어야 합니다. 따라서 적절한 크기의 메모리 개체를 먼저 호스트에 배치하여 커널 내에서 추가로 처리해야 합니다.
그 다음에야 커널을 실행할 때 두 번째 매트릭스의 열을 로컬 메모리에 복사합니다. 이 작업은 작업 그룹의 모든 작업 단위에서 루프 반복의 순환 분포를 사용하여 병렬로 수행됩니다. 그러나 모든 복사는 작업 장치가 주 작업을 시작하기 전에 완료해야 합니다(출력 매트릭스 행 계산).
따라서 복사를 담당하는 루프 뒤에 다음 명령이 삽입됩니다.
barrier(CLK_LOCAL_MEM_FENCE);
이는 그룹 내의 각 작업 유닛이 다른 유닛과 조정된 특정 상태의 로컬 메모리를 "보기"할 수 있도록 하는 "로컬 메모리 벽"입니다. 작업 그룹의 모든 작업 단위는 커널 실행을 진행하기 전에 차단 범위까지 명령을 실행해야 합니다. 즉, 벽은 작업 그룹 내의 작업 단위 간의 특수한 동기화 메커니즘입니다.
작업 그룹 간의 동기화 메커니즘은 OpenCL에서 제공되지 않습니다.
다음은 작동 중인 벽의 예입니다:

그림 17. 작동 중인 벽
사실, 작업 그룹 내의 작업 단위가 코드를 엄격하게 동시에 실행하는 것처럼 보일 뿐입니다. 이는 OpenCL 프로그래밍 모델의 추상화일 뿐입니다.
지금까지 다른 작업 단위에서 실행되는 커널 코드는 커널에서 프로그래밍 방식으로 설정된 명시적 통신이 없었기 때문에 작업의 동기화가 필요하지 않았습니다. 게다가 필요하지도 않았습니다. 그러나 로컬 어레이를 채우는 프로세스가 작업 그룹의 모든 단위 간에 병렬로 분산되므로 이 커널에서 동기화가 필요합니다.
즉, 모든 작업 단위는 이 쓰기 프로세스에서 다른 작업 단위가 얼마나 긴지 알지 못한 채 로컬 데이터 공유(여기서 어레이)에 값을 기록합니다. 장벽은 로컬 배열이 완전히 생성되기 전에 특정 작업 단위가 커널 실행을 진행하지 않도록 하기 위해 존재합니다.
이러한 최적화가 CPU 성능에 거의 도움이 되지 않는다는 점을 이해해야 합니다. Intel의 OpenCL 최적화 가이드에 따르면 CPU에서 커널을 실행할 때 모든 OpenCL 메모리 개체가 하드웨어에 의해 캐시되므로 로컬 메모리를 사용하여 명시적으로 캐슁하면 불필요한(중간) 오버헤드가 발생한다고 합니다.
이 기사의 저자에게 많은 시간이 소요된 또 다른 중요한 점이 있습니다. 로컬 변수는 터미널의 개발자들이 구축한 현재 구현에서 커널 함수 헤더(즉 컴파일 단계에서)에 전달될 수 없다는 사실과 관련이 있습니다. 메모리 개체에 커널 함수 인수로 메모리를 할당하려면 먼저 CLBufferCreate() 함수를 사용하여 CPU 메모리에 해당 개체를 명시적으로 만들고 해당 크기를 함수 매개 변수로 명시적으로 지정해야 하기 때문입니다. 이 함수는 메모리 개체 핸들을 반환하며, 이 핸들은 글로벌 GPU 메모리에 저장될 수 있는 유일한 위치입니다.
그러나 로컬 메모리는 전역 메모리와는 다르기 때문에 생성된 메모리 개체를 작업 그룹의 로컬 메모리에 배치할 수 없습니다.
전체 기능을 갖춘 OpenCL API를 사용하면 메모리 개체(CLSetKernelArg() 함수)를 만들지 않더라도 포인터를 사용하여 필요한 크기의 메모리를 커널 인수에 명시적으로 할당할 수 있습니다. 그러나 CLSetKernelArgMem() 함수의 구문이 전체 기능 API 함수의 MQL5 아날로그인 경우 메모리 개체 자체를 만들지 않고 인수에 할당된 메모리 크기를 전달할 수 없습니다. CLSetKernelArgMem() 함수에 전달할 수 있는 내용은 글로벌 CPU 메모리에서이미 생성된 버퍼 핸들만 글로벌 GPU 메모리로 전송합니다. 역설은 이렇습니다.
