ML Lorentzian Classification for MT5
- Indikatoren
-
Minh Truong Pham
 Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
I will try:
+ Provide best tools base on my 5 years experience as a trader and 10 years as a programmer. - Version: 1.3
- Aktualisiert: 25 Januar 2025
- Aktivierungen: 8
"ÜBERBLICK
EinLorentzian Distance Classifier (LDC) ist ein Klassifikationsalgorithmus des maschinellen Lernens, der historische Daten aus einem mehrdimensionalen Merkmalsraum kategorisieren kann. Dieser Indikator zeigt, wie die Lorentzsche Klassifizierung auch zur Vorhersage der Richtung zukünftiger Kursbewegungen verwendet werden kann, wenn sie als Abstandsmetrik für eine neuartige Implementierung eines ANN-Algorithmus (Approximate Nearest Neighbors) eingesetzt wird.
Dieser Indikator liefert Signale als Puffer, so dass es sehr einfach ist, mit diesem Indikator einen EA zu erstellen
" HINTERGRUND
In der Physik ist der Lorentzsche Raum vielleicht am besten für seine Rolle bei der Beschreibung der Krümmung der Raumzeit in Einsteins Allgemeiner Relativitätstheorie (2) bekannt. Interessanterweise hat dieses abstrakte Konzept aus der theoretischen Physik jedoch auch konkrete Anwendungen in der realen Welt des Handels.
Kürzlich wurde die Hypothese aufgestellt, dass der Lorentzsche Raum auch gut für die Analyse von Zeitreihendaten geeignet ist (4), (5). Diese Hypothese wurde durch mehrere empirische Studien gestützt, die zeigen, dass der Lorentzsche Abstand robuster gegenüber Ausreißern und Rauschen ist als der üblicherweise verwendete Euklidische Abstand (1), (3), (6). Darüber hinaus wurde gezeigt, dass die Lorentz-Distanz Dutzende von anderen hoch angesehenen Distanzmetriken übertrifft, darunter die Manhattan-Distanz, die Bhattacharyya- und die Cosinus-Ähnlichkeit (1), (3). Abgesehen von Dynamic Time Warping-basierten Ansätzen, die leider zu rechenintensiv für PineScript sind, erzielt die Lorentz-Distanz-Metrik durchgängig die höchste mittlere Genauigkeit über eine Vielzahl von Zeitreihen-Datensätzen (1).
Euklidische Distanz wird üblicherweise als Standard-Distanz-Metrik für NN-basierte Suchalgorithmen verwendet, ist aber möglicherweise nicht immer die beste Wahl, wenn es um Finanzmarktdaten geht. Dies liegt daran, dass Finanzmarktdaten durch die Nähe zu wichtigen Weltereignissen wie FOMC-Sitzungen und Black-Swan-Ereignissen erheblich beeinflusst werden können. Diese ereignisbedingte Verzerrung von Marktdaten kann mit der Gravitationsverzerrung verglichen werden, die ein massives Objekt im Raum-Zeit-Kontinuum verursacht. Für die Finanzmärkte kann das analoge Kontinuum, das eine Verzerrung erfährt, als "Preis-Zeit" bezeichnet werden.
