Artículos sobre programación y uso de robots comerciales en el lenguaje MQL5
Los Asesores Expertos creados para la plataforma MetaTrader ejecutan una gran variedad de funciones ideadas por sus desarrolladores. Los robots comerciales son capaces de realizar el seguimiento de los instrumentos financieros 24 horas al día, copiar las operaciones, confeccionar y enviar los informes, analizar las noticias, e incluso facilitar al operador una interfaz gráfica personalizada desarrollada por encargo.
Los artículos contienen las técnicas de programación, ideas matemáticas para el procesamiento de datos, consejos para la creación y el encargo de robots comerciales.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Cómo construir un EA que opere automáticamente (Parte 07): Tipos de cuentas (II)
Aprenda a crear un EA que opere automáticamente de forma sencilla y segura. Uno siempre debe estar al tanto de lo que está haciendo un EA automatizado, y si se descarrila, eliminarlo lo más rápido posible del gráfico, para poner fin a lo que él estaba haciendo y evitar que las cosas se salgan de control.
Preparación de indicadores de símbolo/periodo múltiple
En este artículo analizaremos los principios de la creación de los indicadores de símbolo/periodo múltiple y la obtención de datos de ellos en asesores e indicadores. Asimismo, veremos los principales matices de uso de los indicadores múltiples en asesores e indicadores, y su representación a través de los búferes del indicador personalizado.

Redes neuronales: así de sencillo (Parte 46): Aprendizaje por refuerzo dirigido a objetivos (GCRL)
En el artículo de hoy, nos familiarizaremos con otra tendencia en el campo del aprendizaje por refuerzo. Se denomina aprendizaje por refuerzo dirigido a objetivos (Goal-conditioned reinforcement learning, GCRL). En este enfoque, el agente se entrenará para alcanzar diferentes objetivos en determinados escenarios.

Redes neuronales: así de sencillo (Parte 73): AutoBots para predecir la evolución de los precios
Seguimos hablando de algoritmos para entrenar modelos de predicción de trayectorias. En este artículo nos familiarizaremos con un método llamado "AutoBots".

Añadimos un LLM personalizado a un robot comercial (Parte 1): Desplegando el equipo y el entorno
Los modelos lingüísticos (LLM) son una parte importante de la inteligencia artificial que evoluciona rápidamente, por lo que debemos plantearnos cómo integrar unos LLM potentes en nuestro comercio algorítmico. A la mayoría de la gente le resulta difícil personalizar estos potentes modelos para adaptarlos a sus necesidades, implantarlos de forma local y luego aplicarlos al trading algorítmico. En esta serie de artículos abordaremos un enfoque paso a paso para lograr este objetivo.

Redes neuronales: así de sencillo (Parte 30): Algoritmos genéticos
En el artículo de hoy, hablaremos de un método de aprendizaje ligeramente distinto. Podríamos decir que lo hemos tomado de la teoría de la evolución de Darwin. Probablemente resulte menos controlable que los métodos anteriormente mencionados, pero también nos permite entrenar modelos indiferenciados.

Creación de un modelo de restricción de tendencia de velas (Parte 3): Detección de cambios en las tendencias al utilizar este sistema
Este artículo explora cómo las noticias económicas, el comportamiento de los inversores y diversos factores pueden influir en los cambios de tendencia del mercado. Incluye un vídeo explicativo y procede incorporando código MQL5 a nuestro programa para detectar los cambios de tendencia, alertarnos y tomar las medidas oportunas en función de las condiciones del mercado. Este artículo se basa en otros anteriores de la serie.

Desarrollo de un EA comercial desde cero (Parte 27): Rumbo al futuro (II)
Sigamos avanzando hacia un sistema de órdenes más completo directamente en el gráfico. En este artículo les mostraré una forma de corregir o, más bien, de hacer que el sistema de órdenes sea más intuitivo.