다행히 커널에서 로컬 버퍼를 사용하는 것과 동일한 방법이 있습니다. 이러한 버퍼는 커널 본문에 __local 이라는 한정자를 사용하여 선언하면 됩니다. 작업 그룹에 할당된 로컬 메모리는 컴파일 단계 대신 런타임 중에 결정됩니다.
커널의 장벽 뒤에 오는 명령(코드의 장벽 줄은 빨간색으로 표시됨)은 기본적으로 이전 최적화와 동일합니다. 호스트 프로그램 코드는 그대로 유지됩니다(소스 코드는 matr_mul_col_local.mq5에서 찾을 수 있습니다).
다음은 새로운 커널 코드입니다:
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE rowbuf[ COLSROWS ]; \r\n" " for( int col = 0; col < COLSROWS; col ++ ) \r\n" " rowbuf[ col ] = in1[ r * COLSROWS + col ]; \r\n" " \r\n" " int idlocal = get_local_id( 0 ); \r\n" " int nlocal = get_local_size( 0 ); \r\n" " __local REALTYPE colbuf[ COLSROWS ] ; \r\n" " \r\n" " REALTYPE sum; \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " for( int cr = idlocal; cr < COLSROWS; cr = cr + nlocal ) \r\n" " colbuf[ cr ] = in2[ cr + c * COLSROWS ]; \r\n" " barrier( CLK_LOCAL_MEM_FENCE ); \r\n" " \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr ++ ) \r\n" " sum += rowbuf[ cr ] * colbuf[ cr ]; \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
목록 7. 작업 그룹의 로컬 메모리로 전송된 두 번째 배열의 열
2012.05.27 06:31:46 matr_mul_col_local (EURUSD,H1) CPUTime / GPUTotalTime = 17.630 2012.05.27 06:31:46 matr_mul_col_local (EURUSD,H1) OpenCL total: time = 5.227 sec. 2012.05.27 06:31:46 matr_mul_col_local (EURUSD,H1) read = 4000000 elements 2012.05.27 06:31:40 matr_mul_col_local (EURUSD,H1) CPUTime = 92.150 2012.05.27 06:30:08 matr_mul_col_local (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 06:30:08 matr_mul_col_local (EURUSD,H1) =======================================GPU:
2012.05.27 06:21:36 matr_mul_col_local (EURUSD,H1) CPUTime / GPUTotalTime = 58.069 2012.05.27 06:21:36 matr_mul_col_local (EURUSD,H1) OpenCL total: time = 1.592 sec. 2012.05.27 06:21:36 matr_mul_col_local (EURUSD,H1) read = 4000000 elements 2012.05.27 06:21:34 matr_mul_col_local (EURUSD,H1) CPUTime = 92.446 2012.05.27 06:20:01 matr_mul_col_local (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 06:20:01 matr_mul_col_local (EURUSD,H1) =======================================
두 경우 모두 유의하다고 할 수 없는 성능 저하를 보여 줍니다. 작업 그룹의 크기를 변경함으로써 성능이 저하되지 않고 개선될 수 있습니다. 위의 예제는 로컬 메모리 개체를 사용하는 방법을 보여 주는 다른 용도로 사용할 수 있습니다.
로컬 메모리를 사용할 때 성능 저하를 설명하는 가설이 있습니다. 약 2년 전 habrahabr.ru에 게재된 OpenCL을 CUDA, GLSL 및 OpenMP와 비교한 기사에는 다음과 같은 내용이 나와 있습니다.
즉, 2년 전에 출시된 제품의 로컬 메모리가 글로벌 메모리보다 빠르지 않다는 뜻입니까? 위 내용이 게시된 시점은 2년 전 라데온(Radeon) HD 58xx 시리즈 비디오 카드가 이미 출시됐음을 시사하는 것으로 저자는 낙관과는 거리가 멀었습니다. 특히 AMD의 선정적인 에버그린 시리즈를 볼 때 믿기 어렵습니다. HD 69xx 시리즈와 같은 좀 더 현대적인 카드를 사용하여 확인해 보면 흥미로울 것입니다.
