ML Lorentzian Classification for MT5
- Indicadores
-
Minh Truong Pham
 Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
I will try:
+ Provide best tools base on my 5 years experience as a trader and 10 years as a programmer. - Versión: 1.3
- Actualizado: 25 enero 2025
- Activaciones: 8
"VISIÓN GENERAL
UnClasificador de Distancia Lorentziana (CDL) es un algoritmo de clasificación de Aprendizaje Automático capaz de categorizar datos históricos de un espacio de características multidimensional. Este indicador demuestra cómo la Clasificación Lorentziana también puede utilizarse para predecir la dirección de futuros movimientos de precios cuando se utiliza como métrica de distancia para una novedosa implementación de un algoritmo de Vecinos Cercanos Aproximados (RNA).
Este indicador proporciona la señal como búfer, por lo que es muy fácil para crear EA de este indicador
" ANTECEDENTES
En física, el espacio Lorentziano es quizás mejor conocido por su papel en la descripción de la curvatura del espacio-tiempo en la teoría de Einstein de la Relatividad General (2). Sin embargo, es interesante señalar que este concepto abstracto de la física teórica también tiene aplicaciones tangibles en el mundo real del comercio.
Recientemente, se planteó la hipótesis de que el espacio lorentziano también era adecuado para analizar datos de series temporales (4), (5). Esta hipótesis ha sido corroborada por varios estudios empíricos que demuestran que la distancia lorentziana es más robusta frente a valores atípicos y ruido que la distancia euclidiana, más comúnmente utilizada (1), (3), (6). Además, también se ha demostrado que la distancia Lorentziana supera a docenas de otras métricas de distancia de gran prestigio, como la distancia Manhattan, la similitud Bhattacharyya y la similitud Coseno (1), (3). Aparte de los enfoques basados en la deformación temporal dinámica, que por desgracia son demasiado intensivos desde el punto de vista computacional para PineScript en este momento, la métrica de la distancia lorentziana obtiene sistemáticamente la mayor precisión media en una amplia variedad de conjuntos de datos de series temporales (1).