Cómo construir un EA que opere automáticamente (Parte 10): Automatización (II)
La automatización no significa nada si no se puede controlar el horario. Ningún trabajador puede ser eficiente trabajando 24 horas al día. Sin embargo, muchos creen que un sistema automatizado debe trabajar 24 horas al día. Siempre es bueno tener formas de configurar una franja horaria para el Expert Advisor. En este artículo, vamos a discutir cómo agregar correctamente tal franja horaria.

Redes neuronales: así de sencillo (Parte 57): Stochastic Marginal Actor-Critic (SMAC)
Hoy le proponemos introducir un algoritmo bastante nuevo, el Stochastic Marginal Actor-Critic (SMAC), que permite la construcción de políticas de variable latente dentro de un marco de maximización de la entropía.

Desarrollo y prueba de los sistemas comerciales Aroon
En este artículo, aprenderemos a construir un sistema comercial Aroon, aprendiendo asimilando los fundamentos de los indicadores y los pasos necesarios para crear un sistema comercial basado en el indicador Aroon. Una vez creado este sistema comercial, comprobaremos si puede ser rentable o necesita una mayor optimización.

Redes neuronales: así de sencillo (Parte 47): Espacio continuo de acciones
En este artículo ampliamos el abanico de tareas de nuestro agente. El proceso de entrenamiento incluirá algunos aspectos de la gestión de capital y del riesgo que forma parte integral de cualquier estrategia comercial.

Implementación de un algoritmo de trading de negociación rápida utilizando SAR Parabólico (Stop and Reverse, SAR) y Media Móvil Simple (Simple Moving Average, SMA) en MQL5
En este artículo, desarrollamos un Asesor Experto de trading de ejecución rápida en MQL5, aprovechando los indicadores SAR Parabólico (Stop and Reverse, SAR) y Media Móvil Simple (Simple Moving Average, SMA) para crear una estrategia de trading reactiva y eficiente. Detallamos la implementación de la estrategia, incluyendo el uso de los indicadores, la generación de señales y el proceso de prueba y optimización.

Características del Wizard MQL5 que debe conocer (Parte 3): Entropía de Shannon
El tráder moderno está casi siempre a la búsqueda de nuevas ideas, probando constantemente nuevas estrategias, modificándolas y descartando las que han fracasado. En esta serie de artículos, intentaré demostrar que el Wizard MQL5 es un verdadero apoyo para el tráder.

Otras clases en la biblioteca DoEasy (Parte 71): Eventos de la colección de objetos de gráfico
En el presente artículo, crearemos la funcionalidad necesaria para monitorear algunos eventos de los objetos del gráfico: añadir y eliminar gráficos de símbolos, añadir y eliminar subventanas en el gráfico, y también añadir/eliminar/cambiar indicadores en las ventanas del gráfico.

Desarrollo de un EA comercial desde cero (Parte 24): Dotando de robustez al sistema (I)
En este artículo haremos que el sistema sea más robusto, para que sea más estable y seguro de usar. Una forma de conseguir robustez es intentar reutilizar el código lo máximo posible, de esta forma él mismo será probado todo el tiempo y en diversas ocasiones. Pero esta es solo una de las formas, otra forma es el uso de la programación OOP.

Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 3): Prefijos/sufijos de símbolos y sesión comercial
Últimamente, he recibido comentarios de varios compañeros tráders sobre cómo usar el asesor multidivisa que estamos analizando con brókeres que utilizan prefijos y/o sufijos con nombres de símbolos, así como sobre la forma de implementar zonas horarias comerciales o sesiones comerciales en el asesor.
Introducción a MQL5 (Parte 17): Creación de asesores expertos para reversiones de tendencias
Este artículo enseña a los principiantes cómo crear un Asesor Experto (EA) en MQL5 que opera basándose en el reconocimiento de patrones gráficos utilizando rupturas y reversiones de líneas de tendencia. Al aprender a recuperar dinámicamente los valores de las líneas de tendencia y compararlos con la evolución de los precios, los lectores podrán desarrollar EA capaces de identificar y operar con patrones gráficos como líneas de tendencia ascendentes y descendentes, canales, cuñas, triángulos y mucho más.