추가: GPU Caps Viewer를 시작하면 OpenCL 탭에 다음 항목이 표시됩니다:

그림 18. HD 4870에서 지원되는 주요 OpenCL 매개변수
CL_DEVICE_LOCAL_MEM_TYPE: Global
언어 사양(표 4.3)에 제공되는 매개변수에 대한 설명 다음과 같습니다(페이지 41):
지원되는 로컬 메모리 유형 이 값은 SRAM 또는 CL_GLOBAL과 같은 전용 로컬 메모리 저장소를 의미하는 CL_LOCAL로 설정할 수 있습니다.
따라서 HD 4870 로컬 메모리는 실제로 글로벌 메모리의 일부이며, 따라서 이 비디오 카드의 로컬 메모리 조작은 무용지물이며 글로벌 메모리보다 빠른 결과를 가져오지 않습니다. 여기에서는 AMD 전문가가 HD 4xxx 시리즈에 대해 이 점을 명확히 설명하는 또 다른 링크입니다. 이것은 반드시 보유하고 있는 비디오 카드에 나쁘다는 것을 의미하지는 않습니다. 이 경우 GPU Caps Viewer에서 하드웨어와 관련된 정보를 찾을 수 있는 위치를 보여주기 위한 것입니다.
throughput_arithmetic_CPU_OCL = 16 000000000 / 5.227 ~ 3.061 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 1.592 ~ 10.050 GFlops.
마지막으로 커널을 명시적으로 벡터화하여 몇 가지 마무리 작업을 추가하겠습니다. 첫 번째 어레이의 행을 전용 메모리(matr_mul_row_in_private.mq5)로 전송하는 단계에서 파생된 커널이 가장 빠른 것으로 나타났으므로 초기 커널 역할을 합니다.
2.8. 커널 벡터화
혼동을 방지하기 위해 이 작업을 여러 단계로 세분화하는 것이 좋습니다. 초기 수정에서는 커널 외부 파라미터의 데이터 유형을 변경하지 않고 내부 루프에서만 계산을 벡터화합니다:
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" "#define REALTYPE4 float4 \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE rowbuf[ COLSROWS ]; \r\n" " for( int col = 0; col < COLSROWS; col ++ ) \r\n" " { \r\n" " rowbuf[ col ] = in1[r * COLSROWS + col ]; \r\n" " } \r\n" " \r\n" " REALTYPE sum; \r\n" " \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS; cr += 4 ) \r\n" " sum += dot( ( REALTYPE4 ) ( rowbuf[ cr ], \r\n" " rowbuf[ cr + 1 ], \r\n" " rowbuf[ cr + 2 ], \r\n" " rowbuf[ cr + 3 ] ), \r\n" " ( REALTYPE4 ) ( in2[c * COLSROWS + cr ], \r\n" " in2[c * COLSROWS + cr + 1 ], \r\n" " in2[c * COLSROWS + cr + 2 ], \r\n" " in2[c * COLSROWS + cr + 3 ] ) ); \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
목록 8. float4를 사용한 커널의 부분 벡터화(내부 루프만 해당)입니다.
CPU:
2012.05.27 21:28:16 matr_mul_vect (EURUSD,H1) CPUTime / GPUTotalTime = 18.657 2012.05.27 21:28:16 matr_mul_vect (EURUSD,H1) OpenCL total: time = 4.945 sec. 2012.05.27 21:28:16 matr_mul_vect (EURUSD,H1) read = 4000000 elements 2012.05.27 21:28:11 matr_mul_vect (EURUSD,H1) CPUTime = 92.259 2012.05.27 21:26:38 matr_mul_vect (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 21:26:38 matr_mul_vect (EURUSD,H1) =======================================
GPU:
2012.05.27 21:21:30 matr_mul_vect (EURUSD,H1) CPUTime / GPUTotalTime = 78.079 2012.05.27 21:21:30 matr_mul_vect (EURUSD,H1) OpenCL total: time = 1.186 sec. 2012.05.27 21:21:30 matr_mul_vect (EURUSD,H1) read = 4000000 elements 2012.05.27 21:21:28 matr_mul_vect (EURUSD,H1) CPUTime = 92.602 2012.05.27 21:19:55 matr_mul_vect (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 21:19:55 matr_mul_vect (EURUSD,H1) =======================================
놀랍게도, 이러한 원시 벡터화도 GPU에서 좋은 결과를 산출했습니다; 그리 대단한 것은 아니지만, 약 10%의 이득이 있었습니다.
