
Developing a Neural Network Trading Robot Based on Mamba with Selective State Space Models

Modern algorithmic trading faces a fundamental problem. Classical neural network architectures based on the attention mechanism exhibit quadratic computational complexity O(N²). This means that doubling the length of the time series results in a fourfold increase in processing time. For a trader analyzing thousands of candles of historical data, this inefficiency becomes a critical limitation.
Imagine this situation: your trading system needs to analyze the last 2048 price bars to decide whether to enter a position. The Transformer architecture would require about 4 million attention operations for this, and the processing would take several seconds. In high-frequency trading, where milliseconds decide the outcome of a trade, such a delay is tantamount to a strategy failure.
Moreover, modern markets are characterized by increasing complexity and interconnectedness. Successful forecasting requires the analysis of increasingly longer historical periods, taking into account correlations between different assets and time scales. Traditional architectures fail to address this challenge, limiting traders to context windows of 512-1024 data points.
Time series forecasting trends in 2024-2025: Mamba
In December 2023, researchers from Carnegie Mellon University presented Mamba — a new architecture for processing sequential data. It is based on Selective State Space Models (SSM) and combines high accuracy with linear computational complexity O(N), which distinguishes it from Transformer models.
In 2024–2025, time series forecasting is shifting from attention-based architectures to state-space models. The reason is the need to analyze increasingly longer and more complex sequences, especially in finance, where multi-year cycles and market relationships are important.
Mamba is the result of developments in the field of recurrent architectures. Starting with simple RNNs, moving through LSTMs and GRUs, then through the Transformer revolution and attention mechanisms, the research community came to the realization that a fundamentally new approach was needed. The State Space Models that underlie Mamba combine the best properties of all previous architectures: the efficiency of RNNs, the long-term memory of LSTMs, and the parallelizability of Transformers.
This evolution is driven by the growing need to analyze macroeconomic cycles and long-term market patterns. Traditional models, limited to context windows of several hundred time points, have proven unable to capture seasonal effects, multi-year cycles, and intermarket correlations. Mamba, with its theoretically unlimited context length, opens up the possibility of analyzing ten-year historical periods while maintaining computational efficiency.
The key idea is "selective memory". The model is able to highlight significant events (economic reports, crises, technological breakthroughs) and ignore noise. This is especially valuable for analyzing financial data, where periods of calm alternate with sudden changes. Instead of an attention mechanism, Mamba uses a compact hidden state that is updated only when important information emerges. This approach enables models to be faster and more accurate on long time series.
// State Space Model fundamental equations h(t+1) = A·h(t) + B·x(t) // Update state y(t) = C·h(t) + D·x(t) // Output signal
Here h(t) represents the hidden state of the system at time t, x(t) is the input signal (e.g., the price of an asset), and the matrices A, B, C, D define the dynamics of the system.
An important difference between Mamba and its predecessors is that these matrices are not static — they adapt depending on the input data, ensuring selectivity of information processing.
Selectivity: the key to efficiency
The main innovation of Mamba is selectivity. Unlike traditional State Space Models, which treated all input data equally, Mamba can separate the important from the unimportant. This helps avoid "forgetting" key events and prevents noise from accumulating in a hidden state.
In the selectivity mechanism, the B and C system parameters become functions of the input data:
void ApplySelectiveSSM(Matrix &input_data, Matrix &output) { // Dynamic adaptation of parameters for(int i = 0; i < input_data.cols; i++) { double input_val = input_data.Get(0, i); double selection_weight = Sigmoid(input_val); // Selective updating of parameters adaptive_B.Set(i, j, B.Get(i, j) * selection_weight); adaptive_C.Set(j, i, C.Get(j, i) * selection_weight); } }
This approach allows the model to "forget" insignificant information (for example, small price fluctuations during periods of low volatility) and "remember" critical events (for example, sharp price movements or volume surges).