La distancia euclidianase utiliza habitualmente como métrica de distancia por defecto para los algoritmos de búsqueda basados en NN, pero puede que no sea siempre la mejor opción cuando se trata de datos de mercados financieros. Esto se debe a que los datos de los mercados financieros pueden verse afectados significativamente por la proximidad a los principales acontecimientos mundiales, como las reuniones del FOMC y los acontecimientos del Cisne Negro. Esta distorsión de los datos de mercado basada en acontecimientos puede considerarse similar a la deformación gravitatoria causada por un objeto masivo en el continuo espacio-tiempo. En el caso de los mercados financieros, el continuo análogo que experimenta la deformación puede denominarse "precio-tiempo".
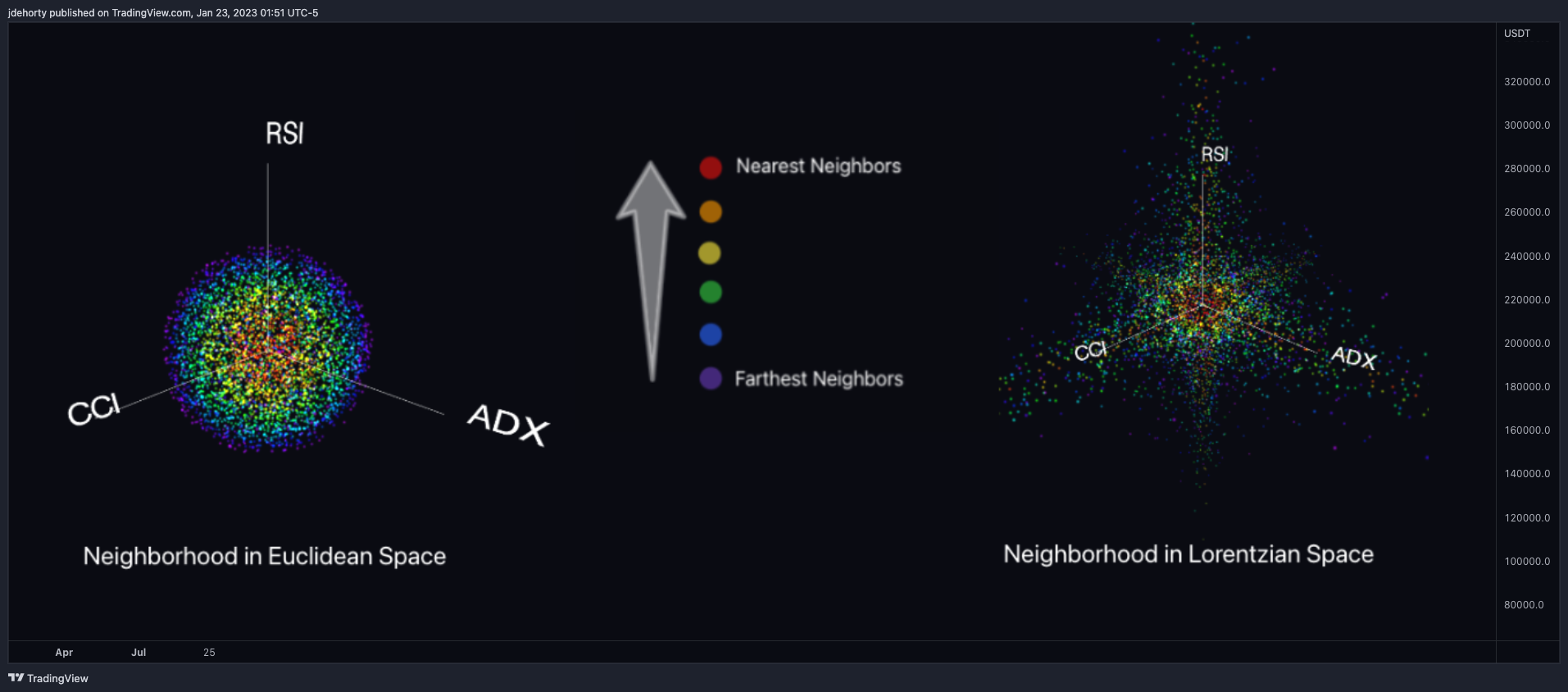
A continuación se muestra una comparación de cómo aparecen las vecindades de puntos históricos similares en el espacio euclidiano tridimensional y en el espacio lorentziano (imagen 2).
Esta figura muestra cómo el espacio lorentziano puede adaptarse mejor a la deformación del precio-tiempo, ya que la función de distancia lorentziana comprime la vecindad euclidiana de tal manera que la nueva distribución de la vecindad en el espacio lorentziano tiende a agruparse alrededor de cada uno de los ejes principales, además del propio origen. Esto significa que, aunque algunos vecinos más cercanos serán los mismos independientemente de la métrica de distancia utilizada, el espacio lorentziano también permitirá considerar puntos históricos que, de otro modo, nunca se considerarían con una métrica de distancia euclidiana.
Intuitivamente, la ventaja inherente a la métrica de distancia lorentziana tiene sentido. Por ejemplo, es lógico que la acción del precio que se produzca en las horas posteriores a que el Presidente Powell termine de pronunciar un discurso se parezca al menos a algunas de las veces anteriores en las que terminó de pronunciar un discurso. Esto puede ser cierto independientemente de otros factores, como si el mercado estaba o no sobrecomprado o sobrevendido en ese momento o si las condiciones macroeconómicas eran más alcistas o bajistas en general. Estos puntos de referencia históricos son extremadamente valiosos para los modelos predictivos, pero la métrica de la distancia euclidiana pasaría por alto a estos vecinos por completo, a menudo en favor de puntos de datos irrelevantes del día anterior al evento. Al utilizar la distancia Lorentziana como métrica, el modelo ML es capaz de considerar la deformación del precio-tiempo causada por el evento y, en última instancia, trascender el sesgo temporal que le imponen las series temporales.
Para más información sobre los detalles de implementación del algoritmo de Vecinos Cercanos Aproximados (RNA) utilizado en este indicador, consulte los comentarios detallados en el código fuente.