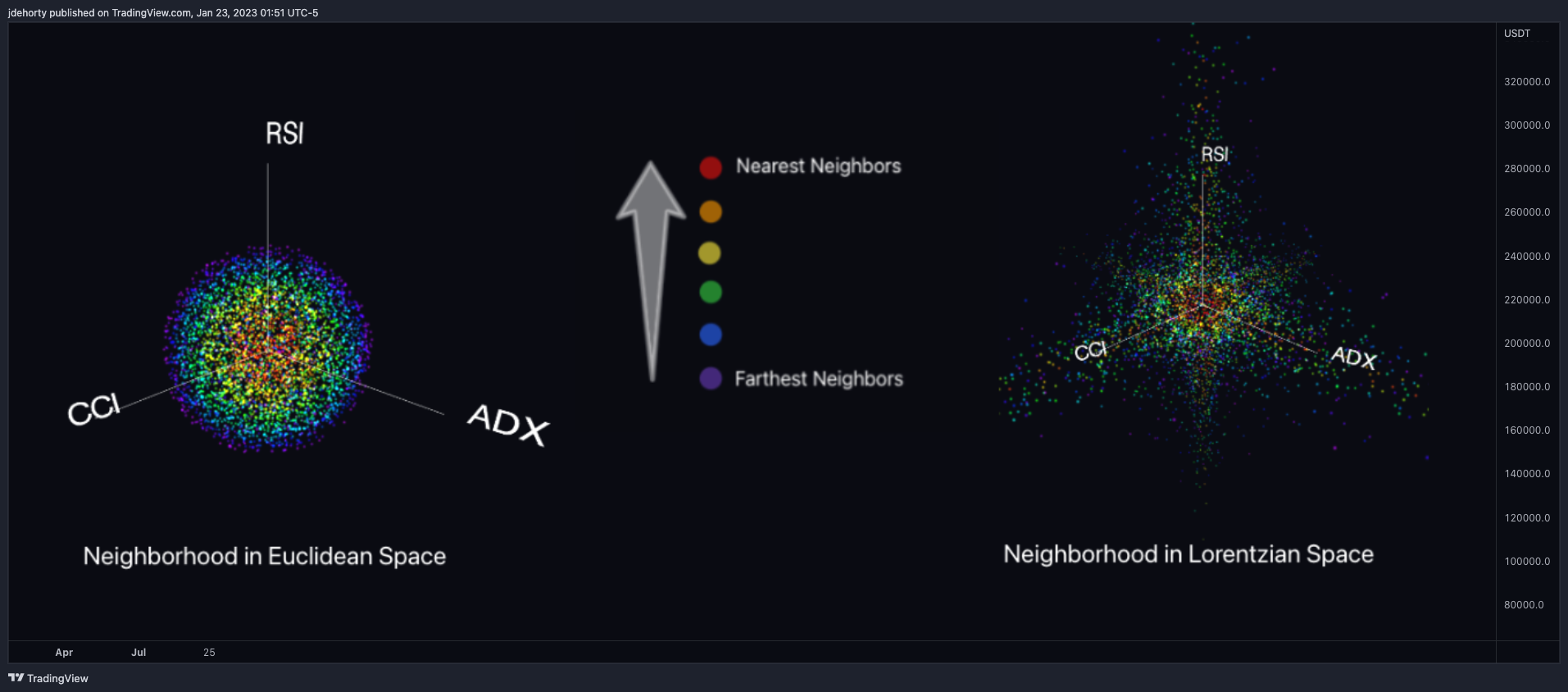
Nachfolgend ein Vergleich, wie Nachbarschaften ähnlicher historischer Punkte im dreidimensionalen euklidischen Raum und im Lorentzschen Raum erscheinen (Bild 2)
Diese Abbildung zeigt, wie der Lorentzsche Raum die Verzerrung der Preiszeit besser berücksichtigen kann, da die Lorentzsche Abstandsfunktion die euklidische Nachbarschaft so komprimiert, dass die neue Nachbarschaftsverteilung im Lorentzschen Raum dazu neigt, sich um jede der Hauptmerkmalsachsen zusätzlich zum Ursprung selbst zu gruppieren. Das bedeutet, dass, obwohl einige der nächsten Nachbarn unabhängig von der verwendeten Abstandsmetrik dieselben sein werden, der Lorentzsche Raum auch die Berücksichtigung historischer Punkte ermöglicht, die andernfalls mit einer euklidischen Abstandsmetrik nie berücksichtigt würden.
Intuitiv macht der Vorteil der Lorentzschen Abstandsmetrik Sinn. So ist es beispielsweise logisch, dass die Kursentwicklung in den Stunden nach Beendigung einer Rede des Vorsitzenden Powell zumindest einigen der früheren Zeiten ähnelt, in denen er eine Rede gehalten hat. Dies kann unabhängig von anderen Faktoren der Fall sein, z. B. davon, ob der Markt zu diesem Zeitpunkt überkauft oder überverkauft war oder ob die makroökonomischen Bedingungen insgesamt eher bullisch oder bearisch waren. Diese historischen Bezugspunkte sind für Prognosemodelle äußerst wertvoll, doch würde die euklidische Abstandsmetrik diese Nachbarn völlig außer Acht lassen, oft zugunsten irrelevanter Datenpunkte vom Vortag des Ereignisses. Durch die Verwendung der Lorentz'schen Distanz als Metrik ist das ML-Modell stattdessen in der Lage, die durch das Ereignis verursachte Verzerrung der Kurszeit zu berücksichtigen und letztlich die zeitliche Verzerrung zu überwinden, die ihm durch die Zeitreihen auferlegt wird.