Practical implementation: From theory to code
Implementing the Mamba architecture in MQL5 requires careful design of the underlying data structures. The central element is the Matrix structure, which provides safe handling of multidimensional arrays:
struct Matrix {
double data[];
int rows, cols;
Matrix() {
rows = 0; cols = 0;
ArrayResize(data, 0);
}
double Get(int r, int c) {
if(r < 0 || r >= rows || c < 0 || c >= cols) return 0.0;
return data[r * cols + c];
}
void Set(int r, int c, double val) {
if(r < 0 || r >= rows || c < 0 || c >= cols) return;
data[r * cols + c] = val;
}
};
The Mamba block architecture is a composition of several components: a local convolution to capture short-term dependencies, a selective SSM for long-term memory, and a gating mechanism to control the information flow:
struct MambaBlock { Matrix A, B, C, D; // SSM parameters Matrix conv_weights; // 1D convolution Matrix gate_weights; // Gating Matrix state; // Hidden state void Forward(Matrix &input_data, Matrix &output) { output.Init(input_data.rows, input_data.cols); for(int t = 0; t < input_data.rows; t++) { // Local processing via convolution Matrix conv_out; conv_out.Init(1, input_data.cols); ApplyConvolution(input_data, t, conv_out); // Selective processing via SSM Matrix gated; gated.Init(1, input_data.cols); ApplySelectiveSSM(conv_out, gated); // Residual connection for learning stability for(int j = 0; j < input_data.cols; j++) { double residual = input_data.Get(t, j); double processed = gated.Get(0, j); output.Set(t, j, residual + processed * 0.5); } } } };
Initialization of the A matrix requires special attention. Research shows that using HiPPO (High-order Polynomial Projection Operators) initialization provides optimal system memory properties:
void InitializeHiPPOMatrix() { for(int i = 0; i < SSM_STATE_SIZE; i++) { for(int j = 0; j < SSM_STATE_SIZE; j++) { if(i == j) { A.Set(i, j, -1.0); // Diagonal stabilization } else if(j < i) { A.Set(i, j, 0.1 / (i - j + 1)); // HiPPO weights } } } }
One of the key innovations in time series processing was the concept of patching — dividing a long sequence into short segments (patches) processed as single tokens. This idea, borrowed from computer vision and adapted for time series in the work of PatchTST, dramatically reduces the computational load.
struct PatchEmbedding { Matrix patch_weights; Matrix position_embedding; void Forward(double &time_series[], Matrix &patches) { int num_patches = (ArraySize(time_series) / 2) / PATCH_SIZE; patches.Init(num_patches, HIDDEN_SIZE); for(int p = 0; p < num_patches; p++) { for(int h = 0; h < HIDDEN_SIZE; h++) { double sum = 0.0; // Handle a patch of PATCH_SIZE for(int i = 0; i < PATCH_SIZE; i++) { int price_idx = (p * PATCH_SIZE + i) * 2; int vol_idx = price_idx + 1; if(price_idx < ArraySize(time_series)) { sum += time_series[price_idx] * patch_weights.Get(i * 2, h); sum += time_series[vol_idx] * patch_weights.Get(i * 2 + 1, h); } } // Positional encoding to preserve temporal information sum += position_embedding.Get(p, h); patches.Set(p, h, sum); } } } };
The application of patching in the context of financial time series is particularly effective. A patch of 16 time points could represent a 4-hour period on a 15-minute chart or a daily period on an hourly chart. This allows the model to operate on semantically meaningful units of time rather than individual price points.