커널 내부에서 계속 벡터화: 명시적 벡터 구성요소의 사양과 함께 '비용이 많이 드는' REALTYPE4 벡터 유형 변환 연산을 사설 변수 rowbuf[]를 채우는 외부 보조 루프에 전송합니다. 커널에 여전히 변경 사항이 없습니다.
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" "#define REALTYPE4 float4 \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE4 rowbuf[ COLSROWS / 4 ]; \r\n" " for( int col = 0; col < COLSROWS / 4; col ++ ) \r\n" " { \r\n" " rowbuf[ col ] = ( REALTYPE4 ) ( in1[r * COLSROWS + 4 * col ], \r\n" " in1[r * COLSROWS + 4 * col + 1 ], \r\n" " in1[r * COLSROWS + 4 * col + 2 ], \r\n" " in1[r * COLSROWS + 4 * col + 3 ] ); \r\n" " } \r\n" " \r\n" " REALTYPE sum; \r\n" " \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS / 4; cr ++ ) \r\n" " sum += dot( rowbuf[ cr ], \r\n" " ( REALTYPE4 ) ( in2[c * COLSROWS + 4 * cr ], \r\n" " in2[c * COLSROWS + 4 * cr + 1 ], \r\n" " in2[c * COLSROWS + 4 * cr + 2 ], \r\n" " in2[c * COLSROWS + 4 * cr + 3 ] ) ); \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
목록 9. 커널의 기본 루프에서 형식 변환의 '비용이 많이 드는' 작업을 제거합니다.
이제 첫 번째 어레이에 필요한 판독 작업이 이전보다 4배 줄어들었기 때문에 내부(보조) 루프 카운터의 최대 카운트 값이 4배 낮아졌습니다. 즉, 판독값이 벡터 연산이 된 것이 분명합니다.
2012.05.27 22:41:43 matr_mul_vect_v2 (EURUSD,H1) CPUTime / GPUTotalTime = 24.480 2012.05.27 22:41:43 matr_mul_vect_v2 (EURUSD,H1) OpenCL total: time = 3.791 sec. 2012.05.27 22:41:43 matr_mul_vect_v2 (EURUSD,H1) read = 4000000 elements 2012.05.27 22:41:39 matr_mul_vect_v2 (EURUSD,H1) CPUTime = 92.805 2012.05.27 22:40:06 matr_mul_vect_v2 (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 22:40:06 matr_mul_vect_v2 (EURUSD,H1) =======================================GPU:
2012.05.27 22:35:28 matr_mul_vect_v2 (EURUSD,H1) CPUTime / GPUTotalTime = 185.605 2012.05.27 22:35:28 matr_mul_vect_v2 (EURUSD,H1) OpenCL total: time = 0.499 sec. 2012.05.27 22:35:28 matr_mul_vect_v2 (EURUSD,H1) read = 4000000 elements 2012.05.27 22:35:27 matr_mul_vect_v2 (EURUSD,H1) CPUTime = 92.617 2012.05.27 22:33:54 matr_mul_vect_v2 (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 22:33:54 matr_mul_vect_v2 (EURUSD,H1) =======================================산술 처리량:
throughput_arithmetic_CPU_OCL = 16 000000000 / 3.791 ~ 4.221 GFlops. throughput_arithmetic_GPU_OCL = 16 000000000 / 0.499 ~ 32.064 GFlops.
보시다시피 CPU의 성능 변화는 상당히 큰 반면 GPU의 성능 변화는 거의 혁신적입니다. 소스 코드는 matr_mul_vect_v2.mq5에서 찾을 수 있습니다.
마지막 커널 변형에 대해 벡터 폭 8만 사용하여 동일한 작업을 수행하도록 하겠습니다. 저자의 결정은 GPU 메모리 대역폭이 256비트(예: 32바이트 또는 8개의 플로트 유형)라는 사실로 설명될 수 있습니다. 따라서 플로트 8의 동시 사용에 해당하는 플로트 8의 동시 처리는 매우 자연스러운 것으로 보입니다.