Implementando OLAP en la negociación (Parte 2): Visualización de los resultados del análisis interactivo de los datos multidimensionales
En este artículo, se consideran diversos aspectos del desarrollo de la interfaz gráfica interactiva de un programa MQL diseñado para el procesamiento analítico en línea (OLAP) del historial de la cuenta y de los informes comerciales. Para obtener un resultado visual, se usan las ventanas maximizadas y de escala, una disposición adaptable de los controles «de goma» y un nuevo control para mostrar diagramas. A base de eso, fue implementado GUI con una selección de indicadores a lo largo de los ejes de coordenadas, funciones agregadas, tipos de los gráficos y ordenaciones.
Redes neuronales en el trading: Modelo de doble atención para la previsión de tendencias
Continuamos la conversación sobre el uso de la representación lineal por partes de las series temporales iniciada en el artículo anterior. Y hoy hablaremos de la combinación de este método con otros enfoques del análisis de series temporales para mejorar la calidad de la previsión de la tendencia del movimiento de precios.
Redes neuronales: así de sencillo (Parte 45): Entrenando habilidades de exploración de estados
El entrenamiento de habilidades útiles sin una función de recompensa explícita es uno de los principales desafíos del aprendizaje por refuerzo jerárquico. Ya nos hemos familiarizado antes con dos algoritmos para resolver este problema, pero el tema de la exploración del entorno sigue abierto. En este artículo, veremos un enfoque distinto en el entrenamiento de habilidades, cuyo uso dependerá directamente del estado actual del sistema.
Redes neuronales: así de sencillo (Parte 22): Aprendizaje no supervisado de modelos recurrentes
Continuamos analizando los algoritmos de aprendizaje no supervisado. Hoy hablaremos sobre el uso de autocodificadores en el entrenamiento de modelos recurrentes.

Usamos algoritmos de optimización para ajustar los parámetros del asesor sobre la marcha
El artículo analizará diversos aspectos prácticos relacionados con el uso de algoritmos de optimización para encontrar los mejores parámetros de un asesor sobre la marcha, y también virtualizar las operaciones comerciales y la lógica del asesor. El lector puede usar este artículo a modo de instrucciones para implementar algoritmos de optimización en un asesor comercial.