" CÓMO UTILIZAR
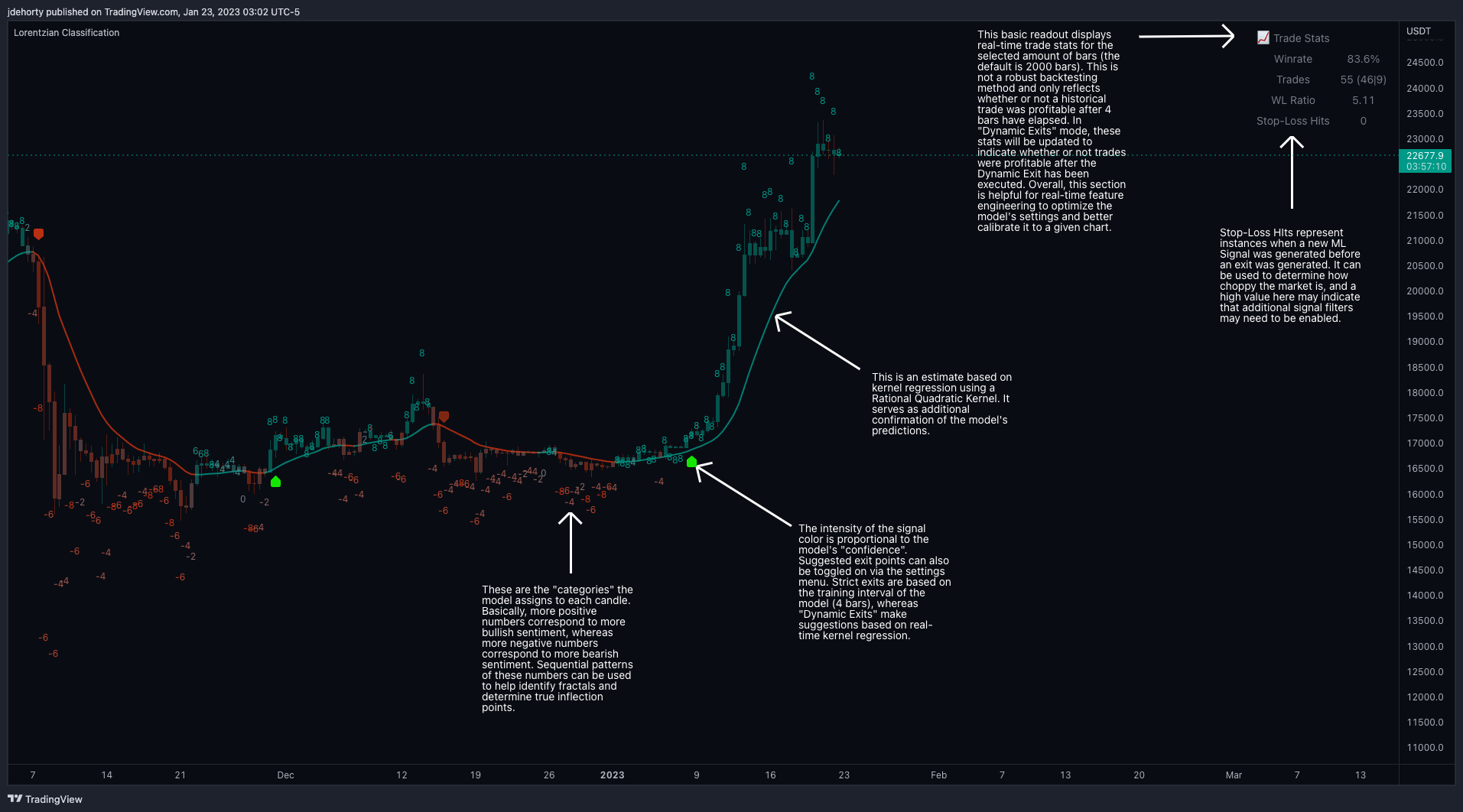
La imagen 3 es un desglose explicativo de las diferentes partes de este indicador tal y como aparece en la interfaz.