이 경우 COLSROWS 값은 8로 적분해야 합니다. 이는 자연스런 요구 사항으로, 미세한 최적화가 보다 구체적인 요구 사항을 데이터로 설정하기 때문입니다.
const string clSrc = "#define COLS2 " + i2s( COLS2 ) + " \r\n" "#define COLSROWS " + i2s( COLSROWS ) + " \r\n" "#define REALTYPE float \r\n" "#define REALTYPE4 float4 \r\n" "#define REALTYPE8 float8 \r\n" " \r\n" "inline REALTYPE dot8( REALTYPE8 a, REALTYPE8 b ) \r\n" "{ \r\n" " REALTYPE8 c = a * b; \r\n" " REALTYPE4 _1 = ( REALTYPE4 ) 1.; \r\n" " return( dot( c.lo + c.hi, _1 ) ); \r\n" "} \r\n" " \r\n" "__kernel void matricesMul( __global REALTYPE *in1, \r\n" " __global REALTYPE *in2, \r\n" " __global REALTYPE *out ) \r\n" "{ \r\n" " int r = get_global_id( 0 ); \r\n" " REALTYPE8 rowbuf[ COLSROWS / 8 ]; \r\n" " for( int col = 0; col < COLSROWS / 8; col ++ ) \r\n" " { \r\n" " rowbuf[ col ] = ( REALTYPE8 ) ( in1[r * COLSROWS + 8 * col ], \r\n" " in1[r * COLSROWS + 8 * col + 1 ], \r\n" " in1[r * COLSROWS + 8 * col + 2 ], \r\n" " in1[r * COLSROWS + 8 * col + 3 ], \r\n" " in1[r * COLSROWS + 8 * col + 4 ], \r\n" " in1[r * COLSROWS + 8 * col + 5 ], \r\n" " in1[r * COLSROWS + 8 * col + 6 ], \r\n" " in1[r * COLSROWS + 8 * col + 7 ] ); \r\n" " } \r\n" " \r\n" " REALTYPE sum; \r\n" " \r\n" " for( int c = 0; c < COLS2; c ++ ) \r\n" " { \r\n" " sum = 0.0; \r\n" " for( int cr = 0; cr < COLSROWS / 8; cr ++ ) \r\n" " sum += dot8( rowbuf[ cr ], \r\n" " ( REALTYPE8 ) ( in2[c * COLSROWS + 8 * cr ], \r\n" " in2[c * COLSROWS + 8 * cr + 1 ], \r\n" " in2[c * COLSROWS + 8 * cr + 2 ], \r\n" " in2[c * COLSROWS + 8 * cr + 3 ], \r\n" " in2[c * COLSROWS + 8 * cr + 4 ], \r\n" " in2[c * COLSROWS + 8 * cr + 5 ], \r\n" " in2[c * COLSROWS + 8 * cr + 6 ], \r\n" " in2[c * COLSROWS + 8 * cr + 7 ] ) ); \r\n" " out[ r * COLS2 + c ] = sum; \r\n" " } \r\n" "} \r\n" ;
목록 10. 8의 벡터 폭을 사용한 커널 벡터화
우리는 너비가 8인 벡터의 스칼라 제품을 계산할 수 있는 인라인 함수 dot8()을 커널 코드에 삽입해야 했습니다. OpenCL에서 표준 함수, standard function dot()은 너비 4까지의 벡터에 대해서만 스칼라 곱을 계산할 수 있습니다. 소스 코드는 matr_mul_vect_v3.mq5에서 찾을 수 있습니다.