Weitere Informationen zu den Implementierungsdetails des in diesem Indikator verwendeten ANN-Algorithmus (Approximate Nearest Neighbors) finden Sie in den detaillierten Kommentaren im Quellcode.
" BEDIENUNGSANLEITUNG
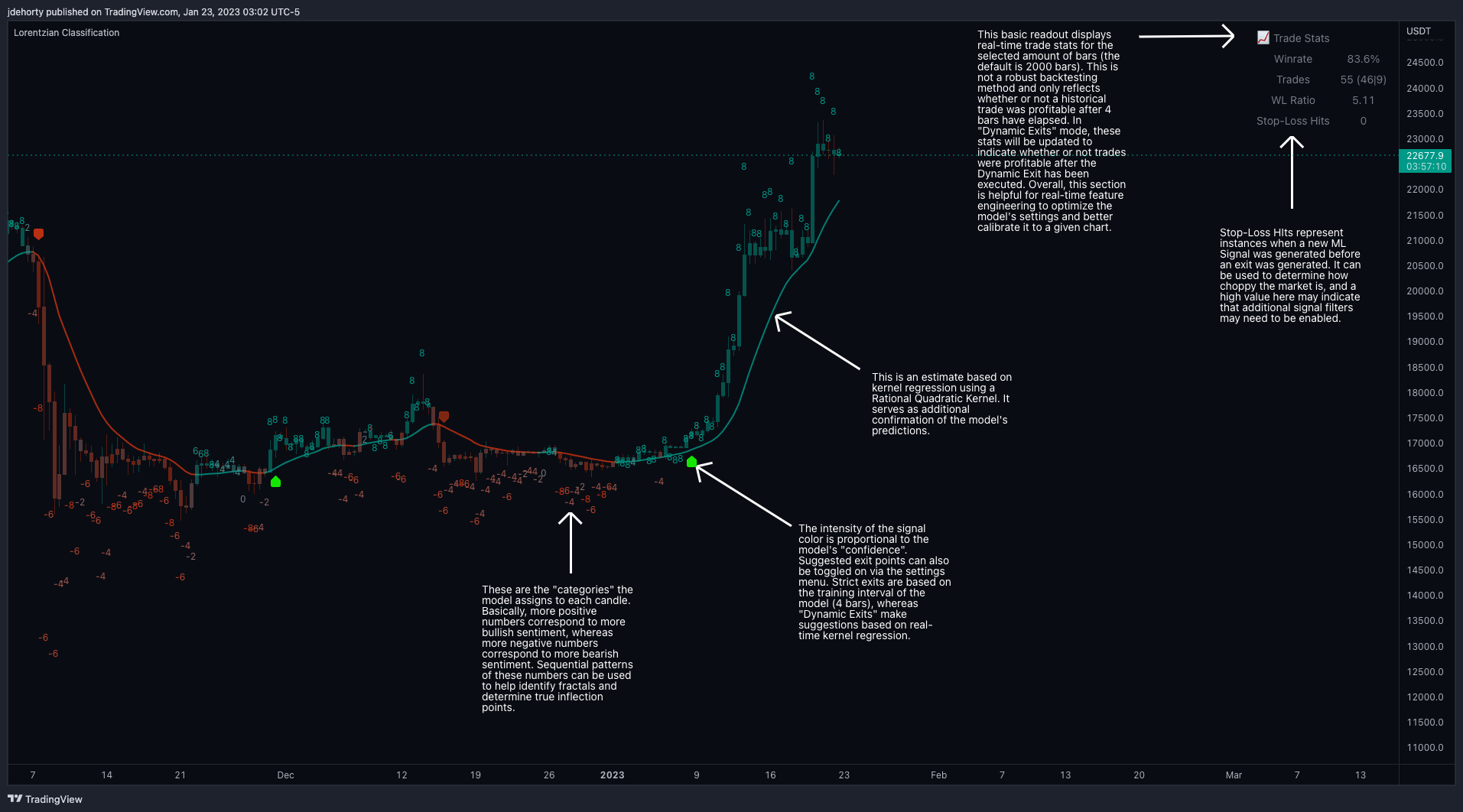
Die Abbildung 3 ist eine erläuternde Aufschlüsselung der verschiedenen Teile dieses Indikators, wie sie in der Benutzeroberfläche erscheint
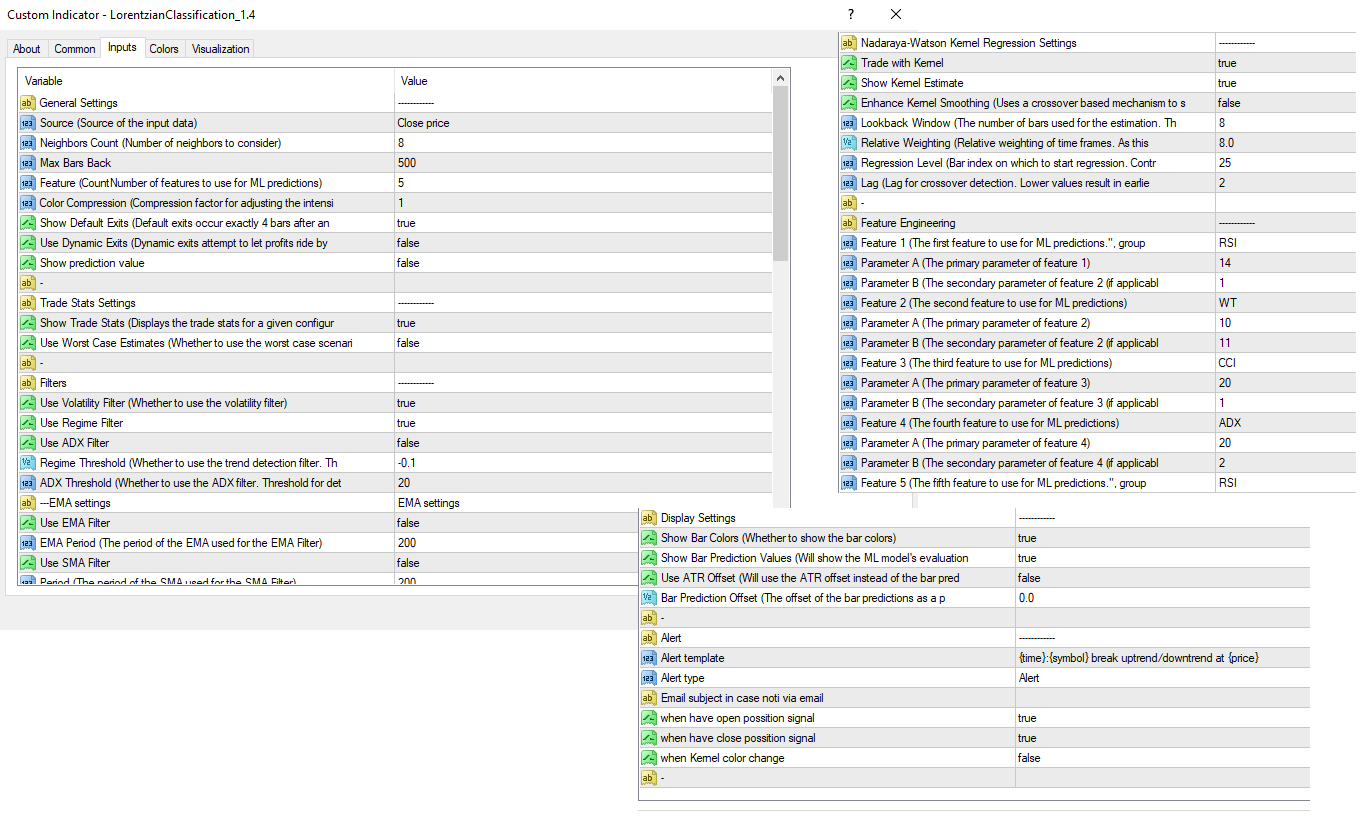
Abbildung 4 zeigt eine Erläuterung der verschiedenen Einstellungen für diesen Indikator
Allgemeine Einstellungen:- Quelle - Dies hat den Standardwert "hlc3" und wird zur Steuerung der Eingangsdatenquelle verwendet.
- Anzahl der Nachbarn - Der Standardwert ist 8, der Mindestwert 1, der Höchstwert 100 und die Schrittweite 1. Damit wird die Anzahl der zu berücksichtigenden Nachbarn gesteuert.
- Max Bars Back - Der Standardwert ist 2000.