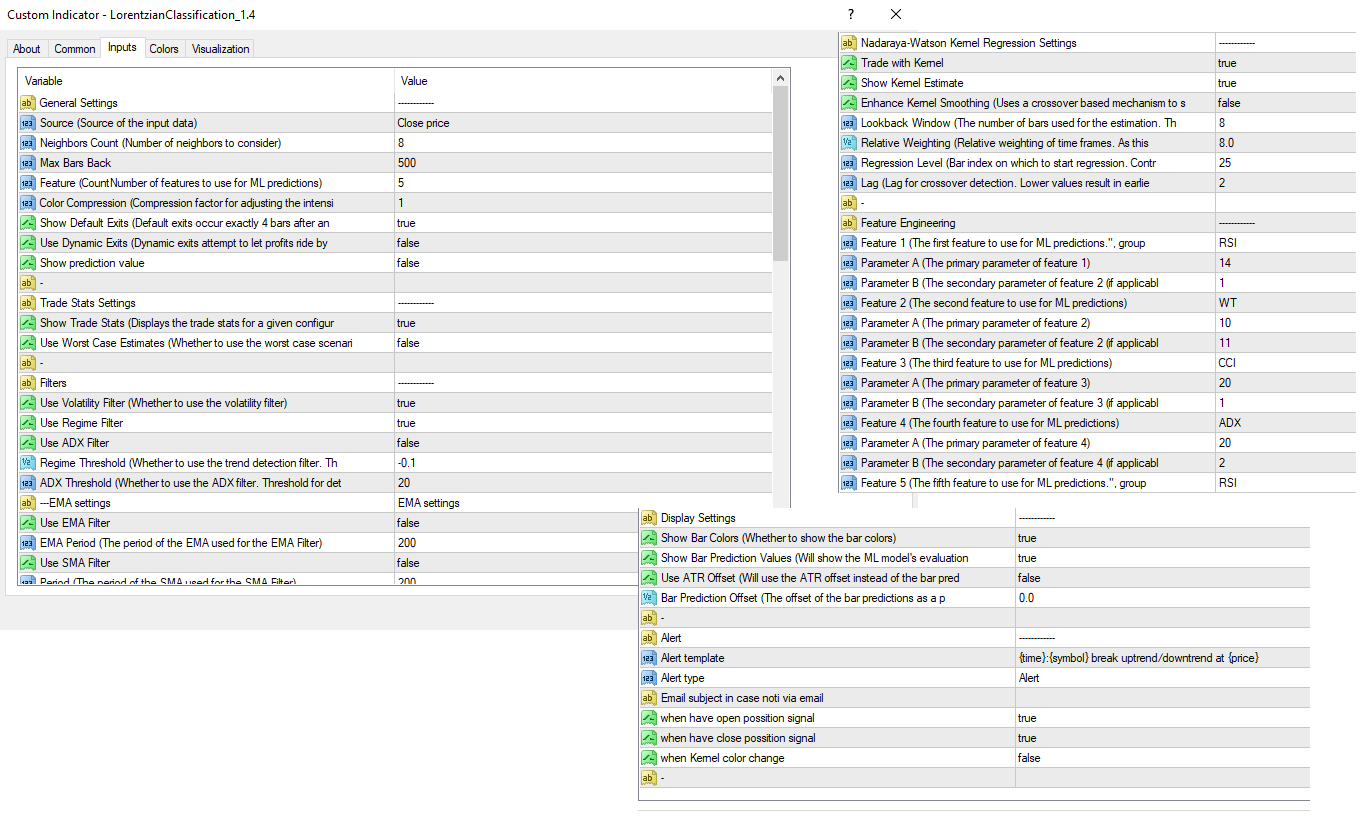
La imagen 4 es una explicación de los diferentes ajustes de este indicador
Configuración general:- Fuente - Tiene un valor por defecto de "hlc3" y se utiliza para controlar la fuente de datos de entrada.
- Recuento de vecinos - Tiene un valor por defecto de 8, un valor mínimo de 1, un valor máximo de 100 y un paso de 1. Se utiliza para controlar el número de vecinos a considerar.