Características del Wizard MQL5 que debe conocer (Parte 1): Análisis de regresión
De manera consciente o inconsciente, el tráder moderno está casi siempre en busca de nuevas ideas, probando constantemente nuevas estrategias, modificándolas y descartando las que han fracasado. Este proceso de investigación requiere mucho tiempo y se ve acompañado por muchos errores. En esta serie de artículos, intentaré demostrar que el Wizard MQL5 es un verdadero apoyo para el tráder. Gracias al Wizard, el tráder podrá ahorrar tiempo a la hora de poner en práctica sus ideas. Asimismo, podrá reducir la probabilidad de que surjan errores por duplicación de código. En lugar de perder el tiempo con el código, los tráders tendrán la posibilidad de poner en práctica su filosofía comercial.
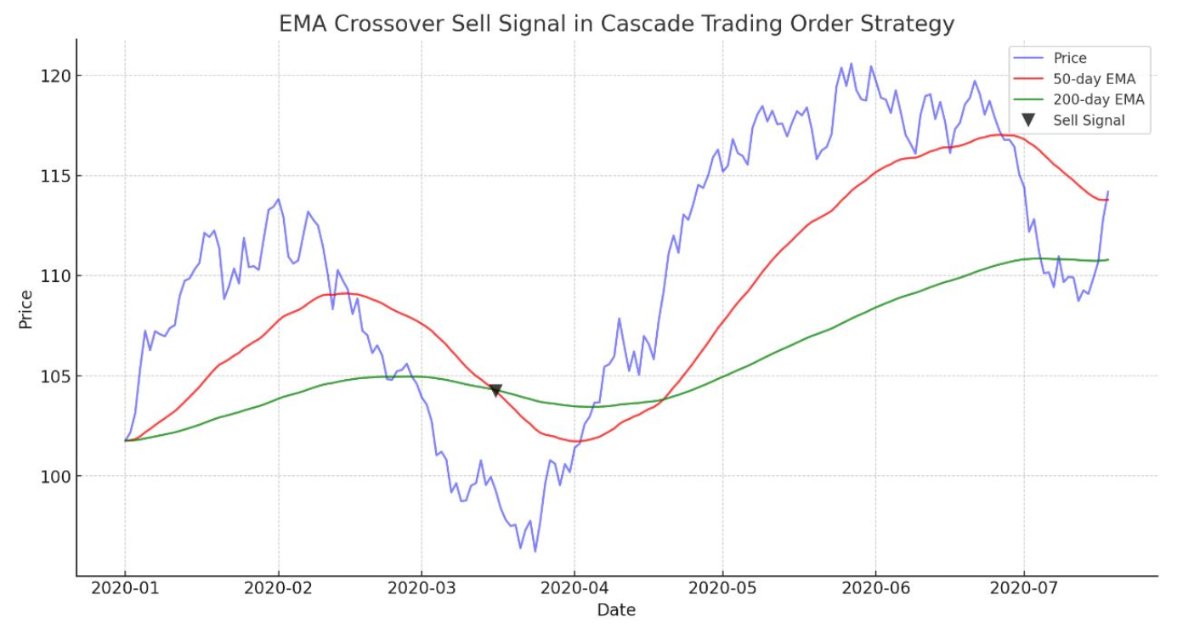
Estrategia de negociación de órdenes en cascada basada en cruces de EMA para MetaTrader 5
El artículo guía en la demostración de un algoritmo automatizado basado en cruces de EMA para MetaTrader 5. Información detallada sobre todos los aspectos de la demostración de un Asesor Experto en MQL5 y su prueba en MetaTrader 5, desde el análisis del comportamiento del rango de precios hasta la gestión de riesgos.
Otras clases en la biblioteca DoEasy (Parte 69): Clases de colección de objetos de gráfico
A partir de este artículo, comenzaremos el desarrollo de una colección de clases de objetos de gráfico que almacenará una colección de lista de objetos de gráfico con sus subventanas y los indicadores en ellas, y nos permitirá trabajar con cualquier gráfico seleccionado y sus subventanas, o bien directamente con una lista de varios gráficos al mismo tiempo.

Redes neuronales: así de sencillo (Parte 59): Dicotomía de control (DoC)
En el artículo anterior nos familiarizamos con el transformador de decisión. Sin embargo, el complejo entorno estocástico del mercado de divisas no nos permitió aprovechar plenamente el potencial del método presentado. Hoy veremos un algoritmo que tiene como objetivo mejorar el rendimiento de los algoritmos en entornos estocásticos.

Desarrollando un cliente MQTT para MetaTrader 5: metodología de TDD
El presente artículo representa el primer intento de desarrollar un cliente MQTT nativo para MQL5. El MQTT es un protocolo de comunicación "publicación-suscripción". Es ligero, abierto, simple y está diseñado para implementarse con facilidad, lo cual permite su uso en muchas situaciones.

Desarrollo de un EA comercial desde cero (Parte 29): Plataforma parlante
En este artículo aprenderemos a hacer hablar a la plataforma MT5. ¿Qué tal si hacemos que el EA sea más divertido? Operar en los mercados financieros suele ser una actividad extremadamente aburrida y monótona, pero podemos hacerla un poco menos tediosa. Este proyecto podría ser peligroso en caso de que tengas un problema que te haga adicto, pero en realidad con las modificaciones todo el escenario podría ser más entretenido, menos aburrido.

Desarrollamos un asesor experto multidivisa (Parte 14): Cambio de volumen adaptable en el gestor de riesgos
El gestor de riesgos que hemos desarrollado en los últimos artículos solo contiene funciones básicas. Hoy trataremos de analizar sus posibles formas de desarrollo, lo que nos permitirá aumentar los resultados comerciales sin interferir con la lógica de las estrategias de negociación.