2012.05.27 23:11:47 matr_mul_vect_v3 (EURUSD,H1) CPUTime / GPUTotalTime = 45.226 2012.05.27 23:11:47 matr_mul_vect_v3 (EURUSD,H1) OpenCL total: time = 2.200 sec. 2012.05.27 23:11:47 matr_mul_vect_v3 (EURUSD,H1) read = 4000000 elements 2012.05.27 23:11:45 matr_mul_vect_v3 (EURUSD,H1) CPUTime = 99.497 2012.05.27 23:10:05 matr_mul_vect_v3 (EURUSD,H1) 1st OCL martices mul: device = 0; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 23:10:05 matr_mul_vect_v3 (EURUSD,H1) =======================================GPU:
2012.05.27 23:20:05 matr_mul_vect_v3 (EURUSD,H1) CPUTime / GPUTotalTime = 170.115 2012.05.27 23:20:05 matr_mul_vect_v3 (EURUSD,H1) OpenCL total: time = 0.546 sec. 2012.05.27 23:20:05 matr_mul_vect_v3 (EURUSD,H1) read = 4000000 elements 2012.05.27 23:20:04 matr_mul_vect_v3 (EURUSD,H1) CPUTime = 92.883 2012.05.27 23:18:31 matr_mul_vect_v3 (EURUSD,H1) 1st OCL martices mul: device = 1; ROWS1 = 2000; COLSROWS = 2000; COLS2 = 2000 2012.05.27 23:18:31 matr_mul_vect_v3 (EURUSD,H1) =======================================
T결과는 예상하지 못했습니다: CPU의 런타임이 이전보다 거의 두 배 줄어든 반면, float8이 HD 4870(256비트)에 적합한 버스 폭임에도 불구하고 GPU의 경우 약간 증가했습니다. 여기서는 GPU Caps Viewer를 다시 사용합니다.
설명은 매개변수 목록의 마지막 한줄의 그림 18에서 찾을 수 있습니다:
CL_DEVICE_PREFERRED_VECTOR_WIDTH_FLOAT: 4
OpenCL 사양을 참조하면 37페이지의 표 4.3 마지막 열에 이 매개변수에 대한 다음 텍스트가 표시됩니다:
벡터에 넣을 수 있는 기본 제공 스칼라 유형에 선호되는 기본 벡터 폭 크기입니다. 벡터 폭은 벡터에 저장할 수 있는 스칼라 요소의 수로 정의됩니다.
따라서 HD 4870의 경우, 벡터 플로트 N의 선호 벡터 폭은 float8 대신 float4입니다.
이제 커널 최적화 사이클을 마칩니다. 우리는 더 많은 것을 성취할 수 있지만 이 글의 길이는 그 정도의 토론은 허용하지 않습니다.
결론
이 문서에서는 커널이 실행되는 기본 하드웨어에 대한 고려 사항이 있을 때 열리는 몇 가지 최적화 기능을 보여 주었습니다.
얻어진 수치는 상한값과는 거리가 멀지만 현재 사용 가능한 기존 리소스(터미널의 개발자가 구현한 OpenCL API는 최적화에 중요한 일부 매개 변수 - 특히 작업 그룹 크기)를 제어할 수 없다는 것을 암시합니다. 호스트 프로그램 실행에 대한 성능 향상은 매우 중요합니다. CPU의 순차적 프로그램에 대한 GPU의 실행 이득은 (매우 최적화되지는 않았지만) 약 200:1입니다.
소중한 조언과 별도의 GPU를 사용할 수 있는 기회를 주신 MetaDriver에게 진심으로 감사드립니다.
첨부된 파일의 내용:
- matr_mul_2dim.mq5 - 2차원 데이터 표현을 사용하는 호스트의 초기 순차적 프로그램;
- matr_mul_1dim.mq5 - 선형 데이터 표현과 MQL5 OpenCL API에 대한 관련 바인딩을 포함한 커널의 첫 번째 구현;
- matr_mul_1dim_coalesced - 병합된 글로벌 메모리 액세스를 특징으로 하는 커널;
- matr_mul_sum_local - 글로벌 메모리에 저장된 출력 배열의 계산된 셀에 액세스하는 대신 스칼라 제품 계산에 도입된 전용 변수;
- matr_mul_row_calc - 커널에 있는 출력 매트릭스의 전체 행의 계산;
- matr_mul_row_in_private - 개인 메모리로 전송된 첫 번째 배열의 행;
- matr_mul_col_local.mq5 - 로컬 메모리로 전송된 두 번째 배열의 열;
- matr_mul_vect.mq5 - 커널의 첫 번째 벡터화(float4 사용, 메인 루프의 내부 하위 루프만 사용);
- matr_mul_vect_v2.mq5 - 메인 루프에서 데이터 변환의 '비용이 많이 드는' 연산 제거;
- matr_mul_vect_v3.mq5 - 벡터 너비 8을 사용한 벡터화
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/407
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

 자동 거래 시스템(Automata-Based Programming)을 위한 새로운 접근 방식
자동 거래 시스템(Automata-Based Programming)을 위한 새로운 접근 방식
 가장 활동적인 MQL5. 커뮤니티 구성원에게 iPhone이 수여되었습니다!