Training the Mamba architecture requires the use of modern optimization algorithms. AdamW (Adam with Weight Decay) is an improved version of the classic Adam that corrects the problem of incorrect regularization:
void UpdateWeightsAdamW(double grad_scale) { step_count++; double effective_lr = learning_rate * adaptive_lr_factor; double weight_decay = 0.01; for(int i = 0; i < output_projection.rows; i++) { for(int j = 0; j < output_projection.cols; j++) { double grad = grad_scale * 0.01; double weight = output_projection.Get(i, j); // Update moments double m = beta1 * output_m.Get(i, j) + (1 - beta1) * grad; double v = beta2 * output_v.Get(i, j) + (1 - beta2) * grad * grad; output_m.Set(i, j, m); output_v.Set(i, j, v); // Bias correction double m_hat = m / (1 - MathPow(beta1, step_count)); double v_hat = v / (1 - MathPow(beta2, step_count)); // Update with weight decay double update = effective_lr * (m_hat / (MathSqrt(v_hat) + epsilon) + weight_decay * weight); output_projection.Set(i, j, weight - update); } } }
Architectural innovation in detail
A deep understanding of Mamba requires considering its architectural components at the level of mathematical operations. The selectivity mechanism represents a fundamental difference from traditional approaches. In classical State Space Models, parameters B and C remain constant over time, which results in the inability of the model to adapt to changing characteristics of the input flow.
The selectivity mechanism in Mamba is implemented through projection functions that transform the input signal into system parameters:
Matrix ComputeSelectiveParameters(Matrix &input_sequence) {
Matrix selective_B, selective_C;
selective_B.Init(input_sequence.rows, SSM_STATE_SIZE);
selective_C.Init(SSM_STATE_SIZE, input_sequence.rows);
for(int t = 0; t < input_sequence.rows; t++) {
// Projection of the input signal into the parameter space
double input_norm = 0.0;
for(int f = 0; f < input_sequence.cols; f++) {
input_norm += input_sequence.Get(t, f) * input_sequence.Get(t, f);
}
input_norm = MathSqrt(input_norm);
// Adaptive scaling of parameters
double adaptation_factor = Tanh(input_norm * 0.1);
for(int s = 0; s < SSM_STATE_SIZE; s++) {
selective_B.Set(t, s, base_B.Get(t, s) * adaptation_factor);
selective_C.Set(s, t, base_C.Get(s, t) * adaptation_factor);
}
}
return selective_parameters;
}
This approach allows the model to dynamically adjust its "sensitivity" to different types of input information. In the context of financial markets, this means the ability to increase focus during periods of high volatility and decrease it during consolidation.
Hardware-Aware optimizations
One of the critical factors for Mamba's success is its optimization for modern computing architectures. Traditional SSMs require sequential processing of time steps, making them poorly suited for parallel computing. Mamba solves this problem through a parallel scan algorithm that allows for efficient use of GPU architectures.
void ParallelScanSSM(Matrix &input_sequence, Matrix &output_sequence) { int sequence_length = input_sequence.rows; Matrix cumulative_states; cumulative_states.Init(sequence_length, SSM_STATE_SIZE); // Phase 1: Upward scan for(int level = 0; level < (int)MathLog2(sequence_length); level++) { int step_size = 1 << level; for(int i = step_size; i < sequence_length; i += step_size * 2) { // Combine states using an associative operation CombineStates(cumulative_states, i - step_size, i); } } // Phase 2: Downward propagation for(int level = (int)MathLog2(sequence_length) - 1; level >= 0; level--) { int step_size = 1 << level; for(int i = step_size * 3; i < sequence_length; i += step_size * 2) { // Propagation of accumulated states PropagateStates(cumulative_states, i - step_size, i); } } // Generate output sequence GenerateOutput(cumulative_states, output_sequence); }
This implementation allows achieving O(log N) time complexity for processing a sequence of length N using N processors, which dramatically improves scalability compared to the sequential O(N) algorithm.