- Max Bars Back - Tiene un valor por defecto de 2000.
- Conteo de Características - Tiene un valor por defecto de 5, un valor mínimo de 2, y un valor máximo de 5. Controla el número de características a utilizar. Controla el número de características a utilizar para las predicciones ML.
- Compresión de color - Tiene un valor por defecto de 1, un valor mínimo de 1 y un valor máximo de 10. Se utiliza para controlar la compresión. Se utiliza para controlar el factor de compresión para ajustar la intensidad de la escala de colores.
- Mostrar Salidas - Tiene un valor por defecto de falso. Controla si se muestra el umbral de salida en el gráfico.
- Utilizar salidas dinámicas - Por defecto, este valor es falso. Se utiliza para controlar si se intenta dejar correr las ganancias ajustando dinámicamente el umbral de salida basado en la regresión del kernel.
Ajustesde Ingeniería de Características:
Nota: La sección de Ingeniería de Características es para afinar las características utilizadas para las predicciones ML. Los valores por defecto están optimizados para los marcos temporales de 4H a 12H para la mayoría de los gráficos, pero también deberían funcionar razonablemente bien para otros marcos temporales. Por defecto, el modelo admite características que aceptan dos parámetros (Parámetro A y Parámetro B, respectivamente). Aunque sólo hay 4 características por defecto, la misma característica con diferentes ajustes cuenta como dos características separadas. Si la función sólo acepta un parámetro, el segundo parámetro adoptará por defecto el suavizado basado en EMA con un valor por defecto de 1. Estas funciones representan la combinación más eficaz que he encontrado en mis pruebas, pero es posible que se añadan otras funciones como opciones adicionales en el futuro.
- Característica 1 - Tiene un valor por defecto de "RSI" y las opciones son: "RSI", "WT", "CCI", "ADX".
- Característica 2 - Tiene un valor por defecto de "WT" y las opciones son: "RSI", "WT", "CCI", "ADX".
- Característica 3 - Tiene el valor por defecto "CCI" y las opciones son: "RSI", "WT", "CCI", "ADX".
- Característica 4 - Este tiene un valor por defecto de "ADX" y las opciones son: "RSI", "WT", "CCI", "ADX".
- Característica 5 - Este tiene un valor por defecto de "RSI" y las opciones son: "RSI", "WT", "CCI", "ADX".
Configuración de filtros:
- Usar Filtro de Volatilidad - Este tiene un valor por defecto de "true". Se utiliza para controlar si se utiliza el filtro de volatilidad.
- Usar Filtro de Régimen - Tiene un valor por defecto de verdadero. Se utiliza para controlar si se utiliza el filtro de detección de tendencia.
- Usar Filtro ADX - Tiene un valor por defecto de falso. Sirve para controlar si se utiliza el filtro ADX.
- Umbral de Régimen - Tiene un valor por defecto de -0.1, un valor mínimo de -10, un valor máximo de 10, y un paso de 0.1. Se utiliza para controlar el Umbral de Régimen. Se utiliza para controlar el filtro de Detección de Régimen para detectar mercados de Tendencia/Rango.
- Umbral ADX - Tiene un valor por defecto de 20, un valor mínimo de 0, un valor máximo de 100 y un paso de 1. Se utiliza para controlar el umbral de detección de Tendencias/Rangos en los mercados.
Ajustes de Regresión Kernel:
- Negociar con Kernel - Tiene un valor por defecto de verdadero. Se utiliza para controlar si se comercia con el kernel.
- Mostrar Estimación del Kernel - Tiene un valor por defecto de verdadero. Se utiliza para controlar si se muestra la estimación del kernel.
- Ventana Lookback - Tiene un valor por defecto de 8 y un valor mínimo de 3. Se utiliza para controlar el número de barras utilizadas para la estimación. Rango recomendado: 3-50
- Ponderación relativa - Tiene un valor por defecto de 8 y un tamaño de paso de 0.25. Se utiliza para controlar la ponderación relativa. Se utiliza para controlar la ponderación relativa de los marcos temporales. Rango recomendado: 0.25-25
- Iniciar Regresión en la Barra - Tiene un valor por defecto de 25. Se utiliza para controlar el índice de la barra. Se utiliza para controlar el índice de la barra en la que se inicia la regresión. Rango recomendado: 0-25
Configuración de pantalla:
- Mostrar colores de barra - Tiene un valor por defecto de verdadero. Sirve para controlar si se muestran los colores de las barras.