- Feature Count - Der Standardwert ist 5, der Mindestwert 2 und der Höchstwert 5. Sie steuert die Anzahl der Merkmale, die für ML-Vorhersagen verwendet werden.
- Farbkomprimierung - Der Standardwert ist 1, der Mindestwert 1 und der Höchstwert 10. Er dient zur Steuerung des Komprimierungsfaktors für die Anpassung der Intensität der Farbskala.
- Ausgänge anzeigen - Der Standardwert für diese Option ist false. Er steuert, ob die Ausstiegsschwelle im Diagramm angezeigt werden soll.
- Dynamische Ausstiege verwenden - Der Standardwert dieser Option ist false. Damit wird gesteuert, ob versucht werden soll, Gewinne mitzunehmen, indem die Ausstiegsschwelle auf der Grundlage der Kernel-Regression dynamisch angepasst wird.
Feature-Engineering-Einstellungen:
Hinweis: Der Abschnitt Feature-Engineering dient der Feinabstimmung der für ML-Vorhersagen verwendeten Features. Die Standardwerte sind für die Zeitrahmen 4H bis 12H für die meisten Charts optimiert, sollten aber auch für andere Zeitrahmen gut funktionieren. Standardmäßig kann das Modell Merkmale unterstützen, die zwei Parameter akzeptieren (Parameter A bzw. Parameter B). Auch wenn standardmäßig nur 4 Merkmale zur Verfügung stehen, zählt dasselbe Merkmal mit unterschiedlichen Einstellungen als zwei separate Merkmale. Wenn das Merkmal nur einen Parameter akzeptiert, wird der zweite Parameter standardmäßig auf die EMA-basierte Glättung mit einem Standardwert von 1 eingestellt. Diese Merkmale stellen die effektivste Kombination dar, auf die ich bei meinen Tests gestoßen bin, aber weitere Merkmale können in Zukunft als zusätzliche Optionen hinzugefügt werden.
- Merkmal 1 - Der Standardwert ist "RSI" und die Optionen sind: "RSI", "WT", "CCI", "ADX".
- Merkmal 2 - Der Standardwert ist "WT" und die Optionen sind: "RSI", "WT", "CCI", "ADX".
- Merkmal 3 - Der Standardwert ist "CCI" und die Optionen sind: "RSI", "WT", "CCI", "ADX".
- Merkmal 4 - Der Standardwert ist "ADX" und die Optionen sind: "RSI", "WT", "CCI", "ADX".
- Merkmal 5 - Der Standardwert ist "RSI" und die Optionen sind: "RSI", "WT", "CCI", "ADX".
Filter-Einstellungen:
- Volatilitätsfilter verwenden - Der Standardwert ist "true". Er wird verwendet, um zu steuern, ob der Volatilitätsfilter verwendet werden soll.
- Regimefilter verwenden - Der Standardwert ist true. Hiermit wird gesteuert, ob der Trenderkennungsfilter verwendet werden soll.
- ADX-Filter verwenden - Der Standardwert ist false. Hiermit wird gesteuert, ob der ADX-Filter verwendet werden soll.
- Regime Threshold - Der Standardwert ist -0,1, der Mindestwert -10, der Höchstwert 10 und die Schrittweite 0,1. Er dient zur Steuerung des Regime-Erkennungsfilters für die Erkennung von Trending/Ranging-Märkten.
- ADX Threshold - Der Standardwert beträgt 20, der Mindestwert 0, der Höchstwert 100 und die Schrittweite 1. Er dient zur Steuerung des Schwellenwerts für die Erkennung von Trending/Ranging-Märkten.
Kernel-Regressionseinstellungen:
- Mit Kernel handeln - Der Standardwert ist true. Damit wird gesteuert, ob mit dem Kernel gehandelt werden soll.
- Kernel-Schätzung anzeigen - Der Standardwert dieser Option ist wahr. Hier können Sie festlegen, ob die Kernel-Schätzung angezeigt werden soll.