Advanced initialization techniques
Initialization of SSM parameters plays a critical role in ensuring the stability of learning and the quality of long-term memory. Research shows that using HiPPO (High-order Polynomial Projection Operators) initialization provides optimal approximation properties for continuous functions:
void InitializeHiPPOAdvanced() { // Calculate the optimal HiPPO coefficients Matrix legendre_matrix; legendre_matrix.Init(SSM_STATE_SIZE, SSM_STATE_SIZE); for(int n = 0; n < SSM_STATE_SIZE; n++) { for(int k = 0; k < SSM_STATE_SIZE; k++) { if(n > k) { // Coefficients of Legendre polynomials double coeff = MathSqrt((2*n + 1) * (2*k + 1)); if((n - k) % 2 == 1) coeff *= -1; legendre_matrix.Set(n, k, coeff); } else if(n == k) { legendre_matrix.Set(n, k, -(2*n + 1)); } } } // Discretization for digital processing double time_scale = 1.0; Matrix discrete_A; discrete_A.Init(SSM_STATE_SIZE, SSM_STATE_SIZE); for(int i = 0; i < SSM_STATE_SIZE; i++) { for(int j = 0; j < SSM_STATE_SIZE; j++) { double continuous_val = legendre_matrix.Get(i, j); // Tustin transform for discretization double discrete_val = (2.0/time_scale - continuous_val) / (2.0/time_scale + continuous_val); discrete_A.Set(i, j, discrete_val); } } A = discrete_A; }
This initialization provides the model with the ability to effectively approximate functions with long-term dependencies, which is critical for the analysis of financial time series with their complex periodic and trend components.
Integration with multiscale analysis
Financial markets are characterized by the presence of structures on different time scales. Daily trends can contradict weekly cycles, which in turn are embedded in monthly and quarterly patterns. The Mamba architecture provides an elegant way to address this problem through multi-scale processing:
struct MultiScaleMambaProcessor { MambaBlock scales[4]; // M5, M15, H1, H4 Matrix fusion_weights; void Init() { // Different parameters for different scales for(int i = 0; i < 4; i++) { scales[i].Init(); // Adapt the state size to the time scale int scale_state_size = SSM_STATE_SIZE * (i + 1); scales[i].ResizeState(scale_state_size); } fusion_weights.Init(4, HIDDEN_SIZE); fusion_weights.Random(0.1); } Matrix ProcessMultiScale(double &price_data[], int timeframes[]) { Matrix scale_outputs[4]; for(int scale = 0; scale < 4; scale++) { // Resample data for the appropriate timeframe double resampled_data[]; ResampleData(price_data, timeframes[scale], resampled_data); // Process using the corresponding Mamba block Matrix scale_input; PrepareScaleInput(resampled_data, scale_input); scales[scale].Forward(scale_input, scale_outputs[scale]); } // Merge information from different scales Matrix fused_output; FuseMultiScaleOutputs(scale_outputs, fused_output); return fused_output; } private: void FuseMultiScaleOutputs(Matrix scale_outputs[], Matrix &fused) { fused.Init(scale_outputs[0].rows, HIDDEN_SIZE); for(int t = 0; t < fused.rows; t++) { for(int h = 0; h < HIDDEN_SIZE; h++) { double weighted_sum = 0.0; double total_weight = 0.0; for(int scale = 0; scale < 4; scale++) { if(t < scale_outputs[scale].rows && h < scale_outputs[scale].cols) { double weight = fusion_weights.Get(scale, h); weighted_sum += scale_outputs[scale].Get(t, h) * weight; total_weight += weight; } } fused.Set(t, h, total_weight > 0 ? weighted_sum / total_weight : 0.0); } } } };
Training Mamba models requires specialized approaches adapted to the specific features of the SSM architecture. One of the key problems is the stabilization of gradients in recurrent computations:
void StabilizedTraining(double &training_data[], double targets[]) { double gradient_norm_threshold = 1.0; double stability_factor = 0.99; for(int epoch = 0; epoch < training_epochs; epoch++) { double epoch_loss = 0.0; int batch_count = 0; for(int batch = 0; batch < num_batches; batch++) { // Forward pass with gradient tracking Matrix intermediate_states[NUM_LAYERS]; double prediction = ForwardWithGradientTracing(training_data, intermediate_states); double loss = ComputeLoss(prediction, targets[batch]); epoch_loss += loss; // Calculate gradients with regularization Matrix gradients[NUM_LAYERS]; ComputeRegularizedGradients(loss, intermediate_states, gradients); // Check