가장 활동적인 MQL5. 커뮤니티 구성원에게 iPhone이 수여되었습니다!
 MQL5 시장이 판매 전략 및 기술 지표에 가장 적합한 이유는 무엇입니까?
MQL5 시장이 판매 전략 및 기술 지표에 가장 적합한 이유는 무엇입니까?
시세도 동기화해야 하나요?
추신: 도움말을 읽어보니 동기화가 필요하다는 것을 알았습니다.
하드웨어 업그레이드를 고려하여 기사의 결과를 다시 계산했습니다.
1년 전: 인텔 펜티엄 G840 CPU(2코어 @ 2.8GHz) + AMD HD4870 비디오 카드.
최근: CPU 인텔 제온 E3-1230v2(4코어/8스레드 @ 3.3GHz, i7-3770보다 약간 뒤처짐) + AMD HD 비디오 카드.6 870.
OpenCL의 계산 결과는 그래프에 표시됩니다(가로-기사에 적용된 최적화 횟수):
계산 시간은 초 단위로 세로로 표시됩니다. "CPU에서 한 번의 타격으로" 스크립트의 실행 시간 (OpenCL없이 하나의 코어에서)은 알고리즘 변경에 따라 95 초 이상 25 초 이내에 다양했습니다.
보시다시피 모든 것이 명확해 보이지만 여전히 명확하지는 않습니다.
명백한 외부인은 듀얼 코어 G840입니다. 글쎄, 그것은 예상되었습니다. 추가 최적화는 실행 시간을 크게 변경하지 않았으며 4 초에서 5.5 초까지 다양했습니다. 이 경우에도 스크립트 실행 가속도는 20배 이상의 값에 도달했습니다.
서로 다른 세대의 두 비디오 카드, 즉 구형 HD4870과 최신 HD6870 간의 경쟁에서 6870이 거의 승자라고 볼 수 있습니다. 고대 괴물 4870이 여전히 명목상의 승리를 거두었던 마지막 최적화 단계를 제외하고는 (거의 항상 뒤처졌지만). 솔직히 말해서 그 이유는 불분명합니다. 셰이더가 더 작고 빈도도 낮지만 여전히 이겼습니다.
이것이 여러 세대의 비디오 카드 개발의 변화라고 가정 해 봅시다. 또는 내 알고리즘의 오류 :)
나는 솔직히 모든 최적화에서 고대 4870보다 낫고 거의 동일한 조건에서 6870과 싸웠고 결국에는 그들 모두를 이길 수 있었던 Xeon에 만족했습니다. 모든 작업에서 항상 그렇게 될 것이라고 말하는 것은 아닙니다. 그러나 이 작업은 계산적으로 매우 어려웠습니다. 결국 2000 x 2000 크기의 두 행렬을 곱하는 것이었기 때문입니다!
결론은 간단합니다. 이미 i7과 같은 적절한 CPU가 있고 OpenCL 계산이 너무 길지 않다면 추가 강력한 히터 (비디오 카드)가 필요하지 않을 수 있습니다. 반면에 수십 초 동안 (긴 계산 중에) 돌을 100%로로드하는 것은 컴퓨터가이 시간 동안 "응답 성을 잃기"때문에 그다지 즐겁지 않습니다.
안녕하세요,
OpenCL이 EveryTick 모드에서 EA 백테스팅 속도를 어떻게 높일 수 있는지 예를 들어 설명해 주시겠습니까? 현재 EveryTick 모드에서 14년 데이터를 실행하는 데 18분이 걸립니다. OpenCL로 테스트 시간을 50% 단축할 수 있다면 많은 트레이더가 관심을 가질 것이라고 생각합니다.
훌륭한 기사, 나는 루프 내부에서 개인 메모리로 행의 전송을 외부로 이동하는 것이 어떻게 속도를 높이는 지 이해하지 못했습니다.
어쨌든 동일한 전송 작업이 발생하지만 내 코드에는 아무런 영향을 미치지 않지만 물론 각 경우가 다릅니다. (그러나 무언가를 추가 한 후 다시 0 영향은 속도가 빨라졌지만 이득이 없음을 의미합니다).
OpenCL 소스에서 이 부분 :
크런치 루프 외부로 이동하는 곳
고마워요