- Mostrar valores de predicción de barras - Tiene un valor por defecto de verdadero. Controla si se muestra la evaluación del modelo ML de cada barra como un número entero.
- Usar Desplazamiento ATR - Tiene un valor por defecto de falso. Controla si se utiliza el offset ATR en lugar del offset de predicción de barra.
- Desplazamiento de predicción de barra: tiene un valor predeterminado de 0 y un valor mínimo de 0. Se utiliza para controlar el desplazamiento de las predicciones de barra como porcentaje del máximo o el cierre de la barra.
Configuración de Backtesting:
- Mostrar resultados de Backtest - Tiene un valor por defecto de true. Se utiliza para controlar si se muestra la tasa de ganancias de la configuración dada.
(1) R. Giusti y G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, y H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems", Pattern Recognition Letters, vol. 84, 170-176, dic. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, y J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms". ResearchGate, 04 de febrero de 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, y Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov y H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Efectos de la elección de la medida de distancia en el rendimiento del clasificador KNN: una revisión". .
=======================
Nota sobre el "repintado":
Para ser claros, una vez que una barra se ha cerrado, este indicador NO se repintará. Esto es cierto tanto para las predicciones ML como para la estimación Kernel.
Nota sobre el requisito de barra para el "aprendizaje":
Es una recomendación valiosa. El uso de un marco de tiempo de H4 o inferior cuando se trabaja con este indicador debido a esto requieren datos históricos de precios para el aprendizaje y el análisis es un enfoque práctico. Se asegura de que usted tiene un número adecuado de barras históricas para permitir que el indicador para aprender y adaptarse eficazmente al comportamiento de los precios (MT4 tiene sólo about1000 bar en el gráfico con mayor marco de tiempo). Si tiene más ideas o preguntas relacionadas con el comercio o indicadores, no dude en compartir o preguntar.
Nota para el buffer
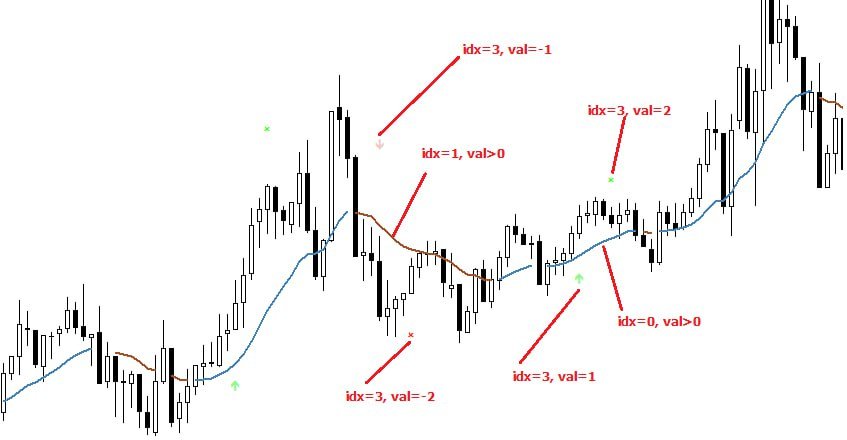
En caso de crear EA con la señal de este indicador por favor utilice iCustom. El índice cuando se utiliza iCustom como sigue:
+ índice 0 es el valor de la línea
+ índice 2 es la dirección de la línea: 1 es hacia arriba; -1 es hacia abajo
+ índice 4 es la señal: 1 es compra; 2 es cerca de compra; -1 es venta; -2 es cerca de venta
+ el índice 5 es la predicción
Recuerde que el indicador sólo calcula la barra cerrada. Por lo que necesita desplazamiento 1 en copyBuffer.