- Lookback-Fenster - Der Standardwert ist 8 und der Mindestwert 3. Damit wird die Anzahl der für die Schätzung verwendeten Balken festgelegt. Empfohlener Bereich: 3-50
- Relative Gewichtung - Der Standardwert ist 8 und die Schrittweite beträgt 0,25. Er dient zur Steuerung der relativen Gewichtung der Zeitrahmen. Empfohlener Bereich: 0.25-25
- Start Regression at Bar - Der Standardwert für diese Option ist 25. Er wird verwendet, um den Bar-Index zu bestimmen, bei dem die Regression beginnen soll. Empfohlener Bereich: 0-25
Anzeigeeinstellungen:
- Balkenfarben anzeigen - Der Standardwert ist true. Hiermit wird gesteuert, ob die Balkenfarben angezeigt werden sollen.
- Balkenvorhersagewerte anzeigen - Der Standardwert für diese Option ist true. Sie steuert, ob die Bewertung des ML-Modells für jeden Balken als Ganzzahl angezeigt werden soll.
- ATR-Offset verwenden - Der Standardwert dieser Option ist false. Er steuert, ob der ATR-Offset anstelle des Offsets der Balkenvorhersage verwendet werden soll.
- Balkenvorhersage-Offset - Der Standardwert ist 0 und der Mindestwert 0. Damit wird der Offset der Balkenvorhersagen als Prozentsatz vom Hoch oder Schluss des Balkens gesteuert.
Backtesting-Einstellungen:
- Backtesting-Ergebnisse anzeigen - Der Standardwert ist true. Damit wird gesteuert, ob die Gewinnrate der gegebenen Konfiguration angezeigt werden soll.
"VERWEISTE ARBEITEN
(1) R. Giusti und G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170-176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al, "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." .
=======================
Hinweis zum "Repainting":
Um das klarzustellen: Sobald ein Balken geschlossen wurde, wird dieser Indikator NICHT neu gezeichnet. Dies gilt sowohl für die ML-Vorhersagen als auch für die Kernel-Schätzung.
Hinweis zu den Bar-Anforderungen für das "Lernen":
Das ist eine wertvolle Empfehlung. Die Verwendung eines Zeitrahmens von H4 oder niedriger bei der Arbeit mit diesem Indikator ist ein praktischer Ansatz, da für das Lernen und die Analyse historische Preisdaten benötigt werden. Es stellt sicher, dass Sie eine ausreichende Anzahl historischer Balken haben, damit der Indikator lernen und sich effektiv an das Preisverhalten anpassen kann (MT4 hat nur etwa 1000 Balken im Chart mit größerem Zeitrahmen). Wenn Sie weitere Erkenntnisse oder Fragen zum Handel oder zu Indikatoren haben, können Sie diese gerne mitteilen oder stellen.
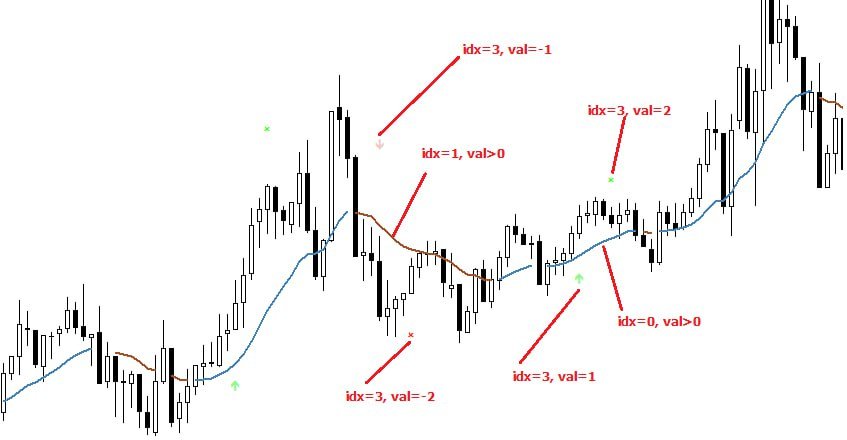
Hinweis für Puffer
Incase erstellen EA mit Signal von diesem Indikator verwenden Sie bitte iCustom. Der Index bei Verwendung von iCustom wie folgt:
+ Index 0 ist der Linienwert
+ Index 2 ist die Richtung der Linie: 1 geht nach oben; -1 geht nach unten
+ Index 4 ist das Signal: 1 ist Kauf; 2 ist nahe Kauf; -1 ist Verkauf; -2 ist nahe Verkauf
+ Index 5 ist die Vorhersage
Denken Sie daran, dass der Indikator nur geschlossene Balken berechnet. Sie benötigen also die Verschiebung 1 in copyBuffer.