the stability of gradients double grad_norm = ComputeGradientNorm(gradients); if(grad_norm > gradient_norm_threshold) { // Scale gradients to prevent explosion ScaleGradients(gradients, gradient_norm_threshold / grad_norm); } // Update parameters with exponential smoothing UpdateParametersSmoothed(gradients, stability_factor); batch_count++; } double avg_loss = epoch_loss / batch_count; // Adaptive learning rate correction if(epoch > 0 && avg_loss > previous_loss * 1.1) { learning_rate *= 0.8; // Decrease in case of instability } else if(avg_loss < previous_loss * 0.95) { learning_rate *= 1.05; // Increase with stable improvement } previous_loss = avg_loss; Print("Epoch ", epoch, " | Loss: ", DoubleToString(avg_loss, 6), " | LR: ", DoubleToString(learning_rate, 6)); } }
Implementing the Mamba architecture into a production trading system requires taking into account many practical factors. A performance monitoring system should track not only the accuracy of predictions, but also the stability of the model's internal states:
struct MambaMonitoringSystem { double state_stability_threshold; double prediction_variance_limit; int monitoring_window; bool MonitorSystemHealth() { // Check the stability of internal states double state_variance = ComputeStateVariance(); if(state_variance > state_stability_threshold) { Print("WARNING: High state variance detected: ", state_variance); return false; } // Analysis of the consistency of predictions double prediction_variance = ComputePredictionVariance(); if(prediction_variance > prediction_variance_limit) { Print("WARNING: Prediction instability: ", prediction_variance); return false; } // Check gradients for anomalies if(DetectGradientAnomalies()) { Print("WARNING: Gradient anomalies detected"); TriggerModelReinitialization(); return false; } return true; } private: double ComputeStateVariance() { double variance_sum = 0.0; for(int layer = 0; layer < NUM_LAYERS; layer++) { Matrix layer_state = mamba_layers[layer].GetCurrentState(); double layer_variance = 0.0; double layer_mean = 0.0; // Calculate the average for(int i = 0; i < layer_state.rows * layer_state.cols; i++) { layer_mean += layer_state.data[i]; } layer_mean /= (layer_state.rows * layer_state.cols); // Calculating the variance for(int i = 0; i < layer_state.rows * layer_state.cols; i++) { double diff = layer_state.data[i] - layer_mean; layer_variance += diff * diff; } layer_variance /= (layer_state.rows * layer_state.cols); variance_sum += layer_variance; } return variance_sum / NUM_LAYERS; } };
Future research directions
The development of the Mamba architecture opens up multiple vectors for further research. Integration with reinforcement learning algorithms could enable the creation of adaptive trading agents capable of self-learning in changing market conditions.
Research into few-shot learning using Mamba can lead to models that can quickly adapt to new financial instruments with minimal training data. This is especially relevant for emerging markets and new cryptocurrencies.
Combining Mamba with meta-learning techniques opens up the possibility of creating universal trading systems that can automatically adapt to various market conditions without the need for manual parameter adjustments.
Practical recommendations for implementation
To test Mamba's performance in real trading conditions, the ModernAI_Expert.mq5 EA was developed. It represents a full-fledged implementation of Selective State Space Models in the MetaTrader 5 ecosystem. Its goal is to demonstrate the practical application of modern machine learning approaches in algorithmic trading.
The EA is built on the principles of a pure AI approach, where all trading decisions are made solely based on neural network predictions. Unlike hybrid systems, ModernAI_Expert relies entirely on the Mamba architecture's ability to identify hidden patterns in market data without the use of traditional technical indicators. The basic implementation of Selective State Space Models supports up to 200 input bars with configurable analysis depth, automatic model retraining every 24 hours, and intelligent signal filtering with configurable confidence thresholds.