Redes neuronales: así de sencillo (Parte 23): Creamos una herramienta para el Transfer Learning
En esta serie de artículos, hemos mencionado el Aprendizaje por Transferencia más de una vez, pero hasta ahora no había sido más que una mención. Le propongo rellenar este vacío y analizar más de cerca el Aprendizaje por Transferencia.

Redes neuronales: así de sencillo (Parte 58): Transformador de decisión (Decision Transformer-DT)
Continuamos nuestro análisis de los métodos de aprendizaje por refuerzo. Y en el presente artículo, presentaremos un algoritmo ligeramente distinto que considera la política del Agente en un paradigma de construcción de secuencias de acciones.

Redes neuronales: así de sencillo (Parte 67): Utilizamos la experiencia adquirida para afrontar nuevos retos
En este artículo, seguiremos hablando de los métodos de recopilación de datos en una muestra de entrenamiento. Obviamente, en el proceso de entrenamiento será necesaria una interacción constante con el entorno, aunque con frecuencia se dan situaciones diferentes.

Desarrollamos un Asesor Experto multidivisas (Parte 2): Transición a posiciones virtuales de estrategias comerciales
Hoy continuaremos con el desarrollo de un asesor multidivisa con varias estrategias funcionando en paralelo. Intentaremos transferir todo el trabajo relacionado con la apertura de posiciones de mercado desde el nivel de las estrategias al nivel de un experto que gestiona estas. Las propias estrategias solo negociarán virtualmente, sin abrir posiciones de mercado.

Creación de un EA limitador de reducción diaria en MQL5
El artículo analiza, desde una perspectiva detallada, cómo implementar la creación de un Asesor Experto (EA) basado en el algoritmo comercial. Esto ayuda a automatizar el sistema en MQL5 y tomar el control de la reducción diaria.

Redes neuronales: así de sencillo (Parte 88): Codificador de series temporales totalmente conectadas (TiDE)
El deseo de obtener las previsiones más exactas impulsa a los investigadores a aumentar la complejidad de los modelos de previsión. Lo que a su vez conlleva un aumento de los costes de entrenamiento y mantenimiento del modelo. Pero, ¿está esto siempre justificado? En el presente artículo, me propongo presentarles un algoritmo que explota la sencillez y rapidez de los modelos lineales y muestra resultados a la altura de los mejores con arquitecturas más complejas.

Criterios de tendencia en el trading
Las tendencias son una parte importante de muchas estrategias comerciales. En este artículo analizaremos algunas de las herramientas utilizadas para identificar tendencias y sus características. Comprender e interpretar correctamente las tendencias puede mejorar sustancialmente los resultados comerciales y minimizar los riesgos.

Automatización de estrategias de trading en MQL5 (Parte 12): Implementación de la estrategia Mitigation Order Blocks (MOB)
En este artículo creamos un sistema de trading en MQL5 que se encarga de detectar de forma automática los "order blocks", un concepto utilizado en el método Smart Money. Describimos las reglas de la estrategia, implementamos la lógica en MQL5 e integramos la gestión de riesgos para una ejecución eficaz de las operaciones. Por último, realizamos pruebas retrospectivas del sistema para evaluar su rendimiento y perfeccionarlo con el fin de obtener resultados óptimos.

Desarrollamos un Asesor Experto multidivisas (Parte 5): Tamaños de posición variables
En las partes anteriores, el Asesor Experto (EA) en desarrollo sólo podía utilizar un tamaño de posición fijo para operar. Esto es aceptable para las pruebas, pero no es aconsejable cuando se opera en una cuenta real. Hagamos posible el comercio utilizando tamaños de posición variables.

Validación cruzada simétrica combinatoria en MQL5
El artículo muestra la implementación de la validación cruzada simétrica combinatoria en MQL5 puro para medir el grado de ajuste tras optimizar la estrategia usando el algoritmo completo lento del simulador de estrategias.