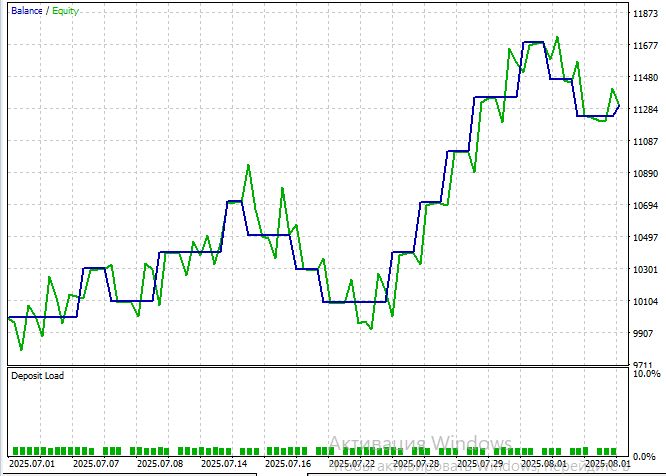
ModernAI_Expert implements an advanced input data normalization system, which is critical for the stable operation of a neural network. The system processes normalized price changes and log-scaled volume, ensuring training stability and preventing one type of data from dominating the other. This approach is particularly critical for financial time series with their high variability and unpredictable bursts of activity.
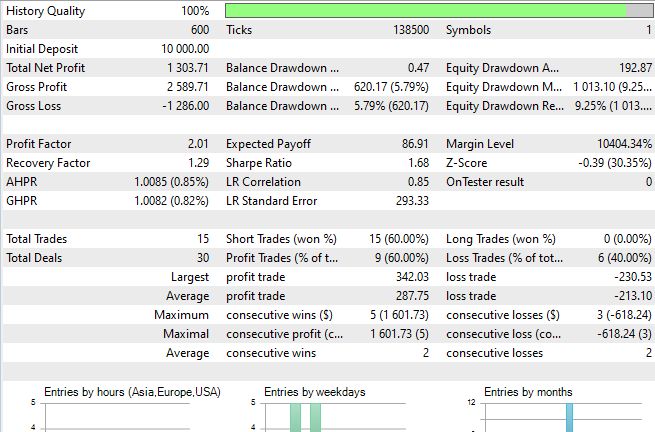
The main feature of ModernAI_Expert is dynamic position management. The size of a transaction depends not only on standard risk management rules, but also on the confidence level of the AI model. Each trade is accompanied by a commentary showing this confidence level, allowing the trader to evaluate the quality of decisions in real time.
Another key feature is intelligent exit signals. Positions are closed not only by stop-loss or take-profit, but also when the model's sentiment changes. Long positions are closed if confidence falls below 40%, and short positions are closed if it rises above 60%. This helps the system respond to changing market conditions before traditional stops are triggered.
Conclusion
The Mamba architecture represents a revolutionary breakthrough in algorithmic trading by solving the fundamental problem of quadratic complexity of Transformer models. The move to O(N) linear complexity and the selective memory mechanism open up possibilities for analyzing extremely long time series while maintaining computational efficiency.
The practical implementation in the form of ModernAI_Expert.mq5 proves the technology's readiness for production use, demonstrating a pure AI approach without traditional technical indicators.
Key findings
The main achievement of the Mamba architecture is a computational breakthrough — the transition from quadratic to linear complexity, which allows analyzing thousands of bars without loss of performance. The selective memory mechanism provides adaptive filtering of information, focusing on significant events and ignoring market noise. The system's scalability opens up the possibility of analyzing long-term historical data to identify macroeconomic cycles.
The technology's production readiness is confirmed by its successful integration into MetaTrader 5 with dynamic position management based on model confidence. This represents a paradigm shift from hybrid systems to a pure AI approach to trading decision making.
Mamba opens a new era of algorithmic trading, where the efficiency of processing long sequences is combined with adaptability to changing market conditions.
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/19047
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
When compiling the ModernTimeSeriesNet.mqh file, the following error occurs: - undeclared
Hello! I have attached the latest version to the updated article. In the previous version, the expert advisor compiled fine as it was; the problem was simply that the required variables were defined in the EA rather than in the mqh file.
Hello! I’ve attached the latest version to the updated article. In the previous version, the expert advisor compiled just fine; the problem was simply that the variables were defined in the EA rather than in m
Thank you, it’s all working now.